Chapter 5 - Advanced Pub-Sub Patterns #
In Chapter 3 - Advanced Request-Reply Patterns and Chapter 4 - Reliable Request-Reply Patterns we looked at advanced use of ZeroMQ’s request-reply pattern. If you managed to digest all that, congratulations. In this chapter we’ll focus on publish-subscribe and extend ZeroMQ’s core pub-sub pattern with higher-level patterns for performance, reliability, state distribution, and monitoring.
We’ll cover:
- When to use publish-subscribe
- How to handle too-slow subscribers (the Suicidal Snail pattern)
- How to design high-speed subscribers (the Black Box pattern)
- How to monitor a pub-sub network (the Espresso pattern)
- How to build a shared key-value store (the Clone pattern)
- How to use reactors to simplify complex servers
- How to use the Binary Star pattern to add failover to a server
Pros and Cons of Pub-Sub #
ZeroMQ’s low-level patterns have their different characters. Pub-sub addresses an old messaging problem, which is multicast or group messaging. It has that unique mix of meticulous simplicity and brutal indifference that characterizes ZeroMQ. It’s worth understanding the trade-offs that pub-sub makes, how these benefit us, and how we can work around them if needed.
First, PUB sends each message to “all of many”, whereas PUSH and DEALER rotate messages to “one of many”. You cannot simply replace PUSH with PUB or vice versa and hope that things will work. This bears repeating because people seem to quite often suggest doing this.
More profoundly, pub-sub is aimed at scalability. This means large volumes of data, sent rapidly to many recipients. If you need millions of messages per second sent to thousands of points, you’ll appreciate pub-sub a lot more than if you need a few messages a second sent to a handful of recipients.
To get scalability, pub-sub uses the same trick as push-pull, which is to get rid of back-chatter. This means that recipients don’t talk back to senders. There are some exceptions, e.g., SUB sockets will send subscriptions to PUB sockets, but it’s anonymous and infrequent.
Killing back-chatter is essential to real scalability. With pub-sub, it’s how the pattern can map cleanly to the PGM multicast protocol, which is handled by the network switch. In other words, subscribers don’t connect to the publisher at all, they connect to a multicast group on the switch, to which the publisher sends its messages.
When we remove back-chatter, our overall message flow becomes much simpler, which lets us make simpler APIs, simpler protocols, and in general reach many more people. But we also remove any possibility to coordinate senders and receivers. What this means is:
-
Publishers can’t tell when subscribers are successfully connected, both on initial connections, and on reconnections after network failures.
-
Subscribers can’t tell publishers anything that would allow publishers to control the rate of messages they send. Publishers only have one setting, which is full-speed, and subscribers must either keep up or lose messages.
-
Publishers can’t tell when subscribers have disappeared due to processes crashing, networks breaking, and so on.
The downside is that we actually need all of these if we want to do reliable multicast. The ZeroMQ pub-sub pattern will lose messages arbitrarily when a subscriber is connecting, when a network failure occurs, or just if the subscriber or network can’t keep up with the publisher.
The upside is that there are many use cases where almost reliable multicast is just fine. When we need this back-chatter, we can either switch to using ROUTER-DEALER (which I tend to do for most normal volume cases), or we can add a separate channel for synchronization (we’ll see an example of this later in this chapter).
Pub-sub is like a radio broadcast; you miss everything before you join, and then how much information you get depends on the quality of your reception. Surprisingly, this model is useful and widespread because it maps perfectly to real world distribution of information. Think of Facebook and Twitter, the BBC World Service, and the sports results.
As we did for request-reply, let’s define reliability in terms of what can go wrong. Here are the classic failure cases for pub-sub:
- Subscribers join late, so they miss messages the server already sent.
- Subscribers can fetch messages too slowly, so queues build up and then overflow.
- Subscribers can drop off and lose messages while they are away.
- Subscribers can crash and restart, and lose whatever data they already received.
- Networks can become overloaded and drop data (specifically, for PGM).
- Networks can become too slow, so publisher-side queues overflow and publishers crash.
A lot more can go wrong but these are the typical failures we see in a realistic system. Since v3.x, ZeroMQ forces default limits on its internal buffers (the so-called high-water mark or HWM), so publisher crashes are rarer unless you deliberately set the HWM to infinite.
All of these failure cases have answers, though not always simple ones. Reliability requires complexity that most of us don’t need, most of the time, which is why ZeroMQ doesn’t attempt to provide it out of the box (even if there was one global design for reliability, which there isn’t).
Pub-Sub Tracing (Espresso Pattern) #
Let’s start this chapter by looking at a way to trace pub-sub networks. In Chapter 2 - Sockets and Patterns we saw a simple proxy that used these to do transport bridging. The zmq_proxy() method has three arguments: a frontend and backend socket that it bridges together, and a capture socket to which it will send all messages.
The code is deceptively simple:
espresso: Espresso Pattern in Ada
espresso: Espresso Pattern in Basic
espresso: Espresso Pattern in C
// Espresso Pattern
// This shows how to capture data using a pub-sub proxy
#include "czmq.h"
// The subscriber thread requests messages starting with
// A and B, then reads and counts incoming messages.
static void
subscriber_thread (void *args, zctx_t *ctx, void *pipe)
{
// Subscribe to "A" and "B"
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_connect (subscriber, "tcp://localhost:6001");
zsocket_set_subscribe (subscriber, "A");
zsocket_set_subscribe (subscriber, "B");
int count = 0;
while (count < 5) {
char *string = zstr_recv (subscriber);
if (!string)
break; // Interrupted
free (string);
count++;
}
zsocket_destroy (ctx, subscriber);
}
// .split publisher thread
// The publisher sends random messages starting with A-J:
static void
publisher_thread (void *args, zctx_t *ctx, void *pipe)
{
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:6000");
while (!zctx_interrupted) {
char string [10];
sprintf (string, "%c-%05d", randof (10) + 'A', randof (100000));
if (zstr_send (publisher, string) == -1)
break; // Interrupted
zclock_sleep (100); // Wait for 1/10th second
}
}
// .split listener thread
// The listener receives all messages flowing through the proxy, on its
// pipe. In CZMQ, the pipe is a pair of ZMQ_PAIR sockets that connect
// attached child threads. In other languages your mileage may vary:
static void
listener_thread (void *args, zctx_t *ctx, void *pipe)
{
// Print everything that arrives on pipe
while (true) {
zframe_t *frame = zframe_recv (pipe);
if (!frame)
break; // Interrupted
zframe_print (frame, NULL);
zframe_destroy (&frame);
}
}
// .split main thread
// The main task starts the subscriber and publisher, and then sets
// itself up as a listening proxy. The listener runs as a child thread:
int main (void)
{
// Start child threads
zctx_t *ctx = zctx_new ();
zthread_fork (ctx, publisher_thread, NULL);
zthread_fork (ctx, subscriber_thread, NULL);
void *subscriber = zsocket_new (ctx, ZMQ_XSUB);
zsocket_connect (subscriber, "tcp://localhost:6000");
void *publisher = zsocket_new (ctx, ZMQ_XPUB);
zsocket_bind (publisher, "tcp://*:6001");
void *listener = zthread_fork (ctx, listener_thread, NULL);
zmq_proxy (subscriber, publisher, listener);
puts (" interrupted");
// Tell attached threads to exit
zctx_destroy (&ctx);
return 0;
}

espresso: Espresso Pattern in C++
#include <iostream>
#include <thread>
#include <zmq.hpp>
#include <string>
#include <chrono>
#include <unistd.h>
// Subscriber thread function
void subscriber_thread(zmq::context_t& ctx) {
zmq::socket_t subscriber(ctx, ZMQ_SUB);
subscriber.connect("tcp://localhost:6001");
subscriber.set(zmq::sockopt::subscribe, "A");
subscriber.set(zmq::sockopt::subscribe, "B");
int count = 0;
while (count < 5) {
zmq::message_t message;
if (subscriber.recv(message)) {
std::string msg = std::string((char*)(message.data()), message.size());
std::cout << "Received: " << msg << std::endl;
count++;
}
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
// Publisher thread function
void publisher_thread(zmq::context_t& ctx) {
zmq::socket_t publisher(ctx, ZMQ_PUB);
publisher.bind("tcp://*:6000");
while (true) {
char string[10];
sprintf(string, "%c-%05d", rand() % 10 + 'A', rand() % 100000);
zmq::message_t message(string, strlen(string));
publisher.send(message, zmq::send_flags::none);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
// Listener thread function
void listener_thread(zmq::context_t& ctx) {
zmq::socket_t listener(ctx, ZMQ_PAIR);
listener.connect("inproc://listener");
while (true) {
zmq::message_t message;
if (listener.recv(message)) {
std::string msg = std::string((char*)(message.data()), message.size());
std::cout << "Listener Received: ";
if (msg[0] == 0 || msg[0] == 1){
std::cout << int(msg[0]);
std::cout << msg[1]<< std::endl;
} else {
std::cout << msg << std::endl;
}
}
}
}
int main() {
zmq::context_t context(1);
// Main thread acts as the listener proxy
zmq::socket_t proxy(context, ZMQ_PAIR);
proxy.bind("inproc://listener");
zmq::socket_t xsub(context, ZMQ_XSUB);
zmq::socket_t xpub(context, ZMQ_XPUB);
xpub.bind("tcp://*:6001");
sleep(1);
// Start publisher and subscriber threads
std::thread pub_thread(publisher_thread, std::ref(context));
std::thread sub_thread(subscriber_thread, std::ref(context));
// Set up listener thread
std::thread lis_thread(listener_thread, std::ref(context));
sleep(1);
xsub.connect("tcp://localhost:6000");
// Proxy messages between SUB and PUB sockets
zmq_proxy(xsub, xpub, proxy);
// Wait for threads to finish
pub_thread.join();
sub_thread.join();
lis_thread.join();
return 0;
}
espresso: Espresso Pattern in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
public static void Espresso(string[] args)
{
//
// Espresso Pattern
// This shows how to capture data using a pub-sub proxy
//
// Author: metadings
//
using (var context = new ZContext())
using (var subscriber = new ZSocket(context, ZSocketType.XSUB))
using (var publisher = new ZSocket(context, ZSocketType.XPUB))
using (var listener = new ZSocket(context, ZSocketType.PAIR))
{
new Thread(() => Espresso_Publisher(context)).Start();
new Thread(() => Espresso_Subscriber(context)).Start();
new Thread(() => Espresso_Listener(context)).Start();
subscriber.Connect("tcp://127.0.0.1:6000");
publisher.Bind("tcp://*:6001");
listener.Bind("inproc://listener");
ZError error;
if (!ZContext.Proxy(subscriber, publisher, listener, out error))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
}
}
static void Espresso_Publisher(ZContext context)
{
// The publisher sends random messages starting with A-J:
using (var publisher = new ZSocket(context, ZSocketType.PUB))
{
publisher.Bind("tcp://*:6000");
ZError error;
while (true)
{
var frame = ZFrame.Create(8);
var bytes = new byte[8];
using (var rng = new System.Security.Cryptography.RNGCryptoServiceProvider())
{
rng.GetBytes(bytes);
}
frame.Write(bytes, 0, 8);
if (!publisher.SendFrame(frame, out error))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
Thread.Sleep(1);
}
}
}
static void Espresso_Subscriber(ZContext context)
{
// The subscriber thread requests messages starting with
// A and B, then reads and counts incoming messages.
using (var subscriber = new ZSocket(context, ZSocketType.SUB))
{
subscriber.Connect("tcp://127.0.0.1:6001");
subscriber.Subscribe("A");
subscriber.Subscribe("B");
ZError error;
ZFrame frame;
int count = 0;
while (count < 5)
{
if (null == (frame = subscriber.ReceiveFrame(out error)))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
++count;
}
Console.WriteLine("I: subscriber counted {0}", count);
}
}
static void Espresso_Listener(ZContext context)
{
// The listener receives all messages flowing through the proxy, on its
// pipe. In CZMQ, the pipe is a pair of ZMQ_PAIR sockets that connect
// attached child threads. In other languages your mileage may vary:
using (var listener = new ZSocket(context, ZSocketType.PAIR))
{
listener.Connect("inproc://listener");
ZError error;
ZFrame frame;
while (true)
{
if (null != (frame = listener.ReceiveFrame(out error)))
{
using (frame)
{
byte first = frame.ReadAsByte();
var rest = new byte[9];
frame.Read(rest, 0, rest.Length);
Console.WriteLine("{0} {1}", (char)first, rest.ToHexString());
if (first == 0x01)
{
// Subscribe
}
else if (first == 0x00)
{
// Unsubscribe
context.Shutdown();
}
}
}
else
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
}
}
}
}
}
espresso: Espresso Pattern in CL
espresso: Espresso Pattern in Delphi
espresso: Espresso Pattern in Erlang
espresso: Espresso Pattern in Elixir
espresso: Espresso Pattern in F#
espresso: Espresso Pattern in Felix
espresso: Espresso Pattern in Go
espresso: Espresso Pattern in Haskell
espresso: Espresso Pattern in Haxe
espresso: Espresso Pattern in Java
package guide;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZThread.IAttachedRunnable;
// Espresso Pattern
// This shows how to capture data using a pub-sub proxy
public class espresso
{
// The subscriber thread requests messages starting with
// A and B, then reads and counts incoming messages.
private static class Subscriber implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
// Subscribe to "A" and "B"
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect("tcp://localhost:6001");
subscriber.subscribe("A".getBytes(ZMQ.CHARSET));
subscriber.subscribe("B".getBytes(ZMQ.CHARSET));
int count = 0;
while (count < 5) {
String string = subscriber.recvStr();
if (string == null)
break; // Interrupted
count++;
}
ctx.destroySocket(subscriber);
}
}
// .split publisher thread
// The publisher sends random messages starting with A-J:
private static class Publisher implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:6000");
Random rand = new Random(System.currentTimeMillis());
while (!Thread.currentThread().isInterrupted()) {
String string = String.format("%c-%05d", 'A' + rand.nextInt(10), rand.nextInt(100000));
if (!publisher.send(string))
break; // Interrupted
try {
Thread.sleep(100); // Wait for 1/10th second
}
catch (InterruptedException e) {
}
}
ctx.destroySocket(publisher);
}
}
// .split listener thread
// The listener receives all messages flowing through the proxy, on its
// pipe. In CZMQ, the pipe is a pair of ZMQ_PAIR sockets that connect
// attached child threads. In other languages your mileage may vary:
private static class Listener implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
// Print everything that arrives on pipe
while (true) {
ZFrame frame = ZFrame.recvFrame(pipe);
if (frame == null)
break; // Interrupted
frame.print(null);
frame.destroy();
}
}
}
// .split main thread
// The main task starts the subscriber and publisher, and then sets
// itself up as a listening proxy. The listener runs as a child thread:
public static void main(String[] argv)
{
try (ZContext ctx = new ZContext()) {
// Start child threads
ZThread.fork(ctx, new Publisher());
ZThread.fork(ctx, new Subscriber());
Socket subscriber = ctx.createSocket(SocketType.XSUB);
subscriber.connect("tcp://localhost:6000");
Socket publisher = ctx.createSocket(SocketType.XPUB);
publisher.bind("tcp://*:6001");
Socket listener = ZThread.fork(ctx, new Listener());
ZMQ.proxy(subscriber, publisher, listener);
System.out.println(" interrupted");
// NB: child threads exit here when the context is closed
}
}
}
espresso: Espresso Pattern in Julia
espresso: Espresso Pattern in Lua
espresso: Espresso Pattern in Node.js
/**
* Pub-Sub Tracing (Espresso Pattern)
* explained in
* https://zguide.zeromq.org/docs/chapter5
*/
"use strict";
Object.defineProperty(exports, "__esModule", { value: true });
exports.runListenerThread = exports.runPubThread = exports.runSubThread = void 0;
const zmq = require("zeromq"),
publisher = new zmq.Publisher,
pubKeypair = zmq.curveKeyPair(),
publicKey = pubKeypair.publicKey;
var interrupted = false;
function getRandomInt(max) {
return Math.floor(Math.random() * Math.floor(max));
}
async function runSubThread() {
const subscriber = new zmq.Subscriber;
const subKeypair = zmq.curveKeyPair();
// Setup encryption.
for (const s of [subscriber]) {
subscriber.curveServerKey = publicKey; // '03P+E+f4AU6bSTcuzvgX&oGnt&Or<rN)FYIPyjQW'
subscriber.curveSecretKey = subKeypair.secretKey;
subscriber.curvePublicKey = subKeypair.publicKey;
}
await subscriber.connect("tcp://127.0.0.1:6000");
console.log('subscriber connected! subscribing A,B,C and D..');
//subscribe all at once - simultaneous subscriptions needed
Promise.all([
subscriber.subscribe("A"),
subscriber.subscribe("B"),
subscriber.subscribe("C"),
subscriber.subscribe("D"),
subscriber.subscribe("E"),
]);
for await (const [msg] of subscriber) {
console.log(`Received at subscriber: ${msg}`);
if (interrupted) {
await subscriber.disconnect("tcp://127.0.0.1:6000");
await subscriber.close();
break;
}
}
}
//Run the Publisher Thread!
async function runPubThread() {
// Setup encryption.
for (const s of [publisher]) {
s.curveServer = true;
s.curvePublicKey = publicKey;
s.curveSecretKey = pubKeypair.secretKey;
}
await publisher.bind("tcp://127.0.0.1:6000");
console.log(`Started publisher at tcp://127.0.0.1:6000 ..`);
var subs = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
while (!interrupted) { //until ctl+c
var str = `${subs.charAt(getRandomInt(10))}-${getRandomInt(100000).toString().padStart(6, '0')}`; //"%c-%05d";
console.log(`Publishing ${str}`);
if (-1 == await publisher.send(str))
break; //Interrupted
await new Promise(resolve => setTimeout(resolve, 1000));
}
//if(! publisher.closed())
await publisher.close();
}
//Run the Pipe
async function runListenerThread() {
//a pipe using 'Pair' which receives and transmits data
const pipe = new zmq.Pair;
await pipe.connect("tcp://127.0.0.1:6000");
await pipe.bind("tcp://127.0.0.1:6001");
console.log('starting pipe (using Pair)..');
while (!interrupted) {
await pipe.send(await pipe.receive());
}
setTimeout(() => {
console.log('Terminating pipe..');
pipe.close();
}, 1000);
//a pipe using 'Proxy' <= not working, but give it a try.
// Still working with Proxy
/*
const pipe = new zmq.Proxy (new zmq.Router, new zmq.Dealer)
await pipe.backEnd.connect("tcp://127.0.0.1:6000")
await pipe.frontEnd.bind("tcp://127.0.0.1:6001")
await pipe.run()
setTimeout(() => {
console.log('Terminating pipe..');
await pipe.terminate()
}, 10000);
*/
}
exports.runSubThread = runSubThread;
exports.runPubThread = runPubThread;
exports.runListenerThread = runListenerThread;
process.on('SIGINT', function () {
interrupted = true;
});
process.setMaxListeners(30);
async function main() {
//execute all at once
Promise.all([
runPubThread(),
runListenerThread(),
runSubThread(),
]);
}
main().catch(err => {
console.error(err);
process.exit(1);
});
espresso: Espresso Pattern in Objective-C
espresso: Espresso Pattern in ooc
espresso: Espresso Pattern in Perl
espresso: Espresso Pattern in PHP
espresso: Espresso Pattern in Python
# Espresso Pattern
# This shows how to capture data using a pub-sub proxy
#
import time
from random import randint
from string import ascii_uppercase as uppercase
from threading import Thread
import zmq
from zmq.devices import monitored_queue
from zhelpers import zpipe
# The subscriber thread requests messages starting with
# A and B, then reads and counts incoming messages.
def subscriber_thread():
ctx = zmq.Context.instance()
# Subscribe to "A" and "B"
subscriber = ctx.socket(zmq.SUB)
subscriber.connect("tcp://localhost:6001")
subscriber.setsockopt(zmq.SUBSCRIBE, b"A")
subscriber.setsockopt(zmq.SUBSCRIBE, b"B")
count = 0
while count < 5:
try:
msg = subscriber.recv_multipart()
except zmq.ZMQError as e:
if e.errno == zmq.ETERM:
break # Interrupted
else:
raise
count += 1
print ("Subscriber received %d messages" % count)
# publisher thread
# The publisher sends random messages starting with A-J:
def publisher_thread():
ctx = zmq.Context.instance()
publisher = ctx.socket(zmq.PUB)
publisher.bind("tcp://*:6000")
while True:
string = "%s-%05d" % (uppercase[randint(0,10)], randint(0,100000))
try:
publisher.send(string.encode('utf-8'))
except zmq.ZMQError as e:
if e.errno == zmq.ETERM:
break # Interrupted
else:
raise
time.sleep(0.1) # Wait for 1/10th second
# listener thread
# The listener receives all messages flowing through the proxy, on its
# pipe. Here, the pipe is a pair of ZMQ_PAIR sockets that connects
# attached child threads via inproc. In other languages your mileage may vary:
def listener_thread (pipe):
# Print everything that arrives on pipe
while True:
try:
print (pipe.recv_multipart())
except zmq.ZMQError as e:
if e.errno == zmq.ETERM:
break # Interrupted
# main thread
# The main task starts the subscriber and publisher, and then sets
# itself up as a listening proxy. The listener runs as a child thread:
def main ():
# Start child threads
ctx = zmq.Context.instance()
p_thread = Thread(target=publisher_thread)
s_thread = Thread(target=subscriber_thread)
p_thread.start()
s_thread.start()
pipe = zpipe(ctx)
subscriber = ctx.socket(zmq.XSUB)
subscriber.connect("tcp://localhost:6000")
publisher = ctx.socket(zmq.XPUB)
publisher.bind("tcp://*:6001")
l_thread = Thread(target=listener_thread, args=(pipe[1],))
l_thread.start()
try:
monitored_queue(subscriber, publisher, pipe[0], b'pub', b'sub')
except KeyboardInterrupt:
print ("Interrupted")
del subscriber, publisher, pipe
ctx.term()
if __name__ == '__main__':
main()
espresso: Espresso Pattern in Q
espresso: Espresso Pattern in Racket
espresso: Espresso Pattern in Ruby
espresso: Espresso Pattern in Rust
espresso: Espresso Pattern in Scala
espresso: Espresso Pattern in Tcl
espresso: Espresso Pattern in OCaml
Espresso works by creating a listener thread that reads a PAIR socket and prints anything it gets. That PAIR socket is one end of a pipe; the other end (another PAIR) is the socket we pass to zmq_proxy(). In practice, you’d filter interesting messages to get the essence of what you want to track (hence the name of the pattern).
The subscriber thread subscribes to “A” and “B”, receives five messages, and then destroys its socket. When you run the example, the listener prints two subscription messages, five data messages, two unsubscribe messages, and then silence:
[002] 0141
[002] 0142
[007] B-91164
[007] B-12979
[007] A-52599
[007] A-06417
[007] A-45770
[002] 0041
[002] 0042
This shows neatly how the publisher socket stops sending data when there are no subscribers for it. The publisher thread is still sending messages. The socket just drops them silently.
Last Value Caching #
If you’ve used commercial pub-sub systems, you may be used to some features that are missing in the fast and cheerful ZeroMQ pub-sub model. One of these is last value caching (LVC). This solves the problem of how a new subscriber catches up when it joins the network. The theory is that publishers get notified when a new subscriber joins and subscribes to some specific topics. The publisher can then rebroadcast the last message for those topics.
I’ve already explained why publishers don’t get notified when there are new subscribers, because in large pub-sub systems, the volumes of data make it pretty much impossible. To make really large-scale pub-sub networks, you need a protocol like PGM that exploits an upscale Ethernet switch’s ability to multicast data to thousands of subscribers. Trying to do a TCP unicast from the publisher to each of thousands of subscribers just doesn’t scale. You get weird spikes, unfair distribution (some subscribers getting the message before others), network congestion, and general unhappiness.
PGM is a one-way protocol: the publisher sends a message to a multicast address at the switch, which then rebroadcasts that to all interested subscribers. The publisher never sees when subscribers join or leave: this all happens in the switch, which we don’t really want to start reprogramming.
However, in a lower-volume network with a few dozen subscribers and a limited number of topics, we can use TCP and then the XSUB and XPUB sockets do talk to each other as we just saw in the Espresso pattern.
Can we make an LVC using ZeroMQ? The answer is yes, if we make a proxy that sits between the publisher and subscribers; an analog for the PGM switch, but one we can program ourselves.
I’ll start by making a publisher and subscriber that highlight the worst case scenario. This publisher is pathological. It starts by immediately sending messages to each of a thousand topics, and then it sends one update a second to a random topic. A subscriber connects, and subscribes to a topic. Without LVC, a subscriber would have to wait an average of 500 seconds to get any data. To add some drama, let’s pretend there’s an escaped convict called Gregor threatening to rip the head off Roger the toy bunny if we can’t fix that 8.3 minutes’ delay.
Here’s the publisher code. Note that it has the command line option to connect to some address, but otherwise binds to an endpoint. We’ll use this later to connect to our last value cache:
pathopub: Pathologic Publisher in Ada
pathopub: Pathologic Publisher in Basic
pathopub: Pathologic Publisher in C
// Pathological publisher
// Sends out 1,000 topics and then one random update per second
#include "czmq.h"
int main (int argc, char *argv [])
{
zctx_t *context = zctx_new ();
void *publisher = zsocket_new (context, ZMQ_PUB);
if (argc == 2)
zsocket_bind (publisher, argv [1]);
else
zsocket_bind (publisher, "tcp://*:5556");
// Ensure subscriber connection has time to complete
sleep (1);
// Send out all 1,000 topic messages
int topic_nbr;
for (topic_nbr = 0; topic_nbr < 1000; topic_nbr++) {
zstr_sendfm (publisher, "%03d", topic_nbr);
zstr_send (publisher, "Save Roger");
}
// Send one random update per second
srandom ((unsigned) time (NULL));
while (!zctx_interrupted) {
sleep (1);
zstr_sendfm (publisher, "%03d", randof (1000));
zstr_send (publisher, "Off with his head!");
}
zctx_destroy (&context);
return 0;
}
pathopub: Pathologic Publisher in C++
// Pathological publisher
// Sends out 1,000 topics and then one random update per second
#include <thread>
#include <chrono>
#include "zhelpers.hpp"
int main (int argc, char *argv [])
{
zmq::context_t context(1);
zmq::socket_t publisher(context, ZMQ_PUB);
// Initialize random number generator
srandom ((unsigned) time (NULL));
if (argc == 2)
publisher.bind(argv [1]);
else
publisher.bind("tcp://*:5556");
// Ensure subscriber connection has time to complete
std::this_thread::sleep_for(std::chrono::seconds(1));
// Send out all 1,000 topic messages
int topic_nbr;
for (topic_nbr = 0; topic_nbr < 1000; topic_nbr++) {
std::stringstream ss;
ss << std::dec << std::setw(3) << std::setfill('0') << topic_nbr;
s_sendmore (publisher, ss.str());
s_send (publisher, std::string("Save Roger"));
}
// Send one random update per second
while (1) {
std::this_thread::sleep_for(std::chrono::seconds(1));
std::stringstream ss;
ss << std::dec << std::setw(3) << std::setfill('0') << within(1000);
s_sendmore (publisher, ss.str());
s_send (publisher, std::string("Off with his head!"));
}
return 0;
}
pathopub: Pathologic Publisher in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
public static void PathoPub(string[] args)
{
//
// Pathological publisher
// Sends out 1,000 topics and then one random update per second
//
// Author: metadings
//
if (args == null || args.Length < 1)
{
Console.WriteLine();
Console.WriteLine("Usage: ./{0} PathoPub [Endpoint]", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
Console.WriteLine(" Endpoint Where PathoPub should connect to.");
Console.WriteLine(" Default is null, Binding on tcp://*:5556");
Console.WriteLine();
args = new string[] { null };
}
using (var context = new ZContext())
using (var publisher = new ZSocket(context, ZSocketType.PUB))
{
if (args[0] != null)
{
publisher.Connect(args[0]);
}
else
{
publisher.Bind("tcp://*:5556");
}
// Ensure subscriber connection has time to complete
Thread.Sleep(100);
// Send out all 1,000 topic messages
for (int topic = 0; topic < 1000; ++topic)
{
publisher.SendMore(new ZFrame(string.Format("{0:D3}", topic)));
publisher.Send(new ZFrame("Save Roger"));
}
// Send one random update per second
var rnd = new Random();
while (true)
{
Thread.Sleep(10);
publisher.SendMore(new ZFrame(string.Format("{0:D3}", rnd.Next(1000))));
publisher.Send(new ZFrame("Off with his head!"));
}
}
}
}
}
pathopub: Pathologic Publisher in CL
pathopub: Pathologic Publisher in Delphi
pathopub: Pathologic Publisher in Erlang
pathopub: Pathologic Publisher in Elixir
pathopub: Pathologic Publisher in F#
pathopub: Pathologic Publisher in Felix
pathopub: Pathologic Publisher in Go
pathopub: Pathologic Publisher in Haskell
pathopub: Pathologic Publisher in Haxe
pathopub: Pathologic Publisher in Java
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
// Pathological publisher
// Sends out 1,000 topics and then one random update per second
public class pathopub
{
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
Socket publisher = context.createSocket(SocketType.PUB);
if (args.length == 1)
publisher.connect(args[0]);
else publisher.bind("tcp://*:5556");
// Ensure subscriber connection has time to complete
Thread.sleep(1000);
// Send out all 1,000 topic messages
int topicNbr;
for (topicNbr = 0; topicNbr < 1000; topicNbr++) {
publisher.send(String.format("%03d", topicNbr), ZMQ.SNDMORE);
publisher.send("Save Roger");
}
// Send one random update per second
Random rand = new Random(System.currentTimeMillis());
while (!Thread.currentThread().isInterrupted()) {
Thread.sleep(1000);
publisher.send(
String.format("%03d", rand.nextInt(1000)), ZMQ.SNDMORE
);
publisher.send("Off with his head!");
}
}
}
}
pathopub: Pathologic Publisher in Julia
pathopub: Pathologic Publisher in Lua
pathopub: Pathologic Publisher in Node.js
pathopub: Pathologic Publisher in Objective-C
pathopub: Pathologic Publisher in ooc
pathopub: Pathologic Publisher in Perl
pathopub: Pathologic Publisher in PHP
pathopub: Pathologic Publisher in Python
#
# Pathological publisher
# Sends out 1,000 topics and then one random update per second
#
import sys
import time
from random import randint
import zmq
def main(url=None):
ctx = zmq.Context.instance()
publisher = ctx.socket(zmq.PUB)
if url:
publisher.bind(url)
else:
publisher.bind("tcp://*:5556")
# Ensure subscriber connection has time to complete
time.sleep(1)
# Send out all 1,000 topic messages
for topic_nbr in range(1000):
publisher.send_multipart([
b"%03d" % topic_nbr,
b"Save Roger",
])
while True:
# Send one random update per second
try:
time.sleep(1)
publisher.send_multipart([
b"%03d" % randint(0,999),
b"Off with his head!",
])
except KeyboardInterrupt:
print "interrupted"
break
if __name__ == '__main__':
main(sys.argv[1] if len(sys.argv) > 1 else None)
pathopub: Pathologic Publisher in Q
pathopub: Pathologic Publisher in Racket
pathopub: Pathologic Publisher in Ruby
pathopub: Pathologic Publisher in Rust
pathopub: Pathologic Publisher in Scala
pathopub: Pathologic Publisher in Tcl
pathopub: Pathologic Publisher in OCaml
And here’s the subscriber:
pathosub: Pathologic Subscriber in Ada
pathosub: Pathologic Subscriber in Basic
pathosub: Pathologic Subscriber in C
// Pathological subscriber
// Subscribes to one random topic and prints received messages
#include "czmq.h"
int main (int argc, char *argv [])
{
zctx_t *context = zctx_new ();
void *subscriber = zsocket_new (context, ZMQ_SUB);
if (argc == 2)
zsocket_connect (subscriber, argv [1]);
else
zsocket_connect (subscriber, "tcp://localhost:5556");
srandom ((unsigned) time (NULL));
char subscription [5];
sprintf (subscription, "%03d", randof (1000));
zsocket_set_subscribe (subscriber, subscription);
while (true) {
char *topic = zstr_recv (subscriber);
if (!topic)
break;
char *data = zstr_recv (subscriber);
assert (streq (topic, subscription));
puts (data);
free (topic);
free (data);
}
zctx_destroy (&context);
return 0;
}
pathosub: Pathologic Subscriber in C++
// Pathological subscriber
// Subscribes to one random topic and prints received messages
#include "zhelpers.hpp"
int main (int argc, char *argv [])
{
zmq::context_t context(1);
zmq::socket_t subscriber (context, ZMQ_SUB);
// Initialize random number generator
srandom ((unsigned) time (NULL));
if (argc == 2)
subscriber.connect(argv [1]);
else
subscriber.connect("tcp://localhost:5556");
std::stringstream ss;
ss << std::dec << std::setw(3) << std::setfill('0') << within(1000);
std::cout << "topic:" << ss.str() << std::endl;
subscriber.set( zmq::sockopt::subscribe, ss.str().c_str());
while (1) {
std::string topic = s_recv (subscriber);
std::string data = s_recv (subscriber);
if (topic != ss.str())
break;
std::cout << data << std::endl;
}
return 0;
}
pathosub: Pathologic Subscriber in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
public static void PathoSub(string[] args)
{
//
// Pathological subscriber
// Subscribes to one random topic and prints received messages
//
// Author: metadings
//
if (args == null || args.Length < 1)
{
Console.WriteLine();
Console.WriteLine("Usage: ./{0} PathoSub [Endpoint]", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
Console.WriteLine(" Endpoint Where PathoSub should connect to.");
Console.WriteLine(" Default is tcp://127.0.0.1:5556");
Console.WriteLine();
args = new string[] { "tcp://127.0.0.1:5556" };
}
using (var context = new ZContext())
using (var subscriber = new ZSocket(context, ZSocketType.SUB))
{
subscriber.Connect(args[0]);
var rnd = new Random();
var subscription = string.Format("{0:D3}", rnd.Next(1000));
subscriber.Subscribe(subscription);
ZMessage msg;
ZError error;
while (true)
{
if (null == (msg = subscriber.ReceiveMessage(out error)))
{
if (error == ZError.ETERM)
break; // Interrupted
throw new ZException(error);
}
using (msg)
{
if (msg[0].ReadString() != subscription)
{
throw new InvalidOperationException();
}
Console.WriteLine(msg[1].ReadString());
}
}
}
}
}
}
pathosub: Pathologic Subscriber in CL
pathosub: Pathologic Subscriber in Delphi
pathosub: Pathologic Subscriber in Erlang
pathosub: Pathologic Subscriber in Elixir
pathosub: Pathologic Subscriber in F#
pathosub: Pathologic Subscriber in Felix
pathosub: Pathologic Subscriber in Go
pathosub: Pathologic Subscriber in Haskell
pathosub: Pathologic Subscriber in Haxe
pathosub: Pathologic Subscriber in Java
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
// Pathological subscriber
// Subscribes to one random topic and prints received messages
public class pathosub
{
public static void main(String[] args)
{
try (ZContext context = new ZContext()) {
Socket subscriber = context.createSocket(SocketType.SUB);
if (args.length == 1)
subscriber.connect(args[0]);
else subscriber.connect("tcp://localhost:5556");
Random rand = new Random(System.currentTimeMillis());
String subscription = String.format("%03d", rand.nextInt(1000));
subscriber.subscribe(subscription.getBytes(ZMQ.CHARSET));
while (true) {
String topic = subscriber.recvStr();
if (topic == null)
break;
String data = subscriber.recvStr();
assert (topic.equals(subscription));
System.out.println(data);
}
}
}
}
pathosub: Pathologic Subscriber in Julia
pathosub: Pathologic Subscriber in Lua
pathosub: Pathologic Subscriber in Node.js
pathosub: Pathologic Subscriber in Objective-C
pathosub: Pathologic Subscriber in ooc
pathosub: Pathologic Subscriber in Perl
pathosub: Pathologic Subscriber in PHP
pathosub: Pathologic Subscriber in Python
#
# Pathological subscriber
# Subscribes to one random topic and prints received messages
#
import sys
import time
from random import randint
import zmq
def main(url=None):
ctx = zmq.Context.instance()
subscriber = ctx.socket(zmq.SUB)
if url is None:
url = "tcp://localhost:5556"
subscriber.connect(url)
subscription = b"%03d" % randint(0,999)
subscriber.setsockopt(zmq.SUBSCRIBE, subscription)
while True:
topic, data = subscriber.recv_multipart()
assert topic == subscription
print data
if __name__ == '__main__':
main(sys.argv[1] if len(sys.argv) > 1 else None)
pathosub: Pathologic Subscriber in Q
pathosub: Pathologic Subscriber in Racket
pathosub: Pathologic Subscriber in Ruby
pathosub: Pathologic Subscriber in Rust
pathosub: Pathologic Subscriber in Scala
pathosub: Pathologic Subscriber in Tcl
pathosub: Pathologic Subscriber in OCaml
Try building and running these: first the subscriber, then the publisher. You’ll see the subscriber reports getting “Save Roger” as you’d expect:
./pathosub &
./pathopub
It’s when you run a second subscriber that you understand Roger’s predicament. You have to leave it an awful long time before it reports getting any data. So, here’s our last value cache. As I promised, it’s a proxy that binds to two sockets and then handles messages on both:
lvcache: Last Value Caching Proxy in Ada
lvcache: Last Value Caching Proxy in Basic
lvcache: Last Value Caching Proxy in C
// Last value cache
// Uses XPUB subscription messages to re-send data
#include "czmq.h"
int main (void)
{
zctx_t *context = zctx_new ();
void *frontend = zsocket_new (context, ZMQ_SUB);
zsocket_connect (frontend, "tcp://*:5557");
void *backend = zsocket_new (context, ZMQ_XPUB);
zsocket_bind (backend, "tcp://*:5558");
// Subscribe to every single topic from publisher
zsocket_set_subscribe (frontend, "");
// Store last instance of each topic in a cache
zhash_t *cache = zhash_new ();
// .split main poll loop
// We route topic updates from frontend to backend, and
// we handle subscriptions by sending whatever we cached,
// if anything:
while (true) {
zmq_pollitem_t items [] = {
{ frontend, 0, ZMQ_POLLIN, 0 },
{ backend, 0, ZMQ_POLLIN, 0 }
};
if (zmq_poll (items, 2, 1000 * ZMQ_POLL_MSEC) == -1)
break; // Interrupted
// Any new topic data we cache and then forward
if (items [0].revents & ZMQ_POLLIN) {
char *topic = zstr_recv (frontend);
char *current = zstr_recv (frontend);
if (!topic)
break;
char *previous = zhash_lookup (cache, topic);
if (previous) {
zhash_delete (cache, topic);
free (previous);
}
zhash_insert (cache, topic, current);
zstr_sendm (backend, topic);
zstr_send (backend, current);
free (topic);
}
// .split handle subscriptions
// When we get a new subscription, we pull data from the cache:
if (items [1].revents & ZMQ_POLLIN) {
zframe_t *frame = zframe_recv (backend);
if (!frame)
break;
// Event is one byte 0=unsub or 1=sub, followed by topic
byte *event = zframe_data (frame);
if (event [0] == 1) {
char *topic = zmalloc (zframe_size (frame));
memcpy (topic, event + 1, zframe_size (frame) - 1);
printf ("Sending cached topic %s\n", topic);
char *previous = zhash_lookup (cache, topic);
if (previous) {
zstr_sendm (backend, topic);
zstr_send (backend, previous);
}
free (topic);
}
zframe_destroy (&frame);
}
}
zctx_destroy (&context);
zhash_destroy (&cache);
return 0;
}
lvcache: Last Value Caching Proxy in C++
// Last value cache
// Uses XPUB subscription messages to re-send data
#include <unordered_map>
#include "zhelpers.hpp"
int main ()
{
zmq::context_t context(1);
zmq::socket_t frontend(context, ZMQ_SUB);
zmq::socket_t backend(context, ZMQ_XPUB);
frontend.connect("tcp://localhost:5557");
backend.bind("tcp://*:5558");
// Subscribe to every single topic from publisher
frontend.set(zmq::sockopt::subscribe, "");
// Store last instance of each topic in a cache
std::unordered_map<std::string, std::string> cache_map;
zmq::pollitem_t items[2] = {
{ static_cast<void*>(frontend), 0, ZMQ_POLLIN, 0 },
{ static_cast<void*>(backend), 0, ZMQ_POLLIN, 0 }
};
// .split main poll loop
// We route topic updates from frontend to backend, and we handle
// subscriptions by sending whatever we cached, if anything:
while (1)
{
if (zmq::poll(items, 2, 1000) == -1)
break; // Interrupted
// Any new topic data we cache and then forward
if (items[0].revents & ZMQ_POLLIN)
{
std::string topic = s_recv(frontend);
std::string data = s_recv(frontend);
if (topic.empty())
break;
cache_map[topic] = data;
s_sendmore(backend, topic);
s_send(backend, data);
}
// .split handle subscriptions
// When we get a new subscription, we pull data from the cache:
if (items[1].revents & ZMQ_POLLIN) {
zmq::message_t msg;
backend.recv(&msg);
if (msg.size() == 0)
break;
// Event is one byte 0=unsub or 1=sub, followed by topic
uint8_t *event = (uint8_t *)msg.data();
if (event[0] == 1) {
std::string topic((char *)(event+1), msg.size()-1);
auto i = cache_map.find(topic);
if (i != cache_map.end())
{
s_sendmore(backend, topic);
s_send(backend, i->second);
}
}
}
}
return 0;
}
lvcache: Last Value Caching Proxy in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
public static void LVCache(string[] args)
{
//
// Last value cache
// Uses XPUB subscription messages to re-send data
//
// Author: metadings
//
using (var context = new ZContext())
using (var frontend = new ZSocket(context, ZSocketType.SUB))
using (var backend = new ZSocket(context, ZSocketType.XPUB))
{
// Subscribe to every single topic from publisher
frontend.Bind("tcp://*:5557");
frontend.SubscribeAll();
backend.Bind("tcp://*:5558");
// Store last instance of each topic in a cache
var cache = new HashSet<LVCacheItem>();
// We route topic updates from frontend to backend, and
// we handle subscriptions by sending whatever we cached,
// if anything:
var p = ZPollItem.CreateReceiver();
ZMessage msg;
ZError error;
while (true)
{
// Any new topic data we cache and then forward
if (frontend.PollIn(p, out msg, out error, TimeSpan.FromMilliseconds(1)))
{
using (msg)
{
string topic = msg[0].ReadString();
string current = msg[1].ReadString();
LVCacheItem previous = cache.FirstOrDefault(item => topic == item.Topic);
if (previous != null)
{
cache.Remove(previous);
}
cache.Add(new LVCacheItem { Topic = topic, Current = current });
backend.Send(msg);
}
}
else
{
if (error == ZError.ETERM)
break; // Interrupted
if (error != ZError.EAGAIN)
throw new ZException(error);
}
// When we get a new subscription, we pull data from the cache:
if (backend.PollIn(p, out msg, out error, TimeSpan.FromMilliseconds(1)))
{
using (msg)
{
// Event is one byte 0=unsub or 1=sub, followed by topic
byte subscribe = msg[0].ReadAsByte();
if (subscribe == 0x01)
{
string topic = msg[0].ReadString();
LVCacheItem previous = cache.FirstOrDefault(item => topic == item.Topic);
if (previous != null)
{
Console.WriteLine("Sending cached topic {0}", topic);
backend.SendMore(new ZFrame(previous.Topic));
backend.Send(new ZFrame(previous.Current));
}
else
{
Console.WriteLine("Failed to send cached topic {0}!", topic);
}
}
}
}
else
{
if (error == ZError.ETERM)
break; // Interrupted
if (error != ZError.EAGAIN)
throw new ZException(error);
}
}
}
}
class LVCacheItem
{
public string Topic;
public string Current;
public override int GetHashCode()
{
return Topic.GetHashCode();
}
}
}
}
lvcache: Last Value Caching Proxy in CL
lvcache: Last Value Caching Proxy in Delphi
lvcache: Last Value Caching Proxy in Erlang
lvcache: Last Value Caching Proxy in Elixir
lvcache: Last Value Caching Proxy in F#
lvcache: Last Value Caching Proxy in Felix
lvcache: Last Value Caching Proxy in Go
lvcache: Last Value Caching Proxy in Haskell
lvcache: Last Value Caching Proxy in Haxe
lvcache: Last Value Caching Proxy in Java
package guide;
import java.util.HashMap;
import java.util.Map;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
// Last value cache
// Uses XPUB subscription messages to re-send data
public class lvcache
{
public static void main(String[] args)
{
try (ZContext context = new ZContext()) {
Socket frontend = context.createSocket(SocketType.SUB);
frontend.bind("tcp://*:5557");
Socket backend = context.createSocket(SocketType.XPUB);
backend.bind("tcp://*:5558");
// Subscribe to every single topic from publisher
frontend.subscribe(ZMQ.SUBSCRIPTION_ALL);
// Store last instance of each topic in a cache
Map<String, String> cache = new HashMap<String, String>();
Poller poller = context.createPoller(2);
poller.register(frontend, Poller.POLLIN);
poller.register(backend, Poller.POLLIN);
// .split main poll loop
// We route topic updates from frontend to backend, and we handle
// subscriptions by sending whatever we cached, if anything:
while (true) {
if (poller.poll(1000) == -1)
break; // Interrupted
// Any new topic data we cache and then forward
if (poller.pollin(0)) {
String topic = frontend.recvStr();
String current = frontend.recvStr();
if (topic == null)
break;
cache.put(topic, current);
backend.sendMore(topic);
backend.send(current);
}
// .split handle subscriptions
// When we get a new subscription, we pull data from the cache:
if (poller.pollin(1)) {
ZFrame frame = ZFrame.recvFrame(backend);
if (frame == null)
break;
// Event is one byte 0=unsub or 1=sub, followed by topic
byte[] event = frame.getData();
if (event[0] == 1) {
String topic = new String(event, 1, event.length - 1, ZMQ.CHARSET);
System.out.printf("Sending cached topic %s\n", topic);
String previous = cache.get(topic);
if (previous != null) {
backend.sendMore(topic);
backend.send(previous);
}
}
frame.destroy();
}
}
}
}
}
lvcache: Last Value Caching Proxy in Julia
lvcache: Last Value Caching Proxy in Lua
lvcache: Last Value Caching Proxy in Node.js
// Last value cache
// Uses XPUB subscription messages to re-send data
var zmq = require('zeromq');
var frontEnd = zmq.socket('sub');
var backend = zmq.socket('xpub');
var cache = {};
frontEnd.connect('tcp://127.0.0.1:5557');
frontEnd.subscribe('');
backend.bindSync('tcp://*:5558');
frontEnd.on('message', function(topic, message) {
cache[topic] = message;
backend.send([topic, message]);
});
backend.on('message', function(frame) {
// frame is one byte 0=unsub or 1=sub, followed by topic
if (frame[0] === 1) {
var topic = frame.slice(1);
var previous = cache[topic];
console.log('Sending cached topic ' + topic);
if (typeof previous !== 'undefined') {
backend.send([topic, previous]);
}
}
});
process.on('SIGINT', function() {
frontEnd.close();
backend.close();
console.log('\nClosed')
});
lvcache: Last Value Caching Proxy in Objective-C
lvcache: Last Value Caching Proxy in ooc
lvcache: Last Value Caching Proxy in Perl
lvcache: Last Value Caching Proxy in PHP
lvcache: Last Value Caching Proxy in Python
#
# Last value cache
# Uses XPUB subscription messages to re-send data
#
import zmq
def main():
ctx = zmq.Context.instance()
frontend = ctx.socket(zmq.SUB)
frontend.connect("tcp://*:5557")
backend = ctx.socket(zmq.XPUB)
backend.bind("tcp://*:5558")
# Subscribe to every single topic from publisher
frontend.setsockopt(zmq.SUBSCRIBE, b"")
# Store last instance of each topic in a cache
cache = {}
# main poll loop
# We route topic updates from frontend to backend, and
# we handle subscriptions by sending whatever we cached,
# if anything:
poller = zmq.Poller()
poller.register(frontend, zmq.POLLIN)
poller.register(backend, zmq.POLLIN)
while True:
try:
events = dict(poller.poll(1000))
except KeyboardInterrupt:
print("interrupted")
break
# Any new topic data we cache and then forward
if frontend in events:
msg = frontend.recv_multipart()
topic, current = msg
cache[topic] = current
backend.send_multipart(msg)
# handle subscriptions
# When we get a new subscription we pull data from the cache:
if backend in events:
event = backend.recv()
# Event is one byte 0=unsub or 1=sub, followed by topic
if event[0] == 1:
topic = event[1:]
if topic in cache:
print ("Sending cached topic %s" % topic)
backend.send_multipart([ topic, cache[topic] ])
if __name__ == '__main__':
main()
lvcache: Last Value Caching Proxy in Q
lvcache: Last Value Caching Proxy in Racket
lvcache: Last Value Caching Proxy in Ruby
lvcache: Last Value Caching Proxy in Rust
lvcache: Last Value Caching Proxy in Scala
lvcache: Last Value Caching Proxy in Tcl
lvcache: Last Value Caching Proxy in OCaml
Now, run the proxy, and then the publisher:
./lvcache &
./pathopub tcp://localhost:5557
And now run as many instances of the subscriber as you want to try, each time connecting to the proxy on port 5558:
./pathosub tcp://localhost:5558
Each subscriber happily reports “Save Roger”, and Gregor the Escaped Convict slinks back to his seat for dinner and a nice cup of hot milk, which is all he really wanted in the first place.
One note: by default, the XPUB socket does not report duplicate subscriptions, which is what you want when you’re naively connecting an XPUB to an XSUB. Our example sneakily gets around this by using random topics so the chance of it not working is one in a million. In a real LVC proxy, you’ll want to use the ZMQ_XPUB_VERBOSE option that we implement in Chapter 6 - The ZeroMQ Community as an exercise.
Slow Subscriber Detection (Suicidal Snail Pattern) #
A common problem you will hit when using the pub-sub pattern in real life is the slow subscriber. In an ideal world, we stream data at full speed from publishers to subscribers. In reality, subscriber applications are often written in interpreted languages, or just do a lot of work, or are just badly written, to the extent that they can’t keep up with publishers.
How do we handle a slow subscriber? The ideal fix is to make the subscriber faster, but that might take work and time. Some of the classic strategies for handling a slow subscriber are:
-
Queue messages on the publisher. This is what Gmail does when I don’t read my email for a couple of hours. But in high-volume messaging, pushing queues upstream has the thrilling but unprofitable result of making publishers run out of memory and crash–especially if there are lots of subscribers and it’s not possible to flush to disk for performance reasons.
-
Queue messages on the subscriber. This is much better, and it’s what ZeroMQ does by default if the network can keep up with things. If anyone’s going to run out of memory and crash, it’ll be the subscriber rather than the publisher, which is fair. This is perfect for “peaky” streams where a subscriber can’t keep up for a while, but can catch up when the stream slows down. However, it’s no answer to a subscriber that’s simply too slow in general.
-
Stop queuing new messages after a while. This is what Gmail does when my mailbox overflows its precious gigabytes of space. New messages just get rejected or dropped. This is a great strategy from the perspective of the publisher, and it’s what ZeroMQ does when the publisher sets a HWM. However, it still doesn’t help us fix the slow subscriber. Now we just get gaps in our message stream.
-
Punish slow subscribers with disconnect. This is what Hotmail (remember that?) did when I didn’t log in for two weeks, which is why I was on my fifteenth Hotmail account when it hit me that there was perhaps a better way. It’s a nice brutal strategy that forces subscribers to sit up and pay attention and would be ideal, but ZeroMQ doesn’t do this, and there’s no way to layer it on top because subscribers are invisible to publisher applications.
None of these classic strategies fit, so we need to get creative. Rather than disconnect the publisher, let’s convince the subscriber to kill itself. This is the Suicidal Snail pattern. When a subscriber detects that it’s running too slowly (where “too slowly” is presumably a configured option that really means “so slowly that if you ever get here, shout really loudly because I need to know, so I can fix this!"), it croaks and dies.
How can a subscriber detect this? One way would be to sequence messages (number them in order) and use a HWM at the publisher. Now, if the subscriber detects a gap (i.e., the numbering isn’t consecutive), it knows something is wrong. We then tune the HWM to the “croak and die if you hit this” level.
There are two problems with this solution. One, if we have many publishers, how do we sequence messages? The solution is to give each publisher a unique ID and add that to the sequencing. Second, if subscribers use ZMQ_SUBSCRIBE filters, they will get gaps by definition. Our precious sequencing will be for nothing.
Some use cases won’t use filters, and sequencing will work for them. But a more general solution is that the publisher timestamps each message. When a subscriber gets a message, it checks the time, and if the difference is more than, say, one second, it does the “croak and die” thing, possibly firing off a squawk to some operator console first.
The Suicide Snail pattern works especially when subscribers have their own clients and service-level agreements and need to guarantee certain maximum latencies. Aborting a subscriber may not seem like a constructive way to guarantee a maximum latency, but it’s the assertion model. Abort today, and the problem will be fixed. Allow late data to flow downstream, and the problem may cause wider damage and take longer to appear on the radar.
Here is a minimal example of a Suicidal Snail:
suisnail: Suicidal Snail in Ada
suisnail: Suicidal Snail in Basic
suisnail: Suicidal Snail in C
// Suicidal Snail
#include "czmq.h"
// This is our subscriber. It connects to the publisher and subscribes
// to everything. It sleeps for a short time between messages to
// simulate doing too much work. If a message is more than one second
// late, it croaks.
#define MAX_ALLOWED_DELAY 1000 // msecs
static void
subscriber (void *args, zctx_t *ctx, void *pipe)
{
// Subscribe to everything
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (subscriber, "");
zsocket_connect (subscriber, "tcp://localhost:5556");
// Get and process messages
while (true) {
char *string = zstr_recv (subscriber);
printf("%s\n", string);
int64_t clock;
int terms = sscanf (string, "%" PRId64, &clock);
assert (terms == 1);
free (string);
// Suicide snail logic
if (zclock_time () - clock > MAX_ALLOWED_DELAY) {
fprintf (stderr, "E: subscriber cannot keep up, aborting\n");
break;
}
// Work for 1 msec plus some random additional time
zclock_sleep (1 + randof (2));
}
zstr_send (pipe, "gone and died");
}
// .split publisher task
// This is our publisher task. It publishes a time-stamped message to its
// PUB socket every millisecond:
static void
publisher (void *args, zctx_t *ctx, void *pipe)
{
// Prepare publisher
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5556");
while (true) {
// Send current clock (msecs) to subscribers
char string [20];
sprintf (string, "%" PRId64, zclock_time ());
zstr_send (publisher, string);
char *signal = zstr_recv_nowait (pipe);
if (signal) {
free (signal);
break;
}
zclock_sleep (1); // 1msec wait
}
}
// .split main task
// The main task simply starts a client and a server, and then
// waits for the client to signal that it has died:
int main (void)
{
zctx_t *ctx = zctx_new ();
void *pubpipe = zthread_fork (ctx, publisher, NULL);
void *subpipe = zthread_fork (ctx, subscriber, NULL);
free (zstr_recv (subpipe));
zstr_send (pubpipe, "break");
zclock_sleep (100);
zctx_destroy (&ctx);
return 0;
}
suisnail: Suicidal Snail in C++
//
// Suicidal Snail
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
#include "zhelpers.hpp"
#include <thread>
// ---------------------------------------------------------------------
// This is our subscriber
// It connects to the publisher and subscribes to everything. It
// sleeps for a short time between messages to simulate doing too
// much work. If a message is more than 1 second late, it croaks.
#define MAX_ALLOWED_DELAY 1000 // msecs
namespace {
bool Exit = false;
};
static void *
subscriber () {
zmq::context_t context(1);
// Subscribe to everything
zmq::socket_t subscriber(context, ZMQ_SUB);
subscriber.connect("tcp://localhost:5556");
subscriber.set(zmq::sockopt::subscribe, "");
std::stringstream ss;
// Get and process messages
while (1) {
ss.clear();
ss.str(s_recv (subscriber));
int64_t clock;
assert ((ss >> clock));
const auto delay = s_clock () - clock;
// Suicide snail logic
if (delay> MAX_ALLOWED_DELAY) {
std::cerr << "E: subscriber cannot keep up, aborting. Delay=" <<delay<< std::endl;
break;
}
// Work for 1 msec plus some random additional time
s_sleep(1000*(1+within(2)));
}
Exit = true;
return (NULL);
}
// ---------------------------------------------------------------------
// This is our server task
// It publishes a time-stamped message to its pub socket every 1ms.
static void *
publisher () {
zmq::context_t context (1);
// Prepare publisher
zmq::socket_t publisher(context, ZMQ_PUB);
publisher.bind("tcp://*:5556");
std::stringstream ss;
while (!Exit) {
// Send current clock (msecs) to subscribers
ss.str("");
ss << s_clock();
s_send (publisher, ss.str());
s_sleep(1);
}
return 0;
}
// This main thread simply starts a client, and a server, and then
// waits for the client to croak.
//
int main (void)
{
std::thread server_thread(&publisher);
std::thread client_thread(&subscriber);
client_thread.join();
server_thread.join();
return 0;
}
suisnail: Suicidal Snail in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
//
// Suicidal Snail
//
// Author: metadings
//
static readonly TimeSpan SuiSnail_MAX_ALLOWED_DELAY = TimeSpan.FromMilliseconds(1000);
static void SuiSnail_Subscriber(ZContext context, ZSocket backend, CancellationTokenSource cancellor, object[] args)
{
// This is our subscriber. It connects to the publisher and subscribes
// to everything. It sleeps for a short time between messages to
// simulate doing too much work. If a message is more than one second
// late, it croaks.
using (var subscriber = new ZSocket(context, ZSocketType.SUB))
{
// Subscribe to everything
subscriber.SubscribeAll();
subscriber.Connect("tcp://127.0.0.1:5556");
ZFrame incoming;
ZError error;
var rnd = new Random();
while (!cancellor.IsCancellationRequested)
{
// Get and process messages
if (null != (incoming = subscriber.ReceiveFrame(out error)))
{
string terms = incoming.ReadString();
Console.WriteLine(terms);
var clock = DateTime.Parse(terms);
// Suicide snail logic
if (DateTime.UtcNow - clock > SuiSnail_MAX_ALLOWED_DELAY)
{
Console.WriteLine("E: subscriber cannot keep up, aborting");
break;
}
// Work for 1 msec plus some random additional time
Thread.Sleep(1 + rnd.Next(200));
}
else
{
if (error == ZError.ETERM)
break; // Interrupted
throw new ZException(error);
}
}
backend.Send(new ZFrame("gone and died"));
}
}
static void SuiSnail_Publisher(ZContext context, ZSocket backend, CancellationTokenSource cancellor, object[] args)
{
// This is our publisher task. It publishes a time-stamped message to its
// PUB socket every millisecond:
using (var publisher = new ZSocket(context, ZSocketType.PUB))
{
// Prepare publisher
publisher.Bind("tcp://*:5556");
ZFrame signal;
ZError error;
while (!cancellor.IsCancellationRequested)
{
// Send current clock (msecs) to subscribers
if (!publisher.Send(new ZFrame(DateTime.UtcNow.ToString("s")), out error))
{
if (error == ZError.ETERM)
break; // Interrupted
throw new ZException(error);
}
if (null == (signal = backend.ReceiveFrame(ZSocketFlags.DontWait, out error)))
{
if (error == ZError.EAGAIN)
{
Thread.Sleep(1); // wait 1 ms
continue;
}
if (error == ZError.ETERM)
break; // Interrupted
throw new ZException(error);
}
// Suicide snail logic
using (signal) break;
}
}
}
public static void SuiSnail(string[] args)
{
// The main task simply starts a client and a server, and then
// waits for the client to signal that it has died:
using (var context = new ZContext())
using (var pubpipe = new ZActor(context, SuiSnail_Publisher))
using (var subpipe = new ZActor(context, SuiSnail_Subscriber))
{
pubpipe.Start();
subpipe.Start();
subpipe.Frontend.ReceiveFrame();
pubpipe.Frontend.Send(new ZFrame("break"));
// wait for the Thread (you'll see how fast it is)
pubpipe.Join(5000);
}
}
}
}
suisnail: Suicidal Snail in CL
suisnail: Suicidal Snail in Delphi
suisnail: Suicidal Snail in Erlang
suisnail: Suicidal Snail in Elixir
suisnail: Suicidal Snail in F#
suisnail: Suicidal Snail in Felix
suisnail: Suicidal Snail in Go
suisnail: Suicidal Snail in Haskell
suisnail: Suicidal Snail in Haxe
suisnail: Suicidal Snail in Java
package guide;
import java.util.Random;
// Suicidal Snail
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZThread;
import org.zeromq.ZThread.IAttachedRunnable;
public class suisnail
{
private static final long MAX_ALLOWED_DELAY = 1000; // msecs
private static Random rand = new Random(System.currentTimeMillis());
// This is our subscriber. It connects to the publisher and subscribes to
// everything. It sleeps for a short time between messages to simulate
// doing too much work. If a message is more than one second late, it
// croaks.
private static class Subscriber implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
// Subscribe to everything
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
subscriber.connect("tcp://localhost:5556");
// Get and process messages
while (true) {
String string = subscriber.recvStr();
System.out.printf("%s\n", string);
long clock = Long.parseLong(string);
// Suicide snail logic
if (System.currentTimeMillis() - clock > MAX_ALLOWED_DELAY) {
System.err.println(
"E: subscriber cannot keep up, aborting"
);
break;
}
// Work for 1 msec plus some random additional time
try {
Thread.sleep(1000 + rand.nextInt(2000));
}
catch (InterruptedException e) {
break;
}
}
pipe.send("gone and died");
}
}
// .split publisher task
// This is our publisher task. It publishes a time-stamped message to its
// PUB socket every millisecond:
private static class Publisher implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
// Prepare publisher
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5556");
while (true) {
// Send current clock (msecs) to subscribers
String string = String.format("%d", System.currentTimeMillis());
publisher.send(string);
String signal = pipe.recvStr(ZMQ.DONTWAIT);
if (signal != null) {
break;
}
try {
Thread.sleep(1);
}
catch (InterruptedException e) {
}
}
}
}
// .split main task
// The main task simply starts a client and a server, and then waits for
// the client to signal that it has died:
public static void main(String[] args) throws Exception
{
try (ZContext ctx = new ZContext()) {
Socket pubpipe = ZThread.fork(ctx, new Publisher());
Socket subpipe = ZThread.fork(ctx, new Subscriber());
subpipe.recvStr();
pubpipe.send("break");
Thread.sleep(100);
}
}
}
suisnail: Suicidal Snail in Julia
suisnail: Suicidal Snail in Lua
--
-- Suicidal Snail
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zhelpers"
-- ---------------------------------------------------------------------
-- This is our subscriber
-- It connects to the publisher and subscribes to everything. It
-- sleeps for a short time between messages to simulate doing too
-- much work. If a message is more than 1 second late, it croaks.
local subscriber = [[
require"zmq"
require"zhelpers"
local MAX_ALLOWED_DELAY = 1000 -- msecs
local context = zmq.init(1)
-- Subscribe to everything
local subscriber = context:socket(zmq.SUB)
subscriber:connect("tcp://localhost:5556")
subscriber:setopt(zmq.SUBSCRIBE, "", 0)
-- Get and process messages
while true do
local msg = subscriber:recv()
local clock = tonumber(msg)
-- Suicide snail logic
if (s_clock () - clock > MAX_ALLOWED_DELAY) then
fprintf (io.stderr, "E: subscriber cannot keep up, aborting\n")
break
end
-- Work for 1 msec plus some random additional time
s_sleep (1 + randof (2))
end
subscriber:close()
context:term()
]]
-- ---------------------------------------------------------------------
-- This is our server task
-- It publishes a time-stamped message to its pub socket every 1ms.
local publisher = [[
require"zmq"
require"zhelpers"
local context = zmq.init(1)
-- Prepare publisher
local publisher = context:socket(zmq.PUB)
publisher:bind("tcp://*:5556")
while true do
-- Send current clock (msecs) to subscribers
publisher:send(tostring(s_clock()))
s_sleep (1); -- 1msec wait
end
publisher:close()
context:term()
]]
-- This main thread simply starts a client, and a server, and then
-- waits for the client to croak.
--
local server_thread = zmq.threads.runstring(nil, publisher)
server_thread:start(true)
local client_thread = zmq.threads.runstring(nil, subscriber)
client_thread:start()
client_thread:join()
suisnail: Suicidal Snail in Node.js
suisnail: Suicidal Snail in Objective-C
suisnail: Suicidal Snail in ooc
suisnail: Suicidal Snail in Perl
suisnail: Suicidal Snail in PHP
<?php
/* Suicidal Snail
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
/* ---------------------------------------------------------------------
* This is our subscriber
* It connects to the publisher and subscribes to everything. It
* sleeps for a short time between messages to simulate doing too
* much work. If a message is more than 1 second late, it croaks.
*/
define("MAX_ALLOWED_DELAY", 100); // msecs
function subscriber()
{
$context = new ZMQContext();
// Subscribe to everything
$subscriber = new ZMQSocket($context, ZMQ::SOCKET_SUB);
$subscriber->connect("tcp://localhost:5556");
$subscriber->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "");
// Get and process messages
while (true) {
$clock = $subscriber->recv();
// Suicide snail logic
if (microtime(true)*100 - $clock*100 > MAX_ALLOWED_DELAY) {
echo "E: subscriber cannot keep up, aborting", PHP_EOL;
break;
}
// Work for 1 msec plus some random additional time
usleep(1000 + rand(0, 1000));
}
}
/* ---------------------------------------------------------------------
* This is our server task
* It publishes a time-stamped message to its pub socket every 1ms.
*/
function publisher()
{
$context = new ZMQContext();
// Prepare publisher
$publisher = new ZMQSocket($context, ZMQ::SOCKET_PUB);
$publisher->bind("tcp://*:5556");
while (true) {
// Send current clock (msecs) to subscribers
$publisher->send(microtime(true));
usleep(1000); // 1msec wait
}
}
/*
* This main thread simply starts a client, and a server, and then
* waits for the client to croak.
*/
$pid = pcntl_fork();
if ($pid == 0) {
publisher();
exit();
}
$pid = pcntl_fork();
if ($pid == 0) {
subscriber();
exit();
}
suisnail: Suicidal Snail in Python
"""
Suicidal Snail
Author: Min RK <benjaminrk@gmail.com>
"""
from __future__ import print_function
import sys
import threading
import time
from pickle import dumps, loads
import random
import zmq
from zhelpers import zpipe
# ---------------------------------------------------------------------
# This is our subscriber
# It connects to the publisher and subscribes to everything. It
# sleeps for a short time between messages to simulate doing too
# much work. If a message is more than 1 second late, it croaks.
MAX_ALLOWED_DELAY = 1.0 # secs
def subscriber(pipe):
# Subscribe to everything
ctx = zmq.Context.instance()
sub = ctx.socket(zmq.SUB)
sub.setsockopt(zmq.SUBSCRIBE, b'')
sub.connect("tcp://localhost:5556")
# Get and process messages
while True:
clock = loads(sub.recv())
# Suicide snail logic
if (time.time() - clock > MAX_ALLOWED_DELAY):
print("E: subscriber cannot keep up, aborting", file=sys.stderr)
break
# Work for 1 msec plus some random additional time
time.sleep(1e-3 * (1+2*random.random()))
pipe.send(b"gone and died")
# ---------------------------------------------------------------------
# This is our server task
# It publishes a time-stamped message to its pub socket every 1ms.
def publisher(pipe):
# Prepare publisher
ctx = zmq.Context.instance()
pub = ctx.socket(zmq.PUB)
pub.bind("tcp://*:5556")
while True:
# Send current clock (secs) to subscribers
pub.send(dumps(time.time()))
try:
signal = pipe.recv(zmq.DONTWAIT)
except zmq.ZMQError as e:
if e.errno == zmq.EAGAIN:
# nothing to recv
pass
else:
raise
else:
# received break message
break
time.sleep(1e-3) # 1msec wait
# This main thread simply starts a client, and a server, and then
# waits for the client to signal it's died.
def main():
ctx = zmq.Context.instance()
pub_pipe, pub_peer = zpipe(ctx)
sub_pipe, sub_peer = zpipe(ctx)
pub_thread = threading.Thread(target=publisher, args=(pub_peer,))
pub_thread.daemon=True
pub_thread.start()
sub_thread = threading.Thread(target=subscriber, args=(sub_peer,))
sub_thread.daemon=True
sub_thread.start()
# wait for sub to finish
sub_pipe.recv()
# tell pub to halt
pub_pipe.send(b"break")
time.sleep(0.1)
if __name__ == '__main__':
main()
suisnail: Suicidal Snail in Q
suisnail: Suicidal Snail in Racket
suisnail: Suicidal Snail in Ruby
suisnail: Suicidal Snail in Rust
suisnail: Suicidal Snail in Scala
suisnail: Suicidal Snail in Tcl
suisnail: Suicidal Snail in OCaml
Here are some things to note about the Suicidal Snail example:
-
The message here consists simply of the current system clock as a number of milliseconds. In a realistic application, you’d have at least a message header with the timestamp and a message body with data.
-
The example has subscriber and publisher in a single process as two threads. In reality, they would be separate processes. Using threads is just convenient for the demonstration.
High-Speed Subscribers (Black Box Pattern) #
Now lets look at one way to make our subscribers faster. A common use case for pub-sub is distributing large data streams like market data coming from stock exchanges. A typical setup would have a publisher connected to a stock exchange, taking price quotes, and sending them out to a number of subscribers. If there are a handful of subscribers, we could use TCP. If we have a larger number of subscribers, we’d probably use reliable multicast, i.e., PGM.
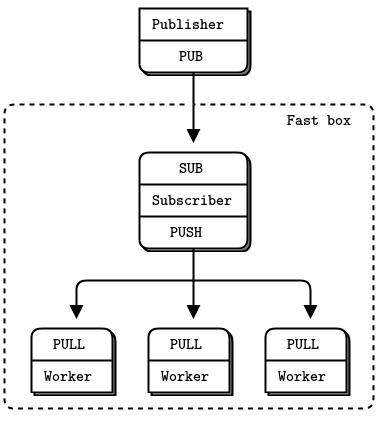
Let’s imagine our feed has an average of 100,000 100-byte messages a second. That’s a typical rate, after filtering market data we don’t need to send on to subscribers. Now we decide to record a day’s data (maybe 250 GB in 8 hours), and then replay it to a simulation network, i.e., a small group of subscribers. While 100K messages a second is easy for a ZeroMQ application, we want to replay it much faster.
So we set up our architecture with a bunch of boxes–one for the publisher and one for each subscriber. These are well-specified boxes–eight cores, twelve for the publisher.
And as we pump data into our subscribers, we notice two things:
-
When we do even the slightest amount of work with a message, it slows down our subscriber to the point where it can’t catch up with the publisher again.
-
We’re hitting a ceiling, at both publisher and subscriber, to around 6M messages a second, even after careful optimization and TCP tuning.
The first thing we have to do is break our subscriber into a multithreaded design so that we can do work with messages in one set of threads, while reading messages in another. Typically, we don’t want to process every message the same way. Rather, the subscriber will filter some messages, perhaps by prefix key. When a message matches some criteria, the subscriber will call a worker to deal with it. In ZeroMQ terms, this means sending the message to a worker thread.
So the subscriber looks something like a queue device. We could use various sockets to connect the subscriber and workers. If we assume one-way traffic and workers that are all identical, we can use PUSH and PULL and delegate all the routing work to ZeroMQ. This is the simplest and fastest approach.
The subscriber talks to the publisher over TCP or PGM. The subscriber talks to its workers, which are all in the same process, over inproc:@<//>@.
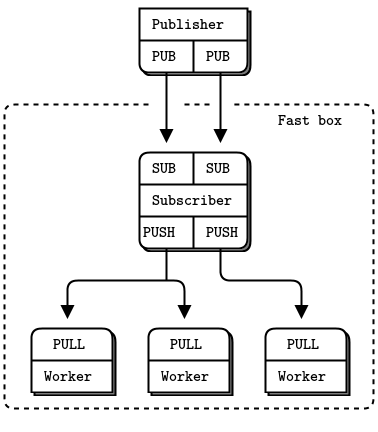
Now to break that ceiling. The subscriber thread hits 100% of CPU and because it is one thread, it cannot use more than one core. A single thread will always hit a ceiling, be it at 2M, 6M, or more messages per second. We want to split the work across multiple threads that can run in parallel.
The approach used by many high-performance products, which works here, is sharding. Using sharding, we split the work into parallel and independent streams, such as half of the topic keys in one stream, and half in another. We could use many streams, but performance won’t scale unless we have free cores. So let’s see how to shard into two streams.
With two streams, working at full speed, we would configure ZeroMQ as follows:
- Two I/O threads, rather than one.
- Two network interfaces (NIC), one per subscriber.
- Each I/O thread bound to a specific NIC.
- Two subscriber threads, bound to specific cores.
- Two SUB sockets, one per subscriber thread.
- The remaining cores assigned to worker threads.
- Worker threads connected to both subscriber PUSH sockets.
Ideally, we want to match the number of fully-loaded threads in our architecture with the number of cores. When threads start to fight for cores and CPU cycles, the cost of adding more threads outweighs the benefits. There would be no benefit, for example, in creating more I/O threads.
Reliable Pub-Sub (Clone Pattern) #
As a larger worked example, we’ll take the problem of making a reliable pub-sub architecture. We’ll develop this in stages. The goal is to allow a set of applications to share some common state. Here are our technical challenges:
- We have a large set of client applications, say thousands or tens of thousands.
- They will join and leave the network arbitrarily.
- These applications must share a single eventually-consistent state.
- Any application can update the state at any point in time.
Let’s say that updates are reasonably low-volume. We don’t have real time goals. The whole state can fit into memory. Some plausible use cases are:
- A configuration that is shared by a group of cloud servers.
- Some game state shared by a group of players.
- Exchange rate data that is updated in real time and available to applications.
Centralized Versus Decentralized #
A first decision we have to make is whether we work with a central server or not. It makes a big difference in the resulting design. The trade-offs are these:
-
Conceptually, a central server is simpler to understand because networks are not naturally symmetrical. With a central server, we avoid all questions of discovery, bind versus connect, and so on.
-
Generally, a fully-distributed architecture is technically more challenging but ends up with simpler protocols. That is, each node must act as server and client in the right way, which is delicate. When done right, the results are simpler than using a central server. We saw this in the Freelance pattern in Chapter 4 - Reliable Request-Reply Patterns.
-
A central server will become a bottleneck in high-volume use cases. If handling scale in the order of millions of messages a second is required, we should aim for decentralization right away.
-
Ironically, a centralized architecture will scale to more nodes more easily than a decentralized one. That is, it’s easier to connect 10,000 nodes to one server than to each other.
So, for the Clone pattern we’ll work with a server that publishes state updates and a set of clients that represent applications.
Representing State as Key-Value Pairs #
We’ll develop Clone in stages, solving one problem at a time. First, let’s look at how to update a shared state across a set of clients. We need to decide how to represent our state, as well as the updates. The simplest plausible format is a key-value store, where one key-value pair represents an atomic unit of change in the shared state.
We have a simple pub-sub example in Chapter 1 - Basics, the weather server and client. Let’s change the server to send key-value pairs, and the client to store these in a hash table. This lets us send updates from one server to a set of clients using the classic pub-sub model.
An update is either a new key-value pair, a modified value for an existing key, or a deleted key. We can assume for now that the whole store fits in memory and that applications access it by key, such as by using a hash table or dictionary. For larger stores and some kind of persistence we’d probably store the state in a database, but that’s not relevant here.
This is the server:
clonesrv1: Clone server, Model One in Ada
clonesrv1: Clone server, Model One in Basic
clonesrv1: Clone server, Model One in C
// Clone server Model One
#include "kvsimple.c"
int main (void)
{
// Prepare our context and publisher socket
zctx_t *ctx = zctx_new ();
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5556");
zclock_sleep (200);
zhash_t *kvmap = zhash_new ();
int64_t sequence = 0;
srandom ((unsigned) time (NULL));
while (!zctx_interrupted) {
// Distribute as key-value message
kvmsg_t *kvmsg = kvmsg_new (++sequence);
kvmsg_fmt_key (kvmsg, "%d", randof (10000));
kvmsg_fmt_body (kvmsg, "%d", randof (1000000));
kvmsg_send (kvmsg, publisher);
kvmsg_store (&kvmsg, kvmap);
}
printf (" Interrupted\n%d messages out\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonesrv1: Clone server, Model One in C++
#include <iostream>
#include <unordered_map>
#include "kvsimple.hpp"
using namespace std;
int main() {
// Prepare our context and publisher socket
zmq::context_t ctx(1);
zmq::socket_t publisher(ctx, ZMQ_PUB);
publisher.bind("tcp://*:5555");
s_sleep(5000); // Sleep for a short while to allow connections to be established
// Initialize key-value map and sequence
unordered_map<string,string> kvmap;
int64_t sequence = 0;
srand(time(NULL));
s_catch_signals();
while (!s_interrupted) {
// Distribute as key-value message
string key = to_string(within(10000));
string body = to_string(within(1000000));
kvmsg kv(key, sequence, (unsigned char *)body.c_str());
kv.send(publisher); // Send key-value message
// Store key-value pair in map
kvmap[key] = body;
sequence++;
// Sleep for a short while before sending the next message
s_sleep(1000);
}
cout << "Interrupted" << endl;
cout << sequence << " messages out" << endl;
return 0;
}
clonesrv1: Clone server, Model One in C#
clonesrv1: Clone server, Model One in CL
clonesrv1: Clone server, Model One in Delphi
clonesrv1: Clone server, Model One in Erlang
clonesrv1: Clone server, Model One in Elixir
clonesrv1: Clone server, Model One in F#
clonesrv1: Clone server, Model One in Felix
clonesrv1: Clone server, Model One in Go
clonesrv1: Clone server, Model One in Haskell
clonesrv1: Clone server, Model One in Haxe
clonesrv1: Clone server, Model One in Java
package guide;
import java.nio.ByteBuffer;
import java.util.Random;
import java.util.concurrent.atomic.AtomicLong;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
/**
*
* Clone server model 1
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonesrv1
{
private static AtomicLong sequence = new AtomicLong();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5556");
try {
Thread.sleep(200);
}
catch (InterruptedException e) {
e.printStackTrace();
}
Random random = new Random();
while (true) {
long currentSequenceNumber = sequence.incrementAndGet();
int key = random.nextInt(10000);
int body = random.nextInt(1000000);
ByteBuffer b = ByteBuffer.allocate(4);
b.asIntBuffer().put(body);
kvsimple kvMsg = new kvsimple(
key + "", currentSequenceNumber, b.array()
);
kvMsg.send(publisher);
System.out.println("sending " + kvMsg);
}
}
}
public static void main(String[] args)
{
new clonesrv1().run();
}
}
clonesrv1: Clone server, Model One in Julia
clonesrv1: Clone server, Model One in Lua
clonesrv1: Clone server, Model One in Node.js
clonesrv1: Clone server, Model One in Objective-C
clonesrv1: Clone server, Model One in ooc
clonesrv1: Clone server, Model One in Perl
clonesrv1: Clone server, Model One in PHP
clonesrv1: Clone server, Model One in Python
"""
Clone server Model One
"""
import random
import time
import zmq
from kvsimple import KVMsg
def main():
# Prepare our context and publisher socket
ctx = zmq.Context()
publisher = ctx.socket(zmq.PUB)
publisher.bind("tcp://*:5556")
time.sleep(0.2)
sequence = 0
random.seed(time.time())
kvmap = {}
try:
while True:
# Distribute as key-value message
sequence += 1
kvmsg = KVMsg(sequence)
kvmsg.key = "%d" % random.randint(1,10000)
kvmsg.body = "%d" % random.randint(1,1000000)
kvmsg.send(publisher)
kvmsg.store(kvmap)
except KeyboardInterrupt:
print " Interrupted\n%d messages out" % sequence
if __name__ == '__main__':
main()
clonesrv1: Clone server, Model One in Q
clonesrv1: Clone server, Model One in Racket
clonesrv1: Clone server, Model One in Ruby
clonesrv1: Clone server, Model One in Rust
clonesrv1: Clone server, Model One in Scala
clonesrv1: Clone server, Model One in Tcl
clonesrv1: Clone server, Model One in OCaml
And here is the client:
clonecli1: Clone client, Model One in Ada
clonecli1: Clone client, Model One in Basic
clonecli1: Clone client, Model One in C
// Clone client Model One
#include "kvsimple.c"
int main (void)
{
// Prepare our context and updates socket
zctx_t *ctx = zctx_new ();
void *updates = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (updates, "");
zsocket_connect (updates, "tcp://localhost:5556");
zhash_t *kvmap = zhash_new ();
int64_t sequence = 0;
while (true) {
kvmsg_t *kvmsg = kvmsg_recv (updates);
if (!kvmsg)
break; // Interrupted
kvmsg_store (&kvmsg, kvmap);
sequence++;
}
printf (" Interrupted\n%d messages in\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonecli1: Clone client, Model One in C++
#include <iostream>
#include <unordered_map>
#include "kvsimple.hpp"
using namespace std;
int main() {
// Prepare our context and updates socket
zmq::context_t ctx(1);
zmq::socket_t updates(ctx, ZMQ_SUB);
updates.set(zmq::sockopt::subscribe, ""); // Subscribe to all messages
updates.connect("tcp://localhost:5555");
// Initialize key-value map and sequence
unordered_map<string, string> kvmap;
int64_t sequence = 0;
while (true) {
// Receive key-value message
auto update_kv_msg = kvmsg::recv(updates);
if (!update_kv_msg) {
cout << "Interrupted" << endl;
return 0;
}
// Convert message to string and extract key-value pair
string key = update_kv_msg->key();
string value = (char *)update_kv_msg->body().c_str();
cout << key << " --- " << value << endl;
// Store key-value pair in map
kvmap[key] = value;
sequence++;
}
return 0;
}
clonecli1: Clone client, Model One in C#
clonecli1: Clone client, Model One in CL
clonecli1: Clone client, Model One in Delphi
clonecli1: Clone client, Model One in Erlang
clonecli1: Clone client, Model One in Elixir
clonecli1: Clone client, Model One in F#
clonecli1: Clone client, Model One in Felix
clonecli1: Clone client, Model One in Go
clonecli1: Clone client, Model One in Haskell
clonecli1: Clone client, Model One in Haxe
clonecli1: Clone client, Model One in Java
package guide;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.atomic.AtomicLong;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
/**
* Clone client model 1
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonecli1
{
private static Map<String, kvsimple> kvMap = new HashMap<String, kvsimple>();
private static AtomicLong sequence = new AtomicLong();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect("tcp://localhost:5556");
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
while (true) {
kvsimple kvMsg = kvsimple.recv(subscriber);
if (kvMsg == null)
break;
clonecli1.kvMap.put(kvMsg.getKey(), kvMsg);
System.out.println("receiving " + kvMsg);
sequence.incrementAndGet();
}
}
}
public static void main(String[] args)
{
new clonecli1().run();
}
}
clonecli1: Clone client, Model One in Julia
clonecli1: Clone client, Model One in Lua
clonecli1: Clone client, Model One in Node.js
clonecli1: Clone client, Model One in Objective-C
clonecli1: Clone client, Model One in ooc
clonecli1: Clone client, Model One in Perl
clonecli1: Clone client, Model One in PHP
clonecli1: Clone client, Model One in Python
"""
Clone Client Model One
Author: Min RK <benjaminrk@gmail.com>
"""
import random
import time
import zmq
from kvsimple import KVMsg
def main():
# Prepare our context and publisher socket
ctx = zmq.Context()
updates = ctx.socket(zmq.SUB)
updates.linger = 0
updates.setsockopt(zmq.SUBSCRIBE, '')
updates.connect("tcp://localhost:5556")
kvmap = {}
sequence = 0
while True:
try:
kvmsg = KVMsg.recv(updates)
except:
break # Interrupted
kvmsg.store(kvmap)
sequence += 1
print "Interrupted\n%d messages in" % sequence
if __name__ == '__main__':
main()
clonecli1: Clone client, Model One in Q
clonecli1: Clone client, Model One in Racket
clonecli1: Clone client, Model One in Ruby
clonecli1: Clone client, Model One in Rust
clonecli1: Clone client, Model One in Scala
clonecli1: Clone client, Model One in Tcl
clonecli1: Clone client, Model One in OCaml
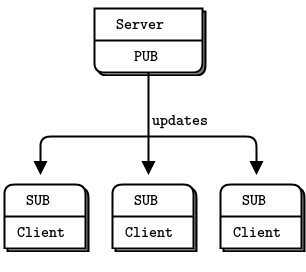
Here are some things to note about this first model:
-
All the hard work is done in a kvmsg class. This class works with key-value message objects, which are multipart ZeroMQ messages structured as three frames: a key (a ZeroMQ string), a sequence number (64-bit value, in network byte order), and a binary body (holds everything else).
-
The server generates messages with a randomized 4-digit key, which lets us simulate a large but not enormous hash table (10K entries).
-
We don’t implement deletions in this version: all messages are inserts or updates.
-
The server does a 200 millisecond pause after binding its socket. This is to prevent slow joiner syndrome, where the subscriber loses messages as it connects to the server’s socket. We’ll remove that in later versions of the Clone code.
-
We’ll use the terms publisher and subscriber in the code to refer to sockets. This will help later when we have multiple sockets doing different things.
Here is the kvmsg class, in the simplest form that works for now:
kvsimple: Key-value message class in Ada
kvsimple: Key-value message class in Basic
kvsimple: Key-value message class in C
// kvsimple class - key-value message class for example applications
#include "kvsimple.h"
#include "zlist.h"
// Keys are short strings
#define KVMSG_KEY_MAX 255
// Message is formatted on wire as 3 frames:
// frame 0: key (0MQ string)
// frame 1: sequence (8 bytes, network order)
// frame 2: body (blob)
#define FRAME_KEY 0
#define FRAME_SEQ 1
#define FRAME_BODY 2
#define KVMSG_FRAMES 3
// The kvmsg class holds a single key-value message consisting of a
// list of 0 or more frames:
struct _kvmsg {
// Presence indicators for each frame
int present [KVMSG_FRAMES];
// Corresponding 0MQ message frames, if any
zmq_msg_t frame [KVMSG_FRAMES];
// Key, copied into safe C string
char key [KVMSG_KEY_MAX + 1];
};
// .split constructor and destructor
// Here are the constructor and destructor for the class:
// Constructor, takes a sequence number for the new kvmsg instance:
kvmsg_t *
kvmsg_new (int64_t sequence)
{
kvmsg_t
*self;
self = (kvmsg_t *) zmalloc (sizeof (kvmsg_t));
kvmsg_set_sequence (self, sequence);
return self;
}
// zhash_free_fn callback helper that does the low level destruction:
void
kvmsg_free (void *ptr)
{
if (ptr) {
kvmsg_t *self = (kvmsg_t *) ptr;
// Destroy message frames if any
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++)
if (self->present [frame_nbr])
zmq_msg_close (&self->frame [frame_nbr]);
// Free object itself
free (self);
}
}
// Destructor
void
kvmsg_destroy (kvmsg_t **self_p)
{
assert (self_p);
if (*self_p) {
kvmsg_free (*self_p);
*self_p = NULL;
}
}
// .split recv method
// This method reads a key-value message from socket, and returns a new
// {{kvmsg}} instance:
kvmsg_t *
kvmsg_recv (void *socket)
{
assert (socket);
kvmsg_t *self = kvmsg_new (0);
// Read all frames off the wire, reject if bogus
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++) {
if (self->present [frame_nbr])
zmq_msg_close (&self->frame [frame_nbr]);
zmq_msg_init (&self->frame [frame_nbr]);
self->present [frame_nbr] = 1;
if (zmq_msg_recv (&self->frame [frame_nbr], socket, 0) == -1) {
kvmsg_destroy (&self);
break;
}
// Verify multipart framing
int rcvmore = (frame_nbr < KVMSG_FRAMES - 1)? 1: 0;
if (zsocket_rcvmore (socket) != rcvmore) {
kvmsg_destroy (&self);
break;
}
}
return self;
}
// .split send method
// This method sends a multiframe key-value message to a socket:
void
kvmsg_send (kvmsg_t *self, void *socket)
{
assert (self);
assert (socket);
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++) {
zmq_msg_t copy;
zmq_msg_init (©);
if (self->present [frame_nbr])
zmq_msg_copy (©, &self->frame [frame_nbr]);
zmq_msg_send (©, socket,
(frame_nbr < KVMSG_FRAMES - 1)? ZMQ_SNDMORE: 0);
zmq_msg_close (©);
}
}
// .split key methods
// These methods let the caller get and set the message key, as a
// fixed string and as a printf formatted string:
char *
kvmsg_key (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_KEY]) {
if (!*self->key) {
size_t size = zmq_msg_size (&self->frame [FRAME_KEY]);
if (size > KVMSG_KEY_MAX)
size = KVMSG_KEY_MAX;
memcpy (self->key,
zmq_msg_data (&self->frame [FRAME_KEY]), size);
self->key [size] = 0;
}
return self->key;
}
else
return NULL;
}
void
kvmsg_set_key (kvmsg_t *self, char *key)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_KEY];
if (self->present [FRAME_KEY])
zmq_msg_close (msg);
zmq_msg_init_size (msg, strlen (key));
memcpy (zmq_msg_data (msg), key, strlen (key));
self->present [FRAME_KEY] = 1;
}
void
kvmsg_fmt_key (kvmsg_t *self, char *format, ...)
{
char value [KVMSG_KEY_MAX + 1];
va_list args;
assert (self);
va_start (args, format);
vsnprintf (value, KVMSG_KEY_MAX, format, args);
va_end (args);
kvmsg_set_key (self, value);
}
// .split sequence methods
// These two methods let the caller get and set the message sequence number:
int64_t
kvmsg_sequence (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_SEQ]) {
assert (zmq_msg_size (&self->frame [FRAME_SEQ]) == 8);
byte *source = zmq_msg_data (&self->frame [FRAME_SEQ]);
int64_t sequence = ((int64_t) (source [0]) << 56)
+ ((int64_t) (source [1]) << 48)
+ ((int64_t) (source [2]) << 40)
+ ((int64_t) (source [3]) << 32)
+ ((int64_t) (source [4]) << 24)
+ ((int64_t) (source [5]) << 16)
+ ((int64_t) (source [6]) << 8)
+ (int64_t) (source [7]);
return sequence;
}
else
return 0;
}
void
kvmsg_set_sequence (kvmsg_t *self, int64_t sequence)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_SEQ];
if (self->present [FRAME_SEQ])
zmq_msg_close (msg);
zmq_msg_init_size (msg, 8);
byte *source = zmq_msg_data (msg);
source [0] = (byte) ((sequence >> 56) & 255);
source [1] = (byte) ((sequence >> 48) & 255);
source [2] = (byte) ((sequence >> 40) & 255);
source [3] = (byte) ((sequence >> 32) & 255);
source [4] = (byte) ((sequence >> 24) & 255);
source [5] = (byte) ((sequence >> 16) & 255);
source [6] = (byte) ((sequence >> 8) & 255);
source [7] = (byte) ((sequence) & 255);
self->present [FRAME_SEQ] = 1;
}
// .split message body methods
// These methods let the caller get and set the message body as a
// fixed string and as a printf formatted string:
byte *
kvmsg_body (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_BODY])
return (byte *) zmq_msg_data (&self->frame [FRAME_BODY]);
else
return NULL;
}
void
kvmsg_set_body (kvmsg_t *self, byte *body, size_t size)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_BODY];
if (self->present [FRAME_BODY])
zmq_msg_close (msg);
self->present [FRAME_BODY] = 1;
zmq_msg_init_size (msg, size);
memcpy (zmq_msg_data (msg), body, size);
}
void
kvmsg_fmt_body (kvmsg_t *self, char *format, ...)
{
char value [255 + 1];
va_list args;
assert (self);
va_start (args, format);
vsnprintf (value, 255, format, args);
va_end (args);
kvmsg_set_body (self, (byte *) value, strlen (value));
}
// .split size method
// This method returns the body size of the most recently read message,
// if any exists:
size_t
kvmsg_size (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_BODY])
return zmq_msg_size (&self->frame [FRAME_BODY]);
else
return 0;
}
// .split store method
// This method stores the key-value message into a hash map, unless
// the key and value are both null. It nullifies the {{kvmsg}} reference
// so that the object is owned by the hash map, not the caller:
void
kvmsg_store (kvmsg_t **self_p, zhash_t *hash)
{
assert (self_p);
if (*self_p) {
kvmsg_t *self = *self_p;
assert (self);
if (self->present [FRAME_KEY]
&& self->present [FRAME_BODY]) {
zhash_update (hash, kvmsg_key (self), self);
zhash_freefn (hash, kvmsg_key (self), kvmsg_free);
}
*self_p = NULL;
}
}
// .split dump method
// This method prints the key-value message to stderr for
// debugging and tracing:
void
kvmsg_dump (kvmsg_t *self)
{
if (self) {
if (!self) {
fprintf (stderr, "NULL");
return;
}
size_t size = kvmsg_size (self);
byte *body = kvmsg_body (self);
fprintf (stderr, "[seq:%" PRId64 "]", kvmsg_sequence (self));
fprintf (stderr, "[key:%s]", kvmsg_key (self));
fprintf (stderr, "[size:%zd] ", size);
int char_nbr;
for (char_nbr = 0; char_nbr < size; char_nbr++)
fprintf (stderr, "%02X", body [char_nbr]);
fprintf (stderr, "\n");
}
else
fprintf (stderr, "NULL message\n");
}
// .split test method
// It's good practice to have a self-test method that tests the class; this
// also shows how it's used in applications:
int
kvmsg_test (int verbose)
{
kvmsg_t
*kvmsg;
printf (" * kvmsg: ");
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *output = zsocket_new (ctx, ZMQ_DEALER);
int rc = zmq_bind (output, "ipc://kvmsg_selftest.ipc");
assert (rc == 0);
void *input = zsocket_new (ctx, ZMQ_DEALER);
rc = zmq_connect (input, "ipc://kvmsg_selftest.ipc");
assert (rc == 0);
zhash_t *kvmap = zhash_new ();
// Test send and receive of simple message
kvmsg = kvmsg_new (1);
kvmsg_set_key (kvmsg, "key");
kvmsg_set_body (kvmsg, (byte *) "body", 4);
if (verbose)
kvmsg_dump (kvmsg);
kvmsg_send (kvmsg, output);
kvmsg_store (&kvmsg, kvmap);
kvmsg = kvmsg_recv (input);
if (verbose)
kvmsg_dump (kvmsg);
assert (streq (kvmsg_key (kvmsg), "key"));
kvmsg_store (&kvmsg, kvmap);
// Shutdown and destroy all objects
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
printf ("OK\n");
return 0;
}
kvsimple: Key-value message class in C++
/* =====================================================================
* kvsimple - simple key-value message class for example applications
* ===================================================================== */
#ifndef __KVSIMPLE_HPP_INCLUDED__
#define __KVSIMPLE_HPP_INCLUDED__
#include "zhelpers.hpp"
#include "zmq.hpp"
#include <cstdint>
#include <iostream>
#include <optional>
#include <sstream>
#include <string>
#include <unordered_map>
using ustring = std::basic_string<unsigned char>;
struct kvmsg {
kvmsg(std::string key, int64_t sequence, ustring body);
kvmsg() = default;
// Reads key-value message from socket, returns new kvmsg instance.
static std::optional<kvmsg> recv(zmq::socket_t &socket);
// Send key-value message to socket; any empty frames are sent as such.
void send(zmq::socket_t &socket);
// Return key from last read message, if any, else NULL
std::string key() const;
// Return sequence nbr from last read message, if any
int64_t sequence() const;
// Return body from last read message, if any, else NULL
ustring body() const;
// Return body size from last read message, if any, else zero
size_t size() const;
// Set message key as provided
void set_key(std::string key);
// Set message sequence number
void set_sequence(int64_t sequence);
// Set message body
void set_body(ustring body);
// Dump message to stderr, for debugging and tracing
std::string to_string();
// Runs self test of class
static bool test(int verbose);
private:
static constexpr uint32_t kvmsg_key_max = 255;
static constexpr uint32_t frame_key = 0;
static constexpr uint32_t frame_seq = 1;
static constexpr uint32_t frame_body = 2;
static constexpr uint32_t kvmsg_frames = 3;
std::string key_;
ustring body_;
int64_t sequence_{};
};
namespace {
std::optional<zmq::message_t> receive_message(zmq::socket_t &socket) {
zmq::message_t message(0);
message.rebuild(0);
try {
if (!socket.recv(message, zmq::recv_flags::none)) {
return {};
}
} catch (zmq::error_t &error) {
std::cerr << "E: " << error.what() << std::endl;
return {};
}
return message;
}
} // namespace
kvmsg::kvmsg(std::string key, int64_t sequence, ustring body)
: key_(key), body_(body), sequence_(sequence) {}
// Reads key-value message from socket, returns new kvmsg instance.
std::optional<kvmsg> kvmsg::recv(zmq::socket_t &socket) {
auto key_message = receive_message(socket);
if (!key_message)
return {};
kvmsg msg;
msg.set_key(
std::string((char *)(*key_message).data(), (*key_message).size()));
auto sequence_message = receive_message(socket);
msg.set_sequence(*(int64_t *)(*sequence_message).data());
if (!sequence_message)
return {};
auto body_message = receive_message(socket);
if (!body_message)
return {};
msg.set_body(
ustring((unsigned char *)(*body_message).data(), (*body_message).size()));
return msg;
}
// Send key-value message to socket; any empty frames are sent as such.
void kvmsg::send(zmq::socket_t &socket) {
{
zmq::message_t message;
message.rebuild(key_.size());
std::memcpy(message.data(), key_.c_str(), key_.size());
socket.send(message, zmq::send_flags::sndmore);
}
{
zmq::message_t message;
message.rebuild(sizeof(sequence_));
std::memcpy(message.data(), (void *)&sequence_, sizeof(sequence_));
socket.send(message, zmq::send_flags::sndmore);
}
{
zmq::message_t message;
message.rebuild(body_.size());
std::memcpy(message.data(), body_.c_str(), body_.size());
socket.send(message, zmq::send_flags::none);
}
}
// Return key from last read message, if any, else NULL
std::string kvmsg::key() const { return key_; }
// Return sequence nbr from last read message, if any
int64_t kvmsg::sequence() const { return sequence_; }
// Return body from last read message, if any, else NULL
ustring kvmsg::body() const { return body_; }
// Return body size from last read message, if any, else zero
size_t kvmsg::size() const { return body_.size(); }
// Set message key as provided
void kvmsg::set_key(std::string key) { key_ = key; }
// Set message sequence number
void kvmsg::set_sequence(int64_t sequence) { sequence_ = sequence; }
// Set message body
void kvmsg::set_body(ustring body) { body_ = body; }
std::string kvmsg::to_string() {
std::stringstream ss;
ss << "key=" << key_ << ",sequence=" << sequence_ << ",body=";
s_dump_message(ss, body_);
return ss.str();
}
// Dump message to stderr, for debugging and tracing
// Runs self test of class
bool kvmsg::test(int verbose) {
zmq::context_t context;
zmq::socket_t output(context, ZMQ_DEALER);
output.bind("ipc://kvmsg_selftest.ipc");
zmq::socket_t input(context, ZMQ_DEALER);
input.connect("ipc://kvmsg_selftest.ipc");
kvmsg message("key", 1, (unsigned char *)"body");
if (verbose) {
std::cout << message.to_string()<<std::endl;
}
message.send(output);
std::unordered_map<std::string, kvmsg> kvmap;
kvmap["key"] = message;
auto input_message_opt = kvmsg::recv(input);
if (!input_message_opt)
return false;
assert((*input_message_opt).key() == "key");
assert((*input_message_opt).sequence() == 1);
assert((*input_message_opt).body() == (unsigned char *)"body");
if (verbose) {
std::cout << (*input_message_opt).to_string()<<std::endl;
}
return true;
}
// Main routine for running the basic test
//int main() {
// std::cout << (kvmsg::test(1) ? "SUCCESS" : "FAILURE") << std::endl;
// return 0;
//}
#endif // Included
kvsimple: Key-value message class in C#
kvsimple: Key-value message class in CL
kvsimple: Key-value message class in Delphi
kvsimple: Key-value message class in Erlang
kvsimple: Key-value message class in Elixir
kvsimple: Key-value message class in F#
kvsimple: Key-value message class in Felix
kvsimple: Key-value message class in Go
kvsimple: Key-value message class in Haskell
kvsimple: Key-value message class in Haxe
kvsimple: Key-value message class in Java
package guide;
import java.nio.ByteBuffer;
import java.util.Arrays;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
/**
*
* A simple getKey value message class
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class kvsimple
{
private final String key;
private long sequence;
private final byte[] body;
public kvsimple(String key, long sequence, byte[] body)
{
this.key = key;
this.sequence = sequence;
this.body = body; // clone if needed
}
public String getKey()
{
return key;
}
public long getSequence()
{
return sequence;
}
public void setSequence(long sequence)
{
this.sequence = sequence;
}
public byte[] getBody()
{
return body;
}
public void send(Socket publisher)
{
publisher.send(key.getBytes(ZMQ.CHARSET), ZMQ.SNDMORE);
ByteBuffer bb = ByteBuffer.allocate(8);
bb.asLongBuffer().put(sequence);
publisher.send(bb.array(), ZMQ.SNDMORE);
publisher.send(body, 0);
}
public static kvsimple recv(Socket updates)
{
byte[] data = updates.recv(0);
if (data == null || !updates.hasReceiveMore())
return null;
String key = new String(data, ZMQ.CHARSET);
data = updates.recv(0);
if (data == null || !updates.hasReceiveMore())
return null;
Long sequence = ByteBuffer.wrap(data).getLong();
byte[] body = updates.recv(0);
if (body == null || updates.hasReceiveMore())
return null;
return new kvsimple(key, sequence, body);
}
@Override
public String toString()
{
return "kvsimple [getKey=" + key + ", getSequence=" + sequence + ", body=" + Arrays.toString(body) + "]";
}
@Override
public int hashCode()
{
final int prime = 31;
int result = 1;
result = prime * result + Arrays.hashCode(body);
result = prime * result + ((key == null) ? 0 : key.hashCode());
result = prime * result + (int) (sequence ^ (sequence >>> 32));
return result;
}
@Override
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
kvsimple other = (kvsimple) obj;
if (!Arrays.equals(body, other.body))
return false;
if (key == null) {
if (other.key != null)
return false;
}
else if (!key.equals(other.key))
return false;
if (sequence != other.sequence)
return false;
return true;
}
}
kvsimple: Key-value message class in Julia
kvsimple: Key-value message class in Lua
kvsimple: Key-value message class in Node.js
kvsimple: Key-value message class in Objective-C
kvsimple: Key-value message class in ooc
kvsimple: Key-value message class in Perl
kvsimple: Key-value message class in PHP
kvsimple: Key-value message class in Python
"""
=====================================================================
kvsimple - simple key-value message class for example applications
Author: Min RK <benjaminrk@gmail.com>
"""
import struct # for packing integers
import sys
import zmq
class KVMsg(object):
"""
Message is formatted on wire as 3 frames:
frame 0: key (0MQ string)
frame 1: sequence (8 bytes, network order)
frame 2: body (blob)
"""
key = None # key (string)
sequence = 0 # int
body = None # blob
def __init__(self, sequence, key=None, body=None):
assert isinstance(sequence, int)
self.sequence = sequence
self.key = key
self.body = body
def store(self, dikt):
"""Store me in a dict if I have anything to store"""
# this seems weird to check, but it's what the C example does
if self.key is not None and self.body is not None:
dikt[self.key] = self
def send(self, socket):
"""Send key-value message to socket; any empty frames are sent as such."""
key = '' if self.key is None else self.key
seq_s = struct.pack('!l', self.sequence)
body = '' if self.body is None else self.body
socket.send_multipart([ key, seq_s, body ])
@classmethod
def recv(cls, socket):
"""Reads key-value message from socket, returns new kvmsg instance."""
key, seq_s, body = socket.recv_multipart()
key = key if key else None
seq = struct.unpack('!l',seq_s)[0]
body = body if body else None
return cls(seq, key=key, body=body)
def dump(self):
if self.body is None:
size = 0
data='NULL'
else:
size = len(self.body)
data=repr(self.body)
print >> sys.stderr, "[seq:{seq}][key:{key}][size:{size}] {data}".format(
seq=self.sequence,
key=self.key,
size=size,
data=data,
)
# ---------------------------------------------------------------------
# Runs self test of class
def test_kvmsg (verbose):
print " * kvmsg: ",
# Prepare our context and sockets
ctx = zmq.Context()
output = ctx.socket(zmq.DEALER)
output.bind("ipc://kvmsg_selftest.ipc")
input = ctx.socket(zmq.DEALER)
input.connect("ipc://kvmsg_selftest.ipc")
kvmap = {}
# Test send and receive of simple message
kvmsg = KVMsg(1)
kvmsg.key = "key"
kvmsg.body = "body"
if verbose:
kvmsg.dump()
kvmsg.send(output)
kvmsg.store(kvmap)
kvmsg2 = KVMsg.recv(input)
if verbose:
kvmsg2.dump()
assert kvmsg2.key == "key"
kvmsg2.store(kvmap)
assert len(kvmap) == 1 # shouldn't be different
print "OK"
if __name__ == '__main__':
test_kvmsg('-v' in sys.argv)
kvsimple: Key-value message class in Q
kvsimple: Key-value message class in Racket
kvsimple: Key-value message class in Ruby
kvsimple: Key-value message class in Rust
kvsimple: Key-value message class in Scala
kvsimple: Key-value message class in Tcl
kvsimple: Key-value message class in OCaml
Later, we’ll make a more sophisticated kvmsg class that will work in real applications.
Both the server and client maintain hash tables, but this first model only works properly if we start all clients before the server and the clients never crash. That’s very artificial.
Getting an Out-of-Band Snapshot #
So now we have our second problem: how to deal with late-joining clients or clients that crash and then restart.
In order to allow a late (or recovering) client to catch up with a server, it has to get a snapshot of the server’s state. Just as we’ve reduced “message” to mean “a sequenced key-value pair”, we can reduce “state” to mean “a hash table”. To get the server state, a client opens a DEALER socket and asks for it explicitly.
To make this work, we have to solve a problem of timing. Getting a state snapshot will take a certain time, possibly fairly long if the snapshot is large. We need to correctly apply updates to the snapshot. But the server won’t know when to start sending us updates. One way would be to start subscribing, get a first update, and then ask for “state for update N”. This would require the server storing one snapshot for each update, which isn’t practical.
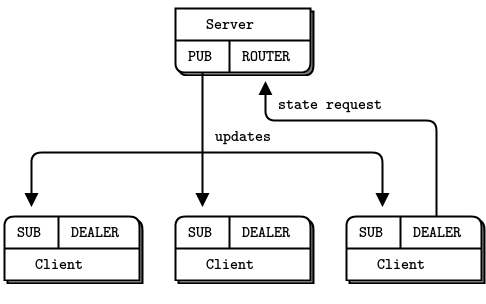
So we will do the synchronization in the client, as follows:
-
The client first subscribes to updates and then makes a state request. This guarantees that the state is going to be newer than the oldest update it has.
-
The client waits for the server to reply with state, and meanwhile queues all updates. It does this simply by not reading them: ZeroMQ keeps them queued on the socket queue.
-
When the client receives its state update, it begins once again to read updates. However, it discards any updates that are older than the state update. So if the state update includes updates up to 200, the client will discard updates up to 201.
-
The client then applies updates to its own state snapshot.
It’s a simple model that exploits ZeroMQ’s own internal queues. Here’s the server:
clonesrv2: Clone server, Model Two in Ada
clonesrv2: Clone server, Model Two in Basic
clonesrv2: Clone server, Model Two in C
// Clone server - Model Two
// Lets us build this source without creating a library
#include "kvsimple.c"
static int s_send_single (const char *key, void *data, void *args);
static void state_manager (void *args, zctx_t *ctx, void *pipe);
int main (void)
{
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5557");
int64_t sequence = 0;
srandom ((unsigned) time (NULL));
// Start state manager and wait for synchronization signal
void *updates = zthread_fork (ctx, state_manager, NULL);
free (zstr_recv (updates));
while (!zctx_interrupted) {
// Distribute as key-value message
kvmsg_t *kvmsg = kvmsg_new (++sequence);
kvmsg_fmt_key (kvmsg, "%d", randof (10000));
kvmsg_fmt_body (kvmsg, "%d", randof (1000000));
kvmsg_send (kvmsg, publisher);
kvmsg_send (kvmsg, updates);
kvmsg_destroy (&kvmsg);
}
printf (" Interrupted\n%d messages out\n", (int) sequence);
zctx_destroy (&ctx);
return 0;
}
// Routing information for a key-value snapshot
typedef struct {
void *socket; // ROUTER socket to send to
zframe_t *identity; // Identity of peer who requested state
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int
s_send_single (const char *key, void *data, void *args)
{
kvroute_t *kvroute = (kvroute_t *) args;
// Send identity of recipient first
zframe_send (&kvroute->identity,
kvroute->socket, ZFRAME_MORE + ZFRAME_REUSE);
kvmsg_t *kvmsg = (kvmsg_t *) data;
kvmsg_send (kvmsg, kvroute->socket);
return 0;
}
// .split state manager
// The state manager task maintains the state and handles requests from
// clients for snapshots:
static void
state_manager (void *args, zctx_t *ctx, void *pipe)
{
zhash_t *kvmap = zhash_new ();
zstr_send (pipe, "READY");
void *snapshot = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (snapshot, "tcp://*:5556");
zmq_pollitem_t items [] = {
{ pipe, 0, ZMQ_POLLIN, 0 },
{ snapshot, 0, ZMQ_POLLIN, 0 }
};
int64_t sequence = 0; // Current snapshot version number
while (!zctx_interrupted) {
int rc = zmq_poll (items, 2, -1);
if (rc == -1 && errno == ETERM)
break; // Context has been shut down
// Apply state update from main thread
if (items [0].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (pipe);
if (!kvmsg)
break; // Interrupted
sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, kvmap);
}
// Execute state snapshot request
if (items [1].revents & ZMQ_POLLIN) {
zframe_t *identity = zframe_recv (snapshot);
if (!identity)
break; // Interrupted
// Request is in second frame of message
char *request = zstr_recv (snapshot);
if (streq (request, "ICANHAZ?"))
free (request);
else {
printf ("E: bad request, aborting\n");
break;
}
// Send state snapshot to client
kvroute_t routing = { snapshot, identity };
// For each entry in kvmap, send kvmsg to client
zhash_foreach (kvmap, s_send_single, &routing);
// Now send END message with sequence number
printf ("Sending state shapshot=%d\n", (int) sequence);
zframe_send (&identity, snapshot, ZFRAME_MORE);
kvmsg_t *kvmsg = kvmsg_new (sequence);
kvmsg_set_key (kvmsg, "KTHXBAI");
kvmsg_set_body (kvmsg, (byte *) "", 0);
kvmsg_send (kvmsg, snapshot);
kvmsg_destroy (&kvmsg);
}
}
zhash_destroy (&kvmap);
}
clonesrv2: Clone server, Model Two in C++
#include "kvsimple.hpp"
#include <thread>
static int s_send_snapshot(std::unordered_map<std::string, kvmsg>& kvmap, zmq::socket_t* snapshot);
static void state_manager(zmq::context_t* ctx);
// simulate zthread_fork, create attached thread and return the pipe socket
std::pair<std::thread, zmq::socket_t> zthread_fork(zmq::context_t& ctx, void (*thread_func)(zmq::context_t*)) {
// create the pipe socket for the main thread to communicate with its child thread
zmq::socket_t pipe(ctx, ZMQ_PAIR);
pipe.connect("inproc://state_manager");
// start child thread
std::thread t(thread_func, &ctx);
return std::make_pair(std::move(t), std::move(pipe));
}
int main(void) {
// Prepare our context and socket
zmq::context_t ctx(1);
zmq::socket_t publisher(ctx, ZMQ_PUB);
publisher.bind("tcp://*:5557");
int64_t sequence = 0;
// Start state manager and wait for synchronization signal
auto [state_manager_thread, state_manager_pipe] = zthread_fork(ctx, state_manager);
zmq::message_t sync_msg;
state_manager_pipe.recv(sync_msg);
s_catch_signals();
while(!s_interrupted) {
kvmsg msg = kvmsg("key", ++sequence, (unsigned char *)"value");
msg.set_key(std::to_string(within(10000)));
msg.set_body((unsigned char *)std::to_string(within(1000000)).c_str());
msg.send(publisher);
msg.send(state_manager_pipe);
s_sleep(500);
}
std::cout << " Interrupted\n" << sequence << " messages out\n" << std::endl;
kvmsg msg("END", sequence, (unsigned char *)"");
msg.send(state_manager_pipe);
state_manager_thread.join();
return 0;
}
// Routing information for a key-value snapshot
typedef struct {
zmq::socket_t *socket; // ROUTER socket to send to
std::string identity; // Identity of peer who requested state
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int s_send_snapshot(std::unordered_map<std::string, kvmsg>& kvmap, kvroute_t& kvroute) {
for (auto& kv : kvmap) {
s_sendmore(*kvroute.socket, kvroute.identity);
kv.second.send(*kvroute.socket);
}
return 0;
}
// .split state manager
// The state manager task maintains the state and handles requests from
// clients for snapshots:
static void state_manager(zmq::context_t *ctx) {
std::unordered_map<std::string, kvmsg> kvmap;
zmq::socket_t pipe(*ctx, ZMQ_PAIR);
pipe.bind("inproc://state_manager");
s_send(pipe, std::string("READY"));
zmq::socket_t snapshot(*ctx, ZMQ_ROUTER);
snapshot.bind("tcp://*:5556");
zmq::pollitem_t items[] = {
{pipe, 0, ZMQ_POLLIN, 0},
{snapshot, 0, ZMQ_POLLIN, 0}
};
int64_t sequence = 0;
while(true) {
zmq::poll(&items[0], 2, -1);
if (items[0].revents & ZMQ_POLLIN) {
auto msg = kvmsg::recv(pipe);
if (!msg || msg->key() == "END") {
break;
}
sequence = msg->sequence();
kvmap[msg->key()] = *msg;
}
// Execute state snapshot request
if (items[1].revents & ZMQ_POLLIN) {
std::string identity = s_recv(snapshot);
std::string request = s_recv(snapshot);
if (request != "ICANHAZ?") {
std::cerr << "E: bad request, aborting\n";
break;
}
// Send state snapshot to client
kvroute_t kvroute = {&snapshot, identity};
// For each entry in kvmap, send kvmsg to client
s_send_snapshot(kvmap, kvroute);
// Now send END message with sequence number
std::cout << "sending state snapshot=" << sequence << std::endl;
s_sendmore(snapshot, identity);
kvmsg msg("KTHXBAI", sequence, (unsigned char *)"");
msg.send(snapshot);
}
}
}
clonesrv2: Clone server, Model Two in C#
clonesrv2: Clone server, Model Two in CL
clonesrv2: Clone server, Model Two in Delphi
clonesrv2: Clone server, Model Two in Erlang
clonesrv2: Clone server, Model Two in Elixir
clonesrv2: Clone server, Model Two in F#
clonesrv2: Clone server, Model Two in Felix
clonesrv2: Clone server, Model Two in Go
clonesrv2: Clone server, Model Two in Haskell
clonesrv2: Clone server, Model Two in Haxe
clonesrv2: Clone server, Model Two in Java
package guide;
import java.nio.ByteBuffer;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZThread;
import org.zeromq.ZThread.IAttachedRunnable;
/**
* Clone server Model Two
*
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonesrv2
{
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5557");
Socket updates = ZThread.fork(ctx, new StateManager());
Random random = new Random();
long sequence = 0;
while (!Thread.currentThread().isInterrupted()) {
long currentSequenceNumber = ++sequence;
int key = random.nextInt(10000);
int body = random.nextInt(1000000);
ByteBuffer b = ByteBuffer.allocate(4);
b.asIntBuffer().put(body);
kvsimple kvMsg = new kvsimple(
key + "", currentSequenceNumber, b.array()
);
kvMsg.send(publisher);
kvMsg.send(updates); // send a message to State Manager thread.
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
}
}
System.out.printf(" Interrupted\n%d messages out\n", sequence);
}
}
public static class StateManager implements IAttachedRunnable
{
private static Map<String, kvsimple> kvMap = new LinkedHashMap<String, kvsimple>();
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
pipe.send("READY"); // optional
Socket snapshot = ctx.createSocket(SocketType.ROUTER);
snapshot.bind("tcp://*:5556");
Poller poller = ctx.createPoller(2);
poller.register(pipe, ZMQ.Poller.POLLIN);
poller.register(snapshot, ZMQ.Poller.POLLIN);
long stateSequence = 0;
while (!Thread.currentThread().isInterrupted()) {
if (poller.poll() < 0)
break; // Context has been shut down
// apply state updates from main thread
if (poller.pollin(0)) {
kvsimple kvMsg = kvsimple.recv(pipe);
if (kvMsg == null)
break;
StateManager.kvMap.put(kvMsg.getKey(), kvMsg);
stateSequence = kvMsg.getSequence();
}
// execute state snapshot request
if (poller.pollin(1)) {
byte[] identity = snapshot.recv(0);
if (identity == null)
break;
String request = new String(snapshot.recv(0), ZMQ.CHARSET);
if (!request.equals("ICANHAZ?")) {
System.out.println("E: bad request, aborting");
break;
}
Iterator<Entry<String, kvsimple>> iter = kvMap.entrySet().iterator();
while (iter.hasNext()) {
Entry<String, kvsimple> entry = iter.next();
kvsimple msg = entry.getValue();
System.out.println("Sending message " + entry.getValue().getSequence());
this.sendMessage(msg, identity, snapshot);
}
// now send end message with getSequence number
System.out.println("Sending state snapshot = " + stateSequence);
snapshot.send(identity, ZMQ.SNDMORE);
kvsimple message = new kvsimple("KTHXBAI", stateSequence, ZMQ.MESSAGE_SEPARATOR);
message.send(snapshot);
}
}
}
private void sendMessage(kvsimple msg, byte[] identity, Socket snapshot)
{
snapshot.send(identity, ZMQ.SNDMORE);
msg.send(snapshot);
}
}
public static void main(String[] args)
{
new clonesrv2().run();
}
}
clonesrv2: Clone server, Model Two in Julia
clonesrv2: Clone server, Model Two in Lua
clonesrv2: Clone server, Model Two in Node.js
clonesrv2: Clone server, Model Two in Objective-C
clonesrv2: Clone server, Model Two in ooc
clonesrv2: Clone server, Model Two in Perl
clonesrv2: Clone server, Model Two in PHP
clonesrv2: Clone server, Model Two in Python
"""
Clone server Model Two
Author: Min RK <benjaminrk@gmail.com>
"""
import random
import threading
import time
import zmq
from kvsimple import KVMsg
from zhelpers import zpipe
def main():
# Prepare our context and publisher socket
ctx = zmq.Context()
publisher = ctx.socket(zmq.PUB)
publisher.bind("tcp://*:5557")
updates, peer = zpipe(ctx)
manager_thread = threading.Thread(target=state_manager, args=(ctx,peer))
manager_thread.daemon=True
manager_thread.start()
sequence = 0
random.seed(time.time())
try:
while True:
# Distribute as key-value message
sequence += 1
kvmsg = KVMsg(sequence)
kvmsg.key = "%d" % random.randint(1,10000)
kvmsg.body = "%d" % random.randint(1,1000000)
kvmsg.send(publisher)
kvmsg.send(updates)
except KeyboardInterrupt:
print " Interrupted\n%d messages out" % sequence
# simple struct for routing information for a key-value snapshot
class Route:
def __init__(self, socket, identity):
self.socket = socket # ROUTER socket to send to
self.identity = identity # Identity of peer who requested state
def send_single(key, kvmsg, route):
"""Send one state snapshot key-value pair to a socket
Hash item data is our kvmsg object, ready to send
"""
# Send identity of recipient first
route.socket.send(route.identity, zmq.SNDMORE)
kvmsg.send(route.socket)
def state_manager(ctx, pipe):
"""This thread maintains the state and handles requests from clients for snapshots.
"""
kvmap = {}
pipe.send("READY")
snapshot = ctx.socket(zmq.ROUTER)
snapshot.bind("tcp://*:5556")
poller = zmq.Poller()
poller.register(pipe, zmq.POLLIN)
poller.register(snapshot, zmq.POLLIN)
sequence = 0 # Current snapshot version number
while True:
try:
items = dict(poller.poll())
except (zmq.ZMQError, KeyboardInterrupt):
break # interrupt/context shutdown
# Apply state update from main thread
if pipe in items:
kvmsg = KVMsg.recv(pipe)
sequence = kvmsg.sequence
kvmsg.store(kvmap)
# Execute state snapshot request
if snapshot in items:
msg = snapshot.recv_multipart()
identity = msg[0]
request = msg[1]
if request == "ICANHAZ?":
pass
else:
print "E: bad request, aborting\n",
break
# Send state snapshot to client
route = Route(snapshot, identity)
# For each entry in kvmap, send kvmsg to client
for k,v in kvmap.items():
send_single(k,v,route)
# Now send END message with sequence number
print "Sending state shapshot=%d\n" % sequence,
snapshot.send(identity, zmq.SNDMORE)
kvmsg = KVMsg(sequence)
kvmsg.key = "KTHXBAI"
kvmsg.body = ""
kvmsg.send(snapshot)
if __name__ == '__main__':
main()
clonesrv2: Clone server, Model Two in Q
clonesrv2: Clone server, Model Two in Racket
clonesrv2: Clone server, Model Two in Ruby
clonesrv2: Clone server, Model Two in Rust
clonesrv2: Clone server, Model Two in Scala
clonesrv2: Clone server, Model Two in Tcl
clonesrv2: Clone server, Model Two in OCaml
And here is the client:
clonecli2: Clone client, Model Two in Ada
clonecli2: Clone client, Model Two in Basic
clonecli2: Clone client, Model Two in C
// Clone client - Model Two
// Lets us build this source without creating a library
#include "kvsimple.c"
int main (void)
{
// Prepare our context and subscriber
zctx_t *ctx = zctx_new ();
void *snapshot = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (snapshot, "tcp://localhost:5556");
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (subscriber, "");
zsocket_connect (subscriber, "tcp://localhost:5557");
zhash_t *kvmap = zhash_new ();
// Get state snapshot
int64_t sequence = 0;
zstr_send (snapshot, "ICANHAZ?");
while (true) {
kvmsg_t *kvmsg = kvmsg_recv (snapshot);
if (!kvmsg)
break; // Interrupted
if (streq (kvmsg_key (kvmsg), "KTHXBAI")) {
sequence = kvmsg_sequence (kvmsg);
printf ("Received snapshot=%d\n", (int) sequence);
kvmsg_destroy (&kvmsg);
break; // Done
}
kvmsg_store (&kvmsg, kvmap);
}
// Now apply pending updates, discard out-of-sequence messages
while (!zctx_interrupted) {
kvmsg_t *kvmsg = kvmsg_recv (subscriber);
if (!kvmsg)
break; // Interrupted
if (kvmsg_sequence (kvmsg) > sequence) {
sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, kvmap);
}
else
kvmsg_destroy (&kvmsg);
}
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonecli2: Clone client, Model Two in C++
#include "kvsimple.hpp"
int main(void) {
zmq::context_t ctx(1);
zmq::socket_t snapshot(ctx, ZMQ_DEALER);
snapshot.connect("tcp://localhost:5556");
zmq::socket_t subscriber(ctx, ZMQ_SUB);
subscriber.set(zmq::sockopt::subscribe, "");
subscriber.connect("tcp://localhost:5557");
std::unordered_map<std::string, kvmsg> kvmap;
// Get state snapshot
int64_t sequence = 0;
s_send(snapshot, std::string("ICANHAZ?"));
while (true) {
auto kv = kvmsg::recv(snapshot);
if (!kv) break;
if (kv->key() == "KTHXBAI") {
sequence = kv->sequence();
std::cout << "Received snapshot=" << sequence << std::endl;
break;
}
kvmap[kv->key()] = *kv;
}
// Now apply pending updates, discard out-of-sequence messages
while(true) {
auto kv = kvmsg::recv(subscriber);
if (!kv) break;
if (kv->sequence() > sequence) {
sequence = kv->sequence();
kvmap[kv->key()] = *kv;
std::cout << "Received update=" << sequence << std::endl;
}
}
return 0;
}
clonecli2: Clone client, Model Two in C#
clonecli2: Clone client, Model Two in CL
clonecli2: Clone client, Model Two in Delphi
clonecli2: Clone client, Model Two in Erlang
clonecli2: Clone client, Model Two in Elixir
clonecli2: Clone client, Model Two in F#
clonecli2: Clone client, Model Two in Felix
clonecli2: Clone client, Model Two in Go
clonecli2: Clone client, Model Two in Haskell
clonecli2: Clone client, Model Two in Haxe
clonecli2: Clone client, Model Two in Java
package guide;
import java.util.HashMap;
import java.util.Map;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
/**
* Clone client Model Two
*
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonecli2
{
private static Map<String, kvsimple> kvMap = new HashMap<String, kvsimple>();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket snapshot = ctx.createSocket(SocketType.DEALER);
snapshot.connect("tcp://localhost:5556");
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect("tcp://localhost:5557");
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
// get state snapshot
snapshot.send("ICANHAZ?".getBytes(ZMQ.CHARSET), 0);
long sequence = 0;
while (true) {
kvsimple kvMsg = kvsimple.recv(snapshot);
if (kvMsg == null)
break;
sequence = kvMsg.getSequence();
if ("KTHXBAI".equalsIgnoreCase(kvMsg.getKey())) {
System.out.println("Received snapshot = " + kvMsg.getSequence());
break; // done
}
System.out.println("receiving " + kvMsg.getSequence());
clonecli2.kvMap.put(kvMsg.getKey(), kvMsg);
}
// now apply pending updates, discard out-of-getSequence messages
while (true) {
kvsimple kvMsg = kvsimple.recv(subscriber);
if (kvMsg == null)
break;
if (kvMsg.getSequence() > sequence) {
sequence = kvMsg.getSequence();
System.out.println("receiving " + sequence);
clonecli2.kvMap.put(kvMsg.getKey(), kvMsg);
}
}
}
}
public static void main(String[] args)
{
new clonecli2().run();
}
}
clonecli2: Clone client, Model Two in Julia
clonecli2: Clone client, Model Two in Lua
clonecli2: Clone client, Model Two in Node.js
clonecli2: Clone client, Model Two in Objective-C
clonecli2: Clone client, Model Two in ooc
clonecli2: Clone client, Model Two in Perl
clonecli2: Clone client, Model Two in PHP
clonecli2: Clone client, Model Two in Python
"""
Clone client Model Two
Author: Min RK <benjaminrk@gmail.com>
"""
import time
import zmq
from kvsimple import KVMsg
def main():
# Prepare our context and subscriber
ctx = zmq.Context()
snapshot = ctx.socket(zmq.DEALER)
snapshot.linger = 0
snapshot.connect("tcp://localhost:5556")
subscriber = ctx.socket(zmq.SUB)
subscriber.linger = 0
subscriber.setsockopt(zmq.SUBSCRIBE, '')
subscriber.connect("tcp://localhost:5557")
kvmap = {}
# Get state snapshot
sequence = 0
snapshot.send("ICANHAZ?")
while True:
try:
kvmsg = KVMsg.recv(snapshot)
except:
break; # Interrupted
if kvmsg.key == "KTHXBAI":
sequence = kvmsg.sequence
print "Received snapshot=%d" % sequence
break # Done
kvmsg.store(kvmap)
# Now apply pending updates, discard out-of-sequence messages
while True:
try:
kvmsg = KVMsg.recv(subscriber)
except:
break # Interrupted
if kvmsg.sequence > sequence:
sequence = kvmsg.sequence
kvmsg.store(kvmap)
if __name__ == '__main__':
main()
clonecli2: Clone client, Model Two in Q
clonecli2: Clone client, Model Two in Racket
clonecli2: Clone client, Model Two in Ruby
clonecli2: Clone client, Model Two in Rust
clonecli2: Clone client, Model Two in Scala
clonecli2: Clone client, Model Two in Tcl
clonecli2: Clone client, Model Two in OCaml
Here are some things to note about these two programs:
-
The server uses two tasks. One thread produces the updates (randomly) and sends these to the main PUB socket, while the other thread handles state requests on the ROUTER socket. The two communicate across PAIR sockets over an inproc:@<//>@ connection.
-
The client is really simple. In C, it consists of about fifty lines of code. A lot of the heavy lifting is done in the kvmsg class. Even so, the basic Clone pattern is easier to implement than it seemed at first.
-
We don’t use anything fancy for serializing the state. The hash table holds a set of kvmsg objects, and the server sends these, as a batch of messages, to the client requesting state. If multiple clients request state at once, each will get a different snapshot.
-
We assume that the client has exactly one server to talk to. The server must be running; we do not try to solve the question of what happens if the server crashes.
Right now, these two programs don’t do anything real, but they correctly synchronize state. It’s a neat example of how to mix different patterns: PAIR-PAIR, PUB-SUB, and ROUTER-DEALER.
Republishing Updates from Clients #
In our second model, changes to the key-value store came from the server itself. This is a centralized model that is useful, for example if we have a central configuration file we want to distribute, with local caching on each node. A more interesting model takes updates from clients, not the server. The server thus becomes a stateless broker. This gives us some benefits:
-
We’re less worried about the reliability of the server. If it crashes, we can start a new instance and feed it new values.
-
We can use the key-value store to share knowledge between active peers.
To send updates from clients back to the server, we could use a variety of socket patterns. The simplest plausible solution is a PUSH-PULL combination.
Why don’t we allow clients to publish updates directly to each other? While this would reduce latency, it would remove the guarantee of consistency. You can’t get consistent shared state if you allow the order of updates to change depending on who receives them. Say we have two clients, changing different keys. This will work fine. But if the two clients try to change the same key at roughly the same time, they’ll end up with different notions of its value.
There are a few strategies for obtaining consistency when changes happen in multiple places at once. We’ll use the approach of centralizing all change. No matter the precise timing of the changes that clients make, they are all pushed through the server, which enforces a single sequence according to the order in which it gets updates.
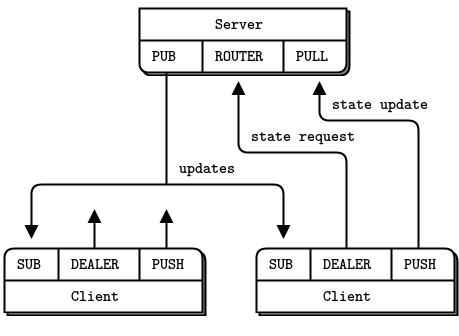
By mediating all changes, the server can also add a unique sequence number to all updates. With unique sequencing, clients can detect the nastier failures, including network congestion and queue overflow. If a client discovers that its incoming message stream has a hole, it can take action. It seems sensible that the client contact the server and ask for the missing messages, but in practice that isn’t useful. If there are holes, they’re caused by network stress, and adding more stress to the network will make things worse. All the client can do is warn its users that it is “unable to continue”, stop, and not restart until someone has manually checked the cause of the problem.
We’ll now generate state updates in the client. Here’s the server:
clonesrv3: Clone server, Model Three in Ada
clonesrv3: Clone server, Model Three in Basic
clonesrv3: Clone server, Model Three in C
// Clone server - Model Three
// Lets us build this source without creating a library
#include "kvsimple.c"
// Routing information for a key-value snapshot
typedef struct {
void *socket; // ROUTER socket to send to
zframe_t *identity; // Identity of peer who requested state
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int
s_send_single (const char *key, void *data, void *args)
{
kvroute_t *kvroute = (kvroute_t *) args;
// Send identity of recipient first
zframe_send (&kvroute->identity,
kvroute->socket, ZFRAME_MORE + ZFRAME_REUSE);
kvmsg_t *kvmsg = (kvmsg_t *) data;
kvmsg_send (kvmsg, kvroute->socket);
return 0;
}
int main (void)
{
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *snapshot = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (snapshot, "tcp://*:5556");
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5557");
void *collector = zsocket_new (ctx, ZMQ_PULL);
zsocket_bind (collector, "tcp://*:5558");
// .split body of main task
// The body of the main task collects updates from clients and
// publishes them back out to clients:
int64_t sequence = 0;
zhash_t *kvmap = zhash_new ();
zmq_pollitem_t items [] = {
{ collector, 0, ZMQ_POLLIN, 0 },
{ snapshot, 0, ZMQ_POLLIN, 0 }
};
while (!zctx_interrupted) {
int rc = zmq_poll (items, 2, 1000 * ZMQ_POLL_MSEC);
// Apply state update sent from client
if (items [0].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (collector);
if (!kvmsg)
break; // Interrupted
kvmsg_set_sequence (kvmsg, ++sequence);
kvmsg_send (kvmsg, publisher);
kvmsg_store (&kvmsg, kvmap);
printf ("I: publishing update %5d\n", (int) sequence);
}
// Execute state snapshot request
if (items [1].revents & ZMQ_POLLIN) {
zframe_t *identity = zframe_recv (snapshot);
if (!identity)
break; // Interrupted
// Request is in second frame of message
char *request = zstr_recv (snapshot);
if (streq (request, "ICANHAZ?"))
free (request);
else {
printf ("E: bad request, aborting\n");
break;
}
// Send state snapshot to client
kvroute_t routing = { snapshot, identity };
// For each entry in kvmap, send kvmsg to client
zhash_foreach (kvmap, s_send_single, &routing);
// Now send END message with sequence number
printf ("I: sending shapshot=%d\n", (int) sequence);
zframe_send (&identity, snapshot, ZFRAME_MORE);
kvmsg_t *kvmsg = kvmsg_new (sequence);
kvmsg_set_key (kvmsg, "KTHXBAI");
kvmsg_set_body (kvmsg, (byte *) "", 0);
kvmsg_send (kvmsg, snapshot);
kvmsg_destroy (&kvmsg);
}
}
printf (" Interrupted\n%d messages handled\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonesrv3: Clone server, Model Three in C++
#include "kvsimple.hpp"
// Routing information for a key-value snapshot
typedef struct {
zmq::socket_t *socket; // ROUTER socket to send to
std::string identity; // Identity of peer who requested state
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int s_send_snapshot(std::unordered_map<std::string, kvmsg>& kvmap, kvroute_t& kvroute) {
for (auto& kv : kvmap) {
s_sendmore(*kvroute.socket, kvroute.identity);
kv.second.send(*kvroute.socket);
}
return 0;
}
int main(void) {
// Prepare our context and sockets
zmq::context_t ctx(1);
zmq::socket_t snapshot(ctx, ZMQ_ROUTER);
snapshot.bind("tcp://*:5556");
zmq::socket_t publisher(ctx, ZMQ_PUB);
publisher.bind("tcp://*:5557");
zmq::socket_t collector(ctx, ZMQ_PULL);
collector.bind("tcp://*:5558");
// .split body of main task
// The body of the main task collects updates from clients and
// publishes them back out to clients:
std::unordered_map<std::string, kvmsg> kvmap;
int64_t sequence = 0;
zmq::pollitem_t items[] = {
{collector, 0, ZMQ_POLLIN, 0},
{snapshot, 0, ZMQ_POLLIN, 0}
};
s_catch_signals();
while(!s_interrupted) {
try {
zmq::poll(items, 2, -1);
} catch (const zmq::error_t& e) {
break; // Interrupted
}
// Apply state update sent from client
if (items[0].revents & ZMQ_POLLIN) {
auto msg = kvmsg::recv(collector);
if (!msg) {
break; // Interrupted
}
msg->set_sequence(++sequence);
kvmap[msg->key()] = *msg;
msg->send(publisher);
std::cout << "I: publishing update " << sequence << std::endl;
}
// Execute state snapshot request
if (items[1].revents & ZMQ_POLLIN) {
std::string identity = s_recv(snapshot);
std::string request = s_recv(snapshot);
if (request != "ICANHAZ?") {
std::cerr << "E: bad request, aborting\n";
break;
}
// Send state snapshot to client
kvroute_t kvroute = {&snapshot, identity};
// For each entry in kvmap, send kvmsg to client
s_send_snapshot(kvmap, kvroute);
// Now send END message with sequence number
std::cout << "I: sending state snapshot=" << sequence << std::endl;
s_sendmore(snapshot, identity);
kvmsg msg("KTHXBAI", sequence, (unsigned char *)"");
msg.send(snapshot);
}
}
std::cout << "Interrupted\n" << sequence << " messages handled\n";
return 0;
}
clonesrv3: Clone server, Model Three in C#
clonesrv3: Clone server, Model Three in CL
clonesrv3: Clone server, Model Three in Delphi
clonesrv3: Clone server, Model Three in Erlang
clonesrv3: Clone server, Model Three in Elixir
clonesrv3: Clone server, Model Three in F#
clonesrv3: Clone server, Model Three in Felix
clonesrv3: Clone server, Model Three in Go
clonesrv3: Clone server, Model Three in Haskell
clonesrv3: Clone server, Model Three in Haxe
clonesrv3: Clone server, Model Three in Java
package guide;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
/**
* Clone server Model Three
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonesrv3
{
private static Map<String, kvsimple> kvMap = new LinkedHashMap<String, kvsimple>();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket snapshot = ctx.createSocket(SocketType.ROUTER);
snapshot.bind("tcp://*:5556");
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5557");
Socket collector = ctx.createSocket(SocketType.PULL);
collector.bind("tcp://*:5558");
Poller poller = ctx.createPoller(2);
poller.register(collector, Poller.POLLIN);
poller.register(snapshot, Poller.POLLIN);
long sequence = 0;
while (!Thread.currentThread().isInterrupted()) {
if (poller.poll(1000) < 0)
break; // Context has been shut down
// apply state updates from main thread
if (poller.pollin(0)) {
kvsimple kvMsg = kvsimple.recv(collector);
if (kvMsg == null) // Interrupted
break;
kvMsg.setSequence(++sequence);
kvMsg.send(publisher);
clonesrv3.kvMap.put(kvMsg.getKey(), kvMsg);
System.out.printf("I: publishing update %5d\n", sequence);
}
// execute state snapshot request
if (poller.pollin(1)) {
byte[] identity = snapshot.recv(0);
if (identity == null)
break; // Interrupted
String request = snapshot.recvStr();
if (!request.equals("ICANHAZ?")) {
System.out.println("E: bad request, aborting");
break;
}
Iterator<Entry<String, kvsimple>> iter = kvMap.entrySet()
.iterator();
while (iter.hasNext()) {
Entry<String, kvsimple> entry = iter.next();
kvsimple msg = entry.getValue();
System.out.println(
"Sending message " + entry.getValue().getSequence()
);
this.sendMessage(msg, identity, snapshot);
}
// now send end message with getSequence number
System.out.println("Sending state snapshot = " + sequence);
snapshot.send(identity, ZMQ.SNDMORE);
kvsimple message = new kvsimple(
"KTHXBAI", sequence, ZMQ.SUBSCRIPTION_ALL
);
message.send(snapshot);
}
}
System.out.printf(" Interrupted\n%d messages handled\n", sequence);
}
}
private void sendMessage(kvsimple msg, byte[] identity, Socket snapshot)
{
snapshot.send(identity, ZMQ.SNDMORE);
msg.send(snapshot);
}
public static void main(String[] args)
{
new clonesrv3().run();
}
}
clonesrv3: Clone server, Model Three in Julia
clonesrv3: Clone server, Model Three in Lua
clonesrv3: Clone server, Model Three in Node.js
clonesrv3: Clone server, Model Three in Objective-C
clonesrv3: Clone server, Model Three in ooc
clonesrv3: Clone server, Model Three in Perl
clonesrv3: Clone server, Model Three in PHP
clonesrv3: Clone server, Model Three in Python
"""
Clone server Model Three
Author: Min RK <benjaminrk@gmail.com
"""
import zmq
from kvsimple import KVMsg
# simple struct for routing information for a key-value snapshot
class Route:
def __init__(self, socket, identity):
self.socket = socket # ROUTER socket to send to
self.identity = identity # Identity of peer who requested state
def send_single(key, kvmsg, route):
"""Send one state snapshot key-value pair to a socket"""
# Send identity of recipient first
route.socket.send(route.identity, zmq.SNDMORE)
kvmsg.send(route.socket)
def main():
# context and sockets
ctx = zmq.Context()
snapshot = ctx.socket(zmq.ROUTER)
snapshot.bind("tcp://*:5556")
publisher = ctx.socket(zmq.PUB)
publisher.bind("tcp://*:5557")
collector = ctx.socket(zmq.PULL)
collector.bind("tcp://*:5558")
sequence = 0
kvmap = {}
poller = zmq.Poller()
poller.register(collector, zmq.POLLIN)
poller.register(snapshot, zmq.POLLIN)
while True:
try:
items = dict(poller.poll(1000))
except:
break # Interrupted
# Apply state update sent from client
if collector in items:
kvmsg = KVMsg.recv(collector)
sequence += 1
kvmsg.sequence = sequence
kvmsg.send(publisher)
kvmsg.store(kvmap)
print "I: publishing update %5d" % sequence
# Execute state snapshot request
if snapshot in items:
msg = snapshot.recv_multipart()
identity = msg[0]
request = msg[1]
if request == "ICANHAZ?":
pass
else:
print "E: bad request, aborting\n",
break
# Send state snapshot to client
route = Route(snapshot, identity)
# For each entry in kvmap, send kvmsg to client
for k,v in kvmap.items():
send_single(k,v,route)
# Now send END message with sequence number
print "Sending state shapshot=%d\n" % sequence,
snapshot.send(identity, zmq.SNDMORE)
kvmsg = KVMsg(sequence)
kvmsg.key = "KTHXBAI"
kvmsg.body = ""
kvmsg.send(snapshot)
print " Interrupted\n%d messages handled" % sequence
if __name__ == '__main__':
main()
clonesrv3: Clone server, Model Three in Q
clonesrv3: Clone server, Model Three in Racket
clonesrv3: Clone server, Model Three in Ruby
clonesrv3: Clone server, Model Three in Rust
clonesrv3: Clone server, Model Three in Scala
clonesrv3: Clone server, Model Three in Tcl
clonesrv3: Clone server, Model Three in OCaml
And here is the client:
clonecli3: Clone client, Model Three in Ada
clonecli3: Clone client, Model Three in Basic
clonecli3: Clone client, Model Three in C
// Clone client - Model Three
// Lets us build this source without creating a library
#include "kvsimple.c"
int main (void)
{
// Prepare our context and subscriber
zctx_t *ctx = zctx_new ();
void *snapshot = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (snapshot, "tcp://localhost:5556");
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (subscriber, "");
zsocket_connect (subscriber, "tcp://localhost:5557");
void *publisher = zsocket_new (ctx, ZMQ_PUSH);
zsocket_connect (publisher, "tcp://localhost:5558");
zhash_t *kvmap = zhash_new ();
srandom ((unsigned) time (NULL));
// .split getting a state snapshot
// We first request a state snapshot:
int64_t sequence = 0;
zstr_send (snapshot, "ICANHAZ?");
while (true) {
kvmsg_t *kvmsg = kvmsg_recv (snapshot);
if (!kvmsg)
break; // Interrupted
if (streq (kvmsg_key (kvmsg), "KTHXBAI")) {
sequence = kvmsg_sequence (kvmsg);
printf ("I: received snapshot=%d\n", (int) sequence);
kvmsg_destroy (&kvmsg);
break; // Done
}
kvmsg_store (&kvmsg, kvmap);
}
// .split processing state updates
// Now we wait for updates from the server and every so often, we
// send a random key-value update to the server:
int64_t alarm = zclock_time () + 1000;
while (!zctx_interrupted) {
zmq_pollitem_t items [] = { { subscriber, 0, ZMQ_POLLIN, 0 } };
int tickless = (int) ((alarm - zclock_time ()));
if (tickless < 0)
tickless = 0;
int rc = zmq_poll (items, 1, tickless * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Context has been shut down
if (items [0].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (subscriber);
if (!kvmsg)
break; // Interrupted
// Discard out-of-sequence kvmsgs, incl. heartbeats
if (kvmsg_sequence (kvmsg) > sequence) {
sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, kvmap);
printf ("I: received update=%d\n", (int) sequence);
}
else
kvmsg_destroy (&kvmsg);
}
// If we timed out, generate a random kvmsg
if (zclock_time () >= alarm) {
kvmsg_t *kvmsg = kvmsg_new (0);
kvmsg_fmt_key (kvmsg, "%d", randof (10000));
kvmsg_fmt_body (kvmsg, "%d", randof (1000000));
kvmsg_send (kvmsg, publisher);
kvmsg_destroy (&kvmsg);
alarm = zclock_time () + 1000;
}
}
printf (" Interrupted\n%d messages in\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonecli3: Clone client, Model Three in C++
// Clone client - Model Three
#include "kvsimple.hpp"
int main(void) {
// Prepare our context and subscriber
zmq::context_t ctx(1);
zmq::socket_t snapshot(ctx, ZMQ_DEALER);
snapshot.connect("tcp://localhost:5556");
zmq::socket_t subscriber(ctx, ZMQ_SUB);
subscriber.set(zmq::sockopt::subscribe, "");
subscriber.connect("tcp://localhost:5557");
zmq::socket_t publisher(ctx, ZMQ_PUSH);
publisher.connect("tcp://localhost:5558");
std::unordered_map<std::string, kvmsg> kvmap;
// .split getting a state snapshot
// We first request a state snapshot:
// Get state snapshot
int64_t sequence = 0;
s_send(snapshot, std::string("ICANHAZ?"));
while (true) {
auto kv = kvmsg::recv(snapshot);
if (!kv) break;
if (kv->key() == "KTHXBAI") {
sequence = kv->sequence();
std::cout << "I: received snapshot=" << sequence << std::endl;
break;
}
kvmap[kv->key()] = *kv;
}
// .split processing state updates
// Now we wait for updates from the server and every so often, we
// send a random key-value update to the server:
std::chrono::time_point<std::chrono::steady_clock> alarm = std::chrono::steady_clock::now() + std::chrono::seconds(1);
s_catch_signals();
while(!s_interrupted) {
zmq::pollitem_t items[] = {
{subscriber, 0, ZMQ_POLLIN, 0}
};
int tickless = std::chrono::duration_cast<std::chrono::milliseconds>(alarm - std::chrono::steady_clock::now()).count();
if (tickless < 0)
tickless = 0;
try {
zmq::poll(items, 1, tickless);
} catch (const zmq::error_t& e) {
break; // Interrupted
}
if (items[0].revents & ZMQ_POLLIN) {
auto kv = kvmsg::recv(subscriber);
if (!kv) break;
if (kv->sequence() > sequence) {
sequence = kv->sequence();
kvmap[kv->key()] = *kv;
std::cout << "I: received update=" << sequence << std::endl;
}
}
if (std::chrono::steady_clock::now() >= alarm) {
// Send random update to server
std::string key = std::to_string(within(10000));
kvmsg kv(key, 0, (unsigned char *)std::to_string(within(1000000)).c_str());
kv.send(publisher);
alarm = std::chrono::steady_clock::now() + std::chrono::seconds(1);
}
}
std::cout << " Interrupted\n" << sequence << " messages in\n" << std::endl;
return 0;
}
clonecli3: Clone client, Model Three in C#
clonecli3: Clone client, Model Three in CL
clonecli3: Clone client, Model Three in Delphi
clonecli3: Clone client, Model Three in Erlang
clonecli3: Clone client, Model Three in Elixir
clonecli3: Clone client, Model Three in F#
clonecli3: Clone client, Model Three in Felix
clonecli3: Clone client, Model Three in Go
clonecli3: Clone client, Model Three in Haskell
clonecli3: Clone client, Model Three in Haxe
clonecli3: Clone client, Model Three in Java
package guide;
import java.nio.ByteBuffer;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
/**
* Clone client Model Three
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonecli3
{
private static Map<String, kvsimple> kvMap = new HashMap<String, kvsimple>();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket snapshot = ctx.createSocket(SocketType.DEALER);
snapshot.connect("tcp://localhost:5556");
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect("tcp://localhost:5557");
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
Socket push = ctx.createSocket(SocketType.PUSH);
push.connect("tcp://localhost:5558");
// get state snapshot
long sequence = 0;
snapshot.send("ICANHAZ?".getBytes(ZMQ.CHARSET), 0);
while (true) {
kvsimple kvMsg = kvsimple.recv(snapshot);
if (kvMsg == null)
break; // Interrupted
sequence = kvMsg.getSequence();
if ("KTHXBAI".equalsIgnoreCase(kvMsg.getKey())) {
System.out.println(
"Received snapshot = " + kvMsg.getSequence()
);
break; // done
}
System.out.println("receiving " + kvMsg.getSequence());
clonecli3.kvMap.put(kvMsg.getKey(), kvMsg);
}
Poller poller = ctx.createPoller(1);
poller.register(subscriber);
Random random = new Random();
// now apply pending updates, discard out-of-getSequence messages
long alarm = System.currentTimeMillis() + 5000;
while (true) {
int rc = poller.poll(
Math.max(0, alarm - System.currentTimeMillis())
);
if (rc == -1)
break; // Context has been shut down
if (poller.pollin(0)) {
kvsimple kvMsg = kvsimple.recv(subscriber);
if (kvMsg == null)
break; // Interrupted
if (kvMsg.getSequence() > sequence) {
sequence = kvMsg.getSequence();
System.out.println("receiving " + sequence);
clonecli3.kvMap.put(kvMsg.getKey(), kvMsg);
}
}
if (System.currentTimeMillis() >= alarm) {
int key = random.nextInt(10000);
int body = random.nextInt(1000000);
ByteBuffer b = ByteBuffer.allocate(4);
b.asIntBuffer().put(body);
kvsimple kvUpdateMsg = new kvsimple(key + "", 0, b.array());
kvUpdateMsg.send(push);
alarm = System.currentTimeMillis() + 1000;
}
}
}
}
public static void main(String[] args)
{
new clonecli3().run();
}
}
clonecli3: Clone client, Model Three in Julia
clonecli3: Clone client, Model Three in Lua
clonecli3: Clone client, Model Three in Node.js
clonecli3: Clone client, Model Three in Objective-C
clonecli3: Clone client, Model Three in ooc
clonecli3: Clone client, Model Three in Perl
clonecli3: Clone client, Model Three in PHP
clonecli3: Clone client, Model Three in Python
"""
Clone client Model Three
Author: Min RK <benjaminrk@gmail.com
"""
import random
import time
import zmq
from kvsimple import KVMsg
def main():
# Prepare our context and subscriber
ctx = zmq.Context()
snapshot = ctx.socket(zmq.DEALER)
snapshot.linger = 0
snapshot.connect("tcp://localhost:5556")
subscriber = ctx.socket(zmq.SUB)
subscriber.linger = 0
subscriber.setsockopt(zmq.SUBSCRIBE, '')
subscriber.connect("tcp://localhost:5557")
publisher = ctx.socket(zmq.PUSH)
publisher.linger = 0
publisher.connect("tcp://localhost:5558")
random.seed(time.time())
kvmap = {}
# Get state snapshot
sequence = 0
snapshot.send("ICANHAZ?")
while True:
try:
kvmsg = KVMsg.recv(snapshot)
except:
return # Interrupted
if kvmsg.key == "KTHXBAI":
sequence = kvmsg.sequence
print "I: Received snapshot=%d" % sequence
break # Done
kvmsg.store(kvmap)
poller = zmq.Poller()
poller.register(subscriber, zmq.POLLIN)
alarm = time.time()+1.
while True:
tickless = 1000*max(0, alarm - time.time())
try:
items = dict(poller.poll(tickless))
except:
break # Interrupted
if subscriber in items:
kvmsg = KVMsg.recv(subscriber)
# Discard out-of-sequence kvmsgs, incl. heartbeats
if kvmsg.sequence > sequence:
sequence = kvmsg.sequence
kvmsg.store(kvmap)
print "I: received update=%d" % sequence
# If we timed-out, generate a random kvmsg
if time.time() >= alarm:
kvmsg = KVMsg(0)
kvmsg.key = "%d" % random.randint(1,10000)
kvmsg.body = "%d" % random.randint(1,1000000)
kvmsg.send(publisher)
kvmsg.store(kvmap)
alarm = time.time() + 1.
print " Interrupted\n%d messages in" % sequence
if __name__ == '__main__':
main()
clonecli3: Clone client, Model Three in Q
clonecli3: Clone client, Model Three in Racket
clonecli3: Clone client, Model Three in Ruby
clonecli3: Clone client, Model Three in Rust
clonecli3: Clone client, Model Three in Scala
clonecli3: Clone client, Model Three in Tcl
clonecli3: Clone client, Model Three in OCaml
Here are some things to note about this third design:
-
The server has collapsed to a single task. It manages a PULL socket for incoming updates, a ROUTER socket for state requests, and a PUB socket for outgoing updates.
-
The client uses a simple tickless timer to send a random update to the server once a second. In a real implementation, we would drive updates from application code.
Working with Subtrees #
As we grow the number of clients, the size of our shared store will also grow. It stops being reasonable to send everything to every client. This is the classic story with pub-sub: when you have a very small number of clients, you can send every message to all clients. As you grow the architecture, this becomes inefficient. Clients specialize in different areas.
So even when working with a shared store, some clients will want to work only with a part of that store, which we call a subtree. The client has to request the subtree when it makes a state request, and it must specify the same subtree when it subscribes to updates.
There are a couple of common syntaxes for trees. One is the path hierarchy, and another is the topic tree. These look like this:
- Path hierarchy: /some/list/of/paths
- Topic tree: some.list.of.topics
We’ll use the path hierarchy, and extend our client and server so that a client can work with a single subtree. Once you see how to work with a single subtree you’ll be able to extend this yourself to handle multiple subtrees, if your use case demands it.
Here’s the server implementing subtrees, a small variation on Model Three:
clonesrv4: Clone server, Model Four in Ada
clonesrv4: Clone server, Model Four in Basic
clonesrv4: Clone server, Model Four in C
// Clone server - Model Four
// Lets us build this source without creating a library
#include "kvsimple.c"
// Routing information for a key-value snapshot
typedef struct {
void *socket; // ROUTER socket to send to
zframe_t *identity; // Identity of peer who requested state
char *subtree; // Client subtree specification
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int
s_send_single (const char *key, void *data, void *args)
{
kvroute_t *kvroute = (kvroute_t *) args;
kvmsg_t *kvmsg = (kvmsg_t *) data;
if (strlen (kvroute->subtree) <= strlen (kvmsg_key (kvmsg))
&& memcmp (kvroute->subtree,
kvmsg_key (kvmsg), strlen (kvroute->subtree)) == 0) {
// Send identity of recipient first
zframe_send (&kvroute->identity,
kvroute->socket, ZFRAME_MORE + ZFRAME_REUSE);
kvmsg_send (kvmsg, kvroute->socket);
}
return 0;
}
// The main task is identical to clonesrv3 except for where it
// handles subtrees.
// .skip
int main (void)
{
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *snapshot = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (snapshot, "tcp://*:5556");
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5557");
void *collector = zsocket_new (ctx, ZMQ_PULL);
zsocket_bind (collector, "tcp://*:5558");
int64_t sequence = 0;
zhash_t *kvmap = zhash_new ();
zmq_pollitem_t items [] = {
{ collector, 0, ZMQ_POLLIN, 0 },
{ snapshot, 0, ZMQ_POLLIN, 0 }
};
while (!zctx_interrupted) {
int rc = zmq_poll (items, 2, 1000 * ZMQ_POLL_MSEC);
// Apply state update sent from client
if (items [0].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (collector);
if (!kvmsg)
break; // Interrupted
kvmsg_set_sequence (kvmsg, ++sequence);
kvmsg_send (kvmsg, publisher);
kvmsg_store (&kvmsg, kvmap);
printf ("I: publishing update %5d\n", (int) sequence);
}
// Execute state snapshot request
if (items [1].revents & ZMQ_POLLIN) {
zframe_t *identity = zframe_recv (snapshot);
if (!identity)
break; // Interrupted
// .until
// Request is in second frame of message
char *request = zstr_recv (snapshot);
char *subtree = NULL;
if (streq (request, "ICANHAZ?")) {
free (request);
subtree = zstr_recv (snapshot);
}
// .skip
else {
printf ("E: bad request, aborting\n");
break;
}
// .until
// Send state snapshot to client
kvroute_t routing = { snapshot, identity, subtree };
// .skip
// For each entry in kvmap, send kvmsg to client
zhash_foreach (kvmap, s_send_single, &routing);
// .until
// Now send END message with sequence number
printf ("I: sending shapshot=%d\n", (int) sequence);
zframe_send (&identity, snapshot, ZFRAME_MORE);
kvmsg_t *kvmsg = kvmsg_new (sequence);
kvmsg_set_key (kvmsg, "KTHXBAI");
kvmsg_set_body (kvmsg, (byte *) subtree, 0);
kvmsg_send (kvmsg, snapshot);
kvmsg_destroy (&kvmsg);
free (subtree);
}
}
// .skip
printf (" Interrupted\n%d messages handled\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonesrv4: Clone server, Model Four in C++
#include "kvsimple.hpp"
// Routing information for a key-value snapshot
typedef struct {
zmq::socket_t *socket; // ROUTER socket to send to
std::string identity; // Identity of peer who requested state
std::string subtree; // Client subtree specification
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int s_send_snapshot(std::unordered_map<std::string, kvmsg>& kvmap, kvroute_t& kvroute) {
for (auto& kv : kvmap) {
if (kvroute.subtree.size() <= kv.first.size() && kv.first.compare(0, kvroute.subtree.size(), kvroute.subtree) == 0) {
s_sendmore(*kvroute.socket, kvroute.identity);
kv.second.send(*kvroute.socket);
}
}
return 0;
}
int main(void) {
// Prepare our context and sockets
zmq::context_t ctx(1);
zmq::socket_t snapshot(ctx, ZMQ_ROUTER);
snapshot.bind("tcp://*:5556");
zmq::socket_t publisher(ctx, ZMQ_PUB);
publisher.bind("tcp://*:5557");
zmq::socket_t collector(ctx, ZMQ_PULL);
collector.bind("tcp://*:5558");
// .split body of main task
// The body of the main task collects updates from clients and
// publishes them back out to clients:
std::unordered_map<std::string, kvmsg> kvmap;
int64_t sequence = 0;
zmq::pollitem_t items[] = {
{collector, 0, ZMQ_POLLIN, 0},
{snapshot, 0, ZMQ_POLLIN, 0}
};
s_catch_signals();
while(!s_interrupted) {
try {
zmq::poll(items, 2, -1);
} catch (const zmq::error_t& e) {
break; // Interrupted
}
// Apply state update sent from client
if (items[0].revents & ZMQ_POLLIN) {
auto msg = kvmsg::recv(collector);
if (!msg) {
break; // Interrupted
}
msg->set_sequence(++sequence);
kvmap[msg->key()] = *msg;
msg->send(publisher);
std::cout << "I: publishing update " << sequence << std::endl;
}
// Execute state snapshot request
if (items[1].revents & ZMQ_POLLIN) {
std::string identity = s_recv(snapshot);
std::string request = s_recv(snapshot);
if (request != "ICANHAZ?") {
std::cerr << "E: bad request, aborting\n";
break;
}
// Client requests a subtree of the state
std::string subtree = s_recv(snapshot);
// Send state snapshot to client
kvroute_t kvroute = {&snapshot, identity, subtree};
// For each entry in kvmap, send kvmsg to client
s_send_snapshot(kvmap, kvroute);
// Now send END message with sequence number
std::cout << "I: sending state snapshot=" << sequence << std::endl;
s_sendmore(snapshot, identity);
kvmsg msg("KTHXBAI", sequence, (unsigned char *)subtree.c_str());
msg.send(snapshot);
}
}
std::cout << "Interrupted\n" << sequence << " messages handled\n";
return 0;
}
clonesrv4: Clone server, Model Four in C#
clonesrv4: Clone server, Model Four in CL
clonesrv4: Clone server, Model Four in Delphi
clonesrv4: Clone server, Model Four in Erlang
clonesrv4: Clone server, Model Four in Elixir
clonesrv4: Clone server, Model Four in F#
clonesrv4: Clone server, Model Four in Felix
clonesrv4: Clone server, Model Four in Go
clonesrv4: Clone server, Model Four in Haskell
clonesrv4: Clone server, Model Four in Haxe
clonesrv4: Clone server, Model Four in Java
package guide;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
/**
* Clone server Model Four
*/
public class clonesrv4
{
private static Map<String, kvsimple> kvMap = new LinkedHashMap<String, kvsimple>();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket snapshot = ctx.createSocket(SocketType.ROUTER);
snapshot.bind("tcp://*:5556");
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5557");
Socket collector = ctx.createSocket(SocketType.PULL);
collector.bind("tcp://*:5558");
Poller poller = ctx.createPoller(2);
poller.register(collector, Poller.POLLIN);
poller.register(snapshot, Poller.POLLIN);
long sequence = 0;
while (!Thread.currentThread().isInterrupted()) {
if (poller.poll(1000) < 0)
break; // Context has been shut down
// apply state updates from main thread
if (poller.pollin(0)) {
kvsimple kvMsg = kvsimple.recv(collector);
if (kvMsg == null) // Interrupted
break;
kvMsg.setSequence(++sequence);
kvMsg.send(publisher);
clonesrv4.kvMap.put(kvMsg.getKey(), kvMsg);
System.out.printf("I: publishing update %5d\n", sequence);
}
// execute state snapshot request
if (poller.pollin(1)) {
byte[] identity = snapshot.recv(0);
if (identity == null)
break; // Interrupted
// .until
// Request is in second frame of message
String request = snapshot.recvStr();
if (!request.equals("ICANHAZ?")) {
System.out.println("E: bad request, aborting");
break;
}
String subtree = snapshot.recvStr();
Iterator<Entry<String, kvsimple>> iter = kvMap.entrySet()
.iterator();
while (iter.hasNext()) {
Entry<String, kvsimple> entry = iter.next();
kvsimple msg = entry.getValue();
System.out.println(
"Sending message " + entry.getValue().getSequence()
);
this.sendMessage(msg, identity, subtree, snapshot);
}
// now send end message with getSequence number
System.out.println("Sending state snapshot = " + sequence);
snapshot.send(identity, ZMQ.SNDMORE);
kvsimple message = new kvsimple(
"KTHXBAI", sequence, ZMQ.SUBSCRIPTION_ALL
);
message.send(snapshot);
}
}
System.out.printf(" Interrupted\n%d messages handled\n", sequence);
}
}
private void sendMessage(kvsimple msg, byte[] identity, String subtree, Socket snapshot)
{
snapshot.send(identity, ZMQ.SNDMORE);
snapshot.send(subtree, ZMQ.SNDMORE);
msg.send(snapshot);
}
public static void main(String[] args)
{
new clonesrv4().run();
}
}
clonesrv4: Clone server, Model Four in Julia
clonesrv4: Clone server, Model Four in Lua
clonesrv4: Clone server, Model Four in Node.js
clonesrv4: Clone server, Model Four in Objective-C
clonesrv4: Clone server, Model Four in ooc
clonesrv4: Clone server, Model Four in Perl
clonesrv4: Clone server, Model Four in PHP
clonesrv4: Clone server, Model Four in Python
"""
Clone server Model Four
Author: Min RK <benjaminrk@gmail.com
"""
import zmq
from kvsimple import KVMsg
# simple struct for routing information for a key-value snapshot
class Route:
def __init__(self, socket, identity, subtree):
self.socket = socket # ROUTER socket to send to
self.identity = identity # Identity of peer who requested state
self.subtree = subtree # Client subtree specification
def send_single(key, kvmsg, route):
"""Send one state snapshot key-value pair to a socket"""
# check front of key against subscription subtree:
if kvmsg.key.startswith(route.subtree):
# Send identity of recipient first
route.socket.send(route.identity, zmq.SNDMORE)
kvmsg.send(route.socket)
def main():
# context and sockets
ctx = zmq.Context()
snapshot = ctx.socket(zmq.ROUTER)
snapshot.bind("tcp://*:5556")
publisher = ctx.socket(zmq.PUB)
publisher.bind("tcp://*:5557")
collector = ctx.socket(zmq.PULL)
collector.bind("tcp://*:5558")
sequence = 0
kvmap = {}
poller = zmq.Poller()
poller.register(collector, zmq.POLLIN)
poller.register(snapshot, zmq.POLLIN)
while True:
try:
items = dict(poller.poll(1000))
except:
break # Interrupted
# Apply state update sent from client
if collector in items:
kvmsg = KVMsg.recv(collector)
sequence += 1
kvmsg.sequence = sequence
kvmsg.send(publisher)
kvmsg.store(kvmap)
print "I: publishing update %5d" % sequence
# Execute state snapshot request
if snapshot in items:
msg = snapshot.recv_multipart()
identity, request, subtree = msg
if request == "ICANHAZ?":
pass
else:
print "E: bad request, aborting\n",
break
# Send state snapshot to client
route = Route(snapshot, identity, subtree)
# For each entry in kvmap, send kvmsg to client
for k,v in kvmap.items():
send_single(k,v,route)
# Now send END message with sequence number
print "Sending state shapshot=%d\n" % sequence,
snapshot.send(identity, zmq.SNDMORE)
kvmsg = KVMsg(sequence)
kvmsg.key = "KTHXBAI"
kvmsg.body = subtree
kvmsg.send(snapshot)
print " Interrupted\n%d messages handled" % sequence
if __name__ == '__main__':
main()
clonesrv4: Clone server, Model Four in Q
clonesrv4: Clone server, Model Four in Racket
clonesrv4: Clone server, Model Four in Ruby
clonesrv4: Clone server, Model Four in Rust
clonesrv4: Clone server, Model Four in Scala
clonesrv4: Clone server, Model Four in Tcl
clonesrv4: Clone server, Model Four in OCaml
And here is the corresponding client:
clonecli4: Clone client, Model Four in Ada
clonecli4: Clone client, Model Four in Basic
clonecli4: Clone client, Model Four in C
// Clone client - Model Four
// Lets us build this source without creating a library
#include "kvsimple.c"
// This client is identical to clonecli3 except for where we
// handles subtrees.
#define SUBTREE "/client/"
// .skip
int main (void)
{
// Prepare our context and subscriber
zctx_t *ctx = zctx_new ();
void *snapshot = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (snapshot, "tcp://localhost:5556");
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (subscriber, "");
// .until
zsocket_connect (subscriber, "tcp://localhost:5557");
zsocket_set_subscribe (subscriber, SUBTREE);
// .skip
void *publisher = zsocket_new (ctx, ZMQ_PUSH);
zsocket_connect (publisher, "tcp://localhost:5558");
zhash_t *kvmap = zhash_new ();
srandom ((unsigned) time (NULL));
// .until
// We first request a state snapshot:
int64_t sequence = 0;
zstr_sendm (snapshot, "ICANHAZ?");
zstr_send (snapshot, SUBTREE);
// .skip
while (true) {
kvmsg_t *kvmsg = kvmsg_recv (snapshot);
if (!kvmsg)
break; // Interrupted
if (streq (kvmsg_key (kvmsg), "KTHXBAI")) {
sequence = kvmsg_sequence (kvmsg);
printf ("I: received snapshot=%d\n", (int) sequence);
kvmsg_destroy (&kvmsg);
break; // Done
}
kvmsg_store (&kvmsg, kvmap);
}
int64_t alarm = zclock_time () + 1000;
while (!zctx_interrupted) {
zmq_pollitem_t items [] = { { subscriber, 0, ZMQ_POLLIN, 0 } };
int tickless = (int) ((alarm - zclock_time ()));
if (tickless < 0)
tickless = 0;
int rc = zmq_poll (items, 1, tickless * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Context has been shut down
if (items [0].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (subscriber);
if (!kvmsg)
break; // Interrupted
// Discard out-of-sequence kvmsgs, incl. heartbeats
if (kvmsg_sequence (kvmsg) > sequence) {
sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, kvmap);
printf ("I: received update=%d\n", (int) sequence);
}
else
kvmsg_destroy (&kvmsg);
}
// .until
// If we timed out, generate a random kvmsg
if (zclock_time () >= alarm) {
kvmsg_t *kvmsg = kvmsg_new (0);
kvmsg_fmt_key (kvmsg, "%s%d", SUBTREE, randof (10000));
kvmsg_fmt_body (kvmsg, "%d", randof (1000000));
kvmsg_send (kvmsg, publisher);
kvmsg_destroy (&kvmsg);
alarm = zclock_time () + 1000;
}
// .skip
}
printf (" Interrupted\n%d messages in\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonecli4: Clone client, Model Four in C++
// Clone client - Model Four
#include "kvsimple.hpp"
// This client is identical to clonecli3 except for where we
// handles subtrees.
#define SUBTREE "/client/"
// .skip
int main (void)
{
// Prepare our context and subscriber
zmq::context_t ctx(1);
zmq::socket_t snapshot(ctx, ZMQ_DEALER);
snapshot.connect("tcp://localhost:5556");
zmq::socket_t subscriber(ctx, ZMQ_SUB);
subscriber.set(zmq::sockopt::subscribe, SUBTREE);
subscriber.connect("tcp://localhost:5557");
zmq::socket_t publisher(ctx, ZMQ_PUSH);
publisher.connect("tcp://localhost:5558");
std::unordered_map<std::string, kvmsg> kvmap;
// .split getting a state snapshot
// We first request a state snapshot:
// Get state snapshot
int64_t sequence = 0;
s_sendmore(snapshot, std::string("ICANHAZ?"));
s_send(snapshot, std::string(SUBTREE));
while(true) {
auto kv = kvmsg::recv(snapshot);
if (!kv) break;
if (kv->key() == "KTHXBAI") {
sequence = kv->sequence();
std::cout << "I: received snapshot=" << sequence << std::endl;
break;
}
kvmap[kv->key()] = *kv;
}
// .split processing state updates
// Now we wait for updates from the server and every so often, we
// send a random key-value update to the server:
std::chrono::time_point<std::chrono::steady_clock> alarm = std::chrono::steady_clock::now() + std::chrono::seconds(1);
s_catch_signals();
while(!s_interrupted) {
zmq::pollitem_t items[] = {
{subscriber, 0, ZMQ_POLLIN, 0}
};
int tickless = std::chrono::duration_cast<std::chrono::milliseconds>(alarm - std::chrono::steady_clock::now()).count();
if (tickless < 0)
tickless = 0;
try {
zmq::poll(items, 1, tickless);
} catch (const zmq::error_t& e) {
break; // Interrupted
}
if (items[0].revents & ZMQ_POLLIN) {
auto kv = kvmsg::recv(subscriber);
if (!kv) break;
if (kv->sequence() > sequence) {
sequence = kv->sequence();
kvmap[kv->key()] = *kv;
std::cout << "I: received update=" << sequence << std::endl;
}
}
if (std::chrono::steady_clock::now() >= alarm) {
// Send random update to server
std::string key = std::string(SUBTREE) + std::to_string(within(10000));
kvmsg kv(key, 0, (unsigned char *)std::to_string(within(1000000)).c_str());
kv.send(publisher);
alarm = std::chrono::steady_clock::now() + std::chrono::seconds(1);
}
}
std::cout << " Interrupted\n" << sequence << " messages in\n" << std::endl;
return 0;
}
clonecli4: Clone client, Model Four in C#
clonecli4: Clone client, Model Four in CL
clonecli4: Clone client, Model Four in Delphi
clonecli4: Clone client, Model Four in Erlang
clonecli4: Clone client, Model Four in Elixir
clonecli4: Clone client, Model Four in F#
clonecli4: Clone client, Model Four in Felix
clonecli4: Clone client, Model Four in Go
clonecli4: Clone client, Model Four in Haskell
clonecli4: Clone client, Model Four in Haxe
clonecli4: Clone client, Model Four in Java
package guide;
import java.nio.ByteBuffer;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
/**
* Clone client Model Four
*
*/
public class clonecli4
{
// This client is identical to clonecli3 except for where we
// handles subtrees.
private final static String SUBTREE = "/client/";
private static Map<String, kvsimple> kvMap = new HashMap<String, kvsimple>();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket snapshot = ctx.createSocket(SocketType.DEALER);
snapshot.connect("tcp://localhost:5556");
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect("tcp://localhost:5557");
subscriber.subscribe(SUBTREE.getBytes(ZMQ.CHARSET));
Socket push = ctx.createSocket(SocketType.PUSH);
push.connect("tcp://localhost:5558");
// get state snapshot
snapshot.sendMore("ICANHAZ?");
snapshot.send(SUBTREE);
long sequence = 0;
while (true) {
kvsimple kvMsg = kvsimple.recv(snapshot);
if (kvMsg == null)
break; // Interrupted
sequence = kvMsg.getSequence();
if ("KTHXBAI".equalsIgnoreCase(kvMsg.getKey())) {
System.out.println(
"Received snapshot = " + kvMsg.getSequence()
);
break; // done
}
System.out.println("receiving " + kvMsg.getSequence());
clonecli4.kvMap.put(kvMsg.getKey(), kvMsg);
}
Poller poller = ctx.createPoller(1);
poller.register(subscriber);
Random random = new Random();
// now apply pending updates, discard out-of-getSequence messages
long alarm = System.currentTimeMillis() + 5000;
while (true) {
int rc = poller.poll(
Math.max(0, alarm - System.currentTimeMillis())
);
if (rc == -1)
break; // Context has been shut down
if (poller.pollin(0)) {
kvsimple kvMsg = kvsimple.recv(subscriber);
if (kvMsg == null)
break; // Interrupted
if (kvMsg.getSequence() > sequence) {
sequence = kvMsg.getSequence();
System.out.println("receiving " + sequence);
clonecli4.kvMap.put(kvMsg.getKey(), kvMsg);
}
}
if (System.currentTimeMillis() >= alarm) {
String key = String.format(
"%s%d", SUBTREE, random.nextInt(10000)
);
int body = random.nextInt(1000000);
ByteBuffer b = ByteBuffer.allocate(4);
b.asIntBuffer().put(body);
kvsimple kvUpdateMsg = new kvsimple(key, 0, b.array());
kvUpdateMsg.send(push);
alarm = System.currentTimeMillis() + 1000;
}
}
}
}
public static void main(String[] args)
{
new clonecli4().run();
}
}
clonecli4: Clone client, Model Four in Julia
clonecli4: Clone client, Model Four in Lua
clonecli4: Clone client, Model Four in Node.js
clonecli4: Clone client, Model Four in Objective-C
clonecli4: Clone client, Model Four in ooc
clonecli4: Clone client, Model Four in Perl
clonecli4: Clone client, Model Four in PHP
clonecli4: Clone client, Model Four in Python
"""
Clone client Model Four
Author: Min RK <benjaminrk@gmail.com
"""
import random
import time
import zmq
from kvsimple import KVMsg
SUBTREE = "/client/"
def main():
# Prepare our context and subscriber
ctx = zmq.Context()
snapshot = ctx.socket(zmq.DEALER)
snapshot.linger = 0
snapshot.connect("tcp://localhost:5556")
subscriber = ctx.socket(zmq.SUB)
subscriber.linger = 0
subscriber.setsockopt(zmq.SUBSCRIBE, SUBTREE)
subscriber.connect("tcp://localhost:5557")
publisher = ctx.socket(zmq.PUSH)
publisher.linger = 0
publisher.connect("tcp://localhost:5558")
random.seed(time.time())
kvmap = {}
# Get state snapshot
sequence = 0
snapshot.send_multipart(["ICANHAZ?", SUBTREE])
while True:
try:
kvmsg = KVMsg.recv(snapshot)
except:
raise
return # Interrupted
if kvmsg.key == "KTHXBAI":
sequence = kvmsg.sequence
print "I: Received snapshot=%d" % sequence
break # Done
kvmsg.store(kvmap)
poller = zmq.Poller()
poller.register(subscriber, zmq.POLLIN)
alarm = time.time()+1.
while True:
tickless = 1000*max(0, alarm - time.time())
try:
items = dict(poller.poll(tickless))
except:
break # Interrupted
if subscriber in items:
kvmsg = KVMsg.recv(subscriber)
# Discard out-of-sequence kvmsgs, incl. heartbeats
if kvmsg.sequence > sequence:
sequence = kvmsg.sequence
kvmsg.store(kvmap)
print "I: received update=%d" % sequence
# If we timed-out, generate a random kvmsg
if time.time() >= alarm:
kvmsg = KVMsg(0)
kvmsg.key = SUBTREE + "%d" % random.randint(1,10000)
kvmsg.body = "%d" % random.randint(1,1000000)
kvmsg.send(publisher)
kvmsg.store(kvmap)
alarm = time.time() + 1.
print " Interrupted\n%d messages in" % sequence
if __name__ == '__main__':
main()
clonecli4: Clone client, Model Four in Q
clonecli4: Clone client, Model Four in Racket
clonecli4: Clone client, Model Four in Ruby
clonecli4: Clone client, Model Four in Rust
clonecli4: Clone client, Model Four in Scala
clonecli4: Clone client, Model Four in Tcl
clonecli4: Clone client, Model Four in OCaml
Ephemeral Values #
An ephemeral value is one that expires automatically unless regularly refreshed. If you think of Clone being used for a registration service, then ephemeral values would let you do dynamic values. A node joins the network, publishes its address, and refreshes this regularly. If the node dies, its address eventually gets removed.
The usual abstraction for ephemeral values is to attach them to a session, and delete them when the session ends. In Clone, sessions would be defined by clients, and would end if the client died. A simpler alternative is to attach a time to live (TTL) to ephemeral values, which the server uses to expire values that haven’t been refreshed in time.
A good design principle that I use whenever possible is to not invent concepts that are not absolutely essential. If we have very large numbers of ephemeral values, sessions will offer better performance. If we use a handful of ephemeral values, it’s fine to set a TTL on each one. If we use masses of ephemeral values, it’s more efficient to attach them to sessions and expire them in bulk. This isn’t a problem we face at this stage, and may never face, so sessions go out the window.
Now we will implement ephemeral values. First, we need a way to encode the TTL in the key-value message. We could add a frame. The problem with using ZeroMQ frames for properties is that each time we want to add a new property, we have to change the message structure. It breaks compatibility. So let’s add a properties frame to the message, and write the code to let us get and put property values.
Next, we need a way to say, “delete this value”. Up until now, servers and clients have always blindly inserted or updated new values into their hash table. We’ll say that if the value is empty, that means “delete this key”.
Here’s a more complete version of the kvmsg class, which implements the properties frame (and adds a UUID frame, which we’ll need later on). It also handles empty values by deleting the key from the hash, if necessary:
kvmsg: Key-value message class: full in Ada
kvmsg: Key-value message class: full in Basic
kvmsg: Key-value message class: full in C
// kvmsg class - key-value message class for example applications
#include "kvmsg.h"
#include <uuid/uuid.h>
#include "zlist.h"
// Keys are short strings
#define KVMSG_KEY_MAX 255
// Message is formatted on wire as 5 frames:
// frame 0: key (0MQ string)
// frame 1: sequence (8 bytes, network order)
// frame 2: uuid (blob, 16 bytes)
// frame 3: properties (0MQ string)
// frame 4: body (blob)
#define FRAME_KEY 0
#define FRAME_SEQ 1
#define FRAME_UUID 2
#define FRAME_PROPS 3
#define FRAME_BODY 4
#define KVMSG_FRAMES 5
// Structure of our class
struct _kvmsg {
// Presence indicators for each frame
int present [KVMSG_FRAMES];
// Corresponding 0MQ message frames, if any
zmq_msg_t frame [KVMSG_FRAMES];
// Key, copied into safe C string
char key [KVMSG_KEY_MAX + 1];
// List of properties, as name=value strings
zlist_t *props;
size_t props_size;
};
// .split property encoding
// These two helpers serialize a list of properties to and from a
// message frame:
static void
s_encode_props (kvmsg_t *self)
{
zmq_msg_t *msg = &self->frame [FRAME_PROPS];
if (self->present [FRAME_PROPS])
zmq_msg_close (msg);
zmq_msg_init_size (msg, self->props_size);
char *prop = zlist_first (self->props);
char *dest = (char *) zmq_msg_data (msg);
while (prop) {
strcpy (dest, prop);
dest += strlen (prop);
*dest++ = '\n';
prop = zlist_next (self->props);
}
self->present [FRAME_PROPS] = 1;
}
static void
s_decode_props (kvmsg_t *self)
{
zmq_msg_t *msg = &self->frame [FRAME_PROPS];
self->props_size = 0;
while (zlist_size (self->props))
free (zlist_pop (self->props));
size_t remainder = zmq_msg_size (msg);
char *prop = (char *) zmq_msg_data (msg);
char *eoln = memchr (prop, '\n', remainder);
while (eoln) {
*eoln = 0;
zlist_append (self->props, strdup (prop));
self->props_size += strlen (prop) + 1;
remainder -= strlen (prop) + 1;
prop = eoln + 1;
eoln = memchr (prop, '\n', remainder);
}
}
// .split constructor and destructor
// Here are the constructor and destructor for the class:
// Constructor, takes a sequence number for the new kvmsg instance:
kvmsg_t *
kvmsg_new (int64_t sequence)
{
kvmsg_t
*self;
self = (kvmsg_t *) zmalloc (sizeof (kvmsg_t));
self->props = zlist_new ();
kvmsg_set_sequence (self, sequence);
return self;
}
// zhash_free_fn callback helper that does the low level destruction:
void
kvmsg_free (void *ptr)
{
if (ptr) {
kvmsg_t *self = (kvmsg_t *) ptr;
// Destroy message frames if any
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++)
if (self->present [frame_nbr])
zmq_msg_close (&self->frame [frame_nbr]);
// Destroy property list
while (zlist_size (self->props))
free (zlist_pop (self->props));
zlist_destroy (&self->props);
// Free object itself
free (self);
}
}
// Destructor
void
kvmsg_destroy (kvmsg_t **self_p)
{
assert (self_p);
if (*self_p) {
kvmsg_free (*self_p);
*self_p = NULL;
}
}
// .split recv method
// This method reads a key-value message from the socket and returns a
// new {{kvmsg}} instance:
kvmsg_t *
kvmsg_recv (void *socket)
{
// This method is almost unchanged from kvsimple
// .skip
assert (socket);
kvmsg_t *self = kvmsg_new (0);
// Read all frames off the wire, reject if bogus
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++) {
if (self->present [frame_nbr])
zmq_msg_close (&self->frame [frame_nbr]);
zmq_msg_init (&self->frame [frame_nbr]);
self->present [frame_nbr] = 1;
if (zmq_msg_recv (&self->frame [frame_nbr], socket, 0) == -1) {
kvmsg_destroy (&self);
break;
}
// Verify multipart framing
int rcvmore = (frame_nbr < KVMSG_FRAMES - 1)? 1: 0;
if (zsocket_rcvmore (socket) != rcvmore) {
kvmsg_destroy (&self);
break;
}
}
// .until
if (self)
s_decode_props (self);
return self;
}
// Send key-value message to socket; any empty frames are sent as such.
void
kvmsg_send (kvmsg_t *self, void *socket)
{
assert (self);
assert (socket);
s_encode_props (self);
// The rest of the method is unchanged from kvsimple
// .skip
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++) {
zmq_msg_t copy;
zmq_msg_init (©);
if (self->present [frame_nbr])
zmq_msg_copy (©, &self->frame [frame_nbr]);
zmq_msg_send (©, socket,
(frame_nbr < KVMSG_FRAMES - 1)? ZMQ_SNDMORE: 0);
zmq_msg_close (©);
}
}
// .until
// .split dup method
// This method duplicates a {{kvmsg}} instance, returns the new instance:
kvmsg_t *
kvmsg_dup (kvmsg_t *self)
{
kvmsg_t *kvmsg = kvmsg_new (0);
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++) {
if (self->present [frame_nbr]) {
zmq_msg_t *src = &self->frame [frame_nbr];
zmq_msg_t *dst = &kvmsg->frame [frame_nbr];
zmq_msg_init_size (dst, zmq_msg_size (src));
memcpy (zmq_msg_data (dst),
zmq_msg_data (src), zmq_msg_size (src));
kvmsg->present [frame_nbr] = 1;
}
}
kvmsg->props_size = zlist_size (self->props);
char *prop = (char *) zlist_first (self->props);
while (prop) {
zlist_append (kvmsg->props, strdup (prop));
prop = (char *) zlist_next (self->props);
}
return kvmsg;
}
// The key, sequence, body, and size methods are the same as in kvsimple.
// .skip
// Return key from last read message, if any, else NULL
char *
kvmsg_key (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_KEY]) {
if (!*self->key) {
size_t size = zmq_msg_size (&self->frame [FRAME_KEY]);
if (size > KVMSG_KEY_MAX)
size = KVMSG_KEY_MAX;
memcpy (self->key,
zmq_msg_data (&self->frame [FRAME_KEY]), size);
self->key [size] = 0;
}
return self->key;
}
else
return NULL;
}
// Set message key as provided
void
kvmsg_set_key (kvmsg_t *self, char *key)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_KEY];
if (self->present [FRAME_KEY])
zmq_msg_close (msg);
zmq_msg_init_size (msg, strlen (key));
memcpy (zmq_msg_data (msg), key, strlen (key));
self->present [FRAME_KEY] = 1;
}
// Set message key using printf format
void
kvmsg_fmt_key (kvmsg_t *self, char *format, ...)
{
char value [KVMSG_KEY_MAX + 1];
va_list args;
assert (self);
va_start (args, format);
vsnprintf (value, KVMSG_KEY_MAX, format, args);
va_end (args);
kvmsg_set_key (self, value);
}
// Return sequence nbr from last read message, if any
int64_t
kvmsg_sequence (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_SEQ]) {
assert (zmq_msg_size (&self->frame [FRAME_SEQ]) == 8);
byte *source = zmq_msg_data (&self->frame [FRAME_SEQ]);
int64_t sequence = ((int64_t) (source [0]) << 56)
+ ((int64_t) (source [1]) << 48)
+ ((int64_t) (source [2]) << 40)
+ ((int64_t) (source [3]) << 32)
+ ((int64_t) (source [4]) << 24)
+ ((int64_t) (source [5]) << 16)
+ ((int64_t) (source [6]) << 8)
+ (int64_t) (source [7]);
return sequence;
}
else
return 0;
}
// Set message sequence number
void
kvmsg_set_sequence (kvmsg_t *self, int64_t sequence)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_SEQ];
if (self->present [FRAME_SEQ])
zmq_msg_close (msg);
zmq_msg_init_size (msg, 8);
byte *source = zmq_msg_data (msg);
source [0] = (byte) ((sequence >> 56) & 255);
source [1] = (byte) ((sequence >> 48) & 255);
source [2] = (byte) ((sequence >> 40) & 255);
source [3] = (byte) ((sequence >> 32) & 255);
source [4] = (byte) ((sequence >> 24) & 255);
source [5] = (byte) ((sequence >> 16) & 255);
source [6] = (byte) ((sequence >> 8) & 255);
source [7] = (byte) ((sequence) & 255);
self->present [FRAME_SEQ] = 1;
}
// Return body from last read message, if any, else NULL
byte *
kvmsg_body (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_BODY])
return (byte *) zmq_msg_data (&self->frame [FRAME_BODY]);
else
return NULL;
}
// Set message body
void
kvmsg_set_body (kvmsg_t *self, byte *body, size_t size)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_BODY];
if (self->present [FRAME_BODY])
zmq_msg_close (msg);
self->present [FRAME_BODY] = 1;
zmq_msg_init_size (msg, size);
memcpy (zmq_msg_data (msg), body, size);
}
// Set message body using printf format
void
kvmsg_fmt_body (kvmsg_t *self, char *format, ...)
{
char value [255 + 1];
va_list args;
assert (self);
va_start (args, format);
vsnprintf (value, 255, format, args);
va_end (args);
kvmsg_set_body (self, (byte *) value, strlen (value));
}
// Return body size from last read message, if any, else zero
size_t
kvmsg_size (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_BODY])
return zmq_msg_size (&self->frame [FRAME_BODY]);
else
return 0;
}
// .until
// .split UUID methods
// These methods get and set the UUID for the key-value message:
byte *
kvmsg_uuid (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_UUID]
&& zmq_msg_size (&self->frame [FRAME_UUID]) == sizeof (uuid_t))
return (byte *) zmq_msg_data (&self->frame [FRAME_UUID]);
else
return NULL;
}
// Sets the UUID to a randomly generated value
void
kvmsg_set_uuid (kvmsg_t *self)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_UUID];
uuid_t uuid;
uuid_generate (uuid);
if (self->present [FRAME_UUID])
zmq_msg_close (msg);
zmq_msg_init_size (msg, sizeof (uuid));
memcpy (zmq_msg_data (msg), uuid, sizeof (uuid));
self->present [FRAME_UUID] = 1;
}
// .split property methods
// These methods get and set a specified message property:
// Get message property, return "" if no such property is defined.
char *
kvmsg_get_prop (kvmsg_t *self, char *name)
{
assert (strchr (name, '=') == NULL);
char *prop = zlist_first (self->props);
size_t namelen = strlen (name);
while (prop) {
if (strlen (prop) > namelen
&& memcmp (prop, name, namelen) == 0
&& prop [namelen] == '=')
return prop + namelen + 1;
prop = zlist_next (self->props);
}
return "";
}
// Set message property. Property name cannot contain '='. Max length of
// value is 255 chars.
void
kvmsg_set_prop (kvmsg_t *self, char *name, char *format, ...)
{
assert (strchr (name, '=') == NULL);
char value [255 + 1];
va_list args;
assert (self);
va_start (args, format);
vsnprintf (value, 255, format, args);
va_end (args);
// Allocate name=value string
char *prop = malloc (strlen (name) + strlen (value) + 2);
// Remove existing property if any
sprintf (prop, "%s=", name);
char *existing = zlist_first (self->props);
while (existing) {
if (memcmp (prop, existing, strlen (prop)) == 0) {
self->props_size -= strlen (existing) + 1;
zlist_remove (self->props, existing);
free (existing);
break;
}
existing = zlist_next (self->props);
}
// Add new name=value property string
strcat (prop, value);
zlist_append (self->props, prop);
self->props_size += strlen (prop) + 1;
}
// .split store method
// This method stores the key-value message into a hash map, unless
// the key and value are both null. It nullifies the {{kvmsg}} reference
// so that the object is owned by the hash map, not the caller:
void
kvmsg_store (kvmsg_t **self_p, zhash_t *hash)
{
assert (self_p);
if (*self_p) {
kvmsg_t *self = *self_p;
assert (self);
if (kvmsg_size (self)) {
if (self->present [FRAME_KEY]
&& self->present [FRAME_BODY]) {
zhash_update (hash, kvmsg_key (self), self);
zhash_freefn (hash, kvmsg_key (self), kvmsg_free);
}
}
else
zhash_delete (hash, kvmsg_key (self));
*self_p = NULL;
}
}
// .split dump method
// This method extends the {{kvsimple}} implementation with support for
// message properties:
void
kvmsg_dump (kvmsg_t *self)
{
// .skip
if (self) {
if (!self) {
fprintf (stderr, "NULL");
return;
}
size_t size = kvmsg_size (self);
byte *body = kvmsg_body (self);
fprintf (stderr, "[seq:%" PRId64 "]", kvmsg_sequence (self));
fprintf (stderr, "[key:%s]", kvmsg_key (self));
// .until
fprintf (stderr, "[size:%zd] ", size);
if (zlist_size (self->props)) {
fprintf (stderr, "[");
char *prop = zlist_first (self->props);
while (prop) {
fprintf (stderr, "%s;", prop);
prop = zlist_next (self->props);
}
fprintf (stderr, "]");
}
// .skip
int char_nbr;
for (char_nbr = 0; char_nbr < size; char_nbr++)
fprintf (stderr, "%02X", body [char_nbr]);
fprintf (stderr, "\n");
}
else
fprintf (stderr, "NULL message\n");
}
// .until
// .split test method
// This method is the same as in {{kvsimple}} with added support
// for the uuid and property features of {{kvmsg}}:
int
kvmsg_test (int verbose)
{
// .skip
kvmsg_t
*kvmsg;
printf (" * kvmsg: ");
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *output = zsocket_new (ctx, ZMQ_DEALER);
int rc = zmq_bind (output, "ipc://kvmsg_selftest.ipc");
assert (rc == 0);
void *input = zsocket_new (ctx, ZMQ_DEALER);
rc = zmq_connect (input, "ipc://kvmsg_selftest.ipc");
assert (rc == 0);
zhash_t *kvmap = zhash_new ();
// .until
// Test send and receive of simple message
kvmsg = kvmsg_new (1);
kvmsg_set_key (kvmsg, "key");
kvmsg_set_uuid (kvmsg);
kvmsg_set_body (kvmsg, (byte *) "body", 4);
if (verbose)
kvmsg_dump (kvmsg);
kvmsg_send (kvmsg, output);
kvmsg_store (&kvmsg, kvmap);
kvmsg = kvmsg_recv (input);
if (verbose)
kvmsg_dump (kvmsg);
assert (streq (kvmsg_key (kvmsg), "key"));
kvmsg_store (&kvmsg, kvmap);
// Test send and receive of message with properties
kvmsg = kvmsg_new (2);
kvmsg_set_prop (kvmsg, "prop1", "value1");
kvmsg_set_prop (kvmsg, "prop2", "value1");
kvmsg_set_prop (kvmsg, "prop2", "value2");
kvmsg_set_key (kvmsg, "key");
kvmsg_set_uuid (kvmsg);
kvmsg_set_body (kvmsg, (byte *) "body", 4);
assert (streq (kvmsg_get_prop (kvmsg, "prop2"), "value2"));
if (verbose)
kvmsg_dump (kvmsg);
kvmsg_send (kvmsg, output);
kvmsg_destroy (&kvmsg);
kvmsg = kvmsg_recv (input);
if (verbose)
kvmsg_dump (kvmsg);
assert (streq (kvmsg_key (kvmsg), "key"));
assert (streq (kvmsg_get_prop (kvmsg, "prop2"), "value2"));
kvmsg_destroy (&kvmsg);
// .skip
// Shutdown and destroy all objects
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
printf ("OK\n");
return 0;
}
// .until
kvmsg: Key-value message class: full in C++
/* =====================================================================
* kvmsg - key-value message class for example applications
* ===================================================================== */
#ifndef __KVMSG_HPP_INCLUDED__
#define __KVMSG_HPP_INCLUDED__
#include <random>
#include <string>
#include <unordered_map>
#include <csignal>
#include <atomic>
#include <cstdlib> // for rand
#include <zmqpp/zmqpp.hpp>
using ustring = std::basic_string<unsigned char>;
class KVMsg {
public:
KVMsg() = default;
// Constructor, sets sequence as provided
KVMsg(int64_t sequence);
// Destructor
~KVMsg();
// Create duplicate of kvmsg
KVMsg(const KVMsg &other);
// Create copy
KVMsg& operator=(const KVMsg &other);
// Reads key-value message from socket, returns new kvmsg instance.
static KVMsg* recv(zmqpp::socket_t &socket);
// Send key-value message to socket; any empty frames are sent as such.
void send(zmqpp::socket_t &socket);
// Return key from last read message, if any, else NULL
std::string key() const;
// Return sequence nbr from last read message, if any
int64_t sequence() const;
// Return body from last read message, if any, else NULL
ustring body() const;
// Return body size from last read message, if any, else zero
size_t size() const;
// Return UUID from last read message, if any, else NULL
std::string uuid() const;
// Set message key as provided
void set_key(std::string key);
// Set message sequence number
void set_sequence(int64_t sequence);
// Set message body
void set_body(ustring body);
// Set message UUID to generated value
void set_uuid();
// Set message key using printf format
void fmt_key(const char *format, ...);
// Set message body using printf format
void fmt_body(const char *format, ...);
// Get message property, if set, else ""
std::string property(const std::string &name) const;
// Set message property
// Names cannot contain '='. Max length of value is 255 chars.
void set_property(const std::string &name, const char *format, ...);
// Store entire kvmsg into hash map, if key/value are set
// Nullifies kvmsg reference, and destroys automatically when no longer
// needed.
void store(std::unordered_map<std::string, KVMsg*> &hash);
// clear the hash map, free elements
static void clear_kvmap(std::unordered_map<std::string, KVMsg*> &hash);
// Dump message to stderr, for debugging and tracing
std::string to_string();
void encode_frames(zmqpp::message &frames);
void decode_frames(zmqpp::message &frames);
// Runs self test of class
static bool test(int verbose);
private:
// Message is formatted on wire as 5 frames:
// frame 0: key (0MQ string)
// frame 1: sequence (8 bytes, network order)
// frame 2: uuid (blob, 16 bytes)
// frame 3: properties (0MQ string)
// frame 4: body (blob)
static constexpr uint32_t FRAME_KEY = 0;
static constexpr uint32_t FRAME_SEQ = 1;
static constexpr uint32_t FRAME_UUID = 2;
static constexpr uint32_t FRAME_PROPS = 3;
static constexpr uint32_t FRAME_BODY = 4;
static constexpr uint32_t KVMSG_FRAMES = 5;
std::string key_;
int64_t sequence_{};
std::string uuid_;
ustring body_;
std::unordered_map<std::string, std::string> properties_;
bool presents_[KVMSG_FRAMES];
};
namespace {
std::string generateUUID() {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, 15);
std::uniform_int_distribution<> dis2(8, 11);
std::stringstream ss;
ss << std::hex;
for (int i = 0; i < 8; ++i) ss << dis(gen);
// ss << "-";
for (int i = 0; i < 4; ++i) ss << dis(gen);
ss << "4"; // UUID version 4
for (int i = 0; i < 3; ++i) ss << dis(gen);
// ss << "-";
ss << dis2(gen); // UUID variant
for (int i = 0; i < 3; ++i) ss << dis(gen);
// ss << "-";
for (int i = 0; i < 12; ++i) ss << dis(gen);
return ss.str();
}
}
KVMsg::KVMsg(int64_t sequence) {
sequence_ = sequence;
presents_[FRAME_SEQ] = true;
}
KVMsg::~KVMsg() {
std::cout << "DEBUG: freeing key=" << key_ << std::endl;
}
KVMsg::KVMsg(const KVMsg &other) {
std::cout << "copy construct\n";
key_ = other.key_;
sequence_ = other.sequence_;
uuid_ = other.uuid_;
body_ = other.body_;
properties_ = other.properties_;
for (int i = 0; i < KVMSG_FRAMES; i++) {
presents_[i] = other.presents_[i];
}
}
KVMsg& KVMsg::operator=(const KVMsg &other) {
std::cout << "copy assign\n";
key_ = other.key_;
sequence_ = other.sequence_;
uuid_ = other.uuid_;
body_ = other.body_;
properties_ = other.properties_;
for (int i = 0; i < KVMSG_FRAMES; i++) {
presents_[i] = other.presents_[i];
}
return *this;
}
// implement the static method recv
KVMsg* KVMsg::recv(zmqpp::socket_t &socket) {
KVMsg* kvmsg = new KVMsg(-1);
zmqpp::message frames;
if (!socket.receive(frames)) {
return nullptr;
}
kvmsg->decode_frames(frames);
return kvmsg;
}
void KVMsg::send(zmqpp::socket_t &socket) {
zmqpp::message frames;
encode_frames(frames);
socket.send(frames);
}
std::string KVMsg::key() const {
return key_;
}
int64_t KVMsg::sequence() const {
return sequence_;
}
ustring KVMsg::body() const {
return body_;
}
size_t KVMsg::size() const {
return body_.size();
}
std::string KVMsg::uuid() const {
return uuid_;
}
void KVMsg::set_key(std::string key) {
key_ = key;
presents_[FRAME_KEY] = true;
}
void KVMsg::set_sequence(int64_t sequence) {
sequence_ = sequence;
presents_[FRAME_SEQ] = true;
}
void KVMsg::set_body(ustring body) {
body_ = body;
presents_[FRAME_BODY] = true;
}
void KVMsg::set_uuid() {
uuid_ = generateUUID();
presents_[FRAME_UUID] = true;
}
void KVMsg::fmt_key(const char *format, ...) {
char buffer[256];
va_list args;
va_start(args, format);
vsnprintf(buffer, 256, format, args);
va_end(args);
key_ = buffer;
presents_[FRAME_KEY] = true;
}
void KVMsg::fmt_body(const char *format, ...) {
char buffer[256];
va_list args;
va_start(args, format);
vsnprintf(buffer, 256, format, args);
va_end(args);
// body_ = ustring(buffer, buffer + strlen(buffer));
body_ = ustring((unsigned char *)buffer, strlen(buffer));
presents_[FRAME_BODY] = true;
}
std::string KVMsg::property(const std::string &name) const {
if (!presents_[FRAME_PROPS]) {
return "";
}
auto it = properties_.find(name);
if (it == properties_.end()) {
return "";
}
return it->second;
}
void KVMsg::set_property(const std::string &name, const char *format, ...) {
char buffer[256];
va_list args;
va_start(args, format);
vsnprintf(buffer, 256, format, args);
va_end(args);
properties_[name] = buffer;
presents_[FRAME_PROPS] = true;
}
void KVMsg::encode_frames(zmqpp::message &frames) {
// assert(frames.parts() == 0);
if (presents_[FRAME_KEY]) {
frames.add(key_);
} else {
frames.add("");
}
if (presents_[FRAME_SEQ]) {
frames.add(sequence_);
} else {
frames.add(-1);
}
if (presents_[FRAME_UUID]) {
frames.add(uuid_);
} else {
frames.add("");
}
if (presents_[FRAME_PROPS]) {
std::string props;
for (auto &prop : properties_) {
props += prop.first + "=" + prop.second + "\n";
}
frames.add(props);
} else {
frames.add("");
}
if (presents_[FRAME_BODY]) {
frames.add_raw(body_.data(), body_.size());
} else {
frames.add("");
}
}
void KVMsg::decode_frames(zmqpp::message &frames) {
assert(frames.parts() == KVMSG_FRAMES);
frames.get(key_, 0);
if (!key_.empty()) {
presents_[FRAME_KEY] = true;
}
frames.get(sequence_, 1);
if (sequence_ != -1) {
presents_[FRAME_SEQ] = true;
}
frames.get(uuid_, 2);
if (!uuid_.empty()) {
presents_[FRAME_UUID] = true;
}
std::string props = frames.get<std::string>(3);
properties_.clear();
if (!props.empty()) {
presents_[FRAME_PROPS] = true;
size_t pos = 0;
while (pos < props.size()) {
size_t end = props.find('=', pos);
std::string name = props.substr(pos, end - pos);
pos = end + 1;
end = props.find('\n', pos);
std::string value = props.substr(pos, end - pos);
pos = end + 1;
properties_[name] = value;
}
}
char const* raw_body = frames.get<char const*>(4);
size_t size = frames.size(4);
if (size > 0) {
presents_[FRAME_BODY] = true;
body_ = ustring((unsigned char const*)raw_body, size);
}
}
void KVMsg::store(std::unordered_map<std::string, KVMsg*> &hash) {
if (size() == 0) {
hash.erase(key_);
return;
}
if (presents_[FRAME_KEY] && presents_[FRAME_BODY]) {
hash[key_] = this;
}
}
void KVMsg::clear_kvmap(std::unordered_map<std::string, KVMsg*> &hash) {
for (auto &kv : hash) {
delete kv.second;
kv.second = nullptr;
}
hash.clear();
}
std::string KVMsg::to_string() {
std::stringstream ss;
ss << "key=" << key_ << ",sequence=" << sequence_ << ",uuid=" << uuid_ << std::endl;
ss << "propes={";
for (auto &prop : properties_) {
ss << prop.first << "=" << prop.second << ",";
}
ss << "},";
ss << "body=";
for (auto &byte : body_) {
ss << std::hex << byte;
}
return ss.str();
}
bool KVMsg::test(int verbose) {
zmqpp::context context;
zmqpp::socket output(context, zmqpp::socket_type::dealer);
output.bind("ipc://kvmsg_selftest.ipc");
zmqpp::socket input(context, zmqpp::socket_type::dealer);
input.connect("ipc://kvmsg_selftest.ipc");
KVMsg kvmsg(1);
kvmsg.set_key("key");
kvmsg.set_uuid();
kvmsg.set_body((unsigned char *)"body");
if (verbose) {
std::cout << kvmsg.to_string() << std::endl;
}
kvmsg.send(output);
std::unordered_map<std::string, KVMsg*> kvmap;
kvmsg.store(kvmap);
std::cout << "print from kvmap[key]" << std::endl;
std::cout << kvmap["key"]->to_string() << std::endl;
KVMsg *kvmsg_p = KVMsg::recv(input);
if (!kvmsg_p) {
return false;
}
assert(kvmsg_p->key() == "key");
delete kvmsg_p;
kvmsg_p = new KVMsg(2);
kvmsg_p->set_key("key2");
kvmsg_p->set_property("prop1", "value1");
kvmsg_p->set_property("prop2", "value2");
kvmsg_p->set_body((unsigned char *)"body2");
kvmsg_p->set_uuid();
assert(kvmsg_p->property("prop2") == "value2");
kvmsg_p->send(output);
delete kvmsg_p;
kvmsg_p = KVMsg::recv(input);
if (!kvmsg_p) {
return false;
}
assert(kvmsg_p->key() == "key2");
assert(kvmsg_p->property("prop2") == "value2");
if (verbose) {
std::cout << kvmsg_p->to_string() << std::endl;
}
delete kvmsg_p;
std::cout << "KVMsg self test passed" << std::endl;
return true;
}
// ---------------------------------------------------------------------
// Signal handling
//
// Call s_catch_signals() in your application at startup, and then exit
// your main loop if s_interrupted is ever 1. Works especially well with
// zmq_poll.
static std::atomic<int> s_interrupted(0);
void s_signal_handler(int signal_value) {
s_interrupted = 1;
}
// setting signal handler
void s_catch_signals() {
std::signal(SIGINT, s_signal_handler);
std::signal(SIGTERM, s_signal_handler);
}
// Provide random number from 0..(num-1)
static int within(int num) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, num - 1);
return dis(gen);
}
#endif // Included
kvmsg: Key-value message class: full in C#
kvmsg: Key-value message class: full in CL
kvmsg: Key-value message class: full in Delphi
kvmsg: Key-value message class: full in Erlang
kvmsg: Key-value message class: full in Elixir
kvmsg: Key-value message class: full in F#
kvmsg: Key-value message class: full in Felix
kvmsg: Key-value message class: full in Go
kvmsg: Key-value message class: full in Haskell
kvmsg: Key-value message class: full in Haxe
kvmsg: Key-value message class: full in Java
package guide;
import java.nio.ByteBuffer;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Properties;
import java.util.UUID;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
public class kvmsg
{
// Keys are short strings
private static final int KVMSG_KEY_MAX = 255;
// Message is formatted on wire as 4 frames:
// frame 0: getKey (0MQ string)
// frame 1: getSequence (8 bytes, network order)
// frame 2: uuid (blob, 16 bytes)
// frame 3: properties (0MQ string)
// frame 4: body (blob)
private static final int FRAME_KEY = 0;
private static final int FRAME_SEQ = 1;
private static final int FRAME_UUID = 2;
private static final int FRAME_PROPS = 3;
private static final int FRAME_BODY = 4;
private static final int KVMSG_FRAMES = 5;
// Presence indicators for each frame
private boolean[] present = new boolean[KVMSG_FRAMES];
// Corresponding 0MQ message frames, if any
private byte[][] frame = new byte[KVMSG_FRAMES][];
// Key, copied into safe string
private String key;
// List of properties, as name=value strings
private Properties props;
private int props_size;
// .split property encoding
// These two helpers serialize a list of properties to and from a
// message frame:
private void encodeProps()
{
ByteBuffer msg = ByteBuffer.allocate(props_size);
for (Entry<Object, Object> o : props.entrySet()) {
String prop = o.getKey().toString() + "=" + o.getValue().toString() + "\n";
msg.put(prop.getBytes(ZMQ.CHARSET));
}
present[FRAME_PROPS] = true;
frame[FRAME_PROPS] = msg.array();
}
private void decodeProps()
{
byte[] msg = frame[FRAME_PROPS];
props_size = msg.length;
props.clear();
if (msg.length == 0)
return;
System.out.println("" + msg.length + " :" + new String(msg, ZMQ.CHARSET));
for (String prop : new String(msg, ZMQ.CHARSET).split("\n")) {
String[] split = prop.split("=");
props.setProperty(split[0], split[1]);
}
}
// .split constructor and destructor
// Here are the constructor and destructor for the class:
// Constructor, takes a getSequence number for the new kvmsg instance:
public kvmsg(long sequence)
{
props = new Properties();
setSequence(sequence);
}
public void destroy()
{
}
// .split recv method
// This method reads a getKey-value message from the socket and returns a
// new {{kvmsg}} instance:
public static kvmsg recv(Socket socket)
{
// This method is almost unchanged from kvsimple
// .skip
assert (socket != null);
kvmsg self = new kvmsg(0);
// Read all frames off the wire, reject if bogus
int frameNbr;
for (frameNbr = 0; frameNbr < KVMSG_FRAMES; frameNbr++) {
//zmq_msg_init (&self->frame [frameNbr]);
self.present[frameNbr] = true;
if ((self.frame[frameNbr] = socket.recv(0)) == null) {
self.destroy();
break;
}
// Verify multipart framing
boolean rcvmore = (frameNbr < KVMSG_FRAMES - 1) ? true : false;
if (socket.hasReceiveMore() != rcvmore) {
self.destroy();
break;
}
}
// .until
self.decodeProps();
return self;
}
// Send getKey-value message to socket; any empty frames are sent as such.
public void send(Socket socket)
{
assert (socket != null);
encodeProps();
// The rest of the method is unchanged from kvsimple
// .skip
int frameNbr;
for (frameNbr = 0; frameNbr < KVMSG_FRAMES; frameNbr++) {
byte[] copy = ZMQ.MESSAGE_SEPARATOR;
if (present[frameNbr])
copy = frame[frameNbr];
socket.send(copy, (frameNbr < KVMSG_FRAMES - 1) ? ZMQ.SNDMORE : 0);
}
}
// .until
// .split dup method
// This method duplicates a {{kvmsg}} instance, returns the new instance:
public kvmsg dup()
{
kvmsg kvmsg = new kvmsg(0);
int frameNbr;
for (frameNbr = 0; frameNbr < KVMSG_FRAMES; frameNbr++) {
if (present[frameNbr]) {
kvmsg.frame[frameNbr] = new byte[frame[frameNbr].length];
System.arraycopy(frame[frameNbr], 0, kvmsg.frame[frameNbr], 0, frame[frameNbr].length);
kvmsg.present[frameNbr] = true;
}
}
kvmsg.props_size = props_size;
kvmsg.props.putAll(props);
return kvmsg;
}
// The getKey, getSequence, body, and size methods are the same as in kvsimple.
// .skip
// Return getKey from last read message, if any, else NULL
public String getKey()
{
if (present[FRAME_KEY]) {
if (key == null) {
int size = frame[FRAME_KEY].length;
if (size > KVMSG_KEY_MAX)
size = KVMSG_KEY_MAX;
byte[] buf = new byte[size];
System.arraycopy(frame[FRAME_KEY], 0, buf, 0, size);
key = new String(buf, ZMQ.CHARSET);
}
return key;
}
else return null;
}
// Set message getKey as provided
public void setKey(String key)
{
byte[] msg = new byte[key.length()];
System.arraycopy(key.getBytes(ZMQ.CHARSET), 0, msg, 0, key.length());
frame[FRAME_KEY] = msg;
present[FRAME_KEY] = true;
}
// Set message getKey using printf format
public void fmtKey(String fmt, Object... args)
{
setKey(String.format(fmt, args));
}
// Return getSequence nbr from last read message, if any
public long getSequence()
{
if (present[FRAME_SEQ]) {
assert (frame[FRAME_SEQ].length == 8);
ByteBuffer source = ByteBuffer.wrap(frame[FRAME_SEQ]);
return source.getLong();
}
else return 0;
}
// Set message getSequence number
public void setSequence(long sequence)
{
ByteBuffer msg = ByteBuffer.allocate(8);
msg.putLong(sequence);
present[FRAME_SEQ] = true;
frame[FRAME_SEQ] = msg.array();
}
// Return body from last read message, if any, else NULL
public byte[] body()
{
if (present[FRAME_BODY])
return frame[FRAME_BODY];
else return null;
}
// Set message body
public void setBody(byte[] body)
{
byte[] msg = new byte[body.length];
System.arraycopy(body, 0, msg, 0, body.length);
frame[FRAME_BODY] = msg;
present[FRAME_BODY] = true;
}
// Set message body using printf format
public void fmtBody(String fmt, Object... args)
{
setBody(String.format(fmt, args).getBytes(ZMQ.CHARSET));
}
// Return body size from last read message, if any, else zero
public int size()
{
if (present[FRAME_BODY])
return frame[FRAME_BODY].length;
else return 0;
}
// .until
// .split UUID methods
// These methods get and set the UUID for the getKey-value message:
public byte[] UUID()
{
if (present[FRAME_UUID])
return frame[FRAME_UUID];
else return null;
}
// Sets the UUID to a randomly generated value
public void setUUID()
{
byte[] msg = UUID.randomUUID().toString().getBytes(ZMQ.CHARSET);
present[FRAME_UUID] = true;
frame[FRAME_UUID] = msg;
}
// .split property methods
// These methods get and set a specified message property:
// Get message property, return "" if no such property is defined.
public String getProp(String name)
{
return props.getProperty(name, "");
}
// Set message property. Property name cannot contain '='. Max length of
// value is 255 chars.
public void setProp(String name, String fmt, Object... args)
{
String value = String.format(fmt, args);
Object old = props.setProperty(name, value);
if (old != null)
props_size -= old.toString().length();
else props_size += name.length() + 2;
props_size += value.length();
}
// .split store method
// This method stores the getKey-value message into a hash map, unless
// the getKey and value are both null. It nullifies the {{kvmsg}} reference
// so that the object is owned by the hash map, not the caller:
public void store(Map<String, kvmsg> hash)
{
if (size() > 0) {
if (present[FRAME_KEY] && present[FRAME_BODY]) {
hash.put(getKey(), this);
}
}
else hash.remove(getKey());
}
// .split dump method
// This method extends the {{kvsimple}} implementation with support for
// message properties:
public void dump()
{
int size = size();
byte[] body = body();
System.err.printf("[seq:%d]", getSequence());
System.err.printf("[getKey:%s]", getKey());
// .until
System.err.printf("[size:%d] ", size);
System.err.printf("[");
for (String key : props.stringPropertyNames()) {
System.err.printf("%s=%s;", key, props.getProperty(key));
}
System.err.printf("]");
// .skip
for (int charNbr = 0; charNbr < size; charNbr++)
System.err.printf("%02X", body[charNbr]);
System.err.printf("\n");
}
// .until
// .split test method
// This method is the same as in {{kvsimple}} with added support
// for the uuid and property features of {{kvmsg}}:
public void test(boolean verbose)
{
System.out.printf(" * kvmsg: ");
// Prepare our context and sockets
try (ZContext ctx = new ZContext()) {
Socket output = ctx.createSocket(SocketType.DEALER);
output.bind("ipc://kvmsg_selftest.ipc");
Socket input = ctx.createSocket(SocketType.DEALER);
input.connect("ipc://kvmsg_selftest.ipc");
Map<String, kvmsg> kvmap = new HashMap<String, kvmsg>();
// .until
// Test send and receive of simple message
kvmsg kvmsg = new kvmsg(1);
kvmsg.setKey("getKey");
kvmsg.setUUID();
kvmsg.setBody("body".getBytes(ZMQ.CHARSET));
if (verbose)
kvmsg.dump();
kvmsg.send(output);
kvmsg.store(kvmap);
kvmsg = guide.kvmsg.recv(input);
if (verbose)
kvmsg.dump();
assert (kvmsg.getKey().equals("getKey"));
kvmsg.store(kvmap);
// Test send and receive of message with properties
kvmsg = new kvmsg(2);
kvmsg.setProp("prop1", "value1");
kvmsg.setProp("prop2", "value1");
kvmsg.setProp("prop2", "value2");
kvmsg.setKey("getKey");
kvmsg.setUUID();
kvmsg.setBody("body".getBytes(ZMQ.CHARSET));
assert (kvmsg.getProp("prop2").equals("value2"));
if (verbose)
kvmsg.dump();
kvmsg.send(output);
kvmsg.destroy();
kvmsg = guide.kvmsg.recv(input);
if (verbose)
kvmsg.dump();
assert (kvmsg.key.equals("getKey"));
assert (kvmsg.getProp("prop2").equals("value2"));
kvmsg.destroy();
}
System.out.printf("OK\n");
}
// .until
}
kvmsg: Key-value message class: full in Julia
kvmsg: Key-value message class: full in Lua
kvmsg: Key-value message class: full in Node.js
kvmsg: Key-value message class: full in Objective-C
kvmsg: Key-value message class: full in ooc
kvmsg: Key-value message class: full in Perl
kvmsg: Key-value message class: full in PHP
kvmsg: Key-value message class: full in Python
"""
=====================================================================
kvmsg - key-value message class for example applications
Author: Min RK <benjaminrk@gmail.com>
"""
import struct # for packing integers
import sys
from uuid import uuid4
import zmq
# zmq.jsonapi ensures bytes, instead of unicode:
def encode_properties(properties_dict):
prop_s = b""
for key, value in properties_dict.items():
prop_s += b"%s=%s\n" % (key, value)
return prop_s
def decode_properties(prop_s):
prop = {}
line_array = prop_s.split(b"\n")
for line in line_array:
try:
key, value = line.split(b"=")
prop[key] = value
except ValueError as e:
#Catch empty line
pass
return prop
class KVMsg(object):
"""
Message is formatted on wire as 5 frames:
frame 0: key (0MQ string)
frame 1: sequence (8 bytes, network order)
frame 2: uuid (blob, 16 bytes)
frame 3: properties (0MQ string)
frame 4: body (blob)
"""
key = None
sequence = 0
uuid=None
properties = None
body = None
def __init__(self, sequence, uuid=None, key=None, properties=None, body=None):
assert isinstance(sequence, int)
self.sequence = sequence
if uuid is None:
uuid = uuid4().bytes
self.uuid = uuid
self.key = key
self.properties = {} if properties is None else properties
self.body = body
# dictionary access maps to properties:
def __getitem__(self, k):
return self.properties[k]
def __setitem__(self, k, v):
self.properties[k] = v
def get(self, k, default=None):
return self.properties.get(k, default)
def store(self, dikt):
"""Store me in a dict if I have anything to store
else delete me from the dict."""
if self.key is not None and self.body is not None:
dikt[self.key] = self
elif self.key in dikt:
del dikt[self.key]
def send(self, socket):
"""Send key-value message to socket; any empty frames are sent as such."""
key = b'' if self.key is None else self.key
seq_s = struct.pack('!q', self.sequence)
body = b'' if self.body is None else self.body
prop_s = encode_properties(self.properties)
socket.send_multipart([ key, seq_s, self.uuid, prop_s, body ])
@classmethod
def recv(cls, socket):
"""Reads key-value message from socket, returns new kvmsg instance."""
return cls.from_msg(socket.recv_multipart())
@classmethod
def from_msg(cls, msg):
"""Construct key-value message from a multipart message"""
key, seq_s, uuid, prop_s, body = msg
key = key if key else None
seq = struct.unpack('!q',seq_s)[0]
body = body if body else None
prop = decode_properties(prop_s)
return cls(seq, uuid=uuid, key=key, properties=prop, body=body)
def __repr__(self):
if self.body is None:
size = 0
data=b'NULL'
else:
size = len(self.body)
data = repr(self.body)
mstr = "[seq:{seq}][key:{key}][size:{size}][props:{props}][data:{data}]".format(
seq=self.sequence,
# uuid=hexlify(self.uuid),
key=self.key,
size=size,
props=encode_properties(self.properties),
data=data,
)
return mstr
def dump(self):
print("<<", str(self), ">>", file=sys.stderr)
# ---------------------------------------------------------------------
# Runs self test of class
def test_kvmsg (verbose):
print(" * kvmsg: ", end='')
# Prepare our context and sockets
ctx = zmq.Context()
output = ctx.socket(zmq.DEALER)
output.bind("ipc://kvmsg_selftest.ipc")
input = ctx.socket(zmq.DEALER)
input.connect("ipc://kvmsg_selftest.ipc")
kvmap = {}
# Test send and receive of simple message
kvmsg = KVMsg(1)
kvmsg.key = b"key"
kvmsg.body = b"body"
if verbose:
kvmsg.dump()
kvmsg.send(output)
kvmsg.store(kvmap)
kvmsg2 = KVMsg.recv(input)
if verbose:
kvmsg2.dump()
assert kvmsg2.key == b"key"
kvmsg2.store(kvmap)
assert len(kvmap) == 1 # shouldn't be different
# test send/recv with properties:
kvmsg = KVMsg(2, key=b"key", body=b"body")
kvmsg[b"prop1"] = b"value1"
kvmsg[b"prop2"] = b"value2"
kvmsg[b"prop3"] = b"value3"
assert kvmsg[b"prop1"] == b"value1"
if verbose:
kvmsg.dump()
kvmsg.send(output)
kvmsg2 = KVMsg.recv(input)
if verbose:
kvmsg2.dump()
# ensure properties were preserved
assert kvmsg2.key == kvmsg.key
assert kvmsg2.body == kvmsg.body
assert kvmsg2.properties == kvmsg.properties
assert kvmsg2[b"prop2"] == kvmsg[b"prop2"]
print("OK")
if __name__ == '__main__':
test_kvmsg('-v' in sys.argv)
kvmsg: Key-value message class: full in Q
kvmsg: Key-value message class: full in Racket
kvmsg: Key-value message class: full in Ruby
kvmsg: Key-value message class: full in Rust
kvmsg: Key-value message class: full in Scala
kvmsg: Key-value message class: full in Tcl
kvmsg: Key-value message class: full in OCaml
The Model Five client is almost identical to Model Four. It uses the full kvmsg class now, and sets a randomized ttl property (measured in seconds) on each message:
kvmsg_set_prop (kvmsg, "ttl", "%d", randof (30));
Using a Reactor #
Until now, we have used a poll loop in the server. In this next model of the server, we switch to using a reactor. In C, we use CZMQ’s zloop class. Using a reactor makes the code more verbose, but easier to understand and build out because each piece of the server is handled by a separate reactor handler.
We use a single thread and pass a server object around to the reactor handlers. We could have organized the server as multiple threads, each handling one socket or timer, but that works better when threads don’t have to share data. In this case all work is centered around the server’s hashmap, so one thread is simpler.
There are three reactor handlers:
- One to handle snapshot requests coming on the ROUTER socket;
- One to handle incoming updates from clients, coming on the PULL socket;
- One to expire ephemeral values that have passed their TTL.
clonesrv5: Clone server, Model Five in Ada
clonesrv5: Clone server, Model Five in Basic
clonesrv5: Clone server, Model Five in C
// Clone server - Model Five
// Lets us build this source without creating a library
#include "kvmsg.c"
// zloop reactor handlers
static int s_snapshots (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int s_collector (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int s_flush_ttl (zloop_t *loop, int timer_id, void *args);
// Our server is defined by these properties
typedef struct {
zctx_t *ctx; // Context wrapper
zhash_t *kvmap; // Key-value store
zloop_t *loop; // zloop reactor
int port; // Main port we're working on
int64_t sequence; // How many updates we're at
void *snapshot; // Handle snapshot requests
void *publisher; // Publish updates to clients
void *collector; // Collect updates from clients
} clonesrv_t;
int main (void)
{
clonesrv_t *self = (clonesrv_t *) zmalloc (sizeof (clonesrv_t));
self->port = 5556;
self->ctx = zctx_new ();
self->kvmap = zhash_new ();
self->loop = zloop_new ();
zloop_set_verbose (self->loop, false);
// Set up our clone server sockets
self->snapshot = zsocket_new (self->ctx, ZMQ_ROUTER);
zsocket_bind (self->snapshot, "tcp://*:%d", self->port);
self->publisher = zsocket_new (self->ctx, ZMQ_PUB);
zsocket_bind (self->publisher, "tcp://*:%d", self->port + 1);
self->collector = zsocket_new (self->ctx, ZMQ_PULL);
zsocket_bind (self->collector, "tcp://*:%d", self->port + 2);
// Register our handlers with reactor
zmq_pollitem_t poller = { 0, 0, ZMQ_POLLIN };
poller.socket = self->snapshot;
zloop_poller (self->loop, &poller, s_snapshots, self);
poller.socket = self->collector;
zloop_poller (self->loop, &poller, s_collector, self);
zloop_timer (self->loop, 1000, 0, s_flush_ttl, self);
// Run reactor until process interrupted
zloop_start (self->loop);
zloop_destroy (&self->loop);
zhash_destroy (&self->kvmap);
zctx_destroy (&self->ctx);
free (self);
return 0;
}
// .split send snapshots
// We handle ICANHAZ? requests by sending snapshot data to the
// client that requested it:
// Routing information for a key-value snapshot
typedef struct {
void *socket; // ROUTER socket to send to
zframe_t *identity; // Identity of peer who requested state
char *subtree; // Client subtree specification
} kvroute_t;
// We call this function for each key-value pair in our hash table
static int
s_send_single (const char *key, void *data, void *args)
{
kvroute_t *kvroute = (kvroute_t *) args;
kvmsg_t *kvmsg = (kvmsg_t *) data;
if (strlen (kvroute->subtree) <= strlen (kvmsg_key (kvmsg))
&& memcmp (kvroute->subtree,
kvmsg_key (kvmsg), strlen (kvroute->subtree)) == 0) {
zframe_send (&kvroute->identity, // Choose recipient
kvroute->socket, ZFRAME_MORE + ZFRAME_REUSE);
kvmsg_send (kvmsg, kvroute->socket);
}
return 0;
}
// .split snapshot handler
// This is the reactor handler for the snapshot socket; it accepts
// just the ICANHAZ? request and replies with a state snapshot ending
// with a KTHXBAI message:
static int
s_snapshots (zloop_t *loop, zmq_pollitem_t *poller, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
zframe_t *identity = zframe_recv (poller->socket);
if (identity) {
// Request is in second frame of message
char *request = zstr_recv (poller->socket);
char *subtree = NULL;
if (streq (request, "ICANHAZ?")) {
free (request);
subtree = zstr_recv (poller->socket);
}
else
printf ("E: bad request, aborting\n");
if (subtree) {
// Send state socket to client
kvroute_t routing = { poller->socket, identity, subtree };
zhash_foreach (self->kvmap, s_send_single, &routing);
// Now send END message with sequence number
zclock_log ("I: sending shapshot=%d", (int) self->sequence);
zframe_send (&identity, poller->socket, ZFRAME_MORE);
kvmsg_t *kvmsg = kvmsg_new (self->sequence);
kvmsg_set_key (kvmsg, "KTHXBAI");
kvmsg_set_body (kvmsg, (byte *) subtree, 0);
kvmsg_send (kvmsg, poller->socket);
kvmsg_destroy (&kvmsg);
free (subtree);
}
zframe_destroy(&identity);
}
return 0;
}
// .split collect updates
// We store each update with a new sequence number, and if necessary, a
// time-to-live. We publish updates immediately on our publisher socket:
static int
s_collector (zloop_t *loop, zmq_pollitem_t *poller, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
kvmsg_t *kvmsg = kvmsg_recv (poller->socket);
if (kvmsg) {
kvmsg_set_sequence (kvmsg, ++self->sequence);
kvmsg_send (kvmsg, self->publisher);
int ttl = atoi (kvmsg_get_prop (kvmsg, "ttl"));
if (ttl)
kvmsg_set_prop (kvmsg, "ttl",
"%" PRId64, zclock_time () + ttl * 1000);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: publishing update=%d", (int) self->sequence);
}
return 0;
}
// .split flush ephemeral values
// At regular intervals, we flush ephemeral values that have expired. This
// could be slow on very large data sets:
// If key-value pair has expired, delete it and publish the
// fact to listening clients.
static int
s_flush_single (const char *key, void *data, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
kvmsg_t *kvmsg = (kvmsg_t *) data;
int64_t ttl;
sscanf (kvmsg_get_prop (kvmsg, "ttl"), "%" PRId64, &ttl);
if (ttl && zclock_time () >= ttl) {
kvmsg_set_sequence (kvmsg, ++self->sequence);
kvmsg_set_body (kvmsg, (byte *) "", 0);
kvmsg_send (kvmsg, self->publisher);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: publishing delete=%d", (int) self->sequence);
}
return 0;
}
static int
s_flush_ttl (zloop_t *loop, int timer_id, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
if (self->kvmap)
zhash_foreach (self->kvmap, s_flush_single, args);
return 0;
}
clonesrv5: Clone server, Model Five in C++
// Clone server - Model Five
#include "kvmsg.hpp"
// Routing information for a key-value snapshot
typedef struct {
zmqpp::socket_t *socket; // ROUTER socket to send to
std::string identity; // Identity of peer who requested state
std::string subtree; // Client subtree specification
} kvroute_t;
typedef struct {
zmqpp::context_t *ctx; // Our context
std::unordered_map<std::string, KVMsg*> kvmap; // Key-value store
int64_t sequence; // How many updates we're at
int port; // Main port we're working on
zmqpp::socket_t* snapshot; // Handle snapshot requests
zmqpp::socket_t* publisher; // Publish updates to clients
zmqpp::socket_t* collector; // Collect updates from clients
} clonesrv_t;
// loop event handlers
static bool s_snapshots(clonesrv_t *self);
static bool s_collector(clonesrv_t *self);
static bool s_flush_ttl(clonesrv_t *self);
int main(void) {
zmqpp::loop loop; // Reactor loop
clonesrv_t *self = new clonesrv_t();
self->port = 5556;
self->ctx = new zmqpp::context_t();
// set up our clone server sockets
self->snapshot = new zmqpp::socket_t(*self->ctx, zmqpp::socket_type::router);
self->snapshot->bind("tcp://*:" + std::to_string(self->port));
self->publisher = new zmqpp::socket_t(*self->ctx, zmqpp::socket_type::pub);
self->publisher->bind("tcp://*:" + std::to_string(self->port + 1));
self->collector = new zmqpp::socket_t(*self->ctx, zmqpp::socket_type::pull);
self->collector->bind("tcp://*:" + std::to_string(self->port + 2));
loop.add(*self->snapshot, std::bind(s_snapshots, self));
loop.add(*self->collector, std::bind(s_collector, self));
loop.add(std::chrono::milliseconds(1000), 0, std::bind(s_flush_ttl, self));
s_catch_signals();
auto end_loop = []() -> bool {
return s_interrupted == 0;
};
loop.add(std::chrono::milliseconds(100), 0, end_loop);
try {
loop.start();
} catch (const std::exception &e) {
std::cerr << "Exception: " << e.what() << std::endl;
}
KVMsg::clear_kvmap(self->kvmap);
std::cout << "Interrupted\n";
return 0;
}
// .split snapshot handler
// This is the reactor handler for the snapshot socket; it accepts
// just the ICANHAZ? request and replies with a state snapshot ending
// with a KTHXBAI message:
static bool s_snapshots(clonesrv_t *self) {
zmqpp::message frames;
if (!self->snapshot->receive(frames)) {
return false;
}
std::string identity;
frames >> identity;
std::string request;
frames >> request;
std::string subtree;
if (request == "ICANHAZ?") {
assert(frames.parts() == 3);
frames >> subtree;
} else {
std::cerr << "E: bad request, aborting" << std::endl;
}
if (!subtree.empty()) {
kvroute_t routing = {self->snapshot, identity, subtree};
for (auto &kv : self->kvmap) {
if (subtree.size() <= kv.first.size() && kv.first.compare(0, subtree.size(), subtree) == 0) {
zmqpp::message_t frames;
frames << identity;
kv.second->encode_frames(frames);
routing.socket->send(frames);
}
}
std::cout << "I: sending snapshot=" << self->sequence << std::endl;
KVMsg *kvmsg = new KVMsg(self->sequence);
kvmsg->set_key("KTHXBAI");
kvmsg->set_body(ustring((unsigned char *)subtree.c_str(), subtree.size()));
// remember to send the identity frame
zmqpp::message_t frames;
frames << identity;
kvmsg->encode_frames(frames);
self->snapshot->send(frames);
delete kvmsg;
}
return true;
}
// .split collect updates
// We store each update with a new sequence number, and if necessary, a
// time-to-live. We publish updates immediately on our publisher socket:
static bool s_collector(clonesrv_t *self) {
KVMsg *kvmsg = KVMsg::recv(*self->collector);
if (!kvmsg) {
return false;
}
kvmsg->set_sequence(++self->sequence);
kvmsg->send(*self->publisher);
std::string ttl_second_str = kvmsg->property("ttl");
if (!ttl_second_str.empty()) {
int ttl_second = std::atoi(ttl_second_str.c_str());
auto now = std::chrono::high_resolution_clock::now();
auto expired_at = std::chrono::duration_cast<std::chrono::milliseconds>(now.time_since_epoch()).count() + ttl_second * 1000;
kvmsg->set_property("ttl", "%lld", expired_at);
}
kvmsg->store(self->kvmap);
return true;
}
// .split flush ephemeral values
// At regular intervals, we flush ephemeral values that have expired. This
// could be slow on very large data sets:
// If key-value pair has expired, delete it and publish the
// fact to listening clients.
static bool s_flush_ttl(clonesrv_t *self) {
auto now = std::chrono::high_resolution_clock::now();
for (auto it = self->kvmap.begin(); it != self->kvmap.end();) {
KVMsg *kvmsg = it->second;
std::string ttl_str = kvmsg->property("ttl");
if (!ttl_str.empty()) {
int64_t ttl = std::atoll(ttl_str.c_str());
if (ttl < std::chrono::duration_cast<std::chrono::milliseconds>(now.time_since_epoch()).count()) {
kvmsg->set_sequence(++self->sequence);
kvmsg->set_body(ustring());
kvmsg->send(*self->publisher);
it = self->kvmap.erase(it);
std::cout << "I: publishing delete=" << self->sequence << std::endl;
} else {
++it;
}
} else {
++it;
}
}
return true;
}
clonesrv5: Clone server, Model Five in C#
clonesrv5: Clone server, Model Five in CL
clonesrv5: Clone server, Model Five in Delphi
clonesrv5: Clone server, Model Five in Erlang
clonesrv5: Clone server, Model Five in Elixir
clonesrv5: Clone server, Model Five in F#
clonesrv5: Clone server, Model Five in Felix
clonesrv5: Clone server, Model Five in Go
clonesrv5: Clone server, Model Five in Haskell
clonesrv5: Clone server, Model Five in Haxe
clonesrv5: Clone server, Model Five in Java
package guide;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZLoop;
import org.zeromq.ZLoop.IZLoopHandler;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.PollItem;
import org.zeromq.ZMQ.Socket;
// Clone server - Model Five
public class clonesrv5
{
private ZContext ctx; // Context wrapper
private Map<String, kvmsg> kvmap; // Key-value store
private ZLoop loop; // zloop reactor
private int port; // Main port we're working on
private long sequence; // How many updates we're at
private Socket snapshot; // Handle snapshot requests
private Socket publisher; // Publish updates to clients
private Socket collector; // Collect updates from clients
// .split snapshot handler
// This is the reactor handler for the snapshot socket; it accepts
// just the ICANHAZ? request and replies with a state snapshot ending
// with a KTHXBAI message:
private static class Snapshots implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv5 srv = (clonesrv5) arg;
Socket socket = item.getSocket();
byte[] identity = socket.recv();
if (identity != null) {
// Request is in second frame of message
String request = socket.recvStr();
String subtree = null;
if (request.equals("ICANHAZ?")) {
subtree = socket.recvStr();
}
else System.out.printf("E: bad request, aborting\n");
if (subtree != null) {
// Send state socket to client
for (Entry<String, kvmsg> entry : srv.kvmap.entrySet()) {
sendSingle(entry.getValue(), identity, subtree, socket);
}
// Now send END message with getSequence number
System.out.printf("I: sending shapshot=%d\n", srv.sequence);
socket.send(identity, ZMQ.SNDMORE);
kvmsg kvmsg = new kvmsg(srv.sequence);
kvmsg.setKey("KTHXBAI");
kvmsg.setBody(subtree.getBytes(ZMQ.CHARSET));
kvmsg.send(socket);
kvmsg.destroy();
}
}
return 0;
}
}
// .split collect updates
// We store each update with a new getSequence number, and if necessary, a
// time-to-live. We publish updates immediately on our publisher socket:
private static class Collector implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv5 srv = (clonesrv5) arg;
Socket socket = item.getSocket();
kvmsg msg = kvmsg.recv(socket);
if (msg != null) {
msg.setSequence(++srv.sequence);
msg.send(srv.publisher);
int ttl = Integer.parseInt(msg.getProp("ttl"));
if (ttl > 0)
msg.setProp("ttl", "%d", System.currentTimeMillis() + ttl * 1000);
msg.store(srv.kvmap);
System.out.printf("I: publishing update=%d\n", srv.sequence);
}
return 0;
}
}
private static class FlushTTL implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv5 srv = (clonesrv5) arg;
if (srv.kvmap != null) {
for (kvmsg msg : new ArrayList<kvmsg>(srv.kvmap.values())) {
srv.flushSingle(msg);
}
}
return 0;
}
}
public clonesrv5()
{
port = 5556;
ctx = new ZContext();
kvmap = new HashMap<String, kvmsg>();
loop = new ZLoop(ctx);
loop.verbose(false);
// Set up our clone server sockets
snapshot = ctx.createSocket(SocketType.ROUTER);
snapshot.bind(String.format("tcp://*:%d", port));
publisher = ctx.createSocket(SocketType.PUB);
publisher.bind(String.format("tcp://*:%d", port + 1));
collector = ctx.createSocket(SocketType.PULL);
collector.bind(String.format("tcp://*:%d", port + 2));
}
public void run()
{
// Register our handlers with reactor
PollItem poller = new PollItem(snapshot, ZMQ.Poller.POLLIN);
loop.addPoller(poller, new Snapshots(), this);
poller = new PollItem(collector, ZMQ.Poller.POLLIN);
loop.addPoller(poller, new Collector(), this);
loop.addTimer(1000, 0, new FlushTTL(), this);
loop.start();
loop.destroy();
ctx.destroy();
}
// We call this function for each getKey-value pair in our hash table
private static void sendSingle(kvmsg msg, byte[] identity, String subtree, Socket socket)
{
if (msg.getKey().startsWith(subtree)) {
socket.send(identity, // Choose recipient
ZMQ.SNDMORE);
msg.send(socket);
}
}
// .split flush ephemeral values
// At regular intervals, we flush ephemeral values that have expired. This
// could be slow on very large data sets:
// If getKey-value pair has expired, delete it and publish the
// fact to listening clients.
private void flushSingle(kvmsg msg)
{
long ttl = Long.parseLong(msg.getProp("ttl"));
if (ttl > 0 && System.currentTimeMillis() >= ttl) {
msg.setSequence(++sequence);
msg.setBody(ZMQ.MESSAGE_SEPARATOR);
msg.send(publisher);
msg.store(kvmap);
System.out.printf("I: publishing delete=%d\n", sequence);
}
}
public static void main(String[] args)
{
clonesrv5 srv = new clonesrv5();
srv.run();
}
}
clonesrv5: Clone server, Model Five in Julia
clonesrv5: Clone server, Model Five in Lua
clonesrv5: Clone server, Model Five in Node.js
clonesrv5: Clone server, Model Five in Objective-C
clonesrv5: Clone server, Model Five in ooc
clonesrv5: Clone server, Model Five in Perl
clonesrv5: Clone server, Model Five in PHP
clonesrv5: Clone server, Model Five in Python
"""
Clone server Model Five
Author: Min RK <benjaminrk@gmail.com
"""
import logging
import time
import zmq
from zmq.eventloop.ioloop import IOLoop, PeriodicCallback
from zmq.eventloop.zmqstream import ZMQStream
from kvmsg import KVMsg
from zhelpers import dump
# simple struct for routing information for a key-value snapshot
class Route:
def __init__(self, socket, identity, subtree):
self.socket = socket # ROUTER socket to send to
self.identity = identity # Identity of peer who requested state
self.subtree = subtree # Client subtree specification
def send_single(key, kvmsg, route):
"""Send one state snapshot key-value pair to a socket"""
# check front of key against subscription subtree:
if kvmsg.key.startswith(route.subtree):
# Send identity of recipient first
route.socket.send(route.identity, zmq.SNDMORE)
kvmsg.send(route.socket)
class CloneServer(object):
# Our server is defined by these properties
ctx = None # Context wrapper
kvmap = None # Key-value store
loop = None # IOLoop reactor
port = None # Main port we're working on
sequence = 0 # How many updates we're at
snapshot = None # Handle snapshot requests
publisher = None # Publish updates to clients
collector = None # Collect updates from clients
def __init__(self, port=5556):
self.port = port
self.ctx = zmq.Context()
self.kvmap = {}
self.loop = IOLoop.instance()
# Set up our clone server sockets
self.snapshot = self.ctx.socket(zmq.ROUTER)
self.publisher = self.ctx.socket(zmq.PUB)
self.collector = self.ctx.socket(zmq.PULL)
self.snapshot.bind("tcp://*:%d" % self.port)
self.publisher.bind("tcp://*:%d" % (self.port + 1))
self.collector.bind("tcp://*:%d" % (self.port + 2))
# Wrap sockets in ZMQStreams for IOLoop handlers
self.snapshot = ZMQStream(self.snapshot)
self.publisher = ZMQStream(self.publisher)
self.collector = ZMQStream(self.collector)
# Register our handlers with reactor
self.snapshot.on_recv(self.handle_snapshot)
self.collector.on_recv(self.handle_collect)
self.flush_callback = PeriodicCallback(self.flush_ttl, 1000)
# basic log formatting:
logging.basicConfig(format="%(asctime)s %(message)s", datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
def start(self):
# Run reactor until process interrupted
self.flush_callback.start()
try:
self.loop.start()
except KeyboardInterrupt:
pass
def handle_snapshot(self, msg):
"""snapshot requests"""
if len(msg) != 3 or msg[1] != b"ICANHAZ?":
print("E: bad request, aborting")
dump(msg)
self.loop.stop()
return
identity, request, subtree = msg
if subtree:
# Send state snapshot to client
route = Route(self.snapshot, identity, subtree)
# For each entry in kvmap, send kvmsg to client
for k,v in self.kvmap.items():
send_single(k,v,route)
# Now send END message with sequence number
logging.info("I: Sending state shapshot=%d" % self.sequence)
self.snapshot.send(identity, zmq.SNDMORE)
kvmsg = KVMsg(self.sequence)
kvmsg.key = b"KTHXBAI"
kvmsg.body = subtree
kvmsg.send(self.snapshot)
def handle_collect(self, msg):
"""Collect updates from clients"""
kvmsg = KVMsg.from_msg(msg)
self.sequence += 1
kvmsg.sequence = self.sequence
kvmsg.send(self.publisher)
ttl = float(kvmsg.get(b'ttl', 0))
if ttl:
kvmsg[b'ttl'] = b'%f' % (time.time() + ttl)
kvmsg.store(self.kvmap)
logging.info("I: publishing update=%d", self.sequence)
def flush_ttl(self):
"""Purge ephemeral values that have expired"""
for key,kvmsg in list(self.kvmap.items()):
# used list() to exhaust the iterator before deleting from the dict
self.flush_single(kvmsg)
def flush_single(self, kvmsg):
"""If key-value pair has expired, delete it and publish the fact
to listening clients."""
ttl = float(kvmsg.get(b'ttl', 0))
if ttl and ttl <= time.time():
kvmsg.body = b""
self.sequence += 1
kvmsg.sequence = self.sequence
kvmsg.send(self.publisher)
del self.kvmap[kvmsg.key]
logging.info("I: publishing delete=%d", self.sequence)
def main():
clone = CloneServer()
clone.start()
if __name__ == '__main__':
main()
clonesrv5: Clone server, Model Five in Q
clonesrv5: Clone server, Model Five in Racket
clonesrv5: Clone server, Model Five in Ruby
clonesrv5: Clone server, Model Five in Rust
clonesrv5: Clone server, Model Five in Scala
clonesrv5: Clone server, Model Five in Tcl
clonesrv5: Clone server, Model Five in OCaml
Adding the Binary Star Pattern for Reliability #
The Clone models we’ve explored up to now have been relatively simple. Now we’re going to get into unpleasantly complex territory, which has me getting up for another espresso. You should appreciate that making “reliable” messaging is complex enough that you always need to ask, “Do we actually need this?” before jumping into it. If you can get away with unreliable or with “good enough” reliability, you can make a huge win in terms of cost and complexity. Sure, you may lose some data now and then. It is often a good trade-off. Having said, that, and… sips… because the espresso is really good, let’s jump in.
As you play with the last model, you’ll stop and restart the server. It might look like it recovers, but of course it’s applying updates to an empty state instead of the proper current state. Any new client joining the network will only get the latest updates instead of the full historical record.
What we want is a way for the server to recover from being killed, or crashing. We also need to provide backup in case the server is out of commission for any length of time. When someone asks for “reliability”, ask them to list the failures they want to handle. In our case, these are:
-
The server process crashes and is automatically or manually restarted. The process loses its state and has to get it back from somewhere.
-
The server machine dies and is offline for a significant time. Clients have to switch to an alternate server somewhere.
-
The server process or machine gets disconnected from the network, e.g., a switch dies or a datacenter gets knocked out. It may come back at some point, but in the meantime clients need an alternate server.
Our first step is to add a second server. We can use the Binary Star pattern from Chapter 4 - Reliable Request-Reply Patterns to organize these into primary and backup. Binary Star is a reactor, so it’s useful that we already refactored the last server model into a reactor style.
We need to ensure that updates are not lost if the primary server crashes. The simplest technique is to send them to both servers. The backup server can then act as a client, and keep its state synchronized by receiving updates as all clients do. It’ll also get new updates from clients. It can’t yet store these in its hash table, but it can hold onto them for a while.
So, Model Six introduces the following changes over Model Five:
-
We use a pub-sub flow instead of a push-pull flow for client updates sent to the servers. This takes care of fanning out the updates to both servers. Otherwise we’d have to use two DEALER sockets.
-
We add heartbeats to server updates (to clients), so that a client can detect when the primary server has died. It can then switch over to the backup server.
-
We connect the two servers using the Binary Star bstar reactor class. Binary Star relies on the clients to vote by making an explicit request to the server they consider active. We’ll use snapshot requests as the voting mechanism.
-
We make all update messages uniquely identifiable by adding a UUID field. The client generates this, and the server propagates it back on republished updates.
-
The passive server keeps a “pending list” of updates that it has received from clients, but not yet from the active server; or updates it’s received from the active server, but not yet from the clients. The list is ordered from oldest to newest, so that it is easy to remove updates off the head.
It’s useful to design the client logic as a finite state machine. The client cycles through three states:
-
The client opens and connects its sockets, and then requests a snapshot from the first server. To avoid request storms, it will ask any given server only twice. One request might get lost, which would be bad luck. Two getting lost would be carelessness.
-
The client waits for a reply (snapshot data) from the current server, and if it gets it, it stores it. If there is no reply within some timeout, it fails over to the next server.
-
When the client has gotten its snapshot, it waits for and processes updates. Again, if it doesn’t hear anything from the server within some timeout, it fails over to the next server.
The client loops forever. It’s quite likely during startup or failover that some clients may be trying to talk to the primary server while others are trying to talk to the backup server. The Binary Star state machine handles this, hopefully accurately. It’s hard to prove software correct; instead we hammer it until we can’t prove it wrong.
Failover happens as follows:
-
The client detects that primary server is no longer sending heartbeats, and concludes that it has died. The client connects to the backup server and requests a new state snapshot.
-
The backup server starts to receive snapshot requests from clients, and detects that primary server has gone, so it takes over as primary.
-
The backup server applies its pending list to its own hash table, and then starts to process state snapshot requests.
When the primary server comes back online, it will:
-
Start up as passive server, and connect to the backup server as a Clone client.
-
Start to receive updates from clients, via its SUB socket.
We make a few assumptions:
-
At least one server will keep running. If both servers crash, we lose all server state and there’s no way to recover it.
-
Multiple clients do not update the same hash keys at the same time. Client updates will arrive at the two servers in a different order. Therefore, the backup server may apply updates from its pending list in a different order than the primary server would or did. Updates from one client will always arrive in the same order on both servers, so that is safe.
Thus the architecture for our high-availability server pair using the Binary Star pattern has two servers and a set of clients that talk to both servers.
Here is the sixth and last model of the Clone server:
clonesrv6: Clone server, Model Six in Ada
clonesrv6: Clone server, Model Six in Basic
clonesrv6: Clone server, Model Six in C
// Clone server Model Six
// Lets us build this source without creating a library
#include "bstar.c"
#include "kvmsg.c"
// .split definitions
// We define a set of reactor handlers and our server object structure:
// Bstar reactor handlers
static int
s_snapshots (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int
s_collector (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int
s_flush_ttl (zloop_t *loop, int timer_id, void *args);
static int
s_send_hugz (zloop_t *loop, int timer_id, void *args);
static int
s_new_active (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int
s_new_passive (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int
s_subscriber (zloop_t *loop, zmq_pollitem_t *poller, void *args);
// Our server is defined by these properties
typedef struct {
zctx_t *ctx; // Context wrapper
zhash_t *kvmap; // Key-value store
bstar_t *bstar; // Bstar reactor core
int64_t sequence; // How many updates we're at
int port; // Main port we're working on
int peer; // Main port of our peer
void *publisher; // Publish updates and hugz
void *collector; // Collect updates from clients
void *subscriber; // Get updates from peer
zlist_t *pending; // Pending updates from clients
bool primary; // true if we're primary
bool active; // true if we're active
bool passive; // true if we're passive
} clonesrv_t;
// .split main task setup
// The main task parses the command line to decide whether to start
// as a primary or backup server. We're using the Binary Star pattern
// for reliability. This interconnects the two servers so they can
// agree on which one is primary and which one is backup. To allow the
// two servers to run on the same box, we use different ports for
// primary and backup. Ports 5003/5004 are used to interconnect the
// servers. Ports 5556/5566 are used to receive voting events (snapshot
// requests in the clone pattern). Ports 5557/5567 are used by the
// publisher, and ports 5558/5568 are used by the collector:
int main (int argc, char *argv [])
{
clonesrv_t *self = (clonesrv_t *) zmalloc (sizeof (clonesrv_t));
if (argc == 2 && streq (argv [1], "-p")) {
zclock_log ("I: primary active, waiting for backup (passive)");
self->bstar = bstar_new (BSTAR_PRIMARY, "tcp://*:5003",
"tcp://localhost:5004");
bstar_voter (self->bstar, "tcp://*:5556",
ZMQ_ROUTER, s_snapshots, self);
self->port = 5556;
self->peer = 5566;
self->primary = true;
}
else
if (argc == 2 && streq (argv [1], "-b")) {
zclock_log ("I: backup passive, waiting for primary (active)");
self->bstar = bstar_new (BSTAR_BACKUP, "tcp://*:5004",
"tcp://localhost:5003");
bstar_voter (self->bstar, "tcp://*:5566",
ZMQ_ROUTER, s_snapshots, self);
self->port = 5566;
self->peer = 5556;
self->primary = false;
}
else {
printf ("Usage: clonesrv6 { -p | -b }\n");
free (self);
exit (0);
}
// Primary server will become first active
if (self->primary)
self->kvmap = zhash_new ();
self->ctx = zctx_new ();
self->pending = zlist_new ();
bstar_set_verbose (self->bstar, true);
// Set up our clone server sockets
self->publisher = zsocket_new (self->ctx, ZMQ_PUB);
self->collector = zsocket_new (self->ctx, ZMQ_SUB);
zsocket_set_subscribe (self->collector, "");
zsocket_bind (self->publisher, "tcp://*:%d", self->port + 1);
zsocket_bind (self->collector, "tcp://*:%d", self->port + 2);
// Set up our own clone client interface to peer
self->subscriber = zsocket_new (self->ctx, ZMQ_SUB);
zsocket_set_subscribe (self->subscriber, "");
zsocket_connect (self->subscriber,
"tcp://localhost:%d", self->peer + 1);
// .split main task body
// After we've setup our sockets, we register our binary star
// event handlers, and then start the bstar reactor. This finishes
// when the user presses Ctrl-C or when the process receives a SIGINT
// interrupt:
// Register state change handlers
bstar_new_active (self->bstar, s_new_active, self);
bstar_new_passive (self->bstar, s_new_passive, self);
// Register our other handlers with the bstar reactor
zmq_pollitem_t poller = { self->collector, 0, ZMQ_POLLIN };
zloop_poller (bstar_zloop (self->bstar), &poller, s_collector, self);
zloop_timer (bstar_zloop (self->bstar), 1000, 0, s_flush_ttl, self);
zloop_timer (bstar_zloop (self->bstar), 1000, 0, s_send_hugz, self);
// Start the bstar reactor
bstar_start (self->bstar);
// Interrupted, so shut down
while (zlist_size (self->pending)) {
kvmsg_t *kvmsg = (kvmsg_t *) zlist_pop (self->pending);
kvmsg_destroy (&kvmsg);
}
zlist_destroy (&self->pending);
bstar_destroy (&self->bstar);
zhash_destroy (&self->kvmap);
zctx_destroy (&self->ctx);
free (self);
return 0;
}
// We handle ICANHAZ? requests exactly as in the clonesrv5 example.
// .skip
// Routing information for a key-value snapshot
typedef struct {
void *socket; // ROUTER socket to send to
zframe_t *identity; // Identity of peer who requested state
char *subtree; // Client subtree specification
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int
s_send_single (const char *key, void *data, void *args)
{
kvroute_t *kvroute = (kvroute_t *) args;
kvmsg_t *kvmsg = (kvmsg_t *) data;
if (strlen (kvroute->subtree) <= strlen (kvmsg_key (kvmsg))
&& memcmp (kvroute->subtree,
kvmsg_key (kvmsg), strlen (kvroute->subtree)) == 0) {
zframe_send (&kvroute->identity, // Choose recipient
kvroute->socket, ZFRAME_MORE + ZFRAME_REUSE);
kvmsg_send (kvmsg, kvroute->socket);
}
return 0;
}
static int
s_snapshots (zloop_t *loop, zmq_pollitem_t *poller, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
zframe_t *identity = zframe_recv (poller->socket);
if (identity) {
// Request is in second frame of message
char *request = zstr_recv (poller->socket);
char *subtree = NULL;
if (streq (request, "ICANHAZ?")) {
free (request);
subtree = zstr_recv (poller->socket);
}
else
printf ("E: bad request, aborting\n");
if (subtree) {
// Send state socket to client
kvroute_t routing = { poller->socket, identity, subtree };
zhash_foreach (self->kvmap, s_send_single, &routing);
// Now send END message with sequence number
zclock_log ("I: sending shapshot=%d", (int) self->sequence);
zframe_send (&identity, poller->socket, ZFRAME_MORE);
kvmsg_t *kvmsg = kvmsg_new (self->sequence);
kvmsg_set_key (kvmsg, "KTHXBAI");
kvmsg_set_body (kvmsg, (byte *) subtree, 0);
kvmsg_send (kvmsg, poller->socket);
kvmsg_destroy (&kvmsg);
free (subtree);
}
zframe_destroy(&identity);
}
return 0;
}
// .until
// .split collect updates
// The collector is more complex than in the clonesrv5 example because the
// way it processes updates depends on whether we're active or passive.
// The active applies them immediately to its kvmap, whereas the passive
// queues them as pending:
// If message was already on pending list, remove it and return true,
// else return false.
static int
s_was_pending (clonesrv_t *self, kvmsg_t *kvmsg)
{
kvmsg_t *held = (kvmsg_t *) zlist_first (self->pending);
while (held) {
if (memcmp (kvmsg_uuid (kvmsg),
kvmsg_uuid (held), sizeof (uuid_t)) == 0) {
zlist_remove (self->pending, held);
return true;
}
held = (kvmsg_t *) zlist_next (self->pending);
}
return false;
}
static int
s_collector (zloop_t *loop, zmq_pollitem_t *poller, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
kvmsg_t *kvmsg = kvmsg_recv (poller->socket);
if (kvmsg) {
if (self->active) {
kvmsg_set_sequence (kvmsg, ++self->sequence);
kvmsg_send (kvmsg, self->publisher);
int ttl = atoi (kvmsg_get_prop (kvmsg, "ttl"));
if (ttl)
kvmsg_set_prop (kvmsg, "ttl",
"%" PRId64, zclock_time () + ttl * 1000);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: publishing update=%d", (int) self->sequence);
}
else {
// If we already got message from active, drop it, else
// hold on pending list
if (s_was_pending (self, kvmsg))
kvmsg_destroy (&kvmsg);
else
zlist_append (self->pending, kvmsg);
}
}
return 0;
}
// We purge ephemeral values using exactly the same code as in
// the previous clonesrv5 example.
// .skip
// If key-value pair has expired, delete it and publish the
// fact to listening clients.
static int
s_flush_single (const char *key, void *data, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
kvmsg_t *kvmsg = (kvmsg_t *) data;
int64_t ttl;
sscanf (kvmsg_get_prop (kvmsg, "ttl"), "%" PRId64, &ttl);
if (ttl && zclock_time () >= ttl) {
kvmsg_set_sequence (kvmsg, ++self->sequence);
kvmsg_set_body (kvmsg, (byte *) "", 0);
kvmsg_send (kvmsg, self->publisher);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: publishing delete=%d", (int) self->sequence);
}
return 0;
}
static int
s_flush_ttl (zloop_t *loop, int timer_id, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
if (self->kvmap)
zhash_foreach (self->kvmap, s_flush_single, args);
return 0;
}
// .until
// .split heartbeating
// We send a HUGZ message once a second to all subscribers so that they
// can detect if our server dies. They'll then switch over to the backup
// server, which will become active:
static int
s_send_hugz (zloop_t *loop, int timer_id, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
kvmsg_t *kvmsg = kvmsg_new (self->sequence);
kvmsg_set_key (kvmsg, "HUGZ");
kvmsg_set_body (kvmsg, (byte *) "", 0);
kvmsg_send (kvmsg, self->publisher);
kvmsg_destroy (&kvmsg);
return 0;
}
// .split handling state changes
// When we switch from passive to active, we apply our pending list so that
// our kvmap is up-to-date. When we switch to passive, we wipe our kvmap
// and grab a new snapshot from the active server:
static int
s_new_active (zloop_t *loop, zmq_pollitem_t *unused, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
self->active = true;
self->passive = false;
// Stop subscribing to updates
zmq_pollitem_t poller = { self->subscriber, 0, ZMQ_POLLIN };
zloop_poller_end (bstar_zloop (self->bstar), &poller);
// Apply pending list to own hash table
while (zlist_size (self->pending)) {
kvmsg_t *kvmsg = (kvmsg_t *) zlist_pop (self->pending);
kvmsg_set_sequence (kvmsg, ++self->sequence);
kvmsg_send (kvmsg, self->publisher);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: publishing pending=%d", (int) self->sequence);
}
return 0;
}
static int
s_new_passive (zloop_t *loop, zmq_pollitem_t *unused, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
zhash_destroy (&self->kvmap);
self->active = false;
self->passive = true;
// Start subscribing to updates
zmq_pollitem_t poller = { self->subscriber, 0, ZMQ_POLLIN };
zloop_poller (bstar_zloop (self->bstar), &poller, s_subscriber, self);
return 0;
}
// .split subscriber handler
// When we get an update, we create a new kvmap if necessary, and then
// add our update to our kvmap. We're always passive in this case:
static int
s_subscriber (zloop_t *loop, zmq_pollitem_t *poller, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
// Get state snapshot if necessary
if (self->kvmap == NULL) {
self->kvmap = zhash_new ();
void *snapshot = zsocket_new (self->ctx, ZMQ_DEALER);
zsocket_connect (snapshot, "tcp://localhost:%d", self->peer);
zclock_log ("I: asking for snapshot from: tcp://localhost:%d",
self->peer);
zstr_sendm (snapshot, "ICANHAZ?");
zstr_send (snapshot, ""); // blank subtree to get all
while (true) {
kvmsg_t *kvmsg = kvmsg_recv (snapshot);
if (!kvmsg)
break; // Interrupted
if (streq (kvmsg_key (kvmsg), "KTHXBAI")) {
self->sequence = kvmsg_sequence (kvmsg);
kvmsg_destroy (&kvmsg);
break; // Done
}
kvmsg_store (&kvmsg, self->kvmap);
}
zclock_log ("I: received snapshot=%d", (int) self->sequence);
zsocket_destroy (self->ctx, snapshot);
}
// Find and remove update off pending list
kvmsg_t *kvmsg = kvmsg_recv (poller->socket);
if (!kvmsg)
return 0;
if (strneq (kvmsg_key (kvmsg), "HUGZ")) {
if (!s_was_pending (self, kvmsg)) {
// If active update came before client update, flip it
// around, store active update (with sequence) on pending
// list and use to clear client update when it comes later
zlist_append (self->pending, kvmsg_dup (kvmsg));
}
// If update is more recent than our kvmap, apply it
if (kvmsg_sequence (kvmsg) > self->sequence) {
self->sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: received update=%d", (int) self->sequence);
}
else
kvmsg_destroy (&kvmsg);
}
else
kvmsg_destroy (&kvmsg);
return 0;
}
clonesrv6: Clone server, Model Six in C++
#include "bstar.hpp"
#include "kvmsg.hpp"
typedef struct {
zmqpp::context_t *ctx; // Our context
std::unordered_map<std::string, KVMsg*>* kvmap; // Key-value store
bstar_t *bstar; // Binary Star reactor core
int64_t sequence; // How many updates we're at
int peer; // Main port of our peer
int port; // Main port we're working on
zmqpp::socket_t* publisher; // Publish updates and hugz
zmqpp::socket_t* collector; // Collect updates from clients
zmqpp::socket_t* subscriber; // Receive updates from peer
std::list<KVMsg*> pending; // Pending updates
bool primary; // true if we're primary
bool active; // true if we're active
bool passive; // true if we're passive
} clonesrv_t;
static void s_snapshot(zmqpp::loop *loop, zmqpp::socket_t *socket, void *arg);
static bool s_collector(clonesrv_t *self);
static bool s_flush_ttl(clonesrv_t *self);
static bool s_send_hugz(clonesrv_t *self);
static bool s_subscriber(clonesrv_t *self);
static void s_new_active(zmqpp::loop *loop, zmqpp::socket_t *socket, void *arg);
static void s_new_passive(zmqpp::loop *loop, zmqpp::socket_t *socket, void *arg);
// .split main task setup
// The main task parses the command line to decide whether to start
// as a primary or backup server. We're using the Binary Star pattern
// for reliability. This interconnects the two servers so they can
// agree on which one is primary and which one is backup. To allow the
// two servers to run on the same box, we use different ports for
// primary and backup. Ports 5003/5004 are used to interconnect the
// servers. Ports 5556/5566 are used to receive voting events (snapshot
// requests in the clone pattern). Ports 5557/5567 are used by the
// publisher, and ports 5558/5568 are used by the collector:
int main(int argc, char *argv[]) {
clonesrv_t *self = new clonesrv_t();
if (argc == 2 && strcmp(argv[1], "-p") == 0) {
std::cout << "I: Primary active, waiting for backup (passive)" << std::endl;
self->bstar = new bstar_t(true, "tcp://*:5003", "tcp://localhost:5004");
self->bstar->register_voter("tcp://*:5556", zmqpp::socket_type::router, s_snapshot, self);
self->port = 5556;
self->peer = 5566;
self->primary = true;
} else if (argc == 2 && strcmp(argv[1], "-b") == 0) {
std::cout << "I: Backup passive, waiting for primary (active)" << std::endl;
self->bstar = new bstar_t(false, "tcp://*:5004", "tcp://localhost:5003");
self->bstar->register_voter("tcp://*:5566", zmqpp::socket_type::router, s_snapshot, self);
self->port = 5566;
self->peer = 5556;
self->primary = false;
} else {
std::cout << "Usage: clonesrv6 { -p | -b }" << std::endl;
delete self;
return 0;
}
if (self->primary) {
self->kvmap = new std::unordered_map<std::string, KVMsg*>();
}
self->ctx = new zmqpp::context_t();
// set up our clone server sockets
self->publisher = new zmqpp::socket_t(*self->ctx, zmqpp::socket_type::pub);
self->publisher->bind("tcp://*:" + std::to_string(self->port + 1));
self->collector = new zmqpp::socket_t(*self->ctx, zmqpp::socket_type::sub);
self->collector->subscribe("");
self->collector->bind("tcp://*:" + std::to_string(self->port + 2)); // allow multiple clients publish updates
// set up our own clone client interface to peer
self->subscriber = new zmqpp::socket_t(*self->ctx, zmqpp::socket_type::sub);
self->subscriber->subscribe("");
self->subscriber->connect("tcp://localhost:" + std::to_string(self->peer + 1));
// .split main task body
// After we've setup our sockets, we register our binary star
// event handlers, and then start the bstar reactor. This finishes
// when the user presses Ctrl-C or when the process receives a SIGINT
// interrupt:
// Register state change handlers
self->bstar->set_new_active(s_new_active, self);
self->bstar->set_new_passive(s_new_passive, self);
// Register our other handlers with the bstar reactor
self->bstar->get_loop()->add(*self->collector, std::bind(s_collector, self));
self->bstar->get_loop()->add(std::chrono::milliseconds(1000), 0, std::bind(s_flush_ttl, self));
self->bstar->get_loop()->add(std::chrono::milliseconds(1000), 0, std::bind(s_send_hugz, self));
s_catch_signals();
auto end_loop = []() -> bool {
return s_interrupted == 0;
};
self->bstar->get_loop()->add(std::chrono::milliseconds(100), 0, end_loop);
// Start the bstar reactor
try {
self->bstar->start();
} catch (const std::exception &e) {
std::cerr << "Exception: " << e.what() << std::endl;
}
// Clean up
KVMsg::clear_kvmap(*self->kvmap);
delete self;
return 0;
}
// Routing information for a key-value snapshot
typedef struct {
zmqpp::socket_t *socket; // ROUTER socket to send to
std::string identity; // Identity of peer who requested state
std::string subtree; // Client subtree specification
} kvroute_t;
static void s_snapshot(zmqpp::loop *loop, zmqpp::socket_t *socket, void *arg) {
clonesrv_t *self = (clonesrv_t *) arg;
zmqpp::message frames;
if (!socket->receive(frames)) {
return;
}
std::string identity;
frames >> identity;
std::string request;
frames >> request;
std::string subtree;
if (request == "ICANHAZ?") {
assert(frames.parts() == 3);
frames >> subtree;
} else {
std::cerr << "E: bad request, aborting" << std::endl;
}
// if (!subtree.empty()) {
kvroute_t routing = {socket, identity, subtree};
for (auto &kv : *self->kvmap) {
if (subtree.size() <= kv.first.size() && kv.first.compare(0, subtree.size(), subtree) == 0) {
zmqpp::message_t frames;
frames << identity;
kv.second->encode_frames(frames);
routing.socket->send(frames);
}
}
std::cout << "I: sending snapshot=" << self->sequence << std::endl;
KVMsg *kvmsg = new KVMsg(self->sequence);
kvmsg->set_key("KTHXBAI");
kvmsg->set_body(ustring((unsigned char *)subtree.c_str(), subtree.size()));
// remember to send the identity frame
zmqpp::message_t response_frames;
response_frames << identity;
kvmsg->encode_frames(response_frames);
socket->send(response_frames);
delete kvmsg;
// }
}
// .split collect updates
// The collector is more complex than in the clonesrv5 example because the
// way it processes updates depends on whether we're active or passive.
// The active applies them immediately to its kvmap, whereas the passive
// queues them as pending:
// If message was already on pending list, remove it and return true,
// else return false.
static bool s_was_pending(clonesrv_t *self, KVMsg *kvmsg) {
for (auto it = self->pending.begin(); it != self->pending.end(); ++it) {
if ((*it)->uuid() == kvmsg->uuid()) {
self->pending.erase(it);
return true;
}
}
return false;
}
static bool s_collector(clonesrv_t *self) {
KVMsg *kvmsg = KVMsg::recv(*self->collector);
if (!kvmsg) {
return false;
}
if (self->active) {
kvmsg->set_sequence(++self->sequence);
kvmsg->send(*self->publisher);
std::string ttl_second_str = kvmsg->property("ttl");
if (!ttl_second_str.empty()) {
int ttl_second = std::atoi(ttl_second_str.c_str());
auto now = std::chrono::high_resolution_clock::now();
auto expired_at = std::chrono::duration_cast<std::chrono::milliseconds>(now.time_since_epoch()).count() + ttl_second * 1000;
kvmsg->set_property("ttl", "%lld", expired_at);
}
kvmsg->store(*self->kvmap);
std::cout << "I: publishing update=" << self->sequence << std::endl;
} else {
// If we already got message from active, drop it, else
// hold on pending list
if (s_was_pending(self, kvmsg)) {
// std::cout << "DEBUG: already got from active server, drop it" << std::endl;
delete kvmsg;
} else {
// std::cout << "DEBUG: hold client request on pending list" << std::endl;
self->pending.push_back(kvmsg);
}
}
return true;
}
// We purge ephemeral values using exactly the same code as in
// the previous clonesrv5 example.
// .skip
// If key-value pair has expired, delete it and publish the
// fact to listening clients.
static bool s_flush_ttl(clonesrv_t *self) {
auto now = std::chrono::high_resolution_clock::now();
if (!self->kvmap) {
return true;
}
for (auto it = self->kvmap->begin(); it != self->kvmap->end();) {
KVMsg *kvmsg = it->second;
std::string ttl_str = kvmsg->property("ttl");
if (!ttl_str.empty()) {
int64_t ttl = std::atoll(ttl_str.c_str());
if (ttl < std::chrono::duration_cast<std::chrono::milliseconds>(now.time_since_epoch()).count()) {
kvmsg->set_sequence(++self->sequence);
kvmsg->set_body(ustring());
kvmsg->send(*self->publisher);
it = self->kvmap->erase(it);
std::cout << "I: publishing delete=" << self->sequence << std::endl;
} else {
++it;
}
} else {
++it;
}
}
return true;
}
// .until
// .split heartbeating
// We send a HUGZ message once a second to all subscribers so that they
// can detect if our server dies. They'll then switch over to the backup
// server, which will become active:
static bool s_send_hugz(clonesrv_t *self) {
KVMsg *kvmsg = new KVMsg(self->sequence);
kvmsg->set_key("HUGZ");
kvmsg->set_body(ustring());
kvmsg->send(*self->publisher);
delete kvmsg;
return true;
}
// .split handling state changes
// When we switch from passive to active, we apply our pending list so that
// our kvmap is up-to-date. When we switch to passive, we wipe our kvmap
// and grab a new snapshot from the active server:
static void s_new_active(zmqpp::loop *loop, zmqpp::socket_t *socket, void *arg) {
clonesrv_t *self = (clonesrv_t *)arg;
self->active = true;
self->passive = false;
// Stop subscribing to updates
self->bstar->get_loop()->remove(*self->subscriber);
// Apply pending list to own hash table
while (!self->pending.empty()) {
KVMsg *kvmsg = self->pending.front();
kvmsg->set_sequence(++self->sequence);
kvmsg->send(*self->publisher);
kvmsg->store(*self->kvmap);
std::cout << "I: publishing pending=" << self->sequence << std::endl;
self->pending.pop_front();
}
}
static void s_new_passive(zmqpp::loop *loop, zmqpp::socket_t *socket, void *arg) {
clonesrv_t *self = (clonesrv_t *)arg;
if (self->kvmap) {
KVMsg::clear_kvmap(*self->kvmap);
self->kvmap = nullptr;
}
self->active = false;
self->passive = true;
// Start subscribing to updates
self->bstar->get_loop()->add(*self->subscriber, std::bind(s_subscriber, self));
}
// .split subscriber handler
// When we get an update, we create a new kvmap if necessary, and then
// add our update to our kvmap. We're always passive in this case:
static bool s_subscriber(clonesrv_t *self) {
// Get state snapshot if necessary
if (self->kvmap == nullptr) {
self->kvmap = new std::unordered_map<std::string, KVMsg*>();
zmqpp::socket_t snapshot(*self->ctx, zmqpp::socket_type::dealer);
snapshot.connect("tcp://localhost:" + std::to_string(self->peer));
std::cout << "I: asking for snapshot from: tcp://localhost:" << self->peer << std::endl;
zmqpp::message_t frames;
frames << "ICANHAZ?" << ""; // blank subtree
snapshot.send(frames);
while (true) {
KVMsg *kvmsg = KVMsg::recv(snapshot);
if (!kvmsg) {
break;
}
if (kvmsg->key() == "KTHXBAI") {
self->sequence = kvmsg->sequence();
delete kvmsg;
break;
}
kvmsg->store(*self->kvmap);
}
std::cout << "I: received snapshot=" << self->sequence << std::endl;
}
KVMsg *kvmsg = KVMsg::recv(*self->subscriber);
if (!kvmsg) {
return false;
}
if (kvmsg->key() != "HUGZ") {
if (!s_was_pending(self, kvmsg)) {
// If active update came before client update, flip it
// around, store active update (with sequence) on pending
// list and use to clear client update when it comes later
self->pending.push_back(kvmsg);
}
// If update is more recent than our kvmap, apply it
if (kvmsg->sequence() > self->sequence) {
self->sequence = kvmsg->sequence();
kvmsg->store(*self->kvmap);
std::cout << "I: received update=" << self->sequence << std::endl;
} else {
delete kvmsg;
}
} else {
delete kvmsg;
}
return true;
}
clonesrv6: Clone server, Model Six in C#
clonesrv6: Clone server, Model Six in CL
clonesrv6: Clone server, Model Six in Delphi
clonesrv6: Clone server, Model Six in Erlang
clonesrv6: Clone server, Model Six in Elixir
clonesrv6: Clone server, Model Six in F#
clonesrv6: Clone server, Model Six in Felix
clonesrv6: Clone server, Model Six in Go
clonesrv6: Clone server, Model Six in Haskell
clonesrv6: Clone server, Model Six in Haxe
clonesrv6: Clone server, Model Six in Java
package guide;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZLoop;
import org.zeromq.ZLoop.IZLoopHandler;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.PollItem;
import org.zeromq.ZMQ.Socket;
// Clone server - Model Six
public class clonesrv6
{
private ZContext ctx; // Context wrapper
private Map<String, kvmsg> kvmap; // Key-value store
private bstar bStar; // Bstar reactor core
private long sequence; // How many updates we're at
private int port; // Main port we're working on
private int peer; // Main port of our peer
private Socket publisher; // Publish updates and hugz
private Socket collector; // Collect updates from clients
private Socket subscriber; // Get updates from peer
private List<kvmsg> pending; // Pending updates from clients
private boolean primary; // TRUE if we're primary
private boolean active; // TRUE if we're active
private boolean passive; // TRUE if we're passive
private static class Snapshots implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
Socket socket = item.getSocket();
byte[] identity = socket.recv();
if (identity != null) {
// Request is in second frame of message
String request = socket.recvStr();
String subtree = null;
if (request.equals("ICANHAZ?")) {
subtree = socket.recvStr();
}
else System.out.printf("E: bad request, aborting\n");
if (subtree != null) {
// Send state socket to client
for (Entry<String, kvmsg> entry : srv.kvmap.entrySet()) {
sendSingle(entry.getValue(), identity, subtree, socket);
}
// Now send END message with getSequence number
System.out.printf("I: sending shapshot=%d\n", srv.sequence);
socket.send(identity, ZMQ.SNDMORE);
kvmsg kvmsg = new kvmsg(srv.sequence);
kvmsg.setKey("KTHXBAI");
kvmsg.setBody(subtree.getBytes(ZMQ.CHARSET));
kvmsg.send(socket);
kvmsg.destroy();
}
}
return 0;
}
}
private static class Collector implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
Socket socket = item.getSocket();
kvmsg msg = kvmsg.recv(socket);
if (msg != null) {
if (srv.active) {
msg.setSequence(++srv.sequence);
msg.send(srv.publisher);
int ttl = Integer.parseInt(msg.getProp("ttl"));
if (ttl > 0)
msg.setProp("ttl", "%d", System.currentTimeMillis() + ttl * 1000);
msg.store(srv.kvmap);
System.out.printf("I: publishing update=%d\n", srv.sequence);
}
else {
// If we already got message from active, drop it, else
// hold on pending list
if (srv.wasPending(msg))
msg.destroy();
else srv.pending.add(msg);
}
}
return 0;
}
}
// .split heartbeating
// We send a HUGZ message once a second to all subscribers so that they
// can detect if our server dies. They'll then switch over to the backup
// server, which will become active:
private static class SendHugz implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
kvmsg msg = new kvmsg(srv.sequence);
msg.setKey("HUGZ");
msg.setBody(ZMQ.MESSAGE_SEPARATOR);
msg.send(srv.publisher);
msg.destroy();
return 0;
}
}
private static class FlushTTL implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
if (srv.kvmap != null) {
for (kvmsg msg : new ArrayList<kvmsg>(srv.kvmap.values())) {
srv.flushSingle(msg);
}
}
return 0;
}
}
// .split handling state changes
// When we switch from passive to active, we apply our pending list so that
// our kvmap is up-to-date. When we switch to passive, we wipe our kvmap
// and grab a new snapshot from the active server:
private static class NewActive implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
srv.active = true;
srv.passive = false;
// Stop subscribing to updates
PollItem poller = new PollItem(srv.subscriber, ZMQ.Poller.POLLIN);
srv.bStar.zloop().removePoller(poller);
// Apply pending list to own hash table
for (kvmsg msg : srv.pending) {
msg.setSequence(++srv.sequence);
msg.send(srv.publisher);
msg.store(srv.kvmap);
System.out.printf("I: publishing pending=%d\n", srv.sequence);
}
return 0;
}
}
private static class NewPassive implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
if (srv.kvmap != null) {
for (kvmsg msg : srv.kvmap.values())
msg.destroy();
}
srv.active = false;
srv.passive = true;
// Start subscribing to updates
PollItem poller = new PollItem(srv.subscriber, ZMQ.Poller.POLLIN);
srv.bStar.zloop().addPoller(poller, new Subscriber(), srv);
return 0;
}
}
// .split subscriber handler
// When we get an update, we create a new kvmap if necessary, and then
// add our update to our kvmap. We're always passive in this case:
private static class Subscriber implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
Socket socket = item.getSocket();
// Get state snapshot if necessary
if (srv.kvmap == null) {
srv.kvmap = new HashMap<String, kvmsg>();
Socket snapshot = srv.ctx.createSocket(SocketType.DEALER);
snapshot.connect(String.format("tcp://localhost:%d", srv.peer));
System.out.printf("I: asking for snapshot from: tcp://localhost:%d\n", srv.peer);
snapshot.sendMore("ICANHAZ?");
snapshot.send(""); // blank subtree to get all
while (true) {
kvmsg msg = kvmsg.recv(snapshot);
if (msg == null)
break; // Interrupted
if (msg.getKey().equals("KTHXBAI")) {
srv.sequence = msg.getSequence();
msg.destroy();
break; // Done
}
msg.store(srv.kvmap);
}
System.out.printf("I: received snapshot=%d\n", srv.sequence);
srv.ctx.destroySocket(snapshot);
}
// Find and remove update off pending list
kvmsg msg = kvmsg.recv(item.getSocket());
if (msg == null)
return 0;
if (!msg.getKey().equals("HUGZ")) {
if (!srv.wasPending(msg)) {
// If active update came before client update, flip it
// around, store active update (with sequence) on pending
// list and use to clear client update when it comes later
srv.pending.add(msg.dup());
}
// If update is more recent than our kvmap, apply it
if (msg.getSequence() > srv.sequence) {
srv.sequence = msg.getSequence();
msg.store(srv.kvmap);
System.out.printf("I: received update=%d\n", srv.sequence);
}
}
msg.destroy();
return 0;
}
}
public clonesrv6(boolean primary)
{
if (primary) {
bStar = new bstar(true, "tcp://*:5003", "tcp://localhost:5004");
bStar.voter("tcp://*:5556", SocketType.ROUTER, new Snapshots(), this);
port = 5556;
peer = 5566;
this.primary = true;
}
else {
bStar = new bstar(false, "tcp://*:5004", "tcp://localhost:5003");
bStar.voter("tcp://*:5566", SocketType.ROUTER, new Snapshots(), this);
port = 5566;
peer = 5556;
this.primary = false;
}
// Primary server will become first active
if (primary)
kvmap = new HashMap<String, kvmsg>();
ctx = new ZContext();
pending = new ArrayList<kvmsg>();
bStar.setVerbose(true);
// Set up our clone server sockets
publisher = ctx.createSocket(SocketType.PUB);
collector = ctx.createSocket(SocketType.SUB);
collector.subscribe(ZMQ.SUBSCRIPTION_ALL);
publisher.bind(String.format("tcp://*:%d", port + 1));
collector.bind(String.format("tcp://*:%d", port + 2));
// Set up our own clone client interface to peer
subscriber = ctx.createSocket(SocketType.SUB);
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
subscriber.connect(String.format("tcp://localhost:%d", peer + 1));
}
// .split main task body
// After we've setup our sockets, we register our binary star
// event handlers, and then start the bstar reactor. This finishes
// when the user presses Ctrl-C or when the process receives a SIGINT
// interrupt:
public void run()
{
// Register state change handlers
bStar.newActive(new NewActive(), this);
bStar.newPassive(new NewPassive(), this);
// Register our other handlers with the bstar reactor
PollItem poller = new PollItem(collector, ZMQ.Poller.POLLIN);
bStar.zloop().addPoller(poller, new Collector(), this);
bStar.zloop().addTimer(1000, 0, new FlushTTL(), this);
bStar.zloop().addTimer(1000, 0, new SendHugz(), this);
// Start the bstar reactor
bStar.start();
// Interrupted, so shut down
for (kvmsg value : pending)
value.destroy();
bStar.destroy();
for (kvmsg value : kvmap.values())
value.destroy();
ctx.destroy();
}
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
private static void sendSingle(kvmsg msg, byte[] identity, String subtree, Socket socket)
{
if (msg.getKey().startsWith(subtree)) {
socket.send(identity, // Choose recipient
ZMQ.SNDMORE);
msg.send(socket);
}
}
// The collector is more complex than in the clonesrv5 example because the
// way it processes updates depends on whether we're active or passive.
// The active applies them immediately to its kvmap, whereas the passive
// queues them as pending:
// If message was already on pending list, remove it and return TRUE,
// else return FALSE.
boolean wasPending(kvmsg msg)
{
Iterator<kvmsg> it = pending.iterator();
while (it.hasNext()) {
if (java.util.Arrays.equals(msg.UUID(), it.next().UUID())) {
it.remove();
return true;
}
}
return false;
}
// We purge ephemeral values using exactly the same code as in
// the previous clonesrv5 example.
// .skip
// If key-value pair has expired, delete it and publish the
// fact to listening clients.
private void flushSingle(kvmsg msg)
{
long ttl = Long.parseLong(msg.getProp("ttl"));
if (ttl > 0 && System.currentTimeMillis() >= ttl) {
msg.setSequence(++sequence);
msg.setBody(ZMQ.MESSAGE_SEPARATOR);
msg.send(publisher);
msg.store(kvmap);
System.out.printf("I: publishing delete=%d\n", sequence);
}
}
// .split main task setup
// The main task parses the command line to decide whether to start
// as a primary or backup server. We're using the Binary Star pattern
// for reliability. This interconnects the two servers so they can
// agree on which one is primary and which one is backup. To allow the
// two servers to run on the same box, we use different ports for
// primary and backup. Ports 5003/5004 are used to interconnect the
// servers. Ports 5556/5566 are used to receive voting events (snapshot
// requests in the clone pattern). Ports 5557/5567 are used by the
// publisher, and ports 5558/5568 are used by the collector:
public static void main(String[] args)
{
clonesrv6 srv = null;
if (args.length == 1 && "-p".equals(args[0])) {
srv = new clonesrv6(true);
}
else if (args.length == 1 && "-b".equals(args[0])) {
srv = new clonesrv6(false);
}
else {
System.out.printf("Usage: clonesrv4 { -p | -b }\n");
System.exit(0);
}
srv.run();
}
}
clonesrv6: Clone server, Model Six in Julia
clonesrv6: Clone server, Model Six in Lua
clonesrv6: Clone server, Model Six in Node.js
clonesrv6: Clone server, Model Six in Objective-C
clonesrv6: Clone server, Model Six in ooc
clonesrv6: Clone server, Model Six in Perl
clonesrv6: Clone server, Model Six in PHP
clonesrv6: Clone server, Model Six in Python
"""
Clone server Model Six
Author: Min RK <benjaminrk@gmail.com
"""
import logging
import time
import zmq
from zmq.eventloop.ioloop import PeriodicCallback
from zmq.eventloop.zmqstream import ZMQStream
from bstar import BinaryStar
from kvmsg import KVMsg
from zhelpers import dump
# simple struct for routing information for a key-value snapshot
class Route:
def __init__(self, socket, identity, subtree):
self.socket = socket # ROUTER socket to send to
self.identity = identity # Identity of peer who requested state
self.subtree = subtree # Client subtree specification
def send_single(key, kvmsg, route):
"""Send one state snapshot key-value pair to a socket"""
# check front of key against subscription subtree:
if kvmsg.key.startswith(route.subtree):
# Send identity of recipient first
route.socket.send(route.identity, zmq.SNDMORE)
kvmsg.send(route.socket)
class CloneServer(object):
# Our server is defined by these properties
ctx = None # Context wrapper
kvmap = None # Key-value store
bstar = None # Binary Star
sequence = 0 # How many updates so far
port = None # Main port we're working on
peer = None # Main port of our peer
publisher = None # Publish updates and hugz
collector = None # Collect updates from clients
subscriber = None # Get updates from peer
pending = None # Pending updates from client
primary = False # True if we're primary
master = False # True if we're master
slave = False # True if we're slave
def __init__(self, primary=True, ports=(5556,5566)):
self.primary = primary
if primary:
self.port, self.peer = ports
frontend = "tcp://*:5003"
backend = "tcp://localhost:5004"
self.kvmap = {}
else:
self.peer, self.port = ports
frontend = "tcp://*:5004"
backend = "tcp://localhost:5003"
self.ctx = zmq.Context.instance()
self.pending = []
self.bstar = BinaryStar(primary, frontend, backend)
self.bstar.register_voter("tcp://*:%i" % self.port, zmq.ROUTER, self.handle_snapshot)
# Set up our clone server sockets
self.publisher = self.ctx.socket(zmq.PUB)
self.collector = self.ctx.socket(zmq.SUB)
self.collector.setsockopt(zmq.SUBSCRIBE, b'')
self.publisher.bind("tcp://*:%d" % (self.port + 1))
self.collector.bind("tcp://*:%d" % (self.port + 2))
# Set up our own clone client interface to peer
self.subscriber = self.ctx.socket(zmq.SUB)
self.subscriber.setsockopt(zmq.SUBSCRIBE, b'')
self.subscriber.connect("tcp://localhost:%d" % (self.peer + 1))
# Register state change handlers
self.bstar.master_callback = self.become_master
self.bstar.slave_callback = self.become_slave
# Wrap sockets in ZMQStreams for IOLoop handlers
self.publisher = ZMQStream(self.publisher)
self.subscriber = ZMQStream(self.subscriber)
self.collector = ZMQStream(self.collector)
# Register our handlers with reactor
self.collector.on_recv(self.handle_collect)
self.flush_callback = PeriodicCallback(self.flush_ttl, 1000)
self.hugz_callback = PeriodicCallback(self.send_hugz, 1000)
# basic log formatting:
logging.basicConfig(format="%(asctime)s %(message)s", datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
def start(self):
# start periodic callbacks
self.flush_callback.start()
self.hugz_callback.start()
# Run bstar reactor until process interrupted
try:
self.bstar.start()
except KeyboardInterrupt:
pass
def handle_snapshot(self, socket, msg):
"""snapshot requests"""
if msg[1] != b"ICANHAZ?" or len(msg) != 3:
logging.error("E: bad request, aborting")
dump(msg)
self.bstar.loop.stop()
return
identity, request = msg[:2]
if len(msg) >= 3:
subtree = msg[2]
# Send state snapshot to client
route = Route(socket, identity, subtree)
# For each entry in kvmap, send kvmsg to client
for k,v in self.kvmap.items():
send_single(k,v,route)
# Now send END message with sequence number
logging.info("I: Sending state shapshot=%d" % self.sequence)
socket.send(identity, zmq.SNDMORE)
kvmsg = KVMsg(self.sequence)
kvmsg.key = b"KTHXBAI"
kvmsg.body = subtree
kvmsg.send(socket)
def handle_collect(self, msg):
"""Collect updates from clients
If we're master, we apply these to the kvmap
If we're slave, or unsure, we queue them on our pending list
"""
kvmsg = KVMsg.from_msg(msg)
if self.master:
self.sequence += 1
kvmsg.sequence = self.sequence
kvmsg.send(self.publisher)
ttl = float(kvmsg.get(b'ttl', 0))
if ttl:
kvmsg[b'ttl'] = b'%f' % (time.time() + ttl)
kvmsg.store(self.kvmap)
logging.info("I: publishing update=%d", self.sequence)
else:
# If we already got message from master, drop it, else
# hold on pending list
if not self.was_pending(kvmsg):
self.pending.append(kvmsg)
def was_pending(self, kvmsg):
"""If message was already on pending list, remove and return True.
Else return False.
"""
found = False
for idx, held in enumerate(self.pending):
if held.uuid == kvmsg.uuid:
found = True
break
if found:
self.pending.pop(idx)
return found
def flush_ttl(self):
"""Purge ephemeral values that have expired"""
if self.kvmap:
for key,kvmsg in list(self.kvmap.items()):
self.flush_single(kvmsg)
def flush_single(self, kvmsg):
"""If key-value pair has expired, delete it and publish the fact
to listening clients."""
ttl = float(kvmsg.get(b'ttl', 0))
if ttl and ttl <= time.time():
kvmsg.body = b""
self.sequence += 1
kvmsg.sequence = self.sequence
logging.info("I: preparing to publish delete=%s", kvmsg.properties)
kvmsg.send(self.publisher)
del self.kvmap[kvmsg.key]
logging.info("I: publishing delete=%d", self.sequence)
def send_hugz(self):
"""Send hugz to anyone listening on the publisher socket"""
kvmsg = KVMsg(self.sequence)
kvmsg.key = b"HUGZ"
kvmsg.body = b""
kvmsg.send(self.publisher)
# ---------------------------------------------------------------------
# State change handlers
def become_master(self):
"""We're becoming master
The backup server applies its pending list to its own hash table,
and then starts to process state snapshot requests.
"""
self.master = True
self.slave = False
# stop receiving subscriber updates while we are master
self.subscriber.stop_on_recv()
# Apply pending list to own kvmap
while self.pending:
kvmsg = self.pending.pop(0)
self.sequence += 1
kvmsg.sequence = self.sequence
kvmsg.store(self.kvmap)
logging.info ("I: publishing pending=%d", self.sequence)
def become_slave(self):
"""We're becoming slave"""
# clear kvmap
self.kvmap = None
self.master = False
self.slave = True
self.subscriber.on_recv(self.handle_subscriber)
def handle_subscriber(self, msg):
"""Collect updates from peer (master)
We're always slave when we get these updates
"""
if self.master:
logging.warn("received subscriber message, but we are master %s", msg)
return
# Get state snapshot if necessary
if self.kvmap is None:
self.kvmap = {}
snapshot = self.ctx.socket(zmq.DEALER)
snapshot.linger = 0
snapshot.connect("tcp://localhost:%i" % self.peer)
logging.info ("I: asking for snapshot from: tcp://localhost:%d",
self.peer)
snapshot.send_multipart([b"ICANHAZ?", b''])
while True:
try:
kvmsg = KVMsg.recv(snapshot)
except KeyboardInterrupt:
# Interrupted
self.bstar.loop.stop()
return
if kvmsg.key == b"KTHXBAI":
self.sequence = kvmsg.sequence
break # Done
kvmsg.store(self.kvmap)
logging.info ("I: received snapshot=%d", self.sequence)
# Find and remove update off pending list
kvmsg = KVMsg.from_msg(msg)
# update float ttl -> timestamp
ttl = float(kvmsg.get(b'ttl', 0))
if ttl:
kvmsg[b'ttl'] = b'%f' % (time.time() + ttl)
if kvmsg.key != b"HUGZ":
if not self.was_pending(kvmsg):
# If master update came before client update, flip it
# around, store master update (with sequence) on pending
# list and use to clear client update when it comes later
self.pending.append(kvmsg)
# If update is more recent than our kvmap, apply it
if (kvmsg.sequence > self.sequence):
self.sequence = kvmsg.sequence
kvmsg.store(self.kvmap)
logging.info ("I: received update=%d", self.sequence)
def main():
import sys
if '-p' in sys.argv:
primary = True
elif '-b' in sys.argv:
primary = False
else:
print("Usage: clonesrv6.py { -p | -b }")
sys.exit(1)
clone = CloneServer(primary)
clone.start()
if __name__ == '__main__':
main()
clonesrv6: Clone server, Model Six in Q
clonesrv6: Clone server, Model Six in Racket
clonesrv6: Clone server, Model Six in Ruby
clonesrv6: Clone server, Model Six in Rust
clonesrv6: Clone server, Model Six in Scala
clonesrv6: Clone server, Model Six in Tcl
clonesrv6: Clone server, Model Six in OCaml
This model is only a few hundred lines of code, but it took quite a while to get working. To be accurate, building Model Six took about a full week of “Sweet god, this is just too complex for an example” hacking. We’ve assembled pretty much everything and the kitchen sink into this small application. We have failover, ephemeral values, subtrees, and so on. What surprised me was that the up-front design was pretty accurate. Still the details of writing and debugging so many socket flows is quite challenging.
The reactor-based design removes a lot of the grunt work from the code, and what remains is simpler and easier to understand. We reuse the bstar reactor from Chapter 4 - Reliable Request-Reply Patterns. The whole server runs as one thread, so there’s no inter-thread weirdness going on–just a structure pointer (self) passed around to all handlers, which can do their thing happily. One nice side effect of using reactors is that the code, being less tightly integrated into a poll loop, is much easier to reuse. Large chunks of Model Six are taken from Model Five.
I built it piece by piece, and got each piece working properly before going onto the next one. Because there are four or five main socket flows, that meant quite a lot of debugging and testing. I debugged just by dumping messages to the console. Don’t use classic debuggers to step through ZeroMQ applications; you need to see the message flows to make any sense of what is going on.
For testing, I always try to use Valgrind, which catches memory leaks and invalid memory accesses. In C, this is a major concern, as you can’t delegate to a garbage collector. Using proper and consistent abstractions like kvmsg and CZMQ helps enormously.
The Clustered Hashmap Protocol #
While the server is pretty much a mashup of the previous model plus the Binary Star pattern, the client is quite a lot more complex. But before we get to that, let’s look at the final protocol. I’ve written this up as a specification on the ZeroMQ RFC website as the Clustered Hashmap Protocol.
Roughly, there are two ways to design a complex protocol such as this one. One way is to separate each flow into its own set of sockets. This is the approach we used here. The advantage is that each flow is simple and clean. The disadvantage is that managing multiple socket flows at once can be quite complex. Using a reactor makes it simpler, but still, it makes a lot of moving pieces that have to fit together correctly.
The second way to make such a protocol is to use a single socket pair for everything. In this case, I’d have used ROUTER for the server and DEALER for the clients, and then done everything over that connection. It makes for a more complex protocol but at least the complexity is all in one place. In Chapter 7 - Advanced Architecture using ZeroMQ we’ll look at an example of a protocol done over a ROUTER-DEALER combination.
Let’s take a look at the CHP specification. Note that “SHOULD”, “MUST” and “MAY” are key words we use in protocol specifications to indicate requirement levels.
Goals
CHP is meant to provide a basis for reliable pub-sub across a cluster of clients connected over a ZeroMQ network. It defines a “hashmap” abstraction consisting of key-value pairs. Any client can modify any key-value pair at any time, and changes are propagated to all clients. A client can join the network at any time.
Architecture
CHP connects a set of client applications and a set of servers. Clients connect to the server. Clients do not see each other. Clients can come and go arbitrarily.
Ports and Connections
The server MUST open three ports as follows:
- A SNAPSHOT port (ZeroMQ ROUTER socket) at port number P.
- A PUBLISHER port (ZeroMQ PUB socket) at port number P + 1.
- A COLLECTOR port (ZeroMQ SUB socket) at port number P + 2.
The client SHOULD open at least two connections:
- A SNAPSHOT connection (ZeroMQ DEALER socket) to port number P.
- A SUBSCRIBER connection (ZeroMQ SUB socket) to port number P + 1.
The client MAY open a third connection, if it wants to update the hashmap:
- A PUBLISHER connection (ZeroMQ PUB socket) to port number P + 2.
This extra frame is not shown in the commands explained below.
State Synchronization
The client MUST start by sending a ICANHAZ command to its snapshot connection. This command consists of two frames as follows:
ICANHAZ command
-----------------------------------
Frame 0: "ICANHAZ?"
Frame 1: subtree specification
Both frames are ZeroMQ strings. The subtree specification MAY be empty. If not empty, it consists of a slash followed by one or more path segments, ending in a slash.
The server MUST respond to a ICANHAZ command by sending zero or more KVSYNC commands to its snapshot port, followed with a KTHXBAI command. The server MUST prefix each command with the identity of the client, as provided by ZeroMQ with the ICANHAZ command. The KVSYNC command specifies a single key-value pair as follows:
KVSYNC command
-----------------------------------
Frame 0: key, as ZeroMQ string
Frame 1: sequence number, 8 bytes in network order
Frame 2: <empty>
Frame 3: <empty>
Frame 4: value, as blob
The sequence number has no significance and may be zero.
The KTHXBAI command takes this form:
KTHXBAI command
-----------------------------------
Frame 0: "KTHXBAI"
Frame 1: sequence number, 8 bytes in network order
Frame 2: <empty>
Frame 3: <empty>
Frame 4: subtree specification
The sequence number MUST be the highest sequence number of the KVSYNC commands previously sent.
When the client has received a KTHXBAI command, it SHOULD start to receive messages from its subscriber connection and apply them.
Server-to-Client Updates
When the server has an update for its hashmap it MUST broadcast this on its publisher socket as a KVPUB command. The KVPUB command has this form:
KVPUB command
-----------------------------------
Frame 0: key, as ZeroMQ string
Frame 1: sequence number, 8 bytes in network order
Frame 2: UUID, 16 bytes
Frame 3: properties, as ZeroMQ string
Frame 4: value, as blob
The sequence number MUST be strictly incremental. The client MUST discard any KVPUB commands whose sequence numbers are not strictly greater than the last KTHXBAI or KVPUB command received.
The UUID is optional and frame 2 MAY be empty (size zero). The properties field is formatted as zero or more instances of “name=value” followed by a newline character. If the key-value pair has no properties, the properties field is empty.
If the value is empty, the client SHOULD delete its key-value entry with the specified key.
In the absence of other updates the server SHOULD send a HUGZ command at regular intervals, e.g., once per second. The HUGZ command has this format:
HUGZ command
-----------------------------------
Frame 0: "HUGZ"
Frame 1: 00000000
Frame 2: <empty>
Frame 3: <empty>
Frame 4: <empty>
The client MAY treat the absence of HUGZ as an indicator that the server has crashed (see Reliability below).
Client-to-Server Updates
When the client has an update for its hashmap, it MAY send this to the server via its publisher connection as a KVSET command. The KVSET command has this form:
KVSET command
-----------------------------------
Frame 0: key, as ZeroMQ string
Frame 1: sequence number, 8 bytes in network order
Frame 2: UUID, 16 bytes
Frame 3: properties, as ZeroMQ string
Frame 4: value, as blob
The sequence number has no significance and may be zero. The UUID SHOULD be a universally unique identifier, if a reliable server architecture is used.
If the value is empty, the server MUST delete its key-value entry with the specified key.
The server SHOULD accept the following properties:
- ttl: specifies a time-to-live in seconds. If the KVSET command has a ttl property, the server SHOULD delete the key-value pair and broadcast a KVPUB with an empty value in order to delete this from all clients when the TTL has expired.
Reliability
CHP may be used in a dual-server configuration where a backup server takes over if the primary server fails. CHP does not specify the mechanisms used for this failover but the Binary Star pattern may be helpful.
To assist server reliability, the client MAY:
- Set a UUID in every KVSET command.
- Detect the lack of HUGZ over a time period and use this as an indicator that the current server has failed.
- Connect to a backup server and re-request a state synchronization.
Scalability and Performance
CHP is designed to be scalable to large numbers (thousands) of clients, limited only by system resources on the broker. Because all updates pass through a single server, the overall throughput will be limited to some millions of updates per second at peak, and probably less.
Security
CHP does not implement any authentication, access control, or encryption mechanisms and should not be used in any deployment where these are required.
Building a Multithreaded Stack and API #
The client stack we’ve used so far isn’t smart enough to handle this protocol properly. As soon as we start doing heartbeats, we need a client stack that can run in a background thread. In the Freelance pattern at the end of Chapter 4 - Reliable Request-Reply Patterns we used a multithreaded API but didn’t explain it in detail. It turns out that multithreaded APIs are quite useful when you start to make more complex ZeroMQ protocols like CHP.
If you make a nontrivial protocol and you expect applications to implement it properly, most developers will get it wrong most of the time. You’re going to be left with a lot of unhappy people complaining that your protocol is too complex, too fragile, and too hard to use. Whereas if you give them a simple API to call, you have some chance of them buying in.
Our multithreaded API consists of a frontend object and a background agent, connected by two PAIR sockets. Connecting two PAIR sockets like this is so useful that your high-level binding should probably do what CZMQ does, which is package a “create new thread with a pipe that I can use to send messages to it” method.
The multithreaded APIs that we see in this book all take the same form:
-
The constructor for the object (clone_new) creates a context and starts a background thread connected with a pipe. It holds onto one end of the pipe so it can send commands to the background thread.
-
The background thread starts an agent that is essentially a zmq_poll loop reading from the pipe socket and any other sockets (here, the DEALER and SUB sockets).
-
The main application thread and the background thread now communicate only via ZeroMQ messages. By convention, the frontend sends string commands so that each method on the class turns into a message sent to the backend agent, like this:
void
clone_connect (clone_t *self, char *address, char *service)
{
assert (self);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "CONNECT");
zmsg_addstr (msg, address);
zmsg_addstr (msg, service);
zmsg_send (&msg, self->pipe);
}
-
If the method needs a return code, it can wait for a reply message from the agent.
-
If the agent needs to send asynchronous events back to the frontend, we add a recv method to the class, which waits for messages on the frontend pipe.
-
We may want to expose the frontend pipe socket handle to allow the class to be integrated into further poll loops. Otherwise any recv method would block the application.
The clone class has the same structure as the flcliapi class from Chapter 4 - Reliable Request-Reply Patterns and adds the logic from the last model of the Clone client. Without ZeroMQ, this kind of multithreaded API design would be weeks of really hard work. With ZeroMQ, it was a day or two of work.
The actual API methods for the clone class are quite simple:
// Create a new clone class instance
clone_t *
clone_new (void);
// Destroy a clone class instance
void
clone_destroy (clone_t **self_p);
// Define the subtree, if any, for this clone class
void
clone_subtree (clone_t *self, char *subtree);
// Connect the clone class to one server
void
clone_connect (clone_t *self, char *address, char *service);
// Set a value in the shared hashmap
void
clone_set (clone_t *self, char *key, char *value, int ttl);
// Get a value from the shared hashmap
char *
clone_get (clone_t *self, char *key);
So here is Model Six of the clone client, which has now become just a thin shell using the clone class:
clonecli6: Clone client, Model Six in Ada
clonecli6: Clone client, Model Six in Basic
clonecli6: Clone client, Model Six in C
// Clone client Model Six
// Lets us build this source without creating a library
#include "clone.c"
#define SUBTREE "/client/"
int main (void)
{
// Create distributed hash instance
clone_t *clone = clone_new ();
// Specify configuration
clone_subtree (clone, SUBTREE);
clone_connect (clone, "tcp://localhost", "5556");
clone_connect (clone, "tcp://localhost", "5566");
// Set random tuples into the distributed hash
while (!zctx_interrupted) {
// Set random value, check it was stored
char key [255];
char value [10];
sprintf (key, "%s%d", SUBTREE, randof (10000));
sprintf (value, "%d", randof (1000000));
clone_set (clone, key, value, randof (30));
sleep (1);
}
clone_destroy (&clone);
return 0;
}
clonecli6: Clone client, Model Six in C++
// Clone client Model Six
#include "clone.hpp"
std::string SUBTREE="/client/";
int main() {
// Create distributed hash instance
clone_t *clone = new clone_t();
// Specify configuration
clone->subtree(SUBTREE);
clone->connect("tcp://localhost", "5556");
clone->connect("tcp://localhost", "5566");
// Set random tuples into the distributed hash
while (true) {
std::string key = SUBTREE + std::to_string(within(10000));
std::string value = std::to_string(within(1000000));
clone->set(key, value, within(30));
std::cout << "I: create key=" << key << " value=" << value << std::endl;
// sleep 1 second
std::this_thread::sleep_for(std::chrono::seconds(1));
}
return 0;
}
clonecli6: Clone client, Model Six in C#
clonecli6: Clone client, Model Six in CL
clonecli6: Clone client, Model Six in Delphi
clonecli6: Clone client, Model Six in Erlang
clonecli6: Clone client, Model Six in Elixir
clonecli6: Clone client, Model Six in F#
clonecli6: Clone client, Model Six in Felix
clonecli6: Clone client, Model Six in Go
clonecli6: Clone client, Model Six in Haskell
clonecli6: Clone client, Model Six in Haxe
clonecli6: Clone client, Model Six in Java
package guide;
import java.util.Random;
/**
* Clone client model 6
*/
public class clonecli6
{
private final static String SUBTREE = "/client/";
public void run()
{
// Create distributed hash instance
clone clone = new clone();
Random rand = new Random(System.nanoTime());
// Specify configuration
clone.subtree(SUBTREE);
clone.connect("tcp://localhost", "5556");
clone.connect("tcp://localhost", "5566");
// Set random tuples into the distributed hash
while (!Thread.currentThread().isInterrupted()) {
// Set random value, check it was stored
String key = String.format("%s%d", SUBTREE, rand.nextInt(10000));
String value = String.format("%d", rand.nextInt(1000000));
clone.set(key, value, rand.nextInt(30));
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
}
}
clone.destroy();
}
public static void main(String[] args)
{
new clonecli6().run();
}
}
clonecli6: Clone client, Model Six in Julia
clonecli6: Clone client, Model Six in Lua
clonecli6: Clone client, Model Six in Node.js
clonecli6: Clone client, Model Six in Objective-C
clonecli6: Clone client, Model Six in ooc
clonecli6: Clone client, Model Six in Perl
clonecli6: Clone client, Model Six in PHP
clonecli6: Clone client, Model Six in Python
"""
Clone server Model Six
"""
import random
import time
import zmq
from clone import Clone
SUBTREE = "/client/"
def main():
# Create and connect clone
clone = Clone()
clone.subtree = SUBTREE.encode()
clone.connect("tcp://localhost", 5556)
clone.connect("tcp://localhost", 5566)
try:
while True:
# Distribute as key-value message
key = b"%d" % random.randint(1,10000)
value = b"%d" % random.randint(1,1000000)
clone.set(key, value, random.randint(0,30))
time.sleep(1)
except KeyboardInterrupt:
pass
if __name__ == '__main__':
main()
clonecli6: Clone client, Model Six in Q
clonecli6: Clone client, Model Six in Racket
clonecli6: Clone client, Model Six in Ruby
clonecli6: Clone client, Model Six in Rust
clonecli6: Clone client, Model Six in Scala
clonecli6: Clone client, Model Six in Tcl
clonecli6: Clone client, Model Six in OCaml
Note the connect method, which specifies one server endpoint. Under the hood, we’re in fact talking to three ports. However, as the CHP protocol says, the three ports are on consecutive port numbers:
- The server state router (ROUTER) is at port P.
- The server updates publisher (PUB) is at port P + 1.
- The server updates subscriber (SUB) is at port P + 2.
So we can fold the three connections into one logical operation (which we implement as three separate ZeroMQ connect calls).
Let’s end with the source code for the clone stack. This is a complex piece of code, but easier to understand when you break it into the frontend object class and the backend agent. The frontend sends string commands (“SUBTREE”, “CONNECT”, “SET”, “GET”) to the agent, which handles these commands as well as talking to the server(s). Here is the agent’s logic:
- Start up by getting a snapshot from the first server
- When we get a snapshot switch to reading from the subscriber socket.
- If we don’t get a snapshot then fail over to the second server.
- Poll on the pipe and the subscriber socket.
- If we got input on the pipe, handle the control message from the frontend object.
- If we got input on the subscriber, store or apply the update.
- If we didn’t get anything from the server within a certain time, fail over.
- Repeat until the process is interrupted by Ctrl-C.
And here is the actual clone class implementation:
clone: Clone class in Ada
clone: Clone class in Basic
clone: Clone class in C
// clone class - Clone client API stack (multithreaded)
#include "clone.h"
// If no server replies within this time, abandon request
#define GLOBAL_TIMEOUT 4000 // msecs
// =====================================================================
// Synchronous part, works in our application thread
// Structure of our class
struct _clone_t {
zctx_t *ctx; // Our context wrapper
void *pipe; // Pipe through to clone agent
};
// This is the thread that handles our real clone class
static void clone_agent (void *args, zctx_t *ctx, void *pipe);
// .split constructor and destructor
// Here are the constructor and destructor for the clone class. Note that
// we create a context specifically for the pipe that connects our
// frontend to the backend agent:
clone_t *
clone_new (void)
{
clone_t
*self;
self = (clone_t *) zmalloc (sizeof (clone_t));
self->ctx = zctx_new ();
self->pipe = zthread_fork (self->ctx, clone_agent, NULL);
return self;
}
void
clone_destroy (clone_t **self_p)
{
assert (self_p);
if (*self_p) {
clone_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self);
*self_p = NULL;
}
}
// .split subtree method
// Specify subtree for snapshot and updates, which we must do before
// connecting to a server as the subtree specification is sent as the
// first command to the server. Sends a [SUBTREE][subtree] command to
// the agent:
void clone_subtree (clone_t *self, char *subtree)
{
assert (self);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "SUBTREE");
zmsg_addstr (msg, subtree);
zmsg_send (&msg, self->pipe);
}
// .split connect method
// Connect to a new server endpoint. We can connect to at most two
// servers. Sends [CONNECT][endpoint][service] to the agent:
void
clone_connect (clone_t *self, char *address, char *service)
{
assert (self);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "CONNECT");
zmsg_addstr (msg, address);
zmsg_addstr (msg, service);
zmsg_send (&msg, self->pipe);
}
// .split set method
// Set a new value in the shared hashmap. Sends a [SET][key][value][ttl]
// command through to the agent which does the actual work:
void
clone_set (clone_t *self, char *key, char *value, int ttl)
{
char ttlstr [10];
sprintf (ttlstr, "%d", ttl);
assert (self);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "SET");
zmsg_addstr (msg, key);
zmsg_addstr (msg, value);
zmsg_addstr (msg, ttlstr);
zmsg_send (&msg, self->pipe);
}
// .split get method
// Look up value in distributed hash table. Sends [GET][key] to the agent and
// waits for a value response. If there is no value available, will eventually
// return NULL:
char *
clone_get (clone_t *self, char *key)
{
assert (self);
assert (key);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "GET");
zmsg_addstr (msg, key);
zmsg_send (&msg, self->pipe);
zmsg_t *reply = zmsg_recv (self->pipe);
if (reply) {
char *value = zmsg_popstr (reply);
zmsg_destroy (&reply);
return value;
}
return NULL;
}
// .split working with servers
// The backend agent manages a set of servers, which we implement using
// our simple class model:
typedef struct {
char *address; // Server address
int port; // Server port
void *snapshot; // Snapshot socket
void *subscriber; // Incoming updates
uint64_t expiry; // When server expires
uint requests; // How many snapshot requests made?
} server_t;
static server_t *
server_new (zctx_t *ctx, char *address, int port, char *subtree)
{
server_t *self = (server_t *) zmalloc (sizeof (server_t));
zclock_log ("I: adding server %s:%d...", address, port);
self->address = strdup (address);
self->port = port;
self->snapshot = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (self->snapshot, "%s:%d", address, port);
self->subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_connect (self->subscriber, "%s:%d", address, port + 1);
zsocket_set_subscribe (self->subscriber, subtree);
zsocket_set_subscribe (self->subscriber, "HUGZ");
return self;
}
static void
server_destroy (server_t **self_p)
{
assert (self_p);
if (*self_p) {
server_t *self = *self_p;
free (self->address);
free (self);
*self_p = NULL;
}
}
// .split backend agent class
// Here is the implementation of the backend agent itself:
// Number of servers to which we will talk to
#define SERVER_MAX 2
// Server considered dead if silent for this long
#define SERVER_TTL 5000 // msecs
// States we can be in
#define STATE_INITIAL 0 // Before asking server for state
#define STATE_SYNCING 1 // Getting state from server
#define STATE_ACTIVE 2 // Getting new updates from server
typedef struct {
zctx_t *ctx; // Context wrapper
void *pipe; // Pipe back to application
zhash_t *kvmap; // Actual key/value table
char *subtree; // Subtree specification, if any
server_t *server [SERVER_MAX];
uint nbr_servers; // 0 to SERVER_MAX
uint state; // Current state
uint cur_server; // If active, server 0 or 1
int64_t sequence; // Last kvmsg processed
void *publisher; // Outgoing updates
} agent_t;
static agent_t *
agent_new (zctx_t *ctx, void *pipe)
{
agent_t *self = (agent_t *) zmalloc (sizeof (agent_t));
self->ctx = ctx;
self->pipe = pipe;
self->kvmap = zhash_new ();
self->subtree = strdup ("");
self->state = STATE_INITIAL;
self->publisher = zsocket_new (self->ctx, ZMQ_PUB);
return self;
}
static void
agent_destroy (agent_t **self_p)
{
assert (self_p);
if (*self_p) {
agent_t *self = *self_p;
int server_nbr;
for (server_nbr = 0; server_nbr < self->nbr_servers; server_nbr++)
server_destroy (&self->server [server_nbr]);
zhash_destroy (&self->kvmap);
free (self->subtree);
free (self);
*self_p = NULL;
}
}
// .split handling a control message
// Here we handle the different control messages from the frontend;
// SUBTREE, CONNECT, SET, and GET:
static int
agent_control_message (agent_t *self)
{
zmsg_t *msg = zmsg_recv (self->pipe);
char *command = zmsg_popstr (msg);
if (command == NULL)
return -1; // Interrupted
if (streq (command, "SUBTREE")) {
free (self->subtree);
self->subtree = zmsg_popstr (msg);
}
else
if (streq (command, "CONNECT")) {
char *address = zmsg_popstr (msg);
char *service = zmsg_popstr (msg);
if (self->nbr_servers < SERVER_MAX) {
self->server [self->nbr_servers++] = server_new (
self->ctx, address, atoi (service), self->subtree);
// We broadcast updates to all known servers
zsocket_connect (self->publisher, "%s:%d",
address, atoi (service) + 2);
}
else
zclock_log ("E: too many servers (max. %d)", SERVER_MAX);
free (address);
free (service);
}
else
// .split set and get commands
// When we set a property, we push the new key-value pair onto
// all our connected servers:
if (streq (command, "SET")) {
char *key = zmsg_popstr (msg);
char *value = zmsg_popstr (msg);
char *ttl = zmsg_popstr (msg);
// Send key-value pair on to server
kvmsg_t *kvmsg = kvmsg_new (0);
kvmsg_set_key (kvmsg, key);
kvmsg_set_uuid (kvmsg);
kvmsg_fmt_body (kvmsg, "%s", value);
kvmsg_set_prop (kvmsg, "ttl", ttl);
kvmsg_send (kvmsg, self->publisher);
kvmsg_store (&kvmsg, self->kvmap);
free (key);
free (value);
free (ttl);
}
else
if (streq (command, "GET")) {
char *key = zmsg_popstr (msg);
kvmsg_t *kvmsg = (kvmsg_t *) zhash_lookup (self->kvmap, key);
byte *value = kvmsg? kvmsg_body (kvmsg): NULL;
if (value)
zmq_send (self->pipe, value, kvmsg_size (kvmsg), 0);
else
zstr_send (self->pipe, "");
free (key);
}
free (command);
zmsg_destroy (&msg);
return 0;
}
// .split backend agent
// The asynchronous agent manages a server pool and handles the
// request-reply dialog when the application asks for it:
static void
clone_agent (void *args, zctx_t *ctx, void *pipe)
{
agent_t *self = agent_new (ctx, pipe);
while (true) {
zmq_pollitem_t poll_set [] = {
{ pipe, 0, ZMQ_POLLIN, 0 },
{ 0, 0, ZMQ_POLLIN, 0 }
};
int poll_timer = -1;
int poll_size = 2;
server_t *server = self->server [self->cur_server];
switch (self->state) {
case STATE_INITIAL:
// In this state we ask the server for a snapshot,
// if we have a server to talk to...
if (self->nbr_servers > 0) {
zclock_log ("I: waiting for server at %s:%d...",
server->address, server->port);
if (server->requests < 2) {
zstr_sendm (server->snapshot, "ICANHAZ?");
zstr_send (server->snapshot, self->subtree);
server->requests++;
}
server->expiry = zclock_time () + SERVER_TTL;
self->state = STATE_SYNCING;
poll_set [1].socket = server->snapshot;
}
else
poll_size = 1;
break;
case STATE_SYNCING:
// In this state we read from snapshot and we expect
// the server to respond, else we fail over.
poll_set [1].socket = server->snapshot;
break;
case STATE_ACTIVE:
// In this state we read from subscriber and we expect
// the server to give HUGZ, else we fail over.
poll_set [1].socket = server->subscriber;
break;
}
if (server) {
poll_timer = (server->expiry - zclock_time ())
* ZMQ_POLL_MSEC;
if (poll_timer < 0)
poll_timer = 0;
}
// .split client poll loop
// We're ready to process incoming messages; if nothing at all
// comes from our server within the timeout, that means the
// server is dead:
int rc = zmq_poll (poll_set, poll_size, poll_timer);
if (rc == -1)
break; // Context has been shut down
if (poll_set [0].revents & ZMQ_POLLIN) {
if (agent_control_message (self))
break; // Interrupted
}
else
if (poll_set [1].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (poll_set [1].socket);
if (!kvmsg)
break; // Interrupted
// Anything from server resets its expiry time
server->expiry = zclock_time () + SERVER_TTL;
if (self->state == STATE_SYNCING) {
// Store in snapshot until we're finished
server->requests = 0;
if (streq (kvmsg_key (kvmsg), "KTHXBAI")) {
self->sequence = kvmsg_sequence (kvmsg);
self->state = STATE_ACTIVE;
zclock_log ("I: received from %s:%d snapshot=%d",
server->address, server->port,
(int) self->sequence);
kvmsg_destroy (&kvmsg);
}
else
kvmsg_store (&kvmsg, self->kvmap);
}
else
if (self->state == STATE_ACTIVE) {
// Discard out-of-sequence updates, incl. HUGZ
if (kvmsg_sequence (kvmsg) > self->sequence) {
self->sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: received from %s:%d update=%d",
server->address, server->port,
(int) self->sequence);
}
else
kvmsg_destroy (&kvmsg);
}
}
else {
// Server has died, failover to next
zclock_log ("I: server at %s:%d didn't give HUGZ",
server->address, server->port);
self->cur_server = (self->cur_server + 1) % self->nbr_servers;
self->state = STATE_INITIAL;
}
}
agent_destroy (&self);
}
clone: Clone class in C++
// clone class - Clone client API stack (multithreaded)
#include <string>
#include <zmqpp/zmqpp.hpp>
#include "kvmsg.hpp"
// If no server replies within this time, abandon request
#define GLOBAL_TIMEOUT 4000 // msecs
class clone_t {
public:
clone_t();
~clone_t();
void connect(std::string endpoint, std::string service);
void subtree(std::string subtree);
void set(const std::string &key, const std::string &value, int ttl = 0);
std::optional<std::string> get(const std::string &key);
private:
bool clone_agent(zmqpp::socket_t *pipe, zmqpp::context_t *ctx);
zmqpp::context_t *ctx; // Our context wrapper
zmqpp::actor *actor; // Pipe through to clone agent
};
class server_t {
public:
server_t(zmqpp::context_t *ctx, std::string address, int port, std::string subtree);
~server_t();
public:
std::string address; // Server address
int port; // Server port
zmqpp::socket_t *snapshot; // DEALER socket for snapshot
zmqpp::socket_t *subscriber; // SUB socket for updates
std::chrono::time_point<std::chrono::steady_clock> expiry; // When server expires
uint requests; // How many snapshot requests made?
};
// .split backend agent class
// Here is the implementation of the backend agent itself:
// Number of servers to which we will talk to
#define SERVER_MAX 2
// Server considered dead if silent for this long
#define SERVER_TTL 5000 // msecs
// States we can be in
#define STATE_INITIAL 0 // Before asking server for state
#define STATE_SYNCING 1 // Getting state from server
#define STATE_ACTIVE 2 // Getting new updates from server
class agent_t {
friend class clone_t;
public:
agent_t(zmqpp::context_t *ctx, zmqpp::socket_t *pipe);
~agent_t();
private:
int agent_control_message();
zmqpp::context_t *ctx; // Context wrapper
zmqpp::socket_t *pipe; // Pipe back to application
std::unordered_map<std::string, KVMsg*> kvmap; // Actual key/value table
std::string subtree; // Subtree specification, if any
server_t *servers[SERVER_MAX];
uint nbr_servers; // 0 to SERVER_MAX
uint state; // Current state
uint cur_server; // If active, server 0 or 1
int64_t sequence; // Last kvmsg processed
zmqpp::socket_t *publisher; // Outgoing updates
};
// Implementations
// .split constructor and destructor
// Here are the constructor and destructor for the clone class. Note that
// we create a context specifically for the pipe that connects our
// frontend to the backend agent:
clone_t::clone_t() {
ctx = new zmqpp::context_t();
actor = new zmqpp::actor(std::bind(&clone_t::clone_agent, this, std::placeholders::_1, ctx));
}
clone_t::~clone_t() {
delete actor;
delete ctx;
}
// .split connect method
// Connect to a new server endpoint. We can connect to at most two
// servers. Sends [CONNECT][endpoint][service] to the agent:
void clone_t::connect(std::string endpoint, std::string service) {
zmqpp::message msg;
msg << "CONNECT" << endpoint << service;
actor->pipe()->send(msg);
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // Allow connection to come up
}
// .split subtree method
// Specify subtree for snapshot and updates, which we must do before
// connecting to a server as the subtree specification is sent as the
// first command to the server. Sends a [SUBTREE][subtree] command to
// the agent:
void clone_t::subtree(std::string subtree) {
zmqpp::message msg;
msg << "SUBTREE" << subtree;
actor->pipe()->send(msg);
}
// .split set method
// Set a new value in the shared hashmap. Sends a [SET][key][value][ttl]
// command through to the agent which does the actual work:
void clone_t::set(const std::string &key, const std::string &value, int ttl) {
zmqpp::message msg;
msg << "SET" << key << value << ttl;
actor->pipe()->send(msg);
}
// .split get method
// Look up value in distributed hash table. Sends [GET][key] to the agent and
// waits for a value response. If there is no value available, will eventually
// return NULL:
std::optional<std::string> clone_t::get(const std::string &key) {
zmqpp::message msg;
msg << "GET" << key;
actor->pipe()->send(msg);
zmqpp::message reply;
actor->pipe()->receive(reply);
if (reply.parts() == 0) {
return std::nullopt;
}
return reply.get(0);
}
// .split working with servers
// The backend agent manages a set of servers, which we implement using
// our simple class model:
server_t::server_t(zmqpp::context_t *ctx, std::string address, int port, std::string subtree) {
this->address = address;
this->port = port;
snapshot = new zmqpp::socket_t(*ctx, zmqpp::socket_type::dealer);
snapshot->connect(address + ":" + std::to_string(port));
std::cout << "server_t: connected to snapshot at " << address << ":" << port << std::endl;
subscriber = new zmqpp::socket_t(*ctx, zmqpp::socket_type::sub);
subscriber->connect(address + ":" + std::to_string(port + 1));
subscriber->set(zmqpp::socket_option::subscribe, subtree);
subscriber->set(zmqpp::socket_option::subscribe, "HUGZ");
std::cout << "server_t: connected to subscribe at " << address << ":" << port+1 << std::endl;
}
server_t::~server_t() {
delete snapshot;
delete subscriber;
}
// .split backend agent class
// Here is the implementation of the backend agent itself:
agent_t::agent_t(zmqpp::context_t *ctx, zmqpp::socket_t *pipe) {
this->ctx = ctx;
this->pipe = pipe;
this->publisher = new zmqpp::socket_t(*ctx, zmqpp::socket_type::pub);
this->state = STATE_INITIAL;
this->cur_server = 0;
this->sequence = 0;
this->nbr_servers = 0;
}
agent_t::~agent_t() {
delete publisher;
for (uint server_nbr = 0; server_nbr < nbr_servers; server_nbr++) {
delete servers[server_nbr];
}
}
// .split handling a control message
// Here we handle the different control messages from the frontend;
// SUBTREE, CONNECT, SET, and GET:
int agent_t::agent_control_message() {
zmqpp::message msg;
pipe->receive(msg);
std::string command;
msg >> command;
std::cout << "I: agent_control_message: " << command << std::endl;
if (command == "") {
return -1; // Interrupted
}
if (command == "SUBTREE") {
msg >> subtree;
} else if (command == "CONNECT") {
std::string address, service;
msg >> address >> service;
if (nbr_servers < SERVER_MAX) {
servers[nbr_servers++] = new server_t(ctx, address, std::stoi(service), subtree);
// We broadcast updates to all known servers
publisher->connect(address + ":" + std::to_string(std::stoi(service) + 2));
std::cout << "I: publish to server at " << address << ":" << service << std::endl;
} else {
std::cerr << "Too many servers" << std::endl;
}
} else if (command == "SET") {
std::string key, value;
int ttl;
msg >> key >> value >> ttl;
KVMsg *kvmsg = new KVMsg(0);
kvmsg->set_key(key);
kvmsg->set_uuid();
kvmsg->fmt_body("%s", value.c_str());
kvmsg->set_property("ttl", "%d", ttl);
kvmsg->store(kvmap);
kvmsg->send(*publisher);
} else if (command == "GET") {
std::string key;
msg >> key;
auto it = kvmap.find(key);
if (it != kvmap.end()) {
KVMsg *kvmsg = it->second;
zmqpp::message reply;
reply << std::string((char *)kvmsg->body().data(), kvmsg->size());
pipe->send(reply);
} else {
pipe->send("");
}
}
return 0;
}
// .split backend agent
// The asynchronous agent manages a server pool and handles the
// request-reply dialog when the application asks for it:
bool clone_t::clone_agent(zmqpp::socket_t *pipe, zmqpp::context_t *ctx) {
pipe->send(zmqpp::signal::ok); // Signal successful startup
std::cout << "I: clone agent started" << std::endl;
agent_t *agent = new agent_t(ctx, pipe);
while (true) {
zmqpp::poller poller;
poller.add(*agent->pipe);
int tickless = 0;
server_t *server = agent->servers[agent->cur_server];
switch (agent->state) {
case STATE_INITIAL:
// In this state we ask the server for a snapshot,
// if we have a server to talk to...
if (agent->nbr_servers > 0) {
std::cout << "Waiting for server at " << server->address << ":" << server->port << std::endl;
if (server->requests < 2) {
zmqpp::message msg;
msg << "ICANHAZ?" << agent->subtree;
server->snapshot->send(msg);
server->requests++;
}
server->expiry = std::chrono::steady_clock::now() + std::chrono::milliseconds(SERVER_TTL);
// std::cout << "server->expiry=" << server->expiry.time_since_epoch().count() << std::endl;
agent->state = STATE_SYNCING;
poller.add(*server->snapshot);
}
break;
case STATE_SYNCING:
// In this state we read from snapshot and we expect
// the server to respond, else we fail over.
poller.add(*server->snapshot);
break;
case STATE_ACTIVE:
// In this state we read from subscriber and we expect
// the server to give HUGZ, else we fail over.
poller.add(*server->subscriber);
break;
}
if (server) {
tickless = std::chrono::duration_cast<std::chrono::milliseconds>(server->expiry - std::chrono::steady_clock::now()).count();
if (tickless < 0)
tickless = 0;
}
// .split client poll loop
// We're ready to process incoming messages; if nothing at all
// comes from our server within the timeout, that means the
// server is dead:
if (poller.poll(tickless)) {
// poll return true if we have event
if (poller.has_input(*agent->pipe)) {
if (agent->agent_control_message() != 0) {
break;
}
} else if (agent->state == STATE_SYNCING && poller.has_input(*server->snapshot)) {
server->expiry = std::chrono::steady_clock::now() + std::chrono::milliseconds(SERVER_TTL);
KVMsg *kvmsg = KVMsg::recv(*server->snapshot);
if (kvmsg) {
if (kvmsg->key() == "KTHXBAI") {
agent->sequence = kvmsg->sequence();
std::cout << "I: recieved from " << server->address << ":" << server->port << " snapshot=" << agent->sequence << std::endl;
delete kvmsg;
agent->state = STATE_ACTIVE;
} else {
kvmsg->store(agent->kvmap);
}
} else {
break;
}
} else if (agent->state == STATE_ACTIVE && poller.has_input(*server->subscriber)) {
server->expiry = std::chrono::steady_clock::now() + std::chrono::milliseconds(SERVER_TTL);
KVMsg *kvmsg = KVMsg::recv(*server->subscriber);
if (kvmsg) {
// Discard out-of-sequence updates, incl. HUGZ
if (kvmsg->sequence() > agent->sequence) {
agent->sequence = kvmsg->sequence();
kvmsg->store(agent->kvmap);
std::cout << "I: recieved from " << server->address << ":" << server->port << " update=" << kvmsg->sequence() << std::endl;
} else {
delete kvmsg;
}
} else {
break;
}
}
} else {
// poll return false if timeout
// Server has died, failover to next
std::cout << "I: server at " << server->address << ":" << server->port << " didn't give HUGZ" << std::endl;
agent->cur_server = (agent->cur_server + 1) % agent->nbr_servers;
agent->state = STATE_INITIAL;
}
}
delete agent;
return true; // will send signal::ok to signal successful shutdown
}
clone: Clone class in C#
clone: Clone class in CL
clone: Clone class in Delphi
clone: Clone class in Erlang
clone: Clone class in Elixir
clone: Clone class in F#
clone: Clone class in Felix
clone: Clone class in Go
clone: Clone class in Haskell
clone: Clone class in Haxe
clone: Clone class in Java
package guide;
import java.util.HashMap;
import java.util.Map;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZThread.IAttachedRunnable;
public class clone
{
private ZContext ctx; // Our context wrapper
private Socket pipe; // Pipe through to clone agent
// .split constructor and destructor
// Here are the constructor and destructor for the clone class. Note that
// we create a context specifically for the pipe that connects our
// frontend to the backend agent:
public clone()
{
ctx = new ZContext();
pipe = ZThread.fork(ctx, new CloneAgent());
}
public void destroy()
{
ctx.destroy();
}
// .split subtree method
// Specify subtree for snapshot and updates, which we must do before
// connecting to a server as the subtree specification is sent as the
// first command to the server. Sends a [SUBTREE][subtree] command to
// the agent:
public void subtree(String subtree)
{
ZMsg msg = new ZMsg();
msg.add("SUBTREE");
msg.add(subtree);
msg.send(pipe);
}
// .split connect method
// Connect to a new server endpoint. We can connect to at most two
// servers. Sends [CONNECT][endpoint][service] to the agent:
public void connect(String address, String service)
{
ZMsg msg = new ZMsg();
msg.add("CONNECT");
msg.add(address);
msg.add(service);
msg.send(pipe);
}
// .split set method
// Set a new value in the shared hashmap. Sends a [SET][key][value][ttl]
// command through to the agent which does the actual work:
public void set(String key, String value, int ttl)
{
ZMsg msg = new ZMsg();
msg.add("SET");
msg.add(key);
msg.add(value);
msg.add(String.format("%d", ttl));
msg.send(pipe);
}
// .split get method
// Look up value in distributed hash table. Sends [GET][key] to the agent and
// waits for a value response. If there is no value available, will eventually
// return NULL:
public String get(String key)
{
ZMsg msg = new ZMsg();
msg.add("GET");
msg.add(key);
msg.send(pipe);
ZMsg reply = ZMsg.recvMsg(pipe);
if (reply != null) {
String value = reply.popString();
reply.destroy();
return value;
}
return null;
}
// .split working with servers
// The backend agent manages a set of servers, which we implement using
// our simple class model:
private static class Server
{
private String address; // Server address
private int port; // Server port
private Socket snapshot; // Snapshot socket
private Socket subscriber; // Incoming updates
private long expiry; // When server expires
private int requests; // How many snapshot requests made?
protected Server(ZContext ctx, String address, int port, String subtree)
{
System.out.printf("I: adding server %s:%d...\n", address, port);
this.address = address;
this.port = port;
snapshot = ctx.createSocket(SocketType.DEALER);
snapshot.connect(String.format("%s:%d", address, port));
subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect(String.format("%s:%d", address, port + 1));
subscriber.subscribe(subtree.getBytes(ZMQ.CHARSET));
}
protected void destroy()
{
}
}
// .split backend agent class
// Here is the implementation of the backend agent itself:
// Number of servers to which we will talk to
private final static int SERVER_MAX = 2;
// Server considered dead if silent for this long
private final static int SERVER_TTL = 5000; // msecs
// States we can be in
private final static int STATE_INITIAL = 0; // Before asking server for state
private final static int STATE_SYNCING = 1; // Getting state from server
private final static int STATE_ACTIVE = 2; // Getting new updates from server
private static class Agent
{
private ZContext ctx; // Context wrapper
private Socket pipe; // Pipe back to application
private Map<String, String> kvmap; // Actual key/value table
private String subtree; // Subtree specification, if any
private Server[] server;
private int nbrServers; // 0 to SERVER_MAX
private int state; // Current state
private int curServer; // If active, server 0 or 1
private long sequence; // Last kvmsg processed
private Socket publisher; // Outgoing updates
protected Agent(ZContext ctx, Socket pipe)
{
this.ctx = ctx;
this.pipe = pipe;
kvmap = new HashMap<String, String>();
subtree = "";
state = STATE_INITIAL;
publisher = ctx.createSocket(SocketType.PUB);
server = new Server[SERVER_MAX];
}
protected void destroy()
{
for (int serverNbr = 0; serverNbr < nbrServers; serverNbr++)
server[serverNbr].destroy();
}
// .split handling a control message
// Here we handle the different control messages from the frontend;
// SUBTREE, CONNECT, SET, and GET:
private boolean controlMessage()
{
ZMsg msg = ZMsg.recvMsg(pipe);
String command = msg.popString();
if (command == null)
return false; // Interrupted
if (command.equals("SUBTREE")) {
subtree = msg.popString();
}
else if (command.equals("CONNECT")) {
String address = msg.popString();
String service = msg.popString();
if (nbrServers < SERVER_MAX) {
server[nbrServers++] = new Server(ctx, address, Integer.parseInt(service), subtree);
// We broadcast updates to all known servers
publisher.connect(String.format("%s:%d", address, Integer.parseInt(service) + 2));
}
else System.out.printf("E: too many servers (max. %d)\n", SERVER_MAX);
}
else
// .split set and get commands
// When we set a property, we push the new key-value pair onto
// all our connected servers:
if (command.equals("SET")) {
String key = msg.popString();
String value = msg.popString();
String ttl = msg.popString();
kvmap.put(key, value);
// Send key-value pair on to server
kvmsg kvmsg = new kvmsg(0);
kvmsg.setKey(key);
kvmsg.setUUID();
kvmsg.fmtBody("%s", value);
kvmsg.setProp("ttl", ttl);
kvmsg.send(publisher);
kvmsg.destroy();
}
else if (command.equals("GET")) {
String key = msg.popString();
String value = kvmap.get(key);
if (value != null)
pipe.send(value);
else pipe.send("");
}
msg.destroy();
return true;
}
}
private static class CloneAgent implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
Agent self = new Agent(ctx, pipe);
Poller poller = ctx.createPoller(1);
poller.register(pipe, Poller.POLLIN);
while (!Thread.currentThread().isInterrupted()) {
long pollTimer = -1;
int pollSize = 2;
Server server = self.server[self.curServer];
switch (self.state) {
case STATE_INITIAL:
// In this state we ask the server for a snapshot,
// if we have a server to talk to...
if (self.nbrServers > 0) {
System.out.printf("I: waiting for server at %s:%d...\n", server.address, server.port);
if (server.requests < 2) {
server.snapshot.sendMore("ICANHAZ?");
server.snapshot.send(self.subtree);
server.requests++;
}
server.expiry = System.currentTimeMillis() + SERVER_TTL;
self.state = STATE_SYNCING;
poller.close();
poller = ctx.createPoller(2);
poller.register(pipe, Poller.POLLIN);
poller.register(server.snapshot, Poller.POLLIN);
}
else pollSize = 1;
break;
case STATE_SYNCING:
// In this state we read from snapshot and we expect
// the server to respond, else we fail over.
poller.close();
poller = ctx.createPoller(2);
poller.register(pipe, Poller.POLLIN);
poller.register(server.snapshot, Poller.POLLIN);
break;
case STATE_ACTIVE:
// In this state we read from subscriber and we expect
// the server to give hugz, else we fail over.
poller.close();
poller = ctx.createPoller(2);
poller.register(pipe, Poller.POLLIN);
poller.register(server.subscriber, Poller.POLLIN);
break;
}
if (server != null) {
pollTimer = server.expiry - System.currentTimeMillis();
if (pollTimer < 0)
pollTimer = 0;
}
// .split client poll loop
// We're ready to process incoming messages; if nothing at all
// comes from our server within the timeout, that means the
// server is dead:
int rc = poller.poll(pollTimer);
if (rc == -1)
break; // Context has been shut down
if (poller.pollin(0)) {
if (!self.controlMessage())
break; // Interrupted
}
else if (pollSize == 2 && poller.pollin(1)) {
kvmsg msg = kvmsg.recv(poller.getSocket(1));
if (msg == null)
break; // Interrupted
// Anything from server resets its expiry time
server.expiry = System.currentTimeMillis() + SERVER_TTL;
if (self.state == STATE_SYNCING) {
// Store in snapshot until we're finished
server.requests = 0;
if (msg.getKey().equals("KTHXBAI")) {
self.sequence = msg.getSequence();
self.state = STATE_ACTIVE;
System.out.printf("I: received from %s:%d snapshot=%d\n", server.address, server.port,
self.sequence);
msg.destroy();
}
}
else if (self.state == STATE_ACTIVE) {
// Discard out-of-sequence updates, incl. hugz
if (msg.getSequence() > self.sequence) {
self.sequence = msg.getSequence();
System.out.printf("I: received from %s:%d update=%d\n", server.address, server.port,
self.sequence);
}
else msg.destroy();
}
}
else {
// Server has died, failover to next
System.out.printf("I: server at %s:%d didn't give hugz\n", server.address, server.port);
self.curServer = (self.curServer + 1) % self.nbrServers;
self.state = STATE_INITIAL;
}
}
self.destroy();
}
}
}
clone: Clone class in Julia
clone: Clone class in Lua
clone: Clone class in Node.js
clone: Clone class in Objective-C
clone: Clone class in ooc
clone: Clone class in Perl
clone: Clone class in PHP
clone: Clone class in Python
"""
clone - client-side Clone Pattern class
Author: Min RK <benjaminrk@gmail.com>
"""
import logging
import threading
import time
import zmq
from zhelpers import zpipe
from kvmsg import KVMsg
# If no server replies within this time, abandon request
GLOBAL_TIMEOUT = 4000 # msecs
# Server considered dead if silent for this long
SERVER_TTL = 5.0 # secs
# Number of servers we will talk to
SERVER_MAX = 2
# basic log formatting:
logging.basicConfig(format="%(asctime)s %(message)s", datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
# =====================================================================
# Synchronous part, works in our application thread
class Clone(object):
ctx = None # Our Context
pipe = None # Pipe through to clone agent
agent = None # agent in a thread
_subtree = None # cache of our subtree value
def __init__(self):
self.ctx = zmq.Context()
self.pipe, peer = zpipe(self.ctx)
self.agent = threading.Thread(target=clone_agent, args=(self.ctx,peer))
self.agent.daemon = True
self.agent.start()
# ---------------------------------------------------------------------
# Clone.subtree is a property, which sets the subtree for snapshot
# and updates
@property
def subtree(self):
return self._subtree
@subtree.setter
def subtree(self, subtree):
"""Sends [SUBTREE][subtree] to the agent"""
self._subtree = subtree
self.pipe.send_multipart([b"SUBTREE", subtree])
def connect(self, address, port):
"""Connect to new server endpoint
Sends [CONNECT][address][port] to the agent
"""
self.pipe.send_multipart([b"CONNECT", (address.encode() if isinstance(address, str) else address), b'%d' % port])
def set(self, key, value, ttl=0):
"""Set new value in distributed hash table
Sends [SET][key][value][ttl] to the agent
"""
self.pipe.send_multipart([b"SET", key, value, b'%i' % ttl])
def get(self, key):
"""Lookup value in distributed hash table
Sends [GET][key] to the agent and waits for a value response
If there is no clone available, will eventually return None.
"""
self.pipe.send_multipart([b"GET", key])
try:
reply = self.pipe.recv_multipart()
except KeyboardInterrupt:
return
else:
return reply[0]
# =====================================================================
# Asynchronous part, works in the background
# ---------------------------------------------------------------------
# Simple class for one server we talk to
class CloneServer(object):
address = None # Server address
port = None # Server port
snapshot = None # Snapshot socket
subscriber = None # Incoming updates
expiry = 0 # Expires at this time
requests = 0 # How many snapshot requests made?
def __init__(self, ctx, address, port, subtree):
self.address = address
self.port = port
self.snapshot = ctx.socket(zmq.DEALER)
self.snapshot.linger = 0
self.snapshot.connect("%s:%i" % (address.decode(),port))
self.subscriber = ctx.socket(zmq.SUB)
self.subscriber.setsockopt(zmq.SUBSCRIBE, subtree)
self.subscriber.setsockopt(zmq.SUBSCRIBE, b'HUGZ')
self.subscriber.connect("%s:%i" % (address.decode(),port+1))
self.subscriber.linger = 0
# ---------------------------------------------------------------------
# Simple class for one background agent
# States we can be in
STATE_INITIAL = 0 # Before asking server for state
STATE_SYNCING = 1 # Getting state from server
STATE_ACTIVE = 2 # Getting new updates from server
class CloneAgent(object):
ctx = None # Own context
pipe = None # Socket to talk back to application
kvmap = None # Actual key/value dict
subtree = '' # Subtree specification, if any
servers = None # list of connected Servers
state = 0 # Current state
cur_server = 0 # If active, index of server in list
sequence = 0 # last kvmsg procesed
publisher = None # Outgoing updates
def __init__(self, ctx, pipe):
self.ctx = ctx
self.pipe = pipe
self.kvmap = {}
self.subtree = ''
self.state = STATE_INITIAL
self.publisher = ctx.socket(zmq.PUB)
self.router = ctx.socket(zmq.ROUTER)
self.servers = []
def control_message (self):
msg = self.pipe.recv_multipart()
command = msg.pop(0)
if command == b"CONNECT":
address = msg.pop(0)
port = int(msg.pop(0))
if len(self.servers) < SERVER_MAX:
self.servers.append(CloneServer(self.ctx, address, port, self.subtree))
self.publisher.connect("%s:%i" % (address.decode(),port+2))
else:
logging.error("E: too many servers (max. %i)", SERVER_MAX)
elif command == b"SET":
key,value,sttl = msg
ttl = int(sttl)
# Send key-value pair on to server
kvmsg = KVMsg(0, key=key, body=value)
kvmsg.store(self.kvmap)
if ttl:
kvmsg[b"ttl"] = sttl
kvmsg.send(self.publisher)
elif command == b"GET":
key = msg[0]
value = self.kvmap.get(key)
self.pipe.send(value.body if value else '')
elif command == b"SUBTREE":
self.subtree = msg[0]
# ---------------------------------------------------------------------
# Asynchronous agent manages server pool and handles request/reply
# dialog when the application asks for it.
def clone_agent(ctx, pipe):
agent = CloneAgent(ctx, pipe)
server = None
while True:
poller = zmq.Poller()
poller.register(agent.pipe, zmq.POLLIN)
poll_timer = None
server_socket = None
if agent.state == STATE_INITIAL:
# In this state we ask the server for a snapshot,
# if we have a server to talk to...
if agent.servers:
server = agent.servers[agent.cur_server]
logging.info ("I: waiting for server at %s:%d...",
server.address, server.port)
if (server.requests < 2):
server.snapshot.send_multipart([b"ICANHAZ?", agent.subtree])
server.requests += 1
server.expiry = time.time() + SERVER_TTL
agent.state = STATE_SYNCING
server_socket = server.snapshot
elif agent.state == STATE_SYNCING:
# In this state we read from snapshot and we expect
# the server to respond, else we fail over.
server_socket = server.snapshot
elif agent.state == STATE_ACTIVE:
# In this state we read from subscriber and we expect
# the server to give hugz, else we fail over.
server_socket = server.subscriber
if server_socket:
# we have a second socket to poll:
poller.register(server_socket, zmq.POLLIN)
if server is not None:
poll_timer = 1e3 * max(0,server.expiry - time.time())
# ------------------------------------------------------------
# Poll loop
try:
items = dict(poller.poll(poll_timer))
except:
raise # DEBUG
break # Context has been shut down
if agent.pipe in items:
agent.control_message()
elif server_socket in items:
kvmsg = KVMsg.recv(server_socket)
# Anything from server resets its expiry time
server.expiry = time.time() + SERVER_TTL
if (agent.state == STATE_SYNCING):
# Store in snapshot until we're finished
server.requests = 0
if kvmsg.key == b"KTHXBAI":
agent.sequence = kvmsg.sequence
agent.state = STATE_ACTIVE
logging.info ("I: received from %s:%d snapshot=%d",
server.address, server.port, agent.sequence)
else:
kvmsg.store(agent.kvmap)
elif (agent.state == STATE_ACTIVE):
# Discard out-of-sequence updates, incl. hugz
if (kvmsg.sequence > agent.sequence):
agent.sequence = kvmsg.sequence
kvmsg.store(agent.kvmap)
action = "update" if kvmsg.body else "delete"
logging.info ("I: received from %s:%d %s=%d",
server.address, server.port, action, agent.sequence)
else:
# Server has died, failover to next
logging.info ("I: server at %s:%d didn't give hugz",
server.address, server.port)
agent.cur_server = (agent.cur_server + 1) % len(agent.servers)
agent.state = STATE_INITIAL