Chapter 3 - Advanced Request-Reply Patterns #
In Chapter 2 - Sockets and Patterns we worked through the basics of using ZeroMQ by developing a series of small applications, each time exploring new aspects of ZeroMQ. We’ll continue this approach in this chapter as we explore advanced patterns built on top of ZeroMQ’s core request-reply pattern.
We’ll cover:
- How the request-reply mechanisms work
- How to combine REQ, REP, DEALER, and ROUTER sockets
- How ROUTER sockets work, in detail
- The load balancing pattern
- Building a simple load balancing message broker
- Designing a high-level API for ZeroMQ
- Building an asynchronous request-reply server
- A detailed inter-broker routing example
The Request-Reply Mechanisms #
We already looked briefly at multipart messages. Let’s now look at a major use case, which is reply message envelopes. An envelope is a way of safely packaging up data with an address, without touching the data itself. By separating reply addresses into an envelope we make it possible to write general purpose intermediaries such as APIs and proxies that create, read, and remove addresses no matter what the message payload or structure is.
In the request-reply pattern, the envelope holds the return address for replies. It is how a ZeroMQ network with no state can create round-trip request-reply dialogs.
When you use REQ and REP sockets you don’t even see envelopes; these sockets deal with them automatically. But for most of the interesting request-reply patterns, you’ll want to understand envelopes and particularly ROUTER sockets. We’ll work through this step-by-step.
The Simple Reply Envelope #
A request-reply exchange consists of a request message, and an eventual reply message. In the simple request-reply pattern, there’s one reply for each request. In more advanced patterns, requests and replies can flow asynchronously. However, the reply envelope always works the same way.
The ZeroMQ reply envelope formally consists of zero or more reply addresses, followed by an empty frame (the envelope delimiter), followed by the message body (zero or more frames). The envelope is created by multiple sockets working together in a chain. We’ll break this down.
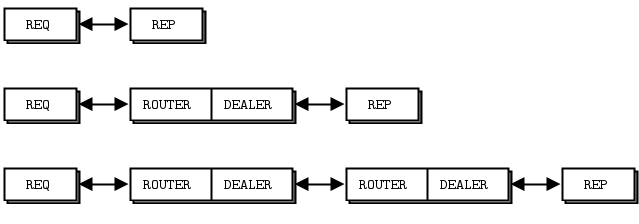
We’ll start by sending “Hello” through a REQ socket. The REQ socket creates the simplest possible reply envelope, which has no addresses, just an empty delimiter frame and the message frame containing the “Hello” string. This is a two-frame message.

The REP socket does the matching work: it strips off the envelope, up to and including the delimiter frame, saves the whole envelope, and passes the “Hello” string up the application. Thus our original Hello World example used request-reply envelopes internally, but the application never saw them.
If you spy on the network data flowing between hwclient and hwserver, this is what you’ll see: every request and every reply is in fact two frames, an empty frame and then the body. It doesn’t seem to make much sense for a simple REQ-REP dialog. However you’ll see the reason when we explore how ROUTER and DEALER handle envelopes.
The Extended Reply Envelope #
Now let’s extend the REQ-REP pair with a ROUTER-DEALER proxy in the middle and see how this affects the reply envelope. This is the extended request-reply pattern we already saw in Chapter 2 - Sockets and Patterns. We can, in fact, insert any number of proxy steps. The mechanics are the same.
The proxy does this, in pseudo-code:
prepare context, frontend and backend sockets
while true:
poll on both sockets
if frontend had input:
read all frames from frontend
send to backend
if backend had input:
read all frames from backend
send to frontend
The ROUTER socket, unlike other sockets, tracks every connection it has, and tells the caller about these. The way it tells the caller is to stick the connection identity in front of each message received. An identity, sometimes called an address, is just a binary string with no meaning except “this is a unique handle to the connection”. Then, when you send a message via a ROUTER socket, you first send an identity frame.
The zmq_socket() man page describes it thus:
When receiving messages a ZMQ_ROUTER socket shall prepend a message part containing the identity of the originating peer to the message before passing it to the application. Messages received are fair-queued from among all connected peers. When sending messages a ZMQ_ROUTER socket shall remove the first part of the message and use it to determine the identity of the peer the message shall be routed to.
As a historical note, ZeroMQ v2.2 and earlier use UUIDs as identities. ZeroMQ v3.0 and later generate a 5 byte identity by default (0 + a random 32bit integer). There’s some impact on network performance, but only when you use multiple proxy hops, which is rare. Mostly the change was to simplify building libzmq by removing the dependency on a UUID library.
Identities are a difficult concept to understand, but it’s essential if you want to become a ZeroMQ expert. The ROUTER socket invents a random identity for each connection with which it works. If there are three REQ sockets connected to a ROUTER socket, it will invent three random identities, one for each REQ socket.
So if we continue our worked example, let’s say the REQ socket has a 3-byte identity ABC. Internally, this means the ROUTER socket keeps a hash table where it can search for ABC and find the TCP connection for the REQ socket.
When we receive the message off the ROUTER socket, we get three frames.

The core of the proxy loop is “read from one socket, write to the other”, so we literally send these three frames out on the DEALER socket. If you now sniffed the network traffic, you would see these three frames flying from the DEALER socket to the REP socket. The REP socket does as before, strips off the whole envelope including the new reply address, and once again delivers the “Hello” to the caller.
Incidentally the REP socket can only deal with one request-reply exchange at a time, which is why if you try to read multiple requests or send multiple replies without sticking to a strict recv-send cycle, it gives an error.
You should now be able to visualize the return path. When hwserver sends “World” back, the REP socket wraps that with the envelope it saved, and sends a three-frame reply message across the wire to the DEALER socket.

Now the DEALER reads these three frames, and sends all three out via the ROUTER socket. The ROUTER takes the first frame for the message, which is the ABC identity, and looks up the connection for this. If it finds that, it then pumps the next two frames out onto the wire.

The REQ socket picks this message up, and checks that the first frame is the empty delimiter, which it is. The REQ socket discards that frame and passes “World” to the calling application, which prints it out to the amazement of the younger us looking at ZeroMQ for the first time.
What’s This Good For? #
To be honest, the use cases for strict request-reply or extended request-reply are somewhat limited. For one thing, there’s no easy way to recover from common failures like the server crashing due to buggy application code. We’ll see more about this in Chapter 4 - Reliable Request-Reply Patterns. However once you grasp the way these four sockets deal with envelopes, and how they talk to each other, you can do very useful things. We saw how ROUTER uses the reply envelope to decide which client REQ socket to route a reply back to. Now let’s express this another way:
- Each time ROUTER gives you a message, it tells you what peer that came from, as an identity.
- You can use this with a hash table (with the identity as key) to track new peers as they arrive.
- ROUTER will route messages asynchronously to any peer connected to it, if you prefix the identity as the first frame of the message.
ROUTER sockets don’t care about the whole envelope. They don’t know anything about the empty delimiter. All they care about is that one identity frame that lets them figure out which connection to send a message to.
Recap of Request-Reply Sockets #
Let’s recap this:
-
The REQ socket sends, to the network, an empty delimiter frame in front of the message data. REQ sockets are synchronous. REQ sockets always send one request and then wait for one reply. REQ sockets talk to one peer at a time. If you connect a REQ socket to multiple peers, requests are distributed to and replies expected from each peer one turn at a time.
-
The REP socket reads and saves all identity frames up to and including the empty delimiter, then passes the following frame or frames to the caller. REP sockets are synchronous and talk to one peer at a time. If you connect a REP socket to multiple peers, requests are read from peers in fair fashion, and replies are always sent to the same peer that made the last request.
-
The DEALER socket is oblivious to the reply envelope and handles this like any multipart message. DEALER sockets are asynchronous and like PUSH and PULL combined. They distribute sent messages among all connections, and fair-queue received messages from all connections.
-
The ROUTER socket is oblivious to the reply envelope, like DEALER. It creates identities for its connections, and passes these identities to the caller as a first frame in any received message. Conversely, when the caller sends a message, it uses the first message frame as an identity to look up the connection to send to. ROUTERS are asynchronous.
Request-Reply Combinations #
We have four request-reply sockets, each with a certain behavior. We’ve seen how they connect in simple and extended request-reply patterns. But these sockets are building blocks that you can use to solve many problems.
These are the legal combinations:
- REQ to REP
- DEALER to REP
- REQ to ROUTER
- DEALER to ROUTER
- DEALER to DEALER
- ROUTER to ROUTER
And these combinations are invalid (and I’ll explain why):
- REQ to REQ
- REQ to DEALER
- REP to REP
- REP to ROUTER
Here are some tips for remembering the semantics. DEALER is like an asynchronous REQ socket, and ROUTER is like an asynchronous REP socket. Where we use a REQ socket, we can use a DEALER; we just have to read and write the envelope ourselves. Where we use a REP socket, we can stick a ROUTER; we just need to manage the identities ourselves.
Think of REQ and DEALER sockets as “clients” and REP and ROUTER sockets as “servers”. Mostly, you’ll want to bind REP and ROUTER sockets, and connect REQ and DEALER sockets to them. It’s not always going to be this simple, but it is a clean and memorable place to start.
The REQ to REP Combination #
We’ve already covered a REQ client talking to a REP server but let’s take one aspect: the REQ client must initiate the message flow. A REP server cannot talk to a REQ client that hasn’t first sent it a request. Technically, it’s not even possible, and the API also returns an EFSM error if you try it.
The DEALER to REP Combination #
Now, let’s replace the REQ client with a DEALER. This gives us an asynchronous client that can talk to multiple REP servers. If we rewrote the “Hello World” client using DEALER, we’d be able to send off any number of “Hello” requests without waiting for replies.
When we use a DEALER to talk to a REP socket, we must accurately emulate the envelope that the REQ socket would have sent, or the REP socket will discard the message as invalid. So, to send a message, we:
- Send an empty message frame with the MORE flag set; then
- Send the message body.
And when we receive a message, we:
- Receive the first frame and if it’s not empty, discard the whole message;
- Receive the next frame and pass that to the application.
The REQ to ROUTER Combination #
In the same way that we can replace REQ with DEALER, we can replace REP with ROUTER. This gives us an asynchronous server that can talk to multiple REQ clients at the same time. If we rewrote the “Hello World” server using ROUTER, we’d be able to process any number of “Hello” requests in parallel. We saw this in the Chapter 2 - Sockets and Patterns mtserver example.
We can use ROUTER in two distinct ways:
- As a proxy that switches messages between frontend and backend sockets.
- As an application that reads the message and acts on it.
In the first case, the ROUTER simply reads all frames, including the artificial identity frame, and passes them on blindly. In the second case the ROUTER must know the format of the reply envelope it’s being sent. As the other peer is a REQ socket, the ROUTER gets the identity frame, an empty frame, and then the data frame.
The DEALER to ROUTER Combination #
Now we can switch out both REQ and REP with DEALER and ROUTER to get the most powerful socket combination, which is DEALER talking to ROUTER. It gives us asynchronous clients talking to asynchronous servers, where both sides have full control over the message formats.
Because both DEALER and ROUTER can work with arbitrary message formats, if you hope to use these safely, you have to become a little bit of a protocol designer. At the very least you must decide whether you wish to emulate the REQ/REP reply envelope. It depends on whether you actually need to send replies or not.
The DEALER to DEALER Combination #
You can swap a REP with a ROUTER, but you can also swap a REP with a DEALER, if the DEALER is talking to one and only one peer.
When you replace a REP with a DEALER, your worker can suddenly go full asynchronous, sending any number of replies back. The cost is that you have to manage the reply envelopes yourself, and get them right, or nothing at all will work. We’ll see a worked example later. Let’s just say for now that DEALER to DEALER is one of the trickier patterns to get right, and happily it’s rare that we need it.
The ROUTER to ROUTER Combination #
This sounds perfect for N-to-N connections, but it’s the most difficult combination to use. You should avoid it until you are well advanced with ZeroMQ. We’ll see one example it in the Freelance pattern in Chapter 4 - Reliable Request-Reply Patterns, and an alternative DEALER to ROUTER design for peer-to-peer work in Chapter 8 - A Framework for Distributed Computing.
Invalid Combinations #
Mostly, trying to connect clients to clients, or servers to servers is a bad idea and won’t work. However, rather than give general vague warnings, I’ll explain in detail:
-
REQ to REQ: both sides want to start by sending messages to each other, and this could only work if you timed things so that both peers exchanged messages at the same time. It hurts my brain to even think about it.
-
REQ to DEALER: you could in theory do this, but it would break if you added a second REQ because DEALER has no way of sending a reply to the original peer. Thus the REQ socket would get confused, and/or return messages meant for another client.
-
REP to REP: both sides would wait for the other to send the first message.
-
REP to ROUTER: the ROUTER socket can in theory initiate the dialog and send a properly-formatted request, if it knows the REP socket has connected and it knows the identity of that connection. It’s messy and adds nothing over DEALER to ROUTER.
The common thread in this valid versus invalid breakdown is that a ZeroMQ socket connection is always biased towards one peer that binds to an endpoint, and another that connects to that. Further, that which side binds and which side connects is not arbitrary, but follows natural patterns. The side which we expect to “be there” binds: it’ll be a server, a broker, a publisher, a collector. The side that “comes and goes” connects: it’ll be clients and workers. Remembering this will help you design better ZeroMQ architectures.
Exploring ROUTER Sockets #
Let’s look at ROUTER sockets a little closer. We’ve already seen how they work by routing individual messages to specific connections. I’ll explain in more detail how we identify those connections, and what a ROUTER socket does when it can’t send a message.
Identities and Addresses #
The identity concept in ZeroMQ refers specifically to ROUTER sockets and how they identify the connections they have to other sockets. More broadly, identities are used as addresses in the reply envelope. In most cases, the identity is arbitrary and local to the ROUTER socket: it’s a lookup key in a hash table. Independently, a peer can have an address that is physical (a network endpoint like “tcp://192.168.55.117:5670”) or logical (a UUID or email address or other unique key).
An application that uses a ROUTER socket to talk to specific peers can convert a logical address to an identity if it has built the necessary hash table. Because ROUTER sockets only announce the identity of a connection (to a specific peer) when that peer sends a message, you can only really reply to a message, not spontaneously talk to a peer.
This is true even if you flip the rules and make the ROUTER connect to the peer rather than wait for the peer to connect to the ROUTER. However you can force the ROUTER socket to use a logical address in place of its identity. The zmq_setsockopt reference page calls this setting the socket identity. It works as follows:
- The peer application sets the ZMQ_IDENTITY option of its peer socket (DEALER or REQ) before binding or connecting.
- Usually the peer then connects to the already-bound ROUTER socket. But the ROUTER can also connect to the peer.
- At connection time, the peer socket tells the router socket, “please use this identity for this connection”.
- If the peer socket doesn’t say that, the router generates its usual arbitrary random identity for the connection.
- The ROUTER socket now provides this logical address to the application as a prefix identity frame for any messages coming in from that peer.
- The ROUTER also expects the logical address as the prefix identity frame for any outgoing messages.
Here is a simple example of two peers that connect to a ROUTER socket, one that imposes a logical address “PEER2”:
identity: Identity check in Ada
identity: Identity check in Basic
identity: Identity check in C
// Demonstrate request-reply identities
#include "zhelpers.h"
int main (void)
{
void *context = zmq_ctx_new ();
void *sink = zmq_socket (context, ZMQ_ROUTER);
zmq_bind (sink, "inproc://example");
// First allow 0MQ to set the identity
void *anonymous = zmq_socket (context, ZMQ_REQ);
zmq_connect (anonymous, "inproc://example");
s_send (anonymous, "ROUTER uses a generated 5 byte identity");
s_dump (sink);
// Then set the identity ourselves
void *identified = zmq_socket (context, ZMQ_REQ);
zmq_setsockopt (identified, ZMQ_IDENTITY, "PEER2", 5);
zmq_connect (identified, "inproc://example");
s_send (identified, "ROUTER socket uses REQ's socket identity");
s_dump (sink);
zmq_close (sink);
zmq_close (anonymous);
zmq_close (identified);
zmq_ctx_destroy (context);
return 0;
}

identity: Identity check in C++
//
// Demonstrate identities as used by the request-reply pattern. Run this
// program by itself.
//
#include <zmq.hpp>
#include "zhelpers.hpp"
int main () {
zmq::context_t context(1);
zmq::socket_t sink(context, ZMQ_ROUTER);
sink.bind( "inproc://example");
// First allow 0MQ to set the identity
zmq::socket_t anonymous(context, ZMQ_REQ);
anonymous.connect( "inproc://example");
s_send (anonymous, std::string("ROUTER uses a generated 5 byte identity"));
s_dump (sink);
// Then set the identity ourselves
zmq::socket_t identified (context, ZMQ_REQ);
identified.set( zmq::sockopt::routing_id, "PEER2");
identified.connect( "inproc://example");
s_send (identified, std::string("ROUTER socket uses REQ's socket identity"));
s_dump (sink);
return 0;
}
identity: Identity check in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
public static void Identity(string[] args)
{
//
// Demonstrate request-reply identities
//
// Author: metadings
//
using (var context = new ZContext())
using (var sink = new ZSocket(context, ZSocketType.ROUTER))
{
sink.Bind("inproc://example");
// First allow 0MQ to set the identity
using (var anonymous = new ZSocket(context, ZSocketType.REQ))
{
anonymous.Connect("inproc://example");
anonymous.Send(new ZFrame("ROUTER uses REQ's generated 5 byte identity"));
}
using (ZMessage msg = sink.ReceiveMessage())
{
msg.DumpZmsg("--------------------------");
}
// Then set the identity ourselves
using (var identified = new ZSocket(context, ZSocketType.REQ))
{
identified.IdentityString = "PEER2";
identified.Connect("inproc://example");
identified.Send(new ZFrame("ROUTER uses REQ's socket identity"));
}
using (ZMessage msg = sink.ReceiveMessage())
{
msg.DumpZmsg("--------------------------");
}
}
}
}
}
identity: Identity check in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Demonstrate identities as used by the request-reply pattern in Common Lisp.
;;; Run this program by itself. Note that the utility functions are
;;; provided by zhelpers.lisp. It gets boring for everyone to keep repeating
;;; this code.
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.identity
(:nicknames #:identity)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.identity)
(defun main ()
(zmq:with-context (context 1)
(zmq:with-socket (sink context zmq:router)
(zmq:bind sink "inproc://example")
;; First allow 0MQ to set the identity
(zmq:with-socket (anonymous context zmq:req)
(zmq:connect anonymous "inproc://example")
(send-text anonymous "ROUTER uses a generated 5 byte identity")
(dump-socket sink)
;; Then set the identity ourselves
(zmq:with-socket (identified context zmq:req)
(zmq:setsockopt identified zmq:identity "PEER2")
(zmq:connect identified "inproc://example")
(send-text identified "ROUTER socket uses REQ's socket identity")
(dump-socket sink)))))
(cleanup))
identity: Identity check in Delphi
program identity;
//
// Demonstrate identities as used by the request-reply pattern. Run this
// program by itself.
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
, zhelpers
;
var
context: TZMQContext;
sink,
anonymous,
identified: TZMQSocket;
begin
context := TZMQContext.create;
sink := context.Socket( stRouter );
sink.bind( 'inproc://example' );
// First allow 0MQ to set the identity
anonymous := context.Socket( stReq );
anonymous.connect( 'inproc://example' );
anonymous.send( 'ROUTER uses a generated 5 byte identity' );
s_dump( sink );
// Then set the identity ourself
identified := context.Socket( stReq );
identified.Identity := 'PEER2';
identified.connect( 'inproc://example' );
identified.send( 'ROUTER socket uses REQ''s socket identity' );
s_dump( sink );
sink.Free;
anonymous.Free;
identified.Free;
context.Free;
end.
identity: Identity check in Erlang
#! /usr/bin/env escript
%%
%% Demonstrate identities as used by the request-reply pattern.
%%
main(_) ->
{ok, Context} = erlzmq:context(),
{ok, Sink} = erlzmq:socket(Context, router),
ok = erlzmq:bind(Sink, "inproc://example"),
%% First allow 0MQ to set the identity
{ok, Anonymous} = erlzmq:socket(Context, req),
ok = erlzmq:connect(Anonymous, "inproc://example"),
ok = erlzmq:send(Anonymous, <<"ROUTER uses a generated 5 byte identity">>),
erlzmq_util:dump(Sink),
%% Then set the identity ourselves
{ok, Identified} = erlzmq:socket(Context, req),
ok = erlzmq:setsockopt(Identified, identity, <<"PEER2">>),
ok = erlzmq:connect(Identified, "inproc://example"),
ok = erlzmq:send(Identified,
<<"ROUTER socket uses REQ's socket identity">>),
erlzmq_util:dump(Sink),
erlzmq:close(Sink),
erlzmq:close(Anonymous),
erlzmq:close(Identified),
erlzmq:term(Context).
identity: Identity check in Elixir
defmodule Identity do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:24
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, sink} = :erlzmq.socket(context, :router)
:ok = :erlzmq.bind(sink, 'inproc://example')
{:ok, anonymous} = :erlzmq.socket(context, :req)
:ok = :erlzmq.connect(anonymous, 'inproc://example')
:ok = :erlzmq.send(anonymous, "ROUTER uses a generated 5 byte identity")
#:erlzmq_util.dump(sink)
IO.inspect(sink, label: "1. sink")
{:ok, identified} = :erlzmq.socket(context, :req)
:ok = :erlzmq.setsockopt(identified, :identity, "PEER2")
:ok = :erlzmq.connect(identified, 'inproc://example')
:ok = :erlzmq.send(identified, "ROUTER socket uses REQ's socket identity")
#:erlzmq_util.dump(sink)
IO.inspect(sink, label: "2. sink")
:erlzmq.close(sink)
:erlzmq.close(anonymous)
:erlzmq.close(identified)
:erlzmq.term(context)
end
end
Identity.main
identity: Identity check in F#
(*
Demonstrate identities as used by the request-reply pattern. Run this
program by itself. Note that the utility functions s_ are provided by
zhelpers.fs. It gets boring for everyone to keep repeating this code.
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
let main () =
use context = new Context(1)
use sink = route context
"inproc://example" |> bind sink
// first allow 0MQ to set the identity
use anonymous = req context
"inproc://example" |> connect anonymous
"ROUTER uses a generated 5 byte identity" |> s_send anonymous
s_dump sink
// then set the identity ourselves
use identified = req context
(ZMQ.IDENTITY,"PEER2"B) |> set identified
"inproc://example" |> connect identified
"ROUTER socket uses REQ's socket identity" |> s_send identified
s_dump sink
EXIT_SUCCESS
main ()
identity: Identity check in Felix
identity: Identity check in Go
//
// Demonstrate identities as used by the request-reply pattern. Run this
// program by itself.
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
)
func dump(sink *zmq.Socket) {
parts, err := sink.RecvMultipart(0)
if err != nil {
fmt.Println(err)
}
for _, msgdata := range parts {
is_text := true
fmt.Printf("[%03d] ", len(msgdata))
for _, char := range msgdata {
if char < 32 || char > 127 {
is_text = false
}
}
if is_text {
fmt.Printf("%s\n", msgdata)
} else {
fmt.Printf("%X\n", msgdata)
}
}
}
func main() {
context, _ := zmq.NewContext()
defer context.Close()
sink, err := context.NewSocket(zmq.ROUTER)
if err != nil {
print(err)
}
defer sink.Close()
sink.Bind("inproc://example")
// First allow 0MQ to set the identity
anonymous, err := context.NewSocket(zmq.REQ)
defer anonymous.Close()
if err != nil {
fmt.Println(err)
}
anonymous.Connect("inproc://example")
err = anonymous.Send([]byte("ROUTER uses a generated 5 byte identity"), 0)
if err != nil {
fmt.Println(err)
}
dump(sink)
// Then set the identity ourselves
identified, err := context.NewSocket(zmq.REQ)
if err != nil {
print(err)
}
defer identified.Close()
identified.SetIdentity("PEER2")
identified.Connect("inproc://example")
identified.Send([]byte("ROUTER socket uses REQ's socket identity"), zmq.NOBLOCK)
dump(sink)
}
identity: Identity check in Haskell
{-# LANGUAGE OverloadedStrings #-}
module Main where
import System.ZMQ4.Monadic
import ZHelpers (dumpSock)
main :: IO ()
main =
runZMQ $ do
sink <- socket Router
bind sink "inproc://example"
anonymous <- socket Req
connect anonymous "inproc://example"
send anonymous [] "ROUTER uses a generated 5 byte identity"
dumpSock sink
identified <- socket Req
setIdentity (restrict "PEER2") identified
connect identified "inproc://example"
send identified [] "ROUTER socket uses REQ's socket identity"
dumpSock sink
identity: Identity check in Haxe
package ;
import ZHelpers;
import neko.Lib;
import neko.Sys;
import haxe.io.Bytes;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQSocket;
/**
* Demonstrate identities as used by the request-reply pattern. Run this
* program by itself.
*/
class Identity
{
public static function main() {
var context:ZContext = new ZContext();
Lib.println("** Identity (see: http://zguide.zeromq.org/page:all#Request-Reply-Envelopes)");
// Socket facing clients
var sink:ZMQSocket = context.createSocket(ZMQ_ROUTER);
sink.bind("inproc://example");
// First allow 0MQ to set the identity
var anonymous:ZMQSocket = context.createSocket(ZMQ_REQ);
anonymous.connect("inproc://example");
anonymous.sendMsg(Bytes.ofString("ROUTER uses a generated 5 byte identity"));
ZHelpers.dump(sink);
// Then set the identity ourselves
var identified:ZMQSocket = context.createSocket(ZMQ_REQ);
identified.setsockopt(ZMQ_IDENTITY, Bytes.ofString("PEER2"));
identified.connect("inproc://example");
identified.sendMsg(Bytes.ofString("ROUTER socket uses REQ's socket identity"));
ZHelpers.dump(sink);
context.destroy();
}
}
identity: Identity check in Java
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
/**
* Demonstrate identities as used by the request-reply pattern.
*/
public class identity
{
public static void main(String[] args) throws InterruptedException
{
try (ZContext context = new ZContext()) {
Socket sink = context.createSocket(SocketType.ROUTER);
sink.bind("inproc://example");
// First allow 0MQ to set the identity, [00] + random 4byte
Socket anonymous = context.createSocket(SocketType.REQ);
anonymous.connect("inproc://example");
anonymous.send("ROUTER uses a generated UUID", 0);
ZHelper.dump(sink);
// Then set the identity ourself
Socket identified = context.createSocket(SocketType.REQ);
identified.setIdentity("PEER2".getBytes(ZMQ.CHARSET));
identified.connect("inproc://example");
identified.send("ROUTER socket uses REQ's socket identity", 0);
ZHelper.dump(sink);
}
}
}
identity: Identity check in Julia
identity: Identity check in Lua
--
-- Demonstrate identities as used by the request-reply pattern. Run this
-- program by itself. Note that the utility functions s_ are provided by
-- zhelpers.h. It gets boring for everyone to keep repeating this code.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zhelpers"
local context = zmq.init(1)
local sink = context:socket(zmq.ROUTER)
sink:bind("inproc://example")
-- First allow 0MQ to set the identity
local anonymous = context:socket(zmq.REQ)
anonymous:connect("inproc://example")
anonymous:send("ROUTER uses a generated 5 byte identity")
s_dump(sink)
-- Then set the identity ourselves
local identified = context:socket(zmq.REQ)
identified:setopt(zmq.IDENTITY, "PEER2")
identified:connect("inproc://example")
identified:send("ROUTER socket uses REQ's socket identity")
s_dump(sink)
sink:close()
anonymous:close()
identified:close()
context:term()
identity: Identity check in Node.js
// Demonstrate request-reply identities
var zmq = require('zeromq'),
zhelpers = require('./zhelpers');
var sink = zmq.socket("router");
sink.bind("inproc://example");
sink.on("message", zhelpers.dumpFrames);
// First allow 0MQ to set the identity
var anonymous = zmq.socket("req");
anonymous.connect("inproc://example");
anonymous.send("ROUTER uses generated 5 byte identity");
// Then set the identity ourselves
var identified = zmq.socket("req");
identified.identity = "PEER2";
identified.connect("inproc://example");
identified.send("ROUTER uses REQ's socket identity");
setTimeout(function() {
anonymous.close();
identified.close();
sink.close();
}, 250);
identity: Identity check in Objective-C
identity: Identity check in ooc
identity: Identity check in Perl
# Demonstrate request-reply identities in Perl
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_ROUTER ZMQ_REQ ZMQ_IDENTITY);
use zhelpers;
my $context = ZMQ::FFI->new();
my $sink = $context->socket(ZMQ_ROUTER);
$sink->bind('inproc://example');
# First allow 0MQ to set the identity
my $anonymous = $context->socket(ZMQ_REQ);
$anonymous->connect('inproc://example');
$anonymous->send('ROUTER uses a generated 5 byte identity');
zhelpers::dump($sink);
# Then set the identity ourselves
my $identified = $context->socket(ZMQ_REQ);
$identified->set_identity('PEER2');
$identified->connect('inproc://example');
$identified->send("ROUTER socket uses REQ's socket identity");
zhelpers::dump($sink);
identity: Identity check in PHP
<?php
/*
* Demonstrate identities as used by the request-reply pattern. Run this
* program by itself. Note that the utility functions s_ are provided by
* zhelpers.h. It gets boring for everyone to keep repeating this code.
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zhelpers.php';
$context = new ZMQContext();
$sink = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$sink->bind("inproc://example");
// First allow 0MQ to set the identity
$anonymous = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$anonymous->connect("inproc://example");
$anonymous->send("ROUTER uses a generated 5 byte identity");
s_dump ($sink);
// Then set the identity ourselves
$identified = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$identified->setSockOpt(ZMQ::SOCKOPT_IDENTITY, "PEER2");
$identified->connect("inproc://example");
$identified->send("ROUTER socket uses REQ's socket identity");
s_dump ($sink);
identity: Identity check in Python
# encoding: utf-8
#
# Demonstrate identities as used by the request-reply pattern. Run this
# program by itself.
#
# Author: Jeremy Avnet (brainsik) <spork(dash)zmq(at)theory(dot)org>
#
import zmq
import zhelpers
context = zmq.Context()
sink = context.socket(zmq.ROUTER)
sink.bind("inproc://example")
# First allow 0MQ to set the identity
anonymous = context.socket(zmq.REQ)
anonymous.connect("inproc://example")
anonymous.send(b"ROUTER uses a generated 5 byte identity")
zhelpers.dump(sink)
# Then set the identity ourselves
identified = context.socket(zmq.REQ)
identified.setsockopt(zmq.IDENTITY, b"PEER2")
identified.connect("inproc://example")
identified.send(b"ROUTER socket uses REQ's socket identity")
zhelpers.dump(sink)
identity: Identity check in Q
// Demonstrate identities as used by the request-reply pattern.
\l qzmq.q
ctx:zctx.new[]
sink:zsocket.new[ctx; zmq`ROUTER]
port:zsocket.bind[sink; `inproc://example]
// First allow 0MQ to set the identity
anonymous:zsocket.new[ctx; zmq`REQ]
zsocket.connect[anonymous; `inproc://example]
m0:zmsg.new[]
zmsg.push[m0; zframe.new["ROUTER uses a generated 5 byte identity"]]
zmsg.send[m0; anonymous]
zmsg.dump[zmsg.recv[sink]]
// Then set the identity ourselves
identified:zsocket.new[ctx; zmq`REQ]
zsockopt.set_identity[identified; "PEER2"]
zsocket.connect[identified; `inproc://example]
m1:zmsg.new[]
zmsg.push[m1; zframe.new["ROUTER socket users REQ's socket identity"]]
zmsg.send[m1; identified]
zmsg.dump[zmsg.recv[sink]]
zsocket.destroy[ctx; sink]
zsocket.destroy[ctx; anonymous]
zsocket.destroy[ctx; identified]
zctx.destroy[ctx]
\\
identity: Identity check in Racket
identity: Identity check in Ruby
identity: Identity check in Rust
identity: Identity check in Scala
identity: Identity check in Tcl
identity: Identity check in OCaml
Here is what the program prints:
----------------------------------------
[005] 006B8B4567
[000]
[039] ROUTER uses a generated 5 byte identity
----------------------------------------
[005] PEER2
[000]
[038] ROUTER uses REQ's socket identity
ROUTER Error Handling #
ROUTER sockets do have a somewhat brutal way of dealing with messages they can’t send anywhere: they drop them silently. It’s an attitude that makes sense in working code, but it makes debugging hard. The “send identity as first frame” approach is tricky enough that we often get this wrong when we’re learning, and the ROUTER’s stony silence when we mess up isn’t very constructive.
Since ZeroMQ v3.2 there’s a socket option you can set to catch this error: ZMQ_ROUTER_MANDATORY. Set that on the ROUTER socket and then when you provide an unroutable identity on a send call, the socket will signal an EHOSTUNREACH error.
The Load Balancing Pattern #
Now let’s look at some code. We’ll see how to connect a ROUTER socket to a REQ socket, and then to a DEALER socket. These two examples follow the same logic, which is a load balancing pattern. This pattern is our first exposure to using the ROUTER socket for deliberate routing, rather than simply acting as a reply channel.
The load balancing pattern is very common and we’ll see it several times in this book. It solves the main problem with simple round robin routing (as PUSH and DEALER offer) which is that round robin becomes inefficient if tasks do not all roughly take the same time.
It’s the post office analogy. If you have one queue per counter, and you have some people buying stamps (a fast, simple transaction), and some people opening new accounts (a very slow transaction), then you will find stamp buyers getting unfairly stuck in queues. Just as in a post office, if your messaging architecture is unfair, people will get annoyed.
The solution in the post office is to create a single queue so that even if one or two counters get stuck with slow work, other counters will continue to serve clients on a first-come, first-serve basis.
One reason PUSH and DEALER use the simplistic approach is sheer performance. If you arrive in any major US airport, you’ll find long queues of people waiting at immigration. The border patrol officials will send people in advance to queue up at each counter, rather than using a single queue. Having people walk fifty yards in advance saves a minute or two per passenger. And because every passport check takes roughly the same time, it’s more or less fair. This is the strategy for PUSH and DEALER: send work loads ahead of time so that there is less travel distance.
This is a recurring theme with ZeroMQ: the world’s problems are diverse and you can benefit from solving different problems each in the right way. The airport isn’t the post office and one size fits no one, really well.
Let’s return to the scenario of a worker (DEALER or REQ) connected to a broker (ROUTER). The broker has to know when the worker is ready, and keep a list of workers so that it can take the least recently used worker each time.
The solution is really simple, in fact: workers send a “ready” message when they start, and after they finish each task. The broker reads these messages one-by-one. Each time it reads a message, it is from the last used worker. And because we’re using a ROUTER socket, we get an identity that we can then use to send a task back to the worker.
It’s a twist on request-reply because the task is sent with the reply, and any response for the task is sent as a new request. The following code examples should make it clearer.
ROUTER Broker and REQ Workers #
Here is an example of the load balancing pattern using a ROUTER broker talking to a set of REQ workers:
rtreq: ROUTER-to-REQ in Ada
rtreq: ROUTER-to-REQ in Basic
rtreq: ROUTER-to-REQ in C
// 2015-01-16T09:56+08:00
// ROUTER-to-REQ example
#include "zhelpers.h"
#include <pthread.h>
#define NBR_WORKERS 10
static void *
worker_task(void *args)
{
void *context = zmq_ctx_new();
void *worker = zmq_socket(context, ZMQ_REQ);
#if (defined (WIN32))
s_set_id(worker, (intptr_t)args);
#else
s_set_id(worker); // Set a printable identity.
#endif
zmq_connect(worker, "tcp://localhost:5671");
int total = 0;
while (1) {
// Tell the broker we're ready for work
s_send(worker, "Hi Boss");
// Get workload from broker, until finished
char *workload = s_recv(worker);
int finished = (strcmp(workload, "Fired!") == 0);
free(workload);
if (finished) {
printf("Completed: %d tasks\n", total);
break;
}
total++;
// Do some random work
s_sleep(randof(500) + 1);
}
zmq_close(worker);
zmq_ctx_destroy(context);
return NULL;
}
// .split main task
// While this example runs in a single process, that is only to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
int main(void)
{
void *context = zmq_ctx_new();
void *broker = zmq_socket(context, ZMQ_ROUTER);
zmq_bind(broker, "tcp://*:5671");
srandom((unsigned)time(NULL));
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
pthread_t worker;
pthread_create(&worker, NULL, worker_task, (void *)(intptr_t)worker_nbr);
}
// Run for five seconds and then tell workers to end
int64_t end_time = s_clock() + 5000;
int workers_fired = 0;
while (1) {
// Next message gives us least recently used worker
char *identity = s_recv(broker);
s_sendmore(broker, identity);
free(identity);
free(s_recv(broker)); // Envelope delimiter
free(s_recv(broker)); // Response from worker
s_sendmore(broker, "");
// Encourage workers until it's time to fire them
if (s_clock() < end_time)
s_send(broker, "Work harder");
else {
s_send(broker, "Fired!");
if (++workers_fired == NBR_WORKERS)
break;
}
}
zmq_close(broker);
zmq_ctx_destroy(context);
return 0;
}rtreq: ROUTER-to-REQ in C++
//
// Custom routing Router to Mama (ROUTER to REQ)
//
#include "zhelpers.hpp"
#include <thread>
#include <vector>
static void *
worker_thread(void *arg) {
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_REQ);
// We use a string identity for ease here
#if (defined (WIN32))
s_set_id(worker, (intptr_t)arg);
worker.connect("tcp://localhost:5671"); // "ipc" doesn't yet work on windows.
#else
s_set_id(worker);
worker.connect("ipc://routing.ipc");
#endif
int total = 0;
while (1) {
// Tell the broker we're ready for work
s_send(worker, std::string("Hi Boss"));
// Get workload from broker, until finished
std::string workload = s_recv(worker);
if ("Fired!" == workload) {
std::cout << "Processed: " << total << " tasks" << std::endl;
break;
}
total++;
// Do some random work
s_sleep(within(500) + 1);
}
return NULL;
}
int main() {
zmq::context_t context(1);
zmq::socket_t broker(context, ZMQ_ROUTER);
#if (defined(WIN32))
broker.bind("tcp://*:5671"); // "ipc" doesn't yet work on windows.
#else
broker.bind("ipc://routing.ipc");
#endif
const int NBR_WORKERS = 10;
std::vector<std::thread> workers;
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
workers.push_back(std::move(std::thread(worker_thread, (void *)(intptr_t)worker_nbr)));
}
// Run for five seconds and then tell workers to end
int64_t end_time = s_clock() + 5000;
int workers_fired = 0;
while (1) {
// Next message gives us least recently used worker
std::string identity = s_recv(broker);
s_recv(broker); // Envelope delimiter
s_recv(broker); // Response from worker
s_sendmore(broker, identity);
s_sendmore(broker, std::string(""));
// Encourage workers until it's time to fire them
if (s_clock() < end_time)
s_send(broker, std::string("Work harder"));
else {
s_send(broker, std::string("Fired!"));
if (++workers_fired == NBR_WORKERS)
break;
}
}
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
workers[worker_nbr].join();
}
return 0;
}
rtreq: ROUTER-to-REQ in C#
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
static int RTReq_Workers = 10;
public static void RTReq(string[] args)
{
//
// ROUTER-to-REQ example
//
// While this example runs in a single process, that is only to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
//
// Author: metadings
//
using (var context = new ZContext())
using (var broker = new ZSocket(context, ZSocketType.ROUTER))
{
broker.Bind("tcp://*:5671");
for (int i = 0; i < RTReq_Workers; ++i)
{
int j = i; new Thread(() => RTReq_Worker(j)).Start();
}
var stopwatch = new Stopwatch();
stopwatch.Start();
// Run for five seconds and then tell workers to end
int workers_fired = 0;
while (true)
{
// Next message gives us least recently used worker
using (ZMessage identity = broker.ReceiveMessage())
{
broker.SendMore(identity[0]);
broker.SendMore(new ZFrame());
// Encourage workers until it's time to fire them
if (stopwatch.Elapsed < TimeSpan.FromSeconds(5))
{
broker.Send(new ZFrame("Work harder!"));
}
else
{
broker.Send(new ZFrame("Fired!"));
if (++workers_fired == RTReq_Workers)
{
break;
}
}
}
}
}
}
static void RTReq_Worker(int i)
{
using (var context = new ZContext())
using (var worker = new ZSocket(context, ZSocketType.REQ))
{
worker.IdentityString = "PEER" + i; // Set a printable identity
worker.Connect("tcp://127.0.0.1:5671");
int total = 0;
while (true)
{
// Tell the broker we're ready for work
worker.Send(new ZFrame("Hi Boss"));
// Get workload from broker, until finished
using (ZFrame frame = worker.ReceiveFrame())
{
bool finished = (frame.ReadString() == "Fired!");
if (finished)
{
break;
}
}
total++;
// Do some random work
Thread.Sleep(1);
}
Console.WriteLine("Completed: PEER{0}, {1} tasks", i, total);
}
}
}
}
rtreq: ROUTER-to-REQ in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Custom routing Router to Mama (ROUTER to REQ) in Common Lisp
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.rtmama
(:nicknames #:rtmama)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.rtmama)
(defparameter *number-workers* 10)
(defun worker-thread (context)
(zmq:with-socket (worker context zmq:req)
;; We use a string identity for ease here
(set-socket-id worker)
(zmq:connect worker "ipc://routing.ipc")
(let ((total 0))
(loop
;; Tell the router we're ready for work
(send-text worker "ready")
;; Get workload from router, until finished
(let ((workload (recv-text worker)))
(when (string= workload "END")
(message "Processed: ~D tasks~%" total)
(return))
(incf total))
;; Do some random work
(isys:usleep (within 100000))))))
(defun main ()
(zmq:with-context (context 1)
(zmq:with-socket (client context zmq:router)
(zmq:bind client "ipc://routing.ipc")
(dotimes (i *number-workers*)
(bt:make-thread (lambda () (worker-thread context))
:name (format nil "worker-thread-~D" i)))
(loop :repeat (* 10 *number-workers*) :do
;; LRU worker is next waiting in queue
(let ((address (recv-text client)))
(recv-text client) ; empty
(recv-text client) ; ready
(send-more-text client address)
(send-more-text client "")
(send-text client "This is the workload")))
;; Now ask mamas to shut down and report their results
(loop :repeat *number-workers* :do
;; LRU worker is next waiting in queue
(let ((address (recv-text client)))
(recv-text client) ; empty
(recv-text client) ; ready
(send-more-text client address)
(send-more-text client "")
(send-text client "END")))
;; Give 0MQ/2.0.x time to flush output
(sleep 1)))
(cleanup))
rtreq: ROUTER-to-REQ in Delphi
program rtreq;
//
// ROUTER-to-REQ example
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, Windows
, zmqapi
, zhelpers
;
const
NBR_WORKERS = 10;
procedure worker_task( args: Pointer );
var
context: TZMQContext;
worker: TZMQSocket;
total: Integer;
workload: Utf8String;
begin
context := TZMQContext.create;
worker := context.Socket( stReq );
s_set_id( worker ); // Set a printable identity
worker.connect( 'tcp://localhost:5671' );
total := 0;
while true do
begin
// Tell the broker we're ready for work
worker.send( 'Hi Boss' );
// Get workload from broker, until finished
worker.recv( workload );
if workload = 'Fired!' then
begin
zNote( Format( 'Completed: %d tasks', [total] ) );
break;
end;
Inc( total );
// Do some random work
sleep( random( 500 ) + 1 );
end;
worker.Free;
context.Free;
end;
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
var
context: TZMQContext;
broker: TZMQSocket;
i,
workers_fired: Integer;
tid: Cardinal;
identity,
s: Utf8String;
fFrequency,
fstart,
fStop,
dt: Int64;
begin
context := TZMQContext.create;
broker := context.Socket( stRouter );
broker.bind( 'tcp://*:5671' );
Randomize;
for i := 0 to NBR_WORKERS - 1 do
BeginThread( nil, 0, @worker_task, nil, 0, tid );
// Start our clock now
QueryPerformanceFrequency( fFrequency );
QueryPerformanceCounter( fStart );
// Run for five seconds and then tell workers to end
workers_fired := 0;
while true do
begin
// Next message gives us least recently used worker
broker.recv( identity );
broker.send( identity, [sfSndMore] );
broker.recv( s ); // Envelope delimiter
broker.recv( s ); // Response from worker
broker.send( '', [sfSndMore] );
QueryPerformanceCounter( fStop );
dt := ( MSecsPerSec * ( fStop - fStart ) ) div fFrequency;
if dt < 5000 then
broker.send( 'Work harder' )
else begin
broker.send( 'Fired!' );
Inc( workers_fired );
if workers_fired = NBR_WORKERS then
break;
end;
end;
broker.Free;
context.Free;
end.
rtreq: ROUTER-to-REQ in Erlang
#! /usr/bin/env escript
%%
%% Custom routing Router to Mama (ROUTER to REQ)
%%
%% While this example runs in a single process, that is just to make
%% it easier to start and stop the example. Each thread has its own
%% context and conceptually acts as a separate process.
%%
-define(NBR_WORKERS, 10).
worker_task() ->
random:seed(now()),
{ok, Context} = erlzmq:context(),
{ok, Worker} = erlzmq:socket(Context, req),
%% We use a string identity for ease here
ok = erlzmq:setsockopt(Worker, identity, pid_to_list(self())),
ok = erlzmq:connect(Worker, "ipc://routing.ipc"),
Total = handle_tasks(Worker, 0),
io:format("Processed ~b tasks~n", [Total]),
erlzmq:close(Worker),
erlzmq:term(Context).
handle_tasks(Worker, TaskCount) ->
%% Tell the router we're ready for work
ok = erlzmq:send(Worker, <<"ready">>),
%% Get workload from router, until finished
case erlzmq:recv(Worker) of
{ok, <<"END">>} -> TaskCount;
{ok, _} ->
%% Do some random work
timer:sleep(random:uniform(1000) + 1),
handle_tasks(Worker, TaskCount + 1)
end.
main(_) ->
{ok, Context} = erlzmq:context(),
{ok, Client} = erlzmq:socket(Context, router),
ok = erlzmq:bind(Client, "ipc://routing.ipc"),
start_workers(?NBR_WORKERS),
route_work(Client, ?NBR_WORKERS * 10),
stop_workers(Client, ?NBR_WORKERS),
ok = erlzmq:close(Client),
ok = erlzmq:term(Context).
start_workers(0) -> ok;
start_workers(N) when N > 0 ->
spawn(fun() -> worker_task() end),
start_workers(N - 1).
route_work(_Client, 0) -> ok;
route_work(Client, N) when N > 0 ->
%% LRU worker is next waiting in queue
{ok, Address} = erlzmq:recv(Client),
{ok, <<>>} = erlzmq:recv(Client),
{ok, <<"ready">>} = erlzmq:recv(Client),
ok = erlzmq:send(Client, Address, [sndmore]),
ok = erlzmq:send(Client, <<>>, [sndmore]),
ok = erlzmq:send(Client, <<"This is the workload">>),
route_work(Client, N - 1).
stop_workers(_Client, 0) -> ok;
stop_workers(Client, N) ->
%% Ask mama to shut down and report their results
{ok, Address} = erlzmq:recv(Client),
{ok, <<>>} = erlzmq:recv(Client),
{ok, _Ready} = erlzmq:recv(Client),
ok = erlzmq:send(Client, Address, [sndmore]),
ok = erlzmq:send(Client, <<>>, [sndmore]),
ok = erlzmq:send(Client, <<"END">>),
stop_workers(Client, N - 1).
rtreq: ROUTER-to-REQ in Elixir
defmodule Rtreq do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:33
"""
defmacrop erlconst_NBR_WORKERS() do
quote do
10
end
end
def worker_task() do
:random.seed(:erlang.now())
{:ok, context} = :erlzmq.context()
{:ok, worker} = :erlzmq.socket(context, :req)
:ok = :erlzmq.setsockopt(worker, :identity, :erlang.pid_to_list(self()))
:ok = :erlzmq.connect(worker, 'ipc://routing.ipc')
total = handle_tasks(worker, 0)
:io.format('Processed ~b tasks~n', [total])
:erlzmq.close(worker)
:erlzmq.term(context)
end
def handle_tasks(worker, taskCount) do
:ok = :erlzmq.send(worker, "ready")
case(:erlzmq.recv(worker)) do
{:ok, "END"} ->
taskCount
{:ok, _} ->
:timer.sleep(:random.uniform(1000) + 1)
handle_tasks(worker, taskCount + 1)
end
end
def main() do
{:ok, context} = :erlzmq.context()
{:ok, client} = :erlzmq.socket(context, :router)
:ok = :erlzmq.bind(client, 'ipc://routing.ipc')
start_workers(erlconst_NBR_WORKERS())
route_work(client, erlconst_NBR_WORKERS() * 10)
stop_workers(client, erlconst_NBR_WORKERS())
:ok = :erlzmq.close(client)
:ok = :erlzmq.term(context)
end
def start_workers(0) do
:ok
end
def start_workers(n) when n > 0 do
:erlang.spawn(fn -> worker_task() end)
start_workers(n - 1)
end
def route_work(_client, 0) do
:ok
end
def route_work(client, n) when n > 0 do
{:ok, address} = :erlzmq.recv(client)
{:ok, <<>>} = :erlzmq.recv(client)
{:ok, "ready"} = :erlzmq.recv(client)
:ok = :erlzmq.send(client, address, [:sndmore])
:ok = :erlzmq.send(client, <<>>, [:sndmore])
:ok = :erlzmq.send(client, "This is the workload")
route_work(client, n - 1)
end
def stop_workers(_client, 0) do
:ok
end
def stop_workers(client, n) do
{:ok, address} = :erlzmq.recv(client)
{:ok, <<>>} = :erlzmq.recv(client)
{:ok, _ready} = :erlzmq.recv(client)
:ok = :erlzmq.send(client, address, [:sndmore])
:ok = :erlzmq.send(client, <<>>, [:sndmore])
:ok = :erlzmq.send(client, "END")
stop_workers(client, n - 1)
end
end
Rtreq.main
rtreq: ROUTER-to-REQ in F#
(*
Custom routing Router to Mama (ROUTER to REQ)
While this example runs in a single process, that is just to make
it easier to start and stop the example. Each thread has its own
context and conceptually acts as a separate process.
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
open System.Threading
let [<Literal>] NBR_WORKERS = 10
let rand = srandom()
let worker_task () =
use context = new Context(1)
use worker = req context
// we use a string identity for ease here
s_setID worker
"tcp://localhost:5571" |> connect worker
let workerID = ZMQ.IDENTITY |> get worker |> decode
let rec loop total =
// tell the router we're ready for work
"ready"B |>> worker
// get workload from router, until finished
let workload = s_recv worker
if workload = "END"
then printfn' "(%s) Processed: %d tasks" workerID total
else // do some random work
sleep (rand.Next(0,1000) + 1)
loop (total + 1)
loop 0
let main () =
use context = new Context(1)
use client = route context
"tcp://*:5571" |> bind client
for _ in 1 .. NBR_WORKERS do
let worker = Thread(ThreadStart(worker_task))
worker.Start()
for _ in 1 .. (NBR_WORKERS * 10) do
// LRU worker is next waiting in queue
let address = recv client
recv client |> ignore // empty
recv client |> ignore // ready
client <~| address
<~| ""B
<<| "This is the workload"B
// now ask the mamas to shut down and report their results
for _ in 1 .. NBR_WORKERS do
let address = recv client
recv client |> ignore // empty
recv client |> ignore // ready
client <~| address
<~| ""B
<<| "END"B
EXIT_SUCCESS
main ()
rtreq: ROUTER-to-REQ in Felix
rtreq: ROUTER-to-REQ in Go
//
// ROUTER-to-REQ example
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"strings"
"time"
)
const NBR_WORKERS = 10
func randomString() string {
source := "abcdefghijklmnopqrstuvwxyz"
target := make([]string, 20)
for i := 0; i < 20; i++ {
target[i] = string(source[rand.Intn(len(source))])
}
return strings.Join(target, "")
}
func workerTask() {
context, _ := zmq.NewContext()
defer context.Close()
worker, _ := context.NewSocket(zmq.REQ)
worker.SetIdentity(randomString())
worker.Connect("tcp://localhost:5671")
defer worker.Close()
total := 0
for {
err := worker.Send([]byte("Hi Boss"), 0)
if err != nil {
print(err)
}
workload, _ := worker.Recv(0)
if string(workload) == "Fired!" {
id, _ := worker.Identity()
fmt.Printf("Completed: %d tasks (%s)\n", total, id)
break
}
total += 1
msec := rand.Intn(1000)
time.Sleep(time.Duration(msec) * time.Millisecond)
}
}
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each goroutine has its own
// context and conceptually acts as a separate process.
func main() {
context, _ := zmq.NewContext()
defer context.Close()
broker, _ := context.NewSocket(zmq.ROUTER)
defer broker.Close()
broker.Bind("tcp://*:5671")
rand.Seed(time.Now().Unix())
for i := 0; i < NBR_WORKERS; i++ {
go workerTask()
}
end_time := time.Now().Unix() + 5
workers_fired := 0
for {
// Next message gives us least recently used worker
parts, err := broker.RecvMultipart(0)
if err != nil {
print(err)
}
identity := parts[0]
now := time.Now().Unix()
if now < end_time {
broker.SendMultipart([][]byte{identity, []byte(""), []byte("Work harder")}, 0)
} else {
broker.SendMultipart([][]byte{identity, []byte(""), []byte("Fired!")}, 0)
workers_fired++
if workers_fired == NBR_WORKERS {
break
}
}
}
}
rtreq: ROUTER-to-REQ in Haskell
{-# LANGUAGE OverloadedStrings #-}
-- |
-- Router broker and REQ workers (p.92)
module Main where
import System.ZMQ4.Monadic
import Control.Concurrent (threadDelay, forkIO)
import Control.Concurrent.MVar (withMVar, newMVar, MVar)
import Data.ByteString.Char8 (unpack)
import Control.Monad (replicateM_, unless)
import ZHelpers (setRandomIdentity)
import Text.Printf
import Data.Time.Clock (diffUTCTime, getCurrentTime, UTCTime)
import System.Random
nbrWorkers :: Int
nbrWorkers = 10
-- In general, although locks are an antipattern in ZeroMQ, we need a lock
-- for the stdout handle, otherwise we will get jumbled text. We don't
-- use the lock for anything zeroMQ related, just output to screen.
workerThread :: MVar () -> IO ()
workerThread lock =
runZMQ $ do
worker <- socket Req
setRandomIdentity worker
connect worker "ipc://routing.ipc"
work worker
where
work = loop 0 where
loop val sock = do
send sock [] "ready"
workload <- receive sock
if unpack workload == "Fired!"
then liftIO $ withMVar lock $ \_ -> printf "Completed: %d tasks\n" (val::Int)
else do
rand <- liftIO $ getStdRandom (randomR (500::Int, 5000))
liftIO $ threadDelay rand
loop (val+1) sock
main :: IO ()
main =
runZMQ $ do
client <- socket Router
bind client "ipc://routing.ipc"
-- We only need MVar for printing the output (so output doesn't become interleaved)
-- The alternative is to Make an ipc channel, but that distracts from the example
-- or to 'NoBuffering' 'stdin'
lock <- liftIO $ newMVar ()
liftIO $ replicateM_ nbrWorkers (forkIO $ workerThread lock)
start <- liftIO getCurrentTime
clientTask client start
-- You need to give some time to the workers so they can exit properly
liftIO $ threadDelay $ 1 * 1000 * 1000
where
clientTask :: Socket z Router -> UTCTime -> ZMQ z ()
clientTask = loop nbrWorkers where
loop c sock start = unless (c <= 0) $ do
-- Next message is the leaset recently used worker
ident <- receive sock
send sock [SendMore] ident
-- Envelope delimiter
receive sock
-- Ready signal from worker
receive sock
-- Send delimiter
send sock [SendMore] ""
-- Send Work unless time is up
now <- liftIO getCurrentTime
if c /= nbrWorkers || diffUTCTime now start > 5
then do
send sock [] "Fired!"
loop (c-1) sock start
else do
send sock [] "Work harder"
loop c sock startrtreq: ROUTER-to-REQ in Haxe
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
#if (neko || cpp)
import neko.vm.Thread;
#end
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
import org.zeromq.ZMQSocket;
import ZHelpers;
/**
* Custom routing Router to Mama (ROUTER to REQ)
*
* While this example runs in a single process (for cpp & neko), that is just
* to make it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: http://zguide.zeromq.org/page:all#Least-Recently-Used-Routing-LRU-Pattern
*/
class RTMama
{
private static inline var NBR_WORKERS = 10;
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
// Use a random string identity for ease here
var id = ZHelpers.setID(worker);
worker.connect("ipc:///tmp/routing.ipc");
var total = 0;
while (true) {
// Tell the router we are ready
ZFrame.newStringFrame("ready").send(worker);
// Get workload from router, until finished
var workload:ZFrame = ZFrame.recvFrame(worker);
if (workload == null) break;
if (workload.streq("END")) {
Lib.println("Processed: " + total + " tasks");
break;
}
total++;
// Do some random work
Sys.sleep((ZHelpers.randof(1000) + 1) / 1000.0);
}
context.destroy();
}
public static function main() {
Lib.println("** RTMama (see: http://zguide.zeromq.org/page:all#Least-Recently-Used-Routing-LRU-Pattern)");
// Implementation note: Had to move php forking before main thread ZMQ Context creation to
// get the main thread to receive messages from the child processes.
for (worker_nbr in 0 ... NBR_WORKERS) {
#if php
forkWorkerTask();
#else
Thread.create(workerTask);
#end
}
var context:ZContext = new ZContext();
var client:ZMQSocket = context.createSocket(ZMQ_ROUTER);
// Implementation note: Had to add the /tmp prefix to get this to work on Linux Ubuntu 10
client.bind("ipc:///tmp/routing.ipc");
Sys.sleep(1);
for (task_nbr in 0 ... NBR_WORKERS * 10) {
// LRU worker is next waiting in queue
var address:ZFrame = ZFrame.recvFrame(client);
var empty:ZFrame = ZFrame.recvFrame(client);
var ready:ZFrame = ZFrame.recvFrame(client);
address.send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("").send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("This is the workload").send(client);
}
// Now ask mamas to shut down and report their results
for (worker_nbr in 0 ... NBR_WORKERS) {
var address:ZFrame = ZFrame.recvFrame(client);
var empty:ZFrame = ZFrame.recvFrame(client);
var ready:ZFrame = ZFrame.recvFrame(client);
address.send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("").send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("END").send(client);
}
context.destroy();
}
#if php
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
RTMama::workerTask();
exit();
}');
return;
}
#end
}rtreq: ROUTER-to-REQ in Java
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
/**
* ROUTER-TO-REQ example
*/
public class rtreq
{
private static Random rand = new Random();
private static final int NBR_WORKERS = 10;
private static class Worker extends Thread
{
@Override
public void run()
{
try (ZContext context = new ZContext()) {
Socket worker = context.createSocket(SocketType.REQ);
ZHelper.setId(worker); // Set a printable identity
worker.connect("tcp://localhost:5671");
int total = 0;
while (true) {
// Tell the broker we're ready for work
worker.send("Hi Boss");
// Get workload from broker, until finished
String workload = worker.recvStr();
boolean finished = workload.equals("Fired!");
if (finished) {
System.out.printf("Completed: %d tasks\n", total);
break;
}
total++;
// Do some random work
try {
Thread.sleep(rand.nextInt(500) + 1);
}
catch (InterruptedException e) {
}
}
}
}
}
/**
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*/
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
Socket broker = context.createSocket(SocketType.ROUTER);
broker.bind("tcp://*:5671");
for (int workerNbr = 0; workerNbr < NBR_WORKERS; workerNbr++) {
Thread worker = new Worker();
worker.start();
}
// Run for five seconds and then tell workers to end
long endTime = System.currentTimeMillis() + 5000;
int workersFired = 0;
while (true) {
// Next message gives us least recently used worker
String identity = broker.recvStr();
broker.sendMore(identity);
broker.recvStr(); // Envelope delimiter
broker.recvStr(); // Response from worker
broker.sendMore("");
// Encourage workers until it's time to fire them
if (System.currentTimeMillis() < endTime)
broker.send("Work harder");
else {
broker.send("Fired!");
if (++workersFired == NBR_WORKERS)
break;
}
}
}
}
}
rtreq: ROUTER-to-REQ in Julia
rtreq: ROUTER-to-REQ in Lua
--
-- Custom routing Router to Mama (ROUTER to REQ)
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zhelpers"
NBR_WORKERS = 10
local pre_code = [[
local identity, seed = ...
local zmq = require"zmq"
require"zhelpers"
math.randomseed(seed)
]]
local worker_task = pre_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.REQ)
-- We use a string identity for ease here
worker:setopt(zmq.IDENTITY, identity)
worker:connect("ipc://routing.ipc")
local total = 0
while true do
-- Tell the router we're ready for work
worker:send("ready")
-- Get workload from router, until finished
local workload = worker:recv()
local finished = (workload == "END")
if (finished) then
printf ("Processed: %d tasks\n", total)
break
end
total = total + 1
-- Do some random work
s_sleep (randof (1000) + 1)
end
worker:close()
context:term()
]]
s_version_assert (2, 1)
local context = zmq.init(1)
local client = context:socket(zmq.ROUTER)
client:bind("ipc://routing.ipc")
math.randomseed(os.time())
local workers = {}
for n=1,NBR_WORKERS do
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(context, worker_task, identity, seed)
workers[n]:start()
end
for n=1,(NBR_WORKERS * 10) do
-- LRU worker is next waiting in queue
local address = client:recv()
local empty = client:recv()
local ready = client:recv()
client:send(address, zmq.SNDMORE)
client:send("", zmq.SNDMORE)
client:send("This is the workload")
end
-- Now ask mamas to shut down and report their results
for n=1,NBR_WORKERS do
local address = client:recv()
local empty = client:recv()
local ready = client:recv()
client:send(address, zmq.SNDMORE)
client:send("", zmq.SNDMORE)
client:send("END")
end
for n=1,NBR_WORKERS do
assert(workers[n]:join())
end
client:close()
context:term()
rtreq: ROUTER-to-REQ in Node.js
var zmq = require('zeromq');
var WORKERS_NUM = 10;
var router = zmq.socket('router');
var d = new Date();
var endTime = d.getTime() + 5000;
router.bindSync('tcp://*:9000');
router.on('message', function () {
// get the identity of current worker
var identity = Array.prototype.slice.call(arguments)[0];
var d = new Date();
var time = d.getTime();
if (time < endTime) {
router.send([identity, '', 'Work harder!'])
} else {
router.send([identity, '', 'Fired!']);
}
});
// To keep it simple we going to use
// workers in closures and tcp instead of
// node clusters and threads
for (var i = 0; i < WORKERS_NUM; i++) {
(function () {
var worker = zmq.socket('req');
worker.connect('tcp://127.0.0.1:9000');
var total = 0;
worker.on('message', function (msg) {
var message = msg.toString();
if (message === 'Fired!'){
console.log('Completed %d tasks', total);
worker.close();
}
total++;
setTimeout(function () {
worker.send('Hi boss!');
}, 1000)
});
worker.send('Hi boss!');
})();
}
rtreq: ROUTER-to-REQ in Objective-C
rtreq: ROUTER-to-REQ in ooc
rtreq: ROUTER-to-REQ in Perl
# ROUTER-to-REQ in Perl
use strict;
use warnings;
use v5.10;
use threads;
use Time::HiRes qw(usleep);
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REQ ZMQ_ROUTER);
my $NBR_WORKERS = 10;
sub worker_task {
my $context = ZMQ::FFI->new();
my $worker = $context->socket(ZMQ_REQ);
$worker->set_identity(Time::HiRes::time());
$worker->connect('tcp://localhost:5671');
my $total = 0;
WORKER_LOOP:
while (1) {
# Tell the broker we're ready for work
$worker->send('Hi Boss');
# Get workload from broker, until finished
my $workload = $worker->recv();
my $finished = $workload eq "Fired!";
if ($finished) {
say "Completed $total tasks";
last WORKER_LOOP;
}
$total++;
# Do some random work
usleep int(rand(500_000)) + 1;
}
}
# While this example runs in a single process, that is only to make
# it easier to start and stop the example. Each thread has its own
# context and conceptually acts as a separate process.
my $context = ZMQ::FFI->new();
my $broker = $context->socket(ZMQ_ROUTER);
$broker->bind('tcp://*:5671');
for my $worker_nbr (1..$NBR_WORKERS) {
threads->create('worker_task')->detach();
}
# Run for five seconds and then tell workers to end
my $end_time = time() + 5;
my $workers_fired = 0;
BROKER_LOOP:
while (1) {
# Next message gives us least recently used worker
my ($identity, $delimiter, $response) = $broker->recv_multipart();
# Encourage workers until it's time to fire them
if ( time() < $end_time ) {
$broker->send_multipart([$identity, '', 'Work harder']);
}
else {
$broker->send_multipart([$identity, '', 'Fired!']);
if ( ++$workers_fired == $NBR_WORKERS) {
last BROKER_LOOP;
}
}
}
rtreq: ROUTER-to-REQ in PHP
<?php
/*
* Custom routing Router to Mama (ROUTER to REQ)
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>a
*/
define("NBR_WORKERS", 10);
function worker_thread()
{
$context = new ZMQContext();
$worker = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$worker->connect("ipc://routing.ipc");
$total = 0;
while (true) {
// Tell the router we're ready for work
$worker->send("ready");
// Get workload from router, until finished
$workload = $worker->recv();
if ($workload == 'END') {
printf ("Processed: %d tasks%s", $total, PHP_EOL);
break;
}
$total++;
// Do some random work
usleep(mt_rand(1, 1000000));
}
}
for ($worker_nbr = 0; $worker_nbr < NBR_WORKERS; $worker_nbr++) {
if (pcntl_fork() == 0) {
worker_thread();
exit();
}
}
$context = new ZMQContext();
$client = $context->getSocket(ZMQ::SOCKET_ROUTER);
$client->bind("ipc://routing.ipc");
for ($task_nbr = 0; $task_nbr < NBR_WORKERS * 10; $task_nbr++) {
// LRU worker is next waiting in queue
$address = $client->recv();
$empty = $client->recv();
$read = $client->recv();
$client->send($address, ZMQ::MODE_SNDMORE);
$client->send("", ZMQ::MODE_SNDMORE);
$client->send("This is the workload");
}
// Now ask mamas to shut down and report their results
for ($task_nbr = 0; $task_nbr < NBR_WORKERS; $task_nbr++) {
// LRU worker is next waiting in queue
$address = $client->recv();
$empty = $client->recv();
$read = $client->recv();
$client->send($address, ZMQ::MODE_SNDMORE);
$client->send("", ZMQ::MODE_SNDMORE);
$client->send("END");
}
sleep (1); // Give 0MQ/2.0.x time to flush output
rtreq: ROUTER-to-REQ in Python
# encoding: utf-8
#
# Custom routing Router to Mama (ROUTER to REQ)
#
# Author: Jeremy Avnet (brainsik) <spork(dash)zmq(at)theory(dot)org>
#
import time
import random
from threading import Thread
import zmq
import zhelpers
NBR_WORKERS = 10
def worker_thread(context=None):
context = context or zmq.Context.instance()
worker = context.socket(zmq.REQ)
# We use a string identity for ease here
zhelpers.set_id(worker)
worker.connect("tcp://localhost:5671")
total = 0
while True:
# Tell the router we're ready for work
worker.send(b"ready")
# Get workload from router, until finished
workload = worker.recv()
finished = workload == b"END"
if finished:
print("Processed: %d tasks" % total)
break
total += 1
# Do some random work
time.sleep(0.1 * random.random())
context = zmq.Context.instance()
client = context.socket(zmq.ROUTER)
client.bind("tcp://*:5671")
for _ in range(NBR_WORKERS):
Thread(target=worker_thread).start()
for _ in range(NBR_WORKERS * 10):
# LRU worker is next waiting in the queue
address, empty, ready = client.recv_multipart()
client.send_multipart([
address,
b'',
b'This is the workload',
])
# Now ask mama to shut down and report their results
for _ in range(NBR_WORKERS):
address, empty, ready = client.recv_multipart()
client.send_multipart([
address,
b'',
b'END',
])
rtreq: ROUTER-to-REQ in Q
rtreq: ROUTER-to-REQ in Racket
rtreq: ROUTER-to-REQ in Ruby
rtreq: ROUTER-to-REQ in Rust
rtreq: ROUTER-to-REQ in Scala
rtreq: ROUTER-to-REQ in Tcl
rtreq: ROUTER-to-REQ in OCaml
The example runs for five seconds and then each worker prints how many tasks they handled. If the routing worked, we’d expect a fair distribution of work:
Completed: 20 tasks
Completed: 18 tasks
Completed: 21 tasks
Completed: 23 tasks
Completed: 19 tasks
Completed: 21 tasks
Completed: 17 tasks
Completed: 17 tasks
Completed: 25 tasks
Completed: 19 tasks
To talk to the workers in this example, we have to create a REQ-friendly envelope consisting of an identity plus an empty envelope delimiter frame.

ROUTER Broker and DEALER Workers #
Anywhere you can use REQ, you can use DEALER. There are two specific differences:
- The REQ socket always sends an empty delimiter frame before any data frames; the DEALER does not.
- The REQ socket will send only one message before it receives a reply; the DEALER is fully asynchronous.
The synchronous versus asynchronous behavior has no effect on our example because we’re doing strict request-reply. It is more relevant when we address recovering from failures, which we’ll come to in Chapter 4 - Reliable Request-Reply Patterns.
Now let’s look at exactly the same example but with the REQ socket replaced by a DEALER socket:
rtdealer: ROUTER-to-DEALER in Ada
rtdealer: ROUTER-to-DEALER in Basic
rtdealer: ROUTER-to-DEALER in C
// 2015-02-27T11:40+08:00
// ROUTER-to-DEALER example
#include "zhelpers.h"
#include <pthread.h>
#define NBR_WORKERS 10
static void *
worker_task(void *args)
{
void *context = zmq_ctx_new();
void *worker = zmq_socket(context, ZMQ_DEALER);
#if (defined (WIN32))
s_set_id(worker, (intptr_t)args);
#else
s_set_id(worker); // Set a printable identity
#endif
zmq_connect (worker, "tcp://localhost:5671");
int total = 0;
while (1) {
// Tell the broker we're ready for work
s_sendmore(worker, "");
s_send(worker, "Hi Boss");
// Get workload from broker, until finished
free(s_recv(worker)); // Envelope delimiter
char *workload = s_recv(worker);
// .skip
int finished = (strcmp(workload, "Fired!") == 0);
free(workload);
if (finished) {
printf("Completed: %d tasks\n", total);
break;
}
total++;
// Do some random work
s_sleep(randof(500) + 1);
}
zmq_close(worker);
zmq_ctx_destroy(context);
return NULL;
}
// .split main task
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
int main(void)
{
void *context = zmq_ctx_new();
void *broker = zmq_socket(context, ZMQ_ROUTER);
zmq_bind(broker, "tcp://*:5671");
srandom((unsigned)time(NULL));
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
pthread_t worker;
pthread_create(&worker, NULL, worker_task, (void *)(intptr_t)worker_nbr);
}
// Run for five seconds and then tell workers to end
int64_t end_time = s_clock() + 5000;
int workers_fired = 0;
while (1) {
// Next message gives us least recently used worker
char *identity = s_recv(broker);
s_sendmore(broker, identity);
free(identity);
free(s_recv(broker)); // Envelope delimiter
free(s_recv(broker)); // Response from worker
s_sendmore(broker, "");
// Encourage workers until it's time to fire them
if (s_clock() < end_time)
s_send(broker, "Work harder");
else {
s_send(broker, "Fired!");
if (++workers_fired == NBR_WORKERS)
break;
}
}
zmq_close(broker);
zmq_ctx_destroy(context);
return 0;
}
// .until
rtdealer: ROUTER-to-DEALER in C++
//
// Custom routing Router to Dealer
//
#include "zhelpers.hpp"
#include <thread>
#include <vector>
static void *
worker_task(void *args)
{
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_DEALER);
#if (defined (WIN32))
s_set_id(worker, (intptr_t)args);
#else
s_set_id(worker); // Set a printable identity
#endif
worker.connect("tcp://localhost:5671");
int total = 0;
while (1) {
// Tell the broker we're ready for work
s_sendmore(worker, std::string(""));
s_send(worker, std::string("Hi Boss"));
// Get workload from broker, until finished
s_recv(worker); // Envelope delimiter
std::string workload = s_recv(worker);
// .skip
if ("Fired!" == workload) {
std::cout << "Completed: " << total << " tasks" << std::endl;
break;
}
total++;
// Do some random work
s_sleep(within(500) + 1);
}
return NULL;
}
// .split main task
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
int main() {
zmq::context_t context(1);
zmq::socket_t broker(context, ZMQ_ROUTER);
broker.bind("tcp://*:5671");
srandom((unsigned)time(NULL));
const int NBR_WORKERS = 10;
std::vector<std::thread> workers;
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
workers.push_back(std::move(std::thread(worker_task, (void *)(intptr_t)worker_nbr)));
}
// Run for five seconds and then tell workers to end
int64_t end_time = s_clock() + 5000;
int workers_fired = 0;
while (1) {
// Next message gives us least recently used worker
std::string identity = s_recv(broker);
{
s_recv(broker); // Envelope delimiter
s_recv(broker); // Response from worker
}
s_sendmore(broker, identity);
s_sendmore(broker, std::string(""));
// Encourage workers until it's time to fire them
if (s_clock() < end_time)
s_send(broker, std::string("Work harder"));
else {
s_send(broker, std::string("Fired!"));
if (++workers_fired == NBR_WORKERS)
break;
}
}
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
workers[worker_nbr].join();
}
return 0;
}
rtdealer: ROUTER-to-DEALER in C#
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
static int RTDealer_Workers = 10;
public static void RTDealer(string[] args)
{
//
// ROUTER-to-DEALER example
//
// While this example runs in a single process, that is only to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
//
// Author: metadings
//
using (var context = new ZContext())
using (var broker = new ZSocket(context, ZSocketType.ROUTER))
{
broker.Bind("tcp://*:5671");
for (int i = 0; i < RTDealer_Workers; ++i)
{
int j = i; new Thread(() => RTDealer_Worker(j)).Start();
}
var stopwatch = new Stopwatch();
stopwatch.Start();
// Run for five seconds and then tell workers to end
int workers_fired = 0;
while (true)
{
// Next message gives us least recently used worker
using (ZMessage identity = broker.ReceiveMessage())
{
broker.SendMore(identity[0]);
broker.SendMore(new ZFrame());
// Encourage workers until it's time to fire them
if (stopwatch.Elapsed < TimeSpan.FromSeconds(5))
{
broker.Send(new ZFrame("Work harder!"));
}
else
{
broker.Send(new ZFrame("Fired!"));
if (++workers_fired == RTDealer_Workers)
{
break;
}
}
}
}
}
}
static void RTDealer_Worker(int i)
{
using (var context = new ZContext())
using (var worker = new ZSocket(context, ZSocketType.DEALER))
{
worker.IdentityString = "PEER" + i; // Set a printable identity
worker.Connect("tcp://127.0.0.1:5671");
int total = 0;
while (true)
{
// Tell the broker we're ready for work
worker.SendMore(new ZFrame(worker.Identity));
worker.SendMore(new ZFrame());
worker.Send(new ZFrame("Hi Boss"));
// Get workload from broker, until finished
using (ZMessage msg = worker.ReceiveMessage())
{
bool finished = (msg[1].ReadString() == "Fired!");
if (finished)
{
break;
}
}
total++;
// Do some random work
Thread.Sleep(1);
}
Console.WriteLine("Completed: PEER{0}, {1} tasks", i, total);
}
}
}
}
rtdealer: ROUTER-to-DEALER in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Custom routing Router to Dealer in Common Lisp
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
;;; We have two workers, here we copy the code, normally these would run on
;;; different boxes...
(defpackage #:zguide.rtdealer
(:nicknames #:rtdealer)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.rtdealer)
(defun worker-a (context)
(zmq:with-socket (worker context zmq:dealer)
(zmq:setsockopt worker zmq:identity "A")
(zmq:connect worker "ipc://routing.ipc")
(let ((total 0))
(loop
;; We receive one part, with the workload
(let ((request (recv-text worker)))
(when (string= request "END")
(message "A received: ~D~%" total)
(return))
(incf total))))))
(defun worker-b (context)
(zmq:with-socket (worker context zmq:dealer)
(zmq:setsockopt worker zmq:identity "B")
(zmq:connect worker "ipc://routing.ipc")
(let ((total 0))
(loop
;; We receive one part, with the workload
(let ((request (recv-text worker)))
(when (string= request "END")
(message "B received: ~D~%" total)
(return))
(incf total))))))
(defun main ()
(zmq:with-context (context 1)
(zmq:with-socket (client context zmq:router)
(zmq:bind client "ipc://routing.ipc")
(bt:make-thread (lambda () (worker-a context))
:name "worker-a")
(bt:make-thread (lambda () (worker-b context))
:name "worker-b")
;; Wait for threads to stabilize
(sleep 1)
;; Send 10 tasks scattered to A twice as often as B
(loop :repeat 10 :do
;; Send two message parts, first the address...
(if (> (1- (within 3)) 0)
(send-more-text client "A")
(send-more-text client "B"))
;; And then the workload
(send-text client "This is the workload"))
(send-more-text client "A")
(send-text client "END")
;; we can get messy output when two threads concurrently print results
;; so Let worker-a to print results first
(sleep 0.1)
(send-more-text client "B")
(send-text client "END")
;; Give 0MQ/2.0.x time to flush output
(sleep 1)))
(cleanup))
rtdealer: ROUTER-to-DEALER in Delphi
program rtdealer;
//
// ROUTER-to-DEALER example
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, Windows
, zmqapi
, zhelpers
;
const
NBR_WORKERS = 10;
procedure worker_task( args: Pointer );
var
context: TZMQContext;
worker: TZMQSocket;
total: Integer;
workload,
s: Utf8String;
begin
context := TZMQContext.create;
worker := context.Socket( stDealer );
s_set_id( worker ); // Set a printable identity
worker.connect( 'tcp://localhost:5671' );
total := 0;
while true do
begin
// Tell the broker we're ready for work
worker.send( ['','Hi Boss'] );
// Get workload from broker, until finished
worker.recv( s ); // Envelope delimiter
worker.recv( workload );
if workload = 'Fired!' then
begin
zNote( Format( 'Completed: %d tasks', [total] ) );
break;
end;
Inc( total );
// Do some random work
sleep( random( 500 ) + 1 );
end;
worker.Free;
context.Free;
end;
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
var
context: TZMQContext;
broker: TZMQSocket;
i,
workers_fired: Integer;
tid: Cardinal;
identity,
s: Utf8String;
fFrequency,
fstart,
fStop,
dt: Int64;
begin
context := TZMQContext.create;
broker := context.Socket( stRouter );
broker.bind( 'tcp://*:5671' );
Randomize;
for i := 0 to NBR_WORKERS - 1 do
BeginThread( nil, 0, @worker_task, nil, 0, tid );
// Start our clock now
QueryPerformanceFrequency( fFrequency );
QueryPerformanceCounter( fStart );
// Run for five seconds and then tell workers to end
workers_fired := 0;
while true do
begin
// Next message gives us least recently used worker
broker.recv( identity );
broker.send( identity, [sfSndMore] );
broker.recv( s ); // Envelope delimiter
broker.recv( s ); // Response from worker
broker.send( '', [sfSndMore] );
QueryPerformanceCounter( fStop );
dt := ( MSecsPerSec * ( fStop - fStart ) ) div fFrequency;
if dt < 5000 then
broker.send( 'Work harder' )
else begin
broker.send( 'Fired!' );
Inc( workers_fired );
if workers_fired = NBR_WORKERS then
break;
end;
end;
broker.Free;
context.Free;
end.
rtdealer: ROUTER-to-DEALER in Erlang
#! /usr/bin/env escript
%%
%% Custom routing Router to Dealer
%%
%% While this example runs in a single process, that is just to make
%% it easier to start and stop the example. Each thread has its own
%% context and conceptually acts as a separate process.
%%
%% We start multiple workers in this process - these would normally be on
%% different nodes...
worker_task(Id) ->
{ok, Context} = erlzmq:context(),
{ok, Worker} = erlzmq:socket(Context, dealer),
ok = erlzmq:setsockopt(Worker, identity, Id),
ok = erlzmq:connect(Worker, "ipc://routing.ipc"),
Count = count_messages(Worker, 0),
io:format("~s received: ~b~n", [Id, Count]),
ok = erlzmq:close(Worker),
ok = erlzmq:term(Context).
count_messages(Socket, Count) ->
case erlzmq:recv(Socket) of
{ok, <<"END">>} -> Count;
{ok, _} -> count_messages(Socket, Count + 1)
end.
main(_) ->
{ok, Context} = erlzmq:context(),
{ok, Client} = erlzmq:socket(Context, router),
ok = erlzmq:bind(Client, "ipc://routing.ipc"),
spawn(fun() -> worker_task(<<"A">>) end),
spawn(fun() -> worker_task(<<"B">>) end),
%% Wait for threads to connect, since otherwise the messages
%% we send won't be routable.
timer:sleep(1000),
%% Send 10 tasks scattered to A twice as often as B
lists:foreach(
fun(Num) ->
%% Send two message parts, first the address
case Num rem 3 of
0 ->
ok = erlzmq:send(Client, <<"B">>, [sndmore]);
_ ->
ok = erlzmq:send(Client, <<"A">>, [sndmore])
end,
%% And then the workload
ok = erlzmq:send(Client, <<"Workload">>)
end, lists:seq(1, 10)),
ok = erlzmq:send(Client, <<"A">>, [sndmore]),
ok = erlzmq:send(Client, <<"END">>),
ok = erlzmq:send(Client, <<"B">>, [sndmore]),
ok = erlzmq:send(Client, <<"END">>),
%% Workers use separate context, so we can't rely on Context term
%% below to wait for them to finish. Manually wait instead.
timer:sleep(100),
ok = erlzmq:close(Client),
ok = erlzmq:term(Context).
rtdealer: ROUTER-to-DEALER in Elixir
defmodule Rtdealer do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:32
"""
def worker_task(id) do
{:ok, context} = :erlzmq.context()
{:ok, worker} = :erlzmq.socket(context, :dealer)
:ok = :erlzmq.setsockopt(worker, :identity, id)
:ok = :erlzmq.connect(worker, 'ipc://routing.ipc')
count = count_messages(worker, 0)
:io.format('~s received: ~b~n', [id, count])
:ok = :erlzmq.close(worker)
:ok = :erlzmq.term(context)
end
def count_messages(socket, count) do
case(:erlzmq.recv(socket)) do
{:ok, "END"} ->
count
{:ok, _} ->
count_messages(socket, count + 1)
end
end
def main() do
{:ok, context} = :erlzmq.context()
{:ok, client} = :erlzmq.socket(context, :router)
:ok = :erlzmq.bind(client, 'ipc://routing.ipc')
:erlang.spawn(fn -> worker_task("A") end)
:erlang.spawn(fn -> worker_task("B") end)
:timer.sleep(1000)
:lists.foreach(fn num ->
case(rem(num, 3)) do
0 ->
:ok = :erlzmq.send(client, "B", [:sndmore])
_ ->
:ok = :erlzmq.send(client, "A", [:sndmore])
end
:ok = :erlzmq.send(client, "Workload")
end, :lists.seq(1, 10))
:ok = :erlzmq.send(client, "A", [:sndmore])
:ok = :erlzmq.send(client, "END")
:ok = :erlzmq.send(client, "B", [:sndmore])
:ok = :erlzmq.send(client, "END")
:timer.sleep(100)
:ok = :erlzmq.close(client)
:ok = :erlzmq.term(context)
end
end
Rtdealer.main
rtdealer: ROUTER-to-DEALER in F#
(*
Custom routing Router to Dealer
While this example runs in a single process, that is just to make
it easier to start and stop the example. Each thread has its own
context and conceptually acts as a separate process.
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Socket
#load "zhelpers.fs"
open System.Threading
let worker_task_a () =
use context = new Context(1)
use worker = deal context
(ZMQ.IDENTITY,"A"B) |> set worker
"tcp://localhost:5570" |> connect worker
let rec loop count =
let message = s_recv worker
if message = "END"
then count
else loop (count + 1)
let total = loop 0
fflush()
printfn' "A received: %d" total
let worker_task_b () =
use context = new Context(1)
use worker = deal context
(ZMQ.IDENTITY,"B"B) |> set worker
"tcp://localhost:5570" |> connect worker
let rec loop count =
let message = s_recv worker
if message = "END"
then count
else loop (count + 1)
let total = loop 0
fflush()
printfn' "B received: %d" total
let main () =
use context = new Context(1)
use client = route context
"tcp://*:5570" |> bind client
let worker_a = Thread(ThreadStart worker_task_a)
worker_a.Start()
let worker_b = Thread(ThreadStart worker_task_b)
worker_b.Start()
// wait for threads to connect,
// since otherwise the messages we send won't be routable.
sleep 100
// send 10 tasks scattered to A twice as often as B
let rand = srandom()
for task_nbr in 0 .. 9 do
// send two message parts, first the address...
( if rand.Next(0,3) > 0
then "A"B |~> client
else "B"B |~> client )
// and then the workload
<<| "This is the workload"B
["A"B;"END"B] |> sendAll client
["B"B;"END"B] |> sendAll client
EXIT_SUCCESS
main ()
rtdealer: ROUTER-to-DEALER in Felix
rtdealer: ROUTER-to-DEALER in Go
//
// ROUTER-to-DEALER example
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"strings"
"time"
)
const NBR_WORKERS int = 10
func randomString() string {
source := "abcdefghijklmnopqrstuvwxyz"
target := make([]string, 20)
for i := 0; i < 20; i++ {
target[i] = string(source[rand.Intn(len(source))])
}
return strings.Join(target, "")
}
func worker_task() {
context, _ := zmq.NewContext()
defer context.Close()
worker, _ := context.NewSocket(zmq.DEALER)
defer worker.Close()
worker.SetIdentity(randomString())
worker.Connect("tcp://localhost:5671")
total := 0
for {
// Tell the broker we're ready for work
worker.SendMultipart([][]byte{[]byte(""), []byte("Hi Boss")}, 0)
// Get workload from broker, until finished
parts, _ := worker.RecvMultipart(0)
workload := parts[1]
if string(workload) == "Fired!" {
id, _ := worker.Identity()
fmt.Printf("Completed: %d tasks (%s)\n", total, id)
break
}
total++
// Do some random work
time.Sleep(time.Duration(rand.Intn(500)) * time.Millisecond)
}
}
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
func main() {
context, _ := zmq.NewContext()
defer context.Close()
broker, _ := context.NewSocket(zmq.ROUTER)
defer broker.Close()
broker.Bind("tcp://*:5671")
rand.Seed(time.Now().Unix())
for i := 0; i < NBR_WORKERS; i++ {
go worker_task()
}
end_time := time.Now().Unix() + 5
workers_fired := 0
for {
// Next message gives us least recently used worker
parts, err := broker.RecvMultipart(0)
if err != nil {
print(err)
}
identity := parts[0]
now := time.Now().Unix()
if now < end_time {
broker.SendMultipart([][]byte{identity, []byte(""), []byte("Work harder")}, 0)
} else {
broker.SendMultipart([][]byte{identity, []byte(""), []byte("Fired!")}, 0)
workers_fired++
if workers_fired == NBR_WORKERS {
break
}
}
}
}
rtdealer: ROUTER-to-DEALER in Haskell
{-# LANGUAGE OverloadedStrings #-}
-- |
-- Router broker and DEALER workers (p.94)
module Main where
import System.ZMQ4.Monadic
import Control.Concurrent (threadDelay, forkIO)
import Control.Concurrent.MVar (withMVar, newMVar, MVar)
import Data.ByteString.Char8 (unpack)
import Control.Monad (replicateM_, unless)
import ZHelpers (setRandomIdentity)
import Text.Printf
import Data.Time.Clock
import System.Random
nbrWorkers :: Int
nbrWorkers = 10
-- In general, although locks are an antipattern in ZeroMQ, we need a lock
-- for the stdout handle, otherwise we will get jumbled text. We don't
-- use the lock for anything zeroMQ related, just output to screen.
workerThread :: MVar () -> IO ()
workerThread lock =
runZMQ $ do
worker <- socket Dealer
setRandomIdentity worker
connect worker "ipc://routing.ipc"
work worker
where
work = loop 0 where
loop val sock = do
-- Send an empty frame manually
-- Unlike the Request socket, the Dealer does not it automatically
send sock [SendMore] ""
send sock [] "Ready"
-- unlike the Request socket we need to read the empty frame
receive sock
workload <- receive sock
if unpack workload == "Fired!"
then liftIO $ withMVar lock $ \_ -> printf "Completed: %d tasks\n" (val::Int)
else do
rand <- liftIO $ getStdRandom (randomR (500 :: Int, 5000))
liftIO $ threadDelay rand
loop (val+1) sock
main :: IO ()
main =
runZMQ $ do
client <- socket Router
bind client "ipc://routing.ipc"
-- We only Need the MVar For Printing the Output (so output doesn't become interleaved)
-- The alternative is to Make an ipc channel, but that distracts from the example
-- Another alternative is to 'NoBuffering' 'stdin' and press Ctr-C manually
lock <- liftIO $ newMVar ()
liftIO $ replicateM_ nbrWorkers (forkIO $ workerThread lock)
start <- liftIO getCurrentTime
sendWork client start
-- You need to give some time to the workers so they can exit properly
liftIO $ threadDelay $ 1 * 1000 * 1000
where
sendWork :: Socket z Router -> UTCTime -> ZMQ z ()
sendWork = loop nbrWorkers where
loop c sock start = unless (c <= 0) $ do
-- Next message is the leaset recently used worker
ident <- receive sock
send sock [SendMore] ident
-- Envelope delimiter
receive sock
-- Ready signal from worker
receive sock
-- Send delimiter
send sock [SendMore] ""
-- Send Work unless time is up
now <- liftIO getCurrentTime
if c /= nbrWorkers || diffUTCTime now start > 5
then do
send sock [] "Fired!"
loop (c-1) sock start
else do
send sock [] "Work harder"
loop c sock startrtdealer: ROUTER-to-DEALER in Haxe
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
#if (neko || cpp)
import neko.Random;
import neko.vm.Thread;
#end
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
import org.zeromq.ZMQSocket;
/**
* Custom routing Router to Dealer
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: http://zguide.zeromq.org/page:all#Router-to-Dealer-Routing
*/
class RTDealer
{
public static function workerTask(id:String) {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_DEALER);
worker.setsockopt(ZMQ_IDENTITY, Bytes.ofString(id));
worker.connect("ipc:///tmp/routing.ipc");
var total = 0;
while (true) {
// We receive one part, with the workload
var request:ZFrame = ZFrame.recvFrame(worker);
if (request == null) break;
if (request.streq("END")) {
Lib.println(id + " received: " + total);
break;
}
total++;
}
context.destroy();
}
public static function main() {
Lib.println("** RTDealer (see: http://zguide.zeromq.org/page:all#Router-to-Dealer-Routing)");
// Implementation note: Had to move php forking before main thread ZMQ Context creation to
// get the main thread to receive messages from the child processes.
#if php
// For PHP, use processes, not threads
forkWorkerTasks();
#else
var workerA = Thread.create(callback(workerTask, "A"));
var workerB = Thread.create(callback(workerTask, "B"));
#end
var context:ZContext = new ZContext();
var client:ZMQSocket = context.createSocket(ZMQ_ROUTER);
// Implementation note: Had to add the /tmp prefix to get this to work on Linux Ubuntu 10
client.bind("ipc:///tmp/routing.ipc");
// Wait for threads to connect, since otherwise the messages
// we send won't be routable.
Sys.sleep(1);
// Send 10 tasks scattered to A twice as often as B
var workload = ZFrame.newStringFrame("This is the workload");
var address:ZFrame;
#if !php
var rnd = new Random();
rnd.setSeed(Date.now().getSeconds());
#end
for (task_nbr in 0 ... 10) {
// Send two message parts, first the address...
var randNumber:Int;
#if php
randNumber = untyped __php__('rand(0, 2)');
#else
randNumber = rnd.int(2);
#end
if (randNumber > 0)
address = ZFrame.newStringFrame("A");
else
address = ZFrame.newStringFrame("B");
address.send(client, ZFrame.ZFRAME_MORE);
// And then the workload
workload.send(client, ZFrame.ZFRAME_REUSE);
}
ZFrame.newStringFrame("A").send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("END").send(client);
ZFrame.newStringFrame("B").send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("END").send(client);
workload.destroy();
context.destroy();
}
#if php
private static inline function forkWorkerTasks() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
RTDealer::workerTask("A");
exit();
}');
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
RTDealer::workerTask("B");
exit();
}');
return;
}
#end
}rtdealer: ROUTER-to-DEALER in Java
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
/**
* ROUTER-TO-REQ example
*/
public class rtdealer
{
private static Random rand = new Random();
private static final int NBR_WORKERS = 10;
private static class Worker extends Thread
{
@Override
public void run()
{
try (ZContext context = new ZContext()) {
Socket worker = context.createSocket(SocketType.DEALER);
ZHelper.setId(worker); // Set a printable identity
worker.connect("tcp://localhost:5671");
int total = 0;
while (true) {
// Tell the broker we're ready for work
worker.sendMore("");
worker.send("Hi Boss");
// Get workload from broker, until finished
worker.recvStr(); // Envelope delimiter
String workload = worker.recvStr();
boolean finished = workload.equals("Fired!");
if (finished) {
System.out.printf("Completed: %d tasks\n", total);
break;
}
total++;
// Do some random work
try {
Thread.sleep(rand.nextInt(500) + 1);
}
catch (InterruptedException e) {
}
}
}
}
}
/**
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*/
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
Socket broker = context.createSocket(SocketType.ROUTER);
broker.bind("tcp://*:5671");
for (int workerNbr = 0; workerNbr < NBR_WORKERS; workerNbr++) {
Thread worker = new Worker();
worker.start();
}
// Run for five seconds and then tell workers to end
long endTime = System.currentTimeMillis() + 5000;
int workersFired = 0;
while (true) {
// Next message gives us least recently used worker
String identity = broker.recvStr();
broker.sendMore(identity);
broker.recv(0); // Envelope delimiter
broker.recv(0); // Response from worker
broker.sendMore("");
// Encourage workers until it's time to fire them
if (System.currentTimeMillis() < endTime)
broker.send("Work harder");
else {
broker.send("Fired!");
if (++workersFired == NBR_WORKERS)
break;
}
}
}
}
}
rtdealer: ROUTER-to-DEALER in Julia
rtdealer: ROUTER-to-DEALER in Lua
--
-- Custom routing Router to Dealer
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zhelpers"
local pre_code = [[
local zmq = require"zmq"
require"zhelpers"
--local threads = require"zmq.threads"
--local context = threads.get_parent_ctx()
]]
-- We have two workers, here we copy the code, normally these would
-- run on different boxes...
--
local worker_task_a = pre_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.DEALER)
worker:setopt(zmq.IDENTITY, "A")
worker:connect("ipc://routing.ipc")
local total = 0
while true do
-- We receive one part, with the workload
local request = worker:recv()
local finished = (request == "END")
if (finished) then
printf ("A received: %d\n", total)
break
end
total = total + 1
end
worker:close()
context:term()
]]
local worker_task_b = pre_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.DEALER)
worker:setopt(zmq.IDENTITY, "B")
worker:connect("ipc://routing.ipc")
local total = 0
while true do
-- We receive one part, with the workload
local request = worker:recv()
local finished = (request == "END")
if (finished) then
printf ("B received: %d\n", total)
break
end
total = total + 1
end
worker:close()
context:term()
]]
s_version_assert (2, 1)
local context = zmq.init(1)
local client = context:socket(zmq.ROUTER)
client:bind("ipc://routing.ipc")
local task_a = zmq.threads.runstring(context, worker_task_a)
task_a:start()
local task_b = zmq.threads.runstring(context, worker_task_b)
task_b:start()
-- Wait for threads to connect, since otherwise the messages
-- we send won't be routable.
s_sleep (1000)
-- Send 10 tasks scattered to A twice as often as B
math.randomseed(os.time())
for n=1,10 do
-- Send two message parts, first the address...
if (randof (3) > 0) then
client:send("A", zmq.SNDMORE)
else
client:send("B", zmq.SNDMORE)
end
-- And then the workload
client:send("This is the workload")
end
client:send("A", zmq.SNDMORE)
client:send("END")
client:send("B", zmq.SNDMORE)
client:send("END")
client:close()
context:term()
assert(task_a:join())
assert(task_b:join())
rtdealer: ROUTER-to-DEALER in Node.js
'use strict';
var cluster = require('cluster')
, zmq = require('zeromq');
var NBR_WORKERS = 3;
function randomBetween(min, max) {
return Math.floor(Math.random() * (max - min) + min);
}
function randomString() {
var source = 'abcdefghijklmnopqrstuvwxyz'
, target = [];
for (var i = 0; i < 20; i++) {
target.push(source[randomBetween(0, source.length)]);
}
return target.join('');
}
function workerTask() {
var dealer = zmq.socket('dealer');
dealer.identity = randomString();
dealer.connect('tcp://localhost:5671');
var total = 0;
var sendMessage = function () {
dealer.send(['', 'Hi Boss']);
};
// Get workload from broker, until finished
dealer.on('message', function onMessage() {
var args = Array.apply(null, arguments);
var workload = args[1].toString('utf8');
if (workload === 'Fired!') {
console.log('Completed: '+total+' tasks ('+dealer.identity+')');
dealer.removeListener('message', onMessage);
dealer.close();
return;
}
total++;
setTimeout(sendMessage, randomBetween(0, 500));
});
// Tell the broker we're ready for work
sendMessage();
}
function main() {
var broker = zmq.socket('router');
broker.bindSync('tcp://*:5671');
var endTime = Date.now() + 5000
, workersFired = 0;
broker.on('message', function () {
var args = Array.apply(null, arguments)
, identity = args[0]
, now = Date.now();
if (now < endTime) {
broker.send([identity, '', 'Work harder']);
} else {
broker.send([identity, '', 'Fired!']);
workersFired++;
if (workersFired === NBR_WORKERS) {
setImmediate(function () {
broker.close();
cluster.disconnect();
});
}
}
});
for (var i=0;i<NBR_WORKERS;i++) {
cluster.fork();
}
}
if (cluster.isMaster) {
main();
} else {
workerTask();
}
rtdealer: ROUTER-to-DEALER in Objective-C
rtdealer: ROUTER-to-DEALER in ooc
rtdealer: ROUTER-to-DEALER in Perl
# ROUTER-to-DEALER in Perl
use strict;
use warnings;
use v5.10;
use threads;
use Time::HiRes qw(usleep);
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_DEALER ZMQ_ROUTER);
my $NBR_WORKERS = 10;
sub worker_task {
my $context = ZMQ::FFI->new();
my $worker = $context->socket(ZMQ_DEALER);
$worker->set_identity(Time::HiRes::time());
$worker->connect('tcp://localhost:5671');
my $total = 0;
WORKER_LOOP:
while (1) {
# Tell the broker we're ready for work
$worker->send_multipart(['', 'Hi Boss']);
# Get workload from broker, until finished
my ($delimiter, $workload) = $worker->recv_multipart();
my $finished = $workload eq "Fired!";
if ($finished) {
say "Completed $total tasks";
last WORKER_LOOP;
}
$total++;
# Do some random work
usleep int(rand(500_000)) + 1;
}
}
# While this example runs in a single process, that is only to make
# it easier to start and stop the example. Each thread has its own
# context and conceptually acts as a separate process.
my $context = ZMQ::FFI->new();
my $broker = $context->socket(ZMQ_ROUTER);
$broker->bind('tcp://*:5671');
for my $worker_nbr (1..$NBR_WORKERS) {
threads->create('worker_task')->detach();
}
# Run for five seconds and then tell workers to end
my $end_time = time() + 5;
my $workers_fired = 0;
BROKER_LOOP:
while (1) {
# Next message gives us least recently used worker
my ($identity, $delimiter, $response) = $broker->recv_multipart();
# Encourage workers until it's time to fire them
if ( time() < $end_time ) {
$broker->send_multipart([$identity, '', 'Work harder']);
}
else {
$broker->send_multipart([$identity, '', 'Fired!']);
if ( ++$workers_fired == $NBR_WORKERS) {
last BROKER_LOOP;
}
}
}
rtdealer: ROUTER-to-DEALER in PHP
<?php
/*
* Custom routing Router to Dealer
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
// We have two workers, here we copy the code, normally these would
// run on different boxes...
function worker_a()
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_DEALER);
$worker->setSockOpt(ZMQ::SOCKOPT_IDENTITY, "A");
$worker->connect("ipc://routing.ipc");
$total = 0;
while (true) {
// We receive one part, with the workload
$request = $worker->recv();
if ($request == 'END') {
printf ("A received: %d%s", $total, PHP_EOL);
break;
}
$total++;
}
}
function worker_b()
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_DEALER);
$worker->setSockOpt(ZMQ::SOCKOPT_IDENTITY, "B");
$worker->connect("ipc://routing.ipc");
$total = 0;
while (true) {
// We receive one part, with the workload
$request = $worker->recv();
if ($request == 'END') {
printf ("B received: %d%s", $total, PHP_EOL);
break;
}
$total++;
}
}
$pid = pcntl_fork();
if ($pid == 0) { worker_a(); exit(); }
$pid = pcntl_fork();
if ($pid == 0) { worker_b(); exit(); }
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$client->bind("ipc://routing.ipc");
// Wait for threads to stabilize
sleep(1);
// Send 10 tasks scattered to A twice as often as B
for ($task_nbr = 0; $task_nbr != 10; $task_nbr++) {
// Send two message parts, first the address...
if (mt_rand(0, 2) > 0) {
$client->send("A", ZMQ::MODE_SNDMORE);
} else {
$client->send("B", ZMQ::MODE_SNDMORE);
}
// And then the workload
$client->send("This is the workload");
}
$client->send("A", ZMQ::MODE_SNDMORE);
$client->send("END");
$client->send("B", ZMQ::MODE_SNDMORE);
$client->send("END");
sleep (1); // Give 0MQ/2.0.x time to flush output
rtdealer: ROUTER-to-DEALER in Python
# encoding: utf-8
#
# Custom routing Router to Dealer
#
# Author: Jeremy Avnet (brainsik) <spork(dash)zmq(at)theory(dot)org>
#
import time
import random
from threading import Thread
import zmq
# We have two workers, here we copy the code, normally these would
# run on different boxes...
#
def worker_a(context=None):
context = context or zmq.Context.instance()
worker = context.socket(zmq.DEALER)
worker.setsockopt(zmq.IDENTITY, b'A')
worker.connect("ipc://routing.ipc")
total = 0
while True:
# We receive one part, with the workload
request = worker.recv()
finished = request == b"END"
if finished:
print("A received: %s" % total)
break
total += 1
def worker_b(context=None):
context = context or zmq.Context.instance()
worker = context.socket(zmq.DEALER)
worker.setsockopt(zmq.IDENTITY, b'B')
worker.connect("ipc://routing.ipc")
total = 0
while True:
# We receive one part, with the workload
request = worker.recv()
finished = request == b"END"
if finished:
print("B received: %s" % total)
break
total += 1
context = zmq.Context.instance()
client = context.socket(zmq.ROUTER)
client.bind("ipc://routing.ipc")
Thread(target=worker_a).start()
Thread(target=worker_b).start()
# Wait for threads to stabilize
time.sleep(1)
# Send 10 tasks scattered to A twice as often as B
for _ in range(10):
# Send two message parts, first the address...
ident = random.choice([b'A', b'A', b'B'])
# And then the workload
work = b"This is the workload"
client.send_multipart([ident, work])
client.send_multipart([b'A', b'END'])
client.send_multipart([b'B', b'END'])
rtdealer: ROUTER-to-DEALER in Q
rtdealer: ROUTER-to-DEALER in Racket
rtdealer: ROUTER-to-DEALER in Ruby
rtdealer: ROUTER-to-DEALER in Rust
rtdealer: ROUTER-to-DEALER in Scala
rtdealer: ROUTER-to-DEALER in Tcl
rtdealer: ROUTER-to-DEALER in OCaml
The code is almost identical except that the worker uses a DEALER socket, and reads and writes that empty frame before the data frame. This is the approach I use when I want to keep compatibility with REQ workers.
However, remember the reason for that empty delimiter frame: it’s to allow multihop extended requests that terminate in a REP socket, which uses that delimiter to split off the reply envelope so it can hand the data frames to its application.
If we never need to pass the message along to a REP socket, we can simply drop the empty delimiter frame at both sides, which makes things simpler. This is usually the design I use for pure DEALER to ROUTER protocols.
A Load Balancing Message Broker #
The previous example is half-complete. It can manage a set of workers with dummy requests and replies, but it has no way to talk to clients. If we add a second frontend ROUTER socket that accepts client requests, and turn our example into a proxy that can switch messages from frontend to backend, we get a useful and reusable tiny load balancing message broker.
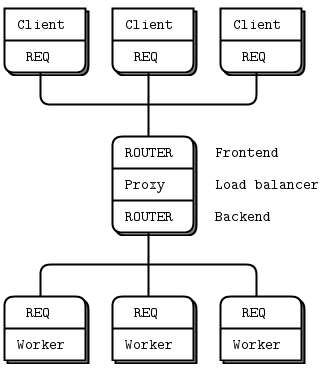
This broker does the following:
- Accepts connections from a set of clients.
- Accepts connections from a set of workers.
- Accepts requests from clients and holds these in a single queue.
- Sends these requests to workers using the load balancing pattern.
- Receives replies back from workers.
- Sends these replies back to the original requesting client.
The broker code is fairly long, but worth understanding:
lbbroker: Load balancing broker in Ada
lbbroker: Load balancing broker in Basic
lbbroker: Load balancing broker in C
// Load-balancing broker
// Clients and workers are shown here in-process
#include "zhelpers.h"
#include <pthread.h>
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
// Dequeue operation for queue implemented as array of anything
#define DEQUEUE(q) memmove (&(q)[0], &(q)[1], sizeof (q) - sizeof (q [0]))
// Basic request-reply client using REQ socket
// Because s_send and s_recv can't handle 0MQ binary identities, we
// set a printable text identity to allow routing.
//
static void *
client_task(void *args)
{
void *context = zmq_ctx_new();
void *client = zmq_socket(context, ZMQ_REQ);
#if (defined (WIN32))
s_set_id(client, (intptr_t)args);
zmq_connect(client, "tcp://localhost:5672"); // frontend
#else
s_set_id(client); // Set a printable identity
zmq_connect(client, "ipc://frontend.ipc");
#endif
// Send request, get reply
s_send(client, "HELLO");
char *reply = s_recv(client);
printf("Client: %s\n", reply);
free(reply);
zmq_close(client);
zmq_ctx_destroy(context);
return NULL;
}
// .split worker task
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
// This is the worker task, using a REQ socket to do load-balancing.
// Because s_send and s_recv can't handle 0MQ binary identities, we
// set a printable text identity to allow routing.
static void *
worker_task(void *args)
{
void *context = zmq_ctx_new();
void *worker = zmq_socket(context, ZMQ_REQ);
#if (defined (WIN32))
s_set_id(worker, (intptr_t)args);
zmq_connect(worker, "tcp://localhost:5673"); // backend
#else
s_set_id(worker);
zmq_connect(worker, "ipc://backend.ipc");
#endif
// Tell broker we're ready for work
s_send(worker, "READY");
while (1) {
// Read and save all frames until we get an empty frame
// In this example there is only 1, but there could be more
char *identity = s_recv(worker);
char *empty = s_recv(worker);
assert(*empty == 0);
free(empty);
// Get request, send reply
char *request = s_recv(worker);
printf("Worker: %s\n", request);
free(request);
s_sendmore(worker, identity);
s_sendmore(worker, "");
s_send(worker, "OK");
free(identity);
}
zmq_close(worker);
zmq_ctx_destroy(context);
return NULL;
}
// .split main task
// This is the main task. It starts the clients and workers, and then
// routes requests between the two layers. Workers signal READY when
// they start; after that we treat them as ready when they reply with
// a response back to a client. The load-balancing data structure is
// just a queue of next available workers.
int main(void)
{
// Prepare our context and sockets
void *context = zmq_ctx_new();
void *frontend = zmq_socket(context, ZMQ_ROUTER);
void *backend = zmq_socket(context, ZMQ_ROUTER);
#if (defined (WIN32))
zmq_bind(frontend, "tcp://*:5672"); // frontend
zmq_bind(backend, "tcp://*:5673"); // backend
#else
zmq_bind(frontend, "ipc://frontend.ipc");
zmq_bind(backend, "ipc://backend.ipc");
#endif
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++) {
pthread_t client;
pthread_create(&client, NULL, client_task, (void *)(intptr_t)client_nbr);
}
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
pthread_t worker;
pthread_create(&worker, NULL, worker_task, (void *)(intptr_t)worker_nbr);
}
// .split main task body
// Here is the main loop for the least-recently-used queue. It has two
// sockets; a frontend for clients and a backend for workers. It polls
// the backend in all cases, and polls the frontend only when there are
// one or more workers ready. This is a neat way to use 0MQ's own queues
// to hold messages we're not ready to process yet. When we get a client
// request, we pop the next available worker and send the request to it,
// including the originating client identity. When a worker replies, we
// requeue that worker and forward the reply to the original client
// using the reply envelope.
// Queue of available workers
int available_workers = 0;
char *worker_queue[10];
while (1) {
zmq_pollitem_t items[] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
int rc = zmq_poll(items, available_workers ? 2 : 1, -1);
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (items[0].revents & ZMQ_POLLIN) {
// Queue worker identity for load-balancing
char *worker_id = s_recv(backend);
assert(available_workers < NBR_WORKERS);
worker_queue[available_workers++] = worker_id;
// Second frame is empty
char *empty = s_recv(backend);
assert(empty[0] == 0);
free(empty);
// Third frame is READY or else a client reply identity
char *client_id = s_recv(backend);
// If client reply, send rest back to frontend
if (strcmp(client_id, "READY") != 0) {
empty = s_recv(backend);
assert(empty[0] == 0);
free(empty);
char *reply = s_recv(backend);
s_sendmore(frontend, client_id);
s_sendmore(frontend, "");
s_send(frontend, reply);
free(reply);
if (--client_nbr == 0)
break; // Exit after N messages
}
free(client_id);
}
// .split handling a client request
// Here is how we handle a client request:
if (items[1].revents & ZMQ_POLLIN) {
// Now get next client request, route to last-used worker
// Client request is [identity][empty][request]
char *client_id = s_recv(frontend);
char *empty = s_recv(frontend);
assert(empty[0] == 0);
free(empty);
char *request = s_recv(frontend);
s_sendmore(backend, worker_queue[0]);
s_sendmore(backend, "");
s_sendmore(backend, client_id);
s_sendmore(backend, "");
s_send(backend, request);
free(client_id);
free(request);
// Dequeue and drop the next worker identity
free(worker_queue[0]);
DEQUEUE(worker_queue);
available_workers--;
}
}
zmq_close(frontend);
zmq_close(backend);
zmq_ctx_destroy(context);
return 0;
}lbbroker: Load balancing broker in C++
// Least-recently used (LRU) queue device
// Clients and workers are shown here in-process
//
#include "zhelpers.hpp"
#include <thread>
#include <queue>
// Basic request-reply client using REQ socket
//
void receive_empty_message(zmq::socket_t& sock)
{
std::string empty = s_recv(sock);
assert(empty.size() == 0);
}
void client_thread(int id) {
zmq::context_t context(1);
zmq::socket_t client(context, ZMQ_REQ);
#if (defined (WIN32))
s_set_id(client, id);
client.connect("tcp://localhost:5672"); // frontend
#else
s_set_id(client); // Set a printable identity
client.connect("ipc://frontend.ipc");
#endif
// Send request, get reply
s_send(client, std::string("HELLO"));
std::string reply = s_recv(client);
std::cout << "Client: " << reply << std::endl;
return;
}
// Worker using REQ socket to do LRU routing
//
void worker_thread(int id) {
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_REQ);
#if (defined (WIN32))
s_set_id(worker, id);
worker.connect("tcp://localhost:5673"); // backend
#else
s_set_id(worker);
worker.connect("ipc://backend.ipc");
#endif
// Tell backend we're ready for work
s_send(worker, std::string("READY"));
while (1) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
std::string address = s_recv(worker);
receive_empty_message(worker);
// Get request, send reply
std::string request = s_recv(worker);
std::cout << "Worker: " << request << std::endl;
s_sendmore(worker, address);
s_sendmore(worker, std::string(""));
s_send(worker, std::string("OK"));
}
return;
}
int main(int argc, char *argv[])
{
// Prepare our context and sockets
zmq::context_t context(1);
zmq::socket_t frontend(context, ZMQ_ROUTER);
zmq::socket_t backend(context, ZMQ_ROUTER);
#if (defined (WIN32))
frontend.bind("tcp://*:5672"); // frontend
backend.bind("tcp://*:5673"); // backend
#else
frontend.bind("ipc://frontend.ipc");
backend.bind("ipc://backend.ipc");
#endif
int client_nbr = 0;
for (; client_nbr < 10; client_nbr++) {
std::thread t(client_thread, client_nbr);
t.detach();
}
for (int worker_nbr = 0; worker_nbr < 3; worker_nbr++) {
std::thread t (worker_thread, worker_nbr);
t.detach();
}
// Logic of LRU loop
// - Poll backend always, frontend only if 1+ worker ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary
// - If client requests, pop next worker and send request to it
//
// A very simple queue structure with known max size
std::queue<std::string> worker_queue;
while (1) {
// Initialize poll set
zmq::pollitem_t items[] = {
// Always poll for worker activity on backend
{ backend, 0, ZMQ_POLLIN, 0 },
// Poll front-end only if we have available workers
{ frontend, 0, ZMQ_POLLIN, 0 }
};
if (worker_queue.size())
zmq::poll(&items[0], 2, -1);
else
zmq::poll(&items[0], 1, -1);
// Handle worker activity on backend
if (items[0].revents & ZMQ_POLLIN) {
// Queue worker address for LRU routing
worker_queue.push(s_recv(backend));
receive_empty_message(backend);
// Third frame is READY or else a client reply address
std::string client_addr = s_recv(backend);
// If client reply, send rest back to frontend
if (client_addr.compare("READY") != 0) {
receive_empty_message(backend);
std::string reply = s_recv(backend);
s_sendmore(frontend, client_addr);
s_sendmore(frontend, std::string(""));
s_send(frontend, reply);
if (--client_nbr == 0)
break;
}
}
if (items[1].revents & ZMQ_POLLIN) {
// Now get next client request, route to LRU worker
// Client request is [address][empty][request]
std::string client_addr = s_recv(frontend);
{
std::string empty = s_recv(frontend);
assert(empty.size() == 0);
}
std::string request = s_recv(frontend);
std::string worker_addr = worker_queue.front();//worker_queue [0];
worker_queue.pop();
s_sendmore(backend, worker_addr);
s_sendmore(backend, std::string(""));
s_sendmore(backend, client_addr);
s_sendmore(backend, std::string(""));
s_send(backend, request);
}
}
return 0;
}
lbbroker: Load balancing broker in C#
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
//
// Load-balancing broker in C#
//
// Clients and workers are shown here in-process.
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread may have its own
// context and conceptually acts as a separate process.
//
// Author: metadings
//
static int LBBroker_Clients = 10;
static int LBBroker_Workers = 3;
// Basic request-reply client using REQ socket
static void LBBroker_Client(ZContext context, int i)
{
// Create a socket
using (var client = new ZSocket(context, ZSocketType.REQ))
{
// Set a printable identity
client.IdentityString = "CLIENT" + i;
// Connect
client.Connect("inproc://frontend");
using (var request = new ZMessage())
{
request.Add(new ZFrame("Hello"));
// Send request
client.Send(request);
}
// Receive reply
using (ZMessage reply = client.ReceiveMessage())
{
Console.WriteLine("CLIENT{0}: {1}", i, reply[0].ReadString());
}
}
}
static void LBBroker_Worker(ZContext context, int i)
{
// This is the worker task, using a REQ socket to do load-balancing.
// Create socket
using (var worker = new ZSocket(context, ZSocketType.REQ))
{
// Set a printable identity
worker.IdentityString = "WORKER" + i;
// Connect
worker.Connect("inproc://backend");
// Tell broker we're ready for work
using (var ready = new ZFrame("READY"))
{
worker.Send(ready);
}
ZError error;
ZMessage request;
while (true)
{
// Get request
if (null == (request = worker.ReceiveMessage(out error)))
{
// We are using "out error",
// to NOT throw a ZException ETERM
if (error == ZError.ETERM)
break;
throw new ZException(error);
}
using (request)
{
string worker_id = request[0].ReadString();
string requestText = request[2].ReadString();
Console.WriteLine("WORKER{0}: {1}", i, requestText);
// Send reply
using (var commit = new ZMessage())
{
commit.Add(new ZFrame(worker_id));
commit.Add(new ZFrame());
commit.Add(new ZFrame("OK"));
worker.Send(commit);
}
}
}
}
}
public static void LBBroker(string[] args)
{
// This is the main task. It starts the clients and workers, and then
// routes requests between the two layers. Workers signal READY when
// they start; after that we treat them as ready when they reply with
// a response back to a client. The load-balancing data structure is
// just a queue of next available workers.
// Prepare our context and sockets
using (var context = new ZContext())
using (var frontend = new ZSocket(context, ZSocketType.ROUTER))
using (var backend = new ZSocket(context, ZSocketType.ROUTER))
{
// Bind
frontend.Bind("inproc://frontend");
// Bind
backend.Bind("inproc://backend");
int clients = 0;
for (; clients < LBBroker_Clients; ++clients)
{
int j = clients;
new Thread(() => LBBroker_Client(context, j)).Start();
}
for (int i = 0; i < LBBroker_Workers; ++i)
{
int j = i;
new Thread(() => LBBroker_Worker(context, j)).Start();
}
// Here is the main loop for the least-recently-used queue. It has two
// sockets; a frontend for clients and a backend for workers. It polls
// the backend in all cases, and polls the frontend only when there are
// one or more workers ready. This is a neat way to use 0MQ's own queues
// to hold messages we're not ready to process yet. When we get a client
// reply, we pop the next available worker and send the request to it,
// including the originating client identity. When a worker replies, we
// requeue that worker and forward the reply to the original client
// using the reply envelope.
// Queue of available workers
var worker_queue = new List<string>();
ZMessage incoming;
ZError error;
var poll = ZPollItem.CreateReceiver();
while (true)
{
if (backend.PollIn(poll, out incoming, out error, TimeSpan.FromMilliseconds(64)))
{
// Handle worker activity on backend
// incoming[0] is worker_id
string worker_id = incoming[0].ReadString();
// Queue worker identity for load-balancing
worker_queue.Add(worker_id);
// incoming[1] is empty
// incoming[2] is READY or else client_id
string client_id = incoming[2].ReadString();
if (client_id != "READY")
{
// incoming[3] is empty
// incoming[4] is reply
string reply = incoming[4].ReadString();
using (var outgoing = new ZMessage())
{
outgoing.Add(new ZFrame(client_id));
outgoing.Add(new ZFrame());
outgoing.Add(new ZFrame(reply));
// Send
frontend.Send(outgoing);
}
if (--clients == 0)
{
// break the while (true) when all clients said Hello
break;
}
}
}
if (worker_queue.Count > 0)
{
// Poll frontend only if we have available workers
if (frontend.PollIn(poll, out incoming, out error, TimeSpan.FromMilliseconds(64)))
{
// Here is how we handle a client request
// incoming[0] is client_id
string client_id = incoming[0].ReadString();
// incoming[1] is empty
// incoming[2] is request
string requestText = incoming[2].ReadString();
using (var outgoing = new ZMessage())
{
outgoing.Add(new ZFrame(worker_queue[0]));
outgoing.Add(new ZFrame());
outgoing.Add(new ZFrame(client_id));
outgoing.Add(new ZFrame());
outgoing.Add(new ZFrame(requestText));
// Send
backend.Send(outgoing);
}
// Dequeue the next worker identity
worker_queue.RemoveAt(0);
}
}
}
}
}
}
}
lbbroker: Load balancing broker in CL
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Least-recently used (LRU) queue device in Common Lisp
;;; Clients and workers are shown here in-process
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.lruqueue
(:nicknames #:lruqueue)
(:use #:cl #:zhelpers)
(:shadow #:message)
(:export #:main))
(in-package :zguide.lruqueue)
(defun message (fmt &rest args)
(let ((new-fmt (format nil "[~A] ~A"
(bt:thread-name (bt:current-thread)) fmt)))
(apply #'zhelpers:message new-fmt args)))
(defparameter *number-clients* 10)
(defparameter *number-workers* 3)
;; Basic request-reply client using REQ socket
(defun client-thread (context)
(zmq:with-socket (client context zmq:req)
(set-socket-id client) ; Makes tracing easier
(zmq:connect client "ipc://frontend.ipc")
;; Send request, get reply
(send-text client "HELLO")
(let ((reply (recv-text client)))
(message "Client: ~A~%" reply))))
;; Worker using REQ socket to do LRU routing
(defun worker-thread (context)
(zmq:with-socket (worker context zmq:req)
(set-socket-id worker) ; Makes tracing easier
(zmq:connect worker "ipc://backend.ipc")
;; Tell broker we're ready for work
(send-text worker "READY")
;; Ignore errors and exit when the context gets terminated
(ignore-errors
(loop
;; Read and save all frames until we get an empty frame
;; In this example there is only 1 but it could be more
(let ((address (recv-text worker)))
(recv-text worker) ; empty
;; Get request, send reply
(let ((request (recv-text worker)))
(message "Worker: ~A~%" request)
(send-more-text worker address)
(send-more-text worker "")
(send-text worker "OK")))))))
(defun main ()
;; Prepare our context and sockets
(zmq:with-context (context 1)
(zmq:with-socket (frontend context zmq:router)
(zmq:with-socket (backend context zmq:router)
(zmq:bind frontend "ipc://frontend.ipc")
(zmq:bind backend "ipc://backend.ipc")
(dotimes (i *number-clients*)
(bt:make-thread (lambda () (client-thread context))
:name (format nil "client-thread-~D" i)))
(dotimes (i *number-workers*)
(bt:make-thread (lambda () (worker-thread context))
:name (format nil "worker-thread-~D" i)))
;; Logic of LRU loop
;; - Poll backend always, frontend only if 1+ worker ready
;; - If worker replies, queue worker as ready and forward reply
;; to client if necessary
;; - If client requests, pop next worker and send request to it
;; Queue of available workers
(let ((number-clients *number-clients*)
(available-workers 0)
(worker-queue (make-queue)))
(loop
;; Initialize poll set
(zmq:with-polls
((items2 .
;; Always poll for worker activity on backend
((backend . zmq:pollin)
(frontend . zmq:pollin)))
(items1 .
;; Poll front-end only if we have available workers
((backend . zmq:pollin))))
(let ((revents
(if (zerop available-workers)
(zmq:poll items1)
(zmq:poll items2))))
;; Handle worker activity on backend
(when (= (first revents) zmq:pollin)
;; Queue worker address for LRU routing
(let ((worker-addr (recv-text backend)))
(assert (< available-workers *number-workers*))
(enqueue worker-queue worker-addr)
(incf available-workers))
;; Second frame is empty
(recv-text backend) ; empty
;; Third frame is READY or else a client reply address
(let ((client-addr (recv-text backend)))
(when (string/= client-addr "READY")
(recv-text backend) ; empty
(let ((reply (recv-text backend)))
(send-more-text frontend client-addr)
(send-more-text frontend "")
(send-text frontend reply))
(when (zerop (decf number-clients))
(return)))))
(when (and (cdr revents)
(= (second revents) zmq:pollin))
;; Now get next client request, route to LRU worker
;; Client request is [address][empty][request]
(let ((client-addr (recv-text frontend)))
(recv-text frontend) ; empty
(let ((request (recv-text frontend)))
(send-more-text backend (dequeue worker-queue))
(send-more-text backend "")
(send-more-text backend client-addr)
(send-more-text backend "")
(send-text backend request))
(decf available-workers)))))))))
(sleep 2))
(cleanup))
lbbroker: Load balancing broker in Delphi
program lbbroker;
//
// Load-balancing broker
// Clients and workers are shown here in-process
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
Windows
, SysUtils
, zmqapi
, zhelpers
;
const
NBR_CLIENTS = 10;
NBR_WORKERS = 3;
// Basic request-reply client using REQ socket
procedure client_task( args: Pointer );
var
context: TZMQContext;
client: TZMQSocket;
reply: Utf8String;
begin
context := TZMQContext.create;
client := context.Socket( stReq );
s_set_id( client ); // Set a printable identity
{$ifdef unix}
client.connect( 'ipc://frontend.ipc' );
{$else}
client.connect( 'tcp://127.0.0.1:5555' );
{$endif}
// Send request, get reply
client.send( 'HELLO' );
client.recv( reply );
zNote( Format('Client: %s',[reply]) );
client.Free;
context.Free;
end;
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
// This is the worker task, using a REQ socket to do load-balancing.
procedure worker_task( args: Pointer );
var
context: TZMQContext;
worker: TZMQSocket;
identity,
empty,
request: Utf8String;
begin
context := TZMQContext.create;
worker := context.Socket( stReq );
s_set_id( worker ); // Set a printable identity
{$ifdef unix}
worker.connect( 'ipc://backend.ipc' );
{$else}
worker.connect( 'tcp://127.0.0.1:5556' );
{$endif}
// Tell broker we're ready for work
worker.send( 'READY' );
while true do
begin
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
worker.recv( identity );
worker.recv( empty );
Assert( empty = '' );
// Get request, send reply
worker.recv( request );
zNote( Format('Worker: %s',[request]) );
worker.send([
identity,
'',
'OK'
]);
end;
worker.Free;
context.Free;
end;
// This is the main task. It starts the clients and workers, and then
// routes requests between the two layers. Workers signal READY when
// they start; after that we treat them as ready when they reply with
// a response back to a client. The load-balancing data structure is
// just a queue of next available workers.
var
context: TZMQContext;
frontend,
backend: TZMQSocket;
i,j,
client_nbr,
poll_c: Integer;
tid: Cardinal;
poller: TZMQPoller;
// Queue of available workers
available_workers: Integer = 0;
worker_queue: Array[0..9] of String;
worker_id,
empty,
client_id,
reply,
request: Utf8String;
begin
// Prepare our context and sockets
context := TZMQContext.create;
frontend := context.Socket( stRouter );
backend := context.Socket( stRouter );
{$ifdef unix}
frontend.bind( 'ipc://frontend.ipc' );
backend.bind( 'ipc://backend.ipc' );
{$else}
frontend.bind( 'tcp://127.0.0.1:5555' );
backend.bind( 'tcp://127.0.0.1:5556' );
{$endif}
for i := 0 to NBR_CLIENTS - 1 do
BeginThread( nil, 0, @client_task, nil, 0, tid );
client_nbr := NBR_CLIENTS;
for i := 0 to NBR_WORKERS - 1 do
BeginThread( nil, 0, @worker_task, nil, 0, tid );
// Here is the main loop for the least-recently-used queue. It has two
// sockets; a frontend for clients and a backend for workers. It polls
// the backend in all cases, and polls the frontend only when there are
// one or more workers ready. This is a neat way to use 0MQ's own queues
// to hold messages we're not ready to process yet. When we get a client
// reply, we pop the next available worker, and send the request to it,
// including the originating client identity. When a worker replies, we
// re-queue that worker, and we forward the reply to the original client,
// using the reply envelope.
poller := TZMQPoller.Create( true );
poller.register( backend, [pePollIn] );
poller.register( frontend, [pePollIn] );
while not context.Terminated and ( client_nbr > 0 ) do
begin
// Poll frontend only if we have available workers
if available_workers > 0 then
poll_c := -1
else
poll_c := 1;
poller.poll( -1, poll_c );
// Handle worker activity on backend
if pePollIn in poller.PollItem[0].revents then
begin
// Queue worker address for LRU routing
backend.recv( worker_id );
Assert( available_workers < NBR_WORKERS );
worker_queue[available_workers] := worker_id;
inc( available_workers );
// Second frame is empty
backend.recv( empty );
Assert( empty = '' );
// Third frame is READY or else a client reply address
backend.recv( client_id );
// If client reply, send rest back to frontend
if client_id <> 'READY' then
begin
backend.recv( empty );
Assert( empty = '' );
backend.recv( reply );
frontend.send([
client_id,
'',
reply
]);
dec( client_nbr );
end;
end;
// Here is how we handle a client request:
if ( poll_c = -1 ) and ( pePollIn in poller.PollItem[1].revents ) then
begin
// Now get next client request, route to last-used worker
// Client request is [address][empty][request]
frontend.recv( client_id );
frontend.recv( empty );
Assert( empty = '' );
frontend.recv( request );
backend.send([
worker_queue[0],
'',
client_id,
'',
request
]);
// Dequeue and drop the next worker address
dec( available_workers );
for j := 0 to available_workers - 1 do
worker_queue[j] := worker_queue[j+1];
end;
end;
poller.Free;
frontend.Free;
backend.Free;
context.Free;
end.
lbbroker: Load balancing broker in Erlang
#! /usr/bin/env escript
%%
%% Least-recently used (LRU) queue device
%% Clients and workers are shown here in-process
%%
%% While this example runs in a single process, that is just to make
%% it easier to start and stop the example. Each thread has its own
%% context and conceptually acts as a separate process.
%%
-define(NBR_CLIENTS, 10).
-define(NBR_WORKERS, 3).
%% Basic request-reply client using REQ socket
%% Since s_send and s_recv can't handle 0MQ binary identities we
%% set a printable text identity to allow routing.
%%
client_task() ->
{ok, Context} = erlzmq:context(),
{ok, Client} = erlzmq:socket(Context, req),
ok = erlzmq:setsockopt(Client, identity, pid_to_list(self())),
ok = erlzmq:connect(Client, "ipc://frontend.ipc"),
%% Send request, get reply
ok = erlzmq:send(Client, <<"HELLO">>),
{ok, Reply} = erlzmq:recv(Client),
io:format("Client: ~s~n", [Reply]),
ok = erlzmq:close(Client),
ok = erlzmq:term(Context).
%% Worker using REQ socket to do LRU routing
%% Since s_send and s_recv can't handle 0MQ binary identities we
%% set a printable text identity to allow routing.
%%
worker_task() ->
{ok, Context} = erlzmq:context(),
{ok, Worker} = erlzmq:socket(Context, req),
ok = erlzmq:setsockopt(Worker, identity, pid_to_list(self())),
ok = erlzmq:connect(Worker, "ipc://backend.ipc"),
%% Tell broker we're ready for work
ok = erlzmq:send(Worker, <<"READY">>),
worker_loop(Worker),
ok = erlzmq:close(Worker),
ok = erlzmq:term(Context).
worker_loop(Worker) ->
%% Read and save all frames until we get an empty frame
%% In this example there is only 1 but it could be more
{ok, Address} = erlzmq:recv(Worker),
{ok, <<>>} = erlzmq:recv(Worker),
%% Get request, send reply
{ok, Request} = erlzmq:recv(Worker),
io:format("Worker: ~s~n", [Request]),
ok = erlzmq:send(Worker, Address, [sndmore]),
ok = erlzmq:send(Worker, <<>>, [sndmore]),
ok = erlzmq:send(Worker, <<"OK">>),
worker_loop(Worker).
main(_) ->
%% Prepare our context and sockets
{ok, Context} = erlzmq:context(),
{ok, Frontend} = erlzmq:socket(Context, [router, {active, true}]),
{ok, Backend} = erlzmq:socket(Context, [router, {active, true}]),
ok = erlzmq:bind(Frontend, "ipc://frontend.ipc"),
ok = erlzmq:bind(Backend, "ipc://backend.ipc"),
start_clients(?NBR_CLIENTS),
start_workers(?NBR_WORKERS),
%% Logic of LRU loop
%% - Poll backend always, frontend only if 1+ worker ready
%% - If worker replies, queue worker as ready and forward reply
%% to client if necessary
%% - If client requests, pop next worker and send request to it
%% Queue of available workers
WorkerQueue = queue:new(),
lru_loop(?NBR_CLIENTS, WorkerQueue, Frontend, Backend),
ok = erlzmq:close(Frontend),
ok = erlzmq:close(Backend),
ok = erlzmq:term(Context).
start_clients(0) -> ok;
start_clients(N) when N > 0 ->
spawn(fun() -> client_task() end),
start_clients(N - 1).
start_workers(0) -> ok;
start_workers(N) when N > 0 ->
spawn(fun() -> worker_task() end),
start_workers(N - 1).
lru_loop(0, _, _, _) -> ok;
lru_loop(NumClients, WorkerQueue, Frontend, Backend) when NumClients > 0 ->
case queue:len(WorkerQueue) of
0 ->
receive
{zmq, Backend, Msg, _} ->
lru_loop_backend(
NumClients, WorkerQueue, Frontend, Backend, Msg)
end;
_ ->
receive
{zmq, Backend, Msg, _} ->
lru_loop_backend(
NumClients, WorkerQueue, Frontend, Backend, Msg);
{zmq, Frontend, Msg, _} ->
lru_loop_frontend(
NumClients, WorkerQueue, Frontend, Backend, Msg)
end
end.
lru_loop_backend(NumClients, WorkerQueue, Frontend, Backend, WorkerAddr) ->
%% Queue worker address for LRU routing
NewWorkerQueue = queue:in(WorkerAddr, WorkerQueue),
{ok, <<>>} = active_recv(Backend),
case active_recv(Backend) of
{ok, <<"READY">>} ->
lru_loop(NumClients, NewWorkerQueue, Frontend, Backend);
{ok, ClientAddr} ->
{ok, <<>>} = active_recv(Backend),
{ok, Reply} = active_recv(Backend),
erlzmq:send(Frontend, ClientAddr, [sndmore]),
erlzmq:send(Frontend, <<>>, [sndmore]),
erlzmq:send(Frontend, Reply),
lru_loop(NumClients - 1, NewWorkerQueue, Frontend, Backend)
end.
lru_loop_frontend(NumClients, WorkerQueue, Frontend, Backend, ClientAddr) ->
%% Get next client request, route to LRU worker
%% Client request is [address][empty][request]
{ok, <<>>} = active_recv(Frontend),
{ok, Request} = active_recv(Frontend),
{{value, WorkerAddr}, NewWorkerQueue} = queue:out(WorkerQueue),
ok = erlzmq:send(Backend, WorkerAddr, [sndmore]),
ok = erlzmq:send(Backend, <<>>, [sndmore]),
ok = erlzmq:send(Backend, ClientAddr, [sndmore]),
ok = erlzmq:send(Backend, <<>>, [sndmore]),
ok = erlzmq:send(Backend, Request),
lru_loop(NumClients, NewWorkerQueue, Frontend, Backend).
active_recv(Socket) ->
receive
{zmq, Socket, Msg, _Flags} -> {ok, Msg}
end.
lbbroker: Load balancing broker in Elixir
defmodule Lbbroker do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:26
"""
defmacrop erlconst_NBR_CLIENTS() do
quote do
10
end
end
defmacrop erlconst_NBR_WORKERS() do
quote do
3
end
end
def client_task() do
{:ok, context} = :erlzmq.context()
{:ok, client} = :erlzmq.socket(context, :req)
:ok = :erlzmq.setsockopt(client, :identity, :erlang.pid_to_list(self()))
:ok = :erlzmq.connect(client, 'ipc://frontend.ipc')
:ok = :erlzmq.send(client, "HELLO")
{:ok, reply} = :erlzmq.recv(client)
:io.format('Client: ~s~n', [reply])
:ok = :erlzmq.close(client)
:ok = :erlzmq.term(context)
end
def worker_task() do
{:ok, context} = :erlzmq.context()
{:ok, worker} = :erlzmq.socket(context, :req)
:ok = :erlzmq.setsockopt(worker, :identity, :erlang.pid_to_list(self()))
:ok = :erlzmq.connect(worker, 'ipc://backend.ipc')
:ok = :erlzmq.send(worker, "READY")
worker_loop(worker)
:ok = :erlzmq.close(worker)
:ok = :erlzmq.term(context)
end
def worker_loop(worker) do
{:ok, address} = :erlzmq.recv(worker)
{:ok, <<>>} = :erlzmq.recv(worker)
{:ok, request} = :erlzmq.recv(worker)
:io.format('Worker: ~s~n', [request])
:ok = :erlzmq.send(worker, address, [:sndmore])
:ok = :erlzmq.send(worker, <<>>, [:sndmore])
:ok = :erlzmq.send(worker, "OK")
worker_loop(worker)
end
def main() do
{:ok, context} = :erlzmq.context()
{:ok, frontend} = :erlzmq.socket(context, [:router, {:active, true}])
{:ok, backend} = :erlzmq.socket(context, [:router, {:active, true}])
:ok = :erlzmq.bind(frontend, 'ipc://frontend.ipc')
:ok = :erlzmq.bind(backend, 'ipc://backend.ipc')
start_clients(erlconst_NBR_CLIENTS())
start_workers(erlconst_NBR_WORKERS())
workerQueue = :queue.new()
lru_loop(erlconst_NBR_CLIENTS(), workerQueue, frontend, backend)
:ok = :erlzmq.close(frontend)
:ok = :erlzmq.close(backend)
:ok = :erlzmq.term(context)
end
def start_clients(0) do
:ok
end
def start_clients(n) when n > 0 do
:erlang.spawn(fn -> client_task() end)
start_clients(n - 1)
end
def start_workers(0) do
:ok
end
def start_workers(n) when n > 0 do
:erlang.spawn(fn -> worker_task() end)
start_workers(n - 1)
end
def lru_loop(0, _, _, _) do
:ok
end
def lru_loop(numClients, workerQueue, frontend, backend) when numClients > 0 do
case(:queue.len(workerQueue)) do
0 ->
receive do
{:zmq, ^backend, msg, _} ->
lru_loop_backend(numClients, workerQueue, frontend, backend, msg)
end
_ ->
receive do
{:zmq, ^backend, msg, _} ->
lru_loop_backend(numClients, workerQueue, frontend, backend, msg)
{:zmq, ^frontend, msg, _} ->
lru_loop_frontend(numClients, workerQueue, frontend, backend, msg)
end
end
end
def lru_loop_backend(numClients, workerQueue, frontend, backend, workerAddr) do
newWorkerQueue = :queue.in(workerAddr, workerQueue)
{:ok, <<>>} = active_recv(backend)
case(active_recv(backend)) do
{:ok, "READY"} ->
lru_loop(numClients, newWorkerQueue, frontend, backend)
{:ok, clientAddr} ->
{:ok, <<>>} = active_recv(backend)
{:ok, reply} = active_recv(backend)
:erlzmq.send(frontend, clientAddr, [:sndmore])
:erlzmq.send(frontend, <<>>, [:sndmore])
:erlzmq.send(frontend, reply)
lru_loop(numClients - 1, newWorkerQueue, frontend, backend)
end
end
def lru_loop_frontend(numClients, workerQueue, frontend, backend, clientAddr) do
{:ok, <<>>} = active_recv(frontend)
{:ok, request} = active_recv(frontend)
{{:value, workerAddr}, newWorkerQueue} = :queue.out(workerQueue)
:ok = :erlzmq.send(backend, workerAddr, [:sndmore])
:ok = :erlzmq.send(backend, <<>>, [:sndmore])
:ok = :erlzmq.send(backend, clientAddr, [:sndmore])
:ok = :erlzmq.send(backend, <<>>, [:sndmore])
:ok = :erlzmq.send(backend, request)
lru_loop(numClients, newWorkerQueue, frontend, backend)
end
def active_recv(socket) do
receive do
{:zmq, ^socket, msg, _flags} ->
{:ok, msg}
end
end
end
Lbbroker.main()
lbbroker: Load balancing broker in F#
(*
Least-recently used (LRU) queue device
Clients and workers are shown here in-process
While this example runs in a single process, that is just to make
it easier to start and stop the example. Each thread has its own
context and conceptually acts as a separate process.
*)
#r @"bin/fszmq.dll"
open fszmq
open fszmq.Context
open fszmq.Polling
open fszmq.Socket
#load "zhelpers.fs"
let [<Literal>] NBR_CLIENTS = 10
let [<Literal>] NBR_WORKERS = 3
open System.Collections.Generic
open System.Threading
// basic request-reply client using REQ socket
// since s_send and s_recv can't handle 0MQ binary identities
// we set a printable text identity to allow routing.
let client_task () =
use context = new Context(1)
use client = req context
s_setID client // set a printable identity
"tcp://localhost:5575" |> connect client
// send request, get reply
"HELLO"B |>> client
let reply = s_recv client
printfn' "Client: %s" reply
// worker using REQ socket to do LRU routing
// since s_send and s_recv can't handle 0MQ binary identities
// we set a printable text identity to allow routing.
let worker_task () =
use context = new Context(1)
use worker = req context
s_setID worker // set a printable identity
"tcp://localhost:5585" |> connect worker
// tell broker we're ready for work
"READY"B |>> worker
while true do
// read and save all frames until we get an empty frame
// in this example there is only 1 but it could be more
let address = recv worker
worker |> recv |> ignore // empty
// get request, send reply
let request = s_recv worker
printfn' "Worker: %s" request
worker <~| address <~| ""B <<| "OK"B
let main () =
// prepare our context and sockets
use context = new Context(1)
use backend = route context
use frontend = route context
"tcp://*:5585" |> bind backend
"tcp://*:5575" |> bind frontend
let client_nbr = ref 0
while !client_nbr < NBR_CLIENTS do
let client = Thread(ThreadStart(client_task))
client.Start()
incr client_nbr
for _ in 1 .. NBR_WORKERS do
let worker = Thread(ThreadStart(worker_task))
worker.Start()
(*
Logic of LRU loop
- Poll backend always, frontend only if 1+ worker ready
- If worker replies, queue worker as ready and forward reply
to client if necessary
- If client requests, pop next worker and send request to it
*)
// queue of available workers
let worker_queue = Queue<byte[]>()
// handle worker activity on backend
let backend_handler _ =
// queue worker address for LRU routing
let worker_addr = recv backend
if worker_queue.Count < NBR_WORKERS then
worker_addr |> worker_queue.Enqueue
// second frame is empty
backend |> recv |> ignore
// third frame is READY or else a client address
let client_addr = recv backend
// if worker reply, send rest back to frontend
if client_addr <> "READY"B then
backend |> recv |> ignore // empty
let reply = recv backend
[client_addr; ""B; reply] |> sendAll frontend
decr client_nbr
// now get next client request, route to LRU worker
let frontend_handler _ =
// client request is [address][empty][request]
let client_addr,request =
match frontend |> recvAll with
| [| address ;_; request |] -> address,request
| _ -> failwith "invalid client request"
let worker_addr = worker_queue.Dequeue()
[ worker_addr; ""B; client_addr; ""B; request ] |> sendAll backend
let backend_poll,frontend_poll =
Poll(ZMQ.POLLIN,backend ,backend_handler ),
Poll(ZMQ.POLLIN,frontend,frontend_handler)
while !client_nbr > 0 do
[ yield backend_poll
if worker_queue.Count > 0 then yield frontend_poll ]
|> poll -1L
|> ignore
EXIT_SUCCESS
main ()
lbbroker: Load balancing broker in Felix
lbbroker: Load balancing broker in Go
//
// Load balancing message broker
// Port of lbbroker.c
// Written by: Aleksandar Janicijevic
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"strings"
)
const (
NBR_CLIENTS int = 10
NBR_WORKERS int = 3
)
func randomString() string {
source := "abcdefghijklmnopqrstuvwxyz"
target := make([]string, 20)
for i := 0; i < 20; i++ {
target[i] = string(source[rand.Intn(len(source))])
}
return strings.Join(target, "")
}
func set_id(socket *zmq.Socket) {
socket.SetIdentity(randomString())
}
func client_task() {
context, _ := zmq.NewContext()
defer context.Close()
client, _ := context.NewSocket(zmq.REQ)
set_id(client)
client.Connect("ipc://frontend.ipc")
defer client.Close()
// Send request, get reply
client.Send([]byte("HELLO"), 0)
reply, _ := client.Recv(0)
fmt.Println("Client: ", string(reply))
}
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each goroutine has its own
// context and conceptually acts as a separate process.
// This is the worker task, using a REQ socket to do load-balancing.
// Since s_send and s_recv can't handle 0MQ binary identities we
// set a printable text identity to allow routing.
func worker_task() {
context, _ := zmq.NewContext()
defer context.Close()
worker, _ := context.NewSocket(zmq.REQ)
defer worker.Close()
set_id(worker)
worker.Connect("ipc://backend.ipc")
// Tell broker we're ready for work
worker.Send([]byte("READY"), 0)
for {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
messageParts, _ := worker.RecvMultipart(0)
identity := messageParts[0]
empty := messageParts[1]
request := messageParts[2]
fmt.Println("Worker: ", string(request))
worker.SendMultipart([][]byte{identity, empty, []byte("OK")}, 0)
}
}
// This is the main task. It starts the clients and workers, and then
// routes requests between the two layers. Workers signal READY when
// they start; after that we treat them as ready when they reply with
// a response back to a client. The load-balancing data structure is
// just a queue of next available workers.
func main() {
context, _ := zmq.NewContext()
defer context.Close()
frontend, _ := context.NewSocket(zmq.ROUTER)
defer frontend.Close()
frontend.Bind("ipc://frontend.ipc")
backend, _ := context.NewSocket(zmq.ROUTER)
defer backend.Close()
backend.Bind("ipc://backend.ipc")
var client_nbr int
var worker_nbr int
for client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++ {
go client_task()
}
for worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++ {
go worker_task()
}
// Here is the main loop for the least-recently-used queue. It has two
// sockets; a frontend for clients and a backend for workers. It polls
// the backend in all cases, and polls the frontend only when there are
// one or more workers ready. This is a neat way to use 0MQ's own queues
// to hold messages we're not ready to process yet. When we get a client
// reply, we pop the next available worker, and send the request to it,
// including the originating client identity. When a worker replies, we
// re-queue that worker, and we forward the reply to the original client,
// using the reply envelope.
// Queue of available workers
available_workers := 0
var worker_queue []string = make([]string, 0)
for {
items := zmq.PollItems{
zmq.PollItem{Socket: backend, Events: zmq.POLLIN},
zmq.PollItem{Socket: frontend, Events: zmq.POLLIN},
}
// Poll frontend only if we have available workers
var err error
if available_workers > 0 {
_, err = zmq.Poll(items, -1)
} else {
_, err = zmq.Poll(items[:1], -1)
}
if err != nil {
break // Interrupted
}
// Handle worker activity on backend
if items[0].REvents&zmq.POLLIN != 0 {
parts, _ := backend.RecvMultipart(0)
// Queue worker identity for load-balancing
worker_id := string(parts[0])
worker_queue = append(worker_queue, worker_id)
available_workers++
// Second frame is empty
empty := parts[1]
// Third frame is READY or else a client reply identity
client_id := parts[2]
// If client reply, send rest back to frontend
if string(client_id) != "READY" {
empty = parts[3]
reply := parts[4]
frontend.SendMultipart([][]byte{client_id, empty, reply}, 0)
client_nbr--
if client_nbr == 0 {
// Exit after N messages
break
}
}
}
// Here is how we handle a client request:
if items[1].REvents&zmq.POLLIN != 0 {
// Now get next client request, route to last-used worker
// Client request is [identity][empty][request]
parts, _ := frontend.RecvMultipart(0)
client_id := parts[0]
empty := parts[1]
request := parts[2]
backend.SendMultipart([][]byte{[]byte(worker_queue[0]), empty, client_id,
empty, request}, 0)
worker_queue = worker_queue[1:]
available_workers--
}
}
}
lbbroker: Load balancing broker in Haskell
{-# LANGUAGE OverloadedStrings #-}
-- |
-- Load balancing broker (p.96)
-- (Clients) [REQ] >-> (frontend) ROUTER (Proxy) ROUTER (backend) >-> [REQ] (Workers)
-- Clients and workers are shown here in-process
-- Compile with -threaded
module Main where
import System.ZMQ4.Monadic
import Control.Concurrent (threadDelay)
import Data.ByteString.Char8 (pack, unpack)
import Control.Monad (forM_, forever, when)
import Control.Applicative ((<$>))
import Text.Printf
nbrClients :: Int
nbrClients = 10
nbrWorkers :: Int
nbrWorkers = 3
workerThread :: Show a => a -> ZMQ z ()
workerThread i = do
sock <- socket Req
let ident = "Worker-" ++ show i
setIdentity (restrict $ pack ident) sock
connect sock "inproc://workers"
send sock [] "READY"
forever $ do
address <- receive sock
receive sock -- empty frame
receive sock >>= liftIO . printf "%s : %s\n" ident . unpack
send sock [SendMore] address
send sock [SendMore] ""
send sock [] "OK"
clientThread :: Show a => a -> ZMQ z ()
clientThread i = do
sock <- socket Req
let ident = "Client-" ++ show i
setIdentity (restrict $ pack ident) sock
connect sock "inproc://clients"
send sock [] "GO"
msg <- receive sock
liftIO $ printf "%s : %s\n" ident (unpack msg)
-- | Handle worker activity on backend
processBackend :: (Receiver r, Sender s) => [String] -> Int -> Socket z r -> Socket z s -> [Event] -> ZMQ z ([String], Int)
processBackend availableWorkers clientCount backend frontend evts
-- A msg can be received without bloking
| In `elem` evts = do
-- the msg comes from a worker: first frame is the worker id
workerId <- unpack <$> receive backend
empty <- unpack <$> receive backend
when (empty /= "") $ error "The second frame should be empty"
let workerQueue = availableWorkers ++ [workerId]
-- the third frame is the msg "READY" from a or a client reply id
msg <- unpack <$> receive backend
if msg == "READY"
then
return (workerQueue, clientCount)
else do
empty' <- unpack <$> receive backend
when (empty' /= "") $ error "The fourth frame should be an empty delimiter"
-- the fifth frame is the client message
reply <- receive backend
-- send back an acknowledge msg to the client (msg is the clientId)
send frontend [SendMore] (pack msg)
send frontend [SendMore] ""
send frontend [] reply
-- decrement clientCount to mark a job done
return (workerQueue, clientCount - 1)
| otherwise = return (availableWorkers, clientCount)
processFrontend :: (Receiver r, Sender s) => [String] -> Socket z r -> Socket z s -> [Event] -> ZMQ z [String]
processFrontend availableWorkers frontend backend evts
| In `elem` evts = do
clientId <- receive frontend
empty <- unpack <$> receive frontend
when (empty /= "") $ error "The second frame should be empty"
request <- receive frontend
send backend [SendMore] (pack $ head availableWorkers)
send backend [SendMore] ""
send backend [SendMore] clientId
send backend [SendMore] ""
send backend [] request
return (tail availableWorkers)
| otherwise = return availableWorkers
lruQueue :: Socket z Router -> Socket z Router -> ZMQ z ()
lruQueue backend frontend =
-- start with an empty list of available workers
loop [] nbrClients
where
loop availableWorkers clientCount = do
[evtsB, evtsF] <- poll (-1) [Sock backend [In] Nothing, Sock frontend [In] Nothing]
-- (always) poll for workers activity
(availableWorkers', clientCount') <- processBackend availableWorkers clientCount backend frontend evtsB
when (clientCount' > 0) $
-- Poll frontend only if we have available workers
if not (null availableWorkers')
then do
availableWorkers'' <- processFrontend availableWorkers' frontend backend evtsF
loop availableWorkers'' clientCount'
else loop availableWorkers' clientCount'
main :: IO ()
main =
runZMQ $ do
frontend <- socket Router
bind frontend "inproc://clients"
backend <- socket Router
bind backend "inproc://workers"
forM_ [1..nbrWorkers] $ \i -> async (workerThread i)
forM_ [1..nbrClients] $ \i -> async (clientThread i)
lruQueue backend frontend
liftIO $ threadDelay $ 1 * 1000 * 1000
lbbroker: Load balancing broker in Haxe
package ;
import haxe.io.Bytes;
import neko.Lib;
#if (neko || cpp)
import neko.vm.Thread;
#end
import haxe.Stack;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQContext;
import org.zeromq.ZMQException;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
/**
* Least - recently used (LRU) queue device
* Clients and workers are shown here in-process
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* NB: LRUQueue deliberately uses the lower-level ZMQxxx.hx classes.
* See LRUQueue2 for a cleaner implementation using the Zxxx.hx classes, modelled on czmq
*
* See: http://zguide.zeromq.org/page:all#A-Request-Reply-Message-Broker
*/
class LRUQueue
{
private static inline var NBR_CLIENTS = 10;
private static inline var NBR_WORKERS = 3;
/**
* Basic request-reply client using REQ socket.
*/
public static function clientTask() {
var context:ZContext = new ZContext();
var client:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(client);
client.connect("ipc:///tmp/frontend.ipc");
// Send request, receive reply
client.sendMsg(Bytes.ofString("HELLO"));
var reply = client.recvMsg();
Lib.println("Client "+id+": " + reply.toString());
context.destroy();
}
/**
* Worker using REQ socket to do LRU routing.
*/
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(worker);
worker.connect("ipc:///tmp/backend.ipc");
// Tell broker we're ready to do work
worker.sendMsg(Bytes.ofString("READY"));
while (true) {
// Read and save all frames until we get an empty frame
// In this example, there is only 1 but it could be more.
var address = worker.recvMsg();
var empty = worker.recvMsg();
// Get request, send reply
var request = worker.recvMsg();
Lib.println("Worker "+id+": " + request.toString());
worker.sendMsg(address, SNDMORE);
worker.sendMsg(empty, SNDMORE);
worker.sendMsg(Bytes.ofString("OK"));
}
context.destroy();
}
public static function main() {
Lib.println("** LRUQueue (see: http://zguide.zeromq.org/page:all#A-Request-Reply-Message-Broker)");
var client_nbr:Int = 0, worker_nbr:Int;
#if php
// PHP appears to require tasks to be forked before main process creates ZMQ context
for (client_nbr in 0 ... NBR_CLIENTS) {
forkClientTask();
}
for (worker_nbr in 0 ... NBR_WORKERS) {
forkWorkerTask();
}
#end
// Prepare our context and sockets
var context:ZContext = new ZContext();
var frontend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
var backend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
frontend.bind("ipc:///tmp/frontend.ipc");
backend.bind("ipc:///tmp/backend.ipc");
#if !php
// Non-PHP targets require threads to be created after main thread has set up ZMQ Context
for (client_nbr in 0 ... NBR_CLIENTS) {
Thread.create(clientTask);
}
for (worker_nbr in 0 ... NBR_WORKERS) {
Thread.create(workerTask);
}
#end
// Logic of LRU loop:
// - Poll backend always, frontend only if 1 or more worker si ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary.
// - If client requests, pop next worker and send request to it.
// Queue of available workers
var workerQueue:List<String> = new List<String>();
var poller:ZMQPoller = new ZMQPoller();
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
client_nbr = NBR_CLIENTS;
while (true) {
poller.unregisterSocket(frontend);
if (workerQueue.length > 0) {
// Only poll frontend if there is at least 1 worker ready to do work
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
}
try {
poller.poll( -1 );
} catch (e:ZMQException) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
// Handle worker activity on backend
if (poller.pollin(1)) {
// Queue worker address for LRU routing
var workerAddr = backend.recvMsg();
if (workerQueue.length < NBR_WORKERS)
workerQueue.add(workerAddr.toString());
// Second frame is empty
var empty = backend.recvMsg();
// Third frame is READY or else a client reply address
var clientAddr = backend.recvMsg();
// If client reply, send rest back to frontend
if (clientAddr.toString() != "READY") {
empty = backend.recvMsg();
var reply = backend.recvMsg();
frontend.sendMsg(clientAddr, SNDMORE);
frontend.sendMsg(Bytes.ofString(""), SNDMORE);
frontend.sendMsg(reply);
if (--client_nbr == 0)
break; // Exit after NBR_CLIENTS messages
}
}
if (poller.pollin(2)) {
// Now get next client request, route to LRU worker
// Client request is [address][empty][request]
var clientAddr = frontend.recvMsg();
var empty = frontend.recvMsg();
var request = frontend.recvMsg();
backend.sendMsg(Bytes.ofString(workerQueue.pop()), SNDMORE);
backend.sendMsg(Bytes.ofString(""), SNDMORE);
backend.sendMsg(clientAddr, SNDMORE);
backend.sendMsg(Bytes.ofString(""), SNDMORE);
backend.sendMsg(request);
}
}
context.destroy();
}
#if php
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue::workerTask();
exit();
}');
return;
}
private static inline function forkClientTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue::clientTask();
exit();
}');
return;
}
#end
}lbbroker: Load balancing broker in Java
package guide;
import java.util.LinkedList;
import java.util.Queue;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
public class lbbroker
{
private static final int NBR_CLIENTS = 10;
private static final int NBR_WORKERS = 3;
/**
* Basic request-reply client using REQ socket
*/
private static class ClientTask extends Thread
{
@Override
public void run()
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket client = context.createSocket(SocketType.REQ);
ZHelper.setId(client); // Set a printable identity
client.connect("ipc://frontend.ipc");
// Send request, get reply
client.send("HELLO");
String reply = client.recvStr();
System.out.println("Client: " + reply);
}
}
}
/**
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
* This is the worker task, using a REQ socket to do load-balancing.
*/
private static class WorkerTask extends Thread
{
@Override
public void run()
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket worker = context.createSocket(SocketType.REQ);
ZHelper.setId(worker); // Set a printable identity
worker.connect("ipc://backend.ipc");
// Tell backend we're ready for work
worker.send("READY");
while (!Thread.currentThread().isInterrupted()) {
String address = worker.recvStr();
String empty = worker.recvStr();
assert (empty.length() == 0);
// Get request, send reply
String request = worker.recvStr();
System.out.println("Worker: " + request);
worker.sendMore(address);
worker.sendMore("");
worker.send("OK");
}
}
}
}
/**
* This is the main task. It starts the clients and workers, and then
* routes requests between the two layers. Workers signal READY when
* they start; after that we treat them as ready when they reply with
* a response back to a client. The load-balancing data structure is
* just a queue of next available workers.
*/
public static void main(String[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket frontend = context.createSocket(SocketType.ROUTER);
Socket backend = context.createSocket(SocketType.ROUTER);
frontend.bind("ipc://frontend.ipc");
backend.bind("ipc://backend.ipc");
int clientNbr;
for (clientNbr = 0; clientNbr < NBR_CLIENTS; clientNbr++)
new ClientTask().start();
for (int workerNbr = 0; workerNbr < NBR_WORKERS; workerNbr++)
new WorkerTask().start();
// Here is the main loop for the least-recently-used queue. It has
// two sockets; a frontend for clients and a backend for workers.
// It polls the backend in all cases, and polls the frontend only
// when there are one or more workers ready. This is a neat way to
// use 0MQ's own queues to hold messages we're not ready to process
// yet. When we get a client reply, we pop the next available
// worker, and send the request to it, including the originating
// client identity. When a worker replies, we re-queue that worker,
// and we forward the reply to the original client, using the reply
// envelope.
// Queue of available workers
Queue<String> workerQueue = new LinkedList<String>();
while (!Thread.currentThread().isInterrupted()) {
// Initialize poll set
Poller items = context.createPoller(2);
// Always poll for worker activity on backend
items.register(backend, Poller.POLLIN);
// Poll front-end only if we have available workers
if (workerQueue.size() > 0)
items.register(frontend, Poller.POLLIN);
if (items.poll() < 0)
break; // Interrupted
// Handle worker activity on backend
if (items.pollin(0)) {
// Queue worker address for LRU routing
workerQueue.add(backend.recvStr());
// Second frame is empty
String empty = backend.recvStr();
assert (empty.length() == 0);
// Third frame is READY or else a client reply address
String clientAddr = backend.recvStr();
// If client reply, send rest back to frontend
if (!clientAddr.equals("READY")) {
empty = backend.recvStr();
assert (empty.length() == 0);
String reply = backend.recvStr();
frontend.sendMore(clientAddr);
frontend.sendMore("");
frontend.send(reply);
if (--clientNbr == 0)
break;
}
}
if (items.pollin(1)) {
// Now get next client request, route to LRU worker
// Client request is [address][empty][request]
String clientAddr = frontend.recvStr();
String empty = frontend.recvStr();
assert (empty.length() == 0);
String request = frontend.recvStr();
String workerAddr = workerQueue.poll();
backend.sendMore(workerAddr);
backend.sendMore("");
backend.sendMore(clientAddr);
backend.sendMore("");
backend.send(request);
}
}
}
}
}
lbbroker: Load balancing broker in Julia
lbbroker: Load balancing broker in Lua
--
-- Least-recently used (LRU) queue device
-- Clients and workers are shown here in-process
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zmq.poller"
require"zhelpers"
local tremove = table.remove
local NBR_CLIENTS = 10
local NBR_WORKERS = 3
local pre_code = [[
local identity, seed = ...
local zmq = require"zmq"
require"zhelpers"
math.randomseed(seed)
]]
-- Basic request-reply client using REQ socket
-- Since s_send and s_recv can't handle 0MQ binary identities we
-- set a printable text identity to allow routing.
--
local client_task = pre_code .. [[
local context = zmq.init(1)
local client = context:socket(zmq.REQ)
client:setopt(zmq.IDENTITY, identity) -- Set a printable identity
client:connect("ipc://frontend.ipc")
-- Send request, get reply
client:send("HELLO")
local reply = client:recv()
printf ("Client: %s\n", reply)
client:close()
context:term()
]]
-- Worker using REQ socket to do LRU routing
-- Since s_send and s_recv can't handle 0MQ binary identities we
-- set a printable text identity to allow routing.
--
local worker_task = pre_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.REQ)
worker:setopt(zmq.IDENTITY, identity) -- Set a printable identity
worker:connect("ipc://backend.ipc")
-- Tell broker we're ready for work
worker:send("READY")
while true do
-- Read and save all frames until we get an empty frame
-- In this example there is only 1 but it could be more
local address = worker:recv()
local empty = worker:recv()
assert (#empty == 0)
-- Get request, send reply
local request = worker:recv()
printf ("Worker: %s\n", request)
worker:send(address, zmq.SNDMORE)
worker:send("", zmq.SNDMORE)
worker:send("OK")
end
worker:close()
context:term()
]]
s_version_assert (2, 1)
-- Prepare our context and sockets
local context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.ROUTER)
frontend:bind("ipc://frontend.ipc")
backend:bind("ipc://backend.ipc")
local clients = {}
for n=1,NBR_CLIENTS do
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
local seed = os.time() + math.random()
clients[n] = zmq.threads.runstring(context, client_task, identity, seed)
clients[n]:start()
end
local workers = {}
for n=1,NBR_WORKERS do
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(context, worker_task, identity, seed)
workers[n]:start(true)
end
-- Logic of LRU loop
-- - Poll backend always, frontend only if 1+ worker ready
-- - If worker replies, queue worker as ready and forward reply
-- to client if necessary
-- - If client requests, pop next worker and send request to it
-- Queue of available workers
local worker_queue = {}
local is_accepting = false
local max_requests = #clients
local poller = zmq.poller(2)
local function frontend_cb()
-- Now get next client request, route to LRU worker
-- Client request is [address][empty][request]
local client_addr = frontend:recv()
local empty = frontend:recv()
assert (#empty == 0)
local request = frontend:recv()
-- Dequeue a worker from the queue.
local worker = tremove(worker_queue, 1)
backend:send(worker, zmq.SNDMORE)
backend:send("", zmq.SNDMORE)
backend:send(client_addr, zmq.SNDMORE)
backend:send("", zmq.SNDMORE)
backend:send(request)
if (#worker_queue == 0) then
-- stop accepting work from clients, when no workers are available.
poller:remove(frontend)
is_accepting = false
end
end
poller:add(backend, zmq.POLLIN, function()
-- Queue worker address for LRU routing
local worker_addr = backend:recv()
worker_queue[#worker_queue + 1] = worker_addr
-- start accepting client requests, if we are not already doing so.
if not is_accepting then
is_accepting = true
poller:add(frontend, zmq.POLLIN, frontend_cb)
end
-- Second frame is empty
local empty = backend:recv()
assert (#empty == 0)
-- Third frame is READY or else a client reply address
local client_addr = backend:recv()
-- If client reply, send rest back to frontend
if (client_addr ~= "READY") then
empty = backend:recv()
assert (#empty == 0)
local reply = backend:recv()
frontend:send(client_addr, zmq.SNDMORE)
frontend:send("", zmq.SNDMORE)
frontend:send(reply)
max_requests = max_requests - 1
if (max_requests == 0) then
poller:stop() -- Exit after N messages
end
end
end)
-- start poller's event loop
poller:start()
frontend:close()
backend:close()
context:term()
for n=1,NBR_CLIENTS do
assert(clients[n]:join())
end
-- workers are detached, we don't need to join with them.
lbbroker: Load balancing broker in Node.js
cluster = require('cluster')
, zmq = require('zeromq')
, backAddr = 'tcp://127.0.0.1:12345'
, frontAddr = 'tcp://127.0.0.1:12346'
, clients = 10
, workers = 3;
function clientProcess() {
var sock = zmq.socket('req');
sock.identity = "client" + process.pid
sock.connect(frontAddr)
sock.send("HELLO")
sock.on('message', function(data) {
console.log(sock.identity + " <- '" + data + "'");
sock.close()
cluster.worker.kill()
})
}
function workerProcess() {
var sock = zmq.socket('req');
sock.identity = "worker" + process.pid
sock.connect(backAddr)
sock.send('READY')
sock.on('message', function() {
var args = Array.apply(null, arguments)
console.log("'" + args + "' -> " + sock.identity);
sock.send([arguments[0], '', 'OK'])
})
}
function loadBalancer() {
var workers = [] // list of available worker id's
var backSvr = zmq.socket('router')
backSvr.identity = 'backSvr' + process.pid
backSvr.bind(backAddr, function(err) {
if (err) throw err;
backSvr.on('message', function() {
// Any worker that messages us is ready for more work
workers.push(arguments[0])
if (arguments[2] != 'READY') {
frontSvr.send([arguments[2], arguments[3], arguments[4]])
}
})
})
var frontSvr = zmq.socket('router');
frontSvr.identity = 'frontSvr' + process.pid;
frontSvr.bind(frontAddr, function(err) {
if (err) throw err;
frontSvr.on('message', function() {
var args = Array.apply(null, arguments)
// What if no workers are available? Delay till one is ready.
// This is because I don't know the equivalent of zmq_poll
// in Node.js zeromq, which is basically an event loop itself.
// I start an interval so that the message is eventually sent. \
// Maybe there is a better way.
var interval = setInterval(function() {
if (workers.length > 0) {
backSvr.send([workers.shift(), '', args[0], '', args[2]])
clearInterval(interval)
}
}, 10)
});
});
}
// Example is finished.
// Node process management noise below
if (cluster.isMaster) {
// create the workers and clients.
// Use env variables to dictate client or worker
for (var i = 0; i < workers; i++) cluster.fork({
"TYPE": 'worker'
});
for (var i = 0; i < clients; i++) cluster.fork({
"TYPE": 'client'
});
cluster.on('death', function(worker) {
console.log('worker ' + worker.pid + ' died');
});
var deadClients = 0;
cluster.on('disconnect', function(worker) {
deadClients++
if (deadClients === clients) {
console.log('finished')
process.exit(0)
}
});
loadBalancer()
} else {
if (process.env.TYPE === 'client') {
clientProcess()
} else {
workerProcess()
}
}
lbbroker: Load balancing broker in Objective-C
lbbroker: Load balancing broker in ooc
lbbroker: Load balancing broker in Perl
# Load-balancing broker
# Clients and workers are shown here in-process
use strict;
use warnings;
use v5.10;
use threads;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REQ ZMQ_ROUTER);
use AnyEvent;
use EV;
my $NBR_CLIENTS = 10;
my $NBR_WORKERS = 3;
# Basic request-reply client using REQ socket
sub client_task {
my ($client_nbr) = @_;
my $context = ZMQ::FFI->new();
my $client = $context->socket(ZMQ_REQ);
$client->set_identity("client-$client_nbr");
$client->connect('ipc://frontend.ipc');
# Send request, get reply
$client->send("HELLO");
my $reply = $client->recv();
say "Client: $reply";
}
# While this example runs in a single process, that is just to make
# it easier to start and stop the example. Each client_thread has its own
# context and conceptually acts as a separate process.
# This is the worker task, using a REQ socket to do load-balancing.
sub worker_task {
my ($worker_nbr) = @_;
my $context = ZMQ::FFI->new();
my $worker = $context->socket(ZMQ_REQ);
$worker->set_identity("worker-$worker_nbr");
$worker->connect('ipc://backend.ipc');
# Tell broker we're ready for work
$worker->send('READY');
while (1) {
# Read and save all frames, including empty frame and request
# This example has only one frame before the empty one,
# but there could be more
my ($identity, $empty, $request) = $worker->recv_multipart();
say "Worker: $request";
# Send reply
$worker->send_multipart([$identity, '', 'OK']);
}
}
# This is the main task. It starts the clients and workers, and then
# routes requests between the two layers. Workers signal READY when
# they start; after that we treat them as ready when they reply with
# a response back to a client. The load-balancing data structure is
# just a queue of next available workers.
# Prepare our context and sockets
my $context = ZMQ::FFI->new();
my $frontend = $context->socket(ZMQ_ROUTER);
my $backend = $context->socket(ZMQ_ROUTER);
$frontend->bind('ipc://frontend.ipc');
$backend->bind('ipc://backend.ipc');
my @client_thr;
my $client_nbr;
for (1..$NBR_CLIENTS) {
push @client_thr, threads->create('client_task', ++$client_nbr);
}
for my $worker_nbr (1..$NBR_WORKERS) {
threads->create('worker_task', $worker_nbr)->detach();
}
# Here is the main loop for the least-recently-used queue. It has two
# sockets; a frontend for clients and a backend for workers. It polls
# the backend in all cases, and polls the frontend only when there are
# one or more workers ready. This is a neat way to use 0MQ's own queues
# to hold messages we're not ready to process yet. When we get a client
# reply, we pop the next available worker and send the request to it,
# including the originating client identity. When a worker replies, we
# requeue that worker and forward the reply to the original client
# using the reply envelope.
# Queue of available workers
my @workers;
# Only poll for requests from backend until workers are available
my $worker_poller = AE::io $backend->get_fd, 0, \&poll_backend;
my $client_poller;
# Start the loop
EV::run;
# Give client threads time to flush final output after main loop finishes
$_->join() for @client_thr;
sub poll_backend {
while ($backend->has_pollin) {
# Handle worker activity on backend
my $worker_id = $backend->recv();
if (!@workers) {
# Poll for clients now that a worker is available
$client_poller = AE::io $frontend->get_fd, 0, \&poll_frontend;
}
# Queue worker identity for load-balancing
push @workers, $worker_id;
# Second frame is empty
$backend->recv();
# Third frame is READY or else a client reply identity
my $client_id = $backend->recv();
# If client reply, send rest back to frontend
if ($client_id ne 'READY') {
my ($empty, $reply) = $backend->recv_multipart();
$frontend->send_multipart([$client_id, '', $reply]);
--$client_nbr;
}
if ($client_nbr == 0) {
# End the loop after N messages
EV::break;
}
}
}
sub poll_frontend {
while ($frontend->has_pollin) {
if (!@workers) {
# Stop polling clients until more workers becomes available
undef $client_poller;
return;
}
# Here is how we handle a client request:
# Get next client request, route to last-used worker
my ($client_id, $empty, $request) = $frontend->recv_multipart();
my $worker_id = shift @workers;
$backend->send_multipart(
[$worker_id, '', $client_id, '', $request]
);
}
}
lbbroker: Load balancing broker in PHP
<?php
/*
* Least-recently used (LRU) queue device
* Clients and workers are shown here as IPC as PHP
* does not have threads.
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
define("NBR_CLIENTS", 10);
define("NBR_WORKERS", 3);
// Basic request-reply client using REQ socket
function client_thread()
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$client->connect("ipc://frontend.ipc");
// Send request, get reply
$client->send("HELLO");
$reply = $client->recv();
printf("Client: %s%s", $reply, PHP_EOL);
}
// Worker using REQ socket to do LRU routing
function worker_thread ()
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_REQ);
$worker->connect("ipc://backend.ipc");
// Tell broker we're ready for work
$worker->send("READY");
while (true) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
$address = $worker->recv();
// Additional logic to clean up workers.
if ($address == "END") {
exit();
}
$empty = $worker->recv();
assert(empty($empty));
// Get request, send reply
$request = $worker->recv();
printf ("Worker: %s%s", $request, PHP_EOL);
$worker->send($address, ZMQ::MODE_SNDMORE);
$worker->send("", ZMQ::MODE_SNDMORE);
$worker->send("OK");
}
}
function main()
{
for ($client_nbr = 0; $client_nbr < NBR_CLIENTS; $client_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
client_thread();
return;
}
}
for ($worker_nbr = 0; $worker_nbr < NBR_WORKERS; $worker_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
worker_thread();
return;
}
}
$context = new ZMQContext();
$frontend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$backend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$frontend->bind("ipc://frontend.ipc");
$backend->bind("ipc://backend.ipc");
// Logic of LRU loop
// - Poll backend always, frontend only if 1+ worker ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary
// - If client requests, pop next worker and send request to it
// Queue of available workers
$available_workers = 0;
$worker_queue = array();
$writeable = $readable = array();
while ($client_nbr > 0) {
$poll = new ZMQPoll();
// Poll front-end only if we have available workers
if ($available_workers > 0) {
$poll->add($frontend, ZMQ::POLL_IN);
}
// Always poll for worker activity on backend
$poll->add($backend, ZMQ::POLL_IN);
$events = $poll->poll($readable, $writeable);
if ($events > 0) {
foreach ($readable as $socket) {
// Handle worker activity on backend
if ($socket === $backend) {
// Queue worker address for LRU routing
$worker_addr = $socket->recv();
assert($available_workers < NBR_WORKERS);
$available_workers++;
array_push($worker_queue, $worker_addr);
// Second frame is empty
$empty = $socket->recv();
assert(empty($empty));
// Third frame is READY or else a client reply address
$client_addr = $socket->recv();
if ($client_addr != "READY") {
$empty = $socket->recv();
assert(empty($empty));
$reply = $socket->recv();
$frontend->send($client_addr, ZMQ::MODE_SNDMORE);
$frontend->send("", ZMQ::MODE_SNDMORE);
$frontend->send($reply);
// exit after all messages relayed
$client_nbr--;
}
} elseif ($socket === $frontend) {
// Now get next client request, route to LRU worker
// Client request is [address][empty][request]
$client_addr = $socket->recv();
$empty = $socket->recv();
assert(empty($empty));
$request = $socket->recv();
$backend->send(array_shift($worker_queue), ZMQ::MODE_SNDMORE);
$backend->send("", ZMQ::MODE_SNDMORE);
$backend->send($client_addr, ZMQ::MODE_SNDMORE);
$backend->send("", ZMQ::MODE_SNDMORE);
$backend->send($request);
$available_workers--;
}
}
}
}
// Clean up our worker processes
foreach ($worker_queue as $worker) {
$backend->send($worker, ZMQ::MODE_SNDMORE);
$backend->send("", ZMQ::MODE_SNDMORE);
$backend->send('END');
}
sleep(1);
}
main();
lbbroker: Load balancing broker in Python
"""
Load-balancing broker
Clients and workers are shown here in-process.
Author: Brandon Carpenter (hashstat) <brandon(dot)carpenter(at)pnnl(dot)gov>
"""
from __future__ import print_function
import multiprocessing
import zmq
NBR_CLIENTS = 10
NBR_WORKERS = 3
def client_task(ident):
"""Basic request-reply client using REQ socket."""
socket = zmq.Context().socket(zmq.REQ)
socket.identity = u"Client-{}".format(ident).encode("ascii")
socket.connect("ipc://frontend.ipc")
# Send request, get reply
socket.send(b"HELLO")
reply = socket.recv()
print("{}: {}".format(socket.identity.decode("ascii"),
reply.decode("ascii")))
def worker_task(ident):
"""Worker task, using a REQ socket to do load-balancing."""
socket = zmq.Context().socket(zmq.REQ)
socket.identity = u"Worker-{}".format(ident).encode("ascii")
socket.connect("ipc://backend.ipc")
# Tell broker we're ready for work
socket.send(b"READY")
while True:
address, empty, request = socket.recv_multipart()
print("{}: {}".format(socket.identity.decode("ascii"),
request.decode("ascii")))
socket.send_multipart([address, b"", b"OK"])
def main():
"""Load balancer main loop."""
# Prepare context and sockets
context = zmq.Context.instance()
frontend = context.socket(zmq.ROUTER)
frontend.bind("ipc://frontend.ipc")
backend = context.socket(zmq.ROUTER)
backend.bind("ipc://backend.ipc")
# Start background tasks
def start(task, *args):
process = multiprocessing.Process(target=task, args=args)
process.daemon = True
process.start()
for i in range(NBR_CLIENTS):
start(client_task, i)
for i in range(NBR_WORKERS):
start(worker_task, i)
# Initialize main loop state
count = NBR_CLIENTS
backend_ready = False
workers = []
poller = zmq.Poller()
# Only poll for requests from backend until workers are available
poller.register(backend, zmq.POLLIN)
while True:
sockets = dict(poller.poll())
if backend in sockets:
# Handle worker activity on the backend
request = backend.recv_multipart()
worker, empty, client = request[:3]
workers.append(worker)
if workers and not backend_ready:
# Poll for clients now that a worker is available and backend was not ready
poller.register(frontend, zmq.POLLIN)
backend_ready = True
if client != b"READY" and len(request) > 3:
# If client reply, send rest back to frontend
empty, reply = request[3:]
frontend.send_multipart([client, b"", reply])
count -= 1
if not count:
break
if frontend in sockets:
# Get next client request, route to last-used worker
client, empty, request = frontend.recv_multipart()
worker = workers.pop(0)
backend.send_multipart([worker, b"", client, b"", request])
if not workers:
# Don't poll clients if no workers are available and set backend_ready flag to false
poller.unregister(frontend)
backend_ready = False
# Clean up
backend.close()
frontend.close()
context.term()
if __name__ == "__main__":
main()
lbbroker: Load balancing broker in Q
lbbroker: Load balancing broker in Racket
lbbroker: Load balancing broker in Ruby
lbbroker: Load balancing broker in Rust
lbbroker: Load balancing broker in Scala
lbbroker: Load balancing broker in Tcl
lbbroker: Load balancing broker in OCaml
The difficult part of this program is (a) the envelopes that each socket reads and writes, and (b) the load balancing algorithm. We’ll take these in turn, starting with the message envelope formats.
Let’s walk through a full request-reply chain from client to worker and back. In this code we set the identity of client and worker sockets to make it easier to trace the message frames. In reality, we’d allow the ROUTER sockets to invent identities for connections. Let’s assume the client’s identity is “CLIENT” and the worker’s identity is “WORKER”. The client application sends a single frame containing “Hello”.

Because the REQ socket adds its empty delimiter frame and the ROUTER socket adds its connection identity, the proxy reads off the frontend ROUTER socket the client address, empty delimiter frame, and the data part.

The broker sends this to the worker, prefixed by the address of the chosen worker, plus an additional empty part to keep the REQ at the other end happy.
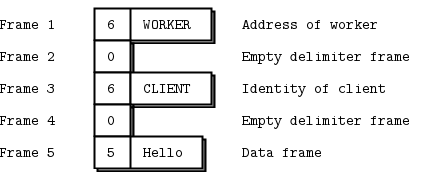
This complex envelope stack gets chewed up first by the backend ROUTER socket, which removes the first frame. Then the REQ socket in the worker removes the empty part, and provides the rest to the worker application.

The worker has to save the envelope (which is all the parts up to and including the empty message frame) and then it can do what’s needed with the data part. Note that a REP socket would do this automatically, but we’re using the REQ-ROUTER pattern so that we can get proper load balancing.
On the return path, the messages are the same as when they come in, i.e., the backend socket gives the broker a message in five parts, and the broker sends the frontend socket a message in three parts, and the client gets a message in one part.
Now let’s look at the load balancing algorithm. It requires that both clients and workers use REQ sockets, and that workers correctly store and replay the envelope on messages they get. The algorithm is:
-
Create a pollset that always polls the backend, and polls the frontend only if there are one or more workers available.
-
Poll for activity with infinite timeout.
-
If there is activity on the backend, we either have a “ready” message or a reply for a client. In either case, we store the worker address (the first part) on our worker queue, and if the rest is a client reply, we send it back to that client via the frontend.
-
If there is activity on the frontend, we take the client request, pop the next worker (which is the last used), and send the request to the backend. This means sending the worker address, empty part, and then the three parts of the client request.
You should now see that you can reuse and extend the load balancing algorithm with variations based on the information the worker provides in its initial “ready” message. For example, workers might start up and do a performance self test, then tell the broker how fast they are. The broker can then choose the fastest available worker rather than the oldest.
A High-Level API for ZeroMQ #
We’re going to push request-reply onto the stack and open a different area, which is the ZeroMQ API itself. There’s a reason for this detour: as we write more complex examples, the low-level ZeroMQ API starts to look increasingly clumsy. Look at the core of the worker thread from our load balancing broker:
while (true) {
// Get one address frame and empty delimiter
char *address = s_recv (worker);
char *empty = s_recv (worker);
assert (*empty == 0);
free (empty);
// Get request, send reply
char *request = s_recv (worker);
printf ("Worker: %s\n", request);
free (request);
s_sendmore (worker, address);
s_sendmore (worker, "");
s_send (worker, "OK");
free (address);
}
That code isn’t even reusable because it can only handle one reply address in the envelope, and it already does some wrapping around the ZeroMQ API. If we used the libzmq simple message API this is what we’d have to write:
while (true) {
// Get one address frame and empty delimiter
char address [255];
int address_size = zmq_recv (worker, address, 255, 0);
if (address_size == -1)
break;
char empty [1];
int empty_size = zmq_recv (worker, empty, 1, 0);
assert (empty_size <= 0);
if (empty_size == -1)
break;
// Get request, send reply
char request [256];
int request_size = zmq_recv (worker, request, 255, 0);
if (request_size == -1)
return NULL;
request [request_size] = 0;
printf ("Worker: %s\n", request);
zmq_send (worker, address, address_size, ZMQ_SNDMORE);
zmq_send (worker, empty, 0, ZMQ_SNDMORE);
zmq_send (worker, "OK", 2, 0);
}
And when code is too long to write quickly, it’s also too long to understand. Up until now, I’ve stuck to the native API because, as ZeroMQ users, we need to know that intimately. But when it gets in our way, we have to treat it as a problem to solve.
We can’t of course just change the ZeroMQ API, which is a documented public contract on which thousands of people agree and depend. Instead, we construct a higher-level API on top based on our experience so far, and most specifically, our experience from writing more complex request-reply patterns.
What we want is an API that lets us receive and send an entire message in one shot, including the reply envelope with any number of reply addresses. One that lets us do what we want with the absolute least lines of code.
Making a good message API is fairly difficult. We have a problem of terminology: ZeroMQ uses “message” to describe both multipart messages, and individual message frames. We have a problem of expectations: sometimes it’s natural to see message content as printable string data, sometimes as binary blobs. And we have technical challenges, especially if we want to avoid copying data around too much.
The challenge of making a good API affects all languages, though my specific use case is C. Whatever language you use, think about how you could contribute to your language binding to make it as good (or better) than the C binding I’m going to describe.
Features of a Higher-Level API #
My solution is to use three fairly natural and obvious concepts: string (already the basis for our s_send and s_recv) helpers, frame (a message frame), and message (a list of one or more frames). Here is the worker code, rewritten onto an API using these concepts:
while (true) {
zmsg_t *msg = zmsg_recv (worker);
zframe_reset (zmsg_last (msg), "OK", 2);
zmsg_send (&msg, worker);
}
Cutting the amount of code we need to read and write complex messages is great: the results are easy to read and understand. Let’s continue this process for other aspects of working with ZeroMQ. Here’s a wish list of things I’d like in a higher-level API, based on my experience with ZeroMQ so far:
-
Automatic handling of sockets. I find it cumbersome to have to close sockets manually, and to have to explicitly define the linger timeout in some (but not all) cases. It’d be great to have a way to close sockets automatically when I close the context.
-
Portable thread management. Every nontrivial ZeroMQ application uses threads, but POSIX threads aren’t portable. So a decent high-level API should hide this under a portable layer.
-
Piping from parent to child threads. It’s a recurrent problem: how to signal between parent and child threads. Our API should provide a ZeroMQ message pipe (using PAIR sockets and inproc automatically).
-
Portable clocks. Even getting the time to a millisecond resolution, or sleeping for some milliseconds, is not portable. Realistic ZeroMQ applications need portable clocks, so our API should provide them.
-
A reactor to replace zmq_poll(). The poll loop is simple, but clumsy. Writing a lot of these, we end up doing the same work over and over: calculating timers, and calling code when sockets are ready. A simple reactor with socket readers and timers would save a lot of repeated work.
-
Proper handling of Ctrl-C. We already saw how to catch an interrupt. It would be useful if this happened in all applications.
The CZMQ High-Level API #
Turning this wish list into reality for the C language gives us CZMQ, a ZeroMQ language binding for C. This high-level binding, in fact, developed out of earlier versions of the examples. It combines nicer semantics for working with ZeroMQ with some portability layers, and (importantly for C, but less for other languages) containers like hashes and lists. CZMQ also uses an elegant object model that leads to frankly lovely code.
Here is the load balancing broker rewritten to use a higher-level API (CZMQ for the C case):
lbbroker2: Load balancing broker using high-level API in Ada
lbbroker2: Load balancing broker using high-level API in Basic
lbbroker2: Load balancing broker using high-level API in C
// Load-balancing broker
// Demonstrates use of the CZMQ API
#include "czmq.h"
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
#define WORKER_READY "READY" // Signals worker is ready
// Basic request-reply client using REQ socket
//
static void
client_task(zsock_t *pipe, void *args)
{
// Signal caller zactor has started
zsock_signal(pipe, 0);
zsock_t *client = zsock_new(ZMQ_REQ);
#if (defined (WIN32))
zsock_connect(client, "tcp://localhost:5672"); // frontend
#else
zsock_connect(client, "ipc://frontend.ipc");
#endif
// Send request, get reply
zstr_send(client, "HELLO");
char *reply = zstr_recv(client);
if (reply) {
printf("Client: %s\n", reply);
free(reply);
}
zsock_destroy(&client);
}
// Worker using REQ socket to do load-balancing
//
static void
worker_task(zsock_t *pipe, void *args)
{
// Signal caller zactor has started
zsock_signal(pipe, 0);
zsock_t *worker = zsock_new(ZMQ_REQ);
#if (defined (WIN32))
zsock_connect(worker, "tcp://localhost:5673"); // backend
#else
zsock_connect(worker, "ipc://backend.ipc");
#endif
// Tell broker we're ready for work
zframe_t *frame = zframe_new(WORKER_READY, strlen(WORKER_READY));
zframe_send(&frame, worker, 0);
// Process messages as they arrive
zpoller_t *poll = zpoller_new(pipe, worker, NULL);
while (true) {
zsock_t *ready = zpoller_wait(poll, -1);
if (ready == pipe)
break; // Done
assert(ready == worker);
zmsg_t *msg = zmsg_recv(worker);
if (!msg)
break; // Interrupted
zframe_print(zmsg_last(msg), "Worker: ");
zframe_reset(zmsg_last(msg), "OK", 2);
zmsg_send(&msg, worker);
}
if (frame)
zframe_destroy(&frame);
zsock_destroy(&worker);
zpoller_destroy(&poll);
// Signal done
zsock_signal(pipe, 0);
}
// .split main task
// Now we come to the main task. This has the identical functionality to
// the previous {{lbbroker}} broker example, but uses CZMQ to start child
// threads, to hold the list of workers, and to read and send messages:
int main(void)
{
zsock_t *frontend = zsock_new(ZMQ_ROUTER);
zsock_t *backend = zsock_new(ZMQ_ROUTER);
// IPC doesn't yet work on MS Windows.
#if (defined (WIN32))
zsock_bind(frontend, "tcp://*:5672");
zsock_bind(backend, "tcp://*:5673");
#else
zsock_bind(frontend, "ipc://frontend.ipc");
zsock_bind(backend, "ipc://backend.ipc");
#endif
int actor_nbr = 0;
zactor_t *actors[NBR_CLIENTS + NBR_WORKERS];
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
actors[actor_nbr++] = zactor_new(client_task, NULL);
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
actors[actor_nbr++] = zactor_new(worker_task, NULL);
// Queue of available workers
zlist_t *workers = zlist_new();
// .split main load-balancer loop
// Here is the main loop for the load balancer. It works the same way
// as the previous example, but is a lot shorter because CZMQ gives
// us an API that does more with fewer calls:
zpoller_t *poll1 = zpoller_new(backend, NULL);
zpoller_t *poll2 = zpoller_new(backend, frontend, NULL);
while (true) {
// Poll frontend only if we have available workers
zpoller_t *poll = zlist_size(workers) ? poll2 : poll1;
zsock_t *ready = zpoller_wait(poll, -1);
if (ready == NULL)
break; // Interrupted
// Handle worker activity on backend
if (ready == backend) {
// Use worker identity for load-balancing
zmsg_t *msg = zmsg_recv(backend);
if (!msg)
break; // Interrupted
#if 0
// zmsg_unwrap is DEPRECATED as over-engineered, poor style
zframe_t *identity = zmsg_unwrap(msg);
#else
zframe_t *identity = zmsg_pop(msg);
zframe_t *delimiter = zmsg_pop(msg);
zframe_destroy(&delimiter);
#endif
zlist_append(workers, identity);
// Forward message to client if it's not a READY
zframe_t *frame = zmsg_first(msg);
if (memcmp(zframe_data(frame), WORKER_READY, strlen(WORKER_READY)) == 0) {
zmsg_destroy(&msg);
} else {
zmsg_send(&msg, frontend);
if (--client_nbr == 0)
break; // Exit after N messages
}
}
else if (ready == frontend) {
// Get client request, route to first available worker
zmsg_t *msg = zmsg_recv(frontend);
if (msg) {
#if 0
// zmsg_wrap is DEPRECATED as unsafe
zmsg_wrap(msg, (zframe_t *)zlist_pop(workers));
#else
zmsg_pushmem(msg, NULL, 0); // delimiter
zmsg_push(msg, (zframe_t *)zlist_pop(workers));
#endif
zmsg_send(&msg, backend);
}
}
}
// When we're done, clean up properly
while (zlist_size(workers)) {
zframe_t *frame = (zframe_t *)zlist_pop(workers);
zframe_destroy(&frame);
}
zlist_destroy(&workers);
for (actor_nbr = 0; actor_nbr < NBR_CLIENTS + NBR_WORKERS; actor_nbr++) {
zactor_destroy(&actors[actor_nbr]);
}
zpoller_destroy(&poll1);
zpoller_destroy(&poll2);
zsock_destroy(&frontend);
zsock_destroy(&backend);
return 0;
}
lbbroker2: Load balancing broker using high-level API in C++
// 2015-05-12T11:55+08:00
// Load-balancing broker
// Demonstrates use of the CZMQ API
#include "czmq.h"
#include <iostream>
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
#define WORKER_READY "READY" // Signals worker is ready
// Basic request-reply client using REQ socket
//
static void *
client_task(void *args)
{
zctx_t *ctx = zctx_new();
void *client = zsocket_new(ctx, ZMQ_REQ);
#if (defined (WIN32))
zsocket_connect(client, "tcp://localhost:5672"); // frontend
#else
zsocket_connect(client, "ipc://frontend.ipc");
#endif
// Send request, get reply
zstr_send(client, "HELLO");
char *reply = zstr_recv(client);
if (reply) {
std::cout << "Client: " << reply << std::endl;
free(reply);
}
zctx_destroy(&ctx);
return NULL;
}
// Worker using REQ socket to do load-balancing
//
static void *
worker_task(void *args)
{
zctx_t *ctx = zctx_new();
void *worker = zsocket_new(ctx, ZMQ_REQ);
#if (defined (WIN32))
zsocket_connect(worker, "tcp://localhost:5673"); // backend
#else
zsocket_connect(worker, "ipc://backend.ipc");
#endif
// Tell broker we're ready for work
zframe_t *frame = zframe_new(WORKER_READY, strlen(WORKER_READY));
zframe_send(&frame, worker, 0);
// Process messages as they arrive
while (1) {
zmsg_t *msg = zmsg_recv(worker);
if (!msg)
break; // Interrupted
zframe_print(zmsg_last(msg), "Worker: ");
zframe_reset(zmsg_last(msg), "OK", 2);
zmsg_send(&msg, worker);
}
zctx_destroy(&ctx);
return NULL;
}
// .split main task
// Now we come to the main task. This has the identical functionality to
// the previous {{lbbroker}} broker example, but uses CZMQ to start child
// threads, to hold the list of workers, and to read and send messages:
int main(void)
{
zctx_t *ctx = zctx_new();
void *frontend = zsocket_new(ctx, ZMQ_ROUTER);
void *backend = zsocket_new(ctx, ZMQ_ROUTER);
// IPC doesn't yet work on MS Windows.
#if (defined (WIN32))
zsocket_bind(frontend, "tcp://*:5672");
zsocket_bind(backend, "tcp://*:5673");
#else
zsocket_bind(frontend, "ipc://frontend.ipc");
zsocket_bind(backend, "ipc://backend.ipc");
#endif
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
zthread_new(client_task, NULL);
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
zthread_new(worker_task, NULL);
// Queue of available workers
zlist_t *workers = zlist_new();
// .split main load-balancer loop
// Here is the main loop for the load balancer. It works the same way
// as the previous example, but is a lot shorter because CZMQ gives
// us an API that does more with fewer calls:
while (1) {
zmq_pollitem_t items[] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
int rc = zmq_poll(items, zlist_size(workers) ? 2 : 1, -1);
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (items[0].revents & ZMQ_POLLIN) {
// Use worker identity for load-balancing
zmsg_t *msg = zmsg_recv(backend);
if (!msg)
break; // Interrupted
#if 0
// zmsg_unwrap is DEPRECATED as over-engineered, poor style
zframe_t *identity = zmsg_unwrap(msg);
#else
zframe_t *identity = zmsg_pop(msg);
zframe_t *delimiter = zmsg_pop(msg);
zframe_destroy(&delimiter);
#endif
zlist_append(workers, identity);
// Forward message to client if it's not a READY
zframe_t *frame = zmsg_first(msg);
if (memcmp(zframe_data(frame), WORKER_READY, strlen(WORKER_READY)) == 0) {
zmsg_destroy(&msg);
} else {
zmsg_send(&msg, frontend);
if (--client_nbr == 0)
break; // Exit after N messages
}
}
if (items[1].revents & ZMQ_POLLIN) {
// Get client request, route to first available worker
zmsg_t *msg = zmsg_recv(frontend);
if (msg) {
#if 0
// zmsg_wrap is DEPRECATED as unsafe
zmsg_wrap(msg, (zframe_t *)zlist_pop(workers));
#else
zmsg_pushmem(msg, NULL, 0); // delimiter
zmsg_push(msg, (zframe_t *)zlist_pop(workers));
#endif
zmsg_send(&msg, backend);
}
}
}
// When we're done, clean up properly
while (zlist_size(workers)) {
zframe_t *frame = (zframe_t *)zlist_pop(workers);
zframe_destroy(&frame);
}
zlist_destroy(&workers);
zctx_destroy(&ctx);
return 0;
}
lbbroker2: Load balancing broker using high-level API in C#
lbbroker2: Load balancing broker using high-level API in CL
lbbroker2: Load balancing broker using high-level API in Delphi
program lbbroker2;
//
// Load-balancing broker
// Clients and workers are shown here in-process
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
Windows
, SysUtils
, zmqapi
, zhelpers
;
const
NBR_CLIENTS = 10;
NBR_WORKERS = 3;
WORKER_READY = '\001'; // Signals worker is ready
// Basic request-reply client using REQ socket
procedure client_task( args: Pointer );
var
context: TZMQContext;
client: TZMQSocket;
reply: Utf8String;
begin
context := TZMQContext.create;
client := context.Socket( stReq );
{$ifdef unix}
client.connect( 'ipc://frontend.ipc' );
{$else}
client.connect( 'tcp://127.0.0.1:5555' );
{$endif}
// Send request, get reply
while not context.Terminated do
try
client.send( 'HELLO' );
client.recv( reply );
zNote( Format('Client: %s',[reply]) );
sleep( 1000 );
except
context.Terminate;
end;
context.Free;
end;
// Worker using REQ socket to do load-balancing
procedure worker_task( args: Pointer );
var
context: TZMQContext;
worker: TZMQSocket;
msg: TZMQMsg;
begin
context := TZMQContext.create;
worker := context.Socket( stReq );
{$ifdef unix}
worker.connect( 'ipc://backend.ipc' );
{$else}
worker.connect( 'tcp://127.0.0.1:5556' );
{$endif}
msg := nil;
// Tell broker we're ready for work
worker.send( WORKER_READY );
// Process messages as they arrive
while not context.Terminated do
try
worker.recv( msg );
msg.last.asUtf8String := 'OK';
worker.send( msg );
except
context.Terminate;
end;
context.Free;
end;
var
context: TZMQContext;
frontend,
backend: TZMQSocket;
i,
poll_c: Integer;
tid: Cardinal;
poller: TZMQPoller;
workers,
msg: TZMQMsg;
begin
context := TZMQContext.create;
frontend := context.Socket( stRouter );
backend := context.Socket( stRouter );
{$ifdef unix}
frontend.bind( 'ipc://frontend.ipc' );
backend.bind( 'ipc://backend.ipc' );
{$else}
frontend.bind( 'tcp://127.0.0.1:5555' );
backend.bind( 'tcp://127.0.0.1:5556' );
{$endif}
for i := 0 to NBR_CLIENTS - 1 do
BeginThread( nil, 0, @client_task, nil, 0, tid );
for i := 0 to NBR_WORKERS - 1 do
BeginThread( nil, 0, @worker_task, nil, 0, tid );
// Queue of available workers
workers := TZMQMsg.Create;
msg := nil;
poller := TZMQPoller.Create( true );
poller.register( backend, [pePollIn] );
poller.register( frontend, [pePollIn] );
while not context.Terminated do
try
// Poll frontend only if we have available workers
if workers.size > 0 then
poll_c := -1
else
poll_c := 1;
poller.poll( -1, poll_c );
// Handle worker activity on backend
if pePollIn in poller.PollItem[0].revents then
begin
// Use worker identity for load-balancing
backend.recv( msg );
workers.add( msg.unwrap );
// Forward message to client if it's not a READY
if msg.first.asUtf8String <> WORKER_READY then
frontend.send( msg )
else
FreeAndNil( msg );
end;
if ( poll_c = -1 ) and ( pePollIn in poller.PollItem[1].revents ) then
begin
// Get client request, route to first available worker
frontend.recv( msg );
msg.wrap( workers.pop );
backend.send( msg );
end;
except
context.Terminate;
end;
poller.Free;
frontend.Free;
backend.Free;
context.Free;
end.
lbbroker2: Load balancing broker using high-level API in Erlang
lbbroker2: Load balancing broker using high-level API in Elixir
lbbroker2: Load balancing broker using high-level API in F#
lbbroker2: Load balancing broker using high-level API in Felix
lbbroker2: Load balancing broker using high-level API in Go
lbbroker2: Load balancing broker using high-level API in Haskell
lbbroker2: Load balancing broker using high-level API in Haxe
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZFrame;
import org.zeromq.ZMsg;
#if (neko || cpp)
import neko.vm.Thread;
#end
import haxe.Stack;
import org.zeromq.ZContext;
import org.zeromq.ZSocket;
using org.zeromq.ZSocket;
import org.zeromq.ZMQ;
import org.zeromq.ZMQException;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
/**
* Least - recently used (LRU) queue device
* Clients and workers are shown here in-process
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: http://zguide.zeromq.org/page:all#A-High-Level-API-for-MQ
*/
class LRUQueue2
{
private static inline var NBR_CLIENTS = 10;
private static inline var NBR_WORKERS = 3;
// Signals workers are ready
private static inline var LRU_READY:String = String.fromCharCode(1);
private static inline var WORKER_DONE:Bytes = Bytes.ofString("OK");
/**
* Basic request-reply client using REQ socket.
*/
public static function clientTask() {
var context:ZContext = new ZContext();
var client:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(client);
client.connectEndpoint("ipc", "/tmp/frontend.ipc");
while (true) {
ZFrame.newStringFrame("HELLO").send(client);
var reply = ZFrame.recvFrame(client);
if (reply == null) {
break;
}
Lib.println("Client "+id+": " + reply.toString());
Sys.sleep(1);
}
context.destroy();
}
/**
* Worker using REQ socket to do LRU routing.
*/
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(worker);
worker.connectEndpoint("ipc", "/tmp/backend.ipc");
// Tell broker we're ready to do work
ZFrame.newStringFrame(LRU_READY).send(worker);
// Process messages as they arrive
while (true) {
var msg:ZMsg = ZMsg.recvMsg(worker);
if (msg == null) {
break;
}
// Lib.println("Worker " + id + " received " + msg.toString());
msg.last().reset(WORKER_DONE);
msg.send(worker);
}
context.destroy();
}
public static function main() {
Lib.println("** LRUQueue2 (see: http://zguide.zeromq.org/page:all#A-High-Level-API-for-MQ)");
#if php
// PHP appears to require tasks to be forked before main process creates ZMQ context
for (client_nbr in 0 ... NBR_CLIENTS) {
forkClientTask();
}
for (worker_nbr in 0 ... NBR_WORKERS) {
forkWorkerTask();
}
#end
// Prepare our context and sockets
var context:ZContext = new ZContext();
var frontend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
var backend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
frontend.bindEndpoint("ipc", "/tmp/frontend.ipc");
backend.bindEndpoint("ipc", "/tmp/backend.ipc");
#if !php
// Non-PHP targets require threads to be created after main thread has set up ZMQ Context
for (client_nbr in 0 ... NBR_CLIENTS) {
Thread.create(clientTask);
}
for (worker_nbr in 0 ... NBR_WORKERS) {
Thread.create(workerTask);
}
#end
// Logic of LRU loop:
// - Poll backend always, frontend only if 1 or more worker si ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary.
// - If client requests, pop next worker and send request to it.
// Queue of available workers
var workerQueue:List<ZFrame> = new List<ZFrame>();
var poller:ZMQPoller = new ZMQPoller();
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
while (true) {
poller.unregisterSocket(frontend);
if (workerQueue.length > 0) {
// Only poll frontend if there is at least 1 worker ready to do work
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
}
try {
poller.poll( -1 );
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
break; // Interrupted or terminated
}
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
// Handle worker activity on backend
if (poller.pollin(1)) {
// Use worker address for LRU routing
var msg:ZMsg = ZMsg.recvMsg(backend);
if (msg == null) {
break;
}
var workerAddr = msg.unwrap();
if (workerQueue.length < NBR_WORKERS)
workerQueue.add(workerAddr);
// Third frame is READY or else a client reply address
var frame = msg.first();
// If client reply, send rest back to frontend
if (frame.toString() == LRU_READY) {
msg.destroy();
} else {
msg.send(frontend);
}
}
if (poller.pollin(2)) {
// get client request, route to first available worker
var msg = ZMsg.recvMsg(frontend);
if (msg != null) {
msg.wrap(workerQueue.pop());
msg.send(backend);
}
}
}
// When we're done, clean up properly
for (f in workerQueue) {
f.destroy();
}
context.destroy();
}
#if php
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue2::workerTask();
exit();
}');
return;
}
private static inline function forkClientTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue2::clientTask();
exit();
}');
return;
}
#end
}lbbroker2: Load balancing broker using high-level API in Java
package guide;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.Queue;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
/**
* Load-balancing broker
* Demonstrates use of the high level API
*/
public class lbbroker2
{
private static final int NBR_CLIENTS = 10;
private static final int NBR_WORKERS = 3;
private static byte[] WORKER_READY = { '\001' }; // Signals worker is ready
/**
* Basic request-reply client using REQ socket
*/
private static class ClientTask implements ZThread.IDetachedRunnable
{
@Override
public void run(Object[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket client = context.createSocket(SocketType.REQ);
ZHelper.setId(client); // Set a printable identity
client.connect("ipc://frontend.ipc");
// Send request, get reply
client.send("HELLO");
String reply = client.recvStr();
System.out.println("Client: " + reply);
}
}
}
/**
* Worker using REQ socket to do load-balancing
*/
private static class WorkerTask implements ZThread.IDetachedRunnable
{
@Override
public void run(Object[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket worker = context.createSocket(SocketType.REQ);
ZHelper.setId(worker); // Set a printable identity
worker.connect("ipc://backend.ipc");
// Tell backend we're ready for work
ZFrame frame = new ZFrame(WORKER_READY);
frame.send(worker, 0);
while (true) {
ZMsg msg = ZMsg.recvMsg(worker);
if (msg == null)
break;
msg.getLast().reset("OK");
msg.send(worker);
}
}
}
}
/**
* This is the main task. This has the identical functionality to
* the previous lbbroker example but uses higher level classes to start child threads
* to hold the list of workers, and to read and send messages:
*/
public static void main(String[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket frontend = context.createSocket(SocketType.ROUTER);
Socket backend = context.createSocket(SocketType.ROUTER);
frontend.bind("ipc://frontend.ipc");
backend.bind("ipc://backend.ipc");
int clientNbr;
for (clientNbr = 0; clientNbr < NBR_CLIENTS; clientNbr++)
ZThread.start(new ClientTask());
for (int workerNbr = 0; workerNbr < NBR_WORKERS; workerNbr++)
ZThread.start(new WorkerTask());
// Queue of available workers
Queue<ZFrame> workerQueue = new LinkedList<ZFrame>();
// Here is the main loop for the load-balancer. It works the same
// way as the previous example, but is a lot shorter because ZMsg
// class gives us an API that does more with fewer calls:
while (!Thread.currentThread().isInterrupted()) {
// Initialize poll set
Poller items = context.createPoller(2);
// Always poll for worker activity on backend
items.register(backend, Poller.POLLIN);
// Poll front-end only if we have available workers
if (workerQueue.size() > 0)
items.register(frontend, Poller.POLLIN);
if (items.poll() < 0)
break; // Interrupted
// Handle worker activity on backend
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
ZFrame identity = msg.unwrap();
// Queue worker address for LRU routing
workerQueue.add(identity);
// Forward message to client if it's not a READY
ZFrame frame = msg.getFirst();
if (Arrays.equals(frame.getData(), WORKER_READY))
msg.destroy();
else msg.send(frontend);
}
if (items.pollin(1)) {
// Get client request, route to first available worker
ZMsg msg = ZMsg.recvMsg(frontend);
if (msg != null) {
msg.wrap(workerQueue.poll());
msg.send(backend);
}
}
}
}
}
}
lbbroker2: Load balancing broker using high-level API in Julia
lbbroker2: Load balancing broker using high-level API in Lua
--
-- Least-recently used (LRU) queue device
-- Demonstrates use of the msg class
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zmq.poller"
require"zmsg"
local tremove = table.remove
local NBR_CLIENTS = 10
local NBR_WORKERS = 3
local pre_code = [[
local identity, seed = ...
local zmq = require"zmq"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(seed)
]]
-- Basic request-reply client using REQ socket
--
local client_task = pre_code .. [[
local context = zmq.init(1)
local client = context:socket(zmq.REQ)
client:setopt(zmq.IDENTITY, identity) -- Set a printable identity
client:connect("ipc://frontend.ipc")
-- Send request, get reply
client:send("HELLO")
local reply = client:recv()
printf ("Client: %s\n", reply)
client:close()
context:term()
]]
-- Worker using REQ socket to do LRU routing
--
local worker_task = pre_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.REQ)
worker:setopt(zmq.IDENTITY, identity) -- Set a printable identity
worker:connect("ipc://backend.ipc")
-- Tell broker we're ready for work
worker:send("READY")
while true do
local msg = zmsg.recv (worker)
printf ("Worker: %s\n", msg:body())
msg:body_set("OK")
msg:send(worker)
end
worker:close()
context:term()
]]
s_version_assert (2, 1)
-- Prepare our context and sockets
local context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.ROUTER)
frontend:bind("ipc://frontend.ipc")
backend:bind("ipc://backend.ipc")
local clients = {}
for n=1,NBR_CLIENTS do
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
local seed = os.time() + math.random()
clients[n] = zmq.threads.runstring(context, client_task, identity, seed)
clients[n]:start()
end
local workers = {}
for n=1,NBR_WORKERS do
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(context, worker_task, identity, seed)
workers[n]:start(true)
end
-- Logic of LRU loop
-- - Poll backend always, frontend only if 1+ worker ready
-- - If worker replies, queue worker as ready and forward reply
-- to client if necessary
-- - If client requests, pop next worker and send request to it
-- Queue of available workers
local worker_queue = {}
local is_accepting = false
local max_requests = #clients
local poller = zmq.poller(2)
local function frontend_cb()
-- Now get next client request, route to next worker
local msg = zmsg.recv (frontend)
-- Dequeue a worker from the queue.
local worker = tremove(worker_queue, 1)
msg:wrap(worker, "")
msg:send(backend)
if (#worker_queue == 0) then
-- stop accepting work from clients, when no workers are available.
poller:remove(frontend)
is_accepting = false
end
end
poller:add(backend, zmq.POLLIN, function()
local msg = zmsg.recv(backend)
-- Use worker address for LRU routing
worker_queue[#worker_queue + 1] = msg:unwrap()
-- start accepting client requests, if we are not already doing so.
if not is_accepting then
is_accepting = true
poller:add(frontend, zmq.POLLIN, frontend_cb)
end
-- Forward message to client if it's not a READY
if (msg:address() ~= "READY") then
msg:send(frontend)
max_requests = max_requests - 1
if (max_requests == 0) then
poller:stop() -- Exit after N messages
end
end
end)
-- start poller's event loop
poller:start()
frontend:close()
backend:close()
context:term()
for n=1,NBR_CLIENTS do
assert(clients[n]:join())
end
-- workers are detached, we don't need to join with them.
lbbroker2: Load balancing broker using high-level API in Node.js
lbbroker2: Load balancing broker using high-level API in Objective-C
lbbroker2: Load balancing broker using high-level API in ooc
lbbroker2: Load balancing broker using high-level API in Perl
lbbroker2: Load balancing broker using high-level API in PHP
<?php
/*
* Least-recently used (LRU) queue device
* Demonstrates use of the zmsg class
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("NBR_CLIENTS", 10);
define("NBR_WORKERS", 3);
// Basic request-reply client using REQ socket
function client_thread()
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$client->connect("ipc://frontend.ipc");
// Send request, get reply
$client->send("HELLO");
$reply = $client->recv();
printf("Client: %s%s", $reply, PHP_EOL);
}
// Worker using REQ socket to do LRU routing
function worker_thread ()
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_REQ);
$worker->connect("ipc://backend.ipc");
// Tell broker we're ready for work
$worker->send("READY");
while (true) {
$zmsg = new Zmsg($worker);
$zmsg->recv();
// Additional logic to clean up workers.
if ($zmsg->address() == "END") {
exit();
}
printf ("Worker: %s\n", $zmsg->body());
$zmsg->body_set("OK");
$zmsg->send();
}
}
function main()
{
for ($client_nbr = 0; $client_nbr < NBR_CLIENTS; $client_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
client_thread();
return;
}
}
for ($worker_nbr = 0; $worker_nbr < NBR_WORKERS; $worker_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
worker_thread();
return;
}
}
$context = new ZMQContext();
$frontend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$backend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$frontend->bind("ipc://frontend.ipc");
$backend->bind("ipc://backend.ipc");
// Logic of LRU loop
// - Poll backend always, frontend only if 1+ worker ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary
// - If client requests, pop next worker and send request to it
// Queue of available workers
$available_workers = 0;
$worker_queue = array();
$writeable = $readable = array();
while ($client_nbr > 0) {
$poll = new ZMQPoll();
// Poll front-end only if we have available workers
if ($available_workers > 0) {
$poll->add($frontend, ZMQ::POLL_IN);
}
// Always poll for worker activity on backend
$poll->add($backend, ZMQ::POLL_IN);
$events = $poll->poll($readable, $writeable);
if ($events > 0) {
foreach ($readable as $socket) {
// Handle worker activity on backend
if ($socket === $backend) {
// Queue worker address for LRU routing
$zmsg = new Zmsg($socket);
$zmsg->recv();
assert($available_workers < NBR_WORKERS);
$available_workers++;
array_push($worker_queue, $zmsg->unwrap());
if ($zmsg->body() != "READY") {
$zmsg->set_socket($frontend)->send();
// exit after all messages relayed
$client_nbr--;
}
} elseif ($socket === $frontend) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
$zmsg->wrap(array_shift($worker_queue), "");
$zmsg->set_socket($backend)->send();
$available_workers--;
}
}
}
}
// Clean up our worker processes
foreach ($worker_queue as $worker) {
$zmsg = new Zmsg($backend);
$zmsg->body_set('END')->wrap($worker, "")->send();
}
sleep(1);
}
main();
lbbroker2: Load balancing broker using high-level API in Python
"""
Least-recently used (LRU) queue device
Clients and workers are shown here in-process
Author: Guillaume Aubert (gaubert) <guillaume(dot)aubert(at)gmail(dot)com>
"""
from __future__ import print_function
import threading
import time
import zmq
NBR_CLIENTS = 10
NBR_WORKERS = 3
def worker_thread(worker_url, context, i):
""" Worker using REQ socket to do LRU routing """
socket = context.socket(zmq.REQ)
# set worker identity
socket.identity = (u"Worker-%d" % (i)).encode('ascii')
socket.connect(worker_url)
# Tell the broker we are ready for work
socket.send(b"READY")
try:
while True:
address, empty, request = socket.recv_multipart()
print("%s: %s\n" % (socket.identity.decode('ascii'),
request.decode('ascii')), end='')
socket.send_multipart([address, b'', b'OK'])
except zmq.ContextTerminated:
# context terminated so quit silently
return
def client_thread(client_url, context, i):
""" Basic request-reply client using REQ socket """
socket = context.socket(zmq.REQ)
# Set client identity. Makes tracing easier
socket.identity = (u"Client-%d" % (i)).encode('ascii')
socket.connect(client_url)
# Send request, get reply
socket.send(b"HELLO")
reply = socket.recv()
print("%s: %s\n" % (socket.identity.decode('ascii'),
reply.decode('ascii')), end='')
def main():
""" main method """
url_worker = "inproc://workers"
url_client = "inproc://clients"
client_nbr = NBR_CLIENTS
# Prepare our context and sockets
context = zmq.Context()
frontend = context.socket(zmq.ROUTER)
frontend.bind(url_client)
backend = context.socket(zmq.ROUTER)
backend.bind(url_worker)
# create workers and clients threads
for i in range(NBR_WORKERS):
thread = threading.Thread(target=worker_thread,
args=(url_worker, context, i, ))
thread.start()
for i in range(NBR_CLIENTS):
thread_c = threading.Thread(target=client_thread,
args=(url_client, context, i, ))
thread_c.start()
# Logic of LRU loop
# - Poll backend always, frontend only if 1+ worker ready
# - If worker replies, queue worker as ready and forward reply
# to client if necessary
# - If client requests, pop next worker and send request to it
# Queue of available workers
available_workers = 0
workers_list = []
# init poller
poller = zmq.Poller()
# Always poll for worker activity on backend
poller.register(backend, zmq.POLLIN)
# Poll front-end only if we have available workers
poller.register(frontend, zmq.POLLIN)
while True:
socks = dict(poller.poll())
# Handle worker activity on backend
if (backend in socks and socks[backend] == zmq.POLLIN):
# Queue worker address for LRU routing
message = backend.recv_multipart()
assert available_workers < NBR_WORKERS
worker_addr = message[0]
# add worker back to the list of workers
available_workers += 1
workers_list.append(worker_addr)
# Second frame is empty
empty = message[1]
assert empty == b""
# Third frame is READY or else a client reply address
client_addr = message[2]
# If client reply, send rest back to frontend
if client_addr != b'READY':
# Following frame is empty
empty = message[3]
assert empty == b""
reply = message[4]
frontend.send_multipart([client_addr, b"", reply])
client_nbr -= 1
if client_nbr == 0:
break # Exit after N messages
# poll on frontend only if workers are available
if available_workers > 0:
if (frontend in socks and socks[frontend] == zmq.POLLIN):
# Now get next client request, route to LRU worker
# Client request is [address][empty][request]
[client_addr, empty, request] = frontend.recv_multipart()
assert empty == b""
# Dequeue and drop the next worker address
available_workers += -1
worker_id = workers_list.pop()
backend.send_multipart([worker_id, b"",
client_addr, b"", request])
#out of infinite loop: do some housekeeping
time.sleep(1)
frontend.close()
backend.close()
context.term()
if __name__ == "__main__":
main()
lbbroker2: Load balancing broker using high-level API in Q
lbbroker2: Load balancing broker using high-level API in Racket
lbbroker2: Load balancing broker using high-level API in Ruby
lbbroker2: Load balancing broker using high-level API in Rust
lbbroker2: Load balancing broker using high-level API in Scala
lbbroker2: Load balancing broker using high-level API in Tcl
lbbroker2: Load balancing broker using high-level API in OCaml
One thing CZMQ provides is clean interrupt handling. This means that Ctrl-C will cause any blocking ZeroMQ call to exit with a return code -1 and errno set to EINTR. The high-level recv methods will return NULL in such cases. So, you can cleanly exit a loop like this:
while (true) {
zstr_send (client, "Hello");
char *reply = zstr_recv (client);
if (!reply)
break; // Interrupted
printf ("Client: %s\n", reply);
free (reply);
sleep (1);
}
Or, if you’re calling zmq_poll(), test on the return code:
if (zmq_poll (items, 2, 1000 * 1000) == -1)
break; // Interrupted
The previous example still uses zmq_poll(). So how about reactors? The CZMQ zloop reactor is simple but functional. It lets you:
- Set a reader on any socket, i.e., code that is called whenever the socket has input.
- Cancel a reader on a socket.
- Set a timer that goes off once or multiple times at specific intervals.
- Cancel a timer.
zloop of course uses zmq_poll() internally. It rebuilds its poll set each time you add or remove readers, and it calculates the poll timeout to match the next timer. Then, it calls the reader and timer handlers for each socket and timer that need attention.
When we use a reactor pattern, our code turns inside out. The main logic looks like this:
zloop_t *reactor = zloop_new ();
zloop_reader (reactor, self->backend, s_handle_backend, self);
zloop_start (reactor);
zloop_destroy (&reactor);
The actual handling of messages sits inside dedicated functions or methods. You may not like the style–it’s a matter of taste. What it does help with is mixing timers and socket activity. In the rest of this text, we’ll use zmq_poll() in simpler cases, and zloop in more complex examples.
Here is the load balancing broker rewritten once again, this time to use zloop:
lbbroker3: Load balancing broker using zloop in Ada
lbbroker3: Load balancing broker using zloop in Basic
lbbroker3: Load balancing broker using zloop in C
// Load-balancing broker
// Demonstrates use of the CZMQ API and reactor style
//
// The client and worker tasks are similar to the previous example.
// .skip
#include "czmq.h"
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
#define WORKER_READY "\001" // Signals worker is ready
// Basic request-reply client using REQ socket
//
static void
client_task (zsock_t *pipe, void *args)
{
// Signal ready
zsock_signal(pipe, 0);
zsock_t *client = zsock_new_req ("ipc://frontend.ipc");
zpoller_t *poller = zpoller_new (pipe, client, NULL);
zpoller_set_nonstop(poller,true);
// Send request, get reply
while (true) {
zstr_send (client, "HELLO");
zsock_t *ready = zpoller_wait (poller, -1);
if (ready == NULL) continue; // Interrupted
else if (ready == pipe) break; // Shutdown
else assert(ready == client); // Data Available
char *reply = zstr_recv (client);
if (!reply)
break;
printf ("Client: %s\n", reply);
free (reply);
sleep (1);
}
zpoller_destroy(&poller);
zsock_destroy(&client);
}
// Worker using REQ socket to do load-balancing
//
static void
worker_task (zsock_t *pipe, void *args)
{
// Signal ready
zsock_signal(pipe, 0);
zsock_t *worker = zsock_new_req ("ipc://backend.ipc");
zpoller_t *poller = zpoller_new (pipe, worker, NULL);
zpoller_set_nonstop(poller, true);
// Tell broker we're ready for work
zframe_t *frame = zframe_new (WORKER_READY, 1);
zframe_send (&frame, worker, 0);
// Process messages as they arrive
while (true) {
zsock_t *ready = zpoller_wait (poller, -1);
if (ready == NULL) continue; // Interrupted
else if (ready == pipe) break; // Shutdown
else assert(ready == worker); // Data Available
zmsg_t *msg = zmsg_recv (worker);
if (!msg)
break; // Interrupted
zframe_print (zmsg_last (msg), "Worker: ");
zframe_reset (zmsg_last (msg), "OK", 2);
zmsg_send (&msg, worker);
}
zpoller_destroy(&poller);
zsock_destroy(&worker);
}
// .until
// Our load-balancer structure, passed to reactor handlers
typedef struct {
zsock_t *frontend; // Listen to clients
zsock_t *backend; // Listen to workers
zlist_t *workers; // List of ready workers
} lbbroker_t;
// .split reactor design
// In the reactor design, each time a message arrives on a socket, the
// reactor passes it to a handler function. We have two handlers; one
// for the frontend, one for the backend:
// Handle input from client, on frontend
static int s_handle_frontend (zloop_t *loop, zsock_t *reader, void *arg)
{
lbbroker_t *self = (lbbroker_t *) arg;
zmsg_t *msg = zmsg_recv (self->frontend);
if (msg) {
zmsg_pushmem (msg, NULL, 0); // delimiter
zmsg_push (msg, (zframe_t *) zlist_pop (self->workers));
zmsg_send (&msg, self->backend);
// Cancel reader on frontend if we went from 1 to 0 workers
if (zlist_size (self->workers) == 0) {
zloop_reader_end (loop, self->frontend);
}
}
return 0;
}
// Handle input from worker, on backend
static int s_handle_backend (zloop_t *loop, zsock_t *reader, void *arg)
{
// Use worker identity for load-balancing
lbbroker_t *self = (lbbroker_t *) arg;
zmsg_t *msg = zmsg_recv (self->backend);
if (msg) {
zframe_t *identity = zmsg_pop (msg);
zframe_t *delimiter = zmsg_pop (msg);
zframe_destroy (&delimiter);
zlist_append (self->workers, identity);
// Enable reader on frontend if we went from 0 to 1 workers
if (zlist_size (self->workers) == 1) {
zloop_reader (loop, self->frontend, s_handle_frontend, self);
}
// Forward message to client if it's not a READY
zframe_t *frame = zmsg_first (msg);
if (memcmp (zframe_data (frame), WORKER_READY, 1) == 0)
zmsg_destroy (&msg);
else
zmsg_send (&msg, self->frontend);
}
return 0;
}
// .split main task
// And the main task now sets up child tasks, then starts its reactor.
// If you press Ctrl-C, the reactor exits and the main task shuts down.
// Because the reactor is a CZMQ class, this example may not translate
// into all languages equally well.
int main (void)
{
lbbroker_t *self = (lbbroker_t *) zmalloc (sizeof (lbbroker_t));
self->frontend = zsock_new_router ("ipc://frontend.ipc");
self->backend = zsock_new_router ("ipc://backend.ipc");
zactor_t *actors[NBR_CLIENTS + NBR_WORKERS];
int actor_nbr = 0;
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
actors[actor_nbr++] = zactor_new (client_task, NULL);
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
actors[actor_nbr++] = zactor_new (worker_task, NULL);
// Queue of available workers
self->workers = zlist_new ();
// Prepare reactor and fire it up
zloop_t *reactor = zloop_new ();
zloop_reader (reactor, self->backend, s_handle_backend, self);
zloop_start (reactor);
zloop_destroy (&reactor);
for (actor_nbr = 0; actor_nbr < NBR_CLIENTS + NBR_WORKERS; actor_nbr++)
zactor_destroy(&actors[actor_nbr]);
// When we're done, clean up properly
while (zlist_size (self->workers)) {
zframe_t *frame = (zframe_t *) zlist_pop (self->workers);
zframe_destroy (&frame);
}
zlist_destroy (&self->workers);
zsock_destroy (&self->frontend);
zsock_destroy (&self->backend);
free (self);
return 0;
}
lbbroker3: Load balancing broker using zloop in C++
lbbroker3: Load balancing broker using zloop in C#
lbbroker3: Load balancing broker using zloop in CL
lbbroker3: Load balancing broker using zloop in Delphi
lbbroker3: Load balancing broker using zloop in Erlang
lbbroker3: Load balancing broker using zloop in Elixir
lbbroker3: Load balancing broker using zloop in F#
lbbroker3: Load balancing broker using zloop in Felix
lbbroker3: Load balancing broker using zloop in Go
lbbroker3: Load balancing broker using zloop in Haskell
lbbroker3: Load balancing broker using zloop in Haxe
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZFrame;
import org.zeromq.ZLoop;
import org.zeromq.ZMsg;
#if (neko || cpp)
import neko.vm.Thread;
#end
import haxe.Stack;
import org.zeromq.ZContext;
import org.zeromq.ZSocket;
using org.zeromq.ZSocket;
import org.zeromq.ZMQ;
import org.zeromq.ZMQException;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
/**
* Least - recently used (LRU) queue device 3
* Demonstrates use of Zxxxx.hx API and reactor style using the ZLoop class.
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: http://zguide.zeromq.org/page:all#A-High-Level-API-for-MQ
*/
class LRUQueue3
{
private static inline var NBR_CLIENTS = 10;
private static inline var NBR_WORKERS = 3;
// Signals workers are ready
private static inline var LRU_READY:String = String.fromCharCode(1);
private static inline var WORKER_DONE:Bytes = Bytes.ofString("OK");
/**
* Basic request-reply client using REQ socket.
*/
public static function clientTask() {
var context:ZContext = new ZContext();
var client:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(client);
client.connectEndpoint("ipc", "/tmp/frontend.ipc");
while (true) {
ZFrame.newStringFrame("HELLO").send(client);
var reply = ZFrame.recvFrame(client);
if (reply == null) {
break;
}
Lib.println("Client "+id+": " + reply.toString());
Sys.sleep(1);
}
context.destroy();
}
/**
* Worker using REQ socket to do LRU routing.
*/
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(worker);
worker.connectEndpoint("ipc", "/tmp/backend.ipc");
// Tell broker we're ready to do work
ZFrame.newStringFrame(LRU_READY).send(worker);
// Process messages as they arrive
while (true) {
var msg:ZMsg = ZMsg.recvMsg(worker);
if (msg == null) {
break;
}
// Lib.println("Worker " + id + " received " + msg.toString());
msg.last().reset(WORKER_DONE);
msg.send(worker);
}
context.destroy();
}
// Hold information baout our LRU Queue structure
private static var frontend:ZMQSocket;
private static var backend:ZMQSocket;
private static var workerQueue:List<ZFrame>;
/**
* Handle input from client, on frontend
* @param loop
* @param socket
* @return
*/
private static function handleFrontEnd(loop:ZLoop, socket:ZMQSocket):Int {
var msg = ZMsg.recvMsg(frontend);
if (msg != null) {
msg.wrap(workerQueue.pop());
msg.send(backend);
// Cancel reader on frontend if we went from 1 to 0 workers
if (workerQueue.length == 0)
loop.unregisterPoller({socket:frontend,event:ZMQ.ZMQ_POLLIN()});
}
return 0;
}
/**
* Hande input from worker on backend
* @param loop
* @param socket
* @return
*/
private static function handleBackEnd(loop:ZLoop, socket:ZMQSocket):Int {
var msg:ZMsg = ZMsg.recvMsg(backend);
if (msg != null) {
var address = msg.unwrap();
workerQueue.add(address);
if (workerQueue.length == 1)
loop.registerPoller( { socket:frontend, event:ZMQ.ZMQ_POLLIN() }, handleFrontEnd);
// Forward message to client if it is not a READY
var frame = msg.first();
if (frame.streq(LRU_READY))
msg.destroy();
else
msg.send(frontend);
}
return 0;
}
public static function main() {
Lib.println("** LRUQueue3 (see: http://zguide.zeromq.org/page:all#A-High-Level-API-for-MQ)");
#if php
// PHP appears to require tasks to be forked before main process creates ZMQ context
for (client_nbr in 0 ... NBR_CLIENTS) {
forkClientTask();
}
for (worker_nbr in 0 ... NBR_WORKERS) {
forkWorkerTask();
}
#end
// Prepare our context and sockets
var context:ZContext = new ZContext();
frontend = context.createSocket(ZMQ_ROUTER);
backend = context.createSocket(ZMQ_ROUTER);
frontend.bindEndpoint("ipc", "/tmp/frontend.ipc");
backend.bindEndpoint("ipc", "/tmp/backend.ipc");
#if !php
// Non-PHP targets require threads to be created after main thread has set up ZMQ Context
for (client_nbr in 0 ... NBR_CLIENTS) {
Thread.create(clientTask);
}
for (worker_nbr in 0 ... NBR_WORKERS) {
Thread.create(workerTask);
}
#end
// Logic of LRU loop:
// - Poll backend always, frontend only if 1 or more worker si ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary.
// - If client requests, pop next worker and send request to it.
// Initialise queue of available workers
workerQueue = new List<ZFrame>();
// Prepare reactor and fire it up
var reactor:ZLoop = new ZLoop();
reactor.registerPoller( { socket:backend, event:ZMQ.ZMQ_POLLIN() }, handleBackEnd);
reactor.start();
reactor.destroy();
// When we're done, clean up properly
for (f in workerQueue) {
f.destroy();
}
context.destroy();
}
#if php
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue3::workerTask();
exit();
}');
return;
}
private static inline function forkClientTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue3::clientTask();
exit();
}');
return;
}
#end
}lbbroker3: Load balancing broker using zloop in Java
package guide;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.Queue;
import org.zeromq.*;
import org.zeromq.ZMQ.PollItem;
import org.zeromq.ZMQ.Socket;
/**
* Load-balancing broker
* Demonstrates use of the ZLoop API and reactor style
*
* The client and worker tasks are identical from the previous example.
*/
public class lbbroker3
{
private static final int NBR_CLIENTS = 10;
private static final int NBR_WORKERS = 3;
private static byte[] WORKER_READY = { '\001' };
/**
* Basic request-reply client using REQ socket
*/
private static class ClientTask implements ZThread.IDetachedRunnable
{
@Override
public void run(Object [] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket client = context.createSocket(SocketType.REQ);
ZHelper.setId(client); // Set a printable identity
client.connect("ipc://frontend.ipc");
// Send request, get reply
client.send("HELLO");
String reply = client.recvStr();
System.out.println("Client: " + reply);
}
}
}
/**
* Worker using REQ socket to do load-balancing
*/
private static class WorkerTask implements ZThread.IDetachedRunnable
{
@Override
public void run(Object [] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket worker = context.createSocket(SocketType.REQ);
ZHelper.setId(worker); // Set a printable identity
worker.connect("ipc://backend.ipc");
// Tell backend we're ready for work
ZFrame frame = new ZFrame(WORKER_READY);
frame.send(worker, 0);
while (true) {
ZMsg msg = ZMsg.recvMsg(worker);
if (msg == null)
break;
msg.getLast().reset("OK");
msg.send(worker);
}
}
}
}
//Our load-balancer structure, passed to reactor handlers
private static class LBBroker
{
Socket frontend; // Listen to clients
Socket backend; // Listen to workers
Queue<ZFrame> workers; // List of ready workers
};
/**
* In the reactor design, each time a message arrives on a socket, the
* reactor passes it to a handler function. We have two handlers; one
* for the frontend, one for the backend:
*/
private static class FrontendHandler implements ZLoop.IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg_)
{
LBBroker arg = (LBBroker) arg_;
ZMsg msg = ZMsg.recvMsg(arg.frontend);
if (msg != null) {
msg.wrap(arg.workers.poll());
msg.send(arg.backend);
// Cancel reader on frontend if we went from 1 to 0 workers
if (arg.workers.size() == 0) {
loop.removePoller(new PollItem(arg.frontend, 0));
}
}
return 0;
}
}
private static class BackendHandler implements ZLoop.IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg_)
{
LBBroker arg = (LBBroker) arg_;
ZMsg msg = ZMsg.recvMsg(arg.backend);
if (msg != null) {
ZFrame address = msg.unwrap();
// Queue worker address for load-balancing
arg.workers.add(address);
// Enable reader on frontend if we went from 0 to 1 workers
if (arg.workers.size() == 1) {
PollItem newItem = new PollItem(arg.frontend, ZMQ.Poller.POLLIN);
loop.addPoller(newItem, frontendHandler, arg);
}
// Forward message to client if it's not a READY
ZFrame frame = msg.getFirst();
if (Arrays.equals(frame.getData(), WORKER_READY))
msg.destroy();
else msg.send(arg.frontend);
}
return 0;
}
}
private final static FrontendHandler frontendHandler = new FrontendHandler();
private final static BackendHandler backendHandler = new BackendHandler();
/**
* And the main task now sets-up child tasks, then starts its reactor.
* If you press Ctrl-C, the reactor exits and the main task shuts down.
*/
public static void main(String[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
LBBroker arg = new LBBroker();
arg.frontend = context.createSocket(SocketType.ROUTER);
arg.backend = context.createSocket(SocketType.ROUTER);
arg.frontend.bind("ipc://frontend.ipc");
arg.backend.bind("ipc://backend.ipc");
int clientNbr;
for (clientNbr = 0; clientNbr < NBR_CLIENTS; clientNbr++)
ZThread.start(new ClientTask());
for (int workerNbr = 0; workerNbr < NBR_WORKERS; workerNbr++)
ZThread.start(new WorkerTask());
// Queue of available workers
arg.workers = new LinkedList<ZFrame>();
// Prepare reactor and fire it up
ZLoop reactor = new ZLoop(context);
PollItem item = new PollItem(arg.backend, ZMQ.Poller.POLLIN);
reactor.addPoller(item, backendHandler, arg);
reactor.start();
}
}
}
lbbroker3: Load balancing broker using zloop in Julia
lbbroker3: Load balancing broker using zloop in Lua
lbbroker3: Load balancing broker using zloop in Node.js
lbbroker3: Load balancing broker using zloop in Objective-C
lbbroker3: Load balancing broker using zloop in ooc
lbbroker3: Load balancing broker using zloop in Perl
lbbroker3: Load balancing broker using zloop in PHP
lbbroker3: Load balancing broker using zloop in Python
"""
Least-recently used (LRU) queue device
Demonstrates use of pyzmq IOLoop reactor
While this example runs in a single process, that is just to make
it easier to start and stop the example. Each thread has its own
context and conceptually acts as a separate process.
Author: Min RK <benjaminrk(at)gmail(dot)com>
Adapted from lruqueue.py by
Guillaume Aubert (gaubert) <guillaume(dot)aubert(at)gmail(dot)com>
"""
from __future__ import print_function
import threading
import time
import zmq
from zmq.eventloop.ioloop import IOLoop
from zmq.eventloop.zmqstream import ZMQStream
NBR_CLIENTS = 10
NBR_WORKERS = 3
def worker_thread(worker_url, i):
""" Worker using REQ socket to do LRU routing """
context = zmq.Context.instance()
socket = context.socket(zmq.REQ)
# set worker identity
socket.identity = (u"Worker-%d" % (i)).encode('ascii')
socket.connect(worker_url)
# Tell the broker we are ready for work
socket.send(b"READY")
try:
while True:
address, empty, request = socket.recv_multipart()
print("%s: %s\n" % (socket.identity.decode('ascii'),
request.decode('ascii')), end='')
socket.send_multipart([address, b'', b'OK'])
except zmq.ContextTerminated:
# context terminated so quit silently
return
def client_thread(client_url, i):
""" Basic request-reply client using REQ socket """
context = zmq.Context.instance()
socket = context.socket(zmq.REQ)
# Set client identity. Makes tracing easier
socket.identity = (u"Client-%d" % (i)).encode('ascii')
socket.connect(client_url)
# Send request, get reply
socket.send(b"HELLO")
reply = socket.recv()
print("%s: %s\n" % (socket.identity.decode('ascii'),
reply.decode('ascii')), end='')
class LRUQueue(object):
"""LRUQueue class using ZMQStream/IOLoop for event dispatching"""
def __init__(self, backend_socket, frontend_socket):
self.available_workers = 0
self.is_workers_ready = False
self.workers = []
self.client_nbr = NBR_CLIENTS
self.backend = ZMQStream(backend_socket)
self.frontend = ZMQStream(frontend_socket)
self.backend.on_recv(self.handle_backend)
self.loop = IOLoop.instance()
def handle_backend(self, msg):
# Queue worker address for LRU routing
worker_addr, empty, client_addr = msg[:3]
assert self.available_workers < NBR_WORKERS
# add worker back to the list of workers
self.available_workers += 1
self.is_workers_ready = True
self.workers.append(worker_addr)
# Second frame is empty
assert empty == b""
# Third frame is READY or else a client reply address
# If client reply, send rest back to frontend
if client_addr != b"READY":
empty, reply = msg[3:]
# Following frame is empty
assert empty == b""
self.frontend.send_multipart([client_addr, b'', reply])
self.client_nbr -= 1
if self.client_nbr == 0:
# Exit after N messages
self.loop.add_timeout(time.time() + 1, self.loop.stop)
if self.is_workers_ready:
# when atleast 1 worker is ready, start accepting frontend messages
self.frontend.on_recv(self.handle_frontend)
def handle_frontend(self, msg):
# Now get next client request, route to LRU worker
# Client request is [address][empty][request]
client_addr, empty, request = msg
assert empty == b""
# Dequeue and drop the next worker address
self.available_workers -= 1
worker_id = self.workers.pop()
self.backend.send_multipart([worker_id, b'', client_addr, b'', request])
if self.available_workers == 0:
# stop receiving until workers become available again
self.is_workers_ready = False
self.frontend.stop_on_recv()
def main():
"""main method"""
url_worker = "ipc://backend.ipc"
url_client = "ipc://frontend.ipc"
# Prepare our context and sockets
context = zmq.Context()
frontend = context.socket(zmq.ROUTER)
frontend.bind(url_client)
backend = context.socket(zmq.ROUTER)
backend.bind(url_worker)
# create workers and clients threads
for i in range(NBR_WORKERS):
thread = threading.Thread(target=worker_thread, args=(url_worker, i, ))
thread.daemon = True
thread.start()
for i in range(NBR_CLIENTS):
thread_c = threading.Thread(target=client_thread,
args=(url_client, i, ))
thread_c.daemon = True
thread_c.start()
# create queue with the sockets
queue = LRUQueue(backend, frontend)
# start reactor
IOLoop.instance().start()
if __name__ == "__main__":
main()
lbbroker3: Load balancing broker using zloop in Q
lbbroker3: Load balancing broker using zloop in Racket
lbbroker3: Load balancing broker using zloop in Ruby
lbbroker3: Load balancing broker using zloop in Rust
lbbroker3: Load balancing broker using zloop in Scala
lbbroker3: Load balancing broker using zloop in Tcl
lbbroker3: Load balancing broker using zloop in OCaml
Getting applications to properly shut down when you send them Ctrl-C can be tricky. If you use the zctx class it’ll automatically set up signal handling, but your code still has to cooperate. You must break any loop if zmq_poll returns -1 or if any of the zstr_recv, zframe_recv, or zmsg_recv methods return NULL. If you have nested loops, it can be useful to make the outer ones conditional on !zctx_interrupted.
If you’re using child threads, they won’t receive the interrupt. To tell them to shutdown, you can either:
- Destroy the context, if they are sharing the same context, in which case any blocking calls they are waiting on will end with ETERM.
- Send them shutdown messages, if they are using their own contexts. For this you’ll need some socket plumbing.
The Asynchronous Client/Server Pattern #
In the ROUTER to DEALER example, we saw a 1-to-N use case where one server talks asynchronously to multiple workers. We can turn this upside down to get a very useful N-to-1 architecture where various clients talk to a single server, and do this asynchronously.
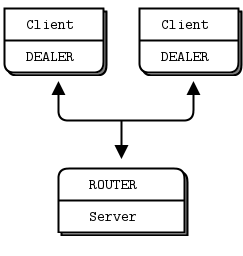
Here’s how it works:
- Clients connect to the server and send requests.
- For each request, the server sends 0 or more replies.
- Clients can send multiple requests without waiting for a reply.
- Servers can send multiple replies without waiting for new requests.
Here’s code that shows how this works:
asyncsrv: Asynchronous client/server in Ada
asyncsrv: Asynchronous client/server in Basic
asyncsrv: Asynchronous client/server in C
// Asynchronous client-to-server (DEALER to ROUTER)
//
// While this example runs in a single process, that is to make
// it easier to start and stop the example. Each task conceptually
// acts as a separate process.
#include "czmq.h"
// This is our client task
// It connects to the server, and then sends a request once per second
// It collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
static void
client_task (zsock_t *pipe, void *args)
{
zsock_signal(pipe, 0);
zsock_t *client = zsock_new (ZMQ_DEALER);
// Set random identity to make tracing easier (must be done before zsock_connect)
char identity [10];
sprintf (identity, "%04X-%04X", randof (0x10000), randof (0x10000));
zsock_set_identity (client, identity);
zsock_connect (client, "tcp://localhost:5570");
zpoller_t *poller = zpoller_new (pipe, client, NULL);
zpoller_set_nonstop(poller, true);
bool signaled = false;
int request_nbr = 0;
while (!signaled) {
// Tick once per second, pulling in arriving messages
int centitick;
for (centitick = 0; centitick < 100; centitick++) {
zsock_t *ready = zpoller_wait(poller, 10 * ZMQ_POLL_MSEC);
if (ready == NULL) continue;
else if (ready == pipe) {
signaled = true;
break;
} else assert (ready == client);
zmsg_t *msg = zmsg_recv (client);
zframe_print (zmsg_last (msg), identity);
zmsg_destroy (&msg);
}
zstr_sendf (client, "request #%d", ++request_nbr);
}
zpoller_destroy(&poller);
zsock_destroy(&client);
}
// .split server task
// This is our server task.
// It uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
static void server_worker (zsock_t *pipe, void *args);
static void server_task (zsock_t *pipe, void *args)
{
zsock_signal(pipe, 0);
// Launch pool of worker threads, precise number is not critical
enum { NBR_THREADS = 5 };
zactor_t *threads[NBR_THREADS];
int thread_nbr;
for (thread_nbr = 0; thread_nbr < NBR_THREADS; thread_nbr++)
threads[thread_nbr] = zactor_new (server_worker, NULL);
// Connect backend to frontend via a zproxy
zactor_t *proxy = zactor_new (zproxy, NULL);
zstr_sendx (proxy, "FRONTEND", "ROUTER", "tcp://*:5570", NULL);
zsock_wait (proxy);
zstr_sendx (proxy, "BACKEND", "DEALER", "inproc://backend", NULL);
zsock_wait (proxy);
// Wait for shutdown signal
zsock_wait(pipe);
zactor_destroy(&proxy);
for (thread_nbr = 0; thread_nbr < NBR_THREADS; thread_nbr++)
zactor_destroy(&threads[thread_nbr]);
}
// .split worker task
// Each worker task works on one request at a time and sends a random number
// of replies back, with random delays between replies:
static void
server_worker (zsock_t *pipe, void *args)
{
zsock_signal(pipe, 0);
zsock_t *worker = zsock_new_dealer ("inproc://backend");
zpoller_t *poller = zpoller_new (pipe, worker, NULL);
zpoller_set_nonstop (poller, true);
while (true) {
zsock_t *ready = zpoller_wait (poller, -1);
if (ready == NULL) continue;
else if (ready == pipe) break;
else assert (ready == worker);
// The DEALER socket gives us the reply envelope and message
zmsg_t *msg = zmsg_recv (worker);
zframe_t *identity = zmsg_pop (msg);
zframe_t *content = zmsg_pop (msg);
assert (content);
zmsg_destroy (&msg);
// Send 0..4 replies back
int reply, replies = randof (5);
for (reply = 0; reply < replies; reply++) {
// Sleep for some fraction of a second
zclock_sleep (randof (1000) + 1);
zframe_send (&identity, worker, ZFRAME_REUSE | ZFRAME_MORE | ZFRAME_DONTWAIT );
zframe_send (&content, worker, ZFRAME_REUSE | ZFRAME_DONTWAIT );
}
zframe_destroy (&identity);
zframe_destroy (&content);
}
zpoller_destroy (&poller);
zsock_destroy (&worker);
}
// The main thread simply starts several clients and a server, and then
// waits for the server to finish.
int main (void)
{
zactor_t *client1 = zactor_new (client_task, NULL);
zactor_t *client2 = zactor_new (client_task, NULL);
zactor_t *client3 = zactor_new (client_task, NULL);
zactor_t *server = zactor_new (server_task, NULL);
zclock_sleep (5 * 1000); // Run for 5 seconds then quit
zsock_signal (server, 0);
zactor_destroy (&server);
zactor_destroy (&client1);
zactor_destroy (&client2);
zactor_destroy (&client3);
return 0;
}
asyncsrv: Asynchronous client/server in C++
// Asynchronous client-to-server (DEALER to ROUTER)
//
// While this example runs in a single process, that is to make
// it easier to start and stop the example. Each task has its own
// context and conceptually acts as a separate process.
#include <vector>
#include <thread>
#include <memory>
#include <functional>
#include <zmq.hpp>
#include "zhelpers.hpp"
// This is our client task class.
// It connects to the server, and then sends a request once per second
// It collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
// Attention! -- this random work well only on linux.
class client_task {
public:
client_task()
: ctx_(1),
client_socket_(ctx_, ZMQ_DEALER)
{}
void start() {
// generate random identity
char identity[10] = {};
sprintf(identity, "%04X-%04X", within(0x10000), within(0x10000));
printf("%s\n", identity);
client_socket_.set(zmq::sockopt::routing_id, identity);
client_socket_.connect("tcp://localhost:5570");
zmq::pollitem_t items[] = {
{ client_socket_, 0, ZMQ_POLLIN, 0 } };
int request_nbr = 0;
try {
while (true) {
for (int i = 0; i < 100; ++i) {
// 10 milliseconds
zmq::poll(items, 1, 10);
if (items[0].revents & ZMQ_POLLIN) {
printf("\n%s ", identity);
s_dump(client_socket_);
}
}
char request_string[16] = {};
sprintf(request_string, "request #%d", ++request_nbr);
client_socket_.send(request_string, strlen(request_string));
}
}
catch (std::exception &e) {}
}
private:
zmq::context_t ctx_;
zmq::socket_t client_socket_;
};
// .split worker task
// Each worker task works on one request at a time and sends a random number
// of replies back, with random delays between replies:
class server_worker {
public:
server_worker(zmq::context_t &ctx, int sock_type)
: ctx_(ctx),
worker_(ctx_, sock_type)
{}
void work() {
worker_.connect("inproc://backend");
try {
while (true) {
zmq::message_t identity;
zmq::message_t msg;
zmq::message_t copied_id;
zmq::message_t copied_msg;
worker_.recv(&identity);
worker_.recv(&msg);
int replies = within(5);
for (int reply = 0; reply < replies; ++reply) {
s_sleep(within(1000) + 1);
copied_id.copy(&identity);
copied_msg.copy(&msg);
worker_.send(copied_id, ZMQ_SNDMORE);
worker_.send(copied_msg);
}
}
}
catch (std::exception &e) {}
}
private:
zmq::context_t &ctx_;
zmq::socket_t worker_;
};
// .split server task
// This is our server task.
// It uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
class server_task {
public:
server_task()
: ctx_(1),
frontend_(ctx_, ZMQ_ROUTER),
backend_(ctx_, ZMQ_DEALER)
{}
enum { kMaxThread = 5 };
void run() {
frontend_.bind("tcp://*:5570");
backend_.bind("inproc://backend");
std::vector<server_worker *> worker;
std::vector<std::thread *> worker_thread;
for (int i = 0; i < kMaxThread; ++i) {
worker.push_back(new server_worker(ctx_, ZMQ_DEALER));
worker_thread.push_back(new std::thread(std::bind(&server_worker::work, worker[i])));
worker_thread[i]->detach();
}
try {
zmq::proxy(static_cast<void*>(frontend_),
static_cast<void*>(backend_),
nullptr);
}
catch (std::exception &e) {}
for (int i = 0; i < kMaxThread; ++i) {
delete worker[i];
delete worker_thread[i];
}
}
private:
zmq::context_t ctx_;
zmq::socket_t frontend_;
zmq::socket_t backend_;
};
// The main thread simply starts several clients and a server, and then
// waits for the server to finish.
int main (void)
{
client_task ct1;
client_task ct2;
client_task ct3;
server_task st;
std::thread t1(std::bind(&client_task::start, &ct1));
std::thread t2(std::bind(&client_task::start, &ct2));
std::thread t3(std::bind(&client_task::start, &ct3));
std::thread t4(std::bind(&server_task::run, &st));
t1.detach();
t2.detach();
t3.detach();
t4.detach();
getchar();
return 0;
}
asyncsrv: Asynchronous client/server in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
static void AsyncSrv_Client(ZContext context, int i)
{
//
// Asynchronous client-to-server (DEALER to ROUTER)
//
// While this example runs in a single process, that is to make
// it easier to start and stop the example. Each task has its own
// context and conceptually acts as a separate process.
//
// Author: metadings
//
// This is our client task
// It connects to the server, and then sends a request once per second
// It collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
using (var client = new ZSocket(context, ZSocketType.DEALER))
{
// Set identity to make tracing easier
client.Identity = Encoding.UTF8.GetBytes("CLIENT" + i);
// Connect
client.Connect("tcp://127.0.0.1:5570");
ZError error;
ZMessage incoming;
var poll = ZPollItem.CreateReceiver();
int requests = 0;
while (true)
{
// Tick once per second, pulling in arriving messages
for (int centitick = 0; centitick < 100; ++centitick)
{
if (!client.PollIn(poll, out incoming, out error, TimeSpan.FromMilliseconds(10)))
{
if (error == ZError.EAGAIN)
{
Thread.Sleep(1);
continue;
}
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
using (incoming)
{
string messageText = incoming[0].ReadString();
Console.WriteLine("[CLIENT{0}] {1}", centitick, messageText);
}
}
using (var outgoing = new ZMessage())
{
outgoing.Add(new ZFrame(client.Identity));
outgoing.Add(new ZFrame("request " + (++requests)));
if (!client.Send(outgoing, out error))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
}
}
}
}
static void AsyncSrv_ServerTask(ZContext context)
{
// This is our server task.
// It uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
using (var frontend = new ZSocket(context, ZSocketType.ROUTER))
using (var backend = new ZSocket(context, ZSocketType.DEALER))
{
// Frontend socket talks to clients over TCP
frontend.Bind("tcp://*:5570");
// Backend socket talks to workers over inproc
backend.Bind("inproc://backend");
// Launch pool of worker threads, precise number is not critical
for (int i = 0; i < 5; ++i)
{
int j = i; new Thread(() => AsyncSrv_ServerWorker(context, j)).Start();
}
// Connect backend to frontend via a proxy
ZError error;
if (!ZContext.Proxy(frontend, backend, out error))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
}
}
static void AsyncSrv_ServerWorker(ZContext context, int i)
{
// Each worker task works on one request at a time and sends a random number
// of replies back, with random delays between replies:
using (var worker = new ZSocket(context, ZSocketType.DEALER))
{
worker.Connect("inproc://backend");
ZError error;
ZMessage request;
var rnd = new Random();
while (true)
{
if (null == (request = worker.ReceiveMessage(out error)))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
using (request)
{
// The DEALER socket gives us the reply envelope and message
string identity = request[1].ReadString();
string content = request[2].ReadString();
// Send 0..4 replies back
int replies = rnd.Next(5);
for (int reply = 0; reply < replies; ++reply)
{
// Sleep for some fraction of a second
Thread.Sleep(rnd.Next(1000) + 1);
using (var response = new ZMessage())
{
response.Add(new ZFrame(identity));
response.Add(new ZFrame(content));
if (!worker.Send(response, out error))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
}
}
}
}
}
}
public static void AsyncSrv(string[] args)
{
// The main thread simply starts several clients and a server, and then
// waits for the server to finish.
using (var context = new ZContext())
{
for (int i = 0; i < 5; ++i)
{
int j = i; new Thread(() => AsyncSrv_Client(context, j)).Start();
}
new Thread(() => AsyncSrv_ServerTask(context)).Start();
// Run for 5 seconds then quit
Thread.Sleep(5 * 1000);
}
}
}
}
asyncsrv: Asynchronous client/server in CL
asyncsrv: Asynchronous client/server in Delphi
program asyncsrv;
//
// Asynchronous client-to-server (DEALER to ROUTER)
//
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each task has its own
// context and conceptually acts as a separate process.
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, Classes
, zmqapi
, zhelpers
;
// ---------------------------------------------------------------------
// This is our client task.
// It connects to the server, and then sends a request once per second
// It collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
procedure client_task( args: Pointer );
var
ctx: TZMQContext;
client: TZMQSocket;
poller: TZMQPoller;
i, request_nbr: Integer;
msg: TZMQMsg;
begin
ctx := TZMQContext.create;
client := ctx.Socket( stDealer );
// Set random identity to make tracing easier
s_set_id( client );
client.connect( 'tcp://localhost:5570' );
poller := TZMQPoller.Create( true );
poller.register( client, [pePollIn] );
msg := nil;
request_nbr := 0;
while true do
begin
// Tick once per second, pulling in arriving messages
for i := 0 to 100 - 1 do
begin
poller.poll( 10 );
if ( pePollIn in poller.PollItem[0].revents ) then
begin
client.recv( msg );
zNote( client.Identity + ': ' + msg.last.dump );
msg.Free;
msg := nil;
end;
end;
request_nbr := request_nbr + 1;
client.send( Format('request #%d',[request_nbr]) )
end;
poller.Free;
ctx.Free;
end;
// This is our server task.
// It uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
procedure server_worker( args: Pointer ); forward;
procedure server_task( args: Pointer );
var
ctx: TZMQContext;
frontend,
backend: TZMQSocket;
i: Integer;
tid: Cardinal;
begin
ctx := TZMQContext.create;
// Frontend socket talks to clients over TCP
frontend := ctx.Socket( stRouter );
frontend.bind( 'tcp://*:5570' );
// Backend socket talks to workers over inproc
backend := ctx.Socket( stDealer );
backend.bind( 'inproc://backend' );
// Launch pool of worker threads, precise number is not critical
for i := 0 to 4 do
BeginThread( nil, 0, @server_worker, ctx, 0, tid );
// Connect backend to frontend via a proxy
ZMQProxy( frontend, backend, nil );
ctx.Free;
end;
// Each worker task works on one request at a time and sends a random number
// of replies back, with random delays between replies:
procedure server_worker( args: Pointer );
var
ctx: TZMQContext;
worker: TZMQSocket;
msg: TZMQMsg;
identity,
content: TZMQFrame;
i,replies: Integer;
begin
ctx := args;
worker := ctx.Socket( stDealer );
worker.connect( 'inproc://backend' );
msg := nil;
while not ctx.Terminated do
begin
// The DEALER socket gives us the reply envelope and message
worker.recv( msg );
identity := msg.pop;
content := msg.pop;
assert(content <> nil);
msg.Free;
msg := nil;
// Send 0..4 replies back
replies := Random( 5 );
for i := 0 to replies - 1 do
begin
// Sleep for some fraction of a second
sleep( Random(1000) + 1 );
msg := TZMQMsg.Create;
msg.add( identity.dup );
msg.add( content.dup );
worker.send( msg );
end;
identity.Free;
content.Free;
end;
end;
var
tid: Cardinal;
begin
// The main thread simply starts several clients, and a server, and then
// waits for the server to finish.
Randomize;
BeginThread( nil, 0, @client_task, nil, 0, tid );
BeginThread( nil, 0, @client_task, nil, 0, tid );
BeginThread( nil, 0, @client_task, nil, 0, tid );
BeginThread( nil, 0, @server_task, nil, 0, tid );
// Run for 5 seconds then quit
sleep( 5 * 1000 );
end.
asyncsrv: Asynchronous client/server in Erlang
#!/usr/bin/env escript
%%
%% Asynchronous client-to-server (DEALER to ROUTER)
%%
%% While this example runs in a single process, that is just to make
%% it easier to start and stop the example. Each task has its own
%% context and conceptually acts as a separate process.
%% ---------------------------------------------------------------------
%% This is our client task
%% It connects to the server, and then sends a request once per second
%% It collects responses as they arrive, and it prints them out. We will
%% run several client tasks in parallel, each with a different random ID.
client_task() ->
{ok, Ctx} = erlzmq:context(),
{ok, Client} = erlzmq:socket(Ctx, dealer),
%% Set identity to make tracing easier
ok = erlzmq:setsockopt(Client, identity, pid_to_list(self())),
ok = erlzmq:connect(Client, "tcp://localhost:5570"),
client_loop(Client, 0),
ok = erlzmq:term(Ctx).
client_loop(Client, RequestNbr) ->
%% Tick once per second, pulling in arriving messages (check 100 times
%% using 10 poll delay for each call)
client_check_messages(Client, 100, 10),
Msg = list_to_binary(io_lib:format("request #~b", [RequestNbr])),
erlzmq:send(Client, Msg),
client_loop(Client, RequestNbr + 1).
client_check_messages(_Client, 0, _PollDelay) -> ok;
client_check_messages(Client, N, PollDelay) when N > 0 ->
case erlzmq:recv(Client, [noblock]) of
{ok, Msg} -> io:format("~s [~p]~n", [Msg, self()]);
{error, eagain} -> timer:sleep(PollDelay)
end,
client_check_messages(Client, N - 1, PollDelay).
%% ---------------------------------------------------------------------
%% This is our server task
%% It uses the multithreaded server model to deal requests out to a pool
%% of workers and route replies back to clients. One worker can handle
%% one request at a time but one client can talk to multiple workers at
%% once.
server_task() ->
{ok, Ctx} = erlzmq:context(),
random:seed(now()),
%% Frontend socket talks to clients over TCP
{ok, Frontend} = erlzmq:socket(Ctx, [router, {active, true}]),
ok = erlzmq:bind(Frontend, "tcp://*:5570"),
%% Backend socket talks to workers over inproc
{ok, Backend} = erlzmq:socket(Ctx, [dealer, {active, true}]),
ok = erlzmq:bind(Backend, "inproc://backend"),
start_server_workers(Ctx, 5),
%% Connect backend to frontend via a queue device
erlzmq_device:queue(Frontend, Backend),
ok = erlzmq:term(Ctx).
start_server_workers(_Ctx, 0) -> ok;
start_server_workers(Ctx, N) when N > 0 ->
spawn(fun() -> server_worker(Ctx) end),
start_server_workers(Ctx, N - 1).
%% Accept a request and reply with the same text a random number of
%% times, with random delays between replies.
%%
server_worker(Ctx) ->
random:seed(now()),
{ok, Worker} = erlzmq:socket(Ctx, dealer),
ok = erlzmq:connect(Worker, "inproc://backend"),
server_worker_loop(Worker).
server_worker_loop(Worker) ->
{ok, Address} = erlzmq:recv(Worker),
{ok, Content} = erlzmq:recv(Worker),
send_replies(Worker, Address, Content, random:uniform(4) - 1),
server_worker_loop(Worker).
send_replies(_, _, _, 0) -> ok;
send_replies(Worker, Address, Content, N) when N > 0 ->
%% Sleep for some fraction of a second
timer:sleep(random:uniform(1000)),
ok = erlzmq:send(Worker, Address, [sndmore]),
ok = erlzmq:send(Worker, Content),
send_replies(Worker, Address, Content, N - 1).
%% This main thread simply starts several clients, and a server, and then
%% waits for the server to finish.
%%
main(_) ->
spawn(fun() -> client_task() end),
spawn(fun() -> client_task() end),
spawn(fun() -> client_task() end),
spawn(fun() -> server_task() end),
timer:sleep(5000).
asyncsrv: Asynchronous client/server in Elixir
defmodule asyncsrv do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:22
"""
def client_task() do
{:ok, ctx} = :erlzmq.context()
{:ok, client} = :erlzmq.socket(ctx, :dealer)
:ok = :erlzmq.setsockopt(client, :identity, :erlang.pid_to_list(self()))
:ok = :erlzmq.connect(client, 'tcp://localhost:5570')
client_loop(client, 0)
:ok = :erlzmq.term(ctx)
end
def client_loop(client, requestNbr) do
client_check_messages(client, 100, 10)
msg = :erlang.list_to_binary(:io_lib.format('request #~b', [requestNbr]))
:erlzmq.send(client, msg)
client_loop(client, requestNbr + 1)
end
def client_check_messages(_client, 0, _pollDelay) do
:ok
end
def client_check_messages(client, n, pollDelay) when n > 0 do
case(:erlzmq.recv(client, [:noblock])) do
{:ok, msg} ->
:io.format('~s [~p]~n', [msg, self()])
{:error, :eagain} ->
:timer.sleep(pollDelay)
end
client_check_messages(client, n - 1, pollDelay)
end
def server_task() do
{:ok, ctx} = :erlzmq.context()
:random.seed(:erlang.now())
{:ok, frontend} = :erlzmq.socket(ctx, [:router, {:active, true}])
:ok = :erlzmq.bind(frontend, 'tcp://*:5570')
{:ok, backend} = :erlzmq.socket(ctx, [:dealer, {:active, true}])
:ok = :erlzmq.bind(backend, 'inproc://backend')
start_server_workers(ctx, 5)
:erlzmq_device.queue(frontend, backend)
:ok = :erlzmq.term(ctx)
end
def start_server_workers(_ctx, 0) do
:ok
end
def start_server_workers(ctx, n) when n > 0 do
:erlang.spawn(fn -> server_worker(ctx) end)
start_server_workers(ctx, n - 1)
end
def server_worker(ctx) do
:random.seed(:erlang.now())
{:ok, worker} = :erlzmq.socket(ctx, :dealer)
:ok = :erlzmq.connect(worker, 'inproc://backend')
server_worker_loop(worker)
end
def server_worker_loop(worker) do
{:ok, address} = :erlzmq.recv(worker)
{:ok, content} = :erlzmq.recv(worker)
send_replies(worker, address, content, :random.uniform(4) - 1)
server_worker_loop(worker)
end
def send_replies(_, _, _, 0) do
:ok
end
def send_replies(worker, address, content, n) when n > 0 do
:timer.sleep(:random.uniform(1000))
:ok = :erlzmq.send(worker, address, [:sndmore])
:ok = :erlzmq.send(worker, content)
send_replies(worker, address, content, n - 1)
end
def main(_) do
:erlang.spawn(fn -> client_task() end)
:erlang.spawn(fn -> client_task() end)
:erlang.spawn(fn -> client_task() end)
:erlang.spawn(fn -> server_task() end)
:timer.sleep(5000)
end
end
asyncsrv: Asynchronous client/server in F#
(*
Asynchronous client-to-server (DEALER to ROUTER)
While this example runs in a single process, that is just to make
it easier to start and stop the example. Each task has its own
context and conceptually acts as a separate process.
*)
#r @"bin/fszmq.dll"
#r @"bin/fszmq.devices.dll"
open fszmq
open fszmq.Context
open fszmq.devices
open fszmq.Polling
open fszmq.Socket
#load "zhelpers.fs"
// this is our client task
// it connects to the server, and then sends a request once per second
// it collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
let client_task () =
use ctx = new Context(1)
use client = deal ctx
// set random identity to make tracing easier
s_setID client
let identity = ZMQ.IDENTITY |> get<byte[]> client |> decode
connect client "tcp://localhost:5570"
let printMsg socket =
let content = match socket |> recvAll with
| [| content |] -> decode content
| _ -> "<NULL>"
printfn' "(%s) %s" identity content
let request_nbr = ref 0
while true do
// tick once per second, pulling in arriving messages
for _ in 1 .. 100 do
[Poll(ZMQ.POLLIN,client,printMsg)] |> poll 10000L |> ignore
incr request_nbr
(sprintf "request %d" !request_nbr) |> s_send client
// accept a request and reply with the same text
// a random number of times, with random delays between replies.
let rand = srandom()
let server_worker (ctx:obj) =
use worker = (ctx :?> Context) |> deal
connect worker "tcp://localhost:5600"
while true do
// The DEALER socket gives us the address envelope and message
let message = worker |> recvAll
// Send 0..4 replies back
let replies = rand.Next(0,5)
for _ in 1 .. replies do
sleep (rand.Next 1000)
message |> sendAll worker
// this is our server task
// it uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
let server_task () =
use ctx = new Context(1)
// frontend socket talks to clients over TCP
use frontend = ctx |> route
bind frontend "tcp://*:5570"
// backend socket talks to workers over inproc
use backend = ctx |> deal
// bind backend "inproc://backend"
// ... except on Windows where 0MQ doesn't have a binding
// for named pipes, so we use TCP instead
bind backend "tcp://*:5600"
// launch pool of worker threads, precise number is not critical
for _ in 1 .. 5 do
ctx |> s_spawnp server_worker |> ignore
// connect backend to frontend via a queue device
// we could do this:
// Devices.queue(frontend,backend)
// but doing it ourselves means we can debug this more easily
// switch messages between frontend and backend
let items =
[ Poll(ZMQ.POLLIN,frontend,
fun _ -> let msg = frontend |> recvAll
//printfn' "request from client:"
//dumpMsg msg
msg |> sendAll backend)
Poll(ZMQ.POLLIN,backend ,
fun _ -> let msg = backend |> recvAll
//printfn' "reply from worker:"
//dumpMsg msg
msg |> sendAll frontend) ]
while items |> poll -1L do ((* loop *))
let main () =
s_spawn client_task |> ignore
s_spawn client_task |> ignore
s_spawn client_task |> ignore
s_spawn server_task |> ignore
// run for 5 seconds then quit
sleep 5000
EXIT_SUCCESS
main ()
asyncsrv: Asynchronous client/server in Felix
asyncsrv: Asynchronous client/server in Go
//
// Asynchronous client-server
// While this example runs in a single process, that is to make
// it easier to start and stop the example. Each task has its own
// context and conceptually acts as a separate process.
//
// Port of asyncsrv.c
// Written by: Aaron Clawson
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
//"strings"
"strconv"
"time"
)
var finished = make(chan int)
func randomString() string {
source := "abcdefghijklmnopqrstuvwxyz1234567890ABCDEFGHIJKLMNOPQRSTUVWXYZ"
target := make([]byte, 20)
for i := 0; i < 20; i++ {
target[i] = source[rand.Intn(len(source))]
}
return string(target)
}
// This is our client task
// It connects to the server, and then sends a request once per second
// It collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
func client_task() {
context, _ := zmq.NewContext()
defer context.Close()
// Set random identity to make tracing easier
identity := "Client-" + randomString()
client, _ := context.NewSocket(zmq.DEALER)
client.SetIdentity(identity)
client.Connect("ipc://frontend.ipc")
defer client.Close()
items := zmq.PollItems{
zmq.PollItem{Socket: client, Events: zmq.POLLIN},
}
reqs := 0
for {
//Read for a response 100 times for every message we send out
for i := 0; i < 100; i++ {
_, err := zmq.Poll(items, time.Millisecond*10)
if err != nil {
break // Interrupted
}
if items[0].REvents&zmq.POLLIN != 0 {
reply, _ := client.Recv(0)
fmt.Println(identity, "received", string(reply))
}
}
reqs += 1
req_str := "Request #" + strconv.Itoa(reqs)
client.Send([]byte(req_str), 0)
}
}
// This is our server task.
// It uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
func server_task() {
context, _ := zmq.NewContext()
defer context.Close()
// Frontend socket talks to clients over TCP
frontend, _ := context.NewSocket(zmq.ROUTER)
frontend.Bind("ipc://frontend.ipc")
defer frontend.Close()
// Backend socket talks to workers over inproc
backend, _ := context.NewSocket(zmq.DEALER)
backend.Bind("ipc://backend.ipc")
defer backend.Close()
// Launch pool of worker threads, precise number is not critical
for i := 0; i < 5; i++ {
go server_worker()
}
// Connect backend to frontend via a proxy
items := zmq.PollItems{
zmq.PollItem{Socket: frontend, Events: zmq.POLLIN},
zmq.PollItem{Socket: backend, Events: zmq.POLLIN},
}
for {
_, err := zmq.Poll(items, -1)
if err != nil {
fmt.Println("Server exited with error:", err)
break
}
if items[0].REvents&zmq.POLLIN != 0 {
parts, _ := frontend.RecvMultipart(0)
backend.SendMultipart(parts, 0)
}
if items[1].REvents&zmq.POLLIN != 0 {
parts, _ := backend.RecvMultipart(0)
frontend.SendMultipart(parts, 0)
}
}
}
// Each worker task works on one request at a time and sends a random number
// of replies back, with random delays between replies:
func server_worker() {
context, _ := zmq.NewContext()
defer context.Close()
// The DEALER socket gives us the reply envelope and message
worker, _ := context.NewSocket(zmq.DEALER)
worker.Connect("ipc://backend.ipc")
defer worker.Close()
for {
parts, _ := worker.RecvMultipart(0)
//Reply with 0..4 responses
replies := rand.Intn(5)
for i := 0; i < replies; i++ {
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
worker.SendMultipart(parts, 0)
}
}
}
// The main thread simply starts several clients and a server, and then
// waits for the server to finish.
func main() {
rand.Seed(time.Now().UTC().UnixNano())
go client_task()
go client_task()
go client_task()
go server_task()
time.Sleep(time.Second * 5) // Run for 5 seconds then quit
}
asyncsrv: Asynchronous client/server in Haskell
-- |
-- Asynchronous client-to-server (DEALER to ROUTER) p.111
-- Compile with -threaded
module Main where
import System.ZMQ4.Monadic
import ZHelpers (setRandomIdentity)
import Control.Concurrent (threadDelay)
import Data.ByteString.Char8 (pack, unpack)
import Control.Monad (forever, forM_, replicateM_)
import System.Random (randomRIO)
import Text.Printf
clientTask :: String -> ZMQ z ()
clientTask ident = do
client <- socket Dealer
setRandomIdentity client
connect client "tcp://localhost:5570"
forM_ [1..] $ \i -> do -- (long enough) forever
-- tick one per second, pulling in arriving messages
forM_ [0..100] $ \_ ->
poll 10 -- timeout of 10 ms
[Sock client [In] -- wait for incoming event
$ Just $ -- if it happens do
\_ -> receive client >>= liftIO . printf "Client %s has received back from worker its msg \"%s\"\n" ident . unpack ]
send client [] (pack $ unwords ["Client", ident, "sends request", show i])
serverTask :: ZMQ z ()
serverTask = do
frontend <- socket Router
bind frontend "tcp://*:5570"
backend <- socket Dealer
bind backend "inproc://backend"
replicateM_ 5 $ async serverWorker
proxy frontend backend Nothing
serverWorker :: ZMQ z ()
serverWorker = do
worker <- socket Dealer
connect worker "inproc://backend"
liftIO $ putStrLn "Worker Started"
forever $ -- receive both ident and msg and send back the msg to the ident client.
receive worker >>= \ident -> receive worker >>= \msg -> sendback worker msg ident
where
-- send back to client 0 to 4 times max
sendback worker msg ident = do
resentNb <- liftIO $ randomRIO (0, 4)
timeoutMsec <- liftIO $ randomRIO (1, 1000)
forM_ [0::Int ..resentNb] $ \_ -> do
liftIO $ threadDelay $ timeoutMsec * 1000
send worker [SendMore] ident
send worker [] msg
main :: IO ()
main =
runZMQ $ do
async $ clientTask "A"
async $ clientTask "B"
async $ clientTask "C"
async serverTask
liftIO $ threadDelay $ 5 * 1000 * 1000asyncsrv: Asynchronous client/server in Haxe
package ;
import neko.Lib;
import org.zeromq.ZMQException;
#if !php
import neko.Random;
import neko.vm.Thread;
#end
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMQ;
import org.zeromq.ZMsg;
/**
* Asynchronous client-server (DEALER to ROUTER)
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: http://zguide.zeromq.org/page:all#Asynchronous-Client-Server
*/
class ASyncSrv
{
#if php
private static inline var internalServerEndpoint:String = "ipc:///tmp/backend";
#else
private static inline var internalServerEndpoint:String = "inproc://backend";
#end
/**
* This is our client task
* It connects to the server, and then sends a request once per second
* It collects responses as they arrive, and it prints them out. We will
* run several client tasks in parallel, each with a different random ID.
*/
public static function clientTask(context:ZContext) {
var client:ZMQSocket = context.createSocket(ZMQ_DEALER);
// Set random identity to make tracing easier
var id = ZHelpers.setID(client);
client.connect("tcp://localhost:5570");
//trace ("Started client " + id);
var poller = new ZMQPoller();
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
var request_nbr = 0;
while (true) {
for (centitick in 0 ... 100) {
try {
poller.poll(10000); // Poll for 10ms
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace (e.toString());
break;
}
if (poller.pollin(1)) {
var msg:ZMsg = ZMsg.recvMsg(client);
Lib.println("Client: " + id + " received:" + msg.last().toString());
msg.destroy();
}
}
if (poller == null)
break; // Interrupted
ZMsg.newStringMsg("request #" + ++request_nbr).send(client);
}
context.destroy();
}
/**
* Accept a request and reply with the same text a random number of
* times, with random delays between replies.
*/
public static function serverWorker(context:ZContext) {
var worker:ZMQSocket = context.createSocket(ZMQ_DEALER);
worker.connect(internalServerEndpoint);
while (true) {
// The DEALER socket gives us the address envelope and message
var msg = ZMsg.recvMsg(worker);
var address:ZFrame = msg.pop();
var content:ZFrame = msg.pop();
//trace ("Got request from " + address.toString());
if (content == null)
break;
msg.destroy();
// Send 0...4 replies back
#if php
var replies = untyped __php__('rand(0, 4)');
#else
var replies = new Random().int(4);
#end
for (reply in 0...replies) {
// Sleep for some fraction of a second
#if php
Sys.sleep((untyped __php__('rand(0, 1000)') + 1) / 1000);
#else
Sys.sleep(new Random().float() + 0.001);
#end
address.send(worker, ZFrame.ZFRAME_MORE + ZFrame.ZFRAME_REUSE);
content.send(worker, ZFrame.ZFRAME_REUSE);
}
address.destroy();
content.destroy();
}
}
/**
* This is our server task
* It uses the multithreaded server model to deal requests out to a pool
* of workers and route replies back to clients. One worker can handle
* one request at a time but one client can talk to multiple workers at
* once.
*/
public static function serverTask(context:ZContext) {
#if php
for (thread_nbr in 0 ... 5) {
forkServerWorker(context);
}
#end
// Frontend socket talks to clients over TCP
var frontend = context.createSocket(ZMQ_ROUTER);
frontend.bind("tcp://*:5570");
// Backend socket talks to workers over inproc
var backend = context.createSocket(ZMQ_DEALER);
backend.bind(internalServerEndpoint);
// Launch pool of worker threads, precise number is not critical
#if !php
for (thread_nbr in 0 ... 5) {
Thread.create(callback(serverWorker,context));
}
#end
// Connect backend to frontend via queue device
// We could do this via
// new ZMQDevice(ZMQ_QUEUE, frontend, backend);
// but doing it ourselves means we can debug this more easily
// Switch messages between frontend and backend
var poller:ZMQPoller = new ZMQPoller();
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
while (true) {
try {
poller.poll( -1);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace (e.toString());
break;
}
if (poller.pollin(1)) {
var msg = ZMsg.recvMsg(frontend);
//trace("Request from client:"+msg.toString());
msg.send(backend);
}
if (poller.pollin(2)) {
var msg = ZMsg.recvMsg(backend);
//trace ("Reply from worker:" + msg.toString());
msg.send(frontend);
}
}
context.destroy();
}
public static function main() {
Lib.println("** ASyncSrv (see: http://zguide.zeromq.org/page:all#Asynchronous-Client-Server)");
var context = new ZContext();
#if php
forkClientTask(context);
forkClientTask(context);
forkClientTask(context);
forkServerTask(context);
#else
Thread.create(callback(clientTask, context));
Thread.create(callback(clientTask, context));
Thread.create(callback(clientTask, context));
Thread.create(callback(serverTask, context));
#end
// Run for 5 seconds then quit
Sys.sleep(5);
context.destroy();
}
#if php
private static inline function forkServerWorker(context:ZContext) {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
ASyncSrv::serverWorker($context);
exit();
}');
return;
}
private static inline function forkClientTask(context:ZContext) {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
ASyncSrv::clientTask($context);
exit();
}');
return;
}
private static inline function forkServerTask(context:ZContext) {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
ASyncSrv::serverTask($context);
exit();
}');
return;
}
#end
}asyncsrv: Asynchronous client/server in Java
package guide;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
//
//Asynchronous client-to-server (DEALER to ROUTER)
//
//While this example runs in a single process, that is just to make
//it easier to start and stop the example. Each task has its own
//context and conceptually acts as a separate process.
public class asyncsrv
{
//---------------------------------------------------------------------
//This is our client task
//It connects to the server, and then sends a request once per second
//It collects responses as they arrive, and it prints them out. We will
//run several client tasks in parallel, each with a different random ID.
private static Random rand = new Random(System.nanoTime());
private static class client_task implements Runnable
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket client = ctx.createSocket(SocketType.DEALER);
// Set random identity to make tracing easier
String identity = String.format(
"%04X-%04X", rand.nextInt(), rand.nextInt()
);
client.setIdentity(identity.getBytes(ZMQ.CHARSET));
client.connect("tcp://localhost:5570");
Poller poller = ctx.createPoller(1);
poller.register(client, Poller.POLLIN);
int requestNbr = 0;
while (!Thread.currentThread().isInterrupted()) {
// Tick once per second, pulling in arriving messages
for (int centitick = 0; centitick < 100; centitick++) {
poller.poll(10);
if (poller.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(client);
msg.getLast().print(identity);
msg.destroy();
}
}
client.send(String.format("request #%d", ++requestNbr), 0);
}
}
}
}
//This is our server task.
//It uses the multithreaded server model to deal requests out to a pool
//of workers and route replies back to clients. One worker can handle
//one request at a time but one client can talk to multiple workers at
//once.
private static class server_task implements Runnable
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
// Frontend socket talks to clients over TCP
Socket frontend = ctx.createSocket(SocketType.ROUTER);
frontend.bind("tcp://*:5570");
// Backend socket talks to workers over inproc
Socket backend = ctx.createSocket(SocketType.DEALER);
backend.bind("inproc://backend");
// Launch pool of worker threads, precise number is not critical
for (int threadNbr = 0; threadNbr < 5; threadNbr++)
new Thread(new server_worker(ctx)).start();
// Connect backend to frontend via a proxy
ZMQ.proxy(frontend, backend, null);
}
}
}
//Each worker task works on one request at a time and sends a random number
//of replies back, with random delays between replies:
private static class server_worker implements Runnable
{
private ZContext ctx;
public server_worker(ZContext ctx)
{
this.ctx = ctx;
}
@Override
public void run()
{
Socket worker = ctx.createSocket(SocketType.DEALER);
worker.connect("inproc://backend");
while (!Thread.currentThread().isInterrupted()) {
// The DEALER socket gives us the address envelope and message
ZMsg msg = ZMsg.recvMsg(worker);
ZFrame address = msg.pop();
ZFrame content = msg.pop();
assert (content != null);
msg.destroy();
// Send 0..4 replies back
int replies = rand.nextInt(5);
for (int reply = 0; reply < replies; reply++) {
// Sleep for some fraction of a second
try {
Thread.sleep(rand.nextInt(1000) + 1);
}
catch (InterruptedException e) {
}
address.send(worker, ZFrame.REUSE + ZFrame.MORE);
content.send(worker, ZFrame.REUSE);
}
address.destroy();
content.destroy();
}
ctx.destroy();
}
}
//The main thread simply starts several clients, and a server, and then
//waits for the server to finish.
public static void main(String[] args) throws Exception
{
new Thread(new client_task()).start();
new Thread(new client_task()).start();
new Thread(new client_task()).start();
new Thread(new server_task()).start();
// Run for 5 seconds then quit
Thread.sleep(5 * 1000);
}
}
asyncsrv: Asynchronous client/server in Julia
asyncsrv: Asynchronous client/server in Lua
--
-- Asynchronous client-to-server (DEALER to ROUTER)
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each task has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zmsg"
require"zhelpers"
local NBR_CLIENTS = 3
-- ---------------------------------------------------------------------
-- This is our client task
-- It connects to the server, and then sends a request once per second
-- It collects responses as they arrive, and it prints them out. We will
-- run several client tasks in parallel, each with a different random ID.
local client_task = [[
local identity, seed = ...
local zmq = require"zmq"
require"zmq.poller"
require"zmq.threads"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(seed)
local context = zmq.init(1)
local client = context:socket(zmq.DEALER)
-- Generate printable identity for the client
client:setopt(zmq.IDENTITY, identity)
client:connect("tcp://localhost:5570")
local poller = zmq.poller(2)
poller:add(client, zmq.POLLIN, function()
local msg = zmsg.recv (client)
printf ("%s: %s\n", identity, msg:body())
end)
local request_nbr = 0
while true do
-- Tick once per second, pulling in arriving messages
local centitick
for centitick=1,100 do
poller:poll(10000)
end
local msg = zmsg.new()
request_nbr = request_nbr + 1
msg:body_fmt("request #%d", request_nbr)
msg:send(client)
end
-- Clean up and end task properly
client:close()
context:term()
]]
-- ---------------------------------------------------------------------
-- This is our server task
-- It uses the multithreaded server model to deal requests out to a pool
-- of workers and route replies back to clients. One worker can handle
-- one request at a time but one client can talk to multiple workers at
-- once.
local server_task = [[
local server_worker = ...
local zmq = require"zmq"
require"zmq.poller"
require"zmq.threads"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(os.time())
local context = zmq.init(1)
-- Frontend socket talks to clients over TCP
local frontend = context:socket(zmq.ROUTER)
frontend:bind("tcp://*:5570")
-- Backend socket talks to workers over inproc
local backend = context:socket(zmq.DEALER)
backend:bind("inproc://backend")
-- Launch pool of worker threads, precise number is not critical
local workers = {}
for n=1,5 do
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(context, server_worker, seed)
workers[n]:start()
end
-- Connect backend to frontend via a queue device
-- We could do this:
-- zmq:device(.QUEUE, frontend, backend)
-- But doing it ourselves means we can debug this more easily
local poller = zmq.poller(2)
poller:add(frontend, zmq.POLLIN, function()
local msg = zmsg.recv (frontend)
--print ("Request from client:")
--msg:dump()
msg:send(backend)
end)
poller:add(backend, zmq.POLLIN, function()
local msg = zmsg.recv (backend)
--print ("Reply from worker:")
--msg:dump()
msg:send(frontend)
end)
-- Switch messages between frontend and backend
poller:start()
for n=1,5 do
assert(workers[n]:join())
end
frontend:close()
backend:close()
context:term()
]]
-- Accept a request and reply with the same text a random number of
-- times, with random delays between replies.
--
local server_worker = [[
local seed = ...
local zmq = require"zmq"
require"zmq.threads"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(seed)
local threads = require"zmq.threads"
local context = threads.get_parent_ctx()
local worker = context:socket(zmq.DEALER)
worker:connect("inproc://backend")
while true do
-- The DEALER socket gives us the address envelope and message
local msg = zmsg.recv (worker)
assert (msg:parts() == 2)
-- Send 0..4 replies back
local reply
local replies = randof (5)
for reply=1,replies do
-- Sleep for some fraction of a second
s_sleep (randof (1000) + 1)
local dup = msg:dup()
dup:send(worker)
end
end
worker:close()
]]
-- This main thread simply starts several clients, and a server, and then
-- waits for the server to finish.
--
s_version_assert (2, 1)
local clients = {}
for n=1,NBR_CLIENTS do
local identity = string.format("%04X", randof (0x10000))
local seed = os.time() + math.random()
clients[n] = zmq.threads.runstring(nil, client_task, identity, seed)
clients[n]:start()
end
local server = zmq.threads.runstring(nil, server_task, server_worker)
assert(server:start())
assert(server:join())
asyncsrv: Asynchronous client/server in Node.js
cluster = require('cluster')
, zmq = require('zeromq')
, backAddr = 'tcp://127.0.0.1:12345'
, frontAddr = 'tcp://127.0.0.1:12346'
, clients = 5
, workers = 2;
// We do this bit repeatedly. Should use with connect or bindSync.
function makeASocket(sockType, idPrefix, addr, bindSyncOrConnect) {
var sock = zmq.socket(sockType)
sock.identity = idPrefix + process.pid
// call the function name in bindSyncOrConnect
sock[bindSyncOrConnect](addr)
return sock
}
function clientTask(){
var sock = makeASocket('dealer', 'client', frontAddr, 'connect')
var count = 0;
var interval = setInterval(function() {
sock.send('request ' + count++)
if (count >= 10){
sock.close()
cluster.worker.kill() // Done after 10 messages
}
}, Math.ceil(Math.random() * 500))
sock.on('message', function(data) {
var args = Array.apply(null, arguments)
console.log(sock.identity + " <- '" + args + "'");
})
}
function serverTask(){
var backSvr = makeASocket('dealer', 'back', backAddr, 'bindSync')
backSvr.on('message', function(){
var args = Array.apply(null, arguments)
frontSvr.send(args)
})
var frontSvr = makeASocket('router', 'front', frontAddr, 'bindSync')
frontSvr.on('message', function(){
var args = Array.apply(null, arguments)
backSvr.send(args)
})
}
function workerTask(){
var sock = makeASocket('dealer', 'wkr', backAddr , 'connect')
sock.on('message', function() {
var args = Array.apply(null, arguments)
var replies = Math.ceil(Math.random() * 4);
var count = 0;
var interval = setInterval(function(){
sock.send([args[0], '', 'response ' + count++])
if (count == replies){
clearInterval(interval)
}
}, Math.floor(Math.random() * 10)) // sleep a small random time
})
}
// Node process management noise below
if (cluster.isMaster) {
// create the workers and clients.
// Use env variables to dictate client or worker
for (var i = 0; i < workers; i++) {
cluster.fork({ "TYPE": 'worker'})
}
for (var i = 0; i < clients; i++) {
cluster.fork({ "TYPE": 'client' })
}
cluster.on('death', function(worker) {
console.log('worker ' + worker.pid + ' died');
});
var deadClients = 0;
cluster.on('disconnect', function(worker) {
deadClients++
if (deadClients === clients) {
console.log('finished')
process.exit(0)
}
});
serverTask()
} else {
if (process.env.TYPE === 'client') {
clientTask()
} else {
workerTask()
}
}
asyncsrv: Asynchronous client/server in Objective-C
asyncsrv: Asynchronous client/server in ooc
asyncsrv: Asynchronous client/server in Perl
asyncsrv: Asynchronous client/server in PHP
<?php
/*
* Asynchronous client-to-server (DEALER to ROUTER)
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each task has its own
* context and conceptually acts as a separate process.
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
/* ---------------------------------------------------------------------
* This is our client task
* It connects to the server, and then sends a request once per second
* It collects responses as they arrive, and it prints them out. We will
* run several client tasks in parallel, each with a different random ID.
*/
function client_task()
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
// Generate printable identity for the client
$identity = sprintf ("%04X", rand(0, 0x10000));
$client->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $identity);
$client->connect("tcp://localhost:5570");
$read = $write = array();
$poll = new ZMQPoll();
$poll->add($client, ZMQ::POLL_IN);
$request_nbr = 0;
while (true) {
// Tick once per second, pulling in arriving messages
for ($centitick = 0; $centitick < 100; $centitick++) {
$events = $poll->poll($read, $write, 1000);
$zmsg = new Zmsg($client);
if ($events) {
$zmsg->recv();
printf ("%s: %s%s", $identity, $zmsg->body(), PHP_EOL);
}
}
$zmsg = new Zmsg($client);
$zmsg->body_fmt("request #%d", ++$request_nbr)->send();
}
}
/* ---------------------------------------------------------------------
* This is our server task
* It uses the multithreaded server model to deal requests out to a pool
* of workers and route replies back to clients. One worker can handle
* one request at a time but one client can talk to multiple workers at
* once.
*/
function server_task()
{
// Launch pool of worker threads, precise number is not critical
for ($thread_nbr = 0; $thread_nbr < 5; $thread_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
server_worker();
exit();
}
}
$context = new ZMQContext();
// Frontend socket talks to clients over TCP
$frontend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$frontend->bind("tcp://*:5570");
// Backend socket talks to workers over ipc
$backend = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
$backend->bind("ipc://backend");
// Connect backend to frontend via a queue device
// We could do this:
// $device = new ZMQDevice($frontend, $backend);
// But doing it ourselves means we can debug this more easily
$read = $write = array();
// Switch messages between frontend and backend
while (true) {
$poll = new ZMQPoll();
$poll->add($frontend, ZMQ::POLL_IN);
$poll->add($backend, ZMQ::POLL_IN);
$poll->poll($read, $write);
foreach ($read as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
if ($socket === $frontend) {
//echo "Request from client:";
//echo $zmsg->__toString();
$zmsg->set_socket($backend)->send();
} elseif ($socket === $backend) {
//echo "Request from worker:";
//echo $zmsg->__toString();
$zmsg->set_socket($frontend)->send();
}
}
}
}
function server_worker()
{
$context = new ZMQContext();
$worker = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
$worker->connect("ipc://backend");
$zmsg = new Zmsg($worker);
while (true) {
// The DEALER socket gives us the address envelope and message
$zmsg->recv();
assert($zmsg->parts() == 2);
// Send 0..4 replies back
$replies = rand(0,4);
for ($reply = 0; $reply < $replies; $reply++) {
// Sleep for some fraction of a second
usleep(rand(0,1000) + 1);
$zmsg->send(false);
}
}
}
/* This main thread simply starts several clients, and a server, and then
* waits for the server to finish.
*/
function main()
{
for ($num_clients = 0; $num_clients < 3; $num_clients++) {
$pid = pcntl_fork();
if ($pid == 0) {
client_task();
exit();
}
}
$pid = pcntl_fork();
if ($pid == 0) {
server_task();
exit();
}
}
main();
asyncsrv: Asynchronous client/server in Python
import zmq
import sys
import threading
import time
from random import randint, random
__author__ = "Felipe Cruz <felipecruz@loogica.net>"
__license__ = "MIT/X11"
def tprint(msg):
"""like print, but won't get newlines confused with multiple threads"""
sys.stdout.write(msg + '\n')
sys.stdout.flush()
class ClientTask(threading.Thread):
"""ClientTask"""
def __init__(self, id):
self.id = id
threading.Thread.__init__ (self)
def run(self):
context = zmq.Context()
socket = context.socket(zmq.DEALER)
identity = u'worker-%d' % self.id
socket.identity = identity.encode('ascii')
socket.connect('tcp://localhost:5570')
print('Client %s started' % (identity))
poll = zmq.Poller()
poll.register(socket, zmq.POLLIN)
reqs = 0
while True:
reqs = reqs + 1
print('Req #%d sent..' % (reqs))
socket.send_string(u'request #%d' % (reqs))
for i in range(5):
sockets = dict(poll.poll(1000))
if socket in sockets:
msg = socket.recv()
tprint('Client %s received: %s' % (identity, msg))
socket.close()
context.term()
class ServerTask(threading.Thread):
"""ServerTask"""
def __init__(self):
threading.Thread.__init__ (self)
def run(self):
context = zmq.Context()
frontend = context.socket(zmq.ROUTER)
frontend.bind('tcp://*:5570')
backend = context.socket(zmq.DEALER)
backend.bind('inproc://backend')
workers = []
for i in range(5):
worker = ServerWorker(context)
worker.start()
workers.append(worker)
zmq.proxy(frontend, backend)
frontend.close()
backend.close()
context.term()
class ServerWorker(threading.Thread):
"""ServerWorker"""
def __init__(self, context):
threading.Thread.__init__ (self)
self.context = context
def run(self):
worker = self.context.socket(zmq.DEALER)
worker.connect('inproc://backend')
tprint('Worker started')
while True:
ident, msg = worker.recv_multipart()
tprint('Worker received %s from %s' % (msg, ident))
replies = randint(0,4)
for i in range(replies):
time.sleep(1. / (randint(1,10)))
worker.send_multipart([ident, msg])
worker.close()
def main():
"""main function"""
server = ServerTask()
server.start()
for i in range(3):
client = ClientTask(i)
client.start()
server.join()
if __name__ == "__main__":
main()
asyncsrv: Asynchronous client/server in Q
asyncsrv: Asynchronous client/server in Racket
asyncsrv: Asynchronous client/server in Ruby
asyncsrv: Asynchronous client/server in Rust
asyncsrv: Asynchronous client/server in Scala
asyncsrv: Asynchronous client/server in Tcl
asyncsrv: Asynchronous client/server in OCaml
The example runs in one process, with multiple threads simulating a real multiprocess architecture. When you run the example, you’ll see three clients (each with a random ID), printing out the replies they get from the server. Look carefully and you’ll see each client task gets 0 or more replies per request.
Some comments on this code:
-
The clients send a request once per second, and get zero or more replies back. To make this work using zmq_poll(), we can’t simply poll with a 1-second timeout, or we’d end up sending a new request only one second after we received the last reply. So we poll at a high frequency (100 times at 1/100th of a second per poll), which is approximately accurate.
-
The server uses a pool of worker threads, each processing one request synchronously. It connects these to its frontend socket using an internal queue. It connects the frontend and backend sockets using a zmq_proxy() call.
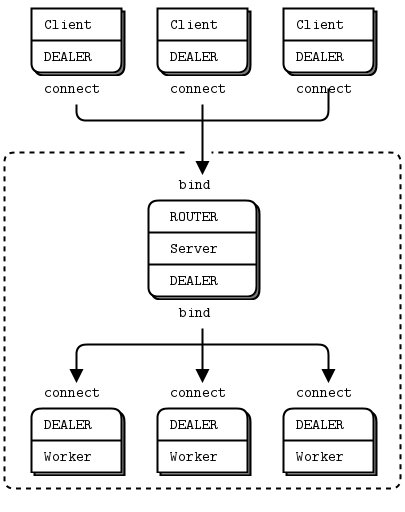
Note that we’re doing DEALER to ROUTER dialog between client and server, but internally between the server main thread and workers, we’re doing DEALER to DEALER. If the workers were strictly synchronous, we’d use REP. However, because we want to send multiple replies, we need an async socket. We do not want to route replies, they always go to the single server thread that sent us the request.
Let’s think about the routing envelope. The client sends a message consisting of a single frame. The server thread receives a two-frame message (original message prefixed by client identity). We send these two frames on to the worker, which treats it as a normal reply envelope, returns that to us as a two frame message. We then use the first frame as an identity to route the second frame back to the client as a reply.
It looks something like this:
client server frontend worker
[ DEALER ]<---->[ ROUTER <----> DEALER <----> DEALER ]
1 part 2 parts 2 parts
Now for the sockets: we could use the load balancing ROUTER to DEALER pattern to talk to workers, but it’s extra work. In this case, a DEALER to DEALER pattern is probably fine: the trade-off is lower latency for each request, but higher risk of unbalanced work distribution. Simplicity wins in this case.
When you build servers that maintain stateful conversations with clients, you will run into a classic problem. If the server keeps some state per client, and clients keep coming and going, eventually it will run out of resources. Even if the same clients keep connecting, if you’re using default identities, each connection will look like a new one.
We cheat in the above example by keeping state only for a very short time (the time it takes a worker to process a request) and then throwing away the state. But that’s not practical for many cases. To properly manage client state in a stateful asynchronous server, you have to:
-
Do heartbeating from client to server. In our example, we send a request once per second, which can reliably be used as a heartbeat.
-
Store state using the client identity (whether generated or explicit) as key.
-
Detect a stopped heartbeat. If there’s no request from a client within, say, two seconds, the server can detect this and destroy any state it’s holding for that client.
Worked Example: Inter-Broker Routing #
Let’s take everything we’ve seen so far, and scale things up to a real application. We’ll build this step-by-step over several iterations. Our best client calls us urgently and asks for a design of a large cloud computing facility. He has this vision of a cloud that spans many data centers, each a cluster of clients and workers, and that works together as a whole. Because we’re smart enough to know that practice always beats theory, we propose to make a working simulation using ZeroMQ. Our client, eager to lock down the budget before his own boss changes his mind, and having read great things about ZeroMQ on Twitter, agrees.
Establishing the Details #
Several espressos later, we want to jump into writing code, but a little voice tells us to get more details before making a sensational solution to entirely the wrong problem. “What kind of work is the cloud doing?”, we ask.
The client explains:
-
Workers run on various kinds of hardware, but they are all able to handle any task. There are several hundred workers per cluster, and as many as a dozen clusters in total.
-
Clients create tasks for workers. Each task is an independent unit of work and all the client wants is to find an available worker, and send it the task, as soon as possible. There will be a lot of clients and they’ll come and go arbitrarily.
-
The real difficulty is to be able to add and remove clusters at any time. A cluster can leave or join the cloud instantly, bringing all its workers and clients with it.
-
If there are no workers in their own cluster, clients’ tasks will go off to other available workers in the cloud.
-
Clients send out one task at a time, waiting for a reply. If they don’t get an answer within X seconds, they’ll just send out the task again. This isn’t our concern; the client API does it already.
-
Workers process one task at a time; they are very simple beasts. If they crash, they get restarted by whatever script started them.
So we double-check to make sure that we understood this correctly:
-
“There will be some kind of super-duper network interconnect between clusters, right?”, we ask. The client says, “Yes, of course, we’re not idiots.”
-
“What kind of volumes are we talking about?”, we ask. The client replies, “Up to a thousand clients per cluster, each doing at most ten requests per second. Requests are small, and replies are also small, no more than 1K bytes each.”
So we do a little calculation and see that this will work nicely over plain TCP. 2,500 clients x 10/second x 1,000 bytes x 2 directions = 50MB/sec or 400Mb/sec, not a problem for a 1Gb network.
It’s a straightforward problem that requires no exotic hardware or protocols, just some clever routing algorithms and careful design. We start by designing one cluster (one data center) and then we figure out how to connect clusters together.
Architecture of a Single Cluster #
Workers and clients are synchronous. We want to use the load balancing pattern to route tasks to workers. Workers are all identical; our facility has no notion of different services. Workers are anonymous; clients never address them directly. We make no attempt here to provide guaranteed delivery, retry, and so on.
For reasons we already examined, clients and workers won’t speak to each other directly. It makes it impossible to add or remove nodes dynamically. So our basic model consists of the request-reply message broker we saw earlier.
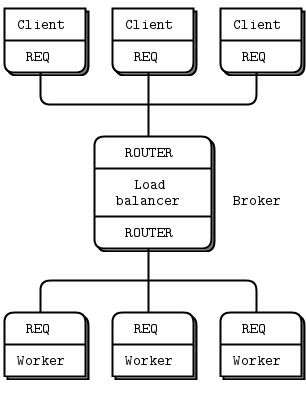
Scaling to Multiple Clusters #
Now we scale this out to more than one cluster. Each cluster has a set of clients and workers, and a broker that joins these together.
The question is: how do we get the clients of each cluster talking to the workers of the other cluster? There are a few possibilities, each with pros and cons:
-
Clients could connect directly to both brokers. The advantage is that we don’t need to modify brokers or workers. But clients get more complex and become aware of the overall topology. If we want to add a third or forth cluster, for example, all the clients are affected. In effect we have to move routing and failover logic into the clients and that’s not nice.
-
Workers might connect directly to both brokers. But REQ workers can’t do that, they can only reply to one broker. We might use REPs but REPs don’t give us customizable broker-to-worker routing like load balancing does, only the built-in load balancing. That’s a fail; if we want to distribute work to idle workers, we precisely need load balancing. One solution would be to use ROUTER sockets for the worker nodes. Let’s label this “Idea #1”.
-
Brokers could connect to each other. This looks neatest because it creates the fewest additional connections. We can’t add clusters on the fly, but that is probably out of scope. Now clients and workers remain ignorant of the real network topology, and brokers tell each other when they have spare capacity. Let’s label this “Idea #2”.
Let’s explore Idea #1. In this model, we have workers connecting to both brokers and accepting jobs from either one.
It looks feasible. However, it doesn’t provide what we wanted, which was that clients get local workers if possible and remote workers only if it’s better than waiting. Also workers will signal “ready” to both brokers and can get two jobs at once, while other workers remain idle. It seems this design fails because again we’re putting routing logic at the edges.
So, idea #2 then. We interconnect the brokers and don’t touch the clients or workers, which are REQs like we’re used to.
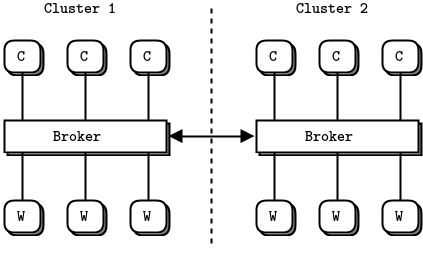
This design is appealing because the problem is solved in one place, invisible to the rest of the world. Basically, brokers open secret channels to each other and whisper, like camel traders, “Hey, I’ve got some spare capacity. If you have too many clients, give me a shout and we’ll deal”.
In effect it is just a more sophisticated routing algorithm: brokers become subcontractors for each other. There are other things to like about this design, even before we play with real code:
-
It treats the common case (clients and workers on the same cluster) as default and does extra work for the exceptional case (shuffling jobs between clusters).
-
It lets us use different message flows for the different types of work. That means we can handle them differently, e.g., using different types of network connection.
-
It feels like it would scale smoothly. Interconnecting three or more brokers doesn’t get overly complex. If we find this to be a problem, it’s easy to solve by adding a super-broker.
We’ll now make a worked example. We’ll pack an entire cluster into one process. That is obviously not realistic, but it makes it simple to simulate, and the simulation can accurately scale to real processes. This is the beauty of ZeroMQ–you can design at the micro-level and scale that up to the macro-level. Threads become processes, and then become boxes and the patterns and logic remain the same. Each of our “cluster” processes contains client threads, worker threads, and a broker thread.
We know the basic model well by now:
- The REQ client (REQ) threads create workloads and pass them to the broker (ROUTER).
- The REQ worker (REQ) threads process workloads and return the results to the broker (ROUTER).
- The broker queues and distributes workloads using the load balancing pattern.
Federation Versus Peering #
There are several possible ways to interconnect brokers. What we want is to be able to tell other brokers, “we have capacity”, and then receive multiple tasks. We also need to be able to tell other brokers, “stop, we’re full”. It doesn’t need to be perfect; sometimes we may accept jobs we can’t process immediately, then we’ll do them as soon as possible.
The simplest interconnect is federation, in which brokers simulate clients and workers for each other. We would do this by connecting our frontend to the other broker’s backend socket. Note that it is legal to both bind a socket to an endpoint and connect it to other endpoints.
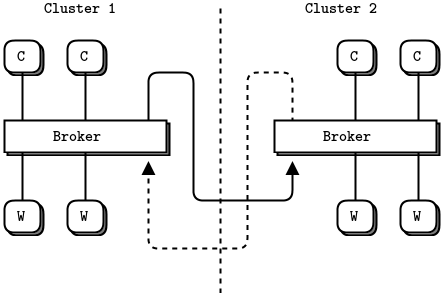
This would give us simple logic in both brokers and a reasonably good mechanism: when there are no workers, tell the other broker “ready”, and accept one job from it. The problem is also that it is too simple for this problem. A federated broker would be able to handle only one task at a time. If the broker emulates a lock-step client and worker, it is by definition also going to be lock-step, and if it has lots of available workers they won’t be used. Our brokers need to be connected in a fully asynchronous fashion.
The federation model is perfect for other kinds of routing, especially service-oriented architectures (SOAs), which route by service name and proximity rather than load balancing or round robin. So don’t dismiss it as useless, it’s just not right for all use cases.
Instead of federation, let’s look at a peering approach in which brokers are explicitly aware of each other and talk over privileged channels. Let’s break this down, assuming we want to interconnect N brokers. Each broker has (N - 1) peers, and all brokers are using exactly the same code and logic. There are two distinct flows of information between brokers:
-
Each broker needs to tell its peers how many workers it has available at any time. This can be fairly simple information–just a quantity that is updated regularly. The obvious (and correct) socket pattern for this is pub-sub. So every broker opens a PUB socket and publishes state information on that, and every broker also opens a SUB socket and connects that to the PUB socket of every other broker to get state information from its peers.
-
Each broker needs a way to delegate tasks to a peer and get replies back, asynchronously. We’ll do this using ROUTER sockets; no other combination works. Each broker has two such sockets: one for tasks it receives and one for tasks it delegates. If we didn’t use two sockets, it would be more work to know whether we were reading a request or a reply each time. That would mean adding more information to the message envelope.
And there is also the flow of information between a broker and its local clients and workers.
The Naming Ceremony #
Three flows x two sockets for each flow = six sockets that we have to manage in the broker. Choosing good names is vital to keeping a multisocket juggling act reasonably coherent in our minds. Sockets do something and what they do should form the basis for their names. It’s about being able to read the code several weeks later on a cold Monday morning before coffee, and not feel any pain.
Let’s do a shamanistic naming ceremony for the sockets. The three flows are:
- A local request-reply flow between the broker and its clients and workers.
- A cloud request-reply flow between the broker and its peer brokers.
- A state flow between the broker and its peer brokers.
Finding meaningful names that are all the same length means our code will align nicely. It’s not a big thing, but attention to details helps. For each flow the broker has two sockets that we can orthogonally call the frontend and backend. We’ve used these names quite often. A frontend receives information or tasks. A backend sends those out to other peers. The conceptual flow is from front to back (with replies going in the opposite direction from back to front).
So in all the code we write for this tutorial, we will use these socket names:
- localfe and localbe for the local flow.
- cloudfe and cloudbe for the cloud flow.
- statefe and statebe for the state flow.
For our transport and because we’re simulating the whole thing on one box, we’ll use ipc for everything. This has the advantage of working like tcp in terms of connectivity (i.e., it’s a disconnected transport, unlike inproc), yet we don’t need IP addresses or DNS names, which would be a pain here. Instead, we will use ipc endpoints called something-local, something-cloud, and something-state, where something is the name of our simulated cluster.
You might be thinking that this is a lot of work for some names. Why not call them s1, s2, s3, s4, etc.? The answer is that if your brain is not a perfect machine, you need a lot of help when reading code, and we’ll see that these names do help. It’s easier to remember “three flows, two directions” than “six different sockets”.
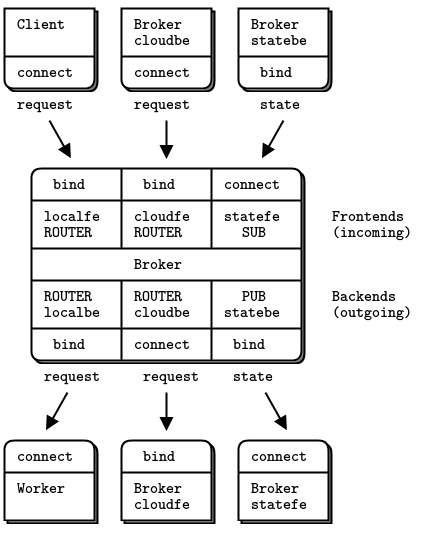
Note that we connect the cloudbe in each broker to the cloudfe in every other broker, and likewise we connect the statebe in each broker to the statefe in every other broker.
Prototyping the State Flow #
Because each socket flow has its own little traps for the unwary, we will test them in real code one-by-one, rather than try to throw the whole lot into code in one go. When we’re happy with each flow, we can put them together into a full program. We’ll start with the state flow.
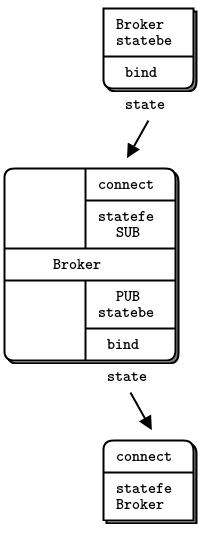
Here is how this works in code:
peering1: Prototype state flow in Ada
peering1: Prototype state flow in Basic
peering1: Prototype state flow in C
// Broker peering simulation (part 1)
// Prototypes the state flow
#include "czmq.h"
int main (int argc, char *argv [])
{
// First argument is this broker's name
// Other arguments are our peers' names
//
if (argc < 2) {
printf ("syntax: peering1 me {you}...\n");
return 0;
}
char *self = argv [1];
printf ("I: preparing broker at %s...\n", self);
srandom ((unsigned) time (NULL));
zctx_t *ctx = zctx_new ();
// Bind state backend to endpoint
void *statebe = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (statebe, "ipc://%s-state.ipc", self);
// Connect statefe to all peers
void *statefe = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (statefe, "");
int argn;
for (argn = 2; argn < argc; argn++) {
char *peer = argv [argn];
printf ("I: connecting to state backend at '%s'\n", peer);
zsocket_connect (statefe, "ipc://%s-state.ipc", peer);
}
// .split main loop
// The main loop sends out status messages to peers, and collects
// status messages back from peers. The zmq_poll timeout defines
// our own heartbeat:
while (true) {
// Poll for activity, or 1 second timeout
zmq_pollitem_t items [] = { { statefe, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, 1000 * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
// Handle incoming status messages
if (items [0].revents & ZMQ_POLLIN) {
char *peer_name = zstr_recv (statefe);
char *available = zstr_recv (statefe);
printf ("%s - %s workers free\n", peer_name, available);
free (peer_name);
free (available);
}
else {
// Send random values for worker availability
zstr_sendm (statebe, self);
zstr_sendf (statebe, "%d", randof (10));
}
}
zctx_destroy (&ctx);
return EXIT_SUCCESS;
}
peering1: Prototype state flow in C++
//
// Created by ninehs on 4/29/22.
//
//
// Broker peering simulation (part 1)
// Prototypes the state flow
//
#include "zhelpers.hpp"
#define ZMQ_POLL_MSEC 1
int main(int argc, char *argv[]) {
// First argument is this broker's name
// Other arguments are our peers' names
if (argc < 2) {
std::cout << "syntax: peering1 me {you} ..." << std::endl;
return 0;
}
std::string self(argv[1]);
std::cout << "I: preparing broker at " << self << " ..." << std::endl;
srandom(static_cast<unsigned int>(time(nullptr)));
zmq::context_t context(1);
// Bind state backend to endpoint
zmq::socket_t statebe(context, zmq::socket_type::pub);
std::string bindURL = std::string("ipc://").append(self).append("-state.ipc");
statebe.bind(bindURL);
// Connect statefe to all peers
zmq::socket_t statefe(context, zmq::socket_type::sub);
statefe.set(zmq::sockopt::subscribe, "");
for(int argn = 2 ; argn < argc ; ++argn) {
std::string peer(argv[argn]);
std::string peerURL = std::string("ipc://").append(peer).append("-state.ipc");
statefe.connect(peerURL);
}
// The main loop sends out status messages to peers, and collects
// status messages back from peers. The zmq_poll timeout defines
// our own heartbeat
while(true) {
//
zmq::pollitem_t items[] = {
{statefe, 0, ZMQ_POLLIN, 0}
};
try {
zmq::poll(items, 1, 1000 * ZMQ_POLL_MSEC);
} catch(...) {
break;
}
if (items[0].revents & ZMQ_POLLIN) {
std::string peer_name(s_recv(statefe));
std::string available(s_recv(statefe));
std::cout << "\"" << self << "\" received subscribed message: \"" << peer_name << "\" has "
<< available << " workers available" << std::endl;
} else {
s_sendmore(statebe, self);
std::ostringstream intStream;
intStream << within(10);
s_send(statebe, intStream.str());
std::cout << "\"" << self << "\" broadcast: " << intStream.str() << " workers available." << std::endl;
}
}
return 0;
}
peering1: Prototype state flow in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
//
// Broker peering simulation (part 1)
// Prototypes the state flow
//
// Author: metadings
//
public static void Peering1(string[] args)
{
// First argument is this broker's name
// Other arguments are our peers' names
//
if (args == null || args.Length < 2)
{
Console.WriteLine();
Console.WriteLine("Usage: {0} Peering1 World Receiver0", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine(" {0} Peering1 Receiver0 World", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
return;
}
string self = args[0];
Console.WriteLine("I: preparing broker as {0}", self);
using (var context = new ZContext())
using (var backend = new ZSocket(context, ZSocketType.PUB))
using (var frontend = new ZSocket(context, ZSocketType.SUB))
{
// Bind backend to endpoint
backend.Bind("tcp://127.0.0.1:" + Peering1_GetPort(self));
// Connect frontend to all peers
frontend.SubscribeAll();
for (int i = 1; i < args.Length; ++i)
{
string peer = args[i];
Console.WriteLine("I: connecting to state backend at {0}", peer);
frontend.Connect("tcp://127.0.0.1:" + Peering1_GetPort(peer));
}
// The main loop sends out status messages to peers, and collects
// status messages back from peers. The zmq_poll timeout defines
// our own heartbeat:
ZError error;
ZMessage incoming;
var poll = ZPollItem.CreateReceiver();
var rnd = new Random();
while (true)
{
// Poll for activity, or 1 second timeout
if (!frontend.PollIn(poll, out incoming, out error, TimeSpan.FromSeconds(1)))
{
if (error == ZError.EAGAIN)
{
using (var output = new ZMessage())
{
output.Add(new ZFrame(self));
var outputNumber = ZFrame.Create(4);
outputNumber.Write(rnd.Next(10));
output.Add(outputNumber);
backend.Send(output);
}
continue;
}
if (error == ZError.ETERM)
return;
throw new ZException(error);
}
using (incoming)
{
string peer_name = incoming[0].ReadString();
int available = incoming[1].ReadInt32();
Console.WriteLine("{0} - {1} workers free", peer_name, available);
}
}
}
}
static Int16 Peering1_GetPort(string name)
{
var hash = (Int16)name.GetHashCode();
if (hash < 1024)
{
hash += 1024;
}
return hash;
}
}
}
peering1: Prototype state flow in CL
peering1: Prototype state flow in Delphi
program peering1;
//
// Broker peering simulation (part 1)
// Prototypes the state flow
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
self,
peer: Utf8String;
ctx: TZMQContext;
statebe,
statefe: TZMQSocket;
i, rc: Integer;
poller: TZMQPoller;
peer_name,
available: Utf8String;
begin
// First argument is this broker's name
// Other arguments are our peers' names
//
if ParamCount < 2 then
begin
Writeln( 'syntax: peering1 me {you}...' );
Halt( 1 );
end;
self := ParamStr( 1 );
Writeln( Format( 'I: preparing broker at %s...', [self]) );
Randomize;
ctx := TZMQContext.create;
// Bind state backend to endpoint
statebe := ctx.Socket( stPub );
{$ifdef unix}
statebe.bind( Format( 'ipc://%s-state.ipc', [self] ) );
{$else}
statebe.bind( Format( 'tcp://127.0.0.1:%s', [self] ) );
{$endif}
// Connect statefe to all peers
statefe := ctx.Socket( stSub );
statefe.Subscribe('');
for i := 2 to ParamCount do
begin
peer := ParamStr( i );
Writeln( Format( 'I: connecting to state backend at "%s"', [peer] ) );
{$ifdef unix}
statefe.connect( Format( 'ipc://%s-state.ipc', [peer] ) );
{$else}
statefe.connect( Format( 'tcp://127.0.0.1:%s', [peer] ) );
{$endif}
end;
// The main loop sends out status messages to peers, and collects
// status messages back from peers. The zmq_poll timeout defines
// our own heartbeat:
while not ctx.Terminated do
begin
// Poll for activity, or 1 second timeout
poller := TZMQPoller.Create( true );
poller.Register( statefe, [pePollIn] );
rc := poller.poll( 1000 );
// Handle incoming status messages
if pePollIn in poller.PollItem[0].revents then
//if pePollIn in poller.PollItem[0].events then
begin
statefe.recv( peer_name );
statefe.recv( available );
Writeln( Format( '%s - %s workers free', [ peer_name, available] ) );
end else
statebe.send( [self, IntToStr( Random( 10 ) ) ] );
end;
ctx.Free;
end.
peering1: Prototype state flow in Erlang
peering1: Prototype state flow in Elixir
peering1: Prototype state flow in F#
(*
Broker peering simulation (part 1)
Prototypes the state flow
*)
#r @"bin/fszmq.dll"
#r @"bin/fszmq.devices.dll"
open fszmq
open fszmq.Context
open fszmq.devices
open fszmq.Polling
open fszmq.Socket
#load "zhelpers.fs"
let main args =
// first argument is this broker's name
// other arguments are our peers' names
match args |> Array.length with
| n when n > 1 ->
let rand = srandom()
let self = args.[1]
printfn "I: preparing broker at %s..." self
// prepare our context and sockets
use ctx = new Context(1)
use statebe = ctx |> pub
bind statebe (sprintf "tcp://*:%s" self)
//NOTE: to run this example on Windows, we must use tcp...
// so when we do, assume inputs are port numbers
// on non-windows systems, we can use ipc (as per the guide)...
// so in *that* case, inputs are alphanumeric identifiers, eg:
//
// bind statebe (sprintf "ipc://%s-state.ipc" self)
//
// connect statefe to all peers
use statefe = ctx |> sub
[""B] |> subscribe statefe
args.[2..] |> Array.iter (fun peer ->
printfn "I: connecting to state backend at '%s'" peer
connect statefe (sprintf "tcp://localhost:%s" peer))
//NOTE: see previous note about Windows and ipc vs. tcp
// send out status messages to peers, and collect from peers
// the zmq_poll timeout defines our own heartbeating
let items =
[ Poll(ZMQ.POLLIN,statefe,fun _ ->
let peer_name = statefe |> recv |> decode
let available = statefe |> recv |> decode
printfn "%s - %s workers free" peer_name available) ]
while true do
if not (items |> poll 10000L) then
// send random value for worker availability
statebe <~| (encode self)
<<| (rand.Next(0,10) |> string |> encode)
EXIT_SUCCESS
| _ ->
printfn "syntax: peering1 me {you}..."
EXIT_FAILURE
main fsi.CommandLineArgs
peering1: Prototype state flow in Felix
peering1: Prototype state flow in Go
// Broker peering simulation (part 1) in Python
//
// Author: amyangfei <amyangfei@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"os"
"time"
)
func main() {
if len(os.Args) < 2 {
fmt.Println("syntax: peering1 me {you}...")
return
}
myself := os.Args[1]
fmt.Printf("I: preparing broker at %s...\n", myself)
rand.Seed(time.Now().UnixNano())
context, _ := zmq.NewContext()
statebe, _ := context.NewSocket(zmq.PUB)
defer context.Close()
defer statebe.Close()
// Bind state backend to endpoint
bindAddress := fmt.Sprintf("ipc://%s-state.ipc", myself)
statebe.Bind(bindAddress)
// Connect statefe to all peers
statefe, _ := context.NewSocket(zmq.SUB)
defer statefe.Close()
statefe.SetSubscribe("")
for i := 2; i < len(os.Args); i++ {
peer := os.Args[i]
fmt.Printf("I: connecting to state backend at '%s'\n", peer)
statefe.Connect(fmt.Sprintf("ipc://%s-state.ipc", peer))
}
items := zmq.PollItems{
zmq.PollItem{Socket: statefe, Events: zmq.POLLIN},
}
for {
zmq.Poll(items, time.Second)
// Handle incomming status messages
if items[0].REvents&zmq.POLLIN != 0 {
msg, _ := statefe.RecvMultipart(0)
fmt.Printf("%s - %s workers free\n", string(msg[0]), string(msg[1]))
} else {
// Send random values for worker availability
statebe.SendMultipart([][]byte{[]byte(myself), []byte(fmt.Sprintf("%d", rand.Intn(10)))}, 0)
}
}
}
peering1: Prototype state flow in Haskell
{-# LANGUAGE OverloadedLists #-}
{-# LANGUAGE OverloadedStrings #-}
module Main where
import Control.Monad (forever, when)
import qualified Data.ByteString.Char8 as C
import Data.Semigroup ((<>))
import System.Environment
import System.Exit
import System.Random
import System.ZMQ4.Monadic
connectPeer :: Socket z t -> String -> String -> ZMQ z ()
connectPeer sock name peer = do
connect sock (connectString peer name)
liftIO . putStrLn $ "Connecting to peer: " ++ connectString peer name
connectString :: String -> String -> String
connectString peer name = "ipc://" ++ peer ++ "-" ++ name ++ ".ipc"
main :: IO ()
main = do
args <- getArgs
when (length args < 2) $ do
putStrLn "Usage: peering1 <me> <you> [<you> ...]"
exitFailure
let self:peers = args
putStrLn $ "Preparing broker at " ++ self
runZMQ $ do
-- Bind state backend to endpoint
stateBack <- socket Pub
bind stateBack (connectString self "state")
-- Connect state frontend to peers
stateFront <- socket Sub
subscribe stateFront ""
mapM_ (connectPeer stateFront "state") peers
-- Send status, collect status
forever $ do
let pollItem = Sock stateFront [In] (Just pollEvent)
pollEvent _ = do
peerName:available:_ <- receiveMulti stateFront
liftIO . C.putStrLn $
peerName <> " " <> available <> " workers free"
pollEvents <- poll oneSec [pollItem]
when (pollEvents == [[]]) $ do
r <- liftIO $ randomRIO (0, 9)
sendMulti stateBack [C.pack self, C.pack (show (r :: Int))]
where
oneSec = 1000
peering1: Prototype state flow in Haxe
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQException;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMsg;
import org.zeromq.ZSocket;
/**
* Broker peering simulation (part 1)
* Prototypes the state flow.
*
* NB: If running from Run.hx, set ARG_OFFSET to 1
* If running directly, set ARG_OFFSET to 0
*/
class Peering1
{
private static inline var ARG_OFFSET = 1;
public static function main() {
Lib.println("** Peering1 (see: http://zguide.zeromq.org/page:all#Prototyping-the-State-Flow)");
// First argument is this broker's name
// Other arguments are our peers' names
if (Sys.args().length < 2+ARG_OFFSET) {
Lib.println("syntax: ./Peering1 me {you} ...");
return;
}
var self = Sys.args()[0+ARG_OFFSET];
Lib.println("I: preparing broker at " + self + " ...");
// Prepare our context and sockets
var ctx = new ZContext();
var statebe = ctx.createSocket(ZMQ_PUB);
statebe.bind("ipc:///tmp/" + self + "-state.ipc");
// Connect statefe to all peers
var statefe = ctx.createSocket(ZMQ_SUB);
statefe.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
for (argn in 1+ARG_OFFSET ... Sys.args().length) {
var peer = Sys.args()[argn];
Lib.println("I: connecting to state backend at '" + peer + "'");
statefe.connect("ipc:///tmp/" + peer + "-state.ipc");
}
// Send out status messages to peers, and collect from peers
// The ZMQPoller timeout defines our own heartbeating
//
var poller = new ZMQPoller();
while (true) {
// Initialise poll set
poller.registerSocket(statefe, ZMQ.ZMQ_POLLIN());
try {
// Poll for activity, or 1 second timeout
var res = poller.poll(1000 * 1000);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace (e.toString());
return;
}
// Handle incoming status messages
if (poller.pollin(1)) {
var msg = ZMsg.recvMsg(statefe);
var peerNameFrame = msg.first();
var availableFrame = msg.last();
Lib.println(peerNameFrame.toString() + " - " + availableFrame.toString() + " workers free");
} else {
// Send random value for worker availability
// We stick our own address onto the envelope
var msg:ZMsg = new ZMsg();
msg.addString(self);
msg.addString(Std.string(ZHelpers.randof(10)));
msg.send(statebe);
}
}
ctx.destroy();
}
}peering1: Prototype state flow in Java
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
// Broker peering simulation (part 1)
// Prototypes the state flow
public class peering1
{
public static void main(String[] argv)
{
// First argument is this broker's name
// Other arguments are our peers' names
//
if (argv.length < 1) {
System.out.println("syntax: peering1 me {you}\n");
System.exit(-1);
}
String self = argv[0];
System.out.println(String.format("I: preparing broker at %s\n", self));
Random rand = new Random(System.nanoTime());
try (ZContext ctx = new ZContext()) {
// Bind state backend to endpoint
Socket statebe = ctx.createSocket(SocketType.PUB);
statebe.bind(String.format("ipc://%s-state.ipc", self));
// Connect statefe to all peers
Socket statefe = ctx.createSocket(SocketType.SUB);
statefe.subscribe(ZMQ.SUBSCRIPTION_ALL);
int argn;
for (argn = 1; argn < argv.length; argn++) {
String peer = argv[argn];
System.out.printf(
"I: connecting to state backend at '%s'\n", peer
);
statefe.connect(String.format("ipc://%s-state.ipc", peer));
}
// The main loop sends out status messages to peers, and collects
// status messages back from peers. The zmq_poll timeout defines
// our own heartbeat.
Poller poller = ctx.createPoller(1);
poller.register(statefe, Poller.POLLIN);
while (true) {
// Poll for activity, or 1 second timeout
int rc = poller.poll(1000);
if (rc == -1)
break; // Interrupted
// Handle incoming status messages
if (poller.pollin(0)) {
String peer_name = new String(statefe.recv(0), ZMQ.CHARSET);
String available = new String(statefe.recv(0), ZMQ.CHARSET);
System.out.printf(
"%s - %s workers free\n", peer_name, available
);
}
else {
// Send random values for worker availability
statebe.send(self, ZMQ.SNDMORE);
statebe.send(String.format("%d", rand.nextInt(10)), 0);
}
}
}
}
}
peering1: Prototype state flow in Julia
peering1: Prototype state flow in Lua
--
-- Broker peering simulation (part 1)
-- Prototypes the state flow
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmsg"
-- First argument is this broker's name
-- Other arguments are our peers' names
--
if (#arg < 1) then
printf ("syntax: peering1 me doyouend...\n")
os.exit(-1)
end
local self = arg[1]
printf ("I: preparing broker at %s...\n", self)
math.randomseed(os.time())
-- Prepare our context and sockets
local context = zmq.init(1)
-- Bind statebe to endpoint
local statebe = context:socket(zmq.PUB)
local endpoint = string.format("ipc://%s-state.ipc", self)
assert(statebe:bind(endpoint))
-- Connect statefe to all peers
local statefe = context:socket(zmq.SUB)
statefe:setopt(zmq.SUBSCRIBE, "", 0)
for n=2,#arg do
local peer = arg[n]
printf ("I: connecting to state backend at '%s'\n", peer)
local endpoint = string.format("ipc://%s-state.ipc", peer)
assert(statefe:connect(endpoint))
end
local poller = zmq.poller(1)
-- Send out status messages to peers, and collect from peers
-- The zmq_poll timeout defines our own heartbeating
--
poller:add(statefe, zmq.POLLIN, function()
local msg = zmsg.recv (statefe)
printf ("%s - %s workers free\n",
msg:address(), msg:body())
end)
while true do
-- Poll for activity, or 1 second timeout
local count = assert(poller:poll(1000000))
-- if no other activity.
if count == 0 then
-- Send random value for worker availability
local msg = zmsg.new()
msg:body_fmt("%d", randof (10))
-- We stick our own address onto the envelope
msg:wrap(self, nil)
msg:send(statebe)
end
end
-- We never get here but clean up anyhow
statebe:close()
statefe:close()
context:term()
peering1: Prototype state flow in Node.js
// Broker peering simulation (part 1)
// Prototypes the state flow
var zmq = require('zeromq')
, util = require('util');
if (process.argv.length < 3) {
console.log('usage: node peering1.js me [you ...]');
process.exit(0);
}
var self = process.argv[2];
console.log("I: preparing broker at %s…", self);
// flag for stopping timer
var done = false;
//
// Backend
//
var statebe = zmq.socket('pub');
statebe.bindSync(util.format("ipc://%s-state.ipc", self));
//
// Frontend
//
var statefe = zmq.socket('sub');
statefe.subscribe('');
for (var i = 3; i < process.argv.length; i++) {
var peer = process.argv[i];
console.log("I: connecting to state backend at '%s'", peer);
statefe.connect(util.format("ipc://%s-state.ipc", peer));
}
process.on('SIGINT', function() {
done = true;
statebe.close();
statefe.close();
});
// The main loop sends out status messages to peers, and collects
// status messages back from peers.
statefe.on('message', function(peer_name, available) {
console.log("%s - %s workers free", peer_name, available);
});
function sendWorkerAvailability() {
if (done) {
return;
}
var num_workers = util.format("%d", Math.floor(10 * Math.random()));
console.log("sending update: %s has %s", self, num_workers);
statebe.send([ self, num_workers ]);
var next_send_delay = Math.floor(3000 * Math.random());
setTimeout(sendWorkerAvailability, next_send_delay);
}
// Start worker update timer loop
sendWorkerAvailability();
peering1: Prototype state flow in Objective-C
peering1: Prototype state flow in ooc
peering1: Prototype state flow in Perl
peering1: Prototype state flow in PHP
<?php
/*
* Broker peering simulation (part 1)
* Prototypes the state flow
*/
// First argument is this broker's name
// Other arguments are our peers' names
if ($_SERVER['argc'] < 2) {
echo "syntax: peering1 me {you}...", PHP_EOL;
exit();
}
$self = $_SERVER['argv'][1];
printf ("I: preparing broker at %s... %s", $self, PHP_EOL);
// Prepare our context and sockets
$context = new ZMQContext();
// Bind statebe to endpoint
$statebe = $context->getSocket(ZMQ::SOCKET_PUB);
$endpoint = sprintf("ipc://%s-state.ipc", $self);
$statebe->bind($endpoint);
// Connect statefe to all peers
$statefe = $context->getSocket(ZMQ::SOCKET_SUB);
$statefe->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "");
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
$peer = $_SERVER['argv'][$argn];
printf ("I: connecting to state backend at '%s'%s", $peer, PHP_EOL);
$endpoint = sprintf("ipc://%s-state.ipc", $peer);
$statefe->connect($endpoint);
}
$readable = $writeable = array();
// Send out status messages to peers, and collect from peers
// The zmq_poll timeout defines our own heartbeating
while (true) {
// Initialize poll set
$poll = new ZMQPoll();
$poll->add($statefe, ZMQ::POLL_IN);
// Poll for activity, or 1 second timeout
$events = $poll->poll($readable, $writeable, 1000);
if ($events > 0) {
// Handle incoming status message
foreach ($readable as $socket) {
$address = $socket->recv();
$body = $socket->recv();
printf ("%s - %s workers free%s", $address, $body, PHP_EOL);
}
} else {
// We stick our own address onto the envelope
$statebe->send($self, ZMQ::MODE_SNDMORE);
// Send random value for worker availability
$statebe->send(mt_rand(1, 10));
}
}
// We never get here
peering1: Prototype state flow in Python
#
# Broker peering simulation (part 1) in Python
# Prototypes the state flow
#
# Author : Piero Cornice
# Contact: root(at)pieroland(dot)net
#
import sys
import time
import random
import zmq
def main(myself, others):
print("Hello, I am %s" % myself)
context = zmq.Context()
# State Back-End
statebe = context.socket(zmq.PUB)
# State Front-End
statefe = context.socket(zmq.SUB)
statefe.setsockopt(zmq.SUBSCRIBE, b'')
bind_address = u"ipc://%s-state.ipc" % myself
statebe.bind(bind_address)
for other in others:
statefe.connect(u"ipc://%s-state.ipc" % other)
time.sleep(1.0)
poller = zmq.Poller()
poller.register(statefe, zmq.POLLIN)
while True:
########## Solution with poll() ##########
socks = dict(poller.poll(1000))
# Handle incoming status message
if socks.get(statefe) == zmq.POLLIN:
msg = statefe.recv_multipart()
print('%s Received: %s' % (myself, msg))
else:
# Send our address and a random value
# for worker availability
msg = [bind_address, (u'%i' % random.randrange(1, 10))]
msg = [ m.encode('ascii') for m in msg]
statebe.send_multipart(msg)
##################################
######### Solution with select() #########
# pollin, pollout, pollerr = zmq.select([statefe], [], [], 1)
#
# if pollin and pollin[0] == statefe:
# # Handle incoming status message
# msg = statefe.recv_multipart()
# print 'Received:', msg
#
# else:
# # Send our address and a random value
# # for worker availability
# msg = [bind_address, str(random.randrange(1, 10))]
# statebe.send_multipart(msg)
##################################
if __name__ == '__main__':
if len(sys.argv) >= 2:
main(myself=sys.argv[1], others=sys.argv[2:])
else:
print("Usage: peering.py <myself> <peer_1> ... <peer_N>")
sys.exit(1)
peering1: Prototype state flow in Q
peering1: Prototype state flow in Racket
peering1: Prototype state flow in Ruby
peering1: Prototype state flow in Rust
peering1: Prototype state flow in Scala
peering1: Prototype state flow in Tcl
peering1: Prototype state flow in OCaml
Notes about this code:
-
Each broker has an identity that we use to construct ipc endpoint names. A real broker would need to work with TCP and a more sophisticated configuration scheme. We’ll look at such schemes later in this book, but for now, using generated ipc names lets us ignore the problem of where to get TCP/IP addresses or names.
-
We use a zmq_poll() loop as the core of the program. This processes incoming messages and sends out state messages. We send a state message only if we did not get any incoming messages and we waited for a second. If we send out a state message each time we get one in, we’ll get message storms.
-
We use a two-part pub-sub message consisting of sender address and data. Note that we will need to know the address of the publisher in order to send it tasks, and the only way is to send this explicitly as a part of the message.
-
We don’t set identities on subscribers because if we did then we’d get outdated state information when connecting to running brokers.
-
We don’t set a HWM on the publisher, but if we were using ZeroMQ v2.x that would be a wise idea.
We can build this little program and run it three times to simulate three clusters. Let’s call them DC1, DC2, and DC3 (the names are arbitrary). We run these three commands, each in a separate window:
peering1 DC1 DC2 DC3 # Start DC1 and connect to DC2 and DC3
peering1 DC2 DC1 DC3 # Start DC2 and connect to DC1 and DC3
peering1 DC3 DC1 DC2 # Start DC3 and connect to DC1 and DC2
You’ll see each cluster report the state of its peers, and after a few seconds they will all happily be printing random numbers once per second. Try this and satisfy yourself that the three brokers all match up and synchronize to per-second state updates.
In real life, we’d not send out state messages at regular intervals, but rather whenever we had a state change, i.e., whenever a worker becomes available or unavailable. That may seem like a lot of traffic, but state messages are small and we’ve established that the inter-cluster connections are super fast.
If we wanted to send state messages at precise intervals, we’d create a child thread and open the statebe socket in that thread. We’d then send irregular state updates to that child thread from our main thread and allow the child thread to conflate them into regular outgoing messages. This is more work than we need here.
Prototyping the Local and Cloud Flows #
Let’s now prototype the flow of tasks via the local and cloud sockets. This code pulls requests from clients and then distributes them to local workers and cloud peers on a random basis.
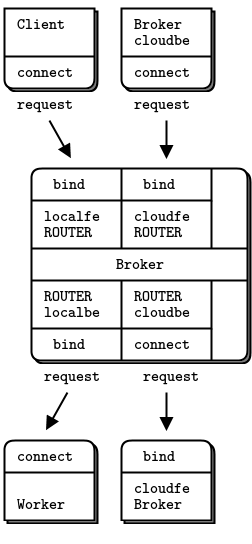
Before we jump into the code, which is getting a little complex, let’s sketch the core routing logic and break it down into a simple yet robust design.
We need two queues, one for requests from local clients and one for requests from cloud clients. One option would be to pull messages off the local and cloud frontends, and pump these onto their respective queues. But this is kind of pointless because ZeroMQ sockets are queues already. So let’s use the ZeroMQ socket buffers as queues.
This was the technique we used in the load balancing broker, and it worked nicely. We only read from the two frontends when there is somewhere to send the requests. We can always read from the backends, as they give us replies to route back. As long as the backends aren’t talking to us, there’s no point in even looking at the frontends.
So our main loop becomes:
-
Poll the backends for activity. When we get a message, it may be “ready” from a worker or it may be a reply. If it’s a reply, route back via the local or cloud frontend.
-
If a worker replied, it became available, so we queue it and count it.
-
While there are workers available, take a request, if any, from either frontend and route to a local worker, or randomly, to a cloud peer.
Randomly sending tasks to a peer broker rather than a worker simulates work distribution across the cluster. It’s dumb, but that is fine for this stage.
We use broker identities to route messages between brokers. Each broker has a name that we provide on the command line in this simple prototype. As long as these names don’t overlap with the ZeroMQ-generated UUIDs used for client nodes, we can figure out whether to route a reply back to a client or to a broker.
Here is how this works in code. The interesting part starts around the comment “Interesting part”.
peering2: Prototype local and cloud flow in Ada
peering2: Prototype local and cloud flow in Basic
peering2: Prototype local and cloud flow in C
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
#include "czmq.h"
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
#define WORKER_READY "\001" // Signals worker is ready
// Our own name; in practice this would be configured per node
static char *self;
// .split client task
// The client task does a request-reply dialog using a standard
// synchronous REQ socket:
static void client_task(zsock_t *pipe, void *args) {
// Signal caller zactor has started
zsock_signal(pipe, 0);
zsock_t *client = zsock_new(ZMQ_REQ);
zsock_connect(client, "ipc://%s-localfe.ipc", self);
zpoller_t *poll = zpoller_new(pipe, client, NULL);
while (true) {
// Send request, get reply
zstr_send (client, "HELLO");
zsock_t *ready = zpoller_wait(poll, -1);
if (ready == pipe || ready == NULL)
break; // Done
assert(ready == client);
char *reply = zstr_recv(client);
if (!reply)
break; // Interrupted
printf ("Client: %s\n", reply);
free (reply);
sleep (1);
}
zsock_destroy(&client);
zpoller_destroy(&poll);
// Signal done
zsock_signal(pipe, 0);
}
// .split worker task
// The worker task plugs into the load-balancer using a REQ
// socket:
static void worker_task(zsock_t *pipe, void *args) {
// Signal caller zactor has started
zsock_signal(pipe, 0);
zsock_t *worker = zsock_new(ZMQ_REQ);
zsock_connect(worker, "ipc://%s-localbe.ipc", self);
// Tell broker we're ready for work
zframe_t *frame = zframe_new(WORKER_READY, 1);
zframe_send(&frame, worker, 0);
// Process messages as they arrive
zpoller_t *poll = zpoller_new(pipe, worker, NULL);
while (true) {
zsock_t *ready = zpoller_wait(poll, -1);
if (ready == pipe || ready == NULL)
break; // Done
assert(ready == worker);
zmsg_t *msg = zmsg_recv(worker);
if (!msg)
break; // Interrupted
zframe_print(zmsg_last(msg), "Worker: ");
zframe_reset(zmsg_last(msg), "OK", 2);
zmsg_send(&msg, worker);
}
if (frame) zframe_destroy(&frame);
zsock_destroy(&worker);
zpoller_destroy(&poll);
// Signal done
zsock_signal(pipe, 0);
}
// .split main task
// The main task begins by setting-up its frontend and backend sockets
// and then starting its client and worker tasks:
int main(int argc, char *argv[]) {
// First argument is this broker's name
// Other arguments are our peers' names
//
if (argc < 2) {
printf("syntax: peering2 me {you}...\n");
return 0;
}
self = argv[1];
printf("I: preparing broker at %s...\n", self);
srandom((unsigned)time(NULL));
// Bind cloud frontend to endpoint
zsock_t *cloudfe = zsock_new(ZMQ_ROUTER);
zsock_set_identity(cloudfe, self);
zsock_bind(cloudfe, "ipc://%s-cloud.ipc", self);
// Connect cloud backend to all peers
zsock_t *cloudbe = zsock_new(ZMQ_ROUTER);
zsock_set_identity(cloudbe, self);
int argn;
for (argn = 2; argn < argc; argn++) {
char *peer = argv[argn];
printf("I: connecting to cloud frontend at '%s'\n", peer);
zsock_connect(cloudbe, "ipc://%s-cloud.ipc", peer);
}
// Prepare local frontend and backend
zsock_t *localfe = zsock_new(ZMQ_ROUTER);
zsock_bind(localfe, "ipc://%s-localfe.ipc", self);
zsock_t *localbe = zsock_new(ZMQ_ROUTER);
zsock_bind(localbe, "ipc://%s-localbe.ipc", self);
// Get user to tell us when we can start...
printf("Press Enter when all brokers are started: ");
getchar();
// Start local workers
int worker_nbr;
zactor_t *worker_actors[NBR_WORKERS];
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
worker_actors[worker_nbr] = zactor_new(worker_task, NULL);
// Start local clients
int client_nbr;
zactor_t *client_actors[NBR_CLIENTS];
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
client_actors[client_nbr] = zactor_new(client_task, NULL);
// Interesting part
// .split request-reply handling
// Here, we handle the request-reply flow. We're using load-balancing
// to poll workers at all times, and clients only when there are one
// or more workers available.
// Least recently used queue of available workers
int capacity = 0;
zlist_t *workers = zlist_new();
zpoller_t *poll_backends = zpoller_new(localbe, cloudbe, NULL);
zpoller_t *poll_frontends = zpoller_new(cloudfe, localfe, NULL);
while (true) {
// First, route any waiting replies from workers
// If we have no workers, wait indefinitely
zsock_t *ready = zpoller_wait(poll_backends, capacity ? 1000 * ZMQ_POLL_MSEC : -1);
zmsg_t *msg = NULL;
if (NULL == ready) {
if (zpoller_terminated(poll_backends))
break; // Interrupted
} else {
// Handle reply from local worker
if (ready == localbe) {
msg = zmsg_recv(localbe);
if (!msg) break; // Interrupted
zframe_t *identity = zmsg_unwrap(msg);
zlist_append(workers, identity);
capacity++;
// If it's READY, don't route the message any further
zframe_t *frame = zmsg_first(msg);
if (memcmp(zframe_data(frame), WORKER_READY, 1) == 0) zmsg_destroy(&msg);
}
// Or handle reply from peer broker
else if (ready == cloudbe) {
msg = zmsg_recv(cloudbe);
if (!msg) break; // Interrupted
// We don't use peer broker identity for anything
zframe_t *identity = zmsg_unwrap(msg);
zframe_destroy(&identity);
}
// Route reply to cloud if it's addressed to a broker
for (argn = 2; msg && argn < argc; argn++) {
char *data = (char *)zframe_data(zmsg_first(msg));
size_t size = zframe_size(zmsg_first(msg));
if (size == strlen(argv[argn]) && memcmp(data, argv[argn], size) == 0)
zmsg_send(&msg, cloudfe);
}
// Route reply to client if we still need to
if (msg) zmsg_send(&msg, localfe);
}
// .split route client requests
// Now we route as many client requests as we have worker capacity
// for. We may reroute requests from our local frontend, but not from
// the cloud frontend. We reroute randomly now, just to test things
// out. In the next version, we'll do this properly by calculating
// cloud capacity:
while (capacity) {
zsock_t *ready = zpoller_wait(poll_frontends, 0);
int reroutable = 0;
// We'll do peer brokers first, to prevent starvation
if (ready == cloudfe) {
msg = zmsg_recv(cloudfe);
reroutable = 0;
} else if (ready == localfe) {
msg = zmsg_recv(localfe);
reroutable = 1;
} else
break; // No work, go back to backends
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
if (reroutable && argc > 2 && randof(5) == 0) {
// Route to random broker peer
int peer = randof(argc - 2) + 2;
zmsg_pushmem(msg, argv[peer], strlen(argv[peer]));
zmsg_send(&msg, cloudbe);
} else {
zframe_t *frame = (zframe_t *)zlist_pop(workers);
zmsg_wrap(msg, frame);
zmsg_send(&msg, localbe);
capacity--;
}
}
}
// When we're done, clean up properly
while (zlist_size(workers)) {
zframe_t *frame = (zframe_t *)zlist_pop(workers);
zframe_destroy(&frame);
}
zlist_destroy(&workers);
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
zactor_destroy(&worker_actors[worker_nbr]);
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
zactor_destroy(&client_actors[client_nbr]);
zpoller_destroy(&poll_backends);
zpoller_destroy(&poll_frontends);
zsock_destroy(&cloudfe);
zsock_destroy(&cloudbe);
zsock_destroy(&localfe);
zsock_destroy(&localbe);
return EXIT_SUCCESS;
}
peering2: Prototype local and cloud flow in C++
//
// created by Jinyang Shao on 8/22/2024
//
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
#include "zhelpers.hpp"
#include <thread>
#include <queue>
#include <vector>
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
#define WORKER_READY "\001" // Signals worker is ready
#define ZMQ_POLL_MSEC 1
void receive_all_frames(zmq::socket_t& sock, std::vector<std::string>& frames) {
frames.clear();
while (1) {
// Process all parts of the message
std::string frame = s_recv(sock);
frames.emplace_back(frame);
int more = 0; // Multipart detection
size_t more_size = sizeof (more);
sock.getsockopt(ZMQ_RCVMORE, &more, &more_size);
if (!more)
break; // Last message part
}
return;
}
void send_all_frames(zmq::socket_t& sock, std::vector<std::string>& frames) {
for (int i = 0; i < frames.size(); i++) {
if (i == frames.size() - 1) {
s_send(sock, frames[i]);
} else {
s_sendmore(sock, frames[i]);
}
}
return;
}
void receive_empty_message(zmq::socket_t& sock)
{
std::string empty = s_recv(sock);
assert(empty.size() == 0);
}
void print_all_frames(std::vector<std::string>& frames) {
std::cout << "------------received------------" << std::endl;
for (std::string &frame : frames)
{
std::cout << frame << std::endl;
std::cout << "----------------------------------------" << std::endl;
}
}
// Broker's identity
static std::string self;
void client_thread(int id) {
zmq::context_t context(1);
zmq::socket_t client(context, ZMQ_REQ);
std::string connURL = std::string("ipc://").append(self).append("-localfe.ipc");
#if (defined (WIN32))
s_set_id(client, id);
client.connect(connURL); // localfe
#else
s_set_id(client); // Set a printable identity
client.connect(connURL);
#endif
while(true) {
// Send request, get reply
s_send(client, std::string("HELLO"));
std::string reply = s_recv(client);
std::cout << "Client" << reply << std::endl;
sleep(1);
}
return;
}
// Worker using REQ socket to do LRU routing
//
void worker_thread(int id) {
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_REQ);
std::string connURL = std::string("ipc://").append(self).append("-localbe.ipc");
#if (defined (WIN32))
s_set_id(worker, id);
worker.connect(connURL); // backend
#else
s_set_id(worker);
worker.connect(connURL);
#endif
// Tell broker we're ready for work
s_send(worker, std::string(WORKER_READY));
while (true) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
std::vector<std::string> frames;
receive_all_frames(worker, frames);
std::cout << "Worker: " << frames[frames.size()-1] << std::endl;
// Send reply
frames[frames.size()-1] = std::string("OK");
send_all_frames(worker, frames);
}
return;
}
int main(int argc, char *argv[]) {
// First argument is this broker's name
// Other arguments are our peers' names
if (argc < 2) {
std::cout << "syntax: peering2 me {you} ..." << std::endl;
return 0;
}
self = std::string(argv[1]);
std::cout << "I: preparing broker at " << self << " ..." << std::endl;
srandom(static_cast<unsigned int>(time(nullptr)));
zmq::context_t context(1);
// Bind cloud frontend to endpoint
zmq::socket_t cloudfe(context, ZMQ_ROUTER);
cloudfe.set(zmq::sockopt::routing_id, self); // remember to set identity
std::string bindURL = std::string("ipc://").append(self).append("-cloud.ipc");
cloudfe.bind(bindURL);
// Connect cloud backend to all peers
zmq::socket_t cloudbe(context, ZMQ_ROUTER);
cloudbe.set(zmq::sockopt::routing_id, self); // remember to set identity
for(int argn = 2 ; argn < argc ; ++argn) {
std::string peer(argv[argn]);
std::cout << "I: connecting to cloud frontend at " << peer << std::endl;
std::string peerURL = std::string("ipc://").append(peer).append("-cloud.ipc");
cloudbe.connect(peerURL);
}
// Prepare local frontend and backend
zmq::socket_t localfe(context, ZMQ_ROUTER);
{
std::string bindURL = std::string("ipc://").append(self).append("-localfe.ipc");
localfe.bind(bindURL);
}
zmq::socket_t localbe(context, ZMQ_ROUTER);
{
std::string bindURL = std::string("ipc://").append(self).append("-localbe.ipc");
localbe.bind(bindURL);
}
// Get user to tell us when we can start...
std::cout << "Press Enter when all brokers are started: " << std::endl;
getchar();
// Start local clients
int client_nbr = 0;
for (; client_nbr < NBR_CLIENTS; client_nbr++)
{
std::thread t(client_thread, client_nbr);
t.detach();
}
// Start local workers
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
{
std::thread t(worker_thread, worker_nbr);
t.detach();
}
// Interesting part
// .split request-reply handling
// Here, we handle the request-reply flow. We're using load-balancing
// to poll workers at all times, and clients only when there are one
// or more workers available.
// Least recently used queue of available workers
int capacity = 0;
std::queue<std::string> worker_queue;
zmq::pollitem_t frontend_items[] = {
{localfe, 0, ZMQ_POLLIN, 0},
{cloudfe, 0, ZMQ_POLLIN, 0}
};
zmq::pollitem_t backend_items[] = {
{localbe, 0, ZMQ_POLLIN, 0},
{cloudbe, 0, ZMQ_POLLIN, 0}
};
while(true) {
// First, route any waiting replies from workers
try {
// If we have no workers, wait indefinitely
std::chrono::milliseconds timeout{(capacity ? 1000 : -1)};
zmq::poll(backend_items, 2, timeout);
} catch(...) {
break;
}
if (backend_items[0].revents & ZMQ_POLLIN) {
// From localbe,Handle reply from local worker
std::string worker_identity = s_recv(localbe);
worker_queue.push(worker_identity);
capacity++;
receive_empty_message(localbe);
// Remain_frames may be:
// 1. [client_addr][0][OK]
// 2. [origin_broker][0][client_addr][0][OK]
// 3. [READY]
std::vector<std::string> remain_frames;
receive_all_frames(localbe, remain_frames);
assert(remain_frames.size() == 1 || remain_frames.size() == 3 || remain_frames.size() == 5);
// Third frame is READY or else a client reply address
std::string third_frame = remain_frames[0];
// If the third_frame is client_addr
if (third_frame.compare(WORKER_READY) != 0 && remain_frames.size() == 3) {
// Send to client
send_all_frames(localfe, remain_frames);
} else if (remain_frames.size() == 5) {
// The third_frame is origin_broker address
// Route the reply to the origin broker
for (int argn = 2; argn < argc; argn++) {
if (third_frame.compare(argv[argn]) == 0) {
send_all_frames(cloudfe, remain_frames);
}
}
}
} else if (backend_items[1].revents & ZMQ_POLLIN) {
// From cloudbe,handle reply from peer broker
std::string peer_broker_identity = s_recv(cloudbe); // useless
receive_empty_message(cloudbe);
std::string client_addr = s_recv(cloudbe);
receive_empty_message(cloudbe);
std::string reply = s_recv(cloudbe);
// Send to the client
s_sendmore(localfe, client_addr);
s_sendmore(localfe, std::string(""));
s_send(localfe, reply);
}
// .split route client requests
// Now we route as many client requests as we have worker capacity
// for. We may reroute requests from our local frontend, but not from
// the cloud frontend. We reroute randomly now, just to test things
// out. In the next version, we'll do this properly by calculating
// cloud capacity:
while (capacity){
try{
// No wait
zmq::poll(frontend_items, 2, 0);
}
catch (...) {
break;
}
bool reroutable = false; // not used in C++
if (frontend_items[0].revents & ZMQ_POLLIN) {
// From localfe, client's request
std::string client_addr = s_recv(localfe);
receive_empty_message(localfe);
std::string request = s_recv(localfe);
reroutable = true;
// Route in 20% of cases
if (argc > 2 && within(5) < 1) {
// Peers exist and routable
int peer = within(argc-2) + 2;
std::string peer_addr = argv[peer];
// Send to cloudbe, routing
s_sendmore(cloudbe, peer_addr);
s_sendmore(cloudbe, std::string(""));
s_sendmore(cloudbe, client_addr);
s_sendmore(cloudbe, std::string(""));
s_send(cloudbe, request);
} else {
// Use local workers
std::string worker_addr = worker_queue.front();
worker_queue.pop();
capacity--;
// Send to local worker
s_sendmore(localbe, worker_addr);
s_sendmore(localbe, std::string(""));
s_sendmore(localbe, client_addr);
s_sendmore(localbe, std::string(""));
s_send(localbe, request);
}
} else if (frontend_items[1].revents & ZMQ_POLLIN) {
// From cloudfe, other broker's request
std::string origin_peer_addr = s_recv(cloudfe);
receive_empty_message(cloudfe);
std::string client_addr = s_recv(cloudfe);
receive_empty_message(cloudfe);
std::string request = s_recv(cloudfe);
reroutable = false;
// Use local workers
std::string worker_addr = worker_queue.front();
worker_queue.pop();
capacity--;
// Send to local worker
s_sendmore(localbe, worker_addr);
s_sendmore(localbe, std::string(""));
s_sendmore(localbe, origin_peer_addr);
s_sendmore(localbe, std::string(""));
s_sendmore(localbe, client_addr);
s_sendmore(localbe, std::string(""));
s_send(localbe, request);
} else {
break; // No work, go back to backends
}
}
}
return 0;
}
peering2: Prototype local and cloud flow in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
//
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
//
// Author: metadings
//
static int Peering2_Clients = 10;
static int Peering2_Workers = 3;
static void Peering2_ClientTask(ZContext context, int i, string name, string message)
{
// The client task does a request-reply dialog
// using a standard synchronous REQ socket
using (var client = new ZSocket(context, ZSocketType.REQ))
{
// Set printable identity
client.IdentityString = name;
// Connect
client.Connect("tcp://127.0.0.1:" + Peering2_GetPort(name) + 1);
ZError error;
while (true)
{
// Send
using (var outgoing = new ZFrame(message))
{
client.Send(outgoing);
}
// Receive
ZFrame incoming = client.ReceiveFrame(out error);
if (incoming == null)
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
using (incoming)
{
Console.WriteLine("Client {0}: {1}", name, incoming.ReadString());
}
}
}
}
static void Peering2_WorkerTask(ZContext context, int i, string name)
{
// The worker task plugs into the load-balancer using a REQ socket
using (var worker = new ZSocket(context, ZSocketType.REQ))
{
// Set printable identity
worker.IdentityString = name;
// Connect
worker.Connect("tcp://127.0.0.1:" + Peering2_GetPort(name) + 2);
// Tell broker we're ready for work
worker.Send(new ZFrame("READY"));
// Process messages as they arrive
ZError error;
while (true)
{
// Receive
ZFrame incoming = worker.ReceiveFrame(out error);
if (incoming == null)
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
using (incoming)
{
Console.WriteLine("Worker {0}: {1}", name, incoming.ReadString());
// Do some heavy work
Thread.Sleep(1);
// Send
using (var outgoing = new ZFrame("OK"))
{
worker.Send(outgoing);
}
}
}
}
}
// The main task begins by setting-up its frontend and backend sockets
// and then starting its client and worker tasks:
public static void Peering2(string[] args)
{
// First argument is this broker's name
// Other arguments are our peers' names
//
if (args == null || args.Length < 3)
{
if (args != null && args.Length == 1)
{
args = new string[] { args[0], "Me", "You" };
}
else
{
Console.WriteLine("Usage: {0} Peering2 Hello Me You", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine(" {0} Peering2 Message You Me", AppDomain.CurrentDomain.FriendlyName);
return;
}
}
string message = args[0];
string name = args[1];
Console.WriteLine("I: preparing broker as {0}", name);
using (var context = new ZContext())
using (var cloudFrontend = new ZSocket(context, ZSocketType.ROUTER))
using (var cloudBackend = new ZSocket(context, ZSocketType.ROUTER))
using (var localFrontend = new ZSocket(context, ZSocketType.ROUTER))
using (var localBackend = new ZSocket(context, ZSocketType.ROUTER))
{
// Bind cloud frontend to endpoint
cloudFrontend.IdentityString = name;
cloudFrontend.Bind("tcp://127.0.0.1:" + Peering2_GetPort(name) + 0);
// Connect cloud backend to all peers
cloudBackend.IdentityString = name;
for (int i = 2; i < args.Length; ++i)
{
string peer = args[i];
Console.WriteLine("I: connecting to cloud frontend at {0}", peer);
cloudBackend.Connect("tcp://127.0.0.1:" + Peering2_GetPort(peer) + 0);
}
// Prepare local frontend and backend
localFrontend.Bind("tcp://127.0.0.1:" + Peering2_GetPort(name) + 1);
localBackend.Bind("tcp://127.0.0.1:" + Peering2_GetPort(name) + 2);
// Get user to tell us when we can start...
Console.WriteLine("Press ENTER when all brokers are started...");
Console.ReadKey(true);
// Start local workers
for (int i = 0; i < Peering2_Workers; ++i)
{
int j = i; new Thread(() => Peering2_WorkerTask(context, j, name)).Start();
}
// Start local clients
for (int i = 0; i < Peering2_Clients; ++i)
{
int j = i; new Thread(() => Peering2_ClientTask(context, j, name, message)).Start();
}
// Here, we handle the request-reply flow. We're using load-balancing
// to poll workers at all times, and clients only when there are one
// or more workers available.
// Least recently used queue of available workers
var workers = new List<string>();
ZError error;
ZMessage incoming;
TimeSpan? wait;
var poll = ZPollItem.CreateReceiver();
while (true)
{
// If we have no workers, wait indefinitely
wait = workers.Count > 0 ? (TimeSpan?)TimeSpan.FromMilliseconds(1000) : null;
// Poll localBackend
if (localBackend.PollIn(poll, out incoming, out error, wait))
{
// Handle reply from local worker
string identity = incoming[0].ReadString();
workers.Add(identity);
// If it's READY, don't route the message any further
string hello = incoming[2].ReadString();
if (hello == "READY")
{
incoming.Dispose();
incoming = null;
}
}
else if (error == ZError.EAGAIN && cloudBackend.PollIn(poll, out incoming, out error, wait))
{
// We don't use peer broker identity for anything
// string identity = incoming[0].ReadString();
// string ok = incoming[2].ReadString();
}
else
{
if (error == ZError.ETERM)
return; // Interrupted
if (error != ZError.EAGAIN)
throw new ZException(error);
}
if (incoming != null)
{
// Route reply to cloud if it's addressed to a broker
string identity = incoming[0].ReadString();
for (int i = 2; i < args.Length; ++i)
{
if (identity == args[i])
{
using (incoming)
cloudFrontend.Send(incoming);
incoming = null;
break;
}
}
}
// Route reply to client if we still need to
if (incoming != null)
{
using (incoming)
localFrontend.Send(incoming);
incoming = null;
}
// Now we route as many client requests as we have worker capacity
// for. We may reroute requests from our local frontend, but not from //
// the cloud frontend. We reroute randomly now, just to test things
// out. In the next version, we'll do this properly by calculating
// cloud capacity://
var rnd = new Random();
while (workers.Count > 0)
{
int reroutable = 0;
// We'll do peer brokers first, to prevent starvation
if (localFrontend.PollIn(poll, out incoming, out error, TimeSpan.FromMilliseconds(64)))
{
reroutable = 0;
}
else if (error == ZError.EAGAIN && cloudFrontend.PollIn(poll, out incoming, out error, TimeSpan.FromMilliseconds(64)))
{
reroutable = 1;
}
else
{
if (error == ZError.ETERM)
return; // Interrupted
if (error == ZError.EAGAIN)
break; // No work, go back to backends
throw new ZException(error);
}
using (incoming)
{
// If reroutable, send to cloud 25% of the time
// Here we'd normally use cloud status information
//
if (reroutable == 1 && rnd.Next(4) == 0)
{
// Route to random broker peer
int peer = rnd.Next(args.Length - 2) + 2;
incoming.ReplaceAt(0, new ZFrame(args[peer]));
/* using (var outgoing = new ZMessage())
{
outgoing.Add(new ZFrame(args[peer]));
outgoing.Add(new ZFrame());
outgoing.Add(incoming[2]);
cloudBackend.Send(outgoing);
} /**/
cloudBackend.Send(incoming);
}
else
{
// Route to local broker peer
string peer = workers[0];
workers.RemoveAt(0);
incoming.ReplaceAt(0, new ZFrame(peer));
/* using (var outgoing = new ZMessage())
{
outgoing.Add(new ZFrame(peer));
outgoing.Add(new ZFrame());
outgoing.Add(incoming[2]);
localBackend.Send(outgoing);
} /**/
localBackend.Send(incoming);
}
}
}
}
}
}
static Int16 Peering2_GetPort(string name)
{
var hash = (Int16)name.GetHashCode();
if (hash < 1024)
{
hash += 1024;
}
return hash;
}
}
}
peering2: Prototype local and cloud flow in CL
peering2: Prototype local and cloud flow in Delphi
program peering2;
//
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
, zhelpers
;
const
NBR_CLIENTS = 10;
NBR_WORKERS = 3;
WORKER_READY = '\001'; // Signals worker is ready
var
// Our own name; in practice this would be configured per node
self: Utf8String;
// The client task does a request-reply dialog using a standard
// synchronous REQ socket:
procedure client_task( args: Pointer; ctx: TZMQContext );
var
client: TZMQSocket;
reply: Utf8String;
begin
client := ctx.Socket( stReq );
{$ifdef unix}
client.connect( Format( 'ipc://%s-localfe.ipc', [self] ) );
{$else}
client.connect( Format( 'tcp://127.0.0.1:%s', [self] ) );
{$endif}
while not ctx.Terminated do
try
client.send( 'HELLO' );
client.recv( reply );
zNote( Format( 'Client: %s', [reply] ) );
sleep( 1000 );
except
end;
end;
// The worker task plugs into the load-balancer using a REQ
// socket:
procedure worker_task( args: Pointer; ctx: TZMQContext );
var
worker: TZMQSocket;
msg: TZMQMsg;
begin
worker := ctx.Socket( stReq );
{$ifdef unix}
worker.connect( Format( 'ipc://%s-localbe.ipc', [self] ) );
{$else}
worker.connect( Format( 'tcp://127.0.0.1:1%s', [self] ) );
{$endif}
// Tell broker we're ready for work
worker.send( WORKER_READY );
// Process messages as they arrive
while not ctx.Terminated do
try
msg := TZMQMsg.create;
worker.recv( msg );
zNote( Format( 'Worker: %s', [msg.last.dump] ) );
msg.last.asUtf8String := 'OK';
worker.send( msg );
except
end;
end;
var
ctx: TZMQContext;
cloudfe,
cloudbe,
localfe,
localbe: TZMQSocket;
i: Integer;
peer,
s: Utf8String;
workers: TZMQMsg;
pollerbe,
pollerfe: TZMQPoller;
rc,timeout: Integer;
msg: TZMQMsg;
identity,
frame: TZMQFrame;
data: Utf8String;
reroutable,
random_peer: Integer;
thr: TZMQThread;
// The main task begins by setting-up its frontend and backend sockets
// and then starting its client and worker tasks:
begin
// First argument is this broker's name
// Other arguments are our peers' names
//
if ParamCount < 2 then
begin
Writeln( 'syntax: peering2 me {you}...' );
halt( 1 );
end;
// on windows it should be a 1024 <= number <= 9999
self := ParamStr( 1 );
writeln( Format( 'I: preparing broker at %s', [self] ) );
randomize;
ctx := TZMQContext.create;
// Bind cloud frontend to endpoint
cloudfe := ctx.Socket( stRouter );
cloudfe.Identity := self;
{$ifdef unix}
cloudfe.bind( Format( 'ipc://%s-cloud.ipc', [self] ) );
{$else}
cloudfe.bind( Format( 'tcp://127.0.0.1:2%s', [self] ) );
{$endif}
// Connect cloud backend to all peers
cloudbe := ctx.Socket( stRouter );
cloudbe.Identity := self;
for i := 2 to ParamCount do
begin
peer := ParamStr( i );
Writeln( Format( 'I: connecting to cloud frontend at "%s"', [peer] ) );
{$ifdef unix}
cloudbe.connect( Format( 'ipc://%s-cloud.ipc', [peer] ) );
{$else}
cloudbe.connect( Format( 'tcp://127.0.0.1:2%s', [peer] ) );
{$endif}
end;
// Prepare local frontend and backend
localfe := ctx.Socket( stRouter );
{$ifdef unix}
localfe.bind( Format( 'ipc://%s-localfe.ipc', [self] ) );
{$else}
localfe.bind( Format( 'tcp://127.0.0.1:%s', [self] ) );
{$endif}
localbe := ctx.Socket( stRouter );
{$ifdef unix}
localbe.bind( Format( 'ipc://%s-localbe.ipc', [self] ) );
{$else}
localbe.bind( Format( 'tcp://127.0.0.1:1%s', [self] ) );
{$endif}
// Get user to tell us when we can start
Writeln( 'Press Enter when all brokers are started: ');
Readln( s );
// Start local workers
for i := 0 to NBR_WORKERS - 1 do
begin
thr := TZMQThread.CreateDetachedProc( worker_task, nil );
thr.FreeOnTerminate := true;
thr.Resume;
end;
// Start local clients
for i := 0 to NBR_CLIENTS - 1 do
begin
thr := TZMQThread.CreateDetachedProc( client_task, nil );
thr.FreeOnTerminate := true;
thr.Resume;
end;
// Here we handle the request-reply flow. We're using load-balancing
// to poll workers at all times, and clients only when there are one or
// more workers available.
// Least recently used queue of available workers
workers := TZMQMsg.Create;
pollerbe := TZMQPoller.Create( true );
pollerbe.Register( localbe, [pePollIn] );
pollerbe.Register( cloudbe, [pePollIn] );
// I could do it with one poller too.
pollerfe := TZMQPoller.Create( true );
pollerfe.Register( localfe, [pePollIn] );
pollerfe.Register( cloudfe, [pePollIn] );
while not ctx.Terminated do
try
// First, route any waiting replies from workers
// If we have no workers anyhow, wait indefinitely
if workers.size = 0 then
timeout := -1
else
timeout := 1000;
pollerbe.poll( timeout );
msg := nil;
// Handle reply from local worker
if pePollIn in pollerbe.PollItem[0].revents then
begin
msg := TZMQMsg.Create;
localbe.recv( msg );
identity := msg.unwrap;
workers.Add( identity );
// If it's READY, don't route the message any further
frame := msg.first;
if frame.asUtf8String = WORKER_READY then
begin
msg.Free;
msg := nil;
end;
// Or handle reply from peer broker
end else
if pePollIn in pollerbe.PollItem[1].revents then
begin
msg := TZMQMsg.create;
cloudbe.recv( msg );
// We don't use peer broker identity for anything
identity := msg.unwrap;
identity.Free;
end;
// Route reply to cloud if it's addressed to a broker
if msg <> nil then
for i := 2 to ParamCount do
begin
data := msg.first.asUtf8String;
if data = ParamStr( i ) then
cloudfe.send( msg );
end;
// Route reply to client if we still need to
if msg <> nil then
localfe.send( msg );
// Now we route as many client requests as we have worker capacity
// for. We may reroute requests from our local frontend, but not from //
// the cloud frontend. We reroute randomly now, just to test things
// out. In the next version we'll do this properly by calculating
// cloud capacity://
while workers.size > 0 do
begin
rc := pollerfe.poll( 0 );
Assert( rc >= 0 );
// We'll do peer brokers first, to prevent starvation
if pePollIn in pollerfe.PollItem[1].revents then
begin
msg := TZMQMsg.create;
cloudfe.recv( msg );
reroutable := 0;
end else
if pePollIn in pollerfe.PollItem[0].revents then
begin
msg := TZMQMsg.create;
localfe.recv( msg );
reroutable := 1;
end else
break; // No work, go back to backends
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
//
if ( reroutable > 0 ) and ( ParamCount >= 2 ) and ( Random( 5 ) = 1 ) then
begin
// Route to random broker peer
random_peer := random( ParamCount - 2 ) + 2;
identity := TZMQFrame.create;
identity.asUtf8String := ParamStr( random_peer );
msg.push( identity );
cloudbe.send( msg );
end else
begin
frame := workers.pop;
msg.wrap( frame );
localbe.send( msg );
end;
end;
except
end;
// When we're done, clean up properly
while workers.size > 0 do
begin
frame := workers.pop;
frame.Free;
end;
workers.Free;
ctx.Free;
end.
peering2: Prototype local and cloud flow in Erlang
peering2: Prototype local and cloud flow in Elixir
peering2: Prototype local and cloud flow in F#
(*
Broker peering simulation (part 2)
Prototypes the request-reply flow
While this example runs in a single process, that is just to make
it easier to start and stop the example. Each thread has its own
context and conceptually acts as a separate process.
*)
#r @"bin/fszmq.dll"
#r @"bin/fszmq.devices.dll"
open fszmq
open fszmq.Context
open fszmq.devices
open fszmq.Polling
open fszmq.Socket
#load "zhelpers.fs"
open System.Collections.Generic
let [<Literal>] NBR_CLIENTS = 10
let [<Literal>] NBR_WORKERS = 3
let LRU_READY = "\001"B
let client_task (o:obj) =
let fePort = o :?> int
use ctx = new Context(1)
use client = ctx |> req
connect client (sprintf "tcp://localhost:%i" fePort)
while true do
// send request, get reply
"HELLO"B |>> client
client
|> recvAll
|> Array.last
|> dumpFrame (Some "Client: ")
sleep 1
let worker_task (o:obj) =
let bePort = o :?> int
use ctx = new Context(1)
use worker = ctx |> req
connect worker (sprintf "tcp://localhost:%i" bePort)
// tell broker we're ready for work
LRU_READY |>> worker
// process messages as they arrive
while true do
let msg = worker |> recvAll
msg |> Array.last |> dumpFrame (Some "Worker: ")
msg.[msg.Length - 1] <- "OK"B
msg |> sendAll worker
let main args =
// first argument is this broker's name
// other arguments are our peers' names
match args |> Array.length with
| argc when argc > 1 ->
let self,peers = args.[1],if argc > 2 then args.[2..] else [||]
printfn' "I: preparing broker at %s..." self
let rand = srandom()
let fePort,bePort = let port = int self in port + 1,port + 2
//NOTE: to run this example on Windows, we must use tcp...
// so when we do, assume inputs are port numbers, and we use
// them as the basis for additional (internal to the cluster)
// port numbers on non-windows systems, we can use ipc (as per
// the guide) so in *that* case, inputs are alphanumeric IDs
// prepare our context and sockets
use ctx = new Context(1)
// bind cloud frontend to endpoint
use cloudfe = ctx |> route
(ZMQ.IDENTITY,encode self) |> set cloudfe
bind cloudfe (sprintf "tcp://*:%s" self)
// connect cloud backend to all peers
use cloudbe = ctx |> route
(ZMQ.IDENTITY,encode self) |> set cloudbe
peers |> Array.iter (fun peer ->
printfn' "I: connecting to cloud frontend at '%s'" peer
connect cloudbe (sprintf "tcp://localhost:%s" peer))
// prepare local frontend and backend
use localfe = ctx |> route
bind localfe (sprintf "tcp://*:%i" fePort)
use localbe = ctx |> route
bind localbe (sprintf "tcp://*:%i" bePort)
// get user to tell us when we can start...
printf' "Press Enter when all brokers are started: "
scanln() |> ignore
// start local workers
for _ in 1 .. NBR_WORKERS do ignore (t_spawnp worker_task bePort)
// start local clients
for _ in 1 .. NBR_CLIENTS do ignore (t_spawnp client_task fePort)
(* Interesting part
-------------------------------------------------------------
Request-reply flow
- Poll backends and process local/cloud replies
- While worker available, route localfe to local or cloud *)
// queue of available workers
let workers = Queue<byte array>()
// holds values collected/generated during polling
let msg = ref Array.empty<_>
let reroutable = ref false
let backends =
[ Poll(ZMQ.POLLIN,localbe,fun _ ->
// handle reply from local worker
let reply = localbe |> recvAll
reply.[0] |> workers.Enqueue
// if it's READY, don't route the message any further
msg := if reply.[2] = LRU_READY then [||] else reply.[2 ..])
Poll(ZMQ.POLLIN,cloudbe,fun _ ->
// or handle reply from peer broker
let frames = cloudbe |> recvAll
// we don't use peer broker address for anything
msg := frames.[2 ..]) ]
let frontends =
[ Poll(ZMQ.POLLIN,cloudfe,fun _ ->
msg := cloudfe |> recvAll
reroutable := false)
Poll(ZMQ.POLLIN,localfe,fun _ ->
msg := localfe |> recvAll
reroutable := true) ]
while true do
let timeout = if workers.Count > 0 then 10000L else -1L
if backends |> poll timeout && (!msg).Length > 0 then
let address = (!msg).[0] |> decode
// route reply to cloud if it's addressed to a broker
// otherwise route reply to client
!msg |> sendAll ( if peers |> Array.exists ((=) address)
then cloudfe
else localfe )
// Now route as many clients requests as we can handle
while workers.Count > 0 && frontends |> poll 0L do
// if reroutable, send to cloud 20% of the time
// here we'd normally use cloud status information
let address,backend =
if !reroutable && peers.Length > 0 && rand.Next(0,5) = 0
then peers.[rand.Next peers.Length] |> encode , cloudbe
else workers.Dequeue() , localbe
!msg
|> Array.append [| address; Array.empty |]
|> sendAll backend
// else ... No work, go back to backends
EXIT_SUCCESS
| _ ->
printfn "syntax: peering2 me {you}..."
EXIT_FAILURE
main fsi.CommandLineArgs
peering2: Prototype local and cloud flow in Felix
peering2: Prototype local and cloud flow in Go
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
//
// Author: amyangfei <amyangfei@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"os"
"time"
)
const NBR_WORKERS = 3
const NBR_CLIENTS = 10
const WORKER_READY = "\001"
func client_task(name string, i int) {
context, _ := zmq.NewContext()
client, _ := context.NewSocket(zmq.REQ)
defer context.Close()
defer client.Close()
client.SetIdentity(fmt.Sprintf("Client-%s-%d", name, i))
client.Connect(fmt.Sprintf("ipc://%s-localfe.ipc", name))
for {
// Send request, get reply
client.Send([]byte("HELLO"), 0)
reply, _ := client.Recv(0)
fmt.Printf("Client-%d: %s\n", i, reply)
time.Sleep(time.Second)
}
}
func worker_task(name string, i int) {
context, _ := zmq.NewContext()
worker, _ := context.NewSocket(zmq.REQ)
defer context.Close()
defer worker.Close()
worker.SetIdentity(fmt.Sprintf("Worker-%s-%d", name, i))
worker.Connect(fmt.Sprintf("ipc://%s-localbe.ipc", name))
// Tell broker we're ready for work
worker.Send([]byte(WORKER_READY), 0)
// Process messages as they arrive
for {
msg, _ := worker.RecvMultipart(0)
fmt.Printf("Worker-%d: %s\n", i, msg)
msg[len(msg)-1] = []byte("OK")
worker.SendMultipart(msg, 0)
}
}
func main() {
if len(os.Args) < 2 {
fmt.Println("syntax: peering2 me {you}...")
return
}
myself := os.Args[1]
fmt.Printf("I: preparing broker at %s...\n", myself)
rand.Seed(time.Now().UnixNano())
context, _ := zmq.NewContext()
defer context.Close()
// Bind cloud fronted to endpoint
cloudfe, _ := context.NewSocket(zmq.ROUTER)
defer cloudfe.Close()
cloudfe.SetIdentity(myself)
cloudfe.Bind(fmt.Sprintf("ipc://%s-cloud.ipc", myself))
// Connect cloud backend to all peers
cloudbe, _ := context.NewSocket(zmq.ROUTER)
defer cloudbe.Close()
cloudbe.SetIdentity(myself)
for i := 2; i < len(os.Args); i++ {
peer := os.Args[i]
fmt.Printf("I: connecting to cloud frontend at '%s'\n", peer)
cloudbe.Connect(fmt.Sprintf("ipc://%s-cloud.ipc", peer))
}
// Prepare local frontend and backend
localfe, _ := context.NewSocket(zmq.ROUTER)
localbe, _ := context.NewSocket(zmq.ROUTER)
defer localfe.Close()
defer localbe.Close()
localfe.Bind(fmt.Sprintf("ipc://%s-localfe.ipc", myself))
localbe.Bind(fmt.Sprintf("ipc://%s-localbe.ipc", myself))
// Get user to tell us when we can start...
var input string
fmt.Printf("Press Enter when all brokers are started: \n")
fmt.Scanln(&input)
// Start local workers
for i := 0; i < NBR_WORKERS; i++ {
go worker_task(myself, i)
}
// Start local clients
for i := 0; i < NBR_CLIENTS; i++ {
go client_task(myself, i)
}
// Interesting part
// Here, we handle the request-reply flow. We're using load-balancing
// to poll workers at all times, and clients only when there are one
// or more workers available.
// Least recently used queue of available workers
workers := make([]string, 0)
pollerbe := zmq.PollItems{
zmq.PollItem{Socket: localbe, Events: zmq.POLLIN},
zmq.PollItem{Socket: cloudbe, Events: zmq.POLLIN},
}
pollerfe := zmq.PollItems{
zmq.PollItem{Socket: localfe, Events: zmq.POLLIN},
zmq.PollItem{Socket: cloudfe, Events: zmq.POLLIN},
}
for {
// If we have no workers, wait indefinitely
timeout := time.Second
if len(workers) == 0 {
timeout = -1
}
zmq.Poll(pollerbe, timeout)
// Handle reply from local workder
var msg [][]byte = nil
var err error = nil
if pollerbe[0].REvents&zmq.POLLIN != 0 {
msg, err = localbe.RecvMultipart(0)
if err != nil {
break
}
address, _ := msg[0], msg[1]
msg = msg[2:]
workers = append(workers, string(address))
// If it's READY, don't route the message any further
if string(msg[len(msg)-1]) == WORKER_READY {
msg = nil
}
} else if pollerbe[1].REvents&zmq.POLLIN != 0 {
msg, err = cloudbe.RecvMultipart(0)
if err != nil {
break
}
// We don't use peer broker identity for anything
msg = msg[2:]
}
if msg != nil {
address := string(msg[0])
for i := 2; i < len(os.Args); i++ {
// Route reply to cloud if it's addressed to a broker
if address == os.Args[i] {
cloudfe.SendMultipart(msg, 0)
msg = nil
break
}
}
// Route reply to client if we still need to
if msg != nil {
localfe.SendMultipart(msg, 0)
}
}
for len(workers) > 0 {
zmq.Poll(pollerfe, 0)
reroutable := false
// We'll do peer brokers first, to prevent starvation
if pollerfe[1].REvents&zmq.POLLIN != 0 {
msg, _ = cloudfe.RecvMultipart(0)
reroutable = false
} else if pollerfe[0].REvents&zmq.POLLIN != 0 {
msg, _ = localfe.RecvMultipart(0)
reroutable = true
} else {
break // No work, go back to backends
}
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
if reroutable && len(os.Args) > 0 && rand.Intn(5) == 0 {
// Route to random broker peer
randPeer := rand.Intn(len(os.Args)-2) + 2
msg = append(msg[:0], append([][]byte{[]byte(os.Args[randPeer]), []byte("")}, msg[0:]...)...)
cloudbe.SendMultipart(msg, 0)
} else {
var worker string
worker, workers = workers[0], workers[1:]
msg = append(msg[:0], append([][]byte{[]byte(worker), []byte("")}, msg[0:]...)...)
localbe.SendMultipart(msg, 0)
}
}
}
}
peering2: Prototype local and cloud flow in Haskell
{-# LANGUAGE OverloadedStrings #-}
module Main where
import Control.Concurrent (threadDelay)
import Control.Monad (forM_, forever, void, when)
import Control.Monad.IO.Class
import qualified Data.ByteString.Char8 as C
import Data.List (find)
import Data.List.NonEmpty (NonEmpty (..), (<|))
import qualified Data.List.NonEmpty as N
import Data.Semigroup ((<>))
import Data.Sequence (Seq, ViewL (..), viewl, (|>))
import qualified Data.Sequence as S
import System.Environment
import System.Exit
import System.Random
import System.ZMQ4.Monadic
workerNum :: Int
workerNum = 3
clientNum :: Int
clientNum = 10
-- | The client task does a request-reply dialog using a standard
-- synchronous REQ socket.
clientTask :: Show a => String -> a -> ZMQ z ()
clientTask self i = do
client <- socket Req
connect client (connectString self "localfe")
let ident = "Client-" <> C.pack self <> C.pack (show i)
setIdentity (restrict ident) client
forever $ do
send client [] "HELLO"
reply <- receiveMulti client
liftIO $ do
C.putStrLn $ "Client: " <> C.pack (show reply)
threadDelay 10000
-- | The worker task plugs into the load-balancer using a REQ socket
workerTask :: Show a => String -> a -> ZMQ z ()
workerTask self i = do
worker <- socket Req
connect worker (connectString self "localbe")
let ident = "Worker-" <> C.pack self <> C.pack (show i)
setIdentity (restrict ident) worker
send worker [] "READY"
forever $ do
msg <- receiveMulti worker
liftIO $ print (ident, "Sending"::String, msg)
sendMulti worker (replaceLast "OK" msg)
-- | This is similar to zframe_reset(zmsg_last (msg), ..) in czmq.
replaceLast :: a -> [a] -> NonEmpty a
replaceLast y (_:[]) = y :| []
replaceLast y (x:xs) = x <| replaceLast y xs
replaceLast y [] = y :| []
-- | Connect a peer using the connectString function
connectPeer :: Socket z t -> String -> String -> ZMQ z ()
connectPeer sock name p = connect sock (connectString p name)
-- | An ipc connection string
connectString :: String -> String -> String
connectString peer name = "ipc://" ++ peer ++ "-" ++ name ++ ".ipc"
type Workers = Seq C.ByteString
-- | Interesting part
-- Here, we handle the request-reply flow. We're using load-balancing
-- to poll workers at all times, and clients only when there are one
-- or more workers available.
clientWorkerPoll
:: (Receiver t1, Receiver t2, Receiver t3, Receiver t4, Sender t1, Sender t2, Sender t3, Sender t4)
=> Socket z t1
-> Socket z t2
-> Socket z t3
-> Socket z t4
-> [String]
-> ZMQ z ()
clientWorkerPoll
localBack
cloudBack
localFront
cloudFront
peers = loop S.empty -- Queue of workers starts empty
where
loop workers = do
-- Poll backends, if we have no workers, wait indefinitely
[localEvents, cloudEvents] <- poll (if S.length workers > 0 then oneSec else -1) backends
availableWorkers <- reqRep workers localEvents cloudEvents
availableWorkers' <- workerLoop availableWorkers
loop availableWorkers'
reqRep workers local cloud
-- Handle reply from local worker
| In `elem` local = do
msg <- receiveMulti localBack
case msg of
-- Worker is READY, don't route the message further
ident:_:"READY":_ -> return (workers |> ident)
-- Worker replied
ident:_:restOfMsg -> do
route restOfMsg
return (workers |> ident)
-- Something strange happened
m -> do
liftIO $ print m
return workers
-- Handle reply from peer broker
| In `elem` cloud = do
msg <- receiveMulti cloudBack
case msg of
-- We don't use the peer broker identity for anything
_:restOfMsg -> route restOfMsg
-- Something strange happened
m -> liftIO $ print m
return workers
| otherwise = return workers
route msg@(ident:_) = do
let msg' = N.fromList msg
peer = find (== ident) bPeers
case peer of
-- Route reply to cloud if it's addressed to a broker
Just _ -> sendMulti cloudFront msg'
-- Route reply to local client
Nothing -> sendMulti localFront msg'
route m = liftIO $ print m -- Something strange happened
-- Now, we route as many client requests as we have worker capacity
-- for. We may reroute requests from our local frontend, but not from
-- the cloud frontend. We reroute randomly now, just to test things
-- out. In the next version, we'll do this properly by calculating
-- cloud capacity.
workerLoop workers = if S.null workers
then return workers
else do
[localEvents, cloudEvents] <- poll 0 frontends
routeRequests workers localEvents cloudEvents
routeRequests workers local cloud
-- We'll do peer brokers first, to prevent starvation
| In `elem` cloud = do
msg <- receiveMulti cloudFront
rerouteReqs workers (Left msg)
| In `elem` local = do
msg <- receiveMulti localFront
rerouteReqs workers (Right msg)
-- No work, go back to backends
| otherwise = return workers
-- If rerouteable, send to cloud 20% of the time
-- Here we'd normally use cloud status information
--
-- Right denotes rerouteable. Left denotes not-rerouteable.
rerouteReqs workers (Right msg) = do
cont <- liftIO $ randomRIO (0::Int,4)
if cont == 0
then do
-- Route to random broker peer
p <- liftIO $ randomRIO (0, length peers - 1)
let randomPeer = bPeers !! p
liftIO $ print ("Sending to random peer"::String, randomPeer)
sendMulti cloudBack (randomPeer :| msg)
return workers
else rerouteReqs workers (Left msg)
rerouteReqs workers (Left msg) = do
let (worker, newWorkers) = popWorker (viewl workers)
case worker of
Nothing -> workerLoop newWorkers
Just w -> do
sendMulti localBack $ w :| [""] ++ msg
return newWorkers
oneSec = 1000
bPeers = map C.pack peers
backends =
[ Sock localBack [In] Nothing
, Sock cloudBack [In] Nothing ]
frontends =
[ Sock localFront [In] Nothing
, Sock cloudFront [In] Nothing ]
popWorker EmptyL = (Nothing, S.empty)
popWorker (l :< s) = (Just l, s)
main :: IO ()
main = do
args <- getArgs
when (length args < 2) $ do
putStrLn "Usage: broker <me> <you> [<you> ...]"
exitFailure
-- First argument is this broker's name
-- Other arguments are our peers' names
let self:peers = args
putStrLn $ "Preparing broker at " ++ self
runZMQ $ do
-- Bind cloud frontend to endpoint
cloudFront <- socket Router
setIdentity (restrict (C.pack self)) cloudFront
bind cloudFront (connectString self "cloud")
-- Connect cloud backend to all peers
cloudBack <- socket Router
setIdentity (restrict (C.pack self)) cloudBack
mapM_ (connectPeer cloudBack "cloud") peers
-- Prepare local frontend and backend
localFront <- socket Router
bind localFront (connectString self "localfe")
localBack <- socket Router
bind localBack (connectString self "localbe")
-- Get user to tell us when we can start...
liftIO $ do
putStrLn "Press Enter when all brokers are started."
void getLine
-- Start workers and clients
forM_ [1..workerNum] $ async . workerTask self
forM_ [1..clientNum] $ async . clientTask self
-- Request reply flow
clientWorkerPoll
localBack
cloudBack
localFront
cloudFront
peers
peering2: Prototype local and cloud flow in Haxe
package ;
import org.zeromq.ZMQException;
import ZHelpers;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import neko.io.File;
import neko.io.FileInput;
#if (neko || cpp)
import neko.vm.Thread;
#end
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZFrame;
/**
* Broker peering simulation (part 2)
* Prototypes the request-reply flow
*
* While this example runs in a single process (for cpp & neko) and forked processes (for php), that is just
* to make it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: http://zguide.zeromq.org/page:all#Prototyping-the-Local-and-Cloud-Flows
*
* NB: If running from Run.hx, set ARG_OFFSET to 1
* If running directly, set ARG_OFFSET to 0
*/
class Peering2
{
private static inline var NBR_CLIENTS = 10;
private static inline var NBR_WORKERS = 3;
private static inline var LRU_READY:String = String.fromCharCode(1); // Signals workers are ready
private static inline var WORKER_DONE = "OK";
// Our own name; in practise this would be configured per node
private static var self:String;
private static inline var ARG_OFFSET = 1;
/**
* Request - reply client using REQ socket
*/
private static function clientTask() {
var ctx = new ZContext();
var client = ctx.createSocket(ZMQ_REQ);
client.connect("ipc:///tmp/" + self + "-localfe.ipc");
while (true) {
ZFrame.newStringFrame("HELLO").send(client);
var reply = ZFrame.recvFrame(client);
if (reply == null) {
break;
}
Lib.println("Client: " + reply.toString());
Sys.sleep(1);
}
ctx.destroy();
}
/**
* Worker using REQ socket to do LRU routing
*/
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
worker.connect("ipc:///tmp/"+self+"-localbe.ipc");
// Tell broker we're ready to do work
ZFrame.newStringFrame(LRU_READY).send(worker);
// Process messages as they arrive
while (true) {
var msg:ZMsg = ZMsg.recvMsg(worker);
if (msg == null) {
break;
}
Lib.println("Worker received " + msg.last().toString());
msg.last().reset(Bytes.ofString(WORKER_DONE));
msg.send(worker);
}
context.destroy();
}
public static function main() {
Lib.println("** Peering2 (see: http://zguide.zeromq.org/page:all#Prototyping-the-Local-and-Cloud-Flows)");
// First argument is this broker's name
// Other arguments are our peers' names
if (Sys.args().length < 2+ARG_OFFSET) {
Lib.println("syntax: ./Peering2 me {you} ...");
return;
}
self = Sys.args()[0 + ARG_OFFSET];
#if php
// Start local workers
for (worker_nbr in 0 ... NBR_WORKERS) {
forkWorkerTask();
}
// Start local clients
for (client_nbr in 0 ... NBR_CLIENTS) {
forkClientTask();
}
#end
Lib.println("I: preparing broker at " + self + " ...");
// Prepare our context and sockets
var ctx = new ZContext();
var endpoint:String;
// Bind cloud frontend to endpoint
var cloudfe = ctx.createSocket(ZMQ_ROUTER);
cloudfe.setsockopt(ZMQ_IDENTITY, Bytes.ofString(self));
cloudfe.bind("ipc:///tmp/" + self + "-cloud.ipc");
// Connect cloud backend to all peers
var cloudbe = ctx.createSocket(ZMQ_ROUTER);
cloudbe.setsockopt(ZMQ_IDENTITY, Bytes.ofString(self));
for (argn in 1 + ARG_OFFSET ... Sys.args().length) {
var peer = Sys.args()[argn];
Lib.println("I: connecting to cloud frontend at '" + peer + "'");
cloudbe.connect("ipc:///tmp/" + peer + "-cloud.ipc");
}
// Prepare local frontend and backend
var localfe = ctx.createSocket(ZMQ_ROUTER);
localfe.bind("ipc:///tmp/" + self + "-localfe.ipc");
var localbe = ctx.createSocket(ZMQ_ROUTER);
localbe.bind("ipc:///tmp/" + self + "-localbe.ipc");
// Get user to tell us when we can start...
Lib.println("Press Enter when all brokers are started: ");
var f:FileInput = File.stdin();
var str:String = f.readLine();
#if !php
// Start local workers
for (worker_nbr in 0 ... NBR_WORKERS) {
Thread.create(workerTask);
}
// Start local clients
for (client_nbr in 0 ... NBR_CLIENTS) {
Thread.create(clientTask);
}
#end
// Interesting part
// -------------------------------------------------------------
// Request-reply flow
// - Poll backends and process local/cloud replies
// - While worker available, route localfe to local or cloud
// Queue of available workers
var capacity = 0;
var workerQueue:List<ZFrame> = new List<ZFrame>();
var backend = new ZMQPoller();
backend.registerSocket(localbe, ZMQ.ZMQ_POLLIN());
backend.registerSocket(cloudbe, ZMQ.ZMQ_POLLIN());
var frontend = new ZMQPoller();
frontend.registerSocket(localfe, ZMQ.ZMQ_POLLIN());
frontend.registerSocket(cloudfe, ZMQ.ZMQ_POLLIN());
while (true) {
var ret = 0;
try {
// If we have no workers anyhow, wait indefinitely
ret = backend.poll( {
if (capacity > 0) 1000 * 1000 else -1; } );
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
break;
}
trace (e.toString());
return;
}
var msg:ZMsg = null;
// Handle reply from local worker
if (backend.pollin(1)) {
msg = ZMsg.recvMsg(localbe);
if (msg == null)
break; // Interrupted
var address = msg.unwrap();
workerQueue.add(address);
capacity++;
// If it's READY, don't route the message any further
var frame = msg.first();
if (frame.streq(LRU_READY))
msg.destroy();
}
// Or handle reply from peer broker
else if (backend.pollin(2)) {
msg = ZMsg.recvMsg(cloudbe);
if (msg == null)
break;
// We don't use peer broker address for anything
var address = msg.unwrap();
}
// Route reply to cloud if it's addressed to a broker
if (msg != null && !msg.isEmpty()) {
for (argv in 1 + ARG_OFFSET ... Sys.args().length) {
if (!msg.isEmpty() && msg.first().streq(Sys.args()[argv])) {
msg.send(cloudfe);
}
}
}
// Route reply to client if we still need to
if (msg != null && !msg.isEmpty()) {
msg.send(localfe);
}
// Now route as many client requests as we can handle
while (capacity > 0) {
try {
ret = frontend.poll(0);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace (e.toString());
return;
}
var reroutable = 0;
// We'll do peer brokers first, to prevent starvation
if (frontend.pollin(2)) {
msg = ZMsg.recvMsg(cloudfe);
reroutable = 0;
} else if (frontend.pollin(1)){
msg = ZMsg.recvMsg(localfe);
reroutable = 1;
} else
break; // No work, go back to the backends
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
//
if (reroutable > 0 && Sys.args().length > 1 + ARG_OFFSET && ZHelpers.randof(5) == 0) {
// Route to random broker peer
var randomPeer = ZHelpers.randof(Sys.args().length - (2 + ARG_OFFSET)) + (1 + ARG_OFFSET);
trace ("Routing to peer#"+randomPeer+":" + Sys.args()[randomPeer]);
msg.wrap(ZFrame.newStringFrame(Sys.args()[randomPeer]));
msg.send(cloudbe);
} else {
msg.wrap(workerQueue.pop());
msg.send(localbe);
capacity--;
}
}
}
// When we're done, clean up properly
ctx.destroy();
}
#if php
private static inline function forkClientTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
Peering2::clientTask();
exit();
}');
return;
}
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
Peering2::workerTask();
exit();
}');
return;
}
#end
}peering2: Prototype local and cloud flow in Java
package guide;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
public class peering2
{
private static final int NBR_CLIENTS = 10;
private static final int NBR_WORKERS = 3;
private static final String WORKER_READY = "\001"; // Signals worker is ready
// Our own name; in practice this would be configured per node
private static String self;
// The client task does a request-reply dialog using a standard
// synchronous REQ socket:
private static class client_task extends Thread
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket client = ctx.createSocket(SocketType.REQ);
client.connect(String.format("ipc://%s-localfe.ipc", self));
while (true) {
// Send request, get reply
client.send("HELLO", 0);
String reply = client.recvStr(0);
if (reply == null)
break; // Interrupted
System.out.printf("Client: %s\n", reply);
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
}
}
}
}
}
// The worker task plugs into the LRU routing dialog using a REQ
// socket:
private static class worker_task extends Thread
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket worker = ctx.createSocket(SocketType.REQ);
worker.connect(String.format("ipc://%s-localbe.ipc", self));
// Tell broker we're ready for work
ZFrame frame = new ZFrame(WORKER_READY);
frame.send(worker, 0);
while (true) {
// Send request, get reply
ZMsg msg = ZMsg.recvMsg(worker, 0);
if (msg == null)
break; // Interrupted
msg.getLast().print("Worker: ");
msg.getLast().reset("OK");
msg.send(worker);
}
}
}
}
// The main task begins by setting-up its frontend and backend sockets
// and then starting its client and worker tasks:
public static void main(String[] argv)
{
// First argument is this broker's name
// Other arguments are our peers' names
//
if (argv.length < 1) {
System.out.println("syntax: peering2 me {you}");
System.exit(-1);
}
self = argv[0];
System.out.printf("I: preparing broker at %s\n", self);
Random rand = new Random(System.nanoTime());
try (ZContext ctx = new ZContext()) {
// Bind cloud frontend to endpoint
Socket cloudfe = ctx.createSocket(SocketType.ROUTER);
cloudfe.setIdentity(self.getBytes(ZMQ.CHARSET));
cloudfe.bind(String.format("ipc://%s-cloud.ipc", self));
// Connect cloud backend to all peers
Socket cloudbe = ctx.createSocket(SocketType.ROUTER);
cloudbe.setIdentity(self.getBytes(ZMQ.CHARSET));
int argn;
for (argn = 1; argn < argv.length; argn++) {
String peer = argv[argn];
System.out.printf(
"I: connecting to cloud forintend at '%s'\n", peer
);
cloudbe.connect(String.format("ipc://%s-cloud.ipc", peer));
}
// Prepare local frontend and backend
Socket localfe = ctx.createSocket(SocketType.ROUTER);
localfe.bind(String.format("ipc://%s-localfe.ipc", self));
Socket localbe = ctx.createSocket(SocketType.ROUTER);
localbe.bind(String.format("ipc://%s-localbe.ipc", self));
// Get user to tell us when we can start
System.out.println("Press Enter when all brokers are started: ");
try {
System.in.read();
}
catch (IOException e) {
e.printStackTrace();
}
// Start local workers
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
new worker_task().start();
// Start local clients
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
new client_task().start();
// Here we handle the request-reply flow. We're using the LRU
// approach to poll workers at all times, and clients only when
// there are one or more workers available.
// Least recently used queue of available workers
int capacity = 0;
ArrayList<ZFrame> workers = new ArrayList<ZFrame>();
Poller backends = ctx.createPoller(2);
backends.register(localbe, Poller.POLLIN);
backends.register(cloudbe, Poller.POLLIN);
Poller frontends = ctx.createPoller(2);
frontends.register(localfe, Poller.POLLIN);
frontends.register(cloudfe, Poller.POLLIN);
while (true) {
// First, route any waiting replies from workers
// If we have no workers anyhow, wait indefinitely
int rc = backends.poll(capacity > 0 ? 1000 : -1);
if (rc == -1)
break; // Interrupted
// Handle reply from local worker
ZMsg msg = null;
if (backends.pollin(0)) {
msg = ZMsg.recvMsg(localbe);
if (msg == null)
break; // Interrupted
ZFrame address = msg.unwrap();
workers.add(address);
capacity++;
// If it's READY, don't route the message any further
ZFrame frame = msg.getFirst();
String frameData = new String(frame.getData(), ZMQ.CHARSET);
if (frameData.equals(WORKER_READY)) {
msg.destroy();
msg = null;
}
}
// Or handle reply from peer broker
else if (backends.pollin(1)) {
msg = ZMsg.recvMsg(cloudbe);
if (msg == null)
break; // Interrupted
// We don't use peer broker address for anything
ZFrame address = msg.unwrap();
address.destroy();
}
// Route reply to cloud if it's addressed to a broker
for (argn = 1; msg != null && argn < argv.length; argn++) {
byte[] data = msg.getFirst().getData();
if (argv[argn].equals(new String(data, ZMQ.CHARSET))) {
msg.send(cloudfe);
msg = null;
}
}
// Route reply to client if we still need to
if (msg != null)
msg.send(localfe);
// Now we route as many client requests as we have worker
// capacity for. We may reroute requests from our local
// frontend, but not from // the cloud frontend. We reroute
// randomly now, just to test things out. In the next version
// we'll do this properly by calculating cloud capacity://
while (capacity > 0) {
rc = frontends.poll(0);
assert (rc >= 0);
int reroutable = 0;
// We'll do peer brokers first, to prevent starvation
if (frontends.pollin(1)) {
msg = ZMsg.recvMsg(cloudfe);
reroutable = 0;
}
else if (frontends.pollin(0)) {
msg = ZMsg.recvMsg(localfe);
reroutable = 1;
}
else break; // No work, go back to backends
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
if (reroutable != 0 &&
argv.length > 1 &&
rand.nextInt(5) == 0) {
// Route to random broker peer
int random_peer = rand.nextInt(argv.length - 1) + 1;
msg.push(argv[random_peer]);
msg.send(cloudbe);
}
else {
ZFrame frame = workers.remove(0);
msg.wrap(frame);
msg.send(localbe);
capacity--;
}
}
}
// When we're done, clean up properly
while (workers.size() > 0) {
ZFrame frame = workers.remove(0);
frame.destroy();
}
}
}
}
peering2: Prototype local and cloud flow in Julia
peering2: Prototype local and cloud flow in Lua
--
-- Broker peering simulation (part 2)
-- Prototypes the request-reply flow
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmq.threads"
require"zmsg"
local tremove = table.remove
local NBR_CLIENTS = 10
local NBR_WORKERS = 3
local pre_code = [[
local self, seed = ...
local zmq = require"zmq"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(seed)
local context = zmq.init(1)
]]
-- Request-reply client using REQ socket
--
local client_task = pre_code .. [[
local client = context:socket(zmq.REQ)
local endpoint = string.format("ipc://%s-localfe.ipc", self)
assert(client:connect(endpoint))
while true do
-- Send request, get reply
local msg = zmsg.new ("HELLO")
msg:send(client)
msg = zmsg.recv (client)
printf ("I: client status: %s\n", msg:body())
end
-- We never get here but if we did, this is how we'd exit cleanly
client:close()
context:term()
]]
-- Worker using REQ socket to do LRU routing
--
local worker_task = pre_code .. [[
local worker = context:socket(zmq.REQ)
local endpoint = string.format("ipc://%s-localbe.ipc", self)
assert(worker:connect(endpoint))
-- Tell broker we're ready for work
local msg = zmsg.new ("READY")
msg:send(worker)
while true do
msg = zmsg.recv (worker)
-- Do some 'work'
s_sleep (1000)
msg:body_fmt("OK - %04x", randof (0x10000))
msg:send(worker)
end
-- We never get here but if we did, this is how we'd exit cleanly
worker:close()
context:term()
]]
-- First argument is this broker's name
-- Other arguments are our peers' names
--
s_version_assert (2, 1)
if (#arg < 1) then
printf ("syntax: peering2 me doyouend...\n")
os.exit(-1)
end
-- Our own name; in practice this'd be configured per node
local self = arg[1]
printf ("I: preparing broker at %s...\n", self)
math.randomseed(os.time())
-- Prepare our context and sockets
local context = zmq.init(1)
-- Bind cloud frontend to endpoint
local cloudfe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-cloud.ipc", self)
cloudfe:setopt(zmq.IDENTITY, self)
assert(cloudfe:bind(endpoint))
-- Connect cloud backend to all peers
local cloudbe = context:socket(zmq.ROUTER)
cloudbe:setopt(zmq.IDENTITY, self)
local peers = {}
for n=2,#arg do
local peer = arg[n]
-- add peer name to peers list.
peers[#peers + 1] = peer
peers[peer] = true -- map peer's name to 'true' for fast lookup
printf ("I: connecting to cloud frontend at '%s'\n", peer)
local endpoint = string.format("ipc://%s-cloud.ipc", peer)
assert(cloudbe:connect(endpoint))
end
-- Prepare local frontend and backend
local localfe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-localfe.ipc", self)
assert(localfe:bind(endpoint))
local localbe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-localbe.ipc", self)
assert(localbe:bind(endpoint))
-- Get user to tell us when we can start...
printf ("Press Enter when all brokers are started: ")
io.read('*l')
-- Start local workers
local workers = {}
for n=1,NBR_WORKERS do
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(nil, worker_task, self, seed)
workers[n]:start(true)
end
-- Start local clients
local clients = {}
for n=1,NBR_CLIENTS do
local seed = os.time() + math.random()
clients[n] = zmq.threads.runstring(nil, client_task, self, seed)
clients[n]:start(true)
end
-- Interesting part
-- -------------------------------------------------------------
-- Request-reply flow
-- - Poll backends and process local/cloud replies
-- - While worker available, route localfe to local or cloud
-- Queue of available workers
local worker_queue = {}
local backends = zmq.poller(2)
local function send_reply(msg)
local address = msg:address()
-- Route reply to cloud if it's addressed to a broker
if peers[address] then
msg:send(cloudfe) -- reply is for a peer.
else
msg:send(localfe) -- reply is for a local client.
end
end
backends:add(localbe, zmq.POLLIN, function()
local msg = zmsg.recv(localbe)
-- Use worker address for LRU routing
worker_queue[#worker_queue + 1] = msg:unwrap()
-- if reply is not "READY" then route reply back to client.
if (msg:address() ~= "READY") then
send_reply(msg)
end
end)
backends:add(cloudbe, zmq.POLLIN, function()
local msg = zmsg.recv(cloudbe)
-- We don't use peer broker address for anything
msg:unwrap()
-- send reply back to client.
send_reply(msg)
end)
local frontends = zmq.poller(2)
local localfe_ready = false
local cloudfe_ready = false
frontends:add(localfe, zmq.POLLIN, function() localfe_ready = true end)
frontends:add(cloudfe, zmq.POLLIN, function() cloudfe_ready = true end)
while true do
local timeout = (#worker_queue > 0) and 1000000 or -1
-- If we have no workers anyhow, wait indefinitely
rc = backends:poll(timeout)
assert (rc >= 0)
-- Now route as many clients requests as we can handle
--
while (#worker_queue > 0) do
rc = frontends:poll(0)
assert (rc >= 0)
local reroutable = false
local msg
-- We'll do peer brokers first, to prevent starvation
if (cloudfe_ready) then
cloudfe_ready = false -- reset flag
msg = zmsg.recv (cloudfe)
reroutable = false
elseif (localfe_ready) then
localfe_ready = false -- reset flag
msg = zmsg.recv (localfe)
reroutable = true
else
break; -- No work, go back to backends
end
-- If reroutable, send to cloud 20% of the time
-- Here we'd normally use cloud status information
--
local percent = randof (5)
if (reroutable and #peers > 0 and percent == 0) then
-- Route to random broker peer
local random_peer = randof (#peers) + 1
msg:wrap(peers[random_peer], nil)
msg:send(cloudbe)
else
-- Dequeue and drop the next worker address
local worker = tremove(worker_queue, 1)
msg:wrap(worker, "")
msg:send(localbe)
end
end
end
-- We never get here but clean up anyhow
localbe:close()
cloudbe:close()
localfe:close()
cloudfe:close()
context:term()
peering2: Prototype local and cloud flow in Node.js
peering2: Prototype local and cloud flow in Objective-C
peering2: Prototype local and cloud flow in ooc
peering2: Prototype local and cloud flow in Perl
peering2: Prototype local and cloud flow in PHP
<?php
/*
* Broker peering simulation (part 2)
* Prototypes the request-reply flow
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("NBR_CLIENTS", 10);
define("NBR_WORKERS", 3);
// Request-reply client using REQ socket
function client_thread($self)
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$endpoint = sprintf("ipc://%s-localfe.ipc", $self);
$client->connect($endpoint);
while (true) {
// Send request, get reply
$client->send("HELLO");
$reply = $client->recv();
printf("I: client status: %s%s", $reply, PHP_EOL);
}
}
// Worker using REQ socket to do LRU routing
function worker_thread ($self)
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_REQ);
$endpoint = sprintf("ipc://%s-localbe.ipc", $self);
$worker->connect($endpoint);
// Tell broker we're ready for work
$worker->send("READY");
while (true) {
$zmsg = new Zmsg($worker);
$zmsg->recv();
sleep(1);
$zmsg->body_fmt("OK - %04x", mt_rand(0, 0x10000));
$zmsg->send();
}
}
// First argument is this broker's name
// Other arguments are our peers' names
if ($_SERVER['argc'] < 2) {
echo "syntax: peering2 me {you}...", PHP_EOL;
exit();
}
$self = $_SERVER['argv'][1];
for ($client_nbr = 0; $client_nbr < NBR_CLIENTS; $client_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
client_thread($self);
return;
}
}
for ($worker_nbr = 0; $worker_nbr < NBR_WORKERS; $worker_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
worker_thread($self);
return;
}
}
printf ("I: preparing broker at %s... %s", $self, PHP_EOL);
// Prepare our context and sockets
$context = new ZMQContext();
// Bind cloud frontend to endpoint
$cloudfe = $context->getSocket(ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-cloud.ipc", $self);
$cloudfe->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $self);
$cloudfe->bind($endpoint);
// Connect cloud backend to all peers
$cloudbe = $context->getSocket(ZMQ::SOCKET_ROUTER);
$cloudbe->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $self);
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
$peer = $_SERVER['argv'][$argn];
printf ("I: connecting to cloud backend at '%s'%s", $peer, PHP_EOL);
$endpoint = sprintf("ipc://%s-cloud.ipc", $peer);
$cloudbe->connect($endpoint);
}
// Prepare local frontend and backend
$localfe = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-localfe.ipc", $self);
$localfe->bind($endpoint);
$localbe = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-localbe.ipc", $self);
$localbe->bind($endpoint);
// Get user to tell us when we can start...
printf ("Press Enter when all brokers are started: ");
$fp = fopen('php://stdin', 'r');
$line = fgets($fp, 512);
fclose($fp);
// Interesting part
// -------------------------------------------------------------
// Request-reply flow
// - Poll backends and process local/cloud replies
// - While worker available, route localfe to local or cloud
// Queue of available workers
$capacity = 0;
$worker_queue = array();
$readable = $writeable = array();
while (true) {
$poll = new ZMQPoll();
$poll->add($localbe, ZMQ::POLL_IN);
$poll->add($cloudbe, ZMQ::POLL_IN);
$events = 0;
// If we have no workers anyhow, wait indefinitely
try {
$events = $poll->poll($readable, $writeable, $capacity ? 1000000 : -1);
} catch (ZMQPollException $e) {
break;
}
if ($events > 0) {
foreach ($readable as $socket) {
$zmsg = new Zmsg($socket);
// Handle reply from local worker
if ($socket === $localbe) {
$zmsg->recv();
// Use worker address for LRU routing
$worker_queue[] = $zmsg->unwrap();
$capacity++;
if ($zmsg->address() == "READY") {
continue;
}
}
// Or handle reply from peer broker
else if ($socket === $cloudbe) {
// We don't use peer broker address for anything
$zmsg->recv()->unwrap();
}
// Route reply to cloud if it's addressed to a broker
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
if ($zmsg->address() == $_SERVER['argv'][$argn]) {
$zmsg->set_socket($cloudfe)->send();
$zmsg = null;
}
}
// Route reply to client if we still need to
if ($zmsg) {
$zmsg->set_socket($localfe)->send();
}
}
}
// Now route as many clients requests as we can handle
while ($capacity) {
$poll = new ZMQPoll();
$poll->add($localfe, ZMQ::POLL_IN);
$poll->add($cloudfe, ZMQ::POLL_IN);
$reroutable = false;
$events = $poll->poll($readable, $writeable, 0);
if ($events > 0) {
foreach ($readable as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
// We'll do peer brokers first, to prevent starvation
if ($socket === $cloudfe) {
$reroutable = false;
} elseif ($socket === $localfe) {
$reroutable = true;
}
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
if ($reroutable && $_SERVER['argc'] > 2 && mt_rand(0, 4) == 0) {
$zmsg->wrap($_SERVER['argv'][mt_rand(2, ($_SERVER['argc']-1))]);
$zmsg->set_socket($cloudbe)->send();
} else {
$zmsg->wrap(array_shift($worker_queue), "");
$zmsg->set_socket($localbe)->send();
$capacity--;
}
}
} else {
break; // No work, go back to backends
}
}
}
peering2: Prototype local and cloud flow in Python
#
# Broker peering simulation (part 2) in Python
# Prototypes the request-reply flow
#
# While this example runs in a single process, that is just to make
# it easier to start and stop the example. Each thread has its own
# context and conceptually acts as a separate process.
#
# Author : Min RK
# Contact: benjaminrk(at)gmail(dot)com
#
import random
import sys
import threading
import time
import zmq
try:
raw_input
except NameError:
# Python 3
raw_input = input
NBR_CLIENTS = 10
NBR_WORKERS = 3
def tprint(msg):
sys.stdout.write(msg + '\n')
sys.stdout.flush()
def client_task(name, i):
"""Request-reply client using REQ socket"""
ctx = zmq.Context()
client = ctx.socket(zmq.REQ)
client.identity = (u"Client-%s-%s" % (name, i)).encode('ascii')
client.connect("ipc://%s-localfe.ipc" % name)
while True:
client.send(b"HELLO")
try:
reply = client.recv()
except zmq.ZMQError:
# interrupted
return
tprint("Client-%s: %s" % (i, reply))
time.sleep(1)
def worker_task(name, i):
"""Worker using REQ socket to do LRU routing"""
ctx = zmq.Context()
worker = ctx.socket(zmq.REQ)
worker.identity = (u"Worker-%s-%s" % (name, i)).encode('ascii')
worker.connect("ipc://%s-localbe.ipc" % name)
# Tell broker we're ready for work
worker.send(b"READY")
# Process messages as they arrive
while True:
try:
msg = worker.recv_multipart()
except zmq.ZMQError:
# interrupted
return
tprint("Worker-%s: %s\n" % (i, msg))
msg[-1] = b"OK"
worker.send_multipart(msg)
def main(myself, peers):
print("I: preparing broker at %s..." % myself)
# Prepare our context and sockets
ctx = zmq.Context()
# Bind cloud frontend to endpoint
cloudfe = ctx.socket(zmq.ROUTER)
if not isinstance(myself, bytes):
ident = myself.encode('ascii')
else:
ident = myself
cloudfe.identity = ident
cloudfe.bind("ipc://%s-cloud.ipc" % myself)
# Connect cloud backend to all peers
cloudbe = ctx.socket(zmq.ROUTER)
cloudbe.identity = ident
for peer in peers:
tprint("I: connecting to cloud frontend at %s" % peer)
cloudbe.connect("ipc://%s-cloud.ipc" % peer)
if not isinstance(peers[0], bytes):
peers = [peer.encode('ascii') for peer in peers]
# Prepare local frontend and backend
localfe = ctx.socket(zmq.ROUTER)
localfe.bind("ipc://%s-localfe.ipc" % myself)
localbe = ctx.socket(zmq.ROUTER)
localbe.bind("ipc://%s-localbe.ipc" % myself)
# Get user to tell us when we can start...
raw_input("Press Enter when all brokers are started: ")
# create workers and clients threads
for i in range(NBR_WORKERS):
thread = threading.Thread(target=worker_task, args=(myself, i))
thread.daemon = True
thread.start()
for i in range(NBR_CLIENTS):
thread_c = threading.Thread(target=client_task, args=(myself, i))
thread_c.daemon = True
thread_c.start()
# Interesting part
# -------------------------------------------------------------
# Request-reply flow
# - Poll backends and process local/cloud replies
# - While worker available, route localfe to local or cloud
workers = []
# setup pollers
pollerbe = zmq.Poller()
pollerbe.register(localbe, zmq.POLLIN)
pollerbe.register(cloudbe, zmq.POLLIN)
pollerfe = zmq.Poller()
pollerfe.register(localfe, zmq.POLLIN)
pollerfe.register(cloudfe, zmq.POLLIN)
while True:
# If we have no workers anyhow, wait indefinitely
try:
events = dict(pollerbe.poll(1000 if workers else None))
except zmq.ZMQError:
break # interrupted
# Handle reply from local worker
msg = None
if localbe in events:
msg = localbe.recv_multipart()
(address, empty), msg = msg[:2], msg[2:]
workers.append(address)
# If it's READY, don't route the message any further
if msg[-1] == b'READY':
msg = None
elif cloudbe in events:
msg = cloudbe.recv_multipart()
(address, empty), msg = msg[:2], msg[2:]
# We don't use peer broker address for anything
if msg is not None:
address = msg[0]
if address in peers:
# Route reply to cloud if it's addressed to a broker
cloudfe.send_multipart(msg)
else:
# Route reply to client if we still need to
localfe.send_multipart(msg)
# Now route as many clients requests as we can handle
while workers:
events = dict(pollerfe.poll(0))
reroutable = False
# We'll do peer brokers first, to prevent starvation
if cloudfe in events:
msg = cloudfe.recv_multipart()
reroutable = False
elif localfe in events:
msg = localfe.recv_multipart()
reroutable = True
else:
break # No work, go back to backends
# If reroutable, send to cloud 20% of the time
# Here we'd normally use cloud status information
if reroutable and peers and random.randint(0, 4) == 0:
# Route to random broker peer
msg = [random.choice(peers), b''] + msg
cloudbe.send_multipart(msg)
else:
msg = [workers.pop(0), b''] + msg
localbe.send_multipart(msg)
if __name__ == '__main__':
if len(sys.argv) >= 2:
main(myself=sys.argv[1], peers=sys.argv[2:])
else:
print("Usage: peering2.py <me> [<peer_1> [... <peer_N>]]")
sys.exit(1)
peering2: Prototype local and cloud flow in Q
peering2: Prototype local and cloud flow in Racket
peering2: Prototype local and cloud flow in Ruby
peering2: Prototype local and cloud flow in Rust
peering2: Prototype local and cloud flow in Scala
peering2: Prototype local and cloud flow in Tcl
peering2: Prototype local and cloud flow in OCaml
Run this by, for instance, starting two instances of the broker in two windows:
peering2 me you
peering2 you me
Some comments on this code:
-
In the C code at least, using the zmsg class makes life much easier, and our code much shorter. It’s obviously an abstraction that works. If you build ZeroMQ applications in C, you should use CZMQ.
-
Because we’re not getting any state information from peers, we naively assume they are running. The code prompts you to confirm when you’ve started all the brokers. In the real case, we’d not send anything to brokers who had not told us they exist.
You can satisfy yourself that the code works by watching it run forever. If there were any misrouted messages, clients would end up blocking, and the brokers would stop printing trace information. You can prove that by killing either of the brokers. The other broker tries to send requests to the cloud, and one-by-one its clients block, waiting for an answer.
Putting it All Together #
Let’s put this together into a single package. As before, we’ll run an entire cluster as one process. We’re going to take the two previous examples and merge them into one properly working design that lets you simulate any number of clusters.
This code is the size of both previous prototypes together, at 270 LoC. That’s pretty good for a simulation of a cluster that includes clients and workers and cloud workload distribution. Here is the code:
peering3: Full cluster simulation in Ada
peering3: Full cluster simulation in Basic
peering3: Full cluster simulation in C
// Broker peering simulation (part 3)
// Prototypes the full flow of status and tasks
#include "czmq.h"
#define NBR_CLIENTS 10
#define NBR_WORKERS 5
#define WORKER_READY "\001" // Signals worker is ready
// Our own name; in practice, this would be configured per node
static char *self;
// .split client task
// This is the client task. It issues a burst of requests and then
// sleeps for a few seconds. This simulates sporadic activity; when
// a number of clients are active at once, the local workers should
// be overloaded. The client uses a REQ socket for requests and also
// pushes statistics to the monitor socket:
static void *
client_task (void *args)
{
zctx_t *ctx = zctx_new ();
void *client = zsocket_new (ctx, ZMQ_REQ);
zsocket_connect (client, "ipc://%s-localfe.ipc", self);
void *monitor = zsocket_new (ctx, ZMQ_PUSH);
zsocket_connect (monitor, "ipc://%s-monitor.ipc", self);
while (true) {
sleep (randof (5));
int burst = randof (15);
while (burst--) {
char task_id [5];
sprintf (task_id, "%04X", randof (0x10000));
// Send request with random hex ID
zstr_send (client, task_id);
// Wait max ten seconds for a reply, then complain
zmq_pollitem_t pollset [1] = { { client, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (pollset, 1, 10 * 1000 * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
if (pollset [0].revents & ZMQ_POLLIN) {
char *reply = zstr_recv (client);
if (!reply)
break; // Interrupted
// Worker is supposed to answer us with our task id
assert (streq (reply, task_id));
zstr_sendf (monitor, "%s", reply);
free (reply);
}
else {
zstr_sendf (monitor,
"E: CLIENT EXIT - lost task %s", task_id);
return NULL;
}
}
}
zctx_destroy (&ctx);
return NULL;
}
// .split worker task
// This is the worker task, which uses a REQ socket to plug into the
// load-balancer. It's the same stub worker task that you've seen in
// other examples:
static void *
worker_task (void *args)
{
zctx_t *ctx = zctx_new ();
void *worker = zsocket_new (ctx, ZMQ_REQ);
zsocket_connect (worker, "ipc://%s-localbe.ipc", self);
// Tell broker we're ready for work
zframe_t *frame = zframe_new (WORKER_READY, 1);
zframe_send (&frame, worker, 0);
// Process messages as they arrive
while (true) {
zmsg_t *msg = zmsg_recv (worker);
if (!msg)
break; // Interrupted
// Workers are busy for 0/1 seconds
sleep (randof (2));
zmsg_send (&msg, worker);
}
zctx_destroy (&ctx);
return NULL;
}
// .split main task
// The main task begins by setting up all its sockets. The local frontend
// talks to clients, and our local backend talks to workers. The cloud
// frontend talks to peer brokers as if they were clients, and the cloud
// backend talks to peer brokers as if they were workers. The state
// backend publishes regular state messages, and the state frontend
// subscribes to all state backends to collect these messages. Finally,
// we use a PULL monitor socket to collect printable messages from tasks:
int main (int argc, char *argv [])
{
// First argument is this broker's name
// Other arguments are our peers' names
if (argc < 2) {
printf ("syntax: peering3 me {you}...\n");
return 0;
}
self = argv [1];
printf ("I: preparing broker at %s...\n", self);
srandom ((unsigned) time (NULL));
// Prepare local frontend and backend
zctx_t *ctx = zctx_new ();
void *localfe = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (localfe, "ipc://%s-localfe.ipc", self);
void *localbe = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (localbe, "ipc://%s-localbe.ipc", self);
// Bind cloud frontend to endpoint
void *cloudfe = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_set_identity (cloudfe, self);
zsocket_bind (cloudfe, "ipc://%s-cloud.ipc", self);
// Connect cloud backend to all peers
void *cloudbe = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_set_identity (cloudbe, self);
int argn;
for (argn = 2; argn < argc; argn++) {
char *peer = argv [argn];
printf ("I: connecting to cloud frontend at '%s'\n", peer);
zsocket_connect (cloudbe, "ipc://%s-cloud.ipc", peer);
}
// Bind state backend to endpoint
void *statebe = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (statebe, "ipc://%s-state.ipc", self);
// Connect state frontend to all peers
void *statefe = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (statefe, "");
for (argn = 2; argn < argc; argn++) {
char *peer = argv [argn];
printf ("I: connecting to state backend at '%s'\n", peer);
zsocket_connect (statefe, "ipc://%s-state.ipc", peer);
}
// Prepare monitor socket
void *monitor = zsocket_new (ctx, ZMQ_PULL);
zsocket_bind (monitor, "ipc://%s-monitor.ipc", self);
// .split start child tasks
// After binding and connecting all our sockets, we start our child
// tasks - workers and clients:
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
zthread_new (worker_task, NULL);
// Start local clients
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
zthread_new (client_task, NULL);
// Queue of available workers
int local_capacity = 0;
int cloud_capacity = 0;
zlist_t *workers = zlist_new ();
// .split main loop
// The main loop has two parts. First, we poll workers and our two service
// sockets (statefe and monitor), in any case. If we have no ready workers,
// then there's no point in looking at incoming requests. These can remain
// on their internal 0MQ queues:
while (true) {
zmq_pollitem_t primary [] = {
{ localbe, 0, ZMQ_POLLIN, 0 },
{ cloudbe, 0, ZMQ_POLLIN, 0 },
{ statefe, 0, ZMQ_POLLIN, 0 },
{ monitor, 0, ZMQ_POLLIN, 0 }
};
// If we have no workers ready, wait indefinitely
int rc = zmq_poll (primary, 4,
local_capacity? 1000 * ZMQ_POLL_MSEC: -1);
if (rc == -1)
break; // Interrupted
// Track if capacity changes during this iteration
int previous = local_capacity;
zmsg_t *msg = NULL; // Reply from local worker
if (primary [0].revents & ZMQ_POLLIN) {
msg = zmsg_recv (localbe);
if (!msg)
break; // Interrupted
zframe_t *identity = zmsg_unwrap (msg);
zlist_append (workers, identity);
local_capacity++;
// If it's READY, don't route the message any further
zframe_t *frame = zmsg_first (msg);
if (memcmp (zframe_data (frame), WORKER_READY, 1) == 0)
zmsg_destroy (&msg);
}
// Or handle reply from peer broker
else
if (primary [1].revents & ZMQ_POLLIN) {
msg = zmsg_recv (cloudbe);
if (!msg)
break; // Interrupted
// We don't use peer broker identity for anything
zframe_t *identity = zmsg_unwrap (msg);
zframe_destroy (&identity);
}
// Route reply to cloud if it's addressed to a broker
for (argn = 2; msg && argn < argc; argn++) {
char *data = (char *) zframe_data (zmsg_first (msg));
size_t size = zframe_size (zmsg_first (msg));
if (size == strlen (argv [argn])
&& memcmp (data, argv [argn], size) == 0)
zmsg_send (&msg, cloudfe);
}
// Route reply to client if we still need to
if (msg)
zmsg_send (&msg, localfe);
// .split handle state messages
// If we have input messages on our statefe or monitor sockets, we
// can process these immediately:
if (primary [2].revents & ZMQ_POLLIN) {
char *peer = zstr_recv (statefe);
char *status = zstr_recv (statefe);
cloud_capacity = atoi (status);
free (peer);
free (status);
}
if (primary [3].revents & ZMQ_POLLIN) {
char *status = zstr_recv (monitor);
printf ("%s\n", status);
free (status);
}
// .split route client requests
// Now route as many clients requests as we can handle. If we have
// local capacity, we poll both localfe and cloudfe. If we have cloud
// capacity only, we poll just localfe. We route any request locally
// if we can, else we route to the cloud.
while (local_capacity + cloud_capacity) {
zmq_pollitem_t secondary [] = {
{ localfe, 0, ZMQ_POLLIN, 0 },
{ cloudfe, 0, ZMQ_POLLIN, 0 }
};
if (local_capacity)
rc = zmq_poll (secondary, 2, 0);
else
rc = zmq_poll (secondary, 1, 0);
assert (rc >= 0);
if (secondary [0].revents & ZMQ_POLLIN)
msg = zmsg_recv (localfe);
else
if (secondary [1].revents & ZMQ_POLLIN)
msg = zmsg_recv (cloudfe);
else
break; // No work, go back to primary
if (local_capacity) {
zframe_t *frame = (zframe_t *) zlist_pop (workers);
zmsg_wrap (msg, frame);
zmsg_send (&msg, localbe);
local_capacity--;
}
else {
// Route to random broker peer
int peer = randof (argc - 2) + 2;
zmsg_pushmem (msg, argv [peer], strlen (argv [peer]));
zmsg_send (&msg, cloudbe);
}
}
// .split broadcast capacity
// We broadcast capacity messages to other peers; to reduce chatter,
// we do this only if our capacity changed.
if (local_capacity != previous) {
// We stick our own identity onto the envelope
zstr_sendm (statebe, self);
// Broadcast new capacity
zstr_sendf (statebe, "%d", local_capacity);
}
}
// When we're done, clean up properly
while (zlist_size (workers)) {
zframe_t *frame = (zframe_t *) zlist_pop (workers);
zframe_destroy (&frame);
}
zlist_destroy (&workers);
zctx_destroy (&ctx);
return EXIT_SUCCESS;
}
peering3: Full cluster simulation in C++
#include "zhelpers.hpp"
#include <thread>
#include <queue>
#include <vector>
#define NBR_CLIENTS 6
#define NBR_WORKERS 3
#define WORKER_READY "\001" // Signals worker is ready
#define ZMQ_POLL_MSEC 1
void receive_all_frames(zmq::socket_t& sock, std::vector<std::string>& frames) {
frames.clear();
while (1) {
// Process all parts of the message
std::string frame = s_recv(sock);
frames.emplace_back(frame);
int more = 0; // Multipart detection
size_t more_size = sizeof (more);
sock.getsockopt(ZMQ_RCVMORE, &more, &more_size);
if (!more)
break; // Last message part
}
return;
}
void send_all_frames(zmq::socket_t& sock, std::vector<std::string>& frames) {
for (int i = 0; i < frames.size(); i++) {
if (i == frames.size() - 1) {
s_send(sock, frames[i]);
} else {
s_sendmore(sock, frames[i]);
}
}
return;
}
void receive_empty_message(zmq::socket_t& sock)
{
std::string empty = s_recv(sock);
assert(empty.size() == 0);
}
void print_all_frames(std::vector<std::string>& frames) {
std::cout << "------------received------------" << std::endl;
for (std::string &frame : frames)
{
std::cout << frame << std::endl;
std::cout << "----------------------------------------" << std::endl;
}
}
// Broker name
static std::string self;
// .split client task
// This is the client task. It issues a burst of requests and then
// sleeps for a few seconds. This simulates sporadic activity; when
// a number of clients are active at once, the local workers should
// be overloaded. The client uses a REQ socket for requests and also
// pushes statistics to the monitor socket:
void client_thread(int id) {
zmq::context_t context(1);
zmq::socket_t client(context, ZMQ_REQ);
std::string connURL = std::string("ipc://").append(self).append("-localfe.ipc");
#if (defined(WIN32))
s_set_id(client, id);
client.connect(connURL); // localfe
#else
s_set_id(client); // Set a printable identity
client.connect(connURL);
#endif
zmq::socket_t monitor(context, ZMQ_PUSH);
std::string moniURL = std::string("ipc://").append(self).append("-monitor.ipc");
monitor.connect(moniURL);
while (true) {
sleep(within(5));
int burst = within(15);
while (burst--) {
char task_id[5];
sprintf(task_id, "%04X", within(0x10000));
// Send request with random hex ID
s_send(client, std::string(task_id));
zmq_pollitem_t items[] = { { client, 0, ZMQ_POLLIN, 0 } };
try{
zmq::poll(items, 1, 10 * 1000 * ZMQ_POLL_MSEC); // 10 seconds timeout
} catch (zmq::error_t& e) {
std::cout << "client_thread: " << e.what() << std::endl;
break;
}
if (items[0].revents & ZMQ_POLLIN) {
std::string reply = s_recv(client);
assert(reply == std::string(task_id));
// Do not print directly, send to monitor
s_send(monitor, reply);
} else {
std::string reply = "E: CLIENT EXIT - lost task " + std::string(task_id);
s_send(monitor, reply);
return;
}
}
}
}
// .split worker task
// This is the worker task, which uses a REQ socket to plug into the
// load-balancer. It's the same stub worker task that you've seen in
// other examples:
void worker_thread(int id) {
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_REQ);
std::string connURL = std::string("ipc://").append(self).append("-localbe.ipc");
#if (defined (WIN32))
s_set_id(worker, id);
worker.connect(connURL); // backend
#else
s_set_id(worker);
worker.connect(connURL);
#endif
// Tell broker we're ready for work
s_send(worker, std::string(WORKER_READY));
while (true) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
std::vector<std::string> frames;
receive_all_frames(worker, frames);
// Workers are busy for 0/1 seconds
sleep(within(2));
send_all_frames(worker, frames);
}
return;
}
// .split main task
// The main task begins by setting up all its sockets. The local frontend
// talks to clients, and our local backend talks to workers. The cloud
// frontend talks to peer brokers as if they were clients, and the cloud
// backend talks to peer brokers as if they were workers. The state
// backend publishes regular state messages, and the state frontend
// subscribes to all state backends to collect these messages. Finally,
// we use a PULL monitor socket to collect printable messages from tasks:
int main(int argc, char *argv []) {
// First argument is this broker's name
// Other arguments are our peers' names
if (argc < 2) {
std::cout << "syntax: peering3 me {you} ..." << std::endl;
return 0;
}
self = std::string(argv[1]);
std::cout << "I: preparing broker at " << self << " ..." << std::endl;
srandom(static_cast<unsigned int>(time(nullptr)));
zmq::context_t context(1);
zmq::socket_t localfe(context, ZMQ_ROUTER);
{
std::string bindURL = std::string("ipc://").append(self).append("-localfe.ipc");
localfe.bind(bindURL);
}
zmq::socket_t localbe(context, ZMQ_ROUTER);
{
std::string bindURL = std::string("ipc://").append(self).append("-localbe.ipc");
localbe.bind(bindURL);
}
// Bind cloud frontend to endpoint
zmq::socket_t cloudfe(context, ZMQ_ROUTER);
cloudfe.set(zmq::sockopt::routing_id, self);
std::string bindURL = std::string("ipc://").append(self).append("-cloud.ipc");
cloudfe.bind(bindURL);
// Connect cloud backend to all peers
zmq::socket_t cloudbe(context, ZMQ_ROUTER);
cloudbe.set(zmq::sockopt::routing_id, self);
for(int argn = 2 ; argn < argc ; ++argn) {
std::string peer(argv[argn]);
std::cout << "I: connecting to cloud frontend at " << peer << std::endl;
std::string peerURL = std::string("ipc://").append(peer).append("-cloud.ipc");
cloudbe.connect(peerURL); // 将自己的cloudbe连接到其他broker的cloudfe
}
// Bind state backend to endpoint
zmq::socket_t statebe(context, ZMQ_PUB);
{
std::string bindURL = std::string("ipc://").append(self).append("-state.ipc");
statebe.bind(bindURL);
}
// Connect statefe to all peers
zmq::socket_t statefe(context, ZMQ_SUB);
statefe.set(zmq::sockopt::subscribe, "");
for(int argn = 2 ; argn < argc ; ++argn) {
std::string peer(argv[argn]);
std::string peerURL = std::string("ipc://").append(peer).append("-state.ipc");
statefe.connect(peerURL);
}
// Prepare monitor socket
zmq::socket_t monitor(context, ZMQ_PULL);
std::string moniURL = std::string("ipc://").append(self).append("-monitor.ipc");
monitor.bind(moniURL);
// .split start child tasks
// After binding and connecting all our sockets, we start our child
// tasks - workers and clients:
// Start local clients
int client_nbr = 0;
for (; client_nbr < NBR_CLIENTS; client_nbr++)
{
std::thread t(client_thread, client_nbr);
t.detach();
}
// Start local workers
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
{
std::thread t(worker_thread, worker_nbr);
t.detach();
}
// Queue of available workers
int local_capacity = 0;
int cloud_capacity = 0;
std::queue<std::string> workers;
// .split main loop
// The main loop has two parts. First, we poll workers and our two service
// sockets (statefe and monitor), in any case. If we have no ready workers,
// then there's no point in looking at incoming requests. These can remain
// on their internal 0MQ queues:
while (true) {
zmq_pollitem_t primary [] = {
{localbe, 0, ZMQ_POLLIN, 0},
{cloudbe, 0, ZMQ_POLLIN, 0},
{statefe, 0, ZMQ_POLLIN, 0},
{monitor, 0, ZMQ_POLLIN, 0}
};
try {
// If we have no workers ready, wait indefinitely
std::chrono::milliseconds timeout{(local_capacity ? 1000 * ZMQ_POLL_MSEC : -1)};
zmq::poll(primary, 4, timeout);
} catch(...) {
break;
}
// Track if capacity changes during this iteration
int previous = local_capacity;
if (primary[0].revents & ZMQ_POLLIN) {
// From localbe, reply from local worker
std::string worker_identity = s_recv(localbe);
workers.push(worker_identity);
local_capacity++;
receive_empty_message(localbe);
std::vector<std::string> remain_frames;
receive_all_frames(localbe, remain_frames);
assert(remain_frames.size() == 1 || remain_frames.size() == 3 || remain_frames.size() == 5);
// Third frame is READY or else a client reply address
std::string third_frame = remain_frames[0];
// If the third_frame is client_addr
if (third_frame.compare(WORKER_READY) != 0 && remain_frames.size() == 3) {
// Send to client
send_all_frames(localfe, remain_frames);
} else if (remain_frames.size() == 5) {
// The third_frame is origin_broker address
// Route the reply to the origin broker
for (int argn = 2; argn < argc; argn++) {
if (third_frame.compare(argv[argn]) == 0) {
send_all_frames(cloudfe, remain_frames);
}
}
}
} else if (primary[1].revents & ZMQ_POLLIN) {
// From cloudbe,handle reply from peer broker
std::string peer_broker_identity = s_recv(cloudbe); // useless
receive_empty_message(cloudbe);
std::string client_addr = s_recv(cloudbe);
receive_empty_message(cloudbe);
std::string reply = s_recv(cloudbe);
// send to the client
s_sendmore(localfe, client_addr);
s_sendmore(localfe, std::string(""));
s_send(localfe, reply);
}
// .split handle state messages
// If we have input messages on our statefe or monitor sockets, we
// can process these immediately:
if (primary[2].revents & ZMQ_POLLIN) {
// From statefe, receive other brokers state
std::string peer(s_recv(statefe));
std::string status(s_recv(statefe));
cloud_capacity = atoi(status.c_str());
}
if (primary[3].revents & ZMQ_POLLIN) {
// From monitor, receive printable message
std::string message(s_recv(monitor));
std::cout << "monitor: " << message << std::endl;
}
// .split route client requests
// Now route as many clients requests as we can handle. If we have
// local capacity, we poll both localfe and cloudfe. If we have cloud
// capacity only, we poll just localfe. We route any request locally
// if we can, else we route to the cloud.
while (local_capacity + cloud_capacity) {
zmq_pollitem_t secondary [] = {
{localfe, 0, ZMQ_POLLIN, 0},
{cloudfe, 0, ZMQ_POLLIN, 0}
};
if (local_capacity) {
try {
zmq::poll(secondary, 2, 0);
} catch(...) {
break;
}
} else {
try {
zmq::poll(secondary, 1, 0);
} catch(...) {
break;
}
}
std::vector<std::string> msg;
if (secondary[0].revents & ZMQ_POLLIN) {
// From localfe, receive client request
receive_all_frames(localfe, msg);
} else if (secondary[1].revents & ZMQ_POLLIN) {
// From cloudfe, receive other broker's request
receive_all_frames(cloudfe, msg);
} else {
break;
}
if (local_capacity) {
// Route to local worker
std::string worker_addr = workers.front();
workers.pop();
local_capacity--;
s_sendmore(localbe, worker_addr);
s_sendmore(localbe, std::string(""));
send_all_frames(localbe, msg);
} else {
// Route to cloud
int peer = within(argc - 2) + 2;
s_sendmore(cloudbe, std::string(argv[peer]));
s_sendmore(cloudbe, std::string(""));
send_all_frames(cloudbe, msg);
}
}
// .split broadcast capacity
// We broadcast capacity messages to other peers; to reduce chatter,
// we do this only if our capacity changed.
if (local_capacity != previous) {
std::ostringstream intStream;
intStream << local_capacity;
s_sendmore(statebe, self);
s_send(statebe, intStream.str());
}
}
return 0;
}
peering3: Full cluster simulation in C#
peering3: Full cluster simulation in CL
peering3: Full cluster simulation in Delphi
program peering3;
//
// Broker peering simulation (part 3)
// Prototypes the full flow of status and tasks
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
, zhelpers
;
const
NBR_CLIENTS = 10;
NBR_WORKERS = 5;
WORKER_READY = '\001'; // Signals worker is ready
var
// Our own name; in practice this would be configured per node
self: Utf8String;
// This is the client task. It issues a burst of requests and then
// sleeps for a few seconds. This simulates sporadic activity; when
// a number of clients are active at once, the local workers should
// be overloaded. The client uses a REQ socket for requests and also
// pushes statistics to the monitor socket:
procedure client_task( args: Pointer; ctx: TZMQContext );
var
client,
monitor: TZMQSocket;
burst,
i: Integer;
task_id,
reply: Utf8String;
poller: TZMQPoller;
begin
client := ctx.Socket( stReq );
{$ifdef unix}
client.connect( Format( 'ipc://%s-localfe.ipc', [self] ) );
{$else}
client.connect( Format( 'tcp://127.0.0.1:%s', [self] ) );
{$endif}
monitor := ctx.Socket( stPush );
{$ifdef unix}
monitor.connect( Format( 'ipc://%s-monitor.ipc', [self] ) );
{$else}
monitor.connect( Format( 'tcp://127.0.0.1:4%s', [self] ) );
{$endif}
poller := TZMQPoller.Create( true );
poller.Register( client, [pePollIn] );
while not ctx.Terminated do
try
sleep( random( 5000 ) );
burst := random( 15 );
for i := 0 to burst - 1 do
begin
task_id := s_random( 5 );
// Send request with random hex ID
client.send( task_id );
// Wait max ten seconds for a reply, then complain
poller.poll( 10000 );
if pePollIn in poller.PollItem[0].revents then
begin
client.recv( reply );
// Worker is supposed to answer us with our task id
assert ( reply = task_id );
monitor.send( reply );
end else
begin
monitor.send( 'E: CLIENT EXIT - lost task ' + task_id );
ctx.Terminate;
end;
end;
except
end;
end;
// This is the worker task, which uses a REQ socket to plug into the
// load-balancer. It's the same stub worker task you've seen in other
// examples:
procedure worker_task( args: Pointer; ctx: TZMQContext );
var
worker: TZMQSocket;
msg: TZMQMsg;
begin
worker := ctx.Socket( stReq );
{$ifdef unix}
worker.connect( Format( 'ipc://%s-localbe.ipc', [self] ) );
{$else}
worker.connect( Format( 'tcp://127.0.0.1:1%s', [self] ) );
{$endif}
// Tell broker we're ready for work
worker.send( WORKER_READY );
// Process messages as they arrive
while not ctx.Terminated do
try
msg := TZMQMsg.Create;
worker.recv( msg );
// Workers are busy for 0/1 seconds
sleep(random (2000));
worker.send( msg );
except
end;
end;
// The main task begins by setting-up all its sockets. The local frontend
// talks to clients, and our local backend talks to workers. The cloud
// frontend talks to peer brokers as if they were clients, and the cloud
// backend talks to peer brokers as if they were workers. The state
// backend publishes regular state messages, and the state frontend
// subscribes to all state backends to collect these messages. Finally,
// we use a PULL monitor socket to collect printable messages from tasks:
var
ctx: TZMQContext;
cloudfe,
cloudbe,
localfe,
localbe,
statefe,
statebe,
monitor: TZMQSocket;
i,
timeout,
previous,
random_peer: Integer;
peer: Utf8String;
thr: TZMQThread;
cloud_capacity: Integer;
workers: TZMQMsg;
primary,
secondary: TZMQPoller;
msg: TZMQMsg;
identity,
frame: TZMQFrame;
data,
status: Utf8String;
begin
// First argument is this broker's name
// Other arguments are our peers' names
//
if ParamCount < 2 then
begin
Writeln( 'syntax: peering2 me {you}...' );
halt( 1 );
end;
// on windows it should be a 1024 <= number <= 9999
self := ParamStr( 1 );
writeln( Format( 'I: preparing broker at %s', [self] ) );
randomize;
ctx := TZMQContext.create;
// Prepare local frontend and backend
localfe := ctx.Socket( stRouter );
{$ifdef unix}
localfe.bind( Format( 'ipc://%s-localfe.ipc', [self] ) );
{$else}
localfe.bind( Format( 'tcp://127.0.0.1:%s', [self] ) );
{$endif}
localbe := ctx.Socket( stRouter );
{$ifdef unix}
localbe.bind( Format( 'ipc://%s-localbe.ipc', [self] ) );
{$else}
localbe.bind( Format( 'tcp://127.0.0.1:1%s', [self] ) );
{$endif}
// Bind cloud frontend to endpoint
cloudfe := ctx.Socket( stRouter );
cloudfe.Identity := self;
{$ifdef unix}
cloudfe.bind( Format( 'ipc://%s-cloud.ipc', [self] ) );
{$else}
cloudfe.bind( Format( 'tcp://127.0.0.1:2%s', [self] ) );
{$endif}
// Connect cloud backend to all peers
cloudbe := ctx.Socket( stRouter );
cloudbe.Identity := self;
for i := 2 to ParamCount do
begin
peer := ParamStr( i );
Writeln( Format( 'I: connecting to cloud frontend at "%s"', [peer] ) );
{$ifdef unix}
cloudbe.connect( Format( 'ipc://%s-cloud.ipc', [peer] ) );
{$else}
cloudbe.connect( Format( 'tcp://127.0.0.1:2%s', [peer] ) );
{$endif}
end;
// Bind state backend to endpoint
statebe := ctx.Socket( stPub );
{$ifdef unix}
statebe.bind( Format( 'ipc://%s-state.ipc', [self] ) );
{$else}
statebe.bind( Format( 'tcp://127.0.0.1:3%s', [self] ) );
{$endif}
// Connect statefe to all peers
statefe := ctx.Socket( stSub );
statefe.Subscribe('');
for i := 2 to ParamCount do
begin
peer := ParamStr( i );
Writeln( Format( 'I: connecting to state backend at "%s"', [peer] ) );
{$ifdef unix}
statefe.connect( Format( 'ipc://%s-state.ipc', [peer] ) );
{$else}
statefe.connect( Format( 'tcp://127.0.0.1:3%s', [peer] ) );
{$endif}
end;
// Prepare monitor socket
monitor := ctx.Socket( stPull );
{$ifdef unix}
monitor.bind( Format( 'ipc://%s-monitor.ipc', [self] ) );
{$else}
monitor.bind( Format( 'tcp://127.0.0.1:4%s', [self] ) );
{$endif}
// After binding and connecting all our sockets, we start our child
// tasks - workers and clients:
for i := 0 to NBR_WORKERS - 1 do
begin
thr := TZMQThread.CreateDetachedProc( worker_task, nil );
thr.FreeOnTerminate := true;
thr.Resume;
end;
// Start local clients
for i := 0 to NBR_CLIENTS - 1 do
begin
thr := TZMQThread.CreateDetachedProc( client_task, nil );
thr.FreeOnTerminate := true;
thr.Resume;
end;
// Queue of available workers
cloud_capacity := 0;
workers := TZMQMsg.Create;
primary := TZMQPoller.Create( true );
primary.Register( localbe, [pePollIn] );
primary.Register( cloudbe, [pePollIn] );
primary.Register( statefe, [pePollIn] );
primary.Register( monitor, [pePollIn] );
secondary := TZMQPoller.Create( true );
secondary.Register( localfe, [pePollIn] );
secondary.Register( cloudfe, [pePollIn] );
// The main loop has two parts. First we poll workers and our two service
// sockets (statefe and monitor), in any case. If we have no ready workers,
// there's no point in looking at incoming requests. These can remain on
// their internal 0MQ queues:
while not ctx.Terminated do
try
// If we have no workers ready, wait indefinitely
if workers.size = 0 then
timeout := -1
else
timeout := 1000;
primary.poll( timeout );
// Track if capacity changes during this iteration
previous := workers.size;
// Handle reply from local worker
msg := nil;
if pePollIn in primary.PollItem[0].revents then
begin
localbe.recv( msg );
identity := msg.unwrap;
workers.add( identity );
// If it's READY, don't route the message any further
if msg.first.asUtf8String = WORKER_READY then
FreeAndNil( msg );
end else
// Or handle reply from peer broker
if pePollIn in primary.PollItem[1].revents then
begin
cloudbe.recv( msg );
// We don't use peer broker identity for anything
msg.unwrap.Free;
end;
// Route reply to cloud if it's addressed to a broker
if msg <> nil then
for i := 2 to ParamCount do
begin
data := msg.first.asUtf8String;
if data = ParamStr( i ) then
cloudfe.send( msg );
end;
// Route reply to client if we still need to
if msg <> nil then
localfe.send( msg );
// If we have input messages on our statefe or monitor sockets we
// can process these immediately:
if pePollIn in primary.PollItem[2].revents then
begin
statefe.recv( peer );
statefe.recv( status );
cloud_capacity := StrToInt( status );
end;
if pePollIn in primary.PollItem[3].revents then
begin
monitor.recv( status );
zNote( status );
end;
// Now route as many clients requests as we can handle. If we have
// local capacity we poll both localfe and cloudfe. If we have cloud
// capacity only, we poll just localfe. We route any request locally
// if we can, else we route to the cloud.
while ( workers.size + cloud_capacity ) > 0 do
begin
if workers.size > 0 then
secondary.poll( 0, 2 )
else
secondary.poll( 0, 1 );
//msg := TZMQMsg.Create;
if pePollIn in secondary.PollItem[0].revents then
localfe.recv( msg ) else
if pePollIn in secondary.PollItem[1].revents then
cloudfe.recv( msg ) else
break; // No work, go back to primary
if workers.size > 0 then
begin
frame := workers.pop;
msg.wrap( frame );
localbe.send( msg );
end else
begin
random_peer := random( ParamCount - 2 ) + 2;
identity := TZMQFrame.create;
identity.asUtf8String := ParamStr( random_peer );
msg.push( identity );
cloudbe.send( msg );
end;
end;
// We broadcast capacity messages to other peers; to reduce chatter
// we do this only if our capacity changed.
if workers.size <> previous then
begin
// We stick our own identity onto the envelope
// Broadcast new capacity
statebe.send( [self, IntToStr( workers.size ) ] );
end;
except
end;
// When we're done, clean up properly
while workers.size > 0 do
begin
frame := workers.pop;
frame.Free;
end;
workers.Free;
ctx.Free;
end.
peering3: Full cluster simulation in Erlang
peering3: Full cluster simulation in Elixir
peering3: Full cluster simulation in F#
(*
Broker peering simulation (part 2)
Prototypes the request-reply flow
While this example runs in a single process, that is just to make
it easier to start and stop the example. Each thread has its own
context and conceptually acts as a separate process.
*)
#r @"bin/fszmq.dll"
#r @"bin/fszmq.devices.dll"
open fszmq
open fszmq.Context
open fszmq.devices
open fszmq.Polling
open fszmq.Socket
#load "zhelpers.fs"
open System.Collections.Generic
let [<Literal>] NBR_CLIENTS = 10
let [<Literal>] NBR_WORKERS = 5
let LRU_READY = [| 1uy |] // signals worker is ready
let rand = srandom()
// request-reply client using REQ socket
// to simulate load, clients issue a burst of requests
// and then sleep for a random period.
let client_task (o:obj) =
let frontPort,monitorPort = o :?> (int * int)
use ctx = new Context(1)
use client = ctx |> req
connect client (sprintf "tcp://localhost:%i" frontPort)
use monitor = ctx |> push
connect monitor (sprintf "tcp://localhost:%i" monitorPort)
let pollset socket taskID =
[Poll(ZMQ.POLLIN,socket,fun s ->
let reply = recv s
// worker is supposed to answer us with our task ID
reply |> dumpFrame (Some "Client: ")
assert ((decode reply) = taskID))]
let rec burst = function
| n when n > 0 ->
let taskID = sprintf "%04X" (rand.Next 0x10000)
// send request with random hex ID
taskID |> encode |>> client
match (taskID |> pollset client) |> poll 100000L with
| true -> burst (n - 1)
| _ -> false,taskID
| _ -> true,"<none>"
let rec loop () =
sleep ((rand.Next 5) * 1000)
match burst (rand.Next 15) with
| false,taskID -> (sprintf "E: CLIENT EXIT - lost task %s" taskID)
|> encode
|>> monitor
| _ -> loop()
loop()
// worker using REQ socket to do LRU routing
let worker_task (o:obj) =
let backPort = o :?> int
use ctx = new Context(1)
use worker = ctx |> req
connect worker (sprintf "tcp://localhost:%i" backPort)
// tell broker we're ready for work
LRU_READY |>> worker
while true do
// workers are busy for 0/1/2 seconds
let msg = recvAll worker
sleep ((rand.Next 3) * 1000)
msg |> sendAll worker
let main args =
// first argument is this broker's name
// other arguments are our peers' names
match args |> Array.length with
| argc when argc > 1 ->
let cloudPort,self = let n = args.[1] in (int n),(encode n)
let peers = if argc > 2 then args.[2..] else [||]
let isPeer address = peers |> Array.exists ((=) address)
let frontPort,backPort,statePort,monitorPort = cloudPort + 1,
cloudPort + 2,
cloudPort + 3,
cloudPort + 4
//NOTE: to run this example on Windows, we must use tcp...
// so when we do, assume inputs are port numbers, and we use
// them as the basis for additional (internal to the cluster)
// port numbers on non-windows systems, we can use ipc (as per
// the guide) so in *that* case, inputs are alphanumeric IDs
printfn' "I: preparing broker at %i..." cloudPort
// prepare our context and sockets
use ctx = new Context(1)
// bind cloud frontend to endpoint
use cloudfe = ctx |> route
(ZMQ.IDENTITY,self) |> set cloudfe
bind cloudfe (sprintf "tcp://*:%i" cloudPort)
// bind state backend / publisher to endpoint
use statebe = ctx |> pub
bind statebe (sprintf "tcp://*:%i" statePort)
// connect cloud backend to all peers
use cloudbe = ctx |> route
(ZMQ.IDENTITY,self) |> set cloudbe
peers |> Array.iter (fun peer ->
printfn' "I: connecting to cloud frontend at '%s'" peer
connect cloudbe (sprintf "tcp://localhost:%s" peer))
// connect statefe to all peers
use statefe = ctx |> sub
[""B] |> subscribe statefe
peers |> Array.iter (fun peer ->
let peerPort = (int peer) + 3
printfn' "I: connecting to state backend at '%i'" peerPort
connect statefe (sprintf "tcp://localhost:%i" peerPort))
// prepare local frontend and backend
use localfe = ctx |> route
bind localfe (sprintf "tcp://*:%i" frontPort)
use localbe = ctx |> route
bind localbe (sprintf "tcp://*:%i" backPort)
// prepare monitor socket
use monitor = ctx |> pull
bind monitor (sprintf "tcp://*:%i" monitorPort)
// start local workers
for _ in 1 .. NBR_WORKERS do
ignore (t_spawnp worker_task backPort)
// start local clients
for _ in 1 .. NBR_CLIENTS do
ignore (t_spawnp client_task (frontPort,monitorPort))
(* Interesting part
-------------------------------------------------------------
Publish-subscribe flow
- Poll statefe and process capacity updates
- Each time capacity changes, broadcast new value
Request-reply flow
- Poll primary and process local/cloud replies
- While worker available, route localfe to local or cloud *)
// queue of available workers
let workers = Queue()
let rec secondary localCapacity cloudCapacity =
if localCapacity + cloudCapacity > 0 then
let message = ref None
let fetchMessage socket = message := Some(recvAll socket)
let pollset =
[ yield Poll( ZMQ.POLLIN,localfe,fetchMessage )
if workers.Count > 0 then
yield Poll( ZMQ.POLLIN,cloudfe,fetchMessage )]
if pollset |> poll 0L then
!message |> Option.iter (fun msg ->
let address,backend =
match localCapacity with
| 0 -> // route to random broker peer
encode peers.[rand.Next peers.Length],cloudbe
| _ -> // route to local worker
workers.Dequeue(),localbe
msg
|> Array.append [| address; Array.empty |]
|> sendAll backend)
secondary workers.Count cloudCapacity
let rec primary () =
let timeout = if workers.Count = 0 then -1L else 100000L
let message = ref None
let cloudCapacity = ref 0
let pollset =
[ Poll( ZMQ.POLLIN,localbe,fun _ ->
// handle reply from local worker
let msg = recvAll localbe
msg.[0] |> workers.Enqueue
// if it's READY, don't route the message any further
message := if msg.[2] = LRU_READY
then None
else msg.[2 ..] |> Some )
Poll( ZMQ.POLLIN,cloudbe,fun _ ->
// handle reply from peer broker
let msg = recvAll cloudbe
// we don't use peer broker address for anything
message := Some(msg.[2 ..]) )
Poll( ZMQ.POLLIN,statefe,fun _ ->
// handle capacity updates
cloudCapacity := (recv >> decode >> int) statefe )
Poll( ZMQ.POLLIN,monitor,fun _ ->
// handle monitor message
(recv >> decode >> (printfn' "%s")) monitor ) ]
if pollset |> poll timeout then
!message |> Option.iter (fun msg ->
let address = decode msg.[0]
// route reply to cloud if it's addressed to a broker
// otherwise route reply to client
msg |> sendAll (if isPeer address then cloudfe else localfe))
// Now route as many clients requests as we can handle
let previous = workers.Count
secondary previous !cloudCapacity
if workers.Count <> previous then
// we stick our own address onto the envelope
statebe <~| (string >> encode) cloudPort
// broadcast new capacity
<<| (string >> encode) workers.Count
primary()
primary()
EXIT_SUCCESS
| _ ->
printfn "syntax: peering3 me {you}..."
EXIT_FAILURE
main fsi.CommandLineArgs
peering3: Full cluster simulation in Felix
peering3: Full cluster simulation in Go
// Broker peering simulation (part 3)
// Prototypes the full flow of status and tasks
//
// Author: amyangfei <amyangfei@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"os"
"strconv"
"time"
)
const NBR_CLIENTS = 10
const NBR_WORKERS = 5
const WORKER_READY = "\001"
func client_task(name string, i int) {
context, _ := zmq.NewContext()
client, _ := context.NewSocket(zmq.REQ)
monitor, _ := context.NewSocket(zmq.PUSH)
defer context.Close()
defer client.Close()
defer monitor.Close()
client.SetIdentity(fmt.Sprintf("Client-%s-%d", name, i))
client.Connect(fmt.Sprintf("ipc://%s-localfe.ipc", name))
monitor.Connect(fmt.Sprintf("ipc://%s-monitor.ipc", name))
for {
time.Sleep(time.Duration(rand.Intn(5)) * time.Second)
burst := rand.Intn(15)
for burst > 0 {
burst--
task_id := fmt.Sprintf("%04X", rand.Intn(0x10000))
// Send request with random hex ID
client.Send([]byte(task_id), 0)
// Wait max ten seconds for a reply, then complain
pollset := zmq.PollItems{
zmq.PollItem{Socket: client, Events: zmq.POLLIN},
}
zmq.Poll(pollset, 10*time.Second)
if pollset[0].REvents&zmq.POLLIN != 0 {
reply, err := client.Recv(0)
if err != nil {
break
}
if string(reply) != task_id {
panic("Worker is supposed to answer us with our task id")
}
monitor.Send(reply, 0)
} else {
monitor.Send([]byte(fmt.Sprintf("E: CLIENT EXIT - lost task %s", task_id)), 0)
}
}
}
}
func worker_task(name string, i int) {
context, _ := zmq.NewContext()
worker, _ := context.NewSocket(zmq.REQ)
defer context.Close()
defer worker.Close()
worker.SetIdentity(fmt.Sprintf("Worker-%s-%d", name, i))
worker.Connect(fmt.Sprintf("ipc://%s-localbe.ipc", name))
// Tell broker we're ready for work
worker.Send([]byte(WORKER_READY), 0)
// Process messages as they arrive
for {
msg, err := worker.RecvMultipart(0)
if err != nil {
break
}
// Workers are busy for 0/1 seconds
time.Sleep(time.Duration(rand.Intn(2)) * time.Second)
fmt.Printf("Worker-%s-%d done: %s\n", name, i, msg)
worker.SendMultipart(msg, 0)
}
}
func main() {
// First argument is this broker's name
// Other arguments are our peers' names
if len(os.Args) < 2 {
fmt.Println("syntax: peering3 me {you}...")
return
}
myself := os.Args[1]
fmt.Printf("I: preparing broker at %s...\n", myself)
rand.Seed(time.Now().UnixNano())
context, _ := zmq.NewContext()
defer context.Close()
// Prepare local frontend and backend
localfe, _ := context.NewSocket(zmq.ROUTER)
localbe, _ := context.NewSocket(zmq.ROUTER)
defer localfe.Close()
defer localbe.Close()
localfe.Bind(fmt.Sprintf("ipc://%s-localfe.ipc", myself))
localbe.Bind(fmt.Sprintf("ipc://%s-localbe.ipc", myself))
// Bind cloud fronted to endpoint
cloudfe, _ := context.NewSocket(zmq.ROUTER)
defer cloudfe.Close()
cloudfe.SetIdentity(myself)
cloudfe.Bind(fmt.Sprintf("ipc://%s-cloud.ipc", myself))
// Connect cloud backend to all peers
cloudbe, _ := context.NewSocket(zmq.ROUTER)
defer cloudbe.Close()
cloudbe.SetIdentity(myself)
for i := 2; i < len(os.Args); i++ {
peer := os.Args[i]
fmt.Printf("I: connecting to cloud frontend at '%s'\n", peer)
cloudbe.Connect(fmt.Sprintf("ipc://%s-cloud.ipc", peer))
}
// Bind state backend to endpoint
statebe, _ := context.NewSocket(zmq.PUB)
defer statebe.Close()
bindAddress := fmt.Sprintf("ipc://%s-state.ipc", myself)
statebe.Bind(bindAddress)
// Connect state frontend to all peers
statefe, _ := context.NewSocket(zmq.SUB)
defer statefe.Close()
statefe.SetSubscribe("")
for i := 2; i < len(os.Args); i++ {
peer := os.Args[i]
fmt.Printf("I: connecting to state backend at '%s'\n", peer)
statefe.Connect(fmt.Sprintf("ipc://%s-state.ipc", peer))
}
// Prepare monitor socket
monitor, _ := context.NewSocket(zmq.PULL)
defer monitor.Close()
monitor.Bind(fmt.Sprintf("ipc://%s-monitor.ipc", myself))
// Start local workers
for i := 0; i < NBR_WORKERS; i++ {
go worker_task(myself, i)
}
// Start local clients
for i := 0; i < NBR_CLIENTS; i++ {
go client_task(myself, i)
}
// Queue of available workers
local_capacity := 0
cloud_capacity := 0
workers := make([]string, 0)
pollerbe := zmq.PollItems{
zmq.PollItem{Socket: localbe, Events: zmq.POLLIN},
zmq.PollItem{Socket: cloudbe, Events: zmq.POLLIN},
zmq.PollItem{Socket: statefe, Events: zmq.POLLIN},
zmq.PollItem{Socket: monitor, Events: zmq.POLLIN},
}
for {
timeout := time.Second
if len(workers) == 0 {
timeout = -1
}
// If we have no workers anyhow, wait indefinitely
zmq.Poll(pollerbe, timeout)
// Track if capacity changes during this iteration
previous := local_capacity
var msg [][]byte = nil
var err error = nil
if pollerbe[0].REvents&zmq.POLLIN != 0 {
msg, err = localbe.RecvMultipart(0)
if err != nil {
break
}
identity, _ := msg[0], msg[1]
msg = msg[2:]
workers = append(workers, string(identity))
local_capacity++
// If it's READY, don't route the message any further
if string(msg[len(msg)-1]) == WORKER_READY {
msg = nil
}
} else if pollerbe[1].REvents&zmq.POLLIN != 0 {
msg, err = cloudbe.RecvMultipart(0)
if err != nil {
break
}
// We don't use peer broker identity for anything
msg = msg[2:]
}
if msg != nil {
identity := string(msg[0])
for i := 2; i < len(os.Args); i++ {
// Route reply to cloud if it's addressed to a broker
if identity == os.Args[i] {
cloudfe.SendMultipart(msg, 0)
msg = nil
break
}
}
// Route reply to client if we still need to
if msg != nil {
localfe.SendMultipart(msg, 0)
}
}
// Handle capacity updates
if pollerbe[2].REvents&zmq.POLLIN != 0 {
msg, _ := statefe.RecvMultipart(0)
status := msg[1]
cloud_capacity, _ = strconv.Atoi(string(status))
}
// handle monitor message
if pollerbe[3].REvents&zmq.POLLIN != 0 {
msg, _ := monitor.Recv(0)
fmt.Println(string(msg))
}
for (local_capacity + cloud_capacity) > 0 {
secondary := zmq.PollItems{
zmq.PollItem{Socket: localfe, Events: zmq.POLLIN},
}
if local_capacity > 0 {
secondary = append(secondary, zmq.PollItem{Socket: cloudfe, Events: zmq.POLLIN})
}
zmq.Poll(secondary, 0)
if secondary[0].REvents&zmq.POLLIN != 0 {
msg, _ = localfe.RecvMultipart(0)
} else if len(secondary) > 1 && secondary[1].REvents&zmq.POLLIN != 0 {
msg, _ = cloudfe.RecvMultipart(0)
} else {
break
}
if local_capacity > 0 {
var worker string
worker, workers = workers[0], workers[1:]
msg = append(msg[:0], append([][]byte{[]byte(worker), []byte("")}, msg[0:]...)...)
localbe.SendMultipart(msg, 0)
local_capacity--
} else {
// Route to random broker peer
randPeer := rand.Intn(len(os.Args)-2) + 2
msg = append(msg[:0], append([][]byte{[]byte(os.Args[randPeer]), []byte("")}, msg[0:]...)...)
cloudbe.SendMultipart(msg, 0)
}
}
if local_capacity != previous {
statebe.SendMultipart([][]byte{[]byte(myself), []byte(strconv.Itoa(local_capacity))}, 0)
}
}
}
peering3: Full cluster simulation in Haskell
{-# LANGUAGE OverloadedStrings #-}
module Main where
import Control.Concurrent (threadDelay)
import Control.Monad (forM_, forever, when)
import Control.Monad.IO.Class
import Data.Attoparsec.ByteString.Char8 hiding (take)
import qualified Data.ByteString.Char8 as C
import Data.List (find, unfoldr)
import Data.List.NonEmpty (NonEmpty (..))
import qualified Data.List.NonEmpty as N
import Data.Semigroup ((<>))
import Data.Sequence (Seq, ViewL (..), viewl, (|>))
import qualified Data.Sequence as S
import System.Environment
import System.Exit
import System.Random
import System.ZMQ4.Monadic
workerNum :: Int
workerNum = 5
clientNum :: Int
clientNum = 10
-- | This is the client task. It issues a burst of requests and then
-- sleeps for a few seconds. This simulates sporadic activity; when
-- a number of clients are active at once, the local workers should
-- be overloaded. The client uses a REQ socket for requests and also
-- pushes statistics over the monitor socket.
clientTask :: Show a => String -> a -> ZMQ z ()
clientTask self i = do
client <- socket Req
connect client (connectString self "localfe")
mon <- socket Push
connect mon (connectString self "monitor")
let ident = "Client-" <> C.pack self <> C.pack (show i)
setIdentity (restrict ident) client
forever $ do
-- Sleep random amount. 0 to 4 seconds.
liftIO $ randomRIO (0,4000000) >>= threadDelay
numTasks <- liftIO $ randomRIO (0,14)
g <- liftIO newStdGen
let taskIds :: [Int]
taskIds = take numTasks $ unfoldr (Just . randomR (0,0x10000)) g
pollset taskId = [ Sock client [In] (Just $ const $ receivedReply taskId) ]
receivedReply taskId = do
reply <- receive client
-- Worker is supposed to answer us with our task ID
when (taskId /= reply) $
liftIO $ print (reply, taskId)
send mon [] reply
forM_ taskIds $ \taskId -> do
-- Send request with random ID
let bTaskId = C.pack (show taskId)
send client [] bTaskId
-- Wait max ten seconds for a reply, then complain
[pollEvt] <- poll 10000 (pollset bTaskId)
when (null pollEvt) $
send mon [] $ "Client exit - lost task " <> bTaskId
-- | This is the worker task, which uses a REQ socket to plug into the
-- load-balancer. It's the same stub worker task that you've seen in
-- other examples.
workerTask :: Show a => String -> a -> ZMQ z ()
workerTask self i = do
worker <- socket Req
connect worker (connectString self "localbe")
let ident = "Worker-" <> C.pack self <> C.pack (show i)
setIdentity (restrict ident) worker
-- Tell broker we're ready for work
send worker [] "READY"
-- Process messages as they arrive
forever $ do
msg <- receiveMulti worker
-- Workers are busy for 0-1 seconds
liftIO $ randomRIO (0,1000000) >>= threadDelay
sendMulti worker (N.fromList msg)
-- | Connect a peer using the connectString function
connectPeer :: Socket z t -> String -> String -> ZMQ z ()
connectPeer sock name p = connect sock (connectString p name)
-- | An ipc connection string
connectString :: String -> String -> String
connectString peer name = "ipc://" ++ peer ++ "-" ++ name ++ ".ipc"
type Workers = Seq C.ByteString
-- | The main loop has two parts. First, we poll workers and our two service
-- sockets (stateFront and mon), in any case. If we have no ready workers,
-- then there's no point in looking at incoming requests. These can remain
-- on their internal 0MQ queues.
clientWorkerPoll
:: ( Receiver t1
, Receiver t2
, Receiver t4
, Receiver t5
, Receiver t6
, Receiver t7
, Sender t1
, Sender t2
, Sender t3
, Sender t4
, Sender t5 )
=> String
-> Socket z t1
-> Socket z t2
-> Socket z t3
-> Socket z t4
-> Socket z t5
-> Socket z t6
-> Socket z t7
-> [String]
-> ZMQ z ()
clientWorkerPoll
self
localBack
cloudBack
stateBack
localFront
cloudFront
stateFront
mon
peers = loop S.empty 0 -- Queue of workers starts empty
where
loop workers cloudCapacity = do
-- Poll primary, if we have no workers, wait indefinitely
[localEvents, cloudEvents, stateEvents, _] <- poll (if S.length workers > 0 then oneSec else -1) primary
availableWorkers <- reqRep workers localEvents cloudEvents
-- If we have input messages on the stateFront socket,
-- process it immediately.
cloudCapacity' <- if In `elem` stateEvents
then stateChange cloudCapacity
else return cloudCapacity
availableWorkers' <- workerLoop workers availableWorkers cloudCapacity'
loop availableWorkers' cloudCapacity'
reqRep workers local cloud
-- Handle reply from local worker
| In `elem` local = do
msg <- receiveMulti localBack
case msg of
-- Worker is READY, don't route the message further
ident:_:"READY":_ -> return (workers |> ident)
-- Worker replied
ident:_:restOfMsg -> do
route restOfMsg
return (workers |> ident)
-- Something strange happened
_ -> return workers
-- Handle reply from peer broker
| In `elem` cloud = do
msg <- receiveMulti cloudBack
case msg of
-- We don't use the peer broker identity for anything
_:restOfMsg -> route restOfMsg
-- Something strange happened
_ -> return ()
return workers
| otherwise = return workers
route msg@(ident:_) = do
let msg' = N.fromList msg
peer = find (== ident) bPeers
case peer of
-- Route reply to cloud if it's addressed to a broker
Just _ -> sendMulti cloudFront msg'
-- Route reply to local client
Nothing -> sendMulti localFront msg'
route _ = return () -- Something strange happened
-- Now, we route as many client requests as we can handle. If we have
-- local capacity, we poll both localFront and cloudFront. If we have
-- cloud capacity only, we poll just localFront. We route any request
-- locally if we can, else we route to the cloud.
workerLoop oldWorkers workers cloudCapacity = if areWorkers || areCloud
then do
evts <- poll 0 ((if areWorkers then id else take 1) secondary)
case evts of
[localEvents] ->
routeRequests oldWorkers workers cloudCapacity localEvents []
[localEvents, cloudEvents] ->
routeRequests oldWorkers workers cloudCapacity localEvents cloudEvents
_ -> return workers
else return workers
where
areWorkers = not (S.null workers)
areCloud = cloudCapacity > 0
routeRequests oldWorkers workers cloudCapacity local cloud
| In `elem` local =
receiveMulti localFront >>= rerouteReqs oldWorkers workers cloudCapacity
| In `elem` cloud =
receiveMulti cloudFront >>= rerouteReqs oldWorkers workers cloudCapacity
-- No work, go back to primary
| otherwise = return workers
rerouteReqs oldWorkers workers cloudCapacity msg = do
newWorkers <- if S.null workers
then do
-- Route to random broker peer
p <- liftIO $ randomRIO (0, length peers - 1)
let randomPeer = bPeers !! p
sendMulti cloudBack (randomPeer :| msg)
return workers
else do
let (worker, newWorkers) = popWorker (viewl workers)
case worker of
Nothing -> return ()
Just w -> sendMulti localBack $ w :| [""] <> msg
return newWorkers
-- We broadcast capacity messages to other peers; to reduce chatter,
-- we do this only if our capacity changed.
when (S.length oldWorkers /= S.length newWorkers) $
sendMulti stateBack $ C.pack self :| [C.pack . show . S.length $ newWorkers]
workerLoop oldWorkers newWorkers cloudCapacity
oneSec = 1000
bPeers = map C.pack peers
-- If the state changed, update the cloud capacity.
stateChange cloudCapacity = do
msg <- receiveMulti stateFront
case msg of
_:status:_ -> do
-- If we can't parse, assume 0...
let statusNum = either (const 0) id (parseOnly decimal status)
return (statusNum :: Int)
_ -> return cloudCapacity -- Could not parse message
primary =
[ Sock localBack [In] Nothing
, Sock cloudBack [In] Nothing
, Sock stateFront [In] Nothing
-- If we have messages on the monitor socket, process it immediately
, Sock mon [In] (Just $ const $ receive mon >>= liftIO . C.putStrLn) ]
secondary =
[ Sock localFront [In] Nothing
, Sock cloudFront [In] Nothing ]
popWorker EmptyL = (Nothing, S.empty)
popWorker (l :< s) = (Just l, s)
-- | The main task begins by setting up all its sockets. The local frontend
-- talks to clients, and our local backend talks to workers. The cloud
-- frontend talks to peer brokers as if they were clients, and the cloud
-- backend talks to peer brokers as if they were workers. The state
-- backend publishes regular state messages, and the state frontend
-- subscribes to all state backends to collect these messages. Finally,
-- we use a PULL monitor socket to sollect printable messages from tasks.
main :: IO ()
main = do
args <- getArgs
when (length args < 2) $ do
putStrLn "Usage: broker <me> <you> [<you> ...]"
exitFailure
-- First argument is this broker's name
-- Other arguments are our peers' names
let self:peers = args
putStrLn $ "Preparing broker at " ++ self
runZMQ $ do
-- Prepare local frontend and backend
localFront <- socket Router
bind localFront (connectString self "localfe")
localBack <- socket Router
bind localBack (connectString self "localbe")
-- Bind cloud frontend to endpoint
cloudFront <- socket Router
setIdentity (restrict (C.pack self)) cloudFront
bind cloudFront (connectString self "cloud")
-- Connect cloud backend to all peers
cloudBack <- socket Router
setIdentity (restrict (C.pack self)) cloudBack
mapM_ (connectPeer cloudBack "cloud") peers
-- Bind state backend to endpoint
stateBack <- socket Pub
bind stateBack (connectString self "state")
-- Connect state frontend to all peers
stateFront <- socket Sub
subscribe stateFront ""
mapM_ (connectPeer stateFront "state") peers
-- Prepare monitor socket
mon <- socket Pull
bind mon (connectString self "monitor")
-- Start workers and clients
forM_ [1..workerNum] $ async . workerTask self
forM_ [1..clientNum] $ async . clientTask self
-- Request reply flow
clientWorkerPoll
self
localBack
cloudBack
stateBack
localFront
cloudFront
stateFront
mon
peers
peering3: Full cluster simulation in Haxe
package ;
import org.zeromq.ZMQException;
import ZHelpers;
import haxe.io.Bytes;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
#if (neko || cpp)
import neko.vm.Thread;
#end
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZFrame;
/**
* Broker peering simulation (part 3)
* Prototypes the full flow of status and tasks
*
* While this example runs in a single process (for cpp & neko) and forked processes (for php), that is just
* to make it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: http://zguide.zeromq.org/page:all#Putting-it-All-Together
*
* NB: If running from Run.hx, set ARG_OFFSET to 1
* If running directly, set ARG_OFFSET to 0
*/
class Peering3
{
private static inline var NBR_CLIENTS = 10;
private static inline var NBR_WORKERS = 3;
private static inline var LRU_READY:String = String.fromCharCode(1); // Signals workers are ready
// Our own name; in practise this would be configured per node
private static var self:String;
private static inline var ARG_OFFSET = 1;
/**
* Request - reply client using REQ socket
* To simulate load, clients issue a burst of requests and then
* sleep for a random period.
*/
private static function clientTask() {
var ctx = new ZContext();
var client = ctx.createSocket(ZMQ_REQ);
client.connect("ipc:///tmp/" + self + "-localfe.ipc");
var monitor = ctx.createSocket(ZMQ_PUSH);
monitor.connect("ipc:///tmp/" + self + "-monitor.ipc");
var poller = new ZMQPoller();
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
while (true) {
Sys.sleep(ZHelpers.randof(5));
var burst = ZHelpers.randof(14);
for (i in 0 ... burst) {
var taskID = StringTools.hex(ZHelpers.randof(0x10000), 4);
// Send request with random hex ID
Lib.println("Client send task " + taskID);
try {
ZFrame.newStringFrame(taskID).send(client);
} catch (e:ZMQException) {
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
return; // quit
} catch (e:Dynamic) {
trace (e);
}
// Wait max ten seconds for a reply, then complain
try {
poller.poll(10 * 1000 * 1000);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
return; // quit
}
if (poller.pollin(1)) {
var reply = ZFrame.recvFrame(client);
if (reply == null)
break;
// Worker is supposed to answer us with our task id
if (!reply.streq(taskID)) {
Lib.println("E: Returned task ID:" + reply.toString() + " does not match requested taskID:" + taskID);
break;
}
} else {
ZMsg.newStringMsg("E: CLIENT EXIT - lost task " + taskID).send(monitor);
}
}
}
ctx.destroy();
}
/**
* Worker using REQ socket to do LRU routing
*/
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
worker.connect("ipc:///tmp/"+self+"-localbe.ipc");
// Tell broker we're ready to do work
ZFrame.newStringFrame(LRU_READY).send(worker);
// Process messages as they arrive
while (true) {
try {
var msg:ZMsg = ZMsg.recvMsg(worker);
if (msg == null) {
context.destroy();
return;
}
Lib.println("Worker received " + msg.last().toString());
// Workers are busy for 0 / 1/ 2 seconds
Sys.sleep(ZHelpers.randof(2));
msg.send(worker);
} catch (e:ZMQException) {
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
}
context.destroy();
}
public static function main() {
Lib.println("** Peering3 (see: http://zguide.zeromq.org/page:all#Putting-it-All-Together)");
// First argument is this broker's name
// Other arguments are our peers' names
if (Sys.args().length < 2+ARG_OFFSET) {
Lib.println("syntax: ./Peering3 me {you} ...");
return;
}
self = Sys.args()[0 + ARG_OFFSET];
#if php
// Start local workers
for (worker_nbr in 0 ... NBR_WORKERS) {
forkWorkerTask();
}
// Start local clients
for (client_nbr in 0 ... NBR_CLIENTS) {
forkClientTask();
}
#end
Lib.println("I: preparing broker at " + self + " ...");
// Prepare our context and sockets
var ctx = new ZContext();
var endpoint:String;
// Bind cloud frontend to endpoint
var cloudfe = ctx.createSocket(ZMQ_ROUTER);
cloudfe.setsockopt(ZMQ_IDENTITY, Bytes.ofString(self));
cloudfe.bind("ipc:///tmp/" + self + "-cloud.ipc");
// Bind state backend / publisher to endpoint
var statebe = ctx.createSocket(ZMQ_PUB);
statebe.bind("ipc:///tmp/" + self + "-state.ipc");
// Connect cloud backend to all peers
var cloudbe = ctx.createSocket(ZMQ_ROUTER);
cloudbe.setsockopt(ZMQ_IDENTITY, Bytes.ofString(self));
for (argn in 1 + ARG_OFFSET ... Sys.args().length) {
var peer = Sys.args()[argn];
Lib.println("I: connecting to cloud frontend at '" + peer + "'");
cloudbe.connect("ipc:///tmp/" + peer + "-cloud.ipc");
}
// Connect statefe to all peers
var statefe = ctx.createSocket(ZMQ_SUB);
statefe.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
for (argn in 1+ARG_OFFSET ... Sys.args().length) {
var peer = Sys.args()[argn];
Lib.println("I: connecting to state backend at '" + peer + "'");
statefe.connect("ipc:///tmp/" + peer + "-state.ipc");
}
// Prepare local frontend and backend
var localfe = ctx.createSocket(ZMQ_ROUTER);
localfe.bind("ipc:///tmp/" + self + "-localfe.ipc");
var localbe = ctx.createSocket(ZMQ_ROUTER);
localbe.bind("ipc:///tmp/" + self + "-localbe.ipc");
// Prepare monitor socket
var monitor = ctx.createSocket(ZMQ_PULL);
monitor.bind("ipc:///tmp/" + self + "-monitor.ipc");
#if !php
// Start local workers
for (worker_nbr in 0 ... NBR_WORKERS) {
Thread.create(workerTask);
}
// Start local clients
for (client_nbr in 0 ... NBR_CLIENTS) {
Thread.create(clientTask);
}
#end
// Interesting part
// -------------------------------------------------------------
// Publish-subscribe flow
// - Poll statefe and process capacity updates
// - Each time capacity changes, broadcast new value
// Request-reply flow
// - Poll primary and process local/cloud replies
// - While worker available, route localfe to local or cloud
// Queue of available workers
var localCapacity = 0;
var cloudCapacity = 0;
var workerQueue:List<ZFrame> = new List<ZFrame>();
var primary = new ZMQPoller();
primary.registerSocket(localbe, ZMQ.ZMQ_POLLIN());
primary.registerSocket(cloudbe, ZMQ.ZMQ_POLLIN());
primary.registerSocket(statefe, ZMQ.ZMQ_POLLIN());
primary.registerSocket(monitor, ZMQ.ZMQ_POLLIN());
while (true) {
trace ("**Start main loop iteration");
var ret = 0;
try {
// If we have no workers anyhow, wait indefinitely
ret = primary.poll( {
if (localCapacity > 0) 1000 * 1000 else -1; } );
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
break;
}
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
return;
}
// Track if capacity changes in this iteration
var previous = localCapacity;
var msg:ZMsg = null;
// Handle reply from local worker
if (primary.pollin(1)) {
msg = ZMsg.recvMsg(localbe);
if (msg == null)
break; // Interrupted
var address = msg.unwrap();
workerQueue.add(address);
localCapacity++;
// If it's READY, don't route the message any further
var frame = msg.first();
if (frame.streq(LRU_READY))
msg.destroy();
}
// Or handle reply from peer broker
else if (primary.pollin(2)) {
msg = ZMsg.recvMsg(cloudbe);
if (msg == null)
break;
// We don't use peer broker address for anything
var address = msg.unwrap();
}
// Route reply to cloud if it's addressed to a broker
if (msg != null && !msg.isEmpty()) {
for (argv in 1 + ARG_OFFSET ... Sys.args().length) {
if (!msg.isEmpty() && msg.first().streq(Sys.args()[argv])) {
trace ("Route reply to peer:" + Sys.args()[argv]);
msg.send(cloudfe);
}
}
}
// Route reply to client if we still need to
if (msg != null && !msg.isEmpty()) {
msg.send(localfe);
}
// Handle capacity updates
if (primary.pollin(3)) {
try {
var msg = ZMsg.recvMsg(statefe);
trace ("State msg received:" + msg.toString());
var availableFrame = msg.last();
cloudCapacity = Std.parseInt(availableFrame.data.toString());
} catch (e:ZMQException) {
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} catch (e:Dynamic) {
trace (e);
}
}
// Handle monitor message
if (primary.pollin(4)) {
try {
var status = ZMsg.recvMsg(monitor);
Lib.println(status.first().data.toString());
return;
} catch (e:ZMQException) {
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} catch (e:Dynamic) {
trace (e);
}
}
trace ("** Polling secondary sockets");
// Now route as many clients requests as we can handle
// - If we have local capacity we poll both localfe and cloudfe
// - If we have cloud capacity only, we poll just localfe
// - Route any request locally if we can, else to cloud
//
while (localCapacity + cloudCapacity > 0) {
trace (" ** polling secondary, with total capacity:" + Std.string(localCapacity + cloudCapacity));
var secondary = new ZMQPoller();
secondary.registerSocket(localfe, ZMQ.ZMQ_POLLIN());
if (localCapacity > 0) {
secondary.registerSocket(cloudfe, ZMQ.ZMQ_POLLIN());
}
try {
ret = secondary.poll(0);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
return;
}
// We'll do peer brokers first, to prevent starvation
trace (" ** Secondary poll completed");
if (secondary.pollin(1)) {
trace (" ** About to receive from localfe");
msg = ZMsg.recvMsg(localfe);
trace (msg.toString());
} else if (secondary.pollin(2)) {
trace (" ** About to receive from cloudfe");
msg = ZMsg.recvMsg(cloudfe);
trace (msg.toString());
} else {
trace (" ** No requests, go back to primary");
break; // No work, go back to the primary
}
if (localCapacity > 0) {
var frame = workerQueue.pop();
msg.wrap(frame);
msg.send(localbe);
localCapacity--;
} else {
// Route to random broker peer
var randomPeer = ZHelpers.randof(Sys.args().length - (2 + ARG_OFFSET)) + (1 + ARG_OFFSET);
trace ("Routing to peer#"+randomPeer+":" + Sys.args()[randomPeer]);
msg.wrap(ZFrame.newStringFrame(Sys.args()[randomPeer]));
msg.send(cloudbe);
}
}
trace ("Updating status :"+ Std.string(localCapacity != previous));
if (localCapacity != previous) {
// We stick our own address onto the envelope
msg = new ZMsg();
msg.add(ZFrame.newStringFrame(Std.string(localCapacity)));
msg.wrap(ZFrame.newStringFrame(self));
trace ("Updating status:" + msg.toString());
msg.send(statebe);
}
}
// When we're done, clean up properly
ctx.destroy();
}
#if php
private static inline function forkClientTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
Peering2::clientTask();
exit();
}');
return;
}
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
Peering2::workerTask();
exit();
}');
return;
}
#end
}peering3: Full cluster simulation in Java
package guide;
import java.util.ArrayList;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
// Broker peering simulation (part 3)
// Prototypes the full flow of status and tasks
public class peering3
{
private static final int NBR_CLIENTS = 10;
private static final int NBR_WORKERS = 5;
// Signals worker is ready
private static final String WORKER_READY = "\001";
// Our own name; in practice this would be configured per node
private static String self;
// This is the client task. It issues a burst of requests and then sleeps
// for a few seconds. This simulates sporadic activity; when a number of
// clients are active at once, the local workers should be overloaded. The
// client uses a REQ socket for requests and also pushes statistics to the
// monitor socket:
private static class client_task extends Thread
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket client = ctx.createSocket(SocketType.REQ);
client.connect(String.format("ipc://%s-localfe.ipc", self));
Socket monitor = ctx.createSocket(SocketType.PUSH);
monitor.connect(String.format("ipc://%s-monitor.ipc", self));
Random rand = new Random(System.nanoTime());
Poller poller = ctx.createPoller(1);
poller.register(client, Poller.POLLIN);
boolean done = false;
while (!done) {
try {
Thread.sleep(rand.nextInt(5) * 1000);
}
catch (InterruptedException e1) {
}
int burst = rand.nextInt(15);
while (burst > 0) {
String taskId = String.format(
"%04X", rand.nextInt(10000)
);
// Send request, get reply
client.send(taskId, 0);
// Wait max ten seconds for a reply, then complain
int rc = poller.poll(10 * 1000);
if (rc == -1)
break; // Interrupted
if (poller.pollin(0)) {
String reply = client.recvStr(0);
if (reply == null)
break; // Interrupted
// Worker is supposed to answer us with our task id
assert (reply.equals(taskId));
monitor.send(String.format("%s", reply), 0);
}
else {
monitor.send(
String.format(
"E: CLIENT EXIT - lost task %s", taskId
),
0);
done = true;
break;
}
burst--;
}
}
}
}
}
// This is the worker task, which uses a REQ socket to plug into the LRU
// router. It's the same stub worker task you've seen in other examples:
private static class worker_task extends Thread
{
@Override
public void run()
{
Random rand = new Random(System.nanoTime());
try (ZContext ctx = new ZContext()) {
Socket worker = ctx.createSocket(SocketType.REQ);
worker.connect(String.format("ipc://%s-localbe.ipc", self));
// Tell broker we're ready for work
ZFrame frame = new ZFrame(WORKER_READY);
frame.send(worker, 0);
while (true) {
// Send request, get reply
ZMsg msg = ZMsg.recvMsg(worker, 0);
if (msg == null)
break; // Interrupted
// Workers are busy for 0/1 seconds
try {
Thread.sleep(rand.nextInt(2) * 1000);
}
catch (InterruptedException e) {
}
msg.send(worker);
}
}
}
}
// The main task begins by setting-up all its sockets. The local frontend
// talks to clients, and our local backend talks to workers. The cloud
// frontend talks to peer brokers as if they were clients, and the cloud
// backend talks to peer brokers as if they were workers. The state
// backend publishes regular state messages, and the state frontend
// subscribes to all state backends to collect these messages. Finally,
// we use a PULL monitor socket to collect printable messages from tasks:
public static void main(String[] argv)
{
// First argument is this broker's name
// Other arguments are our peers' names
//
if (argv.length < 1) {
System.out.println("syntax: peering3 me {you}");
System.exit(-1);
}
self = argv[0];
System.out.printf("I: preparing broker at %s\n", self);
Random rand = new Random(System.nanoTime());
try (ZContext ctx = new ZContext()) {
// Prepare local frontend and backend
Socket localfe = ctx.createSocket(SocketType.ROUTER);
localfe.bind(String.format("ipc://%s-localfe.ipc", self));
Socket localbe = ctx.createSocket(SocketType.ROUTER);
localbe.bind(String.format("ipc://%s-localbe.ipc", self));
// Bind cloud frontend to endpoint
Socket cloudfe = ctx.createSocket(SocketType.ROUTER);
cloudfe.setIdentity(self.getBytes(ZMQ.CHARSET));
cloudfe.bind(String.format("ipc://%s-cloud.ipc", self));
// Connect cloud backend to all peers
Socket cloudbe = ctx.createSocket(SocketType.ROUTER);
cloudbe.setIdentity(self.getBytes(ZMQ.CHARSET));
int argn;
for (argn = 1; argn < argv.length; argn++) {
String peer = argv[argn];
System.out.printf(
"I: connecting to cloud forintend at '%s'\n", peer
);
cloudbe.connect(String.format("ipc://%s-cloud.ipc", peer));
}
// Bind state backend to endpoint
Socket statebe = ctx.createSocket(SocketType.PUB);
statebe.bind(String.format("ipc://%s-state.ipc", self));
// Connect statefe to all peers
Socket statefe = ctx.createSocket(SocketType.SUB);
statefe.subscribe(ZMQ.SUBSCRIPTION_ALL);
for (argn = 1; argn < argv.length; argn++) {
String peer = argv[argn];
System.out.printf(
"I: connecting to state backend at '%s'\n", peer
);
statefe.connect(String.format("ipc://%s-state.ipc", peer));
}
// Prepare monitor socket
Socket monitor = ctx.createSocket(SocketType.PULL);
monitor.bind(String.format("ipc://%s-monitor.ipc", self));
// Start local workers
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
new worker_task().start();
// Start local clients
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
new client_task().start();
// Queue of available workers
int localCapacity = 0;
int cloudCapacity = 0;
ArrayList<ZFrame> workers = new ArrayList<ZFrame>();
// The main loop has two parts. First we poll workers and our two
// service sockets (statefe and monitor), in any case. If we have
// no ready workers, there's no point in looking at incoming
// requests. These can remain on their internal 0MQ queues:
Poller primary = ctx.createPoller(4);
primary.register(localbe, Poller.POLLIN);
primary.register(cloudbe, Poller.POLLIN);
primary.register(statefe, Poller.POLLIN);
primary.register(monitor, Poller.POLLIN);
Poller secondary = ctx.createPoller(2);
secondary.register(localfe, Poller.POLLIN);
secondary.register(cloudfe, Poller.POLLIN);
while (true) {
// First, route any waiting replies from workers
// If we have no workers anyhow, wait indefinitely
int rc = primary.poll(localCapacity > 0 ? 1000 : -1);
if (rc == -1)
break; // Interrupted
// Track if capacity changes during this iteration
int previous = localCapacity;
// Handle reply from local worker
ZMsg msg = null;
if (primary.pollin(0)) {
msg = ZMsg.recvMsg(localbe);
if (msg == null)
break; // Interrupted
ZFrame address = msg.unwrap();
workers.add(address);
localCapacity++;
// If it's READY, don't route the message any further
ZFrame frame = msg.getFirst();
String frameData = new String(frame.getData(), ZMQ.CHARSET);
if (frameData.equals(WORKER_READY)) {
msg.destroy();
msg = null;
}
}
// Or handle reply from peer broker
else if (primary.pollin(1)) {
msg = ZMsg.recvMsg(cloudbe);
if (msg == null)
break; // Interrupted
// We don't use peer broker address for anything
ZFrame address = msg.unwrap();
address.destroy();
}
// Route reply to cloud if it's addressed to a broker
for (argn = 1; msg != null && argn < argv.length; argn++) {
byte[] data = msg.getFirst().getData();
if (argv[argn].equals(new String(data, ZMQ.CHARSET))) {
msg.send(cloudfe);
msg = null;
}
}
// Route reply to client if we still need to
if (msg != null)
msg.send(localfe);
// If we have input messages on our statefe or monitor sockets
// we can process these immediately:
if (primary.pollin(2)) {
String peer = statefe.recvStr();
String status = statefe.recvStr();
cloudCapacity = Integer.parseInt(status);
}
if (primary.pollin(3)) {
String status = monitor.recvStr();
System.out.println(status);
}
// Now we route as many client requests as we have worker
// capacity for. We may reroute requests from our local
// frontend, but not from the cloud frontend. We reroute
// randomly now, just to test things out. In the next version
// we'll do this properly by calculating cloud capacity.
while (localCapacity + cloudCapacity > 0) {
rc = secondary.poll(0);
assert (rc >= 0);
if (secondary.pollin(0)) {
msg = ZMsg.recvMsg(localfe);
}
else if (localCapacity > 0 && secondary.pollin(1)) {
msg = ZMsg.recvMsg(cloudfe);
}
else break; // No work, go back to backends
if (localCapacity > 0) {
ZFrame frame = workers.remove(0);
msg.wrap(frame);
msg.send(localbe);
localCapacity--;
}
else {
// Route to random broker peer
int random_peer = rand.nextInt(argv.length - 1) + 1;
msg.push(argv[random_peer]);
msg.send(cloudbe);
}
}
// We broadcast capacity messages to other peers; to reduce
// chatter we do this only if our capacity changed.
if (localCapacity != previous) {
// We stick our own address onto the envelope
statebe.sendMore(self);
// Broadcast new capacity
statebe.send(String.format("%d", localCapacity), 0);
}
}
// When we're done, clean up properly
while (workers.size() > 0) {
ZFrame frame = workers.remove(0);
frame.destroy();
}
}
}
}
peering3: Full cluster simulation in Julia
peering3: Full cluster simulation in Lua
--
-- Broker peering simulation (part 3)
-- Prototypes the full flow of status and tasks
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmq.threads"
require"zmsg"
local tremove = table.remove
local NBR_CLIENTS = 10
local NBR_WORKERS = 5
local pre_code = [[
local self, seed = ...
local zmq = require"zmq"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(seed)
local context = zmq.init(1)
]]
-- Request-reply client using REQ socket
-- To simulate load, clients issue a burst of requests and then
-- sleep for a random period.
--
local client_task = pre_code .. [[
require"zmq.poller"
local client = context:socket(zmq.REQ)
local endpoint = string.format("ipc://%s-localfe.ipc", self)
assert(client:connect(endpoint))
local monitor = context:socket(zmq.PUSH)
local endpoint = string.format("ipc://%s-monitor.ipc", self)
assert(monitor:connect(endpoint))
local poller = zmq.poller(1)
local task_id = nil
poller:add(client, zmq.POLLIN, function()
local msg = zmsg.recv (client)
-- Worker is supposed to answer us with our task id
assert (msg:body() == task_id)
-- mark task as processed.
task_id = nil
end)
local is_running = true
while is_running do
s_sleep (randof (5) * 1000)
local burst = randof (15)
while (burst > 0) do
burst = burst - 1
-- Send request with random hex ID
task_id = string.format("%04X", randof (0x10000))
local msg = zmsg.new(task_id)
msg:send(client)
-- Wait max ten seconds for a reply, then complain
rc = poller:poll(10 * 1000000)
assert (rc >= 0)
if task_id then
local msg = zmsg.new()
msg:body_fmt(
"E: CLIENT EXIT - lost task %s", task_id)
msg:send(monitor)
-- exit event loop
is_running = false
break
end
end
end
-- We never get here but if we did, this is how we'd exit cleanly
client:close()
monitor:close()
context:term()
]]
-- Worker using REQ socket to do LRU routing
--
local worker_task = pre_code .. [[
local worker = context:socket(zmq.REQ)
local endpoint = string.format("ipc://%s-localbe.ipc", self)
assert(worker:connect(endpoint))
-- Tell broker we're ready for work
local msg = zmsg.new ("READY")
msg:send(worker)
while true do
-- Workers are busy for 0/1/2 seconds
msg = zmsg.recv (worker)
s_sleep (randof (2) * 1000)
msg:send(worker)
end
-- We never get here but if we did, this is how we'd exit cleanly
worker:close()
context:term()
]]
-- First argument is this broker's name
-- Other arguments are our peers' names
--
s_version_assert (2, 1)
if (#arg < 1) then
printf ("syntax: peering3 me doyouend...\n")
os.exit(-1)
end
-- Our own name; in practice this'd be configured per node
local self = arg[1]
printf ("I: preparing broker at %s...\n", self)
math.randomseed(os.time())
-- Prepare our context and sockets
local context = zmq.init(1)
-- Bind cloud frontend to endpoint
local cloudfe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-cloud.ipc", self)
cloudfe:setopt(zmq.IDENTITY, self)
assert(cloudfe:bind(endpoint))
-- Bind state backend / publisher to endpoint
local statebe = context:socket(zmq.PUB)
local endpoint = string.format("ipc://%s-state.ipc", self)
assert(statebe:bind(endpoint))
-- Connect cloud backend to all peers
local cloudbe = context:socket(zmq.ROUTER)
cloudbe:setopt(zmq.IDENTITY, self)
for n=2,#arg do
local peer = arg[n]
printf ("I: connecting to cloud frontend at '%s'\n", peer)
local endpoint = string.format("ipc://%s-cloud.ipc", peer)
assert(cloudbe:connect(endpoint))
end
-- Connect statefe to all peers
local statefe = context:socket(zmq.SUB)
statefe:setopt(zmq.SUBSCRIBE, "", 0)
local peers = {}
for n=2,#arg do
local peer = arg[n]
-- add peer name to peers list.
peers[#peers + 1] = peer
peers[peer] = 0 -- set peer's initial capacity to zero.
printf ("I: connecting to state backend at '%s'\n", peer)
local endpoint = string.format("ipc://%s-state.ipc", peer)
assert(statefe:connect(endpoint))
end
-- Prepare local frontend and backend
local localfe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-localfe.ipc", self)
assert(localfe:bind(endpoint))
local localbe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-localbe.ipc", self)
assert(localbe:bind(endpoint))
-- Prepare monitor socket
local monitor = context:socket(zmq.PULL)
local endpoint = string.format("ipc://%s-monitor.ipc", self)
assert(monitor:bind(endpoint))
-- Start local workers
local workers = {}
for n=1,NBR_WORKERS do
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(nil, worker_task, self, seed)
workers[n]:start(true)
end
-- Start local clients
local clients = {}
for n=1,NBR_CLIENTS do
local seed = os.time() + math.random()
clients[n] = zmq.threads.runstring(nil, client_task, self, seed)
clients[n]:start(true)
end
-- Interesting part
-- -------------------------------------------------------------
-- Publish-subscribe flow
-- - Poll statefe and process capacity updates
-- - Each time capacity changes, broadcast new value
-- Request-reply flow
-- - Poll primary and process local/cloud replies
-- - While worker available, route localfe to local or cloud
-- Queue of available workers
local local_capacity = 0
local cloud_capacity = 0
local worker_queue = {}
local backends = zmq.poller(2)
local function send_reply(msg)
local address = msg:address()
-- Route reply to cloud if it's addressed to a broker
if peers[address] then
msg:send(cloudfe) -- reply is for a peer.
else
msg:send(localfe) -- reply is for a local client.
end
end
backends:add(localbe, zmq.POLLIN, function()
local msg = zmsg.recv(localbe)
-- Use worker address for LRU routing
local_capacity = local_capacity + 1
worker_queue[local_capacity] = msg:unwrap()
-- if reply is not "READY" then route reply back to client.
if (msg:address() ~= "READY") then
send_reply(msg)
end
end)
backends:add(cloudbe, zmq.POLLIN, function()
local msg = zmsg.recv(cloudbe)
-- We don't use peer broker address for anything
msg:unwrap()
-- send reply back to client.
send_reply(msg)
end)
backends:add(statefe, zmq.POLLIN, function()
local msg = zmsg.recv (statefe)
-- TODO: track capacity for each peer
cloud_capacity = tonumber(msg:body())
end)
backends:add(monitor, zmq.POLLIN, function()
local msg = zmsg.recv (monitor)
printf("%s\n", msg:body())
end)
local frontends = zmq.poller(2)
local localfe_ready = false
local cloudfe_ready = false
frontends:add(localfe, zmq.POLLIN, function() localfe_ready = true end)
frontends:add(cloudfe, zmq.POLLIN, function() cloudfe_ready = true end)
local MAX_BACKEND_REPLIES = 20
while true do
-- If we have no workers anyhow, wait indefinitely
local timeout = (local_capacity > 0) and 1000000 or -1
local rc, err = backends:poll(timeout)
assert (rc >= 0, err)
-- Track if capacity changes during this iteration
local previous = local_capacity
-- Now route as many clients requests as we can handle
-- - If we have local capacity we poll both localfe and cloudfe
-- - If we have cloud capacity only, we poll just localfe
-- - Route any request locally if we can, else to cloud
--
while ((local_capacity + cloud_capacity) > 0) do
local rc, err = frontends:poll(0)
assert (rc >= 0, err)
if (localfe_ready) then
localfe_ready = false
msg = zmsg.recv (localfe)
elseif (cloudfe_ready and local_capacity > 0) then
cloudfe_ready = false
-- we have local capacity poll cloud frontend for work.
msg = zmsg.recv (cloudfe)
else
break; -- No work, go back to primary
end
if (local_capacity > 0) then
-- Dequeue and drop the next worker address
local worker = tremove(worker_queue, 1)
local_capacity = local_capacity - 1
msg:wrap(worker, "")
msg:send(localbe)
else
-- Route to random broker peer
printf ("I: route request %s to cloud...\n",
msg:body())
local random_peer = randof (#peers) + 1
msg:wrap(peers[random_peer], nil)
msg:send(cloudbe)
end
end
if (local_capacity ~= previous) then
-- Broadcast new capacity
local msg = zmsg.new()
-- TODO: send our name with capacity.
msg:body_fmt("%d", local_capacity)
-- We stick our own address onto the envelope
msg:wrap(self, nil)
msg:send(statebe)
end
end
-- We never get here but clean up anyhow
localbe:close()
cloudbe:close()
localfe:close()
cloudfe:close()
statefe:close()
monitor:close()
context:term()
peering3: Full cluster simulation in Node.js
peering3: Full cluster simulation in Objective-C
peering3: Full cluster simulation in ooc
peering3: Full cluster simulation in Perl
peering3: Full cluster simulation in PHP
<?php
/*
* Broker peering simulation (part 3)
* Prototypes the full flow of status and tasks
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("NBR_CLIENTS", 10);
define("NBR_WORKERS", 3);
/*
* Request-reply client using REQ socket
* To simulate load, clients issue a burst of requests and then
* sleep for a random period.
*/
function client_thread($self)
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$endpoint = sprintf("ipc://%s-localfe.ipc", $self);
$client->connect($endpoint);
$monitor = new ZMQSocket($context, ZMQ::SOCKET_PUSH);
$endpoint = sprintf("ipc://%s-monitor.ipc", $self);
$monitor->connect($endpoint);
$readable = $writeable = array();
while (true) {
sleep(mt_rand(0, 4));
$burst = mt_rand(1, 14);
while ($burst--) {
// Send request with random hex ID
$task_id = sprintf("%04X", mt_rand(0, 10000));
$client->send($task_id);
// Wait max ten seconds for a reply, then complain
$poll = new ZMQPoll();
$poll->add($client, ZMQ::POLL_IN);
$events = $poll->poll($readable, $writeable, 10 * 1000000);
if ($events > 0) {
foreach ($readable as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
// Worker is supposed to answer us with our task id
assert($zmsg->body() == $task_id);
}
} else {
$monitor->send(sprintf("E: CLIENT EXIT - lost task %s", $task_id));
exit();
}
}
}
}
// Worker using REQ socket to do LRU routing
function worker_thread ($self)
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_REQ);
$endpoint = sprintf("ipc://%s-localbe.ipc", $self);
$worker->connect($endpoint);
// Tell broker we're ready for work
$worker->send("READY");
while (true) {
$zmsg = new Zmsg($worker);
$zmsg->recv();
sleep(mt_rand(0,2));
$zmsg->send();
}
}
// First argument is this broker's name
// Other arguments are our peers' names
if ($_SERVER['argc'] < 2) {
echo "syntax: peering2 me {you}...", PHP_EOL;
exit();
}
$self = $_SERVER['argv'][1];
for ($client_nbr = 0; $client_nbr < NBR_CLIENTS; $client_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
client_thread($self);
return;
}
}
for ($worker_nbr = 0; $worker_nbr < NBR_WORKERS; $worker_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
worker_thread($self);
return;
}
}
printf ("I: preparing broker at %s... %s", $self, PHP_EOL);
// Prepare our context and sockets
$context = new ZMQContext();
// Bind cloud frontend to endpoint
$cloudfe = $context->getSocket(ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-cloud.ipc", $self);
$cloudfe->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $self);
$cloudfe->bind($endpoint);
// Connect cloud backend to all peers
$cloudbe = $context->getSocket(ZMQ::SOCKET_ROUTER);
$cloudbe->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $self);
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
$peer = $_SERVER['argv'][$argn];
printf ("I: connecting to cloud backend at '%s'%s", $peer, PHP_EOL);
$endpoint = sprintf("ipc://%s-cloud.ipc", $peer);
$cloudbe->connect($endpoint);
}
// Bind state backend / publisher to endpoint
$statebe = new ZMQSocket($context, ZMQ::SOCKET_PUB);
$endpoint = sprintf("ipc://%s-state.ipc", $self);
$statebe->bind($endpoint);
// Connect statefe to all peers
$statefe = $context->getSocket(ZMQ::SOCKET_SUB);
$statefe->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "");
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
$peer = $_SERVER['argv'][$argn];
printf ("I: connecting to state backend at '%s'%s", $peer, PHP_EOL);
$endpoint = sprintf("ipc://%s-state.ipc", $peer);
$statefe->connect($endpoint);
}
// Prepare monitor socket
$monitor = new ZMQSocket($context, ZMQ::SOCKET_PULL);
$endpoint = sprintf("ipc://%s-monitor.ipc", $self);
$monitor->bind($endpoint);
// Prepare local frontend and backend
$localfe = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-localfe.ipc", $self);
$localfe->bind($endpoint);
$localbe = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-localbe.ipc", $self);
$localbe->bind($endpoint);
// Interesting part
// -------------------------------------------------------------
// Publish-subscribe flow
// - Poll statefe and process capacity updates
// - Each time capacity changes, broadcast new value
// Request-reply flow
// - Poll primary and process local/cloud replies
// - While worker available, route localfe to local or cloud
// Queue of available workers
$local_capacity = 0;
$cloud_capacity = 0;
$worker_queue = array();
$readable = $writeable = array();
while (true) {
$poll = new ZMQPoll();
$poll->add($localbe, ZMQ::POLL_IN);
$poll->add($cloudbe, ZMQ::POLL_IN);
$poll->add($statefe, ZMQ::POLL_IN);
$poll->add($monitor, ZMQ::POLL_IN);
$events = 0;
// If we have no workers anyhow, wait indefinitely
try {
$events = $poll->poll($readable, $writeable, $local_capacity ? 1000000 : -1);
} catch (ZMQPollException $e) {
break;
}
// Track if capacity changes during this iteration
$previous = $local_capacity;
foreach ($readable as $socket) {
$zmsg = new Zmsg($socket);
// Handle reply from local worker
if ($socket === $localbe) {
// Use worker address for LRU routing
$zmsg->recv();
$worker_queue[] = $zmsg->unwrap();
$local_capacity++;
if ($zmsg->body() == "READY") {
$zmsg = null; // Don't route it
}
}
// Or handle reply from peer broker
else if ($socket === $cloudbe) {
// We don't use peer broker address for anything
$zmsg->recv()->unwrap();
}
// Handle capacity updates
else if ($socket === $statefe) {
$zmsg->recv();
$cloud_capacity = $zmsg->body();
$zmsg = null;
}
// Handle monitor message
else if ($socket === $monitor) {
$zmsg->recv();
echo $zmsg->body(), PHP_EOL;
$zmsg = null;
}
if ($zmsg) {
// Route reply to cloud if it's addressed to a broker
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
if ($zmsg->address() == $_SERVER['argv'][$argn]) {
$zmsg->set_socket($cloudfe)->send();
$zmsg = null;
}
}
}
// Route reply to client if we still need to
if ($zmsg) {
$zmsg->set_socket($localfe)->send();
}
}
// Now route as many clients requests as we can handle
// - If we have local capacity we poll both localfe and cloudfe
// - If we have cloud capacity only, we poll just localfe
// - Route any request locally if we can, else to cloud
while ($local_capacity + $cloud_capacity) {
$poll = new ZMQPoll();
$poll->add($localfe, ZMQ::POLL_IN);
if ($local_capacity) {
$poll->add($cloudfe, ZMQ::POLL_IN);
}
$reroutable = false;
$events = $poll->poll($readable, $writeable, 0);
if ($events > 0) {
foreach ($readable as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
if ($local_capacity) {
$zmsg->wrap(array_shift($worker_queue), "");
$zmsg->set_socket($localbe)->send();
$local_capacity--;
} else {
// Route to random broker peer
printf ("I: route request %s to cloud...%s", $zmsg->body(), PHP_EOL);
$zmsg->wrap($_SERVER['argv'][mt_rand(2, ($_SERVER['argc']-1))]);
$zmsg->set_socket($cloudbe)->send();
}
}
} else {
break; // No work, go back to backends
}
}
if ($local_capacity != $previous) {
// Broadcast new capacity
$zmsg = new Zmsg($statebe);
$zmsg->body_set($local_capacity);
// We stick our own address onto the envelope
$zmsg->wrap($self)->send();
}
}
peering3: Full cluster simulation in Python
#
# Broker peering simulation (part 3) in Python
# Prototypes the full flow of status and tasks
#
# While this example runs in a single process, that is just to make
# it easier to start and stop the example. Each thread has its own
# context and conceptually acts as a separate process.
#
# Author : Min RK
# Contact: benjaminrk(at)gmail(dot)com
#
import random
import sys
import threading
import time
import zmq
NBR_CLIENTS = 10
NBR_WORKERS = 5
def asbytes(obj):
s = str(obj)
if str is not bytes:
# Python 3
s = s.encode('ascii')
return s
def client_task(name, i):
"""Request-reply client using REQ socket"""
ctx = zmq.Context()
client = ctx.socket(zmq.REQ)
client.identity = (u"Client-%s-%s" % (name, i)).encode('ascii')
client.connect("ipc://%s-localfe.ipc" % name)
monitor = ctx.socket(zmq.PUSH)
monitor.connect("ipc://%s-monitor.ipc" % name)
poller = zmq.Poller()
poller.register(client, zmq.POLLIN)
while True:
time.sleep(random.randint(0, 5))
for _ in range(random.randint(0, 15)):
# send request with random hex ID
task_id = u"%04X" % random.randint(0, 10000)
client.send_string(task_id)
# wait max 10 seconds for a reply, then complain
try:
events = dict(poller.poll(10000))
except zmq.ZMQError:
return # interrupted
if events:
reply = client.recv_string()
assert reply == task_id, "expected %s, got %s" % (task_id, reply)
monitor.send_string(reply)
else:
monitor.send_string(u"E: CLIENT EXIT - lost task %s" % task_id)
return
def worker_task(name, i):
"""Worker using REQ socket to do LRU routing"""
ctx = zmq.Context()
worker = ctx.socket(zmq.REQ)
worker.identity = ("Worker-%s-%s" % (name, i)).encode('ascii')
worker.connect("ipc://%s-localbe.ipc" % name)
# Tell broker we're ready for work
worker.send(b"READY")
# Process messages as they arrive
while True:
try:
msg = worker.recv_multipart()
except zmq.ZMQError:
# interrupted
return
# Workers are busy for 0/1 seconds
time.sleep(random.randint(0, 1))
worker.send_multipart(msg)
def main(myself, peers):
print("I: preparing broker at %s..." % myself)
# Prepare our context and sockets
ctx = zmq.Context()
# Bind cloud frontend to endpoint
cloudfe = ctx.socket(zmq.ROUTER)
cloudfe.setsockopt(zmq.IDENTITY, myself)
cloudfe.bind("ipc://%s-cloud.ipc" % myself)
# Bind state backend / publisher to endpoint
statebe = ctx.socket(zmq.PUB)
statebe.bind("ipc://%s-state.ipc" % myself)
# Connect cloud and state backends to all peers
cloudbe = ctx.socket(zmq.ROUTER)
statefe = ctx.socket(zmq.SUB)
statefe.setsockopt(zmq.SUBSCRIBE, b"")
cloudbe.setsockopt(zmq.IDENTITY, myself)
for peer in peers:
print("I: connecting to cloud frontend at %s" % peer)
cloudbe.connect("ipc://%s-cloud.ipc" % peer)
print("I: connecting to state backend at %s" % peer)
statefe.connect("ipc://%s-state.ipc" % peer)
# Prepare local frontend and backend
localfe = ctx.socket(zmq.ROUTER)
localfe.bind("ipc://%s-localfe.ipc" % myself)
localbe = ctx.socket(zmq.ROUTER)
localbe.bind("ipc://%s-localbe.ipc" % myself)
# Prepare monitor socket
monitor = ctx.socket(zmq.PULL)
monitor.bind("ipc://%s-monitor.ipc" % myself)
# Get user to tell us when we can start...
# raw_input("Press Enter when all brokers are started: ")
# create workers and clients threads
for i in range(NBR_WORKERS):
thread = threading.Thread(target=worker_task, args=(myself, i))
thread.daemon = True
thread.start()
for i in range(NBR_CLIENTS):
thread_c = threading.Thread(target=client_task, args=(myself, i))
thread_c.daemon = True
thread_c.start()
# Interesting part
# -------------------------------------------------------------
# Publish-subscribe flow
# - Poll statefe and process capacity updates
# - Each time capacity changes, broadcast new value
# Request-reply flow
# - Poll primary and process local/cloud replies
# - While worker available, route localfe to local or cloud
local_capacity = 0
cloud_capacity = 0
workers = []
# setup backend poller
pollerbe = zmq.Poller()
pollerbe.register(localbe, zmq.POLLIN)
pollerbe.register(cloudbe, zmq.POLLIN)
pollerbe.register(statefe, zmq.POLLIN)
pollerbe.register(monitor, zmq.POLLIN)
while True:
# If we have no workers anyhow, wait indefinitely
try:
events = dict(pollerbe.poll(1000 if local_capacity else None))
except zmq.ZMQError:
break # interrupted
previous = local_capacity
# Handle reply from local worker
msg = None
if localbe in events:
msg = localbe.recv_multipart()
(address, empty), msg = msg[:2], msg[2:]
workers.append(address)
local_capacity += 1
# If it's READY, don't route the message any further
if msg[-1] == b'READY':
msg = None
elif cloudbe in events:
msg = cloudbe.recv_multipart()
(address, empty), msg = msg[:2], msg[2:]
# We don't use peer broker address for anything
if msg is not None:
address = msg[0]
if address in peers:
# Route reply to cloud if it's addressed to a broker
cloudfe.send_multipart(msg)
else:
# Route reply to client if we still need to
localfe.send_multipart(msg)
# Handle capacity updates
if statefe in events:
peer, s = statefe.recv_multipart()
cloud_capacity = int(s)
# handle monitor message
if monitor in events:
print(monitor.recv_string())
# Now route as many clients requests as we can handle
# - If we have local capacity we poll both localfe and cloudfe
# - If we have cloud capacity only, we poll just localfe
# - Route any request locally if we can, else to cloud
while local_capacity + cloud_capacity:
secondary = zmq.Poller()
secondary.register(localfe, zmq.POLLIN)
if local_capacity:
secondary.register(cloudfe, zmq.POLLIN)
events = dict(secondary.poll(0))
# We'll do peer brokers first, to prevent starvation
if cloudfe in events:
msg = cloudfe.recv_multipart()
elif localfe in events:
msg = localfe.recv_multipart()
else:
break # No work, go back to backends
if local_capacity:
msg = [workers.pop(0), b''] + msg
localbe.send_multipart(msg)
local_capacity -= 1
else:
# Route to random broker peer
msg = [random.choice(peers), b''] + msg
cloudbe.send_multipart(msg)
if local_capacity != previous:
statebe.send_multipart([myself, asbytes(local_capacity)])
if __name__ == '__main__':
if len(sys.argv) >= 2:
myself = asbytes(sys.argv[1])
main(myself, peers=[ asbytes(a) for a in sys.argv[2:] ])
else:
print("Usage: peering3.py <me> [<peer_1> [... <peer_N>]]")
sys.exit(1)
peering3: Full cluster simulation in Q
peering3: Full cluster simulation in Racket
peering3: Full cluster simulation in Ruby
peering3: Full cluster simulation in Rust
peering3: Full cluster simulation in Scala
peering3: Full cluster simulation in Tcl
peering3: Full cluster simulation in OCaml
It’s a nontrivial program and took about a day to get working. These are the highlights:
-
The client threads detect and report a failed request. They do this by polling for a response and if none arrives after a while (10 seconds), printing an error message.
-
Client threads don’t print directly, but instead send a message to a monitor socket (PUSH) that the main loop collects (PULL) and prints off. This is the first case we’ve seen of using ZeroMQ sockets for monitoring and logging; this is a big use case that we’ll come back to later.
-
Clients simulate varying loads to get the cluster 100% at random moments, so that tasks are shifted over to the cloud. The number of clients and workers, and delays in the client and worker threads control this. Feel free to play with them to see if you can make a more realistic simulation.
-
The main loop uses two pollsets. It could in fact use three: information, backends, and frontends. As in the earlier prototype, there is no point in taking a frontend message if there is no backend capacity.
These are some of the problems that arose during development of this program:
-
Clients would freeze, due to requests or replies getting lost somewhere. Recall that the ROUTER socket drops messages it can’t route. The first tactic here was to modify the client thread to detect and report such problems. Secondly, I put zmsg_dump() calls after every receive and before every send in the main loop, until the origin of the problems was clear.
-
The main loop was mistakenly reading from more than one ready socket. This caused the first message to be lost. I fixed that by reading only from the first ready socket.
-
The zmsg class was not properly encoding UUIDs as C strings. This caused UUIDs that contain 0 bytes to be corrupted. I fixed that by modifying zmsg to encode UUIDs as printable hex strings.
This simulation does not detect disappearance of a cloud peer. If you start several peers and stop one, and it was broadcasting capacity to the others, they will continue to send it work even if it’s gone. You can try this, and you will get clients that complain of lost requests. The solution is twofold: first, only keep the capacity information for a short time so that if a peer does disappear, its capacity is quickly set to zero. Second, add reliability to the request-reply chain. We’ll look at reliability in the next chapter.