Chapter 7 - Advanced Architecture using ZeroMQ #
One of the effects of using ZeroMQ at large scale is that because we can build distributed architectures so much faster than before, the limitations of our software engineering processes become more visible. Mistakes in slow motion are often harder to see (or rather, easier to rationalize away).
My experience when teaching ZeroMQ to groups of engineers is that it’s rarely sufficient to just explain how ZeroMQ works and then just expect them to start building successful products. Like any technology that removes friction, ZeroMQ opens the door to big blunders. If ZeroMQ is the ACME rocket-propelled shoe of distributed software development, a lot of us are like Wile E. Coyote, slamming full speed into the proverbial desert cliff.
We saw in Chapter 6 - The ZeroMQ Community that ZeroMQ itself uses a formal process for changes. One reason we built this process, over some years, was to stop the repeated cliff-slamming that happened in the library itself.
Partly, it’s about slowing down and partially, it’s about ensuring that when you move fast, you go–and this is essential Dear Reader–in the right direction. It’s my standard interview riddle: what’s the rarest property of any software system, the absolute hardest thing to get right, the lack of which causes the slow or fast death of the vast majority of projects? The answer is not code quality, funding, performance, or even (though it’s a close answer), popularity. The answer is accuracy.
Accuracy is half the challenge, and applies to any engineering work. The other half is distributed computing itself, which sets up a whole range of problems that we need to solve if we are going to create architectures. We need to encode and decode data; we need to define protocols to connect clients and servers; we need to secure these protocols against attackers; and we need to make stacks that are robust. Asynchronous messaging is hard to get right.
This chapter will tackle these challenges, starting with a basic reappraisal of how to design and build software and ending with a fully formed example of a distributed application for large-scale file distribution.
We’ll cover the following juicy topics:
- How to go from idea to working prototype safely (the MOPED pattern)
- Different ways to serialize your data as ZeroMQ messages
- How to code-generate binary serialization codecs
- How to build custom code generators using the GSL tool
- How to write and license a protocol specification
- How to build fast restartable file transfer over ZeroMQ
- How to use credit-based flow control for nonblocking transfers
- How to build protocol servers and clients as state machines
- How to make a secure protocol over ZeroMQ
- A large-scale file publishing system (FileMQ)
Message-Oriented Pattern for Elastic Design #
I’ll introduce Message-Oriented Pattern for Elastic Design (MOPED), a software engineering pattern for ZeroMQ architectures. It was either “MOPED” or “BIKE”, the Backronym-Induced Kinetic Effect. That’s short for “BICICLE”, the Backronym-Inflated See if I Care Less Effect. In life, one learns to go with the least embarrassing choice.
If you’ve read this book carefully, you’ll have seen MOPED in action already. The development of Majordomo in Chapter 4 - Reliable Request-Reply Patterns is a near-perfect case. But cute names are worth a thousand words.
The goal of MOPED is to define a process by which we can take a rough use case for a new distributed application, and go from “Hello World” to fully-working prototype in any language in under a week.
Using MOPED, you grow, more than build, a working ZeroMQ architecture from the ground-up with minimal risk of failure. By focusing on the contracts rather than the implementations, you avoid the risk of premature optimization. By driving the design process through ultra-short test-based cycles, you can be more certain that what you have works before you add more.
We can turn this into five real steps:
- Step 1: internalize the ZeroMQ semantics.
- Step 2: draw a rough architecture.
- Step 3: decide on the contracts.
- Step 4: make a minimal end-to-end solution.
- Step 5: solve one problem and repeat.
Step 1: Internalize the Semantics #
You must learn and digest ZeroMQ’s “language”, that is, the socket patterns and how they work. The only way to learn a language is to use it. There’s no way to avoid this investment, no tapes you can play while you sleep, no chips you can plug in to magically become smarter. Read this book from the start, work through the code examples in whatever language you prefer, understand what’s going on, and (most importantly) write some examples yourself and then throw them away.
At a certain point, you’ll feel a clicking noise in your brain. Maybe you’ll have a weird chili-induced dream where little ZeroMQ tasks run around trying to eat you alive. Maybe you’ll just think “aaahh, so that’s what it means!” If we did our work right, it should take two to three days. However long it takes, until you start thinking in terms of ZeroMQ sockets and patterns, you’re not ready for step 2.
Step 2: Draw a Rough Architecture #
From my experience, it’s essential to be able to draw the core of your architecture. It helps others understand what you are thinking, and it also helps you think through your ideas. There is really no better way to design a good architecture than to explain your ideas to your colleagues, using a whiteboard.
You don’t need to get it right, and you don’t need to make it complete. What you do need to do is break your architecture into pieces that make sense. The nice thing about software architecture (as compared to constructing bridges) is that you really can replace entire layers cheaply if you’ve isolated them.
Start by choosing the core problem that you are going to solve. Ignore anything that’s not essential to that problem: you will add it in later. The problem should be an end-to-end problem: the rope across the gorge.
For example, a client asked us to make a supercomputing cluster with ZeroMQ. Clients create bundles of work, which are sent to a broker that distributes them to workers (running on fast graphics processors), collects the results back, and returns them to the client.
The rope across the gorge is one client talking to a broker talking to one worker. We draw three boxes: client, broker, worker. We draw arrows from box to box showing the request flowing one way and the response flowing back. It’s just like the many diagrams we saw in earlier chapters.
Be minimalistic. Your goal is not to define a real architecture, but to throw a rope across the gorge to bootstrap your process. We make the architecture successfully more complete and realistic over time: e.g., adding multiple workers, adding client and worker APIs, handling failures, and so on.
Step 3: Decide on the Contracts #
A good software architecture depends on contracts, and the more explicit they are, the better things scale. You don’t care how things happen; you only care about the results. If I send an email, I don’t care how it arrives at its destination, as long as the contract is respected. The email contract is: it arrives within a few minutes, no-one modifies it, and it doesn’t get lost.
And to build a large system that works well, you must focus on the contracts before the implementations. It may sound obvious but all too often, people forget or ignore this, or are just too shy to impose themselves. I wish I could say ZeroMQ had done this properly, but for years our public contracts were second-rate afterthoughts instead of primary in-your-face pieces of work.
So what is a contract in a distributed system? There are, in my experience, two types of contract:
-
The APIs to client applications. Remember the Psychological Elements. The APIs need to be as absolutely simple, consistent, and familiar as possible. Yes, you can generate API documentation from code, but you must first design it, and designing an API is often hard.
-
The protocols that connect the pieces. It sounds like rocket science, but it’s really just a simple trick, and one that ZeroMQ makes particularly easy. In fact they’re so simple to write, and need so little bureaucracy that I call them unprotocols.
You write minimal contracts that are mostly just place markers. Most messages and most API methods will be missing or empty. You also want to write down any known technical requirements in terms of throughput, latency, reliability, and so on. These are the criteria on which you will accept or reject any particular piece of work.
Step 4: Write a Minimal End-to-End Solution #
The goal is to test out the overall architecture as rapidly as possible. Make skeleton applications that call the APIs, and skeleton stacks that implement both sides of every protocol. You want to get a working end-to-end “Hello World” as soon as you can. You want to be able to test code as you write it, so that you can weed out the broken assumptions and inevitable errors you make. Do not go off and spend six months writing a test suite! Instead, make a minimal bare-bones application that uses our still-hypothetical API.
If you design an API wearing the hat of the person who implements it, you’ll start to think of performance, features, options, and so on. You’ll make it more complex, more irregular, and more surprising than it should be. But, and here’s the trick (it’s a cheap one, was big in Japan): if you design an API while wearing the hat of the person who has to actually write apps that use it, you use all that laziness and fear to your advantage.
Write down the protocols on a wiki or shared document in such a way that you can explain every command clearly without too much detail. Strip off any real functionality, because it will only create inertia that makes it harder to move stuff around. You can always add weight. Don’t spend effort defining formal message structures: pass the minimum around in the simplest possible fashion using ZeroMQ’s multipart framing.
Our goal is to get the simplest test case working, without any avoidable functionality. Everything you can chop off the list of things to do, you chop. Ignore the groans from colleagues and bosses. I’ll repeat this once again: you can always add functionality, that’s relatively easy. But aim to keep the overall weight to a minimum.
Step 5: Solve One Problem and Repeat #
You’re now in the happy cycle of issue-driven development where you can start to solve tangible problems instead of adding features. Write issues that each state a clear problem, and propose a solution. As you design the API, keep in mind your standards for names, consistency, and behavior. Writing these down in prose often helps keep them sane.
From here, every single change you make to the architecture and code can be proven by running the test case, watching it not work, making the change, and then watching it work.
Now you go through the whole cycle (extending the test case, fixing the API, updating the protocol, and extending the code, as needed), taking problems one at a time and testing the solutions individually. It should take about 10-30 minutes for each cycle, with the occasional spike due to random confusion.
Unprotocols #
Protocols Without The Goats #
When this man thinks of protocols, this man thinks of massive documents written by committees, over years. This man thinks of the IETF, W3C, ISO, Oasis, regulatory capture, FRAND patent license disputes, and soon after, this man thinks of retirement to a nice little farm in northern Bolivia up in the mountains where the only other needlessly stubborn beings are the goats chewing up the coffee plants.
Now, I’ve nothing personal against committees. The useless folk need a place to sit out their lives with minimal risk of reproducing; after all, that only seems fair. But most committee protocols tend towards complexity (the ones that work), or trash (the ones we don’t talk about). There’s a few reasons for this. One is the amount of money at stake. More money means more people who want their particular prejudices and assumptions expressed in prose. But two is the lack of good abstractions on which to build. People have tried to build reusable protocol abstractions, like BEEP. Most did not stick, and those that did, like SOAP and XMPP, are on the complex side of things.
It used to be, decades ago, when the Internet was a young modest thing, that protocols were short and sweet. They weren’t even “standards”, but “requests for comments”, which is as modest as you can get. It’s been one of my goals since we started iMatix in 1995 to find a way for ordinary people like me to write small, accurate protocols without the overhead of the committees.
Now, ZeroMQ does appear to provide a living, successful protocol abstraction layer with its “we’ll carry multipart messages over random transports” way of working. Because ZeroMQ deals silently with framing, connections, and routing, it’s surprisingly easy to write full protocol specs on top of ZeroMQ, and in Chapter 4 - Reliable Request-Reply Patterns and Chapter 5 - Advanced Pub-Sub Patterns I showed how to do this.
Somewhere around mid-2007, I kicked off the Digital Standards Organization to define new simpler ways of producing little standards, protocols, and specifications. In my defense, it was a quiet summer. At the time, I wrote that a new specification should take [http://www.digistan.org/spec:1 “minutes to explain, hours to design, days to write, weeks to prove, months to become mature, and years to replace."]
In 2010, we started calling such little specifications unprotocols, which some people might mistake for a dastardly plan for world domination by a shadowy international organization, but which really just means “protocols without the goats”.
Contracts Are Hard #
Writing contracts is perhaps the most difficult part of large-scale architecture. With unprotocols, we remove as much of the unnecessary friction as possible. What remains is still a hard set of problems to solve. A good contract (be it an API, a protocol, or a rental agreement) has to be simple, unambiguous, technically sound, and easy to enforce.
Like any technical skill, it’s something you have to learn and practice. There are a series of specifications on the ZeroMQ RFC site, which are worth reading and using them as a basis for your own specifications when you find yourself in need.
I’ll try to summarize my experience as a protocol writer:
-
Start simple, and develop your specifications step-by-step. Don’t solve problems you don’t have in front of you.
-
Use very clear and consistent language. A protocol may often break down into commands and fields; use clear short names for these entities.
-
Try to avoid inventing concepts. Reuse anything you can from existing specifications. Use terminology that is obvious and clear to your audience.
-
Make nothing for which you cannot demonstrate an immediate need. Your specification solves problems; it does not provide features. Make the simplest plausible solution for each problem that you identify.
-
Implement your protocol as you build it, so that you are aware of the technical consequences of each choice. Use a language that makes it hard (like C) and not one that makes it easy (like Python).
-
Test your specification as you build it on other people. Your best feedback on a specification is when someone else tries to implement it without the assumptions and knowledge that you have in your head.
-
Cross-test rapidly and consistently, throwing others’ clients against your servers and vice versa.
-
Be prepared to throw it out and start again as often as needed. Plan for this, by layering your architecture so that e.g., you can keep an API but change the underlying protocols.
-
Only use constructs that are independent of programming language and operating system.
-
Solve a large problem in layers, making each layer an independent specification. Beware of creating monolithic protocols. Think about how reusable each layer is. Think about how different teams could build competing specifications at each layer.
And above all, write it down. Code is not a specification. The point about a written specification is that no matter how weak it is, it can be systematically improved. By writing down a specification, you will also spot inconsistencies and gray areas that are impossible to see in code.
If this sounds hard, don’t worry too much. One of the less obvious benefits of using ZeroMQ is that it cuts the effort necessary to write a protocol spec by perhaps 90% or more because it already handles framing, routing, queuing, and so on. This means that you can experiment rapidly, make mistakes cheaply, and thus learn rapidly.
How to Write Unprotocols #
When you start to write an unprotocol specification document, stick to a consistent structure so that your readers know what to expect. Here is the structure I use:
- Cover section: with a 1-line summary, URL to the spec, formal name, version, who to blame.
- License for the text: absolutely needed for public specifications.
- The change process: i.e., how can I as a reader fix problems in the specification?
- Use of language: MUST, MAY, SHOULD, and so on, with a reference to RFC 2119.
- Maturity indicator: is this an experimental, draft, stable, legacy, or retired?
- Goals of the protocol: what problems is it trying to solve?
- Formal grammar: prevents arguments due to different interpretations of the text.
- Technical explanation: semantics of each message, error handling, and so on.
- Security discussion: explicitly, how secure the protocol is.
- References: to other documents, protocols, and so on.
Writing clear, expressive text is hard. Do avoid trying to describe implementations of the protocol. Remember that you’re writing a contract. You describe in clear language the obligations and expectations of each party, the level of obligation, and the penalties for breaking the rules. You do not try to define how each party honors its part of the deal.
Here are some key points about unprotocols:
-
As long as your process is open, then you don’t need a committee: just make clean minimal designs and make sure anyone is free to improve them.
-
If use an existing license, then you don’t have legal worries afterwards. I use GPLv3 for my public specifications and advise you to do the same. For in-house work, standard copyright is perfect.
-
Formality is valuable. That is, learn to write a formal grammar such as ABNF (Augmented Backus-Naur Form) and use this to fully document your messages.
-
Use a market-driven life cycle process like Digistan’s COSS so that people place the right weight on your specs as they mature (or don’t).
Why use the GPLv3 for Public Specifications? #
The license you choose is particularly crucial for public specifications. Traditionally, protocols are published under custom licenses, where the authors own the text and derived works are forbidden. This sounds great (after all, who wants to see a protocol forked?), but it’s in fact highly risky. A protocol committee is vulnerable to capture, and if the protocol is important and valuable, the incentive for capture grows.
Once captured, like some wild animals, an important protocol will often die. The real problem is that there’s no way to free a captive protocol published under a conventional license. The word “free” isn’t just an adjective to describe speech or air, it’s also a verb, and the right to fork a work against the wishes of the owner is essential to avoiding capture.
Let me explain this in shorter words. Imagine that iMatix writes a protocol today that’s really amazing and popular. We publish the spec and many people implement it. Those implementations are fast and awesome, and free as in beer. They start to threaten an existing business. Their expensive commercial product is slower and can’t compete. So one day they come to our iMatix office in Maetang-Dong, South Korea, and offer to buy our firm. Because we’re spending vast amounts on sushi and beer, we accept gratefully. With evil laughter, the new owners of the protocol stop improving the public version, close the specification, and add patented extensions. Their new products support this new protocol version, but the open source versions are legally blocked from doing so. The company takes over the whole market, and competition ends.
When you contribute to an open source project, you really want to know your hard work won’t be used against you by a closed source competitor. This is why the GPL beats the “more permissive” BSD/MIT/X11 licenses for most contributors. These licenses give permission to cheat. This applies just as much to protocols as to source code.
When you implement a GPLv3 specification, your applications are of course yours, and licensed any way you like. But you can be certain of two things. One, that specification will never be embraced and extended into proprietary forms. Any derived forms of the specification must also be GPLv3. Two, no one who ever implements or uses the protocol will ever launch a patent attack on anything it covers, nor can they add their patented technology to it without granting the world a free license.
Using ABNF #
My advice when writing protocol specs is to learn and use a formal grammar. It’s just less hassle than allowing others to interpret what you mean, and then recover from the inevitable false assumptions. The target of your grammar is other people, engineers, not compilers.
My favorite grammar is ABNF, as defined by RFC 2234, because it is probably the simplest and most widely used formal language for defining bidirectional communications protocols. Most IETF (Internet Engineering Task Force) specifications use ABNF, which is good company to be in.
I’ll give a 30-second crash course in writing ABNF. It may remind you of regular expressions. You write the grammar as rules. Each rule takes the form “name = elements”. An element can be another rule (which you define below as another rule) or a pre-defined terminal like CRLF, OCTET, or a number. The RFC lists all the terminals. To define alternative elements, separate with a slash. To define repetition, use an asterisk. To group elements, use parentheses. Read the RFC because it’s not intuitive.
I’m not sure if this extension is proper, but I then prefix elements with “C:” and “S:” to indicate whether they come from the client or server.
Here’s a piece of ABNF for an unprotocol called NOM that we’ll come back to later in this chapter:
nom-protocol = open-peering *use-peering
open-peering = C:OHAI ( S:OHAI-OK / S:WTF )
use-peering = C:ICANHAZ
/ S:CHEEZBURGER
/ C:HUGZ S:HUGZ-OK
/ S:HUGZ C:HUGZ-OK
I’ve actually used these keywords (OHAI, WTF) in commercial projects. They make developers giggly and happy. They confuse management. They’re good in first drafts that you want to throw away later.
The Cheap or Nasty Pattern #
There is a general lesson I’ve learned over a couple of decades of writing protocols small and large. I call this the Cheap or Nasty pattern: you can often split your work into two aspects or layers and solve these separately–one using a “cheap” approach, the other using a “nasty” approach.
The key insight to making Cheap or Nasty work is to realize that many protocols mix a low-volume chatty part for control, and a high-volume asynchronous part for data. For instance, HTTP has a chatty dialog to authenticate and get pages, and an asynchronous dialog to stream data. FTP actually splits this over two ports; one port for control and one port for data.
Protocol designers who don’t separate control from data tend to make horrid protocols, because the trade-offs in the two cases are almost totally opposed. What is perfect for control is bad for data, and what’s ideal for data just doesn’t work for control. It’s especially true when we want high performance at the same time as extensibility and good error checking.
Let’s break this down using a classic client/server use case. The client connects to the server and authenticates. It then asks for some resource. The server chats back, then starts to send data back to the client. Eventually, the client disconnects or the server finishes, and the conversation is over.
Now, before starting to design these messages, stop and think, and let’s compare the control dialog and the data flow:
-
The control dialog lasts a short time and involves very few messages. The data flow could last for hours or days, and involve billions of messages.
-
The control dialog is where all the “normal” errors happen, e.g., not authenticated, not found, payment required, censored, and so on. In contrast, any errors that happen during the data flow are exceptional (disk full, server crashed).
-
The control dialog is where things will change over time as we add more options, parameters, and so on. The data flow should barely change over time because the semantics of a resource are fairly constant over time.
-
The control dialog is essentially a synchronous request/reply dialog. The data flow is essentially a one-way asynchronous flow.
These differences are critical. When we talk about performance, it applies only to data flows. It’s pathological to design a one-time control dialog to be fast. Thus when we talk about the cost of serialization, this only applies to the data flow. The cost of encoding/decoding the control flow could be huge, and for many cases it would not change a thing. So we encode control using Cheap, and we encode data flows using Nasty.
Cheap is essentially synchronous, verbose, descriptive, and flexible. A Cheap message is full of rich information that can change for each application. Your goal as designer is to make this information easy to encode and parse, trivial to extend for experimentation or growth, and highly robust against change both forwards and backwards. The Cheap part of a protocol looks like this:
-
It uses a simple self-describing structured encoding for data, be it XML, JSON, HTTP-style headers, or some other. Any encoding is fine as long as there are standard simple parsers for it in your target languages.
-
It uses a straight request-reply model where each request has a success/failure reply. This makes it trivial to write correct clients and servers for a Cheap dialog.
-
It doesn’t try, even marginally, to be fast. Performance doesn’t matter when you do something only once or a few times per session.
A Cheap parser is something you take off the shelf and throw data at. It shouldn’t crash, shouldn’t leak memory, should be highly tolerant, and should be relatively simple to work with. That’s it.
Nasty however is essentially asynchronous, terse, silent, and inflexible. A Nasty message carries minimal information that practically never changes. Your goal as designer is to make this information ultrafast to parse, and possibly even impossible to extend and experiment with. The ideal Nasty pattern looks like this:
-
It uses a hand-optimized binary layout for data, where every bit is precisely crafted.
-
It uses a pure asynchronous model where one or both peers send data without acknowledgments (or if they do, they use sneaky asynchronous techniques like credit-based flow control).
-
It doesn’t try, even marginally, to be friendly. Performance is all that matters when you are doing something several million times per second.
A Nasty parser is something you write by hand, which writes or reads bits, bytes, words, and integers individually and precisely. It rejects anything it doesn’t like, does no memory allocations at all, and never crashes.
Cheap or Nasty isn’t a universal pattern; not all protocols have this dichotomy. Also, how you use Cheap or Nasty will depend on the situation. In some cases, it can be two parts of a single protocol. In other cases, it can be two protocols, one layered on top of the other.
Error Handling #
Using Cheap or Nasty makes error handling rather simpler. You have two kinds of commands and two ways to signal errors:
- Synchronous control commands: errors are normal: every request has a response that is either OK or an error response.
- Asynchronous data commands: errors are exceptional: bad commands are either discarded silently, or cause the whole connection to be closed.
It’s usually good to distinguish a few kinds of errors, but as always keep it minimal and add only what you need.
Serializing Your Data #
When we start to design a protocol, one of the first questions we face is how we encode data on the wire. There is no universal answer. There are a half-dozen different ways to serialize data, each with pros and cons. We’ll explore some of these.
Abstraction Level #
Before looking at how to put data onto the wire, it’s worth asking what data we actually want to exchange between applications. If we don’t use any abstraction, we literally serialize and deserialize our internal state. That is, the objects and structures we use to implement our functionality.
Putting internal state onto the wire is however a really bad idea. It’s like exposing internal state in an API. When you do this, you are hard-coding your implementation decisions into your protocols. You are also going to produce protocols that are significantly more complex than they need to be.
It’s perhaps the main reason so many older protocols and APIs are so complex: their designers did not think about how to abstract them into simpler concepts. There is of course no guarantee than an abstraction will be simpler; that’s where the hard work comes in.
A good protocol or API abstraction encapsulates natural patterns of use, and gives them name and properties that are predictable and regular. It chooses sensible defaults so that the main use cases can be specified minimally. It aims to be simple for the simple cases, and expressive for the rarer complex cases. It does not make any statements or assumptions about the internal implementation unless that is absolutely needed for interoperability.
ZeroMQ Framing #
The simplest and most widely used serialization format for ZeroMQ applications is ZeroMQ’s own multipart framing. For example, here is how the Majordomo Protocol defines a request:
Frame 0: Empty frame
Frame 1: "MDPW01" (six bytes, representing MDP/Worker v0.1)
Frame 2: 0x02 (one byte, representing REQUEST)
Frame 3: Client address (envelope stack)
Frame 4: Empty (zero bytes, envelope delimiter)
Frames 5+: Request body (opaque binary)
To read and write this in code is easy, but this is a classic example of a control flow (the whole of MDP is really, as it’s a chatty request-reply protocol). When we came to improve MDP for the second version, we had to change this framing. Excellent, we broke all existing implementations!
Backwards compatibility is hard, but using ZeroMQ framing for control flows does not help. Here’s how I should have designed this protocol if I’d followed my own advice (and I’ll fix this in the next version). It’s split into a Cheap part and a Nasty part, and uses the ZeroMQ framing to separate these:
Frame 0: "MDP/2.0" for protocol name and version
Frame 1: command header
Frame 2: command body
Where we’d expect to parse the command header in the various intermediaries (client API, broker, and worker API), and pass the command body untouched from application to application.
Serialization Languages #
Serialization languages have their fashions. XML used to be big as in popular, then it got big as in over-engineered, and then it fell into the hands of “Enterprise Information Architects” and it’s not been seen alive since. Today’s XML is the epitome of “somewhere in that mess is a small, elegant language trying to escape”.
Still XML was way, way better than its predecessors, which included such monsters as the Standard Generalized Markup Language (SGML), which in turn was a cool breeze compared to mind-torturing beasts like EDIFACT. So the history of serialization languages seems to be of gradually emerging sanity, hidden by waves of revolting EIAs doing their best to hold onto their jobs.
JSON popped out of the JavaScript world as a quick-and-dirty “I’d rather resign than use XML here” way to throw data onto the wire and get it back again. JSON is just minimal XML expressed, sneakily, as JavaScript source code.
Here’s a simple example of using JSON in a Cheap protocol:
"protocol": {
"name": "MTL",
"version": 1
},
"virtual-host": "test-env"
The same data in XML would be (XML forces us to invent a single top-level entity):
<command>
<protocol name = "MTL" version = "1" />
<virtual-host>test-env</virtual-host>
</command>
And here it is using plain-old HTTP-style headers:
Protocol: MTL/1.0
Virtual-host: test-env
These are all pretty equivalent as long as you don’t go overboard with validating parsers, schemas, and other “trust us, this is all for your own good” nonsense. A Cheap serialization language gives you space for experimentation for free (“ignore any elements/attributes/headers that you don’t recognize”), and it’s simple to write generic parsers that, for example, thunk a command into a hash table, or vice versa.
However, it’s not all roses. While modern scripting languages support JSON and XML easily enough, older languages do not. If you use XML or JSON, you create nontrivial dependencies. It’s also somewhat of a pain to work with tree-structured data in a language like C.
So you can drive your choice according to the languages for which you’re aiming. If your universe is a scripting language, then go for JSON. If you are aiming to build protocols for wider system use, keep things simple for C developers and stick to HTTP-style headers.
Serialization Libraries #
The msgpack.org site says:
It’s like JSON, but fast and small. MessagePack is an efficient binary serialization format. It lets you exchange data among multiple languages like JSON, but it’s faster and smaller. For example, small integers (like flags or error code) are encoded into a single byte, and typical short strings only require an extra byte in addition to the strings themselves.
I’m going to make the perhaps unpopular claim that “fast and small” are features that solve non-problems. The only real problem that serialization libraries solve is, as far as I can tell, the need to document the message contracts and actually serialize data to and from the wire.
Let’s start by debunking “fast and small”. It’s based on a two-part argument. First, that making your messages smaller and reducing CPU cost for encoding and decoding will make a significant difference to your application’s performance. Second, that this equally valid across-the-board to all messages.
But most real applications tend to fall into one of two categories. Either the speed of serialization and size of encoding is marginal compared to other costs, such as database access or application code performance. Or, network performance really is critical, and then all significant costs occur in a few specific message types.
Thus, aiming for “fast and small” across the board is a false optimization. You neither get the easy flexibility of Cheap for your infrequent control flows, nor do you get the brutal efficiency of Nasty for your high-volume data flows. Worse, the assumption that all messages are equal in some way can corrupt your protocol design. Cheap or Nasty isn’t only about serialization strategies, it’s also about synchronous versus asynchronous, error handling and the cost of change.
My experience is that most performance problems in message-based applications can be solved by (a) improving the application itself and (b) hand-optimizing the high-volume data flows. And to hand-optimize your most critical data flows, you need to cheat; to learn exploit facts about your data, something general purpose serializers cannot do.
Now let’s address documentation and the need to write our contracts explicitly and formally, rather than only in code. This is a valid problem to solve, indeed one of the main ones if we’re to build a long-lasting, large-scale message-based architecture.
Here is how we describe a typical message using the MessagePack interface definition language (IDL):
message Person {
1: string surname
2: string firstname
3: optional string email
}
Now, the same message using the Google protocol buffers IDL:
message Person {
required string surname = 1;
required string firstname = 2;
optional string email = 3;
}
It works, but in most practical cases wins you little over a serialization language backed by decent specifications written by hand or produced mechanically (we’ll come to this). The price you’ll pay is an extra dependency and quite probably, worse overall performance than if you used Cheap or Nasty.
Handwritten Binary Serialization #
As you’ll gather from this book, my preferred language for systems programming is C (upgraded to C99, with a constructor/destructor API model and generic containers). There are two reasons I like this modernized C language. First, I’m too weak-minded to learn a big language like C++. Life just seems filled with more interesting things to understand. Second, I find that this specific level of manual control lets me produce better results, faster.
The point here isn’t C versus C++, but the value of manual control for high-end professional users. It’s no accident that the best cars, cameras, and espresso machines in the world have manual controls. That level of on-the-spot fine tuning often makes the difference between world class success, and being second best.
When you are really, truly concerned about the speed of serialization and/or the size of the result (often these contradict each other), you need handwritten binary serialization. In other words, let’s hear it for Mr. Nasty!
Your basic process for writing an efficient Nasty encoder/decoder (codec) is:
- Build representative data sets and test applications that can stress test your codec.
- Write a first dumb version of the codec.
- Test, measure, improve, and repeat until you run out of time and/or money.
Here are some of the techniques we use to make our codecs better:
-
Use a profiler. There’s simply no way to know what your code is doing until you’ve profiled it for function counts and for CPU cost per function. When you find your hot spots, fix them.
-
Eliminate memory allocations. The heap is very fast on a modern Linux kernel, but it’s still the bottleneck in most naive codecs. On older kernels, the heap can be tragically slow. Use local variables (the stack) instead of the heap where you can.
-
Test on different platforms and with different compilers and compiler options. Apart from the heap, there are many other differences. You need to learn the main ones, and allow for them.
-
Use state to compress better. If you are concerned about codec performance, you are almost definitely sending the same kinds of data many times. There will be redundancy between instances of data. You can detect these and use that to compress (e.g., a short value that means “same as last time”).
-
Know your data. The best compression techniques (in terms of CPU cost for compactness) require knowing about the data. For example, the techniques used to compress a word list, a video, and a stream of stock market data are all different.
-
Be ready to break the rules. Do you really need to encode integers in big-endian network byte order? x86 and ARM account for almost all modern CPUs, yet use little-endian (ARM is actually bi-endian but Android, like Windows and iOS, is little-endian).
Code Generation #
Reading the previous two sections, you might have wondered, “could I write my own IDL generator that was better than a general purpose one?” If this thought wandered into your mind, it probably left pretty soon after, chased by dark calculations about how much work that actually involved.
What if I told you of a way to build custom IDL generators cheaply and quickly? You can have a way to get perfectly documented contracts, code that is as evil and domain-specific as you need it to be, and all you need to do is sign away your soul (who ever really used that, am I right?) just here…
At iMatix, until a few years ago, we used code generation to build ever larger and more ambitious systems until we decided the technology (GSL) was too dangerous for common use, and we sealed the archive and locked it with heavy chains in a deep dungeon. We actually posted it on GitHub. If you want to try the examples that are coming up, grab the repository and build yourself a gsl command. Typing “make” in the src subdirectory should do it (and if you’re that guy who loves Windows, I’m sure you’ll send a patch with project files).
This section isn’t really about GSL at all, but about a useful and little-known trick that’s useful for ambitious architects who want to scale themselves, as well as their work. Once you learn the trick, you can whip up your own code generators in a short time. The code generators most software engineers know about come with a single hard-coded model. For instance, Ragel “compiles executable finite state machines from regular languages”, i.e., Ragel’s model is a regular language. This certainly works for a good set of problems, but it’s far from universal. How do you describe an API in Ragel? Or a project makefile? Or even a finite-state machine like the one we used to design the Binary Star pattern in Chapter 4 - Reliable Request-Reply Patterns?
All these would benefit from code generation, but there’s no universal model. So the trick is to design your own models as you need them, and then make code generators as cheap compilers for that model. You need some experience in how to make good models, and you need a technology that makes it cheap to build custom code generators. A scripting language, like Perl and Python, is a good option. However, we actually built GSL specifically for this, and that’s what I prefer.
Let’s take a simple example that ties into what we already know. We’ll see more extensive examples later, because I really do believe that code generation is crucial knowledge for large-scale work. In Chapter 4 - Reliable Request-Reply Patterns, we developed the Majordomo Protocol (MDP), and wrote clients, brokers, and workers for that. Now could we generate those pieces mechanically, by building our own interface description language and code generators?
When we write a GSL model, we can use any semantics we like, in other words we can invent domain-specific languages on the spot. I’ll invent a couple–see if you can guess what they represent:
slideshow
name = Cookery level 3
page
title = French Cuisine
item = Overview
item = The historical cuisine
item = The nouvelle cuisine
item = Why the French live longer
page
title = Overview
item = Soups and salads
item = Le plat principal
item = Béchamel and other sauces
item = Pastries, cakes, and quiches
item = Soufflé: cheese to strawberry
How about this one:
table
name = person
column
name = firstname
type = string
column
name = lastname
type = string
column
name = rating
type = integer
We could compile the first into a presentation. The second, we could compile into SQL to create and work with a database table. So for this exercise, our domain language, our model, consists of “classes” that contain “messages” that contain “fields” of various types. It’s deliberately familiar. Here is the MDP client protocol:
<class name = "mdp_client">
MDP/Client
<header>
<field name = "empty" type = "string" value = ""
>Empty frame</field>
<field name = "protocol" type = "string" value = "MDPC01"
>Protocol identifier</field>
</header>
<message name = "request">
Client request to broker
<field name = "service" type = "string">Service name</field>
<field name = "body" type = "frame">Request body</field>
</message>
<message name = "reply">
Response back to client
<field name = "service" type = "string">Service name</field>
<field name = "body" type = "frame">Response body</field>
</message>
</class>
And here is the MDP worker protocol:
<class name = "mdp_worker">
MDP/Worker
<header>
<field name = "empty" type = "string" value = ""
>Empty frame</field>
<field name = "protocol" type = "string" value = "MDPW01"
>Protocol identifier</field>
<field name = "id" type = "octet">Message identifier</field>
</header>
<message name = "ready" id = "1">
Worker tells broker it is ready
<field name = "service" type = "string">Service name</field>
</message>
<message name = "request" id = "2">
Client request to broker
<field name = "client" type = "frame">Client address</field>
<field name = "body" type = "frame">Request body</field>
</message>
<message name = "reply" id = "3">
Worker returns reply to broker
<field name = "client" type = "frame">Client address</field>
<field name = "body" type = "frame">Request body</field>
</message>
<message name = "hearbeat" id = "4">
Either peer tells the other it's still alive
</message>
<message name = "disconnect" id = "5">
Either peer tells other the party is over
</message>
</class>
GSL uses XML as its modeling language. XML has a poor reputation, having been dragged through too many enterprise sewers to smell sweet, but it has some strong positives, as long as you keep it simple. Any way to write a self-describing hierarchy of items and attributes would work.
Now here is a short IDL generator written in GSL that turns our protocol models into documentation:
.# Trivial IDL generator (specs.gsl)
.#
.output "$(class.name).md"
## The $(string.trim (class.?''):left) Protocol
.for message
. frames = count (class->header.field) + count (field)
A $(message.NAME) command consists of a multipart message of $(frames)
frames:
. for class->header.field
. if name = "id"
* Frame $(item ()): 0x$(message.id:%02x) (1 byte, $(message.NAME))
. else
* Frame $(item ()): "$(value:)" ($(string.length ("$(value)")) \
bytes, $(field.:))
. endif
. endfor
. index = count (class->header.field) + 1
. for field
* Frame $(index): $(field.?'') \
. if type = "string"
(printable string)
. elsif type = "frame"
(opaque binary)
. index += 1
. else
. echo "E: unknown field type: $(type)"
. endif
. index += 1
. endfor
.endfor
The XML models and this script are in the subdirectory examples/models. To do the code generation, I give this command:
gsl -script:specs mdp_client.xml mdp_worker.xml
Here is the Markdown text we get for the worker protocol:
## The MDP/Worker Protocol
A READY command consists of a multipart message of 4 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x01 (1 byte, READY)
* Frame 4: Service name (printable string)
A REQUEST command consists of a multipart message of 5 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x02 (1 byte, REQUEST)
* Frame 4: Client address (opaque binary)
* Frame 6: Request body (opaque binary)
A REPLY command consists of a multipart message of 5 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x03 (1 byte, REPLY)
* Frame 4: Client address (opaque binary)
* Frame 6: Request body (opaque binary)
A HEARBEAT command consists of a multipart message of 3 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x04 (1 byte, HEARBEAT)
A DISCONNECT command consists of a multipart message of 3 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x05 (1 byte, DISCONNECT)
This, as you can see, is close to what I wrote by hand in the original spec. Now, if you have cloned the zguide repository and you are looking at the code in examples/models, you can generate the MDP client and worker codecs. We pass the same two models to a different code generator:
gsl -script:codec_c mdp_client.xml mdp_worker.xml
Which gives us mdp_client and mdp_worker classes. Actually MDP is so simple that it’s barely worth the effort of writing the code generator. The profit comes when we want to change the protocol (which we did for the standalone Majordomo project). You modify the protocol, run the command, and out pops more perfect code.
The codec_c.gsl code generator is not short, but the resulting codecs are much better than the handwritten code I originally put together for Majordomo. For instance, the handwritten code had no error checking and would die if you passed it bogus messages.
I’m now going to explain the pros and cons of GSL-powered model-oriented code generation. Power does not come for free and one of the greatest traps in our business is the ability to invent concepts out of thin air. GSL makes this particularly easy, so it can be an equally dangerous tool.
Do not invent concepts. The job of a designer is to remove problems, not add features.
Firstly, I will lay out the advantages of model-oriented code generation:
- You can create near-perfect abstractions that map to your real world. So, our protocol model maps 100% to the “real world” of Majordomo. This would be impossible without the freedom to tune and change the model in any way.
- You can develop these perfect models quickly and cheaply.
- You can generate any text output. From a single model, you can create documentation, code in any language, test tools–literally any output you can think of.
- You can generate (and I mean this literally) perfect output because it’s cheap to improve your code generators to any level you want.
- You get a single source that combines specifications and semantics.
- You can leverage a small team to a massive size. At iMatix, we produced the million-line OpenAMQ messaging product out of perhaps 85K lines of input models, including the code generation scripts themselves.
Now let’s look at the disadvantages:
- You add tool dependencies to your project.
- You may get carried away and create models for the pure joy of creating them.
- You may alienate newcomers, who will see “strange stuff”, from your work.
- You may give people a strong excuse not to invest in your project.
Cynically, model-oriented abuse works great in environments where you want to produce huge amounts of perfect code that you can maintain with little effort and which no one can ever take away from you. Personally, I like to cross my rivers and move on. But if long-term job security is your thing, this is almost perfect.
So if you do use GSL and want to create open communities around your work, here is my advice:
- Use it only where you would otherwise be writing tiresome code by hand.
- Design natural models that are what people would expect to see.
- Write the code by hand first so you know what to generate.
- Do not overuse. Keep it simple! Do not get too meta!!
- Introduce gradually into a project.
- Put the generated code into your repositories.
We’re already using GSL in some projects around ZeroMQ. For example, the high-level C binding, CZMQ, uses GSL to generate the socket options class (zsockopt). A 300-line code generator turns 78 lines of XML model into 1,500 lines of perfect, but really boring code. That’s a good win.
Transferring Files #
Let’s take a break from the lecturing and get back to our first love and the reason for doing all of this: code.
“How do I send a file?” is a common question on the ZeroMQ mailing lists. This should not be surprising, because file transfer is perhaps the oldest and most obvious type of messaging. Sending files around networks has lots of use cases apart from annoying the copyright cartels. ZeroMQ is very good out of the box at sending events and tasks, but less good at sending files.
I’ve promised, for a year or two, to write a proper explanation. Here’s a gratuitous piece of information to brighten your morning: the word “proper” comes from the archaic French propre, which means “clean”. The dark age English common folk, not being familiar with hot water and soap, changed the word to mean “foreign” or “upper-class”, as in “that’s proper food!”, but later the word came to mean just “real”, as in “that’s a proper mess you’ve gotten us into!”
So, file transfer. There are several reasons you can’t just pick up a random file, blindfold it, and shove it whole into a message. The most obvious reason being that despite decades of determined growth in RAM sizes (and who among us old-timers doesn’t fondly remember saving up for that 1024-byte memory extension card?!), disk sizes obstinately remain much larger. Even if we could send a file with one instruction (say, using a system call like sendfile), we’d hit the reality that networks are not infinitely fast nor perfectly reliable. After trying to upload a large file several times on a slow flaky network (WiFi, anyone?), you’ll realize that a proper file transfer protocol needs a way to recover from failures. That is, it needs a way to send only the part of a file that wasn’t yet received.
Finally, after all this, if you build a proper file server, you’ll notice that simply sending massive amounts of data to lots of clients creates that situation we like to call, in the technical parlance, “server went belly-up due to all available heap memory being eaten by a poorly designed application”. A proper file transfer protocol needs to pay attention to memory use.
We’ll solve these problems properly, one-by-one, which should hopefully get us to a good and proper file transfer protocol running over ZeroMQ. First, let’s generate a 1GB test file with random data (real power-of-two-giga-like-Von-Neumman-intended, not the fake silicon ones the memory industry likes to sell):
dd if=/dev/urandom of=testdata bs=1M count=1024
This is large enough to be troublesome when we have lots of clients asking for the same file at once, and on many machines, 1GB is going to be too large to allocate in memory anyhow. As a base reference, let’s measure how long it takes to copy this file from disk back to disk. This will tell us how much our file transfer protocol adds on top (including network costs):
$ time cp testdata testdata2
real 0m7.143s
user 0m0.012s
sys 0m1.188s
The 4-figure precision is misleading; expect variations of 25% either way. This is just an “order of magnitude” measurement.
Here’s our first cut at the code, where the client asks for the test data and the server just sends it, without stopping for breath, as a series of messages, where each message holds one chunk:
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml
It’s pretty simple, but we already run into a problem: if we send too much data to the ROUTER socket, we can easily overflow it. The simple but stupid solution is to put an infinite high-water mark on the socket. It’s stupid because we now have no protection against exhausting the server’s memory. Yet without an infinite HWM, we risk losing chunks of large files.
Try this: set the HWM to 1,000 (in ZeroMQ v3.x this is the default) and then reduce the chunk size to 100K so we send 10K chunks in one go. Run the test, and you’ll see it never finishes. As the zmq_socket() man page says with cheerful brutality, for the ROUTER socket: “ZMQ_HWM option action: Drop”.
We have to control the amount of data the server sends up-front. There’s no point in it sending more than the network can handle. Let’s try sending one chunk at a time. In this version of the protocol, the client will explicitly say, “Give me chunk N”, and the server will fetch that specific chunk from disk and send it.
Here’s the improved second model, where the client asks for one chunk at a time, and the server only sends one chunk for each request it gets from the client:
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCamlIt is much slower now, because of the to-and-fro chatting between client and server. We pay about 300 microseconds for each request-reply round-trip, on a local loop connection (client and server on the same box). It doesn’t sound like much but it adds up quickly:
$ time ./fileio1
4296 chunks received, 1073741824 bytes
real 0m0.669s
user 0m0.056s
sys 0m1.048s
$ time ./fileio2
4295 chunks received, 1073741824 bytes
real 0m2.389s
user 0m0.312s
sys 0m2.136s
There are two valuable lessons here. First, while request-reply is easy, it’s also too slow for high-volume data flows. Paying that 300 microseconds once would be fine. Paying it for every single chunk isn’t acceptable, particularly on real networks with latencies of perhaps 1,000 times higher.
The second point is something I’ve said before but will repeat: it’s incredibly easy to experiment, measure, and improve a protocol over ZeroMQ. And when the cost of something comes way down, you can afford a lot more of it. Do learn to develop and prove your protocols in isolation: I’ve seen teams waste time trying to improve poorly designed protocols that are too deeply embedded in applications to be easily testable or fixable.
Our model two file transfer protocol isn’t so bad, apart from performance:
- It completely eliminates any risk of memory exhaustion. To prove that, we set the high-water mark to 1 in both sender and receiver.
- It lets the client choose the chunk size, which is useful because if there’s any tuning of the chunk size to be done, for network conditions, for file types, or to reduce memory consumption further, it’s the client that should be doing this.
- It gives us fully restartable file transfers.
- It allows the client to cancel the file transfer at any point in time.
If we just didn’t have to do a request for each chunk, it’d be a usable protocol. What we need is a way for the server to send multiple chunks without waiting for the client to request or acknowledge each one. What are our choices?
-
The server could send 10 chunks at once, then wait for a single acknowledgment. That’s exactly like multiplying the chunk size by 10, so it’s pointless. And yes, it’s just as pointless for all values of 10.
-
The server could send chunks without any chatter from the client but with a slight delay between each send, so that it would send chunks only as fast as the network could handle them. This would require the server to know what’s happening at the network layer, which sounds like hard work. It also breaks layering horribly. And what happens if the network is really fast, but the client itself is slow? Where are chunks queued then?
-
The server could try to spy on the sending queue, i.e., see how full it is, and send only when the queue isn’t full. Well, ZeroMQ doesn’t allow that because it doesn’t work, for the same reason as throttling doesn’t work. The server and network may be more than fast enough, but the client may be a slow little device.
-
We could modify libzmq to take some other action on reaching HWM. Perhaps it could block? That would mean that a single slow client would block the whole server, so no thank you. Maybe it could return an error to the caller? Then the server could do something smart like… well, there isn’t really anything it could do that’s any better than dropping the message.
Apart from being complex and variously unpleasant, none of these options would even work. What we need is a way for the client to tell the server, asynchronously and in the background, that it’s ready for more. We need some kind of asynchronous flow control. If we do this right, data should flow without interruption from the server to the client, but only as long as the client is reading it. Let’s review our three protocols. This was the first one:
C: fetch
S: chunk 1
S: chunk 2
S: chunk 3
....
And the second introduced a request for each chunk:
C: fetch chunk 1
S: send chunk 1
C: fetch chunk 2
S: send chunk 2
C: fetch chunk 3
S: send chunk 3
C: fetch chunk 4
....
Now–waves hands mysteriously–here’s a changed protocol that fixes the performance problem:
C: fetch chunk 1
C: fetch chunk 2
C: fetch chunk 3
S: send chunk 1
C: fetch chunk 4
S: send chunk 2
S: send chunk 3
....
It looks suspiciously similar. In fact, it’s identical except that we send multiple requests without waiting for a reply for each one. This is a technique called “pipelining” and it works because our DEALER and ROUTER sockets are fully asynchronous.
Here’s the third model of our file transfer test-bench, with pipelining. The client sends a number of requests ahead (the “credit”) and then each time it processes an incoming chunk, it sends one more credit. The server will never send more chunks than the client has asked for:
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCamlThat tweak gives us full control over the end-to-end pipeline including all network buffers and ZeroMQ queues at sender and receiver. We ensure the pipeline is always filled with data while never growing beyond a predefined limit. More than that, the client decides exactly when to send “credit” to the sender. It could be when it receives a chunk, or when it has fully processed a chunk. And this happens asynchronously, with no significant performance cost.
In the third model, I chose a pipeline size of 10 messages (each message is a chunk). This will cost a maximum of 2.5MB memory per client. So with 1GB of memory we can handle at least 400 clients. We can try to calculate the ideal pipeline size. It takes about 0.7 seconds to send the 1GB file, which is about 160 microseconds for a chunk. A round trip is 300 microseconds, so the pipeline needs to be at least 3-5 chunks to keep the server busy. In practice, I still got performance spikes with a pipeline of 5 chunks, probably because the credit messages sometimes get delayed by outgoing data. So at 10 chunks, it works consistently.
$ time ./fileio3
4291 chunks received, 1072741824 bytes
real 0m0.777s
user 0m0.096s
sys 0m1.120s
Do measure rigorously. Your calculations may be good, but the real world tends to have its own opinions.
What we’ve made is clearly not yet a real file transfer protocol, but it proves the pattern and I think it is the simplest plausible design. For a real working protocol, we might want to add some or all of:
-
Authentication and access controls, even without encryption: the point isn’t to protect sensitive data, but to catch errors like sending test data to production servers.
-
A Cheap-style request including file path, optional compression, and other stuff we’ve learned is useful from HTTP (such as If-Modified-Since).
-
A Cheap-style response, at least for the first chunk, that provides meta data such as file size (so the client can pre-allocate, and avoid unpleasant disk-full situations).
-
The ability to fetch a set of files in one go, otherwise the protocol becomes inefficient for large sets of small files.
-
Confirmation from the client when it’s fully received a file, to recover from chunks that might be lost if the client disconnects unexpectedly.
So far, our semantic has been “fetch”; that is, the recipient knows (somehow) that they need a specific file, so they ask for it. The knowledge of which files exist and where they are is then passed out-of-band (e.g., in HTTP, by links in the HTML page).
How about a “push” semantic? There are two plausible use cases for this. First, if we adopt a centralized architecture with files on a main “server” (not something I’m advocating, but people do sometimes like this), then it’s very useful to allow clients to upload files to the server. Second, it lets us do a kind of pub-sub for files, where the client asks for all new files of some type; as the server gets these, it forwards them to the client.
A fetch semantic is synchronous, while a push semantic is asynchronous. Asynchronous is less chatty, so faster. Also, you can do cute things like “subscribe to this path” thus creating a pub-sub file transfer architecture. That is so obviously awesome that I shouldn’t need to explain what problem it solves.
Still, here is the problem with the fetch semantic: that out-of-band route to tell clients what files exist. No matter how you do this, it ends up being complex. Either clients have to poll, or you need a separate pub-sub channel to keep clients up-to-date, or you need user interaction.
Thinking this through a little more, though, we can see that fetch is just a special case of pub-sub. So we can get the best of both worlds. Here is the general design:
- Fetch this path
- Here is credit (repeat)
To make this work (and we will, my dear readers), we need to be a little more explicit about how we send credit to the server. The cute trick of treating a pipelined “fetch chunk” request as credit won’t fly because the client doesn’t know any longer what files actually exist, how large they are, anything. If the client says, “I’m good for 250,000 bytes of data”, this should work equally for 1 file of 250K bytes, or 100 files of 2,500 bytes.
And this gives us “credit-based flow control”, which effectively removes the need for high-water marks, and any risk of memory overflow.
State Machines #
Software engineers tend to think of (finite) state machines as a kind of intermediary interpreter. That is, you take a regular language and compile that into a state machine, then execute the state machine. The state machine itself is rarely visible to the developer: it’s an internal representation–optimized, compressed, and bizarre.
However, it turns out that state machines are also valuable as a first-class modeling languages for protocol handlers, e.g., ZeroMQ clients and servers. ZeroMQ makes it rather easy to design protocols, but we’ve never defined a good pattern for writing those clients and servers properly.
A protocol has at least two levels:
- How we represent individual messages on the wire.
- How messages flow between peers, and the significance of each message.
We’ve seen in this chapter how to produce codecs that handle serialization. That’s a good start. But if we leave the second job to developers, that gives them a lot of room to interpret. As we make more ambitious protocols (file transfer + heartbeating + credit + authentication), it becomes less and less sane to try to implement clients and servers by hand.
Yes, people do this almost systematically. But the costs are high, and they’re avoidable. I’ll explain how to model protocols using state machines, and how to generate neat and solid code from those models.
My experience with using state machines as a software construction tool dates to 1985 and my first real job making tools for application developers. In 1991, I turned that knowledge into a free software tool called Libero, which spat out executable state machines from a simple text model.
The thing about Libero’s model was that it was readable. That is, you described your program logic as named states, each accepting a set of events, each doing some real work. The resulting state machine hooked into your application code, driving it like a boss.
Libero was charmingly good at its job, fluent in many languages, and modestly popular given the enigmatic nature of state machines. We used Libero in anger in dozens of large distributed applications, one of which was finally switched off in 2011 after 20 years of operation. State-machine driven code construction worked so well that it’s somewhat impressive that this approach never hit the mainstream of software engineering.
So in this section I’m going to explain Libero’s model, and demonstrate how to use it to generate ZeroMQ clients and servers. We’ll use GSL again, but like I said, the principles are general and you can put together code generators using any scripting language.
As a worked example, let’s see how to carry-on a stateful dialog with a peer on a ROUTER socket. We’ll develop the server using a state machine (and the client by hand). We have a simple protocol that I’ll call “NOM”. I’m using the oh-so-very-serious keywords for unprotocols proposal:
nom-protocol = open-peering *use-peering
open-peering = C:OHAI ( S:OHAI-OK / S:WTF )
use-peering = C:ICANHAZ
/ S:CHEEZBURGER
/ C:HUGZ S:HUGZ-OK
/ S:HUGZ C:HUGZ-OK
I’ve not found a quick way to explain the true nature of state machine programming. In my experience, it invariably takes a few days of practice. After three or four days’ exposure to the idea, there is a near-audible “click!” as something in the brain connects all the pieces together. We’ll make it concrete by looking at the state machine for our NOM server.
A useful thing about state machines is that you can read them state by state. Each state has a unique descriptive name and one or more events, which we list in any order. For each event, we perform zero or more actions and we then move to a next state (or stay in the same state).
In a ZeroMQ protocol server, we have a state machine instance per client. That sounds complex but it isn’t, as we’ll see. We describe our first state, Start, as having one valid event: OHAI. We check the user’s credentials and then arrive in the Authenticated state.
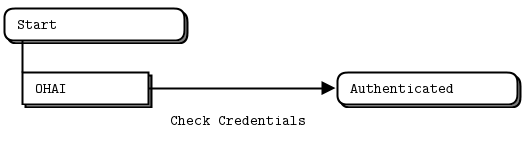
The Check Credentials action produces either an ok or an error event. It’s in the Authenticated state that we handle these two possible events by sending an appropriate reply back to the client. If authentication failed, we return to the Start state where the client can try again.
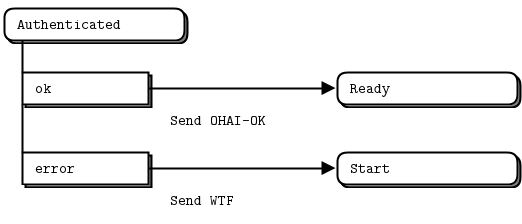
When authentication has succeeded, we arrive in the Ready state. Here we have three possible events: an ICANHAZ or HUGZ message from the client, or a heartbeat timer event.

There are a few more things about this state machine model that are worth knowing:
- Events in upper case (like “HUGZ”) are external events that come from the client as messages.
- Events in lower case (like “heartbeat”) are internal events, produced by code in the server.
- The “Send SOMETHING” actions are shorthand for sending a specific reply back to the client.
- Events that aren’t defined in a particular state are silently ignored.
Now, the original source for these pretty pictures is an XML model:
<class name = "nom_server" script = "server_c">
<state name = "start">
<event name = "OHAI" next = "authenticated">
<action name = "check credentials" />
</event>
</state>
<state name = "authenticated">
<event name = "ok" next = "ready">
<action name = "send" message ="OHAI-OK" />
</event>
<event name = "error" next = "start">
<action name = "send" message = "WTF" />
</event>
</state>
<state name = "ready">
<event name = "ICANHAZ">
<action name = "send" message = "CHEEZBURGER" />
</event>
<event name = "HUGZ">
<action name = "send" message = "HUGZ-OK" />
</event>
<event name = "heartbeat">
<action name = "send" message = "HUGZ" />
</event>
</state>
</class>
The code generator is in examples/models/server_c.gsl. It is a fairly complete tool that I’ll use and expand for more serious work later. It generates:
- A server class in C (nom_server.c, nom_server.h) that implements the whole protocol flow.
- A selftest method that runs the selftest steps listed in the XML file.
- Documentation in the form of graphics (the pretty pictures).
Here’s a simple main program that starts the generated NOM server:
#include "czmq.h"
#include "nom_server.h"
int main (int argc, char *argv [])
{
printf ("Starting NOM protocol server on port 5670...\n");
nom_server_t *server = nom_server_new ();
nom_server_bind (server, "tcp://*:5670");
nom_server_wait (server);
nom_server_destroy (&server);
return 0;
}
The generated nom_server class is a fairly classic model. It accepts client messages on a ROUTER socket, so the first frame on every request is the client’s connection identity. The server manages a set of clients, each with state. As messages arrive, it feeds these as events to the state machine. Here’s the core of the state machine, as a mix of GSL commands and the C code we intend to generate:
client_execute (client_t *self, int event)
{
self->next_event = event;
while (self->next_event) {
self->event = self->next_event;
self->next_event = 0;
switch (self->state) {
.for class.state
case $(name:c)_state:
. for event
. if index () > 1
else
. endif
if (self->event == $(name:c)_event) {
. for action
. if name = "send"
zmsg_addstr (self->reply, "$(message:)");
. else
$(name:c)_action (self);
. endif
. endfor
. if defined (event.next)
self->state = $(next:c)_state;
. endif
}
. endfor
break;
.endfor
}
if (zmsg_size (self->reply) > 1) {
zmsg_send (&self->reply, self->router);
self->reply = zmsg_new ();
zmsg_add (self->reply, zframe_dup (self->address));
}
}
}
Each client is held as an object with various properties, including the variables we need to represent a state machine instance:
event_t next_event; // Next event
state_t state; // Current state
event_t event; // Current event
You will see by now that we are generating technically-perfect code that has the precise design and shape we want. The only clue that the nom_server class isn’t handwritten is that the code is too good. People who complain that code generators produce poor code are accustomed to poor code generators. It is trivial to extend our model as we need it. For example, here’s how we generate the selftest code.
First, we add a “selftest” item to the state machine and write our tests. We’re not using any XML grammar or validation so it really is just a matter of opening the editor and adding half-a-dozen lines of text:
<selftest>
<step send = "OHAI" body = "Sleepy" recv = "WTF" />
<step send = "OHAI" body = "Joe" recv = "OHAI-OK" />
<step send = "ICANHAZ" recv = "CHEEZBURGER" />
<step send = "HUGZ" recv = "HUGZ-OK" />
<step recv = "HUGZ" />
</selftest>
Designing on the fly, I decided that “send” and “recv” were a nice way to express “send this request, then expect this reply”. Here’s the GSL code that turns this model into real code:
.for class->selftest.step
. if defined (send)
msg = zmsg_new ();
zmsg_addstr (msg, "$(send:)");
. if defined (body)
zmsg_addstr (msg, "$(body:)");
. endif
zmsg_send (&msg, dealer);
. endif
. if defined (recv)
msg = zmsg_recv (dealer);
assert (msg);
command = zmsg_popstr (msg);
assert (streq (command, "$(recv:)"));
free (command);
zmsg_destroy (&msg);
. endif
.endfor
Finally, one of the more tricky but absolutely essential parts of any state machine generator is how do I plug this into my own code? As a minimal example for this exercise I wanted to implement the “check credentials” action by accepting all OHAIs from my friend Joe (Hi Joe!) and reject everyone else’s OHAIs. After some thought, I decided to grab code directly from the state machine model, i.e., embed action bodies in the XML file. So in nom_server.xml, you’ll see this:
<action name = "check credentials">
char *body = zmsg_popstr (self->request);
if (body && streq (body, "Joe"))
self->next_event = ok_event;
else
self->next_event = error_event;
free (body);
</action>
And the code generator grabs that C code and inserts it into the generated nom_server.c file:
.for class.action
static void
$(name:c)_action (client_t *self) {
$(string.trim (.):)
}
.endfor
And now we have something quite elegant: a single source file that describes my server state machine and also contains the native implementations for my actions. A nice mix of high-level and low-level that is about 90% smaller than the C code.
Beware, as your head spins with notions of all the amazing things you could produce with such leverage. While this approach gives you real power, it also moves you away from your peers, and if you go too far, you’ll find yourself working alone.
By the way, this simple little state machine design exposes just three variables to our custom code:
- self->next_event
- self->request
- self->reply
In the Libero state machine model, there are a few more concepts that we’ve not used here, but which we will need when we write larger state machines:
- Exceptions, which lets us write terser state machines. When an action raises an exception, further processing on the event stops. The state machine can then define how to handle exception events.
- The Defaults state, where we can define default handling for events (especially useful for exception events).
Authentication Using SASL #
When we designed AMQP in 2007, we chose the Simple Authentication and Security Layer (SASL) for the authentication layer, one of the ideas we took from the BEEP protocol framework. SASL looks complex at first, but it’s actually simple and fits neatly into a ZeroMQ-based protocol. What I especially like about SASL is that it’s scalable. You can start with anonymous access or plain text authentication and no security, and grow to more secure mechanisms over time without changing your protocol.
I’m not going to give a deep explanation now because we’ll see SASL in action somewhat later. But I’ll explain the principle so you’re already somewhat prepared.
In the NOM protocol, the client started with an OHAI command, which the server either accepted (“Hi Joe!") or rejected. This is simple but not scalable because server and client have to agree up-front on the type of authentication they’re going to do.
What SASL introduced, which is genius, is a fully abstracted and negotiable security layer that’s still easy to implement at the protocol level. It works as follows:
- The client connects.
- The server challenges the client, passing a list of security “mechanisms” that it knows about.
- The client chooses a security mechanism that it knows about, and answers the server’s challenge with a blob of opaque data that (and here’s the neat trick) some generic security library calculates and gives to the client.
- The server takes the security mechanism the client chose, and that blob of data, and passes it to its own security library.
- The library either accepts the client’s answer, or the server challenges again.
There are a number of free SASL libraries. When we come to real code, we’ll implement just two mechanisms, ANONYMOUS and PLAIN, which don’t need any special libraries.
To support SASL, we have to add an optional challenge/response step to our “open-peering” flow. Here is what the resulting protocol grammar looks like (I’m modifying NOM to do this):
secure-nom = open-peering *use-peering
open-peering = C:OHAI *( S:ORLY C:YARLY ) ( S:OHAI-OK / S:WTF )
ORLY = 1*mechanism challenge
mechanism = string
challenge = *OCTET
YARLY = mechanism response
response = *OCTET
Where ORLY and YARLY contain a string (a list of mechanisms in ORLY, one mechanism in YARLY) and a blob of opaque data. Depending on the mechanism, the initial challenge from the server may be empty. We don’t care: we just pass this to the security library to deal with.
The SASL RFC goes into detail about other features (that we don’t need), the kinds of ways SASL could be attacked, and so on.
Large-Scale File Publishing: FileMQ #
Let’s put all these techniques together into a file distribution system that I’ll call FileMQ. This is going to be a real product, living on GitHub. What we’ll make here is a first version of FileMQ, as a training tool. If the concept works, the real thing may eventually get its own book.
Why make FileMQ? #
Why make a file distribution system? I already explained how to send large files over ZeroMQ, and it’s really quite simple. But if you want to make messaging accessible to a million times more people than can use ZeroMQ, you need another kind of API. An API that my five-year old son can understand. An API that is universal, requires no programming, and works with just about every single application.
Yes, I’m talking about the file system. It’s the DropBox pattern: chuck your files somewhere and they get magically copied somewhere else when the network connects again.
However, what I’m aiming for is a fully decentralized architecture that looks more like git, that doesn’t need any cloud services (though we could put FileMQ in the cloud), and that does multicast, i.e., can send files to many places at once.
FileMQ must be secure(able), easily hooked into random scripting languages, and as fast as possible across our domestic and office networks.
I want to use it to back up photos from my mobile phone to my laptop over WiFi. To share presentation slides in real time across 50 laptops in a conference. To share documents with colleagues in a meeting. To send earthquake data from sensors to central clusters. To back up video from my phone as I take it, during protests or riots. To synchronize configuration files across a cloud of Linux servers.
A visionary idea, isn’t it? Well, ideas are cheap. The hard part is making this, and making it simple.
Initial Design Cut: the API #
Here’s the way I see the first design. FileMQ has to be distributed, which means that every node can be a server and a client at the same time. But I don’t want the protocol to be symmetrical, because that seems forced. We have a natural flow of files from point A to point B, where A is the “server” and B is the “client”. If files flow back the other way, then we have two flows. FileMQ is not yet directory synchronization protocol, but we’ll bring it quite close.
Thus, I’m going to build FileMQ as two pieces: a client and a server. Then, I’ll put these together in a main application (the filemq tool) that can act both as client and server. The two pieces will look quite similar to the nom_server, with the same kind of API:
fmq_server_t *server = fmq_server_new ();
fmq_server_bind (server, "tcp://*:5670");
fmq_server_publish (server, "/home/ph/filemq/share", "/public");
fmq_server_publish (server, "/home/ph/photos/stream", "/photostream");
fmq_client_t *client = fmq_client_new ();
fmq_client_connect (client, "tcp://pieter.filemq.org:5670");
fmq_client_subscribe (server, "/public/", "/home/ph/filemq/share");
fmq_client_subscribe (server, "/photostream/", "/home/ph/photos/stream");
while (!zctx_interrupted)
sleep (1);
fmq_server_destroy (&server);
fmq_client_destroy (&client);
If we wrap this C API in other languages, we can easily script FileMQ, embed it applications, port it to smartphones, and so on.
Initial Design Cut: the Protocol #
The full name for the protocol is the “File Message Queuing Protocol”, or FILEMQ in uppercase to distinguish it from the software. To start with, we write down the protocol as an ABNF grammar. Our grammar starts with the flow of commands between the client and server. You should recognize these as a combination of the various techniques we’ve seen already:
filemq-protocol = open-peering *use-peering [ close-peering ]
open-peering = C:OHAI *( S:ORLY C:YARLY ) ( S:OHAI-OK / error )
use-peering = C:ICANHAZ ( S:ICANHAZ-OK / error )
/ C:NOM
/ S:CHEEZBURGER
/ C:HUGZ S:HUGZ-OK
/ S:HUGZ C:HUGZ-OK
close-peering = C:KTHXBAI / S:KTHXBAI
error = S:SRSLY / S:RTFM
Here are the commands to and from the server:
; The client opens peering to the server
OHAI = signature %x01 protocol version
signature = %xAA %xA3
protocol = string ; Must be "FILEMQ"
string = size *VCHAR
size = OCTET
version = %x01
; The server challenges the client using the SASL model
ORLY = signature %x02 mechanisms challenge
mechanisms = size 1*mechanism
mechanism = string
challenge = *OCTET ; ZeroMQ frame
; The client responds with SASL authentication information
YARLY = %signature x03 mechanism response
response = *OCTET ; ZeroMQ frame
; The server grants the client access
OHAI-OK = signature %x04
; The client subscribes to a virtual path
ICANHAZ = signature %x05 path options cache
path = string ; Full path or path prefix
options = dictionary
dictionary = size *key-value
key-value = string ; Formatted as name=value
cache = dictionary ; File SHA-1 signatures
; The server confirms the subscription
ICANHAZ-OK = signature %x06
; The client sends credit to the server
NOM = signature %x07 credit
credit = 8OCTET ; 64-bit integer, network order
sequence = 8OCTET ; 64-bit integer, network order
; The server sends a chunk of file data
CHEEZBURGER = signature %x08 sequence operation filename
offset headers chunk
sequence = 8OCTET ; 64-bit integer, network order
operation = OCTET
filename = string
offset = 8OCTET ; 64-bit integer, network order
headers = dictionary
chunk = FRAME
; Client or server sends a heartbeat
HUGZ = signature %x09
; Client or server responds to a heartbeat
HUGZ-OK = signature %x0A
; Client closes the peering
KTHXBAI = signature %x0B
And here are the different ways the server can tell the client things went wrong:
; Server error reply - refused due to access rights
S:SRSLY = signature %x80 reason
; Server error reply - client sent an invalid command
S:RTFM = signature %x81 reason
FILEMQ lives on the ZeroMQ unprotocols website and has a registered TCP port with IANA (the Internet Assigned Numbers Authority), which is port 5670.
Building and Trying FileMQ #
The FileMQ stack is on GitHub. It works like a classic C/C++ project:
git clone git://github.com/zeromq/filemq.git
cd filemq
./autogen.sh
./configure
make check
You want to be using the latest CZMQ master for this. Now try running the track command, which is a simple tool that uses FileMQ to track changes in one directory in another:
cd src
./track ./fmqroot/send ./fmqroot/recv
And open two file navigator windows, one into src/fmqroot/send and one into src/fmqroot/recv. Drop files into the send folder and you’ll see them arrive in the recv folder. The server checks once per second for new files. Delete files in the send folder, and they’re deleted in the recv folder similarly.
I use track for things like updating my MP3 player mounted as a USB drive. As I add or remove files in my laptop’s Music folder, the same changes happen on the MP3 player. FILEMQ isn’t a full replication protocol yet, but we’ll fix that later.
Internal Architecture #
To build FileMQ I used a lot of code generation, possibly too much for a tutorial. However the code generators are all reusable in other stacks and will be important for our final project in Chapter 8 - A Framework for Distributed Computing. They are an evolution of the set we saw earlier:
- codec_c.gsl: generates a message codec for a given protocol.
- server_c.gsl: generates a server class for a protocol and state machine.
- client_c.gsl: generates a client class for a protocol and state machine.
The best way to learn to use GSL code generation is to translate these into a language of your choice and make your own demo protocols and stacks. You’ll find it fairly easy. FileMQ itself doesn’t try to support multiple languages. It could, but it’d make things needlessly complex.
The FileMQ architecture actually slices into two layers. There’s a generic set of classes to handle chunks, directories, files, patches, SASL security, and configuration files. Then, there’s the generated stack: messages, client, and server. If I was creating a new project I’d fork the whole FileMQ project, and go and modify the three models:
- fmq_msg.xml: defines the message formats
- fmq_client.xml: defines the client state machine, API, and implementation.
- fmq_server.xml: does the same for the server.
You’d want to rename things to avoid confusion. Why didn’t I make the reusable classes into a separate library? The answer is two-fold. First, no one actually needs this (yet). Second, it’d make things more complex for you as you build and play with FileMQ. It’s never worth adding complexity to solve a theoretical problem.
Although I wrote FileMQ in C, it’s easy to map to other languages. It is quite amazing how nice C becomes when you add CZMQ’s generic zlist and zhash containers and class style. Let me go through the classes quickly:
-
fmq_sasl: encodes and decodes a SASL challenge. I only implemented the PLAIN mechanism, which is enough to prove the concept.
-
fmq_chunk: works with variable sized blobs. Not as efficient as ZeroMQ’s messages but they do less weirdness and so are easier to understand. The chunk class has methods to read and write chunks from disk.
-
fmq_file: works with files, which may or may not exist on disk. Gives you information about a file (like size), lets you read and write to files, remove files, check if a file exists, and check if a file is “stable” (more on that later).
-
fmq_dir: works with directories, reading them from disk and comparing two directories to see what changed. When there are changes, returns a list of “patches”.
-
fmq_patch: works with one patch, which really just says “create this file” or “delete this file” (referring to a fmq_file item each time).
-
fmq_config: works with configuration data. I’ll come back to client and server configuration later.
Every class has a test method, and the main development cycle is “edit, test”. These are mostly simple self tests, but they make the difference between code I can trust and code I know will still break. It’s a safe bet that any code that isn’t covered by a test case will have undiscovered errors. I’m not a fan of external test harnesses. But internal test code that you write as you write your functionality… that’s like the handle on a knife.
You should, really, be able to read the source code and rapidly understand what these classes are doing. If you can’t read the code happily, tell me. If you want to port the FileMQ implementation into other languages, start by forking the whole repository and later we’ll see if it’s possible to do this in one overall repo.
Public API #
The public API consists of two classes (as we sketched earlier):
-
fmq_client: provides the client API, with methods to connect to a server, configure the client, and subscribe to paths.
-
fmq_server: provides the server API, with methods to bind to a port, configure the server, and publish a path.
These classes provide an multithreaded API, a model we’ve used a few times now. When you create an API instance (i.e., fmq_server_new() or fmq_client_new()), this method kicks off a background thread that does the real work, i.e., runs the server or the client. The other API methods then talk to this thread over ZeroMQ sockets (a pipe consisting of two PAIR sockets over inproc://).
If I was a keen young developer eager to use FileMQ in another language, I’d probably spend a happy weekend writing a binding for this public API, then stick it in a subdirectory of the filemq project called, say, bindings/, and make a pull request.
The actual API methods come from the state machine description, like this (for the server):
<method name = "publish">
<argument name = "location" type = "string" />
<argument name = "alias" type = "string" />
mount_t *mount = mount_new (location, alias);
zlist_append (self->mounts, mount);
</method>
Which gets turned into this code:
void
fmq_server_publish (fmq_server_t *self, char *location, char *alias)
{
assert (self);
assert (location);
assert (alias);
zstr_sendm (self->pipe, "PUBLISH");
zstr_sendfm (self->pipe, "%s", location);
zstr_sendf (self->pipe, "%s", alias);
}
Design Notes #
The hardest part of making FileMQ wasn’t implementing the protocol, but maintaining accurate state internally. An FTP or HTTP server is essentially stateless. But a publish/subscribe server has to maintain subscriptions, at least.
So I’ll go through some of the design aspects:
-
The client detects if the server has died by the lack of heartbeats (HUGZ) coming from the server. It then restarts its dialog by sending an OHAI. There’s no timeout on the OHAI because the ZeroMQ DEALER socket will queue an outgoing message indefinitely.
-
If a client stops replying with (HUGZ-OK) to the heartbeats that the server sends, the server concludes that the client has died and deletes all state for the client including its subscriptions.
-
The client API holds subscriptions in memory and replays them when it has connected successfully. This means the caller can subscribe at any time (and doesn’t care when connections and authentication actually happen).
-
The server and client use virtual paths, much like an HTTP or FTP server. You publish one or more mount points, each corresponding to a directory on the server. Each of these maps to some virtual path, for instance “/” if you have only one mount point. Clients then subscribe to virtual paths, and files arrive in an inbox directory. We don’t send physical file names across the network.
-
There are some timing issues: if the server is creating its mount points while clients are connected and subscribing, the subscriptions won’t attach to the right mount points. So, we bind the server port as last thing.
-
Clients can reconnect at any point; if the client sends OHAI, that signals the end of any previous conversation and the start of a new one. I might one day make subscriptions durable on the server, so they survive a disconnection. The client stack, after reconnecting, replays any subscriptions the caller application already made.
Configuration #
I’ve built several large server products, like the Xitami web server that was popular in the late 90’s, and the OpenAMQ messaging server. Getting configuration easy and obvious was a large part of making these servers fun to use.
We typically aim to solve a number of problems:
- Ship default configuration files with the product.
- Allow users to add custom configuration files that are never overwritten.
- Allow users to configure from the command-line.
And then layer these one on the other, so command-line settings override custom settings, which override default settings. It can be a lot of work to do this right. For FileMQ, I’ve taken a somewhat simpler approach: all configuration is done from the API.
This is how we start and configure the server, for example:
server = fmq_server_new ();
fmq_server_configure (server, "server_test.cfg");
fmq_server_publish (server, "./fmqroot/send", "/");
fmq_server_publish (server, "./fmqroot/logs", "/logs");
fmq_server_bind (server, "tcp://*:5670");
We do use a specific format for the config files, which is ZPL, a minimalist syntax that we started using for ZeroMQ “devices” a few years ago, but which works well for any server:
# Configure server for plain access
#
server
monitor = 1 # Check mount points
heartbeat = 1 # Heartbeat to clients
publish
location = ./fmqroot/logs
virtual = /logs
security
echo = I: use guest/guest to login to server
# These are SASL mechanisms we accept
anonymous = 0
plain = 1
account
login = guest
password = guest
group = guest
account
login = super
password = secret
group = admin
One cute thing (which seems useful) the generated server code does is to parse this config file (when you use the fmq_server_configure() method) and execute any section that matches an API method. Thus the publish section works as a fmq_server_publish() method.
File Stability #
It is quite common to poll a directory for changes and then do something “interesting” with new files. But as one process is writing to a file, other processes have no idea when the file has been fully written. One solution is to add a second “indicator” file that we create after creating the first file. This is intrusive, however.
There is a neater way, which is to detect when a file is “stable”, i.e., no one is writing to it any longer. FileMQ does this by checking the modification time of the file. If it’s more than a second old, then the file is considered stable, at least stable enough to be shipped off to clients. If a process comes along after five minutes and appends to the file, it’ll be shipped off again.
For this to work, and this is a requirement for any application hoping to use FileMQ successfully, do not buffer more than a second’s worth of data in memory before writing. If you use very large block sizes, the file may look stable when it’s not.
Delivery Notifications #
One of the nice things about the multithreaded API model we’re using is that it’s essentially message based. This makes it ideal for returning events back to the caller. A more conventional API approach would be to use callbacks. But callbacks that cross thread boundaries are somewhat delicate. Here’s how the client sends a message back when it has received a complete file:
zstr_sendm (self->pipe, "DELIVER");
zstr_sendm (self->pipe, filename);
zstr_sendf (self->pipe, "%s/%s", inbox, filename);
We can now add a _recv() method to the API that waits for events back from the client. It makes a clean style for the caller: create the client object, configure it, and then receive and process any events it returns.
Symbolic Links #
While using a staging area is a nice, simple API, it also creates costs for senders. If I already have a 2GB video file on a camera, and want to send it via FileMQ, the current implementation asks that I copy it to a staging area before it will be sent to subscribers.
One option is to mount the whole content directory (e.g., /home/me/Movies), but this is fragile because it means the application can’t decide to send individual files. It’s everything or nothing.
A simple answer is to implement portable symbolic links. As Wikipedia explains: “A symbolic link contains a text string that is automatically interpreted and followed by the operating system as a path to another file or directory. This other file or directory is called the target. The symbolic link is a second file that exists independently of its target. If a symbolic link is deleted, its target remains unaffected.”
This doesn’t affect the protocol in any way; it’s an optimization in the server implementation. Let’s make a simple portable implementation:
- A symbolic link consists of a file with the extension .ln.
- The filename without .ln is the published file name.
- The link file contains one line, which is the real path to the file.
Because we’ve collected all operations on files in a single class (fmq_file), it’s a clean change. When we create a new file object, we check if it’s a symbolic link and then all read-only actions (get file size, read file) operate on the target file, not the link.
Recovery and Late Joiners #
As it stands now, FileMQ has one major remaining problem: it provides no way for clients to recover from failures. The scenario is that a client, connected to a server, starts to receive files and then disconnects for some reason. The network may be too slow, or breaks. The client may be on a laptop which is shut down, then resumed. The WiFi may be disconnected. As we move to a more mobile world (see Chapter 8 - A Framework for Distributed Computing) this use case becomes more and more frequent. In some ways it’s becoming a dominant use case.
In the classic ZeroMQ pub-sub pattern, there are two strong underlying assumptions, both of which are usually wrong in FileMQ’s real world. First, that data expires very rapidly so that there’s no interest in asking from old data. Second, that networks are stable and rarely break (so it’s better to invest more in improving the infrastructure and less in addressing recovery).
Take any FileMQ use case and you’ll see that if the client disconnects and reconnects, then it should get anything it missed. A further improvement would be to recover from partial failures, like HTTP and FTP do. But one thing at a time.
One answer to recovery is “durable subscriptions”, and the first drafts of the FILEMQ protocol aimed to support this, with client identifiers that the server could hold onto and store. So if a client reappears after a failure, the server would know what files it had not received.
Stateful servers are, however, nasty to make and difficult to scale. How do we, for example, do failover to a secondary server? Where does it get its subscriptions from? It’s far nicer if each client connection works independently and carries all necessary state with it.
Another nail in the coffin of durable subscriptions is that it requires up-front coordination. Up-front coordination is always a red flag, whether it’s in a team of people working together, or a bunch of processes talking to each other. What about late joiners? In the real world, clients do not neatly line up and then all say “Ready!” at the same time. In the real world, they come and go arbitrarily, and it’s valuable if we can treat a brand new client in the same way as a client that went away and came back.
To address this I will add two concepts to the protocol: a resynchronization option and a cache field (a dictionary). If the client wants recovery, it sets the resynchronization option, and tells the server what files it already has via the cache field. We need both, because there’s no way in the protocol to distinguish between an empty field and a null field. The FILEMQ RFC describes these fields as follows:
The options field provides additional information to the server. The server SHOULD implement these options: RESYNC=1 - if the client sets this, the server SHALL send the full contents of the virtual path to the client, except files the client already has, as identified by their SHA-1 digest in the cache field.
And:
When the client specifies the RESYNC option, the cache dictionary field tells the server which files the client already has. Each entry in the cache dictionary is a “filename=digest” key/value pair where the digest SHALL be a SHA-1 digest in printable hexadecimal format. If the filename starts with “/” then it SHOULD start with the path, otherwise the server MUST ignore it. If the filename does not start with “/” then the server SHALL treat it as relative to the path.
Clients that know they are in the classic pub-sub use case just don’t provide any cache data, and clients that want recovery provide their cache data. It requires no state in the server, no up-front coordination, and works equally well for brand new clients (which may have received files via some out-of-band means), and clients that received some files and were then disconnected for a while.
I decided to use SHA-1 digests for several reasons. First, it’s fast enough: 150msec to digest a 25MB core dump on my laptop. Second, it’s reliable: the chance of getting the same hash for different versions of one file is close enough to zero. Third, it’s the widest supported digest algorithm. A cyclic-redundancy check (e.g., CRC-32) is faster but not reliable. More recent SHA versions (SHA-256, SHA-512) are more secure but take 50% more CPU cycles, and are overkill for our needs.
Here is what a typical ICANHAZ message looks like when we use both caching and resyncing (this is output from the dump method of the generated codec class):
ICANHAZ:
path='/photos'
options={
RESYNC=1
}
cache={
DSCF0001.jpg=1FABCD4259140ACA99E991E7ADD2034AC57D341D
DSCF0006.jpg=01267C7641C5A22F2F4B0174FFB0C94DC59866F6
DSCF0005.jpg=698E88C05B5C280E75C055444227FEA6FB60E564
DSCF0004.jpg=F0149101DD6FEC13238E6FD9CA2F2AC62829CBD0
DSCF0003.jpg=4A49F25E2030B60134F109ABD0AD9642C8577441
DSCF0002.jpg=F84E4D69D854D4BF94B5873132F9892C8B5FA94E
}
Although we don’t do this in FileMQ, the server can use the cache information to help the client catch up with deletions that it missed. To do this, it would have to log deletions, and then compare this log with the client cache when a client subscribes.
Test Use Case: The Track Tool #
To properly test something like FileMQ we need a test case that plays with live data. One of my sysadmin tasks is to manage the MP3 tracks on my music player, which is, by the way, a Sansa Clip reflashed with Rock Box, which I highly recommend. As I download tracks into my Music folder, I want to copy these to my player, and as I find tracks that annoy me, I delete them in the Music folder and want those gone from my player too.
This is kind of overkill for a powerful file distribution protocol. I could write this using a bash or Perl script, but to be honest the hardest work in FileMQ was the directory comparison code and I want to benefit from that. So I put together a simple tool called track, which calls the FileMQ API. From the command line this runs with two arguments; the sending and the receiving directories:
./track /home/ph/Music /media/3230-6364/MUSIC
The code is a neat example of how to use the FileMQ API to do local file distribution. Here is the full program, minus the license text (it’s MIT/X11 licensed):
#include "czmq.h"
#include "../include/fmq.h"
int main (int argc, char *argv [])
{
fmq_server_t *server = fmq_server_new ();
fmq_server_configure (server, "anonymous.cfg");
fmq_server_publish (server, argv [1], "/");
fmq_server_set_anonymous (server, true);
fmq_server_bind (server, "tcp://*:5670");
fmq_client_t *client = fmq_client_new ();
fmq_client_connect (client, "tcp://localhost:5670");
fmq_client_set_inbox (client, argv [2]);
fmq_client_set_resync (client, true);
fmq_client_subscribe (client, "/");
while (true) {
// Get message from fmq_client API
zmsg_t *msg = fmq_client_recv (client);
if (!msg)
break; // Interrupted
char *command = zmsg_popstr (msg);
if (streq (command, "DELIVER")) {
char *filename = zmsg_popstr (msg);
char *fullname = zmsg_popstr (msg);
printf ("I: received %s (%s)\n", filename, fullname);
free (filename);
free (fullname);
}
free (command);
zmsg_destroy (&msg);
}
fmq_server_destroy (&server);
fmq_client_destroy (&client);
return 0;
}
Note how we work with physical paths in this tool. The server publishes the physical path /home/ph/Music and maps this to the virtual path /. The client subscribes to / and receives all files in /media/3230-6364/MUSIC. I could use any structure within the server directory, and it would be copied faithfully to the client’s inbox. Note the API method fmq_client_set_resync(), which causes a server-to-client synchronization.
Getting an Official Port Number #
We’ve been using port 5670 in the examples for FILEMQ. Unlike all the previous examples in this book, this port isn’t arbitrary but was assigned by the Internet Assigned Numbers Authority (IANA), which “is responsible for the global coordination of the DNS Root, IP addressing, and other Internet protocol resources”.
I’ll explain very briefly when and how to request registered port numbers for your application protocols. The main reason is to ensure that your applications can run in the wild without conflict with other protocols. Technically, if you ship any software that uses port numbers between 1024 and 49151, you should be using only IANA registered port numbers. Many products don’t bother with this, however, and tend instead to use the IANA list as “ports to avoid”.
If you aim to make a public protocol of any importance, such as FILEMQ, you’re going to want an IANA-registered port. I’ll explain briefly how to do this:
-
Document your protocol clearly, as IANA will want a specification of how you intend to use the port. It does not have to be a fully-formed protocol specification, but must be solid enough to pass expert review.
-
Decide what transport protocols you want: UDP, TCP, SCTP, and so on. With ZeroMQ you will usually only want TCP.
-
Fill in the application on iana.org, providing all the necessary information.
-
IANA will then continue the process by email until your application is accepted or rejected.
Note that you don’t request a specific port number; IANA will assign you one. It’s therefore wise to start this process before you ship software, not afterwards.