In
Chapter 1 - Basics we took ZeroMQ for a drive, with some basic examples of the main ZeroMQ patterns: request-reply, pub-sub, and pipeline. In this chapter, we’re going to get our hands dirty and start to learn how to use these tools in real programs.
We’ll cover:
How to create and work with ZeroMQ sockets.
How to send and receive messages on sockets.
How to build your apps around ZeroMQ’s asynchronous I/O model.
How to handle multiple sockets in one thread.
How to handle fatal and nonfatal errors properly.
How to handle interrupt signals like Ctrl-C.
How to shut down a ZeroMQ application cleanly.
How to check a ZeroMQ application for memory leaks.
How to send and receive multipart messages.
How to forward messages across networks.
How to build a simple message queuing broker.
How to write multithreaded applications with ZeroMQ.
How to use ZeroMQ to signal between threads.
How to use ZeroMQ to coordinate a network of nodes.
How to create and use message envelopes for pub-sub.
Using the HWM (high-water mark) to protect against memory overflows.
To be perfectly honest, ZeroMQ does a kind of switch-and-bait on you, for which we don’t apologize. It’s for your own good and it hurts us more than it hurts you. ZeroMQ presents a familiar socket-based API, which requires great effort for us to hide a bunch of message-processing engines. However, the result will slowly fix your world view about how to design and write distributed software.
Sockets are the de facto standard API for network programming, as well as being useful for stopping your eyes from falling onto your cheeks. One thing that makes ZeroMQ especially tasty to developers is that it uses sockets and messages instead of some other arbitrary set of concepts. Kudos to Martin Sustrik for pulling this off. It turns “Message Oriented Middleware”, a phrase guaranteed to send the whole room off to Catatonia, into “Extra Spicy Sockets!”, which leaves us with a strange craving for pizza and a desire to know more.
Like a favorite dish, ZeroMQ sockets are easy to digest. Sockets have a life in four parts, just like BSD sockets:
Creating and destroying sockets, which go together to form a karmic circle of socket life (see zmq_socket(), zmq_close()).
Note that sockets are always void pointers, and messages (which we’ll come to very soon) are structures. So in C you pass sockets as-such, but you pass addresses of messages in all functions that work with messages, like zmq_msg_send() and zmq_msg_recv(). As a mnemonic, realize that “in ZeroMQ, all your sockets belong to us”, but messages are things you actually own in your code.
Creating, destroying, and configuring sockets works as you’d expect for any object. But remember that ZeroMQ is an asynchronous, elastic fabric. This has some impact on how we plug sockets into the network topology and how we use the sockets after that.
To create a connection between two nodes, you use zmq_bind() in one node and zmq_connect() in the other. As a general rule of thumb, the node that does zmq_bind() is a “server”, sitting on a well-known network address, and the node which does zmq_connect() is a “client”, with unknown or arbitrary network addresses. Thus we say that we “bind a socket to an endpoint” and “connect a socket to an endpoint”, the endpoint being that well-known network address.
ZeroMQ connections are somewhat different from classic TCP connections. The main notable differences are:
One socket may have many outgoing and many incoming connections.
There is no zmq_accept() method. When a socket is bound to an endpoint it automatically starts accepting connections.
The network connection itself happens in the background, and ZeroMQ will automatically reconnect if the network connection is broken (e.g., if the peer disappears and then comes back).
Your application code cannot work with these connections directly; they are encapsulated under the socket.
Many architectures follow some kind of client/server model, where the server is the component that is most static, and the clients are the components that are most dynamic, i.e., they come and go the most. There are sometimes issues of addressing: servers will be visible to clients, but not necessarily vice versa. So mostly it’s obvious which node should be doing zmq_bind() (the server) and which should be doing zmq_connect() (the client). It also depends on the kind of sockets you’re using, with some exceptions for unusual network architectures. We’ll look at socket types later.
Now, imagine we start the client before we start the server. In traditional networking, we get a big red Fail flag. But ZeroMQ lets us start and stop pieces arbitrarily. As soon as the client node does zmq_connect(), the connection exists and that node can start to write messages to the socket. At some stage (hopefully before messages queue up so much that they start to get discarded, or the client blocks), the server comes alive, does a zmq_bind(), and ZeroMQ starts to deliver messages.
A server node can bind to many endpoints (that is, a combination of protocol and address) and it can do this using a single socket. This means it will accept connections across different transports:
With most transports, you cannot bind to the same endpoint twice, unlike for example in UDP. The ipc transport does, however, let one process bind to an endpoint already used by a first process. It’s meant to allow a process to recover after a crash.
Although ZeroMQ tries to be neutral about which side binds and which side connects, there are differences. We’ll see these in more detail later. The upshot is that you should usually think in terms of “servers” as static parts of your topology that bind to more or less fixed endpoints, and “clients” as dynamic parts that come and go and connect to these endpoints. Then, design your application around this model. The chances that it will “just work” are much better like that.
Sockets have types. The socket type defines the semantics of the socket, its policies for routing messages inwards and outwards, queuing, etc. You can connect certain types of socket together, e.g., a publisher socket and a subscriber socket. Sockets work together in “messaging patterns”. We’ll look at this in more detail later.
It’s the ability to connect sockets in these different ways that gives ZeroMQ its basic power as a message queuing system. There are layers on top of this, such as proxies, which we’ll get to later. But essentially, with ZeroMQ you define your network architecture by plugging pieces together like a child’s construction toy.
To send and receive messages you use the zmq_msg_send() and zmq_msg_recv() methods. The names are conventional, but ZeroMQ’s I/O model is different enough from the classic TCP model that you will need time to get your head around it.
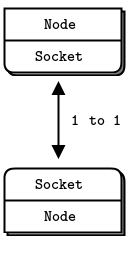
Figure 9 - TCP sockets are 1 to 1
Let’s look at the main differences between TCP sockets and ZeroMQ sockets when it comes to working with data:
ZeroMQ sockets carry messages, like UDP, rather than a stream of bytes as TCP does. A ZeroMQ message is length-specified binary data. We’ll come to messages shortly; their design is optimized for performance and so a little tricky.
ZeroMQ sockets do their I/O in a background thread. This means that messages arrive in local input queues and are sent from local output queues, no matter what your application is busy doing.
ZeroMQ sockets have one-to-N routing behavior built-in, according to the socket type.
The zmq_send() method does not actually send the message to the socket connection(s). It queues the message so that the I/O thread can send it asynchronously. It does not block except in some exception cases. So the message is not necessarily sent when zmq_send() returns to your application.
ZeroMQ provides a set of unicast transports (inproc, ipc, and tcp) and multicast transports (epgm, pgm). Multicast is an advanced technique that we’ll come to later. Don’t even start using it unless you know that your fan-out ratios will make 1-to-N unicast impossible.
For most common cases, use tcp, which is a disconnected TCP transport. It is elastic, portable, and fast enough for most cases. We call this disconnected because ZeroMQ’s tcp transport doesn’t require that the endpoint exists before you connect to it. Clients and servers can connect and bind at any time, can go and come back, and it remains transparent to applications.
The inter-process ipc transport is disconnected, like tcp. It has one limitation: it does not yet work on Windows. By convention we use endpoint names with an “.ipc” extension to avoid potential conflict with other file names. On UNIX systems, if you use ipc endpoints you need to create these with appropriate permissions otherwise they may not be shareable between processes running under different user IDs. You must also make sure all processes can access the files, e.g., by running in the same working directory.
The inter-thread transport, inproc, is a connected signaling transport. It is much faster than tcp or ipc. This transport has a specific limitation compared to tcp and ipc: the server must issue a bind before any client issues a connect. This was fixed in ZeroMQ v4.0 and later versions.
A common question that newcomers to ZeroMQ ask (it’s one I’ve asked myself) is, “how do I write an XYZ server in ZeroMQ?” For example, “how do I write an HTTP server in ZeroMQ?” The implication is that if we use normal sockets to carry HTTP requests and responses, we should be able to use ZeroMQ sockets to do the same, only much faster and better.
The answer used to be “this is not how it works”. ZeroMQ is not a neutral carrier: it imposes a framing on the transport protocols it uses. This framing is not compatible with existing protocols, which tend to use their own framing. For example, compare an HTTP request and a ZeroMQ request, both over TCP/IP.
Figure 10 - HTTP on the Wire
The HTTP request uses CR-LF as its simplest framing delimiter, whereas ZeroMQ uses a length-specified frame. So you could write an HTTP-like protocol using ZeroMQ, using for example the request-reply socket pattern. But it would not be HTTP.
Figure 11 - ZeroMQ on the Wire
Since v3.3, however, ZeroMQ has a socket option called ZMQ_ROUTER_RAW that lets you read and write data without the ZeroMQ framing. You could use this to read and write proper HTTP requests and responses. Hardeep Singh contributed this change so that he could connect to Telnet servers from his ZeroMQ application. At time of writing this is still somewhat experimental, but it shows how ZeroMQ keeps evolving to solve new problems. Maybe the next patch will be yours.
We said that ZeroMQ does I/O in a background thread. One I/O thread (for all sockets) is sufficient for all but the most extreme applications. When you create a new context, it starts with one I/O thread. The general rule of thumb is to allow one I/O thread per gigabyte of data in or out per second. To raise the number of I/O threads, use the zmq_ctx_set() call before creating any sockets:
We’ve seen that one socket can handle dozens, even thousands of connections at once. This has a fundamental impact on how you write applications. A traditional networked application has one process or one thread per remote connection, and that process or thread handles one socket. ZeroMQ lets you collapse this entire structure into a single process and then break it up as necessary for scaling.
If you are using ZeroMQ for inter-thread communications only (i.e., a multithreaded application that does no external socket I/O) you can set the I/O threads to zero. It’s not a significant optimization though, more of a curiosity.
Underneath the brown paper wrapping of ZeroMQ’s socket API lies the world of messaging patterns. If you have a background in enterprise messaging, or know UDP well, these will be vaguely familiar. But to most ZeroMQ newcomers, they are a surprise. We’re so used to the TCP paradigm where a socket maps one-to-one to another node.
Let’s recap briefly what ZeroMQ does for you. It delivers blobs of data (messages) to nodes, quickly and efficiently. You can map nodes to threads, processes, or nodes. ZeroMQ gives your applications a single socket API to work with, no matter what the actual transport (like in-process, inter-process, TCP, or multicast). It automatically reconnects to peers as they come and go. It queues messages at both sender and receiver, as needed. It limits these queues to guard processes against running out of memory. It handles socket errors. It does all I/O in background threads. It uses lock-free techniques for talking between nodes, so there are never locks, waits, semaphores, or deadlocks.
But cutting through that, it routes and queues messages according to precise recipes called patterns. It is these patterns that provide ZeroMQ’s intelligence. They encapsulate our hard-earned experience of the best ways to distribute data and work. ZeroMQ’s patterns are hard-coded but future versions may allow user-definable patterns.
ZeroMQ patterns are implemented by pairs of sockets with matching types. In other words, to understand ZeroMQ patterns you need to understand socket types and how they work together. Mostly, this just takes study; there is little that is obvious at this level.
The built-in core ZeroMQ patterns are:
Request-reply, which connects a set of clients to a set of services. This is a remote procedure call and task distribution pattern.
Pub-sub, which connects a set of publishers to a set of subscribers. This is a data distribution pattern.
Pipeline, which connects nodes in a fan-out/fan-in pattern that can have multiple steps and loops. This is a parallel task distribution and collection pattern.
Exclusive pair, which connects two sockets exclusively. This is a pattern for connecting two threads in a process, not to be confused with “normal” pairs of sockets.
We looked at the first three of these in
Chapter 1 - Basics, and we’ll see the exclusive pair pattern later in this chapter. The zmq_socket() man page is fairly clear about the patterns – it’s worth reading several times until it starts to make sense. These are the socket combinations that are valid for a connect-bind pair (either side can bind):
PUB and SUB
REQ and REP
REQ and ROUTER (take care, REQ inserts an extra null frame)
DEALER and REP (take care, REP assumes a null frame)
DEALER and ROUTER
DEALER and DEALER
ROUTER and ROUTER
PUSH and PULL
PAIR and PAIR
You’ll also see references to XPUB and XSUB sockets, which we’ll come to later (they’re like raw versions of PUB and SUB). Any other combination will produce undocumented and unreliable results, and future versions of ZeroMQ will probably return errors if you try them. You can and will, of course, bridge other socket types via code, i.e., read from one socket type and write to another.
These four core patterns are cooked into ZeroMQ. They are part of the ZeroMQ API, implemented in the core C++ library, and are guaranteed to be available in all fine retail stores.
On top of those, we add high-level messaging patterns. We build these high-level patterns on top of ZeroMQ and implement them in whatever language we’re using for our application. They are not part of the core library, do not come with the ZeroMQ package, and exist in their own space as part of the ZeroMQ community. For example the Majordomo pattern, which we explore in
Chapter 4 - Reliable Request-Reply Patterns, sits in the GitHub Majordomo project in the ZeroMQ organization.
One of the things we aim to provide you with in this book are a set of such high-level patterns, both small (how to handle messages sanely) and large (how to make a reliable pub-sub architecture).
The libzmq core library has in fact two APIs to send and receive messages. The zmq_send() and zmq_recv() methods that we’ve already seen and used are simple one-liners. We will use these often, but zmq_recv() is bad at dealing with arbitrary message sizes: it truncates messages to whatever buffer size you provide. So there’s a second API that works with zmq_msg_t structures, with a richer but more difficult API:
On the wire, ZeroMQ messages are blobs of any size from zero upwards that fit in memory. You do your own serialization using protocol buffers, msgpack, JSON, or whatever else your applications need to speak. It’s wise to choose a data representation that is portable, but you can make your own decisions about trade-offs.
In memory, ZeroMQ messages are zmq_msg_t structures (or classes depending on your language). Here are the basic ground rules for using ZeroMQ messages in C:
You create and pass around zmq_msg_t objects, not blocks of data.
To write a message from new data, you use zmq_msg_init_size() to create a message and at the same time allocate a block of data of some size. You then fill that data using memcpy, and pass the message to zmq_msg_send().
To release (not destroy) a message, you call zmq_msg_close(). This drops a reference, and eventually ZeroMQ will destroy the message.
To access the message content, you use zmq_msg_data(). To know how much data the message contains, use zmq_msg_size().
After you pass a message to zmq_msg_send(), ØMQ will clear the message, i.e., set the size to zero. You cannot send the same message twice, and you cannot access the message data after sending it.
These rules don’t apply if you use zmq_send() and zmq_recv(), to which you pass byte arrays, not message structures.
If you want to send the same message more than once, and it’s sizable, create a second message, initialize it using zmq_msg_init(), and then use zmq_msg_copy() to create a copy of the first message. This does not copy the data but copies a reference. You can then send the message twice (or more, if you create more copies) and the message will only be finally destroyed when the last copy is sent or closed.
ZeroMQ also supports multipart messages, which let you send or receive a list of frames as a single on-the-wire message. This is widely used in real applications and we’ll look at that later in this chapter and in
Chapter 3 - Advanced Request-Reply Patterns.
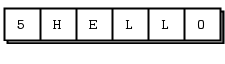
Frames (also called “message parts” in the ZeroMQ reference manual pages) are the basic wire format for ZeroMQ messages. A frame is a length-specified block of data. The length can be zero upwards. If you’ve done any TCP programming you’ll appreciate why frames are a useful answer to the question “how much data am I supposed to read of this network socket now?”
There is a wire-level
protocol called ZMTP that defines how ZeroMQ reads and writes frames on a TCP connection. If you’re interested in how this works, the spec is quite short.
Originally, a ZeroMQ message was one frame, like UDP. We later extended this with multipart messages, which are quite simply series of frames with a “more” bit set to one, followed by one with that bit set to zero. The ZeroMQ API then lets you write messages with a “more” flag and when you read messages, it lets you check if there’s “more”.
In the low-level ZeroMQ API and the reference manual, therefore, there’s some fuzziness about messages versus frames. So here’s a useful lexicon:
A message can be one or more parts.
These parts are also called “frames”.
Each part is a zmq_msg_t object.
You send and receive each part separately, in the low-level API.
Higher-level APIs provide wrappers to send entire multipart messages.
Some other things that are worth knowing about messages:
You may send zero-length messages, e.g., for sending a signal from one thread to another.
ZeroMQ guarantees to deliver all the parts (one or more) for a message, or none of them.
ZeroMQ does not send the message (single or multipart) right away, but at some indeterminate later time. A multipart message must therefore fit in memory.
A message (single or multipart) must fit in memory. If you want to send files of arbitrary sizes, you should break them into pieces and send each piece as separate single-part messages. Using multipart data will not reduce memory consumption.
You must call zmq_msg_close() when finished with a received message, in languages that don’t automatically destroy objects when a scope closes. You don’t call this method after sending a message.
And to be repetitive, do not use zmq_msg_init_data() yet. This is a zero-copy method and is guaranteed to create trouble for you. There are far more important things to learn about ZeroMQ before you start to worry about shaving off microseconds.
This rich API can be tiresome to work with. The methods are optimized for performance, not simplicity. If you start using these you will almost definitely get them wrong until you’ve read the man pages with some care. So one of the main jobs of a good language binding is to wrap this API up in classes that are easier to use.
In all the examples so far, the main loop of most examples has been:
Wait for message on socket.
Process message.
Repeat.
What if we want to read from multiple endpoints at the same time? The simplest way is to connect one socket to all the endpoints and get ZeroMQ to do the fan-in for us. This is legal if the remote endpoints are in the same pattern, but it would be wrong to connect a PULL socket to a PUB endpoint.
To actually read from multiple sockets all at once, use zmq_poll(). An even better way might be to wrap zmq_poll() in a framework that turns it into a nice event-driven reactor, but it’s significantly more work than we want to cover here.
Let’s start with a dirty hack, partly for the fun of not doing it right, but mainly because it lets me show you how to do nonblocking socket reads. Here is a simple example of reading from two sockets using nonblocking reads. This rather confused program acts both as a subscriber to weather updates, and a worker for parallel tasks:
// Reading from multiple sockets
// This version uses a simple recv loop
#include"zhelpers.h"intmain (void)
{
// Connect to task ventilator
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_connect (receiver, "tcp://localhost:5557");
// Connect to weather server
void *subscriber = zmq_socket (context, ZMQ_SUB);
zmq_connect (subscriber, "tcp://localhost:5556");
zmq_setsockopt (subscriber, ZMQ_SUBSCRIBE, "10001 ", 6);
// Process messages from both sockets
// We prioritize traffic from the task ventilator
while (1) {
char msg [256];
while (1) {
int size = zmq_recv (receiver, msg, 255, ZMQ_DONTWAIT);
if (size != -1) {
// Process task
}
elsebreak;
}
while (1) {
int size = zmq_recv (subscriber, msg, 255, ZMQ_DONTWAIT);
if (size != -1) {
// Process weather update
}
elsebreak;
}
// No activity, so sleep for 1 msec
s_sleep (1);
}
zmq_close (receiver);
zmq_close (subscriber);
zmq_ctx_destroy (context);
return0;
}
msreader: Multiple socket reader in C++
//
// Reading from multiple sockets in C++
// This version uses a simple recv loop
//
#include"zhelpers.hpp"intmain (int argc, char *argv[])
{
// Prepare our context and sockets
zmq::context_t context(1);
// Connect to task ventilator
zmq::socket_t receiver(context, ZMQ_PULL);
receiver.connect("tcp://localhost:5557");
// Connect to weather server
zmq::socket_t subscriber(context, ZMQ_SUB);
subscriber.connect("tcp://localhost:5556");
subscriber.set(zmq::sockopt::subscribe, "10001 ");
// Process messages from both sockets
// We prioritize traffic from the task ventilator
while (1) {
// Process any waiting tasks
bool rc;
do {
zmq::message_t task;
if ((rc = receiver.recv(&task, ZMQ_DONTWAIT)) == true) {
// process task
}
} while(rc == true);
// Process any waiting weather updates
do {
zmq::message_t update;
if ((rc = subscriber.recv(&update, ZMQ_DONTWAIT)) == true) {
// process weather update
}
} while(rc == true);
// No activity, so sleep for 1 msec
s_sleep(1);
}
return0;
}
msreader: Multiple socket reader in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid MSReader(string[] args)
{
//
// Reading from multiple sockets
// This version uses a simple recv loop
//
// Author: metadings
//
using (var context = new ZContext())
using (var receiver = new ZSocket(context, ZSocketType.PULL))
using (var subscriber = new ZSocket(context, ZSocketType.SUB))
{
// Connect to task ventilator
receiver.Connect("tcp://127.0.0.1:5557");
// Connect to weather server
subscriber.Connect("tcp://127.0.0.1:5556");
subscriber.SetOption(ZSocketOption.SUBSCRIBE, "10001 ");
// Process messages from both sockets
// We prioritize traffic from the task ventilator
ZError error;
ZFrame frame;
while (true)
{
while (true)
{
if (null != (frame = receiver.ReceiveFrame(ZSocketFlags.DontWait, out error)))
{
// Process task
}
else
{
if (error == ZError.ETERM)
return; // Interrupted
if (error != ZError.EAGAIN)
thrownew ZException(error);
break;
}
}
while (true)
{
if (null != (frame = subscriber.ReceiveFrame(ZSocketFlags.DontWait, out error)))
{
// Process weather update
}
else
{
if (error == ZError.ETERM)
return; // Interrupted
if (error != ZError.EAGAIN)
thrownew ZException(error);
break;
}
}
// No activity, so sleep for 1 msec
Thread.Sleep(1);
}
}
}
}
}
msreader: Multiple socket reader in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Reading from multiple sockets in Common Lisp;;; This version uses a simple recv loop;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.msreader
(:nicknames#:msreader)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.msreader)
(defunmain ()
;; Prepare our context and socket
(zmq:with-context (context1)
;; Connect to task ventilator
(zmq:with-socket (receivercontextzmq:pull)
(zmq:connectreceiver"tcp://localhost:5557")
;; Connect to weather server
(zmq:with-socket (subscribercontextzmq:sub)
(zmq:connectsubscriber"tcp://localhost:5556")
(zmq:setsockoptsubscriberzmq:subscribe"10001 ")
;; Process messages from both sockets;; We prioritize traffic from the task ventilator
(loop
(handler-case
(loop
(let ((task (make-instance'zmq:msg)))
(zmq:recvreceivertaskzmq:noblock)
;; process task
(dump-messagetask)
(finish-output)))
(zmq:error-again () nil))
;; Process any waiting weather updates
(handler-case
(loop
(let ((update (make-instance'zmq:msg)))
(zmq:recvsubscriberupdatezmq:noblock)
;; process weather update
(dump-messageupdate)
(finish-output)))
(zmq:error-again () nil))
;; No activity, so sleep for 1 msec
(isys:usleep1000)))))
(cleanup))
msreader: Multiple socket reader in Delphi
program msreader;
//
// Reading from multiple sockets
// This version uses a simple recv loop
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
receiver,
subscriber: TZMQSocket;
rc: Integer;
task,
update: TZMQFrame;
begin
// Prepare our context and sockets
context := TZMQContext.Create;
// Connect to task ventilator
receiver := Context.Socket( stPull );
receiver.RaiseEAgain := false;
receiver.connect( 'tcp://localhost:5557' );
// Connect to weather server
subscriber := Context.Socket( stSub );
subscriber.RaiseEAgain := false;
subscriber.connect( 'tcp://localhost:5556' );
subscriber.subscribe( '10001' );
// Process messages from both sockets
// We prioritize traffic from the task ventilator
while True do
begin
// Process any waiting tasks
repeat
task := TZMQFrame.create;
rc := receiver.recv( task, [rfDontWait] );
if rc <> -1 then
begin
// process task
end;
task.Free;
until rc = -1;
// Process any waiting weather updates
repeat
update := TZMQFrame.Create;
rc := subscriber.recv( update, [rfDontWait] );
if rc <> -1 then
begin
// process weather update
end;
update.Free;
until rc = -1;
// No activity, so sleep for 1 msec
sleep (1);
end;
// We never get here but clean up anyhow
receiver.Free;
subscriber.Free;
context.Free;
end.
msreader: Multiple socket reader in Erlang
#! /usr/bin/env escript
%%
%% Reading from multiple sockets
%% This version uses a simple recv loop
%%
main(_) ->
%% Prepare our context and sockets
{ok, Context} = erlzmq:context(),
%% Connect to task ventilator
{ok, Receiver} = erlzmq:socket(Context, pull),
ok = erlzmq:connect(Receiver, "tcp://localhost:5557"),
%% Connect to weather server
{ok, Subscriber} = erlzmq:socket(Context, sub),
ok = erlzmq:connect(Subscriber, "tcp://localhost:5556"),
ok = erlzmq:setsockopt(Subscriber, subscribe, <<"10001">>),
%% Process messages from both sockets
loop(Receiver, Subscriber),
%% We never get here but clean up anyhow
ok = erlzmq:close(Receiver),
ok = erlzmq:close(Subscriber),
ok = erlzmq:term(Context).
loop(Receiver, Subscriber) ->
%% We prioritize traffic from the task ventilator
process_tasks(Receiver),
process_weather(Subscriber),
timer:sleep(1000),
loop(Receiver, Subscriber).
process_tasks(S) ->
%% Process any waiting tasks
caseerlzmq:recv(S, [noblock]) of
{error, eagain} -> ok;
{ok, Msg} ->
io:format("Procesing task: ~s~n", [Msg]),
process_tasks(S)
end.
process_weather(S) ->
%% Process any waiting weather updates
caseerlzmq:recv(S, [noblock]) of
{error, eagain} -> ok;
{ok, Msg} ->
io:format("Processing weather update: ~s~n", [Msg]),
process_weather(S)
end.
msreader: Multiple socket reader in Elixir
defmodule Msreader do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:27
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, receiver} = :erlzmq.socket(context, :pull)
:ok = :erlzmq.connect(receiver, 'tcp://localhost:5557')
{:ok, subscriber} = :erlzmq.socket(context, :sub)
:ok = :erlzmq.connect(subscriber, 'tcp://localhost:5556')
:ok = :erlzmq.setsockopt(subscriber, :subscribe, "10001")
loop(receiver, subscriber)
:ok = :erlzmq.close(receiver)
:ok = :erlzmq.close(subscriber)
:ok = :erlzmq.term(context)
end
def loop(receiver, subscriber) do
process_tasks(receiver)
process_weather(subscriber)
:timer.sleep(1000)
loop(receiver, subscriber)
end
#case(:erlzmq.recv(s, [:noblock])) do
def process_tasks(s) do
case(:erlzmq.recv(s, [:dontwait])) do
{:error, :eagain} ->
:ok
{:ok, msg} ->
:io.format('Procesing task: ~s~n', [msg])
process_tasks(s)
end
end
def process_weather(s) do
case(:erlzmq.recv(s, [:dontwait])) do
{:error, :eagain} ->
:ok
{:ok, msg} ->
:io.format('Processing weather update: ~s~n', [msg])
process_weather(s)
end
end
end
Msreader.main
msreader: Multiple socket reader in F#
(*
Reading from multiple sockets
This version uses a simple recv loop
*)
#r @"bin/fszmq.dll"
open fszmq
#load "zhelpers.fs"
open Context
open Socket
let main () =
// Prepare our context and sockets
use context = new Context(1)
// Connect to task ventilator
use receiver = context |> pull
connect receiver "tcp://localhost:5557"
// Connect to weather server
use subscriber = context |> sub
connect subscriber "tcp://localhost:5556"
subscribe subscriber [ encode "10001" ]
// Process messages from both sockets
// We prioritize traffic from the task ventilator
while true do
// Process any waiting tasks
match tryRecv receiver ZMQ.NOBLOCK with
| Some(msg) -> msg |> decode |> printfn "%s" // Process task
| None -> () // Otherwise, do nothing
// Process any waiting weather updates
match tryRecv receiver ZMQ.NOBLOCK with
| Some(msg) -> msg |> decode |> printfn "%s" // Process weather update
| None -> () // Otherwise, do nothing
// No activity, so sleep for 1 msec
sleep 1
// We never get here
EXIT_SUCCESS
main ()
msreader: Multiple socket reader in Felix
//
// Reading from multiple sockets
// This version uses a simple recv loop
//
open ZMQ;
// Prepare our context and sockets
var context = zmq_init 1;
// Connect to task ventilator
var receiver = context.mk_socket ZMQ_PULL;
receiver.connect "tcp://localhost:5557";
// Connect to weather server
var subscriber = context.mk_socket ZMQ_SUB;
subscriber.connect "tcp://localhost:5556";
subscriber.set_opt$ zmq_subscribe "101 ";
// Process messages from both sockets
// We prioritize traffic from the task ventilator
while true do
// Process any waiting tasks
var task = receiver.recv_string_dontwait;
while task != "" do
// process task
task = receiver.recv_string_dontwait;
done
// Process any waiting weather updates
var update = subscriber.recv_string_dontwait;
while update != "" do
// process update
update = subscriber.recv_string_dontwait;
done
Faio::sleep (sys_clock,0.001); // 1 ms
done
msreader: Multiple socket reader in Go
//
// Reading from multiple sockets
// This version uses a simple recv loop
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq""time"
)
funcmain() {
context, _ := zmq.NewContext()
defer context.Close()
// Connect to task ventilator
receiver, _ := context.NewSocket(zmq.PULL)
defer receiver.Close()
receiver.Connect("tcp://localhost:5557")
// Connect to weather server
subscriber, _ := context.NewSocket(zmq.SUB)
defer subscriber.Close()
subscriber.Connect("tcp://localhost:5556")
subscriber.SetSubscribe("10001")
// Process messages from both sockets
// We prioritize traffic from the task ventilator
for {
// ventilator
for b, _ := receiver.Recv(zmq.NOBLOCK); b != nil; {
// fake process task
}
// weather server
for b, _ := subscriber.Recv(zmq.NOBLOCK); b != nil; {
// process task
fmt.Printf("found weather =%s\n", string(b))
}
// No activity, so sleep for 1 msec
time.Sleep(1e6)
}
fmt.Println("done")
}
packageguide;
importorg.zeromq.SocketType;
importorg.zeromq.ZMQ;
importorg.zeromq.ZContext;
//
// Reading from multiple sockets in Java
// This version uses a simple recv loop
//
publicclassmsreader
{
publicstaticvoidmain(String[] args) throws Exception
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
// Connect to task ventilator
ZMQ.Socket receiver = context.createSocket(SocketType.PULL);
receiver.connect("tcp://localhost:5557");
// Connect to weather server
ZMQ.Socket subscriber = context.createSocket(SocketType.SUB);
subscriber.connect("tcp://localhost:5556");
subscriber.subscribe("10001 ".getBytes(ZMQ.CHARSET));
// Process messages from both sockets
// We prioritize traffic from the task ventilator
while (!Thread.currentThread().isInterrupted()) {
// Process any waiting tasks
byte[] task;
while ((task = receiver.recv(ZMQ.DONTWAIT)) != null) {
System.out.println("process task");
}
// Process any waiting weather updates
byte[] update;
while ((update = subscriber.recv(ZMQ.DONTWAIT)) != null) {
System.out.println("process weather update");
}
// No activity, so sleep for 1 msec
Thread.sleep(1000);
}
}
}
}
msreader: Multiple socket reader in Julia
#!/usr/bin/env julia# Reading from multiple sockets# The ZMQ.jl wrapper implements ZMQ.recv as a blocking function. Nonblocking i/o# in Julia is typically done using coroutines (Tasks).# The @async macro puts its enclosed expression in a Task. When the macro is# executed, its Task gets scheduled and execution continues immediately to# whatever follows the macro.# Note: the msreader example in the zguide is presented as a "dirty hack"# using the ZMQ_DONTWAIT and EAGAIN codes. Since the ZMQ.jl wrapper API# does not expose DONTWAIT directly, this example skips the hack and instead# provides an efficient solution.using ZMQ
# Prepare our context and sockets
context = ZMQ.Context()
# Connect to task ventilator
receiver = Socket(context, ZMQ.PULL)
ZMQ.connect(receiver, "tcp://localhost:5557")
# Connect to weather server
subscriber = Socket(context,ZMQ.SUB)
ZMQ.connect(subscriber,"tcp://localhost:5556")
ZMQ.set_subscribe(subscriber, "10001")
whiletrue# Process any waiting tasks@asyncbegin
msg = unsafe_string(ZMQ.recv(receiver))
println(msg)
end# Process any waiting weather updates@asyncbegin
msg = unsafe_string(ZMQ.recv(subscriber))
println(msg)
end# Sleep for 1 msec
sleep(0.001)
end
msreader: Multiple socket reader in Lua
---- Reading from multiple sockets-- This version uses a simple recv loop---- Author: Robert G. Jakabosky <bobby@sharedrealm.com>--
require"zmq"
require"zhelpers"-- Prepare our context and socketslocal context = zmq.init(1)
-- Connect to task ventilatorlocal receiver = context:socket(zmq.PULL)
receiver:connect("tcp://localhost:5557")
-- Connect to weather serverlocal subscriber = context:socket(zmq.SUB)
subscriber:connect("tcp://localhost:5556")
subscriber:setopt(zmq.SUBSCRIBE, "10001 ")
-- Process messages from both sockets-- We prioritize traffic from the task ventilatorwhiletruedo-- Process any waiting taskslocal msg
whiletruedo
msg = receiver:recv(zmq.NOBLOCK)
ifnot msg thenbreakend-- process taskend-- Process any waiting weather updateswhiletruedo
msg = subscriber:recv(zmq.NOBLOCK)
ifnot msg thenbreakend-- process weather updateend-- No activity, so sleep for 1 msec
s_sleep (1)
end-- We never get here but clean up anyhow
receiver:close()
subscriber:close()
context:term()
/* msreader.m: Reads from multiple sockets the hard way.
* *** DON'T DO THIS - see mspoller.m for a better example. *** */#import "ZMQObjC.h"
static NSString *const kTaskVentEndpoint = @"tcp://localhost:5557";
static NSString *const kWeatherServerEndpoint = @"tcp://localhost:5556";
#define MSEC_PER_NSEC (1000000)
intmain(void)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
ZMQContext *ctx = [[[ZMQContext alloc] initWithIOThreads:1U] autorelease];
/* Connect to task ventilator. */
ZMQSocket *receiver = [ctx socketWithType:ZMQ_PULL];
[receiver connectToEndpoint:kTaskVentEndpoint];
/* Connect to weather server. */
ZMQSocket *subscriber = [ctx socketWithType:ZMQ_SUB];
[subscriber connectToEndpoint:kWeatherServerEndpoint];
NSData *subData = [@"10001" dataUsingEncoding:NSUTF8StringEncoding];
[subscriber setData:subData forOption:ZMQ_SUBSCRIBE];
/* Process messages from both sockets, prioritizing the task vent. *//* Could fair queue by checking each socket for activity in turn, rather
* than continuing to service the current socket as long as it is busy. */struct timespec msec = {0, MSEC_PER_NSEC};
for (;;) {
/* Worst case: a task is always pending and we never get to weather,
* or vice versa. In such a case, memory use would rise without
* limit if we did not ensure the objects autoreleased by a single loop
* will be autoreleased whether we leave or continue in the loop. */
NSAutoreleasePool *p;
/* Process any waiting tasks. */for (p = [[NSAutoreleasePool alloc] init];
nil != [receiver receiveDataWithFlags:ZMQ_NOBLOCK];
[p drain], p = [[NSAutoreleasePool alloc] init]);
[p drain];
/* No waiting tasks - process any waiting weather updates. */for (p = [[NSAutoreleasePool alloc] init];
nil != [subscriber receiveDataWithFlags:ZMQ_NOBLOCK];
[p drain], p = [[NSAutoreleasePool alloc] init]);
[p drain];
/* Nothing doing - sleep for a millisecond. */
(void)nanosleep(&msec, NULL);
}
/* NOT REACHED */
[ctx closeSockets];
[pool drain]; /* This finally releases the autoreleased context. */return EXIT_SUCCESS;
}
# Reading from multiple sockets in Perl# This version uses a simple recv loopusestrict;
usewarnings;
usev5.10;
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_PULL ZMQ_SUB ZMQ_DONTWAIT);
useTryCatch;
useTime::HiResqw(usleep);
# Connect to task ventilatormy$context = ZMQ::FFI->new();
my$receiver = $context->socket(ZMQ_PULL);
$receiver->connect('tcp://localhost:5557');
# Connect to weather servermy$subscriber = $context->socket(ZMQ_SUB);
$subscriber->connect('tcp://localhost:5556');
$subscriber->subscribe('10001');
# Process messages from both sockets# We prioritize traffic from the task ventilatorwhile (1) {
PROCESS_TASK:
while (1) {
try {
my$msg = $receiver->recv(ZMQ_DONTWAIT);
# Process task
}
catch {
last PROCESS_TASK;
}
}
PROCESS_UPDATE:
while (1) {
try {
my$msg = $subscriber->recv(ZMQ_DONTWAIT);
# Process weather update
}
catch {
last PROCESS_UPDATE;
}
}
# No activity, so sleep for 1 msec
usleep(1000);
}
msreader: Multiple socket reader in PHP
<?php/*
* Reading from multiple sockets
* This version uses a simple recv loop
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/// Prepare our context and sockets
$context = new ZMQContext();
// Connect to task ventilator
$receiver = new ZMQSocket($context, ZMQ::SOCKET_PULL);
$receiver->connect("tcp://localhost:5557");
// Connect to weather server
$subscriber = new ZMQSocket($context, ZMQ::SOCKET_SUB);
$subscriber->connect("tcp://localhost:5556");
$subscriber->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "10001");
// Process messages from both sockets
// We prioritize traffic from the task ventilator
while (true) {
// Process any waiting tasks
try {
for ($rc = 0; !$rc;) {
if ($rc = $receiver->recv(ZMQ::MODE_NOBLOCK)) {
// process task
}
}
} catch (ZMQSocketException $e) {
// do nothing
}
try {
// Process any waiting weather updates
for ($rc = 0; !$rc;) {
if ($rc = $subscriber->recv(ZMQ::MODE_NOBLOCK)) {
// process weather update
}
}
} catch (ZMQSocketException $e) {
// do nothing
}
// No activity, so sleep for 1 msec
usleep(1);
}
msreader: Multiple socket reader in Python
# encoding: utf-8## Reading from multiple sockets# This version uses a simple recv loop## Author: Jeremy Avnet (brainsik) <spork(dash)zmq(at)theory(dot)org>#importzmqimporttime# Prepare our context and sockets
context = zmq.Context()
# Connect to task ventilator
receiver = context.socket(zmq.PULL)
receiver.connect("tcp://localhost:5557")
# Connect to weather server
subscriber = context.socket(zmq.SUB)
subscriber.connect("tcp://localhost:5556")
subscriber.setsockopt(zmq.SUBSCRIBE, b"10001")
# Process messages from both sockets# We prioritize traffic from the task ventilatorwhile True:
# Process any waiting taskswhile True:
try:
msg = receiver.recv(zmq.DONTWAIT)
except zmq.Again:
break# process task# Process any waiting weather updateswhile True:
try:
msg = subscriber.recv(zmq.DONTWAIT)
except zmq.Again:
break# process weather update# No activity, so sleep for 1 msec
time.sleep(0.001)
The cost of this approach is some additional latency on the first message (the sleep at the end of the loop, when there are no waiting messages to process). This would be a problem in applications where submillisecond latency was vital. Also, you need to check the documentation for nanosleep() or whatever function you use to make sure it does not busy-loop.
You can treat the sockets fairly by reading first from one, then the second rather than prioritizing them as we did in this example.
Now let’s see the same senseless little application done right, using zmq_poll():
// Reading from multiple sockets
// This version uses zmq_poll()
#include"zhelpers.h"intmain (void)
{
// Connect to task ventilator
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_connect (receiver, "tcp://localhost:5557");
// Connect to weather server
void *subscriber = zmq_socket (context, ZMQ_SUB);
zmq_connect (subscriber, "tcp://localhost:5556");
zmq_setsockopt (subscriber, ZMQ_SUBSCRIBE, "10001 ", 6);
zmq_pollitem_t items [] = {
{ receiver, 0, ZMQ_POLLIN, 0 },
{ subscriber, 0, ZMQ_POLLIN, 0 }
};
// Process messages from both sockets
while (1) {
char msg [256];
zmq_poll (items, 2, -1);
if (items [0].revents & ZMQ_POLLIN) {
int size = zmq_recv (receiver, msg, 255, 0);
if (size != -1) {
// Process task
}
}
if (items [1].revents & ZMQ_POLLIN) {
int size = zmq_recv (subscriber, msg, 255, 0);
if (size != -1) {
// Process weather update
}
}
}
zmq_close (subscriber);
zmq_ctx_destroy (context);
return0;
}
mspoller: Multiple socket poller in C++
//
// Reading from multiple sockets in C++
// This version uses zmq_poll()
//
#include"zhelpers.hpp"intmain (int argc, char *argv[])
{
zmq::context_t context(1);
// Connect to task ventilator
zmq::socket_t receiver(context, ZMQ_PULL);
receiver.connect("tcp://localhost:5557");
// Connect to weather server
zmq::socket_t subscriber(context, ZMQ_SUB);
subscriber.connect("tcp://localhost:5556");
subscriber.set(zmq::sockopt::subscribe, "10001 ");
// Initialize poll set
zmq::pollitem_t items [] = {
{ receiver, 0, ZMQ_POLLIN, 0 },
{ subscriber, 0, ZMQ_POLLIN, 0 }
};
// Process messages from both sockets
while (1) {
zmq::message_t message;
zmq::poll (&items [0], 2, -1);
if (items [0].revents & ZMQ_POLLIN) {
receiver.recv(&message);
// Process task
}
if (items [1].revents & ZMQ_POLLIN) {
subscriber.recv(&message);
// Process weather update
}
}
return0;
}
mspoller: Multiple socket poller in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid MSPoller(string[] args)
{
//
// Reading from multiple sockets
// This version uses zmq_poll()
//
// Author: metadings
//
using (var context = new ZContext())
using (var receiver = new ZSocket(context, ZSocketType.PULL))
using (var subscriber = new ZSocket(context, ZSocketType.SUB))
{
// Connect to task ventilator
receiver.Connect("tcp://127.0.0.1:5557");
// Connect to weather server
subscriber.Connect("tcp://127.0.0.1:5556");
subscriber.SetOption(ZSocketOption.SUBSCRIBE, "10001 ");
var sockets = new ZSocket[] { receiver, subscriber };
var polls = new ZPollItem[] { ZPollItem.CreateReceiver(), ZPollItem.CreateReceiver() };
// Process messages from both sockets
ZError error;
ZMessage[] msg;
while (true)
{
if (sockets.PollIn(polls, out msg, out error, TimeSpan.FromMilliseconds(64)))
{
if (msg[0] != null)
{
// Process task
}
if (msg[1] != null)
{
// Process weather update
}
}
else
{
if (error == ZError.ETERM)
return; // Interrupted
if (error != ZError.EAGAIN)
thrownew ZException(error);
}
}
}
}
}
}
mspoller: Multiple socket poller in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Reading from multiple sockets in Common Lisp;;; This version uses zmq_poll();;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.mspoller
(:nicknames#:mspoller)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.mspoller)
(defunmain ()
(zmq:with-context (context1)
;; Connect to task ventilator
(zmq:with-socket (receivercontextzmq:pull)
(zmq:connectreceiver"tcp://localhost:5557")
;; Connect to weather server
(zmq:with-socket (subscribercontextzmq:sub)
(zmq:connectsubscriber"tcp://localhost:5556")
(zmq:setsockoptsubscriberzmq:subscribe"10001 ")
;; Initialize poll set
(zmq:with-polls ((items . ((receiver . zmq:pollin)
(subscriber . zmq:pollin))))
;; Process messages from both sockets
(loop
(let ((revents (zmq:pollitems)))
(when (= (firstrevents) zmq:pollin)
(let ((message (make-instance'zmq:msg)))
(zmq:recvreceivermessage)
;; Process task
(dump-messagemessage)
(finish-output)))
(when (= (secondrevents) zmq:pollin)
(let ((message (make-instance'zmq:msg)))
(zmq:recvsubscribermessage)
;; Process weather update
(dump-messagemessage)
(finish-output)))))))))
(cleanup))
mspoller: Multiple socket poller in Delphi
program mspoller;
//
// Reading from multiple sockets
// This version uses zmq_poll()
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
receiver,
subscriber: TZMQSocket;
i,pc: Integer;
task: TZMQFrame;
poller: TZMQPoller;
pollResult: TZMQPollItem;
begin
// Prepare our context and sockets
context := TZMQContext.Create;
// Connect to task ventilator
receiver := Context.Socket( stPull );
receiver.connect( 'tcp://localhost:5557' );
// Connect to weather server
subscriber := Context.Socket( stSub );
subscriber.connect( 'tcp://localhost:5556' );
subscriber.subscribe( '10001' );
// Initialize poll set
poller := TZMQPoller.Create( true );
poller.Register( receiver, [pePollIn] );
poller.Register( subscriber, [pePollIn] );
task := nil;
// Process messages from both sockets
while True do
begin
pc := poller.poll;
if pePollIn in poller.PollItem[0].revents then
begin
receiver.recv( task );
// Process task
FreeAndNil( task );
end;
if pePollIn in poller.PollItem[1].revents then
begin
subscriber.recv( task );
// Process task
FreeAndNil( task );
end;
end;
// We never get here
poller.Free;
receiver.Free;
subscriber.Free;
context.Free;
end.
mspoller: Multiple socket poller in Erlang
#! /usr/bin/env escript
%%
%% Reading from multiple sockets
%% This version uses active sockets
%%
main(_) ->
{ok,Context} = erlzmq:context(),
%% Connect to task ventilator
{ok, Receiver} = erlzmq:socket(Context, [pull, {active, true}]),
ok = erlzmq:connect(Receiver, "tcp://localhost:5557"),
%% Connect to weather server
{ok, Subscriber} = erlzmq:socket(Context, [sub, {active, true}]),
ok = erlzmq:connect(Subscriber, "tcp://localhost:5556"),
ok = erlzmq:setsockopt(Subscriber, subscribe, <<"10001">>),
%% Process messages from both sockets
loop(Receiver, Subscriber),
%% We never get here
ok = erlzmq:close(Receiver),
ok = erlzmq:close(Subscriber),
ok = erlzmq:term(Context).
loop(Tasks, Weather) ->
receive
{zmq, Tasks, Msg, _Flags} ->
io:format("Processing task: ~s~n",[Msg]),
loop(Tasks, Weather);
{zmq, Weather, Msg, _Flags} ->
io:format("Processing weather update: ~s~n",[Msg]),
loop(Tasks, Weather)
end.
mspoller: Multiple socket poller in Elixir
defmodule Mspoller do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:27
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, receiver} = :erlzmq.socket(context, [:pull, {:active, true}])
:ok = :erlzmq.connect(receiver, 'tcp://localhost:5557')
{:ok, subscriber} = :erlzmq.socket(context, [:sub, {:active, true}])
:ok = :erlzmq.connect(subscriber, 'tcp://localhost:5556')
:ok = :erlzmq.setsockopt(subscriber, :subscribe, "10001")
loop(receiver, subscriber)
:ok = :erlzmq.close(receiver)
:ok = :erlzmq.close(subscriber)
:ok = :erlzmq.term(context)
end
def loop(tasks, weather) do
receive do
{:zmq, ^tasks, msg, _flags} ->
:io.format('Processing task: ~s~n', [msg])
loop(tasks, weather)
{:zmq, ^weather, msg, _flags} ->
:io.format('Processing weather update: ~s~n', [msg])
loop(tasks, weather)
end
end
end
Mspoller.main
mspoller: Multiple socket poller in F#
(*
Reading from multiple sockets
This version uses zmq_poll()
*)
#r @"bin/fszmq.dll"
open fszmq
#load "zhelpers.fs"
open Context
open Socket
let main () =
use context = new Context(1)
// Connect to task ventilator
use receiver = context |> pull
connect receiver "tcp://localhost:5557"
// Connect to weather server
use subscriber = context |> sub
connect subscriber "tcp://localhost:5556"
subscribe subscriber [ encode "10001" ]
// Initialize pollset
let items =
let printNextMessage = recv >> decode >> printfn "%s"
[ Poll(ZMQ.POLLIN,receiver, fun s -> // Process task
printNextMessage s)
Poll(ZMQ.POLLIN,subscriber, fun s -> // Process weather update
printNextMessage s) ]
// Process messages from both sockets
while true do
(Polling.poll -1L items) |> ignore
// We never get here
EXIT_SUCCESS
main ()
mspoller: Multiple socket poller in Felix
//
// Reading from multiple sockets
// This version uses zmq_poll()
//
open ZMQ;
var context = zmq_init 1;
// Connect to task ventilator
var receiver = context.mk_socket ZMQ_PULL;
receiver.connect "tcp://localhost:5557";
// Connect to weather server
var subscriber = context.mk_socket ZMQ_SUB;
subscriber.connect "tcp://localhost:5556";
subscriber.set_opt$ zmq_subscribe "101 ";
// Initialize poll set
var items = varray(
zmq_poll_item (receiver, ZMQ_POLLIN),
zmq_poll_item (subscriber, ZMQ_POLLOUT))
;
// Process messages from both sockets
while true do
C_hack::ignore$ poll (items, -1.0);
if (items.[0].revents \& ZMQ_POLLIN).short != 0s do
var s = receiver.recv_string;
// Process task
done
if (items.[1].revents \& ZMQ_POLLIN).short != 0s do
s = subscriber.recv_string;
done
done
mspoller: Multiple socket poller in Go
//
// Reading from multiple sockets
// This version uses zmq.Poll()
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
)
funcmain() {
context, _ := zmq.NewContext()
defer context.Close()
// Connect to task ventilator
receiver, _ := context.NewSocket(zmq.PULL)
defer receiver.Close()
receiver.Connect("tcp://localhost:5557")
// Connect to weather server
subscriber, _ := context.NewSocket(zmq.SUB)
defer subscriber.Close()
subscriber.Connect("tcp://localhost:5556")
subscriber.SetSubscribe("10001")
pi := zmq.PollItems{
zmq.PollItem{Socket: receiver, Events: zmq.POLLIN},
zmq.PollItem{Socket: subscriber, Events: zmq.POLLIN},
}
// Process messages from both sockets
for {
_, _ = zmq.Poll(pi, -1)
switch {
case pi[0].REvents&zmq.POLLIN != 0:
// Process task
pi[0].Socket.Recv(0) // eat the incoming message
case pi[1].REvents&zmq.POLLIN != 0:
// Process weather update
pi[1].Socket.Recv(0) // eat the incoming message
}
}
fmt.Println("done")
}
mspoller: Multiple socket poller in Haskell
{-# LANGUAGE OverloadedStrings #-}-- Reading from multiple sockets-- This version uses zmq_poll()moduleMainwhereimportControl.MonadimportSystem.ZMQ4.Monadicmain::IO()main= runZMQ $ do-- Connect to task ventilator
receiver <- socket Pull
connect receiver "tcp://localhost:5557"-- Connect to weather server
subscriber <- socket Sub
connect subscriber "tcp://localhost:5556"
subscribe subscriber "10001 "-- Process messages from both sockets
forever $
poll (-1) [ Sock receiver [In] (Just receiver_callback)
, Sock subscriber [In] (Just subscriber_callback)
]
where-- Process task
receiver_callback :: [Event] ->ZMQ z ()
receiver_callback _= return ()-- Process weather update
subscriber_callback :: [Event] ->ZMQ z ()
subscriber_callback _= return ()
---- Reading from multiple sockets-- This version uses :poll()---- Author: Robert G. Jakabosky <bobby@sharedrealm.com>--
require"zmq"
require"zmq.poller"
require"zhelpers"local context = zmq.init(1)
-- Connect to task ventilatorlocal receiver = context:socket(zmq.PULL)
receiver:connect("tcp://localhost:5557")
-- Connect to weather serverlocal subscriber = context:socket(zmq.SUB)
subscriber:connect("tcp://localhost:5556")
subscriber:setopt(zmq.SUBSCRIBE, "10001 ", 6)
local poller = zmq.poller(2)
poller:add(receiver, zmq.POLLIN, function()
local msg = receiver:recv()
-- Process taskend)
poller:add(subscriber, zmq.POLLIN, function()
local msg = subscriber:recv()
-- Process weather updateend)
-- Process messages from both sockets-- start poller's event loop
poller:start()
-- We never get here
receiver:close()
subscriber:close()
context:term()
mspoller: Multiple socket poller in Node.js
// Reading from multiple sockets.
// This version listens for emitted 'message' events.
var zmq = require('zeromq')
// Connect to task ventilator
var receiver = zmq.socket('pull')
receiver.on('message', function(msg) {
console.log("From Task Ventilator:", msg.toString())
})
// Connect to weather server.
var subscriber = zmq.socket('sub')
subscriber.subscribe('10001')
subscriber.on('message', function(msg) {
console.log("Weather Update:", msg.toString())
})
receiver.connect('tcp://localhost:5557')
subscriber.connect('tcp://localhost:5556')
# Reading from multiple sockets in Perl# This version uses AnyEvent to poll the socketsusestrict;
usewarnings;
usev5.10;
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_PULL ZMQ_SUB);
useAnyEvent;
useEV;
# Connect to the task ventilatormy$context = ZMQ::FFI->new();
my$receiver = $context->socket(ZMQ_PULL);
$receiver->connect('tcp://localhost:5557');
# Connect to weather servermy$subscriber = $context->socket(ZMQ_SUB);
$subscriber->connect('tcp://localhost:5556');
$subscriber->subscribe('10001');
my$pull_poller = AE::io $receiver->get_fd, 0, sub {
while ($receiver->has_pollin) {
my$msg = $receiver->recv();
# Process task
}
};
my$sub_poller = AE::io $subscriber->get_fd, 0, sub {
while ($subscriber->has_pollin) {
my$msg = $subscriber->recv();
# Process weather update
}
};
EV::run;
mspoller: Multiple socket poller in PHP
<?php/*
* Reading from multiple sockets
* This version uses zmq_poll()
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/$context = new ZMQContext();
// Connect to task ventilator
$receiver = new ZMQSocket($context, ZMQ::SOCKET_PULL);
$receiver->connect("tcp://localhost:5557");
// Connect to weather server
$subscriber = new ZMQSocket($context, ZMQ::SOCKET_SUB);
$subscriber->connect("tcp://localhost:5556");
$subscriber->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "10001");
// Initialize poll set
$poll = new ZMQPoll();
$poll->add($receiver, ZMQ::POLL_IN);
$poll->add($subscriber, ZMQ::POLL_IN);
$readable = $writeable = array();
// Process messages from both sockets
while (true) {
$events = $poll->poll($readable, $writeable);
if ($events > 0) {
foreach ($readableas$socket) {
if ($socket === $receiver) {
$message = $socket->recv();
// Process task
} elseif ($socket === $subscriber) {
$mesage = $socket->recv();
// Process weather update
}
}
}
}
// We never get here
mspoller: Multiple socket poller in Python
# encoding: utf-8## Reading from multiple sockets# This version uses zmq.Poller()## Author: Jeremy Avnet (brainsik) <spork(dash)zmq(at)theory(dot)org>#importzmq# Prepare our context and sockets
context = zmq.Context()
# Connect to task ventilator
receiver = context.socket(zmq.PULL)
receiver.connect("tcp://localhost:5557")
# Connect to weather server
subscriber = context.socket(zmq.SUB)
subscriber.connect("tcp://localhost:5556")
subscriber.setsockopt(zmq.SUBSCRIBE, b"10001")
# Initialize poll set
poller = zmq.Poller()
poller.register(receiver, zmq.POLLIN)
poller.register(subscriber, zmq.POLLIN)
# Process messages from both socketswhile True:
try:
socks = dict(poller.poll())
except KeyboardInterrupt:
breakif receiver in socks:
message = receiver.recv()
# process taskif subscriber in socks:
message = subscriber.recv()
# process weather update
typedefstruct {
void *socket; // ZeroMQ socket to poll on
int fd; // OR, native file handle to poll on
short events; // Events to poll on
short revents; // Events returned after poll
} zmq_pollitem_t;
ZeroMQ lets us compose a message out of several frames, giving us a “multipart message”. Realistic applications use multipart messages heavily, both for wrapping messages with address information and for simple serialization. We’ll look at reply envelopes later.
What we’ll learn now is simply how to blindly and safely read and write multipart messages in any application (such as a proxy) that needs to forward messages without inspecting them.
When you work with multipart messages, each part is a zmq_msg item. E.g., if you are sending a message with five parts, you must construct, send, and destroy five zmq_msg items. You can do this in advance (and store the zmq_msg items in an array or other structure), or as you send them, one-by-one.
Here is how we send the frames in a multipart message (we receive each frame into a message object):
ZeroMQ aims for decentralized intelligence, but that doesn’t mean your network is empty space in the middle. It’s filled with message-aware infrastructure and quite often, we build that infrastructure with ZeroMQ. The ZeroMQ plumbing can range from tiny pipes to full-blown service-oriented brokers. The messaging industry calls this intermediation, meaning that the stuff in the middle deals with either side. In ZeroMQ, we call these proxies, queues, forwarders, device, or brokers, depending on the context.
This pattern is extremely common in the real world and is why our societies and economies are filled with intermediaries who have no other real function than to reduce the complexity and scaling costs of larger networks. Real-world intermediaries are typically called wholesalers, distributors, managers, and so on.
One of the problems you will hit as you design larger distributed architectures is discovery. That is, how do pieces know about each other? It’s especially difficult if pieces come and go, so we call this the “dynamic discovery problem”.
There are several solutions to dynamic discovery. The simplest is to entirely avoid it by hard-coding (or configuring) the network architecture so discovery is done by hand. That is, when you add a new piece, you reconfigure the network to know about it.
Figure 12 - Small-Scale Pub-Sub Network
In practice, this leads to increasingly fragile and unwieldy architectures. Let’s say you have one publisher and a hundred subscribers. You connect each subscriber to the publisher by configuring a publisher endpoint in each subscriber. That’s easy. Subscribers are dynamic; the publisher is static. Now say you add more publishers. Suddenly, it’s not so easy any more. If you continue to connect each subscriber to each publisher, the cost of avoiding dynamic discovery gets higher and higher.
Figure 13 - Pub-Sub Network with a Proxy
There are quite a few answers to this, but the very simplest answer is to add an intermediary; that is, a static point in the network to which all other nodes connect. In classic messaging, this is the job of the message broker. ZeroMQ doesn’t come with a message broker as such, but it lets us build intermediaries quite easily.
You might wonder, if all networks eventually get large enough to need intermediaries, why don’t we simply have a message broker in place for all applications? For beginners, it’s a fair compromise. Just always use a star topology, forget about performance, and things will usually work. However, message brokers are greedy things; in their role as central intermediaries, they become too complex, too stateful, and eventually a problem.
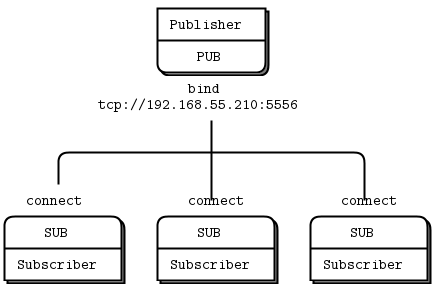
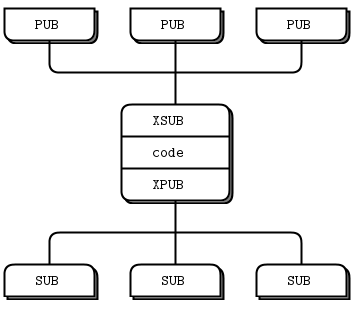
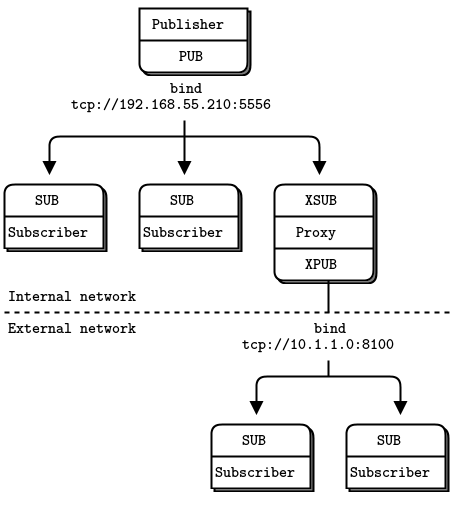
It’s better to think of intermediaries as simple stateless message switches. A good analogy is an HTTP proxy; it’s there, but doesn’t have any special role. Adding a pub-sub proxy solves the dynamic discovery problem in our example. We set the proxy in the “middle” of the network. The proxy opens an XSUB socket, an XPUB socket, and binds each to well-known IP addresses and ports. Then, all other processes connect to the proxy, instead of to each other. It becomes trivial to add more subscribers or publishers.
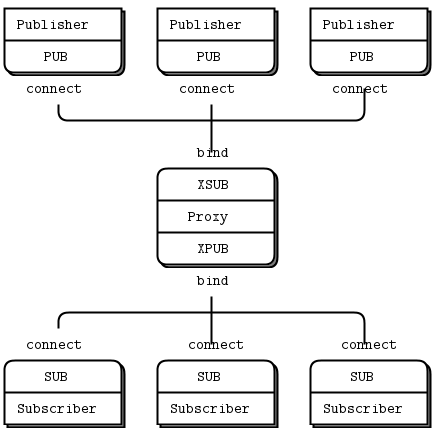
Figure 14 - Extended Pub-Sub
We need XPUB and XSUB sockets because ZeroMQ does subscription forwarding from subscribers to publishers. XSUB and XPUB are exactly like SUB and PUB except they expose subscriptions as special messages. The proxy has to forward these subscription messages from subscriber side to publisher side, by reading them from the XPUB socket and writing them to the XSUB socket. This is the main use case for XSUB and XPUB.
In the Hello World client/server application, we have one client that talks to one service. However, in real cases we usually need to allow multiple services as well as multiple clients. This lets us scale up the power of the service (many threads or processes or nodes rather than just one). The only constraint is that services must be stateless, all state being in the request or in some shared storage such as a database.
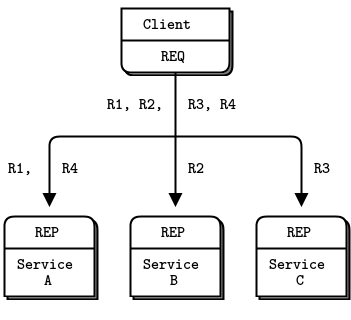
Figure 15 - Request Distribution
There are two ways to connect multiple clients to multiple servers. The brute force way is to connect each client socket to multiple service endpoints. One client socket can connect to multiple service sockets, and the REQ socket will then distribute requests among these services. Let’s say you connect a client socket to three service endpoints; A, B, and C. The client makes requests R1, R2, R3, R4. R1 and R4 go to service A, R2 goes to B, and R3 goes to service C.
This design lets you add more clients cheaply. You can also add more services. Each client will distribute its requests to the services. But each client has to know the service topology. If you have 100 clients and then you decide to add three more services, you need to reconfigure and restart 100 clients in order for the clients to know about the three new services.
That’s clearly not the kind of thing we want to be doing at 3 a.m. when our supercomputing cluster has run out of resources and we desperately need to add a couple of hundred of new service nodes. Too many static pieces are like liquid concrete: knowledge is distributed and the more static pieces you have, the more effort it is to change the topology. What we want is something sitting in between clients and services that centralizes all knowledge of the topology. Ideally, we should be able to add and remove services or clients at any time without touching any other part of the topology.
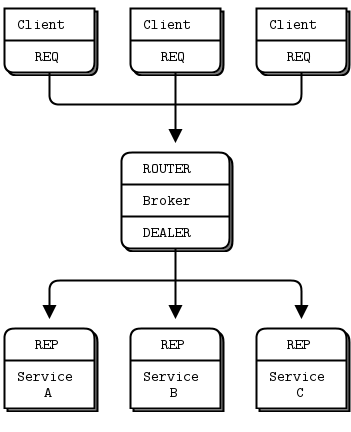
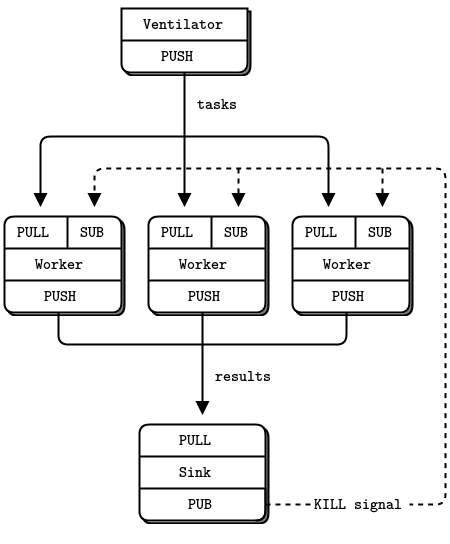
So we’ll write a little message queuing broker that gives us this flexibility. The broker binds to two endpoints, a frontend for clients and a backend for services. It then uses zmq_poll() to monitor these two sockets for activity and when it has some, it shuttles messages between its two sockets. It doesn’t actually manage any queues explicitly–ZeroMQ does that automatically on each socket.
When you use REQ to talk to REP, you get a strictly synchronous request-reply dialog. The client sends a request. The service reads the request and sends a reply. The client then reads the reply. If either the client or the service try to do anything else (e.g., sending two requests in a row without waiting for a response), they will get an error.
But our broker has to be nonblocking. Obviously, we can use zmq_poll() to wait for activity on either socket, but we can’t use REP and REQ.
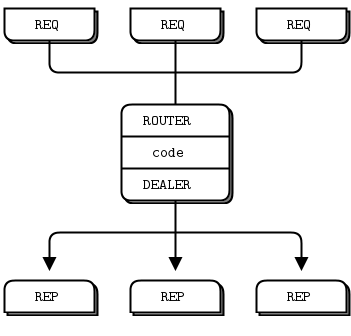
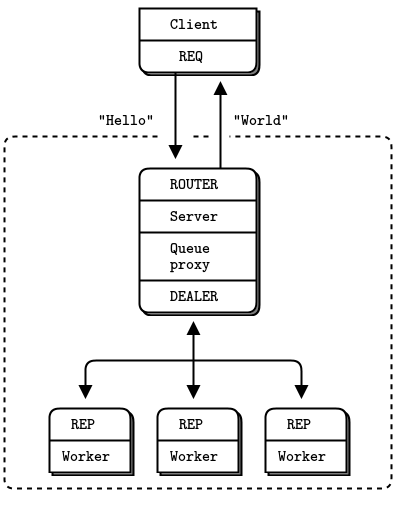
Figure 16 - Extended Request-Reply
Luckily, there are two sockets called DEALER and ROUTER that let you do nonblocking request-response. You’ll see in
Chapter 3 - Advanced Request-Reply Patterns how DEALER and ROUTER sockets let you build all kinds of asynchronous request-reply flows. For now, we’re just going to see how DEALER and ROUTER let us extend REQ-REP across an intermediary, that is, our little broker.
In this simple extended request-reply pattern, REQ talks to ROUTER and DEALER talks to REP. In between the DEALER and ROUTER, we have to have code (like our broker) that pulls messages off the one socket and shoves them onto the other.
The request-reply broker binds to two endpoints, one for clients to connect to (the frontend socket) and one for workers to connect to (the backend). To test this broker, you will want to change your workers so they connect to the backend socket. Here is a client that shows what I mean:
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid RRClient(string[] args)
{
//
// Hello World client
// Connects REQ socket to tcp://127.0.0.1:5559
// Sends "Hello" to server, expects "World" back
//
// Author: metadings
//
// Socket to talk to server
using (var context = new ZContext())
using (var requester = new ZSocket(context, ZSocketType.REQ))
{
requester.Connect("tcp://127.0.0.1:5559");
for (int n = 0; n < 10; ++n)
{
requester.Send(new ZFrame("Hello"));
using (ZFrame reply = requester.ReceiveFrame())
{
Console.WriteLine("Hello {0}!", reply.ReadString());
}
}
}
}
}
}
rrclient: Request-reply client in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Hello World client in Common Lisp;;; Connects REQ socket to tcp://localhost:5555;;; Sends "Hello" to server, expects "World" back;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.rrclient
(:nicknames#:rrclient)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.rrclient)
(defunmain ()
(zmq:with-context (context1)
;; Socket to talk to server
(zmq:with-socket (requestercontextzmq:req)
(zmq:connectrequester"tcp://localhost:5559")
(dotimes (request-nbr10)
(let ((request (make-instance'zmq:msg:data"Hello")))
(zmq:sendrequesterrequest))
(let ((response (make-instance'zmq:msg)))
(zmq:recvrequesterresponse)
(message"Received reply ~D: [~A]~%"request-nbr (zmq:msg-data-as-stringresponse))))))
(cleanup))
rrclient: Request-reply client in Delphi
program rrclient;
//
// Hello World client
// Connects REQ socket to tcp://localhost:5559
// Sends "Hello" to server, expects "World" back
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
requester: TZMQSocket;
i: Integer;
s: Utf8String;
begin
context := TZMQContext.Create;
// Socket to talk to server
requester := Context.Socket( stReq );
requester.connect( 'tcp://localhost:5559' );
for i := 0 to 9 do
begin
requester.send( 'Hello' );
requester.recv( s );
Writeln( Format( 'Received reply %d [%s]',[i, s] ) );
end;
requester.Free;
context.Free;
end.
rrclient: Request-reply client in Erlang
#! /usr/bin/env escript
%%
%% Hello World client
%% Connects REQ socket to tcp://localhost:5559
%% Sends "Hello" to server, expects "World" back
%%
main(_) ->
{ok, Context} = erlzmq:context(),
%% Socket to talk to server
{ok, Requester} = erlzmq:socket(Context, req),
ok = erlzmq:connect(Requester, "tcp://*:5559"),
lists:foreach(
fun(Num) ->
erlzmq:send(Requester, <<"Hello">>),
{ok, Reply} = erlzmq:recv(Requester),
io:format("Received reply ~b [~s]~n", [Num, Reply])
end, lists:seq(1, 10)),
ok = erlzmq:close(Requester),
ok = erlzmq:term(Context).
rrclient: Request-reply client in Elixir
defmodule Rrclient do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:31
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, requester} = :erlzmq.socket(context, :req)
#:ok = :erlzmq.connect(requester, 'tcp://*:5559'):ok = :erlzmq.connect(requester, 'tcp://localhost:5559')
:lists.foreach(fn num ->
:erlzmq.send(requester, "Hello")
{:ok, reply} = :erlzmq.recv(requester)
:io.format('Received reply ~b [~s]~n', [num, reply])
end, :lists.seq(1, 10))
:ok = :erlzmq.close(requester)
:ok = :erlzmq.term(context)
end
end
Rrclient.main()
rrclient: Request-reply client in F#
(*
Hello World client
Connects REQ socket to tcp://localhost:5559
Sends "Hello" to server, expects "World" back
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
let main () =
use context = new Context(1)
// socket to talk to server
use requester = req context
"tcp://localhost:5559" |> connect requester
for request_nbr in 0 .. 9 do
"Hello" |> s_send requester
let message = s_recv requester
printfn "Received reply %d [%s]" request_nbr message
EXIT_SUCCESS
main ()
// Hello World client
// Connects REQ socket to tcp://localhost:5559
// Sends "Hello" to server, expects "World" back
//
// Author: Brendan Mc.
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
)
funcmain() {
context, _ := zmq.NewContext()
defer context.Close()
// Socket to talk to clients
requester, _ := context.NewSocket(zmq.REQ)
defer requester.Close()
requester.Connect("tcp://localhost:5559")
for i := 0; i < 10; i++ {
requester.Send([]byte("Hello"), 0)
reply, _ := requester.Recv(0)
fmt.Printf("Received reply %d [%s]\n", i, reply)
}
}
rrclient: Request-reply client in Haskell
{-# LANGUAGE OverloadedStrings #-}-- |-- Request/Reply Hello World with broker (p.50) -- Binds REQ socket to tcp://localhost:5559-- Sends "Hello" to server, expects "World" back-- -- Use with `rrbroker.hs` and `rrworker.hs`-- You need to start the broker first !moduleMainwhereimportSystem.ZMQ4.MonadicimportControl.Monad (forM_)
importData.ByteString.Char8 (unpack)
importText.Printfmain::IO()main=
runZMQ $ do
requester <- socket Req
connect requester "tcp://localhost:5559"
forM_ [1..10] $ \i ->do
send requester []"Hello"
msg <- receive requester
liftIO $ printf "Received reply %d %s\n" (i ::Int) (unpack msg)
rrclient: Request-reply client in Haxe
package ;
importneko.Lib;
importhaxe.io.Bytes;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQContext;
importorg.zeromq.ZMQSocket;
/**
* Hello World Client
* Connects REQ socket to tcp://localhost:5559
* Sends "Hello" to server, expects "World" back
*
* See: http://zguide.zeromq.org/page:all#A-Request-Reply-Broker
*
* Use with RrServer and RrBroker
*/class RrClient
{
publicstaticfunctionmain() {
var context:ZMQContext = ZMQContext.instance();
Lib.println("** RrClient (see: http://zguide.zeromq.org/page:all#A-Request-Reply-Broker)");
var requester:ZMQSocket = context.socket(ZMQ_REQ);
requester.connect ("tcp://localhost:5559");
Lib.println ("Launch and connect client.");
// Do 10 requests, waiting each time for a responsefor (i in0...10) {
var requestString = "Hello ";
// Send the message
requester.sendMsg(Bytes.ofString(requestString));
// Wait for the replyvar msg:Bytes = requester.recvMsg();
Lib.println("Received reply " + i + ": [" + msg.toString() + "]");
}
// Shut down socket and context
requester.close();
context.term();
}
}
rrclient: Request-reply client in Java
packageguide;
importorg.zeromq.SocketType;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQ.Socket;
importorg.zeromq.ZContext;
/**
* Hello World client
* Connects REQ socket to tcp://localhost:5559
* Sends "Hello" to server, expects "World" back
*/publicclassrrclient
{
publicstaticvoidmain(String[] args)
{
try (ZContext context = new ZContext()) {
// Socket to talk to server
Socket requester = context.createSocket(SocketType.REQ);
requester.connect("tcp://localhost:5559");
System.out.println("launch and connect client.");
for (int request_nbr = 0; request_nbr < 10; request_nbr++) {
requester.send("Hello", 0);
String reply = requester.recvStr(0);
System.out.println(
"Received reply " + request_nbr + " [" + reply + "]"
);
}
}
}
}
---- Hello World client-- Connects REQ socket to tcp://localhost:5559-- Sends "Hello" to server, expects "World" back---- Author: Robert G. Jakabosky <bobby@sharedrealm.com>--
require"zmq"
require"zhelpers"local context = zmq.init(1)
-- Socket to talk to serverlocal requester = context:socket(zmq.REQ)
requester:connect("tcp://localhost:5559")
for n=0,9do
requester:send("Hello")
local msg = requester:recv()
printf ("Received reply %d [%s]\n", n, msg)
end
requester:close()
context:term()
rrclient: Request-reply client in Node.js
// Hello World client in Node.js
// Connects REQ socket to tcp://localhost:5559
// Sends "Hello" to server, expects "World" back
var zmq = require('zeromq')
, requester = zmq.socket('req');
requester.connect('tcp://localhost:5559');
var replyNbr = 0;
requester.on('message', function(msg) {
console.log('got reply', replyNbr, msg.toString());
replyNbr += 1;
});
for (var i = 0; i < 10; ++i) {
requester.send("Hello");
}
// Hello World worker
// Connects REP socket to tcp://localhost:5560
// Expects "Hello" from client, replies with "World"
#include"zhelpers.h"#include<unistd.h>intmain (void)
{
void *context = zmq_ctx_new ();
// Socket to talk to clients
void *responder = zmq_socket (context, ZMQ_REP);
zmq_connect (responder, "tcp://localhost:5560");
while (1) {
// Wait for next request from client
char *string = s_recv (responder);
printf ("Received request: [%s]\n", string);
free (string);
// Do some 'work'
sleep (1);
// Send reply back to client
s_send (responder, "World");
}
// We never get here, but clean up anyhow
zmq_close (responder);
zmq_ctx_destroy (context);
return0;
}
rrworker: Request-reply worker in C++
//
// Request-reply service in C++
// Connects REP socket to tcp://localhost:5560
// Expects "Hello" from client, replies with "World"
//
#include<zmq.hpp>#include<chrono>#include<thread>intmain(int argc, char* argv[])
{
zmq::context_t context{1};
zmq::socket_t responder{context, zmq::socket_type::rep};
responder.connect("tcp://localhost:5560");
while (true) {
// Wait for next request from client
zmq::message_t request_msg;
auto recv_result = responder.recv(request_msg, zmq::recv_flags::none);
std::string string = request_msg.to_string();
std::cout << "Received request: " << string << std::endl;
// Do some 'work'
std::this_thread::sleep_for(std::chrono::seconds(1));
// Send reply back to client
zmq::message_t reply_msg{std::string{"World"}};
responder.send(reply_msg, zmq::send_flags::none);
}
}
rrworker: Request-reply worker in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid RRWorker(string[] args)
{
//
// Hello World worker
// Connects REP socket to tcp://127.0.0.1:5560
// Expects "Hello" from client, replies with "World"
//
// Author: metadings
//
if (args == null || args.Length < 2)
{
Console.WriteLine();
Console.WriteLine("Usage: ./{0} RRWorker [Name] [Endpoint]", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
Console.WriteLine(" Name Your Name");
Console.WriteLine(" Endpoint Where RRWorker should connect to.");
Console.WriteLine(" Default is tcp://127.0.0.1:5560");
Console.WriteLine();
if (args.Length < 1) {
args = newstring[] { "World", "tcp://127.0.0.1:5560" };
} else {
args = newstring[] { args[0], "tcp://127.0.0.1:5560" };
}
}
string name = args[0];
string endpoint = args[1];
// Socket to talk to clients
using (var context = new ZContext())
using (var responder = new ZSocket(context, ZSocketType.REP))
{
responder.Connect(endpoint);
while (true)
{
// Wait for next request from client
using (ZFrame request = responder.ReceiveFrame())
{
Console.Write("{0} ", request.ReadString());
// Do some 'work'
Thread.Sleep(1);
// Send reply back to client
Console.WriteLine("{0}... ", name);
responder.Send(new ZFrame(name));
}
}
}
}
}
}
rrworker: Request-reply worker in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Hello World server in Common Lisp;;; Binds REP socket to tcp://*:5555;;; Expects "Hello" from client, replies with "World";;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.rrserver
(:nicknames#:rrserver)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.rrserver)
(defunmain ()
(zmq:with-context (context1)
;; Socket to talk to clients
(zmq:with-socket (respondercontextzmq:rep)
(zmq:connectresponder"tcp://localhost:5560")
(loop
(let ((request (make-instance'zmq:msg)))
;; Wait for next request from client
(zmq:recvresponderrequest)
(message"Received request: [~A]~%"
(zmq:msg-data-as-stringrequest))
;; Do some 'work'
(sleep1)
;; Send reply back to client
(let ((reply (make-instance'zmq:msg:data"World")))
(zmq:sendresponderreply))))))
(cleanup))
rrworker: Request-reply worker in Delphi
program rrserver;
//
// Hello World server
// Connects REP socket to tcp://*:5560
// Expects "Hello" from client, replies with "World"
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
responder: TZMQSocket;
s: Utf8String;
begin
context := TZMQContext.Create;
// Socket to talk to clients
responder := Context.Socket( stRep );
responder.connect( 'tcp://localhost:5560' );
while True do
begin
// Wait for next request from client
responder.recv( s );
Writeln( Format( 'Received request: [%s]', [ s ] ) );
// Do some 'work'
sleep( 1 );
// Send reply back to client
responder.send( 'World' );
end;
// We never get here but clean up anyhow
responder.Free;
context.Free;
end.
rrworker: Request-reply worker in Erlang
#! /usr/bin/env escript
%%
%% Hello World server
%% Connects REP socket to tcp://*:5560
%% Expects "Hello" from client, replies with "World"
%%
main(_) ->
{ok, Context} = erlzmq:context(),
%% Socket to talk to clients
{ok, Responder} = erlzmq:socket(Context, rep),
ok = erlzmq:connect(Responder, "tcp://*:5560"),
loop(Responder),
%% We never get here but clean up anyhow
ok = erlzmq:close(Responder),
ok = erlzmq:term(Context).
loop(Socket) ->
%% Wait for next request from client
{ok, Req} = erlzmq:recv(Socket),
io:format("Received request: [~s]~n", [Req]),
%% Do some 'work'
timer:sleep(1000),
%% Send reply back to client
ok = erlzmq:send(Socket, <<"World">>),
loop(Socket).
rrworker: Request-reply worker in Elixir
defmodule Rrworker do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:32
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, responder} = :erlzmq.socket(context, :rep)
#:ok = :erlzmq.connect(responder, 'tcp://*:5560'):ok = :erlzmq.connect(responder, 'tcp://localhost:5560')
loop(responder)
:ok = :erlzmq.close(responder)
:ok = :erlzmq.term(context)
end
def loop(socket) do
{:ok, req} = :erlzmq.recv(socket)
:io.format('Received request: [~s]~n', [req])
:timer.sleep(1000)
:ok = :erlzmq.send(socket, "World")
loop(socket)
end
end
Rrworker.main()
rrworker: Request-reply worker in F#
(*
Hello World server
Connects REP socket to tcp://*:5560
Expects "Hello" from client, replies with "World"
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
let main () =
use context = new Context(1)
// socket to talk to clients
use responder = rep context
"tcp://localhost:5560" |> connect responder
while true do
// wait for next request from client
let message = s_recv responder
printfn "Received request: [%s]" message
// do some 'work'
sleep 1
// send reply back to client
"World" |> s_send responder
// we never get here but clean up anyhow
EXIT_SUCCESS
main ()
// Hello World server
// Connects REP socket to tcp://*:5560
// Expects "Hello" from client, replies with "World"
//
// Author: Brendan Mc.
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq""time"
)
funcmain() {
context, _ := zmq.NewContext()
defer context.Close()
// Socket to talk to clients
responder, _ := context.NewSocket(zmq.REP)
defer responder.Close()
responder.Connect("tcp://localhost:5560")
for {
// Wait for next request from client
request, _ := responder.Recv(0)
fmt.Printf("Received request: [%s]\n", request)
// Do some 'work'
time.Sleep(1 * time.Second)
// Send reply back to client
responder.Send([]byte("World"), 0)
}
}
rrworker: Request-reply worker in Haskell
{-# LANGUAGE OverloadedStrings #-}-- |-- A worker that simulates some work with a timeout-- And send back "World"-- Connect REP socket to tcp://*:5560-- Expects "Hello" from client, replies with "World"-- moduleMainwhereimportSystem.ZMQ4.MonadicimportControl.Monad (forever)
importData.ByteString.Char8 (unpack)
importControl.Concurrent (threadDelay)
importText.Printfmain::IO()main=
runZMQ $ do
responder <- socket Rep
connect responder "tcp://localhost:5560"
forever $ do
receive responder >>= liftIO . printf "Received request: [%s]\n" . unpack
-- Simulate doing some 'work' for 1 second
liftIO $ threadDelay (1 * 1000 * 1000)
send responder []"World"
rrworker: Request-reply worker in Haxe
package ;
importhaxe.io.Bytes;
importhaxe.Stack;
importneko.Lib;
importneko.Sys;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQContext;
importorg.zeromq.ZMQException;
importorg.zeromq.ZMQSocket;
/**
* Hello World server in Haxe
* Binds REP to tcp://*:5560
* Expects "Hello" from client, replies with "World"
* Use with RrClient.hx and RrBroker.hx
*
*/class RrServer
{
publicstaticfunctionmain() {
var context:ZMQContext = ZMQContext.instance();
Lib.println("** RrServer (see: http://zguide.zeromq.org/page:all#A-Request-Reply-Broker)");
// Socket to talk to clientsvar responder:ZMQSocket = context.socket(ZMQ_REP);
responder.connect("tcp://localhost:5560");
Lib.println("Launch and connect server.");
ZMQ.catchSignals();
while (true) {
try {
// Wait for next request from clientvar request:Bytes = responder.recvMsg();
trace ("Received request:" + request.toString());
// Do some work
Sys.sleep(1);
// Send reply back to client
responder.sendMsg(Bytes.ofString("World"));
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
break;
}
// Handle other errors
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
}
responder.close();
context.term();
}
}
rrworker: Request-reply worker in Java
packageguide;
importorg.zeromq.SocketType;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQ.Socket;
importorg.zeromq.ZContext;
// Hello World worker
// Connects REP socket to tcp://*:5560
// Expects "Hello" from client, replies with "World"
publicclassrrworker
{
publicstaticvoidmain(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
// Socket to talk to server
Socket responder = context.createSocket(SocketType.REP);
responder.connect("tcp://localhost:5560");
while (!Thread.currentThread().isInterrupted()) {
// Wait for next request from client
String string = responder.recvStr(0);
System.out.printf("Received request: [%s]\n", string);
// Do some 'work'
Thread.sleep(1000);
// Send reply back to client
responder.send("World");
}
}
}
}
---- Hello World server-- Connects REP socket to tcp://*:5560-- Expects "Hello" from client, replies with "World"---- Author: Robert G. Jakabosky <bobby@sharedrealm.com>--
require"zmq"
require"zhelpers"local context = zmq.init(1)
-- Socket to talk to clientslocal responder = context:socket(zmq.REP)
responder:connect("tcp://localhost:5560")
whiletruedo-- Wait for next request from clientlocal msg = responder:recv()
printf ("Received request: [%s]\n", msg)
-- Do some 'work'
s_sleep (1000)
-- Send reply back to client
responder:send("World")
end-- We never get here but clean up anyhow
responder:close()
context:term()
rrworker: Request-reply worker in Node.js
// Hello World server in Node.js
// Connects REP socket to tcp://*:5560
// Expects "Hello" from client, replies with "World"
var zmq = require('zeromq')
, responder = zmq.socket('rep');
responder.connect('tcp://localhost:5560');
responder.on('message', function(msg) {
console.log('received request:', msg.toString());
setTimeout(function() {
responder.send("World");
}, 1000);
});
# Hello world worker in Perl# Connects REP socket to tcp://localhost:5560# Expects "Hello from client, replies with "World"usestrict;
usewarnings;
usev5.10;
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_REP);
my$context = ZMQ::FFI->new();
# Socket to talk to clientsmy$responder = $context->socket(ZMQ_REP);
$responder->connect('tcp://localhost:5560');
while (1) {
# Wait for next request from clientmy$string = $responder->recv();
say "Received request: [$string]";
# Do some 'work'sleep1;
# Send reply back to client$responder->send("World");
}
rrworker: Request-reply worker in PHP
<?php/*
* Hello World server
* Connects REP socket to tcp://*:5560
* Expects "Hello" from client, replies with "World"
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/$context = new ZMQContext();
// Socket to talk to clients
$responder = new ZMQSocket($context, ZMQ::SOCKET_REP);
$responder->connect("tcp://localhost:5560");
while (true) {
// Wait for next request from client
$string = $responder->recv();
printf ("Received request: [%s]%s", $string, PHP_EOL);
// Do some 'work'
sleep(1);
// Send reply back to client
$responder->send("World");
}
rrworker: Request-reply worker in Python
## Request-reply service in Python# Connects REP socket to tcp://localhost:5560# Expects "Hello" from client, replies with "World"#importzmq
context = zmq.Context()
socket = context.socket(zmq.REP)
socket.connect("tcp://localhost:5560")
while True:
message = socket.recv()
print(f"Received request: {message}")
socket.send(b"World")
// Simple request-reply broker
#include"zhelpers.h"intmain (void)
{
// Prepare our context and sockets
void *context = zmq_ctx_new ();
void *frontend = zmq_socket (context, ZMQ_ROUTER);
void *backend = zmq_socket (context, ZMQ_DEALER);
zmq_bind (frontend, "tcp://*:5559");
zmq_bind (backend, "tcp://*:5560");
// Initialize poll set
zmq_pollitem_t items [] = {
{ frontend, 0, ZMQ_POLLIN, 0 },
{ backend, 0, ZMQ_POLLIN, 0 }
};
// Switch messages between sockets
while (1) {
zmq_msg_t message;
zmq_poll (items, 2, -1);
if (items [0].revents & ZMQ_POLLIN) {
while (1) {
// Process all parts of the message
zmq_msg_init (&message);
zmq_msg_recv (&message, frontend, 0);
int more = zmq_msg_more (&message);
zmq_msg_send (&message, backend, more? ZMQ_SNDMORE: 0);
zmq_msg_close (&message);
if (!more)
break; // Last message part
}
}
if (items [1].revents & ZMQ_POLLIN) {
while (1) {
// Process all parts of the message
zmq_msg_init (&message);
zmq_msg_recv (&message, backend, 0);
int more = zmq_msg_more (&message);
zmq_msg_send (&message, frontend, more? ZMQ_SNDMORE: 0);
zmq_msg_close (&message);
if (!more)
break; // Last message part
}
}
}
// We never get here, but clean up anyhow
zmq_close (frontend);
zmq_close (backend);
zmq_ctx_destroy (context);
return0;
}
rrbroker: Request-reply broker in C++
//
// Simple request-reply broker in C++
//
#include"zhelpers.hpp"intmain (int argc, char *argv[])
{
// Prepare our context and sockets
zmq::context_t context(1);
zmq::socket_t frontend (context, ZMQ_ROUTER);
zmq::socket_t backend (context, ZMQ_DEALER);
frontend.bind("tcp://*:5559");
backend.bind("tcp://*:5560");
// Initialize poll set
zmq::pollitem_t items [] = {
{ frontend, 0, ZMQ_POLLIN, 0 },
{ backend, 0, ZMQ_POLLIN, 0 }
};
// Switch messages between sockets
while (1) {
zmq::message_t message;
int more; // Multipart detection
zmq::poll (&items [0], 2, -1);
if (items [0].revents & ZMQ_POLLIN) {
while (1) {
// Process all parts of the message
frontend.recv(&message);
// frontend.recv(message, zmq::recv_flags::none); // new syntax
size_t more_size = sizeof (more);
frontend.getsockopt(ZMQ_RCVMORE, &more, &more_size);
backend.send(message, more? ZMQ_SNDMORE: 0);
// more = frontend.get(zmq::sockopt::rcvmore); // new syntax
// backend.send(message, more? zmq::send_flags::sndmore : zmq::send_flags::none);
if (!more)
break; // Last message part
}
}
if (items [1].revents & ZMQ_POLLIN) {
while (1) {
// Process all parts of the message
backend.recv(&message);
size_t more_size = sizeof (more);
backend.getsockopt(ZMQ_RCVMORE, &more, &more_size);
frontend.send(message, more? ZMQ_SNDMORE: 0);
// more = backend.get(zmq::sockopt::rcvmore); // new syntax
//frontend.send(message, more? zmq::send_flags::sndmore : zmq::send_flags::none);
if (!more)
break; // Last message part
}
}
}
return0;
}
rrbroker: Request-reply broker in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid RRBroker(string[] args)
{
//
// Simple request-reply broker
//
// Author: metadings
//
// Prepare our context and sockets
using (var ctx = new ZContext())
using (var frontend = new ZSocket(ctx, ZSocketType.ROUTER))
using (var backend = new ZSocket(ctx, ZSocketType.DEALER))
{
frontend.Bind("tcp://*:5559");
backend.Bind("tcp://*:5560");
// Initialize poll set
var poll = ZPollItem.CreateReceiver();
// Switch messages between sockets
ZError error;
ZMessage message;
while (true)
{
if (frontend.PollIn(poll, out message, out error, TimeSpan.FromMilliseconds(64)))
{
// Process all parts of the message
Console_WriteZMessage("frontend", 2, message);
backend.Send(message);
}
else
{
if (error == ZError.ETERM)
return; // Interrupted
if (error != ZError.EAGAIN)
thrownew ZException(error);
}
if (backend.PollIn(poll, out message, out error, TimeSpan.FromMilliseconds(64)))
{
// Process all parts of the message
Console_WriteZMessage(" backend", 2, message);
frontend.Send(message);
}
else
{
if (error == ZError.ETERM)
return; // Interrupted
if (error != ZError.EAGAIN)
thrownew ZException(error);
}
}
}
}
}
}
rrbroker: Request-reply broker in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Simple request-reply broker in Common Lisp;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.rrbroker
(:nicknames#:rrbroker)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.rrbroker)
(defunmain ()
;; Prepare our context and sockets
(zmq:with-context (context1)
(zmq:with-socket (frontendcontextzmq:router)
(zmq:with-socket (backendcontextzmq:dealer)
(zmq:bindfrontend"tcp://*:5559")
(zmq:bindbackend"tcp://*:5560")
;; Initialize poll set
(zmq:with-polls ((items . ((frontend . zmq:pollin)
(backend . zmq:pollin))))
;; Switch messages between sockets
(loop
(let ((revents (zmq:pollitems)))
(when (= (firstrevents) zmq:pollin)
(loop;; Process all parts of the message
(let ((message (make-instance'zmq:msg)))
(zmq:recvfrontendmessage)
(if (not (zerop (zmq:getsockoptfrontendzmq:rcvmore)))
(zmq:sendbackendmessagezmq:sndmore)
(progn
(zmq:sendbackendmessage0)
;; Last message part
(return))))))
(when (= (secondrevents) zmq:pollin)
(loop;; Process all parts of the message
(let ((message (make-instance'zmq:msg)))
(zmq:recvbackendmessage)
(if (not (zerop (zmq:getsockoptbackendzmq:rcvmore)))
(zmq:sendfrontendmessagezmq:sndmore)
(progn
(zmq:sendfrontendmessage0)
;; Last message part
(return))))))))))))
(cleanup))
rrbroker: Request-reply broker in Delphi
program rrbroker;
//
// Simple request-reply broker
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
frontend,
backend: TZMQSocket;
poller: TZMQPoller;
msg: TZMQFrame;
more: Boolean;
begin
// Prepare our context and sockets
context := TZMQContext.Create;
frontend := Context.Socket( stRouter );
backend := Context.Socket( stDealer );
frontend.bind( 'tcp://*:5559' );
backend.bind( 'tcp://*:5560' );
// Initialize poll set
poller := TZMQPoller.Create( true );
poller.register( frontend, [pePollIn] );
poller.register( backend, [pePollIn] );
// Switch messages between sockets
while True do
begin
poller.poll;
more := true;
if pePollIn in poller.PollItem[0].revents then
while more do
begin
// Process all parts of the message
msg := TZMQFrame.Create;
frontend.recv( msg );
more := frontend.rcvMore;
if more then
backend.send( msg, [sfSndMore] )
else
backend.send( msg, [] );
end;
if pePollIn in poller.PollItem[1].revents then
while more do
begin
// Process all parts of the message
msg := TZMQFrame.Create;
backend.recv( msg );
more := backend.rcvMore;
if more then
frontend.send( msg, [sfSndMore] )
else
frontend.send( msg, [] );
end;
end;
// We never get here but clean up anyhow
poller.Free;
frontend.Free;
backend.Free;
context.Free;
end.
rrbroker: Request-reply broker in Erlang
#! /usr/bin/env escript
%%
%% Simple request-reply broker
%%
main(_) ->
%% Prepare our context and sockets
{ok, Context} = erlzmq:context(),
{ok, Frontend} = erlzmq:socket(Context, [router, {active, true}]),
{ok, Backend} = erlzmq:socket(Context, [dealer, {active, true}]),
ok = erlzmq:bind(Frontend, "tcp://*:5559"),
ok = erlzmq:bind(Backend, "tcp://*:5560"),
%% Switch messages between sockets
loop(Frontend, Backend),
%% We never get here but clean up anyhow
ok = erlzmq:close(Frontend),
ok = erlzmq:close(Backend),
ok = erlzmq:term(Context).
loop(Frontend, Backend) ->
receive
{zmq, Frontend, Msg, Flags} ->
caseproplists:get_bool(rcvmore, Flags) of
true ->
erlzmq:send(Backend, Msg, [sndmore]);
false ->
erlzmq:send(Backend, Msg)
end;
{zmq, Backend, Msg, Flags} ->
caseproplists:get_bool(rcvmore, Flags) of
true ->
erlzmq:send(Frontend, Msg, [sndmore]);
false ->
erlzmq:send(Frontend, Msg)
endend,
loop(Frontend, Backend).
rrbroker: Request-reply broker in Elixir
defmodule Rrbroker do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:31
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, frontend} = :erlzmq.socket(context, [:router, {:active, true}])
{:ok, backend} = :erlzmq.socket(context, [:dealer, {:active, true}])
:ok = :erlzmq.bind(frontend, 'tcp://*:5559')
:ok = :erlzmq.bind(backend, 'tcp://*:5560')
loop(frontend, backend)
:ok = :erlzmq.close(frontend)
:ok = :erlzmq.close(backend)
:ok = :erlzmq.term(context)
end
def loop(frontend, backend) do
receive do
{:zmq, ^frontend, msg, flags} ->
case(:proplists.get_bool(:rcvmore, flags)) do
true ->
:erlzmq.send(backend, msg, [:sndmore])
false ->
:erlzmq.send(backend, msg)
end
{:zmq, ^backend, msg, flags} ->
case(:proplists.get_bool(:rcvmore, flags)) do
true ->
:erlzmq.send(frontend, msg, [:sndmore])
false ->
:erlzmq.send(frontend, msg)
end
end
loop(frontend, backend)
end
end
Rrbroker.main()
rrbroker: Request-reply broker in F#
(*
Simple request-reply broker
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Polling
open fszmq.Socket
#load "zhelpers.fs"
let main () =
// prepare our context and sockets
use context = new Context(1)
use frontend = route context
use backend = deal context
"tcp://*:5559" |> bind frontend
"tcp://*:5560" |> bind backend
// initialize poll set
let items = [Poll(ZMQ.POLLIN,frontend,fun s -> s >|< backend )
Poll(ZMQ.POLLIN,backend ,fun s -> s >|< frontend)]
//NOTE: the poll item callbacks above use the transfer operator (>|<).
// fs-zmq defines this operator as a convenience for transferring
// all parts of a multi-part message from one socket to another.
// for a lengthier, but more obvious alternative (which more
// closely matches the C version of the guide), see wuproxy.fsx
// switch messages between sockets
while true do items |> poll -1L |> ignore
// we never get here but clean up anyhow
EXIT_SUCCESS
main ()
---- Simple request-reply broker---- Author: Robert G. Jakabosky <bobby@sharedrealm.com>--
require"zmq"
require"zmq.poller"
require"zhelpers"-- Prepare our context and socketslocal context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.DEALER)
frontend:bind("tcp://*:5559")
backend:bind("tcp://*:5560")
-- Switch messages between socketslocal poller = zmq.poller(2)
poller:add(frontend, zmq.POLLIN, function()
whiletruedo-- Process all parts of the messagelocal msg = frontend:recv()
if (frontend:getopt(zmq.RCVMORE) == 1) then
backend:send(msg, zmq.SNDMORE)
else
backend:send(msg, 0)
break; -- Last message partendendend)
poller:add(backend, zmq.POLLIN, function()
whiletruedo-- Process all parts of the messagelocal msg = backend:recv()
if (backend:getopt(zmq.RCVMORE) == 1) then
frontend:send(msg, zmq.SNDMORE)
else
frontend:send(msg, 0)
break; -- Last message partendendend)
-- start poller's event loop
poller:start()
-- We never get here but clean up anyhow
frontend:close()
backend:close()
context:term()
rrbroker: Request-reply broker in Node.js
// Simple request-reply broker in Node.js
var zmq = require('zeromq')
, frontend = zmq.socket('router')
, backend = zmq.socket('dealer');
frontend.bindSync('tcp://*:5559');
backend.bindSync('tcp://*:5560');
frontend.on('message', function() {
// Note that separate message parts come as function arguments.
var args = Array.apply(null, arguments);
// Pass array of strings/buffers to send multipart messages.
backend.send(args);
});
backend.on('message', function() {
var args = Array.apply(null, arguments);
frontend.send(args);
});
Using a request-reply broker makes your client/server architectures easier to scale because clients don’t see workers, and workers don’t see clients. The only static node is the broker in the middle.
You may wonder how a response is routed back to the right client. Router uses envelop for the message that has info on the client to the dealer and dealer response will include envelope that will be used to map the response back to the client.
It turns out that the core loop in the previous section’s rrbroker is very useful, and reusable. It lets us build pub-sub forwarders and shared queues and other little intermediaries with very little effort. ZeroMQ wraps this up in a single method, zmq_proxy():
zmq_proxy (frontend, backend, capture);
The two (or three sockets, if we want to capture data) must be properly connected, bound, and configured. When we call the zmq_proxy method, it’s exactly like starting the main loop of rrbroker. Let’s rewrite the request-reply broker to call zmq_proxy, and re-badge this as an expensive-sounding “message queue” (people have charged houses for code that did less):
// Simple message queuing broker
// Same as request-reply broker but using shared queue proxy
#include"zhelpers.h"intmain (void)
{
void *context = zmq_ctx_new ();
// Socket facing clients
void *frontend = zmq_socket (context, ZMQ_ROUTER);
int rc = zmq_bind (frontend, "tcp://*:5559");
assert (rc == 0);
// Socket facing services
void *backend = zmq_socket (context, ZMQ_DEALER);
rc = zmq_bind (backend, "tcp://*:5560");
assert (rc == 0);
// Start the proxy
zmq_proxy (frontend, backend, NULL);
// We never get here...
zmq_close (frontend);
zmq_close (backend);
zmq_ctx_destroy (context);
return0;
}
msgqueue: Message queue broker in C++
//
// Simple message queuing broker in C++
// Same as request-reply broker but using QUEUE device
//
#include"zhelpers.hpp"intmain (int argc, char *argv[])
{
zmq::context_t context(1);
// Socket facing clients
zmq::socket_t frontend (context, ZMQ_ROUTER);
frontend.bind("tcp://*:5559");
// Socket facing services
zmq::socket_t backend (context, ZMQ_DEALER);
backend.bind("tcp://*:5560");
// Start the proxy
zmq::proxy(static_cast<void*>(frontend),
static_cast<void*>(backend),
nullptr);
return0;
}
msgqueue: Message queue broker in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid MsgQueue(string[] args)
{
//
// Simple message queuing broker
// Same as request-reply broker but using QUEUE device
//
// Author: metadings
//
// Socket facing clients and
// Socket facing services
using (var context = new ZContext())
using (var frontend = new ZSocket(context, ZSocketType.ROUTER))
using (var backend = new ZSocket(context, ZSocketType.DEALER))
{
frontend.Bind("tcp://*:5559");
backend.Bind("tcp://*:5560");
// Start the proxy
ZContext.Proxy(frontend, backend);
}
}
}
}
msgqueue: Message queue broker in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Simple message queuing broker in Common Lisp;;; Same as request-reply broker but using QUEUE device;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.msgqueue
(:nicknames#:msgqueue)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.msgqueue)
(defunmain ()
(zmq:with-context (context1)
;; Socket facing clients
(zmq:with-socket (frontendcontextzmq:router)
(zmq:bindfrontend"tcp://*:5559")
;; Socket facing services
(zmq:with-socket (backendcontextzmq:dealer)
(zmq:bindbackend"tcp://*:5560")
;; Start built-in device
(zmq:devicezmq:queuefrontendbackend))))
(cleanup))
msgqueue: Message queue broker in Delphi
program msgqueue;
//
// Simple message queuing broker
// Same as request-reply broker but using shared queue proxy
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
frontend,
backend: TZMQSocket;
begin
context := TZMQContext.Create;
// Socket facing clients
frontend := Context.Socket( stRouter );
frontend.bind( 'tcp://*:5559' );
// Socket facing services
backend := Context.Socket( stDealer );
backend.bind( 'tcp://*:5560' );
// Start the proxy
ZMQProxy( frontend, backend, nil );
// We never get here...
frontend.Free;
backend.Free;
context.Free;
end.
msgqueue: Message queue broker in Erlang
#!/usr/bin/env escript
%%
%% Simple message queuing broker
%% Same as request-reply broker but using QUEUE device
%%
main(_) ->
{ok, Context} = erlzmq:context(),
%% Socket facing clients
{ok, Frontend} = erlzmq:socket(Context, [router, {active, true}]),
ok = erlzmq:bind(Frontend, "tcp://*:5559"),
%% Socket facing services
{ok, Backend} = erlzmq:socket(Context, [dealer, {active, true}]),
ok = erlzmq:bind(Backend, "tcp://*:5560"),
%% Start built-in device
erlzmq_device:queue(Frontend, Backend),
%% We never get here...
ok = erlzmq:close(Frontend),
ok = erlzmq:close(Backend),
ok = erlzmq:term(Context).
msgqueue: Message queue broker in Elixir
defmodule msgqueue do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:26
"""
def main(_) do
{:ok, context} = :erlzmq.context()
{:ok, frontend} = :erlzmq.socket(context, [:router, {:active, true}])
:ok = :erlzmq.bind(frontend, 'tcp://*:5559')
{:ok, backend} = :erlzmq.socket(context, [:dealer, {:active, true}])
:ok = :erlzmq.bind(backend, 'tcp://*:5560')
:erlzmq_device.queue(frontend, backend)
:ok = :erlzmq.close(frontend)
:ok = :erlzmq.close(backend)
:ok = :erlzmq.term(context)
end
end
msgqueue: Message queue broker in F#
(*
Simple message queuing broker
Same as request-reply broker but using QUEUE device
*)
#r @"bin/fszmq.dll"
#r @"bin/fszmq.devices.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
let main () =
use context = new Context(1)
// socket facing clients
use frontend = route context
"tcp://*:5559" |> bind frontend
// socket facing services
use backend = deal context
"tcp://*:5560" |> bind backend
// start built-in device
(frontend,backend) |> Devices.queue |> ignore
// we never get here...
EXIT_SUCCESS
main ()
If you’re like most ZeroMQ users, at this stage your mind is starting to think, “What kind of evil stuff can I do if I plug random socket types into the proxy?” The short answer is: try it and work out what is happening. In practice, you would usually stick to ROUTER/DEALER, XSUB/XPUB, or PULL/PUSH.
A frequent request from ZeroMQ users is, “How do I connect my ZeroMQ network with technology X?” where X is some other networking or messaging technology.
Figure 18 - Pub-Sub Forwarder Proxy
The simple answer is to build a bridge. A bridge is a small application that speaks one protocol at one socket, and converts to/from a second protocol at another socket. A protocol interpreter, if you like. A common bridging problem in ZeroMQ is to bridge two transports or networks.
As an example, we’re going to write a little proxy that sits in between a publisher and a set of subscribers, bridging two networks. The frontend socket (SUB) faces the internal network where the weather server is sitting, and the backend (PUB) faces subscribers on the external network. It subscribes to the weather service on the frontend socket, and republishes its data on the backend socket.
// Weather proxy device
#include"zhelpers.h"intmain (void)
{
void *context = zmq_ctx_new ();
// This is where the weather server sits
void *frontend = zmq_socket (context, ZMQ_XSUB);
zmq_connect (frontend, "tcp://192.168.55.210:5556");
// This is our public endpoint for subscribers
void *backend = zmq_socket (context, ZMQ_XPUB);
zmq_bind (backend, "tcp://10.1.1.0:8100");
// Run the proxy until the user interrupts us
zmq_proxy (frontend, backend, NULL);
zmq_close (frontend);
zmq_close (backend);
zmq_ctx_destroy (context);
return0;
}
wuproxy: Weather update proxy in C++
//
// Weather proxy device C++
//
#include"zhelpers.hpp"intmain (int argc, char *argv[])
{
zmq::context_t context(1);
// This is where the weather server sits
zmq::socket_t frontend(context, ZMQ_SUB);
frontend.connect("tcp://192.168.55.210:5556");
// This is our public endpoint for subscribers
zmq::socket_t backend (context, ZMQ_PUB);
backend.bind("tcp://10.1.1.0:8100");
// Subscribe on everything
frontend.set(zmq::sockopt::subscribe, "");
// Shunt messages out to our own subscribers
while (1) {
while (1) {
zmq::message_t message;
int more;
size_t more_size = sizeof (more);
// Process all parts of the message
frontend.recv(&message);
frontend.getsockopt( ZMQ_RCVMORE, &more, &more_size);
backend.send(message, more? ZMQ_SNDMORE: 0);
if (!more)
break; // Last message part
}
}
return0;
}
wuproxy: Weather update proxy in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Net;
usingSystem.Net.NetworkInformation;
usingSystem.Net.Sockets;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid WUProxy(string[] args)
{
//
// Weather proxy device
//
// Author: metadings
//
using (var context = new ZContext())
using (var frontend = new ZSocket(context, ZSocketType.XSUB))
using (var backend = new ZSocket(context, ZSocketType.XPUB))
{
// Frontend is where the weather server sits
string localhost = "tcp://127.0.0.1:5556";
Console.WriteLine("I: Connecting to {0}", localhost);
frontend.Connect(localhost);
// Backend is our public endpoint for subscribers
foreach (IPAddress address in WUProxy_GetPublicIPs())
{
var tcpAddress = string.Format("tcp://{0}:8100", address);
Console.WriteLine("I: Binding on {0}", tcpAddress);
backend.Bind(tcpAddress);
var epgmAddress = string.Format("epgm://{0};239.192.1.1:8100", address);
Console.WriteLine("I: Binding on {0}", epgmAddress);
backend.Bind(epgmAddress);
}
using (var subscription = ZFrame.Create(1))
{
subscription.Write(newbyte[] { 0x1 }, 0, 1);
backend.Send(subscription);
}
// Run the proxy until the user interrupts us
ZContext.Proxy(frontend, backend);
}
}
static IEnumerable<IPAddress> WUProxy_GetPublicIPs()
{
var list = new List<IPAddress>();
NetworkInterface[] ifaces = NetworkInterface.GetAllNetworkInterfaces();
foreach (NetworkInterface iface in ifaces)
{
if (iface.NetworkInterfaceType == NetworkInterfaceType.Loopback)
continue;
if (iface.OperationalStatus != OperationalStatus.Up)
continue;
var props = iface.GetIPProperties();
var addresses = props.UnicastAddresses;
foreach (UnicastIPAddressInformation address in addresses)
{
if (address.Address.AddressFamily == AddressFamily.InterNetwork)
list.Add(address.Address);
// if (address.Address.AddressFamily == AddressFamily.InterNetworkV6)
// list.Add(address.Address);
}
}
return list;
}
}
}
wuproxy: Weather update proxy in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Weather proxy device in Common Lisp;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.wuproxy
(:nicknames#:wuproxy)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.wuproxy)
(defunmain ()
(zmq:with-context (context1)
;; This is where the weather server sits
(zmq:with-socket (frontendcontextzmq:sub)
(zmq:connectfrontend"tcp://192.168.55.210:5556")
;; This is our public endpoint for subscribers
(zmq:with-socket (backendcontextzmq:pub)
(zmq:bindbackend"tcp://10.1.1.0:8100")
;; Subscribe on everything
(zmq:setsockoptfrontendzmq:subscribe"")
;; Shunt messages out to our own subscribers
(loop
(loop;; Process all parts of the message
(let ((message (make-instance'zmq:msg)))
(zmq:recvfrontendmessage)
(if (not (zerop (zmq:getsockoptfrontendzmq:rcvmore)))
(zmq:sendbackendmessagezmq:sndmore)
(progn
(zmq:sendbackendmessage0)
;; Last message part
(return)))))))))
(cleanup))
wuproxy: Weather update proxy in Delphi
program wuproxy;
//
// Weather proxy device
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
frontend,
backend: TZMQSocket;
begin
context := TZMQContext.Create;
// This is where the weather server sits
frontend := Context.Socket( stXSub );
frontend.connect( 'tcp://192.168.55.210:5556' );
// This is our public endpoint for subscribers
backend := Context.Socket( stXPub );
backend.bind( 'tcp://10.1.1.0:8100' );
// Run the proxy until the user interrupts us
ZMQProxy( frontend, backend, nil );
frontend.Free;
backend.Free;
context.Free;
end.
wuproxy: Weather update proxy in Erlang
#! /usr/bin/env escript
%%
%% Weather proxy device
%%
main(_) ->
{ok, Context} = erlzmq:context(),
%% This is where the weather server sits
{ok, Frontend} = erlzmq:socket(Context, sub),
ok = erlzmq:connect(Frontend, "tcp://localhost:5556"),
%% This is our public endpoint for subscribers
{ok, Backend} = erlzmq:socket(Context, pub),
ok = erlzmq:bind(Backend, "tcp://*:8100"),
%% Subscribe on everything
ok = erlzmq:setsockopt(Frontend, subscribe, <<>>),
%% Shunt messages out to our own subscribers
loop(Frontend, Backend),
%% We don't actually get here but if we did, we'd shut down neatly
ok = erlzmq:close(Frontend),
ok = erlzmq:close(Backend),
ok = erlzmq:term(Context).
loop(Frontend, Backend) ->
{ok, Msg} = erlzmq:recv(Frontend),
caseerlzmq:getsockopt(Frontend, rcvmore) of
{ok, true} -> erlzmq:send(Backend, Msg, [sndmore]);
{ok, false} -> erlzmq:send(Backend, Msg)
end,
loop(Frontend, Backend).
wuproxy: Weather update proxy in Elixir
defmodule Wuproxy do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:39
"""
def main(_) do
{:ok, context} = :erlzmq.context()
{:ok, frontend} = :erlzmq.socket(context, :sub)
:ok = :erlzmq.connect(frontend, 'tcp://localhost:5556')
{:ok, backend} = :erlzmq.socket(context, :pub)
:ok = :erlzmq.bind(backend, 'tcp://*:8100')
:ok = :erlzmq.setsockopt(frontend, :subscribe, <<>>)
loop(frontend, backend)
:ok = :erlzmq.close(frontend)
:ok = :erlzmq.close(backend)
:ok = :erlzmq.term(context)
end
def loop(frontend, backend) do
{:ok, msg} = :erlzmq.recv(frontend)
case(:erlzmq.getsockopt(frontend, :rcvmore)) do
{:ok, true} ->
:erlzmq.send(backend, msg, [:sndmore])
{:ok, false} ->
:erlzmq.send(backend, msg)
{:ok, 0} ->
:erlzmq.send(backend, msg)
end
loop(frontend, backend)
end
end
Wuproxy.main(:ok)
wuproxy: Weather update proxy in F#
(*
Weather proxy device
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
let main () =
use context = new Context(1)
// this is where the weather server sits
use frontend = context |> sub
connect frontend "tcp://localhost:5556"
// this is our public endpoint for subscribers
use backend = context |> pub
bind backend "tcp://*:8100"
// subscribe on everything
subscribe frontend [""B]
// shunt messages out to our own subscribers
while true do
let more = ref true
while !more do
// process all parts of the message
let message = frontend |> recv
more := frontend |> recvMore
if !more then sendMore backend message |> ignore
else send backend message
//NOTE: fs-zmq contains other idioms (eg: sendAll,recvAll,transfer)
// which allow for more concise (and possibly more efficient)
// implementations of the previous loop...
// but this example translates most directly to it's C cousin
// for a very concise alternative, see rrbroker.fsx
// we don't actually get here but if we did, we'd shut down neatly
EXIT_SUCCESS
main ()
// Weather proxy device
//
// Author: Brendan Mc.
// Requires: http://github.com/alecthomas/gozmq
package main
import (
zmq "github.com/alecthomas/gozmq"
)
funcmain() {
context, _ := zmq.NewContext()
defer context.Close()
// This is where the weather server sits
frontend, _ := context.NewSocket(zmq.SUB)
defer frontend.Close()
frontend.Connect("tcp://localhost:5556")
// This is our public endpoint for subscribers
backend, _ := context.NewSocket(zmq.PUB)
defer backend.Close()
backend.Bind("tcp://*:8100")
// Subscribe on everything
frontend.SetSubscribe("")
// Shunt messages out to our own subscribers
for {
message, _ := frontend.Recv(0)
backend.Send(message, 0)
}
}
wuproxy: Weather update proxy in Haskell
-- Weather proxy devicemoduleMainwhereimportSystem.ZMQ4.Monadicmain::IO()main= runZMQ $ do-- This is where the weather service sits
frontend <- socket XSub
connect frontend "tcp://192.168.55.210:5556"-- This is our public endpoint for subscribers
backend <- socket XPub
bind backend "tcp://10.1.1.0:8100"-- Run the proxy until the user interrupts us
proxy frontend backend Nothing
wuproxy: Weather update proxy in Haxe
package ;
importhaxe.io.Bytes;
importhaxe.Stack;
importneko.Lib;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQContext;
importorg.zeromq.ZMQSocket;
importorg.zeromq.ZMQException;
/**
* Weather proxy device.
*
* See: http://zguide.zeromq.org/page:all#A-Publish-Subscribe-Proxy-Server
*
* Use with WUClient and WUServer
*/class WUProxy
{
publicstaticfunctionmain() {
var context:ZMQContext = ZMQContext.instance();
Lib.println("** WUProxy (see: http://zguide.zeromq.org/page:all#A-Publish-Subscribe-Proxy-Server)");
// This is where the weather service sitsvar frontend:ZMQSocket = context.socket(ZMQ_SUB);
frontend.connect("tcp://localhost:5556");
// This is our public endpoint for subscribersvar backend:ZMQSocket = context.socket(ZMQ_PUB);
backend.bind("tcp://10.1.1.0:8100");
// Subscribe on everything
frontend.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
var more = false;
var msgBytes:Bytes;
ZMQ.catchSignals();
var stopped = false;
while (!stopped) {
try {
msgBytes = frontend.recvMsg();
more = frontend.hasReceiveMore();
// proxy it
backend.sendMsg(msgBytes, { if (more) SNDMORE elsenull; } );
if (!more) {
stopped = true;
}
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
stopped = true;
} else {
// Handle other errors
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
}
}
frontend.close();
backend.close();
context.term();
}
}
wuproxy: Weather update proxy in Java
packageguide;
importorg.zeromq.SocketType;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQ.Socket;
importorg.zeromq.ZContext;
/**
* Weather proxy device.
*/publicclasswuproxy
{
publicstaticvoidmain(String[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
// This is where the weather server sits
Socket frontend = context.createSocket(SocketType.SUB);
frontend.connect("tcp://192.168.55.210:5556");
// This is our public endpoint for subscribers
Socket backend = context.createSocket(SocketType.PUB);
backend.bind("tcp://10.1.1.0:8100");
// Subscribe on everything
frontend.subscribe(ZMQ.SUBSCRIPTION_ALL);
// Run the proxy until the user interrupts us
ZMQ.proxy(frontend, backend, null);
}
}
}
---- Weather proxy device---- Author: Robert G. Jakabosky <bobby@sharedrealm.com>--
require"zmq"local context = zmq.init(1)
-- This is where the weather server sitslocal frontend = context:socket(zmq.SUB)
frontend:connect(arg[1] or"tcp://192.168.55.210:5556")
-- This is our public endpolocal for subscriberslocal backend = context:socket(zmq.PUB)
backend:bind(arg[2] or"tcp://10.1.1.0:8100")
-- Subscribe on everything
frontend:setopt(zmq.SUBSCRIBE, "")
-- Shunt messages out to our own subscriberswhiletruedowhiletruedo-- Process all parts of the messagelocal message = frontend:recv()
if frontend:getopt(zmq.RCVMORE) == 1then
backend:send(message, zmq.SNDMORE)
else
backend:send(message)
break-- Last message partendendend-- We don't actually get here but if we did, we'd shut down neatly
frontend:close()
backend:close()
context:term()
wuproxy: Weather update proxy in Node.js
// Weather proxy device in Node.js
var zmq = require('zeromq')
, frontend = zmq.socket('sub')
, backend = zmq.socket('pub');
backend.bindSync("tcp://10.1.1.0:8100");
frontend.subscribe('');
frontend.connect("tcp://192.168.55.210:5556");
frontend.on('message', function() {
// all parts of a message come as function arguments
var args = Array.apply(null, arguments);
backend.send(args);
});
# Weather proxy device in Perlusestrict;
usewarnings;
usev5.10;
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_XSUB ZMQ_XPUB);
my$context = ZMQ::FFI->new();
# This is where the weather server sitsmy$frontend = $context->socket(ZMQ_XSUB);
$frontend->connect('tcp://192.168.55.210:5556');
# This is our public endpoing fro subscribersmy$backend = $context->socket(ZMQ_XPUB);
$backend->bind('tcp://10.1.1.0:8100');
# Run the proxy until the user interrupts us$context->proxy($frontend, $backend);
wuproxy: Weather update proxy in PHP
<?php/*
* Weather proxy device
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/$context = new ZMQContext();
// This is where the weather server sits
$frontend = new ZMQSocket($context, ZMQ::SOCKET_SUB);
$frontend->connect("tcp://192.168.55.210:5556");
// This is our public endpoint for subscribers
$backend = new ZMQSocket($context, ZMQ::SOCKET_PUB);
$backend->bind("tcp://10.1.1.0:8100");
// Subscribe on everything
$frontend->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "");
// Shunt messages out to our own subscribers
while (true) {
while (true) {
// Process all parts of the message
$message = $frontend->recv();
$more = $frontend->getSockOpt(ZMQ::SOCKOPT_RCVMORE);
$backend->send($message, $more ? ZMQ::MODE_SNDMORE : 0);
if (!$more) {
break; // Last message part
}
}
}
wuproxy: Weather update proxy in Python
# Weather proxy device## Author: Lev Givon <lev(at)columbia(dot)edu>importzmq
context = zmq.Context()
# This is where the weather server sits
frontend = context.socket(zmq.SUB)
frontend.connect("tcp://192.168.55.210:5556")
# This is our public endpoint for subscribers
backend = context.socket(zmq.PUB)
backend.bind("tcp://10.1.1.0:8100")
# Subscribe on everything
frontend.setsockopt(zmq.SUBSCRIBE, b'')
# Shunt messages out to our own subscriberswhile True:
# Process all parts of the message
message = frontend.recv_multipart()
backend.send_multipart(message)
It looks very similar to the earlier proxy example, but the key part is that the frontend and backend sockets are on two different networks. We can use this model for example to connect a multicast network (pgm transport) to a tcp publisher.
ZeroMQ’s error handling philosophy is a mix of fail-fast and resilience. Processes, we believe, should be as vulnerable as possible to internal errors, and as robust as possible against external attacks and errors. To give an analogy, a living cell will self-destruct if it detects a single internal error, yet it will resist attack from the outside by all means possible.
Assertions, which pepper the ZeroMQ code, are absolutely vital to robust code; they just have to be on the right side of the cellular wall. And there should be such a wall. If it is unclear whether a fault is internal or external, that is a design flaw to be fixed. In C/C++, assertions stop the application immediately with an error. In other languages, you may get exceptions or halts.
When ZeroMQ detects an external fault it returns an error to the calling code. In some rare cases, it drops messages silently if there is no obvious strategy for recovering from the error.
In most of the C examples we’ve seen so far there’s been no error handling. Real code should do error handling on every single ZeroMQ call. If you’re using a language binding other than C, the binding may handle errors for you. In C, you do need to do this yourself. There are some simple rules, starting with POSIX conventions:
Methods that create objects return NULL if they fail.
Methods that process data may return the number of bytes processed, or -1 on an error or failure.
Other methods return 0 on success and -1 on an error or failure.
The error code is provided in errno or zmq_errno().
A descriptive error text for logging is provided by zmq_strerror().
There are two main exceptional conditions that you should handle as nonfatal:
When your code receives a message with the ZMQ_DONTWAIT option and there is no waiting data, ZeroMQ will return -1 and set errno to EAGAIN.
When one thread calls zmq_ctx_destroy(), and other threads are still doing blocking work, the zmq_ctx_destroy() call closes the context and all blocking calls exit with -1, and errno set to ETERM.
In C/C++, asserts can be removed entirely in optimized code, so don’t make the mistake of wrapping the whole ZeroMQ call in an assert(). It looks neat; then the optimizer removes all the asserts and the calls you want to make, and your application breaks in impressive ways.
Figure 19 - Parallel Pipeline with Kill Signaling
Let’s see how to shut down a process cleanly. We’ll take the parallel pipeline example from the previous section. If we’ve started a whole lot of workers in the background, we now want to kill them when the batch is finished. Let’s do this by sending a kill message to the workers. The best place to do this is the sink because it really knows when the batch is done.
How do we connect the sink to the workers? The PUSH/PULL sockets are one-way only. We could switch to another socket type, or we could mix multiple socket flows. Let’s try the latter: using a pub-sub model to send kill messages to the workers:
The sink creates a PUB socket on a new endpoint.
Workers connect their input socket to this endpoint.
When the sink detects the end of the batch, it sends a kill to its PUB socket.
When a worker detects this kill message, it exits.
It doesn’t take much new code in the sink:
void *controller = zmq_socket (context, ZMQ_PUB);
zmq_bind (controller, "tcp://*:5559");
...
// Send kill signal to workers
s_send (controller, "KILL");
Here is the worker process, which manages two sockets (a PULL socket getting tasks, and a SUB socket getting control commands), using the zmq_poll() technique we saw earlier:
taskwork2: Parallel task worker with kill signaling in Ada
taskwork2: Parallel task worker with kill signaling in C
// Task worker - design 2
// Adds pub-sub flow to receive and respond to kill signal
#include"zhelpers.h"intmain (void)
{
// Socket to receive messages on
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_connect (receiver, "tcp://localhost:5557");
// Socket to send messages to
void *sender = zmq_socket (context, ZMQ_PUSH);
zmq_connect (sender, "tcp://localhost:5558");
// Socket for control input
void *controller = zmq_socket (context, ZMQ_SUB);
zmq_connect (controller, "tcp://localhost:5559");
zmq_setsockopt (controller, ZMQ_SUBSCRIBE, "", 0);
// Process messages from either socket
while (1) {
zmq_pollitem_t items [] = {
{ receiver, 0, ZMQ_POLLIN, 0 },
{ controller, 0, ZMQ_POLLIN, 0 }
};
zmq_poll (items, 2, -1);
if (items [0].revents & ZMQ_POLLIN) {
char *string = s_recv (receiver);
printf ("%s.", string); // Show progress
fflush (stdout);
s_sleep (atoi (string)); // Do the work
free (string);
s_send (sender, ""); // Send results to sink
}
// Any waiting controller command acts as 'KILL'
if (items [1].revents & ZMQ_POLLIN)
break; // Exit loop
}
zmq_close (receiver);
zmq_close (sender);
zmq_close (controller);
zmq_ctx_destroy (context);
return0;
}
taskwork2: Parallel task worker with kill signaling in C++
//
// Task worker in C++ - design 2
// Adds pub-sub flow to receive and respond to kill signal
//
#include"zhelpers.hpp"#include<string>intmain (int argc, char *argv[])
{
zmq::context_t context(1);
// Socket to receive messages on
zmq::socket_t receiver(context, ZMQ_PULL);
receiver.connect("tcp://localhost:5557");
// Socket to send messages to
zmq::socket_t sender(context, ZMQ_PUSH);
sender.connect("tcp://localhost:5558");
// Socket for control input
zmq::socket_t controller (context, ZMQ_SUB);
controller.connect("tcp://localhost:5559");
controller.set(zmq::sockopt::subscribe, "");
// Process messages from receiver and controller
zmq::pollitem_t items [] = {
{ receiver, 0, ZMQ_POLLIN, 0 },
{ controller, 0, ZMQ_POLLIN, 0 }
};
// Process messages from both sockets
while (1) {
zmq::message_t message;
zmq::poll (&items [0], 2, -1);
if (items [0].revents & ZMQ_POLLIN) {
receiver.recv(&message);
// Process task
int workload; // Workload in msecs
std::string sdata(static_cast<char*>(message.data()), message.size());
std::istringstream iss(sdata);
iss >> workload;
// Do the work
s_sleep(workload);
// Send results to sink
message.rebuild();
sender.send(message);
// Simple progress indicator for the viewer
std::cout << "." << std::flush;
}
// Any waiting controller command acts as 'KILL'
if (items [1].revents & ZMQ_POLLIN) {
std::cout << std::endl;
break; // Exit loop
}
}
// Finished
return0;
}
taskwork2: Parallel task worker with kill signaling in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid TaskWork2(string[] args)
{
//
// Task worker - design 2
// Adds pub-sub flow to receive and respond to kill signal
//
// Author: metadings
//
// Socket to receive messages on,
// Socket to send messages to and
// Socket for control input
using (var context = new ZContext())
using (var receiver = new ZSocket(context, ZSocketType.PULL))
using (var sender = new ZSocket(context, ZSocketType.PUSH))
using (var controller = new ZSocket(context, ZSocketType.SUB))
{
receiver.Connect("tcp://127.0.0.1:5557");
sender.Connect("tcp://127.0.0.1:5558");
controller.Connect("tcp://127.0.0.1:5559");
controller.SubscribeAll();
var poll = ZPollItem.CreateReceiver();
ZError error;
ZMessage message;
while (true)
{
// Process messages from either socket
if (receiver.PollIn(poll, out message, out error, TimeSpan.FromMilliseconds(64)))
{
int workload = message[0].ReadInt32();
Console.WriteLine("{0}.", workload); // Show progress
Thread.Sleep(workload); // Do the work
sender.Send(newbyte[0], 0, 0); // Send results to sink
}
// Any waiting controller command acts as 'KILL'
if (controller.PollIn(poll, out message, out error, TimeSpan.FromMilliseconds(64)))
{
break; // Exit loop
}
}
}
}
}
}
taskwork2: Parallel task worker with kill signaling in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Task worker - design 2 in Common Lisp;;; Connects PULL socket to tcp://localhost:5557;;; Collects workloads from ventilator via that socket;;; Connects PUSH socket to tcp://localhost:5558;;; Sends results to sink via that socket;;; Adds pub-sub flow to receive and respond to kill signal;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.taskwork2
(:nicknames#:taskwork2)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.taskwork2)
(defunmain ()
(zmq:with-context (context1)
;; Socket to receive messages on
(zmq:with-socket (receivercontextzmq:pull)
(zmq:connectreceiver"tcp://localhost:5557")
;; Socket to send messages to
(zmq:with-socket (sendercontextzmq:push)
(zmq:connectsender"tcp://localhost:5558")
;; Socket for control input
(zmq:with-socket (controllercontextzmq:sub)
(zmq:connectcontroller"tcp://localhost:5559")
(zmq:setsockoptcontrollerzmq:subscribe"")
;; Process messages from receiver and controller
(zmq:with-polls ((items . ((receiver . zmq:pollin)
(controller . zmq:pollin))))
(loop
(let ((revents (zmq:pollitems)))
(when (= (firstrevents) zmq:pollin)
(let ((pull-msg (make-instance'zmq:msg)))
(zmq:recvreceiverpull-msg)
;; Process task
(let* ((string (zmq:msg-data-as-stringpull-msg))
(delay (* (parse-integerstring) 1000)))
;; Simple progress indicator for the viewer
(message"~A."string)
;; Do the work
(isys:usleepdelay)
;; Send results to sink
(let ((push-msg (make-instance'zmq:msg:data"")))
(zmq:sendsenderpush-msg)))))
(when (= (secondrevents) zmq:pollin)
;; Any waiting controller command acts as 'KILL'
(return)))))))))
(cleanup))
taskwork2: Parallel task worker with kill signaling in Delphi
program taskwork2;
//
// Task worker - design 2
// Adds pub-sub flow to receive and respond to kill signal
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
receiver,
sender,
controller: TZMQSocket;
frame: TZMQFrame;
poller: TZMQPoller;
begin
context := TZMQContext.Create;
// Socket to receive messages on
receiver := Context.Socket( stPull );
receiver.connect( 'tcp://localhost:5557' );
// Socket to send messages to
sender := Context.Socket( stPush );
sender.connect( 'tcp://localhost:5558' );
// Socket for control input
controller := Context.Socket( stSub );
controller.connect( 'tcp://localhost:5559' );
controller.subscribe('');
// Process messages from receiver and controller
poller := TZMQPoller.Create( true );
poller.register( receiver, [pePollIn] );
poller.register( controller, [pePollIn] );
// Process messages from both sockets
while true do
begin
poller.poll;
if pePollIn in poller.PollItem[0].revents then
begin
frame := TZMQFrame.create;
receiver.recv( frame );
// Do the work
sleep( StrToInt( frame.asUtf8String ) );
frame.Free;
// Send results to sink
sender.send('');
// Simple progress indicator for the viewer
writeln('.');
end;
// Any waiting controller command acts as 'KILL'
if pePollIn in poller.PollItem[1].revents then
break; // Exit loop
end;
receiver.Free;
sender.Free;
controller.Free;
poller.Free;
context.Free;
end.
taskwork2: Parallel task worker with kill signaling in Erlang
#! /usr/bin/env escript
%%
%% Task worker - design 2
%% Adds pub-sub flow to receive and respond to kill signal
%%
main(_) ->
{ok, Context} = erlzmq:context(),
%% Socket to receive messages on
{ok, Receiver} = erlzmq:socket(Context, [pull, {active, true}]),
ok = erlzmq:connect(Receiver, "tcp://localhost:5557"),
%% Socket to send messages to
{ok, Sender} = erlzmq:socket(Context, push),
ok = erlzmq:connect(Sender, "tcp://localhost:5558"),
%% Socket for control input
{ok, Controller} = erlzmq:socket(Context, [sub, {active, true}]),
ok = erlzmq:connect(Controller, "tcp://localhost:5559"),
ok = erlzmq:setsockopt(Controller, subscribe, <<>>),
%% Process messages from receiver and controller
process_messages(Receiver, Controller, Sender),
%% Finished
ok = erlzmq:close(Receiver),
ok = erlzmq:close(Sender),
ok = erlzmq:close(Controller),
ok = erlzmq:term(Context).
process_messages(Receiver, Controller, Sender) ->
receive
{zmq, Receiver, Msg, _Flags} ->
%% Do the work
timer:sleep(list_to_integer(binary_to_list(Msg))),
%% Send results to sink
ok = erlzmq:send(Sender, Msg),
%% Simple progress indicator for the viewer
io:format("."),
process_messages(Receiver, Controller, Sender);
{zmq, Controller, _Msg, _Flags} ->
%% Any waiting controller command acts as 'KILL'
ok
end.
taskwork2: Parallel task worker with kill signaling in Elixir
taskwork2: Parallel task worker with kill signaling in F#
(*
Task worker - design 2
Adds pub-sub flow to receive and respond to kill signal
*)
#r @"bin/fszmq.dll"
open fszmq
#load "zhelpers.fs"
open Context
open Socket
open Polling
let main () =
use context = new Context(1)
// Socket to receive messages on
use receiver = context |> pull
connect receiver "tcp://localhost:5557"
// Socket to send messages to
use sender = context |> push
connect sender "tcp://localhost:5558"
// Socket for control input
use controller = context |> sub
connect controller "tcp://localhost:5559"
subscribe controller [ ""B ]
// Process messages from receiver and controller
let doLoop = ref true
let items =
[ Poll(ZMQ.POLLIN,receiver,
fun s -> let msg = s |> recv |> decode
// Do the work
sleep (int msg)
// Send results to sink
s_send sender ""
// Simple progress indicator for the viewer
fflush()
printf "%s." msg)
Poll(ZMQ.POLLIN,controller,
fun _ -> // Any waiting controller command acts as 'KILL')
doLoop := false) ]
// Process messages from both sockets
while !doLoop do (poll -1L items) |> ignore
// Finished
EXIT_SUCCESS
main ()
taskwork2: Parallel task worker with kill signaling in Felix
taskwork2: Parallel task worker with kill signaling in Lua
---- Task worker - design 2-- Adds pub-sub flow to receive and respond to kill signal---- Author: Robert G. Jakabosky <bobby@sharedrealm.com>--
require"zmq"
require"zmq.poller"
require"zhelpers"local context = zmq.init(1)
-- Socket to receive messages onlocal receiver = context:socket(zmq.PULL)
receiver:connect("tcp://localhost:5557")
-- Socket to send messages tolocal sender = context:socket(zmq.PUSH)
sender:connect("tcp://localhost:5558")
-- Socket for control inputlocal controller = context:socket(zmq.SUB)
controller:connect("tcp://localhost:5559")
controller:setopt(zmq.SUBSCRIBE, "", 0)
-- Process messages from receiver and controllerlocal poller = zmq.poller(2)
poller:add(receiver, zmq.POLLIN, function()
local msg = receiver:recv()
-- Do the work
s_sleep(tonumber(msg))
-- Send results to sink
sender:send("")
-- Simple progress indicator for the viewer
io.write(".")
io.stdout:flush()
end)
poller:add(controller, zmq.POLLIN, function()
poller:stop() -- Exit loopend)
-- start poller's event loop
poller:start()
-- Finished
receiver:close()
sender:close()
controller:close()
context:term()
taskwork2: Parallel task worker with kill signaling in Node.js
// Task worker in Node.js
// Connects PULL socket to tcp://localhost:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://localhost:5558
// Sends results to sink via that socket
var zmq = require('zeromq')
, receiver = zmq.socket('pull')
, sender = zmq.socket('push')
, controller = zmq.socket('sub');
receiver.on('message', function(buf) {
var msec = parseInt(buf.toString(), 10);
// simple progress indicator for the viewer
process.stdout.write(buf.toString() + ".");
// do the work
// not a great node sample for zeromq,
// node receives messages while timers run.
setTimeout(function() {
sender.send("");
}, msec);
});
controller.on('message', function() {
// received KILL signal
receiver.close();
sender.close();
controller.close();
process.exit();
});
receiver.connect('tcp://localhost:5557');
sender.connect('tcp://localhost:5558');
controller.subscribe('');
controller.connect('tcp://localhost:5559');
taskwork2: Parallel task worker with kill signaling in Objective-C
/* taskwork2.m: PULLs workload from tcp://localhost:5557
* PUSHes results to tcp://localhost:5558
* SUBs to tcp://localhost:5559 to receive kill signal (*** NEW ***)
*/#import <Foundation/Foundation.h>
#import "ZMQObjC.h"
#define NSEC_PER_MSEC (1000000)
intmain(void)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
ZMQContext *ctx = [[[ZMQContext alloc] initWithIOThreads:1U] autorelease];
/* (jws/2011-02-05)!!!: Do NOT terminate the endpoint with a final slash.
* If you connect to @"tcp://localhost:5557/", you will get
* Assertion failed: rc == 0 (zmq_connecter.cpp:46)
* instead of a connected socket. Binding works fine, though. */
ZMQSocket *pull = [ctx socketWithType:ZMQ_PULL];
[pull connectToEndpoint:@"tcp://localhost:5557"];
ZMQSocket *push = [ctx socketWithType:ZMQ_PUSH];
[push connectToEndpoint:@"tcp://localhost:5558"];
ZMQSocket *control = [ctx socketWithType:ZMQ_SUB];
[control setData:nil forOption:ZMQ_SUBSCRIBE];
[control connectToEndpoint:@"tcp://localhost:5559"];
/* Process tasks forever, multiplexing between |pull| and |control|. */enum {POLL_PULL, POLL_CONTROL};
zmq_pollitem_t items[2];
[pull getPollItem:&items[POLL_PULL] forEvents:ZMQ_POLLIN];
[control getPollItem:&items[POLL_CONTROL] forEvents:ZMQ_POLLIN];
size_t itemCount = sizeof(items)/sizeof(*items);
struct timespec t;
NSData *emptyData = [NSData data];
bool shouldExit = false;
while (!shouldExit) {
NSAutoreleasePool *p = [[NSAutoreleasePool alloc] init];
[ZMQContext pollWithItems:items count:itemCount
timeoutAfterUsec:ZMQPollTimeoutNever];
if (items[POLL_PULL].revents & ZMQ_POLLIN) {
NSData *d = [pull receiveDataWithFlags:0];
NSString *s = [NSString stringWithUTF8String:[d bytes]];
t.tv_sec = 0;
t.tv_nsec = [s integerValue] * NSEC_PER_MSEC;
printf("%d.", [s intValue]);
fflush(stdout);
/* Do work, then report finished. */
(void)nanosleep(&t, NULL);
[push sendData:emptyData withFlags:0];
}
/* Any inbound data on |control| signals us to die. */if (items[POLL_CONTROL].revents & ZMQ_POLLIN) {
/* Do NOT just break here: |p| must be drained first. */
shouldExit = true;
}
[p drain];
}
[ctx closeSockets];
[pool drain];
return EXIT_SUCCESS;
}
taskwork2: Parallel task worker with kill signaling in ooc
taskwork2: Parallel task worker with kill signaling in Perl
# Task worker - design 2 in Perl# Adds pub-sub flow to receive and respond to kill signalusestrict;
usewarnings;
usev5.10;
$| = 1; # autoflush stdout after each printuseZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_PULL ZMQ_PUSH ZMQ_SUB);
useTime::HiResqw(usleep);
useAnyEvent;
useEV;
# Socket to receive messages onmy$context = ZMQ::FFI->new();
my$receiver = $context->socket(ZMQ_PULL);
$receiver->connect('tcp://localhost:5557');
# Socket to send messages tomy$sender = $context->socket(ZMQ_PUSH);
$sender->connect('tcp://localhost:5558');
# Socket for control inputmy$controller = $context->socket(ZMQ_SUB);
$controller->connect('tcp://localhost:5559');
$controller->subscribe('');
# Process messages from either socketmy$receiver_poller = AE::io $receiver->get_fd, 0, sub {
while ($receiver->has_pollin) {
my$string = $receiver->recv();
print"$string."; # Show progress
usleep $string*1000; # Do the work$sender->send(''); # Send results to sink
}
};
# Any controller command acts as 'KILL'my$controller_poller = AE::io $controller->get_fd, 0, sub {
if ($controller->has_pollin) {
EV::break; # Exit loop
}
};
EV::run;
taskwork2: Parallel task worker with kill signaling in PHP
<?php/*
* Task worker - design 2
* Adds pub-sub flow to receive and respond to kill signal
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/$context = new ZMQContext();
// Socket to receive messages on
$receiver = new ZMQSocket($context, ZMQ::SOCKET_PULL);
$receiver->connect("tcp://localhost:5557");
// Socket to send messages to
$sender = new ZMQSocket($context, ZMQ::SOCKET_PUSH);
$sender->connect("tcp://localhost:5558");
// Socket for control input
$controller = new ZMQSocket($context, ZMQ::SOCKET_SUB);
$controller->connect("tcp://localhost:5559");
$controller->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "");
// Process messages from receiver and controller
$poll = new ZMQPoll();
$poll->add($receiver, ZMQ::POLL_IN);
$poll->add($controller, ZMQ::POLL_IN);
$readable = $writeable = array();
// Process messages from both sockets
while (true) {
$events = $poll->poll($readable, $writeable);
if ($events > 0) {
foreach ($readableas$socket) {
if ($socket === $receiver) {
$message = $socket->recv();
// Simple progress indicator for the viewer
echo$message, PHP_EOL;
// Do the work
usleep($message * 1000);
// Send results to sink
$sender->send("");
}
// Any waiting controller command acts as 'KILL'
elseif ($socket === $controller) {
exit();
}
}
}
}
taskwork2: Parallel task worker with kill signaling in Python
# encoding: utf-8## Task worker - design 2# Adds pub-sub flow to receive and respond to kill signal## Author: Jeremy Avnet (brainsik) <spork(dash)zmq(at)theory(dot)org>#importsysimporttimeimportzmq
context = zmq.Context()
# Socket to receive messages on
receiver = context.socket(zmq.PULL)
receiver.connect("tcp://localhost:5557")
# Socket to send messages to
sender = context.socket(zmq.PUSH)
sender.connect("tcp://localhost:5558")
# Socket for control input
controller = context.socket(zmq.SUB)
controller.connect("tcp://localhost:5559")
controller.setsockopt(zmq.SUBSCRIBE, b"")
# Process messages from receiver and controller
poller = zmq.Poller()
poller.register(receiver, zmq.POLLIN)
poller.register(controller, zmq.POLLIN)
# Process messages from both socketswhile True:
socks = dict(poller.poll())
if socks.get(receiver) == zmq.POLLIN:
message = receiver.recv_string()
# Process task
workload = int(message) # Workload in msecs# Do the work
time.sleep(workload / 1000.0)
# Send results to sink
sender.send_string(message)
# Simple progress indicator for the viewer
sys.stdout.write(".")
sys.stdout.flush()
# Any waiting controller command acts as 'KILL'if socks.get(controller) == zmq.POLLIN:
break# Finished
receiver.close()
sender.close()
controller.close()
context.term()
taskwork2: Parallel task worker with kill signaling in Q
tasksink2: Parallel task sink with kill signaling in C
// Task sink - design 2
// Adds pub-sub flow to send kill signal to workers
#include"zhelpers.h"intmain (void)
{
// Socket to receive messages on
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_bind (receiver, "tcp://*:5558");
// Socket for worker control
void *controller = zmq_socket (context, ZMQ_PUB);
zmq_bind (controller, "tcp://*:5559");
// Wait for start of batch
char *string = s_recv (receiver);
free (string);
// Start our clock now
int64_t start_time = s_clock ();
// Process 100 confirmations
int task_nbr;
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
char *string = s_recv (receiver);
free (string);
if (task_nbr % 10 == 0)
printf (":");
else
printf (".");
fflush (stdout);
}
printf ("Total elapsed time: %d msec\n",
(int) (s_clock () - start_time));
// Send kill signal to workers
s_send (controller, "KILL");
zmq_close (receiver);
zmq_close (controller);
zmq_ctx_destroy (context);
return0;
}
tasksink2: Parallel task sink with kill signaling in C++
//
// Task sink in C++ - design 2
// Adds pub-sub flow to send kill signal to workers
//
#include"zhelpers.hpp"intmain (int argc, char *argv[])
{
zmq::context_t context(1);
// Socket to receive messages on
zmq::socket_t receiver (context, ZMQ_PULL);
receiver.bind("tcp://*:5558");
// Socket for worker control
zmq::socket_t controller (context, ZMQ_PUB);
controller.bind("tcp://*:5559");
// Wait for start of batch
s_recv (receiver);
// Start our clock now
structtimeval tstart;
gettimeofday (&tstart, NULL);
// Process 100 confirmations
int task_nbr;
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
s_recv (receiver);
if (task_nbr % 10 == 0)
std::cout << ":" ;
else
std::cout << "." ;
}
// Calculate and report duration of batch
structtimeval tend, tdiff;
gettimeofday (&tend, NULL);
if (tend.tv_usec < tstart.tv_usec) {
tdiff.tv_sec = tend.tv_sec - tstart.tv_sec - 1;
tdiff.tv_usec = 1000000 + tend.tv_usec - tstart.tv_usec;
}
else {
tdiff.tv_sec = tend.tv_sec - tstart.tv_sec;
tdiff.tv_usec = tend.tv_usec - tstart.tv_usec;
}
int total_msec = tdiff.tv_sec * 1000 + tdiff.tv_usec / 1000;
std::cout << "\nTotal elapsed time: " << total_msec
<< " msec\n" << std::endl;
// Send kill signal to workers
s_send (controller, std::string("KILL"));
// Finished
sleep (1); // Give 0MQ time to deliver
return0;
}
tasksink2: Parallel task sink with kill signaling in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Diagnostics;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid TaskSink2(string[] args)
{
//
// Task sink - design 2
// Adds pub-sub flow to send kill signal to workers
//
// Author: metadings
//
// Socket to receive messages on and
// Socket for worker control
using (var context = new ZContext())
using (var receiver = new ZSocket(context, ZSocketType.PULL))
using (var controller = new ZSocket(context, ZSocketType.PUB))
{
receiver.Bind("tcp://*:5558");
controller.Bind("tcp://*:5559");
// Wait for start of batch
receiver.ReceiveFrame();
// Start our clock now
var stopwatch = new Stopwatch();
stopwatch.Start();
// Process 100 confirmations
for (int i = 0; i < 100; ++i)
{
receiver.ReceiveFrame();
if ((i / 10) * 10 == i)
Console.Write(":");
else
Console.Write(".");
}
stopwatch.Stop();
Console.WriteLine("Total elapsed time: {0} ms", stopwatch.ElapsedMilliseconds);
// Send kill signal to workers
controller.Send(new ZFrame("KILL"));
}
}
}
}
tasksink2: Parallel task sink with kill signaling in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Task sink - design 2 in Common Lisp;;; Binds PULL socket to tcp://localhost:5558;;; Collects results from workers via that socket;;; Adds pub-sub flow to send kill signal to workers;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.tasksink2
(:nicknames#:tasksink2)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.tasksink2)
(defunmain ()
(zmq:with-context (context1)
;; Socket to receive messages on
(zmq:with-socket (receivercontextzmq:pull)
(zmq:bindreceiver"tcp://*:5558")
;; Socket for worker control
(zmq:with-socket (controllercontextzmq:pub)
(zmq:bindcontroller"tcp://*:5559")
;; Wait for start of batch
(let ((msg (make-instance'zmq:msg)))
(zmq:recvreceivermsg))
;; Start our clock now
(let ((elapsed-time
(with-stopwatch
(dotimes (task-nbr100)
(let ((msg (make-instance'zmq:msg)))
(zmq:recvreceivermsg)
(let ((string (zmq:msg-data-as-stringmsg)))
(declare (ignorestring))
(if (=1 (denominator (/task-nbr10)))
(message":")
(message"."))))))))
;; Calculate and report duration of batch
(message"Total elapsed time: ~F msec~%" (/elapsed-time1000.0)))
;; Send kill signal to workers
(let ((kill (make-instance'zmq:msg:data"KILL")))
(zmq:sendcontrollerkill))
;; Give 0MQ time to deliver
(sleep1))))
(cleanup))
tasksink2: Parallel task sink with kill signaling in Delphi
program tasksink2;
//
// Task sink - design 2
// Adds pub-sub flow to send kill signal to workers
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, Windows
, zmqapi
;
const
task_count = 100;
var
context: TZMQContext;
receiver,
controller: TZMQSocket;
s: Utf8String;
task_nbr: Integer;
fFrequency,
fstart,
fStop : Int64;
begin
// Prepare our context and socket
context := TZMQContext.Create;
receiver := Context.Socket( stPull );
receiver.bind( 'tcp://*:5558' );
// Socket for worker control
controller := Context.Socket( stPub );
controller.bind( 'tcp://*:5559' );
// Wait for start of batch
receiver.recv( s );
// Start our clock now
QueryPerformanceFrequency( fFrequency );
QueryPerformanceCounter( fStart );
// Process 100 confirmations
for task_nbr := 0 to task_count - 1 do
begin
receiver.recv( s );
if ((task_nbr / 10) * 10 = task_nbr) then
Write( ':' )
else
Write( '.' );
end;
// Calculate and report duration of batch
QueryPerformanceCounter( fStop );
Writeln( Format( 'Total elapsed time: %d msec', [
((MSecsPerSec * (fStop - fStart)) div fFrequency) ]) );
controller.send( 'KILL' );
// Finished
sleep(1000); // Give 0MQ time to deliver
receiver.Free;
controller.Free;
context.Free;
end.
tasksink2: Parallel task sink with kill signaling in Erlang
#! /usr/bin/env escript
%%
%% Task sink - design 2
%% Adds pub-sub flow to send kill signal to workers
%%
main(_) ->
{ok, Context} = erlzmq:context(),
%% Socket to receive messages on
{ok, Receiver} = erlzmq:socket(Context, pull),
ok = erlzmq:bind(Receiver, "tcp://*:5558"),
%% Socket for worker control
{ok, Controller} = erlzmq:socket(Context, pub),
ok = erlzmq:bind(Controller, "tcp://*:5559"),
%% Wait for start of batch
{ok, _} = erlzmq:recv(Receiver),
%% Start our clock now
Start = now(),
%% Process 100 confirmations
process_confirmations(Receiver, 100),
io:format("Total elapsed time: ~b msec~n",
[timer:now_diff(now(), Start) div1000]),
%% Send kill signal to workers
ok = erlzmq:send(Controller, <<"KILL">>),
%% Finished
ok = erlzmq:close(Controller),
ok = erlzmq:close(Receiver),
ok = erlzmq:term(Context, 1000).
process_confirmations(_Receiver, 0) -> ok;
process_confirmations(Receiver, N) whenN > 0 ->
{ok, _} = erlzmq:recv(Receiver),
caseN - 1rem10of0 -> io:format(":");
_ -> io:format(".")
end,
process_confirmations(Receiver, N - 1).
tasksink2: Parallel task sink with kill signaling in Elixir
defmodule Tasksink2 do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:35
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, receiver} = :erlzmq.socket(context, :pull)
:ok = :erlzmq.bind(receiver, 'tcp://*:5558')
{:ok, controller} = :erlzmq.socket(context, :pub)
:ok = :erlzmq.bind(controller, 'tcp://*:5559')
{:ok, _} = :erlzmq.recv(receiver)
start = :erlang.now()
process_confirmations(receiver, 100)
:io.format('Total elapsed time: ~b msec~n', [div(:timer.now_diff(:erlang.now(), start), 1000)])
:ok = :erlzmq.send(controller, "KILL")
:ok = :erlzmq.close(controller)
:ok = :erlzmq.close(receiver)
:ok = :erlzmq.term(context, 1000)
end
def process_confirmations(_receiver, 0) do
:ok
end
def process_confirmations(receiver, n) when n > 0 do
{:ok, _} = :erlzmq.recv(receiver)
case(n - rem(1, 10)) do
0 ->
:io.format(':')
_ ->
:io.format('.')
end
process_confirmations(receiver, n - 1)
end
end
Tasksink2.main
tasksink2: Parallel task sink with kill signaling in F#
(*
Task sink - design 2
Adds pub-sub flow to send kill signal to workers
*)
#r @"bin/fszmq.dll"
open fszmq
#load "zhelpers.fs"
open Context
open Socket
open Polling
let main () =
// Prepare our context and socket
use context = new Context(1)
use receiver = context |> pull
bind receiver "tcp://*:5558"
// Socket for worker control
use controller = context |> pub
bind controller "tcp://*:5559"
// Wait for start of batch
s_recv receiver |> ignore
// Start our clock now
let watch = s_clock_start()
// Process 100 confirmations
for task_nbr in 0 .. 99 do
s_recv receiver |> ignore
printf (if (task_nbr / 10) * 10 = task_nbr then ":" else ".")
fflush()
// Calculate and report duration of batch
printfn "\nTotal elapsed time: %d msec" (s_clock_stop watch)
// Send kill signal to workers
s_send controller "KILL"
// Finished
sleep 1 // Give 0MQ time to deliver
EXIT_SUCCESS
main ()
tasksink2: Parallel task sink with kill signaling in Felix
Realistic applications need to shut down cleanly when interrupted with Ctrl-C or another signal such as SIGTERM. By default, these simply kill the process, meaning messages won’t be flushed, files won’t be closed cleanly, and so on.
Here is how we handle a signal in various languages:
program interrupt;
//
// Shows how to handle Ctrl-C
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
socket: TZMQSocket;
frame: TZMQFrame;
begin
context := TZMQContext.Create;
socket := Context.Socket( stRep );
socket.bind( 'tcp://*:5555' );
while not context.Terminated do
begin
frame := TZMQFrame.Create;
try
socket.recv( frame );
except
on e: Exception do
Writeln( 'Exception, ' + e.Message );
end;
FreeAndNil( frame );
if socket.context.Terminated then
begin
Writeln( 'W: interrupt received, killing server...');
break;
end;
end;
socket.Free;
context.Free;
end.
interrupt: Handling Ctrl-C cleanly in Erlang
#! /usr/bin/env escript
%%
%% Illustrates the equivalent in Erlang to signal handling for shutdown
%%
%% Erlang applications don't use system signals for shutdown (they can't
%% without some sort of custom native extension). Instead they rely on an
%% explicit shutdown routine, either per process (as illustrated here) or
%% system wide (e.g. init:stop() and OTP application shutdown).
%%
main(_) ->
%% Start a process that manages its own ZeroMQ startup and shutdown
Server = start_server(),
%% Run for a while
timer:sleep(5000),
%% Send the process a shutdown message - this could be triggered any number
%% of ways (e.g. handling `terminate` in an OTP compliant process)
Server ! {shutdown, self()},
%% Wait for notification that the process has exited cleanly
receive
{ok, Server} -> ok
end.
start_server() ->
%% Start the server in a separate Erlang process
spawn(
fun() ->
%% The process manages its own ZeroMQ context
{ok, Context} = erlzmq:context(),
{ok, Socket} = erlzmq:socket(Context, [rep, {active, true}]),
ok = erlzmq:bind(Socket, "tcp://*:5555"),
io:format("Server started on port 5555~n"),
loop(Context, Socket)
end).
loop(Context, Socket) ->
receive
{zmq, Socket, Msg, _Flags} ->
erlzmq:send(Socket, <<"You said: ", Msg/binary>>),
timer:sleep(1000),
loop(Context, Socket);
{shutdown, From} ->
io:format("Stopping server... "),
ok = erlzmq:close(Socket),
ok = erlzmq:term(Context),
io:format("done~n"),
From ! {ok, self()}
end.
interrupt: Handling Ctrl-C cleanly in Elixir
defmodule Interrupt do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:25
"""
def main() do
server = start_server()
:timer.sleep(5000)
send(server, {:shutdown, self()})
receive do
{:ok, ^server} ->
:ok
end
end
def start_server() do
:erlang.spawn(fn ->
{:ok, context} = :erlzmq.context()
{:ok, socket} = :erlzmq.socket(context, [:rep, {:active, true}])
:ok = :erlzmq.bind(socket, 'tcp://*:5555')
:io.format('Server started on port 5555~n')
loop(context, socket)
end)
end
def loop(context, socket) do
receive do
{:zmq, ^socket, msg, _flags} ->
:erlzmq.send(socket, <<"You said: ", msg::binary>>)
:timer.sleep(1000)
loop(context, socket)
{:shutdown, from} ->
:io.format('Stopping server... ')
:ok = :erlzmq.close(socket)
:ok = :erlzmq.term(context)
:io.format('done~n')
send(from, {:ok, self()})
end
end
end
Interrupt.main
---- Shows how to handle Ctrl-C---- Author: Robert G. Jakabosky <bobby@sharedrealm.com>--
require"zmq"
require"zhelpers"local context = zmq.init(1)
local server = context:socket(zmq.REP)
server:bind("tcp://*:5555")
s_catch_signals ()
whiletruedo-- Blocking read will exit on a signallocal request = server:recv()
if (s_interrupted) then
printf ("W: interrupt received, killing server...\n")
breakend
server:send("World")
end
server:close()
context:term()
interrupt: Handling Ctrl-C cleanly in Node.js
// Show how to handle Ctrl+C in Node.js
var zmq = require('zeromq')
, socket = zmq.createSocket('rep');
socket.on('message', function(buf) {
// echo request back
socket.send(buf);
});
process.on('SIGINT', function() {
socket.close();
process.exit();
});
socket.bindSync('tcp://*:5555');
# Shows how to handle Ctrl-C (SIGINT) and SIGTERM in Perlusestrict;
usewarnings;
usev5.10;
useErrnoqw(EINTR);
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_REP);
my$interrupted;
$SIG{INT} = sub { $interrupted = 1; };
$SIG{TERM} = sub { $interrupted = 1; };
my$context = ZMQ::FFI->new();
my$socket = $context->socket(ZMQ_REP);
$socket->bind('tcp://*:5558');
$socket->die_on_error(0);
while (!$interrupted) {
$socket->recv();
if ($socket->last_errno != EINTR) {
die$socket->last_strerror;
}
}
warn"interrupt received, killing server...";
interrupt: Handling Ctrl-C cleanly in PHP
<?php/*
* Interrupt in PHP
* Shows how to handle CTRL+C
* @author Nicolas Van Eenaeme <nicolas(at)poison(dot)be>
*/declare(ticks=1); // PHP internal, make signal handling work
if (!function_exists('pcntl_signal'))
{
printf("Error, you need to enable the pcntl extension in your php binary, see http://www.php.net/manual/en/pcntl.installation.php for more info%s", PHP_EOL);
exit(1);
}
$running = true;
functionsignalHandler($signo)
{
global$running;
$running = false;
printf("Warning: interrupt received, killing server...%s", PHP_EOL);
}
pcntl_signal(SIGINT, 'signalHandler');
$context = new ZMQContext();
// Socket to talk to clients
$responder = new ZMQSocket($context, ZMQ::SOCKET_REP);
$responder->bind("tcp://*:5558");
while ($running)
{
// Wait for next request from client
try
{
$string = $responder->recv(); // The recv call will throw an ZMQSocketException when interrupted
// PHP Fatal error: Uncaught exception 'ZMQSocketException' with message 'Failed to receive message: Interrupted system call' in interrupt.php:35
}
catch (ZMQSocketException $e)
{
if ($e->getCode() == 4) // 4 == EINTR, interrupted system call (Ctrl+C will interrupt the blocking call as well)
{
usleep(1); // Don't just continue, otherwise the ticks function won't be processed, and the signal will be ignored, try it!
continue; // Ignore it, if our signal handler caught the interrupt as well, the $running flag will be set to false, so we'll break out
}
throw$e; // It's another exception, don't hide it to the user
}
printf("Received request: [%s]%s", $string, PHP_EOL);
// Do some 'work'
sleep(1);
// Send reply back to client
$responder->send("World");
}
// Do here all the cleanup that needs to be done
printf("Program ended cleanly%s", PHP_EOL);
interrupt: Handling Ctrl-C cleanly in Python
## Shows how to handle Ctrl-C#importsignalimporttimeimportzmq
context = zmq.Context()
socket = context.socket(zmq.REP)
socket.bind("tcp://*:5558")
# SIGINT will normally raise a KeyboardInterrupt, just like any other Python calltry:
socket.recv()
except KeyboardInterrupt:
print("W: interrupt received, stopping...")
finally:
# clean up
socket.close()
context.term()
The program provides s_catch_signals(), which traps Ctrl-C (SIGINT) and SIGTERM. When either of these signals arrive, the s_catch_signals() handler sets the global variable s_interrupted. Thanks to your signal handler, your application will not die automatically. Instead, you have a chance to clean up and exit gracefully. You have to now explicitly check for an interrupt and handle it properly. Do this by calling s_catch_signals() (copy this from interrupt.c) at the start of your main code. This sets up the signal handling. The interrupt will affect ZeroMQ calls as follows:
If your code is blocking in a blocking call (sending a message, receiving a message, or polling), then when a signal arrives, the call will return with EINTR.
Wrappers like s_recv() return NULL if they are interrupted.
So check for an EINTR return code, a NULL return, and/or s_interrupted.
Here is a typical code fragment:
s_catch_signals ();
client = zmq_socket (...);
while (!s_interrupted) {
char *message = s_recv (client);
if (!message)
break; // Ctrl-C used
}
zmq_close (client);
If you call s_catch_signals() and don’t test for interrupts, then your application will become immune to Ctrl-C and SIGTERM, which may be useful, but is usually not.
Any long-running application has to manage memory correctly, or eventually it’ll use up all available memory and crash. If you use a language that handles this automatically for you, congratulations. If you program in C or C++ or any other language where you’re responsible for memory management, here’s a short tutorial on using valgrind, which among other things will report on any leaks your programs have.
To install valgrind, e.g., on Ubuntu or Debian, issue this command:
sudo apt-get install valgrind
By default, ZeroMQ will cause valgrind to complain a lot. To remove these warnings, create a file called vg.supp that contains this:
Fix your applications to exit cleanly after Ctrl-C. For any application that exits by itself, that’s not needed, but for long-running applications, this is essential, otherwise valgrind will complain about all currently allocated memory.
Build your application with -DDEBUG if it’s not your default setting. That ensures valgrind can tell you exactly where memory is being leaked.
ZeroMQ is perhaps the nicest way ever to write multithreaded (MT) applications. Whereas ZeroMQ sockets require some readjustment if you are used to traditional sockets, ZeroMQ multithreading will take everything you know about writing MT applications, throw it into a heap in the garden, pour gasoline over it, and set it alight. It’s a rare book that deserves burning, but most books on concurrent programming do.
To make utterly perfect MT programs (and I mean that literally), we don’t need mutexes, locks, or any other form of inter-thread communication except messages sent across ZeroMQ sockets.
By “perfect MT programs”, I mean code that’s easy to write and understand, that works with the same design approach in any programming language, and on any operating system, and that scales across any number of CPUs with zero wait states and no point of diminishing returns.
If you’ve spent years learning tricks to make your MT code work at all, let alone rapidly, with locks and semaphores and critical sections, you will be disgusted when you realize it was all for nothing. If there’s one lesson we’ve learned from 30+ years of concurrent programming, it is: just don’t share state. It’s like two drunkards trying to share a beer. It doesn’t matter if they’re good buddies. Sooner or later, they’re going to get into a fight. And the more drunkards you add to the table, the more they fight each other over the beer. The tragic majority of MT applications look like drunken bar fights.
The list of weird problems that you need to fight as you write classic shared-state MT code would be hilarious if it didn’t translate directly into stress and risk, as code that seems to work suddenly fails under pressure. A large firm with world-beating experience in buggy code released its list of “11 Likely Problems In Your Multithreaded Code”, which covers forgotten synchronization, incorrect granularity, read and write tearing, lock-free reordering, lock convoys, two-step dance, and priority inversion.
Yeah, we counted seven problems, not eleven. That’s not the point though. The point is, do you really want that code running the power grid or stock market to start getting two-step lock convoys at 3 p.m. on a busy Thursday? Who cares what the terms actually mean? This is not what turned us on to programming, fighting ever more complex side effects with ever more complex hacks.
Some widely used models, despite being the basis for entire industries, are fundamentally broken, and shared state concurrency is one of them. Code that wants to scale without limit does it like the Internet does, by sending messages and sharing nothing except a common contempt for broken programming models.
You should follow some rules to write happy multithreaded code with ZeroMQ:
Isolate data privately within its thread and never share data in multiple threads. The only exception to this are ZeroMQ contexts, which are threadsafe.
Stay away from the classic concurrency mechanisms like as mutexes, critical sections, semaphores, etc. These are an anti-pattern in ZeroMQ applications.
Create one ZeroMQ context at the start of your process, and pass that to all threads that you want to connect via inproc sockets.
Use attached threads to create structure within your application, and connect these to their parent threads using PAIR sockets over inproc. The pattern is: bind parent socket, then create child thread which connects its socket.
Use detached threads to simulate independent tasks, with their own contexts. Connect these over tcp. Later you can move these to stand-alone processes without changing the code significantly.
All interaction between threads happens as ZeroMQ messages, which you can define more or less formally.
Don’t share ZeroMQ sockets between threads. ZeroMQ sockets are not threadsafe. Technically it’s possible to migrate a socket from one thread to another but it demands skill. The only place where it’s remotely sane to share sockets between threads are in language bindings that need to do magic like garbage collection on sockets.
If you need to start more than one proxy in an application, for example, you will want to run each in their own thread. It is easy to make the error of creating the proxy frontend and backend sockets in one thread, and then passing the sockets to the proxy in another thread. This may appear to work at first but will fail randomly in real use. Remember: Do not use or close sockets except in the thread that created them.
If you follow these rules, you can quite easily build elegant multithreaded applications, and later split off threads into separate processes as you need to. Application logic can sit in threads, processes, or nodes: whatever your scale needs.
ZeroMQ uses native OS threads rather than virtual “green” threads. The advantage is that you don’t need to learn any new threading API, and that ZeroMQ threads map cleanly to your operating system. You can use standard tools like Intel’s ThreadChecker to see what your application is doing. The disadvantages are that native threading APIs are not always portable, and that if you have a huge number of threads (in the thousands), some operating systems will get stressed.
Let’s see how this works in practice. We’ll turn our old Hello World server into something more capable. The original server ran in a single thread. If the work per request is low, that’s fine: one ØMQ thread can run at full speed on a CPU core, with no waits, doing an awful lot of work. But realistic servers have to do nontrivial work per request. A single core may not be enough when 10,000 clients hit the server all at once. So a realistic server will start multiple worker threads. It then accepts requests as fast as it can and distributes these to its worker threads. The worker threads grind through the work and eventually send their replies back.
You can, of course, do all this using a proxy broker and external worker processes, but often it’s easier to start one process that gobbles up sixteen cores than sixteen processes, each gobbling up one core. Further, running workers as threads will cut out a network hop, latency, and network traffic.
The MT version of the Hello World service basically collapses the broker and workers into a single process:
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid MTServer(string[] args)
{
//
// Multithreaded Hello World server
//
// Author: metadings
//
// Socket to talk to clients and
// Socket to talk to workers
using (var ctx = new ZContext())
using (var clients = new ZSocket(ctx, ZSocketType.ROUTER))
using (var workers = new ZSocket(ctx, ZSocketType.DEALER))
{
clients.Bind("tcp://*:5555");
workers.Bind("inproc://workers");
// Launch pool of worker threads
for (int i = 0; i < 5; ++i)
{
new Thread(() => MTServer_Worker(ctx)).Start();
}
// Connect work threads to client threads via a queue proxy
ZContext.Proxy(clients, workers);
}
}
staticvoid MTServer_Worker(ZContext ctx)
{
// Socket to talk to dispatcher
using (var server = new ZSocket(ctx, ZSocketType.REP))
{
server.Connect("inproc://workers");
while (true)
{
using (ZFrame frame = server.ReceiveFrame())
{
Console.Write("Received: {0}", frame.ReadString());
// Do some 'work'
Thread.Sleep(1);
// Send reply back to client
string replyText = "World";
Console.WriteLine(", Sending: {0}", replyText);
server.Send(new ZFrame(replyText));
}
}
}
}
}
}
mtserver: Multithreaded service in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Multithreaded Hello World server in Common Lisp;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.mtserver
(:nicknames#:mtserver)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.mtserver)
(defunworker-routine (context)
;; Socket to talk to dispatcher
(zmq:with-socket (receivercontextzmq:rep)
(zmq:connectreceiver"inproc://workers")
(loop
(let ((request (make-instance'zmq:msg)))
(zmq:recvreceiverrequest)
(message"Received request: [~A]~%" (zmq:msg-data-as-stringrequest))
;; Do some 'work'
(sleep1)
;; Send reply back to client
(let ((reply (make-instance'zmq:msg:data"World")))
(zmq:sendreceiverreply))))))
(defunmain ()
;; Prepare our context and socket
(zmq:with-context (context1)
;; Socket to talk to clients
(zmq:with-socket (clientscontextzmq:router)
(zmq:bindclients"tcp://*:5555")
;; Socket to talk to workers
(zmq:with-socket (workerscontextzmq:dealer)
(zmq:bindworkers"inproc://workers")
;; Launch pool of worker threads
(dotimes (i5)
(bt:make-thread (lambda () (worker-routinecontext))
:name (formatnil"worker-~D"i)))
;; Connect work threads to client threads via a queue
(zmq:devicezmq:queueclientsworkers))))
(cleanup))
mtserver: Multithreaded service in Delphi
program mtserver;
//
// Multithreaded Hello World server
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
procedure worker_routine( lcontext: TZMQContext );
var
receiver: TZMQSocket;
s: Utf8String;
begin
// Socket to talk to dispatcher
receiver := lContext.Socket( stRep );
receiver.connect( 'inproc://workers' );
while True do
begin
receiver.recv( s );
Writeln( Format( 'Received request: [%s]', [s] ) );
// Do some 'work'
sleep (1000);
// Send reply back to client
receiver.send( 'World' );
end;
receiver.Free;
end;
var
context: TZMQContext;
clients,
workers: TZMQSocket;
i: Integer;
tid: Cardinal;
begin
context := TZMQContext.Create;
// Socket to talk to clients
clients := Context.Socket( stRouter );
clients.bind( 'tcp://*:5555' );
// Socket to talk to workers
workers := Context.Socket( stDealer );
workers.bind( 'inproc://workers' );
// Launch pool of worker threads
for i := 0 to 4 do
BeginThread( nil, 0, @worker_routine, context, 0, tid );
// Connect work threads to client threads via a queue
ZMQProxy( clients, workers, nil );
// We never get here but clean up anyhow
clients.Free;
workers.Free;
context.Free;
end.
mtserver: Multithreaded service in Erlang
#!/usr/bin/env escript
%%
%% Multiprocess Hello World server (analogous to C threads example)
%%
worker_routine(Context) ->
%% Socket to talk to dispatcher
{ok, Receiver} = erlzmq:socket(Context, rep),
ok = erlzmq:connect(Receiver, "inproc://workers"),
worker_loop(Receiver),
ok = erlzmq:close(Receiver).
worker_loop(Receiver) ->
{ok, Msg} = erlzmq:recv(Receiver),
io:format("Received ~s [~p]~n", [Msg, self()]),
%% Do some work
timer:sleep(1000),
erlzmq:send(Receiver, <<"World">>),
worker_loop(Receiver).
main(_) ->
{ok, Context} = erlzmq:context(),
%% Socket to talk to clients
{ok, Clients} = erlzmq:socket(Context, [router, {active, true}]),
ok = erlzmq:bind(Clients, "tcp://*:5555"),
%% Socket to talk to workers
{ok, Workers} = erlzmq:socket(Context, [dealer, {active, true}]),
ok = erlzmq:bind(Workers, "inproc://workers"),
%% Start worker processes
start_workers(Context, 5),
%% Connect work threads to client threads via a queue
erlzmq_device:queue(Clients, Workers),
%% We never get here but cleanup anyhow
ok = erlzmq:close(Clients),
ok = erlzmq:close(Workers),
ok = erlzmq:term(Context).
start_workers(_Context, 0) -> ok;
start_workers(Context, N) whenN > 0 ->
spawn(fun() -> worker_routine(Context) end),
start_workers(Context, N - 1).
mtserver: Multithreaded service in Elixir
defmodule Mtserver do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:29
"""
def worker_routine(context) do
{:ok, receiver} = :erlzmq.socket(context, :rep)
:ok = :erlzmq.connect(receiver, 'inproc://workers')
worker_loop(receiver)
:ok = :erlzmq.close(receiver)
end
def worker_loop(receiver) do
{:ok, msg} = :erlzmq.recv(receiver)
:io.format('Received ~s [~p]~n', [msg, self()])
:timer.sleep(1000)
:erlzmq.send(receiver, "World")
worker_loop(receiver)
end
def main() do
{:ok, context} = :erlzmq.context()
{:ok, clients} = :erlzmq.socket(context, [:router, {:active, true}])
:ok = :erlzmq.bind(clients, 'tcp://*:5555')
{:ok, workers} = :erlzmq.socket(context, [:dealer, {:active, true}])
:ok = :erlzmq.bind(workers, 'inproc://workers')
start_workers(context, 5)
:erlzmq_device.queue(clients, workers)
:ok = :erlzmq.close(clients)
:ok = :erlzmq.close(workers)
:ok = :erlzmq.term(context)
end
def start_workers(_context, 0) do
:ok
end
def start_workers(context, n) when n > 0 do
:erlang.spawn(fn -> worker_routine(context) end)
start_workers(context, n - 1)
end
end
Mtserver.main
mtserver: Multithreaded service in F#
(*
Multithreaded Hello World server
*)
#r @"bin/fszmq.dll"
#r @"bin/fszmq.devices.dll"
open fszmq
open fszmq.Context
open fszmq.Devices
open fszmq.Socket
#load "zhelpers.fs"
open System.Threading
let worker_routine (o:obj) =
// socket to talk to dispatcher
use receiver = (o :?> Context) |> rep
"inproc://workers" |> connect receiver
while true do
let message = s_recv receiver
printfn "Received request: [%s]" message
// do some 'work'
sleep 1
"World" |> s_send receiver
let main () =
use context = new Context(1)
// socket to talk to clients
use clients = route context
"tcp://*:5555" |> bind clients
// socket to talk to clients
use workers = deal context
"inproc://workers" |> bind workers
// launch pool of worker threads
for thread_nbr in 0 .. 4 do
let t = Thread(ParameterizedThreadStart worker_routine)
t.Start(context)
// connect work threads to client threads via a queue
(clients,workers) |> queue |> ignore
// we never get here but clen up anyhow
EXIT_SUCCESS
main ()
// Multithreaded Hello World server.
// Uses Goroutines. We could also use channels (a native form of
// inproc), but I stuck to the example.
//
// Author: Brendan Mc.
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq""time"
)
funcmain() {
// Launch pool of worker threads
for i := 0; i != 5; i = i + 1 {
goworker()
}
// Prepare our context and sockets
context, _ := zmq.NewContext()
defer context.Close()
// Socket to talk to clients
clients, _ := context.NewSocket(zmq.ROUTER)
defer clients.Close()
clients.Bind("tcp://*:5555")
// Socket to talk to workers
workers, _ := context.NewSocket(zmq.DEALER)
defer workers.Close()
workers.Bind("ipc://workers.ipc")
// connect work threads to client threads via a queue
zmq.Device(zmq.QUEUE, clients, workers)
}
funcworker() {
context, _ := zmq.NewContext()
defer context.Close()
// Socket to talk to dispatcher
receiver, _ := context.NewSocket(zmq.REP)
defer receiver.Close()
receiver.Connect("ipc://workers.ipc")
fortrue {
received, _ := receiver.Recv(0)
fmt.Printf("Received request [%s]\n", received)
// Do some 'work'
time.Sleep(time.Second)
// Send reply back to client
receiver.Send([]byte("World"), 0)
}
}
mtserver: Multithreaded service in Haskell
{-# LANGUAGE OverloadedStrings #-}-- |-- Multithreaded Hello World server (p.65)-- (Client) REQ >-> ROUTER (Proxy) DEALER >-> REP ([Worker])-- The client is provided by `hwclient.hs`-- Compile with -threadedmoduleMainwhereimportSystem.ZMQ4.MonadicimportControl.Monad (forever, replicateM_)
importData.ByteString.Char8 (unpack)
importControl.Concurrent (threadDelay)
importText.Printfmain::IO()main=
runZMQ $ do-- Server frontend socket to talk to clients
server <- socket Router
bind server "tcp://*:5555"-- Socket to talk to workers
workers <- socket Dealer
bind workers "inproc://workers"-- using inproc (inter-thread) we expect to share the same context
replicateM_ 5 (async worker)
-- Connect work threads to client threads via a queue
proxy server workers Nothingworker::ZMQ z ()worker=do
receiver <- socket Rep
connect receiver "inproc://workers"
forever $ do
receive receiver >>= liftIO . printf "Received request:%s\n" . unpack
-- Simulate doing some 'work' for 1 second
liftIO $ threadDelay (1 * 1000 * 1000)
send receiver []"World"
mtserver: Multithreaded service in Haxe
package ;
importhaxe.io.Bytes;
importhaxe.Stack;
importneko.Lib;
importneko.Sys;
#if !phpimportneko.vm.Thread;
#endimportorg.zeromq.ZMQ;
importorg.zeromq.ZMQContext;
importorg.zeromq.ZMQPoller;
importorg.zeromq.ZMQSocket;
importorg.zeromq.ZMQException;
/**
* Multithreaded Hello World Server
*
* See: http://zguide.zeromq.org/page:all#Multithreading-with-MQ
* Use with HelloWorldClient.hx
*
*/class MTServer
{
staticfunctionworker() {
var context:ZMQContext = ZMQContext.instance();
// Socket to talk to dispatchervar responder:ZMQSocket = context.socket(ZMQ_REP);
#if (neko || cpp)
responder.connect("inproc://workers");
#elseif php
responder.connect("ipc://workers.ipc");
#end
ZMQ.catchSignals();
while (true) {
try {
// Wait for next request from clientvar request:Bytes = responder.recvMsg();
trace ("Received request:" + request.toString());
// Do some work
Sys.sleep(1);
// Send reply back to client
responder.sendMsg(Bytes.ofString("World"));
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
break;
}
trace (e.toString());
}
}
responder.close();
returnnull;
}
/**
* Implements a reqeust/reply QUEUE broker device
* Returns if poll is interrupted
* @param ctx
* @param frontend
* @param backend
*/staticfunctionqueueDevice(ctx:ZMQContext, frontend:ZMQSocket, backend:ZMQSocket) {
// Initialise pollsetvar poller:ZMQPoller = ctx.poller();
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
ZMQ.catchSignals();
while (true) {
try {
poller.poll();
if (poller.pollin(1)) {
var more:Bool = true;
while (more) {
// Receive messagevar msg = frontend.recvMsg();
more = frontend.hasReceiveMore();
// Broker it
backend.sendMsg(msg, { if (more) SNDMORE elsenull; } );
}
}
if (poller.pollin(2)) {
var more:Bool = true;
while (more) {
// Receive messagevar msg = backend.recvMsg();
more = backend.hasReceiveMore();
// Broker it
frontend.sendMsg(msg, { if (more) SNDMORE elsenull; } );
}
}
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
break;
}
// Handle other errors
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
}
}
publicstaticfunctionmain() {
var context:ZMQContext = ZMQContext.instance();
Lib.println ("** MTServer (see: http://zguide.zeromq.org/page:all#Multithreading-with-MQ)");
// Socket to talk to clientsvar clients:ZMQSocket = context.socket(ZMQ_ROUTER);
clients.bind ("tcp://*:5556");
// Socket to talk to workersvar workers:ZMQSocket = context.socket(ZMQ_DEALER);
#if (neko || cpp)
workers.bind ("inproc://workers");
// Launch worker thread poolvar workerThreads:List<Thread> = new List<Thread>();
for (thread_nbr in0 ... 5) {
workerThreads.add(Thread.create(worker));
}
#elseif php
workers.bind ("ipc://workers.ipc");
// Launch pool of worker processes, due to php's lack of thread support// See: https://github.com/imatix/zguide/blob/master/examples/PHP/mtserver.phpfor (thread_nbr in0 ... 5) {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
// Running in child process
worker();
exit();
}');
}
#end// Invoke request / reply broker (aka QUEUE device) to connect clients to workers
queueDevice(context, clients, workers);
// Close up shop
clients.close();
workers.close();
context.term();
}
}
mtserver: Multithreaded service in Java
packageguide;
importorg.zeromq.SocketType;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQ.Socket;
importorg.zeromq.ZContext;
/**
* Multi threaded Hello World server
*/publicclassmtserver
{
privatestaticclassWorkerextends Thread
{
private ZContext context;
privateWorker(ZContext context)
{
this.context = context;
}
@Overridepublicvoidrun()
{
ZMQ.Socket socket = context.createSocket(SocketType.REP);
socket.connect("inproc://workers");
while (true) {
// Wait for next request from client (C string)
String request = socket.recvStr(0);
System.out.println(Thread.currentThread().getName() + " Received request: [" + request + "]");
// Do some 'work'
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
}
// Send reply back to client (C string)
socket.send("world", 0);
}
}
}
publicstaticvoidmain(String[] args)
{
try (ZContext context = new ZContext()) {
Socket clients = context.createSocket(SocketType.ROUTER);
clients.bind("tcp://*:5555");
Socket workers = context.createSocket(SocketType.DEALER);
workers.bind("inproc://workers");
for (int thread_nbr = 0; thread_nbr < 5; thread_nbr++) {
Thread worker = new Worker(context);
worker.start();
}
// Connect work threads to client threads via a queue
ZMQ.proxy(clients, workers, null);
}
}
}
---- Multithreaded Hello World server---- Author: Robert G. Jakabosky <bobby@sharedrealm.com>--
require"zmq"
require"zmq.threads"
require"zhelpers"local worker_code = [[
local id = ...
local zmq = require"zmq"
require"zhelpers"
local threads = require"zmq.threads"
local context = threads.get_parent_ctx()
-- Socket to talk to dispatcher
local receiver = context:socket(zmq.REP)
assert(receiver:connect("inproc://workers"))
while true do
local msg = receiver:recv()
printf ("Received request: [%s]\n", msg)
-- Do some 'work'
s_sleep (1000)
-- Send reply back to client
receiver:send("World")
end
receiver:close()
return nil
]]
s_version_assert (2, 1)
local context = zmq.init(1)
-- Socket to talk to clientslocal clients = context:socket(zmq.ROUTER)
clients:bind("tcp://*:5555")
-- Socket to talk to workerslocal workers = context:socket(zmq.DEALER)
workers:bind("inproc://workers")
-- Launch pool of worker threadslocal worker_pool = {}
for n=1,5do
worker_pool[n] = zmq.threads.runstring(context, worker_code, n)
worker_pool[n]:start()
end-- Connect work threads to client threads via a queue
print("start queue device.")
zmq.device(zmq.QUEUE, clients, workers)
-- We never get here but clean up anyhow
clients:close()
workers:close()
context:term()
# Multithreaded Hello World server in Perlusestrict;
usewarnings;
usev5.10;
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_REP ZMQ_ROUTER ZMQ_DEALER);
usethreads;
subworker_routine {
my ($context) = @_;
# Socket to talk to dispatchermy$receiver = $context->socket(ZMQ_REP);
$receiver->connect('inproc://workers');
while (1) {
my$string = $receiver->recv();
say "Received request: [$string]";
# Do some 'work'sleep1;
# Send reply back to client$receiver->send('World');
}
}
my$context = ZMQ::FFI->new();
# Socket to talk to clientsmy$clients = $context->socket(ZMQ_ROUTER);
$clients->bind('tcp://*:5555');
# Socket to talk to workersmy$workers = $context->socket(ZMQ_DEALER);
$workers->bind('inproc://workers');
# Launch pool of worker threadsfor (1..5) {
threads->create('worker_routine', $context);
}
# Connect work threads to client threads via a queue proxy$context->proxy($clients, $workers);
# We never get here
mtserver: Multithreaded service in PHP
<?php/*
* Multithreaded Hello World server. Uses proceses due
* to PHP's lack of threads!
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/functionworker_routine()
{
$context = new ZMQContext();
// Socket to talk to dispatcher
$receiver = new ZMQSocket($context, ZMQ::SOCKET_REP);
$receiver->connect("ipc://workers.ipc");
while (true) {
$string = $receiver->recv();
printf ("Received request: [%s]%s", $string, PHP_EOL);
// Do some 'work'
sleep(1);
// Send reply back to client
$receiver->send("World");
}
}
// Launch pool of worker threads
for ($thread_nbr = 0; $thread_nbr != 5; $thread_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
worker_routine();
exit();
}
}
// Prepare our context and sockets
$context = new ZMQContext();
// Socket to talk to clients
$clients = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$clients->bind("tcp://*:5555");
// Socket to talk to workers
$workers = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
$workers->bind("ipc://workers.ipc");
// Connect work threads to client threads via a queue
$device = new ZMQDevice($clients, $workers);
$device->run ();
mtserver: Multithreaded service in Python
"""
Multithreaded Hello World server
Author: Guillaume Aubert (gaubert) <guillaume(dot)aubert(at)gmail(dot)com>
"""importtimeimportthreadingimportzmqdefworker_routine(worker_url: str,
context: zmq.Context = None):
"""Worker routine"""
context = context or zmq.Context.instance()
# Socket to talk to dispatcher
socket = context.socket(zmq.REP)
socket.connect(worker_url)
while True:
string = socket.recv()
print(f"Received request: [ {string} ]")
# Do some 'work'
time.sleep(1)
# Send reply back to client
socket.send(b"World")
defmain():
"""Server routine"""
url_worker = "inproc://workers"
url_client = "tcp://*:5555"# Prepare our context and sockets
context = zmq.Context.instance()
# Socket to talk to clients
clients = context.socket(zmq.ROUTER)
clients.bind(url_client)
# Socket to talk to workers
workers = context.socket(zmq.DEALER)
workers.bind(url_worker)
# Launch pool of worker threadsfor i inrange(5):
thread = threading.Thread(target=worker_routine, args=(url_worker,))
thread.daemon = True
thread.start()
zmq.proxy(clients, workers)
# We never get here but clean up anyhow
clients.close()
workers.close()
context.term()
if __name__ == "__main__":
main()
mtserver: Multithreaded service in Q
// Multithreaded Hello World server
\l qzmq.q
worker_routine:{[args; ctx; pipe]
// Socket to talk to dispatcher
receiver:zsocket.new[ctx; zmq.REP];
zsocket.connect[receiver; `inproc://workers];
while[1b;
s:zstr.recv[receiver];
// Do some 'work'
zclock.sleep 1;
// Send reply back to client
zstr.send[receiver; "World"]];
zsocket.destroy[ctx; receiver]}
ctx:zctx.new[]
// Socket to talk to clients
clients:zsocket.new[ctx; zmq.ROUTER]
clientsport:zsocket.bind[clients; `$"tcp://*:5555"]
// Socket to talk to workers
workers:zsocket.new[ctx; zmq.DEALER]
workersport:zsocket.bind[workers; `inproc://workers]
// Launch pool of worker threads
do[5; zthread.fork[ctx; `worker_routine; 0]]
// Connect work threads to client threads via a queue
rc:libzmq.device[zmq.QUEUE; clients; workers]
if[rc<>-1; '`fail]
// We never get here but clean up anyhow
zsocket.destroy[ctx; clients]
zsocket.destroy[ctx; workers]
zctx.destroy[ctx]
\\
All the code should be recognizable to you by now. How it works:
The server starts a set of worker threads. Each worker thread creates a REP socket and then processes requests on this socket. Worker threads are just like single-threaded servers. The only differences are the transport (inproc instead of tcp), and the bind-connect direction.
The server creates a ROUTER socket to talk to clients and binds this to its external interface (over tcp).
The server creates a DEALER socket to talk to the workers and binds this to its internal interface (over inproc).
The server starts a proxy that connects the two sockets. The proxy pulls incoming requests fairly from all clients, and distributes those out to workers. It also routes replies back to their origin.
Note that creating threads is not portable in most programming languages. The POSIX library is pthreads, but on Windows you have to use a different API. In our example, the pthread_create call starts up a new thread running the worker_routine function we defined. We’ll see in
Chapter 3 - Advanced Request-Reply Patterns how to wrap this in a portable API.
Here the “work” is just a one-second pause. We could do anything in the workers, including talking to other nodes. This is what the MT server looks like in terms of ØMQ sockets and nodes. Note how the request-reply chain is REQ-ROUTER-queue-DEALER-REP.
When you start making multithreaded applications with ZeroMQ, you’ll encounter the question of how to coordinate your threads. Though you might be tempted to insert “sleep” statements, or use multithreading techniques such as semaphores or mutexes, the only mechanism that you should use are ZeroMQ messages. Remember the story of The Drunkards and The Beer Bottle.
Let’s make three threads that signal each other when they are ready. In this example, we use PAIR sockets over the inproc transport:
/*
author: Saad Hussain <saadnasir31@gmail.com>
*/#include<iostream>#include<thread>#include<zmq.hpp>voidstep1(zmq::context_t &context) {
// Connect to step2 and tell it we're ready
zmq::socket_t xmitter(context, zmq::socket_type::pair);
xmitter.connect("inproc://step2");
std::cout << "Step 1 ready, signaling step 2" << std::endl;
zmq::message_t msg("READY");
xmitter.send(msg, zmq::send_flags::none);
}
voidstep2(zmq::context_t &context) {
// Bind inproc socket before starting step1
zmq::socket_t receiver(context, zmq::socket_type::pair);
receiver.bind("inproc://step2");
std::thread thd(step1, std::ref(context));
// Wait for signal and pass it on
zmq::message_t msg;
receiver.recv(msg, zmq::recv_flags::none);
// Connect to step3 and tell it we're ready
zmq::socket_t xmitter(context, zmq::socket_type::pair);
xmitter.connect("inproc://step3");
std::cout << "Step 2 ready, signaling step 3" << std::endl;
xmitter.send(zmq::str_buffer("READY"), zmq::send_flags::none);
thd.join();
}
intmain() {
zmq::context_t context(1);
// Bind inproc socket before starting step2
zmq::socket_t receiver(context, zmq::socket_type::pair);
receiver.bind("inproc://step3");
std::thread thd(step2, std::ref(context));
// Wait for signal
zmq::message_t msg;
receiver.recv(msg, zmq::recv_flags::none);
std::cout << "Test successful!" << std::endl;
thd.join();
return0;
}
mtrelay: Multithreaded relay in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid MTRelay(string[] args)
{
//
// Multithreaded relay
//
// Author: metadings
//
// Bind inproc socket before starting step2
using (var ctx = new ZContext())
using (var receiver = new ZSocket(ctx, ZSocketType.PAIR))
{
receiver.Bind("inproc://step3");
new Thread(() => MTRelay_step2(ctx)).Start();
// Wait for signal
receiver.ReceiveFrame();
Console.WriteLine("Test successful!");
}
}
staticvoid MTRelay_step2(ZContext ctx)
{
// Bind inproc socket before starting step1
using (var receiver = new ZSocket(ctx, ZSocketType.PAIR))
{
receiver.Bind("inproc://step2");
new Thread(() => MTRelay_step1(ctx)).Start();
// Wait for signal and pass it on
receiver.ReceiveFrame();
}
// Connect to step3 and tell it we're ready
using (var xmitter = new ZSocket(ctx, ZSocketType.PAIR))
{
xmitter.Connect("inproc://step3");
Console.WriteLine("Step 2 ready, signaling step 3");
xmitter.Send(new ZFrame("READY"));
}
}
staticvoid MTRelay_step1(ZContext ctx)
{
// Connect to step2 and tell it we're ready
using (var xmitter = new ZSocket(ctx, ZSocketType.PAIR))
{
xmitter.Connect("inproc://step2");
Console.WriteLine("Step 1 ready, signaling step 2");
xmitter.Send(new ZFrame("READY"));
}
}
}
}
mtrelay: Multithreaded relay in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Multithreaded relay in Common Lisp;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.mtrelay
(:nicknames#:mtrelay)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.mtrelay)
(defunstep1 (context)
;; Signal downstream to step 2
(zmq:with-socket (sendercontextzmq:pair)
(zmq:connectsender"inproc://step2")
(let ((msg (make-instance'zmq:msg:data"")))
(zmq:sendsendermsg))))
(defunstep2 (context)
;; Bind to inproc: endpoint, then start upstream thread
(zmq:with-socket (receivercontextzmq:pair)
(zmq:bindreceiver"inproc://step2")
(bt:make-thread (lambda () (step1context)))
;; Wait for signal
(let ((msg (make-instance'zmq:msg)))
(zmq:recvreceivermsg))
;; Signal downstream to step 3
(zmq:with-socket (sendercontextzmq:pair)
(zmq:connectsender"inproc://step3")
(let ((msg (make-instance'zmq:msg:data"")))
(zmq:sendsendermsg)))))
(defunmain ()
(zmq:with-context (context1)
;; Bind to inproc: endpoint, then start upstream thread
(zmq:with-socket (receivercontextzmq:pair)
(zmq:bindreceiver"inproc://step3")
(bt:make-thread (lambda () (step2context)))
;; Wait for signal
(let ((msg (make-instance'zmq:msg)))
(zmq:recvreceivermsg)))
(message"Test successful!~%"))
(cleanup))
mtrelay: Multithreaded relay in Delphi
program mtrelay;
//
// Multithreaded relay
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
procedure step1( lcontext: TZMQContext );
var
xmitter: TZMQSocket;
begin
// Connect to step2 and tell it we're ready
xmitter := lContext.Socket( stPair );
xmitter.connect( 'inproc://step2' );
Writeln( 'Step 1 ready, signaling step 2' );
xmitter.send( 'READY' );
xmitter.Free;
end;
procedure step2( lcontext: TZMQContext );
var
receiver,
xmitter: TZMQSocket;
s: Utf8String;
tid: Cardinal;
begin
// Bind inproc socket before starting step1
receiver := lContext.Socket( stPair );
receiver.bind( 'inproc://step2' );
BeginThread( nil, 0, @step1, lcontext, 0, tid );
// Wait for signal and pass it on
receiver.recv( s );
receiver.Free;
// Connect to step3 and tell it we're ready
xmitter := lContext.Socket( stPair );
xmitter.connect( 'inproc://step3' );
Writeln( 'Step 2 ready, signaling step 3' );
xmitter.send( 'READY' );
xmitter.Free;
end;
var
context: TZMQContext;
receiver: TZMQSocket;
tid: Cardinal;
s: Utf8String;
begin
context := TZMQContext.Create;
// Bind inproc socket before starting step2
receiver := Context.Socket( stPair );
receiver.bind( 'inproc://step3' );
BeginThread( nil, 0, @step2, context, 0, tid );
// Wait for signal
receiver.recv ( s );
receiver.Free;
Writeln( 'Test successful!' );
context.Free;
end.
mtrelay: Multithreaded relay in Erlang
#!/usr/bin/env escript
%%
%% Multithreaded relay
%%
%% This example illustrates how inproc sockets can be used to communicate
%% across "threads". Erlang of course supports this natively, but it's fun to
%% see how 0MQ lets you do this across other languages!
%%
step1(Context) ->
%% Connect to step2 and tell it we're ready
{ok, Xmitter} = erlzmq:socket(Context, pair),
ok = erlzmq:connect(Xmitter, "inproc://step2"),
io:format("Step 1 ready, signaling step 2~n"),
ok = erlzmq:send(Xmitter, <<"READY">>),
ok = erlzmq:close(Xmitter).
step2(Context) ->
%% Bind inproc socket before starting step1
{ok, Receiver} = erlzmq:socket(Context, pair),
ok = erlzmq:bind(Receiver, "inproc://step2"),
spawn(fun() -> step1(Context) end),
%% Wait for signal and pass it on
{ok, _} = erlzmq:recv(Receiver),
ok = erlzmq:close(Receiver),
%% Connect to step3 and tell it we're ready
{ok, Xmitter} = erlzmq:socket(Context, pair),
ok = erlzmq:connect(Xmitter, "inproc://step3"),
io:format("Step 2 ready, signaling step 3~n"),
ok = erlzmq:send(Xmitter, <<"READY">>),
ok = erlzmq:close(Xmitter).
main(_) ->
{ok, Context} = erlzmq:context(),
%% Bind inproc socket before starting step2
{ok, Receiver} = erlzmq:socket(Context, pair),
ok = erlzmq:bind(Receiver, "inproc://step3"),
spawn(fun() -> step2(Context) end),
%% Wait for signal
{ok, _} = erlzmq:recv(Receiver),
erlzmq:close(Receiver),
io:format("Test successful~n"),
ok = erlzmq:term(Context).
(*
Multithreaded relay
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
open System.Threading
let step1 (o:obj) =
// connect to step2 and tell it we're ready
use xmitter = (o :?> Context) |> pair
"inproc://step2" |> connect xmitter
printfn "Step 1 ready, signaling step 2"
"READY" |> s_send xmitter
let step2 (o:obj) =
let context : Context = downcast o
// bind inproc socket before starting step1
use receiver = pair context
"inproc://step2" |> bind receiver
let t = Thread(ParameterizedThreadStart step1)
t.Start(o)
// wait for signal and pass it on
s_recv receiver |> ignore
// connect to step3 and tell it we're ready
use xmitter = pair context
"inproc://step3" |> connect xmitter
printfn "Step 2 ready, signaling step 3"
"READY" |> s_send xmitter
let main () =
use context = new Context(1)
// bind inproc socket before starting step2
use receiver = pair context
"inproc://step3" |> bind receiver
let t = Thread(ParameterizedThreadStart step2)
t.Start(context)
// wait for signal
s_recv receiver |> ignore
printfn "Test successful"
EXIT_SUCCESS
main ()
# Multithreaded relay in Perlusestrict;
usewarnings;
usev5.10;
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_PAIR);
usethreads;
substep1 {
my ($context) = @_;
# Connect to step2 and tell it we're readymy$xmitter = $context->socket(ZMQ_PAIR);
$xmitter->connect('inproc://step2');
say "Step 1 ready, signaling step 2";
$xmitter->send("READY");
}
substep2 {
my ($context) = @_;
# Bind inproc socket before starting step1my$receiver = $context->socket(ZMQ_PAIR);
$receiver->bind('inproc://step2');
threads->create('step1', $context)
->detach();
# Wait for signal and pass it onmy$string = $receiver->recv();
# Connect to step3 and tell it we're readymy$xmitter = $context->socket(ZMQ_PAIR);
$xmitter->connect('inproc://step3');
say "Step 2 ready, signaling step 3";
$xmitter->send("READY");
}
my$context = ZMQ::FFI->new();
# Bind inproc socket before starting step2my$receiver = $context->socket(ZMQ_PAIR);
$receiver->bind('inproc://step3');
threads->create('step2', $context)
->detach();
# Wait for signal$receiver->recv();
say "Test successful!";
mtrelay: Multithreaded relay in PHP
<?php/*
* Multithreaded relay. Actually using processes due a lack
* of PHP threads.
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/functionstep1()
{
$context = new ZMQContext();
// Signal downstream to step 2
$sender = new ZMQSocket($context, ZMQ::SOCKET_PAIR);
$sender->connect("ipc://step2.ipc");
$sender->send("");
}
functionstep2()
{
$pid = pcntl_fork();
if ($pid == 0) {
step1();
exit();
}
$context = new ZMQContext();
// Bind to ipc: endpoint, then start upstream thread
$receiver = new ZMQSocket($context, ZMQ::SOCKET_PAIR);
$receiver->bind("ipc://step2.ipc");
// Wait for signal
$receiver->recv();
// Signal downstream to step 3
$sender = new ZMQSocket($context, ZMQ::SOCKET_PAIR);
$sender->connect("ipc://step3.ipc");
$sender->send("");
}
// Start upstream thread then bind to icp: endpoint
$pid = pcntl_fork();
if ($pid == 0) {
step2();
exit();
}
$context = new ZMQContext();
$receiver = new ZMQSocket($context, ZMQ::SOCKET_PAIR);
$receiver->bind("ipc://step3.ipc");
// Wait for signal
$receiver->recv();
echo"Test succesful!", PHP_EOL;
mtrelay: Multithreaded relay in Python
"""
Multithreaded relay
Author: Guillaume Aubert (gaubert) <guillaume(dot)aubert(at)gmail(dot)com>
"""importthreadingimportzmqdefstep1(context: zmq.Context = None):
"""Step 1"""
context = context or zmq.Context.instance()
# Signal downstream to step 2
sender = context.socket(zmq.PAIR)
sender.connect("inproc://step2")
sender.send(b"")
defstep2(context: zmq.Context = None):
"""Step 2"""
context = context or zmq.Context.instance()
# Bind to inproc: endpoint, then start upstream thread
receiver = context.socket(zmq.PAIR)
receiver.bind("inproc://step2")
thread = threading.Thread(target=step1)
thread.start()
# Wait for signal
msg = receiver.recv()
# Signal downstream to step 3
sender = context.socket(zmq.PAIR)
sender.connect("inproc://step3")
sender.send(b"")
defmain():
""" server routine """# Prepare our context and sockets
context = zmq.Context.instance()
# Bind to inproc: endpoint, then start upstream thread
receiver = context.socket(zmq.PAIR)
receiver.bind("inproc://step3")
thread = threading.Thread(target=step2)
thread.start()
# Wait for signal
string = receiver.recv()
print("Test successful!")
receiver.close()
context.term()
if __name__ == "__main__":
main()
mtrelay: Multithreaded relay in Q
// Multithreaded relay
\l qzmq.q
step1:{[args; ctx; pipe]
// Connect to step2 and tell it we're ready
xmitter:zsocket.new[ctx; zmq.PAIR];
zsocket.connect[xmitter; `inproc://step2];
zclock.log "Step 1 ready, signaling step 2";
zstr.send[xmitter; "READY"];
zsocket.destroy[ctx; xmitter]}
step2:{[args; ctx; pipe]
// Bind inproc socket before starting step1
receiver:zsocket.new[ctx; zmq.PAIR];
port:zsocket.bind[receiver; `inproc://step2];
pipe:zthread.fork[ctx; `step1; 0N];
// Wait for signal and pass it on
zclock.log s:zstr.recv[receiver];
// Connect to step3 and tell it we're ready
xmitter:zsocket.new[ctx; zmq.PAIR];
zsocket.connect[xmitter; `inproc://step3];
zclock.log "Step 2 ready, signaling step 3";
zstr.send[xmitter; "READY"];
zsocket.destroy[ctx; xmitter]}
ctx:zctx.new[]
// Bind inproc socket before starting step2
receiver:zsocket.new[ctx; zmq.PAIR]
port:zsocket.bind[receiver; `inproc://step3]
pipe:zthread.fork[ctx; `step2; 0N]
// Wait for signal
zclock.log s:zstr.recv[receiver]
zclock.log "Test successful!"
zctx.destroy[ctx]
\\
This is a classic pattern for multithreading with ZeroMQ:
Two threads communicate over inproc, using a shared context.
The parent thread creates one socket, binds it to an inproc:@<*>@ endpoint, and *then// starts the child thread, passing the context to it.
The child thread creates the second socket, connects it to that inproc:@<*>@ endpoint, and *then// signals to the parent thread that it’s ready.
Note that multithreading code using this pattern is not scalable out to processes. If you use inproc and socket pairs, you are building a tightly-bound application, i.e., one where your threads are structurally interdependent. Do this when low latency is really vital. The other design pattern is a loosely bound application, where threads have their own context and communicate over ipc or tcp. You can easily break loosely bound threads into separate processes.
This is the first time we’ve shown an example using PAIR sockets. Why use PAIR? Other socket combinations might seem to work, but they all have side effects that could interfere with signaling:
You can use PUSH for the sender and PULL for the receiver. This looks simple and will work, but remember that PUSH will distribute messages to all available receivers. If you by accident start two receivers (e.g., you already have one running and you start a second), you’ll “lose” half of your signals. PAIR has the advantage of refusing more than one connection; the pair is exclusive.
You can use DEALER for the sender and ROUTER for the receiver. ROUTER, however, wraps your message in an “envelope”, meaning your zero-size signal turns into a multipart message. If you don’t care about the data and treat anything as a valid signal, and if you don’t read more than once from the socket, that won’t matter. If, however, you decide to send real data, you will suddenly find ROUTER providing you with “wrong” messages. DEALER also distributes outgoing messages, giving the same risk as PUSH.
You can use PUB for the sender and SUB for the receiver. This will correctly deliver your messages exactly as you sent them and PUB does not distribute as PUSH or DEALER do. However, you need to configure the subscriber with an empty subscription, which is annoying.
For these reasons, PAIR makes the best choice for coordination between pairs of threads.
When you want to coordinate a set of nodes on a network, PAIR sockets won’t work well any more. This is one of the few areas where the strategies for threads and nodes are different. Principally, nodes come and go whereas threads are usually static. PAIR sockets do not automatically reconnect if the remote node goes away and comes back.
Figure 22 - Pub-Sub Synchronization
The second significant difference between threads and nodes is that you typically have a fixed number of threads but a more variable number of nodes. Let’s take one of our earlier scenarios (the weather server and clients) and use node coordination to ensure that subscribers don’t lose data when starting up.
This is how the application will work:
The publisher knows in advance how many subscribers it expects. This is just a magic number it gets from somewhere.
The publisher starts up and waits for all subscribers to connect. This is the node coordination part. Each subscriber subscribes and then tells the publisher it’s ready via another socket.
When the publisher has all subscribers connected, it starts to publish data.
In this case, we’ll use a REQ-REP socket flow to synchronize subscribers and publisher. Here is the publisher:
// Synchronized publisher
#include"zhelpers.h"#define SUBSCRIBERS_EXPECTED 10 // We wait for 10 subscribers
intmain (void)
{
void *context = zmq_ctx_new ();
// Socket to talk to clients
void *publisher = zmq_socket (context, ZMQ_PUB);
int sndhwm = 1100000;
zmq_setsockopt (publisher, ZMQ_SNDHWM, &sndhwm, sizeof (int));
zmq_bind (publisher, "tcp://*:5561");
// Socket to receive signals
void *syncservice = zmq_socket (context, ZMQ_REP);
zmq_bind (syncservice, "tcp://*:5562");
// Get synchronization from subscribers
printf ("Waiting for subscribers\n");
int subscribers = 0;
while (subscribers < SUBSCRIBERS_EXPECTED) {
// - wait for synchronization request
char *string = s_recv (syncservice);
free (string);
// - send synchronization reply
s_send (syncservice, "");
subscribers++;
}
// Now broadcast exactly 1M updates followed by END
printf ("Broadcasting messages\n");
int update_nbr;
for (update_nbr = 0; update_nbr < 1000000; update_nbr++)
s_send (publisher, "Rhubarb");
s_send (publisher, "END");
zmq_close (publisher);
zmq_close (syncservice);
zmq_ctx_destroy (context);
return0;
}
syncpub: Synchronized publisher in C++
//
// Synchronized publisher in C++
//
#include"zhelpers.hpp"// We wait for 10 subscribers
#define SUBSCRIBERS_EXPECTED 10
intmain () {
zmq::context_t context(1);
// Socket to talk to clients
zmq::socket_t publisher (context, ZMQ_PUB);
int sndhwm = 0;
publisher.setsockopt (ZMQ_SNDHWM, &sndhwm, sizeof (sndhwm));
publisher.bind("tcp://*:5561");
// Socket to receive signals
zmq::socket_t syncservice (context, ZMQ_REP);
syncservice.bind("tcp://*:5562");
// Get synchronization from subscribers
int subscribers = 0;
while (subscribers < SUBSCRIBERS_EXPECTED) {
// - wait for synchronization request
s_recv (syncservice);
// - send synchronization reply
s_send (syncservice, std::string(""));
subscribers++;
}
// Now broadcast exactly 1M updates followed by END
int update_nbr;
for (update_nbr = 0; update_nbr < 1000000; update_nbr++) {
s_send (publisher, std::string("Rhubarb"));
}
s_send (publisher, std::string("END"));
sleep (1); // Give 0MQ time to flush output
return0;
}
syncpub: Synchronized publisher in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
constint SyncPub_SubscribersExpected = 3; // We wait for 3 subscribers
publicstaticvoid SyncPub(string[] args)
{
//
// Synchronized publisher
//
// Author: metadings
//
// Socket to talk to clients and
// Socket to receive signals
using (var context = new ZContext())
using (var publisher = new ZSocket(context, ZSocketType.PUB))
using (var syncservice = new ZSocket(context, ZSocketType.REP))
{
publisher.SendHighWatermark = 1100000;
publisher.Bind("tcp://*:5561");
syncservice.Bind("tcp://*:5562");
// Get synchronization from subscribers
int subscribers = SyncPub_SubscribersExpected;
do
{
Console.WriteLine("Waiting for {0} subscriber" + (subscribers > 1 ? "s" : string.Empty) + "...", subscribers);
// - wait for synchronization request
syncservice.ReceiveFrame();
// - send synchronization reply
syncservice.Send(new ZFrame());
}
while (--subscribers > 0);
// Now broadcast exactly 20 updates followed by END
Console.WriteLine("Broadcasting messages:");
for (int i = 0; i < 20; ++i)
{
Console.WriteLine("Sending {0}...", i);
publisher.Send(new ZFrame(i));
}
publisher.Send(new ZFrame("END"));
}
}
}
}
syncpub: Synchronized publisher in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Synchronized publisher in Common Lisp;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.syncpub
(:nicknames#:syncpub)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.syncpub)
;; We wait for 10 subscribers
(defparameter *expected-subscribers* 10)
(defunmain ()
(zmq:with-context (context1)
;; Socket to talk to clients
(zmq:with-socket (publishercontextzmq:pub)
(zmq:bindpublisher"tcp://*:5561")
;; Socket to receive signals
(zmq:with-socket (syncservicecontextzmq:rep)
(zmq:bindsyncservice"tcp://*:5562")
;; Get synchronization from subscribers
(loop:repeat *expected-subscribers* :do;; - wait for synchronization request
(let ((msg (make-instance'zmq:msg)))
(zmq:recvsyncservicemsg))
;; - send synchronization reply
(let ((msg (make-instance'zmq:msg:data"")))
(zmq:sendsyncservicemsg)))
;; Now broadcast exactly 1M updates followed by END
(loop:repeat1000000:do
(let ((msg (make-instance'zmq:msg:data"Rhubarb")))
(zmq:sendpublishermsg)))
(let ((msg (make-instance'zmq:msg:data"END")))
(zmq:sendpublishermsg))))
;; Give 0MQ/2.0.x time to flush output
(sleep1))
(cleanup))
syncpub: Synchronized publisher in Delphi
program syncpub;
//
// Synchronized publisher
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqApi
;
// We wait for 10 subscribers
const
SUBSCRIBERS_EXPECTED = 2;
var
context: TZMQContext;
publisher,
syncservice: TZMQSocket;
subscribers: Integer;
str: Utf8String;
i: Integer;
begin
context := TZMQContext.create;
// Socket to talk to clients
publisher := Context.Socket( stPub );
publisher.setSndHWM( 1000001 );
publisher.bind( 'tcp://*:5561' );
// Socket to receive signals
syncservice := Context.Socket( stRep );
syncservice.bind( 'tcp://*:5562' );
// Get synchronization from subscribers
Writeln( 'Waiting for subscribers' );
subscribers := 0;
while ( subscribers < SUBSCRIBERS_EXPECTED ) do
begin
// - wait for synchronization request
syncservice.recv( str );
// - send synchronization reply
syncservice.send( '' );
Inc( subscribers );
end;
// Now broadcast exactly 1M updates followed by END
Writeln( 'Broadcasting messages' );
for i := 0 to 1000000 - 1 do
publisher.send( 'Rhubarb' );
publisher.send( 'END' );
publisher.Free;
syncservice.Free;
context.Free;
end.
syncpub: Synchronized publisher in Erlang
#! /usr/bin/env escript
%%
%% Synchronized publisher
%%
%% We wait for 10 subscribers
-define(SUBSCRIBERS_EXPECTED, 10).
main(_) ->
{ok, Context} = erlzmq:context(),
%% Socket to talk to clients
{ok, Publisher} = erlzmq:socket(Context, pub),
ok = erlzmq:bind(Publisher, "tcp://*:5561"),
%% Socket to receive signals
{ok, Syncservice} = erlzmq:socket(Context, rep),
ok = erlzmq:bind(Syncservice, "tcp://*:5562"),
%% Get synchronization from subscribers
io:format("Waiting for subscribers~n"),
sync_subscribers(Syncservice, ?SUBSCRIBERS_EXPECTED),
%% Now broadcast exactly 1M updates followed by END
io:format("Broadcasting messages~n"),
broadcast(Publisher, 1000000),
ok = erlzmq:send(Publisher, <<"END">>),
ok = erlzmq:close(Publisher),
ok = erlzmq:close(Syncservice),
ok = erlzmq:term(Context).
sync_subscribers(_Syncservice, 0) -> ok;
sync_subscribers(Syncservice, N) whenN > 0 ->
%% Wait for synchornization request
{ok, _} = erlzmq:recv(Syncservice),
%% Send synchronization reply
ok = erlzmq:send(Syncservice, <<>>),
sync_subscribers(Syncservice, N - 1).
broadcast(_Publisher, 0) -> ok;
broadcast(Publisher, N) whenN > 0 ->
ok = erlzmq:send(Publisher, <<"Rhubarb">>),
broadcast(Publisher, N - 1).
syncpub: Synchronized publisher in Elixir
defmodule Syncpub do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:34
"""
defmacrop erlconst_SUBSCRIBERS_EXPECTED() do
quote do
2
end
end
def main() do
{:ok, context} = :erlzmq.context()
{:ok, publisher} = :erlzmq.socket(context, :pub)
:ok = :erlzmq.bind(publisher, 'tcp://*:5561')
{:ok, syncservice} = :erlzmq.socket(context, :rep)
:ok = :erlzmq.bind(syncservice, 'tcp://*:5562')
:io.format('Waiting for subscribers. Please start 2 subscribers.~n')
sync_subscribers(syncservice, erlconst_SUBSCRIBERS_EXPECTED())
:io.format('Broadcasting messages~n')
broadcast(publisher, 1000000)
:ok = :erlzmq.send(publisher, "END")
:ok = :erlzmq.close(publisher)
:ok = :erlzmq.close(syncservice)
:ok = :erlzmq.term(context)
end
def sync_subscribers(_syncservice, 0) do
:ok
end
def sync_subscribers(syncservice, n) when n > 0 do
{:ok, _} = :erlzmq.recv(syncservice)
:ok = :erlzmq.send(syncservice, <<>>)
sync_subscribers(syncservice, n - 1)
end
def broadcast(_publisher, 0) do
:ok
end
def broadcast(publisher, n) when n > 0 do
:ok = :erlzmq.send(publisher, "Rhubarb")
broadcast(publisher, n - 1)
end
end
Syncpub.main
syncpub: Synchronized publisher in F#
(*
Synchronized publisher
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
// we wait for 10 subscribers
let [<Literal>] SUBSCRIBERS_EXPECTED = 10
let main () =
use context = new Context(1)
// socket to talk to clients
use publisher = pub context
"tcp://*:5561" |> bind publisher
// socket to receive signals
use syncservice = rep context
"tcp://*:5562" |> bind syncservice
// get synchronization from subscribers
printfn "Waiting for subscribers"
let subscribers = ref 0
while !subscribers < SUBSCRIBERS_EXPECTED do
// - wait for synchronization request
syncservice |> s_recv |> ignore
// - send synchronization reply
"" |> s_send syncservice
incr subscribers
// now broadcast exactly 1M updates followed by END
printfn "Broadcasting messages"
for update_nbr in 0 .. 999999 do "Rhubarb" |> s_send publisher
"END" |> s_send publisher
EXIT_SUCCESS
main ()
# Synchronized publisher in Perlusestrict;
usewarnings;
usev5.10;
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_PUB ZMQ_REP ZMQ_SNDHWM);
my$SUBSCRIBERS_EXPECTED = 10; # We wait for 10 subscribersmy$context = ZMQ::FFI->new();
# Socket to talk to clientsmy$publisher = $context->socket(ZMQ_PUB);
$publisher->set(ZMQ_SNDHWM, 'int', 0);
$publisher->set_linger(-1);
$publisher->bind('tcp://*:5561');
# Socket to receive signalsmy$syncservice = $context->socket(ZMQ_REP);
$syncservice->bind('tcp://*:5562');
# Get synchronization from subscribers
say "Waiting for subscribers";
formy$subscribers (1..$SUBSCRIBERS_EXPECTED) {
# wait for synchronization request$syncservice->recv();
# send synchronization reply$syncservice->send('');
say "+1 subscriber ($subscribers/$SUBSCRIBERS_EXPECTED)";
}
# Now broadcast exactly 1M updates followed by END
say "Broadcasting messages";
for (1..1_000_000) {
$publisher->send("Rhubarb");
}
$publisher->send("END");
say "Done";
syncpub: Synchronized publisher in PHP
<?php/*
* Synchronized publisher
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/// We wait for 10 subscribers
define("SUBSCRIBERS_EXPECTED", 10);
$context = new ZMQContext();
// Socket to talk to clients
$publisher = new ZMQSocket($context, ZMQ::SOCKET_PUB);
$publisher->bind("tcp://*:5561");
// Socket to receive signals
$syncservice = new ZMQSocket($context, ZMQ::SOCKET_REP);
$syncservice->bind("tcp://*:5562");
// Get synchronization from subscribers
$subscribers = 0;
while ($subscribers < SUBSCRIBERS_EXPECTED) {
// - wait for synchronization request
$string = $syncservice->recv();
// - send synchronization reply
$syncservice->send("");
$subscribers++;
}
// Now broadcast exactly 1M updates followed by END
for ($update_nbr = 0; $update_nbr < 1000000; $update_nbr++) {
$publisher->send("Rhubarb");
}
$publisher->send("END");
sleep (1); // Give 0MQ/2.0.x time to flush output
syncpub: Synchronized publisher in Python
## Synchronized publisher#importzmq# We wait for 10 subscribers
SUBSCRIBERS_EXPECTED = 10defmain():
context = zmq.Context()
# Socket to talk to clients
publisher = context.socket(zmq.PUB)
# set SNDHWM, so we don't drop messages for slow subscribers
publisher.sndhwm = 1100000
publisher.bind("tcp://*:5561")
# Socket to receive signals
syncservice = context.socket(zmq.REP)
syncservice.bind("tcp://*:5562")
# Get synchronization from subscribers
subscribers = 0while subscribers < SUBSCRIBERS_EXPECTED:
# wait for synchronization request
msg = syncservice.recv()
# send synchronization reply
syncservice.send(b'')
subscribers += 1print(f"+1 subscriber ({subscribers}/{SUBSCRIBERS_EXPECTED})")
# Now broadcast exactly 1M updates followed by ENDfor i inrange(1000000):
publisher.send(b"Rhubarb")
publisher.send(b"END")
if __name__ == "__main__":
main()
// Synchronized subscriber
#include"zhelpers.h"#include<unistd.h>intmain (void)
{
void *context = zmq_ctx_new ();
// First, connect our subscriber socket
void *subscriber = zmq_socket (context, ZMQ_SUB);
zmq_connect (subscriber, "tcp://localhost:5561");
zmq_setsockopt (subscriber, ZMQ_SUBSCRIBE, "", 0);
// 0MQ is so fast, we need to wait a while...
sleep (1);
// Second, synchronize with publisher
void *syncclient = zmq_socket (context, ZMQ_REQ);
zmq_connect (syncclient, "tcp://localhost:5562");
// - send a synchronization request
s_send (syncclient, "");
// - wait for synchronization reply
char *string = s_recv (syncclient);
free (string);
// Third, get our updates and report how many we got
int update_nbr = 0;
while (1) {
char *string = s_recv (subscriber);
if (strcmp (string, "END") == 0) {
free (string);
break;
}
free (string);
update_nbr++;
}
printf ("Received %d updates\n", update_nbr);
zmq_close (subscriber);
zmq_close (syncclient);
zmq_ctx_destroy (context);
return0;
}
syncsub: Synchronized subscriber in C++
//
// Synchronized subscriber in C++
//
#include"zhelpers.hpp"intmain (int argc, char *argv[])
{
zmq::context_t context(1);
// First, connect our subscriber socket
zmq::socket_t subscriber (context, ZMQ_SUB);
subscriber.connect("tcp://localhost:5561");
subscriber.set(zmq::sockopt::subscribe, "");
// Second, synchronize with publisher
zmq::socket_t syncclient (context, ZMQ_REQ);
syncclient.connect("tcp://localhost:5562");
// - send a synchronization request
s_send (syncclient, std::string(""));
// - wait for synchronization reply
s_recv (syncclient);
// Third, get our updates and report how many we got
int update_nbr = 0;
while (1) {
if (s_recv (subscriber).compare("END") == 0) {
break;
}
update_nbr++;
}
std::cout << "Received " << update_nbr << " updates" << std::endl;
return0;
}
syncsub: Synchronized subscriber in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid SyncSub(string[] args)
{
//
// Synchronized subscriber
//
// Author: metadings
//
using (var context = new ZContext())
using (var subscriber = new ZSocket(context, ZSocketType.SUB))
using (var syncclient = new ZSocket(context, ZSocketType.REQ))
{
// First, connect our subscriber socket
subscriber.Connect("tcp://127.0.0.1:5561");
subscriber.SubscribeAll();
// 0MQ is so fast, we need to wait a while…
Thread.Sleep(1);
// Second, synchronize with publisher
syncclient.Connect("tcp://127.0.0.1:5562");
// - send a synchronization request
syncclient.Send(new ZFrame());
// - wait for synchronization reply
syncclient.ReceiveFrame();
// Third, get our updates and report how many we got
int i = 0;
while (true)
{
using (ZFrame frame = subscriber.ReceiveFrame())
{
string text = frame.ReadString();
if (text == "END")
{
break;
}
frame.Position = 0;
Console.WriteLine("Receiving {0}...", frame.ReadInt32());
++i;
}
}
Console.WriteLine("Received {0} updates.", i);
}
}
}
}
syncsub: Synchronized subscriber in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Synchronized subscriber in Common Lisp;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.syncsub
(:nicknames#:syncsub)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.syncsub)
(defunmain ()
(zmq:with-context (context1)
;; First, connect our subscriber socket
(zmq:with-socket (subscribercontextzmq:sub)
(zmq:connectsubscriber"tcp://localhost:5561")
(zmq:setsockoptsubscriberzmq:subscribe"")
;; Second, synchronize with publisher
(zmq:with-socket (syncclientcontextzmq:req)
(zmq:connectsyncclient"tcp://localhost:5562")
;; - send a synchronization request
(let ((msg (make-instance'zmq:msg:data"")))
(zmq:sendsyncclientmsg))
;; - wait for synchronization reply
(let ((msg (make-instance'zmq:msg)))
(zmq:recvsyncclientmsg))
;; Third, get our updates and report how many we got
(let ((updates0))
(loop
(let ((msg (make-instance'zmq:msg)))
(zmq:recvsubscribermsg)
(when (string="END" (zmq:msg-data-as-stringmsg))
(return))
(incfupdates)))
(message"Received ~D updates~%"updates)))))
(cleanup))
syncsub: Synchronized subscriber in Delphi
program syncsub;
//
// Synchronized subscriber
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqApi
;
var
context: TZMQContext;
subscriber,
syncclient: TZMQSocket;
str: Utf8String;
i: Integer;
begin
context := TZMQContext.Create;
// First, connect our subscriber socket
subscriber := Context.Socket( stSub );
subscriber.RcvHWM := 1000001;
subscriber.connect( 'tcp://localhost:5561' );
subscriber.Subscribe( '' );
// 0MQ is so fast, we need to wait a while...
sleep (1000);
// Second, synchronize with publisher
syncclient := Context.Socket( stReq );
syncclient.connect( 'tcp://localhost:5562' );
// - send a synchronization request
syncclient.send( '' );
// - wait for synchronization reply
syncclient.recv( str );
// Third, get our updates and report how many we got
i := 0;
while True do
begin
subscriber.recv( str );
if str = 'END' then
break;
inc( i );
end;
Writeln( Format( 'Received %d updates', [i] ) );
subscriber.Free;
syncclient.Free;
context.Free;
end.
syncsub: Synchronized subscriber in Erlang
#! /usr/bin/env escript
%%
%% Synchronized subscriber
%%
main(_) ->
{ok, Context} = erlzmq:context(),
%% First, connect our subscriber socket
{ok, Subscriber} = erlzmq:socket(Context, sub),
ok = erlzmq:connect(Subscriber, "tcp://localhost:5561"),
ok = erlzmq:setsockopt(Subscriber, subscribe, <<>>),
%% Second, synchronize with publisher
{ok, Syncclient} = erlzmq:socket(Context, req),
ok = erlzmq:connect(Syncclient, "tcp://localhost:5562"),
%% - send a synchronization request
ok = erlzmq:send(Syncclient, <<>>),
%% - wait for synchronization reply
{ok, <<>>} = erlzmq:recv(Syncclient),
%% Third, get our updates and report how many we got
Updates = acc_updates(Subscriber, 0),
io:format("Received ~b updates~n", [Updates]),
ok = erlzmq:close(Subscriber),
ok = erlzmq:close(Syncclient),
ok = erlzmq:term(Context).
acc_updates(Subscriber, N) ->
caseerlzmq:recv(Subscriber) of
{ok, <<"END">>} -> N;
{ok, _} -> acc_updates(Subscriber, N + 1)
end.
syncsub: Synchronized subscriber in Elixir
defmodule Syncsub do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:34
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, subscriber} = :erlzmq.socket(context, :sub)
:ok = :erlzmq.connect(subscriber, 'tcp://localhost:5561')
:ok = :erlzmq.setsockopt(subscriber, :subscribe, <<>>)
{:ok, syncclient} = :erlzmq.socket(context, :req)
:ok = :erlzmq.connect(syncclient, 'tcp://localhost:5562')
:ok = :erlzmq.send(syncclient, <<>>)
{:ok, <<>>} = :erlzmq.recv(syncclient)
updates = acc_updates(subscriber, 0)
:io.format('Received ~b updates~n', [updates])
:ok = :erlzmq.close(subscriber)
:ok = :erlzmq.close(syncclient)
:ok = :erlzmq.term(context)
end
def acc_updates(subscriber, n) do
case(:erlzmq.recv(subscriber)) do
{:ok, "END"} ->
n
{:ok, _} ->
acc_updates(subscriber, n + 1)
end
end
end
Syncsub.main
syncsub: Synchronized subscriber in F#
(*
Synchronized subscriber
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
let main () =
use context = new Context(1)
// first, connect our subscriber socket
use subscriber = sub context
"tcp://localhost:5561" |> connect subscriber
[ ""B ] |> subscribe subscriber
// 0MQ is so fast, we need to wait a while...
sleep 1
// second, synchronize with publisher
use syncclient = req context
"tcp://localhost:5562" |> connect syncclient
// - send a synchronization request
"" |> s_send syncclient
// - wait for synchronization reply
syncclient |> s_recv |> ignore
// third, get our updates and report how many we got
let rec loop count =
let message = s_recv subscriber
if message <> "END"
then loop (count + 1)
else count
let update_nbr = loop 0
printfn "Received %d updates" update_nbr
EXIT_SUCCESS
main ()
// Synchronized subscriber
//
// Author: Aleksandar Janicijevic
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq""time"
)
funcmain() {
context, _ := zmq.NewContext()
defer context.Close()
subscriber, _ := context.NewSocket(zmq.SUB)
defer subscriber.Close()
subscriber.Connect("tcp://localhost:5561")
subscriber.SetSubscribe("")
// 0MQ is so fast, we need to wait a while...
time.Sleep(time.Second)
// Second, synchronize with publisher
syncclient, _ := context.NewSocket(zmq.REQ)
defer syncclient.Close()
syncclient.Connect("tcp://localhost:5562")
// - send a synchronization request
fmt.Println("Send synchronization request")
syncclient.Send([]byte(""), 0)
fmt.Println("Wait for synchronization reply")
// - wait for synchronization reply
syncclient.Recv(0)
fmt.Println("Get updates")
// Third, get our updates and report how many we got
update_nbr := 0for {
reply, _ := subscriber.Recv(0)
ifstring(reply) == "END" {
break
}
update_nbr++
}
fmt.Printf("Received %d updates\n", update_nbr)
}
syncsub: Synchronized subscriber in Haskell
{-# LANGUAGE OverloadedStrings #-}-- Synchronized subscribermoduleMainwhereimportControl.ConcurrentimportData.FunctionimportSystem.ZMQ4.MonadicimportText.Printfmain::IO()main= runZMQ $ do-- First, connect our subscriber socket
subscriber <- socket Sub
connect subscriber "tcp://localhost:5561"
subscribe subscriber ""-- 0MQ is so fast, we need to wait a while...
liftIO $ threadDelay 1000000-- Second, synchronize with the publisher
syncclient <- socket Req
connect syncclient "tcp://localhost:5562"-- Send a synchronization request
send syncclient []""-- Wait for a synchronization reply
receive syncclient
let-- go :: (Int -> ZMQ z Int) -> Int -> ZMQ z Int
go loop =\n ->do
string <- receive subscriber
if string == "END"then return n
else loop (n+1)
-- Third, get our updates and report how many we got
update_nbr <- fix go (0::Int)
liftIO $ printf "Received %d updates\n" update_nbr
syncsub: Synchronized subscriber in Haxe
package ;
importneko.Lib;
importhaxe.io.Bytes;
importneko.Sys;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQContext;
importorg.zeromq.ZMQSocket;
/**
* Synchronised subscriber
*
* See: http://zguide.zeromq.org/page:all#Node-Coordination
*
* Use with SyncPub.hx
*/class SyncSub
{
publicstaticfunctionmain() {
var context:ZMQContext = ZMQContext.instance();
Lib.println("** SyncSub (see: http://zguide.zeromq.org/page:all#Node-Coordination)");
// First connect our subscriber socketvar subscriber:ZMQSocket = context.socket(ZMQ_SUB);
subscriber.connect("tcp://127.0.0.1:5561");
subscriber.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
// 0MQ is so fast, we need to wait a little while
Sys.sleep(1.0);
// Second, synchronise with publishervar syncClient:ZMQSocket = context.socket(ZMQ_REQ);
syncClient.connect("tcp://127.0.0.1:5562");
// Send a synchronisation request
syncClient.sendMsg(Bytes.ofString(""));
// Wait for a synchronisation replyvar msgBytes:Bytes = syncClient.recvMsg();
// Third, get our updates and report how many we gotvar update_nbr = 0;
while (true) {
msgBytes = subscriber.recvMsg();
if (msgBytes.toString() == "END") {
break;
}
msgBytes = null;
update_nbr++;
}
Lib.println("Received " + update_nbr + " updates\n");
subscriber.close();
syncClient.close();
context.term();
}
}
syncsub: Synchronized subscriber in Java
packageguide;
importorg.zeromq.SocketType;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQ.Socket;
importorg.zeromq.ZContext;
/**
* Synchronized subscriber.
*/publicclasssyncsub
{
publicstaticvoidmain(String[] args)
{
try (ZContext context = new ZContext()) {
// First, connect our subscriber socket
Socket subscriber = context.createSocket(SocketType.SUB);
subscriber.connect("tcp://localhost:5561");
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
// Second, synchronize with publisher
Socket syncclient = context.createSocket(SocketType.REQ);
syncclient.connect("tcp://localhost:5562");
// - send a synchronization request
syncclient.send(ZMQ.MESSAGE_SEPARATOR, 0);
// - wait for synchronization reply
syncclient.recv(0);
// Third, get our updates and report how many we got
int update_nbr = 0;
while (true) {
String string = subscriber.recvStr(0);
if (string.equals("END")) {
break;
}
update_nbr++;
}
System.out.println("Received " + update_nbr + " updates.");
}
}
}
# Synchronized subscriber in Perlusestrict;
usewarnings;
usev5.10;
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_SUB ZMQ_REQ ZMQ_RCVHWM);
my$context = ZMQ::FFI->new();
# First, connect our subscriber socketmy$subscriber = $context->socket(ZMQ_SUB);
$subscriber->set(ZMQ_RCVHWM, 'int', 0);
$subscriber->connect('tcp://localhost:5561');
$subscriber->subscribe('');
# 0MQ is so fast, we need to wait a while...sleep3;
# Second, synchronize with publishermy$syncclient = $context->socket(ZMQ_REQ);
$syncclient->connect('tcp://localhost:5562');
# send a synchronization request$syncclient->send('');
# wait for synchronization reply$syncclient->recv();
# Third, get our updates and report how many we gotmy$update_nbr = 0;
while (1) {
lastif$subscriber->recv() eq"END";
$update_nbr++;
}
say "Received $update_nbr updates";
syncsub: Synchronized subscriber in PHP
<?php/*
* Synchronized subscriber
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/$context = new ZMQContext();
// First, connect our subscriber socket
$subscriber = $context->getSocket(ZMQ::SOCKET_SUB);
$subscriber->connect("tcp://localhost:5561");
$subscriber->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "");
// Second, synchronize with publisher
$syncclient = $context->getSocket(ZMQ::SOCKET_REQ);
$syncclient->connect("tcp://localhost:5562");
// - send a synchronization request
$syncclient->send("");
// - wait for synchronization reply
$string = $syncclient->recv();
// Third, get our updates and report how many we got
$update_nbr = 0;
while (true) {
$string = $subscriber->recv();
if ($string == "END") {
break;
}
$update_nbr++;
}
printf ("Received %d updates %s", $update_nbr, PHP_EOL);
syncsub: Synchronized subscriber in Python
## Synchronized subscriber#importtimeimportzmqdefmain():
context = zmq.Context()
# First, connect our subscriber socket
subscriber = context.socket(zmq.SUB)
subscriber.connect("tcp://localhost:5561")
subscriber.setsockopt(zmq.SUBSCRIBE, b'')
time.sleep(1)
# Second, synchronize with publisher
syncclient = context.socket(zmq.REQ)
syncclient.connect("tcp://localhost:5562")
# send a synchronization request
syncclient.send(b'')
# wait for synchronization reply
syncclient.recv()
# Third, get our updates and report how many we got
nbr = 0while True:
msg = subscriber.recv()
if msg == b"END":
break
nbr += 1print(f"Received {nbr} updates")
if __name__ == "__main__":
main()
This Bash shell script will start ten subscribers and then the publisher:
echo "Starting subscribers..."
for ((a=0; a<10; a++)); do
syncsub &
done
echo "Starting publisher..."
syncpub
Which gives us this satisfying output:
Starting subscribers...
Starting publisher...
Received 1000000 updates
Received 1000000 updates
...
Received 1000000 updates
Received 1000000 updates
We can’t assume that the SUB connect will be finished by the time the REQ/REP dialog is complete. There are no guarantees that outbound connects will finish in any order whatsoever, if you’re using any transport except inproc. So, the example does a brute force sleep of one second between subscribing, and sending the REQ/REP synchronization.
ZeroMQ’s message API lets you send and receive messages directly from and to application buffers without copying data. We call this zero-copy, and it can improve performance in some applications.
You should think about using zero-copy in the specific case where you are sending large blocks of memory (thousands of bytes), at a high frequency. For short messages, or for lower message rates, using zero-copy will make your code messier and more complex with no measurable benefit. Like all optimizations, use this when you know it helps, and measure before and after.
To do zero-copy, you use zmq_msg_init_data() to create a message that refers to a block of data already allocated with malloc() or some other allocator, and then you pass that to zmq_msg_send(). When you create the message, you also pass a function that ZeroMQ will call to free the block of data, when it has finished sending the message. This is the simplest example, assuming buffer is a block of 1,000 bytes allocated on the heap:
voidmy_free (void *data, void *hint) {
free (data);
}
// Send message from buffer, which we allocate and ZeroMQ will free for us
zmq_msg_t message;
zmq_msg_init_data (&message, buffer, 1000, my_free, NULL);
zmq_msg_send (&message, socket, 0);
Note that you don’t call zmq_msg_close() after sending a message–libzmq will do this automatically when it’s actually done sending the message.
There is no way to do zero-copy on receive: ZeroMQ delivers you a buffer that you can store as long as you wish, but it will not write data directly into application buffers.
On writing, ZeroMQ’s multipart messages work nicely together with zero-copy. In traditional messaging, you need to marshal different buffers together into one buffer that you can send. That means copying data. With ZeroMQ, you can send multiple buffers coming from different sources as individual message frames. Send each field as a length-delimited frame. To the application, it looks like a series of send and receive calls. But internally, the multiple parts get written to the network and read back with single system calls, so it’s very efficient.
In the pub-sub pattern, we can split the key into a separate message frame that we call an envelope. If you want to use pub-sub envelopes, make them yourself. It’s optional, and in previous pub-sub examples we didn’t do this. Using a pub-sub envelope is a little more work for simple cases, but it’s cleaner especially for real cases, where the key and the data are naturally separate things.
Figure 23 - Pub-Sub Envelope with Separate Key
Subscriptions do a prefix match. That is, they look for “all messages starting with XYZ”. The obvious question is: how to delimit keys from data so that the prefix match doesn’t accidentally match data. The best answer is to use an envelope because the match won’t cross a frame boundary. Here is a minimalist example of how pub-sub envelopes look in code. This publisher sends messages of two types, A and B.
// Pubsub envelope publisher
// Note that the zhelpers.h file also provides s_sendmore
#include"zhelpers.h"#include<unistd.h>intmain (void)
{
// Prepare our context and publisher
void *context = zmq_ctx_new ();
void *publisher = zmq_socket (context, ZMQ_PUB);
zmq_bind (publisher, "tcp://*:5563");
while (1) {
// Write two messages, each with an envelope and content
s_sendmore (publisher, "A");
s_send (publisher, "We don't want to see this");
s_sendmore (publisher, "B");
s_send (publisher, "We would like to see this");
sleep (1);
}
// We never get here, but clean up anyhow
zmq_close (publisher);
zmq_ctx_destroy (context);
return0;
}
psenvpub: Pub-Sub envelope publisher in C++
//
// Pubsub envelope publisher
// Note that the zhelpers.h file also provides s_sendmore
//
#include"zhelpers.hpp"intmain () {
// Prepare our context and publisher
zmq::context_t context(1);
zmq::socket_t publisher(context, ZMQ_PUB);
publisher.bind("tcp://*:5563");
while (1) {
// Write two messages, each with an envelope and content
s_sendmore (publisher, std::string("A"));
s_send (publisher, std::string("We don't want to see this"));
s_sendmore (publisher, std::string("B"));
s_send (publisher, std::string("We would like to see this"));
sleep (1);
}
return0;
}
psenvpub: Pub-Sub envelope publisher in C#
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading;
usingZeroMQ;
namespaceExamples
{
staticpartialclassProgram
{
publicstaticvoid PSEnvPub(string[] args)
{
//
// Pubsub envelope publisher
//
// Author: metadings
//
// Prepare our context and publisher
using (var context = new ZContext())
using (var publisher = new ZSocket(context, ZSocketType.PUB))
{
publisher.Linger = TimeSpan.Zero;
publisher.Bind("tcp://*:5563");
int published = 0;
while (true)
{
// Write two messages, each with an envelope and content
using (var message = new ZMessage())
{
published++;
message.Add(new ZFrame(string.Format("A {0}", published)));
message.Add(new ZFrame(string.Format(" We don't like to see this.")));
Thread.Sleep(1000);
Console_WriteZMessage("Publishing ", message);
publisher.Send(message);
}
using (var message = new ZMessage())
{
published++;
message.Add(new ZFrame(string.Format("B {0}", published)));
message.Add(new ZFrame(string.Format(" We do like to see this.")));
Thread.Sleep(1000);
Console_WriteZMessage("Publishing ", message);
publisher.Send(message);
}
}
}
}
}
}
psenvpub: Pub-Sub envelope publisher in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-;;;;;; Pubsub envelope publisher in Common Lisp;;; Note that the zhelpers package also provides send-text and send-more-text;;;;;; Kamil Shakirov <kamils80@gmail.com>;;;
(defpackage#:zguide.psenvpub
(:nicknames#:psenvpub)
(:use#:cl#:zhelpers)
(:export#:main))
(in-package:zguide.psenvpub)
(defunmain ()
;; Prepare our context and publisher
(zmq:with-context (context1)
(zmq:with-socket (publishercontextzmq:pub)
(zmq:bindpublisher"tcp://*:5563")
(loop;; Write two messages, each with an envelope and content
(send-more-textpublisher"A")
(send-textpublisher"We don't want to see this")
(send-more-textpublisher"B")
(send-textpublisher"We would like to see this")
(sleep1))))
(cleanup))
psenvpub: Pub-Sub envelope publisher in Delphi
program psenvpub;
//
// Pubsub envelope publisher
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
publisher: TZMQSocket;
begin
// Prepare our context and publisher
context := TZMQContext.Create;
publisher := context.Socket( stPub );
publisher.bind( 'tcp://*:5563' );
while true do
begin
// Write two messages, each with an envelope and content
publisher.send( ['A', 'We don''t want to see this'] );
publisher.send( ['B', 'We would like to see this'] );
sleep(1000);
end;
publisher.Free;
context.Free;
end.
psenvpub: Pub-Sub envelope publisher in Erlang
#! /usr/bin/env escript
%%
%% Pubsub envelope publisher
%%
main(_) ->
%% Prepare our context and publisher
{ok, Context} = erlzmq:context(),
{ok, Publisher} = erlzmq:socket(Context, pub),
ok = erlzmq:bind(Publisher, "tcp://*:5563"),
loop(Publisher),
%% We never get here but clean up anyhow
ok = erlzmq:close(Publisher),
ok = erlzmq:term(Context).
loop(Publisher) ->
%% Write two messages, each with an envelope and content
ok = erlzmq:send(Publisher, <<"A">>, [sndmore]),
ok = erlzmq:send(Publisher, <<"We don't want to see this">>),
ok = erlzmq:send(Publisher, <<"B">>, [sndmore]),
ok = erlzmq:send(Publisher, <<"We would like to see this">>),
timer:sleep(1000),
loop(Publisher).
psenvpub: Pub-Sub envelope publisher in Elixir
defmodule Psenvpub do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:29
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, publisher} = :erlzmq.socket(context, :pub)
:ok = :erlzmq.bind(publisher, 'tcp://*:5563')
loop(publisher)
:ok = :erlzmq.close(publisher)
:ok = :erlzmq.term(context)
end
def loop(publisher) do
:ok = :erlzmq.send(publisher, "A", [:sndmore])
:ok = :erlzmq.send(publisher, "We don't want to see this")
:ok = :erlzmq.send(publisher, "B", [:sndmore])
:ok = :erlzmq.send(publisher, "We would like to see this")
:timer.sleep(1000)
loop(publisher)
end
end
Psenvpub.main
psenvpub: Pub-Sub envelope publisher in F#
(*
Pubsub envelope publisher
Note that the zhelpers.fs file also provides s_sendmore
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
let main () =
// prepare our context and publisher
use context = new Context(1)
use publisher = pub context
"tcp://*:5563" |> bind publisher
while true do
// write two messages, each with an envelope and content
"A" |> s_sendmore publisher
"We don't want to see this" |> s_send publisher
"B" |> s_sendmore publisher
"We would like to see this" |> s_send publisher
sleep 1
// we never get here but clean up anyhow
EXIT_SUCCESS
main ()
//
// Pubsub envelope publisher
//
package main
import (
zmq "github.com/alecthomas/gozmq""time"
)
funcmain() {
context, _ := zmq.NewContext()
defer context.Close()
publisher, _ := context.NewSocket(zmq.PUB)
defer publisher.Close()
publisher.Bind("tcp://*:5563")
for {
publisher.SendMultipart([][]byte{[]byte("A"), []byte("We don't want to see this")}, 0)
publisher.SendMultipart([][]byte{[]byte("B"), []byte("We would like to see this")}, 0)
time.Sleep(time.Second)
}
}
psenvpub: Pub-Sub envelope publisher in Haskell
{-# LANGUAGE OverloadedLists #-}{-# LANGUAGE OverloadedStrings #-}-- Pubsub envelope publishermoduleMainwhereimportControl.ConcurrentimportControl.MonadimportSystem.ZMQ4.Monadicmain::IO()main= runZMQ $ do-- Prepare our publisher
publisher <- socket Pub
bind publisher "tcp://*:5563"
forever $ do-- Write two messages, each with an envelope and content
sendMulti publisher ["A", "We don't want to see this"]
sendMulti publisher ["B", "We would like to see this"]
liftIO $ threadDelay 1000000
psenvpub: Pub-Sub envelope publisher in Haxe
package ;
importhaxe.io.Bytes;
importneko.Lib;
importneko.Sys;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQContext;
importorg.zeromq.ZMQException;
importorg.zeromq.ZMQSocket;
/**
* Pubsub envelope publisher
*
* See: http://zguide.zeromq.org/page:all#Pub-sub-Message-Envelopes
*
* Use with PSEnvSub
*/class PSEnvPub
{
publicstaticfunctionmain() {
var context:ZMQContext = ZMQContext.instance();
Lib.println("** PSEnvPub (see: http://zguide.zeromq.org/page:all#Pub-sub-Message-Envelopes)");
var publisher:ZMQSocket = context.socket(ZMQ_PUB);
publisher.bind("tcp://*:5563");
ZMQ.catchSignals();
while (true) {
publisher.sendMsg(Bytes.ofString("A"), SNDMORE);
publisher.sendMsg(Bytes.ofString("We don't want to see this"));
publisher.sendMsg(Bytes.ofString("B"), SNDMORE);
publisher.sendMsg(Bytes.ofString("We would like to see this"));
Sys.sleep(1.0);
}
// We never get here but clean up anyhow
publisher.close();
context.term();
}
}
psenvpub: Pub-Sub envelope publisher in Java
packageguide;
importorg.zeromq.SocketType;
importorg.zeromq.ZMQ;
importorg.zeromq.ZMQ.Socket;
importorg.zeromq.ZContext;
/**
* Pubsub envelope publisher
*/publicclasspsenvpub
{
publicstaticvoidmain(String[] args) throws Exception
{
// Prepare our context and publisher
try (ZContext context = new ZContext()) {
Socket publisher = context.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5563");
while (!Thread.currentThread().isInterrupted()) {
// Write two messages, each with an envelope and content
publisher.sendMore("A");
publisher.send("We don't want to see this");
publisher.sendMore("B");
publisher.send("We would like to see this");
}
}
}
}
---- Pubsub envelope publisher-- Note that the zhelpers.h file also provides s_sendmore---- Author: Robert G. Jakabosky <bobby@sharedrealm.com>--
require"zmq"
require"zhelpers"-- Prepare our context and publisherlocal context = zmq.init(1)
local publisher = context:socket(zmq.PUB)
publisher:bind("tcp://*:5563")
whiletruedo-- Write two messages, each with an envelope and content
publisher:send("A", zmq.SNDMORE)
publisher:send("We don't want to see this")
publisher:send("B", zmq.SNDMORE)
publisher:send("We would like to see this")
s_sleep (1000)
end-- We never get here but clean up anyhow
publisher:close()
context:term()
psenvpub: Pub-Sub envelope publisher in Node.js
var zmq = require('zeromq')
var publisher = zmq.socket('pub')
publisher.bind('tcp://*:5563', function(err) {
if(err)
console.log(err)
else
console.log('Listening on 5563...')
})
setInterval(function() {
//if you pass an array, send() uses SENDMORE flag automatically
publisher.send(["A", "We do not want to see this"]);
//if you want, you can set it explicitly
publisher.send("B", zmq.ZMQ_SNDMORE);
publisher.send("We would like to see this");
},1000);
psenvpub: Pub-Sub envelope publisher in Objective-C
# Pubsub envelope publisher in Perlusestrict;
usewarnings;
usev5.10;
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_PUB);
# Prepare our context and publishermy$context = ZMQ::FFI->new();
my$publisher = $context->socket(ZMQ_PUB);
$publisher->bind('tcp://*:5563');
while (1) {
# Write two messages, each with an envelope and content$publisher->send_multipart(["A", "We don't want to see this"]);
$publisher->send_multipart(["B", "We would like to see this"]);
sleep1;
}
# We never get here
psenvpub: Pub-Sub envelope publisher in PHP
<?php/*
* Pubsub envelope publisher
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/// Prepare our context and publisher
$context = new ZMQContext();
$publisher = new ZMQSocket($context, ZMQ::SOCKET_PUB);
$publisher->bind("tcp://*:5563");
while (true) {
// Write two messages, each with an envelope and content
$publisher->send("A", ZMQ::MODE_SNDMORE);
$publisher->send("We don't want to see this");
$publisher->send("B", ZMQ::MODE_SNDMORE);
$publisher->send("We would like to see this");
sleep (1);
}
// We never get here
psenvpub: Pub-Sub envelope publisher in Python
"""
Pubsub envelope publisher
Author: Guillaume Aubert (gaubert) <guillaume(dot)aubert(at)gmail(dot)com>
"""importtimeimportzmqdefmain():
"""main method"""# Prepare our context and publisher
context = zmq.Context()
publisher = context.socket(zmq.PUB)
publisher.bind("tcp://*:5563")
while True:
# Write two messages, each with an envelope and content
publisher.send_multipart([b"A", b"We don't want to see this"])
publisher.send_multipart([b"B", b"We would like to see this"])
time.sleep(1)
# We never get here but clean up anyhow
publisher.close()
context.term()
if __name__ == "__main__":
main()
#! /usr/bin/env escript
%%
%% Pubsub envelope subscriber
%%
main(_) ->
%% Prepare our context and subscriber
{ok, Context} = erlzmq:context(),
{ok, Subscriber} = erlzmq:socket(Context, sub),
ok = erlzmq:connect(Subscriber, "tcp://localhost:5563"),
ok = erlzmq:setsockopt(Subscriber, subscribe, <<"B">>),
loop(Subscriber),
%% We never get here but clean up anyhow
ok = erlzmq:close(Subscriber),
ok = erlzmq:term(Context).
loop(Subscriber) ->
%% Read envelope with address
{ok, Address} = erlzmq:recv(Subscriber),
%% Read message contents
{ok, Contents} = erlzmq:recv(Subscriber),
io:format("[~s] ~s~n", [Address, Contents]),
loop(Subscriber).
psenvsub: Pub-Sub envelope subscriber in Elixir
defmodule Psenvsub do
@moduledoc"""
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:30
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, subscriber} = :erlzmq.socket(context, :sub)
:ok = :erlzmq.connect(subscriber, 'tcp://localhost:5563')
:ok = :erlzmq.setsockopt(subscriber, :subscribe, "B")
loop(subscriber)
:ok = :erlzmq.close(subscriber)
:ok = :erlzmq.term(context)
end
def loop(subscriber) do
{:ok, address} = :erlzmq.recv(subscriber)
{:ok, contents} = :erlzmq.recv(subscriber)
:io.format('[~s] ~s~n', [address, contents])
loop(subscriber)
end
end
Psenvsub.main
psenvsub: Pub-Sub envelope subscriber in F#
(*
Pubsub envelope subscriber
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
let main () =
// prepare our context and publisher
use context = new Context(1)
use subscriber = sub context
"tcp://localhost:5563" |> connect subscriber
[ "B"B ] |> subscribe subscriber
while true do
// read envelope with address
let address = s_recv subscriber
// read message contents
let contents = s_recv subscriber
printfn "[%s] %s" address contents
// we never get here but clean up anyhow
EXIT_SUCCESS
main ()
# Pubsub envelope subscriber in Perlusestrict;
usewarnings;
usev5.10;
useZMQ::FFI;
useZMQ::FFI::Constantsqw(ZMQ_SUB);
# Prepare our context and subscribermy$context = ZMQ::FFI->new();
my$subscriber = $context->socket(ZMQ_SUB);
$subscriber->connect('tcp://localhost:5563');
$subscriber->subscribe('B');
while (1) {
# Read envelope with addressmy ($address, $contents) = $subscriber->recv_multipart();
say "[$address] $contents";
}
# We never get here
psenvsub: Pub-Sub envelope subscriber in PHP
<?php/*
* Pubsub envelope subscriber
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/// Prepare our context and subscriber
$context = new ZMQContext();
$subscriber = new ZMQSocket($context, ZMQ::SOCKET_SUB);
$subscriber->connect("tcp://localhost:5563");
$subscriber->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "B");
while (true) {
// Read envelope with address
$address = $subscriber->recv();
// Read message contents
$contents = $subscriber->recv();
printf ("[%s] %s%s", $address, $contents, PHP_EOL);
}
// We never get here
psenvsub: Pub-Sub envelope subscriber in Python
"""
Pubsub envelope subscriber
Author: Guillaume Aubert (gaubert) <guillaume(dot)aubert(at)gmail(dot)com>
"""importzmqdefmain():
""" main method """# Prepare our context and publisher
context = zmq.Context()
subscriber = context.socket(zmq.SUB)
subscriber.connect("tcp://localhost:5563")
subscriber.setsockopt(zmq.SUBSCRIBE, b"B")
while True:
# Read envelope with address
[address, contents] = subscriber.recv_multipart()
print(f"[{address}] {contents}")
# We never get here but clean up anyhow
subscriber.close()
context.term()
if __name__ == "__main__":
main()
When you run the two programs, the subscriber should show you this:
[B] We would like to see this
[B] We would like to see this
[B] We would like to see this
...
This example shows that the subscription filter rejects or accepts the entire multipart message (key plus data). You won’t get part of a multipart message, ever. If you subscribe to multiple publishers and you want to know their address so that you can send them data via another socket (and this is a typical use case), create a three-part message.
When you can send messages rapidly from process to process, you soon discover that memory is a precious resource, and one that can be trivially filled up. A few seconds of delay somewhere in a process can turn into a backlog that blows up a server unless you understand the problem and take precautions.
The problem is this: imagine you have process A sending messages at high frequency to process B, which is processing them. Suddenly B gets very busy (garbage collection, CPU overload, whatever), and can’t process the messages for a short period. It could be a few seconds for some heavy garbage collection, or it could be much longer, if there’s a more serious problem. What happens to the messages that process A is still trying to send frantically? Some will sit in B’s network buffers. Some will sit on the Ethernet wire itself. Some will sit in A’s network buffers. And the rest will accumulate in A’s memory, as rapidly as the application behind A sends them. If you don’t take some precaution, A can easily run out of memory and crash.
It is a consistent, classic problem with message brokers. What makes it hurt more is that it’s B’s fault, superficially, and B is typically a user-written application which A has no control over.
What are the answers? One is to pass the problem upstream. A is getting the messages from somewhere else. So tell that process, “Stop!” And so on. This is called flow control. It sounds plausible, but what if you’re sending out a Twitter feed? Do you tell the whole world to stop tweeting while B gets its act together?
Flow control works in some cases, but not in others. The transport layer can’t tell the application layer to “stop” any more than a subway system can tell a large business, “please keep your staff at work for another half an hour. I’m too busy”. The answer for messaging is to set limits on the size of buffers, and then when we reach those limits, to take some sensible action. In some cases (not for a subway system, though), the answer is to throw away messages. In others, the best strategy is to wait.
ZeroMQ uses the concept of HWM (high-water mark) to define the capacity of its internal pipes. Each connection out of a socket or into a socket has its own pipe, and HWM for sending, and/or receiving, depending on the socket type. Some sockets (PUB, PUSH) only have send buffers. Some (SUB, PULL, REQ, REP) only have receive buffers. Some (DEALER, ROUTER, PAIR) have both send and receive buffers.
In ZeroMQ v2.x, the HWM was infinite by default. This was easy but also typically fatal for high-volume publishers. In ZeroMQ v3.x, it’s set to 1,000 by default, which is more sensible. If you’re still using ZeroMQ v2.x, you should always set a HWM on your sockets, be it 1,000 to match ZeroMQ v3.x or another figure that takes into account your message sizes and expected subscriber performance.
When your socket reaches its HWM, it will either block or drop data depending on the socket type. PUB and ROUTER sockets will drop data if they reach their HWM, while other socket types will block. Over the inproc transport, the sender and receiver share the same buffers, so the real HWM is the sum of the HWM set by both sides.
Lastly, the HWMs are not exact; while you may get up to 1,000 messages by default, the real buffer size may be much lower (as little as half), due to the way libzmq implements its queues.
As you build applications with ZeroMQ, you will come across this problem more than once: losing messages that you expect to receive. We have put together a diagram that walks through the most common causes for this.
Figure 25 - Missing Message Problem Solver
Here’s a summary of what the graphic says:
On SUB sockets, set a subscription using zmq_setsockopt() with ZMQ_SUBSCRIBE, or you won’t get messages. Because you subscribe to messages by prefix, if you subscribe to "” (an empty subscription), you will get everything.
If you start the SUB socket (i.e., establish a connection to a PUB socket) after the PUB socket has started sending out data, you will lose whatever it published before the connection was made. If this is a problem, set up your architecture so the SUB socket starts first, then the PUB socket starts publishing.
Even if you synchronize a SUB and PUB socket, you may still lose messages. It’s due to the fact that internal queues aren’t created until a connection is actually created. If you can switch the bind/connect direction so the SUB socket binds, and the PUB socket connects, you may find it works more as you’d expect.
If you’re using REP and REQ sockets, and you’re not sticking to the synchronous send/recv/send/recv order, ZeroMQ will report errors, which you might ignore. Then, it would look like you’re losing messages. If you use REQ or REP, stick to the send/recv order, and always, in real code, check for errors on ZeroMQ calls.
If you’re using PUSH sockets, you’ll find that the first PULL socket to connect will grab an unfair share of messages. The accurate rotation of messages only happens when all PULL sockets are successfully connected, which can take some milliseconds. As an alternative to PUSH/PULL, for lower data rates, consider using ROUTER/DEALER and the load balancing pattern.
If you’re sharing sockets across threads, don’t. It will lead to random weirdness, and crashes.
If you’re using inproc, make sure both sockets are in the same context. Otherwise the connecting side will in fact fail. Also, bind first, then connect. inproc is not a disconnected transport like tcp.
If you’re using ROUTER sockets, it’s remarkably easy to lose messages by accident, by sending malformed identity frames (or forgetting to send an identity frame). In general setting the ZMQ_ROUTER_MANDATORY option on ROUTER sockets is a good idea, but do also check the return code on every send call.
Lastly, if you really can’t figure out what’s going wrong, make a minimal test case that reproduces the problem, and ask for help from the ZeroMQ community.