Chapter 4 - Reliable Request-Reply Patterns #
Chapter 3 - Advanced Request-Reply Patterns covered advanced uses of ZeroMQ’s request-reply pattern with working examples. This chapter looks at the general question of reliability and builds a set of reliable messaging patterns on top of ZeroMQ’s core request-reply pattern.
In this chapter, we focus heavily on user-space request-reply patterns, reusable models that help you design your own ZeroMQ architectures:
- The Lazy Pirate pattern: reliable request-reply from the client side
- The Simple Pirate pattern: reliable request-reply using load balancing
- The Paranoid Pirate pattern: reliable request-reply with heartbeating
- The Majordomo pattern: service-oriented reliable queuing
- The Titanic pattern: disk-based/disconnected reliable queuing
- The Binary Star pattern: primary-backup server failover
- The Freelance pattern: brokerless reliable request-reply
What is “Reliability”? #
Most people who speak of “reliability” don’t really know what they mean. We can only define reliability in terms of failure. That is, if we can handle a certain set of well-defined and understood failures, then we are reliable with respect to those failures. No more, no less. So let’s look at the possible causes of failure in a distributed ZeroMQ application, in roughly descending order of probability:
-
Application code is the worst offender. It can crash and exit, freeze and stop responding to input, run too slowly for its input, exhaust all memory, and so on.
-
System code–such as brokers we write using ZeroMQ–can die for the same reasons as application code. System code should be more reliable than application code, but it can still crash and burn, and especially run out of memory if it tries to queue messages for slow clients.
-
Message queues can overflow, typically in system code that has learned to deal brutally with slow clients. When a queue overflows, it starts to discard messages. So we get “lost” messages.
-
Networks can fail (e.g., WiFi gets switched off or goes out of range). ZeroMQ will automatically reconnect in such cases, but in the meantime, messages may get lost.
-
Hardware can fail and take with it all the processes running on that box.
-
Networks can fail in exotic ways, e.g., some ports on a switch may die and those parts of the network become inaccessible.
-
Entire data centers can be struck by lightning, earthquakes, fire, or more mundane power or cooling failures.
To make a software system fully reliable against all of these possible failures is an enormously difficult and expensive job and goes beyond the scope of this book.
Because the first five cases in the above list cover 99.9% of real world requirements outside large companies (according to a highly scientific study I just ran, which also told me that 78% of statistics are made up on the spot, and moreover never to trust a statistic that we didn’t falsify ourselves), that’s what we’ll examine. If you’re a large company with money to spend on the last two cases, contact my company immediately! There’s a large hole behind my beach house waiting to be converted into an executive swimming pool.
Designing Reliability #
So to make things brutally simple, reliability is “keeping things working properly when code freezes or crashes”, a situation we’ll shorten to “dies”. However, the things we want to keep working properly are more complex than just messages. We need to take each core ZeroMQ messaging pattern and see how to make it work (if we can) even when code dies.
Let’s take them one-by-one:
-
Request-reply: if the server dies (while processing a request), the client can figure that out because it won’t get an answer back. Then it can give up in a huff, wait and try again later, find another server, and so on. As for the client dying, we can brush that off as “someone else’s problem” for now.
-
Pub-sub: if the client dies (having gotten some data), the server doesn’t know about it. Pub-sub doesn’t send any information back from client to server. But the client can contact the server out-of-band, e.g., via request-reply, and ask, “please resend everything I missed”. As for the server dying, that’s out of scope for here. Subscribers can also self-verify that they’re not running too slowly, and take action (e.g., warn the operator and die) if they are.
-
Pipeline: if a worker dies (while working), the ventilator doesn’t know about it. Pipelines, like the grinding gears of time, only work in one direction. But the downstream collector can detect that one task didn’t get done, and send a message back to the ventilator saying, “hey, resend task 324!” If the ventilator or collector dies, whatever upstream client originally sent the work batch can get tired of waiting and resend the whole lot. It’s not elegant, but system code should really not die often enough to matter.
In this chapter we’ll focus just on request-reply, which is the low-hanging fruit of reliable messaging.
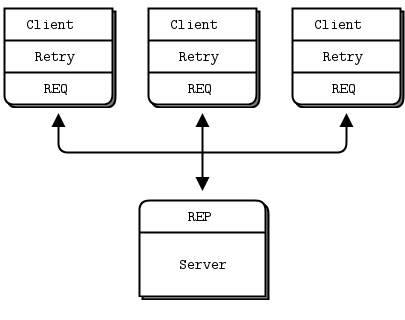
The basic request-reply pattern (a REQ client socket doing a blocking send/receive to a REP server socket) scores low on handling the most common types of failure. If the server crashes while processing the request, the client just hangs forever. If the network loses the request or the reply, the client hangs forever.
Request-reply is still much better than TCP, thanks to ZeroMQ’s ability to reconnect peers silently, to load balance messages, and so on. But it’s still not good enough for real work. The only case where you can really trust the basic request-reply pattern is between two threads in the same process where there’s no network or separate server process to die.
However, with a little extra work, this humble pattern becomes a good basis for real work across a distributed network, and we get a set of reliable request-reply (RRR) patterns that I like to call the Pirate patterns (you’ll eventually get the joke, I hope).
There are, in my experience, roughly three ways to connect clients to servers. Each needs a specific approach to reliability:
-
Multiple clients talking directly to a single server. Use case: a single well-known server to which clients need to talk. Types of failure we aim to handle: server crashes and restarts, and network disconnects.
-
Multiple clients talking to a broker proxy that distributes work to multiple workers. Use case: service-oriented transaction processing. Types of failure we aim to handle: worker crashes and restarts, worker busy looping, worker overload, queue crashes and restarts, and network disconnects.
-
Multiple clients talking to multiple servers with no intermediary proxies. Use case: distributed services such as name resolution. Types of failure we aim to handle: service crashes and restarts, service busy looping, service overload, and network disconnects.
Each of these approaches has its trade-offs and often you’ll mix them. We’ll look at all three in detail.
Client-Side Reliability (Lazy Pirate Pattern) #
We can get very simple reliable request-reply with some changes to the client. We call this the Lazy Pirate pattern. Rather than doing a blocking receive, we:
- Poll the REQ socket and receive from it only when it’s sure a reply has arrived.
- Resend a request, if no reply has arrived within a timeout period.
- Abandon the transaction if there is still no reply after several requests.
If you try to use a REQ socket in anything other than a strict send/receive fashion, you’ll get an error (technically, the REQ socket implements a small finite-state machine to enforce the send/receive ping-pong, and so the error code is called “EFSM”). This is slightly annoying when we want to use REQ in a pirate pattern, because we may send several requests before getting a reply.
The pretty good brute force solution is to close and reopen the REQ socket after an error:
lpclient: Lazy Pirate client in Ada
lpclient: Lazy Pirate client in Basic
lpclient: Lazy Pirate client in C
#include <czmq.h>
#define REQUEST_TIMEOUT 2500 // msecs, (>1000!)
#define REQUEST_RETRIES 3 // Before we abandon
#define SERVER_ENDPOINT "tcp://localhost:5555"
int main()
{
zsock_t *client = zsock_new_req(SERVER_ENDPOINT);
printf("I: Connecting to server...\n");
assert(client);
int sequence = 0;
int retries_left = REQUEST_RETRIES;
printf("Entering while loop...\n");
while(retries_left) // interrupt needs to be handled
{
// We send a request, then we get a reply
char request[10];
sprintf(request, "%d", ++sequence);
zstr_send(client, request);
int expect_reply = 1;
while(expect_reply)
{
printf("Expecting reply....\n");
zmq_pollitem_t items [] = {{zsock_resolve(client), 0, ZMQ_POLLIN, 0}};
printf("After polling\n");
int rc = zmq_poll(items, 1, REQUEST_TIMEOUT * ZMQ_POLL_MSEC);
printf("Polling Done.. \n");
if (rc == -1)
break; // Interrupted
// Here we process a server reply and exit our loop if the
// reply is valid. If we didn't get a reply we close the
// client socket, open it again and resend the request. We
// try a number times before finally abandoning:
if (items[0].revents & ZMQ_POLLIN)
{
// We got a reply from the server, must match sequence
char *reply = zstr_recv(client);
if(!reply)
break; // interrupted
if (atoi(reply) == sequence)
{
printf("I: server replied OK (%s)\n", reply);
retries_left=REQUEST_RETRIES;
expect_reply = 0;
}
else
{
printf("E: malformed reply from server: %s\n", reply);
}
free(reply);
}
else
{
if(--retries_left == 0)
{
printf("E: Server seems to be offline, abandoning\n");
break;
}
else
{
printf("W: no response from server, retrying...\n");
zsock_destroy(&client);
printf("I: reconnecting to server...\n");
client = zsock_new_req(SERVER_ENDPOINT);
zstr_send(client, request);
}
}
}
zsock_destroy(&client);
return 0;
}
}
lpclient: Lazy Pirate client in C++
//
// Lazy Pirate client
// Use zmq_poll to do a safe request-reply
// To run, start piserver and then randomly kill/restart it
//
#include "zhelpers.hpp"
#include <sstream>
#define REQUEST_TIMEOUT 2500 // msecs, (> 1000!)
#define REQUEST_RETRIES 3 // Before we abandon
// Helper function that returns a new configured socket
// connected to the Hello World server
//
static zmq::socket_t * s_client_socket (zmq::context_t & context) {
std::cout << "I: connecting to server..." << std::endl;
zmq::socket_t * client = new zmq::socket_t (context, ZMQ_REQ);
client->connect ("tcp://localhost:5555");
// Configure socket to not wait at close time
int linger = 0;
client->setsockopt (ZMQ_LINGER, &linger, sizeof (linger));
return client;
}
int main () {
zmq::context_t context (1);
zmq::socket_t * client = s_client_socket (context);
int sequence = 0;
int retries_left = REQUEST_RETRIES;
while (retries_left) {
std::stringstream request;
request << ++sequence;
s_send (*client, request.str());
sleep (1);
bool expect_reply = true;
while (expect_reply) {
// Poll socket for a reply, with timeout
zmq::pollitem_t items[] = {
{ *client, 0, ZMQ_POLLIN, 0 } };
zmq::poll (&items[0], 1, REQUEST_TIMEOUT);
// If we got a reply, process it
if (items[0].revents & ZMQ_POLLIN) {
// We got a reply from the server, must match sequence
std::string reply = s_recv (*client);
if (atoi (reply.c_str ()) == sequence) {
std::cout << "I: server replied OK (" << reply << ")" << std::endl;
retries_left = REQUEST_RETRIES;
expect_reply = false;
}
else {
std::cout << "E: malformed reply from server: " << reply << std::endl;
}
}
else
if (--retries_left == 0) {
std::cout << "E: server seems to be offline, abandoning" << std::endl;
expect_reply = false;
break;
}
else {
std::cout << "W: no response from server, retrying..." << std::endl;
// Old socket will be confused; close it and open a new one
delete client;
client = s_client_socket (context);
// Send request again, on new socket
s_send (*client, request.str());
}
}
}
delete client;
return 0;
}
lpclient: Lazy Pirate client in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
//
// Lazy Pirate client
// Use zmq_poll (pollItem.PollIn) to do a safe request-reply
// To run, start lpserver and then randomly kill/restart it
//
// Author: metadings
//
static TimeSpan LPClient_RequestTimeout = TimeSpan.FromMilliseconds(2000);
static int LPClient_RequestRetries = 3;
static ZSocket LPClient_CreateZSocket(ZContext context, string name, out ZError error)
{
// Helper function that returns a new configured socket
// connected to the Lazy Pirate queue
var requester = new ZSocket(context, ZSocketType.REQ);
requester.IdentityString = name;
requester.Linger = TimeSpan.FromMilliseconds(1);
if (!requester.Connect("tcp://127.0.0.1:5555", out error))
{
return null;
}
return requester;
}
public static void LPClient(string[] args)
{
if (args == null || args.Length < 1)
{
Console.WriteLine();
Console.WriteLine("Usage: ./{0} LPClient [Name]", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
Console.WriteLine(" Name Your name. Default: People");
Console.WriteLine();
args = new string[] { "People" };
}
string name = args[0];
using (var context = new ZContext())
{
ZSocket requester = null;
try
{ // using (requester)
ZError error;
if (null == (requester = LPClient_CreateZSocket(context, name, out error)))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
int sequence = 0;
int retries_left = LPClient_RequestRetries;
var poll = ZPollItem.CreateReceiver();
while (retries_left > 0)
{
// We send a request, then we work to get a reply
using (var outgoing = ZFrame.Create(4))
{
outgoing.Write(++sequence);
if (!requester.Send(outgoing, out error))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
}
ZMessage incoming;
while (true)
{
// Here we process a server reply and exit our loop
// if the reply is valid.
// If we didn't a reply, we close the client socket
// and resend the request. We try a number of times
// before finally abandoning:
// Poll socket for a reply, with timeout
if (requester.PollIn(poll, out incoming, out error, LPClient_RequestTimeout))
{
using (incoming)
{
// We got a reply from the server
int incoming_sequence = incoming[0].ReadInt32();
if (sequence == incoming_sequence)
{
Console.WriteLine("I: server replied OK ({0})", incoming_sequence);
retries_left = LPClient_RequestRetries;
break;
}
else
{
Console_WriteZMessage("E: malformed reply from server", incoming);
}
}
}
else
{
if (error == ZError.EAGAIN)
{
if (--retries_left == 0)
{
Console.WriteLine("E: server seems to be offline, abandoning");
break;
}
Console.WriteLine("W: no response from server, retrying...");
// Old socket is confused; close it and open a new one
requester.Dispose();
if (null == (requester = LPClient_CreateZSocket(context, name, out error)))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
Console.WriteLine("I: reconnected");
// Send request again, on new socket
using (var outgoing = ZFrame.Create(4))
{
outgoing.Write(sequence);
if (!requester.Send(outgoing, out error))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
}
continue;
}
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
}
}
}
finally
{
if (requester != null)
{
requester.Dispose();
requester = null;
}
}
}
}
}
}
lpclient: Lazy Pirate client in CL
lpclient: Lazy Pirate client in Delphi
program lpclient;
//
// Lazy Pirate client
// Use zmq_poll to do a safe request-reply
// To run, start lpserver and then randomly kill/restart it
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
const
REQUEST_TIMEOUT = 2500; // msecs, (> 1000!)
REQUEST_RETRIES = 3; // Before we abandon
SERVER_ENDPOINT = 'tcp://localhost:5555';
var
ctx: TZMQContext;
client: TZMQSocket;
sequence,
retries_left,
expect_reply: Integer;
request,
reply: Utf8String;
poller: TZMQPoller;
begin
ctx := TZMQContext.create;
Writeln( 'I: connecting to server...' );
client := ctx.Socket( stReq );
client.Linger := 0;
client.connect( SERVER_ENDPOINT );
poller := TZMQPoller.Create( true );
poller.Register( client, [pePollIn] );
sequence := 0;
retries_left := REQUEST_RETRIES;
while ( retries_left > 0 ) and not ctx.Terminated do
try
// We send a request, then we work to get a reply
inc( sequence );
request := Format( '%d', [sequence] );
client.send( request );
expect_reply := 1;
while ( expect_reply > 0 ) do
begin
// Poll socket for a reply, with timeout
poller.poll( REQUEST_TIMEOUT );
// Here we process a server reply and exit our loop if the
// reply is valid. If we didn't a reply we close the client
// socket and resend the request. We try a number of times
// before finally abandoning:
if pePollIn in poller.PollItem[0].revents then
begin
// We got a reply from the server, must match sequence
client.recv( reply );
if StrToInt( reply ) = sequence then
begin
Writeln( Format( 'I: server replied OK (%s)', [reply] ) );
retries_left := REQUEST_RETRIES;
expect_reply := 0;
end else
Writeln( Format( 'E: malformed reply from server: %s', [ reply ] ) );
end else
begin
dec( retries_left );
if retries_left = 0 then
begin
Writeln( 'E: server seems to be offline, abandoning' );
break;
end else
begin
Writeln( 'W: no response from server, retrying...' );
// Old socket is confused; close it and open a new one
poller.Deregister( client, [pePollIn] );
client.Free;
Writeln( 'I: reconnecting to server...' );
client := ctx.Socket( stReq );
client.Linger := 0;
client.connect( SERVER_ENDPOINT );
poller.Register( client, [pePollIn] );
// Send request again, on new socket
client.send( request );
end;
end;
end;
except
end;
poller.Free;
ctx.Free;
end.
lpclient: Lazy Pirate client in Erlang
lpclient: Lazy Pirate client in Elixir
lpclient: Lazy Pirate client in F#
lpclient: Lazy Pirate client in Felix
lpclient: Lazy Pirate client in Go
// Lazy Pirate client
// Use zmq_poll to do a safe request-reply
// To run, start lpserver and then randomly kill/restart it
//
// Author: iano <scaly.iano@gmail.com>
// Based on C example
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"strconv"
"time"
)
const (
REQUEST_TIMEOUT = time.Duration(2500) * time.Millisecond
REQUEST_RETRIES = 3
SERVER_ENDPOINT = "tcp://localhost:5555"
)
func main() {
context, _ := zmq.NewContext()
defer context.Close()
fmt.Println("I: Connecting to server...")
client, _ := context.NewSocket(zmq.REQ)
client.Connect(SERVER_ENDPOINT)
for sequence, retriesLeft := 1, REQUEST_RETRIES; retriesLeft > 0; sequence++ {
fmt.Printf("I: Sending (%d)\n", sequence)
client.Send([]byte(strconv.Itoa(sequence)), 0)
for expectReply := true; expectReply; {
// Poll socket for a reply, with timeout
items := zmq.PollItems{
zmq.PollItem{Socket: client, Events: zmq.POLLIN},
}
if _, err := zmq.Poll(items, REQUEST_TIMEOUT); err != nil {
panic(err) // Interrupted
}
// .split process server reply
// Here we process a server reply and exit our loop if the
// reply is valid. If we didn't a reply we close the client
// socket and resend the request. We try a number of times
// before finally abandoning:
if item := items[0]; item.REvents&zmq.POLLIN != 0 {
// We got a reply from the server, must match sequence
reply, err := item.Socket.Recv(0)
if err != nil {
panic(err) // Interrupted
}
if replyInt, err := strconv.Atoi(string(reply)); replyInt == sequence && err == nil {
fmt.Printf("I: Server replied OK (%s)\n", reply)
retriesLeft = REQUEST_RETRIES
expectReply = false
} else {
fmt.Printf("E: Malformed reply from server: %s", reply)
}
} else if retriesLeft--; retriesLeft == 0 {
fmt.Println("E: Server seems to be offline, abandoning")
client.SetLinger(0)
client.Close()
break
} else {
fmt.Println("W: No response from server, retrying...")
// Old socket is confused; close it and open a new one
client.SetLinger(0)
client.Close()
client, _ = context.NewSocket(zmq.REQ)
client.Connect(SERVER_ENDPOINT)
fmt.Printf("I: Resending (%d)\n", sequence)
// Send request again, on new socket
client.Send([]byte(strconv.Itoa(sequence)), 0)
}
}
}
}
lpclient: Lazy Pirate client in Haskell
{--
Lazy Pirate client in Haskell
--}
module Main where
import System.ZMQ4.Monadic
import System.Random (randomRIO)
import System.Exit (exitSuccess)
import Control.Monad (forever, when)
import Control.Concurrent (threadDelay)
import Data.ByteString.Char8 (pack, unpack)
requestRetries = 3
requestTimeout_ms = 2500
serverEndpoint = "tcp://localhost:5555"
main :: IO ()
main =
runZMQ $ do
liftIO $ putStrLn "I: Connecting to server"
client <- socket Req
connect client serverEndpoint
sendServer 1 requestRetries client
sendServer :: Int -> Int -> Socket z Req -> ZMQ z ()
sendServer _ 0 _ = return ()
sendServer seq retries client = do
send client [] (pack $ show seq)
pollServer seq retries client
pollServer :: Int -> Int -> Socket z Req -> ZMQ z ()
pollServer seq retries client = do
[evts] <- poll requestTimeout_ms [Sock client [In] Nothing]
if In `elem` evts
then do
reply <- receive client
if (read . unpack $ reply) == seq
then do
liftIO $ putStrLn $ "I: Server replied OK " ++ (unpack reply)
sendServer (seq+1) requestRetries client
else do
liftIO $ putStrLn $ "E: malformed reply from server: " ++ (unpack reply)
pollServer seq retries client
else
if retries == 0
then liftIO $ putStrLn "E: Server seems to be offline, abandoning" >> exitSuccess
else do
liftIO $ putStrLn $ "W: No response from server, retrying..."
client' <- socket Req
connect client' serverEndpoint
send client' [] (pack $ show seq)
pollServer seq (retries-1) client'
lpclient: Lazy Pirate client in Haxe
package ;
import haxe.Stack;
import neko.Lib;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQException;
import org.zeromq.ZMQPoller;
import org.zeromq.ZSocket;
/**
* Lazy Pirate client
* Use zmq_poll to do a safe request-reply
* To run, start lpserver and then randomly kill / restart it.
*
* @see http://zguide.zeromq.org/page:all#Client-side-Reliability-Lazy-Pirate-Pattern
*/
class LPClient
{
private static inline var REQUEST_TIMEOUT = 2500; // msecs, (> 1000!)
private static inline var REQUEST_RETRIES = 3; // Before we abandon
private static inline var SERVER_ENDPOINT = "tcp://localhost:5555";
public static function main() {
Lib.println("** LPClient (see: http://zguide.zeromq.org/page:all#Client-side-Reliability-Lazy-Pirate-Pattern)");
var ctx:ZContext = new ZContext();
Lib.println("I: connecting to server ...");
var client = ctx.createSocket(ZMQ_REQ);
if (client == null)
return;
client.connect(SERVER_ENDPOINT);
var sequence = 0;
var retries_left = REQUEST_RETRIES;
var poller = new ZMQPoller();
while (retries_left > 0 && !ZMQ.isInterrupted()) {
// We send a request, then we work to get a reply
var request = Std.string(++sequence);
ZFrame.newStringFrame(request).send(client);
var expect_reply = true;
while (expect_reply) {
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
// Poll socket for a reply, with timeout
try {
var res = poller.poll(REQUEST_TIMEOUT * 1000);
} catch (e:ZMQException) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
ctx.destroy();
return;
}
// If we got a reply, process it
if (poller.pollin(1)) {
// We got a reply from the server, must match sequence
var replyFrame = ZFrame.recvFrame(client);
if (replyFrame == null)
break; // Interrupted
if (Std.parseInt(replyFrame.toString()) == sequence) {
Lib.println("I: server replied OK (" + sequence + ")");
retries_left = REQUEST_RETRIES;
expect_reply = false;
} else
Lib.println("E: malformed reply from server: " + replyFrame.toString());
replyFrame.destroy();
} else if (--retries_left == 0) {
Lib.println("E: server seems to be offline, abandoning");
break;
} else {
Lib.println("W: no response from server, retrying...");
// Old socket is confused, close it and open a new one
ctx.destroySocket(client);
Lib.println("I: reconnecting to server...");
client = ctx.createSocket(ZMQ_REQ);
client.connect(SERVER_ENDPOINT);
// Send request again, on new socket
ZFrame.newStringFrame(request).send(client);
}
poller.unregisterAllSockets();
}
}
ctx.destroy();
}
}lpclient: Lazy Pirate client in Java
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
//
// Lazy Pirate client
// Use zmq_poll to do a safe request-reply
// To run, start lpserver and then randomly kill/restart it
//
public class lpclient
{
private final static int REQUEST_TIMEOUT = 2500; // msecs, (> 1000!)
private final static int REQUEST_RETRIES = 3; // Before we abandon
private final static String SERVER_ENDPOINT = "tcp://localhost:5555";
public static void main(String[] argv)
{
try (ZContext ctx = new ZContext()) {
System.out.println("I: connecting to server");
Socket client = ctx.createSocket(SocketType.REQ);
assert (client != null);
client.connect(SERVER_ENDPOINT);
Poller poller = ctx.createPoller(1);
poller.register(client, Poller.POLLIN);
int sequence = 0;
int retriesLeft = REQUEST_RETRIES;
while (retriesLeft > 0 && !Thread.currentThread().isInterrupted()) {
// We send a request, then we work to get a reply
String request = String.format("%d", ++sequence);
client.send(request);
int expect_reply = 1;
while (expect_reply > 0) {
// Poll socket for a reply, with timeout
int rc = poller.poll(REQUEST_TIMEOUT);
if (rc == -1)
break; // Interrupted
// Here we process a server reply and exit our loop if the
// reply is valid. If we didn't a reply we close the client
// socket and resend the request. We try a number of times
// before finally abandoning:
if (poller.pollin(0)) {
// We got a reply from the server, must match
// getSequence
String reply = client.recvStr();
if (reply == null)
break; // Interrupted
if (Integer.parseInt(reply) == sequence) {
System.out.printf(
"I: server replied OK (%s)\n", reply
);
retriesLeft = REQUEST_RETRIES;
expect_reply = 0;
}
else System.out.printf(
"E: malformed reply from server: %s\n", reply
);
}
else if (--retriesLeft == 0) {
System.out.println(
"E: server seems to be offline, abandoning\n"
);
break;
}
else {
System.out.println(
"W: no response from server, retrying\n"
);
// Old socket is confused; close it and open a new one
poller.unregister(client);
ctx.destroySocket(client);
System.out.println("I: reconnecting to server\n");
client = ctx.createSocket(SocketType.REQ);
client.connect(SERVER_ENDPOINT);
poller.register(client, Poller.POLLIN);
// Send request again, on new socket
client.send(request);
}
}
}
}
}
}
lpclient: Lazy Pirate client in Julia
lpclient: Lazy Pirate client in Lua
--
-- Lazy Pirate client
-- Use zmq_poll to do a safe request-reply
-- To run, start lpserver and then randomly kill/restart it
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zhelpers"
local REQUEST_TIMEOUT = 2500 -- msecs, (> 1000!)
local REQUEST_RETRIES = 3 -- Before we abandon
-- Helper function that returns a new configured socket
-- connected to the Hello World server
--
local function s_client_socket(context)
printf ("I: connecting to server...\n")
local client = context:socket(zmq.REQ)
client:connect("tcp://localhost:5555")
-- Configure socket to not wait at close time
client:setopt(zmq.LINGER, 0)
return client
end
s_version_assert (2, 1)
local context = zmq.init(1)
local client = s_client_socket (context)
local sequence = 0
local retries_left = REQUEST_RETRIES
local expect_reply = true
local poller = zmq.poller(1)
local function client_cb()
-- We got a reply from the server, must match sequence
--local reply = assert(client:recv(zmq.NOBLOCK))
local reply = client:recv()
if (tonumber(reply) == sequence) then
printf ("I: server replied OK (%s)\n", reply)
retries_left = REQUEST_RETRIES
expect_reply = false
else
printf ("E: malformed reply from server: %s\n", reply)
end
end
poller:add(client, zmq.POLLIN, client_cb)
while (retries_left > 0) do
sequence = sequence + 1
-- We send a request, then we work to get a reply
local request = string.format("%d", sequence)
client:send(request)
expect_reply = true
while (expect_reply) do
-- Poll socket for a reply, with timeout
local cnt = assert(poller:poll(REQUEST_TIMEOUT * 1000))
-- Check if there was no reply
if (cnt == 0) then
retries_left = retries_left - 1
if (retries_left == 0) then
printf ("E: server seems to be offline, abandoning\n")
break
else
printf ("W: no response from server, retrying...\n")
-- Old socket is confused; close it and open a new one
poller:remove(client)
client:close()
client = s_client_socket (context)
poller:add(client, zmq.POLLIN, client_cb)
-- Send request again, on new socket
client:send(request)
end
end
end
end
client:close()
context:term()
lpclient: Lazy Pirate client in Node.js
lpclient: Lazy Pirate client in Objective-C
lpclient: Lazy Pirate client in ooc
lpclient: Lazy Pirate client in Perl
# Lazy Pirate client in Perl
# Use poll to do a safe request-reply
# To run, start lpserver.pl then randomly kill/restart it
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REQ);
use EV;
my $REQUEST_TIMEOUT = 2500; # msecs
my $REQUEST_RETRIES = 3; # Before we abandon
my $SERVER_ENDPOINT = 'tcp://localhost:5555';
my $ctx = ZMQ::FFI->new();
say 'I: connecting to server...';
my $client = $ctx->socket(ZMQ_REQ);
$client->connect($SERVER_ENDPOINT);
my $sequence = 0;
my $retries_left = $REQUEST_RETRIES;
REQUEST_LOOP:
while ($retries_left) {
# We send a request, then we work to get a reply
my $request = ++$sequence;
$client->send($request);
my $expect_reply = 1;
RETRY_LOOP:
while ($expect_reply) {
# Poll socket for a reply, with timeout
EV::once $client->get_fd, EV::READ, $REQUEST_TIMEOUT / 1000, sub {
my ($revents) = @_;
# Here we process a server reply and exit our loop if the
# reply is valid. If we didn't get a reply we close the client
# socket and resend the request. We try a number of times
# before finally abandoning:
if ($revents == EV::READ) {
while ($client->has_pollin) {
# We got a reply from the server, must match sequence
my $reply = $client->recv();
if ($reply == $sequence) {
say "I: server replied OK ($reply)";
$retries_left = $REQUEST_RETRIES;
$expect_reply = 0;
}
else {
say "E: malformed reply from server: $reply";
}
}
}
elsif (--$retries_left == 0) {
say 'E: server seems to be offline, abandoning';
}
else {
say "W: no response from server, retrying...";
# Old socket is confused; close it and open a new one
$client->close;
say "reconnecting to server...";
$client = $ctx->socket(ZMQ_REQ);
$client->connect($SERVER_ENDPOINT);
# Send request again, on new socket
$client->send($request);
}
};
last RETRY_LOOP if $retries_left == 0;
EV::run;
}
}
lpclient: Lazy Pirate client in PHP
<?php
/*
* Lazy Pirate client
* Use zmq_poll to do a safe request-reply
* To run, start lpserver and then randomly kill/restart it
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
define("REQUEST_TIMEOUT", 2500); // msecs, (> 1000!)
define("REQUEST_RETRIES", 3); // Before we abandon
/*
* Helper function that returns a new configured socket
* connected to the Hello World server
*/
function client_socket(ZMQContext $context)
{
echo "I: connecting to server...", PHP_EOL;
$client = new ZMQSocket($context,ZMQ::SOCKET_REQ);
$client->connect("tcp://localhost:5555");
// Configure socket to not wait at close time
$client->setSockOpt(ZMQ::SOCKOPT_LINGER, 0);
return $client;
}
$context = new ZMQContext();
$client = client_socket($context);
$sequence = 0;
$retries_left = REQUEST_RETRIES;
$read = $write = array();
while ($retries_left) {
// We send a request, then we work to get a reply
$client->send(++$sequence);
$expect_reply = true;
while ($expect_reply) {
// Poll socket for a reply, with timeout
$poll = new ZMQPoll();
$poll->add($client, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, REQUEST_TIMEOUT);
// If we got a reply, process it
if ($events > 0) {
// We got a reply from the server, must match sequence
$reply = $client->recv();
if (intval($reply) == $sequence) {
printf ("I: server replied OK (%s)%s", $reply, PHP_EOL);
$retries_left = REQUEST_RETRIES;
$expect_reply = false;
} else {
printf ("E: malformed reply from server: %s%s", $reply, PHP_EOL);
}
} elseif (--$retries_left == 0) {
echo "E: server seems to be offline, abandoning", PHP_EOL;
break;
} else {
echo "W: no response from server, retrying...", PHP_EOL;
// Old socket will be confused; close it and open a new one
$client = client_socket($context);
// Send request again, on new socket
$client->send($sequence);
}
}
}
lpclient: Lazy Pirate client in Python
#
# Lazy Pirate client
# Use zmq_poll to do a safe request-reply
# To run, start lpserver and then randomly kill/restart it
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import itertools
import logging
import sys
import zmq
logging.basicConfig(format="%(levelname)s: %(message)s", level=logging.INFO)
REQUEST_TIMEOUT = 2500
REQUEST_RETRIES = 3
SERVER_ENDPOINT = "tcp://localhost:5555"
context = zmq.Context()
logging.info("Connecting to server…")
client = context.socket(zmq.REQ)
client.connect(SERVER_ENDPOINT)
for sequence in itertools.count():
request = str(sequence).encode()
logging.info("Sending (%s)", request)
client.send(request)
retries_left = REQUEST_RETRIES
while True:
if (client.poll(REQUEST_TIMEOUT) & zmq.POLLIN) != 0:
reply = client.recv()
if int(reply) == sequence:
logging.info("Server replied OK (%s)", reply)
retries_left = REQUEST_RETRIES
break
else:
logging.error("Malformed reply from server: %s", reply)
continue
retries_left -= 1
logging.warning("No response from server")
# Socket is confused. Close and remove it.
client.setsockopt(zmq.LINGER, 0)
client.close()
if retries_left == 0:
logging.error("Server seems to be offline, abandoning")
sys.exit()
logging.info("Reconnecting to server…")
# Create new connection
client = context.socket(zmq.REQ)
client.connect(SERVER_ENDPOINT)
logging.info("Resending (%s)", request)
client.send(request)
lpclient: Lazy Pirate client in Q
lpclient: Lazy Pirate client in Racket
lpclient: Lazy Pirate client in Ruby
lpclient: Lazy Pirate client in Rust
lpclient: Lazy Pirate client in Scala
lpclient: Lazy Pirate client in Tcl
lpclient: Lazy Pirate client in OCaml
Run this together with the matching server:
lpserver: Lazy Pirate server in Ada
lpserver: Lazy Pirate server in Basic
lpserver: Lazy Pirate server in C
// Lazy Pirate server
// Binds REQ socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
#include "zhelpers.h"
#include <unistd.h>
int main (void)
{
srandom ((unsigned) time (NULL));
void *context = zmq_ctx_new ();
void *server = zmq_socket (context, ZMQ_REP);
zmq_bind (server, "tcp://*:5555");
int cycles = 0;
while (1) {
char *request = s_recv (server);
cycles++;
// Simulate various problems, after a few cycles
if (cycles > 3 && randof (3) == 0) {
printf ("I: simulating a crash\n");
break;
}
else
if (cycles > 3 && randof (3) == 0) {
printf ("I: simulating CPU overload\n");
sleep (2);
}
printf ("I: normal request (%s)\n", request);
sleep (1); // Do some heavy work
s_send (server, request);
free (request);
}
zmq_close (server);
zmq_ctx_destroy (context);
return 0;
}
lpserver: Lazy Pirate server in C++
//
// Lazy Pirate server
// Binds REQ socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
//
#include "zhelpers.hpp"
int main ()
{
srandom ((unsigned) time (NULL));
zmq::context_t context(1);
zmq::socket_t server(context, ZMQ_REP);
server.bind("tcp://*:5555");
int cycles = 0;
while (1) {
std::string request = s_recv (server);
cycles++;
// Simulate various problems, after a few cycles
if (cycles > 3 && within (3) == 0) {
std::cout << "I: simulating a crash" << std::endl;
break;
}
else
if (cycles > 3 && within (3) == 0) {
std::cout << "I: simulating CPU overload" << std::endl;
sleep (2);
}
std::cout << "I: normal request (" << request << ")" << std::endl;
sleep (1); // Do some heavy work
s_send (server, request);
}
return 0;
}
lpserver: Lazy Pirate server in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
//
// Lazy Pirate server
// Binds REP socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
//
// Author: metadings
//
public static void LPServer(string[] args)
{
using (var context = new ZContext())
using (var responder = new ZSocket(context, ZSocketType.REP))
{
responder.Bind("tcp://*:5555");
ZError error;
int cycles = 0;
var rnd = new Random();
while (true)
{
ZMessage incoming;
if (null == (incoming = responder.ReceiveMessage(out error)))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
using (incoming)
{
++cycles;
// Simulate various problems, after a few cycles
if (cycles > 16 && rnd.Next(16) == 0)
{
Console.WriteLine("I: simulating a crash");
break;
}
else if (cycles > 4 && rnd.Next(4) == 0)
{
Console.WriteLine("I: simulating CPU overload");
Thread.Sleep(1000);
}
Console.WriteLine("I: normal request ({0})", incoming[0].ReadInt32());
Thread.Sleep(1); // Do some heavy work
responder.Send(incoming);
}
}
}
}
}
}
lpserver: Lazy Pirate server in CL
lpserver: Lazy Pirate server in Delphi
program lpserver;
//
// Lazy Pirate server
// Binds REQ socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
server: TZMQSocket;
cycles: Integer;
request: Utf8String;
begin
Randomize;
context := TZMQContext.create;
server := context.socket( stRep );
server.bind( 'tcp://*:5555' );
cycles := 0;
while not context.Terminated do
try
server.recv( request );
inc( cycles );
// Simulate various problems, after a few cycles
if ( cycles > 3 ) and ( random(3) = 0) then
begin
Writeln( 'I: simulating a crash' );
break;
end else
if ( cycles > 3 ) and ( random(3) = 0 ) then
begin
Writeln( 'I: simulating CPU overload' );
sleep(2000);
end;
Writeln( Format( 'I: normal request (%s)', [request] ) );
sleep (1000); // Do some heavy work
server.send( request );
except
end;
context.Free;
end.
lpserver: Lazy Pirate server in Erlang
lpserver: Lazy Pirate server in Elixir
lpserver: Lazy Pirate server in F#
lpserver: Lazy Pirate server in Felix
lpserver: Lazy Pirate server in Go
// Lazy Pirate server
// Binds REQ socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
//
// Author: iano <scaly.iano@gmail.com>
// Based on C example
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"time"
)
const (
SERVER_ENDPOINT = "tcp://*:5555"
)
func main() {
src := rand.NewSource(time.Now().UnixNano())
random := rand.New(src)
context, _ := zmq.NewContext()
defer context.Close()
server, _ := context.NewSocket(zmq.REP)
defer server.Close()
server.Bind(SERVER_ENDPOINT)
for cycles := 1; ; cycles++ {
request, _ := server.Recv(0)
// Simulate various problems, after a few cycles
if cycles > 3 {
switch r := random.Intn(3); r {
case 0:
fmt.Println("I: Simulating a crash")
return
case 1:
fmt.Println("I: simulating CPU overload")
time.Sleep(2 * time.Second)
}
}
fmt.Printf("I: normal request (%s)\n", request)
time.Sleep(1 * time.Second) // Do some heavy work
server.Send(request, 0)
}
}
lpserver: Lazy Pirate server in Haskell
{--
Lazy Pirate server in Haskell
--}
module Main where
import System.ZMQ4.Monadic
import System.Random (randomRIO)
import System.Exit (exitSuccess)
import Control.Monad (forever, when)
import Control.Concurrent (threadDelay)
import Data.ByteString.Char8 (pack, unpack)
main :: IO ()
main =
runZMQ $ do
server <- socket Rep
bind server "tcp://*:5555"
sendClient 0 server
sendClient :: Int -> Socket z Rep -> ZMQ z ()
sendClient cycles server = do
req <- receive server
chance <- liftIO $ randomRIO (0::Int, 3)
when (cycles > 3 && chance == 0) $ do
liftIO crash
chance' <- liftIO $ randomRIO (0::Int, 3)
when (cycles > 3 && chance' == 0) $ do
liftIO overload
liftIO $ putStrLn $ "I: normal request " ++ (unpack req)
liftIO $ threadDelay $ 1 * 1000 * 1000
send server [] req
sendClient (cycles+1) server
crash = do
putStrLn "I: Simulating a crash"
exitSuccess
overload = do
putStrLn "I: Simulating CPU overload"
threadDelay $ 2 * 1000 * 1000
lpserver: Lazy Pirate server in Haxe
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
/**
* Lazy Pirate server
* Binds REP socket to tcp://*:5555
* Like HWServer except:
* - echoes request as-is
* - randomly runs slowly, or exists to simulate a crash.
*
* @see http://zguide.zeromq.org/page:all#Client-side-Reliability-Lazy-Pirate-Pattern
*
*/
class LPServer
{
public static function main() {
Lib.println("** LPServer (see: http://zguide.zeromq.org/page:all#Client-side-Reliability-Lazy-Pirate-Pattern)");
var ctx = new ZContext();
var server = ctx.createSocket(ZMQ_REP);
server.bind("tcp://*:5555");
var cycles = 0;
while (true) {
var requestFrame = ZFrame.recvFrame(server);
cycles++;
// Simulate various problems, after a few cycles
if (cycles > 3 && ZHelpers.randof(3) == 0) {
Lib.println("I: simulating a crash");
break;
}
else if (cycles > 3 && ZHelpers.randof(3) == 0) {
Lib.println("I: simulating CPU overload");
Sys.sleep(2.0);
}
Lib.println("I: normal request (" + requestFrame.toString() + ")");
Sys.sleep(1.0); // Do some heavy work
requestFrame.send(server);
requestFrame.destroy();
}
server.close();
ctx.destroy();
}
}lpserver: Lazy Pirate server in Java
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
//
// Lazy Pirate server
// Binds REQ socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
//
public class lpserver
{
public static void main(String[] argv) throws Exception
{
Random rand = new Random(System.nanoTime());
try (ZContext context = new ZContext()) {
Socket server = context.createSocket(SocketType.REP);
server.bind("tcp://*:5555");
int cycles = 0;
while (true) {
String request = server.recvStr();
cycles++;
// Simulate various problems, after a few cycles
if (cycles > 3 && rand.nextInt(3) == 0) {
System.out.println("I: simulating a crash");
break;
}
else if (cycles > 3 && rand.nextInt(3) == 0) {
System.out.println("I: simulating CPU overload");
Thread.sleep(2000);
}
System.out.printf("I: normal request (%s)\n", request);
Thread.sleep(1000); // Do some heavy work
server.send(request);
}
}
}
}
lpserver: Lazy Pirate server in Julia
lpserver: Lazy Pirate server in Lua
--
-- Lazy Pirate server
-- Binds REQ socket to tcp://*:5555
-- Like hwserver except:
-- - echoes request as-is
-- - randomly runs slowly, or exits to simulate a crash.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zhelpers"
math.randomseed(os.time())
local context = zmq.init(1)
local server = context:socket(zmq.REP)
server:bind("tcp://*:5555")
local cycles = 0
while true do
local request = server:recv()
cycles = cycles + 1
-- Simulate various problems, after a few cycles
if (cycles > 3 and randof (3) == 0) then
printf("I: simulating a crash\n")
break
elseif (cycles > 3 and randof (3) == 0) then
printf("I: simulating CPU overload\n")
s_sleep(2000)
end
printf("I: normal request (%s)\n", request)
s_sleep(1000) -- Do some heavy work
server:send(request)
end
server:close()
context:term()
lpserver: Lazy Pirate server in Node.js
lpserver: Lazy Pirate server in Objective-C
lpserver: Lazy Pirate server in ooc
lpserver: Lazy Pirate server in Perl
# Lazy Pirate server in Perl
# Binds REQ socket to tcp://*:5555
# Like hwserver except:
# - echoes request as-is
# - randomly runs slowly, or exits to simulate a crash.
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REP);
my $context = ZMQ::FFI->new();
my $server = $context->socket(ZMQ_REP);
$server->bind('tcp://*:5555');
my $cycles = 0;
SERVER_LOOP:
while (1) {
my $request = $server->recv();
$cycles++;
# Simulate various problems, after a few cycles
if ($cycles > 3 && int(rand(3)) == 0) {
say "I: simulating a crash";
last SERVER_LOOP;
}
elsif ($cycles > 3 && int(rand(3)) == 0) {
say "I: simulating CPU overload";
sleep 2;
}
say "I: normal request ($request)";
sleep 1; # Do some heavy work
$server->send($request);
}
lpserver: Lazy Pirate server in PHP
<?php
/*
* Lazy Pirate server
* Binds REQ socket to tcp://*:5555
* Like hwserver except:
* - echoes request as-is
* - randomly runs slowly, or exits to simulate a crash.
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
$context = new ZMQContext();
$server = new ZMQSocket($context, ZMQ::SOCKET_REP);
$server->bind("tcp://*:5555");
$cycles = 0;
while (true) {
$request = $server->recv();
$cycles++;
// Simulate various problems, after a few cycles
if ($cycles > 3 && rand(0, 3) == 0) {
echo "I: simulating a crash", PHP_EOL;
break;
} elseif ($cycles > 3 && rand(0, 3) == 0) {
echo "I: simulating CPU overload", PHP_EOL;
sleep(5);
}
printf ("I: normal request (%s)%s", $request, PHP_EOL);
sleep(1); // Do some heavy work
$server->send($request);
}
lpserver: Lazy Pirate server in Python
#
# Lazy Pirate server
# Binds REQ socket to tcp://*:5555
# Like hwserver except:
# - echoes request as-is
# - randomly runs slowly, or exits to simulate a crash.
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
from random import randint
import itertools
import logging
import time
import zmq
logging.basicConfig(format="%(levelname)s: %(message)s", level=logging.INFO)
context = zmq.Context()
server = context.socket(zmq.REP)
server.bind("tcp://*:5555")
for cycles in itertools.count():
request = server.recv()
# Simulate various problems, after a few cycles
if cycles > 3 and randint(0, 3) == 0:
logging.info("Simulating a crash")
break
elif cycles > 3 and randint(0, 3) == 0:
logging.info("Simulating CPU overload")
time.sleep(2)
logging.info("Normal request (%s)", request)
time.sleep(1) # Do some heavy work
server.send(request)
lpserver: Lazy Pirate server in Q
lpserver: Lazy Pirate server in Racket
lpserver: Lazy Pirate server in Ruby
lpserver: Lazy Pirate server in Rust
lpserver: Lazy Pirate server in Scala
lpserver: Lazy Pirate server in Tcl
lpserver: Lazy Pirate server in OCaml
To run this test case, start the client and the server in two console windows. The server will randomly misbehave after a few messages. You can check the client’s response. Here is typical output from the server:
I: normal request (1)
I: normal request (2)
I: normal request (3)
I: simulating CPU overload
I: normal request (4)
I: simulating a crash
And here is the client’s response:
I: connecting to server...
I: server replied OK (1)
I: server replied OK (2)
I: server replied OK (3)
W: no response from server, retrying...
I: connecting to server...
W: no response from server, retrying...
I: connecting to server...
E: server seems to be offline, abandoning
The client sequences each message and checks that replies come back exactly in order: that no requests or replies are lost, and no replies come back more than once, or out of order. Run the test a few times until you’re convinced that this mechanism actually works. You don’t need sequence numbers in a production application; they just help us trust our design.
The client uses a REQ socket, and does the brute force close/reopen because REQ sockets impose that strict send/receive cycle. You might be tempted to use a DEALER instead, but it would not be a good decision. First, it would mean emulating the secret sauce that REQ does with envelopes (if you’ve forgotten what that is, it’s a good sign you don’t want to have to do it). Second, it would mean potentially getting back replies that you didn’t expect.
Handling failures only at the client works when we have a set of clients talking to a single server. It can handle a server crash, but only if recovery means restarting that same server. If there’s a permanent error, such as a dead power supply on the server hardware, this approach won’t work. Because the application code in servers is usually the biggest source of failures in any architecture, depending on a single server is not a great idea.
So, pros and cons:
- Pro: simple to understand and implement.
- Pro: works easily with existing client and server application code.
- Pro: ZeroMQ automatically retries the actual reconnection until it works.
- Con: doesn’t failover to backup or alternate servers.
Basic Reliable Queuing (Simple Pirate Pattern) #
Our second approach extends the Lazy Pirate pattern with a queue proxy that lets us talk, transparently, to multiple servers, which we can more accurately call “workers”. We’ll develop this in stages, starting with a minimal working model, the Simple Pirate pattern.
In all these Pirate patterns, workers are stateless. If the application requires some shared state, such as a shared database, we don’t know about it as we design our messaging framework. Having a queue proxy means workers can come and go without clients knowing anything about it. If one worker dies, another takes over. This is a nice, simple topology with only one real weakness, namely the central queue itself, which can become a problem to manage, and a single point of failure.
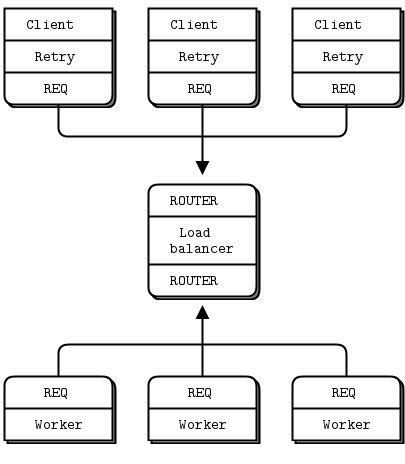
The basis for the queue proxy is the load balancing broker from Chapter 3 - Advanced Request-Reply Patterns. What is the very minimum we need to do to handle dead or blocked workers? Turns out, it’s surprisingly little. We already have a retry mechanism in the client. So using the load balancing pattern will work pretty well. This fits with ZeroMQ’s philosophy that we can extend a peer-to-peer pattern like request-reply by plugging naive proxies in the middle.
We don’t need a special client; we’re still using the Lazy Pirate client. Here is the queue, which is identical to the main task of the load balancing broker:
spqueue: Simple Pirate queue in Ada
spqueue: Simple Pirate queue in Basic
spqueue: Simple Pirate queue in C
// Simple Pirate broker
// This is identical to load-balancing pattern, with no reliability
// mechanisms. It depends on the client for recovery. Runs forever.
#include "czmq.h"
#define WORKER_READY "\001" // Signals worker is ready
int main (void)
{
zctx_t *ctx = zctx_new ();
void *frontend = zsocket_new (ctx, ZMQ_ROUTER);
void *backend = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (frontend, "tcp://*:5555"); // For clients
zsocket_bind (backend, "tcp://*:5556"); // For workers
// Queue of available workers
zlist_t *workers = zlist_new ();
// The body of this example is exactly the same as lbbroker2.
// .skip
while (true) {
zmq_pollitem_t items [] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
int rc = zmq_poll (items, zlist_size (workers)? 2: 1, -1);
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (items [0].revents & ZMQ_POLLIN) {
// Use worker identity for load-balancing
zmsg_t *msg = zmsg_recv (backend);
if (!msg)
break; // Interrupted
zframe_t *identity = zmsg_unwrap (msg);
zlist_append (workers, identity);
// Forward message to client if it's not a READY
zframe_t *frame = zmsg_first (msg);
if (memcmp (zframe_data (frame), WORKER_READY, 1) == 0)
zmsg_destroy (&msg);
else
zmsg_send (&msg, frontend);
}
if (items [1].revents & ZMQ_POLLIN) {
// Get client request, route to first available worker
zmsg_t *msg = zmsg_recv (frontend);
if (msg) {
zmsg_wrap (msg, (zframe_t *) zlist_pop (workers));
zmsg_send (&msg, backend);
}
}
}
// When we're done, clean up properly
while (zlist_size (workers)) {
zframe_t *frame = (zframe_t *) zlist_pop (workers);
zframe_destroy (&frame);
}
zlist_destroy (&workers);
zctx_destroy (&ctx);
return 0;
// .until
}
spqueue: Simple Pirate queue in C++
//
// Simple Pirate queue
// This is identical to the LRU pattern, with no reliability mechanisms
// at all. It depends on the client for recovery. Runs forever.
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at
#include "zmsg.hpp"
#include <queue>
#define MAX_WORKERS 100
int main (void)
{
s_version_assert (2, 1);
// Prepare our context and sockets
zmq::context_t context(1);
zmq::socket_t frontend (context, ZMQ_ROUTER);
zmq::socket_t backend (context, ZMQ_ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind("tcp://*:5556"); // For workers
// Queue of available workers
std::queue<std::string> worker_queue;
while (1) {
zmq::pollitem_t items [] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
if (worker_queue.size())
zmq::poll (items, 2, -1);
else
zmq::poll (items, 1, -1);
// Handle worker activity on backend
if (items [0].revents & ZMQ_POLLIN) {
zmsg zm(backend);
//zmsg_t *zmsg = zmsg_recv (backend);
// Use worker address for LRU routing
assert (worker_queue.size() < MAX_WORKERS);
worker_queue.push(zm.unwrap());
// Return reply to client if it's not a READY
if (strcmp (zm.address(), "READY") == 0)
zm.clear();
else
zm.send (frontend);
}
if (items [1].revents & ZMQ_POLLIN) {
// Now get next client request, route to next worker
zmsg zm(frontend);
// REQ socket in worker needs an envelope delimiter
zm.wrap(worker_queue.front().c_str(), "");
zm.send(backend);
// Dequeue and drop the next worker address
worker_queue.pop();
}
}
// We never exit the main loop
return 0;
}
spqueue: Simple Pirate queue in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
public static void SPQueue(string[] args)
{
//
// Simple Pirate broker
// This is identical to load-balancing pattern, with no reliability
// mechanisms. It depends on the client for recovery. Runs forever.
//
// Author: metadings
//
using (var context = new ZContext())
using (var frontend = new ZSocket(context, ZSocketType.ROUTER))
using (var backend = new ZSocket(context, ZSocketType.ROUTER))
{
frontend.Bind("tcp://*:5555");
backend.Bind("tcp://*:5556");
// Queue of available workers
var worker_queue = new List<string>();
ZError error;
ZMessage incoming;
var poll = ZPollItem.CreateReceiver();
while (true)
{
if (backend.PollIn(poll, out incoming, out error, TimeSpan.FromMilliseconds(64)))
{
using (incoming)
{
// Handle worker activity on backend
// incoming[0] is worker_id
string worker_id = incoming[0].ReadString();
// Queue worker identity for load-balancing
worker_queue.Add(worker_id);
// incoming[1] is empty
// incoming[2] is READY or else client_id
string client_id = incoming[2].ReadString();
if (client_id == "READY")
{
Console.WriteLine("I: ({0}) worker ready", worker_id);
}
else
{
// incoming[3] is empty
// incoming[4] is reply
// string reply = incoming[4].ReadString();
// int reply = incoming[4].ReadInt32();
Console.WriteLine("I: ({0}) work complete", worker_id);
using (var outgoing = new ZMessage())
{
outgoing.Add(new ZFrame(client_id));
outgoing.Add(new ZFrame());
outgoing.Add(incoming[4]);
// Send
frontend.Send(outgoing);
}
}
}
}
else
{
if (error == ZError.ETERM)
return;
if (error != ZError.EAGAIN)
throw new ZException(error);
}
if (worker_queue.Count > 0)
{
// Poll frontend only if we have available workers
if (frontend.PollIn(poll, out incoming, out error, TimeSpan.FromMilliseconds(64)))
{
using (incoming)
{
// Here is how we handle a client request
// Dequeue the next worker identity
string worker_id = worker_queue[0];
worker_queue.RemoveAt(0);
// incoming[0] is client_id
string client_id = incoming[0].ReadString();
// incoming[1] is empty
// incoming[2] is request
// string request = incoming[2].ReadString();
int request = incoming[2].ReadInt32();
Console.WriteLine("I: ({0}) working on ({1}) {2}", worker_id, client_id, request);
using (var outgoing = new ZMessage())
{
outgoing.Add(new ZFrame(worker_id));
outgoing.Add(new ZFrame());
outgoing.Add(new ZFrame(client_id));
outgoing.Add(new ZFrame());
outgoing.Add(incoming[2]);
// Send
backend.Send(outgoing);
}
}
}
else
{
if (error == ZError.ETERM)
return;
if (error != ZError.EAGAIN)
throw new ZException(error);
}
}
}
}
}
}
}
spqueue: Simple Pirate queue in CL
spqueue: Simple Pirate queue in Delphi
program spqueue;
//
// Simple Pirate broker
// This is identical to load-balancing pattern, with no reliability
// mechanisms. It depends on the client for recovery. Runs forever.
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
const
WORKER_READY = '\001'; // Signals worker is ready
var
ctx: TZMQContext;
frontend,
backend: TZMQSocket;
workers: TZMQMsg;
poller: TZMQPoller;
pc: Integer;
msg: TZMQMsg;
identity,
frame: TZMQFrame;
begin
ctx := TZMQContext.create;
frontend := ctx.Socket( stRouter );
backend := ctx.Socket( stRouter );
frontend.bind( 'tcp://*:5555' ); // For clients
backend.bind( 'tcp://*:5556' ); // For workers
// Queue of available workers
workers := TZMQMsg.create;
poller := TZMQPoller.Create( true );
poller.Register( backend, [pePollIn] );
poller.Register( frontend, [pePollIn] );
// The body of this example is exactly the same as lbbroker2.
while not ctx.Terminated do
try
// Poll frontend only if we have available workers
if workers.size > 0 then
pc := 2
else
pc := 1;
poller.poll( 1000, pc );
// Handle worker activity on backend
if pePollIn in poller.PollItem[0].revents then
begin
// Use worker identity for load-balancing
backend.recv( msg );
identity := msg.unwrap;
workers.add( identity );
// Forward message to client if it's not a READY
frame := msg.first;
if frame.asUtf8String = WORKER_READY then
begin
msg.Free;
msg := nil;
end else
frontend.send( msg );
end;
if pePollIn in poller.PollItem[1].revents then
begin
// Get client request, route to first available worker
frontend.recv( msg );
msg.wrap( workers.pop );
backend.send( msg );
end;
except
end;
workers.Free;
ctx.Free;
end.
spqueue: Simple Pirate queue in Erlang
spqueue: Simple Pirate queue in Elixir
spqueue: Simple Pirate queue in F#
spqueue: Simple Pirate queue in Felix
spqueue: Simple Pirate queue in Go
// Simple Pirate broker
// This is identical to load-balancing pattern, with no reliability
// mechanisms. It depends on the client for recovery. Runs forever.
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
zmq "github.com/alecthomas/gozmq"
)
const LRU_READY = "\001"
func main() {
context, _ := zmq.NewContext()
defer context.Close()
frontend, _ := context.NewSocket(zmq.ROUTER)
defer frontend.Close()
frontend.Bind("tcp://*:5555") // For clients
backend, _ := context.NewSocket(zmq.ROUTER)
defer backend.Close()
backend.Bind("tcp://*:5556") // For workers
// Queue of available workers
workers := make([][]byte, 0, 0)
for {
items := zmq.PollItems{
zmq.PollItem{Socket: backend, Events: zmq.POLLIN},
zmq.PollItem{Socket: frontend, Events: zmq.POLLIN},
}
// Poll frontend only if we have available workers
if len(workers) > 0 {
zmq.Poll(items, -1)
} else {
zmq.Poll(items[:1], -1)
}
// Handle worker activity on backend
if items[0].REvents&zmq.POLLIN != 0 {
// Use worker identity for load-balancing
msg, err := backend.RecvMultipart(0)
if err != nil {
panic(err) // Interrupted
}
address := msg[0]
workers = append(workers, address)
// Forward message to client if it's not a READY
if reply := msg[2:]; string(reply[0]) != LRU_READY {
frontend.SendMultipart(reply, 0)
}
}
if items[1].REvents&zmq.POLLIN != 0 {
// Get client request, route to first available worker
msg, err := frontend.RecvMultipart(0)
if err != nil {
panic(err) // Interrupted
}
last := workers[len(workers)-1]
workers = workers[:len(workers)-1]
request := append([][]byte{last, nil}, msg...)
backend.SendMultipart(request, 0)
}
}
}
spqueue: Simple Pirate queue in Haskell
{--
Simple Pirate queue in Haskell
--}
module Main where
import System.ZMQ4.Monadic
import Control.Concurrent (threadDelay)
import Control.Applicative ((<$>))
import Control.Monad (when)
import Data.ByteString.Char8 (pack, unpack, empty)
import Data.List (intercalate)
type SockID = String
workerReady = "\001"
main :: IO ()
main =
runZMQ $ do
frontend <- socket Router
bind frontend "tcp://*:5555"
backend <- socket Router
bind backend "tcp://*:5556"
pollPeers frontend backend []
pollPeers :: Socket z Router -> Socket z Router -> [SockID] -> ZMQ z ()
pollPeers frontend backend workers = do
let toPoll = getPollList workers
evts <- poll 0 toPoll
workers' <- getBackend backend frontend evts workers
workers'' <- getFrontend frontend backend evts workers'
pollPeers frontend backend workers''
where getPollList [] = [Sock backend [In] Nothing]
getPollList _ = [Sock backend [In] Nothing, Sock frontend [In] Nothing]
getBackend :: Socket z Router -> Socket z Router ->
[[Event]] -> [SockID] -> ZMQ z ([SockID])
getBackend backend frontend evts workers =
if (In `elem` (evts !! 0))
then do
wkrID <- receive backend
id <- (receive backend >> receive backend)
msg <- (receive backend >> receive backend)
when ((unpack msg) /= workerReady) $ do
liftIO $ putStrLn $ "I: sending backend - " ++ (unpack msg)
send frontend [SendMore] id
send frontend [SendMore] empty
send frontend [] msg
return $ (unpack wkrID):workers
else return workers
getFrontend :: Socket z Router -> Socket z Router ->
[[Event]] -> [SockID] -> ZMQ z [SockID]
getFrontend frontend backend evts workers =
if (length evts > 1 && In `elem` (evts !! 1))
then do
id <- receive frontend
msg <- (receive frontend >> receive frontend)
liftIO $ putStrLn $ "I: msg on frontend - " ++ (unpack msg)
let wkrID = head workers
send backend [SendMore] (pack wkrID)
send backend [SendMore] empty
send backend [SendMore] id
send backend [SendMore] empty
send backend [] msg
return $ tail workers
else return workers
spqueue: Simple Pirate queue in Haxe
package ;
import haxe.Stack;
import neko.Lib;
import org.zeromq.ZFrame;
import org.zeromq.ZContext;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQ;
import org.zeromq.ZMsg;
import org.zeromq.ZMQException;
/**
* Simple Pirate queue
* This is identical to the LRU pattern, with no reliability mechanisms
* at all. It depends on the client for recovery. Runs forever.
*
* @see http://zguide.zeromq.org/page:all#Basic-Reliable-Queuing-Simple-Pirate-Pattern
*/
class SPQueue
{
// Signals workers are ready
private static inline var LRU_READY:String = String.fromCharCode(1);
public static function main() {
Lib.println("** SPQueue (see: http://zguide.zeromq.org/page:all#Basic-Reliable-Queuing-Simple-Pirate-Pattern)");
// Prepare our context and sockets
var context:ZContext = new ZContext();
var frontend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
var backend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind("tcp://*:5556"); // For workers
// Queue of available workers
var workerQueue:List<ZFrame> = new List<ZFrame>();
var poller:ZMQPoller = new ZMQPoller();
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
while (true) {
poller.unregisterSocket(frontend);
if (workerQueue.length > 0) {
// Only poll frontend if there is at least 1 worker ready to do work
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
}
try {
poller.poll( -1 );
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
if (poller.pollin(1)) {
// Use worker address for LRU routing
var msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
var address = msg.unwrap();
workerQueue.add(address);
// Forward message to client if it's not a READY
var frame = msg.first();
if (frame.streq(LRU_READY))
msg.destroy();
else
msg.send(frontend);
}
if (poller.pollin(2)) {
// Get client request, route to first available worker
var msg = ZMsg.recvMsg(frontend);
if (msg != null) {
msg.wrap(workerQueue.pop());
msg.send(backend);
}
}
}
// When we're done, clean up properly
for (f in workerQueue) {
f.destroy();
}
context.destroy();
}
}spqueue: Simple Pirate queue in Java
package guide;
import java.util.ArrayList;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
//
// Simple Pirate queue
// This is identical to load-balancing pattern, with no reliability mechanisms
// at all. It depends on the client for recovery. Runs forever.
//
public class spqueue
{
private final static String WORKER_READY = "\001"; // Signals worker is ready
public static void main(String[] args)
{
try (ZContext ctx = new ZContext()) {
Socket frontend = ctx.createSocket(SocketType.ROUTER);
Socket backend = ctx.createSocket(SocketType.ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind("tcp://*:5556"); // For workers
// Queue of available workers
ArrayList<ZFrame> workers = new ArrayList<ZFrame>();
Poller poller = ctx.createPoller(2);
poller.register(backend, Poller.POLLIN);
poller.register(frontend, Poller.POLLIN);
// The body of this example is exactly the same as lruqueue2.
while (true) {
boolean workersAvailable = workers.size() > 0;
int rc = poller.poll(-1);
// Poll frontend only if we have available workers
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (poller.pollin(0)) {
// Use worker address for LRU routing
ZMsg msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
ZFrame address = msg.unwrap();
workers.add(address);
// Forward message to client if it's not a READY
ZFrame frame = msg.getFirst();
if (new String(frame.getData(), ZMQ.CHARSET).equals(WORKER_READY))
msg.destroy();
else msg.send(frontend);
}
if (workersAvailable && poller.pollin(1)) {
// Get client request, route to first available worker
ZMsg msg = ZMsg.recvMsg(frontend);
if (msg != null) {
msg.wrap(workers.remove(0));
msg.send(backend);
}
}
}
// When we're done, clean up properly
while (workers.size() > 0) {
ZFrame frame = workers.remove(0);
frame.destroy();
}
workers.clear();
}
}
}
spqueue: Simple Pirate queue in Julia
spqueue: Simple Pirate queue in Lua
--
-- Simple Pirate queue
-- This is identical to the LRU pattern, with no reliability mechanisms
-- at all. It depends on the client for recovery. Runs forever.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zhelpers"
require"zmsg"
local tremove = table.remove
local MAX_WORKERS = 100
s_version_assert (2, 1)
-- Prepare our context and sockets
local context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.ROUTER)
frontend:bind("tcp://*:5555"); -- For clients
backend:bind("tcp://*:5556"); -- For workers
-- Queue of available workers
local worker_queue = {}
local is_accepting = false
local poller = zmq.poller(2)
local function frontend_cb()
-- Now get next client request, route to next worker
local msg = zmsg.recv (frontend)
-- Dequeue a worker from the queue.
local worker = tremove(worker_queue, 1)
msg:wrap(worker, "")
msg:send(backend)
if (#worker_queue == 0) then
-- stop accepting work from clients, when no workers are available.
poller:remove(frontend)
is_accepting = false
end
end
-- Handle worker activity on backend
poller:add(backend, zmq.POLLIN, function()
local msg = zmsg.recv(backend)
-- Use worker address for LRU routing
worker_queue[#worker_queue + 1] = msg:unwrap()
-- start accepting client requests, if we are not already doing so.
if not is_accepting then
is_accepting = true
poller:add(frontend, zmq.POLLIN, frontend_cb)
end
-- Forward message to client if it's not a READY
if (msg:address() ~= "READY") then
msg:send(frontend)
end
end)
-- start poller's event loop
poller:start()
-- We never exit the main loop
spqueue: Simple Pirate queue in Node.js
spqueue: Simple Pirate queue in Objective-C
spqueue: Simple Pirate queue in ooc
spqueue: Simple Pirate queue in Perl
spqueue: Simple Pirate queue in PHP
<?php
/*
* Simple Pirate queue
* This is identical to the LRU pattern, with no reliability mechanisms
* at all. It depends on the client for recovery. Runs forever.
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("MAX_WORKERS", 100);
// Prepare our context and sockets
$context = new ZMQContext();
$frontend = $context->getSocket(ZMQ::SOCKET_ROUTER);
$backend = $context->getSocket(ZMQ::SOCKET_ROUTER);
$frontend->bind("tcp://*:5555"); // For clients
$backend->bind("tcp://*:5556"); // For workers
// Queue of available workers
$available_workers = 0;
$worker_queue = array();
$read = $write = array();
while (true) {
$poll = new ZMQPoll();
$poll->add($backend, ZMQ::POLL_IN);
// Poll frontend only if we have available workers
if ($available_workers) {
$poll->add($frontend, ZMQ::POLL_IN);
}
$events = $poll->poll($read, $write);
foreach ($read as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
// Handle worker activity on backend
if ($socket === $backend) {
// Use worker address for LRU routing
assert($available_workers < MAX_WORKERS);
array_push($worker_queue, $zmsg->unwrap());
$available_workers++;
// Return reply to client if it's not a READY
if ($zmsg->address() != "READY") {
$zmsg->set_socket($frontend)->send();
}
} elseif ($socket === $frontend) {
// Now get next client request, route to next worker
// REQ socket in worker needs an envelope delimiter
// Dequeue and drop the next worker address
$zmsg->wrap(array_shift($worker_queue), "");
$zmsg->set_socket($backend)->send();
$available_workers--;
}
}
// We never exit the main loop
}
spqueue: Simple Pirate queue in Python
#
# Simple Pirate queue
# This is identical to the LRU pattern, with no reliability mechanisms
# at all. It depends on the client for recovery. Runs forever.
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import zmq
LRU_READY = "\x01"
context = zmq.Context(1)
frontend = context.socket(zmq.ROUTER) # ROUTER
backend = context.socket(zmq.ROUTER) # ROUTER
frontend.bind("tcp://*:5555") # For clients
backend.bind("tcp://*:5556") # For workers
poll_workers = zmq.Poller()
poll_workers.register(backend, zmq.POLLIN)
poll_both = zmq.Poller()
poll_both.register(frontend, zmq.POLLIN)
poll_both.register(backend, zmq.POLLIN)
workers = []
while True:
if workers:
socks = dict(poll_both.poll())
else:
socks = dict(poll_workers.poll())
# Handle worker activity on backend
if socks.get(backend) == zmq.POLLIN:
# Use worker address for LRU routing
msg = backend.recv_multipart()
if not msg:
break
address = msg[0]
workers.append(address)
# Everything after the second (delimiter) frame is reply
reply = msg[2:]
# Forward message to client if it's not a READY
if reply[0] != LRU_READY:
frontend.send_multipart(reply)
if socks.get(frontend) == zmq.POLLIN:
# Get client request, route to first available worker
msg = frontend.recv_multipart()
request = [workers.pop(0), ''.encode()] + msg
backend.send_multipart(request)
spqueue: Simple Pirate queue in Q
spqueue: Simple Pirate queue in Racket
spqueue: Simple Pirate queue in Ruby
spqueue: Simple Pirate queue in Rust
spqueue: Simple Pirate queue in Scala
spqueue: Simple Pirate queue in Tcl
spqueue: Simple Pirate queue in OCaml
Here is the worker, which takes the Lazy Pirate server and adapts it for the load balancing pattern (using the REQ “ready” signaling):
spworker: Simple Pirate worker in Ada
spworker: Simple Pirate worker in Basic
spworker: Simple Pirate worker in C
// Simple Pirate worker
// Connects REQ socket to tcp://*:5556
// Implements worker part of load-balancing
#include "czmq.h"
#define WORKER_READY "\001" // Signals worker is ready
int main (void)
{
zctx_t *ctx = zctx_new ();
void *worker = zsocket_new (ctx, ZMQ_REQ);
// Set random identity to make tracing easier
srandom ((unsigned) time (NULL));
char identity [10];
sprintf (identity, "%04X-%04X", randof (0x10000), randof (0x10000));
zmq_setsockopt (worker, ZMQ_IDENTITY, identity, strlen (identity));
zsocket_connect (worker, "tcp://localhost:5556");
// Tell broker we're ready for work
printf ("I: (%s) worker ready\n", identity);
zframe_t *frame = zframe_new (WORKER_READY, 1);
zframe_send (&frame, worker, 0);
int cycles = 0;
while (true) {
zmsg_t *msg = zmsg_recv (worker);
if (!msg)
break; // Interrupted
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && randof (5) == 0) {
printf ("I: (%s) simulating a crash\n", identity);
zmsg_destroy (&msg);
break;
}
else
if (cycles > 3 && randof (5) == 0) {
printf ("I: (%s) simulating CPU overload\n", identity);
sleep (3);
if (zctx_interrupted)
break;
}
printf ("I: (%s) normal reply\n", identity);
sleep (1); // Do some heavy work
zmsg_send (&msg, worker);
}
zctx_destroy (&ctx);
return 0;
}
spworker: Simple Pirate worker in C++
//
// Simple Pirate worker
// Connects REQ socket to tcp://*:5556
// Implements worker part of LRU queueing
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
#include "zmsg.hpp"
int main (void)
{
srandom ((unsigned) time (NULL));
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_REQ);
// Set random identity to make tracing easier
std::string identity = s_set_id(worker);
worker.connect("tcp://localhost:5556");
// Tell queue we're ready for work
std::cout << "I: (" << identity << ") worker ready" << std::endl;
s_send (worker, std::string("READY"));
int cycles = 0;
while (1) {
zmsg zm (worker);
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && within (5) == 0) {
std::cout << "I: (" << identity << ") simulating a crash" << std::endl;
zm.clear ();
break;
}
else
if (cycles > 3 && within (5) == 0) {
std::cout << "I: (" << identity << ") simulating CPU overload" << std::endl;
sleep (5);
}
std::cout << "I: (" << identity << ") normal reply - " << zm.body () << std::endl;
sleep (1); // Do some heavy work
zm.send(worker);
}
return 0;
}
spworker: Simple Pirate worker in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
public static void SPWorker(string[] args)
{
//
// Simple Pirate worker
// Connects REQ socket to tcp://127.0.0.1:5556
// Implements worker part of load-balancing
//
// Author: metadings
//
var rnd = new Random();
if (args == null || args.Length < 1)
{
args = new string[] { "World" + rnd.Next() };
}
string name = args[0];
using (var context = new ZContext())
using (var worker = new ZSocket(context, ZSocketType.REQ))
{
worker.Identity = Encoding.UTF8.GetBytes(name);
worker.Connect("tcp://127.0.0.1:5556");
Console.WriteLine("I: ({0}) worker ready", name);
using (var outgoing = new ZFrame("READY"))
{
worker.Send(outgoing);
}
int cycles = 0;
ZError error;
ZMessage incoming;
while (true)
{
if (null == (incoming = worker.ReceiveMessage(out error)))
{
if (error == ZError.ETERM)
return;
throw new ZException(error);
}
using (incoming)
{
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && rnd.Next(5) == 0)
{
Console.WriteLine("I: ({0}) simulating a crash", name);
return;
}
else if (cycles > 3 && rnd.Next(5) == 0)
{
Console.WriteLine("I: ({0}) simulating CPU overload", name);
Thread.Sleep(500);
}
Console.WriteLine("I: ({0}) normal reply", name);
Thread.Sleep(1); // Do some heavy work
// Send message back
worker.Send(incoming);
}
}
}
}
}
}
spworker: Simple Pirate worker in CL
spworker: Simple Pirate worker in Delphi
program spworker;
//
// Simple Pirate worker
// Connects REQ socket to tcp://*:5556
// Implements worker part of load-balancing
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
, zhelpers
;
const
WORKER_READY = '\001'; // Signals worker is ready
var
ctx: TZMQContext;
worker: TZMQSocket;
identity: String;
frame: TZMQFrame;
cycles: Integer;
msg: TZMQMsg;
begin
ctx := TZMQContext.create;
worker := ctx.Socket( stReq );
// Set random identity to make tracing easier
identity := s_random( 8 );
worker.Identity := identity;
worker.connect( 'tcp://localhost:5556' );
// Tell broker we're ready for work
Writeln( Format( 'I: (%s) worker ready', [identity] ) );
frame := TZMQFrame.create;
frame.asUtf8String := WORKER_READY;
worker.send( frame );
cycles := 0;
while not ctx.Terminated do
try
worker.recv( msg );
// Simulate various problems, after a few cycles
Inc( cycles );
if ((cycles > 3) and (random(5) = 0)) then
begin
Writeln( Format( 'I: (%s) simulating a crash', [identity] ) );
msg.Free;
msg := nil;
break;
end else
if ( (cycles > 3) and (random(5) = 0) ) then
begin
Writeln( Format( 'I: (%s) simulating CPU overload', [identity] ));
sleep (3000);
end;
Writeln( Format('I: (%s) normal reply', [identity]) );
sleep(1000); // Do some heavy work
worker.send( msg );
except
end;
ctx.Free;
end.
spworker: Simple Pirate worker in Erlang
spworker: Simple Pirate worker in Elixir
spworker: Simple Pirate worker in F#
spworker: Simple Pirate worker in Felix
spworker: Simple Pirate worker in Go
// Simple Pirate worker
// Connects REQ socket to tcp://*:5556
// Implements worker part of load-balancing
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"time"
)
const LRU_READY = "\001"
func main() {
context, _ := zmq.NewContext()
defer context.Close()
worker, _ := context.NewSocket(zmq.REQ)
defer worker.Close()
// Set random identity to make tracing easier
src := rand.NewSource(time.Now().UnixNano())
random := rand.New(src)
identity := fmt.Sprintf("%04X-%04X", random.Intn(0x10000), random.Intn(0x10000))
worker.SetIdentity(identity)
worker.Connect("tcp://localhost:5556")
// Tell broker we're ready for work
fmt.Printf("I: (%s) worker ready\n", identity)
worker.Send([]byte(LRU_READY), 0)
for cycles := 1; ; cycles++ {
msg, err := worker.RecvMultipart(0)
if err != nil {
panic(err) // Interrupted
}
if cycles > 3 {
switch r := random.Intn(5); r {
case 0:
fmt.Printf("I: (%s) simulating a crash\n", identity)
return
case 1:
fmt.Printf("I: (%s) simulating CPU overload\n", identity)
time.Sleep(3 * time.Second)
}
}
fmt.Printf("I: (%s) normal reply\n", identity)
time.Sleep(1 * time.Second) // Do some heavy work
worker.SendMultipart(msg, 0)
}
}
spworker: Simple Pirate worker in Haskell
{--
Simple Pirate worker in Haskell
--}
module Main where
import System.ZMQ4.Monadic
import ZHelpers
import System.Random (randomRIO)
import System.Exit (exitSuccess)
import Control.Monad (when)
import Control.Concurrent (threadDelay)
import Control.Applicative ((<$>))
import Data.ByteString.Char8 (pack, unpack, empty)
workerReady = "\001"
main :: IO ()
main =
runZMQ $ do
worker <- socket Req
setRandomIdentity worker
connect worker "tcp://localhost:5556"
id <- identity worker
liftIO $ putStrLn $ "I: Worker ready " ++ unpack id
send worker [SendMore] empty
send worker [SendMore] empty
send worker [] (pack workerReady)
sendRequests worker 1
sendRequests :: Socket z Req -> Int -> ZMQ z ()
sendRequests worker cycles = do
clID <- receive worker
msg <- (receive worker >> receive worker)
chance <- liftIO $ randomRIO (0::Int, 5)
id <- identity worker
if cycles > 3 && chance == 0
then do
liftIO $ putStrLn $ "I: Simulating a crash " ++ unpack id
liftIO $ exitSuccess
else do
chance' <- liftIO $ randomRIO (0::Int, 5)
when (cycles > 3 && chance' == 0) $ do
liftIO $ putStrLn $ "I: Simulating overload " ++ unpack id
liftIO $ threadDelay $ 3 * 1000 * 1000
liftIO $ putStrLn $ "I: Normal reply " ++ unpack id
liftIO $ threadDelay $ 1 * 1000 * 1000
send worker [SendMore] clID
send worker [SendMore] (pack "")
send worker [] msg
sendRequests worker (cycles+1)
spworker: Simple Pirate worker in Haxe
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
/**
* Simple Pirate worker
* Connects REQ socket to tcp://*:5556
* Implements worker part of LRU queuing
* @see http://zguide.zeromq.org/page:all#Basic-Reliable-Queuing-Simple-Pirate-Pattern
*/
class SPWorker
{
// Signals workers are ready
private static inline var LRU_READY:String = String.fromCharCode(1);
public static function main() {
Lib.println("** SPWorker (see: http://zguide.zeromq.org/page:all#Basic-Reliable-Queuing-Simple-Pirate-Pattern)");
var ctx = new ZContext();
var worker = ctx.createSocket(ZMQ_REQ);
// Set random identity to make tracing easier
var identity = ZHelpers.setID(worker);
worker.connect("tcp://localhost:5556");
// Tell broker we're ready for work
Lib.println("I: (" + identity + ") worker ready");
ZFrame.newStringFrame(LRU_READY).send(worker);
var cycles = 0;
while (true) {
var msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
cycles++;
// Simulate various problems, after a few cycles
if (cycles > 3 && ZHelpers.randof(5) == 0) {
Lib.println("I: simulating a crash");
break;
}
else if (cycles > 3 && ZHelpers.randof(5) == 0) {
Lib.println("I: simulating CPU overload");
Sys.sleep(3.0);
if (ZMQ.isInterrupted())
break;
}
Lib.println("I: ("+identity+") normal reply");
Sys.sleep(1.0); // Do some heavy work
msg.send(worker);
}
ctx.destroy();
}
}spworker: Simple Pirate worker in Java
package guide;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Socket;
//
// Simple Pirate worker
// Connects REQ socket to tcp://*:5556
// Implements worker part of load-balancing queueing
//
public class spworker
{
private final static String WORKER_READY = "\001"; // Signals worker is ready
public static void main(String[] args) throws Exception
{
try (ZContext ctx = new ZContext()) {
Socket worker = ctx.createSocket(SocketType.REQ);
// Set random identity to make tracing easier
Random rand = new Random(System.nanoTime());
String identity = String.format(
"%04X-%04X", rand.nextInt(0x10000), rand.nextInt(0x10000)
);
worker.setIdentity(identity.getBytes(ZMQ.CHARSET));
worker.connect("tcp://localhost:5556");
// Tell broker we're ready for work
System.out.printf("I: (%s) worker ready\n", identity);
ZFrame frame = new ZFrame(WORKER_READY);
frame.send(worker, 0);
int cycles = 0;
while (true) {
ZMsg msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && rand.nextInt(5) == 0) {
System.out.printf("I: (%s) simulating a crash\n", identity);
msg.destroy();
break;
}
else if (cycles > 3 && rand.nextInt(5) == 0) {
System.out.printf(
"I: (%s) simulating CPU overload\n", identity
);
Thread.sleep(3000);
}
System.out.printf("I: (%s) normal reply\n", identity);
Thread.sleep(1000); // Do some heavy work
msg.send(worker);
}
}
}
}
spworker: Simple Pirate worker in Julia
spworker: Simple Pirate worker in Lua
--
-- Simple Pirate worker
-- Connects REQ socket to tcp://*:5556
-- Implements worker part of LRU queueing
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmsg"
math.randomseed(os.time())
local context = zmq.init(1)
local worker = context:socket(zmq.REQ)
-- Set random identity to make tracing easier
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
worker:setopt(zmq.IDENTITY, identity)
worker:connect("tcp://localhost:5556")
-- Tell queue we're ready for work
printf ("I: (%s) worker ready\n", identity)
worker:send("READY")
local cycles = 0
while true do
local msg = zmsg.recv (worker)
-- Simulate various problems, after a few cycles
cycles = cycles + 1
if (cycles > 3 and randof (5) == 0) then
printf ("I: (%s) simulating a crash\n", identity)
break
elseif (cycles > 3 and randof (5) == 0) then
printf ("I: (%s) simulating CPU overload\n", identity)
s_sleep (5000)
end
printf ("I: (%s) normal reply - %s\n",
identity, msg:body())
s_sleep (1000) -- Do some heavy work
msg:send(worker)
end
worker:close()
context:term()
spworker: Simple Pirate worker in Node.js
spworker: Simple Pirate worker in Objective-C
spworker: Simple Pirate worker in ooc
spworker: Simple Pirate worker in Perl
spworker: Simple Pirate worker in PHP
<?php
/*
* Simple Pirate worker
* Connects REQ socket to tcp://*:5556
* Implements worker part of LRU queueing
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
$context = new ZMQContext();
$worker = new ZMQSocket($context, ZMQ::SOCKET_REQ);
// Set random identity to make tracing easier
$identity = sprintf ("%04X-%04X", rand(0, 0x10000), rand(0, 0x10000));
$worker->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $identity);
$worker->connect("tcp://localhost:5556");
// Tell queue we're ready for work
printf ("I: (%s) worker ready%s", $identity, PHP_EOL);
$worker->send("READY");
$cycles = 0;
while (true) {
$zmsg = new Zmsg($worker);
$zmsg->recv();
$cycles++;
// Simulate various problems, after a few cycles
if ($cycles > 3 && rand(0, 3) == 0) {
printf ("I: (%s) simulating a crash%s", $identity, PHP_EOL);
break;
} elseif ($cycles > 3 && rand(0, 3) == 0) {
printf ("I: (%s) simulating CPU overload%s", $identity, PHP_EOL);
sleep(5);
}
printf ("I: (%s) normal reply - %s%s", $identity, $zmsg->body(), PHP_EOL);
sleep(1); // Do some heavy work
$zmsg->send();
}
spworker: Simple Pirate worker in Python
#
# Simple Pirate worker
# Connects REQ socket to tcp://*:5556
# Implements worker part of LRU queueing
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
from random import randint
import time
import zmq
LRU_READY = "\x01"
context = zmq.Context(1)
worker = context.socket(zmq.REQ)
identity = "%04X-%04X" % (randint(0, 0x10000), randint(0,0x10000))
worker.setsockopt_string(zmq.IDENTITY, identity)
worker.connect("tcp://localhost:5556")
print("I: (%s) worker ready" % identity)
worker.send_string(LRU_READY)
cycles = 0
while True:
msg = worker.recv_multipart()
if not msg:
break
cycles += 1
if cycles>0 and randint(0, 5) == 0:
print("I: (%s) simulating a crash" % identity)
break
elif cycles>3 and randint(0, 5) == 0:
print("I: (%s) simulating CPU overload" % identity)
time.sleep(3)
print("I: (%s) normal reply" % identity)
time.sleep(1) # Do some heavy work
worker.send_multipart(msg)spworker: Simple Pirate worker in Q
spworker: Simple Pirate worker in Racket
spworker: Simple Pirate worker in Ruby
spworker: Simple Pirate worker in Rust
spworker: Simple Pirate worker in Scala
spworker: Simple Pirate worker in Tcl
spworker: Simple Pirate worker in OCaml
To test this, start a handful of workers, a Lazy Pirate client, and the queue, in any order. You’ll see that the workers eventually all crash and burn, and the client retries and then gives up. The queue never stops, and you can restart workers and clients ad nauseam. This model works with any number of clients and workers.
Robust Reliable Queuing (Paranoid Pirate Pattern) #
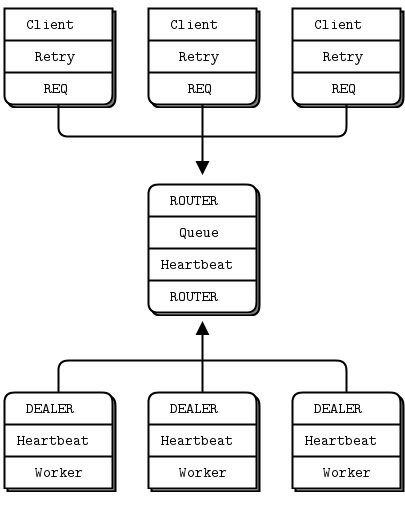
The Simple Pirate Queue pattern works pretty well, especially because it’s just a combination of two existing patterns. Still, it does have some weaknesses:
-
It’s not robust in the face of a queue crash and restart. The client will recover, but the workers won’t. While ZeroMQ will reconnect workers’ sockets automatically, as far as the newly started queue is concerned, the workers haven’t signaled ready, so don’t exist. To fix this, we have to do heartbeating from queue to worker so that the worker can detect when the queue has gone away.
-
The queue does not detect worker failure, so if a worker dies while idle, the queue can’t remove it from its worker queue until the queue sends it a request. The client waits and retries for nothing. It’s not a critical problem, but it’s not nice. To make this work properly, we do heartbeating from worker to queue, so that the queue can detect a lost worker at any stage.
We’ll fix these in a properly pedantic Paranoid Pirate Pattern.
We previously used a REQ socket for the worker. For the Paranoid Pirate worker, we’ll switch to a DEALER socket. This has the advantage of letting us send and receive messages at any time, rather than the lock-step send/receive that REQ imposes. The downside of DEALER is that we have to do our own envelope management (re-read Chapter 3 - Advanced Request-Reply Patterns for background on this concept).
We’re still using the Lazy Pirate client. Here is the Paranoid Pirate queue proxy:
ppqueue: Paranoid Pirate queue in Ada
ppqueue: Paranoid Pirate queue in Basic
ppqueue: Paranoid Pirate queue in C
// Paranoid Pirate queue
#include "czmq.h"
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 1000 // msecs
// Paranoid Pirate Protocol constants
#define PPP_READY "\001" // Signals worker is ready
#define PPP_HEARTBEAT "\002" // Signals worker heartbeat
// .split worker class structure
// Here we define the worker class; a structure and a set of functions that
// act as constructor, destructor, and methods on worker objects:
typedef struct {
zframe_t *identity; // Identity of worker
char *id_string; // Printable identity
int64_t expiry; // Expires at this time
} worker_t;
// Construct new worker
static worker_t *
s_worker_new (zframe_t *identity)
{
worker_t *self = (worker_t *) zmalloc (sizeof (worker_t));
self->identity = identity;
self->id_string = zframe_strhex (identity);
self->expiry = zclock_time ()
+ HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
return self;
}
// Destroy specified worker object, including identity frame.
static void
s_worker_destroy (worker_t **self_p)
{
assert (self_p);
if (*self_p) {
worker_t *self = *self_p;
zframe_destroy (&self->identity);
free (self->id_string);
free (self);
*self_p = NULL;
}
}
// .split worker ready method
// The ready method puts a worker to the end of the ready list:
static void
s_worker_ready (worker_t *self, zlist_t *workers)
{
worker_t *worker = (worker_t *) zlist_first (workers);
while (worker) {
if (streq (self->id_string, worker->id_string)) {
zlist_remove (workers, worker);
s_worker_destroy (&worker);
break;
}
worker = (worker_t *) zlist_next (workers);
}
zlist_append (workers, self);
}
// .split get next available worker
// The next method returns the next available worker identity:
static zframe_t *
s_workers_next (zlist_t *workers)
{
worker_t *worker = zlist_pop (workers);
assert (worker);
zframe_t *frame = worker->identity;
worker->identity = NULL;
s_worker_destroy (&worker);
return frame;
}
// .split purge expired workers
// The purge method looks for and kills expired workers. We hold workers
// from oldest to most recent, so we stop at the first alive worker:
static void
s_workers_purge (zlist_t *workers)
{
worker_t *worker = (worker_t *) zlist_first (workers);
while (worker) {
if (zclock_time () < worker->expiry)
break; // Worker is alive, we're done here
zlist_remove (workers, worker);
s_worker_destroy (&worker);
worker = (worker_t *) zlist_first (workers);
}
}
// .split main task
// The main task is a load-balancer with heartbeating on workers so we
// can detect crashed or blocked worker tasks:
int main (void)
{
zctx_t *ctx = zctx_new ();
void *frontend = zsocket_new (ctx, ZMQ_ROUTER);
void *backend = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (frontend, "tcp://*:5555"); // For clients
zsocket_bind (backend, "tcp://*:5556"); // For workers
// List of available workers
zlist_t *workers = zlist_new ();
// Send out heartbeats at regular intervals
uint64_t heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
while (true) {
zmq_pollitem_t items [] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
int rc = zmq_poll (items, zlist_size (workers)? 2: 1,
HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (items [0].revents & ZMQ_POLLIN) {
// Use worker identity for load-balancing
zmsg_t *msg = zmsg_recv (backend);
if (!msg)
break; // Interrupted
// Any sign of life from worker means it's ready
zframe_t *identity = zmsg_unwrap (msg);
worker_t *worker = s_worker_new (identity);
s_worker_ready (worker, workers);
// Validate control message, or return reply to client
if (zmsg_size (msg) == 1) {
zframe_t *frame = zmsg_first (msg);
if (memcmp (zframe_data (frame), PPP_READY, 1)
&& memcmp (zframe_data (frame), PPP_HEARTBEAT, 1)) {
printf ("E: invalid message from worker");
zmsg_dump (msg);
}
zmsg_destroy (&msg);
}
else
zmsg_send (&msg, frontend);
}
if (items [1].revents & ZMQ_POLLIN) {
// Now get next client request, route to next worker
zmsg_t *msg = zmsg_recv (frontend);
if (!msg)
break; // Interrupted
zframe_t *identity = s_workers_next (workers);
zmsg_prepend (msg, &identity);
zmsg_send (&msg, backend);
}
// .split handle heartbeating
// We handle heartbeating after any socket activity. First, we send
// heartbeats to any idle workers if it's time. Then, we purge any
// dead workers:
if (zclock_time () >= heartbeat_at) {
worker_t *worker = (worker_t *) zlist_first (workers);
while (worker) {
zframe_send (&worker->identity, backend,
ZFRAME_REUSE + ZFRAME_MORE);
zframe_t *frame = zframe_new (PPP_HEARTBEAT, 1);
zframe_send (&frame, backend, 0);
worker = (worker_t *) zlist_next (workers);
}
heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
}
s_workers_purge (workers);
}
// When we're done, clean up properly
while (zlist_size (workers)) {
worker_t *worker = (worker_t *) zlist_pop (workers);
s_worker_destroy (&worker);
}
zlist_destroy (&workers);
zctx_destroy (&ctx);
return 0;
}
ppqueue: Paranoid Pirate queue in C++
//
// Paranoid Pirate queue
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "zmsg.hpp"
#include <stdint.h>
#include <vector>
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 1000 // msecs
// This defines one active worker in our worker queue
typedef struct {
std::string identity; // Address of worker
int64_t expiry; // Expires at this time
} worker_t;
// Insert worker at end of queue, reset expiry
// Worker must not already be in queue
static void
s_worker_append (std::vector<worker_t> &queue, std::string &identity)
{
bool found = false;
for (std::vector<worker_t>::iterator it = queue.begin(); it < queue.end(); it++) {
if (it->identity.compare(identity) == 0) {
std::cout << "E: duplicate worker identity " << identity.c_str() << std::endl;
found = true;
break;
}
}
if (!found) {
worker_t worker;
worker.identity = identity;
worker.expiry = s_clock() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
queue.push_back(worker);
}
}
// Remove worker from queue, if present
static void
s_worker_delete (std::vector<worker_t> &queue, std::string &identity)
{
for (std::vector<worker_t>::iterator it = queue.begin(); it < queue.end(); it++) {
if (it->identity.compare(identity) == 0) {
it = queue.erase(it);
break;
}
}
}
// Reset worker expiry, worker must be present
static void
s_worker_refresh (std::vector<worker_t> &queue, std::string &identity)
{
bool found = false;
for (std::vector<worker_t>::iterator it = queue.begin(); it < queue.end(); it++) {
if (it->identity.compare(identity) == 0) {
it->expiry = s_clock ()
+ HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
found = true;
break;
}
}
if (!found) {
std::cout << "E: worker " << identity << " not ready" << std::endl;
}
}
// Pop next available worker off queue, return identity
static std::string
s_worker_dequeue (std::vector<worker_t> &queue)
{
assert (queue.size());
std::string identity = queue[0].identity;
queue.erase(queue.begin());
return identity;
}
// Look for & kill expired workers
static void
s_queue_purge (std::vector<worker_t> &queue)
{
int64_t clock = s_clock();
for (std::vector<worker_t>::iterator it = queue.begin(); it < queue.end(); it++) {
if (clock > it->expiry) {
it = queue.erase(it)-1;
}
}
}
int main (void)
{
s_version_assert (4, 0);
// Prepare our context and sockets
zmq::context_t context(1);
zmq::socket_t frontend(context, ZMQ_ROUTER);
zmq::socket_t backend (context, ZMQ_ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind ("tcp://*:5556"); // For workers
// Queue of available workers
std::vector<worker_t> queue;
// Send out heartbeats at regular intervals
int64_t heartbeat_at = s_clock () + HEARTBEAT_INTERVAL;
while (1) {
zmq::pollitem_t items [] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
if (queue.size()) {
zmq::poll (items, 2, HEARTBEAT_INTERVAL);
} else {
zmq::poll (items, 1, HEARTBEAT_INTERVAL);
}
// Handle worker activity on backend
if (items [0].revents & ZMQ_POLLIN) {
zmsg msg (backend);
std::string identity(msg.unwrap ());
// Return reply to client if it's not a control message
if (msg.parts () == 1) {
if (strcmp (msg.address (), "READY") == 0) {
s_worker_delete (queue, identity);
s_worker_append (queue, identity);
}
else {
if (strcmp (msg.address (), "HEARTBEAT") == 0) {
s_worker_refresh (queue, identity);
} else {
std::cout << "E: invalid message from " << identity << std::endl;
msg.dump ();
}
}
}
else {
msg.send (frontend);
s_worker_append (queue, identity);
}
}
if (items [1].revents & ZMQ_POLLIN) {
// Now get next client request, route to next worker
zmsg msg (frontend);
std::string identity = std::string(s_worker_dequeue (queue));
msg.push_front((char*)identity.c_str());
msg.send (backend);
}
// Send heartbeats to idle workers if it's time
if (s_clock () > heartbeat_at) {
for (std::vector<worker_t>::iterator it = queue.begin(); it < queue.end(); it++) {
zmsg msg ("HEARTBEAT");
msg.wrap (it->identity.c_str(), NULL);
msg.send (backend);
}
heartbeat_at = s_clock () + HEARTBEAT_INTERVAL;
}
s_queue_purge(queue);
}
// We never exit the main loop
// But pretend to do the right shutdown anyhow
queue.clear();
return 0;
}
ppqueue: Paranoid Pirate queue in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
using PP;
//
// Paranoid Pirate queue
//
// Author: metadings
//
// Here we define the worker class; a structure and a set of functions that
// act as constructor, destructor, and methods on worker objects:
namespace PP
{
public class Worker : IDisposable
{
public const int PPP_HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
public static readonly TimeSpan PPP_HEARTBEAT_INTERVAL = TimeSpan.FromMilliseconds(500);
public static readonly TimeSpan PPP_TICK = TimeSpan.FromMilliseconds(250);
public const string PPP_READY = "READY";
public const string PPP_HEARTBEAT = "HEARTBEAT";
public const int PPP_INTERVAL_INIT = 1000;
public const int PPP_INTERVAL_MAX = 32000;
public ZFrame Identity;
public DateTime Expiry;
public string IdentityString {
get {
Identity.Position = 0;
return Identity.ReadString();
}
set {
if (Identity != null)
{
Identity.Dispose();
}
Identity = new ZFrame(value);
}
}
// Construct new worker
public Worker(ZFrame identity)
{
Identity = identity;
this.Expiry = DateTime.UtcNow + TimeSpan.FromMilliseconds(
PPP_HEARTBEAT_INTERVAL.Milliseconds * PPP_HEARTBEAT_LIVENESS
);
}
// Destroy specified worker object, including identity frame.
public void Dispose()
{
GC.SuppressFinalize(this);
Dispose(true);
}
protected void Dispose(bool disposing)
{
if (disposing)
{
if (Identity != null)
{
Identity.Dispose();
Identity = null;
}
}
}
}
public static class Workers
{
public static void Ready(this IList<Worker> workers, Worker worker)
{
workers.Add(worker);
}
public static ZFrame Next(this IList<Worker> workers)
{
Worker worker = workers[0];
workers.RemoveAt(0);
ZFrame identity = worker.Identity;
worker.Identity = null;
worker.Dispose();
return identity;
}
public static void Purge(this IList<Worker> workers)
{
foreach (Worker worker in workers.ToList())
{
if (DateTime.UtcNow < worker.Expiry)
continue; // Worker is alive, we're done here
workers.Remove(worker);
}
}
}
}
static partial class Program
{
public static void PPQueue(string[] args)
{
using (var context = new ZContext())
using (var backend = new ZSocket(context, ZSocketType.ROUTER))
using (var frontend = new ZSocket(context, ZSocketType.ROUTER))
{
backend.Bind("tcp://*:5556");
frontend.Bind("tcp://*:5555");
// List of available workers
var workers = new List<Worker>();
// Send out heartbeats at regular intervals
DateTime heartbeat_at = DateTime.UtcNow + Worker.PPP_HEARTBEAT_INTERVAL;
// Create a Receiver ZPollItem (ZMQ_POLLIN)
var poll = ZPollItem.CreateReceiver();
ZError error;
ZMessage incoming;
while (true)
{
// Handle worker activity on backend
if (backend.PollIn(poll, out incoming, out error, Worker.PPP_TICK))
{
using (incoming)
{
// Any sign of life from worker means it's ready
ZFrame identity = incoming.Unwrap();
var worker = new Worker(identity);
workers.Ready(worker);
// Validate control message, or return reply to client
if (incoming.Count == 1)
{
string message = incoming[0].ReadString();
if (message == Worker.PPP_READY)
{
Console.WriteLine("I: worker ready ({0})", worker.IdentityString);
}
else if (message == Worker.PPP_HEARTBEAT)
{
Console.WriteLine("I: receiving heartbeat ({0})", worker.IdentityString);
}
else
{
Console_WriteZMessage("E: invalid message from worker", incoming);
}
}
else
{
if (Verbose) Console_WriteZMessage("I: [backend sending to frontend] ({0})", incoming, worker.IdentityString);
frontend.Send(incoming);
}
}
}
else
{
if (error == ZError.ETERM)
break; // Interrupted
if (error != ZError.EAGAIN)
throw new ZException(error);
}
// Handle client activity on frontend
if (workers.Count > 0)
{
// Poll frontend only if we have available workers
if (frontend.PollIn(poll, out incoming, out error, Worker.PPP_TICK))
{
// Now get next client request, route to next worker
using (incoming)
{
ZFrame workerIdentity = workers.Next();
incoming.Prepend(workerIdentity);
if (Verbose) Console_WriteZMessage("I: [frontend sending to backend] ({0})", incoming, workerIdentity.ReadString());
backend.Send(incoming);
}
}
else
{
if (error == ZError.ETERM)
break; // Interrupted
if (error != ZError.EAGAIN)
throw new ZException(error);
}
}
// We handle heartbeating after any socket activity. First, we send
// heartbeats to any idle workers if it's time. Then, we purge any
// dead workers:
if (DateTime.UtcNow > heartbeat_at)
{
heartbeat_at = DateTime.UtcNow + Worker.PPP_HEARTBEAT_INTERVAL;
foreach (Worker worker in workers)
{
using (var outgoing = new ZMessage())
{
outgoing.Add(ZFrame.CopyFrom(worker.Identity));
outgoing.Add(new ZFrame(Worker.PPP_HEARTBEAT));
Console.WriteLine("I: sending heartbeat ({0})", worker.IdentityString);
backend.Send(outgoing);
}
}
}
workers.Purge();
}
// When we're done, clean up properly
foreach (Worker worker in workers)
{
worker.Dispose();
}
}
}
}
}
ppqueue: Paranoid Pirate queue in CL
ppqueue: Paranoid Pirate queue in Delphi
ppqueue: Paranoid Pirate queue in Erlang
ppqueue: Paranoid Pirate queue in Elixir
ppqueue: Paranoid Pirate queue in F#
ppqueue: Paranoid Pirate queue in Felix
ppqueue: Paranoid Pirate queue in Go
// Paranoid Pirate queue
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
"container/list"
"fmt"
zmq "github.com/alecthomas/gozmq"
"time"
)
const (
HEARTBEAT_INTERVAL = time.Second // time.Duration
// Paranoid Pirate Protocol constants
PPP_READY = "\001" // Signals worker is ready
PPP_HEARTBEAT = "\002" // Signals worker heartbeat
)
type PPWorker struct {
address []byte // Address of worker
expiry time.Time // Expires at this time
}
func NewPPWorker(address []byte) *PPWorker {
return &PPWorker{
address: address,
expiry: time.Now().Add(HEARTBEAT_LIVENESS * HEARTBEAT_INTERVAL),
}
}
type WorkerQueue struct {
queue *list.List
}
func NewWorkerQueue() *WorkerQueue {
return &WorkerQueue{
queue: list.New(),
}
}
func (workers *WorkerQueue) Len() int {
return workers.queue.Len()
}
func (workers *WorkerQueue) Next() []byte {
elem := workers.queue.Back()
worker, _ := elem.Value.(*PPWorker)
workers.queue.Remove(elem)
return worker.address
}
func (workers *WorkerQueue) Ready(worker *PPWorker) {
for elem := workers.queue.Front(); elem != nil; elem = elem.Next() {
if w, _ := elem.Value.(*PPWorker); string(w.address) == string(worker.address) {
workers.queue.Remove(elem)
break
}
}
workers.queue.PushBack(worker)
}
func (workers *WorkerQueue) Purge() {
now := time.Now()
for elem := workers.queue.Front(); elem != nil; elem = workers.queue.Front() {
if w, _ := elem.Value.(*PPWorker); w.expiry.After(now) {
break
}
workers.queue.Remove(elem)
}
}
func main() {
context, _ := zmq.NewContext()
defer context.Close()
frontend, _ := context.NewSocket(zmq.ROUTER)
defer frontend.Close()
frontend.Bind("tcp://*:5555") // For clients
backend, _ := context.NewSocket(zmq.ROUTER)
defer backend.Close()
backend.Bind("tcp://*:5556") // For workers
workers := NewWorkerQueue()
heartbeatAt := time.Now().Add(HEARTBEAT_INTERVAL)
for {
items := zmq.PollItems{
zmq.PollItem{Socket: backend, Events: zmq.POLLIN},
zmq.PollItem{Socket: frontend, Events: zmq.POLLIN},
}
// Poll frontend only if we have available workers
if workers.Len() > 0 {
zmq.Poll(items, HEARTBEAT_INTERVAL)
} else {
zmq.Poll(items[:1], HEARTBEAT_INTERVAL)
}
// Handle worker activity on backend
if items[0].REvents&zmq.POLLIN != 0 {
frames, err := backend.RecvMultipart(0)
if err != nil {
panic(err) // Interrupted
}
address := frames[0]
workers.Ready(NewPPWorker(address))
// Validate control message, or return reply to client
if msg := frames[1:]; len(msg) == 1 {
switch status := string(msg[0]); status {
case PPP_READY:
fmt.Println("I: PPWorker ready")
case PPP_HEARTBEAT:
fmt.Println("I: PPWorker heartbeat")
default:
fmt.Println("E: Invalid message from worker: ", msg)
}
} else {
frontend.SendMultipart(msg, 0)
}
}
if items[1].REvents&zmq.POLLIN != 0 {
// Now get next client request, route to next worker
frames, err := frontend.RecvMultipart(0)
if err != nil {
panic(err)
}
frames = append([][]byte{workers.Next()}, frames...)
backend.SendMultipart(frames, 0)
}
// .split handle heartbeating
// We handle heartbeating after any socket activity. First we send
// heartbeats to any idle workers if it's time. Then we purge any
// dead workers:
if heartbeatAt.Before(time.Now()) {
for elem := workers.queue.Front(); elem != nil; elem = elem.Next() {
w, _ := elem.Value.(*PPWorker)
msg := [][]byte{w.address, []byte(PPP_HEARTBEAT)}
backend.SendMultipart(msg, 0)
}
heartbeatAt = time.Now().Add(HEARTBEAT_INTERVAL)
}
workers.Purge()
}
}
ppqueue: Paranoid Pirate queue in Haskell
{-
Paranoid Pirate Pattern queue in Haskell.
Uses heartbeating to detect crashed or blocked workers.
-}
module Main where
import System.ZMQ4.Monadic
import ZHelpers
import Control.Monad (when, forM_)
import Control.Applicative ((<$>))
import System.IO (hSetEncoding, stdout, utf8)
import Data.ByteString.Char8 (pack, unpack, empty)
import qualified Data.List.NonEmpty as N
type SockID = String
data Worker = Worker {
sockID :: SockID
, expiry :: Integer
} deriving (Show)
heartbeatLiveness = 3
heartbeatInterval_ms = 1000
pppReady = "\001"
pppHeartbeat = "\002"
main :: IO ()
main =
runZMQ $ do
frontend <- socket Router
bind frontend "tcp://*:5555"
backend <- socket Router
bind backend "tcp://*:5556"
liftIO $ hSetEncoding stdout utf8
heartbeat_at <- liftIO $ nextHeartbeatTime_ms heartbeatInterval_ms
pollPeers frontend backend [] heartbeat_at
createWorker :: SockID -> IO Worker
createWorker id = do
currTime <- currentTime_ms
let expiry = currTime + heartbeatInterval_ms * heartbeatLiveness
return (Worker id expiry)
pollPeers :: Socket z Router -> Socket z Router -> [Worker] -> Integer -> ZMQ z ()
pollPeers frontend backend workers heartbeat_at = do
let toPoll = getPollList workers
evts <- poll (fromInteger heartbeatInterval_ms) toPoll
workers' <- getBackend backend frontend evts workers
workers'' <- getFrontend frontend backend evts workers'
newHeartbeatAt <- heartbeat backend workers'' heartbeat_at
workersPurged <- purge workers''
pollPeers frontend backend workersPurged newHeartbeatAt
where getPollList [] = [Sock backend [In] Nothing]
getPollList _ = [Sock backend [In] Nothing, Sock frontend [In] Nothing]
getBackend :: Socket z Router -> Socket z Router ->
[[Event]] -> [Worker] -> ZMQ z ([Worker])
getBackend backend frontend evts workers =
if (In `elem` (evts !! 0))
then do
frame <- receiveMulti backend
let wkrID = frame !! 0
msg = frame !! 1
if ((length frame) == 2) -- PPP message
then when (unpack msg `notElem` [pppReady, pppHeartbeat]) $ do
liftIO $ putStrLn $ "E: Invalid message from worker " ++ (unpack msg)
else do -- Route the message to the client
liftIO $ putStrLn "I: Sending normal message to client"
let id = frame !! 1
msg = frame !! 3
send frontend [SendMore] id
send frontend [SendMore] empty
send frontend [] msg
newWorker <- liftIO $ createWorker $ unpack wkrID
return $ workers ++ [newWorker]
else return workers
getFrontend :: Socket z Router -> Socket z Router ->
[[Event]] -> [Worker] -> ZMQ z ([Worker])
getFrontend frontend backend evts workers =
if (length evts > 1 && In `elem` (evts !! 1))
then do -- Route message to workers
frame <- receiveMulti frontend
let wkrID = sockID . head $ workers
send backend [SendMore] (pack wkrID)
send backend [SendMore] empty
sendMulti backend (N.fromList frame)
return $ tail workers
else return workers
heartbeat :: Socket z Router -> [Worker] -> Integer -> ZMQ z Integer
heartbeat backend workers heartbeat_at = do
currTime <- liftIO currentTime_ms
if (currTime >= heartbeat_at)
then do
forM_ workers (\worker -> do
send backend [SendMore] (pack $ sockID worker)
send backend [SendMore] empty
send backend [] (pack pppHeartbeat)
liftIO $ putStrLn $ "I: sending heartbeat to '" ++ (sockID worker) ++ "'")
liftIO $ nextHeartbeatTime_ms heartbeatInterval_ms
else return heartbeat_at
purge :: [Worker] -> ZMQ z ([Worker])
purge workers = do
currTime <- liftIO currentTime_ms
return $ filter (\wkr -> expiry wkr > currTime) workers
ppqueue: Paranoid Pirate queue in Haxe
package ;
import haxe.Stack;
import neko.Lib;
import org.zeromq.ZFrame;
import org.zeromq.ZContext;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQ;
import org.zeromq.ZMsg;
import org.zeromq.ZMQException;
/**
* Paranoid Pirate Queue
*
* @see http://zguide.zeromq.org/page:all#Robust-Reliable-Queuing-Paranoid-Pirate-Pattern
*
* Author: rsmith (at) rsbatechnology (dot) co (dot) uk
*/
class PPQueue
{
private static inline var HEARTBEAT_LIVENESS = 3;
private static inline var HEARTBEAT_INTERVAL = 1000; // msecs
private static inline var PPP_READY = String.fromCharCode(1);
private static inline var PPP_HEARTBEAT = String.fromCharCode(2);
public static function main() {
Lib.println("** PPQueue (see: http://zguide.zeromq.org/page:all#Robust-Reliable-Queuing-Paranoid-Pirate-Pattern)");
// Prepare our context and sockets
var context:ZContext = new ZContext();
var frontend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
var backend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind("tcp://*:5556"); // For workerQueue
// Queue of available workerQueue
var workerQueue = new WorkerQueue(HEARTBEAT_LIVENESS, HEARTBEAT_INTERVAL);
// Send out heartbeats at regular intervals
var heartbeatAt = Date.now().getTime() + HEARTBEAT_INTERVAL;
var poller = new ZMQPoller();
while (true) {
poller.unregisterAllSockets();
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
// Only poll frontend clients if we have at least one worker to do stuff
if (workerQueue.size() > 0) {
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
}
try {
poller.poll(HEARTBEAT_INTERVAL * 1000);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
// Handle worker activity
if (poller.pollin(1)) {
// use worker addressFrame for LRU routing
var msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
// Any sign of life from worker means it's ready
var addressFrame = msg.unwrap();
var identity = addressFrame.toString();
// Validate control message, or return reply to client
if (msg.size() == 1) {
var frame = msg.first();
if (frame.streq(PPP_READY)) {
workerQueue.delete(identity);
workerQueue.append(addressFrame,identity);
} else if (frame.streq(PPP_HEARTBEAT)) {
workerQueue.refresh(identity);
} else {
Lib.println("E: invalid message from worker");
Lib.println(msg.toString());
}
msg.destroy();
} else {
msg.send(frontend);
workerQueue.append(addressFrame, identity);
}
}
if (poller.pollin(2)) {
// Now get next client request, route to next worker
var msg = ZMsg.recvMsg(frontend);
if (msg == null)
break; // Interrupted
var worker = workerQueue.dequeue();
msg.push(worker.addressFrame.duplicate());
msg.send(backend);
}
// Send heartbeats to idle workerQueue if it's time
if (Date.now().getTime() >= heartbeatAt) {
for ( w in workerQueue) {
var msg = new ZMsg();
msg.add(w.addressFrame.duplicate()); // Add a duplicate of the stored worker addressFrame frame,
// to prevent w.addressFrame ZFrame object from being destroyed when msg is sent
msg.addString(PPP_HEARTBEAT);
msg.send(backend);
}
heartbeatAt = Date.now().getTime() + HEARTBEAT_INTERVAL;
}
workerQueue.purge();
}
// When we're done, clean up properly
context.destroy();
}
}
typedef WorkerT = {
addressFrame:ZFrame,
identity:String,
expiry:Float // in msecs since 1 Jan 1970
};
/**
* Internal class managing a queue of workerQueue
*/
private class WorkerQueue {
// Stores hash of worker heartbeat expiries, keyed by worker identity
private var queue:List<WorkerT>;
private var heartbeatLiveness:Int;
private var heartbeatInterval:Int;
/**
* Constructor
* @param liveness
* @param interval
*/
public function new(liveness:Int, interval:Int) {
queue = new List<WorkerT>();
heartbeatLiveness = liveness;
heartbeatInterval = interval;
}
// Implement Iterable typedef signature
public function iterator():Iterator<WorkerT> {
return queue.iterator();
}
/**
* Insert worker at end of queue, reset expiry
* Worker must not already be in queue
* @param identity
*/
public function append(addressFrame:ZFrame,identity:String) {
if (get(identity) != null)
Lib.println("E: duplicate worker identity " + identity);
else
queue.add({addressFrame:addressFrame, identity:identity, expiry:generateExpiry()});
}
/**
* Remove worker from queue, if present
* @param identity
*/
public function delete(identity:String) {
var w = get(identity);
if (w != null) {
queue.remove(w);
}
}
public function refresh(identity:String) {
var w = get(identity);
if (w == null)
Lib.println("E: worker " + identity + " not ready");
else
w.expiry = generateExpiry();
}
/**
* Pop next worker off queue, return WorkerT
* @param identity
*/
public function dequeue():WorkerT {
return queue.pop();
}
/**
* Look for & kill expired workerQueue
*/
public function purge() {
for (w in queue) {
if (Date.now().getTime() > w.expiry) {
queue.remove(w);
}
}
}
/**
* Return the size of this worker Queue
* @return
*/
public function size():Int {
return queue.length;
}
/**
* Returns a WorkerT anon object if exists in the queue, else null
* @param identity
* @return
*/
private function get(identity:String):WorkerT {
for (w in queue) {
if (w.identity == identity)
return w;
}
return null; // nothing found
}
private inline function generateExpiry():Float {
return Date.now().getTime() + heartbeatInterval * heartbeatLiveness;
}
}
ppqueue: Paranoid Pirate queue in Java
package guide;
import java.util.ArrayList;
import java.util.Iterator;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
//
// Paranoid Pirate queue
//
public class ppqueue
{
private final static int HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
private final static int HEARTBEAT_INTERVAL = 1000; // msecs
// Paranoid Pirate Protocol constants
private final static String PPP_READY = "\001"; // Signals worker is ready
private final static String PPP_HEARTBEAT = "\002"; // Signals worker heartbeat
// Here we define the worker class; a structure and a set of functions that
// as constructor, destructor, and methods on worker objects:
private static class Worker
{
ZFrame address; // Address of worker
String identity; // Printable identity
long expiry; // Expires at this time
protected Worker(ZFrame address)
{
this.address = address;
identity = new String(address.getData(), ZMQ.CHARSET);
expiry = System.currentTimeMillis() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
}
// The ready method puts a worker to the end of the ready list:
protected void ready(ArrayList<Worker> workers)
{
Iterator<Worker> it = workers.iterator();
while (it.hasNext()) {
Worker worker = it.next();
if (identity.equals(worker.identity)) {
it.remove();
break;
}
}
workers.add(this);
}
// The next method returns the next available worker address:
protected static ZFrame next(ArrayList<Worker> workers)
{
Worker worker = workers.remove(0);
assert (worker != null);
ZFrame frame = worker.address;
return frame;
}
// The purge method looks for and kills expired workers. We hold workers
// from oldest to most recent, so we stop at the first alive worker:
protected static void purge(ArrayList<Worker> workers)
{
Iterator<Worker> it = workers.iterator();
while (it.hasNext()) {
Worker worker = it.next();
if (System.currentTimeMillis() < worker.expiry) {
break;
}
it.remove();
}
}
};
// The main task is an LRU queue with heartbeating on workers so we can
// detect crashed or blocked worker tasks:
public static void main(String[] args)
{
try (ZContext ctx = new ZContext()) {
Socket frontend = ctx.createSocket(SocketType.ROUTER);
Socket backend = ctx.createSocket(SocketType.ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind("tcp://*:5556"); // For workers
// List of available workers
ArrayList<Worker> workers = new ArrayList<Worker>();
// Send out heartbeats at regular intervals
long heartbeat_at = System.currentTimeMillis() + HEARTBEAT_INTERVAL;
Poller poller = ctx.createPoller(2);
poller.register(backend, Poller.POLLIN);
poller.register(frontend, Poller.POLLIN);
while (true) {
boolean workersAvailable = workers.size() > 0;
int rc = poller.poll(HEARTBEAT_INTERVAL);
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (poller.pollin(0)) {
// Use worker address for LRU routing
ZMsg msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
// Any sign of life from worker means it's ready
ZFrame address = msg.unwrap();
Worker worker = new Worker(address);
worker.ready(workers);
// Validate control message, or return reply to client
if (msg.size() == 1) {
ZFrame frame = msg.getFirst();
String data = new String(frame.getData(), ZMQ.CHARSET);
if (!data.equals(PPP_READY) &&
!data.equals(PPP_HEARTBEAT)) {
System.out.println(
"E: invalid message from worker"
);
msg.dump(System.out);
}
msg.destroy();
}
else msg.send(frontend);
}
if (workersAvailable && poller.pollin(1)) {
// Now get next client request, route to next worker
ZMsg msg = ZMsg.recvMsg(frontend);
if (msg == null)
break; // Interrupted
msg.push(Worker.next(workers));
msg.send(backend);
}
// We handle heartbeating after any socket activity. First we
// send heartbeats to any idle workers if it's time. Then we
// purge any dead workers:
if (System.currentTimeMillis() >= heartbeat_at) {
for (Worker worker : workers) {
worker.address.send(
backend, ZFrame.REUSE + ZFrame.MORE
);
ZFrame frame = new ZFrame(PPP_HEARTBEAT);
frame.send(backend, 0);
}
long now = System.currentTimeMillis();
heartbeat_at = now + HEARTBEAT_INTERVAL;
}
Worker.purge(workers);
}
// When we're done, clean up properly
workers.clear();
}
}
}
ppqueue: Paranoid Pirate queue in Julia
ppqueue: Paranoid Pirate queue in Lua
--
-- Paranoid Pirate queue
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmsg"
local MAX_WORKERS = 100
local HEARTBEAT_LIVENESS = 3 -- 3-5 is reasonable
local HEARTBEAT_INTERVAL = 1000 -- msecs
local tremove = table.remove
-- Insert worker at end of queue, reset expiry
-- Worker must not already be in queue
local function s_worker_append(queue, identity)
if queue[identity] then
printf ("E: duplicate worker identity %s", identity)
else
assert (#queue < MAX_WORKERS)
queue[identity] = s_clock() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
queue[#queue + 1] = identity
end
end
-- Remove worker from queue, if present
local function s_worker_delete(queue, identity)
for i=1,#queue do
if queue[i] == identity then
tremove(queue, i)
break
end
end
queue[identity] = nil
end
-- Reset worker expiry, worker must be present
local function s_worker_refresh(queue, identity)
if queue[identity] then
queue[identity] = s_clock() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
else
printf("E: worker %s not ready\n", identity)
end
end
-- Pop next available worker off queue, return identity
local function s_worker_dequeue(queue)
assert (#queue > 0)
local identity = tremove(queue, 1)
queue[identity] = nil
return identity
end
-- Look for & kill expired workers
local function s_queue_purge(queue)
local curr_clock = s_clock()
-- Work backwards from end to simplify removal
for i=#queue,1,-1 do
local id = queue[i]
if (curr_clock > queue[id]) then
tremove(queue, i)
queue[id] = nil
end
end
end
s_version_assert (2, 1)
-- Prepare our context and sockets
local context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.ROUTER)
frontend:bind("tcp://*:5555"); -- For clients
backend:bind("tcp://*:5556"); -- For workers
-- Queue of available workers
local queue = {}
local is_accepting = false
-- Send out heartbeats at regular intervals
local heartbeat_at = s_clock() + HEARTBEAT_INTERVAL
local poller = zmq.poller(2)
local function frontend_cb()
-- Now get next client request, route to next worker
local msg = zmsg.recv(frontend)
local identity = s_worker_dequeue (queue)
msg:push(identity)
msg:send(backend)
if (#queue == 0) then
-- stop accepting work from clients, when no workers are available.
poller:remove(frontend)
is_accepting = false
end
end
-- Handle worker activity on backend
poller:add(backend, zmq.POLLIN, function()
local msg = zmsg.recv(backend)
local identity = msg:unwrap()
-- Return reply to client if it's not a control message
if (msg:parts() == 1) then
if (msg:address() == "READY") then
s_worker_delete(queue, identity)
s_worker_append(queue, identity)
elseif (msg:address() == "HEARTBEAT") then
s_worker_refresh(queue, identity)
else
printf("E: invalid message from %s\n", identity)
msg:dump()
end
else
-- reply for client.
msg:send(frontend)
s_worker_append(queue, identity)
end
-- start accepting client requests, if we are not already doing so.
if not is_accepting and #queue > 0 then
is_accepting = true
poller:add(frontend, zmq.POLLIN, frontend_cb)
end
end)
-- start poller's event loop
while true do
local cnt = assert(poller:poll(HEARTBEAT_INTERVAL * 1000))
-- Send heartbeats to idle workers if it's time
if (s_clock() > heartbeat_at) then
for i=1,#queue do
local msg = zmsg.new("HEARTBEAT")
msg:wrap(queue[i], nil)
msg:send(backend)
end
heartbeat_at = s_clock() + HEARTBEAT_INTERVAL
end
s_queue_purge(queue)
end
-- We never exit the main loop
-- But pretend to do the right shutdown anyhow
while (#queue > 0) do
s_worker_dequeue(queue)
end
frontend:close()
backend:close()
ppqueue: Paranoid Pirate queue in Node.js
ppqueue: Paranoid Pirate queue in Objective-C
ppqueue: Paranoid Pirate queue in ooc
ppqueue: Paranoid Pirate queue in Perl
ppqueue: Paranoid Pirate queue in PHP
<?php
/*
* Paranoid Pirate queue
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("MAX_WORKERS", 100);
define("HEARTBEAT_LIVENESS", 3); // 3-5 is reasonable
define("HEARTBEAT_INTERVAL", 1); // secs
class Queue_T implements Iterator
{
private $queue = array();
/* Iterator functions */
public function rewind() { return reset($this->queue); }
public function valid() { return current($this->queue); }
public function key() { return key($this->queue); }
public function next() { return next($this->queue); }
public function current() { return current($this->queue); }
/*
* Insert worker at end of queue, reset expiry
* Worker must not already be in queue
*/
public function s_worker_append($identity)
{
if (isset($this->queue[$identity])) {
printf ("E: duplicate worker identity %s", $identity);
} else {
$this->queue[$identity] = microtime(true) + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
}
}
/*
* Remove worker from queue, if present
*/
public function s_worker_delete($identity)
{
unset($this->queue[$identity]);
}
/*
* Reset worker expiry, worker must be present
*/
public function s_worker_refresh($identity)
{
if (!isset($this->queue[$identity])) {
printf ("E: worker %s not ready\n", $identity);
} else {
$this->queue[$identity] = microtime(true) + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
}
}
/*
* Pop next available worker off queue, return identity
*/
public function s_worker_dequeue()
{
reset($this->queue);
$identity = key($this->queue);
unset($this->queue[$identity]);
return $identity;
}
/*
* Look for & kill expired workers
*/
public function s_queue_purge()
{
foreach ($this->queue as $id => $expiry) {
if (microtime(true) > $expiry) {
unset($this->queue[$id]);
}
}
}
/*
* Return the size of the queue
*/
public function size()
{
return count($this->queue);
}
}
// Prepare our context and sockets
$context = new ZMQContext();
$frontend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$backend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$frontend->bind("tcp://*:5555"); // For clients
$backend->bind("tcp://*:5556"); // For workers
$read = $write = array();
// Queue of available workers
$queue = new Queue_T();
// Send out heartbeats at regular intervals
$heartbeat_at = microtime(true) + HEARTBEAT_INTERVAL;
while (true) {
$poll = new ZMQPoll();
$poll->add($backend, ZMQ::POLL_IN);
// Poll frontend only if we have available workers
if ($queue->size()) {
$poll->add($frontend, ZMQ::POLL_IN);
}
$events = $poll->poll($read, $write, HEARTBEAT_INTERVAL * 1000 ); // milliseconds
if ($events > 0) {
foreach ($read as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
// Handle worker activity on backend
if ($socket === $backend) {
$identity = $zmsg->unwrap();
// Return reply to client if it's not a control message
if ($zmsg->parts() == 1) {
if ($zmsg->address() == "READY") {
$queue->s_worker_delete($identity);
$queue->s_worker_append($identity);
} elseif ($zmsg->address() == 'HEARTBEAT') {
$queue->s_worker_refresh($identity);
} else {
printf ("E: invalid message from %s%s%s", $identity, PHP_EOL, $zmsg->__toString());
}
} else {
$zmsg->set_socket($frontend)->send();
$queue->s_worker_append($identity);
}
} else {
// Now get next client request, route to next worker
$identity = $queue->s_worker_dequeue();
$zmsg->wrap($identity);
$zmsg->set_socket($backend)->send();
}
}
if (microtime(true) > $heartbeat_at) {
foreach ($queue as $id => $expiry) {
$zmsg = new Zmsg($backend);
$zmsg->body_set("HEARTBEAT");
$zmsg->wrap($identity, NULL);
$zmsg->send();
}
$heartbeat_at = microtime(true) + HEARTBEAT_INTERVAL;
}
$queue->s_queue_purge();
}
}
ppqueue: Paranoid Pirate queue in Python
#
## Paranoid Pirate queue
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
from collections import OrderedDict
import time
import zmq
HEARTBEAT_LIVENESS = 3 # 3..5 is reasonable
HEARTBEAT_INTERVAL = 1.0 # Seconds
# Paranoid Pirate Protocol constants
PPP_READY = b"\x01" # Signals worker is ready
PPP_HEARTBEAT = b"\x02" # Signals worker heartbeat
class Worker(object):
def __init__(self, address):
self.address = address
self.expiry = time.time() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
class WorkerQueue(object):
def __init__(self):
self.queue = OrderedDict()
def ready(self, worker):
self.queue.pop(worker.address, None)
self.queue[worker.address] = worker
def purge(self):
"""Look for & kill expired workers."""
t = time.time()
expired = []
for address, worker in self.queue.items():
if t > worker.expiry: # Worker expired
expired.append(address)
for address in expired:
print("W: Idle worker expired: %s" % address)
self.queue.pop(address, None)
def next(self):
address, worker = self.queue.popitem(False)
return address
context = zmq.Context(1)
frontend = context.socket(zmq.ROUTER) # ROUTER
backend = context.socket(zmq.ROUTER) # ROUTER
frontend.bind("tcp://*:5555") # For clients
backend.bind("tcp://*:5556") # For workers
poll_workers = zmq.Poller()
poll_workers.register(backend, zmq.POLLIN)
poll_both = zmq.Poller()
poll_both.register(frontend, zmq.POLLIN)
poll_both.register(backend, zmq.POLLIN)
workers = WorkerQueue()
heartbeat_at = time.time() + HEARTBEAT_INTERVAL
while True:
if len(workers.queue) > 0:
poller = poll_both
else:
poller = poll_workers
socks = dict(poller.poll(HEARTBEAT_INTERVAL * 1000))
# Handle worker activity on backend
if socks.get(backend) == zmq.POLLIN:
# Use worker address for LRU routing
frames = backend.recv_multipart()
if not frames:
break
address = frames[0]
workers.ready(Worker(address))
# Validate control message, or return reply to client
msg = frames[1:]
if len(msg) == 1:
if msg[0] not in (PPP_READY, PPP_HEARTBEAT):
print("E: Invalid message from worker: %s" % msg)
else:
frontend.send_multipart(msg)
# Send heartbeats to idle workers if it's time
if time.time() >= heartbeat_at:
for worker in workers.queue:
msg = [worker, PPP_HEARTBEAT]
backend.send_multipart(msg)
heartbeat_at = time.time() + HEARTBEAT_INTERVAL
if socks.get(frontend) == zmq.POLLIN:
frames = frontend.recv_multipart()
if not frames:
break
frames.insert(0, workers.next())
backend.send_multipart(frames)
workers.purge()
ppqueue: Paranoid Pirate queue in Q
ppqueue: Paranoid Pirate queue in Racket
ppqueue: Paranoid Pirate queue in Ruby
ppqueue: Paranoid Pirate queue in Rust
ppqueue: Paranoid Pirate queue in Scala
ppqueue: Paranoid Pirate queue in Tcl
ppqueue: Paranoid Pirate queue in OCaml
The queue extends the load balancing pattern with heartbeating of workers. Heartbeating is one of those “simple” things that can be difficult to get right. I’ll explain more about that in a second.
Here is the Paranoid Pirate worker:
ppworker: Paranoid Pirate worker in Ada
ppworker: Paranoid Pirate worker in Basic
ppworker: Paranoid Pirate worker in C
// Paranoid Pirate worker
#include "czmq.h"
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 1000 // msecs
#define INTERVAL_INIT 1000 // Initial reconnect
#define INTERVAL_MAX 32000 // After exponential backoff
// Paranoid Pirate Protocol constants
#define PPP_READY "\001" // Signals worker is ready
#define PPP_HEARTBEAT "\002" // Signals worker heartbeat
// Helper function that returns a new configured socket
// connected to the Paranoid Pirate queue
static void *
s_worker_socket (zctx_t *ctx) {
void *worker = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (worker, "tcp://localhost:5556");
// Tell queue we're ready for work
printf ("I: worker ready\n");
zframe_t *frame = zframe_new (PPP_READY, 1);
zframe_send (&frame, worker, 0);
return worker;
}
// .split main task
// We have a single task that implements the worker side of the
// Paranoid Pirate Protocol (PPP). The interesting parts here are
// the heartbeating, which lets the worker detect if the queue has
// died, and vice versa:
int main (void)
{
zctx_t *ctx = zctx_new ();
void *worker = s_worker_socket (ctx);
// If liveness hits zero, queue is considered disconnected
size_t liveness = HEARTBEAT_LIVENESS;
size_t interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
uint64_t heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
srandom ((unsigned) time (NULL));
int cycles = 0;
while (true) {
zmq_pollitem_t items [] = { { worker, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
if (items [0].revents & ZMQ_POLLIN) {
// Get message
// - 3-part envelope + content -> request
// - 1-part HEARTBEAT -> heartbeat
zmsg_t *msg = zmsg_recv (worker);
if (!msg)
break; // Interrupted
// .split simulating problems
// To test the robustness of the queue implementation we
// simulate various typical problems, such as the worker
// crashing or running very slowly. We do this after a few
// cycles so that the architecture can get up and running
// first:
if (zmsg_size (msg) == 3) {
cycles++;
if (cycles > 3 && randof (5) == 0) {
printf ("I: simulating a crash\n");
zmsg_destroy (&msg);
break;
}
else
if (cycles > 3 && randof (5) == 0) {
printf ("I: simulating CPU overload\n");
sleep (3);
if (zctx_interrupted)
break;
}
printf ("I: normal reply\n");
zmsg_send (&msg, worker);
liveness = HEARTBEAT_LIVENESS;
sleep (1); // Do some heavy work
if (zctx_interrupted)
break;
}
else
// .split handle heartbeats
// When we get a heartbeat message from the queue, it means the
// queue was (recently) alive, so we must reset our liveness
// indicator:
if (zmsg_size (msg) == 1) {
zframe_t *frame = zmsg_first (msg);
if (memcmp (zframe_data (frame), PPP_HEARTBEAT, 1) == 0)
liveness = HEARTBEAT_LIVENESS;
else {
printf ("E: invalid message\n");
zmsg_dump (msg);
}
zmsg_destroy (&msg);
}
else {
printf ("E: invalid message\n");
zmsg_dump (msg);
}
interval = INTERVAL_INIT;
}
else
// .split detecting a dead queue
// If the queue hasn't sent us heartbeats in a while, destroy the
// socket and reconnect. This is the simplest most brutal way of
// discarding any messages we might have sent in the meantime:
if (--liveness == 0) {
printf ("W: heartbeat failure, can't reach queue\n");
printf ("W: reconnecting in %zd msec...\n", interval);
zclock_sleep (interval);
if (interval < INTERVAL_MAX)
interval *= 2;
zsocket_destroy (ctx, worker);
worker = s_worker_socket (ctx);
liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (zclock_time () > heartbeat_at) {
heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
printf ("I: worker heartbeat\n");
zframe_t *frame = zframe_new (PPP_HEARTBEAT, 1);
zframe_send (&frame, worker, 0);
}
}
zctx_destroy (&ctx);
return 0;
}
ppworker: Paranoid Pirate worker in C++
//
// Paranoid Pirate worker
//
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "zmsg.hpp"
#include <iomanip>
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 1000 // msecs
#define INTERVAL_INIT 1000 // Initial reconnect
#define INTERVAL_MAX 32000 // After exponential backoff
// Helper function that returns a new configured socket
// connected to the Hello World server
//
std::string identity;
static zmq::socket_t *
s_worker_socket (zmq::context_t &context) {
zmq::socket_t * worker = new zmq::socket_t(context, ZMQ_DEALER);
// Set random identity to make tracing easier
identity = s_set_id(*worker);
worker->connect ("tcp://localhost:5556");
// Configure socket to not wait at close time
int linger = 0;
worker->setsockopt (ZMQ_LINGER, &linger, sizeof (linger));
// Tell queue we're ready for work
std::cout << "I: (" << identity << ") worker ready" << std::endl;
s_send (*worker, std::string("READY"));
return worker;
}
int main (void)
{
s_version_assert (4, 0);
srandom ((unsigned) time (NULL));
zmq::context_t context (1);
zmq::socket_t * worker = s_worker_socket (context);
// If liveness hits zero, queue is considered disconnected
size_t liveness = HEARTBEAT_LIVENESS;
size_t interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
int64_t heartbeat_at = s_clock () + HEARTBEAT_INTERVAL;
int cycles = 0;
while (1) {
zmq::pollitem_t items[] = {
{static_cast<void*>(*worker), 0, ZMQ_POLLIN, 0 } };
zmq::poll (items, 1, HEARTBEAT_INTERVAL);
if (items [0].revents & ZMQ_POLLIN) {
// Get message
// - 3-part envelope + content -> request
// - 1-part "HEARTBEAT" -> heartbeat
zmsg msg (*worker);
if (msg.parts () == 3) {
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && within (5) == 0) {
std::cout << "I: (" << identity << ") simulating a crash" << std::endl;
msg.clear ();
break;
}
else {
if (cycles > 3 && within (5) == 0) {
std::cout << "I: (" << identity << ") simulating CPU overload" << std::endl;
sleep (5);
}
}
std::cout << "I: (" << identity << ") normal reply - " << msg.body() << std::endl;
msg.send (*worker);
liveness = HEARTBEAT_LIVENESS;
sleep (1); // Do some heavy work
}
else {
if (msg.parts () == 1
&& strcmp (msg.body (), "HEARTBEAT") == 0) {
liveness = HEARTBEAT_LIVENESS;
}
else {
std::cout << "E: (" << identity << ") invalid message" << std::endl;
msg.dump ();
}
}
interval = INTERVAL_INIT;
}
else
if (--liveness == 0) {
std::cout << "W: (" << identity << ") heartbeat failure, can't reach queue" << std::endl;
std::cout << "W: (" << identity << ") reconnecting in " << interval << " msec..." << std::endl;
s_sleep (interval);
if (interval < INTERVAL_MAX) {
interval *= 2;
}
delete worker;
worker = s_worker_socket (context);
liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (s_clock () > heartbeat_at) {
heartbeat_at = s_clock () + HEARTBEAT_INTERVAL;
std::cout << "I: (" << identity << ") worker heartbeat" << std::endl;
s_send (*worker, std::string("HEARTBEAT"));
}
}
delete worker;
return 0;
}
ppworker: Paranoid Pirate worker in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
using PP;
//
// Paranoid Pirate worker
//
// We have a single task that implements the worker side of the
// Paranoid Pirate Protocol (PPP). The interesting parts here are
// the heartbeating, which lets the worker detect if the queue has
// died, and vice versa:
//
// Author: metadings
//
static partial class Program
{
static ZSocket PPWorker_CreateZSocket(ZContext context, string name, out ZError error)
{
// Helper function that returns a new configured socket
// connected to the Paranoid Pirate queue
var worker = new ZSocket(context, ZSocketType.DEALER);
worker.IdentityString = name;
if (!worker.Connect("tcp://127.0.0.1:5556", out error))
{
return null; // Interrupted
}
// Tell queue we're ready for work
using (var outgoing = new ZFrame(Worker.PPP_READY))
{
worker.Send(outgoing);
}
Console.WriteLine("I: worker ready");
return worker;
}
public static void PPWorker(string[] args)
{
if (args == null || args.Length == 0)
{
Console.WriteLine();
Console.WriteLine("Usage: ./{0} PPWorker [Name]", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
Console.WriteLine(" Name Your name. Default: World");
Console.WriteLine();
args = new string[] { "World" };
}
string name = args[0];
ZError error;
using (var context = new ZContext())
{
ZSocket worker = null;
try // using (worker)
{
if (null == (worker = PPWorker_CreateZSocket(context, name, out error)))
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
// If liveness hits zero, queue is considered disconnected
int liveness = Worker.PPP_HEARTBEAT_LIVENESS;
int interval = Worker.PPP_INTERVAL_INIT;
// Send out heartbeats at regular intervals
DateTime heartbeat_at = DateTime.UtcNow + Worker.PPP_HEARTBEAT_INTERVAL;
ZMessage incoming;
int cycles = 0;
var poll = ZPollItem.CreateReceiver();
var rnd = new Random();
while (true)
{
if (worker.PollIn(poll, out incoming, out error, Worker.PPP_TICK))
{
// Get message
// - 3-part envelope + content -> request
// - 1-part HEARTBEAT -> heartbeat
using (incoming)
{
// To test the robustness of the queue implementation we
// simulate various typical problems, such as the worker
// crashing or running very slowly. We do this after a few
// cycles so that the architecture can get up and running
// first:
if (incoming.Count >= 3)
{
Console_WriteZMessage("I: receiving reply", incoming);
cycles++;
if (cycles > 3 && rnd.Next(5) == 0)
{
Console.WriteLine("I: simulating a crash");
return;
}
if (cycles > 3 && rnd.Next(3) == 0)
{
Console.WriteLine("I: simulating CPU overload");
Thread.Sleep(100);
}
Thread.Sleep(1); // Do some heavy work
Console.WriteLine("I: sending reply");
worker.Send(incoming);
liveness = Worker.PPP_HEARTBEAT_LIVENESS;
}
// When we get a heartbeat message from the queue, it means the
// queue was (recently) alive, so we must reset our liveness
// indicator:
else if (incoming.Count == 1)
{
string identity = incoming[0].ReadString();
if (identity == Worker.PPP_HEARTBEAT)
{
Console.WriteLine("I: receiving heartbeat");
liveness = Worker.PPP_HEARTBEAT_LIVENESS;
}
else
{
Console_WriteZMessage("E: invalid message", incoming);
}
}
else
{
Console_WriteZMessage("E: invalid message", incoming);
}
}
interval = Worker.PPP_INTERVAL_INIT;
}
else
{
if (error == ZError.ETERM)
break; // Interrupted
if (error != ZError.EAGAIN)
throw new ZException(error);
}
if (error == ZError.EAGAIN)
{
// If the queue hasn't sent us heartbeats in a while, destroy the
// socket and reconnect. This is the simplest most brutal way of
// discarding any messages we might have sent in the meantime:
if (--liveness == 0)
{
Console.WriteLine("W: heartbeat failure, can't reach queue");
Console.WriteLine("W: reconnecting in {0} ms", interval);
Thread.Sleep(interval);
if (interval < Worker.PPP_INTERVAL_MAX)
{
interval *= 2;
}
else {
Console.WriteLine("E: interrupted");
break;
}
worker.Dispose();
if (null == (worker = PPWorker_CreateZSocket(context, name, out error)))
{
if (error == ZError.ETERM)
break; // Interrupted
throw new ZException(error);
}
liveness = Worker.PPP_HEARTBEAT_LIVENESS;
}
}
// Send heartbeat to queue if it's time
if (DateTime.UtcNow > heartbeat_at)
{
heartbeat_at = DateTime.UtcNow + Worker.PPP_HEARTBEAT_INTERVAL;
Console.WriteLine("I: sending heartbeat");
using (var outgoing = new ZFrame(Worker.PPP_HEARTBEAT))
{
worker.Send(outgoing);
}
}
}
}
finally
{
if (worker != null)
{
worker.Dispose();
worker = null;
}
}
}
}
}
}
ppworker: Paranoid Pirate worker in CL
ppworker: Paranoid Pirate worker in Delphi
ppworker: Paranoid Pirate worker in Erlang
ppworker: Paranoid Pirate worker in Elixir
ppworker: Paranoid Pirate worker in F#
ppworker: Paranoid Pirate worker in Felix
ppworker: Paranoid Pirate worker in Go
// Paranoid Pirate worker
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"time"
)
const (
HEARTBEAT_INTERVAL = time.Second // time.Duration
INTERVAL_INIT = time.Second // Initial reconnect
INTERVAL_MAX = 32 * time.Second // After exponential backoff
// Paranoid Pirate Protocol constants
PPP_READY = "\001" // Signals worker is ready
PPP_HEARTBEAT = "\002" // Signals worker heartbeat
)
// Helper function that returns a new configured socket
// connected to the Paranoid Pirate queue
func WorkerSocket(context *zmq.Context) *zmq.Socket {
worker, _ := context.NewSocket(zmq.DEALER)
worker.Connect("tcp://localhost:5556")
// Tell queue we're ready for work
fmt.Println("I: worker ready")
worker.Send([]byte(PPP_READY), 0)
return worker
}
// .split main task
// We have a single task, which implements the worker side of the
// Paranoid Pirate Protocol (PPP). The interesting parts here are
// the heartbeating, which lets the worker detect if the queue has
// died, and vice-versa:
func main() {
src := rand.NewSource(time.Now().UnixNano())
random := rand.New(src)
context, _ := zmq.NewContext()
defer context.Close()
worker := WorkerSocket(context)
liveness := HEARTBEAT_LIVENESS
interval := INTERVAL_INIT
heartbeatAt := time.Now().Add(HEARTBEAT_INTERVAL)
cycles := 0
for {
items := zmq.PollItems{
zmq.PollItem{Socket: worker, Events: zmq.POLLIN},
}
zmq.Poll(items, HEARTBEAT_INTERVAL)
if items[0].REvents&zmq.POLLIN != 0 {
frames, err := worker.RecvMultipart(0)
if err != nil {
panic(err)
}
if len(frames) == 3 {
cycles++
if cycles > 3 {
switch r := random.Intn(5); r {
case 0:
fmt.Println("I: Simulating a crash")
worker.Close()
return
case 1:
fmt.Println("I: Simulating CPU overload")
time.Sleep(3 * time.Second)
}
}
fmt.Println("I: Normal reply")
worker.SendMultipart(frames, 0)
liveness = HEARTBEAT_LIVENESS
time.Sleep(1 * time.Second)
} else if len(frames) == 1 && string(frames[0]) == PPP_HEARTBEAT {
fmt.Println("I: Queue heartbeat")
liveness = HEARTBEAT_LIVENESS
} else {
fmt.Println("E: Invalid message")
}
interval = INTERVAL_INIT
} else if liveness--; liveness == 0 {
fmt.Println("W: Heartbeat failure, can't reach queue")
fmt.Printf("W: Reconnecting in %ds...\n", interval/time.Second)
time.Sleep(interval)
if interval < INTERVAL_MAX {
interval *= 2
}
worker.Close()
worker = WorkerSocket(context)
liveness = HEARTBEAT_LIVENESS
}
if heartbeatAt.Before(time.Now()) {
heartbeatAt = time.Now().Add(HEARTBEAT_INTERVAL)
worker.Send([]byte(PPP_HEARTBEAT), 0)
}
}
}
ppworker: Paranoid Pirate worker in Haskell
{-
Paranoid Pirate worker in Haskell.
Uses heartbeating to detect crashed queue.
-}
module Main where
import System.ZMQ4.Monadic
import ZHelpers
import System.Random (randomRIO)
import System.Exit (exitSuccess)
import System.IO (hSetEncoding, stdout, utf8)
import Control.Monad (when)
import Control.Concurrent (threadDelay)
import Data.ByteString.Char8 (pack, unpack, empty)
heartbeatLiveness = 3
heartbeatInterval_ms = 1000 :: Integer
reconnectIntervalInit = 1000
reconnectIntervalLimit = 32000
pppReady = pack "\001"
pppHeartbeat = pack "\002"
createWorkerSocket :: ZMQ z (Socket z Dealer)
createWorkerSocket = do
worker <- socket Dealer
connect worker "tcp://localhost:5556"
liftIO $ putStrLn "I: worker ready"
send worker [] pppReady
return worker
main :: IO ()
main =
runZMQ $ do
worker <- createWorkerSocket
heartbeatAt <- liftIO $ nextHeartbeatTime_ms heartbeatInterval_ms
liftIO $ hSetEncoding stdout utf8
pollWorker worker heartbeatAt heartbeatLiveness reconnectIntervalInit 0
pollWorker :: Socket z Dealer -> Integer -> Integer -> Integer -> Int -> ZMQ z ()
pollWorker worker heartbeat liveness reconnectInterval cycles = do
[evts] <- poll (fromInteger heartbeatInterval_ms) [Sock worker [In] Nothing]
if In `elem` evts
then do
frame <- receiveMulti worker
if length frame == 4 -- Handle normal message
then do
chance <- liftIO $ randomRIO (0::Int, 5)
if cycles > 3 && chance == 0
then do
liftIO $ putStrLn "I: Simulating a crash"
liftIO $ exitSuccess
else do
chance' <- liftIO $ randomRIO (0::Int, 5)
when (cycles > 3 && chance' == 0) $ do
liftIO $ putStrLn "I: Simulating CPU overload"
liftIO $ threadDelay $ 3 * 1000 * 1000
let id = frame !! 1
info = frame !! 3
liftIO $ putStrLn "I: Normal reply"
send worker [SendMore] id
send worker [SendMore] empty
send worker [] info
liftIO $ threadDelay $ 1 * 1000 * 1000
pollWorker worker heartbeat heartbeatLiveness reconnectIntervalInit (cycles+1)
else if length frame == 2 -- Handle heartbeat or eventual invalid message
then do
let msg = frame !! 1
if msg == pppHeartbeat
then pollWorker worker heartbeat heartbeatLiveness reconnectIntervalInit cycles
else do
liftIO $ putStrLn "E: invalid message"
pollWorker worker heartbeat liveness reconnectIntervalInit cycles
else do
liftIO $ putStrLn "E: invalid message"
pollWorker worker heartbeat liveness reconnectIntervalInit cycles
else do
when (liveness == 0) $ do -- Try to reconnect
liftIO $ putStrLn "W: heartbeat failure, can't reach queue"
liftIO $ putStrLn $ "W: reconnecting in " ++ (show reconnectInterval) ++ " msec..."
liftIO $ threadDelay $ (fromInteger reconnectInterval) * 1000
worker' <- createWorkerSocket
if (reconnectInterval < reconnectIntervalLimit)
then pollWorker worker' heartbeat heartbeatLiveness (reconnectInterval * 2) cycles
else pollWorker worker' heartbeat heartbeatLiveness reconnectInterval cycles
currTime <- liftIO $ currentTime_ms -- Send heartbeat
when (currTime > heartbeat) $ do
liftIO $ putStrLn "I: worker heartbeat"
send worker [] pppHeartbeat
newHeartbeat <- liftIO $ nextHeartbeatTime_ms heartbeat
pollWorker worker newHeartbeat (liveness-1) reconnectInterval cycles
pollWorker worker heartbeat (liveness-1) reconnectInterval cycles
ppworker: Paranoid Pirate worker in Haxe
package ;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMQException;
import org.zeromq.ZMsg;
import org.zeromq.ZSocket;
/**
* Paranoid Pirate worker
*
* @see http://zguide.zeromq.org/page:all#Robust-Reliable-Queuing-Paranoid-Pirate-Pattern
*
* Author: rsmith (at) rsbatechnology (dot) co (dot) uk
*/
class PPWorker
{
private static inline var HEARTBEAT_LIVENESS = 3;
private static inline var HEARTBEAT_INTERVAL = 1000; // msecs
private static inline var INTERVAL_INIT = 1000; // Initial reconnect
private static inline var INTERVAL_MAX = 32000; // After exponential backoff
private static inline var PPP_READY = String.fromCharCode(1);
private static inline var PPP_HEARTBEAT = String.fromCharCode(2);
/**
* Helper function that returns a new configured socket
* connected to the Paranid Pirate queue
* @param ctx
* @return
*/
private static function workerSocket(ctx:ZContext):ZMQSocket {
var worker = ctx.createSocket(ZMQ_DEALER);
worker.connect("tcp://localhost:5556");
// Tell queue we're ready for work
Lib.println("I: worker ready");
ZFrame.newStringFrame(PPP_READY).send(worker);
return worker;
}
public static function main() {
Lib.println("** PPWorker (see: http://zguide.zeromq.org/page:all#Robust-Reliable-Queuing-Paranoid-Pirate-Pattern)");
var ctx = new ZContext();
var worker = workerSocket(ctx);
// If liveness hits zero, queue is considered disconnected
var liveness = HEARTBEAT_LIVENESS;
var interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
var heartbeatAt = Date.now().getTime() + HEARTBEAT_INTERVAL;
var cycles = 0;
var poller = new ZMQPoller();
poller.registerSocket(worker, ZMQ.ZMQ_POLLIN());
while (true) {
try {
poller.poll(HEARTBEAT_INTERVAL * 1000);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
if (poller.pollin(1)) {
// Get message
// - 3-part envelope + content -> request
// - 1-part HEARTBEAT -> heartbeat
var msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
if (msg.size() == 3) {
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && ZHelpers.randof(5) == 0) {
Lib.println("I: simulating a crash");
msg.destroy();
break;
} else if (cycles > 3 && ZHelpers.randof(5) == 0) {
Lib.println("I: simulating CPU overload");
Sys.sleep(3.0);
if (ZMQ.isInterrupted())
break;
}
Lib.println("I: normal reply");
msg.send(worker);
liveness = HEARTBEAT_LIVENESS;
Sys.sleep(1.0); // Do some heavy work
if (ZMQ.isInterrupted())
break;
} else if (msg.size() == 1) {
var frame = msg.first();
if (frame.streq(PPP_HEARTBEAT))
liveness = HEARTBEAT_LIVENESS;
else {
Lib.println("E: invalid message");
Lib.println(msg.toString());
}
msg.destroy();
} else {
Lib.println("E: invalid message");
Lib.println(msg.toString());
}
interval = INTERVAL_INIT;
} else if (--liveness == 0) {
Lib.println("W: heartbeat failure, can't reach queue");
Lib.println("W: reconnecting in " + interval + " msec...");
Sys.sleep(interval / 1000.0);
if (interval < INTERVAL_MAX)
interval *= 2;
ctx.destroySocket(worker);
worker = workerSocket(ctx);
poller.unregisterAllSockets();
poller.registerSocket(worker, ZMQ.ZMQ_POLLIN());
liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (Date.now().getTime() > heartbeatAt) {
heartbeatAt = Date.now().getTime() + HEARTBEAT_INTERVAL;
Lib.println("I: worker heartbeat");
ZFrame.newStringFrame(PPP_HEARTBEAT).send(worker);
}
}
ctx.destroy();
}
}ppworker: Paranoid Pirate worker in Java
package guide;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
//
// Paranoid Pirate worker
//
public class ppworker
{
private final static int HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
private final static int HEARTBEAT_INTERVAL = 1000; // msecs
private final static int INTERVAL_INIT = 1000; // Initial reconnect
private final static int INTERVAL_MAX = 32000; // After exponential backoff
// Paranoid Pirate Protocol constants
private final static String PPP_READY = "\001"; // Signals worker is ready
private final static String PPP_HEARTBEAT = "\002"; // Signals worker heartbeat
// Helper function that returns a new configured socket
// connected to the Paranoid Pirate queue
private static Socket worker_socket(ZContext ctx)
{
Socket worker = ctx.createSocket(SocketType.DEALER);
worker.connect("tcp://localhost:5556");
// Tell queue we're ready for work
System.out.println("I: worker ready\n");
ZFrame frame = new ZFrame(PPP_READY);
frame.send(worker, 0);
return worker;
}
// We have a single task, which implements the worker side of the
// Paranoid Pirate Protocol (PPP). The interesting parts here are
// the heartbeating, which lets the worker detect if the queue has
// died, and vice-versa:
public static void main(String[] args)
{
try (ZContext ctx = new ZContext()) {
Socket worker = worker_socket(ctx);
Poller poller = ctx.createPoller(1);
poller.register(worker, Poller.POLLIN);
// If liveness hits zero, queue is considered disconnected
int liveness = HEARTBEAT_LIVENESS;
int interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
long heartbeat_at = System.currentTimeMillis() + HEARTBEAT_INTERVAL;
Random rand = new Random(System.nanoTime());
int cycles = 0;
while (true) {
int rc = poller.poll(HEARTBEAT_INTERVAL);
if (rc == -1)
break; // Interrupted
if (poller.pollin(0)) {
// Get message
// - 3-part envelope + content -> request
// - 1-part HEARTBEAT -> heartbeat
ZMsg msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
// To test the robustness of the queue implementation we
// simulate various typical problems, such as the worker
// crashing, or running very slowly. We do this after a few
// cycles so that the architecture can get up and running
// first:
if (msg.size() == 3) {
cycles++;
if (cycles > 3 && rand.nextInt(5) == 0) {
System.out.println("I: simulating a crash\n");
msg.destroy();
msg = null;
break;
}
else if (cycles > 3 && rand.nextInt(5) == 0) {
System.out.println("I: simulating CPU overload\n");
try {
Thread.sleep(3000);
}
catch (InterruptedException e) {
break;
}
}
System.out.println("I: normal reply\n");
msg.send(worker);
liveness = HEARTBEAT_LIVENESS;
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
break;
} // Do some heavy work
}
else
// When we get a heartbeat message from the queue, it
// means the queue was (recently) alive, so reset our
// liveness indicator:
if (msg.size() == 1) {
ZFrame frame = msg.getFirst();
String frameData = new String(
frame.getData(), ZMQ.CHARSET
);
if (PPP_HEARTBEAT.equals(frameData))
liveness = HEARTBEAT_LIVENESS;
else {
System.out.println("E: invalid message\n");
msg.dump(System.out);
}
msg.destroy();
}
else {
System.out.println("E: invalid message\n");
msg.dump(System.out);
}
interval = INTERVAL_INIT;
}
else
// If the queue hasn't sent us heartbeats in a while,
// destroy the socket and reconnect. This is the simplest
// most brutal way of discarding any messages we might have
// sent in the meantime.
if (--liveness == 0) {
System.out.println(
"W: heartbeat failure, can't reach queue\n"
);
System.out.printf(
"W: reconnecting in %sd msec\n", interval
);
try {
Thread.sleep(interval);
}
catch (InterruptedException e) {
e.printStackTrace();
}
if (interval < INTERVAL_MAX)
interval *= 2;
ctx.destroySocket(worker);
worker = worker_socket(ctx);
liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (System.currentTimeMillis() > heartbeat_at) {
long now = System.currentTimeMillis();
heartbeat_at = now + HEARTBEAT_INTERVAL;
System.out.println("I: worker heartbeat\n");
ZFrame frame = new ZFrame(PPP_HEARTBEAT);
frame.send(worker, 0);
}
}
}
}
}
ppworker: Paranoid Pirate worker in Julia
ppworker: Paranoid Pirate worker in Lua
--
-- Paranoid Pirate worker
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmsg"
local HEARTBEAT_LIVENESS = 3 -- 3-5 is reasonable
local HEARTBEAT_INTERVAL = 1000 -- msecs
local INTERVAL_INIT = 1000 -- Initial reconnect
local INTERVAL_MAX = 32000 -- After exponential backoff
-- Helper function that returns a new configured socket
-- connected to the Hello World server
--
local identity
local function s_worker_socket (context)
local worker = context:socket(zmq.DEALER)
-- Set random identity to make tracing easier
identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
worker:setopt(zmq.IDENTITY, identity)
worker:connect("tcp://localhost:5556")
-- Configure socket to not wait at close time
worker:setopt(zmq.LINGER, 0)
-- Tell queue we're ready for work
printf("I: (%s) worker ready\n", identity)
worker:send("READY")
return worker
end
s_version_assert (2, 1)
math.randomseed(os.time())
local context = zmq.init(1)
local worker = s_worker_socket (context)
-- If liveness hits zero, queue is considered disconnected
local liveness = HEARTBEAT_LIVENESS
local interval = INTERVAL_INIT
-- Send out heartbeats at regular intervals
local heartbeat_at = s_clock () + HEARTBEAT_INTERVAL
local poller = zmq.poller(1)
local is_running = true
local cycles = 0
local function worker_cb()
-- Get message
-- - 3-part envelope + content -> request
-- - 1-part "HEARTBEAT" -> heartbeat
local msg = zmsg.recv (worker)
if (msg:parts() == 3) then
-- Simulate various problems, after a few cycles
cycles = cycles + 1
if (cycles > 3 and randof (5) == 0) then
printf ("I: (%s) simulating a crash\n", identity)
is_running = false
return
elseif (cycles > 3 and randof (5) == 0) then
printf ("I: (%s) simulating CPU overload\n",
identity)
s_sleep (5000)
end
printf ("I: (%s) normal reply - %s\n",
identity, msg:body())
msg:send(worker)
liveness = HEARTBEAT_LIVENESS
s_sleep(1000); -- Do some heavy work
elseif (msg:parts() == 1 and msg:body() == "HEARTBEAT") then
liveness = HEARTBEAT_LIVENESS
else
printf ("E: (%s) invalid message\n", identity)
msg:dump()
end
interval = INTERVAL_INIT
end
poller:add(worker, zmq.POLLIN, worker_cb)
while is_running do
local cnt = assert(poller:poll(HEARTBEAT_INTERVAL * 1000))
if (cnt == 0) then
liveness = liveness - 1
if (liveness == 0) then
printf ("W: (%s) heartbeat failure, can't reach queue\n",
identity)
printf ("W: (%s) reconnecting in %d msec...\n",
identity, interval)
s_sleep (interval)
if (interval < INTERVAL_MAX) then
interval = interval * 2
end
poller:remove(worker)
worker:close()
worker = s_worker_socket (context)
poller:add(worker, zmq.POLLIN, worker_cb)
liveness = HEARTBEAT_LIVENESS
end
end
-- Send heartbeat to queue if it's time
if (s_clock () > heartbeat_at) then
heartbeat_at = s_clock () + HEARTBEAT_INTERVAL
printf("I: (%s) worker heartbeat\n", identity)
worker:send("HEARTBEAT")
end
end
worker:close()
context:term()
ppworker: Paranoid Pirate worker in Node.js
ppworker: Paranoid Pirate worker in Objective-C
ppworker: Paranoid Pirate worker in ooc
ppworker: Paranoid Pirate worker in Perl
ppworker: Paranoid Pirate worker in PHP
<?php
/*
* Paranoid Pirate worker
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("HEARTBEAT_LIVENESS", 3); // 3-5 is reasonable
define("HEARTBEAT_INTERVAL", 1); // secs
define("INTERVAL_INIT", 1000); // Initial reconnect
define("INTERVAL_MAX", 32000); // After exponential backoff
/*
* Helper function that returns a new configured socket
* connected to the Hello World server
*/
function s_worker_socket($context)
{
$worker = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
// Set random identity to make tracing easier
$identity = sprintf ("%04X-%04X", rand(0, 0x10000), rand(0, 0x10000));
$worker->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $identity);
$worker->connect("tcp://localhost:5556");
// Configure socket to not wait at close time
$worker->setSockOpt(ZMQ::SOCKOPT_LINGER, 0);
// Tell queue we're ready for work
printf ("I: (%s) worker ready%s", $identity, PHP_EOL);
$worker->send("READY");
return array($worker, $identity);
}
$context = new ZMQContext();
list($worker, $identity) = s_worker_socket($context);
// If liveness hits zero, queue is considered disconnected
$liveness = HEARTBEAT_LIVENESS;
$interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
$heartbeat_at = microtime(true) + HEARTBEAT_INTERVAL;
$read = $write = array();
$cycles = 0;
while (true) {
$poll = new ZMQPoll();
$poll->add($worker, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, HEARTBEAT_INTERVAL * 1000);
if ($events) {
// Get message
// - 3-part envelope + content -> request
// - 1-part "HEARTBEAT" -> heartbeat
$zmsg = new Zmsg($worker);
$zmsg->recv();
if ($zmsg->parts() == 3) {
// Simulate various problems, after a few cycles
$cycles++;
if ($cycles > 3 && rand(0, 5) == 0) {
printf ("I: (%s) simulating a crash%s", $identity, PHP_EOL);
break;
} elseif ($cycles > 3 && rand(0, 5) == 0) {
printf ("I: (%s) simulating CPU overload%s", $identity, PHP_EOL);
sleep(5);
}
printf ("I: (%s) normal reply - %s%s", $identity, $zmsg->body(), PHP_EOL);
$zmsg->send();
$liveness = HEARTBEAT_LIVENESS;
sleep(1); // Do some heavy work
} elseif ($zmsg->parts() == 1 && $zmsg->body() == 'HEARTBEAT') {
$liveness = HEARTBEAT_LIVENESS;
} else {
printf ("E: (%s) invalid message%s%s", $identity, PHP_EOL, $zmsg->__toString());
}
$interval = INTERVAL_INIT;
} elseif (--$liveness == 0) {
printf ("W: (%s) heartbeat failure, can't reach queue%s", $identity, PHP_EOL);
printf ("W: (%s) reconnecting in %d msec...%s", $identity, $interval, PHP_EOL);
usleep ($interval * 1000);
if ($interval < INTERVAL_MAX) {
$interval *= 2;
}
list($worker, $identity) = s_worker_socket ($context);
$liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (microtime(true) > $heartbeat_at) {
$heartbeat_at = microtime(true) + HEARTBEAT_INTERVAL;
printf ("I: (%s) worker heartbeat%s", $identity, PHP_EOL);
$worker->send("HEARTBEAT");
}
}
ppworker: Paranoid Pirate worker in Python
#
## Paranoid Pirate worker
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
from random import randint
import time
import zmq
HEARTBEAT_LIVENESS = 3
HEARTBEAT_INTERVAL = 1
INTERVAL_INIT = 1
INTERVAL_MAX = 32
# Paranoid Pirate Protocol constants
PPP_READY = b"\x01" # Signals worker is ready
PPP_HEARTBEAT = b"\x02" # Signals worker heartbeat
def worker_socket(context, poller):
"""Helper function that returns a new configured socket
connected to the Paranoid Pirate queue"""
worker = context.socket(zmq.DEALER) # DEALER
identity = b"%04X-%04X" % (randint(0, 0x10000), randint(0, 0x10000))
worker.setsockopt(zmq.IDENTITY, identity)
poller.register(worker, zmq.POLLIN)
worker.connect("tcp://localhost:5556")
worker.send(PPP_READY)
return worker
context = zmq.Context(1)
poller = zmq.Poller()
liveness = HEARTBEAT_LIVENESS
interval = INTERVAL_INIT
heartbeat_at = time.time() + HEARTBEAT_INTERVAL
worker = worker_socket(context, poller)
cycles = 0
while True:
socks = dict(poller.poll(HEARTBEAT_INTERVAL * 1000))
# Handle worker activity on backend
if socks.get(worker) == zmq.POLLIN:
# Get message
# - 3-part envelope + content -> request
# - 1-part HEARTBEAT -> heartbeat
frames = worker.recv_multipart()
if not frames:
break # Interrupted
if len(frames) == 3:
# Simulate various problems, after a few cycles
cycles += 1
if cycles > 3 and randint(0, 5) == 0:
print("I: Simulating a crash")
break
if cycles > 3 and randint(0, 5) == 0:
print("I: Simulating CPU overload")
time.sleep(3)
print("I: Normal reply")
worker.send_multipart(frames)
liveness = HEARTBEAT_LIVENESS
time.sleep(1) # Do some heavy work
elif len(frames) == 1 and frames[0] == PPP_HEARTBEAT:
print("I: Queue heartbeat")
liveness = HEARTBEAT_LIVENESS
else:
print("E: Invalid message: %s" % frames)
interval = INTERVAL_INIT
else:
liveness -= 1
if liveness == 0:
print("W: Heartbeat failure, can't reach queue")
print("W: Reconnecting in %0.2fs..." % interval)
time.sleep(interval)
if interval < INTERVAL_MAX:
interval *= 2
poller.unregister(worker)
worker.setsockopt(zmq.LINGER, 0)
worker.close()
worker = worker_socket(context, poller)
liveness = HEARTBEAT_LIVENESS
if time.time() > heartbeat_at:
heartbeat_at = time.time() + HEARTBEAT_INTERVAL
print("I: Worker heartbeat")
worker.send(PPP_HEARTBEAT)
ppworker: Paranoid Pirate worker in Q
ppworker: Paranoid Pirate worker in Racket
ppworker: Paranoid Pirate worker in Ruby
ppworker: Paranoid Pirate worker in Rust
ppworker: Paranoid Pirate worker in Scala
ppworker: Paranoid Pirate worker in Tcl
ppworker: Paranoid Pirate worker in OCaml
Some comments about this example:
-
The code includes simulation of failures, as before. This makes it (a) very hard to debug, and (b) dangerous to reuse. When you want to debug this, disable the failure simulation.
-
The worker uses a reconnect strategy similar to the one we designed for the Lazy Pirate client, with two major differences: (a) it does an exponential back-off, and (b) it retries indefinitely (whereas the client retries a few times before reporting a failure).
Try the client, queue, and workers, such as by using a script like this:
ppqueue &
for i in 1 2 3 4; do
ppworker &
sleep 1
done
lpclient &
You should see the workers die one-by-one as they simulate a crash, and the client eventually give up. You can stop and restart the queue and both client and workers will reconnect and carry on. And no matter what you do to queues and workers, the client will never get an out-of-order reply: the whole chain either works, or the client abandons.
Heartbeating #
Heartbeating solves the problem of knowing whether a peer is alive or dead. This is not an issue specific to ZeroMQ. TCP has a long timeout (30 minutes or so), that means that it can be impossible to know whether a peer has died, been disconnected, or gone on a weekend to Prague with a case of vodka, a redhead, and a large expense account.
It’s not easy to get heartbeating right. When writing the Paranoid Pirate examples, it took about five hours to get the heartbeating working properly. The rest of the request-reply chain took perhaps ten minutes. It is especially easy to create “false failures”, i.e., when peers decide that they are disconnected because the heartbeats aren’t sent properly.
We’ll look at the three main answers people use for heartbeating with ZeroMQ.
Shrugging It Off #
The most common approach is to do no heartbeating at all and hope for the best. Many if not most ZeroMQ applications do this. ZeroMQ encourages this by hiding peers in many cases. What problems does this approach cause?
-
When we use a ROUTER socket in an application that tracks peers, as peers disconnect and reconnect, the application will leak memory (resources that the application holds for each peer) and get slower and slower.
-
When we use SUB- or DEALER-based data recipients, we can’t tell the difference between good silence (there’s no data) and bad silence (the other end died). When a recipient knows the other side died, it can for example switch over to a backup route.
-
If we use a TCP connection that stays silent for a long while, it will, in some networks, just die. Sending something (technically, a “keep-alive” more than a heartbeat), will keep the network alive.
One-Way Heartbeats #
A second option is to send a heartbeat message from each node to its peers every second or so. When one node hears nothing from another within some timeout (several seconds, typically), it will treat that peer as dead. Sounds good, right? Sadly, no. This works in some cases but has nasty edge cases in others.
For pub-sub, this does work, and it’s the only model you can use. SUB sockets cannot talk back to PUB sockets, but PUB sockets can happily send “I’m alive” messages to their subscribers.
As an optimization, you can send heartbeats only when there is no real data to send. Furthermore, you can send heartbeats progressively slower and slower, if network activity is an issue (e.g., on mobile networks where activity drains the battery). As long as the recipient can detect a failure (sharp stop in activity), that’s fine.
Here are the typical problems with this design:
-
It can be inaccurate when we send large amounts of data, as heartbeats will be delayed behind that data. If heartbeats are delayed, you can get false timeouts and disconnections due to network congestion. Thus, always treat any incoming data as a heartbeat, whether or not the sender optimizes out heartbeats.
-
While the pub-sub pattern will drop messages for disappeared recipients, PUSH and DEALER sockets will queue them. So if you send heartbeats to a dead peer and it comes back, it will get all the heartbeats you sent, which can be thousands. Whoa, whoa!
-
This design assumes that heartbeat timeouts are the same across the whole network. But that won’t be accurate. Some peers will want very aggressive heartbeating in order to detect faults rapidly. And some will want very relaxed heartbeating, in order to let sleeping networks lie and save power.
Ping-Pong Heartbeats #
The third option is to use a ping-pong dialog. One peer sends a ping command to the other, which replies with a pong command. Neither command has any payload. Pings and pongs are not correlated. Because the roles of “client” and “server” are arbitrary in some networks, we usually specify that either peer can in fact send a ping and expect a pong in response. However, because the timeouts depend on network topologies known best to dynamic clients, it is usually the client that pings the server.
This works for all ROUTER-based brokers. The same optimizations we used in the second model make this work even better: treat any incoming data as a pong, and only send a ping when not otherwise sending data.
Heartbeating for Paranoid Pirate #
For Paranoid Pirate, we chose the second approach. It might not have been the simplest option: if designing this today, I’d probably try a ping-pong approach instead. However the principles are similar. The heartbeat messages flow asynchronously in both directions, and either peer can decide the other is “dead” and stop talking to it.
In the worker, this is how we handle heartbeats from the queue:
- We calculate a liveness, which is how many heartbeats we can still miss before deciding the queue is dead. It starts at three and we decrement it each time we miss a heartbeat.
- We wait, in the zmq_poll loop, for one second each time, which is our heartbeat interval.
- If there’s any message from the queue during that time, we reset our liveness to three.
- If there’s no message during that time, we count down our liveness.
- If the liveness reaches zero, we consider the queue dead.
- If the queue is dead, we destroy our socket, create a new one, and reconnect.
- To avoid opening and closing too many sockets, we wait for a certain interval before reconnecting, and we double the interval each time until it reaches 32 seconds.
And this is how we handle heartbeats to the queue:
- We calculate when to send the next heartbeat; this is a single variable because we’re talking to one peer, the queue.
- In the zmq_poll loop, whenever we pass this time, we send a heartbeat to the queue.
Here’s the essential heartbeating code for the worker:
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 1000 // msecs
#define INTERVAL_INIT 1000 // Initial reconnect
#define INTERVAL_MAX 32000 // After exponential backoff
...
// If liveness hits zero, queue is considered disconnected
size_t liveness = HEARTBEAT_LIVENESS;
size_t interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
uint64_t heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
while (true) {
zmq_pollitem_t items [] = { { worker, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC);
if (items [0].revents & ZMQ_POLLIN) {
// Receive any message from queue
liveness = HEARTBEAT_LIVENESS;
interval = INTERVAL_INIT;
}
else
if (--liveness == 0) {
zclock_sleep (interval);
if (interval < INTERVAL_MAX)
interval *= 2;
zsocket_destroy (ctx, worker);
...
liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (zclock_time () > heartbeat_at) {
heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
// Send heartbeat message to queue
}
}
The queue does the same, but manages an expiration time for each worker.
Here are some tips for your own heartbeating implementation:
-
Use zmq_poll or a reactor as the core of your application’s main task.
-
Start by building the heartbeating between peers, test it by simulating failures, and then build the rest of the message flow. Adding heartbeating afterwards is much trickier.
-
Use simple tracing, i.e., print to console, to get this working. To help you trace the flow of messages between peers, use a dump method such as zmsg offers, and number your messages incrementally so you can see if there are gaps.
-
In a real application, heartbeating must be configurable and usually negotiated with the peer. Some peers will want aggressive heartbeating, as low as 10 msecs. Other peers will be far away and want heartbeating as high as 30 seconds.
-
If you have different heartbeat intervals for different peers, your poll timeout should be the lowest (shortest time) of these. Do not use an infinite timeout.
-
Do heartbeating on the same socket you use for messages, so your heartbeats also act as a keep-alive to stop the network connection from going stale (some firewalls can be unkind to silent connections).
Contracts and Protocols #
If you’re paying attention, you’ll realize that Paranoid Pirate is not interoperable with Simple Pirate, because of the heartbeats. But how do we define “interoperable”? To guarantee interoperability, we need a kind of contract, an agreement that lets different teams in different times and places write code that is guaranteed to work together. We call this a “protocol”.
It’s fun to experiment without specifications, but that’s not a sensible basis for real applications. What happens if we want to write a worker in another language? Do we have to read code to see how things work? What if we want to change the protocol for some reason? Even a simple protocol will, if it’s successful, evolve and become more complex.
Lack of contracts is a sure sign of a disposable application. So let’s write a contract for this protocol. How do we do that?
There’s a wiki at rfc.zeromq.org that we made especially as a home for public ZeroMQ contracts. To create a new specification, register on the wiki if needed, and follow the instructions. It’s fairly straightforward, though writing technical texts is not everyone’s cup of tea.
It took me about fifteen minutes to draft the new Pirate Pattern Protocol. It’s not a big specification, but it does capture enough to act as the basis for arguments (“your queue isn’t PPP compatible; please fix it!").
Turning PPP into a real protocol would take more work:
-
There should be a protocol version number in the READY command so that it’s possible to distinguish between different versions of PPP.
-
Right now, READY and HEARTBEAT are not entirely distinct from requests and replies. To make them distinct, we would need a message structure that includes a “message type” part.
Service-Oriented Reliable Queuing (Majordomo Pattern) #
The nice thing about progress is how fast it happens when lawyers and committees aren’t involved. The one-page MDP specification turns PPP into something more solid. This is how we should design complex architectures: start by writing down the contracts, and only then write software to implement them.
The Majordomo Protocol (MDP) extends and improves on PPP in one interesting way: it adds a “service name” to requests that the client sends, and asks workers to register for specific services. Adding service names turns our Paranoid Pirate queue into a service-oriented broker. The nice thing about MDP is that it came out of working code, a simpler ancestor protocol (PPP), and a precise set of improvements that each solved a clear problem. This made it easy to draft.
To implement Majordomo, we need to write a framework for clients and workers. It’s really not sane to ask every application developer to read the spec and make it work, when they could be using a simpler API that does the work for them.
So while our first contract (MDP itself) defines how the pieces of our distributed architecture talk to each other, our second contract defines how user applications talk to the technical framework we’re going to design.
Majordomo has two halves, a client side and a worker side. Because we’ll write both client and worker applications, we will need two APIs. Here is a sketch for the client API, using a simple object-oriented approach:
mdcli_t *mdcli_new (char *broker);
void mdcli_destroy (mdcli_t **self_p);
zmsg_t *mdcli_send (mdcli_t *self, char *service, zmsg_t **request_p);
That’s it. We open a session to the broker, send a request message, get a reply message back, and eventually close the connection. Here’s a sketch for the worker API:
mdwrk_t *mdwrk_new (char *broker,char *service);
void mdwrk_destroy (mdwrk_t **self_p);
zmsg_t *mdwrk_recv (mdwrk_t *self, zmsg_t *reply);
It’s more or less symmetrical, but the worker dialog is a little different. The first time a worker does a recv(), it passes a null reply. Thereafter, it passes the current reply, and gets a new request.
The client and worker APIs were fairly simple to construct because they’re heavily based on the Paranoid Pirate code we already developed. Here is the client API:
mdcliapi: Majordomo client API in Ada
mdcliapi: Majordomo client API in Basic
mdcliapi: Majordomo client API in C
// mdcliapi class - Majordomo Protocol Client API
// Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
#include "mdcliapi.h"
// Structure of our class
// We access these properties only via class methods
struct _mdcli_t {
zctx_t *ctx; // Our context
char *broker;
void *client; // Socket to broker
int verbose; // Print activity to stdout
int timeout; // Request timeout
int retries; // Request retries
};
// Connect or reconnect to broker
void s_mdcli_connect_to_broker (mdcli_t *self)
{
if (self->client)
zsocket_destroy (self->ctx, self->client);
self->client = zsocket_new (self->ctx, ZMQ_REQ);
zmq_connect (self->client, self->broker);
if (self->verbose)
zclock_log ("I: connecting to broker at %s...", self->broker);
}
// .split constructor and destructor
// Here we have the constructor and destructor for our class:
// Constructor
mdcli_t *
mdcli_new (char *broker, int verbose)
{
assert (broker);
mdcli_t *self = (mdcli_t *) zmalloc (sizeof (mdcli_t));
self->ctx = zctx_new ();
self->broker = strdup (broker);
self->verbose = verbose;
self->timeout = 2500; // msecs
self->retries = 3; // Before we abandon
s_mdcli_connect_to_broker (self);
return self;
}
// Destructor
void
mdcli_destroy (mdcli_t **self_p)
{
assert (self_p);
if (*self_p) {
mdcli_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self->broker);
free (self);
*self_p = NULL;
}
}
// .split configure retry behavior
// These are the class methods. We can set the request timeout and number
// of retry attempts before sending requests:
// Set request timeout
void
mdcli_set_timeout (mdcli_t *self, int timeout)
{
assert (self);
self->timeout = timeout;
}
// Set request retries
void
mdcli_set_retries (mdcli_t *self, int retries)
{
assert (self);
self->retries = retries;
}
// .split send request and wait for reply
// Here is the {{send}} method. It sends a request to the broker and gets
// a reply even if it has to retry several times. It takes ownership of
// the request message, and destroys it when sent. It returns the reply
// message, or NULL if there was no reply after multiple attempts:
zmsg_t *
mdcli_send (mdcli_t *self, char *service, zmsg_t **request_p)
{
assert (self);
assert (request_p);
zmsg_t *request = *request_p;
// Prefix request with protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
zmsg_pushstr (request, service);
zmsg_pushstr (request, MDPC_CLIENT);
if (self->verbose) {
zclock_log ("I: send request to '%s' service:", service);
zmsg_dump (request);
}
int retries_left = self->retries;
while (retries_left && !zctx_interrupted) {
zmsg_t *msg = zmsg_dup (request);
zmsg_send (&msg, self->client);
zmq_pollitem_t items [] = {
{ self->client, 0, ZMQ_POLLIN, 0 }
};
// .split body of send
// On any blocking call, {{libzmq}} will return -1 if there was
// an error; we could in theory check for different error codes,
// but in practice it's OK to assume it was {{EINTR}} (Ctrl-C):
int rc = zmq_poll (items, 1, self->timeout * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
// If we got a reply, process it
if (items [0].revents & ZMQ_POLLIN) {
zmsg_t *msg = zmsg_recv (self->client);
if (self->verbose) {
zclock_log ("I: received reply:");
zmsg_dump (msg);
}
// We would handle malformed replies better in real code
assert (zmsg_size (msg) >= 3);
zframe_t *header = zmsg_pop (msg);
assert (zframe_streq (header, MDPC_CLIENT));
zframe_destroy (&header);
zframe_t *reply_service = zmsg_pop (msg);
assert (zframe_streq (reply_service, service));
zframe_destroy (&reply_service);
zmsg_destroy (&request);
return msg; // Success
}
else
if (--retries_left) {
if (self->verbose)
zclock_log ("W: no reply, reconnecting...");
s_mdcli_connect_to_broker (self);
}
else {
if (self->verbose)
zclock_log ("W: permanent error, abandoning");
break; // Give up
}
}
if (zctx_interrupted)
printf ("W: interrupt received, killing client...\n");
zmsg_destroy (&request);
return NULL;
}
mdcliapi: Majordomo client API in C++
#ifndef __MDCLIAPI_HPP_INCLUDED__
#define __MDCLIAPI_HPP_INCLUDED__
//#include "mdcliapi.h"
#include "zmsg.hpp"
#include "mdp.h"
class mdcli {
public:
// ---------------------------------------------------------------------
// Constructor
mdcli (std::string broker, int verbose): m_broker(broker), m_verbose(verbose)
{
assert (broker.size()!=0);
s_version_assert (4, 0);
m_context = new zmq::context_t(1);
s_catch_signals ();
connect_to_broker ();
}
// Destructor
virtual
~mdcli ()
{
delete m_client;
delete m_context;
}
// ---------------------------------------------------------------------
// Connect or reconnect to broker
void connect_to_broker ()
{
if (m_client) {
delete m_client;
}
m_client = new zmq::socket_t (*m_context, ZMQ_REQ);
s_set_id(*m_client);
int linger = 0;
m_client->setsockopt(ZMQ_LINGER, &linger, sizeof (linger));
m_client->connect (m_broker.c_str());
if (m_verbose) {
s_console ("I: connecting to broker at %s...", m_broker.c_str());
}
}
// ---------------------------------------------------------------------
// Set request timeout
void
set_timeout (int timeout)
{
m_timeout = timeout;
}
// ---------------------------------------------------------------------
// Set request retries
void
set_retries (int retries)
{
m_retries = retries;
}
// ---------------------------------------------------------------------
// Send request to broker and get reply by hook or crook
// Takes ownership of request message and destroys it when sent.
// Returns the reply message or NULL if there was no reply.
zmsg *
send (std::string service, zmsg *&request_p)
{
assert (request_p);
zmsg *request = request_p;
// Prefix request with protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
request->push_front(service.c_str());
request->push_front(k_mdp_client.data());
if (m_verbose) {
s_console ("I: send request to '%s' service:", service.c_str());
request->dump();
}
int retries_left = m_retries;
while (retries_left && !s_interrupted) {
zmsg * msg = new zmsg(*request);
msg->send(*m_client);
while (!s_interrupted) {
// Poll socket for a reply, with timeout
zmq::pollitem_t items [] = {
{ *m_client, 0, ZMQ_POLLIN, 0 } };
zmq::poll (items, 1, m_timeout);
// If we got a reply, process it
if (items [0].revents & ZMQ_POLLIN) {
zmsg * recv_msg = new zmsg(*m_client);
if (m_verbose) {
s_console ("I: received reply:");
recv_msg->dump ();
}
// Don't try to handle errors, just assert noisily
assert (recv_msg->parts () >= 3);
ustring header = recv_msg->pop_front();
assert (header.compare((unsigned char *)k_mdp_client.data()) == 0);
ustring reply_service = recv_msg->pop_front();
assert (reply_service.compare((unsigned char *)service.c_str()) == 0);
delete request;
return recv_msg; // Success
}
else {
if (--retries_left) {
if (m_verbose) {
s_console ("W: no reply, reconnecting...");
}
// Reconnect, and resend message
connect_to_broker ();
zmsg msg (*request);
msg.send (*m_client);
}
else {
if (m_verbose) {
s_console ("W: permanent error, abandoning request");
}
break; // Give up
}
}
}
}
if (s_interrupted) {
std::cout << "W: interrupt received, killing client..." << std::endl;
}
delete request;
return 0;
}
private:
const std::string m_broker;
zmq::context_t * m_context;
zmq::socket_t * m_client{nullptr}; // Socket to broker
const int m_verbose; // Print activity to stdout
int m_timeout{2500}; // Request timeout
int m_retries{3}; // Request retries
};
#endif
mdcliapi: Majordomo client API in C#
using System;
using System.Threading;
using ZeroMQ;
namespace Examples
{
namespace MDCliApi
{
//
// mdcliapi class - Majordomo Protocol Client API
// Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
//
// Author: metadings
//
public class MajordomoClient : IDisposable
{
// Structure of our class
// We access these properties only via class methods
// Our context
readonly ZContext _context;
// Majordomo broker
public string Broker { get; protected set; }
// Socket to broker
public ZSocket Client { get; protected set; }
// Print activity to console
public bool Verbose { get; protected set; }
// Request timeout
public TimeSpan Timeout { get; protected set; }
// Request retries
public int Retries { get; protected set; }
public void ConnectToBroker()
{
// Connect or reconnect to broker
Client = new ZSocket(_context, ZSocketType.REQ);
Client.Connect(Broker);
if (Verbose)
"I: connecting to broker at '{0}'...".DumpString(Broker);
}
public MajordomoClient(string broker, bool verbose)
{
if(broker == null)
throw new InvalidOperationException();
_context = new ZContext();
Broker = broker;
Verbose = verbose;
Timeout = TimeSpan.FromMilliseconds(2500);
Retries = 3;
ConnectToBroker();
}
~MajordomoClient()
{
Dispose(false);
}
public void Dispose()
{
GC.SuppressFinalize(this);
Dispose(true);
}
protected void Dispose(bool disposing)
{
if (disposing)
{
// Destructor
if (Client != null)
{
Client.Dispose();
Client = null;
}
//Do not Dispose Context: cuz of weird shutdown behavior, stucks in using calls
}
}
// .split configure retry behavior
// These are the class methods. We can set the request timeout and number
// of retry attempts before sending requests:
// Set request timeout
public void Set_Timeout(int timeoutInMs)
{
Timeout = TimeSpan.FromMilliseconds(timeoutInMs);
}
// Set request retries
public void Set_Retries(int retries)
{
Retries = retries;
}
// .split send request and wait for reply
// Here is the {{send}} method. It sends a request to the broker and gets
// a reply even if it has to retry several times. It takes ownership of
// the request message, and destroys it when sent. It returns the reply
// message, or NULL if there was no reply after multiple attempts:
public ZMessage Send(string service, ZMessage request, CancellationTokenSource cancellor)
{
if (request == null)
throw new InvalidOperationException();
// Prefix request with protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
request.Prepend(new ZFrame(service));
request.Prepend(new ZFrame(MdpCommon.MDPC_CLIENT));
if (Verbose)
request.DumpZmsg("I: send request to '{0}' service:", service);
int retriesLeft = Retries;
while (retriesLeft > 0 && !cancellor.IsCancellationRequested)
{
if (cancellor.IsCancellationRequested
|| (Console.KeyAvailable && Console.ReadKey(true).Key == ConsoleKey.Escape))
_context.Shutdown();
// Copy the Request and send on Client
ZMessage msgreq = request.Duplicate();
ZError error;
if (!Client.Send(msgreq, out error))
{
if (Equals(error, ZError.ETERM))
{
cancellor.Cancel();
break; // Interrupted
}
}
var p = ZPollItem.CreateReceiver();
ZMessage msg;
// .split body of send
// On any blocking call, {{libzmq}} will return -1 if there was
// an error; we could in theory check for different error codes,
// but in practice it's OK to assume it was {{EINTR}} (Ctrl-C):
// Poll the client Message
if (Client.PollIn(p, out msg, out error, Timeout))
{
// If we got a reply, process it
if (Verbose)
msg.DumpZmsg("I: received reply");
if(msg.Count < 3)
throw new InvalidOperationException();
using (ZFrame header = msg.Pop())
if (!header.ToString().Equals(MdpCommon.MDPC_CLIENT))
throw new InvalidOperationException();
using (ZFrame replyService = msg.Pop())
if(!replyService.ToString().Equals(service))
throw new InvalidOperationException();
request.Dispose();
return msg;
}
else if (Equals(error, ZError.ETERM))
{
cancellor.Cancel();
break; // Interrupted
}
else if (Equals(error, ZError.EAGAIN))
{
if (--retriesLeft > 0)
{
if (Verbose)
"W: no reply, reconnecting...".DumpString();
ConnectToBroker();
}
else
{
if (Verbose)
"W: permanent error, abandoning".DumpString();
break; // Give up
}
}
}
if (cancellor.IsCancellationRequested)
{
"W: interrupt received, killing client...\n".DumpString();
}
request.Dispose();
return null;
}
}
}
}
mdcliapi: Majordomo client API in CL
mdcliapi: Majordomo client API in Delphi
mdcliapi: Majordomo client API in Erlang
mdcliapi: Majordomo client API in Elixir
mdcliapi: Majordomo client API in F#
mdcliapi: Majordomo client API in Felix
mdcliapi: Majordomo client API in Go
// mdcliapi class - Majordomo Protocol Client API
// Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
zmq "github.com/alecthomas/gozmq"
"log"
"time"
)
type Client interface {
Close()
Send([]byte, [][]byte) [][]byte
}
type mdClient struct {
broker string
client *zmq.Socket
context *zmq.Context
retries int
timeout time.Duration
verbose bool
}
func NewClient(broker string, verbose bool) Client {
context, _ := zmq.NewContext()
self := &mdClient{
broker: broker,
context: context,
retries: 3,
timeout: 2500 * time.Millisecond,
verbose: verbose,
}
self.reconnect()
return self
}
func (self *mdClient) reconnect() {
if self.client != nil {
self.client.Close()
}
self.client, _ = self.context.NewSocket(zmq.REQ)
self.client.SetLinger(0)
self.client.Connect(self.broker)
if self.verbose {
log.Printf("I: connecting to broker at %s...\n", self.broker)
}
}
func (self *mdClient) Close() {
if self.client != nil {
self.client.Close()
}
self.context.Close()
}
func (self *mdClient) Send(service []byte, request [][]byte) (reply [][]byte) {
// Prefix request with protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
frame := append([][]byte{[]byte(MDPC_CLIENT), service}, request...)
if self.verbose {
log.Printf("I: send request to '%s' service:", service)
Dump(request)
}
for retries := self.retries; retries > 0; {
self.client.SendMultipart(frame, 0)
items := zmq.PollItems{
zmq.PollItem{Socket: self.client, Events: zmq.POLLIN},
}
_, err := zmq.Poll(items, self.timeout)
if err != nil {
panic(err) // Interrupted
}
if item := items[0]; item.REvents&zmq.POLLIN != 0 {
msg, _ := self.client.RecvMultipart(0)
if self.verbose {
log.Println("I: received reply: ")
Dump(msg)
}
// We would handle malformed replies better in real code
if len(msg) < 3 {
panic("Error msg len")
}
header := msg[0]
if string(header) != MDPC_CLIENT {
panic("Error header")
}
replyService := msg[1]
if string(service) != string(replyService) {
panic("Error reply service")
}
reply = msg[2:]
break
} else if retries--; retries > 0 {
if self.verbose {
log.Println("W: no reply, reconnecting...")
}
self.reconnect()
} else {
if self.verbose {
log.Println("W: permanent error, abandoning")
}
break
}
}
return
}
mdcliapi: Majordomo client API in Haskell
mdcliapi: Majordomo client API in Haxe
package ;
import haxe.Stack;
import neko.Lib;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import MDP;
/**
* Majordomo Protocol Client API
* Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7
*/
class MDCliAPI
{
/** Request timeout (in msec) */
public var timeout:Int;
/** Request #retries */
public var retries:Int;
// Private instance fields
/** Our context */
private var ctx:ZContext;
/** Connection string to reach broker */
private var broker:String;
/** Socket to broker */
private var client:ZMQSocket;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/**
* Constructor
* @param broker
* @param verbose
*/
public function new(broker:String, ?verbose:Bool=false, ?logger:Dynamic->Void) {
ctx = new ZContext();
this.broker = broker;
this.verbose = verbose;
this.timeout = 2500; // msecs
this.retries = 3; // before we abandon
if (logger != null)
log = logger;
else
log = Lib.println;
connectToBroker();
}
/**
* Connect or reconnect to broker
*/
public function connectToBroker() {
if (client != null)
client.close();
client = ctx.createSocket(ZMQ_REQ);
client.setsockopt(ZMQ_LINGER, 0);
client.connect(broker);
if (verbose)
log("I: client connecting to broker at " + broker + "...");
}
/**
* Destructor
*/
public function destroy() {
ctx.destroy();
}
/**
* Send request to broker and get reply by hook or crook.
* Takes ownership of request message and destroys it when sent.
* Returns the reply message or NULL if there was no reply after #retries
* @param service
* @param request
* @return
*/
public function send(service:String, request:ZMsg):ZMsg {
// Prefix request with MDP protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client)
// Frame 2: Service name (printable string)
request.push(ZFrame.newStringFrame(service));
request.push(ZFrame.newStringFrame(MDP.MDPC_CLIENT));
if (verbose) {
log("I: send request to '" + service + "' service:");
log(request.toString());
}
var retries_left = retries;
var poller = new ZMQPoller();
while (retries_left > 0 && !ZMQ.isInterrupted()) {
// We send a request, then we work to get a reply
var msg = request.duplicate();
msg.send(client);
var expect_reply = true;
while (expect_reply) {
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
// Poll socket for a reply, with timeout
try {
var res = poller.poll(timeout * 1000);
} catch (e:ZMQException) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
ctx.destroy();
return null;
}
// If we got a reply, process it
if (poller.pollin(1)) {
// We got a reply from the server, must match sequence
var msg = ZMsg.recvMsg(client);
if (msg == null)
break; // Interrupted
if (verbose)
log("I: received reply:" + msg.toString());
if (msg.size() < 3)
break; // Don't try to handle errors
var header = msg.pop();
if (!header.streq(MDP.MDPC_CLIENT))
break; // Assert
header.destroy();
var reply_service = msg.pop();
if (!reply_service.streq(service))
break; // Assert
reply_service.destroy();
request.destroy();
return msg; // Success
} else if (--retries_left > 0) {
if (verbose)
log("W: no reply, reconnecting...");
// Reconnect , and resend message
connectToBroker();
msg = request.duplicate();
msg.send(client);
} else {
if (verbose)
log("E: permanent error, abandoning");
break;
}
poller.unregisterAllSockets();
}
}
return null;
}
}
mdcliapi: Majordomo client API in Java
package guide;
import java.util.Formatter;
import org.zeromq.*;
/**
* Majordomo Protocol Client API, Java version Implements the MDP/Worker spec at
* http://rfc.zeromq.org/spec:7.
*
*/
public class mdcliapi
{
private String broker;
private ZContext ctx;
private ZMQ.Socket client;
private long timeout = 2500;
private int retries = 3;
private boolean verbose;
private Formatter log = new Formatter(System.out);
public long getTimeout()
{
return timeout;
}
public void setTimeout(long timeout)
{
this.timeout = timeout;
}
public int getRetries()
{
return retries;
}
public void setRetries(int retries)
{
this.retries = retries;
}
public mdcliapi(String broker, boolean verbose)
{
this.broker = broker;
this.verbose = verbose;
ctx = new ZContext();
reconnectToBroker();
}
/**
* Connect or reconnect to broker
*/
void reconnectToBroker()
{
if (client != null) {
ctx.destroySocket(client);
}
client = ctx.createSocket(SocketType.REQ);
client.connect(broker);
if (verbose)
log.format("I: connecting to broker at %s\n", broker);
}
/**
* Send request to broker and get reply by hook or crook Takes ownership of
* request message and destroys it when sent. Returns the reply message or
* NULL if there was no reply.
*
* @param service
* @param request
* @return
*/
public ZMsg send(String service, ZMsg request)
{
request.push(new ZFrame(service));
request.push(MDP.C_CLIENT.newFrame());
if (verbose) {
log.format("I: send request to '%s' service: \n", service);
request.dump(log.out());
}
ZMsg reply = null;
int retriesLeft = retries;
while (retriesLeft > 0 && !Thread.currentThread().isInterrupted()) {
request.duplicate().send(client);
// Poll socket for a reply, with timeout
ZMQ.Poller items = ctx.createPoller(1);
items.register(client, ZMQ.Poller.POLLIN);
if (items.poll(timeout) == -1)
break; // Interrupted
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(client);
if (verbose) {
log.format("I: received reply: \n");
msg.dump(log.out());
}
// Don't try to handle errors, just assert noisily
assert (msg.size() >= 3);
ZFrame header = msg.pop();
assert (MDP.C_CLIENT.equals(header.toString()));
header.destroy();
ZFrame replyService = msg.pop();
assert (service.equals(replyService.toString()));
replyService.destroy();
reply = msg;
break;
}
else {
items.unregister(client);
if (--retriesLeft == 0) {
log.format("W: permanent error, abandoning\n");
break;
}
log.format("W: no reply, reconnecting\n");
reconnectToBroker();
}
items.close();
}
request.destroy();
return reply;
}
public void destroy()
{
ctx.destroy();
}
}
mdcliapi: Majordomo client API in Julia
mdcliapi: Majordomo client API in Lua
--
-- mdcliapi.lua - Majordomo Protocol Client API
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
local setmetatable = setmetatable
local mdp = require"mdp"
local zmq = require"zmq"
local zpoller = require"zmq.poller"
local zmsg = require"zmsg"
require"zhelpers"
local s_version_assert = s_version_assert
local obj_mt = {}
obj_mt.__index = obj_mt
function obj_mt:set_timeout(timeout)
self.timeout = timeout
end
function obj_mt:set_retries(retries)
self.retries = retries
end
function obj_mt:destroy()
if self.client then self.client:close() end
self.context:term()
end
local function s_mdcli_connect_to_broker(self)
-- close old socket.
if self.client then
self.poller:remove(self.client)
self.client:close()
end
self.client = assert(self.context:socket(zmq.REQ))
assert(self.client:setopt(zmq.LINGER, 0))
assert(self.client:connect(self.broker))
if self.verbose then
s_console("I: connecting to broker at %s...", self.broker)
end
-- add socket to poller
self.poller:add(self.client, zmq.POLLIN, function()
self.got_reply = true
end)
end
--
-- Send request to broker and get reply by hook or crook
-- Returns the reply message or nil if there was no reply.
--
function obj_mt:send(service, request)
-- Prefix request with protocol frames
-- Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
-- Frame 2: Service name (printable string)
request:push(service)
request:push(mdp.MDPC_CLIENT)
if self.verbose then
s_console("I: send request to '%s' service:", service)
request:dump()
end
local retries = self.retries
while (retries > 0) do
local msg = request:dup()
msg:send(self.client)
self.got_reply = false
while true do
local cnt = assert(self.poller:poll(self.timeout * 1000))
if cnt ~= 0 and self.got_reply then
local msg = zmsg.recv(self.client)
if self.verbose then
s_console("I: received reply:")
msg:dump()
end
assert(msg:parts() >= 3)
local header = msg:pop()
assert(header == mdp.MDPC_CLIENT)
local reply_service = msg:pop()
assert(reply_service == service)
return msg
else
retries = retries - 1
if (retries > 0) then
if self.verbose then
s_console("W: no reply, reconnecting...")
end
-- Reconnect
s_mdcli_connect_to_broker(self)
break -- outer loop will resend request.
else
if self.verbose then
s_console("W: permanent error, abandoning request")
end
return nil -- Giving up
end
end
end
end
end
module(...)
function new(broker, verbose)
s_version_assert (2, 1);
local self = setmetatable({
context = zmq.init(1),
poller = zpoller.new(1),
broker = broker,
verbose = verbose,
timeout = 2500, -- msecs
retries = 3, -- before we abandon
}, obj_mt)
s_mdcli_connect_to_broker(self)
return self
end
setmetatable(_M, { __call = function(self, ...) return new(...) end })
mdcliapi: Majordomo client API in Node.js
mdcliapi: Majordomo client API in Objective-C
mdcliapi: Majordomo client API in ooc
mdcliapi: Majordomo client API in Perl
mdcliapi: Majordomo client API in PHP
<?php
/* =====================================================================
* mdcliapi.h
*
* Majordomo Protocol Client API
* Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
*/
include_once 'zmsg.php';
include_once 'mdp.php';
class MDCli
{
// Structure of our class
// We access these properties only via class methods
private $broker;
private $context;
private $client; // Socket to broker
private $verbose; // Print activity to stdout
private $timeout; // Request timeout
private $retries; // Request retries
/**
* Constructor
*
* @param string $broker
* @param boolean $verbose
*/
public function __construct($broker, $verbose = false)
{
$this->broker = $broker;
$this->context = new ZMQContext();
$this->verbose = $verbose;
$this->timeout = 2500; // msecs
$this->retries = 3; // Before we abandon
$this->connect_to_broker();
}
/**
* Connect or reconnect to broker
*/
protected function connect_to_broker()
{
if ($this->client) {
unset($this->client);
}
$this->client = new ZMQSocket($this->context, ZMQ::SOCKET_REQ);
$this->client->setSockOpt(ZMQ::SOCKOPT_LINGER, 0);
$this->client->connect($this->broker);
if ($this->verbose) {
printf("I: connecting to broker at %s...", $this->broker);
}
}
/**
* Set request timeout
*
* @param int $timeout (msecs)
*/
public function set_timeout($timeout)
{
$this->timeout = $timeout;
}
/**
* Set request retries
*
* @param int $retries
*/
public function set_retries($retries)
{
$this->retries = $retries;
}
/**
* Send request to broker and get reply by hook or crook
* Takes ownership of request message and destroys it when sent.
* Returns the reply message or NULL if there was no reply.
*
* @param string $service
* @param Zmsg $request
* @param string $client
* @return Zmsg
*/
public function send($service, Zmsg $request)
{
// Prefix request with protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client
// Frame 2: Service name (printable string)
$request->push($service);
$request->push(MDPC_CLIENT);
if ($this->verbose) {
printf ("I: send request to '%s' service:", $service);
echo $request->__toString();
}
$retries_left = $this->retries;
$read = $write = array();
while ($retries_left) {
$request->set_socket($this->client)->send();
// Poll socket for a reply, with timeout
$poll = new ZMQPoll();
$poll->add($this->client, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, $this->timeout);
// If we got a reply, process it
if ($events) {
$request->recv();
if ($this->verbose) {
echo "I: received reply:", $request->__toString(), PHP_EOL;
}
// Don't try to handle errors, just assert noisily
assert ($request->parts() >= 3);
$header = $request->pop();
assert($header == MDPC_CLIENT);
$reply_service = $request->pop();
assert($reply_service == $service);
return $request; // Success
} elseif ($retries_left--) {
if ($this->verbose) {
echo "W: no reply, reconnecting...", PHP_EOL;
}
// Reconnect, and resend message
$this->connect_to_broker();
$request->send();
} else {
echo "W: permanent error, abandoning request", PHP_EOL;
break; // Give up
}
}
}
}
mdcliapi: Majordomo client API in Python
"""Majordomo Protocol Client API, Python version.
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
Author: Min RK <benjaminrk@gmail.com>
Based on Java example by Arkadiusz Orzechowski
"""
import logging
import zmq
import MDP
from zhelpers import dump
class MajorDomoClient(object):
"""Majordomo Protocol Client API, Python version.
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
"""
broker = None
ctx = None
client = None
poller = None
timeout = 2500
retries = 3
verbose = False
def __init__(self, broker, verbose=False):
self.broker = broker
self.verbose = verbose
self.ctx = zmq.Context()
self.poller = zmq.Poller()
logging.basicConfig(format="%(asctime)s %(message)s", datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
self.reconnect_to_broker()
def reconnect_to_broker(self):
"""Connect or reconnect to broker"""
if self.client:
self.poller.unregister(self.client)
self.client.close()
self.client = self.ctx.socket(zmq.REQ)
self.client.linger = 0
self.client.connect(self.broker)
self.poller.register(self.client, zmq.POLLIN)
if self.verbose:
logging.info("I: connecting to broker at %s...", self.broker)
def send(self, service, request):
"""Send request to broker and get reply by hook or crook.
Takes ownership of request message and destroys it when sent.
Returns the reply message or None if there was no reply.
"""
if not isinstance(request, list):
request = [request]
request = [MDP.C_CLIENT, service] + request
if self.verbose:
logging.warn("I: send request to '%s' service: ", service)
dump(request)
reply = None
retries = self.retries
while retries > 0:
self.client.send_multipart(request)
try:
items = self.poller.poll(self.timeout)
except KeyboardInterrupt:
break # interrupted
if items:
msg = self.client.recv_multipart()
if self.verbose:
logging.info("I: received reply:")
dump(msg)
# Don't try to handle errors, just assert noisily
assert len(msg) >= 3
header = msg.pop(0)
assert MDP.C_CLIENT == header
reply_service = msg.pop(0)
assert service == reply_service
reply = msg
break
else:
if retries:
logging.warn("W: no reply, reconnecting...")
self.reconnect_to_broker()
else:
logging.warn("W: permanent error, abandoning")
break
retries -= 1
return reply
def destroy(self):
self.context.destroy()
mdcliapi: Majordomo client API in Q
mdcliapi: Majordomo client API in Racket
mdcliapi: Majordomo client API in Ruby
mdcliapi: Majordomo client API in Rust
mdcliapi: Majordomo client API in Scala
mdcliapi: Majordomo client API in Tcl
mdcliapi: Majordomo client API in OCaml
Let’s see how the client API looks in action, with an example test program that does 100K request-reply cycles:
mdclient: Majordomo client application in Ada
mdclient: Majordomo client application in Basic
mdclient: Majordomo client application in C
// Majordomo Protocol client example
// Uses the mdcli API to hide all MDP aspects
// Lets us build this source without creating a library
#include "mdcliapi.c"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
mdcli_t *session = mdcli_new ("tcp://localhost:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
zmsg_t *request = zmsg_new ();
zmsg_pushstr (request, "Hello world");
zmsg_t *reply = mdcli_send (session, "echo", &request);
if (reply)
zmsg_destroy (&reply);
else
break; // Interrupt or failure
}
printf ("%d requests/replies processed\n", count);
mdcli_destroy (&session);
return 0;
}
mdclient: Majordomo client application in C++
//
// Majordomo Protocol client example
// Uses the mdcli API to hide all MDP aspects
//
// Lets us 'build mdclient' and 'build all'
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "mdcliapi.hpp"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && strcmp (argv [1], "-v") == 0);
mdcli session ("tcp://localhost:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
zmsg * request = new zmsg("Hello world");
zmsg * reply = session.send ("echo", request);
if (reply) {
delete reply;
} else {
break; // Interrupt or failure
}
}
std::cout << count << " requests/replies processed" << std::endl;
return 0;
}
mdclient: Majordomo client application in C#
using System;
using System.Linq;
using System.Threading;
using ZeroMQ;
namespace Examples
{
using MDCliApi; // Let us build this source without creating a library
static partial class Program
{
// Majordomo Protocol client example
// Uses the mdcli API to hide all MDP aspects
public static void MDClient(string[] args)
{
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (s, ea) =>
{
ea.Cancel = true;
cts.Cancel();
};
using (MajordomoClient session = new MajordomoClient("tcp://127.0.0.1:5555", Verbose))
{
int count;
for (count = 0; count < 100000; count++)
{
ZMessage request = new ZMessage();
request.Prepend(new ZFrame("Hello world"));
using (ZMessage reply = session.Send("echo", request, cts))
if (reply == null)
break; // Interrupt or failure
}
Console.WriteLine("{0} requests/replies processed\n", count);
}
}
}
}
mdclient: Majordomo client application in CL
mdclient: Majordomo client application in Delphi
mdclient: Majordomo client application in Erlang
mdclient: Majordomo client application in Elixir
mdclient: Majordomo client application in F#
mdclient: Majordomo client application in Felix
mdclient: Majordomo client application in Go
// Majordomo Protocol client example
// Uses the mdcli API to hide all MDP aspects
//
// To run this example, you may need to run multiple *.go files as below
// go run mdp.go zhelpers.go mdcliapi.go mdclient.go [-v]
//
// Author: iano <scaly.iano@gmail.com>
package main
import (
"fmt"
"os"
)
func main() {
verbose := len(os.Args) >= 2 && os.Args[1] == "-v"
client := NewClient("tcp://localhost:5555", verbose)
defer client.Close()
count := 0
for ; count < 1e5; count++ {
request := [][]byte{[]byte("Hello world")}
reply := client.Send([]byte("echo"), request)
if len(reply) == 0 {
break
}
}
fmt.Printf("%d requests/replies processed\n", count)
}
mdclient: Majordomo client application in Haskell
import MDClientAPI
import ZHelpers
import System.Environment
import Control.Monad (forM_, when)
import Data.ByteString.Char8 (unpack, pack)
main :: IO ()
main = do
args <- getArgs
when (length args /= 1) $
error "usage: mdclient <is_verbose(True|False)>"
let isVerbose = read (args !! 0) :: Bool
withMDCli "tcp://localhost:5555" isVerbose $ \api ->
forM_ [0..10000] $ \i -> do
mdSend api "echo" [pack "Hello world"]
mdclient: Majordomo client application in Haxe
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol client example
* Uses the MDPCli API to hide all MDP aspects
*
* @author Richard J Smith
*/
class MDClient
{
public static function main() {
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var session = new MDCliAPI("tcp://localhost:5555", verbose);
var count = 0;
for (i in 0 ... 100000) {
var request = new ZMsg();
request.pushString("Hello world: "+i);
var reply = session.send("echo", request);
if (reply != null)
reply.destroy();
else
break; // Interrupt or failure
count++;
}
Lib.println(count + " requests/replies processed");
session.destroy();
}
}mdclient: Majordomo client application in Java
package guide;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol client example. Uses the mdcli API to hide all MDP aspects
*/
public class mdclient
{
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && "-v".equals(args[0]));
mdcliapi clientSession = new mdcliapi("tcp://localhost:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
ZMsg request = new ZMsg();
request.addString("Hello world");
ZMsg reply = clientSession.send("echo", request);
if (reply != null)
reply.destroy();
else break; // Interrupt or failure
}
System.out.printf("%d requests/replies processed\n", count);
clientSession.destroy();
}
}
mdclient: Majordomo client application in Julia
mdclient: Majordomo client application in Lua
--
-- Majordomo Protocol client example
-- Uses the mdcli API to hide all MDP aspects
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"mdcliapi"
require"zmsg"
require"zhelpers"
local verbose = (arg[1] == "-v")
local session = mdcliapi.new("tcp://localhost:5555", verbose)
local count=1
repeat
local request = zmsg.new("Hello world")
local reply = session:send("echo", request)
if not reply then
break -- Interrupt or failure
end
count = count + 1
until (count == 100000)
printf("%d requests/replies processed\n", count)
session:destroy()
mdclient: Majordomo client application in Node.js
mdclient: Majordomo client application in Objective-C
mdclient: Majordomo client application in ooc
mdclient: Majordomo client application in Perl
mdclient: Majordomo client application in PHP
<?php
/*
* Majordomo Protocol client example
* Uses the mdcli API to hide all MDP aspects
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'mdcliapi.php';
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$session = new MDCli("tcp://localhost:5555", $verbose);
for ($count = 0; $count < 100000; $count++) {
$request = new Zmsg();
$request->body_set("Hello world");
$reply = $session->send("echo", $request);
if (!$reply) {
break; // Interrupt or failure
}
}
printf ("%d requests/replies processed", $count);
echo PHP_EOL;
mdclient: Majordomo client application in Python
"""
Majordomo Protocol client example. Uses the mdcli API to hide all MDP aspects
Author : Min RK <benjaminrk@gmail.com>
"""
import sys
from mdcliapi import MajorDomoClient
def main():
verbose = '-v' in sys.argv
client = MajorDomoClient("tcp://localhost:5555", verbose)
count = 0
while count < 100000:
request = b"Hello world"
try:
reply = client.send(b"echo", request)
except KeyboardInterrupt:
break
else:
# also break on failure to reply:
if reply is None:
break
count += 1
print ("%i requests/replies processed" % count)
if __name__ == '__main__':
main()
mdclient: Majordomo client application in Q
mdclient: Majordomo client application in Racket
mdclient: Majordomo client application in Ruby
mdclient: Majordomo client application in Rust
mdclient: Majordomo client application in Scala
mdclient: Majordomo client application in Tcl
mdclient: Majordomo client application in OCaml
And here is the worker API:
mdwrkapi: Majordomo worker API in Ada
mdwrkapi: Majordomo worker API in Basic
mdwrkapi: Majordomo worker API in C
// mdwrkapi class - Majordomo Protocol Worker API
// Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
#include "mdwrkapi.h"
// Reliability parameters
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
// .split worker class structure
// This is the structure of a worker API instance. We use a pseudo-OO
// approach in a lot of the C examples, as well as the CZMQ binding:
// Structure of our class
// We access these properties only via class methods
struct _mdwrk_t {
zctx_t *ctx; // Our context
char *broker;
char *service;
void *worker; // Socket to broker
int verbose; // Print activity to stdout
// Heartbeat management
uint64_t heartbeat_at; // When to send HEARTBEAT
size_t liveness; // How many attempts left
int heartbeat; // Heartbeat delay, msecs
int reconnect; // Reconnect delay, msecs
int expect_reply; // Zero only at start
zframe_t *reply_to; // Return identity, if any
};
// .split utility functions
// We have two utility functions; to send a message to the broker and
// to (re)connect to the broker:
// Send message to broker
// If no msg is provided, creates one internally
static void
s_mdwrk_send_to_broker (mdwrk_t *self, char *command, char *option,
zmsg_t *msg)
{
msg = msg? zmsg_dup (msg): zmsg_new ();
// Stack protocol envelope to start of message
if (option)
zmsg_pushstr (msg, option);
zmsg_pushstr (msg, command);
zmsg_pushstr (msg, MDPW_WORKER);
zmsg_pushstr (msg, "");
if (self->verbose) {
zclock_log ("I: sending %s to broker",
mdps_commands [(int) *command]);
zmsg_dump (msg);
}
zmsg_send (&msg, self->worker);
}
// Connect or reconnect to broker
void s_mdwrk_connect_to_broker (mdwrk_t *self)
{
if (self->worker)
zsocket_destroy (self->ctx, self->worker);
self->worker = zsocket_new (self->ctx, ZMQ_DEALER);
zmq_connect (self->worker, self->broker);
if (self->verbose)
zclock_log ("I: connecting to broker at %s...", self->broker);
// Register service with broker
s_mdwrk_send_to_broker (self, MDPW_READY, self->service, NULL);
// If liveness hits zero, queue is considered disconnected
self->liveness = HEARTBEAT_LIVENESS;
self->heartbeat_at = zclock_time () + self->heartbeat;
}
// .split constructor and destructor
// Here we have the constructor and destructor for our mdwrk class:
// Constructor
mdwrk_t *
mdwrk_new (char *broker,char *service, int verbose)
{
assert (broker);
assert (service);
mdwrk_t *self = (mdwrk_t *) zmalloc (sizeof (mdwrk_t));
self->ctx = zctx_new ();
self->broker = strdup (broker);
self->service = strdup (service);
self->verbose = verbose;
self->heartbeat = 2500; // msecs
self->reconnect = 2500; // msecs
s_mdwrk_connect_to_broker (self);
return self;
}
// Destructor
void
mdwrk_destroy (mdwrk_t **self_p)
{
assert (self_p);
if (*self_p) {
mdwrk_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self->broker);
free (self->service);
free (self);
*self_p = NULL;
}
}
// .split configure worker
// We provide two methods to configure the worker API. You can set the
// heartbeat interval and retries to match the expected network performance.
// Set heartbeat delay
void
mdwrk_set_heartbeat (mdwrk_t *self, int heartbeat)
{
self->heartbeat = heartbeat;
}
// Set reconnect delay
void
mdwrk_set_reconnect (mdwrk_t *self, int reconnect)
{
self->reconnect = reconnect;
}
// .split recv method
// This is the {{recv}} method; it's a little misnamed because it first sends
// any reply and then waits for a new request. If you have a better name
// for this, let me know.
// Send reply, if any, to broker and wait for next request.
zmsg_t *
mdwrk_recv (mdwrk_t *self, zmsg_t **reply_p)
{
// Format and send the reply if we were provided one
assert (reply_p);
zmsg_t *reply = *reply_p;
assert (reply || !self->expect_reply);
if (reply) {
assert (self->reply_to);
zmsg_wrap (reply, self->reply_to);
s_mdwrk_send_to_broker (self, MDPW_REPLY, NULL, reply);
zmsg_destroy (reply_p);
}
self->expect_reply = 1;
while (true) {
zmq_pollitem_t items [] = {
{ self->worker, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, self->heartbeat * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
if (items [0].revents & ZMQ_POLLIN) {
zmsg_t *msg = zmsg_recv (self->worker);
if (!msg)
break; // Interrupted
if (self->verbose) {
zclock_log ("I: received message from broker:");
zmsg_dump (msg);
}
self->liveness = HEARTBEAT_LIVENESS;
// Don't try to handle errors, just assert noisily
assert (zmsg_size (msg) >= 3);
zframe_t *empty = zmsg_pop (msg);
assert (zframe_streq (empty, ""));
zframe_destroy (&empty);
zframe_t *header = zmsg_pop (msg);
assert (zframe_streq (header, MDPW_WORKER));
zframe_destroy (&header);
zframe_t *command = zmsg_pop (msg);
if (zframe_streq (command, MDPW_REQUEST)) {
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
self->reply_to = zmsg_unwrap (msg);
zframe_destroy (&command);
// .split process message
// Here is where we actually have a message to process; we
// return it to the caller application:
return msg; // We have a request to process
}
else
if (zframe_streq (command, MDPW_HEARTBEAT))
; // Do nothing for heartbeats
else
if (zframe_streq (command, MDPW_DISCONNECT))
s_mdwrk_connect_to_broker (self);
else {
zclock_log ("E: invalid input message");
zmsg_dump (msg);
}
zframe_destroy (&command);
zmsg_destroy (&msg);
}
else
if (--self->liveness == 0) {
if (self->verbose)
zclock_log ("W: disconnected from broker - retrying...");
zclock_sleep (self->reconnect);
s_mdwrk_connect_to_broker (self);
}
// Send HEARTBEAT if it's time
if (zclock_time () > self->heartbeat_at) {
s_mdwrk_send_to_broker (self, MDPW_HEARTBEAT, NULL, NULL);
self->heartbeat_at = zclock_time () + self->heartbeat;
}
}
if (zctx_interrupted)
printf ("W: interrupt received, killing worker...\n");
return NULL;
}
mdwrkapi: Majordomo worker API in C++
#ifndef __MDWRKAPI_HPP_INCLUDED__
#define __MDWRKAPI_HPP_INCLUDED__
#include "zmsg.hpp"
#include "mdp.h"
// Reliability parameters
// Structure of our class
// We access these properties only via class methods
class mdwrk {
public:
// ---------------------------------------------------------------------
// Constructor
mdwrk (std::string broker, std::string service, int verbose): m_broker(broker), m_service(service),m_verbose(verbose)
{
s_version_assert (4, 0);
m_context = new zmq::context_t (1);
s_catch_signals ();
connect_to_broker ();
}
// ---------------------------------------------------------------------
// Destructor
virtual
~mdwrk ()
{
delete m_worker;
delete m_context;
}
// ---------------------------------------------------------------------
// Send message to broker
// If no _msg is provided, creates one internally
void send_to_broker(const char *command, std::string option, zmsg *_msg)
{
zmsg *msg = _msg? new zmsg(*_msg): new zmsg ();
// Stack protocol envelope to start of message
if (!option.empty()) {
msg->push_front (option.c_str());
}
msg->push_front (command);
msg->push_front (k_mdpw_worker.data());
msg->push_front ("");
if (m_verbose) {
s_console ("I: sending %s to broker",
mdps_commands [(int) *command].data());
msg->dump ();
}
msg->send (*m_worker);
delete msg;
}
// ---------------------------------------------------------------------
// Connect or reconnect to broker
void connect_to_broker ()
{
if (m_worker) {
delete m_worker;
}
m_worker = new zmq::socket_t (*m_context, ZMQ_DEALER);
int linger = 0;
m_worker->setsockopt (ZMQ_LINGER, &linger, sizeof (linger));
s_set_id(*m_worker);
m_worker->connect (m_broker.c_str());
if (m_verbose)
s_console ("I: connecting to broker at %s...", m_broker.c_str());
// Register service with broker
send_to_broker (k_mdpw_ready.data(), m_service, NULL);
// If liveness hits zero, queue is considered disconnected
m_liveness = n_heartbeat_liveness;
m_heartbeat_at = s_clock () + m_heartbeat;
}
// ---------------------------------------------------------------------
// Set heartbeat delay
void
set_heartbeat (int heartbeat)
{
m_heartbeat = heartbeat;
}
// ---------------------------------------------------------------------
// Set reconnect delay
void
set_reconnect (int reconnect)
{
m_reconnect = reconnect;
}
// ---------------------------------------------------------------------
// Send reply, if any, to broker and wait for next request.
zmsg *
recv (zmsg *&reply_p)
{
// Format and send the reply if we were provided one
zmsg *reply = reply_p;
assert (reply || !m_expect_reply);
if (reply) {
assert (m_reply_to.size()!=0);
reply->wrap (m_reply_to.c_str(), "");
m_reply_to = "";
send_to_broker (k_mdpw_reply.data(), "", reply);
delete reply_p;
reply_p = 0;
}
m_expect_reply = true;
while (!s_interrupted) {
zmq::pollitem_t items[] = {
{ *m_worker, 0, ZMQ_POLLIN, 0 } };
zmq::poll (items, 1, m_heartbeat);
if (items[0].revents & ZMQ_POLLIN) {
zmsg *msg = new zmsg(*m_worker);
if (m_verbose) {
s_console ("I: received message from broker:");
msg->dump ();
}
m_liveness = n_heartbeat_liveness;
// Don't try to handle errors, just assert noisily
assert (msg->parts () >= 3);
ustring empty = msg->pop_front ();
assert (empty.compare((unsigned char *)"") == 0);
//assert (strcmp (empty, "") == 0);
//free (empty);
ustring header = msg->pop_front ();
assert (header.compare((unsigned char *)k_mdpw_worker.data()) == 0);
//free (header);
std::string command =(char*) msg->pop_front ().c_str();
if (command.compare (k_mdpw_request.data()) == 0) {
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
m_reply_to = msg->unwrap ();
return msg; // We have a request to process
}
else if (command.compare (k_mdpw_heartbeat.data()) == 0) {
// Do nothing for heartbeats
}
else if (command.compare (k_mdpw_disconnect.data()) == 0) {
connect_to_broker ();
}
else {
s_console ("E: invalid input message (%d)",
(int) *(command.c_str()));
msg->dump ();
}
delete msg;
}
else
if (--m_liveness == 0) {
if (m_verbose) {
s_console ("W: disconnected from broker - retrying...");
}
s_sleep (m_reconnect);
connect_to_broker ();
}
// Send HEARTBEAT if it's time
if (s_clock () >= m_heartbeat_at) {
send_to_broker (k_mdpw_heartbeat.data(), "", NULL);
m_heartbeat_at += m_heartbeat;
}
}
if (s_interrupted)
printf ("W: interrupt received, killing worker...\n");
return NULL;
}
private:
static constexpr uint32_t n_heartbeat_liveness = 3;// 3-5 is reasonable
const std::string m_broker;
const std::string m_service;
zmq::context_t *m_context;
zmq::socket_t *m_worker{}; // Socket to broker
const int m_verbose; // Print activity to stdout
// Heartbeat management
int64_t m_heartbeat_at; // When to send HEARTBEAT
size_t m_liveness; // How many attempts left
int m_heartbeat{2500}; // Heartbeat delay, msecs
int m_reconnect{2500}; // Reconnect delay, msecs
// Internal state
bool m_expect_reply{false}; // Zero only at start
// Return address, if any
std::string m_reply_to;
};
#endif
mdwrkapi: Majordomo worker API in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Runtime.CompilerServices;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
namespace MDWrkApi
{
//
// mdwrkapi class - Majordomo Protocol Worker API
// Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
//
// Author: chubbson
//
public class MajordomoWorker : IDisposable
{
// Structure of our class
// We access these properties only via class methods
// Our context
private ZContext _context;
// Majordomo broker
public string Broker { get; protected set; }
public string Service { get; protected set; }
// Socket to broker
public ZSocket Worker { get; protected set; }
// Print activity to console
public bool Verbose { get; protected set; }
#region Heartbeat management
// When to send HEARTBEAT
public DateTime HeartbeatAt { get; protected set; }
// How many attempts left
public UInt64 Liveness { get; protected set; }
// Heartbeat delay, msecs
public TimeSpan Heartbeat { get; protected set; }
// Reconnect delay, msecs
public TimeSpan Reconnect { get; protected set; }
#endregion
#region Unknown to port
// Zero only at start
private bool _expectReply;
// Return identity, if any
private ZFrame _replyTo;
#endregion
public void SendToBroker(string command, string option, ZMessage msg)
{
using (msg = msg != null ? msg.Duplicate() : new ZMessage())
{
if (!string.IsNullOrEmpty(option))
msg.Prepend(new ZFrame(option));
msg.Prepend(new ZFrame(command));
msg.Prepend(new ZFrame(MdpCommon.MDPW_WORKER));
msg.Prepend(new ZFrame(string.Empty));
if (Verbose)
msg.DumpZmsg("I: sending '{0:X}|{0}' to broker", command.ToMdCmd());
Worker.Send(msg);
}
}
public void ConnectToBroker()
{
// Connect or reconnect to broker
Worker = new ZSocket(_context, ZSocketType.DEALER);
Worker.Connect(Broker);
if (Verbose)
"I: connecting to broker at {0}...".DumpString(Broker);
// Register service with broker
SendToBroker(MdpCommon.MdpwCmd.READY.ToHexString(), Service, null);
// if liveness hits zero, queue is considered disconnected
Liveness = MdpCommon.HEARTBEAT_LIVENESS;
HeartbeatAt = DateTime.UtcNow + Heartbeat;
}
public MajordomoWorker(string broker, string service, bool verbose)
{
if(broker == null)
throw new InvalidOperationException();
if(service == null)
throw new InvalidOperationException();
_context = new ZContext();
Broker = broker;
Service = service;
Verbose = verbose;
Heartbeat = MdpCommon.HEARTBEAT_DELAY;
Reconnect = MdpCommon.RECONNECT_DELAY;
ConnectToBroker();
}
~MajordomoWorker()
{
Dispose(false);
}
public void Dispose()
{
GC.SuppressFinalize(this);
Dispose(true);
}
protected void Dispose(bool disposing)
{
if (disposing)
{
// Destructor
if (Worker != null)
{
Worker.Dispose();
Worker = null;
}
//Do not Dispose Context: cuz of weird shutdown behavior, stucks in using calls
}
}
// .split configure worker
// We provide two methods to configure the worker API. You can set the
// heartbeat interval and retries to match the expected network performance.
// Set heartbeat delay
public void Set_Heartbeat(int heartbeatInMs)
{
Heartbeat = TimeSpan.FromMilliseconds(heartbeatInMs);
}
// Set reconnect delay
public void Set_Reconnect(int reconnectInMs)
{
Reconnect = TimeSpan.FromMilliseconds(reconnectInMs);
}
// .split recv method
// This is the {{recv}} method; it's a little misnamed because it first sends
// any reply and then waits for a new request. If you have a better name
// for this, let me know.
// Send reply, if any, to broker and wait for next request.
public ZMessage Recv(ZMessage reply, CancellationTokenSource cancellor)
{
if (reply == null
&& _expectReply)
throw new InvalidOperationException();
if (reply != null)
{
if(_replyTo == null)
throw new InvalidOperationException();
reply.Wrap(_replyTo);
SendToBroker(MdpCommon.MdpwCmd.REPLY.ToHexString(), string.Empty, reply);
}
_expectReply = true;
while (true)
{
if (cancellor.IsCancellationRequested
|| (Console.KeyAvailable && Console.ReadKey(true).Key == ConsoleKey.Escape))
_context.Shutdown();
var p = ZPollItem.CreateReceiver();
ZMessage msg;
ZError error;
if (Worker.PollIn(p, out msg, out error, Heartbeat))
{
using (msg)
{
// If we got a reply
if (Verbose)
msg.DumpZmsg("I: received message from broker:");
Liveness = MdpCommon.HEARTBEAT_LIVENESS;
// Don't try to handle errors, just assert noisily
if(msg.Count < 3)
throw new InvalidOperationException();
using (ZFrame empty = msg.Pop())
{
if (!empty.ToString().Equals(""))
throw new InvalidOperationException();
}
using (ZFrame header = msg.Pop())
{
if (!header.ToString().Equals(MdpCommon.MDPW_WORKER))
throw new InvalidOperationException();
}
//header.ReadString().Equals(MDPW_WORKER);
using (ZFrame command = msg.Pop())
{
if (command.StrHexEq(MdpCommon.MdpwCmd.REQUEST))
{
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
_replyTo = msg.Unwrap();
// .split process message
// Here is where we actually have a message to process; we
// return it to the caller application:
return msg.Duplicate();
}
else if (command.StrHexEq(MdpCommon.MdpwCmd.HEARTBEAT))
{
// Do nothing for heartbeats
}
else if (command.StrHexEq(MdpCommon.MdpwCmd.DISCONNECT))
{
ConnectToBroker();
}
else
"E: invalid input message: '{0}'".DumpString(command.ToString());
}
}
}
else if (Equals(error, ZError.ETERM))
{
cancellor.Cancel();
break; // Interrupted
}
else if (Equals(error, ZError.EAGAIN)
&& --Liveness == 0)
{
if (Verbose)
"W: disconnected from broker - retrying...".DumpString();
Thread.Sleep(Reconnect);
ConnectToBroker();
}
// Send HEARTBEAT if it's time
if (DateTime.UtcNow > HeartbeatAt)
{
SendToBroker(MdpCommon.MdpwCmd.HEARTBEAT.ToHexString(), null, null);
HeartbeatAt = DateTime.UtcNow + Heartbeat;
}
}
if (cancellor.IsCancellationRequested)
"W: interrupt received, killing worker...\n".DumpString();
return null;
}
}
}
}
mdwrkapi: Majordomo worker API in CL
mdwrkapi: Majordomo worker API in Delphi
mdwrkapi: Majordomo worker API in Erlang
mdwrkapi: Majordomo worker API in Elixir
mdwrkapi: Majordomo worker API in F#
mdwrkapi: Majordomo worker API in Felix
mdwrkapi: Majordomo worker API in Go
// mdwrkapi class - Majordomo Protocol Worker API
// Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
zmq "github.com/alecthomas/gozmq"
"log"
"time"
)
type Worker interface {
Close()
Recv([][]byte) [][]byte
}
type mdWorker struct {
broker string
context *zmq.Context
service string
verbose bool
worker *zmq.Socket
heartbeat time.Duration
heartbeatAt time.Time
liveness int
reconnect time.Duration
expectReply bool
replyTo []byte
}
func NewWorker(broker, service string, verbose bool) Worker {
context, _ := zmq.NewContext()
self := &mdWorker{
broker: broker,
context: context,
service: service,
verbose: verbose,
heartbeat: 2500 * time.Millisecond,
liveness: 0,
reconnect: 2500 * time.Millisecond,
}
self.reconnectToBroker()
return self
}
func (self *mdWorker) reconnectToBroker() {
if self.worker != nil {
self.worker.Close()
}
self.worker, _ = self.context.NewSocket(zmq.DEALER)
self.worker.SetLinger(0)
self.worker.Connect(self.broker)
if self.verbose {
log.Printf("I: connecting to broker at %s...\n", self.broker)
}
self.sendToBroker(MDPW_READY, []byte(self.service), nil)
self.liveness = HEARTBEAT_LIVENESS
self.heartbeatAt = time.Now().Add(self.heartbeat)
}
func (self *mdWorker) sendToBroker(command string, option []byte, msg [][]byte) {
if len(option) > 0 {
msg = append([][]byte{option}, msg...)
}
msg = append([][]byte{nil, []byte(MDPW_WORKER), []byte(command)}, msg...)
if self.verbose {
log.Printf("I: sending %X to broker\n", command)
Dump(msg)
}
self.worker.SendMultipart(msg, 0)
}
func (self *mdWorker) Close() {
if self.worker != nil {
self.worker.Close()
}
self.context.Close()
}
func (self *mdWorker) Recv(reply [][]byte) (msg [][]byte) {
// Format and send the reply if we were provided one
if len(reply) == 0 && self.expectReply {
panic("Error reply")
}
if len(reply) > 0 {
if len(self.replyTo) == 0 {
panic("Error replyTo")
}
reply = append([][]byte{self.replyTo, nil}, reply...)
self.sendToBroker(MDPW_REPLY, nil, reply)
}
self.expectReply = true
for {
items := zmq.PollItems{
zmq.PollItem{Socket: self.worker, Events: zmq.POLLIN},
}
_, err := zmq.Poll(items, self.heartbeat)
if err != nil {
panic(err) // Interrupted
}
if item := items[0]; item.REvents&zmq.POLLIN != 0 {
msg, _ = self.worker.RecvMultipart(0)
if self.verbose {
log.Println("I: received message from broker: ")
Dump(msg)
}
self.liveness = HEARTBEAT_LIVENESS
if len(msg) < 3 {
panic("Invalid msg") // Interrupted
}
header := msg[1]
if string(header) != MDPW_WORKER {
panic("Invalid header") // Interrupted
}
switch command := string(msg[2]); command {
case MDPW_REQUEST:
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
self.replyTo = msg[3]
msg = msg[5:]
return
case MDPW_HEARTBEAT:
// do nothin
case MDPW_DISCONNECT:
self.reconnectToBroker()
default:
log.Println("E: invalid input message:")
Dump(msg)
}
} else if self.liveness--; self.liveness <= 0 {
if self.verbose {
log.Println("W: disconnected from broker - retrying...")
}
time.Sleep(self.reconnect)
self.reconnectToBroker()
}
// Send HEARTBEAT if it's time
if self.heartbeatAt.Before(time.Now()) {
self.sendToBroker(MDPW_HEARTBEAT, nil, nil)
self.heartbeatAt = time.Now().Add(self.heartbeat)
}
}
return
}
mdwrkapi: Majordomo worker API in Haskell
mdwrkapi: Majordomo worker API in Haxe
package ;
import MDP;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
/**
* Majordomo Protocol Worker API
* Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7
*/
class MDWrkAPI
{
/** When to send HEARTBEAT */
public var heartbeatAt:Float;
/** Reconnect delay, in msecs */
public var reconnect:Int;
// Private instance fields
/** Our context */
private var ctx:ZContext;
/** Connection string to broker */
private var broker:String;
/** Socket to broker */
private var worker:ZMQSocket;
/** Defines service string provided by this worker */
private var service:String;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/** How many attempts left */
private var liveness:Int;
/** Heartbeat delay, in msecs */
private var heartbeat:Int;
/** Internal state */
private var expect_reply:Bool;
/** Return address frame, if any */
private var replyTo:ZFrame;
/** Reliability parameters */
private static inline var HEARTBEAT_LIVENESS = 3;
/**
* Constructor
* @param broker
* @param service
* @param ?verbose
* @param ?logger
*/
public function new(broker:String, service:String, ?verbose:Bool = false, ?logger:Dynamic->Void) {
ctx = new ZContext();
this.broker = broker;
this.service = service;
this.verbose = verbose;
this.heartbeat = 2500; // msecs
this.reconnect = 2500; // msecs
if (logger != null)
log = logger;
else
log = neko.Lib.println;
expect_reply = false;
connectToBroker();
}
/**
* Connect or reconnect to broker
*/
public function connectToBroker() {
if (worker != null)
worker.close();
worker = ctx.createSocket(ZMQ_DEALER);
worker.setsockopt(ZMQ_LINGER, 0);
worker.connect(broker);
if (verbose)
log("I: worker connecting to broker at " + broker + "...");
sendToBroker(MDP.MDPW_READY, service);
// If liveness hits zero, queue is considered disconnected
liveness = HEARTBEAT_LIVENESS;
heartbeatAt = Date.now().getTime() + heartbeat;
}
/**
* Destructor
*/
public function destroy() {
ctx.destroy();
}
/**
* Send message to broker
* If no msg is provided, creates one internally
*
* @param command
* @param option
* @param ?msg
*/
public function sendToBroker(command:String, option:String, ?msg:ZMsg) {
var _msg:ZMsg = { if (msg != null) msg.duplicate(); else new ZMsg(); }
// Stack protocol envelope to start of message
if (option != null) {
_msg.pushString(option);
}
_msg.pushString(command);
_msg.pushString(MDP.MDPW_WORKER);
_msg.pushString("");
if (verbose)
log("I: sending " + MDP.MDPS_COMMANDS[command.charCodeAt(0)] + " to broker " + _msg.toString());
_msg.send(worker);
}
/**
* Send reply, if any, to broker and wait for next request
*
* @param reply Message to send back. Destroyed if send if successful
* @return ZMsg Returns if there is a request to process
*/
public function recv(?reply:ZMsg):ZMsg {
if (reply == null && expect_reply)
return null;
if (reply != null) {
if (replyTo == null)
return null; // Cannot send if we dont know which client to reply to
reply.wrap(replyTo);
sendToBroker(MDP.MDPW_REPLY, null, reply);
reply.destroy();
}
expect_reply = true;
var poller = new ZMQPoller();
poller.registerSocket(worker, ZMQ.ZMQ_POLLIN());
while (true) {
// Poll socket for a reply, with timeout
try {
var res = poller.poll(heartbeat * 1000);
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else {
Lib.println("W: interrupt received, killing worker...");
}
ctx.destroy();
return null;
}
if (poller.pollin(1)) {
var msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
if (verbose)
log("I: received message from broker:" + msg.toString());
liveness = HEARTBEAT_LIVENESS;
if (msg.size() < 2)
return null; // Don't handle errors, just quit quietly
msg.pop();
var header = msg.pop();
if (!header.streq(MDP.MDPW_WORKER))
return null; // Don't handle errors, just quit quietly
header.destroy();
var command = msg.pop();
if (command.streq(MDP.MDPW_REQUEST)) {
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
replyTo = msg.unwrap();
command.destroy();
return msg; // We have a request to process
} else if (command.streq(MDP.MDPW_HEARTBEAT)) {
// Do nothing for heartbeats
} else if (command.streq(MDP.MDPW_DISCONNECT)) {
connectToBroker();
poller.unregisterAllSockets();
poller.registerSocket(worker, ZMQ.ZMQ_POLLIN());
} else {
log("E: invalid input message:" + msg.toString());
}
command.destroy();
msg.destroy();
} else if (--liveness == 0) {
if (verbose)
log("W: disconnected from broker - retrying...");
Sys.sleep(reconnect / 1000);
connectToBroker();
poller.unregisterAllSockets();
poller.registerSocket(worker, ZMQ.ZMQ_POLLIN());
}
// Send HEARTBEAT if it's time
if (Date.now().getTime() > heartbeatAt) {
sendToBroker(MDP.MDPW_HEARTBEAT, null, null);
heartbeatAt = Date.now().getTime() + heartbeat;
}
}
return null;
}
}
mdwrkapi: Majordomo worker API in Java
package guide;
import java.util.Formatter;
import org.zeromq.*;
/**
* Majordomo Protocol Client API, Java version Implements the MDP/Worker spec at
* http://rfc.zeromq.org/spec:7.
*/
public class mdwrkapi
{
private static final int HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
private String broker;
private ZContext ctx;
private String service;
private ZMQ.Socket worker; // Socket to broker
private long heartbeatAt; // When to send HEARTBEAT
private int liveness; // How many attempts left
private int heartbeat = 2500; // Heartbeat delay, msecs
private int reconnect = 2500; // Reconnect delay, msecs
// Internal state
private boolean expectReply = false; // false only at start
private long timeout = 2500;
private boolean verbose; // Print activity to stdout
private Formatter log = new Formatter(System.out);
// Return address, if any
private ZFrame replyTo;
public mdwrkapi(String broker, String service, boolean verbose)
{
assert (broker != null);
assert (service != null);
this.broker = broker;
this.service = service;
this.verbose = verbose;
ctx = new ZContext();
reconnectToBroker();
}
/**
* Send message to broker If no msg is provided, creates one internally
*
* @param command
* @param option
* @param msg
*/
void sendToBroker(MDP command, String option, ZMsg msg)
{
msg = msg != null ? msg.duplicate() : new ZMsg();
// Stack protocol envelope to start of message
if (option != null)
msg.addFirst(new ZFrame(option));
msg.addFirst(command.newFrame());
msg.addFirst(MDP.W_WORKER.newFrame());
msg.addFirst(new ZFrame(ZMQ.MESSAGE_SEPARATOR));
if (verbose) {
log.format("I: sending %s to broker\n", command);
msg.dump(log.out());
}
msg.send(worker);
}
/**
* Connect or reconnect to broker
*/
void reconnectToBroker()
{
if (worker != null) {
ctx.destroySocket(worker);
}
worker = ctx.createSocket(SocketType.DEALER);
worker.connect(broker);
if (verbose)
log.format("I: connecting to broker at %s\n", broker);
// Register service with broker
sendToBroker(MDP.W_READY, service, null);
// If liveness hits zero, queue is considered disconnected
liveness = HEARTBEAT_LIVENESS;
heartbeatAt = System.currentTimeMillis() + heartbeat;
}
/**
* Send reply, if any, to broker and wait for next request.
*/
public ZMsg receive(ZMsg reply)
{
// Format and send the reply if we were provided one
assert (reply != null || !expectReply);
if (reply != null) {
assert (replyTo != null);
reply.wrap(replyTo);
sendToBroker(MDP.W_REPLY, null, reply);
reply.destroy();
}
expectReply = true;
while (!Thread.currentThread().isInterrupted()) {
// Poll socket for a reply, with timeout
ZMQ.Poller items = ctx.createPoller(1);
items.register(worker, ZMQ.Poller.POLLIN);
if (items.poll(timeout) == -1)
break; // Interrupted
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
if (verbose) {
log.format("I: received message from broker: \n");
msg.dump(log.out());
}
liveness = HEARTBEAT_LIVENESS;
// Don't try to handle errors, just assert noisily
assert (msg != null && msg.size() >= 3);
ZFrame empty = msg.pop();
assert (empty.getData().length == 0);
empty.destroy();
ZFrame header = msg.pop();
assert (MDP.W_WORKER.frameEquals(header));
header.destroy();
ZFrame command = msg.pop();
if (MDP.W_REQUEST.frameEquals(command)) {
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one
replyTo = msg.unwrap();
command.destroy();
return msg; // We have a request to process
}
else if (MDP.W_HEARTBEAT.frameEquals(command)) {
// Do nothing for heartbeats
}
else if (MDP.W_DISCONNECT.frameEquals(command)) {
reconnectToBroker();
}
else {
log.format("E: invalid input message: \n");
msg.dump(log.out());
}
command.destroy();
msg.destroy();
}
else if (--liveness == 0) {
if (verbose)
log.format("W: disconnected from broker - retrying\n");
try {
Thread.sleep(reconnect);
}
catch (InterruptedException e) {
Thread.currentThread().interrupt(); // Restore the
// interrupted status
break;
}
reconnectToBroker();
}
// Send HEARTBEAT if it's time
if (System.currentTimeMillis() > heartbeatAt) {
sendToBroker(MDP.W_HEARTBEAT, null, null);
heartbeatAt = System.currentTimeMillis() + heartbeat;
}
items.close();
}
if (Thread.currentThread().isInterrupted())
log.format("W: interrupt received, killing worker\n");
return null;
}
public void destroy()
{
ctx.destroy();
}
// ============== getters and setters =================
public int getHeartbeat()
{
return heartbeat;
}
public void setHeartbeat(int heartbeat)
{
this.heartbeat = heartbeat;
}
public int getReconnect()
{
return reconnect;
}
public void setReconnect(int reconnect)
{
this.reconnect = reconnect;
}
}
mdwrkapi: Majordomo worker API in Julia
mdwrkapi: Majordomo worker API in Lua
--
-- mdwrkapi.lua - Majordomo Protocol Worker API
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
local HEARTBEAT_LIVENESS = 3 -- 3-5 is reasonable
local setmetatable = setmetatable
local mdp = require"mdp"
local zmq = require"zmq"
local zpoller = require"zmq.poller"
local zmsg = require"zmsg"
require"zhelpers"
local s_version_assert = s_version_assert
local obj_mt = {}
obj_mt.__index = obj_mt
function obj_mt:set_heartbeat(heartbeat)
self.heartbeat = heartbeat
end
function obj_mt:set_reconnect(reconnect)
self.reconnect = reconnect
end
function obj_mt:destroy()
if self.worker then self.worker:close() end
self.context:term()
end
-- Send message to broker
-- If no msg is provided, create one internally
local function s_mdwrk_send_to_broker(self, command, option, msg)
msg = msg or zmsg.new()
-- Stack protocol envelope to start of message
if option then
msg:push(option)
end
msg:push(command)
msg:push(mdp.MDPW_WORKER)
msg:push("")
if self.verbose then
s_console("I: sending %s to broker", mdp.mdps_commands[command])
msg:dump()
end
msg:send(self.worker)
end
local function s_mdwrk_connect_to_broker(self)
-- close old socket.
if self.worker then
self.poller:remove(self.worker)
self.worker:close()
end
self.worker = assert(self.context:socket(zmq.DEALER))
assert(self.worker:setopt(zmq.LINGER, 0))
assert(self.worker:connect(self.broker))
if self.verbose then
s_console("I: connecting to broker at %s...", self.broker)
end
-- Register service with broker
s_mdwrk_send_to_broker(self, mdp.MDPW_READY, self.service)
-- If liveness hits zero, queue is considered disconnected
self.liveness = HEARTBEAT_LIVENESS
self.heartbeat_at = s_clock() + self.heartbeat
-- add socket to poller
self.poller:add(self.worker, zmq.POLLIN, function()
self.got_msg = true
end)
end
--
-- Send reply, if any, to broker and wait for next request.
--
function obj_mt:recv(reply)
-- Format and send the reply if we are provided one
if reply then
assert(self.reply_to)
reply:wrap(self.reply_to, "")
self.reply_to = nil
s_mdwrk_send_to_broker(self, mdp.MDPW_REPLY, nil, reply)
end
self.expect_reply = true
self.got_msg = false
while true do
local cnt = assert(self.poller:poll(self.heartbeat * 1000))
if cnt ~= 0 and self.got_msg then
self.got_msg = false
local msg = zmsg.recv(self.worker)
if self.verbose then
s_console("I: received message from broker:")
msg:dump()
end
self.liveness = HEARTBEAT_LIVENESS
-- Don't try to handle errors, just assert noisily
assert(msg:parts() >= 3)
local empty = msg:pop()
assert(empty == "")
local header = msg:pop()
assert(header == mdp.MDPW_WORKER)
local command = msg:pop()
if command == mdp.MDPW_REQUEST then
-- We should pop and save as many addresses as there are
-- up to a null part, but for now, just save one...
self.reply_to = msg:unwrap()
return msg -- We have a request to process
elseif command == mdp.MDPW_HEARTBEAT then
-- Do nothing for heartbeats
elseif command == mdp.MDPW_DISCONNECT then
-- dis-connect and re-connect to broker.
s_mdwrk_connect_to_broker(self)
else
s_console("E: invalid input message (%d)", command:byte(1,1))
msg:dump()
end
else
self.liveness = self.liveness - 1
if (self.liveness == 0) then
if self.verbose then
s_console("W: disconnected from broker - retrying...")
end
-- sleep then Reconnect
s_sleep(self.reconnect)
s_mdwrk_connect_to_broker(self)
end
-- Send HEARTBEAT if it's time
if (s_clock() > self.heartbeat_at) then
s_mdwrk_send_to_broker(self, mdp.MDPW_HEARTBEAT)
self.heartbeat_at = s_clock() + self.heartbeat
end
end
end
end
module(...)
function new(broker, service, verbose)
s_version_assert(2, 1);
local self = setmetatable({
context = zmq.init(1),
poller = zpoller.new(1),
broker = broker,
service = service,
verbose = verbose,
heartbeat = 2500, -- msecs
reconnect = 2500, -- msecs
}, obj_mt)
s_mdwrk_connect_to_broker(self)
return self
end
setmetatable(_M, { __call = function(self, ...) return new(...) end })
mdwrkapi: Majordomo worker API in Node.js
mdwrkapi: Majordomo worker API in Objective-C
mdwrkapi: Majordomo worker API in ooc
mdwrkapi: Majordomo worker API in Perl
mdwrkapi: Majordomo worker API in PHP
<?php
/* =====================================================================
* mdwrkapi.php
*
* Majordomo Protocol Worker API
* Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
*/
include_once 'zmsg.php';
include_once 'mdp.php';
// Reliability parameters
define("HEARTBEAT_LIVENESS", 3); // 3-5 is reasonable
// Structure of our class
// We access these properties only via class methods
class MDWrk
{
private $ctx; // Our context
private $broker;
private $service;
private $worker; // Socket to broker
private $verbose = false; // Print activity to stdout
// Heartbeat management
private $heartbeat_at; // When to send HEARTBEAT
private $liveness; // How many attempts left
private $heartbeat; // Heartbeat delay, msecs
private $reconnect; // Reconnect delay, msecs
// Internal state
private $expect_reply = 0;
// Return address, if any
private $reply_to;
/**
* Constructor
*
* @param string $broker
* @param string $service
* @param boolean $verbose
*/
public function __construct($broker, $service, $verbose = false)
{
$this->ctx = new ZMQContext();
$this->broker = $broker;
$this->service = $service;
$this->verbose = $verbose;
$this->heartbeat = 2500; // msecs
$this->reconnect = 2500; // msecs
$this->connect_to_broker();
}
/**
* Send message to broker
* If no msg is provided, creates one internally
*
* @param string $command
* @param string $option
* @param Zmsg $msg
*/
public function send_to_broker($command, $option, $msg = null)
{
$msg = $msg ? $msg : new Zmsg();
if ($option) {
$msg->push($option);
}
$msg->push($command);
$msg->push(MDPW_WORKER);
$msg->push("");
if ($this->verbose) {
printf("I: sending %s to broker %s", $command, PHP_EOL);
echo $msg->__toString();
}
$msg->set_socket($this->worker)->send();
}
/**
* Connect or reconnect to broker
*/
public function connect_to_broker()
{
$this->worker = new ZMQSocket($this->ctx, ZMQ::SOCKET_DEALER);
$this->worker->connect($this->broker);
if ($this->verbose) {
printf("I: connecting to broker at %s... %s", $this->broker, PHP_EOL);
}
// Register service with broker
$this->send_to_broker(MDPW_READY, $this->service, NULL);
// If liveness hits zero, queue is considered disconnected
$this->liveness = HEARTBEAT_LIVENESS;
$this->heartbeat_at = microtime(true) + ($this->heartbeat / 1000);
}
/**
* Set heartbeat delay
*
* @param int $heartbeat
*/
public function set_heartbeat($heartbeat)
{
$this->heartbeat = $heartbeat;
}
/**
* Set reconnect delay
*
* @param int $reconnect
*/
public function set_reconnect($reconnect)
{
$this->reconnect = $reconnect;
}
/**
* Send reply, if any, to broker and wait for next request.
*
* @param Zmsg $reply
* @return Zmsg Returns if there is a request to process
*/
public function recv($reply = null)
{
// Format and send the reply if we were provided one
assert ($reply || !$this->expect_reply);
if ($reply) {
$reply->wrap($this->reply_to);
$this->send_to_broker(MDPW_REPLY, NULL, $reply);
}
$this->expect_reply = true;
$read = $write = array();
while (true) {
$poll = new ZMQPoll();
$poll->add($this->worker, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, $this->heartbeat);
if ($events) {
$zmsg = new Zmsg($this->worker);
$zmsg->recv();
if ($this->verbose) {
echo "I: received message from broker:", PHP_EOL;
echo $zmsg->__toString();
}
$this->liveness = HEARTBEAT_LIVENESS;
// Don't try to handle errors, just assert noisily
assert ($zmsg->parts() >= 3);
$zmsg->pop();
$header = $zmsg->pop();
assert($header == MDPW_WORKER);
$command = $zmsg->pop();
if ($command == MDPW_REQUEST) {
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
$this->reply_to = $zmsg->unwrap();
return $zmsg;// We have a request to process
} elseif ($command == MDPW_HEARTBEAT) {
// Do nothing for heartbeats
} elseif ($command == MDPW_DISCONNECT) {
$this->connect_to_broker();
} else {
echo "E: invalid input message", PHP_EOL;
echo $zmsg->__toString();
}
} elseif (--$this->liveness == 0) { // poll ended on timeout, $event being false
if ($this->verbose) {
echo "W: disconnected from broker - retrying...", PHP_EOL;
}
usleep($this->reconnect*1000);
$this->connect_to_broker();
}
// Send HEARTBEAT if it's time
if (microtime(true) > $this->heartbeat_at) {
$this->send_to_broker(MDPW_HEARTBEAT, NULL, NULL);
$this->heartbeat_at = microtime(true) + ($this->heartbeat/1000);
}
}
}
}
mdwrkapi: Majordomo worker API in Python
"""Majordomo Protocol Worker API, Python version
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
Author: Min RK <benjaminrk@gmail.com>
Based on Java example by Arkadiusz Orzechowski
"""
import logging
import time
import zmq
from zhelpers import dump
# MajorDomo protocol constants:
import MDP
class MajorDomoWorker(object):
"""Majordomo Protocol Worker API, Python version
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
"""
HEARTBEAT_LIVENESS = 3 # 3-5 is reasonable
broker = None
ctx = None
service = None
worker = None # Socket to broker
heartbeat_at = 0 # When to send HEARTBEAT (relative to time.time(), so in seconds)
liveness = 0 # How many attempts left
heartbeat = 2500 # Heartbeat delay, msecs
reconnect = 2500 # Reconnect delay, msecs
# Internal state
expect_reply = False # False only at start
timeout = 2500 # poller timeout
verbose = False # Print activity to stdout
# Return address, if any
reply_to = None
def __init__(self, broker, service, verbose=False):
self.broker = broker
self.service = service
self.verbose = verbose
self.ctx = zmq.Context()
self.poller = zmq.Poller()
logging.basicConfig(format="%(asctime)s %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
self.reconnect_to_broker()
def reconnect_to_broker(self):
"""Connect or reconnect to broker"""
if self.worker:
self.poller.unregister(self.worker)
self.worker.close()
self.worker = self.ctx.socket(zmq.DEALER)
self.worker.linger = 0
self.worker.connect(self.broker)
self.poller.register(self.worker, zmq.POLLIN)
if self.verbose:
logging.info("I: connecting to broker at %s...", self.broker)
# Register service with broker
self.send_to_broker(MDP.W_READY, self.service, [])
# If liveness hits zero, queue is considered disconnected
self.liveness = self.HEARTBEAT_LIVENESS
self.heartbeat_at = time.time() + 1e-3 * self.heartbeat
def send_to_broker(self, command, option=None, msg=None):
"""Send message to broker.
If no msg is provided, creates one internally
"""
if msg is None:
msg = []
elif not isinstance(msg, list):
msg = [msg]
if option:
msg = [option] + msg
msg = [b'', MDP.W_WORKER, command] + msg
if self.verbose:
logging.info("I: sending %s to broker", command)
dump(msg)
self.worker.send_multipart(msg)
def recv(self, reply=None):
"""Send reply, if any, to broker and wait for next request."""
# Format and send the reply if we were provided one
assert reply is not None or not self.expect_reply
if reply is not None:
assert self.reply_to is not None
reply = [self.reply_to, b''] + reply
self.send_to_broker(MDP.W_REPLY, msg=reply)
self.expect_reply = True
while True:
# Poll socket for a reply, with timeout
try:
items = self.poller.poll(self.timeout)
except KeyboardInterrupt:
break # Interrupted
if items:
msg = self.worker.recv_multipart()
if self.verbose:
logging.info("I: received message from broker: ")
dump(msg)
self.liveness = self.HEARTBEAT_LIVENESS
# Don't try to handle errors, just assert noisily
assert len(msg) >= 3
empty = msg.pop(0)
assert empty == b''
header = msg.pop(0)
assert header == MDP.W_WORKER
command = msg.pop(0)
if command == MDP.W_REQUEST:
# We should pop and save as many addresses as there are
# up to a null part, but for now, just save one...
self.reply_to = msg.pop(0)
# pop empty
empty = msg.pop(0)
assert empty == b''
return msg # We have a request to process
elif command == MDP.W_HEARTBEAT:
# Do nothing for heartbeats
pass
elif command == MDP.W_DISCONNECT:
self.reconnect_to_broker()
else :
logging.error("E: invalid input message: ")
dump(msg)
else:
self.liveness -= 1
if self.liveness == 0:
if self.verbose:
logging.warn("W: disconnected from broker - retrying...")
try:
time.sleep(1e-3*self.reconnect)
except KeyboardInterrupt:
break
self.reconnect_to_broker()
# Send HEARTBEAT if it's time
if time.time() > self.heartbeat_at:
self.send_to_broker(MDP.W_HEARTBEAT)
self.heartbeat_at = time.time() + 1e-3*self.heartbeat
logging.warn("W: interrupt received, killing worker...")
return None
def destroy(self):
# context.destroy depends on pyzmq >= 2.1.10
self.ctx.destroy(0)
mdwrkapi: Majordomo worker API in Q
mdwrkapi: Majordomo worker API in Racket
mdwrkapi: Majordomo worker API in Ruby
mdwrkapi: Majordomo worker API in Rust
mdwrkapi: Majordomo worker API in Scala
mdwrkapi: Majordomo worker API in Tcl
mdwrkapi: Majordomo worker API in OCaml
Let’s see how the worker API looks in action, with an example test program that implements an echo service:
mdworker: Majordomo worker application in Ada
mdworker: Majordomo worker application in Basic
mdworker: Majordomo worker application in C
// Majordomo Protocol worker example
// Uses the mdwrk API to hide all MDP aspects
// Lets us build this source without creating a library
#include "mdwrkapi.c"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
mdwrk_t *session = mdwrk_new (
"tcp://localhost:5555", "echo", verbose);
zmsg_t *reply = NULL;
while (true) {
zmsg_t *request = mdwrk_recv (session, &reply);
if (request == NULL)
break; // Worker was interrupted
reply = request; // Echo is complex... :-)
}
mdwrk_destroy (&session);
return 0;
}
mdworker: Majordomo worker application in C++
//
// Majordomo Protocol worker example
// Uses the mdwrk API to hide all MDP aspects
//
// Lets us 'build mdworker' and 'build all'
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "mdwrkapi.hpp"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && strcmp (argv [1], "-v") == 0);
mdwrk session ("tcp://localhost:5555", "echo", verbose);
zmsg *reply = 0;
while (1) {
zmsg *request = session.recv (reply);
if (request == 0) {
break; // Worker was interrupted
}
reply = request; // Echo is complex... :-)
}
return 0;
}
mdworker: Majordomo worker application in C#
using System;
using System.Linq;
using System.Threading;
using ZeroMQ;
namespace Examples
{
using MDWrkApi; // Let us build this source without creating a library
static partial class Program
{
// Majordomo Protocol worker example
// Uses the mdwrk API to hide all MDP aspects
public static void MDWorker(string[] args)
{
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (s, ea) =>
{
ea.Cancel = true;
cts.Cancel();
};
using (MajordomoWorker session = new MajordomoWorker("tcp://127.0.0.1:5555", "echo", Verbose))
{
ZMessage reply = null;
while (true)
{
ZMessage request = session.Recv(reply, cts);
if (request == null)
break; // worker was interrupted
reply = request; // Echo is complex
}
}
}
}
}
mdworker: Majordomo worker application in CL
mdworker: Majordomo worker application in Delphi
mdworker: Majordomo worker application in Erlang
mdworker: Majordomo worker application in Elixir
mdworker: Majordomo worker application in F#
mdworker: Majordomo worker application in Felix
mdworker: Majordomo worker application in Go
// Majordomo Protocol worker example
// Uses the mdwrk API to hide all MDP aspects
//
// To run this example, you may need to run multiple *.go files as below
// go run mdp.go zhelpers.go mdwrkapi.go mdworker.go [-v]
//
// Author: iano <scaly.iano@gmail.com>
package main
import (
"os"
)
func main() {
verbose := len(os.Args) >= 2 && os.Args[1] == "-v"
worker := NewWorker("tcp://localhost:5555", "echo", verbose)
for reply := [][]byte{}; ; {
request := worker.Recv(reply)
if len(request) == 0 {
break
}
reply = request
}
}
mdworker: Majordomo worker application in Haskell
import MDWorkerAPI
import ZHelpers
import System.Environment (getArgs)
import System.IO (hSetBuffering, stdout, BufferMode(NoBuffering))
import Control.Monad (forever, mapM_, when)
import Data.ByteString.Char8 (unpack, empty, ByteString(..))
main :: IO ()
main = do
args <- getArgs
when (length args /= 1) $
error "usage: mdworker <isVerbose(True|False)>"
let isVerbose = read (args !! 0) :: Bool
hSetBuffering stdout NoBuffering
withMDWorker "tcp://localhost:5555" "echo" isVerbose $ \session ->
doEcho session [empty]
where doEcho session reply = do
request <- mdwkrExchange session reply
doEcho (fst request) (snd request)
mdworker: Majordomo worker application in Haxe
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol worker example
* Uses the MDWrk API to hde all MDP aspects
* @author Richard J Smith
*/
class MDWorker
{
public static function main() {
Lib.println("** MDWorker (see: http://zguide.zeromq.org/page:all#Service-Oriented-Reliable-Queuing-Majordomo-Pattern)");
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var session = new MDWrkAPI("tcp://localhost:5555", "echo", verbose);
var reply:ZMsg = null;
while (true) {
var request = session.recv(reply);
if (request == null)
break; // Interrupted
reply = request;
}
session.destroy();
}
}mdworker: Majordomo worker application in Java
package guide;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol worker example. Uses the mdwrk API to hide all MDP aspects
*
*/
public class mdworker
{
/**
* @param args
*/
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && "-v".equals(args[0]));
mdwrkapi workerSession = new mdwrkapi("tcp://localhost:5555", "echo", verbose);
ZMsg reply = null;
while (!Thread.currentThread().isInterrupted()) {
ZMsg request = workerSession.receive(reply);
if (request == null)
break; //Interrupted
reply = request; // Echo is complex :-)
}
workerSession.destroy();
}
}
mdworker: Majordomo worker application in Julia
mdworker: Majordomo worker application in Lua
--
-- Majordomo Protocol worker example
-- Uses the mdwrk API to hide all MDP aspects
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"mdwrkapi"
require"zmsg"
local verbose = (arg[1] == "-v")
local session = mdwrkapi.new("tcp://localhost:5555", "echo", verbose)
local reply
while true do
local request = session:recv(reply)
if not request then
break -- Worker was interrupted
end
reply = request -- Echo is complex... :-)
end
session:destroy()
mdworker: Majordomo worker application in Node.js
mdworker: Majordomo worker application in Objective-C
mdworker: Majordomo worker application in ooc
mdworker: Majordomo worker application in Perl
mdworker: Majordomo worker application in PHP
<?php
/*
* Majordomo Protocol worker example
* Uses the mdwrk API to hide all MDP aspects
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'mdwrkapi.php';
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == "-v";
$mdwrk = new Mdwrk("tcp://localhost:5555", "echo", $verbose);
$reply = null;
while (true) {
$request = $mdwrk->recv($reply);
$reply = $request; // Echo is complex... :-)
}
mdworker: Majordomo worker application in Python
"""Majordomo Protocol worker example.
Uses the mdwrk API to hide all MDP aspects
Author: Min RK <benjaminrk@gmail.com>
"""
import sys
from mdwrkapi import MajorDomoWorker
def main():
verbose = '-v' in sys.argv
worker = MajorDomoWorker("tcp://localhost:5555", b"echo", verbose)
reply = None
while True:
request = worker.recv(reply)
if request is None:
break # Worker was interrupted
reply = request # Echo is complex... :-)
if __name__ == '__main__':
main()
mdworker: Majordomo worker application in Q
mdworker: Majordomo worker application in Racket
mdworker: Majordomo worker application in Ruby
mdworker: Majordomo worker application in Rust
mdworker: Majordomo worker application in Scala
mdworker: Majordomo worker application in Tcl
mdworker: Majordomo worker application in OCaml
Here are some things to note about the worker API code:
-
The APIs are single-threaded. This means, for example, that the worker won’t send heartbeats in the background. Happily, this is exactly what we want: if the worker application gets stuck, heartbeats will stop and the broker will stop sending requests to the worker.
-
The worker API doesn’t do an exponential back-off; it’s not worth the extra complexity.
-
The APIs don’t do any error reporting. If something isn’t as expected, they raise an assertion (or exception depending on the language). This is ideal for a reference implementation, so any protocol errors show immediately. For real applications, the API should be robust against invalid messages.
You might wonder why the worker API is manually closing its socket and opening a new one, when ZeroMQ will automatically reconnect a socket if the peer disappears and comes back. Look back at the Simple Pirate and Paranoid Pirate workers to understand. Although ZeroMQ will automatically reconnect workers if the broker dies and comes back up, this isn’t sufficient to re-register the workers with the broker. I know of at least two solutions. The simplest, which we use here, is for the worker to monitor the connection using heartbeats, and if it decides the broker is dead, to close its socket and start afresh with a new socket. The alternative is for the broker to challenge unknown workers when it gets a heartbeat from the worker and ask them to re-register. That would require protocol support.
Now let’s design the Majordomo broker. Its core structure is a set of queues, one per service. We will create these queues as workers appear (we could delete them as workers disappear, but forget that for now because it gets complex). Additionally, we keep a queue of workers per service.
And here is the broker:
mdbroker: Majordomo broker in Ada
mdbroker: Majordomo broker in Basic
mdbroker: Majordomo broker in C
// Majordomo Protocol broker
// A minimal C implementation of the Majordomo Protocol as defined in
// http://rfc.zeromq.org/spec:7 and http://rfc.zeromq.org/spec:8.
#include "czmq.h"
#include "mdp.h"
// We'd normally pull these from config data
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 2500 // msecs
#define HEARTBEAT_EXPIRY HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
// .split broker class structure
// The broker class defines a single broker instance:
typedef struct {
zctx_t *ctx; // Our context
void *socket; // Socket for clients & workers
int verbose; // Print activity to stdout
char *endpoint; // Broker binds to this endpoint
zhash_t *services; // Hash of known services
zhash_t *workers; // Hash of known workers
zlist_t *waiting; // List of waiting workers
uint64_t heartbeat_at; // When to send HEARTBEAT
} broker_t;
static broker_t *
s_broker_new (int verbose);
static void
s_broker_destroy (broker_t **self_p);
static void
s_broker_bind (broker_t *self, char *endpoint);
static void
s_broker_worker_msg (broker_t *self, zframe_t *sender, zmsg_t *msg);
static void
s_broker_client_msg (broker_t *self, zframe_t *sender, zmsg_t *msg);
static void
s_broker_purge (broker_t *self);
// .split service class structure
// The service class defines a single service instance:
typedef struct {
broker_t *broker; // Broker instance
char *name; // Service name
zlist_t *requests; // List of client requests
zlist_t *waiting; // List of waiting workers
size_t workers; // How many workers we have
} service_t;
static service_t *
s_service_require (broker_t *self, zframe_t *service_frame);
static void
s_service_destroy (void *argument);
static void
s_service_dispatch (service_t *service, zmsg_t *msg);
// .split worker class structure
// The worker class defines a single worker, idle or active:
typedef struct {
broker_t *broker; // Broker instance
char *id_string; // Identity of worker as string
zframe_t *identity; // Identity frame for routing
service_t *service; // Owning service, if known
int64_t expiry; // When worker expires, if no heartbeat
} worker_t;
static worker_t *
s_worker_require (broker_t *self, zframe_t *identity);
static void
s_worker_delete (worker_t *self, int disconnect);
static void
s_worker_destroy (void *argument);
static void
s_worker_send (worker_t *self, char *command, char *option,
zmsg_t *msg);
static void
s_worker_waiting (worker_t *self);
// .split broker constructor and destructor
// Here are the constructor and destructor for the broker:
static broker_t *
s_broker_new (int verbose)
{
broker_t *self = (broker_t *) zmalloc (sizeof (broker_t));
// Initialize broker state
self->ctx = zctx_new ();
self->socket = zsocket_new (self->ctx, ZMQ_ROUTER);
self->verbose = verbose;
self->services = zhash_new ();
self->workers = zhash_new ();
self->waiting = zlist_new ();
self->heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
return self;
}
static void
s_broker_destroy (broker_t **self_p)
{
assert (self_p);
if (*self_p) {
broker_t *self = *self_p;
zctx_destroy (&self->ctx);
zhash_destroy (&self->services);
zhash_destroy (&self->workers);
zlist_destroy (&self->waiting);
free (self);
*self_p = NULL;
}
}
// .split broker bind method
// This method binds the broker instance to an endpoint. We can call
// this multiple times. Note that MDP uses a single socket for both clients
// and workers:
void
s_broker_bind (broker_t *self, char *endpoint)
{
zsocket_bind (self->socket, endpoint);
zclock_log ("I: MDP broker/0.2.0 is active at %s", endpoint);
}
// .split broker worker_msg method
// This method processes one READY, REPLY, HEARTBEAT, or
// DISCONNECT message sent to the broker by a worker:
static void
s_broker_worker_msg (broker_t *self, zframe_t *sender, zmsg_t *msg)
{
assert (zmsg_size (msg) >= 1); // At least, command
zframe_t *command = zmsg_pop (msg);
char *id_string = zframe_strhex (sender);
int worker_ready = (zhash_lookup (self->workers, id_string) != NULL);
free (id_string);
worker_t *worker = s_worker_require (self, sender);
if (zframe_streq (command, MDPW_READY)) {
if (worker_ready) // Not first command in session
s_worker_delete (worker, 1);
else
if (zframe_size (sender) >= 4 // Reserved service name
&& memcmp (zframe_data (sender), "mmi.", 4) == 0)
s_worker_delete (worker, 1);
else {
// Attach worker to service and mark as idle
zframe_t *service_frame = zmsg_pop (msg);
worker->service = s_service_require (self, service_frame);
worker->service->workers++;
s_worker_waiting (worker);
zframe_destroy (&service_frame);
}
}
else
if (zframe_streq (command, MDPW_REPLY)) {
if (worker_ready) {
// Remove and save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
zframe_t *client = zmsg_unwrap (msg);
zmsg_pushstr (msg, worker->service->name);
zmsg_pushstr (msg, MDPC_CLIENT);
zmsg_wrap (msg, client);
zmsg_send (&msg, self->socket);
s_worker_waiting (worker);
}
else
s_worker_delete (worker, 1);
}
else
if (zframe_streq (command, MDPW_HEARTBEAT)) {
if (worker_ready)
worker->expiry = zclock_time () + HEARTBEAT_EXPIRY;
else
s_worker_delete (worker, 1);
}
else
if (zframe_streq (command, MDPW_DISCONNECT))
s_worker_delete (worker, 0);
else {
zclock_log ("E: invalid input message");
zmsg_dump (msg);
}
free (command);
zmsg_destroy (&msg);
}
// .split broker client_msg method
// Process a request coming from a client. We implement MMI requests
// directly here (at present, we implement only the mmi.service request):
static void
s_broker_client_msg (broker_t *self, zframe_t *sender, zmsg_t *msg)
{
assert (zmsg_size (msg) >= 2); // Service name + body
zframe_t *service_frame = zmsg_pop (msg);
service_t *service = s_service_require (self, service_frame);
// Set reply return identity to client sender
zmsg_wrap (msg, zframe_dup (sender));
// If we got a MMI service request, process that internally
if (zframe_size (service_frame) >= 4
&& memcmp (zframe_data (service_frame), "mmi.", 4) == 0) {
char *return_code;
if (zframe_streq (service_frame, "mmi.service")) {
char *name = zframe_strdup (zmsg_last (msg));
service_t *service =
(service_t *) zhash_lookup (self->services, name);
return_code = service && service->workers? "200": "404";
free (name);
}
else
return_code = "501";
zframe_reset (zmsg_last (msg), return_code, strlen (return_code));
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
zframe_t *client = zmsg_unwrap (msg);
zmsg_prepend (msg, &service_frame);
zmsg_pushstr (msg, MDPC_CLIENT);
zmsg_wrap (msg, client);
zmsg_send (&msg, self->socket);
}
else
// Else dispatch the message to the requested service
s_service_dispatch (service, msg);
zframe_destroy (&service_frame);
}
// .split broker purge method
// This method deletes any idle workers that haven't pinged us in a
// while. We hold workers from oldest to most recent so we can stop
// scanning whenever we find a live worker. This means we'll mainly stop
// at the first worker, which is essential when we have large numbers of
// workers (we call this method in our critical path):
static void
s_broker_purge (broker_t *self)
{
worker_t *worker = (worker_t *) zlist_first (self->waiting);
while (worker) {
if (zclock_time () < worker->expiry)
break; // Worker is alive, we're done here
if (self->verbose)
zclock_log ("I: deleting expired worker: %s",
worker->id_string);
s_worker_delete (worker, 0);
worker = (worker_t *) zlist_first (self->waiting);
}
}
// .split service methods
// Here is the implementation of the methods that work on a service:
// Lazy constructor that locates a service by name or creates a new
// service if there is no service already with that name.
static service_t *
s_service_require (broker_t *self, zframe_t *service_frame)
{
assert (service_frame);
char *name = zframe_strdup (service_frame);
service_t *service =
(service_t *) zhash_lookup (self->services, name);
if (service == NULL) {
service = (service_t *) zmalloc (sizeof (service_t));
service->broker = self;
service->name = name;
service->requests = zlist_new ();
service->waiting = zlist_new ();
zhash_insert (self->services, name, service);
zhash_freefn (self->services, name, s_service_destroy);
if (self->verbose)
zclock_log ("I: added service: %s", name);
}
else
free (name);
return service;
}
// Service destructor is called automatically whenever the service is
// removed from broker->services.
static void
s_service_destroy (void *argument)
{
service_t *service = (service_t *) argument;
while (zlist_size (service->requests)) {
zmsg_t *msg = zlist_pop (service->requests);
zmsg_destroy (&msg);
}
zlist_destroy (&service->requests);
zlist_destroy (&service->waiting);
free (service->name);
free (service);
}
// .split service dispatch method
// This method sends requests to waiting workers:
static void
s_service_dispatch (service_t *self, zmsg_t *msg)
{
assert (self);
if (msg) // Queue message if any
zlist_append (self->requests, msg);
s_broker_purge (self->broker);
while (zlist_size (self->waiting) && zlist_size (self->requests)) {
worker_t *worker = zlist_pop (self->waiting);
zlist_remove (self->broker->waiting, worker);
zmsg_t *msg = zlist_pop (self->requests);
s_worker_send (worker, MDPW_REQUEST, NULL, msg);
zmsg_destroy (&msg);
}
}
// .split worker methods
// Here is the implementation of the methods that work on a worker:
// Lazy constructor that locates a worker by identity, or creates a new
// worker if there is no worker already with that identity.
static worker_t *
s_worker_require (broker_t *self, zframe_t *identity)
{
assert (identity);
// self->workers is keyed off worker identity
char *id_string = zframe_strhex (identity);
worker_t *worker =
(worker_t *) zhash_lookup (self->workers, id_string);
if (worker == NULL) {
worker = (worker_t *) zmalloc (sizeof (worker_t));
worker->broker = self;
worker->id_string = id_string;
worker->identity = zframe_dup (identity);
zhash_insert (self->workers, id_string, worker);
zhash_freefn (self->workers, id_string, s_worker_destroy);
if (self->verbose)
zclock_log ("I: registering new worker: %s", id_string);
}
else
free (id_string);
return worker;
}
// This method deletes the current worker.
static void
s_worker_delete (worker_t *self, int disconnect)
{
assert (self);
if (disconnect)
s_worker_send (self, MDPW_DISCONNECT, NULL, NULL);
if (self->service) {
zlist_remove (self->service->waiting, self);
self->service->workers--;
}
zlist_remove (self->broker->waiting, self);
// This implicitly calls s_worker_destroy
zhash_delete (self->broker->workers, self->id_string);
}
// Worker destructor is called automatically whenever the worker is
// removed from broker->workers.
static void
s_worker_destroy (void *argument)
{
worker_t *self = (worker_t *) argument;
zframe_destroy (&self->identity);
free (self->id_string);
free (self);
}
// .split worker send method
// This method formats and sends a command to a worker. The caller may
// also provide a command option, and a message payload:
static void
s_worker_send (worker_t *self, char *command, char *option, zmsg_t *msg)
{
msg = msg? zmsg_dup (msg): zmsg_new ();
// Stack protocol envelope to start of message
if (option)
zmsg_pushstr (msg, option);
zmsg_pushstr (msg, command);
zmsg_pushstr (msg, MDPW_WORKER);
// Stack routing envelope to start of message
zmsg_wrap (msg, zframe_dup (self->identity));
if (self->broker->verbose) {
zclock_log ("I: sending %s to worker",
mdps_commands [(int) *command]);
zmsg_dump (msg);
}
zmsg_send (&msg, self->broker->socket);
}
// This worker is now waiting for work
static void
s_worker_waiting (worker_t *self)
{
// Queue to broker and service waiting lists
assert (self->broker);
zlist_append (self->broker->waiting, self);
zlist_append (self->service->waiting, self);
self->expiry = zclock_time () + HEARTBEAT_EXPIRY;
s_service_dispatch (self->service, NULL);
}
// .split main task
// Finally, here is the main task. We create a new broker instance and
// then process messages on the broker socket:
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
broker_t *self = s_broker_new (verbose);
s_broker_bind (self, "tcp://*:5555");
// Get and process messages forever or until interrupted
while (true) {
zmq_pollitem_t items [] = {
{ self->socket, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
// Process next input message, if any
if (items [0].revents & ZMQ_POLLIN) {
zmsg_t *msg = zmsg_recv (self->socket);
if (!msg)
break; // Interrupted
if (self->verbose) {
zclock_log ("I: received message:");
zmsg_dump (msg);
}
zframe_t *sender = zmsg_pop (msg);
zframe_t *empty = zmsg_pop (msg);
zframe_t *header = zmsg_pop (msg);
if (zframe_streq (header, MDPC_CLIENT))
s_broker_client_msg (self, sender, msg);
else
if (zframe_streq (header, MDPW_WORKER))
s_broker_worker_msg (self, sender, msg);
else {
zclock_log ("E: invalid message:");
zmsg_dump (msg);
zmsg_destroy (&msg);
}
zframe_destroy (&sender);
zframe_destroy (&empty);
zframe_destroy (&header);
}
// Disconnect and delete any expired workers
// Send heartbeats to idle workers if needed
if (zclock_time () > self->heartbeat_at) {
s_broker_purge (self);
worker_t *worker = (worker_t *) zlist_first (self->waiting);
while (worker) {
s_worker_send (worker, MDPW_HEARTBEAT, NULL, NULL);
worker = (worker_t *) zlist_next (self->waiting);
}
self->heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
}
}
if (zctx_interrupted)
printf ("W: interrupt received, shutting down...\n");
s_broker_destroy (&self);
return 0;
}
mdbroker: Majordomo broker in C++
//
// Majordomo Protocol broker
// A minimal implementation of http://rfc.zeromq.org/spec:7 and spec:8
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "zmsg.hpp"
#include "mdp.h"
#include <map>
#include <set>
#include <deque>
#include <list>
// We'd normally pull these from config data
static constexpr uint32_t n_heartbeat_liveness = 3;
static constexpr uint32_t n_heartbeat_interval = 2500; // msecs
static constexpr uint32_t n_heartbeat_expiry = n_heartbeat_interval * n_heartbeat_liveness; // msecs
struct service;
// This defines one worker, idle or active
struct worker
{
std::string m_identity; // Address of worker
service * m_service; // Owning service, if known
int64_t m_expiry; // Expires at unless heartbeat
worker(std::string identity, service * service = nullptr, int64_t expiry = 0): m_identity(identity), m_service(service), m_expiry(expiry) {}
};
// This defines a single service
struct service
{
~service ()
{
for(size_t i = 0; i < m_requests.size(); i++) {
delete m_requests[i];
}
}
const std::string m_name; // Service name
std::deque<zmsg*> m_requests; // List of client requests
std::list<worker*> m_waiting; // List of waiting workers
size_t m_workers; // How many workers we have
service(std::string name): m_name(name) {}
};
// This defines a single broker
class broker {
public:
// ---------------------------------------------------------------------
// Constructor for broker object
broker (int verbose):m_verbose(verbose)
{
// Initialize broker state
m_context = new zmq::context_t(1);
m_socket = new zmq::socket_t(*m_context, ZMQ_ROUTER);
}
// ---------------------------------------------------------------------
// Destructor for broker object
virtual
~broker ()
{
while (! m_services.empty())
{
delete m_services.begin()->second;
m_services.erase(m_services.begin());
}
while (! m_workers.empty())
{
delete m_workers.begin()->second;
m_workers.erase(m_workers.begin());
}
}
// ---------------------------------------------------------------------
// Bind broker to endpoint, can call this multiple times
// We use a single socket for both clients and workers.
void
bind (std::string endpoint)
{
m_endpoint = endpoint;
m_socket->bind(m_endpoint.c_str());
s_console ("I: MDP broker/0.1.1 is active at %s", endpoint.c_str());
}
private:
// ---------------------------------------------------------------------
// Delete any idle workers that haven't pinged us in a while.
void
purge_workers ()
{
std::deque<worker*> toCull;
int64_t now = s_clock();
for (auto wrk = m_waiting.begin(); wrk != m_waiting.end(); ++wrk)
{
if ((*wrk)->m_expiry <= now)
toCull.push_back(*wrk);
}
for (auto wrk = toCull.begin(); wrk != toCull.end(); ++wrk)
{
if (m_verbose) {
s_console ("I: deleting expired worker: %s",
(*wrk)->m_identity.c_str());
}
worker_delete(*wrk, 0);
}
}
// ---------------------------------------------------------------------
// Locate or create new service entry
service *
service_require (std::string name)
{
assert (!name.empty());
if (m_services.count(name)) {
return m_services.at(name);
}
service * srv = new service(name);
m_services.insert(std::pair{name, srv});
if (m_verbose) {
s_console("I: added service: %s", name.c_str());
}
return srv;
}
// ---------------------------------------------------------------------
// Dispatch requests to waiting workers as possible
void
service_dispatch (service *srv, zmsg *msg)
{
assert (srv);
if (msg) { // Queue message if any
srv->m_requests.push_back(msg);
}
purge_workers ();
while (! srv->m_waiting.empty() && ! srv->m_requests.empty())
{
// Choose the most recently seen idle worker; others might be about to expire
auto wrk = srv->m_waiting.begin();
auto next = wrk;
for (++next; next != srv->m_waiting.end(); ++next)
{
if ((*next)->m_expiry > (*wrk)->m_expiry)
wrk = next;
}
zmsg *msg = srv->m_requests.front();
srv->m_requests.pop_front();
worker_send (*wrk, k_mdpw_request.data(), "", msg);
m_waiting.erase(*wrk);
srv->m_waiting.erase(wrk);
delete msg;
}
}
// ---------------------------------------------------------------------
// Handle internal service according to 8/MMI specification
void
service_internal (std::string service_name, zmsg *msg)
{
if (service_name.compare("mmi.service") == 0) {
// service *srv = m_services[msg->body()]; // Dangerous! Silently add key with default value
service *srv = m_services.count(msg->body()) ? m_services.at(msg->body()) : nullptr;
if (srv && srv->m_workers) {
msg->body_set("200");
} else {
msg->body_set("404");
}
} else {
msg->body_set("501");
}
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
std::string client = msg->unwrap();
msg->wrap(k_mdp_client.data(), service_name.c_str());
msg->wrap(client.c_str(), "");
msg->send (*m_socket);
delete msg;
}
// ---------------------------------------------------------------------
// Creates worker if necessary
worker *
worker_require (std::string identity)
{
assert (!identity.empty());
// self->workers is keyed off worker identity
if (m_workers.count(identity)) {
return m_workers.at(identity);
} else {
worker *wrk = new worker(identity);
m_workers.insert(std::make_pair(identity, wrk));
if (m_verbose) {
s_console ("I: registering new worker: %s", identity.c_str());
}
return wrk;
}
}
// ---------------------------------------------------------------------
// Deletes worker from all data structures, and destroys worker
void
worker_delete (worker *&wrk, int disconnect)
{
assert (wrk);
if (disconnect) {
worker_send (wrk, k_mdpw_disconnect.data(), "", NULL);
}
if (wrk->m_service) {
for(auto it = wrk->m_service->m_waiting.begin();
it != wrk->m_service->m_waiting.end();) {
if (*it == wrk) {
it = wrk->m_service->m_waiting.erase(it);
}
else {
++it;
}
}
wrk->m_service->m_workers--;
}
m_waiting.erase(wrk);
// This implicitly calls the worker destructor
m_workers.erase(wrk->m_identity);
delete wrk;
}
// ---------------------------------------------------------------------
// Process message sent to us by a worker
void
worker_process (std::string sender, zmsg *msg)
{
assert (msg && msg->parts() >= 1); // At least, command
std::string command = (char *)msg->pop_front().c_str();
bool worker_ready = m_workers.count(sender)>0;
worker *wrk = worker_require (sender);
if (command.compare (k_mdpw_ready.data()) == 0) {
if (worker_ready) { // Not first command in session
worker_delete (wrk, 1);
}
else {
if (sender.size() >= 4 // Reserved service name
&& sender.find_first_of("mmi.") == 0) {
worker_delete (wrk, 1);
} else {
// Attach worker to service and mark as idle
std::string service_name = (char *) msg->pop_front ().c_str();
wrk->m_service = service_require (service_name);
wrk->m_service->m_workers++;
worker_waiting (wrk);
}
}
} else {
if (command.compare (k_mdpw_reply.data()) == 0) {
if (worker_ready) {
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
std::string client = msg->unwrap ();
msg->wrap (k_mdp_client.data(), wrk->m_service->m_name.c_str());
msg->wrap (client.c_str(), "");
msg->send (*m_socket);
worker_waiting (wrk);
}
else {
worker_delete (wrk, 1);
}
} else {
if (command.compare (k_mdpw_heartbeat.data()) == 0) {
if (worker_ready) {
wrk->m_expiry = s_clock () + n_heartbeat_expiry;
} else {
worker_delete (wrk, 1);
}
} else {
if (command.compare (k_mdpw_disconnect.data()) == 0) {
worker_delete (wrk, 0);
} else {
s_console ("E: invalid input message (%d)", (int) *command.c_str());
msg->dump ();
}
}
}
}
delete msg;
}
// ---------------------------------------------------------------------
// Send message to worker
// If pointer to message is provided, sends that message
void
worker_send (worker *worker,
const char *command, std::string option, zmsg *msg)
{
msg = (msg ? new zmsg(*msg) : new zmsg ());
// Stack protocol envelope to start of message
if (option.size()>0) { // Optional frame after command
msg->push_front (option.c_str());
}
msg->push_front (command);
msg->push_front (k_mdpw_worker.data());
// Stack routing envelope to start of message
msg->wrap(worker->m_identity.c_str(), "");
if (m_verbose) {
s_console ("I: sending %s to worker",
mdps_commands [(int) *command].data());
msg->dump ();
}
msg->send (*m_socket);
delete msg;
}
// ---------------------------------------------------------------------
// This worker is now waiting for work
void
worker_waiting (worker *worker)
{
assert (worker);
// Queue to broker and service waiting lists
m_waiting.insert(worker);
worker->m_service->m_waiting.push_back(worker);
worker->m_expiry = s_clock () + n_heartbeat_expiry;
// Attempt to process outstanding requests
service_dispatch (worker->m_service, 0);
}
// ---------------------------------------------------------------------
// Process a request coming from a client
void
client_process (std::string sender, zmsg *msg)
{
assert (msg && msg->parts () >= 2); // Service name + body
std::string service_name =(char *) msg->pop_front().c_str();
service *srv = service_require (service_name);
// Set reply return address to client sender
msg->wrap (sender.c_str(), "");
if (service_name.length() >= 4
&& service_name.find_first_of("mmi.") == 0) {
service_internal (service_name, msg);
} else {
service_dispatch (srv, msg);
}
}
public:
// Get and process messages forever or until interrupted
void
start_brokering() {
int64_t now = s_clock();
int64_t heartbeat_at = now + n_heartbeat_interval;
while (!s_interrupted) {
zmq::pollitem_t items [] = {
{ *m_socket, 0, ZMQ_POLLIN, 0} };
int64_t timeout = heartbeat_at - now;
if (timeout < 0)
timeout = 0;
zmq::poll (items, 1, (long)timeout);
// Process next input message, if any
if (items [0].revents & ZMQ_POLLIN) {
zmsg *msg = new zmsg(*m_socket);
if (m_verbose) {
s_console ("I: received message:");
msg->dump ();
}
std::string sender = (char*)msg->pop_front ().c_str();
msg->pop_front (); //empty message
std::string header = (char*)msg->pop_front ().c_str();
if (header.compare(k_mdp_client.data()) == 0) {
client_process (sender, msg);
}
else if (header.compare(k_mdpw_worker.data()) == 0) {
worker_process (sender, msg);
}
else {
s_console ("E: invalid message:");
msg->dump ();
delete msg;
}
}
// Disconnect and delete any expired workers
// Send heartbeats to idle workers if needed
now = s_clock();
if (now >= heartbeat_at) {
purge_workers ();
for (auto it = m_waiting.begin();
it != m_waiting.end() && (*it)!=0; it++) {
worker_send (*it, k_mdpw_heartbeat.data(), "", NULL);
}
heartbeat_at += n_heartbeat_interval;
now = s_clock();
}
}
}
private:
zmq::context_t * m_context; // 0MQ context
zmq::socket_t * m_socket; // Socket for clients & workers
const int m_verbose; // Print activity to stdout
std::string m_endpoint; // Broker binds to this endpoint
std::map<std::string, service*> m_services; // Hash of known services
std::map<std::string, worker*> m_workers; // Hash of known workers
std::set<worker*> m_waiting; // List of waiting workers
};
// ---------------------------------------------------------------------
// Main broker work happens here
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && strcmp (argv [1], "-v") == 0);
s_version_assert (4, 0);
s_catch_signals ();
broker brk(verbose);
brk.bind ("tcp://*:5555");
brk.start_brokering();
if (s_interrupted)
printf ("W: interrupt received, shutting down...\n");
return 0;
}
mdbroker: Majordomo broker in C#
using System;
using System.Collections.Generic;
using System.Globalization;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
using MDBroker;
namespace MDBroker
{
public class Broker : IDisposable
{
// Majordomo Protocol broker
// A minimal C implementation of the Majordomo Protocol as defined in
// http://rfc.zeromq.org/spec:7 and http://rfc.zeromq.org/spec:8.
// .split broker class structure
// The broker class defines a single broker instance:
// Our Context
private ZContext _context;
//Socket for clients & workers
public ZSocket Socket;
// Print activity to console
public bool Verbose { get; protected set; }
// Broker binds to this endpoint
public string Endpoint { get; protected set; }
// Hash of known services
public Dictionary<string, Service> Services;
// Hash of known workes
public Dictionary<string, Worker> Workers;
// Waiting workers
public List<Worker> Waiting;
// When to send HEARTBEAT
public DateTime HeartbeatAt;
// waiting
// heartbeat_at
public Broker(bool verbose)
{
// Constructor
_context = new ZContext();
Socket = new ZSocket(_context, ZSocketType.ROUTER);
Verbose = verbose;
Services = new Dictionary<string, Service>(); //new HashSet<Service>();
Workers = new Dictionary<string, Worker>(); //new HashSet<Worker>();
Waiting = new List<Worker>();
HeartbeatAt = DateTime.UtcNow + MdpCommon.HEARTBEAT_INTERVAL;
}
~Broker()
{
Dispose(false);
}
public void Dispose()
{
GC.SuppressFinalize(this);
Dispose(true);
}
protected void Dispose(bool disposing)
{
if (disposing)
{
// Destructor
if (Socket != null)
{
Socket.Dispose();
Socket = null;
}
if (_context != null)
{
// Do Context.Dispose()
_context.Dispose();
_context = null;
}
}
}
// added ShutdownContext, to call shutdown in main method.
public void ShutdownContext()
{
if (_context != null)
_context.Shutdown();
}
// .split broker bind method
// This method binds the broker instance to an endpoint. We can call
// this multiple times. Note that MDP uses a single Socket for both clients
// and workers:
public void Bind(string endpoint)
{
Socket.Bind(endpoint);
// if you dont wanna see utc timeshift, remove zzz and use DateTime.UtcNow instead
"I: MDP broker/0.2.0 is active at {0}".DumpString(endpoint);
}
// .split broker worker_msg method
// This method processes one READY, REPLY, HEARTBEAT, or
// DISCONNECT message sent to the broker by a worker:
public void WorkerMsg(ZFrame sender, ZMessage msg)
{
if(msg.Count < 1) // At least, command
throw new InvalidOperationException();
ZFrame command = msg.Pop();
//string id_string = sender.ReadString();
bool isWorkerReady;
//string id_string;
using (var sfrm = sender.Duplicate())
{
var idString = sfrm.Read().ToHexString();
isWorkerReady = Workers.ContainsKey(idString);
}
Worker worker = RequireWorker(sender);
using (msg)
using (command)
{
if (command.StrHexEq(MdpCommon.MdpwCmd.READY))
{
if (isWorkerReady)
// Not first command in session
worker.Delete(true);
else if (command.Length >= 4
&& command.ToString().StartsWith("mmi."))
// Reserd servicee name
worker.Delete(true);
else
{
// Attach worker to service and mark as idle
using (ZFrame serviceFrame = msg.Pop())
{
worker.Service = RequireService(serviceFrame);
worker.Service.Workers++;
worker.Waiting();
}
}
}
else if (command.StrHexEq(MdpCommon.MdpwCmd.REPLY))
{
if (isWorkerReady)
{
// Remove and save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
ZFrame client = msg.Unwrap();
msg.Prepend(new ZFrame(worker.Service.Name));
msg.Prepend(new ZFrame(MdpCommon.MDPC_CLIENT));
msg.Wrap(client);
Socket.Send(msg);
worker.Waiting();
}
else
{
worker.Delete(true);
}
}
else if (command.StrHexEq(MdpCommon.MdpwCmd.HEARTBEAT))
{
if (isWorkerReady)
{
worker.Expiry = DateTime.UtcNow + MdpCommon.HEARTBEAT_EXPIRY;
}
else
{
worker.Delete(true);
}
}
else if (command.StrHexEq(MdpCommon.MdpwCmd.DISCONNECT))
worker.Delete(false);
else
{
msg.DumpZmsg("E: invalid input message");
}
}
}
// .split broker client_msg method
// Process a request coming from a client. We implement MMI requests
// directly here (at present, we implement only the mmi.service request):
public void ClientMsg(ZFrame sender, ZMessage msg)
{
// service & body
if(msg.Count < 2)
throw new InvalidOperationException();
using (ZFrame serviceFrame = msg.Pop())
{
Service service = RequireService(serviceFrame);
// Set reply return identity to client sender
msg.Wrap(sender.Duplicate());
//if we got a MMI Service request, process that internally
if (serviceFrame.Length >= 4
&& serviceFrame.ToString().StartsWith("mmi."))
{
string returnCode;
if (serviceFrame.ToString().Equals("mmi.service"))
{
string name = msg.Last().ToString();
returnCode = Services.ContainsKey(name)
&& Services[name].Workers > 0
? "200"
: "404";
}
else
returnCode = "501";
var client = msg.Unwrap();
msg.Clear();
msg.Add(new ZFrame(returnCode));
msg.Prepend(serviceFrame);
msg.Prepend(new ZFrame(MdpCommon.MDPC_CLIENT));
msg.Wrap(client);
Socket.Send(msg);
}
else
{
// Else dispatch the message to the requested Service
service.Dispatch(msg);
}
}
}
// .split broker purge method
// This method deletes any idle workers that haven't pinged us in a
// while. We hold workers from oldest to most recent so we can stop
// scanning whenever we find a live worker. This means we'll mainly stop
// at the first worker, which is essential when we have large numbers of
// workers (we call this method in our critical path):
public void Purge()
{
Worker worker = Waiting.FirstOrDefault();
while (worker != null)
{
if (DateTime.UtcNow < worker.Expiry)
break; // Worker is alive, we're done here
if(Verbose)
"I: deleting expired worker: '{0}'".DumpString(worker.IdString);
worker.Delete(false);
worker = Waiting.FirstOrDefault();
}
}
// .split service methods
// Here is the implementation of the methods that work on a service:
// Lazy constructor that locates a service by name or creates a new
// service if there is no service already with that name.
public Service RequireService(ZFrame serviceFrame)
{
if(serviceFrame == null)
throw new InvalidOperationException();
string name = serviceFrame.ToString();
Service service;
if (Services.ContainsKey(name))
{
service = Services[name];
}
else
{
service = new Service(this, name);
Services[name] = service;
//zhash_freefn(self->workers, id_string, s_worker_destroy);
if (Verbose)
"I: added service: '{0}'".DumpString(name);
}
return service;
}
// .split worker methods
// Here is the implementation of the methods that work on a worker:
// Lazy constructor that locates a worker by identity, or creates a new
// worker if there is no worker already with that identity.
public Worker RequireWorker(ZFrame identity)
{
if (identity == null)
throw new InvalidOperationException();
string idString;
using (var tstfrm = identity.Duplicate())
{
idString = tstfrm.Read().ToHexString();
}
Worker worker = Workers.ContainsKey(idString)
? Workers[idString]
: null;
if (worker == null)
{
worker = new Worker(idString, this, identity);
Workers[idString] = worker;
if(Verbose)
"I: registering new worker: '{0}'".DumpString(idString);
}
return worker;
}
}
public class Service : IDisposable
{
// Broker Instance
public Broker Broker { get; protected set; }
// Service Name
public string Name { get; protected set; }
// List of client requests
public List<ZMessage> Requests { get; protected set; }
// List of waiting workers
public List<Worker> Waiting { get; protected set; }
// How many workers we are
public int Workers;
//ToDo check workers var
internal Service(Broker broker, string name)
{
Broker = broker;
Name = name;
Requests = new List<ZMessage>();
Waiting = new List<Worker>();
}
~Service()
{
Dispose(false);
}
public void Dispose()
{
GC.SuppressFinalize(this);
Dispose(true);
}
protected void Dispose(bool disposing)
{
if (disposing)
{
foreach (var r in Requests)
{
// probably obsolete?
using (r)
{
}
}
}
}
// .split service dispatch method
// This method sends requests to waiting workers:
public void Dispatch(ZMessage msg)
{
if (msg != null) // queue msg if any
Requests.Add(msg);
Broker.Purge();
while (Waiting.Count > 0
&& Requests.Count > 0)
{
Worker worker = Waiting[0];
Waiting.RemoveAt(0);
Broker.Waiting.Remove(worker);
ZMessage reqMsg = Requests[0];
Requests.RemoveAt(0);
using (reqMsg)
worker.Send(MdpCommon.MdpwCmd.REQUEST.ToHexString(), null, reqMsg);
}
}
}
public class Worker
{
// .split worker class structure
// The worker class defines a single worker, idle or active:
// Broker Instance
public Broker Broker { get; protected set; }
// Identity of worker as string
public string IdString { get; protected set; }
// Identity frame for routing
public ZFrame Identity { get; protected set; }
//Ownling service, if known
public Service Service { get; set; }
//When worker expires, if no heartbeat;
public DateTime Expiry { get; set; }
/// <summary>
///
/// </summary>
/// <param name="idString"></param>
/// <param name="broker"></param>
/// <param name="identity">will be dublicated inside the constructor</param>
public Worker(string idString, Broker broker, ZFrame identity)
{
Broker = broker;
IdString = idString;
Identity = identity.Duplicate();
}
~Worker()
{
Dispose(false);
}
public void Dispose()
{
GC.SuppressFinalize(this);
Dispose(true);
}
protected void Dispose(bool disposing)
{
if (disposing)
{
using (Identity)
{}
}
}
public void Delete(bool disconnect)
{
if(disconnect)
Send(MdpCommon.MdpwCmd.DISCONNECT.ToHexString(), null, null);
if (Service != null)
{
Service.Waiting.Remove(this);
Service.Workers--;
}
Broker.Waiting.Remove(this);
if (Broker.Workers.ContainsKey(IdString))
Broker.Workers.Remove(IdString);
}
// .split worker send method
// This method formats and sends a command to a worker. The caller may
// also provide a command option, and a message payload:
public void Send(string command, string option, ZMessage msg)
{
msg = msg != null
? msg.Duplicate()
: new ZMessage();
// Stack protocol envelope to start of message
if (!string.IsNullOrEmpty(option))
msg.Prepend(new ZFrame(option));
msg.Prepend(new ZFrame(command));
msg.Prepend(new ZFrame(MdpCommon.MDPW_WORKER));
// Stack routing envelope to start of message
msg.Wrap(Identity.Duplicate());
if(Broker.Verbose)
msg.DumpZmsg("I: sending '{0:X}|{0}' to worker", command.ToMdCmd());
Broker.Socket.Send(msg);
}
// This worker is now waiting for work
public void Waiting()
{
// queue to broker and service waiting lists
if (Broker == null)
throw new InvalidOperationException();
Broker.Waiting.Add(this);
Service.Waiting.Add(this);
Expiry = DateTime.UtcNow + MdpCommon.HEARTBEAT_EXPIRY;
Service.Dispatch(null);
}
}
}
static partial class Program
{
// .split main task
// Finally, here is the main task. We create a new broker instance and
// then process messages on the broker Socket:
public static void MDBroker(string[] args)
{
CancellationTokenSource cancellor = new CancellationTokenSource();
Console.CancelKeyPress += (s, ea) =>
{
ea.Cancel = true;
cancellor.Cancel();
};
using (Broker broker = new Broker(Verbose))
{
broker.Bind("tcp://*:5555");
// Get and process messages forever or until interrupted
while (true)
{
if (cancellor.IsCancellationRequested
|| (Console.KeyAvailable && Console.ReadKey(true).Key == ConsoleKey.Escape))
broker.ShutdownContext();
var p = ZPollItem.CreateReceiver();
ZMessage msg;
ZError error;
if (broker.Socket.PollIn(p, out msg, out error, MdpCommon.HEARTBEAT_INTERVAL))
{
if (Verbose)
msg.DumpZmsg("I: received message:");
using (ZFrame sender = msg.Pop())
using (ZFrame empty = msg.Pop())
using (ZFrame header = msg.Pop())
{
if (header.ToString().Equals(MdpCommon.MDPC_CLIENT))
broker.ClientMsg(sender, msg);
else if (header.ToString().Equals(MdpCommon.MDPW_WORKER))
broker.WorkerMsg(sender, msg);
else
{
msg.DumpZmsg("E: invalid message:");
msg.Dispose();
}
}
}
else
{
if (Equals(error, ZError.ETERM))
{
"W: interrupt received, shutting down...".DumpString();
break; // Interrupted
}
if (!Equals(error, ZError.EAGAIN))
throw new ZException(error);
}
// Disconnect and delete any expired workers
// Send heartbeats to idle workes if needed
if (DateTime.UtcNow > broker.HeartbeatAt)
{
broker.Purge();
foreach (var waitingworker in broker.Waiting)
{
waitingworker.Send(MdpCommon.MdpwCmd.HEARTBEAT.ToHexString(), null, null);
}
broker.HeartbeatAt = DateTime.UtcNow + MdpCommon.HEARTBEAT_INTERVAL;
}
}
}
}
}
}
mdbroker: Majordomo broker in CL
mdbroker: Majordomo broker in Delphi
mdbroker: Majordomo broker in Erlang
mdbroker: Majordomo broker in Elixir
mdbroker: Majordomo broker in F#
mdbroker: Majordomo broker in Felix
mdbroker: Majordomo broker in Go
// Majordomo Protocol broker
// A minimal C implementation of the Majordomo Protocol as defined in
// http://rfc.zeromq.org/spec:7 and http://rfc.zeromq.org/spec:8.
//
// To run this example, you may need to run multiple *.go files as below
// go run mdp.go zhelpers.go mdbroker.go [-v]
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
"encoding/hex"
zmq "github.com/alecthomas/gozmq"
"log"
"os"
"time"
)
const (
INTERNAL_SERVICE_PREFIX = "mmi."
HEARTBEAT_INTERVAL = 2500 * time.Millisecond
HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
)
type Broker interface {
Close()
Run()
}
type mdbWorker struct {
identity string // Hex Identity of worker
address []byte // Address to route to
expiry time.Time // Expires at this point, unless heartbeat
service *mdService // Owning service, if known
}
type mdService struct {
broker Broker
name string
requests [][][]byte // List of client requests
waiting *ZList // List of waiting workers
}
type mdBroker struct {
context *zmq.Context // Context
heartbeatAt time.Time // When to send HEARTBEAT
services map[string]*mdService // Known services
socket *zmq.Socket // Socket for clients & workers
waiting *ZList // Idle workers
workers map[string]*mdbWorker // Known workers
verbose bool // Print activity to stdout
}
func NewBroker(endpoint string, verbose bool) Broker {
context, _ := zmq.NewContext()
socket, _ := context.NewSocket(zmq.ROUTER)
socket.SetLinger(0)
socket.Bind(endpoint)
log.Printf("I: MDP broker/0.1.1 is active at %s\n", endpoint)
return &mdBroker{
context: context,
heartbeatAt: time.Now().Add(HEARTBEAT_INTERVAL),
services: make(map[string]*mdService),
socket: socket,
waiting: NewList(),
workers: make(map[string]*mdbWorker),
verbose: verbose,
}
}
// Deletes worker from all data structures, and deletes worker.
func (self *mdBroker) deleteWorker(worker *mdbWorker, disconnect bool) {
if worker == nil {
panic("Nil worker")
}
if disconnect {
self.sendToWorker(worker, MDPW_DISCONNECT, nil, nil)
}
if worker.service != nil {
worker.service.waiting.Delete(worker)
}
self.waiting.Delete(worker)
delete(self.workers, worker.identity)
}
// Dispatch requests to waiting workers as possible
func (self *mdBroker) dispatch(service *mdService, msg [][]byte) {
if service == nil {
panic("Nil service")
}
// Queue message if any
if len(msg) != 0 {
service.requests = append(service.requests, msg)
}
self.purgeWorkers()
for service.waiting.Len() > 0 && len(service.requests) > 0 {
msg, service.requests = service.requests[0], service.requests[1:]
elem := service.waiting.Pop()
self.waiting.Remove(elem)
worker, _ := elem.Value.(*mdbWorker)
self.sendToWorker(worker, MDPW_REQUEST, nil, msg)
}
}
// Process a request coming from a client.
func (self *mdBroker) processClient(sender []byte, msg [][]byte) {
// Service name + body
if len(msg) < 2 {
panic("Invalid msg")
}
service := msg[0]
// Set reply return address to client sender
msg = append([][]byte{sender, nil}, msg[1:]...)
if string(service[:4]) == INTERNAL_SERVICE_PREFIX {
self.serviceInternal(service, msg)
} else {
self.dispatch(self.requireService(string(service)), msg)
}
}
// Process message sent to us by a worker.
func (self *mdBroker) processWorker(sender []byte, msg [][]byte) {
// At least, command
if len(msg) < 1 {
panic("Invalid msg")
}
command, msg := msg[0], msg[1:]
identity := hex.EncodeToString(sender)
worker, workerReady := self.workers[identity]
if !workerReady {
worker = &mdbWorker{
identity: identity,
address: sender,
expiry: time.Now().Add(HEARTBEAT_EXPIRY),
}
self.workers[identity] = worker
if self.verbose {
log.Printf("I: registering new worker: %s\n", identity)
}
}
switch string(command) {
case MDPW_READY:
// At least, a service name
if len(msg) < 1 {
panic("Invalid msg")
}
service := msg[0]
// Not first command in session or Reserved service name
if workerReady || string(service[:4]) == INTERNAL_SERVICE_PREFIX {
self.deleteWorker(worker, true)
} else {
// Attach worker to service and mark as idle
worker.service = self.requireService(string(service))
self.workerWaiting(worker)
}
case MDPW_REPLY:
if workerReady {
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
client := msg[0]
msg = append([][]byte{client, nil, []byte(MDPC_CLIENT), []byte(worker.service.name)}, msg[2:]...)
self.socket.SendMultipart(msg, 0)
self.workerWaiting(worker)
} else {
self.deleteWorker(worker, true)
}
case MDPW_HEARTBEAT:
if workerReady {
worker.expiry = time.Now().Add(HEARTBEAT_EXPIRY)
} else {
self.deleteWorker(worker, true)
}
case MDPW_DISCONNECT:
self.deleteWorker(worker, false)
default:
log.Println("E: invalid message:")
Dump(msg)
}
}
// Look for & kill expired workers.
// Workers are oldest to most recent, so we stop at the first alive worker.
func (self *mdBroker) purgeWorkers() {
now := time.Now()
for elem := self.waiting.Front(); elem != nil; elem = self.waiting.Front() {
worker, _ := elem.Value.(*mdbWorker)
if worker.expiry.After(now) {
break
}
self.deleteWorker(worker, false)
}
}
// Locates the service (creates if necessary).
func (self *mdBroker) requireService(name string) *mdService {
if len(name) == 0 {
panic("Invalid service name")
}
service, ok := self.services[name]
if !ok {
service = &mdService{
name: name,
waiting: NewList(),
}
self.services[name] = service
}
return service
}
// Send message to worker.
// If message is provided, sends that message.
func (self *mdBroker) sendToWorker(worker *mdbWorker, command string, option []byte, msg [][]byte) {
// Stack routing and protocol envelopes to start of message and routing envelope
if len(option) > 0 {
msg = append([][]byte{option}, msg...)
}
msg = append([][]byte{worker.address, nil, []byte(MDPW_WORKER), []byte(command)}, msg...)
if self.verbose {
log.Printf("I: sending %X to worker\n", command)
Dump(msg)
}
self.socket.SendMultipart(msg, 0)
}
// Handle internal service according to 8/MMI specification
func (self *mdBroker) serviceInternal(service []byte, msg [][]byte) {
returncode := "501"
if string(service) == "mmi.service" {
name := string(msg[len(msg)-1])
if _, ok := self.services[name]; ok {
returncode = "200"
} else {
returncode = "404"
}
}
msg[len(msg)-1] = []byte(returncode)
// insert the protocol header and service name after the routing envelope
msg = append([][]byte{msg[0], nil, []byte(MDPC_CLIENT), service}, msg[2:]...)
self.socket.SendMultipart(msg, 0)
}
// This worker is now waiting for work.
func (self *mdBroker) workerWaiting(worker *mdbWorker) {
// Queue to broker and service waiting lists
self.waiting.PushBack(worker)
worker.service.waiting.PushBack(worker)
worker.expiry = time.Now().Add(HEARTBEAT_EXPIRY)
self.dispatch(worker.service, nil)
}
func (self *mdBroker) Close() {
if self.socket != nil {
self.socket.Close()
}
self.context.Close()
}
// Main broker working loop
func (self *mdBroker) Run() {
for {
items := zmq.PollItems{
zmq.PollItem{Socket: self.socket, Events: zmq.POLLIN},
}
_, err := zmq.Poll(items, HEARTBEAT_INTERVAL)
if err != nil {
panic(err) // Interrupted
}
if item := items[0]; item.REvents&zmq.POLLIN != 0 {
msg, _ := self.socket.RecvMultipart(0)
if self.verbose {
log.Printf("I: received message:")
Dump(msg)
}
sender := msg[0]
header := msg[2]
msg = msg[3:]
if string(header) == MDPC_CLIENT {
self.processClient(sender, msg)
} else if string(header) == MDPW_WORKER {
self.processWorker(sender, msg)
} else {
log.Println("E: invalid message:")
Dump(msg)
}
}
if self.heartbeatAt.Before(time.Now()) {
self.purgeWorkers()
for elem := self.waiting.Front(); elem != nil; elem = elem.Next() {
worker, _ := elem.Value.(*mdbWorker)
self.sendToWorker(worker, MDPW_HEARTBEAT, nil, nil)
}
self.heartbeatAt = time.Now().Add(HEARTBEAT_INTERVAL)
}
}
}
func main() {
verbose := len(os.Args) >= 2 && os.Args[1] == "-v"
broker := NewBroker("tcp://*:5555", verbose)
defer broker.Close()
broker.Run()
}
mdbroker: Majordomo broker in Haskell
{-
Majordomo Protocol Broker
-}
module Main where
import System.ZMQ4
import ZHelpers
import MDPDef
import System.Environment
import System.Exit
import Control.Exception (bracket)
import Control.Monad (forever, forM_, mapM_, foldM, when)
import Data.Maybe (catMaybes, maybeToList, fromJust, isJust)
import qualified Data.ByteString.Char8 as B
import qualified Data.Map as M
import qualified Data.List as L
import qualified Data.List.NonEmpty as N
heartbeatLiveness = 1
heartbeatInterval = 2500
heartbeatExpiry = heartbeatInterval * heartbeatLiveness
data Broker = Broker {
ctx :: Context
, bSocket :: Socket Router
, verbose :: Bool
, endpoint :: String
, services :: M.Map B.ByteString Service
, workers :: M.Map B.ByteString Worker
, bWaiting :: [Worker]
, heartbeatAt :: Integer
}
data Service = Service {
name :: B.ByteString
, requests :: [Message]
, sWaiting :: [Worker]
, workersCount :: Int
}
data Worker = Worker {
wId :: B.ByteString
, serviceName :: B.ByteString
, identityFrame :: Frame
, expiry :: Integer
} deriving (Eq)
withBroker :: Bool -> (Broker -> IO a) -> IO a
withBroker verbose action =
bracket (s_brokerNew verbose)
(s_brokerDestroy)
action
-- Broker functions
s_brokerNew :: Bool -> IO Broker
s_brokerNew verbose = do
ctx <- context
bSocket <- socket ctx Router
nextHeartbeat <- nextHeartbeatTime_ms heartbeatInterval
return Broker { ctx = ctx
, bSocket = bSocket
, verbose = verbose
, services = M.empty
, workers = M.empty
, bWaiting = []
, heartbeatAt = nextHeartbeat
, endpoint = []
}
s_brokerDestroy :: Broker -> IO ()
s_brokerDestroy broker = do
close $ bSocket broker
shutdown $ ctx broker
s_brokerBind :: Broker -> String -> IO ()
s_brokerBind broker endpoint = do
bind (bSocket broker) endpoint
putStrLn $ "I: MDP broker/0.2.0 is active at " ++ endpoint
-- Processes READY, REPLY, HEARTBEAT, or DISCONNECT worker message
s_brokerWorkerMsg :: Broker -> Frame -> Message -> IO Broker
s_brokerWorkerMsg broker senderFrame msg = do
when (L.length msg < 1) $ do
error "E: Too little frames in message for worker"
let (cmdFrame, msg') = z_pop msg
id_string = senderFrame
isWorkerReady = M.member id_string (workers broker)
(worker, newBroker) = s_workerRequire broker id_string
case cmdFrame of
cmd | cmd == mdpwReady ->
-- Not first cmd in session or reserved service frame.
if isWorkerReady || (B.pack "mmi.") `B.isPrefixOf` senderFrame
then do
s_workerSendDisconnect newBroker worker
return $ s_brokerDeleteWorker newBroker worker
else do
let (serviceFrame, _) = z_pop msg'
(service, newBroker') = s_serviceRequire newBroker serviceFrame
newService = service { workersCount = workersCount service + 1 }
s_workerWaiting newBroker' newService worker
| cmd == mdpwReply ->
if isWorkerReady
then do
let (client, msg'') = z_unwrap msg'
finalMsg = z_wrap (mdpcClient : serviceName worker : msg'') client
wkrService = (services broker) M.! (serviceName worker)
sendMulti (bSocket newBroker) (N.fromList finalMsg)
s_workerWaiting newBroker wkrService worker
else do
s_workerSendDisconnect newBroker worker
return $ s_brokerDeleteWorker newBroker worker
| cmd == mdpwHeartbeat ->
if isWorkerReady
then do
currTime <- currentTime_ms
let newWorker = worker { expiry = currTime + heartbeatExpiry }
return newBroker { workers = M.insert (wId newWorker) newWorker (workers newBroker) }
else do
s_workerSendDisconnect newBroker worker
return $ s_brokerDeleteWorker newBroker worker
| cmd == mdpwDisconnect ->
return $ s_brokerDeleteWorker newBroker worker
| otherwise -> do
putStrLn $ "E: Invalid input message " ++ (B.unpack cmd)
dumpMsg msg'
return newBroker
-- Process a request coming from a client.
s_brokerClientMsg :: Broker -> Frame -> Message -> IO Broker
s_brokerClientMsg broker senderFrame msg = do
when (L.length msg < 2) $ do
error "E: Too little frames in message for client"
let (serviceFrame, msg') = z_pop msg
(service, newBroker) = s_serviceRequire broker serviceFrame
msg'' = z_wrap msg' senderFrame
if (B.pack "mmi.") `B.isPrefixOf` serviceFrame
then do
let returnCode = B.pack $ checkService service serviceFrame msg''
returnMsg = L.init msg'' ++ [returnCode]
(client, msg''') = z_unwrap returnMsg
finalMsg = z_wrap (mdpcClient : serviceFrame : msg''') client
sendMulti (bSocket newBroker) (N.fromList finalMsg)
return newBroker
else do
s_serviceDispatch newBroker service (Just msg'')
where checkService service serviceFrame msg =
if serviceFrame == B.pack "mmi.service"
then let name = last msg
namedService = M.lookup name (services broker)
in if isJust namedService && workersCount (fromJust namedService) > 0
then "200"
else "404"
else "501"
s_brokerDeleteWorker :: Broker -> Worker -> Broker
s_brokerDeleteWorker broker worker =
let purgedServices = M.map purgeWorker (services broker)
in broker { bWaiting = L.delete worker (bWaiting broker)
, workers = M.delete (wId worker) (workers broker)
, services = purgedServices }
where purgeWorker service =
service { sWaiting = L.delete worker (sWaiting service)
, workersCount = workersCount service - 1 }
-- Removes expired workers from the broker and its services
s_brokerPurge :: Broker -> IO Broker
s_brokerPurge broker = do
currTime <- currentTime_ms
let (toPurge, rest) = L.span (\worker -> currTime >= expiry worker)
(bWaiting broker)
leftInMap = M.filterWithKey (isNotPurgedKey toPurge) (workers broker)
purgedServices = purgeWorkersFromServices toPurge (services broker)
return broker { bWaiting = rest
, workers = leftInMap
, services = purgedServices
}
where isNotPurgedKey toPurge key _ =
key `notElem` (map wId toPurge)
purgeWorkersFromServices workers = M.map (purge workers)
purge workers service =
let (toPurge, rest) = L.partition (\worker -> worker `elem` workers)
(sWaiting service)
in service { sWaiting = rest
, workersCount = (workersCount service) - (length toPurge)
}
-- Service functions
-- Inserts a new service in the broker's services if that service didn't exist.
s_serviceRequire :: Broker -> Frame -> (Service, Broker)
s_serviceRequire broker serviceFrame =
let foundService = M.lookup serviceFrame (services broker)
in case foundService of
Nothing -> createNewService
Just fs -> (fs, broker)
where createNewService =
let newService = Service { name = serviceFrame
, requests = []
, sWaiting = []
, workersCount = 0
}
in (newService
, broker { services = M.insert (name newService) newService (services broker) })
-- Dispatch queued messages from workers
s_serviceDispatch :: Broker -> Service -> Maybe Message -> IO Broker
s_serviceDispatch broker service msg = do
purgedBroker <- s_brokerPurge broker
let workersWithMessages = zip (sWaiting newService) (requests newService)
wkrsToRemain = filter (\wkr -> wkr `notElem` (map fst workersWithMessages)) (bWaiting purgedBroker)
rqsToRemain = filter (\rq -> rq `notElem` (map snd workersWithMessages)) (requests newService)
forM_ workersWithMessages $ \wkrMsg -> do
s_workerSend purgedBroker (fst wkrMsg) mdpwRequest Nothing (Just $ snd wkrMsg)
return ( purgedBroker { bWaiting = wkrsToRemain
, services = M.insert (name newService)
(newService { requests = rqsToRemain
, sWaiting = wkrsToRemain
, workersCount = length wkrsToRemain })
(services purgedBroker) }
)
where newService =
if isJust msg
then service { requests = requests service ++ [(fromJust msg)] }
else service
-- Worker functions
-- Inserts a new worker in the broker's workers if that worker didn't exist.
s_workerRequire :: Broker -> Frame -> (Worker, Broker)
s_workerRequire broker identity =
let foundWorker = M.lookup identity (workers broker)
in case foundWorker of
Nothing -> createNewWorker
Just fw -> (fw, broker)
where createNewWorker =
let newWorker = Worker { wId = identity
, serviceName = B.empty
, identityFrame = identity
, expiry = 0
}
in (newWorker
, broker { workers = M.insert (wId newWorker) newWorker (workers broker) })
s_workerSendDisconnect :: Broker -> Worker -> IO ()
s_workerSendDisconnect broker worker =
s_workerSend broker worker mdpwDisconnect Nothing Nothing
-- Sends a message to the client
s_workerSend :: Broker -> Worker -> Frame -> Maybe Frame -> Maybe Message -> IO ()
s_workerSend broker worker cmd option msg = do
let msgOpts = [Just mdpwWorker, Just cmd, option]
msgFinal = (catMaybes msgOpts) ++ (concat . maybeToList $ msg)
msgWithId = z_wrap msgFinal (wId worker)
when (verbose broker) $ do
putStrLn $ "I: sending '" ++ (B.unpack $ mdpsCommands !! mdpGetIdx (B.unpack cmd)) ++ "' to worker"
dumpMsg msgWithId
sendMulti (bSocket broker) (N.fromList msgWithId)
-- Adds a worker to the waiting lists
s_workerWaiting :: Broker -> Service -> Worker -> IO Broker
s_workerWaiting broker wService worker = do
currTime <- currentTime_ms
let newWorker = worker { expiry = currTime + heartbeatExpiry
, serviceName = name wService }
newService = wService { sWaiting = sWaiting wService ++ [newWorker] }
newBroker = broker { bWaiting = bWaiting broker ++ [newWorker]
, services = M.insert (name newService) newService (services broker)
, workers = M.insert (wId newWorker) newWorker (workers broker) }
s_serviceDispatch newBroker newService Nothing
-- Main. Create a new broker and process messages on its socket.
main :: IO ()
main = do
args <- getArgs
when (length args /= 1) $ do
putStrLn "usage: mdbroker <isVerbose(True|False)>"
exitFailure
let isVerbose = read (args !! 0) :: Bool
withBroker isVerbose $ \broker -> do
s_brokerBind broker "tcp://*:5555"
process broker
where process broker = do
[evts] <- poll (fromInteger $ heartbeatInterval)
[Sock (bSocket broker) [In] Nothing]
when (In `L.elem` evts) $ do
msg <- receiveMulti (bSocket broker)
when (verbose broker) $ do
putStrLn "I: Received message: "
dumpMsg msg
let (sender, msg') = z_pop msg
(empty, msg'') = z_pop msg'
(header, finalMsg) = z_pop msg''
case header of
head | head == mdpcClient -> do
newBroker <- s_brokerClientMsg broker sender finalMsg
process newBroker
| head == mdpwWorker -> do
newBroker <- s_brokerWorkerMsg broker sender finalMsg
process newBroker
| otherwise -> do
putStrLn $ "E: Invalid message: " ++ (B.unpack head)
dumpMsg finalMsg
process broker
currTime <- currentTime_ms
when (currTime > heartbeatAt broker) $ do
newBroker <- s_brokerPurge broker
mapM_ (\worker -> s_workerSend newBroker worker mdpwHeartbeat Nothing Nothing) (bWaiting broker)
currTime <- currentTime_ms
process newBroker { heartbeatAt = currTime + heartbeatInterval }
process broker
mdbroker: Majordomo broker in Haxe
package ;
import haxe.io.Bytes;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import MDP;
/**
* Majordomo Protocol broker
* A minimal implementation of http://rfc.zeromq.org/spec:7 and spec:8
*/
class MDBroker
{
public static function main() {
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var log = Lib.println;
var broker = new Broker(verbose, log);
broker.bind("tcp://*:5555");
var poller = new ZMQPoller();
poller.registerSocket(broker.socket, ZMQ.ZMQ_POLLIN());
// Get and process messages forever or until interrupted
while (true) {
try {
var res = poller.poll(Constants.HEARTBEAT_INTERVAL);
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else {
Lib.println("W: interrupt received, killing broker...");
}
broker.destroy();
return;
}
// Process next input message, if any
if (poller.pollin(1)) {
var msg = ZMsg.recvMsg(broker.socket);
if (msg == null)
break; // Interrupted
if (verbose)
log("I: received message:" + msg.toString());
var sender = msg.pop();
var empty = msg.pop();
var header = msg.pop();
if (header.streq(MDP.MDPC_CLIENT))
broker.processClient(sender, msg);
else if (header.streq(MDP.MDPW_WORKER))
broker.processWorker(sender, msg);
else {
log("E: invalid message:" + msg.toString());
msg.destroy();
}
sender.destroy();
empty.destroy();
header.destroy();
}
// Disconnect and delete any expired workers
// Send heartbeats to idle workers if needed
if (Date.now().getTime() > broker.heartbeatAt) {
broker.purgeWorkers();
for (w in broker.waiting) {
broker.sendWorker(w, MDP.MDPW_HEARTBEAT, null, null);
}
broker.heartbeatAt = Date.now().getTime() + Constants.HEARTBEAT_INTERVAL;
}
}
if (ZMQ.isInterrupted())
log("W: interrupt received, shutting down...");
broker.destroy();
}
}
private class Constants {
// We'd normally pull these from config data
public static inline var HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
public static inline var HEARTBEAT_INTERVAL = 2500; // msecs
public static inline var HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
}
/**
* Internal class, managing a single service
*/
private class Service {
/** Service name */
public var name(default, null):String;
/** List of client requests */
public var requests:List<ZMsg>;
/** List of waiting service workers */
public var waiting:List<Worker>;
/** How many workers the service has */
public var numWorkers:Int;
/**
* Constructor
* @param name
*/
public function new(name:String) {
this.name = name;
this.requests = new List<ZMsg>();
this.waiting = new List<Worker>();
this.numWorkers = 0;
}
/**
* Destructor
*/
public function destroy() {
for (r in requests) {
r.destroy();
}
requests = null;
waiting = null;
}
public function removeWorker(worker:Worker) {
if (worker == null)
return;
waiting.remove(worker);
numWorkers--;
}
}
/**
* Internal class, managing a single worker
*/
private class Worker {
/** Identity of worker */
public var identity(default, null):String;
/** Address frame to route to */
public var address(default, null):ZFrame;
/** Owning service, if known */
public var service:Service;
/** Expires at unless heartbeat */
public var expiry:Float;
public function new(address:ZFrame, identity:String, ?service:Service, ?expiry:Float = 0.0) {
this.address = address;
this.identity = identity;
this.service = service;
this.expiry = expiry;
}
/**
* Deconstructor
*/
public function destroy() {
address.destroy();
}
/**
* Return true if worker has expired and must be deleted
* @return
*/
public function expired():Bool {
return expiry < Date.now().getTime();
}
}
/**
* Main class definining state and behaviour of a MDBroker
*/
private class Broker {
/** Socket for clients and workers */
public var socket(default, null):ZMQSocket;
/** When to send heartbeat */
public var heartbeatAt:Float;
/** Hash of waiting workers */
public var waiting(default, null):List<Worker>;
// Private fields
/** Our context */
private var ctx:ZContext;
/** Broker binds to this endpoint */
private var endpoint:String;
/** Hash of known services */
private var services:Hash<Service>;
/** Hash of known workers */
private var workers:Hash<Worker>;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/**
* Construct new broker
*/
public function new(?verbose:Bool = false, ?logger:Dynamic->Void)
{
ctx = new ZContext();
socket = ctx.createSocket(ZMQ_ROUTER);
services = new Hash<Service>();
workers = new Hash<Worker>();
waiting = new List<Worker>();
heartbeatAt = Date.now().getTime() + Constants.HEARTBEAT_INTERVAL;
this.verbose = verbose;
if (logger != null)
log = logger;
else
log = Lib.println;
}
/**
* Destructor
*/
public function destroy() {
ctx.destroy();
}
/**
* Bind broker to endpoint, can call this multiple times
* We use a single socket for both clients and workers.
* @param endpoint
*/
public function bind(endpoint:String) {
socket.bind(endpoint);
log("I: MDP broker/0.1.1 is active at " + endpoint);
}
/**
* Delete any idle workers that haven't pinged us in a while
*/
public function purgeWorkers() {
for (w in waiting) {
if (Date.now().getTime() < w.expiry)
continue; // Worker is alive, we're done here
if (verbose)
log("I: deleting expired worker: " + w.identity);
deleteWorker(w, false);
}
}
/**
* Locate or create a new service entry
* @param name
* @return
*/
private function requireService(name:String):Service {
if (name == null)
return null;
if (services.exists(name))
return services.get(name);
else {
var srv = new Service(name);
services.set(name, srv);
if (verbose)
log("I: Added service :" + name);
return srv;
}
return null;
}
/**
* Dispatch as many requests to waiting workers as possible
* @param service
* @param msg
*/
private function dispatchService(service:Service, ?msg:ZMsg) {
// Tidy up workers first
purgeWorkers();
if (msg != null)
service.requests.add(msg);
while (!service.waiting.isEmpty() && !service.requests.isEmpty()) {
var worker = service.waiting.pop();
waiting.remove(worker);
var _msg = service.requests.pop();
sendWorker(worker, MDP.MDPW_REQUEST, null, _msg);
}
}
/**
* Handle internal service according to 8/MMI specification
* @param serviceFrame
* @param msg
* @return
*/
private function internalService(serviceFrame:ZFrame, msg:ZMsg) {
var returnCode = "";
if (serviceFrame == null || msg == null)
return;
if (serviceFrame.streq("mmi.service")) {
var name = msg.last().toString();
var service = services.get(name);
returnCode = {
if ((service != null) && (service.numWorkers > 0))
"200";
else
"404";
};
} else
returnCode = "501";
msg.last().reset(Bytes.ofString(returnCode));
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
var client = msg.unwrap();
msg.push(serviceFrame.duplicate());
msg.pushString(MDP.MDPC_CLIENT);
msg.wrap(client);
msg.send(socket);
}
/**
* Creates worker if necessary
* @param address
* @return
*/
private function requireWorker(address:ZFrame):Worker {
if (address == null)
return null;
// workers Hash is keyed off worker identity
var identity = address.strhex();
var worker = workers.get(identity);
if (worker == null) {
worker = new Worker(address.duplicate(), identity);
workers.set(identity, worker);
if (verbose)
log("I: registering new worker: " + identity);
}
return worker;
}
/**
* Deletes worker from all data structures, and destroys worker object itself
* @param worker
* @param disconnect
*/
private function deleteWorker(worker:Worker, disconnect:Bool) {
if (worker == null)
return;
if (disconnect)
sendWorker(worker, MDP.MDPW_DISCONNECT, null, null);
if (worker.service != null)
worker.service.removeWorker(worker);
waiting.remove(worker);
workers.remove(worker.identity);
worker.destroy();
}
/**
* Process message sent to us by a worker
* @param sender
* @param msg
*/
public function processWorker(sender:ZFrame, msg:ZMsg) {
if (msg.size() < 1)
return; // At least, command
var command = msg.pop();
var identity = sender.strhex();
var workerReady = workers.exists(identity);
var worker = requireWorker(sender);
if (command.streq(MDP.MDPW_READY)) {
if (workerReady) // Not first command in session
deleteWorker(worker, true); // Disconnect worker
else if ( sender.size() >= 4 // Reserved for service name
&& sender.toString().indexOf("mmi.") == 0)
deleteWorker(worker, true);
else {
// Attach worker to service and mark as idle
var serviceFrame = msg.pop();
worker.service = requireService(serviceFrame.toString());
worker.service.numWorkers++;
waitingWorker(worker);
serviceFrame.destroy();
}
} else if (command.streq(MDP.MDPW_REPLY)) {
if (workerReady) {
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
var client = msg.unwrap();
msg.pushString(worker.service.name);
msg.pushString(MDP.MDPC_CLIENT);
msg.wrap(client);
msg.send(socket);
waitingWorker(worker);
} else
deleteWorker(worker, true);
} else if (command.streq(MDP.MDPW_HEARTBEAT)) {
if (workerReady)
worker.expiry = Date.now().getTime() + Constants.HEARTBEAT_EXPIRY;
else
deleteWorker(worker, true);
} else if (command.streq(MDP.MDPW_DISCONNECT))
deleteWorker(worker, false);
else
log("E: invalid input message:" + msg.toString());
if (msg != null)
msg.destroy();
}
/**
* Send message to worker
* If message is provided, sends that message. Does not
* destroy the message, this is the caller's job.
* @param worker
* @param command
* @param option
* @param msg
*/
public function sendWorker(worker:Worker, command:String, option:String, msg:ZMsg) {
var _msg = { if (msg != null) msg.duplicate(); else new ZMsg(); };
// Stack protocol envelope to start of message
if (option != null)
_msg.pushString(option);
_msg.pushString(command);
_msg.pushString(MDP.MDPW_WORKER);
// Stack routing envelope to start of message
_msg.wrap(worker.address.duplicate());
if (verbose)
log("I: sending " + MDP.MDPS_COMMANDS[command.charCodeAt(0)] + " to worker: " + _msg.toString());
_msg.send(socket);
}
/**
* This worker is now waiting for work
* @param worker
*/
private function waitingWorker(worker:Worker) {
waiting.add(worker);
worker.service.waiting.add(worker);
worker.expiry = Date.now().getTime() + Constants.HEARTBEAT_EXPIRY;
dispatchService(worker.service);
}
public function processClient(sender:ZFrame, msg:ZMsg) {
if (msg.size() < 2) // Service name and body
return;
var serviceFrame = msg.pop();
var service = requireService(serviceFrame.toString());
// Set reply return address to client sender
msg.wrap(sender.duplicate());
if ( serviceFrame.size() >= 4 // Reserved for service name
&& serviceFrame.toString().indexOf("mmi.") == 0)
internalService(serviceFrame, msg);
else
dispatchService(service, msg);
serviceFrame.destroy();
}
}
mdbroker: Majordomo broker in Java
package guide;
import java.util.ArrayDeque;
import java.util.Deque;
import java.util.Formatter;
import java.util.HashMap;
import java.util.Map;
import org.zeromq.*;
/**
* Majordomo Protocol broker
* A minimal implementation of http://rfc.zeromq.org/spec:7 and spec:8
*/
public class mdbroker
{
// We'd normally pull these from config data
private static final String INTERNAL_SERVICE_PREFIX = "mmi.";
private static final int HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
private static final int HEARTBEAT_INTERVAL = 2500; // msecs
private static final int HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
// ---------------------------------------------------------------------
/**
* This defines a single service.
*/
private static class Service
{
public final String name; // Service name
Deque<ZMsg> requests; // List of client requests
Deque<Worker> waiting; // List of waiting workers
public Service(String name)
{
this.name = name;
this.requests = new ArrayDeque<ZMsg>();
this.waiting = new ArrayDeque<Worker>();
}
}
/**
* This defines one worker, idle or active.
*/
private static class Worker
{
String identity;// Identity of worker
ZFrame address; // Address frame to route to
Service service; // Owning service, if known
long expiry; // Expires at unless heartbeat
public Worker(String identity, ZFrame address)
{
this.address = address;
this.identity = identity;
this.expiry = System.currentTimeMillis() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
}
}
// ---------------------------------------------------------------------
private ZContext ctx; // Our context
private ZMQ.Socket socket; // Socket for clients & workers
private long heartbeatAt;// When to send HEARTBEAT
private Map<String, Service> services; // known services
private Map<String, Worker> workers; // known workers
private Deque<Worker> waiting; // idle workers
private boolean verbose = false; // Print activity to stdout
private Formatter log = new Formatter(System.out);
// ---------------------------------------------------------------------
/**
* Main method - create and start new broker.
*/
public static void main(String[] args)
{
mdbroker broker = new mdbroker(args.length > 0 && "-v".equals(args[0]));
// Can be called multiple times with different endpoints
broker.bind("tcp://*:5555");
broker.mediate();
}
/**
* Initialize broker state.
*/
public mdbroker(boolean verbose)
{
this.verbose = verbose;
this.services = new HashMap<String, Service>();
this.workers = new HashMap<String, Worker>();
this.waiting = new ArrayDeque<Worker>();
this.heartbeatAt = System.currentTimeMillis() + HEARTBEAT_INTERVAL;
this.ctx = new ZContext();
this.socket = ctx.createSocket(SocketType.ROUTER);
}
// ---------------------------------------------------------------------
/**
* Main broker work happens here
*/
public void mediate()
{
while (!Thread.currentThread().isInterrupted()) {
ZMQ.Poller items = ctx.createPoller(1);
items.register(socket, ZMQ.Poller.POLLIN);
if (items.poll(HEARTBEAT_INTERVAL) == -1)
break; // Interrupted
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(socket);
if (msg == null)
break; // Interrupted
if (verbose) {
log.format("I: received message:\n");
msg.dump(log.out());
}
ZFrame sender = msg.pop();
ZFrame empty = msg.pop();
ZFrame header = msg.pop();
if (MDP.C_CLIENT.frameEquals(header)) {
processClient(sender, msg);
}
else if (MDP.W_WORKER.frameEquals(header))
processWorker(sender, msg);
else {
log.format("E: invalid message:\n");
msg.dump(log.out());
msg.destroy();
}
sender.destroy();
empty.destroy();
header.destroy();
}
items.close();
purgeWorkers();
sendHeartbeats();
}
destroy(); // interrupted
}
/**
* Disconnect all workers, destroy context.
*/
private void destroy()
{
Worker[] deleteList = workers.entrySet().toArray(new Worker[0]);
for (Worker worker : deleteList) {
deleteWorker(worker, true);
}
ctx.destroy();
}
/**
* Process a request coming from a client.
*/
private void processClient(ZFrame sender, ZMsg msg)
{
assert (msg.size() >= 2); // Service name + body
ZFrame serviceFrame = msg.pop();
// Set reply return address to client sender
msg.wrap(sender.duplicate());
if (serviceFrame.toString().startsWith(INTERNAL_SERVICE_PREFIX))
serviceInternal(serviceFrame, msg);
else dispatch(requireService(serviceFrame), msg);
serviceFrame.destroy();
}
/**
* Process message sent to us by a worker.
*/
private void processWorker(ZFrame sender, ZMsg msg)
{
assert (msg.size() >= 1); // At least, command
ZFrame command = msg.pop();
boolean workerReady = workers.containsKey(sender.strhex());
Worker worker = requireWorker(sender);
if (MDP.W_READY.frameEquals(command)) {
// Not first command in session || Reserved service name
if (workerReady || sender.toString().startsWith(INTERNAL_SERVICE_PREFIX))
deleteWorker(worker, true);
else {
// Attach worker to service and mark as idle
ZFrame serviceFrame = msg.pop();
worker.service = requireService(serviceFrame);
workerWaiting(worker);
serviceFrame.destroy();
}
}
else if (MDP.W_REPLY.frameEquals(command)) {
if (workerReady) {
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
ZFrame client = msg.unwrap();
msg.addFirst(worker.service.name);
msg.addFirst(MDP.C_CLIENT.newFrame());
msg.wrap(client);
msg.send(socket);
workerWaiting(worker);
}
else {
deleteWorker(worker, true);
}
}
else if (MDP.W_HEARTBEAT.frameEquals(command)) {
if (workerReady) {
worker.expiry = System.currentTimeMillis() + HEARTBEAT_EXPIRY;
}
else {
deleteWorker(worker, true);
}
}
else if (MDP.W_DISCONNECT.frameEquals(command))
deleteWorker(worker, false);
else {
log.format("E: invalid message:\n");
msg.dump(log.out());
}
msg.destroy();
}
/**
* Deletes worker from all data structures, and destroys worker.
*/
private void deleteWorker(Worker worker, boolean disconnect)
{
assert (worker != null);
if (disconnect) {
sendToWorker(worker, MDP.W_DISCONNECT, null, null);
}
if (worker.service != null)
worker.service.waiting.remove(worker);
workers.remove(worker);
worker.address.destroy();
}
/**
* Finds the worker (creates if necessary).
*/
private Worker requireWorker(ZFrame address)
{
assert (address != null);
String identity = address.strhex();
Worker worker = workers.get(identity);
if (worker == null) {
worker = new Worker(identity, address.duplicate());
workers.put(identity, worker);
if (verbose)
log.format("I: registering new worker: %s\n", identity);
}
return worker;
}
/**
* Locates the service (creates if necessary).
*/
private Service requireService(ZFrame serviceFrame)
{
assert (serviceFrame != null);
String name = serviceFrame.toString();
Service service = services.get(name);
if (service == null) {
service = new Service(name);
services.put(name, service);
}
return service;
}
/**
* Bind broker to endpoint, can call this multiple times. We use a single
* socket for both clients and workers.
*/
private void bind(String endpoint)
{
socket.bind(endpoint);
log.format("I: MDP broker/0.1.1 is active at %s\n", endpoint);
}
/**
* Handle internal service according to 8/MMI specification
*/
private void serviceInternal(ZFrame serviceFrame, ZMsg msg)
{
String returnCode = "501";
if ("mmi.service".equals(serviceFrame.toString())) {
String name = msg.peekLast().toString();
returnCode = services.containsKey(name) ? "200" : "400";
}
msg.peekLast().reset(returnCode.getBytes(ZMQ.CHARSET));
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
ZFrame client = msg.unwrap();
msg.addFirst(serviceFrame.duplicate());
msg.addFirst(MDP.C_CLIENT.newFrame());
msg.wrap(client);
msg.send(socket);
}
/**
* Send heartbeats to idle workers if it's time
*/
public synchronized void sendHeartbeats()
{
// Send heartbeats to idle workers if it's time
if (System.currentTimeMillis() >= heartbeatAt) {
for (Worker worker : waiting) {
sendToWorker(worker, MDP.W_HEARTBEAT, null, null);
}
heartbeatAt = System.currentTimeMillis() + HEARTBEAT_INTERVAL;
}
}
/**
* Look for & kill expired workers. Workers are oldest to most recent, so we
* stop at the first alive worker.
*/
public synchronized void purgeWorkers()
{
for (Worker w = waiting.peekFirst(); w != null
&& w.expiry < System.currentTimeMillis(); w = waiting.peekFirst()) {
log.format("I: deleting expired worker: %s\n", w.identity);
deleteWorker(waiting.pollFirst(), false);
}
}
/**
* This worker is now waiting for work.
*/
public synchronized void workerWaiting(Worker worker)
{
// Queue to broker and service waiting lists
waiting.addLast(worker);
worker.service.waiting.addLast(worker);
worker.expiry = System.currentTimeMillis() + HEARTBEAT_EXPIRY;
dispatch(worker.service, null);
}
/**
* Dispatch requests to waiting workers as possible
*/
private void dispatch(Service service, ZMsg msg)
{
assert (service != null);
if (msg != null)// Queue message if any
service.requests.offerLast(msg);
purgeWorkers();
while (!service.waiting.isEmpty() && !service.requests.isEmpty()) {
msg = service.requests.pop();
Worker worker = service.waiting.pop();
waiting.remove(worker);
sendToWorker(worker, MDP.W_REQUEST, null, msg);
msg.destroy();
}
}
/**
* Send message to worker. If message is provided, sends that message. Does
* not destroy the message, this is the caller's job.
*/
public void sendToWorker(Worker worker, MDP command, String option, ZMsg msgp)
{
ZMsg msg = msgp == null ? new ZMsg() : msgp.duplicate();
// Stack protocol envelope to start of message
if (option != null)
msg.addFirst(new ZFrame(option));
msg.addFirst(command.newFrame());
msg.addFirst(MDP.W_WORKER.newFrame());
// Stack routing envelope to start of message
msg.wrap(worker.address.duplicate());
if (verbose) {
log.format("I: sending %s to worker\n", command);
msg.dump(log.out());
}
msg.send(socket);
}
}
mdbroker: Majordomo broker in Julia
mdbroker: Majordomo broker in Lua
--
-- Majordomo Protocol broker
-- A minimal implementation of http://rfc.zeromq.org/spec:7 and spec:8
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmsg"
require"zhelpers"
require"mdp"
local tremove = table.remove
-- We'd normally pull these from config data
local HEARTBEAT_LIVENESS = 3 -- 3-5 is reasonable
local HEARTBEAT_INTERVAL = 2500 -- msecs
local HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
-- ---------------------------------------------------------------------
-- Constructor for broker object
-- ---------------------------------------------------------------------
-- Broker object's metatable.
local broker_mt = {}
broker_mt.__index = broker_mt
function broker_new(verbose)
local context = zmq.init(1)
-- Initialize broker state
return setmetatable({
context = context,
socket = context:socket(zmq.ROUTER),
verbose = verbose,
services = {},
workers = {},
waiting = {},
heartbeat_at = s_clock() + HEARTBEAT_INTERVAL,
}, broker_mt)
end
-- ---------------------------------------------------------------------
-- Service object
local service_mt = {}
service_mt.__index = service_mt
-- Worker object
local worker_mt = {}
worker_mt.__index = worker_mt
-- helper list remove function
local function zlist_remove(list, item)
for n=#list,1,-1 do
if list[n] == item then
tremove(list, n)
end
end
end
-- ---------------------------------------------------------------------
-- Destructor for broker object
function broker_mt:destroy()
self.socket:close()
self.context:term()
for name, service in pairs(self.services) do
service:destroy()
end
for id, worker in pairs(self.workers) do
worker:destroy()
end
end
-- ---------------------------------------------------------------------
-- Bind broker to endpoint, can call this multiple times
-- We use a single socket for both clients and workers.
function broker_mt:bind(endpoint)
self.socket:bind(endpoint)
s_console("I: MDP broker/0.1.1 is active at %s", endpoint)
end
-- ---------------------------------------------------------------------
-- Delete any idle workers that haven't pinged us in a while.
function broker_mt:purge_workers()
local waiting = self.waiting
for n=1,#waiting do
local worker = waiting[n]
if (worker:expired()) then
if (self.verbose) then
s_console("I: deleting expired worker: %s", worker.identity)
end
self:worker_delete(worker, false)
end
end
end
-- ---------------------------------------------------------------------
-- Locate or create new service entry
function broker_mt:service_require(name)
assert (name)
local service = self.services[name]
if not service then
service = setmetatable({
name = name,
requests = {},
waiting = {},
workers = 0,
}, service_mt)
self.services[name] = service
if (self.verbose) then
s_console("I: received message:")
end
end
return service
end
-- ---------------------------------------------------------------------
-- Destroy service object, called when service is removed from
-- broker.services.
function service_mt:destroy()
end
-- ---------------------------------------------------------------------
-- Dispatch requests to waiting workers as possible
function broker_mt:service_dispatch(service, msg)
assert (service)
local requests = service.requests
if (msg) then -- Queue message if any
requests[#requests + 1] = msg
end
self:purge_workers()
local waiting = service.waiting
while (#waiting > 0 and #requests > 0) do
local worker = tremove(waiting, 1) -- pop worker from service's waiting queue.
zlist_remove(self.waiting, worker) -- also remove worker from broker's waiting queue.
local msg = tremove(requests, 1) -- pop request from service's request queue.
self:worker_send(worker, mdp.MDPW_REQUEST, nil, msg)
end
end
-- ---------------------------------------------------------------------
-- Handle internal service according to 8/MMI specification
function broker_mt:service_internal(service_name, msg)
if (service_name == "mmi.service") then
local name = msg:body()
local service = self.services[name]
if (service and service.workers) then
msg:body_set("200")
else
msg:body_set("404")
end
else
msg:body_set("501")
end
-- Remove & save client return envelope and insert the
-- protocol header and service name, then rewrap envelope.
local client = msg:unwrap()
msg:wrap(mdp.MDPC_CLIENT, service_name)
msg:wrap(client, "")
msg:send(self.socket)
end
-- ---------------------------------------------------------------------
-- Creates worker if necessary
function broker_mt:worker_require(identity)
assert (identity)
-- self.workers is keyed off worker identity
local worker = self.workers[identity]
if (not worker) then
worker = setmetatable({
identity = identity,
expiry = 0,
}, worker_mt)
self.workers[identity] = worker
if (self.verbose) then
s_console("I: registering new worker: %s", identity)
end
end
return worker
end
-- ---------------------------------------------------------------------
-- Deletes worker from all data structures, and destroys worker
function broker_mt:worker_delete(worker, disconnect)
assert (worker)
if (disconnect) then
self:worker_send(worker, mdp.MDPW_DISCONNECT)
end
local service = worker.service
if (service) then
zlist_remove (service.waiting, worker)
service.workers = service.workers - 1
end
zlist_remove (self.waiting, worker)
self.workers[worker.identity] = nil
worker:destroy()
end
-- ---------------------------------------------------------------------
-- Destroy worker object, called when worker is removed from
-- broker.workers.
function worker_mt:destroy(argument)
end
-- ---------------------------------------------------------------------
-- Process message sent to us by a worker
function broker_mt:worker_process(sender, msg)
assert (msg:parts() >= 1) -- At least, command
local command = msg:pop()
local worker_ready = (self.workers[sender] ~= nil)
local worker = self:worker_require(sender)
if (command == mdp.MDPW_READY) then
if (worker_ready) then -- Not first command in session then
self:worker_delete(worker, true)
elseif (sender:sub(1,4) == "mmi.") then -- Reserved service name
self:worker_delete(worker, true)
else
-- Attach worker to service and mark as idle
local service_name = msg:pop()
local service = self:service_require(service_name)
worker.service = service
service.workers = service.workers + 1
self:worker_waiting(worker)
end
elseif (command == mdp.MDPW_REPLY) then
if (worker_ready) then
-- Remove & save client return envelope and insert the
-- protocol header and service name, then rewrap envelope.
local client = msg:unwrap()
msg:wrap(mdp.MDPC_CLIENT, worker.service.name)
msg:wrap(client, "")
msg:send(self.socket)
self:worker_waiting(worker)
else
self:worker_delete(worker, true)
end
elseif (command == mdp.MDPW_HEARTBEAT) then
if (worker_ready) then
worker.expiry = s_clock() + HEARTBEAT_EXPIRY
else
self:worker_delete(worker, true)
end
elseif (command == mdp.MDPW_DISCONNECT) then
self:worker_delete(worker, false)
else
s_console("E: invalid input message (%d)", command:byte(1,1))
msg:dump()
end
end
-- ---------------------------------------------------------------------
-- Send message to worker
-- If pointer to message is provided, sends & destroys that message
function broker_mt:worker_send(worker, command, option, msg)
msg = msg and msg:dup() or zmsg.new()
-- Stack protocol envelope to start of message
if (option) then -- Optional frame after command
msg:push(option)
end
msg:push(command)
msg:push(mdp.MDPW_WORKER)
-- Stack routing envelope to start of message
msg:wrap(worker.identity, "")
if (self.verbose) then
s_console("I: sending %s to worker", mdp.mdps_commands[command])
msg:dump()
end
msg:send(self.socket)
end
-- ---------------------------------------------------------------------
-- This worker is now waiting for work
function broker_mt:worker_waiting(worker)
-- Queue to broker and service waiting lists
self.waiting[#self.waiting + 1] = worker
worker.service.waiting[#worker.service.waiting + 1] = worker
worker.expiry = s_clock() + HEARTBEAT_EXPIRY
self:service_dispatch(worker.service, nil)
end
-- ---------------------------------------------------------------------
-- Return 1 if worker has expired and must be deleted
function worker_mt:expired()
return (self.expiry < s_clock())
end
-- ---------------------------------------------------------------------
-- Process a request coming from a client
function broker_mt:client_process(sender, msg)
assert (msg:parts() >= 2) -- Service name + body
local service_name = msg:pop()
local service = self:service_require(service_name)
-- Set reply return address to client sender
msg:wrap(sender, "")
if (service_name:sub(1,4) == "mmi.") then
self:service_internal(service_name, msg)
else
self:service_dispatch(service, msg)
end
end
-- ---------------------------------------------------------------------
-- Main broker work happens here
local verbose = (arg[1] == "-v")
s_version_assert (2, 1)
s_catch_signals ()
local self = broker_new(verbose)
self:bind("tcp://*:5555")
local poller = zmq.poller.new(1)
-- Process next input message, if any
poller:add(self.socket, zmq.POLLIN, function()
local msg = zmsg.recv(self.socket)
if (self.verbose) then
s_console("I: received message:")
msg:dump()
end
local sender = msg:pop()
local empty = msg:pop()
local header = msg:pop()
if (header == mdp.MDPC_CLIENT) then
self:client_process(sender, msg)
elseif (header == mdp.MDPW_WORKER) then
self:worker_process(sender, msg)
else
s_console("E: invalid message:")
msg:dump()
end
end)
-- Get and process messages forever or until interrupted
while (not s_interrupted) do
local cnt = assert(poller:poll(HEARTBEAT_INTERVAL * 1000))
-- Disconnect and delete any expired workers
-- Send heartbeats to idle workers if needed
if (s_clock() > self.heartbeat_at) then
self:purge_workers()
local waiting = self.waiting
for n=1,#waiting do
local worker = waiting[n]
self:worker_send(worker, mdp.MDPW_HEARTBEAT)
end
self.heartbeat_at = s_clock() + HEARTBEAT_INTERVAL
end
end
if (s_interrupted) then
printf("W: interrupt received, shutting down...\n")
end
self:destroy()
mdbroker: Majordomo broker in Node.js
mdbroker: Majordomo broker in Objective-C
mdbroker: Majordomo broker in ooc
mdbroker: Majordomo broker in Perl
mdbroker: Majordomo broker in PHP
<?php
/*
* Majordomo Protocol broker
* A minimal implementation of http://rfc.zeromq.org/spec:7 and spec:8
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'zmsg.php';
include_once 'mdp.php';
// We'd normally pull these from config data
define("HEARTBEAT_LIVENESS", 3); // 3-5 is reasonable
define("HEARTBEAT_INTERVAL", 2500); // msecs
define("HEARTBEAT_EXPIRY", HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS);
/* Main broker work happens here */
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$broker = new Mdbroker($verbose);
$broker->bind("tcp://*:5555");
$broker->listen();
class mdbroker
{
private $ctx; // Our context
private $socket; // Socket for clients & workers
private $endpoint; // Broker binds to this endpoint
private $services = array(); // Hash of known services
private $workers = array(); // Hash of known workers
private $waiting = array(); // List of waiting workers
private $verbose = false; // Print activity to stdout
// Heartbeat management
private $heartbeat_at; // When to send HEARTBEAT
/**
* Constructor
*
* @param boolean $verbose
*/
public function __construct($verbose = false)
{
$this->ctx = new ZMQContext();
$this->socket = new ZMQSocket($this->ctx, ZMQ::SOCKET_ROUTER);
$this->verbose = $verbose;
$this->heartbeat_at = microtime(true) + (HEARTBEAT_INTERVAL/1000);
}
/**
* Bind broker to endpoint, can call this multiple time
* We use a single socket for both clients and workers.
*
* @param string $endpoint
*/
public function bind($endpoint)
{
$this->socket->bind($endpoint);
if ($this->verbose) {
printf("I: MDP broker/0.1.1 is active at %s %s", $endpoint, PHP_EOL);
}
}
/**
* This is the main listen and process loop
*/
public function listen()
{
$read = $write = array();
// Get and process messages forever or until interrupted
while (true) {
$poll = new ZMQPoll();
$poll->add($this->socket, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, HEARTBEAT_INTERVAL);
// Process next input message, if any
if ($events) {
$zmsg = new Zmsg($this->socket);
$zmsg->recv();
if ($this->verbose) {
echo "I: received message:", PHP_EOL, $zmsg->__toString();
}
$sender = $zmsg->pop();
$empty = $zmsg->pop();
$header = $zmsg->pop();
if ($header == MDPC_CLIENT) {
$this->client_process($sender, $zmsg);
} elseif ($header == MDPW_WORKER) {
$this->worker_process($sender, $zmsg);
} else {
echo "E: invalid message", PHP_EOL, $zmsg->__toString();
}
}
// Disconnect and delete any expired workers
// Send heartbeats to idle workers if needed
if (microtime(true) > $this->heartbeat_at) {
$this->purge_workers();
foreach ($this->workers as $worker) {
$this->worker_send($worker, MDPW_HEARTBEAT, NULL, NULL);
}
$this->heartbeat_at = microtime(true) + (HEARTBEAT_INTERVAL/1000);
}
}
}
/**
* Delete any idle workers that haven't pinged us in a while.
* We know that workers are ordered from oldest to most recent.
*/
public function purge_workers()
{
foreach ($this->waiting as $id => $worker) {
if (microtime(true) < $worker->expiry) {
break; // Worker is alive, we're done here
}
if ($this->verbose) {
printf("I: deleting expired worker: %s %s",
$worker->identity, PHP_EOL);
}
$this->worker_delete($worker);
}
}
/**
* Locate or create new service entry
*
* @param string $name
* @return stdClass
*/
public function service_require($name)
{
$service = isset($this->services[$name]) ? $this->services[$name] : NULL;
if ($service == NULL) {
$service = new stdClass();
$service->name = $name;
$service->requests = array();
$service->waiting = array();
$service->workers = 0;
$this->services[$name] = $service;
}
return $service;
}
/**
* Dispatch requests to waiting workers as possible
*
* @param type $service
* @param type $msg
*/
public function service_dispatch($service, $msg)
{
if ($msg) {
$service->requests[] = $msg;
}
$this->purge_workers();
while (count($service->waiting) && count($service->requests)) {
$worker = array_shift($service->waiting);
$msg = array_shift($service->requests);
$this->worker_remove_from_array($worker, $this->waiting);
$this->worker_send($worker, MDPW_REQUEST, NULL, $msg);
}
}
/**
* Handle internal service according to 8/MMI specification
*
* @param string $frame
* @param Zmsg $msg
*/
public function service_internal($frame, $msg)
{
if ($frame == "mmi.service") {
$name = $msg->last();
$service = $this->services[$name];
$return_code = $service && $service->workers ? "200" : "404";
} else {
$return_code = "501";
}
$msg->set_last($return_code);
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope
$client = $msg->unwrap();
$msg->push($frame);
$msg->push(MDPC_CLIENT);
$msg->wrap($client, "");
$msg->set_socket($this->socket)->send();
}
/**
* Creates worker if necessary
*
* @param string $address
* @return stdClass
*/
public function worker_require($address)
{
$worker = isset($this->workers[$address]) ? $this->workers[$address] : NULL;
if ($worker == NULL) {
$worker = new stdClass();
$worker->identity = $address;
$worker->address = $address;
if ($this->verbose) {
printf("I: registering new worker: %s %s", $address, PHP_EOL);
}
$this->workers[$address] = $worker;
}
return $worker;
}
/**
* Remove a worker
*
* @param stdClass $worker
* @param boolean $disconnect
*/
public function worker_delete($worker, $disconnect = false)
{
if ($disconnect) {
$this->worker_send($worker, MDPW_DISCONNECT, NULL, NULL);
}
if (isset($worker->service)) {
$sw = $this->worker_remove_from_array($worker, $worker->service->waiting);
} else {
$sw = null;
}
$w = $this->worker_remove_from_array($worker, $this->waiting);
if ($sw || $w && $sw === false) {
$worker->service->workers--;
}
unset($this->workers[$worker->identity]);
}
private function worker_remove_from_array($worker, &$array)
{
$index = array_search($worker, $array);
if ($index !== false) {
unset($array[$index]);
return true;
}
return false;
}
/**
* Process message sent to us by a worker
*
* @param string $sender
* @param Zmsg $msg
*/
public function worker_process($sender, $msg)
{
$command = $msg->pop();
$worker_ready = isset($this->workers[$sender]);
$worker = $this->worker_require($sender);
if ($command == MDPW_READY) {
if ($worker_ready) {
$this->worker_delete($worker, true); // Not first command in session
} else if(strlen($sender) >= 4 // Reserved service name
&& substr($sender, 0, 4) == 'mmi.') {
$this->worker_delete($worker, true);
} else {
// Attach worker to service and mark as idle
$service_frame = $msg->pop();
$worker->service = $this->service_require($service_frame);
$worker->service->workers++;
$this->worker_waiting($worker);
}
} elseif ($command == MDPW_REPLY) {
if ($worker_ready) {
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
$client = $msg->unwrap();
$msg->push($worker->service->name);
$msg->push(MDPC_CLIENT);
$msg->wrap($client, "");
$msg->set_socket($this->socket)->send();
$this->worker_waiting($worker);
} else {
$this->worker_delete($worker, true);
}
} elseif ($command == MDPW_HEARTBEAT) {
if ($worker_ready) {
$worker->expiry = microtime(true) + (HEARTBEAT_EXPIRY/1000);
} else {
$this->worker_delete($worker, true);
}
} elseif ($command == MDPW_DISCONNECT) {
$this->worker_delete($worker, true);
} else {
echo "E: invalid input message", PHP_EOL, $msg->__toString();
}
}
/**
* Send message to worker
*
* @param stdClass $worker
* @param string $command
* @param mixed $option
* @param Zmsg $msg
*/
public function worker_send($worker, $command, $option, $msg)
{
$msg = $msg ? $msg : new Zmsg();
// Stack protocol envelope to start of message
if ($option) {
$msg->push($option);
}
$msg->push($command);
$msg->push(MDPW_WORKER);
// Stack routing envelope to start of message
$msg->wrap($worker->address, "");
if ($this->verbose) {
printf("I: sending %s to worker %s",
$command, PHP_EOL);
echo $msg->__toString();
}
$msg->set_socket($this->socket)->send();
}
/**
* This worker is now waiting for work
*
* @param stdClass $worker
*/
public function worker_waiting($worker)
{
// Queue to broker and service waiting lists
$this->waiting[] = $worker;
$worker->service->waiting[] = $worker;
$worker->expiry = microtime(true) + (HEARTBEAT_EXPIRY/1000);
$this->service_dispatch($worker->service, NULL);
}
/**
* Process a request coming from a client
*
* @param string $sender
* @param Zmsg $msg
*/
public function client_process($sender, $msg)
{
$service_frame = $msg->pop();
$service = $this->service_require($service_frame);
// Set reply return address to client sender
$msg->wrap($sender, "");
if (substr($service_frame, 0, 4) == 'mmi.') {
$this->service_internal($service_frame, $msg);
} else {
$this->service_dispatch($service, $msg);
}
}
}
mdbroker: Majordomo broker in Python
"""
Majordomo Protocol broker
A minimal implementation of http:#rfc.zeromq.org/spec:7 and spec:8
Author: Min RK <benjaminrk@gmail.com>
Based on Java example by Arkadiusz Orzechowski
"""
import logging
import sys
import time
from binascii import hexlify
import zmq
# local
import MDP
from zhelpers import dump
class Service(object):
"""a single Service"""
name = None # Service name
requests = None # List of client requests
waiting = None # List of waiting workers
def __init__(self, name):
self.name = name
self.requests = []
self.waiting = []
class Worker(object):
"""a Worker, idle or active"""
identity = None # hex Identity of worker
address = None # Address to route to
service = None # Owning service, if known
expiry = None # expires at this point, unless heartbeat
def __init__(self, identity, address, lifetime):
self.identity = identity
self.address = address
self.expiry = time.time() + 1e-3*lifetime
class MajorDomoBroker(object):
"""
Majordomo Protocol broker
A minimal implementation of http:#rfc.zeromq.org/spec:7 and spec:8
"""
# We'd normally pull these from config data
INTERNAL_SERVICE_PREFIX = b"mmi."
HEARTBEAT_LIVENESS = 3 # 3-5 is reasonable
HEARTBEAT_INTERVAL = 2500 # msecs
HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
# ---------------------------------------------------------------------
ctx = None # Our context
socket = None # Socket for clients & workers
poller = None # our Poller
heartbeat_at = None# When to send HEARTBEAT
services = None # known services
workers = None # known workers
waiting = None # idle workers
verbose = False # Print activity to stdout
# ---------------------------------------------------------------------
def __init__(self, verbose=False):
"""Initialize broker state."""
self.verbose = verbose
self.services = {}
self.workers = {}
self.waiting = []
self.heartbeat_at = time.time() + 1e-3*self.HEARTBEAT_INTERVAL
self.ctx = zmq.Context()
self.socket = self.ctx.socket(zmq.ROUTER)
self.socket.linger = 0
self.poller = zmq.Poller()
self.poller.register(self.socket, zmq.POLLIN)
logging.basicConfig(format="%(asctime)s %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
# ---------------------------------------------------------------------
def mediate(self):
"""Main broker work happens here"""
while True:
try:
items = self.poller.poll(self.HEARTBEAT_INTERVAL)
except KeyboardInterrupt:
break # Interrupted
if items:
msg = self.socket.recv_multipart()
if self.verbose:
logging.info("I: received message:")
dump(msg)
sender = msg.pop(0)
empty = msg.pop(0)
assert empty == b''
header = msg.pop(0)
if (MDP.C_CLIENT == header):
self.process_client(sender, msg)
elif (MDP.W_WORKER == header):
self.process_worker(sender, msg)
else:
logging.error("E: invalid message:")
dump(msg)
self.purge_workers()
self.send_heartbeats()
def destroy(self):
"""Disconnect all workers, destroy context."""
while self.workers:
self.delete_worker(self.workers.values()[0], True)
self.ctx.destroy(0)
def process_client(self, sender, msg):
"""Process a request coming from a client."""
assert len(msg) >= 2 # Service name + body
service = msg.pop(0)
# Set reply return address to client sender
msg = [sender, b''] + msg
if service.startswith(self.INTERNAL_SERVICE_PREFIX):
self.service_internal(service, msg)
else:
self.dispatch(self.require_service(service), msg)
def process_worker(self, sender, msg):
"""Process message sent to us by a worker."""
assert len(msg) >= 1 # At least, command
command = msg.pop(0)
worker_ready = hexlify(sender) in self.workers
worker = self.require_worker(sender)
if (MDP.W_READY == command):
assert len(msg) >= 1 # At least, a service name
service = msg.pop(0)
# Not first command in session or Reserved service name
if (worker_ready or service.startswith(self.INTERNAL_SERVICE_PREFIX)):
self.delete_worker(worker, True)
else:
# Attach worker to service and mark as idle
worker.service = self.require_service(service)
self.worker_waiting(worker)
elif (MDP.W_REPLY == command):
if (worker_ready):
# Remove & save client return envelope and insert the
# protocol header and service name, then rewrap envelope.
client = msg.pop(0)
empty = msg.pop(0) # ?
msg = [client, b'', MDP.C_CLIENT, worker.service.name] + msg
self.socket.send_multipart(msg)
self.worker_waiting(worker)
else:
self.delete_worker(worker, True)
elif (MDP.W_HEARTBEAT == command):
if (worker_ready):
worker.expiry = time.time() + 1e-3*self.HEARTBEAT_EXPIRY
else:
self.delete_worker(worker, True)
elif (MDP.W_DISCONNECT == command):
self.delete_worker(worker, False)
else:
logging.error("E: invalid message:")
dump(msg)
def delete_worker(self, worker, disconnect):
"""Deletes worker from all data structures, and deletes worker."""
assert worker is not None
if disconnect:
self.send_to_worker(worker, MDP.W_DISCONNECT, None, None)
if worker.service is not None:
worker.service.waiting.remove(worker)
self.workers.pop(worker.identity)
def require_worker(self, address):
"""Finds the worker (creates if necessary)."""
assert (address is not None)
identity = hexlify(address)
worker = self.workers.get(identity)
if (worker is None):
worker = Worker(identity, address, self.HEARTBEAT_EXPIRY)
self.workers[identity] = worker
if self.verbose:
logging.info("I: registering new worker: %s", identity)
return worker
def require_service(self, name):
"""Locates the service (creates if necessary)."""
assert (name is not None)
service = self.services.get(name)
if (service is None):
service = Service(name)
self.services[name] = service
return service
def bind(self, endpoint):
"""Bind broker to endpoint, can call this multiple times.
We use a single socket for both clients and workers.
"""
self.socket.bind(endpoint)
logging.info("I: MDP broker/0.1.1 is active at %s", endpoint)
def service_internal(self, service, msg):
"""Handle internal service according to 8/MMI specification"""
returncode = b"501"
if b"mmi.service" == service:
name = msg[-1]
returncode = b"200" if name in self.services else b"404"
msg[-1] = returncode
# insert the protocol header and service name after the routing envelope ([client, ''])
msg = msg[:2] + [MDP.C_CLIENT, service] + msg[2:]
self.socket.send_multipart(msg)
def send_heartbeats(self):
"""Send heartbeats to idle workers if it's time"""
if (time.time() > self.heartbeat_at):
for worker in self.waiting:
self.send_to_worker(worker, MDP.W_HEARTBEAT, None, None)
self.heartbeat_at = time.time() + 1e-3*self.HEARTBEAT_INTERVAL
def purge_workers(self):
"""Look for & kill expired workers.
Workers are oldest to most recent, so we stop at the first alive worker.
"""
while self.waiting:
w = self.waiting[0]
if w.expiry < time.time():
logging.info("I: deleting expired worker: %s", w.identity)
self.delete_worker(w,False)
self.waiting.pop(0)
else:
break
def worker_waiting(self, worker):
"""This worker is now waiting for work."""
# Queue to broker and service waiting lists
self.waiting.append(worker)
worker.service.waiting.append(worker)
worker.expiry = time.time() + 1e-3*self.HEARTBEAT_EXPIRY
self.dispatch(worker.service, None)
def dispatch(self, service, msg):
"""Dispatch requests to waiting workers as possible"""
assert (service is not None)
if msg is not None:# Queue message if any
service.requests.append(msg)
self.purge_workers()
while service.waiting and service.requests:
msg = service.requests.pop(0)
worker = service.waiting.pop(0)
self.waiting.remove(worker)
self.send_to_worker(worker, MDP.W_REQUEST, None, msg)
def send_to_worker(self, worker, command, option, msg=None):
"""Send message to worker.
If message is provided, sends that message.
"""
if msg is None:
msg = []
elif not isinstance(msg, list):
msg = [msg]
# Stack routing and protocol envelopes to start of message
# and routing envelope
if option is not None:
msg = [option] + msg
msg = [worker.address, b'', MDP.W_WORKER, command] + msg
if self.verbose:
logging.info("I: sending %r to worker", command)
dump(msg)
self.socket.send_multipart(msg)
def main():
"""create and start new broker"""
verbose = '-v' in sys.argv
broker = MajorDomoBroker(verbose)
broker.bind("tcp://*:5555")
broker.mediate()
if __name__ == '__main__':
main()
mdbroker: Majordomo broker in Q
mdbroker: Majordomo broker in Racket
mdbroker: Majordomo broker in Ruby
mdbroker: Majordomo broker in Rust
mdbroker: Majordomo broker in Scala
mdbroker: Majordomo broker in Tcl
mdbroker: Majordomo broker in OCaml
This is by far the most complex example we’ve seen. It’s almost 500 lines of code. To write this and make it somewhat robust took two days. However, this is still a short piece of code for a full service-oriented broker.
Here are some things to note about the broker code:
-
The Majordomo Protocol lets us handle both clients and workers on a single socket. This is nicer for those deploying and managing the broker: it just sits on one ZeroMQ endpoint rather than the two that most proxies need.
-
The broker implements all of MDP/0.1 properly (as far as I know), including disconnection if the broker sends invalid commands, heartbeating, and the rest.
-
It can be extended to run multiple threads, each managing one socket and one set of clients and workers. This could be interesting for segmenting large architectures. The C code is already organized around a broker class to make this trivial.
-
A primary/failover or live/live broker reliability model is easy, as the broker essentially has no state except service presence. It’s up to clients and workers to choose another broker if their first choice isn’t up and running.
-
The examples use five-second heartbeats, mainly to reduce the amount of output when you enable tracing. Realistic values would be lower for most LAN applications. However, any retry has to be slow enough to allow for a service to restart, say 10 seconds at least.
We later improved and extended the protocol and the Majordomo implementation, which now sits in its own Github project. If you want a properly usable Majordomo stack, use the GitHub project.
Asynchronous Majordomo Pattern #
The Majordomo implementation in the previous section is simple and stupid. The client is just the original Simple Pirate, wrapped up in a sexy API. When I fire up a client, broker, and worker on a test box, it can process 100,000 requests in about 14 seconds. That is partially due to the code, which cheerfully copies message frames around as if CPU cycles were free. But the real problem is that we’re doing network round-trips. ZeroMQ disables Nagle’s algorithm, but round-tripping is still slow.
Theory is great in theory, but in practice, practice is better. Let’s measure the actual cost of round-tripping with a simple test program. This sends a bunch of messages, first waiting for a reply to each message, and second as a batch, reading all the replies back as a batch. Both approaches do the same work, but they give very different results. We mock up a client, broker, and worker:
tripping: Round-trip demonstrator in Ada
tripping: Round-trip demonstrator in Basic
tripping: Round-trip demonstrator in C
// Round-trip demonstrator
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. The client task signals to
// main when it's ready.
#include "czmq.h"
static void
client_task (void *args, zctx_t *ctx, void *pipe)
{
void *client = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (client, "tcp://localhost:5555");
printf ("Setting up test...\n");
zclock_sleep (100);
int requests;
int64_t start;
printf ("Synchronous round-trip test...\n");
start = zclock_time ();
for (requests = 0; requests < 10000; requests++) {
zstr_send (client, "hello");
char *reply = zstr_recv (client);
free (reply);
}
printf (" %d calls/second\n",
(1000 * 10000) / (int) (zclock_time () - start));
printf ("Asynchronous round-trip test...\n");
start = zclock_time ();
for (requests = 0; requests < 100000; requests++)
zstr_send (client, "hello");
for (requests = 0; requests < 100000; requests++) {
char *reply = zstr_recv (client);
free (reply);
}
printf (" %d calls/second\n",
(1000 * 100000) / (int) (zclock_time () - start));
zstr_send (pipe, "done");
}
// .split worker task
// Here is the worker task. All it does is receive a message, and
// bounce it back the way it came:
static void *
worker_task (void *args)
{
zctx_t *ctx = zctx_new ();
void *worker = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (worker, "tcp://localhost:5556");
while (true) {
zmsg_t *msg = zmsg_recv (worker);
zmsg_send (&msg, worker);
}
zctx_destroy (&ctx);
return NULL;
}
// .split broker task
// Here is the broker task. It uses the {{zmq_proxy}} function to switch
// messages between frontend and backend:
static void *
broker_task (void *args)
{
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *frontend = zsocket_new (ctx, ZMQ_DEALER);
zsocket_bind (frontend, "tcp://*:5555");
void *backend = zsocket_new (ctx, ZMQ_DEALER);
zsocket_bind (backend, "tcp://*:5556");
zmq_proxy (frontend, backend, NULL);
zctx_destroy (&ctx);
return NULL;
}
// .split main task
// Finally, here's the main task, which starts the client, worker, and
// broker, and then runs until the client signals it to stop:
int main (void)
{
// Create threads
zctx_t *ctx = zctx_new ();
void *client = zthread_fork (ctx, client_task, NULL);
zthread_new (worker_task, NULL);
zthread_new (broker_task, NULL);
// Wait for signal on client pipe
char *signal = zstr_recv (client);
free (signal);
zctx_destroy (&ctx);
return 0;
}
tripping: Round-trip demonstrator in C++
//
// Round-trip demonstrator
//
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "zmsg.hpp"
static void *
client_task (void *args)
{
zmq::context_t context (1);
zmq::socket_t client (context, ZMQ_DEALER);
client.set(zmq::sockopt::routing_id, "C");
client.connect ("tcp://localhost:5555");
std::cout << "Setting up test..." << std::endl;
s_sleep (100);
int requests;
int64_t start;
std::cout << "Synchronous round-trip test..." << std::endl;
start = s_clock ();
for (requests = 0; requests < 10000; requests++) {
zmsg msg ("HELLO");
msg.send (client);
msg.recv (client);
}
std::cout << (1000 * 10000) / (int) (s_clock () - start) << " calls/second" << std::endl;
std::cout << "Asynchronous round-trip test..." << std::endl;
start = s_clock ();
for (requests = 0; requests < 100000; requests++) {
zmsg msg ("HELLO");
msg.send (client);
}
for (requests = 0; requests < 100000; requests++) {
zmsg msg (client);
}
std::cout << (1000 * 100000) / (int) (s_clock () - start) << " calls/second" << std::endl;
return 0;
}
static void *
worker_task (void *args)
{
zmq::context_t context (1);
zmq::socket_t worker (context, ZMQ_DEALER);
worker.set(zmq::sockopt::routing_id, "W");
worker.connect ("tcp://localhost:5556");
while (1) {
zmsg msg (worker);
msg.send (worker);
}
return 0;
}
static void *
broker_task (void *args)
{
// Prepare our context and sockets
zmq::context_t context (1);
zmq::socket_t frontend (context, ZMQ_ROUTER);
zmq::socket_t backend (context, ZMQ_ROUTER);
frontend.bind ("tcp://*:5555");
backend.bind ("tcp://*:5556");
// Initialize poll set
zmq::pollitem_t items [] = {
{ frontend, 0, ZMQ_POLLIN, 0 },
{ backend, 0, ZMQ_POLLIN, 0 }
};
while (1) {
zmq::poll (items, 2, -1);
if (items [0].revents & ZMQ_POLLIN) {
zmsg msg (frontend);
msg.pop_front ();
msg.push_front ((char *)"W");
msg.send (backend);
}
if (items [1].revents & ZMQ_POLLIN) {
zmsg msg (backend);
msg.pop_front ();
msg.push_front ((char *)"C");
msg.send (frontend);
}
}
return 0;
}
int main ()
{
s_version_assert (2, 1);
pthread_t client;
pthread_create (&client, NULL, client_task, NULL);
pthread_t worker;
pthread_create (&worker, NULL, worker_task, NULL);
pthread_t broker;
pthread_create (&broker, NULL, broker_task, NULL);
pthread_join (client, NULL);
return 0;
}
tripping: Round-trip demonstrator in C#
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Runtime.Remoting.Messaging;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
// Round-trip demonstrator
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. The client task signals to
// main when it's ready.
public static void Tripping(string[] args)
{
CancellationTokenSource cancellor = new CancellationTokenSource();
Console.CancelKeyPress += (s, ea) =>
{
ea.Cancel = true;
cancellor.Cancel();
};
using (ZContext ctx = new ZContext())
{
using (var client = new ZActor(ctx, Tripping_ClientTask))
{
(new Thread(() => Tripping_WorkerTask(ctx))).Start();
(new Thread(() => Tripping_BrokerTask(ctx))).Start();
client.Start();
using (var signal = client.Frontend.ReceiveFrame())
if (Verbose)
signal.ToString().DumpString();
}
}
}
static void Tripping_ClientTask(ZContext ctx, ZSocket pipe, CancellationTokenSource cancellor, object[] args)
{
using (ZSocket client = new ZSocket(ctx, ZSocketType.DEALER))
{
client.Connect("tcp://127.0.0.1:5555");
"Setting up test...".DumpString();
Thread.Sleep(100);
int requests;
"Synchronous round-trip test...".DumpString();
var start = DateTime.Now;
Stopwatch sw = Stopwatch.StartNew();
for (requests = 0; requests < 10000; requests++)
{
using (var outgoing = new ZFrame("hello"))
{
client.Send(outgoing);
using (var reply = client.ReceiveFrame())
{
if (Verbose)
reply.ToString().DumpString();
}
}
}
sw.Stop();
" {0} calls - {1} ms => {2} calls / second".DumpString(requests, sw.ElapsedMilliseconds, requests * 1000 / sw.ElapsedMilliseconds);
"Asynchronous round-trip test...".DumpString();
sw.Restart();
for (requests = 0; requests < 100000; requests++)
using (var outgoing = new ZFrame("hello"))
client.SendFrame(outgoing);
for (requests = 0; requests < 100000; requests++)
using (var reply = client.ReceiveFrame())
if (Verbose)
reply.ToString().DumpString();
sw.Stop();
" {0} calls - {1} ms => {2} calls / second".DumpString(requests, sw.ElapsedMilliseconds, requests * 1000 / sw.ElapsedMilliseconds);
using (var outgoing = new ZFrame("done"))
pipe.SendFrame(outgoing);
}
}
// .split worker task
// Here is the worker task. All it does is receive a message, and
// bounce it back the way it came:
static void Tripping_WorkerTask(ZContext ctx)
{
using (var worker = new ZSocket(ctx, ZSocketType.DEALER))
{
worker.Connect("tcp://127.0.0.1:5556");
while (true)
{
ZError error;
ZMessage msg = worker.ReceiveMessage(out error);
if (error == null && worker.Send(msg, out error))
continue;
// errorhandling, context terminated or sth else
if (error.Equals(ZError.ETERM))
return; // Interrupted
throw new ZException(error);
}
}
}
// .split broker task
// Here is the broker task. It uses the {{zmq_proxy}} function to switch
// messages between frontend and backend:
static void Tripping_BrokerTask(ZContext ctx)
{
using (var frontend = new ZSocket(ctx, ZSocketType.DEALER))
using (var backend = new ZSocket(ctx, ZSocketType.DEALER))
{
frontend.Bind("tcp://*:5555");
backend.Bind("tcp://*:5556");
ZError error;
if (!ZContext.Proxy(frontend, backend, out error))
{
if (Equals(error, ZError.ETERM))
return; // Interrupted
throw new ZException(error);
}
}
}
}
}
tripping: Round-trip demonstrator in CL
tripping: Round-trip demonstrator in Delphi
tripping: Round-trip demonstrator in Erlang
tripping: Round-trip demonstrator in Elixir
tripping: Round-trip demonstrator in F#
tripping: Round-trip demonstrator in Felix
tripping: Round-trip demonstrator in Go
//
// Round-trip demonstrator
//
// Author: amyangfei <amyangfei@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"time"
)
func client_task(c chan string) {
context, _ := zmq.NewContext()
client, _ := context.NewSocket(zmq.DEALER)
defer context.Close()
defer client.Close()
client.SetIdentity("C")
client.Connect("tcp://localhost:5555")
fmt.Println("Setting up test...")
time.Sleep(time.Duration(100) * time.Millisecond)
fmt.Println("Synchronous round-trip test...")
start := time.Now()
requests := 10000
for i := 0; i < requests; i++ {
client.Send([]byte("hello"), 0)
client.Recv(0)
}
fmt.Printf("%d calls/second\n", int64(float64(requests)/time.Since(start).Seconds()))
fmt.Println("Asynchronous round-trip test...")
start = time.Now()
for i := 0; i < requests; i++ {
client.Send([]byte("hello"), 0)
}
for i := 0; i < requests; i++ {
client.Recv(0)
}
fmt.Printf("%d calls/second\n", int64(float64(requests)/time.Since(start).Seconds()))
c <- "done"
}
func worker_task() {
context, _ := zmq.NewContext()
worker, _ := context.NewSocket(zmq.DEALER)
defer context.Close()
defer worker.Close()
worker.SetIdentity("W")
worker.Connect("tcp://localhost:5556")
for {
msg, _ := worker.RecvMultipart(0)
worker.SendMultipart(msg, 0)
}
}
func broker_task() {
context, _ := zmq.NewContext()
frontend, _ := context.NewSocket(zmq.ROUTER)
backend, _ := context.NewSocket(zmq.ROUTER)
defer context.Close()
defer frontend.Close()
defer backend.Close()
frontend.Bind("tcp://*:5555")
backend.Bind("tcp://*:5556")
// Initialize poll set
items := zmq.PollItems{
zmq.PollItem{Socket: frontend, Events: zmq.POLLIN},
zmq.PollItem{Socket: backend, Events: zmq.POLLIN},
}
for {
zmq.Poll(items, -1)
switch {
case items[0].REvents&zmq.POLLIN != 0:
msg, _ := frontend.RecvMultipart(0)
msg[0][0] = 'W'
backend.SendMultipart(msg, 0)
case items[1].REvents&zmq.POLLIN != 0:
msg, _ := backend.RecvMultipart(0)
msg[0][0] = 'C'
frontend.SendMultipart(msg, 0)
}
}
}
func main() {
done := make(chan string)
go client_task(done)
go worker_task()
go broker_task()
<-done
}
tripping: Round-trip demonstrator in Haskell
{-
Round-trip demonstrator.
Runs as a single process for easier testing.
The client task signals to main when it's ready.
-}
import System.ZMQ4
import Control.Concurrent
import Control.Monad (forM_, forever)
import Data.ByteString.Char8 (pack, unpack)
import Data.Time.Clock (getCurrentTime, diffUTCTime)
client_task :: Context -> Socket Pair -> IO ()
client_task ctx pipe =
withSocket ctx Dealer $ \client -> do
connect client "tcp://localhost:5555"
putStrLn "Setting up test..."
threadDelay $ 100 * 1000
putStrLn "Synchronous round-trip test..."
start <- getCurrentTime
forM_ [0..10000] $ \_ -> do
send client [] (pack "hello")
receive client
end <- getCurrentTime
let elapsed_ms = (diffUTCTime end start) * 1000
putStrLn $ " " ++ (show $ (1000 * 10000) `quot` (round elapsed_ms)) ++ " calls/second"
putStrLn "Asynchronous round-trip test..."
start <- getCurrentTime
forM_ [0..10000] $ \_ -> do
send client [] (pack "hello")
forM_ [0..10000] $ \_ -> do
receive client
end <- getCurrentTime
let elapsed_ms = (diffUTCTime end start) * 1000
putStrLn $ " " ++ (show $ (1000 * 10000) `quot` (round elapsed_ms)) ++ " calls/second"
send pipe [] (pack "done")
worker_task :: IO ()
worker_task =
withContext $ \ctx ->
withSocket ctx Dealer $ \worker -> do
connect worker "tcp://localhost:5556"
forever $ do
msg <- receive worker
send worker [] msg
broker_task :: IO ()
broker_task =
withContext $ \ctx ->
withSocket ctx Dealer $ \frontend ->
withSocket ctx Dealer $ \backend -> do
bind frontend "tcp://*:5555"
bind backend "tcp://*:5556"
proxy frontend backend Nothing
main :: IO ()
main =
withContext $ \ctx ->
withSocket ctx Pair $ \pipeServer ->
withSocket ctx Pair $ \pipeClient -> do
bind pipeServer "inproc://my-pipe"
connect pipeClient "inproc://my-pipe"
forkIO (client_task ctx pipeClient)
forkIO worker_task
forkIO broker_task
signal <- receive pipeServer
putStrLn $ unpack signal
tripping: Round-trip demonstrator in Haxe
package ;
import haxe.Stack;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQException;
import org.zeromq.ZThread;
/**
* Round-trip demonstrator
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Client thread signals to
* main when it's ready.
*
* @author Richard J Smith
*/
class Tripping
{
private static function clientTask(ctx:ZContext, pipe:ZMQSocket, ?args:Dynamic) {
var hello = Bytes.ofString("hello");
var client = ctx.createSocket(ZMQ_DEALER);
client.setsockopt(ZMQ_IDENTITY, Bytes.ofString("C"));
client.connect("tcp://localhost:5555");
Lib.println("Setting up test...");
Sys.sleep(0.1); // 100 msecs
var start:Float = 0.0;
Lib.println("Synchronous round-trip test...");
start = Date.now().getTime();
for (requests in 0 ... 10000) {
client.sendMsg(hello);
var reply = client.recvMsg();
}
Lib.println(" " + Std.int((1000.0 * 10000.0) / (Date.now().getTime() - start)) + " calls/second");
Lib.println("Asynchronous round-trip test...");
start = Date.now().getTime();
for (requests in 0 ... 10000)
client.sendMsg(hello);
for (requests in 0 ... 10000) {
var reply = client.recvMsg();
}
Lib.println(" " + Std.int((1000.0 * 10000.0) / (Date.now().getTime() - start)) + " calls/second");
pipe.sendMsg(Bytes.ofString("done"));
}
private static function workerTask(?args:Dynamic) {
var ctx = new ZContext();
var worker = ctx.createSocket(ZMQ_DEALER);
worker.setsockopt(ZMQ_IDENTITY, Bytes.ofString("W"));
worker.connect("tcp://localhost:5556");
while (true) {
var msg = ZMsg.recvMsg(worker);
msg.send(worker);
}
ctx.destroy();
}
private static function brokerTask(?args:Dynamic) {
// Prepare our contexts and sockets
var ctx = new ZContext();
var frontend = ctx.createSocket(ZMQ_ROUTER);
var backend = ctx.createSocket(ZMQ_ROUTER);
frontend.bind("tcp://*:5555");
backend.bind("tcp://*:5556");
// Initialise pollset
var poller = new ZMQPoller();
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
while (true) {
try {
poller.poll(-1);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
ctx.destroy();
return;
}
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
if (poller.pollin(1)) {
var msg = ZMsg.recvMsg(frontend);
var address = msg.pop();
msg.pushString("W");
msg.send(backend);
}
if (poller.pollin(2)) {
var msg = ZMsg.recvMsg(backend);
var address = msg.pop();
msg.pushString("C");
msg.send(frontend);
}
}
}
public static function main() {
Lib.println("** Tripping (see: http://zguide.zeromq.org/page:all#Asynchronous-Majordomo-Pattern)");
// Create threads
var ctx = new ZContext();
var client = ZThread.attach(ctx, clientTask, null);
ZThread.detach(workerTask, null);
ZThread.detach(brokerTask, null);
// Wait for signal on client pipe
var signal = client.recvMsg();
ctx.destroy();
}
}tripping: Round-trip demonstrator in Java
package guide;
import org.zeromq.*;
import org.zeromq.ZMQ.Socket;
/**
* Round-trip demonstrator. Broker, Worker and Client are mocked as separate
* threads.
*/
public class tripping
{
static class Broker implements Runnable
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket frontend = ctx.createSocket(SocketType.ROUTER);
Socket backend = ctx.createSocket(SocketType.ROUTER);
frontend.setHWM(0);
backend.setHWM(0);
frontend.bind("tcp://*:5555");
backend.bind("tcp://*:5556");
while (!Thread.currentThread().isInterrupted()) {
ZMQ.Poller items = ctx.createPoller(2);
items.register(frontend, ZMQ.Poller.POLLIN);
items.register(backend, ZMQ.Poller.POLLIN);
if (items.poll() == -1)
break; // Interrupted
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(frontend);
if (msg == null)
break; // Interrupted
ZFrame address = msg.pop();
address.destroy();
msg.addFirst(new ZFrame("W"));
msg.send(backend);
}
if (items.pollin(1)) {
ZMsg msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
ZFrame address = msg.pop();
address.destroy();
msg.addFirst(new ZFrame("C"));
msg.send(frontend);
}
items.close();
}
}
}
}
static class Worker implements Runnable
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket worker = ctx.createSocket(SocketType.DEALER);
worker.setHWM(0);
worker.setIdentity("W".getBytes(ZMQ.CHARSET));
worker.connect("tcp://localhost:5556");
while (!Thread.currentThread().isInterrupted()) {
ZMsg msg = ZMsg.recvMsg(worker);
msg.send(worker);
}
}
}
}
static class Client implements Runnable
{
private static int SAMPLE_SIZE = 10000;
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket client = ctx.createSocket(SocketType.DEALER);
client.setHWM(0);
client.setIdentity("C".getBytes(ZMQ.CHARSET));
client.connect("tcp://localhost:5555");
System.out.println("Setting up test");
try {
Thread.sleep(100);
}
catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
int requests;
long start;
System.out.println("Synchronous round-trip test");
start = System.currentTimeMillis();
for (requests = 0; requests < SAMPLE_SIZE; requests++) {
ZMsg req = new ZMsg();
req.addString("hello");
req.send(client);
ZMsg.recvMsg(client).destroy();
}
long now = System.currentTimeMillis();
System.out.printf(
" %d calls/second\n", (1000 * SAMPLE_SIZE) / (now - start)
);
System.out.println("Asynchronous round-trip test");
start = System.currentTimeMillis();
for (requests = 0; requests < SAMPLE_SIZE; requests++) {
ZMsg req = new ZMsg();
req.addString("hello");
req.send(client);
}
for (requests = 0;
requests < SAMPLE_SIZE && !Thread.currentThread()
.isInterrupted();
requests++) {
ZMsg.recvMsg(client).destroy();
}
long now2 = System.currentTimeMillis();
System.out.printf(
" %d calls/second\n", (1000 * SAMPLE_SIZE) / (now2 - start)
);
}
}
}
public static void main(String[] args)
{
if (args.length == 1)
Client.SAMPLE_SIZE = Integer.parseInt(args[0]);
Thread brokerThread = new Thread(new Broker());
Thread workerThread = new Thread(new Worker());
Thread clientThread = new Thread(new Client());
brokerThread.setDaemon(true);
workerThread.setDaemon(true);
brokerThread.start();
workerThread.start();
clientThread.start();
try {
clientThread.join();
workerThread.interrupt();
brokerThread.interrupt();
Thread.sleep(200);// give them some time
}
catch (InterruptedException e) {
}
}
}
tripping: Round-trip demonstrator in Julia
tripping: Round-trip demonstrator in Lua
--
-- Round-trip demonstrator
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zmsg"
local common_code = [[
require"zmq"
require"zmsg"
require"zhelpers"
]]
local client_task = common_code .. [[
local context = zmq.init(1)
local client = context:socket(zmq.DEALER)
client:setopt(zmq.IDENTITY, "C", 1)
client:connect("tcp://localhost:5555")
printf("Setting up test...\n")
s_sleep(100)
local requests
local start
printf("Synchronous round-trip test...\n")
requests = 10000
start = s_clock()
for n=1,requests do
local msg = zmsg.new("HELLO")
msg:send(client)
msg = zmsg.recv(client)
end
printf(" %d calls/second\n",
(1000 * requests) / (s_clock() - start))
printf("Asynchronous round-trip test...\n")
requests = 100000
start = s_clock()
for n=1,requests do
local msg = zmsg.new("HELLO")
msg:send(client)
end
for n=1,requests do
local msg = zmsg.recv(client)
end
printf(" %d calls/second\n",
(1000 * requests) / (s_clock() - start))
client:close()
context:term()
]]
local worker_task = common_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.DEALER)
worker:setopt(zmq.IDENTITY, "W", 1)
worker:connect("tcp://localhost:5556")
while true do
local msg = zmsg.recv(worker)
msg:send(worker)
end
worker:close()
context:term()
]]
local broker_task = common_code .. [[
-- Prepare our context and sockets
local context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.ROUTER)
frontend:bind("tcp://*:5555")
backend:bind("tcp://*:5556")
require"zmq.poller"
local poller = zmq.poller(2)
poller:add(frontend, zmq.POLLIN, function()
local msg = zmsg.recv(frontend)
--msg[1] = "W"
msg:pop()
msg:push("W")
msg:send(backend)
end)
poller:add(backend, zmq.POLLIN, function()
local msg = zmsg.recv(backend)
--msg[1] = "C"
msg:pop()
msg:push("C")
msg:send(frontend)
end)
poller:start()
frontend:close()
backend:close()
context:term()
]]
s_version_assert(2, 1)
local client = zmq.threads.runstring(nil, client_task)
assert(client:start())
local worker = zmq.threads.runstring(nil, worker_task)
assert(worker:start(true))
local broker = zmq.threads.runstring(nil, broker_task)
assert(broker:start(true))
assert(client:join())
tripping: Round-trip demonstrator in Node.js
tripping: Round-trip demonstrator in Objective-C
tripping: Round-trip demonstrator in ooc
tripping: Round-trip demonstrator in Perl
tripping: Round-trip demonstrator in PHP
<?php
/*
* Round-trip demonstrator
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
function client_task()
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
$client->setSockOpt(ZMQ::SOCKOPT_IDENTITY, "C");
$client->connect("tcp://localhost:5555");
echo "Setting up test...", PHP_EOL;
usleep(10000);
echo "Synchronous round-trip test...", PHP_EOL;
$start = microtime(true);
$text = "HELLO";
for ($requests = 0; $requests < 10000; $requests++) {
$client->send($text);
$msg = $client->recv();
}
printf (" %d calls/second%s",
(1000 * 10000) / (int) ((microtime(true) - $start) * 1000),
PHP_EOL);
echo "Asynchronous round-trip test...", PHP_EOL;
$start = microtime(true);
for ($requests = 0; $requests < 100000; $requests++) {
$client->send($text);
}
for ($requests = 0; $requests < 100000; $requests++) {
$client->recv();
}
printf (" %d calls/second%s",
(1000 * 100000) / (int) ((microtime(true) - $start) * 1000),
PHP_EOL);
}
function worker_task()
{
$context = new ZMQContext();
$worker = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
$worker->setSockOpt(ZMQ::SOCKOPT_IDENTITY, "W");
$worker->connect("tcp://localhost:5556");
while (true) {
$zmsg = new Zmsg($worker);
$zmsg->recv();
$zmsg->send();
}
}
function broker_task()
{
// Prepare our context and sockets
$context = new ZMQContext();
$frontend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$backend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$frontend->bind("tcp://*:5555");
$backend->bind("tcp://*:5556");
// Initialize poll set
$poll = new ZMQPoll();
$poll->add($frontend, ZMQ::POLL_IN);
$poll->add($backend, ZMQ::POLL_IN);
$read = $write = array();
while (true) {
$events = $poll->poll($read, $write);
foreach ($read as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
if ($socket === $frontend) {
$zmsg->push("W");
$zmsg->set_socket($backend)->send();
} elseif ($socket === $backend) {
$zmsg->pop();
$zmsg->push("C");
$zmsg->set_socket($frontend)->send();
}
}
}
}
$wpid = pcntl_fork();
if ($wpid == 0) {
worker_task();
exit;
}
$bpid = pcntl_fork();
if ($bpid == 0) {
broker_task();
exit;
}
sleep(1);
client_task();
posix_kill($wpid, SIGKILL);
posix_kill($bpid, SIGKILL);
tripping: Round-trip demonstrator in Python
"""Round-trip demonstrator
While this example runs in a single process, that is just to make
it easier to start and stop the example. Client thread signals to
main when it's ready.
"""
import sys
import threading
import time
import zmq
from zhelpers import zpipe
def client_task (ctx, pipe):
client = ctx.socket(zmq.DEALER)
client.identity = b'C'
client.connect("tcp://localhost:5555")
print ("Setting up test...")
time.sleep(0.1)
print ("Synchronous round-trip test...")
start = time.time()
requests = 10000
for r in range(requests):
client.send(b"hello")
client.recv()
print (" %d calls/second" % (requests / (time.time()-start)))
print ("Asynchronous round-trip test...")
start = time.time()
for r in range(requests):
client.send(b"hello")
for r in range(requests):
client.recv()
print (" %d calls/second" % (requests / (time.time()-start)))
# signal done:
pipe.send(b"done")
def worker_task():
ctx = zmq.Context()
worker = ctx.socket(zmq.DEALER)
worker.identity = b'W'
worker.connect("tcp://localhost:5556")
while True:
msg = worker.recv_multipart()
worker.send_multipart(msg)
ctx.destroy(0)
def broker_task():
# Prepare our context and sockets
ctx = zmq.Context()
frontend = ctx.socket(zmq.ROUTER)
backend = ctx.socket(zmq.ROUTER)
frontend.bind("tcp://*:5555")
backend.bind("tcp://*:5556")
# Initialize poll set
poller = zmq.Poller()
poller.register(backend, zmq.POLLIN)
poller.register(frontend, zmq.POLLIN)
while True:
try:
items = dict(poller.poll())
except:
break # Interrupted
if frontend in items:
msg = frontend.recv_multipart()
msg[0] = b'W'
backend.send_multipart(msg)
if backend in items:
msg = backend.recv_multipart()
msg[0] = b'C'
frontend.send_multipart(msg)
def main():
# Create threads
ctx = zmq.Context()
client,pipe = zpipe(ctx)
client_thread = threading.Thread(target=client_task, args=(ctx, pipe))
worker_thread = threading.Thread(target=worker_task)
worker_thread.daemon=True
broker_thread = threading.Thread(target=broker_task)
broker_thread.daemon=True
worker_thread.start()
broker_thread.start()
client_thread.start()
# Wait for signal on client pipe
client.recv()
if __name__ == '__main__':
main()
tripping: Round-trip demonstrator in Q
tripping: Round-trip demonstrator in Racket
tripping: Round-trip demonstrator in Ruby
tripping: Round-trip demonstrator in Rust
tripping: Round-trip demonstrator in Scala
tripping: Round-trip demonstrator in Tcl
tripping: Round-trip demonstrator in OCaml
On my development box, this program says:
Setting up test...
Synchronous round-trip test...
9057 calls/second
Asynchronous round-trip test...
173010 calls/second
Note that the client thread does a small pause before starting. This is to get around one of the “features” of the router socket: if you send a message with the address of a peer that’s not yet connected, the message gets discarded. In this example we don’t use the load balancing mechanism, so without the sleep, if the worker thread is too slow to connect, it will lose messages, making a mess of our test.
As we see, round-tripping in the simplest case is 20 times slower than the asynchronous, “shove it down the pipe as fast as it’ll go” approach. Let’s see if we can apply this to Majordomo to make it faster.
First, we modify the client API to send and receive in two separate methods:
mdcli_t *mdcli_new (char *broker);
void mdcli_destroy (mdcli_t **self_p);
int mdcli_send (mdcli_t *self, char *service, zmsg_t **request_p);
zmsg_t *mdcli_recv (mdcli_t *self);
It’s literally a few minutes’ work to refactor the synchronous client API to become asynchronous:
mdcliapi2: Majordomo asynchronous client API in Ada
mdcliapi2: Majordomo asynchronous client API in Basic
mdcliapi2: Majordomo asynchronous client API in C
// mdcliapi2 class - Majordomo Protocol Client API
// Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
#include "mdcliapi2.h"
// Structure of our class
// We access these properties only via class methods
struct _mdcli_t {
zctx_t *ctx; // Our context
char *broker;
void *client; // Socket to broker
int verbose; // Print activity to stdout
int timeout; // Request timeout
};
// Connect or reconnect to broker. In this asynchronous class we use a
// DEALER socket instead of a REQ socket; this lets us send any number
// of requests without waiting for a reply.
void s_mdcli_connect_to_broker (mdcli_t *self)
{
if (self->client)
zsocket_destroy (self->ctx, self->client);
self->client = zsocket_new (self->ctx, ZMQ_DEALER);
zmq_connect (self->client, self->broker);
if (self->verbose)
zclock_log ("I: connecting to broker at %s...", self->broker);
}
// The constructor and destructor are the same as in mdcliapi, except
// we don't do retries, so there's no retries property.
// .skip
// ---------------------------------------------------------------------
// Constructor
mdcli_t *
mdcli_new (char *broker, int verbose)
{
assert (broker);
mdcli_t *self = (mdcli_t *) zmalloc (sizeof (mdcli_t));
self->ctx = zctx_new ();
self->broker = strdup (broker);
self->verbose = verbose;
self->timeout = 2500; // msecs
s_mdcli_connect_to_broker (self);
return self;
}
// Destructor
void
mdcli_destroy (mdcli_t **self_p)
{
assert (self_p);
if (*self_p) {
mdcli_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self->broker);
free (self);
*self_p = NULL;
}
}
// Set request timeout
void
mdcli_set_timeout (mdcli_t *self, int timeout)
{
assert (self);
self->timeout = timeout;
}
// .until
// .skip
// The send method now just sends one message, without waiting for a
// reply. Since we're using a DEALER socket we have to send an empty
// frame at the start, to create the same envelope that the REQ socket
// would normally make for us:
int
mdcli_send (mdcli_t *self, char *service, zmsg_t **request_p)
{
assert (self);
assert (request_p);
zmsg_t *request = *request_p;
// Prefix request with protocol frames
// Frame 0: empty (REQ emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
zmsg_pushstr (request, service);
zmsg_pushstr (request, MDPC_CLIENT);
zmsg_pushstr (request, "");
if (self->verbose) {
zclock_log ("I: send request to '%s' service:", service);
zmsg_dump (request);
}
zmsg_send (&request, self->client);
return 0;
}
// .skip
// The recv method waits for a reply message and returns that to the
// caller.
// ---------------------------------------------------------------------
// Returns the reply message or NULL if there was no reply. Does not
// attempt to recover from a broker failure, this is not possible
// without storing all unanswered requests and resending them all...
zmsg_t *
mdcli_recv (mdcli_t *self)
{
assert (self);
// Poll socket for a reply, with timeout
zmq_pollitem_t items [] = { { self->client, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, self->timeout * ZMQ_POLL_MSEC);
if (rc == -1)
return NULL; // Interrupted
// If we got a reply, process it
if (items [0].revents & ZMQ_POLLIN) {
zmsg_t *msg = zmsg_recv (self->client);
if (self->verbose) {
zclock_log ("I: received reply:");
zmsg_dump (msg);
}
// Don't try to handle errors, just assert noisily
assert (zmsg_size (msg) >= 4);
zframe_t *empty = zmsg_pop (msg);
assert (zframe_streq (empty, ""));
zframe_destroy (&empty);
zframe_t *header = zmsg_pop (msg);
assert (zframe_streq (header, MDPC_CLIENT));
zframe_destroy (&header);
zframe_t *service = zmsg_pop (msg);
zframe_destroy (&service);
return msg; // Success
}
if (zctx_interrupted)
printf ("W: interrupt received, killing client...\n");
else
if (self->verbose)
zclock_log ("W: permanent error, abandoning request");
return NULL;
}
mdcliapi2: Majordomo asynchronous client API in C++
#ifndef __MDCLIAPI_HPP_INCLUDED__
#define __MDCLIAPI_HPP_INCLUDED__
#include "zmsg.hpp"
#include "mdp.h"
// Structure of our class
// We access these properties only via class methods
class mdcli {
public:
// ---------------------------------------------------------------------
// Constructor
mdcli (std::string broker, int verbose): m_broker(broker), m_verbose(verbose)
{
s_version_assert (4, 0);
m_context = new zmq::context_t (1);
s_catch_signals ();
connect_to_broker ();
}
// ---------------------------------------------------------------------
// Destructor
virtual
~mdcli ()
{
delete m_client;
delete m_context;
}
// ---------------------------------------------------------------------
// Connect or reconnect to broker
void connect_to_broker ()
{
if (m_client) {
delete m_client;
}
m_client = new zmq::socket_t (*m_context, ZMQ_DEALER);
int linger = 0;
m_client->setsockopt (ZMQ_LINGER, &linger, sizeof (linger));
s_set_id(*m_client);
m_client->connect (m_broker.c_str());
if (m_verbose)
s_console ("I: connecting to broker at %s...", m_broker.c_str());
}
// ---------------------------------------------------------------------
// Set request timeout
void
set_timeout (int timeout)
{
m_timeout = timeout;
}
// ---------------------------------------------------------------------
// Send request to broker
// Takes ownership of request message and destroys it when sent.
int
send (std::string service, zmsg *&request_p)
{
assert (request_p);
zmsg *request = request_p;
// Prefix request with protocol frames
// Frame 0: empty (REQ emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
request->push_front (service.c_str());
request->push_front (k_mdp_client.data());
request->push_front ("");
if (m_verbose) {
s_console ("I: send request to '%s' service:", service.c_str());
request->dump ();
}
request->send (*m_client);
return 0;
}
// ---------------------------------------------------------------------
// Returns the reply message or NULL if there was no reply. Does not
// attempt to recover from a broker failure, this is not possible
// without storing all unanswered requests and resending them all...
zmsg *
recv ()
{
// Poll socket for a reply, with timeout
zmq::pollitem_t items[] = {
{ *m_client, 0, ZMQ_POLLIN, 0 } };
zmq::poll (items, 1, m_timeout);
// If we got a reply, process it
if (items[0].revents & ZMQ_POLLIN) {
zmsg *msg = new zmsg (*m_client);
if (m_verbose) {
s_console ("I: received reply:");
msg->dump ();
}
// Don't try to handle errors, just assert noisily
assert (msg->parts () >= 4);
assert (msg->pop_front ().length() == 0); // empty message
ustring header = msg->pop_front();
assert (header.compare((unsigned char *)k_mdp_client.data()) == 0);
ustring service = msg->pop_front();
assert (service.compare((unsigned char *)service.c_str()) == 0);
return msg; // Success
}
if (s_interrupted)
std::cout << "W: interrupt received, killing client..." << std::endl;
else
if (m_verbose)
s_console ("W: permanent error, abandoning request");
return 0;
}
private:
const std::string m_broker;
zmq::context_t * m_context;
zmq::socket_t * m_client{}; // Socket to broker
const int m_verbose; // Print activity to stdout
int m_timeout{2500}; // Request timeout
};
#endif
mdcliapi2: Majordomo asynchronous client API in C#
using System;
using System.Threading;
using ZeroMQ;
namespace Examples
{
namespace MDCliApi2
{
//
// mdcliapi class - Majordomo Protocol Client API
// Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
//
// Author: metadings
//
public class MajordomoClient : IDisposable
{
// Structure of our class
// We access these properties only via class methods
// Our context
readonly ZContext _context;
// Majordomo broker
public string Broker { get; protected set; }
// Socket to broker
public ZSocket Client { get; protected set; }
// Print activity to console
public bool Verbose { get; protected set; }
// Request timeout
public TimeSpan Timeout { get; protected set; }
public void ConnectToBroker()
{
// Connect or reconnect to broker. In this asynchronous class we use a
// DEALER socket instead of a REQ socket; this lets us send any number
// of requests without waiting for a reply.
Client = new ZSocket(_context, ZSocketType.DEALER);
Client.Connect(Broker);
if (Verbose)
"I: connecting to broker at '{0}'...".DumpString(Broker);
}
// The constructor and destructor are the same as in mdcliapi, except
// we don't do retries, so there's no retries property.
// .skip
// ---------------------------------------------------------------------
public MajordomoClient(string broker, bool verbose)
{
if(broker == null)
throw new InvalidOperationException();
_context = new ZContext();
Broker = broker;
Verbose = verbose;
Timeout = TimeSpan.FromMilliseconds(2500);
ConnectToBroker();
}
~MajordomoClient()
{
Dispose(false);
}
public void Dispose()
{
GC.SuppressFinalize(this);
Dispose(true);
}
protected void Dispose(bool disposing)
{
if (disposing)
{
// Destructor
if (Client != null)
{
Client.Dispose();
Client = null;
}
//Do not Dispose Context: cuz of weird shutdown behavior, stucks in using calls
}
}
// Set request timeout
public void Set_Timeout(int timeoutInMs)
{
Timeout = TimeSpan.FromMilliseconds(timeoutInMs);
}
// .until
// .skip
// The send method now just sends one message, without waiting for a
// reply. Since we're using a DEALER socket we have to send an empty
// frame at the start, to create the same envelope that the REQ socket
// would normally make for us:
public int Send(string service, ZMessage request, CancellationTokenSource cancellor)
{
if (request == null)
throw new NotImplementedException();
if (cancellor.IsCancellationRequested
|| (Console.KeyAvailable && Console.ReadKey(true).Key == ConsoleKey.Escape))
_context.Shutdown();
// Prefix request with protocol frames
// Frame 0: empty (REQ emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
request.Prepend(new ZFrame(service));
request.Prepend(new ZFrame(MdpCommon.MDPC_CLIENT));
request.Prepend(new ZFrame(string.Empty));
if (Verbose)
request.DumpZmsg("I: send request to '{0}' service:", service);
ZError error;
if(!Client.Send(request, out error));
{
if (Equals(error, ZError.ETERM))
cancellor.Cancel(); // Interrupted
//throw new ZException(error);
}
return 0;
}
// .skip
// The recv method waits for a reply message and returns that to the
// caller.
// ---------------------------------------------------------------------
// Returns the reply message or NULL if there was no reply. Does not
// attempt to recover from a broker failure, this is not possible
// without storing all unanswered requests and resending them all...
public ZMessage Recv(CancellationTokenSource cancellor)
{
// Poll socket for a reply, with timeout
var p = ZPollItem.CreateReceiver();
ZMessage msg;
ZError error;
// .split body of send
// On any blocking call, {{libzmq}} will return -1 if there was
// an error; we could in theory check for different error codes,
// but in practice it's OK to assume it was {{EINTR}} (Ctrl-C):
// Poll the client Message
if (Client.PollIn(p, out msg, out error, Timeout))
{
// If we got a reply, process it
if (Verbose)
msg.DumpZmsg("I: received reply");
// Don't try to handle errors, just assert noisily
if (msg.Count < 4)
throw new InvalidOperationException();
using (ZFrame empty = msg.Pop())
if (!empty.ToString().Equals(string.Empty))
throw new InvalidOperationException();
using (ZFrame header = msg.Pop())
if (!header.ToString().Equals(MdpCommon.MDPC_CLIENT))
throw new InvalidOperationException();
using (ZFrame replyService = msg.Pop())
{}
return msg;
}
else if (Equals(error, ZError.ETERM))
{
"W: interrupt received, killing client...\n".DumpString();
cancellor.Cancel();
}
else
{
if (Verbose)
"W: permanent error, abandoning Error: {0}".DumpString(error);
}
return null;
}
}
}
}
mdcliapi2: Majordomo asynchronous client API in CL
mdcliapi2: Majordomo asynchronous client API in Delphi
mdcliapi2: Majordomo asynchronous client API in Erlang
mdcliapi2: Majordomo asynchronous client API in Elixir
mdcliapi2: Majordomo asynchronous client API in F#
mdcliapi2: Majordomo asynchronous client API in Felix
mdcliapi2: Majordomo asynchronous client API in Go
mdcliapi2: Majordomo asynchronous client API in Haskell
mdcliapi2: Majordomo asynchronous client API in Haxe
package ;
import haxe.Stack;
import neko.Lib;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import MDP;
/**
* Majordomo Protocol Client API (async version)
* Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7
*/
class MDCliAPI2
{
/** Request timeout (in msec) */
public var timeout:Int;
// Private instance fields
/** Our context */
private var ctx:ZContext;
/** Connection string to reach broker */
private var broker:String;
/** Socket to broker */
private var client:ZMQSocket;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/**
* Constructor
* @param broker
* @param verbose
*/
public function new(broker:String, ?verbose:Bool=false, ?logger:Dynamic->Void) {
ctx = new ZContext();
this.broker = broker;
this.verbose = verbose;
this.timeout = 2500; // msecs
if (logger != null)
log = logger;
else
log = Lib.println;
connectToBroker();
}
/**
* Connect or reconnect to broker
*/
public function connectToBroker() {
if (client != null)
client.close();
client = ctx.createSocket(ZMQ_DEALER);
client.setsockopt(ZMQ_LINGER, 0);
client.connect(broker);
if (verbose)
log("I: connecting to broker at " + broker + "...");
}
/**
* Destructor
*/
public function destroy() {
ctx.destroy();
}
/**
* Send request to broker
* Takes ownership of request message and destroys it when sent.
* @param service
* @param request
* @return
*/
public function send(service:String, request:ZMsg) {
// Prefix request with MDP protocol frames
// Frame 0: empty (REQ socket emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client)
// Frame 2: Service name (printable string)
request.push(ZFrame.newStringFrame(service));
request.push(ZFrame.newStringFrame(MDP.MDPC_CLIENT));
request.push(ZFrame.newStringFrame(""));
if (verbose) {
log("I: send request to '" + service + "' service:");
log(request.toString());
}
request.send(client);
}
/**
* Returns the reply message or NULL if there was no reply. Does not
* attempt to recover from a broker failure, this is not possible
* without storing all answered requests and re-sending them all...
* @return
*/
public function recv():ZMsg {
var poller = new ZMQPoller();
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
// Poll socket for a reply, with timeout
try {
var res = poller.poll(timeout * 1000);
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else
log("W: interrupt received, killing client...");
ctx.destroy();
return null;
}
// If we got a reply, process it
if (poller.pollin(1)) {
// We got a reply from the server, must match sequence
var msg = ZMsg.recvMsg(client);
if (msg == null)
return null; // Interrupted
if (verbose)
log("I: received reply:" + msg.toString());
if (msg.size() < 3)
return null; // Don't try to handle errors
var empty = msg.pop(); // Empty frame
if (empty.size() != 0) {
return null; // Assert
}
empty.destroy();
var header = msg.pop();
if (!header.streq(MDP.MDPC_CLIENT)) {
return null; // Assert
}
header.destroy();
var reply_service = msg.pop();
reply_service.destroy();
return msg; // Success
} else {
if (verbose)
log("E: permanent error, abandoning");
}
return null;
}
}
mdcliapi2: Majordomo asynchronous client API in Java
package guide;
import java.util.Formatter;
import org.zeromq.*;
/**
* Majordomo Protocol Client API, asynchronous Java version. Implements the
* MDP/Worker spec at http://rfc.zeromq.org/spec:7.
*/
public class mdcliapi2
{
private String broker;
private ZContext ctx;
private ZMQ.Socket client;
private long timeout = 2500;
private boolean verbose;
private Formatter log = new Formatter(System.out);
public long getTimeout()
{
return timeout;
}
public void setTimeout(long timeout)
{
this.timeout = timeout;
}
public mdcliapi2(String broker, boolean verbose)
{
this.broker = broker;
this.verbose = verbose;
ctx = new ZContext();
reconnectToBroker();
}
/**
* Connect or reconnect to broker
*/
void reconnectToBroker()
{
if (client != null) {
ctx.destroySocket(client);
}
client = ctx.createSocket(SocketType.DEALER);
client.connect(broker);
if (verbose)
log.format("I: connecting to broker at %s...\n", broker);
}
/**
* Returns the reply message or NULL if there was no reply. Does not attempt
* to recover from a broker failure, this is not possible without storing
* all unanswered requests and resending them all…
*/
public ZMsg recv()
{
ZMsg reply = null;
// Poll socket for a reply, with timeout
ZMQ.Poller items = ctx.createPoller(1);
items.register(client, ZMQ.Poller.POLLIN);
if (items.poll(timeout * 1000) == -1)
return null; // Interrupted
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(client);
if (verbose) {
log.format("I: received reply: \n");
msg.dump(log.out());
}
// Don't try to handle errors, just assert noisily
assert (msg.size() >= 4);
ZFrame empty = msg.pop();
assert (empty.getData().length == 0);
empty.destroy();
ZFrame header = msg.pop();
assert (MDP.C_CLIENT.equals(header.toString()));
header.destroy();
ZFrame replyService = msg.pop();
replyService.destroy();
reply = msg;
}
items.close();
return reply;
}
/**
* Send request to broker and get reply by hook or crook Takes ownership of
* request message and destroys it when sent.
*/
public boolean send(String service, ZMsg request)
{
assert (request != null);
// Prefix request with protocol frames
// Frame 0: empty (REQ emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
request.addFirst(service);
request.addFirst(MDP.C_CLIENT.newFrame());
request.addFirst("");
if (verbose) {
log.format("I: send request to '%s' service: \n", service);
request.dump(log.out());
}
return request.send(client);
}
public void destroy()
{
ctx.destroy();
}
}
mdcliapi2: Majordomo asynchronous client API in Julia
mdcliapi2: Majordomo asynchronous client API in Lua
--
-- mdcliapi2.lua - Majordomo Protocol Client API (async version)
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
local setmetatable = setmetatable
local mdp = require"mdp"
local zmq = require"zmq"
local zpoller = require"zmq.poller"
local zmsg = require"zmsg"
require"zhelpers"
local s_version_assert = s_version_assert
local obj_mt = {}
obj_mt.__index = obj_mt
function obj_mt:set_timeout(timeout)
self.timeout = timeout
end
function obj_mt:destroy()
if self.client then self.client:close() end
self.context:term()
end
local function s_mdcli_connect_to_broker(self)
-- close old socket.
if self.client then
self.poller:remove(self.client)
self.client:close()
end
self.client = assert(self.context:socket(zmq.DEALER))
assert(self.client:setopt(zmq.LINGER, 0))
assert(self.client:connect(self.broker))
if self.verbose then
s_console("I: connecting to broker at %s...", self.broker)
end
-- add socket to poller
self.poller:add(self.client, zmq.POLLIN, function()
self.got_reply = true
end)
end
--
-- Send request to broker and get reply by hook or crook
--
function obj_mt:send(service, request)
-- Prefix request with protocol frames
-- Frame 0: empty (REQ emulation)
-- Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
-- Frame 2: Service name (printable string)
request:push(service)
request:push(mdp.MDPC_CLIENT)
request:push("")
if self.verbose then
s_console("I: send request to '%s' service:", service)
request:dump()
end
request:send(self.client)
return 0
end
-- Returns the reply message or NULL if there was no reply. Does not
-- attempt to recover from a broker failure, this is not possible
-- without storing all unanswered requests and resending them all...
function obj_mt:recv()
self.got_reply = false
local cnt = assert(self.poller:poll(self.timeout * 1000))
if cnt ~= 0 and self.got_reply then
local msg = zmsg.recv(self.client)
if self.verbose then
s_console("I: received reply:")
msg:dump()
end
assert(msg:parts() >= 3)
local empty = msg:pop()
assert(empty == "")
local header = msg:pop()
assert(header == mdp.MDPC_CLIENT)
return msg
end
if self.verbose then
s_console("W: permanent error, abandoning request")
end
return nil -- Giving up
end
module(...)
function new(broker, verbose)
s_version_assert (2, 1);
local self = setmetatable({
context = zmq.init(1),
poller = zpoller.new(1),
broker = broker,
verbose = verbose,
timeout = 2500, -- msecs
}, obj_mt)
s_mdcli_connect_to_broker(self)
return self
end
setmetatable(_M, { __call = function(self, ...) return new(...) end })
mdcliapi2: Majordomo asynchronous client API in Node.js
mdcliapi2: Majordomo asynchronous client API in Objective-C
mdcliapi2: Majordomo asynchronous client API in ooc
mdcliapi2: Majordomo asynchronous client API in Perl
mdcliapi2: Majordomo asynchronous client API in PHP
<?php
/* =====================================================================
* mdcliapi2.c
*
* Majordomo Protocol Client API (async version)
* Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
*/
include_once 'zmsg.php';
include_once 'mdp.php';
class MDCli
{
// Structure of our class
// We access these properties only via class methods
private $broker;
private $context;
private $client; // Socket to broker
private $verbose; // Print activity to stdout
private $timeout; // Request timeout
private $retries; // Request retries
/**
* Constructor
*
* @param string $broker
* @param boolean $verbose
*/
public function __construct($broker, $verbose = false)
{
$this->broker = $broker;
$this->context = new ZMQContext();
$this->verbose = $verbose;
$this->timeout = 2500; // msecs
$this->connect_to_broker();
}
/**
* Connect or reconnect to broker
*/
protected function connect_to_broker()
{
if ($this->client) {
unset($this->client);
}
$this->client = new ZMQSocket($this->context, ZMQ::SOCKET_DEALER);
$this->client->setSockOpt(ZMQ::SOCKOPT_LINGER, 0);
$this->client->connect($this->broker);
if ($this->verbose) {
printf("I: connecting to broker at %s...", $this->broker);
}
}
/**
* Set request timeout
*
* @param int $timeout (msecs)
*/
public function set_timeout($timeout)
{
$this->timeout = $timeout;
}
/**
* Send request to broker
* Takes ownership of request message and destroys it when sent.
*
* @param string $service
* @param Zmsg $request
*/
public function send($service, Zmsg $request)
{
// Prefix request with protocol frames
// Frame 0: empty (REQ emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
$request->push($service);
$request->push(MDPC_CLIENT);
$request->push("");
if ($this->verbose) {
printf ("I: send request to '%s' service: %s", $service, PHP_EOL);
echo $request->__toString();
}
$request->set_socket($this->client)->send();
}
/**
* Returns the reply message or NULL if there was no reply. Does not
* attempt to recover from a broker failure, this is not possible
* without storing all unanswered requests and resending them all...
*
*/
public function recv()
{
$read = $write = array();
// Poll socket for a reply, with timeout
$poll = new ZMQPoll();
$poll->add($this->client, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, $this->timeout);
// If we got a reply, process it
if ($events) {
$msg = new Zmsg($this->client);
$msg->recv();
if ($this->verbose) {
echo "I: received reply:", $msg->__toString(), PHP_EOL;
}
// Don't try to handle errors, just assert noisily
assert ($msg->parts() >= 4);
$msg->pop(); // empty
$header = $msg->pop();
assert($header == MDPC_CLIENT);
$reply_service = $msg->pop();
return $msg; // Success
} else {
echo "W: permanent error, abandoning request", PHP_EOL;
return; // Give up
}
}
}
mdcliapi2: Majordomo asynchronous client API in Python
"""Majordomo Protocol Client API, Python version.
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
Author: Min RK <benjaminrk@gmail.com>
Based on Java example by Arkadiusz Orzechowski
"""
import logging
import zmq
import MDP
from zhelpers import dump
class MajorDomoClient(object):
"""Majordomo Protocol Client API, Python version.
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
"""
broker = None
ctx = None
client = None
poller = None
timeout = 2500
verbose = False
def __init__(self, broker, verbose=False):
self.broker = broker
self.verbose = verbose
self.ctx = zmq.Context()
self.poller = zmq.Poller()
logging.basicConfig(format="%(asctime)s %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
self.reconnect_to_broker()
def reconnect_to_broker(self):
"""Connect or reconnect to broker"""
if self.client:
self.poller.unregister(self.client)
self.client.close()
self.client = self.ctx.socket(zmq.DEALER)
self.client.linger = 0
self.client.connect(self.broker)
self.poller.register(self.client, zmq.POLLIN)
if self.verbose:
logging.info("I: connecting to broker at %s...", self.broker)
def send(self, service, request):
"""Send request to broker
"""
if not isinstance(request, list):
request = [request]
# Prefix request with protocol frames
# Frame 0: empty (REQ emulation)
# Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
# Frame 2: Service name (printable string)
request = [b'', MDP.C_CLIENT, service] + request
if self.verbose:
logging.warn("I: send request to '%s' service: ", service)
dump(request)
self.client.send_multipart(request)
def recv(self):
"""Returns the reply message or None if there was no reply."""
try:
items = self.poller.poll(self.timeout)
except KeyboardInterrupt:
return # interrupted
if items:
# if we got a reply, process it
msg = self.client.recv_multipart()
if self.verbose:
logging.info("I: received reply:")
dump(msg)
# Don't try to handle errors, just assert noisily
assert len(msg) >= 4
empty = msg.pop(0)
header = msg.pop(0)
assert MDP.C_CLIENT == header
service = msg.pop(0)
return msg
else:
logging.warn("W: permanent error, abandoning request")
mdcliapi2: Majordomo asynchronous client API in Q
mdcliapi2: Majordomo asynchronous client API in Racket
mdcliapi2: Majordomo asynchronous client API in Ruby
mdcliapi2: Majordomo asynchronous client API in Rust
mdcliapi2: Majordomo asynchronous client API in Scala
mdcliapi2: Majordomo asynchronous client API in Tcl
mdcliapi2: Majordomo asynchronous client API in OCaml
The differences are:
- We use a DEALER socket instead of REQ, so we emulate REQ with an empty delimiter frame before each request and each response.
- We don’t retry requests; if the application needs to retry, it can do this itself.
- We break the synchronous send method into separate send and recv methods.
- The send method is asynchronous and returns immediately after sending. The caller can thus send a number of messages before getting a response.
- The recv method waits for (with a timeout) one response and returns that to the caller.
And here’s the corresponding client test program, which sends 100,000 messages and then receives 100,000 back:
mdclient2: Majordomo client application in Ada
mdclient2: Majordomo client application in Basic
mdclient2: Majordomo client application in C
// Majordomo Protocol client example - asynchronous
// Uses the mdcli API to hide all MDP aspects
// Lets us build this source without creating a library
#include "mdcliapi2.c"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
mdcli_t *session = mdcli_new ("tcp://localhost:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
zmsg_t *request = zmsg_new ();
zmsg_pushstr (request, "Hello world");
mdcli_send (session, "echo", &request);
}
for (count = 0; count < 100000; count++) {
zmsg_t *reply = mdcli_recv (session);
if (reply)
zmsg_destroy (&reply);
else
break; // Interrupted by Ctrl-C
}
printf ("%d replies received\n", count);
mdcli_destroy (&session);
return 0;
}
mdclient2: Majordomo client application in C++
//
// Majordomo Protocol client example - asynchronous
// Uses the mdcli API to hide all MDP aspects
//
// Lets us 'build mdclient' and 'build all'
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "mdcliapi2.hpp"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && strcmp (argv [1], "-v") == 0);
mdcli session ("tcp://localhost:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
zmsg * request = new zmsg("Hello world");
session.send ("echo", request);
}
for (count = 0; count < 100000; count++) {
zmsg *reply = session.recv ();
if (reply) {
delete reply;
} else {
break; // Interrupted by Ctrl-C
}
}
std::cout << count << " replies received" << std::endl;
return 0;
}
mdclient2: Majordomo client application in C#
using System;
using System.Linq;
using System.Threading;
using ZeroMQ;
namespace Examples
{
using MDCliApi2; // Let us build this source without creating a library
static partial class Program
{
// Majordomo Protocol client example
// Uses the mdcli API to hide all MDP aspects
public static void MDClient2(string[] args)
{
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (s, ea) =>
{
ea.Cancel = true;
cts.Cancel();
};
using (MajordomoClient session = new MajordomoClient("tcp://127.0.0.1:5555", Verbose))
{
int count;
for (count = 0; count < 100000 && !cts.IsCancellationRequested; count++)
{
ZMessage request = new ZMessage();
request.Prepend(new ZFrame("Hello world"));
session.Send("echo", request, cts);
}
for (count = 0; count < 100000 && !cts.IsCancellationRequested; count++)
{
using (ZMessage reply = session.Recv(cts))
if (reply == null)
break; // Interrupt or failure
}
Console.WriteLine("{0} replies received\n", count);
}
}
}
}
mdclient2: Majordomo client application in CL
mdclient2: Majordomo client application in Delphi
mdclient2: Majordomo client application in Erlang
mdclient2: Majordomo client application in Elixir
mdclient2: Majordomo client application in F#
mdclient2: Majordomo client application in Felix
mdclient2: Majordomo client application in Go
mdclient2: Majordomo client application in Haskell
mdclient2: Majordomo client application in Haxe
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol client example (asynchronous)
* Uses the MDPCli API to hide all MDP aspects
*
* @author Richard J Smith
*/
class MDClient2
{
public static function main() {
Lib.println("** MDClient2 (see: http://zguide.zeromq.org/page:all#Asynchronous-Majordomo-Pattern)");
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var session = new MDCliAPI2("tcp://localhost:5555", verbose);
for (i in 0 ... 100000) {
var request = new ZMsg();
request.pushString("Hello world: "+i);
session.send("echo", request);
}
var count = 0;
for (i in 0 ... 100000) {
var reply = session.recv();
if (reply != null)
reply.destroy();
else
break; // Interrupt or failure
count++;
}
Lib.println(count + " requests/replies processed");
session.destroy();
}
}mdclient2: Majordomo client application in Java
package guide;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol client example, asynchronous. Uses the mdcli API to hide
* all MDP aspects
*/
public class mdclient2
{
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && "-v".equals(args[0]));
mdcliapi2 clientSession = new mdcliapi2("tcp://localhost:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
ZMsg request = new ZMsg();
request.addString("Hello world");
clientSession.send("echo", request);
}
for (count = 0; count < 100000; count++) {
ZMsg reply = clientSession.recv();
if (reply != null)
reply.destroy();
else break; // Interrupt or failure
}
System.out.printf("%d requests/replies processed\n", count);
clientSession.destroy();
}
}
mdclient2: Majordomo client application in Julia
mdclient2: Majordomo client application in Lua
--
-- Majordomo Protocol client example - asynchronous
-- Uses the mdcli API to hide all MDP aspects
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"mdcliapi2"
require"zmsg"
require"zhelpers"
local verbose = (arg[1] == "-v")
local session = mdcliapi2.new("tcp://localhost:5555", verbose)
local count=100000
for n=1,count do
local request = zmsg.new("Hello world")
session:send("echo", request)
end
for n=1,count do
local reply = session:recv()
if not reply then
break -- Interrupted by Ctrl-C
end
end
printf("%d replies received\n", count)
session:destroy()
mdclient2: Majordomo client application in Node.js
mdclient2: Majordomo client application in Objective-C
mdclient2: Majordomo client application in ooc
mdclient2: Majordomo client application in Perl
mdclient2: Majordomo client application in PHP
<?php
/*
* Majordomo Protocol client example - asynchronous
* Uses the mdcli API to hide all MDP aspects
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'mdcliapi2.php';
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$session = new MDCli("tcp://localhost:5555", $verbose);
for ($count = 0; $count < 10000; $count++) {
$request = new Zmsg();
$request->body_set("Hello world");
$session->send("echo", $request);
}
for ($count = 0; $count < 10000; $count++) {
$reply = $session->recv();
if (!$reply) {
break; // Interrupt or failure
}
}
printf ("%d replies received", $count);
echo PHP_EOL;
mdclient2: Majordomo client application in Python
"""
Majordomo Protocol client example. Uses the mdcli API to hide all MDP aspects
Author : Min RK <benjaminrk@gmail.com>
"""
import sys
from mdcliapi2 import MajorDomoClient
def main():
verbose = '-v' in sys.argv
client = MajorDomoClient("tcp://localhost:5555", verbose)
requests = 100000
for i in range(requests):
request = b"Hello world"
try:
client.send(b"echo", request)
except KeyboardInterrupt:
print ("send interrupted, aborting")
return
count = 0
while count < requests:
try:
reply = client.recv()
except KeyboardInterrupt:
break
else:
# also break on failure to reply:
if reply is None:
break
count += 1
print ("%i requests/replies processed" % count)
if __name__ == '__main__':
main()
mdclient2: Majordomo client application in Q
mdclient2: Majordomo client application in Racket
mdclient2: Majordomo client application in Ruby
mdclient2: Majordomo client application in Rust
mdclient2: Majordomo client application in Scala
mdclient2: Majordomo client application in Tcl
mdclient2: Majordomo client application in OCaml
The broker and worker are unchanged because we’ve not modified the protocol at all. We see an immediate improvement in performance. Here’s the synchronous client chugging through 100K request-reply cycles:
$ time mdclient
100000 requests/replies processed
real 0m14.088s
user 0m1.310s
sys 0m2.670s
And here’s the asynchronous client, with a single worker:
$ time mdclient2
100000 replies received
real 0m8.730s
user 0m0.920s
sys 0m1.550s
Twice as fast. Not bad, but let’s fire up 10 workers and see how it handles the traffic
$ time mdclient2
100000 replies received
real 0m3.863s
user 0m0.730s
sys 0m0.470s
It isn’t fully asynchronous because workers get their messages on a strict last-used basis. But it will scale better with more workers. On my PC, after eight or so workers, it doesn’t get any faster. Four cores only stretches so far. But we got a 4x improvement in throughput with just a few minutes’ work. The broker is still unoptimized. It spends most of its time copying message frames around, instead of doing zero-copy, which it could. But we’re getting 25K reliable request/reply calls a second, with pretty low effort.
However, the asynchronous Majordomo pattern isn’t all roses. It has a fundamental weakness, namely that it cannot survive a broker crash without more work. If you look at the mdcliapi2 code you’ll see it does not attempt to reconnect after a failure. A proper reconnect would require the following:
- A number on every request and a matching number on every reply, which would ideally require a change to the protocol to enforce.
- Tracking and holding onto all outstanding requests in the client API, i.e., those for which no reply has yet been received.
- In case of failover, for the client API to resend all outstanding requests to the broker.
It’s not a deal breaker, but it does show that performance often means complexity. Is this worth doing for Majordomo? It depends on your use case. For a name lookup service you call once per session, no. For a web frontend serving thousands of clients, probably yes.
Service Discovery #
So, we have a nice service-oriented broker, but we have no way of knowing whether a particular service is available or not. We know whether a request failed, but we don’t know why. It is useful to be able to ask the broker, “is the echo service running?” The most obvious way would be to modify our MDP/Client protocol to add commands to ask this. But MDP/Client has the great charm of being simple. Adding service discovery to it would make it as complex as the MDP/Worker protocol.
Another option is to do what email does, and ask that undeliverable requests be returned. This can work well in an asynchronous world, but it also adds complexity. We need ways to distinguish returned requests from replies and to handle these properly.
Let’s try to use what we’ve already built, building on top of MDP instead of modifying it. Service discovery is, itself, a service. It might indeed be one of several management services, such as “disable service X”, “provide statistics”, and so on. What we want is a general, extensible solution that doesn’t affect the protocol or existing applications.
So here’s a small RFC that layers this on top of MDP: the Majordomo Management Interface (MMI). We already implemented it in the broker, though unless you read the whole thing you probably missed that. I’ll explain how it works in the broker:
-
When a client requests a service that starts with mmi., instead of routing this to a worker, we handle it internally.
-
We handle just one service in this broker, which is mmi.service, the service discovery service.
-
The payload for the request is the name of an external service (a real one, provided by a worker).
-
The broker returns “200” (OK) or “404” (Not found), depending on whether there are workers registered for that service or not.
Here’s how we use the service discovery in an application:
mmiecho: Service discovery over Majordomo in Ada
mmiecho: Service discovery over Majordomo in Basic
mmiecho: Service discovery over Majordomo in C
// MMI echo query example
// Lets us build this source without creating a library
#include "mdcliapi.c"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
mdcli_t *session = mdcli_new ("tcp://localhost:5555", verbose);
// This is the service we want to look up
zmsg_t *request = zmsg_new ();
zmsg_addstr (request, "echo");
// This is the service we send our request to
zmsg_t *reply = mdcli_send (session, "mmi.service", &request);
if (reply) {
char *reply_code = zframe_strdup (zmsg_first (reply));
printf ("Lookup echo service: %s\n", reply_code);
free (reply_code);
zmsg_destroy (&reply);
}
else
printf ("E: no response from broker, make sure it's running\n");
mdcli_destroy (&session);
return 0;
}
mmiecho: Service discovery over Majordomo in C++
#include "mdcliapi.hpp"
int main(int argc, char **argv) {
int verbose = (argc > 1 && strcmp(argv[1], "-v")== 0);
mdcli session("tcp://localhost:5555", verbose);
zmsg* request = new zmsg("echo");
zmsg *reply = session.send("mmi.service", request);
if (reply) {
ustring status = reply->pop_front();
std::cout << "Lookup echo service: " <<(char *) status.c_str() << std::endl;
delete reply;
}
return 0;
}
mmiecho: Service discovery over Majordomo in C#
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Runtime.Remoting.Messaging;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
// Lets us build this source without creating a library
using MDCliApi;
static partial class Program
{
// MMI echo query example
public static void MMIEcho(string[] args)
{
CancellationTokenSource cancellor = new CancellationTokenSource();
Console.CancelKeyPress += (s, ea) =>
{
ea.Cancel = true;
cancellor.Cancel();
};
using (MajordomoClient session = new MajordomoClient("tcp://127.0.0.1:5555", Verbose))
{
ZMessage request = new ZMessage();
request.Add(new ZFrame("echo"));
ZMessage reply = session.Send("mmi.service", request, cancellor);
if (reply != null)
{
var replycode = reply[0].ToString();
"Loopup echo service: {0}\n".DumpString(replycode);
reply.Dispose();
}
else
"E: no response from broker, make sure it's running\n".DumpString();
}
}
}
}
mmiecho: Service discovery over Majordomo in CL
mmiecho: Service discovery over Majordomo in Delphi
mmiecho: Service discovery over Majordomo in Erlang
mmiecho: Service discovery over Majordomo in Elixir
mmiecho: Service discovery over Majordomo in F#
mmiecho: Service discovery over Majordomo in Felix
mmiecho: Service discovery over Majordomo in Go
//
// MMI echo query example
//
// Author: amyangfei <amyangfei@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
"os"
)
func main() {
verbose := len(os.Args) > 1 && os.Args[1] == "-v"
client := NewClient("tcp://localhost:5555", verbose)
defer client.Close()
// This is the service we send our request to
reply := client.Send([]byte("mmi.service"), [][]byte{[]byte("echo")})
fmt.Println("here")
if len(reply) > 0 {
reply_code := reply[0]
fmt.Printf("Lookup echo service: %s\n", reply_code)
} else {
fmt.Printf("E: no response from broker, make sure it's running\n")
}
}
mmiecho: Service discovery over Majordomo in Haskell
mmiecho: Service discovery over Majordomo in Haxe
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMsg;
/**
* MMI echo query example
*/
class MMIEcho
{
public static function main() {
Lib.println("** MMIEcho (see: http://zguide.zeromq.org/page:all#Service-Discovery)");
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var session = new MDCliAPI("tcp://localhost:5555", verbose);
// This is the service we want to look up
var request = new ZMsg();
request.addString("echo");
// This is the service we send our request to
var reply = session.send("mmi.service", request);
if (reply != null) {
var replyCode = reply.first().toString();
Lib.println("Lookup echo service: " + replyCode);
} else
Lib.println("E: no response from broker, make sure it's running");
session.destroy();
}
}mmiecho: Service discovery over Majordomo in Java
package guide;
import org.zeromq.ZMsg;
/**
* MMI echo query example
*/
public class mmiecho
{
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && "-v".equals(args[0]));
mdcliapi clientSession = new mdcliapi("tcp://localhost:5555", verbose);
ZMsg request = new ZMsg();
// This is the service we want to look up
request.addString("echo");
// This is the service we send our request to
ZMsg reply = clientSession.send("mmi.service", request);
if (reply != null) {
String replyCode = reply.getFirst().toString();
System.out.printf("Lookup echo service: %s\n", replyCode);
}
else {
System.out.println("E: no response from broker, make sure it's running");
}
clientSession.destroy();
}
}
mmiecho: Service discovery over Majordomo in Julia
mmiecho: Service discovery over Majordomo in Lua
--
-- MMI echo query example
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"mdcliapi"
require"zmsg"
require"zhelpers"
local verbose = (arg[1] == "-v")
local session = mdcliapi.new("tcp://localhost:5555", verbose)
-- This is the service we want to look up
local request = zmsg.new("echo")
-- This is the service we send our request to
local reply = session:send("mmi.service", request)
if (reply) then
printf ("Lookup echo service: %s\n", reply:body())
else
printf ("E: no response from broker, make sure it's running\n")
end
session:destroy()
mmiecho: Service discovery over Majordomo in Node.js
mmiecho: Service discovery over Majordomo in Objective-C
mmiecho: Service discovery over Majordomo in ooc
mmiecho: Service discovery over Majordomo in Perl
mmiecho: Service discovery over Majordomo in PHP
<?php
/*
* MMI echo query example
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'mdcliapi.php';
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$session = new MDCli("tcp://localhost:5555", $verbose);
// This is the service we want to look up
$request = new Zmsg();
$request->body_set("echo");
// This is the service we send our request to
$reply = $session->send("mmi.service", $request);
if ($reply) {
$reply_code = $reply->pop();
printf ("Lookup echo service: %s %s", $reply_code, PHP_EOL);
}
mmiecho: Service discovery over Majordomo in Python
"""
MMI echo query example
Author : Min RK <benjaminrk@gmail.com>
"""
import sys
from mdcliapi import MajorDomoClient
def main():
verbose = '-v' in sys.argv
client = MajorDomoClient("tcp://localhost:5555", verbose)
request = b"echo"
reply = client.send(b"mmi.service", request)
if reply:
replycode = reply[0]
print ("Lookup echo service:", replycode)
else:
print ("E: no response from broker, make sure it's running")
if __name__ == '__main__':
main()
mmiecho: Service discovery over Majordomo in Q
mmiecho: Service discovery over Majordomo in Racket
mmiecho: Service discovery over Majordomo in Ruby
mmiecho: Service discovery over Majordomo in Rust
mmiecho: Service discovery over Majordomo in Scala
mmiecho: Service discovery over Majordomo in Tcl
mmiecho: Service discovery over Majordomo in OCaml
Try this with and without a worker running, and you should see the little program report “200” or “404” accordingly. The implementation of MMI in our example broker is flimsy. For example, if a worker disappears, services remain “present”. In practice, a broker should remove services that have no workers after some configurable timeout.
Idempotent Services #
Idempotency is not something you take a pill for. What it means is that it’s safe to repeat an operation. Checking the clock is idempotent. Lending ones credit card to ones children is not. While many client-to-server use cases are idempotent, some are not. Examples of idempotent use cases include:
-
Stateless task distribution, i.e., a pipeline where the servers are stateless workers that compute a reply based purely on the state provided by a request. In such a case, it’s safe (though inefficient) to execute the same request many times.
-
A name service that translates logical addresses into endpoints to bind or connect to. In such a case, it’s safe to make the same lookup request many times.
And here are examples of a non-idempotent use cases:
-
A logging service. One does not want the same log information recorded more than once.
-
Any service that has impact on downstream nodes, e.g., sends on information to other nodes. If that service gets the same request more than once, downstream nodes will get duplicate information.
-
Any service that modifies shared data in some non-idempotent way; e.g., a service that debits a bank account is not idempotent without extra work.
When our server applications are not idempotent, we have to think more carefully about when exactly they might crash. If an application dies when it’s idle, or while it’s processing a request, that’s usually fine. We can use database transactions to make sure a debit and a credit are always done together, if at all. If the server dies while sending its reply, that’s a problem, because as far as it’s concerned, it has done its work.
If the network dies just as the reply is making its way back to the client, the same problem arises. The client will think the server died and will resend the request, and the server will do the same work twice, which is not what we want.
To handle non-idempotent operations, use the fairly standard solution of detecting and rejecting duplicate requests. This means:
-
The client must stamp every request with a unique client identifier and a unique message number.
-
The server, before sending back a reply, stores it using the combination of client ID and message number as a key.
-
The server, when getting a request from a given client, first checks whether it has a reply for that client ID and message number. If so, it does not process the request, but just resends the reply.
Disconnected Reliability (Titanic Pattern) #
Once you realize that Majordomo is a “reliable” message broker, you might be tempted to add some spinning rust (that is, ferrous-based hard disk platters). After all, this works for all the enterprise messaging systems. It’s such a tempting idea that it’s a little sad to have to be negative toward it. But brutal cynicism is one of my specialties. So, some reasons you don’t want rust-based brokers sitting in the center of your architecture are:
-
As you’ve seen, the Lazy Pirate client performs surprisingly well. It works across a whole range of architectures, from direct client-to-server to distributed queue proxies. It does tend to assume that workers are stateless and idempotent. But we can work around that limitation without resorting to rust.
-
Rust brings a whole set of problems, from slow performance to additional pieces that you have to manage, repair, and handle 6 a.m. panics from, as they inevitably break at the start of daily operations. The beauty of the Pirate patterns in general is their simplicity. They won’t crash. And if you’re still worried about the hardware, you can move to a peer-to-peer pattern that has no broker at all. I’ll explain later in this chapter.
Having said this, however, there is one sane use case for rust-based reliability, which is an asynchronous disconnected network. It solves a major problem with Pirate, namely that a client has to wait for an answer in real time. If clients and workers are only sporadically connected (think of email as an analogy), we can’t use a stateless network between clients and workers. We have to put state in the middle.
So, here’s the Titanic pattern, in which we write messages to disk to ensure they never get lost, no matter how sporadically clients and workers are connected. As we did for service discovery, we’re going to layer Titanic on top of MDP rather than extend it. It’s wonderfully lazy because it means we can implement our fire-and-forget reliability in a specialized worker, rather than in the broker. This is excellent for several reasons:
- It is much easier because we divide and conquer: the broker handles message routing and the worker handles reliability.
- It lets us mix brokers written in one language with workers written in another.
- It lets us evolve the fire-and-forget technology independently.
The only downside is that there’s an extra network hop between broker and hard disk. The benefits are easily worth it.
There are many ways to make a persistent request-reply architecture. We’ll aim for one that is simple and painless. The simplest design I could come up with, after playing with this for a few hours, is a “proxy service”. That is, Titanic doesn’t affect workers at all. If a client wants a reply immediately, it talks directly to a service and hopes the service is available. If a client is happy to wait a while, it talks to Titanic instead and asks, “hey, buddy, would you take care of this for me while I go buy my groceries?”
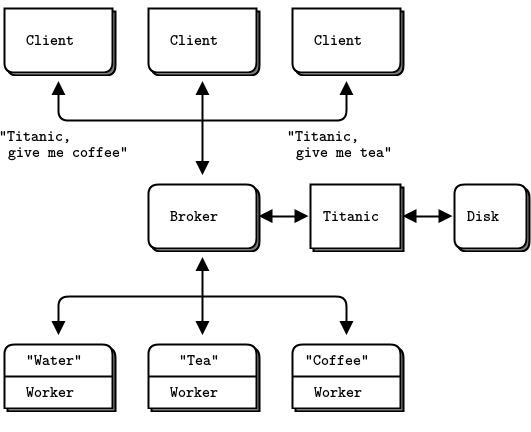
Titanic is thus both a worker and a client. The dialog between client and Titanic goes along these lines:
- Client: Please accept this request for me. Titanic: OK, done.
- Client: Do you have a reply for me? Titanic: Yes, here it is. Or, no, not yet.
- Client: OK, you can wipe that request now, I’m happy. Titanic: OK, done.
Whereas the dialog between Titanic and broker and worker goes like this:
- Titanic: Hey, Broker, is there an coffee service? Broker: Uhm, Yeah, seems like.
- Titanic: Hey, coffee service, please handle this for me.
- Coffee: Sure, here you are.
- Titanic: Sweeeeet!
You can work through this and the possible failure scenarios. If a worker crashes while processing a request, Titanic retries indefinitely. If a reply gets lost somewhere, Titanic will retry. If the request gets processed but the client doesn’t get the reply, it will ask again. If Titanic crashes while processing a request or a reply, the client will try again. As long as requests are fully committed to safe storage, work can’t get lost.
The handshaking is pedantic, but can be pipelined, i.e., clients can use the asynchronous Majordomo pattern to do a lot of work and then get the responses later.
We need some way for a client to request its replies. We’ll have many clients asking for the same services, and clients disappear and reappear with different identities. Here is a simple, reasonably secure solution:
- Every request generates a universally unique ID (UUID), which Titanic returns to the client after it has queued the request.
- When a client asks for a reply, it must specify the UUID for the original request.
In a realistic case, the client would want to store its request UUIDs safely, e.g., in a local database.
Before we jump off and write yet another formal specification (fun, fun!), let’s consider how the client talks to Titanic. One way is to use a single service and send it three different request types. Another way, which seems simpler, is to use three services:
- titanic.request: store a request message, and return a UUID for the request.
- titanic.reply: fetch a reply, if available, for a given request UUID.
- titanic.close: confirm that a reply has been stored and processed.
We’ll just make a multithreaded worker, which as we’ve seen from our multithreading experience with ZeroMQ, is trivial. However, let’s first sketch what Titanic would look like in terms of ZeroMQ messages and frames. This gives us the Titanic Service Protocol (TSP).
Using TSP is clearly more work for client applications than accessing a service directly via MDP. Here’s the shortest robust “echo” client example:
ticlient: Titanic client example in Ada
ticlient: Titanic client example in Basic
ticlient: Titanic client example in C
// Titanic client example
// Implements client side of http://rfc.zeromq.org/spec:9
// Lets build this source without creating a library
#include "mdcliapi.c"
// Calls a TSP service
// Returns response if successful (status code 200 OK), else NULL
//
static zmsg_t *
s_service_call (mdcli_t *session, char *service, zmsg_t **request_p)
{
zmsg_t *reply = mdcli_send (session, service, request_p);
if (reply) {
zframe_t *status = zmsg_pop (reply);
if (zframe_streq (status, "200")) {
zframe_destroy (&status);
return reply;
}
else
if (zframe_streq (status, "400")) {
printf ("E: client fatal error, aborting\n");
exit (EXIT_FAILURE);
}
else
if (zframe_streq (status, "500")) {
printf ("E: server fatal error, aborting\n");
exit (EXIT_FAILURE);
}
}
else
exit (EXIT_SUCCESS); // Interrupted or failed
zmsg_destroy (&reply);
return NULL; // Didn't succeed; don't care why not
}
// .split main task
// The main task tests our service call by sending an echo request:
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
mdcli_t *session = mdcli_new ("tcp://localhost:5555", verbose);
// 1. Send 'echo' request to Titanic
zmsg_t *request = zmsg_new ();
zmsg_addstr (request, "echo");
zmsg_addstr (request, "Hello world");
zmsg_t *reply = s_service_call (
session, "titanic.request", &request);
zframe_t *uuid = NULL;
if (reply) {
uuid = zmsg_pop (reply);
zmsg_destroy (&reply);
zframe_print (uuid, "I: request UUID ");
}
// 2. Wait until we get a reply
while (!zctx_interrupted) {
zclock_sleep (100);
request = zmsg_new ();
zmsg_add (request, zframe_dup (uuid));
zmsg_t *reply = s_service_call (
session, "titanic.reply", &request);
if (reply) {
char *reply_string = zframe_strdup (zmsg_last (reply));
printf ("Reply: %s\n", reply_string);
free (reply_string);
zmsg_destroy (&reply);
// 3. Close request
request = zmsg_new ();
zmsg_add (request, zframe_dup (uuid));
reply = s_service_call (session, "titanic.close", &request);
zmsg_destroy (&reply);
break;
}
else {
printf ("I: no reply yet, trying again...\n");
zclock_sleep (5000); // Try again in 5 seconds
}
}
zframe_destroy (&uuid);
mdcli_destroy (&session);
return 0;
}
ticlient: Titanic client example in C++
//
// created by Jinyang Shao on 9/3/2024
//
#include "mdcliapi.hpp"
static zmsg*
s_service_call(mdcli* session, std::string service, zmsg *&request) {
zmsg* reply = session->send(service, request);
if (reply) {
std::string status = (char *)reply->pop_front().c_str();
if (status.compare("200") == 0) {
return reply;
} else if (status.compare("400") == 0) {
std::cout << "E: client fatal error, aborting\n" << std::endl;
exit(EXIT_FAILURE);
} else if (status.compare("500") == 0) {
std::cout << "E: server fatal error, aborting\n" << std::endl;
exit(EXIT_FAILURE);
}
} else {
exit(EXIT_SUCCESS); // interrupted or failed
}
delete reply;
return nullptr; // Didn't succeed; don't care why not
}
// .split main task
// The main task tests our service call by sending an echo request:
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && strcmp (argv [1], "-v") == 0);
mdcli session("tcp://localhost:5555", verbose);
session.set_timeout(3000);
session.set_retries(10);
// 1. Send 'echo' request to Titanic
zmsg *request = new zmsg("Hello world");
request->push_front("echo");
zmsg *reply = s_service_call(&session, "titanic.request", request);
ustring uuid;
if (reply) {
uuid = reply->pop_front();
delete reply;
std::cout << "I: request UUID: " << uuid.c_str() << std::endl;
}
// 2. Wait until we get a reply
while (!s_interrupted) {
s_sleep(100); // 100 ms
request = new zmsg((char *)uuid.c_str());
zmsg *reply = s_service_call(&session, "titanic.reply", request);
if (reply) {
std::cout << "Reply: " << reply->body() << std::endl;
delete reply;
// 3. Close request
request = new zmsg((char *)uuid.c_str());
reply = s_service_call(&session, "titanic.close", request);
delete reply;
break;
} else {
std::cout << "I: no reply yet, trying again...\n" << std::endl;
s_sleep(5000); // 5 sec
}
}
return 0;
}
ticlient: Titanic client example in C#
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Runtime.CompilerServices;
using System.Runtime.Remoting.Messaging;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
// Titanic client example
// Implements client side of http://rfc.zeromq.org/spec:9
// Lets us build this source without creating a library
using MDCliApi;
static partial class Program
{
public static void TIClient(string[] args)
{
CancellationTokenSource cancellor = new CancellationTokenSource();
Console.CancelKeyPress += (s, ea) =>
{
ea.Cancel = true;
cancellor.Cancel();
};
using (MajordomoClient session = new MajordomoClient("tcp://127.0.0.1:5555", Verbose))
{
// 1. Send 'echo' request to Titanic
ZMessage request = new ZMessage();
request.Add(new ZFrame("echo"));
request.Add(new ZFrame("Hello World"));
Guid uuid = Guid.Empty;
using (var reply = TIClient_ServiceCall(session, "titanic.request", request, cancellor))
{
if (reply != null)
{
uuid = Guid.Parse(reply.PopString());
"I: request UUID {0}".DumpString(uuid);
}
}
// 2. Wait until we get a reply
while (!cancellor.IsCancellationRequested)
{
Thread.Sleep(100);
request.Dispose();
request = new ZMessage();
request.Add(new ZFrame(uuid.ToString()));
var reply = TIClient_ServiceCall(session, "titanic.reply", request, cancellor);
if (reply != null)
{
string replystring = reply.Last().ToString();
"Reply: {0}\n".DumpString(replystring);
reply.Dispose();
// 3. Close Request
request.Dispose();
request = new ZMessage();
request.Add(new ZFrame(uuid.ToString()));
reply = TIClient_ServiceCall(session, "titanic.close", request, cancellor);
reply.Dispose();
break;
}
else
{
"I: no reply yet, trying again...\n".DumpString();
Thread.Sleep(5000); // try again in 5 seconds
}
}
}
}
// Calls a TSP service
// Returns response if successful (status code 200 OK), else NULL
static ZMessage TIClient_ServiceCall (MajordomoClient session, string service, ZMessage request, CancellationTokenSource cts)
{
using (var reply = session.Send(service, request, cts))
{
if (reply != null)
{
var status = reply.PopString();
if (status.Equals("200"))
{
return reply.Duplicate();
}
else if (status.Equals("400"))
{
"E: client fatal error, aborting".DumpString();
cts.Cancel();
}
else if (status.Equals("500"))
{
"E: server fatal error, aborting".DumpString();
cts.Cancel();
}
}
else
{
cts.Cancel(); // Interrupted or failed
}
}
return null;
}
}
}
ticlient: Titanic client example in CL
ticlient: Titanic client example in Delphi
ticlient: Titanic client example in Erlang
ticlient: Titanic client example in Elixir
ticlient: Titanic client example in F#
ticlient: Titanic client example in Felix
ticlient: Titanic client example in Go
ticlient: Titanic client example in Haskell
ticlient: Titanic client example in Haxe
package ;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import MDP;
import MDCliAPI;
/**
* Titanic client example
* Implements client side of http://rfc.zeromq.org/spec:9
*
* Wraps MDCltAPI
*
* @author Richard J Smith
*/
class TIClient
{
public static function main()
{
Lib.println("** TIClient (see: http://zguide.zeromq.org/page:all#Disconnected-Reliability-Titanic-Pattern)");
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var session = new TICltAPI("tcp://localhost:5555", verbose);
// 1. Send 'echo' request to Titanic
var request = ZMsg.newStringMsg("Hello World");
var reply = session.request("echo", request);
var uuid:ZFrame = null;
if (reply != null) {
uuid = reply.pop();
Lib.println("I: request UUID:" + uuid.toString());
// 2. Wait until we get a reply
while (!ZMQ.isInterrupted()) {
Sys.sleep(0.1);
reply = session.reply(uuid);
if (reply != null) {
var replyString = reply.last().toString();
Lib.println("I: Reply: " + replyString);
// 3. Close request
reply = session.close(uuid);
break;
} else {
Lib.println("I: no reply yet, trying again...");
Sys.sleep(5.0); // Try again in 5 seconds
}
}
}
session.destroy();
}
}
/**
* Titanic Protocol Client API class (synchronous)
*/
private class TICltAPI {
// Private instance fields
/** Synchronous Majordomo Client API object */
private var clientAPI:MDCliAPI;
/** Connection string to reach broker */
private var broker:String;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/**
* Constructor
* @param broker
* @param verbose
*/
public function new(broker:String, ?verbose:Bool=false, ?logger:Dynamic->Void) {
this.broker = broker;
this.verbose = verbose;
this.clientAPI = new MDCliAPI(broker, verbose, logger);
if (logger != null)
log = logger;
else
log = Lib.println;
clientAPI.connectToBroker();
}
/**
* Destructor
*/
public function destroy() {
clientAPI.destroy();
}
/**
* Sends a TI request message to a designated MD service, via a TI proxy
* Takes ownership of request message and destroys it when sent.
* @param service
* @param request
* @return
*/
public function request(service:String, request:ZMsg):ZMsg {
request.pushString(service);
var ret = callService("titanic.request", request);
return {
if (ret.OK)
ret.msg;
else
null;
};
}
/**
* Sends a TI Reply message to a TI server
* @param uuid UUID of original TI Request message, as returned from previous sendRequest method call
* @return
*/
public function reply(uuid:ZFrame):ZMsg {
var request = new ZMsg();
request.add(uuid.duplicate());
var ret = callService("titanic.reply", request);
return {
if (ret.OK)
ret.msg;
else
null;
};
}
/**
* Sends a TI Close message to a TI server
* @param uuid UUID of original TI Request message, as returned from previous sendRequest method call
* @return
*/
public function close(uuid:ZFrame):ZMsg {
var request = new ZMsg();
request.add(uuid.duplicate());
var ret = callService("titanic.close", request);
return {
if (ret.OK)
ret.msg;
else
null;
};
}
/**
* Calls TSP service
* Returns response if successful (status code 200 OK), else null
* @param service
* @param request
* @return
*/
private function callService(service:String, request:ZMsg): { msg:ZMsg, OK:Bool} {
var reply = clientAPI.send(service, request);
if (reply != null) {
var status = reply.pop();
if (status.streq("200")) {
return {msg:reply, OK:true};
}
else
if (status.streq("400")) {
log("E: client fatal error");
return {msg:null, OK: false};
}
else
if (status.streq("500")) {
log("E: server fatal error");
return {msg:null, OK:false};
}
}
return {msg:null, OK:true}; // Interrupted or failed
}
}ticlient: Titanic client example in Java
package guide;
// Titanic client example
// Implements client side of http://rfc.zeromq.org/spec:9
// Calls a TSP service
// Returns response if successful (status code 200 OK), else NULL
//
import org.zeromq.ZFrame;
import org.zeromq.ZMsg;
public class ticlient
{
static ZMsg serviceCall(mdcliapi session, String service, ZMsg request)
{
ZMsg reply = session.send(service, request);
if (reply != null) {
ZFrame status = reply.pop();
if (status.streq("200")) {
status.destroy();
return reply;
}
else if (status.streq("400")) {
System.out.println("E: client fatal error, aborting");
}
else if (status.streq("500")) {
System.out.println("E: server fatal error, aborting");
}
reply.destroy();
}
return null; // Didn't succeed; don't care why not
}
public static void main(String[] args) throws Exception
{
boolean verbose = (args.length > 0 && args[0].equals("-v"));
mdcliapi session = new mdcliapi("tcp://localhost:5555", verbose);
// 1. Send 'echo' request to Titanic
ZMsg request = new ZMsg();
request.add("echo");
request.add("Hello world");
ZMsg reply = serviceCall(session, "titanic.request", request);
ZFrame uuid = null;
if (reply != null) {
uuid = reply.pop();
reply.destroy();
uuid.print("I: request UUID ");
}
// 2. Wait until we get a reply
while (!Thread.currentThread().isInterrupted()) {
Thread.sleep(100);
request = new ZMsg();
request.add(uuid.duplicate());
reply = serviceCall(session, "titanic.reply", request);
if (reply != null) {
String replyString = reply.getLast().toString();
System.out.printf("Reply: %s\n", replyString);
reply.destroy();
// 3. Close request
request = new ZMsg();
request.add(uuid.duplicate());
reply = serviceCall(session, "titanic.close", request);
reply.destroy();
break;
}
else {
System.out.println("I: no reply yet, trying again...");
Thread.sleep(5000); // Try again in 5 seconds
}
}
uuid.destroy();
session.destroy();
}
}
ticlient: Titanic client example in Julia
ticlient: Titanic client example in Lua
ticlient: Titanic client example in Node.js
ticlient: Titanic client example in Objective-C
ticlient: Titanic client example in ooc
ticlient: Titanic client example in Perl
ticlient: Titanic client example in PHP
<?php
/* Titanic client example
* Implements client side of http://rfc.zeromq.org/spec:9
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'mdcliapi.php';
/**
* Calls a TSP service
* Returns response if successful (status code 200 OK), else NULL
*
* @param string $session
* @param string $service
* @param Zmsg $request
*/
function s_service_call($session, $service, $request)
{
$reply = $session->send($service, $request);
if ($reply) {
$status = $reply->pop();
if ($status == "200") {
return $reply;
} elseif ($status == "404") {
echo "E: client fatal error, aborting", PHP_EOL;
exit(1);
} elseif ($status == "500") {
echo "E: server fatal error, aborting", PHP_EOL;
exit(1);
}
} else {
exit(0);
}
return NULL; // Didn't succeed, don't care why not
}
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$session = new Mdcli("tcp://localhost:5555", $verbose);
// 1. Send 'echo' request to Titanic
$request = new Zmsg();
$request->push("Hello world");
$request->push("echo");
$reply = s_service_call($session, "titanic.request", $request);
$uuid = null;
if ($reply) {
$uuid = $reply->pop();
printf("I: request UUID %s %s", $uuid, PHP_EOL);
}
// 2. Wait until we get a reply
while (true) {
usleep(100000);
$request = new Zmsg();
$request->push($uuid);
$reply = s_service_call ($session, "titanic.reply", $request);
if ($reply) {
$reply_string = $reply->last();
printf ("Reply: %s %s", $reply_string, PHP_EOL);
// 3. Close request
$request = new Zmsg();
$request->push($uuid);
$reply = s_service_call ($session, "titanic.close", $request);
break;
} else {
echo "I: no reply yet, trying again...", PHP_EOL;
usleep (5000000); // Try again in 5 seconds
}
}
ticlient: Titanic client example in Python
"""
Titanic client example
Implements client side of http:rfc.zeromq.org/spec:9
Author : Min RK <benjaminrk@gmail.com>
"""
import sys
import time
from mdcliapi import MajorDomoClient
def service_call (session, service, request):
"""Calls a TSP service
Returns reponse if successful (status code 200 OK), else None
"""
reply = session.send(service, request)
if reply:
status = reply.pop(0)
if status == b"200":
return reply
elif status == b"400":
print ("E: client fatal error 400, aborting")
sys.exit (1)
elif status == b"500":
print ("E: server fatal error 500, aborting")
sys.exit (1)
else:
sys.exit (0); # Interrupted or failed
def main():
verbose = '-v' in sys.argv
session = MajorDomoClient("tcp://localhost:5555", verbose)
# 1. Send 'echo' request to Titanic
request = [b"echo", b"Hello world"]
reply = service_call(session, b"titanic.request", request)
uuid = None
if reply:
uuid = reply.pop(0)
print ("I: request UUID ", uuid)
# 2. Wait until we get a reply
while True:
time.sleep (.1)
request = [uuid]
reply = service_call (session, b"titanic.reply", request)
if reply:
reply_string = reply[-1]
print ("I: reply:", reply_string)
# 3. Close request
request = [uuid]
reply = service_call (session, b"titanic.close", request)
break
else:
print ("I: no reply yet, trying again...")
time.sleep(5) # Try again in 5 seconds
return 0
if __name__ == '__main__':
main()
ticlient: Titanic client example in Q
ticlient: Titanic client example in Racket
ticlient: Titanic client example in Ruby
ticlient: Titanic client example in Rust
ticlient: Titanic client example in Scala
ticlient: Titanic client example in Tcl
ticlient: Titanic client example in OCaml
Of course this can be, and should be, wrapped up in some kind of framework or API. It’s not healthy to ask average application developers to learn the full details of messaging: it hurts their brains, costs time, and offers too many ways to make buggy complexity. Additionally, it makes it hard to add intelligence.
For example, this client blocks on each request whereas in a real application, we’d want to be doing useful work while tasks are executed. This requires some nontrivial plumbing to build a background thread and talk to that cleanly. It’s the kind of thing you want to wrap in a nice simple API that the average developer cannot misuse. It’s the same approach that we used for Majordomo.
Here’s the Titanic implementation. This server handles the three services using three threads, as proposed. It does full persistence to disk using the most brutal approach possible: one file per message. It’s so simple, it’s scary. The only complex part is that it keeps a separate queue of all requests, to avoid reading the directory over and over:
titanic: Titanic broker example in Ada
titanic: Titanic broker example in Basic
titanic: Titanic broker example in C
// Titanic service
// Implements server side of http://rfc.zeromq.org/spec:9
// Lets us build this source without creating a library
#include "mdwrkapi.c"
#include "mdcliapi.c"
#include "zfile.h"
#include <uuid/uuid.h>
// Return a new UUID as a printable character string
// Caller must free returned string when finished with it
static char *
s_generate_uuid (void)
{
char hex_char [] = "0123456789ABCDEF";
char *uuidstr = zmalloc (sizeof (uuid_t) * 2 + 1);
uuid_t uuid;
uuid_generate (uuid);
int byte_nbr;
for (byte_nbr = 0; byte_nbr < sizeof (uuid_t); byte_nbr++) {
uuidstr [byte_nbr * 2 + 0] = hex_char [uuid [byte_nbr] >> 4];
uuidstr [byte_nbr * 2 + 1] = hex_char [uuid [byte_nbr] & 15];
}
return uuidstr;
}
// Returns freshly allocated request filename for given UUID
#define TITANIC_DIR ".titanic"
static char *
s_request_filename (char *uuid) {
char *filename = malloc (256);
snprintf (filename, 256, TITANIC_DIR "/%s.req", uuid);
return filename;
}
// Returns freshly allocated reply filename for given UUID
static char *
s_reply_filename (char *uuid) {
char *filename = malloc (256);
snprintf (filename, 256, TITANIC_DIR "/%s.rep", uuid);
return filename;
}
// .split Titanic request service
// The {{titanic.request}} task waits for requests to this service. It writes
// each request to disk and returns a UUID to the client. The client picks
// up the reply asynchronously using the {{titanic.reply}} service:
static void
titanic_request (void *args, zctx_t *ctx, void *pipe)
{
mdwrk_t *worker = mdwrk_new (
"tcp://localhost:5555", "titanic.request", 0);
zmsg_t *reply = NULL;
while (true) {
// Send reply if it's not null
// And then get next request from broker
zmsg_t *request = mdwrk_recv (worker, &reply);
if (!request)
break; // Interrupted, exit
// Ensure message directory exists
zfile_mkdir (TITANIC_DIR);
// Generate UUID and save message to disk
char *uuid = s_generate_uuid ();
char *filename = s_request_filename (uuid);
FILE *file = fopen (filename, "w");
assert (file);
zmsg_save (request, file);
fclose (file);
free (filename);
zmsg_destroy (&request);
// Send UUID through to message queue
reply = zmsg_new ();
zmsg_addstr (reply, uuid);
zmsg_send (&reply, pipe);
// Now send UUID back to client
// Done by the mdwrk_recv() at the top of the loop
reply = zmsg_new ();
zmsg_addstr (reply, "200");
zmsg_addstr (reply, uuid);
free (uuid);
}
mdwrk_destroy (&worker);
}
// .split Titanic reply service
// The {{titanic.reply}} task checks if there's a reply for the specified
// request (by UUID), and returns a 200 (OK), 300 (Pending), or 400
// (Unknown) accordingly:
static void *
titanic_reply (void *context)
{
mdwrk_t *worker = mdwrk_new (
"tcp://localhost:5555", "titanic.reply", 0);
zmsg_t *reply = NULL;
while (true) {
zmsg_t *request = mdwrk_recv (worker, &reply);
if (!request)
break; // Interrupted, exit
char *uuid = zmsg_popstr (request);
char *req_filename = s_request_filename (uuid);
char *rep_filename = s_reply_filename (uuid);
if (zfile_exists (rep_filename)) {
FILE *file = fopen (rep_filename, "r");
assert (file);
reply = zmsg_load (NULL, file);
zmsg_pushstr (reply, "200");
fclose (file);
}
else {
reply = zmsg_new ();
if (zfile_exists (req_filename))
zmsg_pushstr (reply, "300"); //Pending
else
zmsg_pushstr (reply, "400"); //Unknown
}
zmsg_destroy (&request);
free (uuid);
free (req_filename);
free (rep_filename);
}
mdwrk_destroy (&worker);
return 0;
}
// .split Titanic close task
// The {{titanic.close}} task removes any waiting replies for the request
// (specified by UUID). It's idempotent, so it is safe to call more than
// once in a row:
static void *
titanic_close (void *context)
{
mdwrk_t *worker = mdwrk_new (
"tcp://localhost:5555", "titanic.close", 0);
zmsg_t *reply = NULL;
while (true) {
zmsg_t *request = mdwrk_recv (worker, &reply);
if (!request)
break; // Interrupted, exit
char *uuid = zmsg_popstr (request);
char *req_filename = s_request_filename (uuid);
char *rep_filename = s_reply_filename (uuid);
zfile_delete (req_filename);
zfile_delete (rep_filename);
free (uuid);
free (req_filename);
free (rep_filename);
zmsg_destroy (&request);
reply = zmsg_new ();
zmsg_addstr (reply, "200");
}
mdwrk_destroy (&worker);
return 0;
}
// .split worker task
// This is the main thread for the Titanic worker. It starts three child
// threads; for the request, reply, and close services. It then dispatches
// requests to workers using a simple brute force disk queue. It receives
// request UUIDs from the {{titanic.request}} service, saves these to a disk
// file, and then throws each request at MDP workers until it gets a
// response.
static int s_service_success (char *uuid);
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
zctx_t *ctx = zctx_new ();
void *request_pipe = zthread_fork (ctx, titanic_request, NULL);
zthread_new (titanic_reply, NULL);
zthread_new (titanic_close, NULL);
// Main dispatcher loop
while (true) {
// We'll dispatch once per second, if there's no activity
zmq_pollitem_t items [] = { { request_pipe, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, 1000 * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
if (items [0].revents & ZMQ_POLLIN) {
// Ensure message directory exists
zfile_mkdir (TITANIC_DIR);
// Append UUID to queue, prefixed with '-' for pending
zmsg_t *msg = zmsg_recv (request_pipe);
if (!msg)
break; // Interrupted
FILE *file = fopen (TITANIC_DIR "/queue", "a");
char *uuid = zmsg_popstr (msg);
fprintf (file, "-%s\n", uuid);
fclose (file);
free (uuid);
zmsg_destroy (&msg);
}
// Brute force dispatcher
char entry [] = "?.......:.......:.......:.......:";
FILE *file = fopen (TITANIC_DIR "/queue", "r+");
while (file && fread (entry, 33, 1, file) == 1) {
// UUID is prefixed with '-' if still waiting
if (entry [0] == '-') {
if (verbose)
printf ("I: processing request %s\n", entry + 1);
if (s_service_success (entry + 1)) {
// Mark queue entry as processed
fseek (file, -33, SEEK_CUR);
fwrite ("+", 1, 1, file);
fseek (file, 32, SEEK_CUR);
}
}
// Skip end of line, LF or CRLF
if (fgetc (file) == '\r')
fgetc (file);
if (zctx_interrupted)
break;
}
if (file)
fclose (file);
}
return 0;
}
// .split try to call a service
// Here, we first check if the requested MDP service is defined or not,
// using a MMI lookup to the Majordomo broker. If the service exists,
// we send a request and wait for a reply using the conventional MDP
// client API. This is not meant to be fast, just very simple:
static int
s_service_success (char *uuid)
{
// Load request message, service will be first frame
char *filename = s_request_filename (uuid);
FILE *file = fopen (filename, "r");
free (filename);
// If the client already closed request, treat as successful
if (!file)
return 1;
zmsg_t *request = zmsg_load (NULL, file);
fclose (file);
zframe_t *service = zmsg_pop (request);
char *service_name = zframe_strdup (service);
// Create MDP client session with short timeout
mdcli_t *client = mdcli_new ("tcp://localhost:5555", false);
mdcli_set_timeout (client, 1000); // 1 sec
mdcli_set_retries (client, 1); // only 1 retry
// Use MMI protocol to check if service is available
zmsg_t *mmi_request = zmsg_new ();
zmsg_add (mmi_request, service);
zmsg_t *mmi_reply = mdcli_send (client, "mmi.service", &mmi_request);
int service_ok = (mmi_reply
&& zframe_streq (zmsg_first (mmi_reply), "200"));
zmsg_destroy (&mmi_reply);
int result = 0;
if (service_ok) {
zmsg_t *reply = mdcli_send (client, service_name, &request);
if (reply) {
filename = s_reply_filename (uuid);
FILE *file = fopen (filename, "w");
assert (file);
zmsg_save (reply, file);
fclose (file);
free (filename);
result = 1;
}
zmsg_destroy (&reply);
}
else
zmsg_destroy (&request);
mdcli_destroy (&client);
free (service_name);
return result;
}
titanic: Titanic broker example in C++
#include <iostream>
#include <random>
#include <sstream>
#include <iomanip>
#include <thread>
#include <filesystem>
#include <fstream>
#include "mdcliapi.hpp"
#include "mdwrkapi.hpp"
#define ZMQ_POLL_MSEC 1
#define BROKER_ENDPOINT "tcp://localhost:5555"
std::string generateUUID() {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, 15);
std::uniform_int_distribution<> dis2(8, 11);
std::stringstream ss;
ss << std::hex;
for (int i = 0; i < 8; ++i) ss << dis(gen);
// ss << "-";
for (int i = 0; i < 4; ++i) ss << dis(gen);
ss << "4"; // UUID version 4
for (int i = 0; i < 3; ++i) ss << dis(gen);
// ss << "-";
ss << dis2(gen); // UUID variant
for (int i = 0; i < 3; ++i) ss << dis(gen);
// ss << "-";
for (int i = 0; i < 12; ++i) ss << dis(gen);
return ss.str();
}
// Returns freshly allocated request filename for given UUID
#define TITANIC_DIR ".titanic"
static std::string s_request_filename(std::string uuid) {
return std::string(TITANIC_DIR) + "/" + uuid + ".req";
}
// Returns freshly allocated reply filename for given UUID
static std::string s_reply_filename(std::string uuid) {
return std::string(TITANIC_DIR) + "/" + uuid + ".rep";
}
static bool s_zmsg_save(zmsg *msg, const std::filesystem::path &filepath) {
std::ofstream ofs(filepath);
if (ofs) {
while (msg->parts() > 0)
{
ofs << msg->pop_front().c_str() << std::endl;
}
std::cout << "File created and data written: " << filepath << std::endl;
return true;
}
else {
std::cerr << "Failed to create or write to file: " << filepath << std::endl;
return false;
}
}
static zmsg* s_zmsg_load(const std::filesystem::path &filepath) {
zmsg *msg = new zmsg();
std::ifstream ifs(filepath);
if (ifs) {
std::string line;
while (std::getline(ifs, line)) {
msg->push_back(line.c_str());
}
ifs.close();
return msg;
}
else {
std::cerr << "Failed to read file: " << filepath << std::endl;
return nullptr;
}
}
// .split Titanic request service
// The {{titanic.request}} task waits for requests to this service. It writes
// each request to disk and returns a UUID to the client. The client picks
// up the reply asynchronously using the {{titanic.reply}} service:
static void titanic_request(zmq::context_t *ctx) {
mdwrk *worker = new mdwrk(BROKER_ENDPOINT, "titanic.request", 0);
worker->set_heartbeat(3000);
zmsg *reply = nullptr;
// communicate with parent thread
zmq::socket_t pipe(*ctx, ZMQ_PAIR);
pipe.bind("inproc://titanic_request");
while (true) {
// Send reply if it's not null
// And then get next request from broker
zmsg *request = worker->recv(reply);
std::cout << "titanic_request: received request" << std::endl;
request->dump();
if (!request) {
break; // Interrupted, exit
}
// Ensure message directory exists
std::filesystem::path titanic_dir(TITANIC_DIR);
std::filesystem::create_directory(titanic_dir);
// std::cout << "I: creating " << TITANIC_DIR << " directory" << std::endl;
// Generate UUID and save message to disk
std::string uuid = generateUUID();
std::filesystem::path request_file(s_request_filename(uuid));
if (!s_zmsg_save(request, request_file)) {
break; // dump file failed, exit
}
delete request;
// Send UUID through to message queue
reply = new zmsg(uuid.c_str());
reply->send(pipe);
std::cout << "titanic_request: sent reply to parent" << std::endl;
// Now send UUID back to client
// Done by the mdwrk_recv() at the top of the loop
reply = new zmsg("200");
reply->push_back(uuid.c_str());
}
delete worker;
return;
}
// .split Titanic reply service
// The {{titanic.reply}} task checks if there's a reply for the specified
// request (by UUID), and returns a 200 (OK), 300 (Pending), or 400
// (Unknown) accordingly:
static void titanic_reply(zmq::context_t *ctx) {
mdwrk *worker = new mdwrk(BROKER_ENDPOINT, "titanic.reply", 0);
worker->set_heartbeat(3000);
zmsg *reply = nullptr;
while(true) {
zmsg *request = worker->recv(reply);
if (!request) {
break; // Interrupted, exit
}
std::string uuid = std::string((char *)request->pop_front().c_str());
std::filesystem::path request_filename(s_request_filename(uuid));
std::filesystem::path reply_filename(s_reply_filename(uuid));
// Try to read the reply file
if (std::filesystem::exists(reply_filename)) {
reply = s_zmsg_load(reply_filename);
assert(reply);
reply->push_front("200");
}
else {
reply = new zmsg();
if (std::filesystem::exists(request_filename)) {
reply->push_front("300"); //Pending
}
else {
reply->push_front("400"); //Unknown
}
}
delete request;
}
delete worker;
}
// .split Titanic close task
// The {{titanic.close}} task removes any waiting replies for the request
// (specified by UUID). It's idempotent, so it is safe to call more than
// once in a row:
static void titanic_close(zmq::context_t *ctx) {
mdwrk *worker = new mdwrk(BROKER_ENDPOINT, "titanic.close", 0);
worker->set_heartbeat(3000);
zmsg *reply = nullptr;
while (true) {
zmsg *request = worker->recv(reply);
if (!request) {
break; // Interrupted, exit
}
std::string uuid = std::string((char *)request->pop_front().c_str());
std::filesystem::path request_filename(s_request_filename(uuid));
std::filesystem::path reply_filename(s_reply_filename(uuid));
std::filesystem::remove(request_filename);
std::filesystem::remove(reply_filename);
delete request;
reply = new zmsg("200");
}
delete worker;
return;
}
// .split worker task
// This is the main thread for the Titanic worker. It starts three child
// threads; for the request, reply, and close services. It then dispatches
// requests to workers using a simple brute force disk queue. It receives
// request UUIDs from the {{titanic.request}} service, saves these to a disk
// file, and then throws each request at MDP workers until it gets a
// response.
static bool s_service_success(std::string uuid);
// simulate zthread_fork, create attached thread and return the pipe socket
std::pair<std::thread, zmq::socket_t> zthread_fork(zmq::context_t& ctx, void (*thread_func)(zmq::context_t*)) {
// create the pipe socket for the main thread to communicate with its child thread
zmq::socket_t pipe(ctx, ZMQ_PAIR);
pipe.connect("inproc://titanic_request");
// start child thread
std::thread t(thread_func, &ctx);
return std::make_pair(std::move(t), std::move(pipe));
}
int main(int argc, char *argv[]) {
// std::string uuid = generateUUID();
// std::cout << "Generated UUID: " << uuid << std::endl;
// return 0;
int verbose = (argc > 1 && strcmp(argv[1], "-v") == 0);
zmq::context_t ctx(1);
// start the child threads
auto [titanic_request_thread, request_pipe] = zthread_fork(ctx, titanic_request);
std::thread titanic_reply_thread(titanic_reply, &ctx);
titanic_reply_thread.detach();
std::thread titanic_close_thread(titanic_close, &ctx);
titanic_close_thread.detach();
if (verbose) {
std::cout << "I: all service threads started(request, reply, close)" << std::endl;
}
// Main dispatcher loop
while (true) {
// We'll dispatch once per second, if there's no activity
zmq::pollitem_t items[] = {
{request_pipe, 0, ZMQ_POLLIN, 0}
};
try {
zmq::poll(items, 1, 1000 * ZMQ_POLL_MSEC);
} catch(...) {
break; // Interrupted
}
std::filesystem::path titanic_dir(TITANIC_DIR);
if (items[0].revents & ZMQ_POLLIN) {
// Ensure message directory exists
std::cout << "I: creating " << TITANIC_DIR << " directory" << std::endl;
std::filesystem::create_directory(titanic_dir);
// Append UUID to queue, prefixed with '-' for pending
zmsg *msg = new zmsg(request_pipe);
if (!msg) {
break; // Interrupted
}
std::ofstream ofs(titanic_dir / "queue", std::ios::app); // create if not exist, append
std::string uuid = std::string((char *)msg->pop_front().c_str());
ofs << "-" << uuid << std::endl;
delete msg;
}
// Brute force dispatcher
// std::array<char, 33> entry; // "?.......:.......:.......:.......:"
std::string line;
bool need_commit = false;
std::vector<std::string> new_lines;
std::ifstream file(titanic_dir / "queue");
if (!file.is_open()) {
if (verbose) {
std::cout << "I: queue file not open" << std::endl;
}
continue;
}
if (verbose) {
std::cout << "I: read from queue file" << std::endl;
}
while (std::getline(file, line)) {
if (line[0] == '-') {
std::string uuid = line.substr(1, 32);
if (verbose) {
std::cout << "I: processing request " << uuid << std::endl;
}
if (s_service_success(uuid)) {
line[0] = '+'; // Mark completed
need_commit = true;
}
}
new_lines.push_back(line);
}
file.close();
// Commit update
if (need_commit) {
std::ofstream outfile(titanic_dir / "queue");
if (!outfile.is_open()) {
std::cerr << "I: unable to open queue file" << std::endl;
return 1;
}
for (const auto &line : new_lines) {
outfile << line << std::endl;
}
outfile.close();
}
}
return 0;
}
// .split try to call a service
// Here, we first check if the requested MDP service is defined or not,
// using a MMI lookup to the Majordomo broker. If the service exists,
// we send a request and wait for a reply using the conventional MDP
// client API. This is not meant to be fast, just very simple:
static bool s_service_success(std::string uuid) {
// Load request message, service will be first frame
std::filesystem::path request_filepath(s_request_filename(uuid));
std::ifstream ifs(request_filepath);
// If the client already closed request, treat as successful
if (!ifs) {
return 1;
}
zmsg *request = s_zmsg_load(request_filepath);
char* service_name = (char *)request->pop_front().c_str();
// Create MDP client session with short timeout
mdcli client(BROKER_ENDPOINT, 1);
client.set_timeout(1000); // 1 sec
client.set_retries(1);
// Use MMI protocol to check if service is available
zmsg *mmi_request = new zmsg();
mmi_request->push_back(service_name);
zmsg *mmi_reply = client.send("mmi.service", mmi_request);
bool service_ok = (mmi_reply && strcmp(mmi_reply->address(), "200")==0);
delete mmi_reply;
bool result = false;
if (service_ok) {
zmsg *reply = client.send(service_name, request);
if (reply) {
std::filesystem::path reply_filepath(s_reply_filename(uuid));
s_zmsg_save(reply, reply_filepath);
result = true;
}
delete reply;
} else {
std::cout << "service not available: " << service_name << std::endl;
delete request;
}
return result;
}
titanic: Titanic broker example in C#
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading;
using System.Xml.Serialization;
using ZeroMQ;
namespace Examples
{
using MDWrkApi;
using MDCliApi;
public static class TitanicCommon
{
public static readonly string TITANIC_DIR = ".titanic";
public static readonly string QUEUE_FILE = "queue";
public static readonly string QUEUE_LINEFORMAT = "-{0}\n";
public static Guid GenerateUuid()
{
return Guid.NewGuid();
}
// Returns request filename for given UUID
public static string RequestFilename(Guid uuid)
{
return string.Format("{0}/{1}.req", TITANIC_DIR, uuid);
}
// Returns reply filename for given UUID
public static string ReplyFilename(Guid uuid)
{
return string.Format("{0}/{1}.rep", TITANIC_DIR, uuid);
}
public static void SerializeToXml<T>(this T obj, String path)
where T : ZMessage
{
var msg = ((ZMessage) obj);
List<byte[]> l = msg.Select(e => e.Read()).ToList();
XmlSerializer serializer = new XmlSerializer(typeof(List<byte[]>));
using (StreamWriter writer = new StreamWriter(path))
{
serializer.Serialize(writer, l);
}
}
public static T DeserializeFromXml<T>(this String path)
where T : ZMessage
{
ZMessage msg = new ZMessage();
XmlSerializer serializer = new XmlSerializer(typeof(List<byte[]>));
using (StreamReader reader = new StreamReader(path))
{
var res = (List<byte[]>)serializer.Deserialize(reader);
foreach (var e in res)
{
msg.Add(new ZFrame(e));
}
}
return (T)msg;
}
public static bool TryFileOpenRead(this String path, out FileStream fs)
{
fs = null;
try
{
fs = File.OpenRead(path);
return true;
}
catch (Exception ex)
{
if (ex is ArgumentException
|| ex is ArgumentNullException
|| ex is PathTooLongException
|| ex is DirectoryNotFoundException
|| ex is UnauthorizedAccessException
|| ex is FileNotFoundException
|| ex is NotSupportedException)
return false;
throw;
}
}
}
static partial class Program
{
// .split Titanic request service
// The {{titanic.request}} task waits for requests to this service. It writes
// each request to disk and returns a UUID to the client. The client picks
// up the reply asynchronously using the {{titanic.reply}} service:
private static void Titanic_Request(ZContext ctx, ZSocket backendpipe, CancellationTokenSource cancellor, object[] args)
{
using (MajordomoWorker worker = new MajordomoWorker("tcp://127.0.0.1:5555", "titanic.request", (bool)args[0]))
{
ZMessage reply = null;
while (true)
{
// Send reply if it's not null
// And then get next request from broker
ZMessage request = worker.Recv(reply, cancellor);
if (request == null)
break; // Interrupted, exit
// Ensure message directory exists
Directory.CreateDirectory(TitanicCommon.TITANIC_DIR);
// Generate UUID and save mesage to disk
Guid uuid = TitanicCommon.GenerateUuid();
string fn = TitanicCommon.RequestFilename(uuid);
request.SerializeToXml(fn);
request.Dispose();
// Send UUID through tho message queue
reply = new ZMessage();
reply.Add(new ZFrame(uuid.ToString()));
ZError error;
if (!backendpipe.Send(reply, out error))
{
if(error.Equals(ZError.ETERM))
break;
}
//backendpipe.Send(reply);
// Now send UUID back to client
// Done by the mdwrk_recv() at the top of the loop
reply = new ZMessage();
reply.Add(new ZFrame("200"));
reply.Add(new ZFrame(uuid.ToString()));
}
}
}
// .split Titanic reply service
// The {{titanic.reply}} task checks if there's a reply for the specified
// request (by UUID), and returns a 200 (OK), 300 (Pending), or 400
// (Unknown) accordingly:
private static void Titanic_Reply(ZContext context, CancellationTokenSource cts, bool verbose)
{
using (var worker = new MajordomoWorker("tcp://127.0.0.1:5555", "titanic.reply", verbose))
{
ZMessage reply = null;
while (true)
{
var request = worker.Recv(reply, cts);
if (request == null)
break; // Interrupted, exit
var g = Guid.Parse(request.Pop().ReadString());
var reqfn = TitanicCommon.RequestFilename(g);
var repfn = TitanicCommon.ReplyFilename(g);
if (File.Exists(repfn))
{
reply = repfn.DeserializeFromXml<ZMessage>();
reply.Prepend(new ZFrame("200"));
}
else
{
reply = new ZMessage();
if(File.Exists(reqfn))
reply.Prepend(new ZFrame("300")); //Pending
else
reply.Prepend(new ZFrame("400")); //Unknown
}
request.Dispose();
}
}
}
// .split Titanic close task
// The {{titanic.close}} task removes any waiting replies for the request
// (specified by UUID). It's idempotent, so it is safe to call more than
// once in a row:
private static void Titanic_Close(ZContext context, CancellationTokenSource cts, bool verbose)
{
using (var worker = new MajordomoWorker("tcp://127.0.0.1:5555", "titanic.close", verbose))
{
ZMessage reply = null;
while (true)
{
ZMessage request = worker.Recv(reply, cts);
if (request == null)
break;
var g = Guid.Parse(request.Pop().ReadString());
var reqfn = TitanicCommon.RequestFilename(g);
var repfn = TitanicCommon.ReplyFilename(g);
File.Delete(reqfn);
File.Delete(repfn);
request.Dispose();
reply = new ZMessage();
reply.Add(new ZFrame("200"));
}
}
}
// .split try to call a service
// Here, we first check if the requested MDP service is defined or not,
// using a MMI lookup to the Majordomo broker. If the service exists,
// we send a request and wait for a reply using the conventional MDP
// client API. This is not meant to be fast, just very simple:
static bool Titanic_ServiceSuccess(Guid uuid, CancellationTokenSource cts)
{
// Load request message, service will be first frame
string fn = TitanicCommon.RequestFilename(uuid);
FileStream fs;
if (!fn.TryFileOpenRead(out fs))
// If the client already close request, treat as successful
return true;
fs.Dispose();
ZMessage request = fn.DeserializeFromXml<ZMessage>();
var service = request.Pop();
string servicename = service.ToString();
bool res = false;
// Create MDP client session with short timeout
using (var client = new MajordomoClient("tcp://127.0.0.1:5555", false))
{
client.Set_Timeout(1000); // 1sec
client.Set_Retries(1); // only 1 retry
// Use MMI protocol to check if service is available
ZMessage mmirequest = new ZMessage {service};
bool service_ok;
using (var mmireply = client.Send("mmi.service", mmirequest, cts))
service_ok = (mmireply != null
&& mmireply.First().ToString().Equals("200"));
res = false;
if(service_ok)
using (ZMessage reply = client.Send(servicename, request, cts))
if (reply != null)
{
fn = TitanicCommon.ReplyFilename(uuid);
reply.SerializeToXml(fn);
res = true;
}
else
request.Dispose();
}
return res;
}
// Titanic service
// Implements server side of http://rfc.zeromq.org/spec:9
public static void Titanic(string[] args)
{
CancellationTokenSource cancellor = new CancellationTokenSource();
Console.CancelKeyPress += (s, ea) =>
{
ea.Cancel = true;
cancellor.Cancel();
};
ZContext ctx = new ZContext();
using (var requestPipe = new ZActor(ctx, Titanic_Request, Verbose))
{
(new Thread(() => Titanic_Reply(ctx, cancellor, Verbose))).Start();
(new Thread(() => Titanic_Close(ctx, cancellor, Verbose))).Start();
////////////////////
/// HINT: Use requestPipe.Start instead of requestPipe.Start(cancellor)
/// => with cancellor consturctor needed frontent pipe will not be initializes!!
////////////////////
requestPipe.Start();
Thread.Sleep(1500);
// Main dispatcher loop
while (true)
{
//continue;
if (cancellor.IsCancellationRequested
|| (Console.KeyAvailable && Console.ReadKey(true).Key == ConsoleKey.Escape))
ctx.Shutdown();
var path = Path.Combine(TitanicCommon.TITANIC_DIR, TitanicCommon.QUEUE_FILE);
var p = ZPollItem.CreateReceiver();
ZMessage msg;
ZError error;
if (requestPipe.Frontend.PollIn(p, out msg, out error, TimeSpan.FromMilliseconds(1000)))
{
using (msg)
{
// Ensure message directory exists
Directory.CreateDirectory(TitanicCommon.TITANIC_DIR);
// Append UUID to queue, prefixed with '-' for pending
var uuid = Guid.Parse(msg.PopString());
using (var sw = File.AppendText(path))
{
sw.Write(TitanicCommon.QUEUE_LINEFORMAT, uuid);
}
}
}
else if (error.Equals(ZError.ETERM))
{
cancellor.Cancel();
break; // Interrupted
}
else if (error.Equals(ZError.EAGAIN))
//continue;
{
Thread.Sleep(1);
}
else
break; // Interrupted
// Brute force dispatcher
if(File.Exists(path))
using (FileStream fs = File.Open(path, FileMode.Open, FileAccess.ReadWrite, FileShare.ReadWrite))
{
int numBytesRead = 0;
int numBytesToRead = (new UTF8Encoding().GetBytes(String.Format(TitanicCommon.QUEUE_LINEFORMAT, Guid.NewGuid()))).Length;
byte[] readBytes = new byte[numBytesToRead];
while (numBytesToRead > 0)
{
var n = fs.Read(readBytes, 0, numBytesToRead);
if (n == 0)
break;
var line = (new UTF8Encoding()).GetString(readBytes, 0, n);
// UUID is prefixed with '-' if still waiting
if (line.StartsWith("-"))
{
var uuid = Guid.Parse(line.Substring(1, Guid.NewGuid().ToString().Length));
if (Verbose)
"I: processing request {0}".DumpString(uuid);
if (Titanic_ServiceSuccess(uuid, cancellor))
{
// Mark queue entry as processed
var newval = (new UTF8Encoding()).GetBytes("+");
fs.Seek(-n, SeekOrigin.Current);
fs.Write(newval, 0, newval.Length);
fs.Seek(n - newval.Length, SeekOrigin.Current);
}
}
if (cancellor.IsCancellationRequested)
break;
numBytesRead += n;
numBytesToRead = n;
}
}
}
}
}
}
}
titanic: Titanic broker example in CL
titanic: Titanic broker example in Delphi
titanic: Titanic broker example in Erlang
titanic: Titanic broker example in Elixir
titanic: Titanic broker example in F#
titanic: Titanic broker example in Felix
titanic: Titanic broker example in Go
titanic: Titanic broker example in Haskell
titanic: Titanic broker example in Haxe
package ;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import haxe.io.Input;
import neko.FileSystem;
import neko.io.File;
import neko.io.FileInput;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZThread;
import org.zeromq.ZMQException;
/**
* Titanic service
* Implements server side of http://rfc.zeromq.org/spec:9
* @author Richard Smith
*/
class Titanic
{
/** Connection string to broker */
private var broker:String;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
private static inline var UID = "0123456789ABCDEF";
private static inline var TITANIC_DIR = ".titanic";
/**
* Main method
*/
public static function main() {
Lib.println("** Titanic (see: http://zguide.zeromq.org/page:all#Disconnected-Reliability-Titanic-Pattern)");
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var log = Lib.println;
var ctx = new ZContext();
// Create Titanic worker class
var titanic = new Titanic("tcp://localhost:5555", verbose);
// Create MDP client session with short timeout
var client = new MDCliAPI("tcp://localhost:5555", verbose);
client.timeout = 1000; // 1 sec
client.retries = 1; // Only 1 retry
var requestPipe = ZThread.attach(ctx, titanic.titanicRequest,"tcp://localhost:5555");
ZThread.detach(titanic.titanicReply, "tcp://localhost:5555");
ZThread.detach(titanic.titanicClose, "tcp://localhost:5555");
var poller = new ZMQPoller();
poller.registerSocket(requestPipe, ZMQ.ZMQ_POLLIN());
// Main dispatcher loop
while (true) {
// We'll dispatch once per second, if there's no activity
try {
var res = poller.poll(1000 * 1000); // 1 sec
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else
log("W: interrupt received, sinking the titanic...");
ctx.destroy();
client.destroy();
return;
}
if (poller.pollin(1)) {
// Ensure message directory exists
if (!FileSystem.exists(TITANIC_DIR))
FileSystem.createDirectory(TITANIC_DIR);
// Append UUID to queue, prefixed with "-" for pending
var msg = ZMsg.recvMsg(requestPipe);
if (msg == null)
break; // Interrupted
var file = File.append(TITANIC_DIR + "/queue", false);
var uuid = msg.pop().toString();
file.writeString("-" + uuid);
file.flush();
file.close();
}
// Brute-force dispatcher
if (FileSystem.exists(TITANIC_DIR + "/queue")) {
try {
var filec = File.getContent(TITANIC_DIR + "/queue");
FileSystem.deleteFile(TITANIC_DIR + "/queue");
var fileh = File.write(TITANIC_DIR + "/queue", false);
var index = 0;
while (index+33 <= filec.length) {
var str = filec.substr(index, 33);
var prefix = "-";
// UUID is prefixed with '-' if still waiting
if (str.charAt(0) == "-") {
if (verbose)
log("I: processing request " + str.substr(1));
if (titanic.serviceSuccess(client, str.substr(1))) {
// Mark queue entry as processed
prefix = "+";
}
}
fileh.writeString(prefix + str.substr(1));
index += 33;
}
fileh.flush();
fileh.close();
} catch (e:Dynamic) {
log("E: error reading queue file " +e);
}
}
}
client.destroy();
ctx.destroy();
}
/**
* Constructor
* @param broker
* @param ?verbose
* @param ?logger
*/
public function new(broker:String, ?verbose:Bool, ?logger:Dynamic->Void) {
this.broker = broker;
this.verbose = verbose;
if (logger != null)
log = logger;
else
log = neko.Lib.println;
}
/**
* Returns a new UUID as a printable String
* @param ?size
* @return
*/
private function generateUUID(?size:Int):String {
if (size == null) size = 32;
var nchars = UID.length;
var uid = new StringBuf();
for (i in 0 ... size) {
uid.add(UID.charAt(ZHelpers.randof(nchars-1)));
}
return uid.toString();
}
/**
* Returns request filename for given UUID
* @param uuid
* @return
*/
private function requestFilename(uuid:String):String {
return TITANIC_DIR + "/" + uuid + ".req";
}
/**
* Returns reply filename for given UUID
* @param uuid
* @return
*/
private function replyFilename(uuid:String):String {
return TITANIC_DIR + "/" + uuid + ".rep";
}
/**
* Implements Titanic request service "titanic.request"
* @param ctx
* @param pipe
*/
public function titanicRequest(ctx:ZContext, pipe:ZMQSocket, broker:String) {
var worker = new MDWrkAPI(broker, "titanic.request", verbose);
var reply:ZMsg = null;
while (true) {
if (reply != null) trace("reply object:" + reply.toString());
// Send reply if it's not null
// and then get next request from broker
var request = worker.recv(reply);
if (request == null)
break; // Interrupted, exit
// Ensure message directory exists
if (!FileSystem.exists(TITANIC_DIR))
FileSystem.createDirectory(TITANIC_DIR);
// Generate UUID and save message to disk
var uuid = generateUUID();
var filename = requestFilename(uuid);
var file = File.write(filename, false);
ZMsg.save(request, file);
file.close();
request.destroy();
// Send UUID through to message queue
reply = new ZMsg();
reply.addString(uuid);
reply.send(pipe);
// Now send UUID back to client
// Done by the worker.recv() call at the top of the loop
reply = new ZMsg();
reply.addString("200");
reply.addString(uuid);
}
worker.destroy();
}
/**
* Implements titanic reply service "titanic.reply"
*/
public function titanicReply(broker:String) {
var worker = new MDWrkAPI(broker, "titanic.reply", verbose);
var reply:ZMsg = null;
while (true) {
// Send reply if it's not null
// and then get next request from broker
var request = worker.recv(reply);
if (request == null)
break; // Interrupted, exit
// Ensure message directory exists
if (!FileSystem.exists(TITANIC_DIR))
FileSystem.createDirectory(TITANIC_DIR);
// Generate UUID and save message to disk
var uuid = request.popString();
var reqfilename = requestFilename(uuid);
var repfilename = replyFilename(uuid);
if (FileSystem.exists(repfilename)) {
var file = File.read(repfilename, false);
reply = ZMsg.load(file);
reply.pushString("200");
file.close();
} else {
reply = new ZMsg();
if (FileSystem.exists(reqfilename))
reply.pushString("300"); // Pending
else
reply.pushString("400");
request.destroy();
}
}
worker.destroy();
}
/**
* Implements titanic close service "titanic.close"
* @param broker
*/
public function titanicClose(broker:String) {
var worker = new MDWrkAPI(broker, "titanic.close", verbose);
var reply:ZMsg = null;
while (true) {
// Send reply if it's not null
// and then get next request from broker
var request = worker.recv(reply);
if (request == null)
break; // Interrupted, exit
// Ensure message directory exists
if (!FileSystem.exists(TITANIC_DIR))
FileSystem.createDirectory(TITANIC_DIR);
// Generate UUID and save message to disk
var uuid = request.popString();
var reqfilename = requestFilename(uuid);
var repfilename = replyFilename(uuid);
FileSystem.deleteFile(reqfilename);
FileSystem.deleteFile(repfilename);
request.destroy();
reply = new ZMsg();
reply.addString("200");
}
worker.destroy();
}
/**
* Attempt to process a single service request message, return true if successful
* @param client
* @param uuid
* @return
*/
public function serviceSuccess(client:MDCliAPI, uuid:String):Bool {
// Load request message, service will be first frame
var filename = requestFilename(uuid);
var file = File.read(filename, false);
var request:ZMsg = null;
try {
request = ZMsg.load(file);
file.close();
} catch (e:Dynamic) {
log("E: Error loading file:" + filename + ", details:" + e);
return false;
}
var service = request.pop();
var serviceName = service.toString();
// Use MMI protocol to check if service is available
var mmiRequest = new ZMsg();
mmiRequest.add(service);
var mmiReply = client.send("mmi.service", mmiRequest);
var serviceOK = (mmiReply != null && mmiReply.first().streq("200"));
if (serviceOK) {
// Now call requested service and store reply from service
var reply = client.send(serviceName, request);
if (reply != null) {
filename = replyFilename(uuid);
try {
var file = File.write(filename, false);
ZMsg.save(reply, file);
file.close();
return true;
} catch (e:Dynamic) {
log("E: Error writing file:" + filename + ", details:" + e);
return false;
}
}
reply.destroy();
} else
request.destroy();
return false;
}
}titanic: Titanic broker example in Java
package guide;
import java.io.BufferedWriter;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.UUID;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZMsg;
import org.zeromq.ZThread;
import org.zeromq.ZThread.IAttachedRunnable;
import org.zeromq.ZThread.IDetachedRunnable;
public class titanic
{
// Return a new UUID as a printable character string
// Caller must free returned string when finished with it
static String generateUUID()
{
return UUID.randomUUID().toString();
}
private static final String TITANIC_DIR = ".titanic";
// Returns freshly allocated request filename for given UUID
private static String requestFilename(String uuid)
{
String filename = String.format("%s/%s.req", TITANIC_DIR, uuid);
return filename;
}
// Returns freshly allocated reply filename for given UUID
private static String replyFilename(String uuid)
{
String filename = String.format("%s/%s.rep", TITANIC_DIR, uuid);
return filename;
}
// .split Titanic request service
// The {{titanic.request}} task waits for requests to this service. It
// writes each request to disk and returns a UUID to the client. The client
// picks up the reply asynchronously using the {{titanic.reply}} service:
static class TitanicRequest implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
mdwrkapi worker = new mdwrkapi(
"tcp://localhost:5555", "titanic.request", false
);
ZMsg reply = null;
while (true) {
// Send reply if it's not null
// And then get next request from broker
ZMsg request = worker.receive(reply);
if (request == null)
break; // Interrupted, exit
// Ensure message directory exists
new File(TITANIC_DIR).mkdirs();
// Generate UUID and save message to disk
String uuid = generateUUID();
String filename = requestFilename(uuid);
DataOutputStream file = null;
try {
file = new DataOutputStream(new FileOutputStream(filename));
ZMsg.save(request, file);
}
catch (IOException e) {
e.printStackTrace();
}
finally {
try {
if (file != null)
file.close();
}
catch (IOException e) {
}
}
request.destroy();
// Send UUID through to message queue
reply = new ZMsg();
reply.add(uuid);
reply.send(pipe);
// Now send UUID back to client
// Done by the mdwrk_recv() at the top of the loop
reply = new ZMsg();
reply.add("200");
reply.add(uuid);
}
worker.destroy();
}
}
// .split Titanic reply service
// The {{titanic.reply}} task checks if there's a reply for the specified
// request (by UUID), and returns a 200 (OK), 300 (Pending), or 400
// (Unknown) accordingly:
static class TitanicReply implements IDetachedRunnable
{
@Override
public void run(Object[] args)
{
mdwrkapi worker = new mdwrkapi(
"tcp://localhost:5555", "titanic.reply", false
);
ZMsg reply = null;
while (true) {
ZMsg request = worker.receive(reply);
if (request == null)
break; // Interrupted, exit
String uuid = request.popString();
String reqFilename = requestFilename(uuid);
String repFilename = replyFilename(uuid);
if (new File(repFilename).exists()) {
DataInputStream file = null;
try {
file = new DataInputStream(
new FileInputStream(repFilename)
);
reply = ZMsg.load(file);
reply.push("200");
}
catch (IOException e) {
e.printStackTrace();
}
finally {
try {
if (file != null)
file.close();
}
catch (IOException e) {
}
}
}
else {
reply = new ZMsg();
if (new File(reqFilename).exists())
reply.push("300"); //Pending
else reply.push("400"); //Unknown
}
request.destroy();
}
worker.destroy();
}
}
// .split Titanic close task
// The {{titanic.close}} task removes any waiting replies for the request
// (specified by UUID). It's idempotent, so it is safe to call more than
// once in a row:
static class TitanicClose implements IDetachedRunnable
{
@Override
public void run(Object[] args)
{
mdwrkapi worker = new mdwrkapi(
"tcp://localhost:5555", "titanic.close", false
);
ZMsg reply = null;
while (true) {
ZMsg request = worker.receive(reply);
if (request == null)
break; // Interrupted, exit
String uuid = request.popString();
String req_filename = requestFilename(uuid);
String rep_filename = replyFilename(uuid);
new File(rep_filename).delete();
new File(req_filename).delete();
request.destroy();
reply = new ZMsg();
reply.add("200");
}
worker.destroy();
}
}
// .split worker task
// This is the main thread for the Titanic worker. It starts three child
// threads; for the request, reply, and close services. It then dispatches
// requests to workers using a simple brute force disk queue. It receives
// request UUIDs from the {{titanic.request}} service, saves these to a
// disk file, and then throws each request at MDP workers until it gets a
// response.
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && "-v".equals(args[0]));
try (ZContext ctx = new ZContext()) {
Socket requestPipe = ZThread.fork(ctx, new TitanicRequest());
ZThread.start(new TitanicReply());
ZThread.start(new TitanicClose());
Poller poller = ctx.createPoller(1);
poller.register(requestPipe, ZMQ.Poller.POLLIN);
// Main dispatcher loop
while (true) {
// We'll dispatch once per second, if there's no activity
int rc = poller.poll(1000);
if (rc == -1)
break; // Interrupted
if (poller.pollin(0)) {
// Ensure message directory exists
new File(TITANIC_DIR).mkdirs();
// Append UUID to queue, prefixed with '-' for pending
ZMsg msg = ZMsg.recvMsg(requestPipe);
if (msg == null)
break; // Interrupted
String uuid = msg.popString();
BufferedWriter wfile = null;
try {
wfile = new BufferedWriter(
new FileWriter(TITANIC_DIR + "/queue", true)
);
wfile.write("-" + uuid + "\n");
}
catch (IOException e) {
e.printStackTrace();
break;
}
finally {
try {
if (wfile != null)
wfile.close();
}
catch (IOException e) {
}
}
msg.destroy();
}
// Brute force dispatcher
// "?........:....:....:....:............:";
byte[] entry = new byte[37];
RandomAccessFile file = null;
try {
file = new RandomAccessFile(TITANIC_DIR + "/queue", "rw");
while (file.read(entry) > 0) {
// UUID is prefixed with '-' if still waiting
if (entry[0] == '-') {
if (verbose)
System.out.printf(
"I: processing request %s\n",
new String(
entry, 1, entry.length - 1, ZMQ.CHARSET
)
);
if (serviceSuccess(
new String(
entry, 1, entry.length - 1, ZMQ.CHARSET
)
)) {
// Mark queue entry as processed
file.seek(file.getFilePointer() - 37);
file.writeBytes("+");
file.seek(file.getFilePointer() + 36);
}
}
// Skip end of line, LF or CRLF
if (file.readByte() == '\r')
file.readByte();
if (Thread.currentThread().isInterrupted())
break;
}
}
catch (FileNotFoundException e) {
}
catch (IOException e) {
e.printStackTrace();
}
finally {
if (file != null) {
try {
file.close();
}
catch (IOException e) {
}
}
}
}
}
}
// .split try to call a service
// Here, we first check if the requested MDP service is defined or not,
// using a MMI lookup to the Majordomo broker. If the service exists, we
// send a request and wait for a reply using the conventional MDP client
// API. This is not meant to be fast, just very simple:
static boolean serviceSuccess(String uuid)
{
// Load request message, service will be first frame
String filename = requestFilename(uuid);
// If the client already closed request, treat as successful
if (!new File(filename).exists())
return true;
DataInputStream file = null;
ZMsg request;
try {
file = new DataInputStream(new FileInputStream(filename));
request = ZMsg.load(file);
}
catch (IOException e) {
e.printStackTrace();
return true;
}
finally {
try {
if (file != null)
file.close();
}
catch (IOException e) {
}
}
ZFrame service = request.pop();
String serviceName = service.toString();
// Create MDP client session with short timeout
mdcliapi client = new mdcliapi("tcp://localhost:5555", false);
client.setTimeout(1000); // 1 sec
client.setRetries(1); // only 1 retry
// Use MMI protocol to check if service is available
ZMsg mmiRequest = new ZMsg();
mmiRequest.add(service);
ZMsg mmiReply = client.send("mmi.service", mmiRequest);
boolean serviceOK = (mmiReply != null &&
mmiReply.getFirst().toString().equals("200"));
mmiReply.destroy();
boolean result = false;
if (serviceOK) {
ZMsg reply = client.send(serviceName, request);
if (reply != null) {
filename = replyFilename(uuid);
DataOutputStream ofile = null;
try {
ofile = new DataOutputStream(new FileOutputStream(filename));
ZMsg.save(reply, ofile);
}
catch (IOException e) {
e.printStackTrace();
return true;
}
finally {
try {
if (file != null)
file.close();
}
catch (IOException e) {
}
}
result = true;
}
reply.destroy();
}
else request.destroy();
client.destroy();
return result;
}
}
titanic: Titanic broker example in Julia
titanic: Titanic broker example in Lua
titanic: Titanic broker example in Node.js
titanic: Titanic broker example in Objective-C
titanic: Titanic broker example in ooc
titanic: Titanic broker example in Perl
titanic: Titanic broker example in PHP
<?php
/*
* Titanic service
*
* Implements server side of http://rfc.zeromq.org/spec:9
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'mdwrkapi.php';
include_once 'mdcliapi.php';
/* Return a new UUID as a printable character string */
function s_generate_uuid()
{
$uuid = sprintf('%04x%04x%04x%03x4%04x%04x%04x%04x',
mt_rand(0, 65535), mt_rand(0, 65535), // 32 bits for "time_low"
mt_rand(0, 65535), // 16 bits for "time_mid"
mt_rand(0, 4095), // 12 bits before the 0100 of (version) 4 for "time_hi_and_version"
bindec(substr_replace(sprintf('%016b', mt_rand(0, 65535)), '01', 6, 2)),
// 8 bits, the last two of which (positions 6 and 7) are 01, for "clk_seq_hi_res"
// (hence, the 2nd hex digit after the 3rd hyphen can only be 1, 5, 9 or d)
// 8 bits for "clk_seq_low"
mt_rand(0, 65535), mt_rand(0, 65535), mt_rand(0, 65535) // 48 bits for "node"
);
return $uuid;
}
define("TITANIC_DIR", ".titanic");
/**
* Returns freshly allocated request filename for given UUID
*/
function s_request_filename($uuid)
{
return TITANIC_DIR . "/" . $uuid . ".req";
}
/**
* Returns freshly allocated reply filename for given UUID
*/
function s_reply_filename($uuid)
{
return TITANIC_DIR . "/" . $uuid . ".rep";
}
/**
* Titanic request service
*/
function titanic_request($pipe)
{
$worker = new Mdwrk("tcp://localhost:5555", "titanic.request");
$reply = null;
while (true) {
// Get next request from broker
$request = $worker->recv($reply);
// Ensure message directory exists
if (!is_dir(TITANIC_DIR)) {
mkdir(TITANIC_DIR);
}
// Generate UUID and save message to disk
$uuid = s_generate_uuid();
$filename = s_request_filename($uuid);
$fh = fopen($filename, "w");
$request->save($fh);
fclose($fh);
// Send UUID through to message queue
$reply = new Zmsg($pipe);
$reply->push($uuid);
$reply->send();
// Now send UUID back to client
// - sent in the next loop iteration
$reply = new Zmsg();
$reply->push($uuid);
$reply->push("200");
}
}
/**
* Titanic reply service
*/
function titanic_reply()
{
$worker = new Mdwrk( "tcp://localhost:5555", "titanic.reply", false);
$reply = null;
while (true) {
$request = $worker->recv($reply);
$uuid = $request->pop();
$req_filename = s_request_filename($uuid);
$rep_filename = s_reply_filename($uuid);
if (file_exists($rep_filename)) {
$fh = fopen($rep_filename, "r");
assert($fh);
$reply = new Zmsg();
$reply->load($fh);
$reply->push("200");
fclose($fh);
} else {
$reply = new Zmsg();
if (file_exists($req_filename)) {
$reply->push("300"); // Pending
} else {
$reply->push("400"); // Unknown
}
}
}
}
/**
* Titanic close service
*/
function titanic_close()
{
$worker = new Mdwrk("tcp://localhost:5555", "titanic.close", false);
$reply = null;
while (true) {
$request = $worker->recv($reply);
$uuid = $request->pop();
$req_filename = s_request_filename($uuid);
$rep_filename = s_reply_filename($uuid);
unlink($req_filename);
unlink($rep_filename);
$reply = new Zmsg();
$reply->push("200");
}
}
/**
* Attempt to process a single request, return 1 if successful
*
* @param Mdcli $client
* @param string $uuid
*/
function s_service_success($client, $uuid)
{
// Load request message, service will be first frame
$filename = s_request_filename($uuid);
$fh = fopen($filename, "r");
// If the client already closed request, treat as successful
if (!$fh) {
return true;
}
$request = new Zmsg();
$request->load($fh);
fclose($fh);
$service = $request->pop();
// Use MMI protocol to check if service is available
$mmi_request = new Zmsg();
$mmi_request->push($service);
$mmi_reply = $client->send("mmi.service", $mmi_request);
$service_ok = $mmi_reply && $mmi_reply->pop() == "200";
if ($service_ok) {
$reply = $client->send($service, $request);
$filename = s_reply_filename($uuid);
$fh = fopen($filename, "w");
assert($fh);
$reply->save($fh);
fclose($fh);
return true;
}
return false;
}
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$pid = pcntl_fork();
if ($pid == 0) {
titanic_reply();
exit();
}
$pid = pcntl_fork();
if ($pid == 0) {
titanic_close();
exit();
}
$pid = pcntl_fork();
if ($pid == 0) {
$pipe = new ZMQSocket(new ZMQContext(), ZMQ::SOCKET_PAIR);
$pipe->connect("ipc://" . sys_get_temp_dir() . "/titanicpipe");
titanic_request($pipe);
exit();
}
// Create MDP client session with short timeout
$client = new Mdcli("tcp://localhost:5555", $verbose);
$client->set_timeout(1000); // 1 sec
$client->set_retries(1); // only 1 retry
$request_pipe = new ZMQSocket(new ZMQContext(), ZMQ::SOCKET_PAIR);
$request_pipe->bind("ipc://" . sys_get_temp_dir() . "/titanicpipe");
$read = $write = array();
// Main dispatcher loop
while (true) {
// We'll dispatch once per second, if there's no activity
$poll = new ZMQPoll();
$poll->add($request_pipe, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, 1000);
if ($events) {
// Ensure message directory exists
if (!is_dir(TITANIC_DIR)) {
mkdir(TITANIC_DIR);
}
// Append UUID to queue, prefixed with '-' for pending
$msg = new Zmsg($request_pipe);
$msg->recv();
$fh = fopen(TITANIC_DIR . "/queue", "a");
$uuid = $msg->pop();
fprintf($fh, "-%s\n", $uuid);
fclose($fh);
}
// Brute-force dispatcher
if (file_exists(TITANIC_DIR . "/queue")) {
$fh = fopen(TITANIC_DIR . "/queue", "r+");
while ($fh && $entry = fread($fh, 33)) {
// UUID is prefixed with '-' if still waiting
if ($entry[0] == "-") {
if ($verbose) {
printf ("I: processing request %s%s", substr($entry, 1), PHP_EOL);
}
if (s_service_success($client, substr($entry, 1))) {
// Mark queue entry as processed
fseek($fh, -33, SEEK_CUR);
fwrite ($fh, "+");
fseek($fh, 32, SEEK_CUR);
}
}
// Skip end of line, LF or CRLF
if (fgetc($fh) == "\r") {
fgetc($fh);
}
}
if ($fh) {
fclose($fh);
}
}
}
titanic: Titanic broker example in Python
"""
Titanic service
Implements server side of http:#rfc.zeromq.org/spec:9
Author: Min RK <benjaminrk@gmail.com>
"""
import pickle
import os
import sys
import threading
import time
from uuid import uuid4
import zmq
from mdwrkapi import MajorDomoWorker
from mdcliapi import MajorDomoClient
from zhelpers import zpipe
TITANIC_DIR = ".titanic"
def request_filename (suuid):
"""Returns freshly allocated request filename for given UUID str"""
return os.path.join(TITANIC_DIR, "%s.req" % suuid)
#
def reply_filename (suuid):
"""Returns freshly allocated reply filename for given UUID str"""
return os.path.join(TITANIC_DIR, "%s.rep" % suuid)
# ---------------------------------------------------------------------
# Titanic request service
def titanic_request (pipe):
worker = MajorDomoWorker("tcp://localhost:5555", b"titanic.request")
reply = None
while True:
# Send reply if it's not null
# And then get next request from broker
request = worker.recv(reply)
if not request:
break # Interrupted, exit
# Ensure message directory exists
if not os.path.exists(TITANIC_DIR):
os.mkdir(TITANIC_DIR)
# Generate UUID and save message to disk
suuid = uuid4().hex
filename = request_filename (suuid)
with open(filename, 'wb') as f:
pickle.dump(request, f)
# Send UUID through to message queue
pipe.send_string(suuid)
# Now send UUID back to client
# Done by the worker.recv() at the top of the loop
reply = [b"200", suuid.encode('utf-8')]
# ---------------------------------------------------------------------
# Titanic reply service
def titanic_reply ():
worker = MajorDomoWorker("tcp://localhost:5555", b"titanic.reply")
reply = None
while True:
request = worker.recv(reply)
if not request:
break # Interrupted, exit
suuid = request.pop(0).decode('utf-8')
req_filename = request_filename(suuid)
rep_filename = reply_filename(suuid)
if os.path.exists(rep_filename):
with open(rep_filename, 'rb') as f:
reply = pickle.load(f)
reply = [b"200"] + reply
else:
if os.path.exists(req_filename):
reply = [b"300"] # pending
else:
reply = [b"400"] # unknown
# ---------------------------------------------------------------------
# Titanic close service
def titanic_close():
worker = MajorDomoWorker("tcp://localhost:5555", b"titanic.close")
reply = None
while True:
request = worker.recv(reply)
if not request:
break # Interrupted, exit
suuid = request.pop(0).decode('utf-8')
req_filename = request_filename(suuid)
rep_filename = reply_filename(suuid)
# should these be protected? Does zfile_delete ignore files
# that have already been removed? That's what we are doing here.
if os.path.exists(req_filename):
os.remove(req_filename)
if os.path.exists(rep_filename):
os.remove(rep_filename)
reply = [b"200"]
def service_success(client, suuid):
"""Attempt to process a single request, return True if successful"""
# Load request message, service will be first frame
filename = request_filename (suuid)
# If the client already closed request, treat as successful
if not os.path.exists(filename):
return True
with open(filename, 'rb') as f:
request = pickle.load(f)
service = request.pop(0)
# Use MMI protocol to check if service is available
mmi_request = [service]
mmi_reply = client.send(b"mmi.service", mmi_request)
service_ok = mmi_reply and mmi_reply[0] == b"200"
if service_ok:
reply = client.send(service, request)
if reply:
filename = reply_filename (suuid)
with open(filename, "wb") as f:
pickle.dump(reply, f)
return True
return False
def main():
verbose = '-v' in sys.argv
ctx = zmq.Context()
# Create MDP client session with short timeout
client = MajorDomoClient("tcp://localhost:5555", verbose)
client.timeout = 1000 # 1 sec
client.retries = 1 # only 1 retry
request_pipe, peer = zpipe(ctx)
request_thread = threading.Thread(target=titanic_request, args=(peer,))
request_thread.daemon = True
request_thread.start()
reply_thread = threading.Thread(target=titanic_reply)
reply_thread.daemon = True
reply_thread.start()
close_thread = threading.Thread(target=titanic_close)
close_thread.daemon = True
close_thread.start()
poller = zmq.Poller()
poller.register(request_pipe, zmq.POLLIN)
queue_filename = os.path.join(TITANIC_DIR, 'queue')
# Main dispatcher loop
while True:
# Ensure message directory exists
if not os.path.exists(TITANIC_DIR):
os.mkdir(TITANIC_DIR)
f = open(queue_filename,'wb')
f.close()
# We'll dispatch once per second, if there's no activity
try:
items = poller.poll(1000)
except KeyboardInterrupt:
break; # Interrupted
if items:
# Append UUID to queue, prefixed with '-' for pending
suuid = request_pipe.recv().decode('utf-8')
with open(queue_filename, 'ab') as f:
line = "-%s\n" % suuid
f.write(line.encode('utf-8'))
# Brute-force dispatcher
with open(queue_filename, 'rb+') as f:
for entry in f.readlines():
entry = entry.decode('utf-8')
# UUID is prefixed with '-' if still waiting
if entry[0] == '-':
suuid = entry[1:].rstrip() # rstrip '\n' etc.
print ("I: processing request %s" % suuid)
if service_success(client, suuid):
# mark queue entry as processed
here = f.tell()
f.seek(-1*len(entry), os.SEEK_CUR)
f.write('+'.encode('utf-8'))
f.seek(here, os.SEEK_SET)
if __name__ == '__main__':
main()
titanic: Titanic broker example in Q
titanic: Titanic broker example in Racket
titanic: Titanic broker example in Ruby
titanic: Titanic broker example in Rust
titanic: Titanic broker example in Scala
titanic: Titanic broker example in Tcl
titanic: Titanic broker example in OCaml
To test this, start mdbroker and titanic, and then run ticlient. Now start mdworker arbitrarily, and you should see the client getting a response and exiting happily.
Some notes about this code:
- Note that some loops start by sending, others by receiving messages. This is because Titanic acts both as a client and a worker in different roles.
- The Titanic broker uses the MMI service discovery protocol to send requests only to services that appear to be running. Since the MMI implementation in our little Majordomo broker is quite poor, this won’t work all the time.
- We use an inproc connection to send new request data from the titanic.request service through to the main dispatcher. This saves the dispatcher from having to scan the disk directory, load all request files, and sort them by date/time.
The important thing about this example is not performance (which, although I haven’t tested it, is surely terrible), but how well it implements the reliability contract. To try it, start the mdbroker and titanic programs. Then start the ticlient, and then start the mdworker echo service. You can run all four of these using the -v option to do verbose activity tracing. You can stop and restart any piece except the client and nothing will get lost.
If you want to use Titanic in real cases, you’ll rapidly be asking “how do we make this faster?”
Here’s what I’d do, starting with the example implementation:
- Use a single disk file for all data, rather than multiple files. Operating systems are usually better at handling a few large files than many smaller ones.
- Organize that disk file as a circular buffer so that new requests can be written contiguously (with very occasional wraparound). One thread, writing full speed to a disk file, can work rapidly.
- Keep the index in memory and rebuild the index at startup time, from the disk buffer. This saves the extra disk head flutter needed to keep the index fully safe on disk. You would want an fsync after every message, or every N milliseconds if you were prepared to lose the last M messages in case of a system failure.
- Use a solid-state drive rather than spinning iron oxide platters.
- Pre-allocate the entire file, or allocate it in large chunks, which allows the circular buffer to grow and shrink as needed. This avoids fragmentation and ensures that most reads and writes are contiguous.
And so on. What I’d not recommend is storing messages in a database, not even a “fast” key/value store, unless you really like a specific database and don’t have performance worries. You will pay a steep price for the abstraction, ten to a thousand times over a raw disk file.
If you want to make Titanic even more reliable, duplicate the requests to a second server, which you’d place in a second location just far away enough to survive a nuclear attack on your primary location, yet not so far that you get too much latency.
If you want to make Titanic much faster and less reliable, store requests and replies purely in memory. This will give you the functionality of a disconnected network, but requests won’t survive a crash of the Titanic server itself.
High-Availability Pair (Binary Star Pattern) #
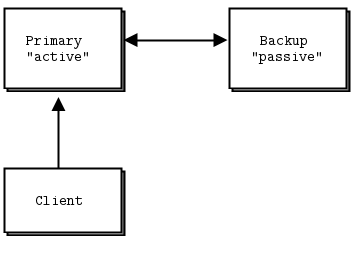
The Binary Star pattern puts two servers in a primary-backup high-availability pair. At any given time, one of these (the active) accepts connections from client applications. The other (the passive) does nothing, but the two servers monitor each other. If the active disappears from the network, after a certain time the passive takes over as active.
We developed the Binary Star pattern at iMatix for our OpenAMQ server. We designed it:
- To provide a straightforward high-availability solution.
- To be simple enough to actually understand and use.
- To fail over reliably when needed, and only when needed.
Assuming we have a Binary Star pair running, here are the different scenarios that will result in a failover:
- The hardware running the primary server has a fatal problem (power supply explodes, machine catches fire, or someone simply unplugs it by mistake), and disappears. Applications see this, and reconnect to the backup server.
- The network segment on which the primary server sits crashes–perhaps a router gets hit by a power spike–and applications start to reconnect to the backup server.
- The primary server crashes or is killed by the operator and does not restart automatically.
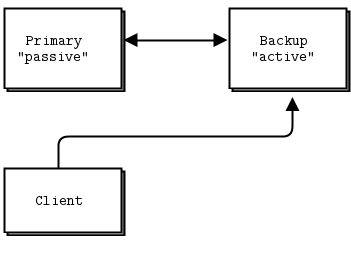
Recovery from failover works as follows:
- The operators restart the primary server and fix whatever problems were causing it to disappear from the network.
- The operators stop the backup server at a moment when it will cause minimal disruption to applications.
- When applications have reconnected to the primary server, the operators restart the backup server.
Recovery (to using the primary server as active) is a manual operation. Painful experience teaches us that automatic recovery is undesirable. There are several reasons:
-
Failover creates an interruption of service to applications, possibly lasting 10-30 seconds. If there is a real emergency, this is much better than total outage. But if recovery creates a further 10-30 second outage, it is better that this happens off-peak, when users have gone off the network.
-
When there is an emergency, the absolute first priority is certainty for those trying to fix things. Automatic recovery creates uncertainty for system administrators, who can no longer be sure which server is in charge without double-checking.
-
Automatic recovery can create situations where networks fail over and then recover, placing operators in the difficult position of analyzing what happened. There was an interruption of service, but the cause isn’t clear.
Having said this, the Binary Star pattern will fail back to the primary server if this is running (again) and the backup server fails. In fact, this is how we provoke recovery.
The shutdown process for a Binary Star pair is to either:
- Stop the passive server and then stop the active server at any later time, or
- Stop both servers in any order but within a few seconds of each other.
Stopping the active and then the passive server with any delay longer than the failover timeout will cause applications to disconnect, then reconnect, and then disconnect again, which may disturb users.
Detailed Requirements #
Binary Star is as simple as it can be, while still working accurately. In fact, the current design is the third complete redesign. Each of the previous designs we found to be too complex, trying to do too much, and we stripped out functionality until we came to a design that was understandable, easy to use, and reliable enough to be worth using.
These are our requirements for a high-availability architecture:
-
The failover is meant to provide insurance against catastrophic system failures, such as hardware breakdown, fire, accident, and so on. There are simpler ways to recover from ordinary server crashes and we already covered these.
-
Failover time should be under 60 seconds and preferably under 10 seconds.
-
Failover has to happen automatically, whereas recovery must happen manually. We want applications to switch over to the backup server automatically, but we do not want them to switch back to the primary server except when the operators have fixed whatever problem there was and decided that it is a good time to interrupt applications again.
-
The semantics for client applications should be simple and easy for developers to understand. Ideally, they should be hidden in the client API.
-
There should be clear instructions for network architects on how to avoid designs that could lead to split brain syndrome, in which both servers in a Binary Star pair think they are the active server.
-
There should be no dependencies on the order in which the two servers are started.
-
It must be possible to make planned stops and restarts of either server without stopping client applications (though they may be forced to reconnect).
-
Operators must be able to monitor both servers at all times.
-
It must be possible to connect the two servers using a high-speed dedicated network connection. That is, failover synchronization must be able to use a specific IP route.
We make the following assumptions:
-
A single backup server provides enough insurance; we don’t need multiple levels of backup.
-
The primary and backup servers are equally capable of carrying the application load. We do not attempt to balance load across the servers.
-
There is sufficient budget to cover a fully redundant backup server that does nothing almost all the time.
We don’t attempt to cover the following:
-
The use of an active backup server or load balancing. In a Binary Star pair, the backup server is inactive and does no useful work until the primary server goes offline.
-
The handling of persistent messages or transactions in any way. We assume the existence of a network of unreliable (and probably untrusted) servers or Binary Star pairs.
-
Any automatic exploration of the network. The Binary Star pair is manually and explicitly defined in the network and is known to applications (at least in their configuration data).
-
Replication of state or messages between servers. All server-side state must be recreated by applications when they fail over.
Here is the key terminology that we use in Binary Star:
-
Primary: the server that is normally or initially active.
-
Backup: the server that is normally passive. It will become active if and when the primary server disappears from the network, and when client applications ask the backup server to connect.
-
Active: the server that accepts client connections. There is at most one active server.
-
Passive: the server that takes over if the active disappears. Note that when a Binary Star pair is running normally, the primary server is active, and the backup is passive. When a failover has happened, the roles are switched.
To configure a Binary Star pair, you need to:
- Tell the primary server where the backup server is located.
- Tell the backup server where the primary server is located.
- Optionally, tune the failover response times, which must be the same for both servers.
The main tuning concern is how frequently you want the servers to check their peering status, and how quickly you want to activate failover. In our example, the failover timeout value defaults to 2,000 msec. If you reduce this, the backup server will take over as active more rapidly but may take over in cases where the primary server could recover. For example, you may have wrapped the primary server in a shell script that restarts it if it crashes. In that case, the timeout should be higher than the time needed to restart the primary server.
For client applications to work properly with a Binary Star pair, they must:
- Know both server addresses.
- Try to connect to the primary server, and if that fails, to the backup server.
- Detect a failed connection, typically using heartbeating.
- Try to reconnect to the primary, and then backup (in that order), with a delay between retries that is at least as high as the server failover timeout.
- Recreate all of the state they require on a server.
- Retransmit messages lost during a failover, if messages need to be reliable.
It’s not trivial work, and we’d usually wrap this in an API that hides it from real end-user applications.
These are the main limitations of the Binary Star pattern:
- A server process cannot be part of more than one Binary Star pair.
- A primary server can have a single backup server, and no more.
- The passive server does no useful work, and is thus wasted.
- The backup server must be capable of handling full application loads.
- Failover configuration cannot be modified at runtime.
- Client applications must do some work to benefit from failover.
Preventing Split-Brain Syndrome #
Split-brain syndrome occurs when different parts of a cluster think they are active at the same time. It causes applications to stop seeing each other. Binary Star has an algorithm for detecting and eliminating split brain, which is based on a three-way decision mechanism (a server will not decide to become active until it gets application connection requests and it cannot see its peer server).
However, it is still possible to (mis)design a network to fool this algorithm. A typical scenario would be a Binary Star pair, that is distributed between two buildings, where each building also had a set of applications and where there was a single network link between both buildings. Breaking this link would create two sets of client applications, each with half of the Binary Star pair, and each failover server would become active.
To prevent split-brain situations, we must connect a Binary Star pair using a dedicated network link, which can be as simple as plugging them both into the same switch or, better, using a crossover cable directly between two machines.
We must not split a Binary Star architecture into two islands, each with a set of applications. While this may be a common type of network architecture, you should use federation, not high-availability failover, in such cases.
A suitably paranoid network configuration would use two private cluster interconnects, rather than a single one. Further, the network cards used for the cluster would be different from those used for message traffic, and possibly even on different paths on the server hardware. The goal is to separate possible failures in the network from possible failures in the cluster. Network ports can have a relatively high failure rate.
Binary Star Implementation #
Without further ado, here is a proof-of-concept implementation of the Binary Star server. The primary and backup servers run the same code, you choose their roles when you run the code:
bstarsrv: Binary Star server in Ada
bstarsrv: Binary Star server in Basic
bstarsrv: Binary Star server in C
// Binary Star server proof-of-concept implementation. This server does no
// real work; it just demonstrates the Binary Star failover model.
#include "czmq.h"
// States we can be in at any point in time
typedef enum {
STATE_PRIMARY = 1, // Primary, waiting for peer to connect
STATE_BACKUP = 2, // Backup, waiting for peer to connect
STATE_ACTIVE = 3, // Active - accepting connections
STATE_PASSIVE = 4 // Passive - not accepting connections
} state_t;
// Events, which start with the states our peer can be in
typedef enum {
PEER_PRIMARY = 1, // HA peer is pending primary
PEER_BACKUP = 2, // HA peer is pending backup
PEER_ACTIVE = 3, // HA peer is active
PEER_PASSIVE = 4, // HA peer is passive
CLIENT_REQUEST = 5 // Client makes request
} event_t;
// Our finite state machine
typedef struct {
state_t state; // Current state
event_t event; // Current event
int64_t peer_expiry; // When peer is considered 'dead'
} bstar_t;
// We send state information this often
// If peer doesn't respond in two heartbeats, it is 'dead'
#define HEARTBEAT 1000 // In msecs
// .split Binary Star state machine
// The heart of the Binary Star design is its finite-state machine (FSM).
// The FSM runs one event at a time. We apply an event to the current state,
// which checks if the event is accepted, and if so, sets a new state:
static bool
s_state_machine (bstar_t *fsm)
{
bool exception = false;
// These are the PRIMARY and BACKUP states; we're waiting to become
// ACTIVE or PASSIVE depending on events we get from our peer:
if (fsm->state == STATE_PRIMARY) {
if (fsm->event == PEER_BACKUP) {
printf ("I: connected to backup (passive), ready active\n");
fsm->state = STATE_ACTIVE;
}
else
if (fsm->event == PEER_ACTIVE) {
printf ("I: connected to backup (active), ready passive\n");
fsm->state = STATE_PASSIVE;
}
// Accept client connections
}
else
if (fsm->state == STATE_BACKUP) {
if (fsm->event == PEER_ACTIVE) {
printf ("I: connected to primary (active), ready passive\n");
fsm->state = STATE_PASSIVE;
}
else
// Reject client connections when acting as backup
if (fsm->event == CLIENT_REQUEST)
exception = true;
}
else
// .split active and passive states
// These are the ACTIVE and PASSIVE states:
if (fsm->state == STATE_ACTIVE) {
if (fsm->event == PEER_ACTIVE) {
// Two actives would mean split-brain
printf ("E: fatal error - dual actives, aborting\n");
exception = true;
}
}
else
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
if (fsm->state == STATE_PASSIVE) {
if (fsm->event == PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
printf ("I: primary (passive) is restarting, ready active\n");
fsm->state = STATE_ACTIVE;
}
else
if (fsm->event == PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
printf ("I: backup (passive) is restarting, ready active\n");
fsm->state = STATE_ACTIVE;
}
else
if (fsm->event == PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
printf ("E: fatal error - dual passives, aborting\n");
exception = true;
}
else
if (fsm->event == CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert (fsm->peer_expiry > 0);
if (zclock_time () >= fsm->peer_expiry) {
// If peer is dead, switch to the active state
printf ("I: failover successful, ready active\n");
fsm->state = STATE_ACTIVE;
}
else
// If peer is alive, reject connections
exception = true;
}
}
return exception;
}
// .split main task
// This is our main task. First we bind/connect our sockets with our
// peer and make sure we will get state messages correctly. We use
// three sockets; one to publish state, one to subscribe to state, and
// one for client requests/replies:
int main (int argc, char *argv [])
{
// Arguments can be either of:
// -p primary server, at tcp://localhost:5001
// -b backup server, at tcp://localhost:5002
zctx_t *ctx = zctx_new ();
void *statepub = zsocket_new (ctx, ZMQ_PUB);
void *statesub = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (statesub, "");
void *frontend = zsocket_new (ctx, ZMQ_ROUTER);
bstar_t fsm = { 0 };
if (argc == 2 && streq (argv [1], "-p")) {
printf ("I: Primary active, waiting for backup (passive)\n");
zsocket_bind (frontend, "tcp://*:5001");
zsocket_bind (statepub, "tcp://*:5003");
zsocket_connect (statesub, "tcp://localhost:5004");
fsm.state = STATE_PRIMARY;
}
else
if (argc == 2 && streq (argv [1], "-b")) {
printf ("I: Backup passive, waiting for primary (active)\n");
zsocket_bind (frontend, "tcp://*:5002");
zsocket_bind (statepub, "tcp://*:5004");
zsocket_connect (statesub, "tcp://localhost:5003");
fsm.state = STATE_BACKUP;
}
else {
printf ("Usage: bstarsrv { -p | -b }\n");
zctx_destroy (&ctx);
exit (0);
}
// .split handling socket input
// We now process events on our two input sockets, and process these
// events one at a time via our finite-state machine. Our "work" for
// a client request is simply to echo it back:
// Set timer for next outgoing state message
int64_t send_state_at = zclock_time () + HEARTBEAT;
while (!zctx_interrupted) {
zmq_pollitem_t items [] = {
{ frontend, 0, ZMQ_POLLIN, 0 },
{ statesub, 0, ZMQ_POLLIN, 0 }
};
int time_left = (int) ((send_state_at - zclock_time ()));
if (time_left < 0)
time_left = 0;
int rc = zmq_poll (items, 2, time_left * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Context has been shut down
if (items [0].revents & ZMQ_POLLIN) {
// Have a client request
zmsg_t *msg = zmsg_recv (frontend);
fsm.event = CLIENT_REQUEST;
if (s_state_machine (&fsm) == false)
// Answer client by echoing request back
zmsg_send (&msg, frontend);
else
zmsg_destroy (&msg);
}
if (items [1].revents & ZMQ_POLLIN) {
// Have state from our peer, execute as event
char *message = zstr_recv (statesub);
fsm.event = atoi (message);
free (message);
if (s_state_machine (&fsm))
break; // Error, so exit
fsm.peer_expiry = zclock_time () + 2 * HEARTBEAT;
}
// If we timed out, send state to peer
if (zclock_time () >= send_state_at) {
char message [2];
sprintf (message, "%d", fsm.state);
zstr_send (statepub, message);
send_state_at = zclock_time () + HEARTBEAT;
}
}
if (zctx_interrupted)
printf ("W: interrupted\n");
// Shutdown sockets and context
zctx_destroy (&ctx);
return 0;
}
bstarsrv: Binary Star server in C++
// Binary Star server proof-of-concept implementation. This server does no
// real work; it just demonstrates the Binary Star failover model.
#include "zmsg.hpp"
#define ZMQ_POLL_MSEC 1 // One second
// States we can be in at any point in time
typedef enum {
STATE_NOTSET = 0, // Before we start, or if the state is invalid
STATE_PRIMARY = 1, // Primary, waiting for peer to connect
STATE_BACKUP = 2, // Backup, waiting for peer to connect
STATE_ACTIVE = 3, // Active - accepting connections
STATE_PASSIVE = 4 // Passive - not accepting connections
} state_t;
// Events, which start with the states our peer can be in
typedef enum {
EVENT_NOTSET = 0, // Before we start, or if the event is invalid
PEER_PRIMARY = 1, // HA peer is pending primary
PEER_BACKUP = 2, // HA peer is pending backup
PEER_ACTIVE = 3, // HA peer is active
PEER_PASSIVE = 4, // HA peer is passive
CLIENT_REQUEST = 5 // Client makes request
} event_t;
// We send state information this often
// If peer doesn't respond in two heartbeats, it is 'dead'
#define HEARTBEAT 1000 // In msecs
// .split Binary Star state machine
// The heart of the Binary Star design is its finite-state machine (FSM).
// The FSM runs one event at a time. We apply an event to the current state,
// which checks if the event is accepted, and if so, sets a new state:
// Our finite state machine
class bstar {
public:
bstar() : m_state(STATE_NOTSET), m_event(EVENT_NOTSET), m_peer_expiry(0) {}
bool state_machine(event_t event) {
m_event = event;
bool exception = false;
// These are the PRIMARY and BACKUP states; we're waiting to become
// ACTIVE or PASSIVE depending on events we get from our peer:
if (m_state == STATE_PRIMARY) {
if (m_event == PEER_BACKUP) {
std::cout << "I: connected to backup (passive), ready active" << std::endl;
m_state = STATE_ACTIVE;
} else if (m_event == PEER_ACTIVE) {
std::cout << "I: connected to backup (active), ready passive" << std::endl;
m_state = STATE_PASSIVE;
}
// Accept client connections
} else if (m_state == STATE_BACKUP) {
if (m_event == PEER_ACTIVE) {
std::cout << "I: connected to primary (active), ready passive" << std::endl;
m_state = STATE_PASSIVE;
} else if (m_event == CLIENT_REQUEST) {
// Reject client connections when acting as backup
exception = true;
}
// .split active and passive states
// These are the ACTIVE and PASSIVE states:
} else if (m_state == STATE_ACTIVE) {
if (m_event == PEER_ACTIVE) {
std::cout << "E: fatal error - dual actives, aborting" << std::endl;
exception = true;
}
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
} else if (m_state == STATE_PASSIVE) {
if (m_event == PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
std::cout << "I: primary (passive) is restarting, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else if (m_event == PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
std::cout << "I: backup (passive) is restarting, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else if (m_event == PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
std::cout << "E: fatal error - dual passives, aborting" << std::endl;
exception = true;
} else if (m_event == CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert(m_peer_expiry > 0);
if (s_clock() >= m_peer_expiry) {
std::cout << "I: failover successful, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else {
// If peer is alive, reject connections
exception = true;
}
}
}
return exception;
}
void set_state(state_t state) {
m_state = state;
}
state_t get_state() {
return m_state;
}
void set_peer_expiry(int64_t expiry) {
m_peer_expiry = expiry;
}
private:
state_t m_state; // Current state
event_t m_event; // Current event
int64_t m_peer_expiry; // When peer is considered 'dead', milliseconds
};
int main(int argc, char *argv []) {
// Arguments can be either of:
// -p primary server, at tcp://localhost:5001
// -b backup server, at tcp://localhost:5002
zmq::context_t context(1);
zmq::socket_t statepub(context, ZMQ_PUB);
zmq::socket_t statesub(context, ZMQ_SUB);
statesub.set(zmq::sockopt::subscribe, "");
zmq::socket_t frontend(context, ZMQ_ROUTER);
bstar fsm;
if (argc == 2 && strcmp(argv[1], "-p") == 0) {
std::cout << "I: Primary active, waiting for backup (passive)" << std::endl;
frontend.bind("tcp://*:5001");
statepub.bind("tcp://*:5003");
statesub.connect("tcp://localhost:5004");
fsm.set_state(STATE_PRIMARY);
} else if (argc == 2 && strcmp(argv[1], "-b") == 0) {
std::cout << "I: Backup passive, waiting for primary (active)" << std::endl;
frontend.bind("tcp://*:5002");
statepub.bind("tcp://*:5004");
statesub.connect("tcp://localhost:5003");
fsm.set_state(STATE_BACKUP);
} else {
std::cout << "Usage: bstarsrv { -p | -b }" << std::endl;
return 0;
}
// .split handling socket input
// We now process events on our two input sockets, and process these
// events one at a time via our finite-state machine. Our "work" for
// a client request is simply to echo it back:
// Set timer for next outgoing state message
int64_t send_state_at = s_clock() + HEARTBEAT;
s_catch_signals(); // catch SIGINT and SIGTERM
while(!s_interrupted) {
zmq::pollitem_t items [] = {
{ frontend, 0, ZMQ_POLLIN, 0 },
{ statesub, 0, ZMQ_POLLIN, 0 }
};
int time_left = (int) (send_state_at - s_clock());
if (time_left < 0)
time_left = 0;
try {
zmq::poll(items, 2, time_left * ZMQ_POLL_MSEC);
} catch (zmq::error_t &e) {
break; // Interrupted
}
if (items[0].revents & ZMQ_POLLIN) {
// Have client request, process it
zmsg msg;
msg.recv(frontend);
if (msg.parts() == 0)
break; // Ctrl-C
if (fsm.state_machine(CLIENT_REQUEST) == false) {
// Answer client by echoing request back
msg.send(frontend);
}
}
if (items[1].revents & ZMQ_POLLIN) {
// Have state from our peer, execute as event
std::string message = s_recv(statesub);
std::cout << "I: received state msg:" << message << std::endl;
event_t event = (event_t)std::stoi(message); // peer's state is our event
if (fsm.state_machine(event) == true) {
break; // Error, exit
}
fsm.set_peer_expiry(s_clock() + 2 * HEARTBEAT);
}
// If we timed out, send state to peer
if (s_clock() >= send_state_at) {
std::string state = std::to_string(fsm.get_state());
std::cout << "sending state:" << state << std::endl;
s_send(statepub, state);
// std::cout << "error: " << zmq_strerror(zmq_errno()) << std::endl;
send_state_at = s_clock() + HEARTBEAT;
}
}
if (s_interrupted) {
std::cout << "W: interrupt received, shutting down..." << std::endl;
}
return 0;
}
bstarsrv: Binary Star server in C#
bstarsrv: Binary Star server in CL
bstarsrv: Binary Star server in Delphi
bstarsrv: Binary Star server in Erlang
bstarsrv: Binary Star server in Elixir
bstarsrv: Binary Star server in F#
bstarsrv: Binary Star server in Felix
bstarsrv: Binary Star server in Go
bstarsrv: Binary Star server in Haskell
bstarsrv: Binary Star server in Haxe
package ;
import haxe.io.Bytes;
import haxe.Stack;
import neko.Sys;
import neko.Lib;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import org.zeromq.ZMsg;
import org.zeromq.ZSocket;
/**
* Binary Star Server
* @author Richard J Smith
*
* @see http://zguide.zeromq.org/page:all#Binary-Star-Implementation
*/
class BStarSrv
{
private static inline var HEARTBEAT = 100;
/** Current state */
public var state:StateT;
/** Current event */
public var event:EventT;
/** When peer is considered 'dead' */
public var peerExpiry:Float;
/**
* BStarSrv constructor
* @param state Initial state
*/
public function new(state:StateT) {
this.state = state;
}
/**
* Main binary star server loop
*/
public function run() {
var ctx = new ZContext();
var statePub = ctx.createSocket(ZMQ_PUB);
var stateSub = ctx.createSocket(ZMQ_SUB);
var frontend = ctx.createSocket(ZMQ_ROUTER);
switch (state) {
case STATE_PRIMARY:
Lib.println("I: primary master, waiting for backup (slave)");
frontend.bind("tcp://*:5001");
statePub.bind("tcp://*:5003");
stateSub.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
stateSub.connect("tcp://localhost:5004");
case STATE_BACKUP:
Lib.println("I: backup slave, waiting for primary (master)");
frontend.bind("tcp://*:5002");
statePub.bind("tcp://*:5004");
stateSub.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
stateSub.connect("tcp://localhost:5003");
default:
ctx.destroy();
return;
}
// Set timer for next outgoing state message
var sendStateAt = Date.now().getTime() + HEARTBEAT;
var poller = new ZMQPoller();
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
poller.registerSocket(stateSub, ZMQ.ZMQ_POLLIN());
while (!ZMQ.isInterrupted()) {
var timeLeft = Std.int(sendStateAt - Date.now().getTime());
if (timeLeft < 0)
timeLeft = 0;
try {
var res = poller.poll(timeLeft * 1000); // Convert timeout to microseconds
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else {
Lib.println("W: interrupt received, killing server...");
}
ctx.destroy();
return;
}
if (poller.pollin(1)) {
// Have a client request
var msg = ZMsg.recvMsg(frontend);
event = CLIENT_REQUEST;
if (!stateMachine())
// Answer client by echoing request back
msg.send(frontend); // Pretend do some work and then reply
else
msg.destroy();
}
if (poller.pollin(2)) {
// Have state from our peer, execute as event
var message = stateSub.recvMsg().toString();
event = Type.createEnumIndex(EventT, Std.parseInt(message));
if (stateMachine())
break; // Error, so exit
peerExpiry = Date.now().getTime() + (2 * HEARTBEAT);
}
// If we timed-out, send state to peer
if (Date.now().getTime() >= sendStateAt) {
statePub.sendMsg(Bytes.ofString(Std.string(Type.enumIndex(state))));
sendStateAt = Date.now().getTime() + HEARTBEAT;
}
}
ctx.destroy();
}
/**
* Executes finite state machine (apply event to this state)
* Returns true if there was an exception
* @return
*/
public function stateMachine():Bool
{
var exception = false;
switch (state) {
case STATE_PRIMARY:
// Primary server is waiting for peer to connect
// Accepts CLIENT_REQUEST events in this state
switch (event) {
case PEER_BACKUP:
Lib.println("I: connected to backup (slave), ready as master");
state = STATE_ACTIVE;
case PEER_ACTIVE:
Lib.println("I: connected to backup (master), ready as slave");
state = STATE_PASSIVE;
default:
}
case STATE_BACKUP:
// Backup server is waiting for peer to connect
// Rejects CLIENT_REQUEST events in this state
switch (event) {
case PEER_ACTIVE:
Lib.println("I: connected to primary (master), ready as slave");
state = STATE_PASSIVE;
case CLIENT_REQUEST:
exception = true;
default:
}
case STATE_ACTIVE:
// Server is active
// Accepts CLIENT_REQUEST events in this state
switch (event) {
case PEER_ACTIVE:
// Two masters would mean split-brain
Lib.println("E: fatal error - dual masters, aborting");
exception = true;
default:
}
case STATE_PASSIVE:
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
switch (event) {
case PEER_PRIMARY:
// Peer is restarting - become active, peer will go passive
Lib.println("I: primary (slave) is restarting, ready as master");
state = STATE_ACTIVE;
case PEER_BACKUP:
// Peer is restarting - become active, peer will go passive
Lib.println("I: backup (slave) is restarting, ready as master");
state = STATE_ACTIVE;
case PEER_PASSIVE:
// Two passives would mean cluster would be non-responsive
Lib.println("E: fatal error - dual slaves, aborting");
exception = true;
case CLIENT_REQUEST:
// Peer becomes master if timeout as passed
// It's the client request that triggers the failover
if (Date.now().getTime() >= peerExpiry) {
// If peer is dead, switch to the active state
Lib.println("I: failover successful, ready as master");
state = STATE_ACTIVE;
} else {
Lib.println("I: peer is active, so ignore connection");
exception = true;
}
default:
}
}
return exception;
}
public static function main() {
Lib.println("** BStarSrv (see: http://zguide.zeromq.org/page:all#Binary-Star-Implementation)");
var state:StateT = null;
var argArr = Sys.args();
if (argArr.length > 1 && argArr[argArr.length - 1] == "-p") {
state = STATE_PRIMARY;
} else if (argArr.length > 1 && argArr[argArr.length - 1] == "-b") {
state = STATE_BACKUP;
} else {
Lib.println("Usage: bstartsrv { -p | -b }");
return;
}
var bstarServer = new BStarSrv(state);
bstarServer.run();
}
}
// States we can be in at any time
private enum StateT {
STATE_PRIMARY; // Primary, waiting for peer to connect
STATE_BACKUP; // Backup, waiting for peer to connect
STATE_ACTIVE; // Active - accepting connections
STATE_PASSIVE; // Passive - not accepting connections
}
private enum EventT {
PEER_PRIMARY; // HA peer is pending primary
PEER_BACKUP; // HA peer is pending backup
PEER_ACTIVE; // HA peer is active
PEER_PASSIVE; // HA peer is passive
CLIENT_REQUEST; // Client makes request
}
bstarsrv: Binary Star server in Java
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZMsg;
// Binary Star server proof-of-concept implementation. This server does no
// real work; it just demonstrates the Binary Star failover model.
public class bstarsrv
{
// States we can be in at any point in time
enum State
{
STATE_PRIMARY, // Primary, waiting for peer to connect
STATE_BACKUP, // Backup, waiting for peer to connect
STATE_ACTIVE, // Active - accepting connections
STATE_PASSIVE // Passive - not accepting connections
}
// Events, which start with the states our peer can be in
enum Event
{
PEER_PRIMARY, // HA peer is pending primary
PEER_BACKUP, // HA peer is pending backup
PEER_ACTIVE, // HA peer is active
PEER_PASSIVE, // HA peer is passive
CLIENT_REQUEST // Client makes request
}
// Our finite state machine
private State state; // Current state
private Event event; // Current event
private long peerExpiry; // When peer is considered 'dead'
// We send state information this often
// If peer doesn't respond in two heartbeats, it is 'dead'
private final static long HEARTBEAT = 1000; // In msecs
// .split Binary Star state machine
// The heart of the Binary Star design is its finite-state machine (FSM).
// The FSM runs one event at a time. We apply an event to the current state,
// which checks if the event is accepted, and if so, sets a new state:
private boolean stateMachine()
{
boolean exception = false;
// These are the PRIMARY and BACKUP states; we're waiting to become
// ACTIVE or PASSIVE depending on events we get from our peer:
if (state == State.STATE_PRIMARY) {
if (event == Event.PEER_BACKUP) {
System.out.printf("I: connected to backup (passive), ready active\n");
state = State.STATE_ACTIVE;
}
else if (event == Event.PEER_ACTIVE) {
System.out.printf("I: connected to backup (active), ready passive\n");
state = State.STATE_PASSIVE;
}
// Accept client connections
}
else if (state == State.STATE_BACKUP) {
if (event == Event.PEER_ACTIVE) {
System.out.printf("I: connected to primary (active), ready passive\n");
state = State.STATE_PASSIVE;
}
else
// Reject client connections when acting as backup
if (event == Event.CLIENT_REQUEST)
exception = true;
}
else
// .split active and passive states
// These are the ACTIVE and PASSIVE states:
if (state == State.STATE_ACTIVE) {
if (event == Event.PEER_ACTIVE) {
// Two actives would mean split-brain
System.out.printf("E: fatal error - dual actives, aborting\n");
exception = true;
}
}
else
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
if (state == State.STATE_PASSIVE) {
if (event == Event.PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
System.out.printf("I: primary (passive) is restarting, ready active\n");
state = State.STATE_ACTIVE;
}
else if (event == Event.PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
System.out.printf("I: backup (passive) is restarting, ready active\n");
state = State.STATE_ACTIVE;
}
else if (event == Event.PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
System.out.printf("E: fatal error - dual passives, aborting\n");
exception = true;
}
else if (event == Event.CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert (peerExpiry > 0);
if (System.currentTimeMillis() >= peerExpiry) {
// If peer is dead, switch to the active state
System.out.printf("I: failover successful, ready active\n");
state = State.STATE_ACTIVE;
}
else
// If peer is alive, reject connections
exception = true;
}
}
return exception;
}
// .split main task
// This is our main task. First we bind/connect our sockets with our
// peer and make sure we will get state messages correctly. We use
// three sockets; one to publish state, one to subscribe to state, and
// one for client requests/replies:
public static void main(String[] argv)
{
// Arguments can be either of:
// -p primary server, at tcp://localhost:5001
// -b backup server, at tcp://localhost:5002
try (ZContext ctx = new ZContext()) {
Socket statepub = ctx.createSocket(SocketType.PUB);
Socket statesub = ctx.createSocket(SocketType.SUB);
statesub.subscribe(ZMQ.SUBSCRIPTION_ALL);
Socket frontend = ctx.createSocket(SocketType.ROUTER);
bstarsrv fsm = new bstarsrv();
if (argv.length == 1 && argv[0].equals("-p")) {
System.out.printf("I: Primary active, waiting for backup (passive)\n");
frontend.bind("tcp://*:5001");
statepub.bind("tcp://*:5003");
statesub.connect("tcp://localhost:5004");
fsm.state = State.STATE_PRIMARY;
}
else if (argv.length == 1 && argv[0].equals("-b")) {
System.out.printf("I: Backup passive, waiting for primary (active)\n");
frontend.bind("tcp://*:5002");
statepub.bind("tcp://*:5004");
statesub.connect("tcp://localhost:5003");
fsm.state = State.STATE_BACKUP;
}
else {
System.out.printf("Usage: bstarsrv { -p | -b }\n");
ctx.destroy();
System.exit(0);
}
// .split handling socket input
// We now process events on our two input sockets, and process
// these events one at a time via our finite-state machine. Our
// "work" for a client request is simply to echo it back.
Poller poller = ctx.createPoller(2);
poller.register(frontend, ZMQ.Poller.POLLIN);
poller.register(statesub, ZMQ.Poller.POLLIN);
// Set timer for next outgoing state message
long sendStateAt = System.currentTimeMillis() + HEARTBEAT;
while (!Thread.currentThread().isInterrupted()) {
int timeLeft = (int) ((sendStateAt - System.currentTimeMillis()));
if (timeLeft < 0)
timeLeft = 0;
int rc = poller.poll(timeLeft);
if (rc == -1)
break; // Context has been shut down
if (poller.pollin(0)) {
// Have a client request
ZMsg msg = ZMsg.recvMsg(frontend);
fsm.event = Event.CLIENT_REQUEST;
if (fsm.stateMachine() == false)
// Answer client by echoing request back
msg.send(frontend);
else msg.destroy();
}
if (poller.pollin(1)) {
// Have state from our peer, execute as event
String message = statesub.recvStr();
fsm.event = Event.values()[Integer.parseInt(message)];
if (fsm.stateMachine())
break; // Error, so exit
fsm.peerExpiry = System.currentTimeMillis() + 2 * HEARTBEAT;
}
// If we timed out, send state to peer
if (System.currentTimeMillis() >= sendStateAt) {
statepub.send(String.valueOf(fsm.state.ordinal()));
sendStateAt = System.currentTimeMillis() + HEARTBEAT;
}
}
if (Thread.currentThread().isInterrupted())
System.out.printf("W: interrupted\n");
}
}
}
bstarsrv: Binary Star server in Julia
bstarsrv: Binary Star server in Lua
bstarsrv: Binary Star server in Node.js
bstarsrv: Binary Star server in Objective-C
bstarsrv: Binary Star server in ooc
bstarsrv: Binary Star server in Perl
bstarsrv: Binary Star server in PHP
bstarsrv: Binary Star server in Python
# Binary Star Server
#
# Author: Dan Colish <dcolish@gmail.com>
from argparse import ArgumentParser
import time
from zhelpers import zmq
STATE_PRIMARY = 1
STATE_BACKUP = 2
STATE_ACTIVE = 3
STATE_PASSIVE = 4
PEER_PRIMARY = 1
PEER_BACKUP = 2
PEER_ACTIVE = 3
PEER_PASSIVE = 4
CLIENT_REQUEST = 5
HEARTBEAT = 1000
class BStarState(object):
def __init__(self, state, event, peer_expiry):
self.state = state
self.event = event
self.peer_expiry = peer_expiry
class BStarException(Exception):
pass
fsm_states = {
STATE_PRIMARY: {
PEER_BACKUP: ("I: connected to backup (slave), ready as master",
STATE_ACTIVE),
PEER_ACTIVE: ("I: connected to backup (master), ready as slave",
STATE_PASSIVE)
},
STATE_BACKUP: {
PEER_ACTIVE: ("I: connected to primary (master), ready as slave",
STATE_PASSIVE),
CLIENT_REQUEST: ("", False)
},
STATE_ACTIVE: {
PEER_ACTIVE: ("E: fatal error - dual masters, aborting", False)
},
STATE_PASSIVE: {
PEER_PRIMARY: ("I: primary (slave) is restarting, ready as master",
STATE_ACTIVE),
PEER_BACKUP: ("I: backup (slave) is restarting, ready as master",
STATE_ACTIVE),
PEER_PASSIVE: ("E: fatal error - dual slaves, aborting", False),
CLIENT_REQUEST: (CLIENT_REQUEST, True) # Say true, check peer later
}
}
def run_fsm(fsm):
# There are some transitional states we do not want to handle
state_dict = fsm_states.get(fsm.state, {})
res = state_dict.get(fsm.event)
if res:
msg, state = res
else:
return
if state is False:
raise BStarException(msg)
elif msg == CLIENT_REQUEST:
assert fsm.peer_expiry > 0
if int(time.time() * 1000) > fsm.peer_expiry:
fsm.state = STATE_ACTIVE
else:
raise BStarException()
else:
print(msg)
fsm.state = state
def main():
parser = ArgumentParser()
group = parser.add_mutually_exclusive_group()
group.add_argument("-p", "--primary", action="store_true", default=False)
group.add_argument("-b", "--backup", action="store_true", default=False)
args = parser.parse_args()
ctx = zmq.Context()
statepub = ctx.socket(zmq.PUB)
statesub = ctx.socket(zmq.SUB)
statesub.setsockopt_string(zmq.SUBSCRIBE, u"")
frontend = ctx.socket(zmq.ROUTER)
fsm = BStarState(0, 0, 0)
if args.primary:
print("I: Primary master, waiting for backup (slave)")
frontend.bind("tcp://*:5001")
statepub.bind("tcp://*:5003")
statesub.connect("tcp://localhost:5004")
fsm.state = STATE_PRIMARY
elif args.backup:
print("I: Backup slave, waiting for primary (master)")
frontend.bind("tcp://*:5002")
statepub.bind("tcp://*:5004")
statesub.connect("tcp://localhost:5003")
statesub.setsockopt_string(zmq.SUBSCRIBE, u"")
fsm.state = STATE_BACKUP
send_state_at = int(time.time() * 1000 + HEARTBEAT)
poller = zmq.Poller()
poller.register(frontend, zmq.POLLIN)
poller.register(statesub, zmq.POLLIN)
while True:
time_left = send_state_at - int(time.time() * 1000)
if time_left < 0:
time_left = 0
socks = dict(poller.poll(time_left))
if socks.get(frontend) == zmq.POLLIN:
msg = frontend.recv_multipart()
fsm.event = CLIENT_REQUEST
try:
run_fsm(fsm)
frontend.send_multipart(msg)
except BStarException:
del msg
if socks.get(statesub) == zmq.POLLIN:
msg = statesub.recv()
fsm.event = int(msg)
del msg
try:
run_fsm(fsm)
fsm.peer_expiry = int(time.time() * 1000) + (2 * HEARTBEAT)
except BStarException:
break
if int(time.time() * 1000) >= send_state_at:
statepub.send("%d" % fsm.state)
send_state_at = int(time.time() * 1000) + HEARTBEAT
if __name__ == '__main__':
main()
bstarsrv: Binary Star server in Q
bstarsrv: Binary Star server in Racket
bstarsrv: Binary Star server in Ruby
bstarsrv: Binary Star server in Rust
bstarsrv: Binary Star server in Scala
bstarsrv: Binary Star server in Tcl
bstarsrv: Binary Star server in OCaml
And here is the client:
bstarcli: Binary Star client in Ada
bstarcli: Binary Star client in Basic
bstarcli: Binary Star client in C
// Binary Star client proof-of-concept implementation. This client does no
// real work; it just demonstrates the Binary Star failover model.
#include "czmq.h"
#define REQUEST_TIMEOUT 1000 // msecs
#define SETTLE_DELAY 2000 // Before failing over
int main (void)
{
zctx_t *ctx = zctx_new ();
char *server [] = { "tcp://localhost:5001", "tcp://localhost:5002" };
uint server_nbr = 0;
printf ("I: connecting to server at %s...\n", server [server_nbr]);
void *client = zsocket_new (ctx, ZMQ_REQ);
zsocket_connect (client, server [server_nbr]);
int sequence = 0;
while (!zctx_interrupted) {
// We send a request, then we work to get a reply
char request [10];
sprintf (request, "%d", ++sequence);
zstr_send (client, request);
int expect_reply = 1;
while (expect_reply) {
// Poll socket for a reply, with timeout
zmq_pollitem_t items [] = { { client, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, REQUEST_TIMEOUT * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
// .split main body of client
// We use a Lazy Pirate strategy in the client. If there's no
// reply within our timeout, we close the socket and try again.
// In Binary Star, it's the client vote that decides which
// server is primary; the client must therefore try to connect
// to each server in turn:
if (items [0].revents & ZMQ_POLLIN) {
// We got a reply from the server, must match sequence
char *reply = zstr_recv (client);
if (atoi (reply) == sequence) {
printf ("I: server replied OK (%s)\n", reply);
expect_reply = 0;
sleep (1); // One request per second
}
else
printf ("E: bad reply from server: %s\n", reply);
free (reply);
}
else {
printf ("W: no response from server, failing over\n");
// Old socket is confused; close it and open a new one
zsocket_destroy (ctx, client);
server_nbr = (server_nbr + 1) % 2;
zclock_sleep (SETTLE_DELAY);
printf ("I: connecting to server at %s...\n",
server [server_nbr]);
client = zsocket_new (ctx, ZMQ_REQ);
zsocket_connect (client, server [server_nbr]);
// Send request again, on new socket
zstr_send (client, request);
}
}
}
zctx_destroy (&ctx);
return 0;
}
bstarcli: Binary Star client in C++
// Binary Star client proof-of-concept implementation. This client does no
// real work; it just demonstrates the Binary Star failover model.
#include "zmsg.hpp"
#define REQUEST_TIMEOUT 1000 // msecs
#define SETTLE_DELAY 2000 // Before failing over
#define ZMQ_POLL_MSEC 1 // zmq_poll delay
int main(void) {
zmq::context_t context(1);
char *server [] = {"tcp://localhost:5001", "tcp://localhost:5002"};
uint server_nbr = 0;
std::cout << "I: connecting to " << server[server_nbr] << "..." << std::endl;
zmq::socket_t *client = new zmq::socket_t(context, ZMQ_REQ);
// Configure socket to not wait at close time
int linger = 0;
client->setsockopt (ZMQ_LINGER, &linger, sizeof (linger));
client->connect(server[server_nbr]);
int sequence = 0;
while(true) {
// We send a request, then we work to get a reply
std::string request_string = std::to_string(++sequence);
s_send(*client, request_string);
int expect_reply = 1;
while(expect_reply) {
zmq::pollitem_t items[] = {{*client, 0, ZMQ_POLLIN, 0}};
try {
zmq::poll(items, 1, REQUEST_TIMEOUT * ZMQ_POLL_MSEC);
} catch (std::exception &e) {
break; // Interrupted
}
// .split main body of client
// We use a Lazy Pirate strategy in the client. If there's no
// reply within our timeout, we close the socket and try again.
// In Binary Star, it's the client vote that decides which
// server is primary; the client must therefore try to connect
// to each server in turn:
if (items[0].revents & ZMQ_POLLIN) {
// We got a reply from the server, must match sequence
std::string reply = s_recv(*client);
if (std::stoi(reply) == sequence) {
std::cout << "I: server replied OK (" << reply << ")" << std::endl;
expect_reply = 0;
s_sleep(1000); // One request per second
} else {
std::cout << "E: bad reply from server: " << reply << std::endl;
}
} else {
std::cout << "W: no response from server, failing over" << std::endl;
// Old socket is confused; close it and open a new one
delete client;
server_nbr = (server_nbr + 1) % 2;
s_sleep(SETTLE_DELAY);
std::cout << "I: connecting to " << server[server_nbr] << "..." << std::endl;
client = new zmq::socket_t(context, ZMQ_REQ);
linger = 0;
client->setsockopt(ZMQ_LINGER, &linger, sizeof(linger));
client->connect(server[server_nbr]);
// Send request again, on new socket
s_send(*client, request_string);
}
}
}
return 0;
}
bstarcli: Binary Star client in C#
bstarcli: Binary Star client in CL
bstarcli: Binary Star client in Delphi
bstarcli: Binary Star client in Erlang
bstarcli: Binary Star client in Elixir
bstarcli: Binary Star client in F#
bstarcli: Binary Star client in Felix
bstarcli: Binary Star client in Go
bstarcli: Binary Star client in Haskell
bstarcli: Binary Star client in Haxe
package ;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMsg;
import org.zeromq.ZMQException;
/**
* Binary Star Client
* @author Richard J Smith
*
* @see http://zguide.zeromq.org/page:all#Binary-Star-Implementation
*/
class BStarCli
{
private static inline var REQUEST_TIMEOUT = 1000; // msecs
private static inline var SETTLE_DELAY = 2000; // Before failing over
public static function main()
{
Lib.println("** BStarCli (see: http://zguide.zeromq.org/page:all#Binary-Star-Implementation)");
var ctx = new ZContext();
var server = ["tcp://localhost:5001", "tcp://localhost:5002"];
var server_nbr = 0;
Lib.println("I: connecting to server at " + server[server_nbr]);
var client = ctx.createSocket(ZMQ_REQ);
client.connect(server[server_nbr]);
var sequence = 0;
var poller = new ZMQPoller();
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
while (!ZMQ.isInterrupted()) {
// We send a request, then we work to get a reply
var request = Std.string(++sequence);
ZMsg.newStringMsg(request).send(client);
var expectReply = true;
while (expectReply) {
// Poll socket for a reply, with timeout
try {
var res = poller.poll(REQUEST_TIMEOUT * 1000); // Convert timeout to microseconds
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else {
Lib.println("W: interrupt received, killing client...");
}
ctx.destroy();
return;
}
if (poller.pollin(1)) {
// We got a reply from the server, must match sequence
var reply = client.recvMsg().toString();
if (reply != null && Std.parseInt(reply) == sequence) {
Lib.println("I: server replied OK (" + reply + ")");
expectReply = false;
Sys.sleep(1.0); // One request per second
} else
Lib.println("E: malformed reply from server: " + reply);
} else {
Lib.println("W: no response from server, failing over");
// Old socket is confused; close it and open a new one
ctx.destroySocket(client);
server_nbr = (server_nbr + 1) % 2;
Sys.sleep(SETTLE_DELAY / 1000);
Lib.println("I: connecting to server at " + server[server_nbr]);
client = ctx.createSocket(ZMQ_REQ);
client.connect(server[server_nbr]);
poller.unregisterAllSockets();
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
ZMsg.newStringMsg(request).send(client);
}
}
}
ctx.destroy();
}
}bstarcli: Binary Star client in Java
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
// Binary Star client proof-of-concept implementation. This client does no
// real work; it just demonstrates the Binary Star failover model.
public class bstarcli
{
private static final long REQUEST_TIMEOUT = 1000; // msecs
private static final long SETTLE_DELAY = 2000; // Before failing over
public static void main(String[] argv) throws Exception
{
try (ZContext ctx = new ZContext()) {
String[] server = { "tcp://localhost:5001",
"tcp://localhost:5002" };
int serverNbr = 0;
System.out.printf("I: connecting to server at %s...\n",
server[serverNbr]);
Socket client = ctx.createSocket(SocketType.REQ);
client.connect(server[serverNbr]);
Poller poller = ctx.createPoller(1);
poller.register(client, ZMQ.Poller.POLLIN);
int sequence = 0;
while (!Thread.currentThread().isInterrupted()) {
// We send a request, then we work to get a reply
String request = String.format("%d", ++sequence);
client.send(request);
boolean expectReply = true;
while (expectReply) {
// Poll socket for a reply, with timeout
int rc = poller.poll(REQUEST_TIMEOUT);
if (rc == -1)
break; // Interrupted
// .split main body of client
// We use a Lazy Pirate strategy in the client. If there's
// no reply within our timeout, we close the socket and try
// again. In Binary Star, it's the client vote that
// decides which server is primary; the client must
// therefore try to connect to each server in turn:
if (poller.pollin(0)) {
// We got a reply from the server, must match getSequence
String reply = client.recvStr();
if (Integer.parseInt(reply) == sequence) {
System.out.printf("I: server replied OK (%s)\n", reply);
expectReply = false;
Thread.sleep(1000); // One request per second
}
else System.out.printf("E: bad reply from server: %s\n", reply);
}
else {
System.out.printf("W: no response from server, failing over\n");
// Old socket is confused; close it and open a new one
poller.unregister(client);
ctx.destroySocket(client);
serverNbr = (serverNbr + 1) % 2;
Thread.sleep(SETTLE_DELAY);
System.out.printf("I: connecting to server at %s...\n", server[serverNbr]);
client = ctx.createSocket(SocketType.REQ);
client.connect(server[serverNbr]);
poller.register(client, ZMQ.Poller.POLLIN);
// Send request again, on new socket
client.send(request);
}
}
}
}
}
}
bstarcli: Binary Star client in Julia
bstarcli: Binary Star client in Lua
bstarcli: Binary Star client in Node.js
bstarcli: Binary Star client in Objective-C
bstarcli: Binary Star client in ooc
bstarcli: Binary Star client in Perl
bstarcli: Binary Star client in PHP
bstarcli: Binary Star client in Python
from time import sleep
import zmq
REQUEST_TIMEOUT = 1000 # msecs
SETTLE_DELAY = 2000 # before failing over
def main():
server = ['tcp://localhost:5001', 'tcp://localhost:5002']
server_nbr = 0
ctx = zmq.Context()
client = ctx.socket(zmq.REQ)
client.connect(server[server_nbr])
poller = zmq.Poller()
poller.register(client, zmq.POLLIN)
sequence = 0
while True:
client.send_string("%s" % sequence)
expect_reply = True
while expect_reply:
socks = dict(poller.poll(REQUEST_TIMEOUT))
if socks.get(client) == zmq.POLLIN:
reply = client.recv_string()
if int(reply) == sequence:
print("I: server replied OK (%s)" % reply)
expect_reply = False
sequence += 1
sleep(1)
else:
print("E: malformed reply from server: %s" % reply)
else:
print("W: no response from server, failing over")
sleep(SETTLE_DELAY / 1000)
poller.unregister(client)
client.close()
server_nbr = (server_nbr + 1) % 2
print("I: connecting to server at %s.." % server[server_nbr])
client = ctx.socket(zmq.REQ)
poller.register(client, zmq.POLLIN)
# reconnect and resend request
client.connect(server[server_nbr])
client.send_string("%s" % sequence)
if __name__ == '__main__':
main()
bstarcli: Binary Star client in Q
bstarcli: Binary Star client in Racket
bstarcli: Binary Star client in Ruby
bstarcli: Binary Star client in Rust
bstarcli: Binary Star client in Scala
bstarcli: Binary Star client in Tcl
bstarcli: Binary Star client in OCaml
To test Binary Star, start the servers and client in any order:
bstarsrv -p # Start primary
bstarsrv -b # Start backup
bstarcli
You can then provoke failover by killing the primary server, and recovery by restarting the primary and killing the backup. Note how it’s the client vote that triggers failover, and recovery.
Binary star is driven by a finite state machine. Events are the peer state, so “Peer Active” means the other server has told us it’s active. “Client Request” means we’ve received a client request. “Client Vote” means we’ve received a client request AND our peer is inactive for two heartbeats.
Note that the servers use PUB-SUB sockets for state exchange. No other socket combination will work here. PUSH and DEALER block if there is no peer ready to receive a message. PAIR does not reconnect if the peer disappears and comes back. ROUTER needs the address of the peer before it can send it a message.
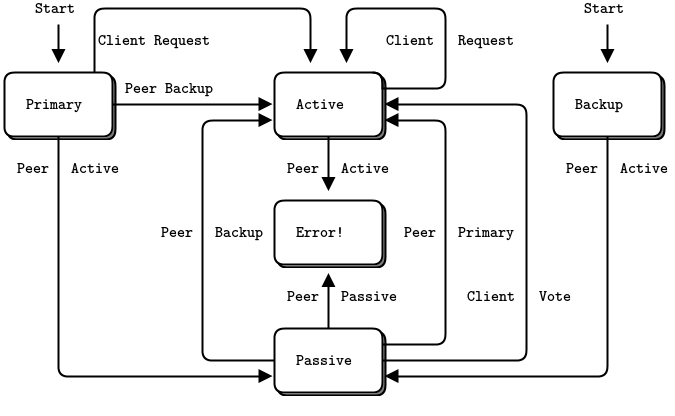
Binary Star Reactor #
Binary Star is useful and generic enough to package up as a reusable reactor class. The reactor then runs and calls our code whenever it has a message to process. This is much nicer than copying/pasting the Binary Star code into each server where we want that capability.
In C, we wrap the CZMQ zloop class that we saw before. zloop lets you register handlers to react on socket and timer events. In the Binary Star reactor, we provide handlers for voters and for state changes (active to passive, and vice versa). Here is the bstar API:
// Create a new Binary Star instance, using local (bind) and
// remote (connect) endpoints to set up the server peering.
bstar_t *bstar_new (int primary, char *local, char *remote);
// Destroy a Binary Star instance
void bstar_destroy (bstar_t **self_p);
// Return underlying zloop reactor, for timer and reader
// registration and cancelation.
zloop_t *bstar_zloop (bstar_t *self);
// Register voting reader
int bstar_voter (bstar_t *self, char *endpoint, int type,
zloop_fn handler, void *arg);
// Register main state change handlers
void bstar_new_active (bstar_t *self, zloop_fn handler, void *arg);
void bstar_new_passive (bstar_t *self, zloop_fn handler, void *arg);
// Start the reactor, which ends if a callback function returns -1,
// or the process received SIGINT or SIGTERM.
int bstar_start (bstar_t *self);
And here is the class implementation:
bstar: Binary Star core class in Ada
bstar: Binary Star core class in Basic
bstar: Binary Star core class in C
// bstar class - Binary Star reactor
#include "bstar.h"
// States we can be in at any point in time
typedef enum {
STATE_PRIMARY = 1, // Primary, waiting for peer to connect
STATE_BACKUP = 2, // Backup, waiting for peer to connect
STATE_ACTIVE = 3, // Active - accepting connections
STATE_PASSIVE = 4 // Passive - not accepting connections
} state_t;
// Events, which start with the states our peer can be in
typedef enum {
PEER_PRIMARY = 1, // HA peer is pending primary
PEER_BACKUP = 2, // HA peer is pending backup
PEER_ACTIVE = 3, // HA peer is active
PEER_PASSIVE = 4, // HA peer is passive
CLIENT_REQUEST = 5 // Client makes request
} event_t;
// Structure of our class
struct _bstar_t {
zctx_t *ctx; // Our private context
zloop_t *loop; // Reactor loop
void *statepub; // State publisher
void *statesub; // State subscriber
state_t state; // Current state
event_t event; // Current event
int64_t peer_expiry; // When peer is considered 'dead'
zloop_fn *voter_fn; // Voting socket handler
void *voter_arg; // Arguments for voting handler
zloop_fn *active_fn; // Call when become active
void *active_arg; // Arguments for handler
zloop_fn *passive_fn; // Call when become passive
void *passive_arg; // Arguments for handler
};
// The finite-state machine is the same as in the proof-of-concept server.
// To understand this reactor in detail, first read the CZMQ zloop class.
// .skip
// We send state information every this often
// If peer doesn't respond in two heartbeats, it is 'dead'
#define BSTAR_HEARTBEAT 1000 // In msecs
// Binary Star finite state machine (applies event to state)
// Returns -1 if there was an exception, 0 if event was valid.
static int
s_execute_fsm (bstar_t *self)
{
int rc = 0;
// Primary server is waiting for peer to connect
// Accepts CLIENT_REQUEST events in this state
if (self->state == STATE_PRIMARY) {
if (self->event == PEER_BACKUP) {
zclock_log ("I: connected to backup (passive), ready as active");
self->state = STATE_ACTIVE;
if (self->active_fn)
(self->active_fn) (self->loop, NULL, self->active_arg);
}
else
if (self->event == PEER_ACTIVE) {
zclock_log ("I: connected to backup (active), ready as passive");
self->state = STATE_PASSIVE;
if (self->passive_fn)
(self->passive_fn) (self->loop, NULL, self->passive_arg);
}
else
if (self->event == CLIENT_REQUEST) {
// Allow client requests to turn us into the active if we've
// waited sufficiently long to believe the backup is not
// currently acting as active (i.e., after a failover)
assert (self->peer_expiry > 0);
if (zclock_time () >= self->peer_expiry) {
zclock_log ("I: request from client, ready as active");
self->state = STATE_ACTIVE;
if (self->active_fn)
(self->active_fn) (self->loop, NULL, self->active_arg);
} else
// Don't respond to clients yet - it's possible we're
// performing a failback and the backup is currently active
rc = -1;
}
}
else
// Backup server is waiting for peer to connect
// Rejects CLIENT_REQUEST events in this state
if (self->state == STATE_BACKUP) {
if (self->event == PEER_ACTIVE) {
zclock_log ("I: connected to primary (active), ready as passive");
self->state = STATE_PASSIVE;
if (self->passive_fn)
(self->passive_fn) (self->loop, NULL, self->passive_arg);
}
else
if (self->event == CLIENT_REQUEST)
rc = -1;
}
else
// Server is active
// Accepts CLIENT_REQUEST events in this state
// The only way out of ACTIVE is death
if (self->state == STATE_ACTIVE) {
if (self->event == PEER_ACTIVE) {
// Two actives would mean split-brain
zclock_log ("E: fatal error - dual actives, aborting");
rc = -1;
}
}
else
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
if (self->state == STATE_PASSIVE) {
if (self->event == PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
zclock_log ("I: primary (passive) is restarting, ready as active");
self->state = STATE_ACTIVE;
}
else
if (self->event == PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
zclock_log ("I: backup (passive) is restarting, ready as active");
self->state = STATE_ACTIVE;
}
else
if (self->event == PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
zclock_log ("E: fatal error - dual passives, aborting");
rc = -1;
}
else
if (self->event == CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert (self->peer_expiry > 0);
if (zclock_time () >= self->peer_expiry) {
// If peer is dead, switch to the active state
zclock_log ("I: failover successful, ready as active");
self->state = STATE_ACTIVE;
}
else
// If peer is alive, reject connections
rc = -1;
}
// Call state change handler if necessary
if (self->state == STATE_ACTIVE && self->active_fn)
(self->active_fn) (self->loop, NULL, self->active_arg);
}
return rc;
}
static void
s_update_peer_expiry (bstar_t *self)
{
self->peer_expiry = zclock_time () + 2 * BSTAR_HEARTBEAT;
}
// Reactor event handlers...
// Publish our state to peer
int s_send_state (zloop_t *loop, int timer_id, void *arg)
{
bstar_t *self = (bstar_t *) arg;
zstr_sendf (self->statepub, "%d", self->state);
return 0;
}
// Receive state from peer, execute finite state machine
int s_recv_state (zloop_t *loop, zmq_pollitem_t *poller, void *arg)
{
bstar_t *self = (bstar_t *) arg;
char *state = zstr_recv (poller->socket);
if (state) {
self->event = atoi (state);
s_update_peer_expiry (self);
free (state);
}
return s_execute_fsm (self);
}
// Application wants to speak to us, see if it's possible
int s_voter_ready (zloop_t *loop, zmq_pollitem_t *poller, void *arg)
{
bstar_t *self = (bstar_t *) arg;
// If server can accept input now, call appl handler
self->event = CLIENT_REQUEST;
if (s_execute_fsm (self) == 0)
(self->voter_fn) (self->loop, poller, self->voter_arg);
else {
// Destroy waiting message, no-one to read it
zmsg_t *msg = zmsg_recv (poller->socket);
zmsg_destroy (&msg);
}
return 0;
}
// .until
// .split constructor
// This is the constructor for our {{bstar}} class. We have to tell it
// whether we're primary or backup server, as well as our local and
// remote endpoints to bind and connect to:
bstar_t *
bstar_new (int primary, char *local, char *remote)
{
bstar_t
*self;
self = (bstar_t *) zmalloc (sizeof (bstar_t));
// Initialize the Binary Star
self->ctx = zctx_new ();
self->loop = zloop_new ();
self->state = primary? STATE_PRIMARY: STATE_BACKUP;
// Create publisher for state going to peer
self->statepub = zsocket_new (self->ctx, ZMQ_PUB);
zsocket_bind (self->statepub, local);
// Create subscriber for state coming from peer
self->statesub = zsocket_new (self->ctx, ZMQ_SUB);
zsocket_set_subscribe (self->statesub, "");
zsocket_connect (self->statesub, remote);
// Set-up basic reactor events
zloop_timer (self->loop, BSTAR_HEARTBEAT, 0, s_send_state, self);
zmq_pollitem_t poller = { self->statesub, 0, ZMQ_POLLIN };
zloop_poller (self->loop, &poller, s_recv_state, self);
return self;
}
// .split destructor
// The destructor shuts down the bstar reactor:
void
bstar_destroy (bstar_t **self_p)
{
assert (self_p);
if (*self_p) {
bstar_t *self = *self_p;
zloop_destroy (&self->loop);
zctx_destroy (&self->ctx);
free (self);
*self_p = NULL;
}
}
// .split zloop method
// This method returns the underlying zloop reactor, so we can add
// additional timers and readers:
zloop_t *
bstar_zloop (bstar_t *self)
{
return self->loop;
}
// .split voter method
// This method registers a client voter socket. Messages received
// on this socket provide the CLIENT_REQUEST events for the Binary Star
// FSM and are passed to the provided application handler. We require
// exactly one voter per {{bstar}} instance:
int
bstar_voter (bstar_t *self, char *endpoint, int type, zloop_fn handler,
void *arg)
{
// Hold actual handler+arg so we can call this later
void *socket = zsocket_new (self->ctx, type);
zsocket_bind (socket, endpoint);
assert (!self->voter_fn);
self->voter_fn = handler;
self->voter_arg = arg;
zmq_pollitem_t poller = { socket, 0, ZMQ_POLLIN };
return zloop_poller (self->loop, &poller, s_voter_ready, self);
}
// .split register state-change handlers
// Register handlers to be called each time there's a state change:
void
bstar_new_active (bstar_t *self, zloop_fn handler, void *arg)
{
assert (!self->active_fn);
self->active_fn = handler;
self->active_arg = arg;
}
void
bstar_new_passive (bstar_t *self, zloop_fn handler, void *arg)
{
assert (!self->passive_fn);
self->passive_fn = handler;
self->passive_arg = arg;
}
// .split enable/disable tracing
// Enable/disable verbose tracing, for debugging:
void bstar_set_verbose (bstar_t *self, bool verbose)
{
zloop_set_verbose (self->loop, verbose);
}
// .split start the reactor
// Finally, start the configured reactor. It will end if any handler
// returns -1 to the reactor, or if the process receives SIGINT or SIGTERM:
int
bstar_start (bstar_t *self)
{
assert (self->voter_fn);
s_update_peer_expiry (self);
return zloop_start (self->loop);
}
bstar: Binary Star core class in C++
#include <zmqpp/zmqpp.hpp>
// We send state information every this often
// If peer doesn't respond in two heartbeats, it is 'dead'
#define BSTAR_HEARTBEAT 1000 // In msecs
// States we can be in at any point in time
typedef enum {
STATE_NOTSET = 0, // Before we start, or if the state is invalid
STATE_PRIMARY = 1, // Primary, waiting for peer to connect
STATE_BACKUP = 2, // Backup, waiting for peer to connect
STATE_ACTIVE = 3, // Active - accepting connections
STATE_PASSIVE = 4 // Passive - not accepting connections
} state_t;
// Events, which start with the states our peer can be in
typedef enum {
EVENT_NOTSET = 0, // Before we start, or if the event is invalid
PEER_PRIMARY = 1, // HA peer is pending primary
PEER_BACKUP = 2, // HA peer is pending backup
PEER_ACTIVE = 3, // HA peer is active
PEER_PASSIVE = 4, // HA peer is passive
CLIENT_REQUEST = 5 // Client makes request
} event_t;
class bstar_t {
public:
bstar_t() = delete;
bstar_t(bool primary, std::string local, std::string remote) {
this->ctx = new zmqpp::context_t();
this->loop = new zmqpp::loop();
this->m_state = primary ? STATE_PRIMARY : STATE_BACKUP;
// Create publisher for state going to peer
this->statepub = new zmqpp::socket_t(*this->ctx, zmqpp::socket_type::pub);
this->statepub->bind(local);
// Create subscriber for state coming from peer
this->statesub = new zmqpp::socket_t(*this->ctx, zmqpp::socket_type::sub);
this->statesub->subscribe("");
this->statesub->connect(remote);
// Set-up basic reactor events
this->loop->add(*this->statesub, std::bind(&bstar_t::s_recv_state, this));
this->loop->add(std::chrono::milliseconds(BSTAR_HEARTBEAT), 0, std::bind(&bstar_t::s_send_state, this));
}
~bstar_t() {
if (statepub) delete statepub;
if (statesub) delete statesub;
if (loop) delete loop;
if (ctx) delete ctx;
}
bstar_t(const bstar_t &) = delete;
bstar_t &operator=(const bstar_t &) = delete;
bstar_t(bstar_t &&src) = default;
bstar_t &operator=(bstar_t &&src) = default;
void set_state(state_t state) {
m_state = state;
}
state_t get_state() {
return m_state;
}
void set_peer_expiry(int64_t expiry) {
m_peer_expiry = expiry;
}
void set_voter(std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> fn, void *arg) {
voter_fn = fn;
voter_arg = arg;
}
void set_new_active(std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> fn, void *arg) {
active_fn = fn;
active_arg = arg;
}
void set_new_passive(std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> fn, void *arg) {
passive_fn = fn;
passive_arg = arg;
}
zmqpp::loop *get_loop() {
return loop;
}
// Binary Star finite state machine (applies event to state)
// Returns true if there was an exception, false if event was valid.
bool execute_fsm(event_t event) {
m_event = event;
bool exception = false;
// These are the PRIMARY and BACKUP states; we're waiting to become
// ACTIVE or PASSIVE depending on events we get from our peer:
if (m_state == STATE_PRIMARY) {
if (m_event == PEER_BACKUP) {
std::cout << "I: connected to backup (passive), ready active" << std::endl;
m_state = STATE_ACTIVE;
if (active_fn) {
active_fn(loop, nullptr, active_arg);
}
} else if (m_event == PEER_ACTIVE) {
std::cout << "I: connected to backup (active), ready passive" << std::endl;
m_state = STATE_PASSIVE;
if (passive_fn) {
passive_fn(loop, nullptr, passive_arg);
}
}
// Accept client connections
} else if (m_state == STATE_BACKUP) {
if (m_event == PEER_ACTIVE) {
std::cout << "I: connected to primary (active), ready passive" << std::endl;
m_state = STATE_PASSIVE;
if (passive_fn) {
passive_fn(loop, nullptr, passive_arg);
}
} else if (m_event == CLIENT_REQUEST) {
// Reject client connections when acting as backup
exception = true;
}
// .split active and passive states
// These are the ACTIVE and PASSIVE states:
} else if (m_state == STATE_ACTIVE) {
if (m_event == PEER_ACTIVE) {
std::cout << "E: fatal error - dual actives, aborting" << std::endl;
exception = true;
}
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
} else if (m_state == STATE_PASSIVE) {
if (m_event == PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
std::cout << "I: primary (passive) is restarting, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else if (m_event == PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
std::cout << "I: backup (passive) is restarting, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else if (m_event == PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
std::cout << "E: fatal error - dual passives, aborting" << std::endl;
exception = true;
} else if (m_event == CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert(m_peer_expiry > 0);
auto now = std::chrono::system_clock::now();
if (std::chrono::duration_cast<std::chrono::milliseconds>(now.time_since_epoch()).count() >= m_peer_expiry) {
std::cout << "I: failover successful, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else {
// If peer is alive, reject connections
exception = true;
}
}
// Call state change handler if necessary
if (m_state == STATE_ACTIVE && active_fn) {
active_fn(loop, nullptr, active_arg);
}
}
return exception;
}
void update_peer_expiry() {
m_peer_expiry = std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now().time_since_epoch()).count() + 2 * BSTAR_HEARTBEAT;
}
static bool s_send_state(bstar_t *self) {
zmqpp::message_t msg;
msg << static_cast<int>(self->m_state);
std::cout << "I: publishing state " << self->m_state << std::endl;
self->statepub->send(msg);
return true;
}
static bool s_recv_state(bstar_t *self) {
zmqpp::message_t msg;
bool rc = self->statesub->receive(msg);
if (rc) {
int state;
msg >> state;
self->m_event = static_cast<event_t>(state);
self->update_peer_expiry();
}
bool exception = self->execute_fsm(self->m_event);
return !exception;
}
static bool s_voter_ready(bstar_t *self, zmqpp::socket_t *socket) {
self->m_event = CLIENT_REQUEST;
if (self->execute_fsm(self->m_event) == false) {
if (self->voter_fn) {
self->voter_fn(self->loop, socket, self->voter_arg);
}
} else {
// Destroy waiting message, no-one to read it
zmqpp::message_t msg;
socket->receive(msg);
}
return true;
}
// .split voter method
// This method registers a client voter socket. Messages received
// on this socket provide the CLIENT_REQUEST events for the Binary Star
// FSM and are passed to the provided application handler. We require
// exactly one voter per {{bstar}} instance:
int register_voter(std::string endpoint, zmqpp::socket_type type, std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> fn, void *arg) {
zmqpp::socket_t *socket = new zmqpp::socket_t(*ctx, type);
socket->bind(endpoint);
assert(!voter_fn);
voter_fn = fn;
voter_arg = arg;
loop->add(*socket, std::bind(&bstar_t::s_voter_ready, this, socket));
return 0;
}
int start() {
assert(voter_fn);
update_peer_expiry();
loop->start();
return 0;
}
private:
zmqpp::context_t *ctx; // Our context
zmqpp::loop *loop; // Reactor loop
zmqpp::socket_t *statepub; // State publisher
zmqpp::socket_t *statesub; // State subscriber
state_t m_state; // Current state
event_t m_event; // Current event
int64_t m_peer_expiry; // When peer is considered 'dead', milliseconds
std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> voter_fn; // Voting socket handler
void *voter_arg; // Arguments for voting handler
std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> active_fn; // Call when become active
void *active_arg; // Arguments for handler
std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> passive_fn; // Call when become passive
void *passive_arg; // Arguments for handler
};
bstar: Binary Star core class in C#
bstar: Binary Star core class in CL
bstar: Binary Star core class in Delphi
bstar: Binary Star core class in Erlang
bstar: Binary Star core class in Elixir
bstar: Binary Star core class in F#
bstar: Binary Star core class in Felix
bstar: Binary Star core class in Go
bstar: Binary Star core class in Haskell
bstar: Binary Star core class in Haxe
package ;
import haxe.io.Bytes;
import haxe.Stack;
import neko.Sys;
import neko.Lib;
import org.zeromq.ZContext;
import org.zeromq.ZLoop;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZSocket;
// States we can be in at any time
private enum StateT {
STATE_PRIMARY; // Primary, waiting for peer to connect
STATE_BACKUP; // Backup, waiting for peer to connect
STATE_ACTIVE; // Active - accepting connections
STATE_PASSIVE; // Passive - not accepting connections
}
private enum EventT {
PEER_PRIMARY; // HA peer is pending primary
PEER_BACKUP; // HA peer is pending backup
PEER_ACTIVE; // HA peer is active
PEER_PASSIVE; // HA peer is passive
CLIENT_REQUEST; // Client makes request
}
/**
* Shortcut typedef for method signature of BStar reactor handler functions
*/
typedef HandlerFunctionType = ZLoop->ZMQSocket->Dynamic->Int;
/**
* Binary Star Reactor
*/
class BStar
{
/** We send state information every this often
* If peer doesn't respond in two heartbeats, it is 'dead'
*/
private static inline var BSTAR_HEARTBEAT = 100;
/** Our context */
private var ctx:ZContext;
/** Reactor loop */
public var loop(default, null):ZLoop;
/** State publisher socket */
private var statePub:ZMQSocket;
/** State subscriber socket */
private var stateSub:ZMQSocket;
/** Current state */
public var state(default, null):StateT;
/** Current event */
public var event(default, null):EventT;
/** When peer is considered 'dead' */
public var peerExpiry:Float;
/** Voting socket handler */
private var voterFn:HandlerFunctionType;
/** Arguments for voting handler */
private var voterArgs:Dynamic;
/** Master socket handler, called when become Master */
private var masterFn:HandlerFunctionType;
/** Arguments for Master handler */
private var masterArgs:Dynamic;
/** Slave socket handler, called when become Slave */
private var slaveFn:HandlerFunctionType;
/** Arguments for slave handler */
private var slaveArgs:Dynamic;
/** Print activity to stdout */
public var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/**
* BStar Constructor
* @param isPrimary True if this instance is the primary instance, else false if slave
* @param local Network address to bind the statePub socket of this instance to
* @param remote Network address to connect the stateSub socket of this instance to
* @param ?verbose True to generate logging info
* @param ?logger Logger function
*/
public function new(isPrimary:Bool, local:String, remote:String, ?verbose:Bool = false, ?logger:Dynamic->Void)
{
// Initialise the binary star server
ctx = new ZContext();
loop = new ZLoop(logger);
loop.verbose = verbose;
state = { if (isPrimary) STATE_PRIMARY; else STATE_BACKUP; };
// Create publisher for state going to peer
statePub = ctx.createSocket(ZMQ_PUB);
statePub.bind(local);
// Create subscriber for state coming from peer
stateSub = ctx.createSocket(ZMQ_SUB);
stateSub.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
stateSub.connect(remote);
// Set up basic reactor events
loop.registerTimer(BSTAR_HEARTBEAT, 0, sendState);
var item = { socket: stateSub, event: ZMQ.ZMQ_POLLIN() };
loop.registerPoller(item, recvState);
this.verbose = verbose;
if (logger != null)
log = logger;
else
log = Lib.println;
}
/**
* Destructor
* Cleans up internal ZLoop reactor object and ZContext objects.
*/
public function destroy() {
if (loop != null)
loop.destroy();
if (ctx != null)
ctx.destroy();
}
/**
* Create socket, bind to local endpoint, and register as reader for
* voting. The socket will only be available if the Binary Star state
* machine allows it. Input on the socket will act as a "vote" in the
* Binary Star scheme. We require exactly one voter per bstar instance.
*
* @param endpoint Endpoint address
* @param type Socket Type to bind to endpoint
* @param handler Voter Handler method
* @param args Optional args to pass to Voter Handfler method when called.
* @return
*/
public function setVoter(endpoint:String, type:SocketType, handler:HandlerFunctionType, ?args:Dynamic):Bool {
// Hold actual handler + arg so we can call this later
var socket = ctx.createSocket(type);
socket.bind(endpoint);
voterFn = handler;
voterArgs = args;
return loop.registerPoller( { socket:socket, event:ZMQ.ZMQ_POLLIN() }, voterReady);
}
/**
* Sets handler method called when instance becomes Master
* @param handler
* @param ?args
*/
public function setMaster(handler:HandlerFunctionType, ?args:Dynamic) {
if (masterFn == null) {
masterFn = handler;
masterArgs = args;
}
}
/**
* Sets handler method called when instance becomes Slave
* @param handler
* @param ?args
*/
public function setSlave(handler:HandlerFunctionType, ?args:Dynamic) {
if (slaveFn == null) {
slaveFn = handler;
slaveArgs = args;
}
}
/**
* Executes finite state machine (apply event to this state)
* Returns true if there was an exception
* @return
*/
public function stateMachine():Bool
{
var exception = false;
switch (state) {
case STATE_PRIMARY:
// Primary server is waiting for peer to connect
// Accepts CLIENT_REQUEST events in this state
switch (event) {
case PEER_BACKUP:
if (verbose)
log("I: connected to backup (slave), ready as master");
state = STATE_ACTIVE;
if (masterFn != null)
masterFn(loop, null, masterArgs);
case PEER_ACTIVE:
if (verbose)
log("I: connected to backup (master), ready as slave");
state = STATE_PASSIVE;
if (slaveFn != null)
slaveFn(loop, null, slaveArgs);
case CLIENT_REQUEST:
if (verbose)
log("I: request from client, ready as master");
state = STATE_ACTIVE;
if (masterFn != null)
masterFn(loop, null, masterArgs);
default:
}
case STATE_BACKUP:
// Backup server is waiting for peer to connect
// Rejects CLIENT_REQUEST events in this state
switch (event) {
case PEER_ACTIVE:
if (verbose)
log("I: connected to primary (master), ready as slave");
state = STATE_PASSIVE;
if (slaveFn != null)
slaveFn(loop, null, slaveArgs);
case CLIENT_REQUEST:
exception = true;
default:
}
case STATE_ACTIVE:
// Server is active
// Accepts CLIENT_REQUEST events in this state
switch (event) {
case PEER_ACTIVE:
// Two masters would mean split-brain
log("E: fatal error - dual masters, aborting");
exception = true;
default:
}
case STATE_PASSIVE:
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
switch (event) {
case PEER_PRIMARY:
// Peer is restarting - I become active, peer will go passive
if (verbose)
log("I: primary (slave) is restarting, ready as master");
state = STATE_ACTIVE;
case PEER_BACKUP:
// Peer is restarting - become active, peer will go passive
if (verbose)
log("I: backup (slave) is restarting, ready as master");
state = STATE_ACTIVE;
case PEER_PASSIVE:
// Two passives would mean cluster would be non-responsive
log("E: fatal error - dual slaves, aborting");
exception = true;
case CLIENT_REQUEST:
// Peer becomes master if timeout as passed
// It's the client request that triggers the failover
if (Date.now().getTime() >= peerExpiry) {
// If peer is dead, switch to the active state
if (verbose)
log("I: failover successful, ready as master");
state = STATE_ACTIVE;
} else {
if (verbose)
log("I: peer is active, so ignore connection");
exception = true;
}
default:
}
}
return exception;
}
/**
* Reactor event handler
* Publish our state to peer
* @param loop
* @param socket
* @param arg
* @return
*/
public function sendState(loop:ZLoop, socket:ZMQSocket):Int {
statePub.sendMsg(Bytes.ofString(Std.string(Type.enumIndex(state))));
return 0;
}
/**
* Reactor event handler
* Receive state from peer, execute finite state machine.
* @param loop
* @param socket
* @return
*/
public function recvState(loop:ZLoop, socket:ZMQSocket):Int {
var message = stateSub.recvMsg().toString();
event = Type.createEnumIndex(EventT, Std.parseInt(message));
peerExpiry = Date.now().getTime() + (2 * BSTAR_HEARTBEAT);
return {
if (stateMachine())
-1; // Error, so exit
else
0;
};
}
/**
* Application wants to speak to us, see if it's possible
* @param loop
* @param socket
* @return
*/
public function voterReady(loop:ZLoop, socket:ZMQSocket):Int {
// If server can accept input now, call application handler
event = CLIENT_REQUEST;
if (stateMachine()) {
// Destroy waiting message, no-one to read it
var msg = socket.recvMsg();
} else {
if (verbose)
log("I: CLIENT REQUEST");
voterFn(loop, socket, voterArgs);
}
return 0;
}
/**
* Start the reactor, ends if a callback function returns -1, or the
* process receives SIGINT or SIGTERM
* @return 0 if interrupted or invalid, -1 if cancelled by handler
*/
public function start():Int {
if (voterFn != null && loop != null)
return loop.start();
else
return 0;
}
}
bstar: Binary Star core class in Java
package guide;
import org.zeromq.*;
import org.zeromq.ZLoop.IZLoopHandler;
import org.zeromq.ZMQ.PollItem;
import org.zeromq.ZMQ.Socket;
// bstar class - Binary Star reactor
public class bstar
{
// States we can be in at any point in time
enum State
{
STATE_PRIMARY, // Primary, waiting for peer to connect
STATE_BACKUP, // Backup, waiting for peer to connect
STATE_ACTIVE, // Active - accepting connections
STATE_PASSIVE // Passive - not accepting connections
}
// Events, which start with the states our peer can be in
enum Event
{
PEER_PRIMARY, // HA peer is pending primary
PEER_BACKUP, // HA peer is pending backup
PEER_ACTIVE, // HA peer is active
PEER_PASSIVE, // HA peer is passive
CLIENT_REQUEST // Client makes request
}
private ZContext ctx; // Our private context
private ZLoop loop; // Reactor loop
private Socket statepub; // State publisher
private Socket statesub; // State subscriber
private State state; // Current state
private Event event; // Current event
private long peerExpiry; // When peer is considered 'dead'
private ZLoop.IZLoopHandler voterFn; // Voting socket handler
private Object voterArg; // Arguments for voting handler
private ZLoop.IZLoopHandler activeFn; // Call when become active
private Object activeArg; // Arguments for handler
private ZLoop.IZLoopHandler passiveFn; // Call when become passive
private Object passiveArg; // Arguments for handler
// The finite-state machine is the same as in the proof-of-concept server.
// To understand this reactor in detail, first read the ZLoop class.
// .skip
// We send state information this often
// If peer doesn't respond in two heartbeats, it is 'dead'
private final static int BSTAR_HEARTBEAT = 1000; // In msecs
// Binary Star finite state machine (applies event to state)
// Returns false if there was an exception, true if event was valid.
private boolean execute()
{
boolean rc = true;
// Primary server is waiting for peer to connect
// Accepts CLIENT_REQUEST events in this state
if (state == State.STATE_PRIMARY) {
if (event == Event.PEER_BACKUP) {
System.out.printf("I: connected to backup (passive), ready active\n");
state = State.STATE_ACTIVE;
if (activeFn != null)
activeFn.handle(loop, null, activeArg);
}
else if (event == Event.PEER_ACTIVE) {
System.out.printf("I: connected to backup (active), ready passive\n");
state = State.STATE_PASSIVE;
if (passiveFn != null)
passiveFn.handle(loop, null, passiveArg);
}
else if (event == Event.CLIENT_REQUEST) {
// Allow client requests to turn us into the active if we've
// waited sufficiently long to believe the backup is not
// currently acting as active (i.e., after a failover)
assert (peerExpiry > 0);
if (System.currentTimeMillis() >= peerExpiry) {
System.out.printf("I: request from client, ready as active\n");
state = State.STATE_ACTIVE;
if (activeFn != null)
activeFn.handle(loop, null, activeArg);
}
else
// Don't respond to clients yet - it's possible we're
// performing a failback and the backup is currently active
rc = false;
}
}
else if (state == State.STATE_BACKUP) {
if (event == Event.PEER_ACTIVE) {
System.out.printf("I: connected to primary (active), ready passive\n");
state = State.STATE_PASSIVE;
if (passiveFn != null)
passiveFn.handle(loop, null, passiveArg);
}
else
// Reject client connections when acting as backup
if (event == Event.CLIENT_REQUEST)
rc = false;
}
else
// .split active and passive states
// These are the ACTIVE and PASSIVE states:
if (state == State.STATE_ACTIVE) {
if (event == Event.PEER_ACTIVE) {
// Two actives would mean split-brain
System.out.printf("E: fatal error - dual actives, aborting\n");
rc = false;
}
}
else
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
if (state == State.STATE_PASSIVE) {
if (event == Event.PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
System.out.printf("I: primary (passive) is restarting, ready active\n");
state = State.STATE_ACTIVE;
}
else if (event == Event.PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
System.out.printf("I: backup (passive) is restarting, ready active\n");
state = State.STATE_ACTIVE;
}
else if (event == Event.PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
System.out.printf("E: fatal error - dual passives, aborting\n");
rc = false;
}
else if (event == Event.CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert (peerExpiry > 0);
if (System.currentTimeMillis() >= peerExpiry) {
// If peer is dead, switch to the active state
System.out.printf("I: failover successful, ready active\n");
state = State.STATE_ACTIVE;
}
else
// If peer is alive, reject connections
rc = false;
// Call state change handler if necessary
if (state == State.STATE_ACTIVE && activeFn != null)
activeFn.handle(loop, null, activeArg);
}
}
return rc;
}
private void updatePeerExpiry()
{
peerExpiry = System.currentTimeMillis() + 2 * BSTAR_HEARTBEAT;
}
// Reactor event handlers...
// Publish our state to peer
private static IZLoopHandler SendState = new IZLoopHandler()
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
bstar self = (bstar) arg;
self.statepub.send(String.format("%d", self.state.ordinal()));
return 0;
}
};
// Receive state from peer, execute finite state machine
private static IZLoopHandler RecvState = new IZLoopHandler()
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
bstar self = (bstar) arg;
String state = item.getSocket().recvStr();
if (state != null) {
self.event = Event.values()[Integer.parseInt(state)];
self.updatePeerExpiry();
}
return self.execute() ? 0 : -1;
}
};
// Application wants to speak to us, see if it's possible
private static IZLoopHandler VoterReady = new IZLoopHandler()
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
bstar self = (bstar) arg;
// If server can accept input now, call appl handler
self.event = Event.CLIENT_REQUEST;
if (self.execute())
self.voterFn.handle(loop, item, self.voterArg);
else {
// Destroy waiting message, no-one to read it
ZMsg msg = ZMsg.recvMsg(item.getSocket());
msg.destroy();
}
return 0;
}
};
// .until
// .split constructor
// This is the constructor for our {{bstar}} class. We have to tell it
// whether we're primary or backup server, as well as our local and
// remote endpoints to bind and connect to:
public bstar(boolean primary, String local, String remote)
{
// Initialize the Binary Star
ctx = new ZContext();
loop = new ZLoop(ctx);
state = primary ? State.STATE_PRIMARY : State.STATE_BACKUP;
// Create publisher for state going to peer
statepub = ctx.createSocket(SocketType.PUB);
statepub.bind(local);
// Create subscriber for state coming from peer
statesub = ctx.createSocket(SocketType.SUB);
statesub.subscribe(ZMQ.SUBSCRIPTION_ALL);
statesub.connect(remote);
// Set-up basic reactor events
loop.addTimer(BSTAR_HEARTBEAT, 0, SendState, this);
PollItem poller = new PollItem(statesub, ZMQ.Poller.POLLIN);
loop.addPoller(poller, RecvState, this);
}
// .split destructor
// The destructor shuts down the bstar reactor:
public void destroy()
{
loop.destroy();
ctx.destroy();
}
// .split zloop method
// This method returns the underlying zloop reactor, so we can add
// additional timers and readers:
public ZLoop zloop()
{
return loop;
}
// .split voter method
// This method registers a client voter socket. Messages received
// on this socket provide the CLIENT_REQUEST events for the Binary Star
// FSM and are passed to the provided application handler. We require
// exactly one voter per {{bstar}} instance:
public int voter(String endpoint, SocketType type, IZLoopHandler handler, Object arg)
{
// Hold actual handler+arg so we can call this later
Socket socket = ctx.createSocket(type);
socket.bind(endpoint);
voterFn = handler;
voterArg = arg;
PollItem poller = new PollItem(socket, ZMQ.Poller.POLLIN);
return loop.addPoller(poller, VoterReady, this);
}
// .split register state-change handlers
// Register handlers to be called each time there's a state change:
public void newActive(IZLoopHandler handler, Object arg)
{
activeFn = handler;
activeArg = arg;
}
public void newPassive(IZLoopHandler handler, Object arg)
{
passiveFn = handler;
passiveArg = arg;
}
// .split enable/disable tracing
// Enable/disable verbose tracing, for debugging:
public void setVerbose(boolean verbose)
{
loop.verbose(verbose);
}
// .split start the reactor
// Finally, start the configured reactor. It will end if any handler
// returns -1 to the reactor, or if the process receives Interrupt
public int start()
{
assert (voterFn != null);
updatePeerExpiry();
return loop.start();
}
}
bstar: Binary Star core class in Julia
bstar: Binary Star core class in Lua
bstar: Binary Star core class in Node.js
bstar: Binary Star core class in Objective-C
bstar: Binary Star core class in ooc
bstar: Binary Star core class in Perl
bstar: Binary Star core class in PHP
bstar: Binary Star core class in Python
"""
Binary Star server
Author: Min RK <benjaminrk@gmail.com>
"""
import time
import zmq
from zmq.eventloop.ioloop import IOLoop, PeriodicCallback
from zmq.eventloop.zmqstream import ZMQStream
# States we can be in at any point in time
STATE_PRIMARY = 1 # Primary, waiting for peer to connect
STATE_BACKUP = 2 # Backup, waiting for peer to connect
STATE_ACTIVE = 3 # Active - accepting connections
STATE_PASSIVE = 4 # Passive - not accepting connections
# Events, which start with the states our peer can be in
PEER_PRIMARY = 1 # HA peer is pending primary
PEER_BACKUP = 2 # HA peer is pending backup
PEER_ACTIVE = 3 # HA peer is active
PEER_PASSIVE = 4 # HA peer is passive
CLIENT_REQUEST = 5 # Client makes request
# We send state information every this often
# If peer doesn't respond in two heartbeats, it is 'dead'
HEARTBEAT = 1000 # In msecs
class FSMError(Exception):
"""Exception class for invalid state"""
pass
class BinaryStar(object):
def __init__(self, primary, local, remote):
# initialize the Binary Star
self.ctx = zmq.Context() # Our private context
self.loop = IOLoop.instance() # Reactor loop
self.state = STATE_PRIMARY if primary else STATE_BACKUP
self.event = None # Current event
self.peer_expiry = 0 # When peer is considered 'dead'
self.voter_callback = None # Voting socket handler
self.master_callback = None # Call when become master
self.slave_callback = None # Call when become slave
# Create publisher for state going to peer
self.statepub = self.ctx.socket(zmq.PUB)
self.statepub.bind(local)
# Create subscriber for state coming from peer
self.statesub = self.ctx.socket(zmq.SUB)
self.statesub.setsockopt_string(zmq.SUBSCRIBE, u'')
self.statesub.connect(remote)
# wrap statesub in ZMQStream for event triggers
self.statesub = ZMQStream(self.statesub, self.loop)
# setup basic reactor events
self.heartbeat = PeriodicCallback(self.send_state,
HEARTBEAT, self.loop)
self.statesub.on_recv(self.recv_state)
def update_peer_expiry(self):
"""Update peer expiry time to be 2 heartbeats from now."""
self.peer_expiry = time.time() + 2e-3 * HEARTBEAT
def start(self):
self.update_peer_expiry()
self.heartbeat.start()
return self.loop.start()
def execute_fsm(self):
"""Binary Star finite state machine (applies event to state)
returns True if connections should be accepted, False otherwise.
"""
accept = True
if self.state == STATE_PRIMARY:
# Primary server is waiting for peer to connect
# Accepts CLIENT_REQUEST events in this state
if self.event == PEER_BACKUP:
print("I: connected to backup (slave), ready as master")
self.state = STATE_ACTIVE
if self.master_callback:
self.loop.add_callback(self.master_callback)
elif self.event == PEER_ACTIVE:
print("I: connected to backup (master), ready as slave")
self.state = STATE_PASSIVE
if self.slave_callback:
self.loop.add_callback(self.slave_callback)
elif self.event == CLIENT_REQUEST:
if time.time() >= self.peer_expiry:
print("I: request from client, ready as master")
self.state = STATE_ACTIVE
if self.master_callback:
self.loop.add_callback(self.master_callback)
else:
# don't respond to clients yet - we don't know if
# the backup is currently Active as a result of
# a successful failover
accept = False
elif self.state == STATE_BACKUP:
# Backup server is waiting for peer to connect
# Rejects CLIENT_REQUEST events in this state
if self.event == PEER_ACTIVE:
print("I: connected to primary (master), ready as slave")
self.state = STATE_PASSIVE
if self.slave_callback:
self.loop.add_callback(self.slave_callback)
elif self.event == CLIENT_REQUEST:
accept = False
elif self.state == STATE_ACTIVE:
# Server is active
# Accepts CLIENT_REQUEST events in this state
# The only way out of ACTIVE is death
if self.event == PEER_ACTIVE:
# Two masters would mean split-brain
print("E: fatal error - dual masters, aborting")
raise FSMError("Dual Masters")
elif self.state == STATE_PASSIVE:
# Server is passive
# CLIENT_REQUEST events can trigger failover if peer looks dead
if self.event == PEER_PRIMARY:
# Peer is restarting - become active, peer will go passive
print("I: primary (slave) is restarting, ready as master")
self.state = STATE_ACTIVE
elif self.event == PEER_BACKUP:
# Peer is restarting - become active, peer will go passive
print("I: backup (slave) is restarting, ready as master")
self.state = STATE_ACTIVE
elif self.event == PEER_PASSIVE:
# Two passives would mean cluster would be non-responsive
print("E: fatal error - dual slaves, aborting")
raise FSMError("Dual slaves")
elif self.event == CLIENT_REQUEST:
# Peer becomes master if timeout has passed
# It's the client request that triggers the failover
assert self.peer_expiry > 0
if time.time() >= self.peer_expiry:
# If peer is dead, switch to the active state
print("I: failover successful, ready as master")
self.state = STATE_ACTIVE
else:
# If peer is alive, reject connections
accept = False
# Call state change handler if necessary
if self.state == STATE_ACTIVE and self.master_callback:
self.loop.add_callback(self.master_callback)
return accept
# ---------------------------------------------------------------------
# Reactor event handlers...
def send_state(self):
"""Publish our state to peer"""
self.statepub.send_string("%d" % self.state)
def recv_state(self, msg):
"""Receive state from peer, execute finite state machine"""
state = msg[0]
if state:
self.event = int(state)
self.update_peer_expiry()
self.execute_fsm()
def voter_ready(self, msg):
"""Application wants to speak to us, see if it's possible"""
# If server can accept input now, call appl handler
self.event = CLIENT_REQUEST
if self.execute_fsm():
print("CLIENT REQUEST")
self.voter_callback(self.voter_socket, msg)
else:
# Message will be ignored
pass
# -------------------------------------------------------------------------
#
def register_voter(self, endpoint, type, handler):
"""Create socket, bind to local endpoint, and register as reader for
voting. The socket will only be available if the Binary Star state
machine allows it. Input on the socket will act as a "vote" in the
Binary Star scheme. We require exactly one voter per bstar instance.
handler will always be called with two arguments: (socket,msg)
where socket is the one we are creating here, and msg is the message
that triggered the POLLIN event.
"""
assert self.voter_callback is None
socket = self.ctx.socket(type)
socket.bind(endpoint)
self.voter_socket = socket
self.voter_callback = handler
stream = ZMQStream(socket, self.loop)
stream.on_recv(self.voter_ready)
bstar: Binary Star core class in Q
bstar: Binary Star core class in Racket
bstar: Binary Star core class in Ruby
bstar: Binary Star core class in Rust
bstar: Binary Star core class in Scala
bstar: Binary Star core class in Tcl
bstar: Binary Star core class in OCaml
This gives us the following short main program for the server:
bstarsrv2: Binary Star server, using core class in Ada
bstarsrv2: Binary Star server, using core class in Basic
bstarsrv2: Binary Star server, using core class in C
// Binary Star server, using bstar reactor
// Lets us build this source without creating a library
#include "bstar.c"
// Echo service
int s_echo (zloop_t *loop, zmq_pollitem_t *poller, void *arg)
{
zmsg_t *msg = zmsg_recv (poller->socket);
zmsg_send (&msg, poller->socket);
return 0;
}
int main (int argc, char *argv [])
{
// Arguments can be either of:
// -p primary server, at tcp://localhost:5001
// -b backup server, at tcp://localhost:5002
bstar_t *bstar;
if (argc == 2 && streq (argv [1], "-p")) {
printf ("I: Primary active, waiting for backup (passive)\n");
bstar = bstar_new (BSTAR_PRIMARY,
"tcp://*:5003", "tcp://localhost:5004");
bstar_voter (bstar, "tcp://*:5001", ZMQ_ROUTER, s_echo, NULL);
}
else
if (argc == 2 && streq (argv [1], "-b")) {
printf ("I: Backup passive, waiting for primary (active)\n");
bstar = bstar_new (BSTAR_BACKUP,
"tcp://*:5004", "tcp://localhost:5003");
bstar_voter (bstar, "tcp://*:5002", ZMQ_ROUTER, s_echo, NULL);
}
else {
printf ("Usage: bstarsrvs { -p | -b }\n");
exit (0);
}
bstar_start (bstar);
bstar_destroy (&bstar);
return 0;
}
bstarsrv2: Binary Star server, using core class in C++
// Binary Star server, using bstar reactor
#include "bstar.hpp"
// Echo service
void s_echo(zmqpp::loop *loop, zmqpp::socket_t *socket, void *arg) {
zmqpp::message_t msg;
socket->receive(msg);
socket->send(msg);
}
int main(int argc, char *argv []) {
// Arguments can be either of:
// -p primary server, at tcp://localhost:5001
// -b backup server, at tcp://localhost:5002
bstar_t *bstar = nullptr;
if (argc == 2 && strcmp(argv[1], "-p") == 0) {
std::cout << "I: Primary active, waiting for backup (passive)" << std::endl;
bstar = new bstar_t(true, "tcp://*:5003", "tcp://localhost:5004");
bstar->register_voter("tcp://*:5001", zmqpp::socket_type::router, s_echo, NULL);
} else if (argc == 2 && strcmp(argv[1], "-b") == 0) {
std::cout << "I: Backup passive, waiting for primary (active)" << std::endl;
bstar = new bstar_t(false, "tcp://*:5004", "tcp://localhost:5003");
bstar->register_voter("tcp://*:5002", zmqpp::socket_type::router, s_echo, NULL);
} else {
std::cout << "Usage: bstarsrv2 { -p | -b }" << std::endl;
return 0;
}
try {
std::cout << "starting bstar...\n";
bstar->start();
} catch (const std::exception &e) {
std::cerr << "Exception: " << e.what() << std::endl;
}
delete bstar;
return 0;
}
bstarsrv2: Binary Star server, using core class in C#
bstarsrv2: Binary Star server, using core class in CL
bstarsrv2: Binary Star server, using core class in Delphi
bstarsrv2: Binary Star server, using core class in Erlang
bstarsrv2: Binary Star server, using core class in Elixir
bstarsrv2: Binary Star server, using core class in F#
bstarsrv2: Binary Star server, using core class in Felix
bstarsrv2: Binary Star server, using core class in Go
bstarsrv2: Binary Star server, using core class in Haskell
bstarsrv2: Binary Star server, using core class in Haxe
package ;
/**
* Binary Star server, using BStar reactor class
* @author Richard J Smith
*
* See: http://zguide.zeromq.org/page:all#Binary-Star-Reactor
*/
import BStar;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZLoop;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
class BStarSrv2
{
/**
* Echo service
* @param loop
* @param socket
* @return
*/
private static function echo(loop:ZLoop, socket:ZMQSocket, args:Dynamic):Int {
var msg = ZMsg.recvMsg(socket);
msg.send(socket);
return 0;
}
public static function main() {
Lib.println("** BStarSrv2 (see: http://zguide.zeromq.org/page:all#Binary-Star-Reactor)");
var bstar:BStar = null;
// Arguments can be either of:
// -p primary server, at tcp://localhost:5001
// -b backup server, at tcp://localhost:5002
var argArr = Sys.args();
if (argArr.length > 1 && argArr[argArr.length - 1] == "-p") {
Lib.println("I: primary master, waiting for backup (slave)");
bstar = new BStar(true, "tcp://*:5003", "tcp://localhost:5004", true, null);
bstar.setVoter("tcp://*:5001", ZMQ_ROUTER, echo);
} else if (argArr.length > 1 && argArr[argArr.length - 1] == "-b") {
Lib.println("I: backup slave, waiting for primary (master)");
bstar = new BStar(false, "tcp://*:5004", "tcp://localhost:5003", true, null);
bstar.setVoter("tcp://*:5002", ZMQ_ROUTER, echo);
} else {
Lib.println("Usage: bstartsrv2 { -p | -b }");
return;
}
bstar.start();
bstar.destroy();
}
}bstarsrv2: Binary Star server, using core class in Java
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZLoop;
import org.zeromq.ZLoop.IZLoopHandler;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.PollItem;
import org.zeromq.ZMsg;
// Binary Star server, using bstar reactor
public class bstarsrv2
{
private static IZLoopHandler Echo = new IZLoopHandler()
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
ZMsg msg = ZMsg.recvMsg(item.getSocket());
msg.send(item.getSocket());
return 0;
}
};
public static void main(String[] argv)
{
// Arguments can be either of:
// -p primary server, at tcp://localhost:5001
// -b backup server, at tcp://localhost:5002
bstar bs = null;
if (argv.length == 1 && argv[0].equals("-p")) {
System.out.printf("I: Primary active, waiting for backup (passive)\n");
bs = new bstar(true, "tcp://*:5003", "tcp://localhost:5004");
bs.voter("tcp://*:5001", SocketType.ROUTER, Echo, null);
}
else if (argv.length == 1 && argv[0].equals("-b")) {
System.out.printf("I: Backup passive, waiting for primary (active)\n");
bs = new bstar(false, "tcp://*:5004", "tcp://localhost:5003");
bs.voter("tcp://*:5002", SocketType.ROUTER, Echo, null);
}
else {
System.out.printf("Usage: bstarsrv { -p | -b }\n");
System.exit(0);
}
bs.start();
bs.destroy();
}
}
bstarsrv2: Binary Star server, using core class in Julia
bstarsrv2: Binary Star server, using core class in Lua
bstarsrv2: Binary Star server, using core class in Node.js
bstarsrv2: Binary Star server, using core class in Objective-C
bstarsrv2: Binary Star server, using core class in ooc
bstarsrv2: Binary Star server, using core class in Perl
bstarsrv2: Binary Star server, using core class in PHP
bstarsrv2: Binary Star server, using core class in Python
"""
Binary Star server, using bstar reactor
Author: Min RK <benjaminrk@gmail.com>
"""
import sys
import zmq
from bstar import BinaryStar
def echo(socket, msg):
"""Echo service"""
socket.send_multipart(msg)
def main():
# Arguments can be either of:
# -p primary server, at tcp://localhost:5001
# -b backup server, at tcp://localhost:5002
if '-p' in sys.argv:
star = BinaryStar(True, "tcp://*:5003", "tcp://localhost:5004")
star.register_voter("tcp://*:5001", zmq.ROUTER, echo)
elif '-b' in sys.argv:
star = BinaryStar(False, "tcp://*:5004", "tcp://localhost:5003")
star.register_voter("tcp://*:5002", zmq.ROUTER, echo)
else:
print("Usage: bstarsrv2.py { -p | -b }\n")
return
star.start()
if __name__ == '__main__':
main()
bstarsrv2: Binary Star server, using core class in Q
bstarsrv2: Binary Star server, using core class in Racket
bstarsrv2: Binary Star server, using core class in Ruby
bstarsrv2: Binary Star server, using core class in Rust
bstarsrv2: Binary Star server, using core class in Scala
bstarsrv2: Binary Star server, using core class in Tcl
bstarsrv2: Binary Star server, using core class in OCaml
Brokerless Reliability (Freelance Pattern) #
It might seem ironic to focus so much on broker-based reliability, when we often explain ZeroMQ as “brokerless messaging”. However, in messaging, as in real life, the middleman is both a burden and a benefit. In practice, most messaging architectures benefit from a mix of distributed and brokered messaging. You get the best results when you can decide freely what trade-offs you want to make. This is why I can drive twenty minutes to a wholesaler to buy five cases of wine for a party, but I can also walk ten minutes to a corner store to buy one bottle for a dinner. Our highly context-sensitive relative valuations of time, energy, and cost are essential to the real world economy. And they are essential to an optimal message-based architecture.
This is why ZeroMQ does not impose a broker-centric architecture, though it does give you the tools to build brokers, aka proxies, and we’ve built a dozen or so different ones so far, just for practice.
So we’ll end this chapter by deconstructing the broker-based reliability we’ve built so far, and turning it back into a distributed peer-to-peer architecture I call the Freelance pattern. Our use case will be a name resolution service. This is a common problem with ZeroMQ architectures: how do we know the endpoint to connect to? Hard-coding TCP/IP addresses in code is insanely fragile. Using configuration files creates an administration nightmare. Imagine if you had to hand-configure your web browser, on every PC or mobile phone you used, to realize that “google.com” was “74.125.230.82”.
A ZeroMQ name service (and we’ll make a simple implementation) must do the following:
-
Resolve a logical name into at least a bind endpoint, and a connect endpoint. A realistic name service would provide multiple bind endpoints, and possibly multiple connect endpoints as well.
-
Allow us to manage multiple parallel environments, e.g., “test” versus “production”, without modifying code.
-
Be reliable, because if it is unavailable, applications won’t be able to connect to the network.
Putting a name service behind a service-oriented Majordomo broker is clever from some points of view. However, it’s simpler and much less surprising to just expose the name service as a server to which clients can connect directly. If we do this right, the name service becomes the only global network endpoint we need to hard-code in our code or configuration files.
The types of failure we aim to handle are server crashes and restarts, server busy looping, server overload, and network issues. To get reliability, we’ll create a pool of name servers so if one crashes or goes away, clients can connect to another, and so on. In practice, two would be enough. But for the example, we’ll assume the pool can be any size.
In this architecture, a large set of clients connect to a small set of servers directly. The servers bind to their respective addresses. It’s fundamentally different from a broker-based approach like Majordomo, where workers connect to the broker. Clients have a couple of options:
-
Use REQ sockets and the Lazy Pirate pattern. Easy, but would need some additional intelligence so clients don’t stupidly try to reconnect to dead servers over and over.
-
Use DEALER sockets and blast out requests (which will be load balanced to all connected servers) until they get a reply. Effective, but not elegant.
-
Use ROUTER sockets so clients can address specific servers. But how does the client know the identity of the server sockets? Either the server has to ping the client first (complex), or the server has to use a hard-coded, fixed identity known to the client (nasty).
We’ll develop each of these in the following subsections.
Model One: Simple Retry and Failover #
So our menu appears to offer: simple, brutal, complex, or nasty. Let’s start with simple and then work out the kinks. We take Lazy Pirate and rewrite it to work with multiple server endpoints.
Start one or several servers first, specifying a bind endpoint as the argument:
flserver1: Freelance server, Model One in Ada
flserver1: Freelance server, Model One in Basic
flserver1: Freelance server, Model One in C
// Freelance server - Model 1
// Trivial echo service
#include "czmq.h"
int main (int argc, char *argv [])
{
if (argc < 2) {
printf ("I: syntax: %s <endpoint>\n", argv [0]);
return 0;
}
zctx_t *ctx = zctx_new ();
void *server = zsocket_new (ctx, ZMQ_REP);
zsocket_bind (server, argv [1]);
printf ("I: echo service is ready at %s\n", argv [1]);
while (true) {
zmsg_t *msg = zmsg_recv (server);
if (!msg)
break; // Interrupted
zmsg_send (&msg, server);
}
if (zctx_interrupted)
printf ("W: interrupted\n");
zctx_destroy (&ctx);
return 0;
}
flserver1: Freelance server, Model One in C++
// Freelance server - Model 1
// Trivial echo service
#include <iostream>
#include <zmq.hpp>
int main(int argc, char* argv[]) {
if (argc < 2) {
std::cout << "I: syntax: " << argv[0] << " <endpoint>" << std::endl;
return 0;
}
zmq::context_t context{1};
zmq::socket_t server(context, zmq::socket_type::rep);
server.bind(argv[1]);
std::cout << "I: echo service is ready at " << argv[1] << std::endl;
while (true) {
zmq::message_t message;
try {
server.recv(message, zmq::recv_flags::none);
} catch (zmq::error_t& e) {
if (e.num() == EINTR)
std::cout << "W: interrupted" << std::endl;
else
std::cout << "E: error, errnum = " << e.num() << ", what = " << e.what()
<< std::endl;
break; // Interrupted
}
server.send(message, zmq::send_flags::none);
}
return 0;
}
flserver1: Freelance server, Model One in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
public static void FLServer1(string[] args)
{
//
// Freelance server - Model 1
// Trivial echo service
//
// Author: metadings
//
if (args == null || args.Length < 1)
{
Console.WriteLine();
Console.WriteLine("Usage: ./{0} FLServer1 [Endpoint]", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
Console.WriteLine(" Endpoint Where FLServer1 should bind on.");
Console.WriteLine(" Default is tcp://127.0.0.1:7780");
Console.WriteLine();
args = new string[] { "tcp://127.0.0.1:7780" };
}
using (var context = new ZContext())
using (var server = new ZSocket(context, ZSocketType.REP))
{
server.Bind(args[0]);
Console.WriteLine("I: echo service is ready at {0}", args[0]);
ZMessage message;
ZError error;
while (true)
{
if (null != (message = server.ReceiveMessage(out error)))
{
using (message)
{
server.Send(message);
}
}
else
{
if (error == ZError.ETERM)
return; // Interrupted
throw new ZException(error);
}
}
}
}
}
}
flserver1: Freelance server, Model One in CL
flserver1: Freelance server, Model One in Delphi
flserver1: Freelance server, Model One in Erlang
flserver1: Freelance server, Model One in Elixir
flserver1: Freelance server, Model One in F#
flserver1: Freelance server, Model One in Felix
flserver1: Freelance server, Model One in Go
flserver1: Freelance server, Model One in Haskell
flserver1: Freelance server, Model One in Haxe
flserver1: Freelance server, Model One in Java
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZMsg;
// Freelance server - Model 1
// Trivial echo service
public class flserver1
{
public static void main(String[] args)
{
if (args.length < 1) {
System.out.printf("I: syntax: flserver1 <endpoint>\n");
System.exit(0);
}
try (ZContext ctx = new ZContext()) {
Socket server = ctx.createSocket(SocketType.REP);
server.bind(args[0]);
System.out.printf("I: echo service is ready at %s\n", args[0]);
while (true) {
ZMsg msg = ZMsg.recvMsg(server);
if (msg == null)
break; // Interrupted
msg.send(server);
}
if (Thread.currentThread().isInterrupted())
System.out.printf("W: interrupted\n");
}
}
}
flserver1: Freelance server, Model One in Julia
flserver1: Freelance server, Model One in Lua
--
-- Freelance server - Model 1
-- Trivial echo service
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmsg"
require"zmq"
if (#arg < 1) then
printf("I: syntax: %s <endpoint>\n", arg[0])
os.exit(0)
end
local context = zmq.init(1)
s_catch_signals()
-- Implement basic echo service
local server = context:socket(zmq.REP)
server:bind(arg[1])
printf("I: echo service is ready at %s\n", arg[1])
while (not s_interrupted) do
local msg, err = zmsg.recv(server)
if err then
print('recv error:', err)
break -- Interrupted
end
msg:send(server)
end
if (s_interrupted) then
printf("W: interrupted\n")
end
server:close()
context:term()
flserver1: Freelance server, Model One in Node.js
flserver1: Freelance server, Model One in Objective-C
flserver1: Freelance server, Model One in ooc
flserver1: Freelance server, Model One in Perl
flserver1: Freelance server, Model One in PHP
<?php
/*
* Freelance server - Model 1
* Trivial echo service
*
* Author: Rob Gagnon <rgagnon24(at)gmail(dot)com>
*/
if (count($argv) < 2) {
printf("I: Syntax: %s <endpoint>\n", $argv[0]);
exit;
}
$endpoint = $argv[1];
$context = new ZMQContext();
$server = $context->getSocket(ZMQ::SOCKET_REP);
$server->bind($endpoint);
printf("I: Echo service is ready at %s\n", $endpoint);
while (true) {
$msg = $server->recvMulti();
$server->sendMulti($msg);
}
flserver1: Freelance server, Model One in Python
#
# Freelance server - Model 1
# Trivial echo service
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import sys
import zmq
if len(sys.argv) < 2:
print "I: Syntax: %s <endpoint>" % sys.argv[0]
sys.exit(0)
endpoint = sys.argv[1]
context = zmq.Context()
server = context.socket(zmq.REP)
server.bind(endpoint)
print "I: Echo service is ready at %s" % endpoint
while True:
msg = server.recv_multipart()
if not msg:
break # Interrupted
server.send_multipart(msg)
server.setsockopt(zmq.LINGER, 0) # Terminate immediately
flserver1: Freelance server, Model One in Q
flserver1: Freelance server, Model One in Racket
flserver1: Freelance server, Model One in Ruby
flserver1: Freelance server, Model One in Rust
flserver1: Freelance server, Model One in Scala
flserver1: Freelance server, Model One in Tcl
flserver1: Freelance server, Model One in OCaml
Then start the client, specifying one or more connect endpoints as arguments:
flclient1: Freelance client, Model One in Ada
flclient1: Freelance client, Model One in Basic
flclient1: Freelance client, Model One in C
// Freelance client - Model 1
// Uses REQ socket to query one or more services
#include "czmq.h"
#define REQUEST_TIMEOUT 1000
#define MAX_RETRIES 3 // Before we abandon
static zmsg_t *
s_try_request (zctx_t *ctx, char *endpoint, zmsg_t *request)
{
printf ("I: trying echo service at %s...\n", endpoint);
void *client = zsocket_new (ctx, ZMQ_REQ);
zsocket_connect (client, endpoint);
// Send request, wait safely for reply
zmsg_t *msg = zmsg_dup (request);
zmsg_send (&msg, client);
zmq_pollitem_t items [] = { { client, 0, ZMQ_POLLIN, 0 } };
zmq_poll (items, 1, REQUEST_TIMEOUT * ZMQ_POLL_MSEC);
zmsg_t *reply = NULL;
if (items [0].revents & ZMQ_POLLIN)
reply = zmsg_recv (client);
// Close socket in any case, we're done with it now
zsocket_destroy (ctx, client);
return reply;
}
// .split client task
// The client uses a Lazy Pirate strategy if it only has one server to talk
// to. If it has two or more servers to talk to, it will try each server just
// once:
int main (int argc, char *argv [])
{
zctx_t *ctx = zctx_new ();
zmsg_t *request = zmsg_new ();
zmsg_addstr (request, "Hello world");
zmsg_t *reply = NULL;
int endpoints = argc - 1;
if (endpoints == 0)
printf ("I: syntax: %s <endpoint> ...\n", argv [0]);
else
if (endpoints == 1) {
// For one endpoint, we retry N times
int retries;
for (retries = 0; retries < MAX_RETRIES; retries++) {
char *endpoint = argv [1];
reply = s_try_request (ctx, endpoint, request);
if (reply)
break; // Successful
printf ("W: no response from %s, retrying...\n", endpoint);
}
}
else {
// For multiple endpoints, try each at most once
int endpoint_nbr;
for (endpoint_nbr = 0; endpoint_nbr < endpoints; endpoint_nbr++) {
char *endpoint = argv [endpoint_nbr + 1];
reply = s_try_request (ctx, endpoint, request);
if (reply)
break; // Successful
printf ("W: no response from %s\n", endpoint);
}
}
if (reply)
printf ("Service is running OK\n");
zmsg_destroy (&request);
zmsg_destroy (&reply);
zctx_destroy (&ctx);
return 0;
}
flclient1: Freelance client, Model One in C++
// Freelance client - Model 1
// Uses REQ socket to query one or more services
#include <iostream>
#include <zmq.hpp>
#include <zmq_addon.hpp>
const int REQUEST_TIMEOUT = 1000;
const int MAX_RETRIES = 3; // Before we abandon
static std::unique_ptr<zmq::message_t> s_try_request(zmq::context_t &context,
const std::string &endpoint,
const zmq::const_buffer &request) {
std::cout << "I: trying echo service at " << endpoint << std::endl;
zmq::socket_t client(context, zmq::socket_type::req);
// Set ZMQ_LINGER to REQUEST_TIMEOUT milliseconds, otherwise if we send a message to a server
// that is not working properly or even not exist, we may never be able to exit the program
client.setsockopt(ZMQ_LINGER, REQUEST_TIMEOUT);
client.connect(endpoint);
// Send request, wait safely for reply
zmq::message_t message(request.data(), request.size());
client.send(message, zmq::send_flags::none);
zmq_pollitem_t items[] = {{client, 0, ZMQ_POLLIN, 0}};
zmq::poll(items, 1, REQUEST_TIMEOUT);
std::unique_ptr<zmq::message_t> reply = std::make_unique<zmq::message_t>();
zmq::recv_result_t recv_result;
if (items[0].revents & ZMQ_POLLIN) recv_result = client.recv(*reply, zmq::recv_flags::none);
if (!recv_result) {
reply.release();
}
return reply;
}
// .split client task
// The client uses a Lazy Pirate strategy if it only has one server to talk
// to. If it has two or more servers to talk to, it will try each server just
// once:
int main(int argc, char *argv[]) {
zmq::context_t context{1};
zmq::const_buffer request = zmq::str_buffer("Hello World!");
std::unique_ptr<zmq::message_t> reply;
int endpoints = argc - 1;
if (endpoints == 0)
std::cout << "I: syntax: " << argv[0] << "<endpoint> ..." << std::endl;
else if (endpoints == 1) {
// For one endpoint, we retry N times
int retries;
for (retries = 0; retries < MAX_RETRIES; retries++) {
std::string endpoint = std::string(argv[1]);
reply = s_try_request(context, endpoint, request);
if (reply) break; // Successful
std::cout << "W: no response from " << endpoint << " retrying...\n" << std::endl;
}
} else {
// For multiple endpoints, try each at most once
int endpoint_nbr;
for (endpoint_nbr = 0; endpoint_nbr < endpoints; endpoint_nbr++) {
std::string endpoint = std::string(argv[endpoint_nbr + 1]);
reply = s_try_request(context, endpoint, request);
if (reply) break; // Successful
std::cout << "W: no response from " << endpoint << std::endl;
}
}
if (reply)
std::cout << "Service is running OK. Received message: " << reply->to_string() << std::endl;
return 0;
}
flclient1: Freelance client, Model One in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
static readonly TimeSpan FLClient1_REQUEST_TIMEOUT = TimeSpan.FromMilliseconds(2500);
static int FLClient1_MAX_RETRIES = 3; // Before we abandon
public static void FLClient1(string[] args)
{
//
// Freelance client - Model 1
// Uses REQ socket to query one or more services
//
// Author: metadings
//
if (args == null || args.Length < 1)
{
Console.WriteLine();
Console.WriteLine("Usage: ./{0} FLClient1 [Endpoint]", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
Console.WriteLine(" Endpoint Where FLClient1 should connect to.");
Console.WriteLine(" Default is tcp://127.0.0.1:7780");
Console.WriteLine();
args = new string[] { "tcp://127.0.0.1:7780" };
}
// The client uses a Lazy Pirate strategy if it only has one server to talk
// to. If it has two or more servers to talk to, it will try each server just
// once:
using (var context = new ZContext())
using (var request = new ZFrame("Hello World"))
{
ZFrame reply = null;
if (args.Length == 1)
{
// For one endpoint, we retry N times
string endpoint = args[0];
for (int retries = 0; retries < FLClient1_MAX_RETRIES; ++retries)
{
if (null != (reply = FLClient1_TryRequest(context, endpoint, request)))
{
break; // Successful
}
Console.WriteLine("W: no response from {0}, retrying...", endpoint);
}
}
else
{
// For multiple endpoints, try each at most once
for (int endpoint_nbr = 0; endpoint_nbr < args.Length; ++endpoint_nbr)
{
string endpoint = args[endpoint_nbr];
if (null != (reply = FLClient1_TryRequest(context, endpoint, request)))
{
break; // Successful
}
Console.WriteLine("W: no response from {0}, retrying...", endpoint);
}
}
if (reply != null)
{
Console.WriteLine("Service is running OK");
}
}
}
static ZFrame FLClient1_TryRequest(ZContext context, string endpoint, ZFrame request)
{
Console.WriteLine("I: trying echo service at {0}...", endpoint);
using (var client = new ZSocket(context, ZSocketType.REQ))
{
client.Connect(endpoint);
// Send request, wait safely for reply
using (var message = ZFrame.CopyFrom(request))
{
client.Send(message);
}
var poll = ZPollItem.CreateReceiver();
ZError error;
ZMessage incoming;
if (client.PollIn(poll, out incoming, out error, FLClient1_REQUEST_TIMEOUT))
{
return incoming[0];
}
}
return null;
}
}
}
flclient1: Freelance client, Model One in CL
flclient1: Freelance client, Model One in Delphi
flclient1: Freelance client, Model One in Erlang
flclient1: Freelance client, Model One in Elixir
flclient1: Freelance client, Model One in F#
flclient1: Freelance client, Model One in Felix
flclient1: Freelance client, Model One in Go
flclient1: Freelance client, Model One in Haskell
flclient1: Freelance client, Model One in Haxe
flclient1: Freelance client, Model One in Java
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZMsg;
// Freelance client - Model 1
// Uses REQ socket to query one or more services
public class flclient1
{
private static final int REQUEST_TIMEOUT = 1000;
private static final int MAX_RETRIES = 3; // Before we abandon
private static ZMsg tryRequest(ZContext ctx, String endpoint, ZMsg request)
{
System.out.printf("I: trying echo service at %s...\n", endpoint);
Socket client = ctx.createSocket(SocketType.REQ);
client.connect(endpoint);
// Send request, wait safely for reply
ZMsg msg = request.duplicate();
msg.send(client);
Poller poller = ctx.createPoller(1);
poller.register(client, Poller.POLLIN);
poller.poll(REQUEST_TIMEOUT);
ZMsg reply = null;
if (poller.pollin(0))
reply = ZMsg.recvMsg(client);
// Close socket in any case, we're done with it now
ctx.destroySocket(client);
poller.close();
return reply;
}
// .split client task
// The client uses a Lazy Pirate strategy if it only has one server to talk
// to. If it has two or more servers to talk to, it will try each server just
// once:
public static void main(String[] argv)
{
try (ZContext ctx = new ZContext()) {
ZMsg request = new ZMsg();
request.add("Hello world");
ZMsg reply = null;
int endpoints = argv.length;
if (endpoints == 0)
System.out.printf("I: syntax: flclient1 <endpoint> ...\n");
else if (endpoints == 1) {
// For one endpoint, we retry N times
int retries;
for (retries = 0; retries < MAX_RETRIES; retries++) {
String endpoint = argv[0];
reply = tryRequest(ctx, endpoint, request);
if (reply != null)
break; // Successful
System.out.printf(
"W: no response from %s, retrying...\n", endpoint
);
}
}
else {
// For multiple endpoints, try each at most once
int endpointNbr;
for (endpointNbr = 0; endpointNbr < endpoints; endpointNbr++) {
String endpoint = argv[endpointNbr];
reply = tryRequest(ctx, endpoint, request);
if (reply != null)
break; // Successful
System.out.printf("W: no response from %s\n", endpoint);
}
}
if (reply != null) {
System.out.printf("Service is running OK\n");
reply.destroy();
}
request.destroy();
}
}
}
flclient1: Freelance client, Model One in Julia
flclient1: Freelance client, Model One in Lua
flclient1: Freelance client, Model One in Node.js
flclient1: Freelance client, Model One in Objective-C
flclient1: Freelance client, Model One in ooc
flclient1: Freelance client, Model One in Perl
flclient1: Freelance client, Model One in PHP
<?php
/*
* Freelance Client - Model 1
* Uses REQ socket to query one or more services
*
* Author: Rob Gagnon <rgagnon24(at)gmail(dot)com>
*/
$request_timeout = 1000; // ms
$max_retries = 3; # Before we abandon
/**
* @param ZMQContext $ctx
* @param string $endpoint
* @param string $request
*/
function try_request($ctx, $endpoint, $request)
{
global $request_timeout;
printf("I: Trying echo service at %s...\n", $endpoint);
$client = $ctx->getSocket(ZMQ::SOCKET_REQ);
$client->connect($endpoint);
$client->send($request);
$poll = new ZMQPoll();
$poll->add($client, ZMQ::POLL_IN);
$readable = $writable = array();
$events = $poll->poll($readable, $writable, $request_timeout);
$reply = null;
foreach ($readable as $sock) {
if ($sock == $client) {
$reply = $client->recvMulti();
} else {
$reply = null;
}
}
$poll->remove($client);
$poll = null;
$client = null;
return $reply;
}
$context = new ZMQContext();
$request = 'Hello world';
$reply = null;
$cmd = array_shift($argv);
$endpoints = count($argv);
if ($endpoints == 0) {
printf("I: syntax: %s <endpoint> ...\n", $cmd);
exit;
}
if ($endpoints == 1) {
// For one endpoint, we retry N times
$endpoint = $argv[0];
for ($retries = 0; $retries < $max_retries; $retries++) {
$reply = try_request($context, $endpoint, $request);
if (isset($reply)) {
break; // Success
}
printf("W: No response from %s, retrying\n", $endpoint);
}
} else {
// For multiple endpoints, try each at most once
foreach ($argv as $endpoint) {
$reply = try_request($context, $endpoint, $request);
if (isset($reply)) {
break; // Success
}
printf("W: No response from %s\n", $endpoint);
}
}
if (isset($reply)) {
print "Service is running OK\n";
}
flclient1: Freelance client, Model One in Python
#
# Freelance Client - Model 1
# Uses REQ socket to query one or more services
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import sys
import time
import zmq
REQUEST_TIMEOUT = 1000 # ms
MAX_RETRIES = 3 # Before we abandon
def try_request(ctx, endpoint, request):
print "I: Trying echo service at %s..." % endpoint
client = ctx.socket(zmq.REQ)
client.setsockopt(zmq.LINGER, 0) # Terminate early
client.connect(endpoint)
client.send(request)
poll = zmq.Poller()
poll.register(client, zmq.POLLIN)
socks = dict(poll.poll(REQUEST_TIMEOUT))
if socks.get(client) == zmq.POLLIN:
reply = client.recv_multipart()
else:
reply = ''
poll.unregister(client)
client.close()
return reply
context = zmq.Context()
request = "Hello world"
reply = None
endpoints = len(sys.argv) - 1
if endpoints == 0:
print "I: syntax: %s <endpoint> ..." % sys.argv[0]
elif endpoints == 1:
# For one endpoint, we retry N times
endpoint = sys.argv[1]
for retries in xrange(MAX_RETRIES):
reply = try_request(context, endpoint, request)
if reply:
break # Success
print "W: No response from %s, retrying" % endpoint
else:
# For multiple endpoints, try each at most once
for endpoint in sys.argv[1:]:
reply = try_request(context, endpoint, request)
if reply:
break # Success
print "W: No response from %s" % endpoint
if reply:
print "Service is running OK"
flclient1: Freelance client, Model One in Q
flclient1: Freelance client, Model One in Racket
flclient1: Freelance client, Model One in Ruby
flclient1: Freelance client, Model One in Rust
flclient1: Freelance client, Model One in Scala
flclient1: Freelance client, Model One in Tcl
flclient1: Freelance client, Model One in OCaml
A sample run is:
flserver1 tcp://*:5555 &
flserver1 tcp://*:5556 &
flclient1 tcp://localhost:5555 tcp://localhost:5556
Although the basic approach is Lazy Pirate, the client aims to just get one successful reply. It has two techniques, depending on whether you are running a single server or multiple servers:
- With a single server, the client will retry several times, exactly as for Lazy Pirate.
- With multiple servers, the client will try each server at most once until it’s received a reply or has tried all servers.
This solves the main weakness of Lazy Pirate, namely that it could not fail over to backup or alternate servers.
However, this design won’t work well in a real application. If we’re connecting many sockets and our primary name server is down, we’re going to experience this painful timeout each time.
Model Two: Brutal Shotgun Massacre #
Let’s switch our client to using a DEALER socket. Our goal here is to make sure we get a reply back within the shortest possible time, no matter whether a particular server is up or down. Our client takes this approach:
- We set things up, connecting to all servers.
- When we have a request, we blast it out as many times as we have servers.
- We wait for the first reply, and take that.
- We ignore any other replies.
What will happen in practice is that when all servers are running, ZeroMQ will distribute the requests so that each server gets one request and sends one reply. When any server is offline and disconnected, ZeroMQ will distribute the requests to the remaining servers. So a server may in some cases get the same request more than once.
What’s more annoying for the client is that we’ll get multiple replies back, but there’s no guarantee we’ll get a precise number of replies. Requests and replies can get lost (e.g., if the server crashes while processing a request).
So we have to number requests and ignore any replies that don’t match the request number. Our Model One server will work because it’s an echo server, but coincidence is not a great basis for understanding. So we’ll make a Model Two server that chews up the message and returns a correctly numbered reply with the content “OK”. We’ll use messages consisting of two parts: a sequence number and a body.
Start one or more servers, specifying a bind endpoint each time:
flserver2: Freelance server, Model Two in Ada
flserver2: Freelance server, Model Two in Basic
flserver2: Freelance server, Model Two in C
// Freelance server - Model 2
// Does some work, replies OK, with message sequencing
#include "czmq.h"
int main (int argc, char *argv [])
{
if (argc < 2) {
printf ("I: syntax: %s <endpoint>\n", argv [0]);
return 0;
}
zctx_t *ctx = zctx_new ();
void *server = zsocket_new (ctx, ZMQ_REP);
zsocket_bind (server, argv [1]);
printf ("I: service is ready at %s\n", argv [1]);
while (true) {
zmsg_t *request = zmsg_recv (server);
if (!request)
break; // Interrupted
// Fail nastily if run against wrong client
assert (zmsg_size (request) == 2);
zframe_t *identity = zmsg_pop (request);
zmsg_destroy (&request);
zmsg_t *reply = zmsg_new ();
zmsg_add (reply, identity);
zmsg_addstr (reply, "OK");
zmsg_send (&reply, server);
}
if (zctx_interrupted)
printf ("W: interrupted\n");
zctx_destroy (&ctx);
return 0;
}
flserver2: Freelance server, Model Two in C++
// Freelance server - Model 2
// Does some work, replies OK, with message sequencing
#include <iostream>
#include <zmqpp/zmqpp.hpp>
int main(int argc, char *argv[]) {
if (argc < 2) {
std::cout << "I: syntax: " << argv[0] << " <endpoint>" << std::endl;
return 0;
}
zmqpp::context context;
zmqpp::socket server(context, zmqpp::socket_type::reply);
server.bind(argv[1]);
std::cout << "I: echo service is ready at " << argv[1] << std::endl;
while (true) {
zmqpp::message request;
try {
server.receive(request);
} catch (zmqpp::zmq_internal_exception &e) {
if (e.zmq_error() == EINTR)
std::cout << "W: interrupted" << std::endl;
else
std::cout << "E: error, errnum = " << e.zmq_error() << ", what = " << e.what()
<< std::endl;
break; // Interrupted
}
// Fail nastily if run against wrong client
assert(request.parts() == 2);
uint identity;
request.get(identity, 0);
// std::cout << "Received sequence: " << identity << std::endl;
zmqpp::message reply;
reply.push_back(identity);
reply.push_back("OK");
server.send(reply);
}
return 0;
}
flserver2: Freelance server, Model Two in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
public static void FLServer2(string[] args)
{
//
// Freelance server - Model 2
// Does some work, replies OK, with message sequencing
//
// Author: metadings
//
if (args == null || args.Length < 1)
{
Console.WriteLine();
Console.WriteLine("Usage: ./{0} FLServer2 [Endpoint]", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
Console.WriteLine(" Endpoint Where FLServer2 should bind on.");
Console.WriteLine(" Default is tcp://127.0.0.1:7781");
Console.WriteLine();
args = new string[] { "tcp://127.0.0.1:7781" };
}
string endpoint = args[0];
using (var context = new ZContext())
using (var server = new ZSocket(context, ZSocketType.REP))
{
server.Bind(endpoint);
Console.WriteLine("I: server is ready as {0}", endpoint);
ZError error;
ZMessage incoming;
while (true)
{
if (null == (incoming = server.ReceiveMessage(out error)))
{
if (error == ZError.ETERM)
break; // Interrupted
throw new ZException(error);
}
ZFrame identity;
using (incoming)
{
// Fail nastily if run against wrong client
if (incoming.Count < 2)
{
throw new InvalidOperationException();
}
identity = incoming.RemoveAt(0, false);
}
using (identity)
using (var outgoing = new ZMessage())
{
outgoing.Add(identity);
outgoing.Add(new ZFrame("OK"));
if (!server.Send(outgoing, out error))
{
if (error == ZError.ETERM)
break; // Interrupted
throw new ZException(error);
}
}
}
if (error == ZError.ETERM)
{
Console.WriteLine("W: interrupted");
}
}
}
}
}
flserver2: Freelance server, Model Two in CL
flserver2: Freelance server, Model Two in Delphi
flserver2: Freelance server, Model Two in Erlang
flserver2: Freelance server, Model Two in Elixir
flserver2: Freelance server, Model Two in F#
flserver2: Freelance server, Model Two in Felix
flserver2: Freelance server, Model Two in Go
flserver2: Freelance server, Model Two in Haskell
flserver2: Freelance server, Model Two in Haxe
flserver2: Freelance server, Model Two in Java
package guide;
import org.zeromq.*;
import org.zeromq.ZMQ.Socket;
// Freelance server - Model 2
// Does some work, replies OK, with message sequencing
public class flserver2
{
public static void main(String[] args)
{
if (args.length < 1) {
System.out.printf("I: syntax: flserver2 <endpoint>\n");
System.exit(0);
}
try (ZContext ctx = new ZContext()) {
Socket server = ctx.createSocket(SocketType.REP);
server.bind(args[0]);
System.out.printf("I: echo service is ready at %s\n", args[0]);
while (true) {
ZMsg request = ZMsg.recvMsg(server);
if (request == null)
break; // Interrupted
// Fail nastily if run against wrong client
assert (request.size() == 2);
ZFrame identity = request.pop();
request.destroy();
ZMsg reply = new ZMsg();
reply.add(identity);
reply.add("OK");
reply.send(server);
}
if (Thread.currentThread().isInterrupted())
System.out.printf("W: interrupted\n");
}
}
}
flserver2: Freelance server, Model Two in Julia
flserver2: Freelance server, Model Two in Lua
--
-- Freelance server - Model 2
-- Does some work, replies OK, with message sequencing
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmsg"
if (#arg < 1) then
printf ("I: syntax: %s <endpoint>\n", arg[0])
os.exit (0)
end
local context = zmq.init(1)
s_catch_signals()
local server = context:socket(zmq.REP)
server:bind(arg[1])
printf ("I: service is ready at %s\n", arg[1])
while (not s_interrupted) do
local msg, err = zmsg.recv(server)
if err then
print('recv error:', err)
break -- Interrupted
end
-- Fail nastily if run against wrong client
assert (msg:parts() == 2)
msg:body_set("OK")
msg:send(server)
end
if (s_interrupted) then
printf("W: interrupted\n")
end
server:close()
context:term()
flserver2: Freelance server, Model Two in Node.js
flserver2: Freelance server, Model Two in Objective-C
flserver2: Freelance server, Model Two in ooc
flserver2: Freelance server, Model Two in Perl
flserver2: Freelance server, Model Two in PHP
<?php
/*
* Freelance server - Model 2
* Does some work, replies OK, with message sequencing
*
* Author: Rob Gagnon <rgagnon24(at)gmail(dot)com>
*/
if (count($argv) < 2) {
printf("I: Syntax: %s <endpoint>\n", $argv[0]);
exit;
}
$endpoint = $argv[1];
$context = new ZMQContext();
$server = $context->getSocket(ZMQ::SOCKET_REP);
$server->bind($endpoint);
printf("I: Echo service is ready at %s\n", $endpoint);
while (true) {
$request = $server->recvMulti();
if (count($request) != 2) {
// Fail nastily if run against wrong client
exit(-1);
}
$address = $request[0];
$reply = array($address, 'OK');
$server->sendMulti($reply);
}
flserver2: Freelance server, Model Two in Python
#
# Freelance server - Model 2
# Does some work, replies OK, with message sequencing
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import sys
import zmq
if len(sys.argv) < 2:
print "I: Syntax: %s <endpoint>" % sys.argv[0]
sys.exit(0)
endpoint = sys.argv[1]
context = zmq.Context()
server = context.socket(zmq.REP)
server.bind(endpoint)
print "I: Service is ready at %s" % endpoint
while True:
request = server.recv_multipart()
if not request:
break # Interrupted
# Fail nastily if run against wrong client
assert len(request) == 2
address = request[0]
reply = [address, "OK"]
server.send_multipart(reply)
server.setsockopt(zmq.LINGER, 0) # Terminate early
flserver2: Freelance server, Model Two in Q
flserver2: Freelance server, Model Two in Racket
flserver2: Freelance server, Model Two in Ruby
flserver2: Freelance server, Model Two in Rust
flserver2: Freelance server, Model Two in Scala
flserver2: Freelance server, Model Two in Tcl
flserver2: Freelance server, Model Two in OCaml
Then start the client, specifying the connect endpoints as arguments:
flclient2: Freelance client, Model Two in Ada
flclient2: Freelance client, Model Two in Basic
flclient2: Freelance client, Model Two in C
// Freelance client - Model 2
// Uses DEALER socket to blast one or more services
#include "czmq.h"
// We design our client API as a class, using the CZMQ style
#ifdef __cplusplus
extern "C" {
#endif
typedef struct _flclient_t flclient_t;
flclient_t *flclient_new (void);
void flclient_destroy (flclient_t **self_p);
void flclient_connect (flclient_t *self, char *endpoint);
zmsg_t *flclient_request (flclient_t *self, zmsg_t **request_p);
#ifdef __cplusplus
}
#endif
// If not a single service replies within this time, give up
#define GLOBAL_TIMEOUT 2500
int main (int argc, char *argv [])
{
if (argc == 1) {
printf ("I: syntax: %s <endpoint> ...\n", argv [0]);
return 0;
}
// Create new freelance client object
flclient_t *client = flclient_new ();
// Connect to each endpoint
int argn;
for (argn = 1; argn < argc; argn++)
flclient_connect (client, argv [argn]);
// Send a bunch of name resolution 'requests', measure time
int requests = 10000;
uint64_t start = zclock_time ();
while (requests--) {
zmsg_t *request = zmsg_new ();
zmsg_addstr (request, "random name");
zmsg_t *reply = flclient_request (client, &request);
if (!reply) {
printf ("E: name service not available, aborting\n");
break;
}
zmsg_destroy (&reply);
}
printf ("Average round trip cost: %d usec\n",
(int) (zclock_time () - start) / 10);
flclient_destroy (&client);
return 0;
}
// .split class implementation
// Here is the {{flclient}} class implementation. Each instance has a
// context, a DEALER socket it uses to talk to the servers, a counter
// of how many servers it's connected to, and a request sequence number:
struct _flclient_t {
zctx_t *ctx; // Our context wrapper
void *socket; // DEALER socket talking to servers
size_t servers; // How many servers we have connected to
uint sequence; // Number of requests ever sent
};
// Constructor
flclient_t *
flclient_new (void)
{
flclient_t
*self;
self = (flclient_t *) zmalloc (sizeof (flclient_t));
self->ctx = zctx_new ();
self->socket = zsocket_new (self->ctx, ZMQ_DEALER);
return self;
}
// Destructor
void
flclient_destroy (flclient_t **self_p)
{
assert (self_p);
if (*self_p) {
flclient_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self);
*self_p = NULL;
}
}
// Connect to new server endpoint
void
flclient_connect (flclient_t *self, char *endpoint)
{
assert (self);
zsocket_connect (self->socket, endpoint);
self->servers++;
}
// .split request method
// This method does the hard work. It sends a request to all
// connected servers in parallel (for this to work, all connections
// must be successful and completed by this time). It then waits
// for a single successful reply, and returns that to the caller.
// Any other replies are just dropped:
zmsg_t *
flclient_request (flclient_t *self, zmsg_t **request_p)
{
assert (self);
assert (*request_p);
zmsg_t *request = *request_p;
// Prefix request with sequence number and empty envelope
char sequence_text [10];
sprintf (sequence_text, "%u", ++self->sequence);
zmsg_pushstr (request, sequence_text);
zmsg_pushstr (request, "");
// Blast the request to all connected servers
int server;
for (server = 0; server < self->servers; server++) {
zmsg_t *msg = zmsg_dup (request);
zmsg_send (&msg, self->socket);
}
// Wait for a matching reply to arrive from anywhere
// Since we can poll several times, calculate each one
zmsg_t *reply = NULL;
uint64_t endtime = zclock_time () + GLOBAL_TIMEOUT;
while (zclock_time () < endtime) {
zmq_pollitem_t items [] = { { self->socket, 0, ZMQ_POLLIN, 0 } };
zmq_poll (items, 1, (endtime - zclock_time ()) * ZMQ_POLL_MSEC);
if (items [0].revents & ZMQ_POLLIN) {
// Reply is [empty][sequence][OK]
reply = zmsg_recv (self->socket);
assert (zmsg_size (reply) == 3);
free (zmsg_popstr (reply));
char *sequence = zmsg_popstr (reply);
int sequence_nbr = atoi (sequence);
free (sequence);
if (sequence_nbr == self->sequence)
break;
zmsg_destroy (&reply);
}
}
zmsg_destroy (request_p);
return reply;
}
flclient2: Freelance client, Model Two in C++
// Freelance client - Model 2
// Uses DEALER socket to blast one or more services
#include <chrono>
#include <iostream>
#include <memory>
#include <zmqpp/zmqpp.hpp>
// If not a single service replies within this time, give up
const int GLOBAL_TIMEOUT = 2500;
// Total requests times
const int TOTAL_REQUESTS = 10000;
// .split class implementation
// Here is the {{flclient}} class implementation. Each instance has a
// context, a DEALER socket it uses to talk to the servers, a counter
// of how many servers it's connected to, and a request sequence number:
class flclient {
public:
flclient();
~flclient() {}
void connect(const std::string &endpoint);
std::unique_ptr<zmqpp::message> request(zmqpp::message &request);
private:
zmqpp::context context_; // Our context
zmqpp::socket socket_; // DEALER socket talking to servers
size_t servers_; // How many servers we have connected to
uint sequence_; // Number of requests ever sent
};
// Constructor
flclient::flclient() : socket_(context_, zmqpp::socket_type::dealer) {
socket_.set(zmqpp::socket_option::linger, GLOBAL_TIMEOUT);
servers_ = 0;
sequence_ = 0;
}
// Connect to new server endpoint
void flclient::connect(const std::string &endpoint) {
socket_.connect(endpoint);
servers_++;
}
// .split request method
// This method does the hard work. It sends a request to all
// connected servers in parallel (for this to work, all connections
// must be successful and completed by this time). It then waits
// for a single successful reply, and returns that to the caller.
// Any other replies are just dropped:
std::unique_ptr<zmqpp::message> flclient::request(zmqpp::message &request) {
// Prefix request with sequence number and empty envelope
request.push_front(++sequence_);
request.push_front("");
// Blast the request to all connected servers
size_t server;
for (server = 0; server < servers_; server++) {
zmqpp::message msg;
msg.copy(request);
socket_.send(msg);
}
// Wait for a matching reply to arrive from anywhere
// Since we can poll several times, calculate each one
std::unique_ptr<zmqpp::message> reply;
zmqpp::poller poller;
poller.add(socket_, zmqpp::poller::poll_in);
auto endTime = std::chrono::system_clock::now() + std::chrono::milliseconds(GLOBAL_TIMEOUT);
while (std::chrono::system_clock::now() < endTime) {
int milliSecondsToWait = std::chrono::duration_cast<std::chrono::milliseconds>(
endTime - std::chrono::system_clock::now())
.count();
if (poller.poll(milliSecondsToWait)) {
if (poller.has_input(socket_)) {
reply = std::make_unique<zmqpp::message>();
// Reply is [empty][sequence][OK]
socket_.receive(*reply);
assert(reply->parts() == 3);
reply->pop_front();
uint sequence;
reply->get(sequence, 0);
reply->pop_front();
// std::cout << "Current sequence: " << sequence_ << ", Server reply: " << sequence
// << std::endl;
if (sequence == sequence_)
break;
else
reply.release();
}
}
}
return reply;
}
int main(int argc, char *argv[]) {
if (argc == 1) {
std::cout << "I: syntax: " << argv[0] << " <endpoint> ..." << std::endl;
return 0;
}
// Create new freelance client object
flclient client;
// Connect to each endpoint
int argn;
for (argn = 1; argn < argc; argn++) client.connect(argv[argn]);
// Send a bunch of name resolution 'requests', measure time
int requests = TOTAL_REQUESTS;
auto startTime = std::chrono::steady_clock::now();
while (requests--) {
zmqpp::message request;
request.push_back("random name");
std::unique_ptr<zmqpp::message> reply;
reply = client.request(request);
if (!reply) {
std::cout << "E: name service not available, aborting" << std::endl;
break;
}
}
auto endTime = std::chrono::steady_clock::now();
std::cout
<< "Average round trip cost: "
<< std::chrono::duration_cast<std::chrono::microseconds>(endTime - startTime).count() /
TOTAL_REQUESTS
<< " µs" << std::endl;
return 0;
}
flclient2: Freelance client, Model Two in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
using FLClient2;
//
// Freelance client - Model 2
// Uses DEALER socket to blast one or more services
//
// Author: metadings
//
namespace FLClient2
{
public class FLClient : IDisposable
{
// If not a single service replies within this time, give up
static readonly TimeSpan GLOBAL_TIMEOUT = TimeSpan.FromMilliseconds(2500);
// Here is the flclient class implementation. Each instance has a
// context, a DEALER socket it uses to talk to the servers, a counter
// of how many servers it's connected to, and a request sequence number:
// Our context wrapper
ZContext context;
// DEALER socket talking to servers
ZSocket socket;
// How many servers we have connected to
int servers;
// Number of requests ever sent
int sequence;
public FLClient()
{
// Constructor
context = new ZContext();
socket = new ZSocket(context, ZSocketType.DEALER);
socket.Linger = GLOBAL_TIMEOUT;
}
~FLClient()
{
Dispose(false);
}
public void Dispose()
{
GC.SuppressFinalize(this);
Dispose(true);
}
protected void Dispose(bool disposing)
{
if (disposing)
{
// Destructor
if (socket != null)
{
socket.Dispose();
socket = null;
}
if (context != null)
{
context.Dispose();
context = null;
}
}
}
public void Connect(string endpoint)
{
// Connect to new server endpoint
socket.Connect(endpoint);
servers++;
}
public ZMessage Request(ZMessage request)
{
// This method does the hard work. It sends a request to all
// connected servers in parallel (for this to work, all connections
// must be successful and completed by this time). It then waits
// for a single successful reply, and returns that to the caller.
// Any other replies are just dropped:
ZMessage reply = null;
using (request)
{
// Prefix request with sequence number and empty envelope
this.sequence++;
request.Prepend(new ZFrame(this.sequence));
request.Prepend(new ZFrame());
// Blast the request to all connected servers
for (int server = 0; server < this.servers; ++server)
{
using (var outgoing = request.Duplicate())
{
this.socket.Send(outgoing);
}
}
// Wait for a matching reply to arrive from anywhere
// Since we can poll several times, calculate each one
ZError error;
DateTime endtime = DateTime.UtcNow + GLOBAL_TIMEOUT;
var poll = ZPollItem.CreateReceiver();
while (endtime > DateTime.UtcNow)
{
if (this.socket.PollIn(poll, out reply, out error, endtime - DateTime.UtcNow))
{
// Reply is [empty][sequence][OK]
if (reply.Count < 3)
{
throw new InvalidOperationException();
}
reply.RemoveAt(0);
using (ZFrame sequenceFrame = reply.RemoveAt(0, false))
{
int sequence = sequenceFrame.ReadInt32();
if (sequence == this.sequence)
{
break; // Reply is ok
}
}
reply.Dispose();
}
else
{
if (error == ZError.ETERM)
break; // Interrupted
if (error != ZError.EAGAIN)
throw new ZException(error);
}
}
}
return reply;
}
}
}
static partial class Program
{
public static void FLClient2(string[] args)
{
if (args == null || args.Length < 1)
{
Console.WriteLine();
Console.WriteLine("Usage: ./{0} FLClient2 [Endpoint] ...", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
Console.WriteLine(" Endpoint Where FLClient2 should connect to.");
Console.WriteLine(" Default is tcp://127.0.0.1:7781");
Console.WriteLine();
args = new string[] { "tcp://127.0.0.1:7781" };
}
// Create new freelance client object
using (var client = new FLClient())
{
// Connect to each endpoint
for (int i = 0; i < args.Length; ++i)
{
client.Connect(args[i]);
}
// Send a bunch of name resolution 'requests', measure time
int requests = 0;
DateTime starttime = DateTime.UtcNow;
var error = ZError.None;
while (++requests < 10000)
{
var outgoing = new ZMessage();
outgoing.Add(new ZFrame("random name"));
ZMessage incoming = client.Request(outgoing);
if (incoming == null)
{
error = ZError.ETERM;
break;
}
incoming.Dispose(); // using (incoming) ;
}
if (error == ZError.ETERM)
Console.WriteLine("E: name service not available, aborted.");
else
Console.WriteLine("Average round trip cost: {0} ms", (DateTime.UtcNow - starttime).TotalMilliseconds / requests);
}
}
}
}
flclient2: Freelance client, Model Two in CL
flclient2: Freelance client, Model Two in Delphi
flclient2: Freelance client, Model Two in Erlang
flclient2: Freelance client, Model Two in Elixir
flclient2: Freelance client, Model Two in F#
flclient2: Freelance client, Model Two in Felix
flclient2: Freelance client, Model Two in Go
flclient2: Freelance client, Model Two in Haskell
flclient2: Freelance client, Model Two in Haxe
flclient2: Freelance client, Model Two in Java
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZMsg;
// Freelance client - Model 2
// Uses DEALER socket to blast one or more services
public class flclient2
{
// If not a single service replies within this time, give up
private static final int GLOBAL_TIMEOUT = 2500;
// .split class implementation
// Here is the {{flclient}} class implementation. Each instance has a
// context, a DEALER socket it uses to talk to the servers, a counter
// of how many servers it's connected to, and a request getSequence number:
private ZContext ctx; // Our context wrapper
private Socket socket; // DEALER socket talking to servers
private int servers; // How many servers we have connected to
private int sequence; // Number of requests ever sent
public flclient2()
{
ctx = new ZContext();
socket = ctx.createSocket(SocketType.DEALER);
}
public void destroy()
{
ctx.destroy();
}
private void connect(String endpoint)
{
socket.connect(endpoint);
servers++;
}
private ZMsg request(ZMsg request)
{
// Prefix request with getSequence number and empty envelope
String sequenceText = String.format("%d", ++sequence);
request.push(sequenceText);
request.push("");
// Blast the request to all connected servers
int server;
for (server = 0; server < servers; server++) {
ZMsg msg = request.duplicate();
msg.send(socket);
}
// Wait for a matching reply to arrive from anywhere
// Since we can poll several times, calculate each one
ZMsg reply = null;
long endtime = System.currentTimeMillis() + GLOBAL_TIMEOUT;
Poller poller = ctx.createPoller(1);
poller.register(socket, Poller.POLLIN);
while (System.currentTimeMillis() < endtime) {
poller.poll(endtime - System.currentTimeMillis());
if (poller.pollin(0)) {
// Reply is [empty][getSequence][OK]
reply = ZMsg.recvMsg(socket);
assert (reply.size() == 3);
reply.pop();
String sequenceStr = reply.popString();
int sequenceNbr = Integer.parseInt(sequenceStr);
if (sequenceNbr == sequence)
break;
reply.destroy();
}
}
poller.close();
request.destroy();
return reply;
}
public static void main(String[] argv)
{
if (argv.length == 0) {
System.out.printf("I: syntax: flclient2 <endpoint> ...\n");
System.exit(0);
}
// Create new freelance client object
flclient2 client = new flclient2();
// Connect to each endpoint
int argn;
for (argn = 0; argn < argv.length; argn++)
client.connect(argv[argn]);
// Send a bunch of name resolution 'requests', measure time
int requests = 10000;
long start = System.currentTimeMillis();
while (requests-- > 0) {
ZMsg request = new ZMsg();
request.add("random name");
ZMsg reply = client.request(request);
if (reply == null) {
System.out.printf("E: name service not available, aborting\n");
break;
}
reply.destroy();
}
System.out.printf("Average round trip cost: %d usec\n", (int) (System.currentTimeMillis() - start) / 10);
client.destroy();
}
}
flclient2: Freelance client, Model Two in Julia
flclient2: Freelance client, Model Two in Lua
flclient2: Freelance client, Model Two in Node.js
flclient2: Freelance client, Model Two in Objective-C
flclient2: Freelance client, Model Two in ooc
flclient2: Freelance client, Model Two in Perl
flclient2: Freelance client, Model Two in PHP
<?php
/*
* Freelance Client - Model 2
* Uses DEALER socket to blast one or more services
*
* Author: Rob Gagnon <rgagnon24(at)gmail(dot)com>
*/
class FLClient
{
const GLOBAL_TIMEOUT = 2500; // ms
private $servers = 0;
private $sequence = 0;
/** @var ZMQContext */
private $context = null;
/** @var ZMQSocket */
private $socket = null;
public function __construct()
{
$this->servers = 0;
$this->sequence = 0;
$this->context = new ZMQContext();
$this->socket = $this->context->getSocket(ZMQ::SOCKET_DEALER);
}
public function __destruct()
{
$this->socket->setSockOpt(ZMQ::SOCKOPT_LINGER, 0);
$this->socket = null;
$this->context = null;
}
/**
* @param string $endpoint
*/
public function connect($endpoint)
{
$this->socket->connect($endpoint);
$this->servers++;
printf("I: Connected to %s\n", $endpoint);
}
/**
* @param string $request
*/
public function request($request)
{
// Prefix request with sequence number and empty envelope
$this->sequence++;
$msg = array('', $this->sequence, $request);
// Blast the request to all connected servers
for ($server = 1; $server <= $this->servers; $server++) {
$this->socket->sendMulti($msg);
}
// Wait for a matching reply to arrive from anywhere
// Since we can poll several times, calculate each one
$poll = new ZMQPoll();
$poll->add($this->socket, ZMQ::POLL_IN);
$reply = null;
$endtime = time() + self::GLOBAL_TIMEOUT / 1000;
while (time() < $endtime) {
$readable = $writable = array();
$events = $poll->poll($readable, $writable, ($endtime - time()) * 1000);
foreach ($readable as $sock) {
if ($sock == $this->socket) {
$reply = $this->socket->recvMulti();
if (count($reply) != 3) {
exit;
}
$sequence = $reply[1];
if ($sequence == $this->sequence) {
break;
}
}
}
}
return $reply;
}
}
$cmd = array_shift($argv);
if (count($argv) == 0) {
printf("I: syntax: %s <endpoint> ...\n", $cmd);
exit;
}
// Create new freelance client object
$client = new FLClient();
foreach ($argv as $endpoint) {
$client->connect($endpoint);
}
$start = time();
for ($requests = 0; $requests < 10000; $requests++) {
$request = "random name";
$reply = $client->request($request);
if (!isset($reply)) {
print "E: name service not available, aborting\n";
break;
}
}
printf("Average round trip cost: %i ms\n", ((time() - $start) / 100));
$client = null;
flclient2: Freelance client, Model Two in Python
#
# Freelance Client - Model 2
# Uses DEALER socket to blast one or more services
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import sys
import time
import zmq
GLOBAL_TIMEOUT = 2500 # ms
class FLClient(object):
def __init__(self):
self.servers = 0
self.sequence = 0
self.context = zmq.Context()
self.socket = self.context.socket(zmq.DEALER) # DEALER
def destroy(self):
self.socket.setsockopt(zmq.LINGER, 0) # Terminate early
self.socket.close()
self.context.term()
def connect(self, endpoint):
self.socket.connect(endpoint)
self.servers += 1
print "I: Connected to %s" % endpoint
def request(self, *request):
# Prefix request with sequence number and empty envelope
self.sequence += 1
msg = ['', str(self.sequence)] + list(request)
# Blast the request to all connected servers
for server in xrange(self.servers):
self.socket.send_multipart(msg)
# Wait for a matching reply to arrive from anywhere
# Since we can poll several times, calculate each one
poll = zmq.Poller()
poll.register(self.socket, zmq.POLLIN)
reply = None
endtime = time.time() + GLOBAL_TIMEOUT / 1000
while time.time() < endtime:
socks = dict(poll.poll((endtime - time.time()) * 1000))
if socks.get(self.socket) == zmq.POLLIN:
reply = self.socket.recv_multipart()
assert len(reply) == 3
sequence = int(reply[1])
if sequence == self.sequence:
break
return reply
if len(sys.argv) == 1:
print "I: Usage: %s <endpoint> ..." % sys.argv[0]
sys.exit(0)
# Create new freelance client object
client = FLClient()
for endpoint in sys.argv[1:]:
client.connect(endpoint)
start = time.time()
for requests in xrange(10000):
request = "random name"
reply = client.request(request)
if not reply:
print "E: Name service not available, aborting"
break
print "Average round trip cost: %i usec" % ((time.time() - start) / 100)
client.destroy()
flclient2: Freelance client, Model Two in Q
flclient2: Freelance client, Model Two in Racket
flclient2: Freelance client, Model Two in Ruby
flclient2: Freelance client, Model Two in Rust
flclient2: Freelance client, Model Two in Scala
flclient2: Freelance client, Model Two in Tcl
flclient2: Freelance client, Model Two in OCaml
Here are some things to note about the client implementation:
-
The client is structured as a nice little class-based API that hides the dirty work of creating ZeroMQ contexts and sockets and talking to the server. That is, if a shotgun blast to the midriff can be called “talking”.
-
The client will abandon the chase if it can’t find any responsive server within a few seconds.
-
The client has to create a valid REP envelope, i.e., add an empty message frame to the front of the message.
The client performs 10,000 name resolution requests (fake ones, as our server does essentially nothing) and measures the average cost. On my test box, talking to one server, this requires about 60 microseconds. Talking to three servers, it takes about 80 microseconds.
The pros and cons of our shotgun approach are:
- Pro: it is simple, easy to make and easy to understand.
- Pro: it does the job of failover, and works rapidly, so long as there is at least one server running.
- Con: it creates redundant network traffic.
- Con: we can’t prioritize our servers, i.e., Primary, then Secondary.
- Con: the server can do at most one request at a time, period.
Model Three: Complex and Nasty #
The shotgun approach seems too good to be true. Let’s be scientific and work through all the alternatives. We’re going to explore the complex/nasty option, even if it’s only to finally realize that we preferred brutal. Ah, the story of my life.
We can solve the main problems of the client by switching to a ROUTER socket. That lets us send requests to specific servers, avoid servers we know are dead, and in general be as smart as we want to be. We can also solve the main problem of the server (single-threadedness) by switching to a ROUTER socket.
But doing ROUTER to ROUTER between two anonymous sockets (which haven’t set an identity) is not possible. Both sides generate an identity (for the other peer) only when they receive a first message, and thus neither can talk to the other until it has first received a message. The only way out of this conundrum is to cheat, and use hard-coded identities in one direction. The proper way to cheat, in a client/server case, is to let the client “know” the identity of the server. Doing it the other way around would be insane, on top of complex and nasty, because any number of clients should be able to arise independently. Insane, complex, and nasty are great attributes for a genocidal dictator, but terrible ones for software.
Rather than invent yet another concept to manage, we’ll use the connection endpoint as identity. This is a unique string on which both sides can agree without more prior knowledge than they already have for the shotgun model. It’s a sneaky and effective way to connect two ROUTER sockets.
Remember how ZeroMQ identities work. The server ROUTER socket sets an identity before it binds its socket. When a client connects, they do a little handshake to exchange identities, before either side sends a real message. The client ROUTER socket, having not set an identity, sends a null identity to the server. The server generates a random UUID to designate the client for its own use. The server sends its identity (which we’ve agreed is going to be an endpoint string) to the client.
This means that our client can route a message to the server (i.e., send on its ROUTER socket, specifying the server endpoint as identity) as soon as the connection is established. That’s not immediately after doing a zmq_connect(), but some random time thereafter. Herein lies one problem: we don’t know when the server will actually be available and complete its connection handshake. If the server is online, it could be after a few milliseconds. If the server is down and the sysadmin is out to lunch, it could be an hour from now.
There’s a small paradox here. We need to know when servers become connected and available for work. In the Freelance pattern, unlike the broker-based patterns we saw earlier in this chapter, servers are silent until spoken to. Thus we can’t talk to a server until it’s told us it’s online, which it can’t do until we’ve asked it.
My solution is to mix in a little of the shotgun approach from model 2, meaning we’ll fire (harmless) shots at anything we can, and if anything moves, we know it’s alive. We’re not going to fire real requests, but rather a kind of ping-pong heartbeat.
This brings us to the realm of protocols again, so here’s a short spec that defines how a Freelance client and server exchange ping-pong commands and request-reply commands.
It is short and sweet to implement as a server. Here’s our echo server, Model Three, now speaking FLP:
flserver3: Freelance server, Model Three in Ada
flserver3: Freelance server, Model Three in Basic
flserver3: Freelance server, Model Three in C
// Freelance server - Model 3
// Uses an ROUTER/ROUTER socket but just one thread
#include "czmq.h"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
zctx_t *ctx = zctx_new ();
// Prepare server socket with predictable identity
char *bind_endpoint = "tcp://*:5555";
char *connect_endpoint = "tcp://localhost:5555";
void *server = zsocket_new (ctx, ZMQ_ROUTER);
zmq_setsockopt (server,
ZMQ_IDENTITY, connect_endpoint, strlen (connect_endpoint));
zsocket_bind (server, bind_endpoint);
printf ("I: service is ready at %s\n", bind_endpoint);
while (!zctx_interrupted) {
zmsg_t *request = zmsg_recv (server);
if (verbose && request)
zmsg_dump (request);
if (!request)
break; // Interrupted
// Frame 0: identity of client
// Frame 1: PING, or client control frame
// Frame 2: request body
zframe_t *identity = zmsg_pop (request);
zframe_t *control = zmsg_pop (request);
zmsg_t *reply = zmsg_new ();
if (zframe_streq (control, "PING"))
zmsg_addstr (reply, "PONG");
else {
zmsg_add (reply, control);
zmsg_addstr (reply, "OK");
}
zmsg_destroy (&request);
zmsg_prepend (reply, &identity);
if (verbose && reply)
zmsg_dump (reply);
zmsg_send (&reply, server);
}
if (zctx_interrupted)
printf ("W: interrupted\n");
zctx_destroy (&ctx);
return 0;
}
flserver3: Freelance server, Model Three in C++
// Freelance server - Model 3
// Uses an ROUTER/ROUTER socket but just one thread
#include <iostream>
#include <zmqpp/zmqpp.hpp>
void dump_binary(const zmqpp::message &msg);
int main(int argc, char *argv[]) {
int verbose = (argc > 1 && (std::string(argv[1]) == "-v"));
if (verbose) std::cout << "verbose active" << std::endl;
zmqpp::context context;
// Prepare server socket with predictable identity
std::string bind_endpoint = "tcp://*:5555";
std::string connect_endpoint = "tcp://localhost:5555";
zmqpp::socket server(context, zmqpp::socket_type::router);
server.set(zmqpp::socket_option::identity, connect_endpoint);
server.bind(bind_endpoint);
std::cout << "I: service is ready at " << bind_endpoint << std::endl;
while (true) {
zmqpp::message request;
try {
server.receive(request);
} catch (zmqpp::zmq_internal_exception &e) {
if (e.zmq_error() == EINTR)
std::cout << "W: interrupted" << std::endl;
else
std::cout << "E: error, errnum = " << e.zmq_error() << ", what = " << e.what()
<< std::endl;
break; // Interrupted
}
if (verbose) {
std::cout << "Message received from client, all data will dump. " << std::endl;
dump_binary(request);
}
// Frame 0: identity of client
// Frame 1: PING, or client control frame
// Frame 2: request body
std::string identity;
std::string control;
request >> identity >> control;
zmqpp::message reply;
if (control == "PING")
reply.push_back("PONG");
else {
reply.push_back(control);
reply.push_back("OK");
}
reply.push_front(identity);
if (verbose) {
std::cout << "Message reply to client dump." << std::endl;
dump_binary(reply);
}
server.send(reply);
}
return 0;
}
void dump_binary(const zmqpp::message &msg) {
std::cout << "Dump message ..." << std::endl;
for (size_t part = 0; part < msg.parts(); ++part) {
std::cout << "Part: " << part << std::endl;
const unsigned char *bin = static_cast<const unsigned char *>(msg.raw_data(part));
for (size_t i = 0; i < msg.size(part); ++i) {
std::cout << std::hex << static_cast<uint16_t>(*(bin++)) << " ";
}
std::cout << std::endl;
}
std::cout << "Dump finish ..." << std::endl;
}
flserver3: Freelance server, Model Three in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
static partial class Program
{
public static void FLServer3(string[] args)
{
//
// Freelance server - Model 3
// Uses an ROUTER/ROUTER socket but just one thread
//
// Author: metadings
//
// Prepare server socket with predictable identity
string bind_endpoint = "tcp://*:5555";
string connect_endpoint = "tcp://127.0.0.1:5555";
using (var context = new ZContext())
using (var server = new ZSocket(context, ZSocketType.ROUTER))
{
Console.CancelKeyPress += (s, ea) =>
{
ea.Cancel = true;
context.Shutdown();
};
server.IdentityString = connect_endpoint;
server.Bind(bind_endpoint);
Console.WriteLine("I: service is ready as {0}", bind_endpoint);
ZError error;
ZMessage request;
while (true)
{
if (null == (request = server.ReceiveMessage(out error)))
{
if (error == ZError.ETERM)
break; // Interrupted
throw new ZException(error);
}
using (var response = new ZMessage())
{
ZFrame identity;
using (request)
{
if (Verbose) Console_WriteZMessage("Receiving", request);
// Frame 0: identity of client
// Frame 1: PING, or client control frame
// Frame 2: request body
identity = request.Pop();
ZFrame control = request.Pop();
string controlMessage = control.ReadString();
if (controlMessage == "PING")
{
control.Dispose();
response.Add(new ZFrame("PONG"));
}
else
{
response.Add(control);
response.Add(new ZFrame("OK"));
}
}
response.Prepend(identity);
if (Verbose) Console_WriteZMessage("Sending ", response);
if (!server.Send(response, out error))
{
if (error == ZError.ETERM)
break; // Interrupted
throw new ZException(error);
}
}
}
if (error == ZError.ETERM)
{
Console.WriteLine("W: interrupted");
}
}
}
}
}
flserver3: Freelance server, Model Three in CL
flserver3: Freelance server, Model Three in Delphi
flserver3: Freelance server, Model Three in Erlang
flserver3: Freelance server, Model Three in Elixir
flserver3: Freelance server, Model Three in F#
flserver3: Freelance server, Model Three in Felix
flserver3: Freelance server, Model Three in Go
flserver3: Freelance server, Model Three in Haskell
flserver3: Freelance server, Model Three in Haxe
flserver3: Freelance server, Model Three in Java
package guide;
import org.zeromq.*;
import org.zeromq.ZMQ.Socket;
// Freelance server - Model 3
// Uses an ROUTER/ROUTER socket but just one thread
public class flserver3
{
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && args[0].equals("-v"));
try (ZContext ctx = new ZContext()) {
// Prepare server socket with predictable identity
String bindEndpoint = "tcp://*:5555";
String connectEndpoint = "tcp://localhost:5555";
Socket server = ctx.createSocket(SocketType.ROUTER);
server.setIdentity(connectEndpoint.getBytes(ZMQ.CHARSET));
server.bind(bindEndpoint);
System.out.printf("I: service is ready at %s\n", bindEndpoint);
while (!Thread.currentThread().isInterrupted()) {
ZMsg request = ZMsg.recvMsg(server);
if (verbose && request != null)
request.dump(System.out);
if (request == null)
break; // Interrupted
// Frame 0: identity of client
// Frame 1: PING, or client control frame
// Frame 2: request body
ZFrame identity = request.pop();
ZFrame control = request.pop();
ZMsg reply = new ZMsg();
if (control.equals(new ZFrame("PING")))
reply.add("PONG");
else {
reply.add(control);
reply.add("OK");
}
request.destroy();
reply.push(identity);
if (verbose && reply != null)
reply.dump(System.out);
reply.send(server);
}
if (Thread.currentThread().isInterrupted())
System.out.printf("W: interrupted\n");
}
}
}
flserver3: Freelance server, Model Three in Julia
flserver3: Freelance server, Model Three in Lua
--
-- Freelance server - Model 3
-- Uses an ROUTER/ROUTER socket but just one thread
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmsg"
local verbose = (arg[1] == "-v")
local context = zmq.init(1)
s_catch_signals ()
-- Prepare server socket with predictable identity
local bind_endpoint = "tcp://*:5555"
local connect_endpoint = "tcp://localhost:5555"
local server = context:socket(zmq.ROUTER)
server:setopt(zmq.IDENTITY, connect_endpoint)
server:bind(bind_endpoint)
printf ("I: service is ready at %s\n", bind_endpoint)
while (not s_interrupted) do
local request = zmsg.recv (server)
local reply = nil
if (not request) then
break -- Interrupted
end
if (verbose) then
request:dump()
end
-- Frame 0: identity of client
-- Frame 1: PING, or client control frame
-- Frame 2: request body
local address = request:pop()
if (request:parts() == 1 and request:body() == "PING") then
reply = zmsg.new ("PONG")
elseif (request:parts() > 1) then
reply = request
request = nil
reply:body_set("OK")
end
reply:push(address)
if (verbose and reply) then
reply:dump()
end
reply:send(server)
end
if (s_interrupted) then
printf ("W: interrupted\n")
end
server:close()
context:term()
flserver3: Freelance server, Model Three in Node.js
flserver3: Freelance server, Model Three in Objective-C
flserver3: Freelance server, Model Three in ooc
flserver3: Freelance server, Model Three in Perl
flserver3: Freelance server, Model Three in PHP
flserver3: Freelance server, Model Three in Python
"""Freelance server - Model 3
Uses an ROUTER/ROUTER socket but just one thread
Author: Min RK <benjaminrk@gmail.com>
"""
import sys
import zmq
from zhelpers import dump
def main():
verbose = '-v' in sys.argv
ctx = zmq.Context()
# Prepare server socket with predictable identity
bind_endpoint = "tcp://*:5555"
connect_endpoint = "tcp://localhost:5555"
server = ctx.socket(zmq.ROUTER)
server.identity = connect_endpoint
server.bind(bind_endpoint)
print "I: service is ready at", bind_endpoint
while True:
try:
request = server.recv_multipart()
except:
break # Interrupted
# Frame 0: identity of client
# Frame 1: PING, or client control frame
# Frame 2: request body
address, control = request[:2]
reply = [address, control]
if control == "PING":
reply[1] = "PONG"
else:
reply.append("OK")
if verbose:
dump(reply)
server.send_multipart(reply)
print "W: interrupted"
if __name__ == '__main__':
main()
flserver3: Freelance server, Model Three in Q
flserver3: Freelance server, Model Three in Racket
flserver3: Freelance server, Model Three in Ruby
flserver3: Freelance server, Model Three in Rust
flserver3: Freelance server, Model Three in Scala
flserver3: Freelance server, Model Three in Tcl
flserver3: Freelance server, Model Three in OCaml
The Freelance client, however, has gotten large. For clarity, it’s split into an example application and a class that does the hard work. Here’s the top-level application:
flclient3: Freelance client, Model Three in Ada
flclient3: Freelance client, Model Three in Basic
flclient3: Freelance client, Model Three in C
// Freelance client - Model 3
// Uses flcliapi class to encapsulate Freelance pattern
// Lets us build this source without creating a library
#include "flcliapi.c"
int main (void)
{
// Create new freelance client object
flcliapi_t *client = flcliapi_new ();
// Connect to several endpoints
flcliapi_connect (client, "tcp://localhost:5555");
flcliapi_connect (client, "tcp://localhost:5556");
flcliapi_connect (client, "tcp://localhost:5557");
// Send a bunch of name resolution 'requests', measure time
int requests = 10000;
uint64_t start = zclock_time ();
while (requests--) {
zmsg_t *request = zmsg_new ();
zmsg_addstr (request, "random name");
zmsg_t *reply = flcliapi_request (client, &request);
if (!reply) {
printf ("E: name service not available, aborting\n");
break;
}
zmsg_destroy (&reply);
}
printf ("Average round trip cost: %d usec\n",
(int) (zclock_time () - start) / 10);
flcliapi_destroy (&client);
return 0;
}
flclient3: Freelance client, Model Three in C++
// Freelance client - Model 3
// Uses flcliapi class to encapsulate Freelance pattern
#include <chrono>
#include "flcliapi.hpp"
const int TOTAL_REQUESTS = 10000;
int main(void) {
// Create new freelance client object
Flcliapi client;
// Connect to several endpoints
client.connect("tcp://localhost:5555");
client.connect("tcp://localhost:5556");
client.connect("tcp://localhost:5557");
// Send a bunch of name resolution 'requests', measure time
int requests = TOTAL_REQUESTS;
auto startTime = std::chrono::steady_clock::now();
while (requests--) {
zmqpp::message request;
request.push_back("random name");
std::unique_ptr<zmqpp::message> reply;
reply = client.request(request);
if (!reply) {
std::cout << "E: name service not available, aborting" << std::endl;
break;
}
}
auto endTime = std::chrono::steady_clock::now();
std::cout
<< "Average round trip cost: "
<< std::chrono::duration_cast<std::chrono::microseconds>(endTime - startTime).count() /
TOTAL_REQUESTS
<< " µs" << std::endl;
return 0;
}
flclient3: Freelance client, Model Three in C#
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
using FLCliApi; // Lets us build this source without creating a library
static partial class Program
{
public static void FLClient3(string[] args)
{
//
// Freelance client - Model 3
// Uses FLCliApi.FreelanceClient class to encapsulate Freelance pattern
//
// Author: metadings
//
if (args == null || args.Length < 2)
{
Console.WriteLine();
Console.WriteLine("Usage: ./{0} FLClient3 [Name] [Endpoint]", AppDomain.CurrentDomain.FriendlyName);
Console.WriteLine();
Console.WriteLine(" Name Your Name");
Console.WriteLine(" Endpoint Where FLClient3 should connect to.");
Console.WriteLine(" Default: tcp://127.0.0.1:5555");
Console.WriteLine();
if (args.Length < 1)
args = new string[] { "World", "tcp://127.0.0.1:5555" };
else
args = new string[] { args[0], "tcp://127.0.0.1:5555" };
}
string name = args[0];
// Create new freelance client object
using (var client = new FreelanceClient())
{
// Connect to one or more endpoints
for (int i = 0; i < args.Length - 1; ++i)
{
client.Connect(args[1]);
}
// Send a bunch of name resolution 'requests', measure time
var stopwatch = new Stopwatch();
stopwatch.Start();
int requests = 0;
while (requests++ < 100)
{
using (var request = new ZMessage())
{
request.Add(new ZFrame(name));
using (ZMessage reply = client.Request(request))
{
}
}
}
stopwatch.Stop();
Console.WriteLine("Average round trip cost: {0} ms", stopwatch.ElapsedMilliseconds / requests);
}
}
}
}
flclient3: Freelance client, Model Three in CL
flclient3: Freelance client, Model Three in Delphi
flclient3: Freelance client, Model Three in Erlang
flclient3: Freelance client, Model Three in Elixir
flclient3: Freelance client, Model Three in F#
flclient3: Freelance client, Model Three in Felix
flclient3: Freelance client, Model Three in Go
flclient3: Freelance client, Model Three in Haskell
flclient3: Freelance client, Model Three in Haxe
flclient3: Freelance client, Model Three in Java
package guide;
import org.zeromq.ZMsg;
// Freelance client - Model 3
// Uses flcliapi class to encapsulate Freelance pattern
public class flclient3
{
public static void main(String[] argv)
{
// Create new freelance client object
flcliapi client = new flcliapi();
// Connect to several endpoints
client.connect("tcp://localhost:5555");
client.connect("tcp://localhost:5556");
client.connect("tcp://localhost:5557");
// Send a bunch of name resolution 'requests', measure time
int requests = 10000;
long start = System.currentTimeMillis();
while (requests-- > 0) {
ZMsg request = new ZMsg();
request.add("random name");
ZMsg reply = client.request(request);
if (reply == null) {
System.out.printf("E: name service not available, aborting\n");
break;
}
reply.destroy();
}
System.out.printf("Average round trip cost: %d usec\n", (int) (System.currentTimeMillis() - start) / 10);
client.destroy();
}
}
flclient3: Freelance client, Model Three in Julia
flclient3: Freelance client, Model Three in Lua
flclient3: Freelance client, Model Three in Node.js
flclient3: Freelance client, Model Three in Objective-C
flclient3: Freelance client, Model Three in ooc
flclient3: Freelance client, Model Three in Perl
flclient3: Freelance client, Model Three in PHP
flclient3: Freelance client, Model Three in Python
"""
Freelance client - Model 3
Uses flcliapi class to encapsulate Freelance pattern
Author : Min RK <benjaminrk@gmail.com>
"""
import time
from flcliapi import FreelanceClient
def main():
# Create new freelance client object
client = FreelanceClient()
# Connect to several endpoints
client.connect ("tcp://localhost:5555")
client.connect ("tcp://localhost:5556")
client.connect ("tcp://localhost:5557")
# Send a bunch of name resolution 'requests', measure time
requests = 10000
start = time.time()
for i in range(requests):
request = ["random name"]
reply = client.request(request)
if not reply:
print "E: name service not available, aborting"
return
print "Average round trip cost: %d usec" % (1e6*(time.time() - start) / requests)
if __name__ == '__main__':
main()
flclient3: Freelance client, Model Three in Q
flclient3: Freelance client, Model Three in Racket
flclient3: Freelance client, Model Three in Ruby
flclient3: Freelance client, Model Three in Rust
flclient3: Freelance client, Model Three in Scala
flclient3: Freelance client, Model Three in Tcl
flclient3: Freelance client, Model Three in OCaml
And here, almost as complex and large as the Majordomo broker, is the client API class:
flcliapi: Freelance client API in Ada
flcliapi: Freelance client API in Basic
flcliapi: Freelance client API in C
// flcliapi class - Freelance Pattern agent class
// Implements the Freelance Protocol at http://rfc.zeromq.org/spec:10
#include "flcliapi.h"
// If no server replies within this time, abandon request
#define GLOBAL_TIMEOUT 3000 // msecs
// PING interval for servers we think are alive
#define PING_INTERVAL 2000 // msecs
// Server considered dead if silent for this long
#define SERVER_TTL 6000 // msecs
// .split API structure
// This API works in two halves, a common pattern for APIs that need to
// run in the background. One half is an frontend object our application
// creates and works with; the other half is a backend "agent" that runs
// in a background thread. The frontend talks to the backend over an
// inproc pipe socket:
// Structure of our frontend class
struct _flcliapi_t {
zctx_t *ctx; // Our context wrapper
void *pipe; // Pipe through to flcliapi agent
};
// This is the thread that handles our real flcliapi class
static void flcliapi_agent (void *args, zctx_t *ctx, void *pipe);
// Constructor
flcliapi_t *
flcliapi_new (void)
{
flcliapi_t
*self;
self = (flcliapi_t *) zmalloc (sizeof (flcliapi_t));
self->ctx = zctx_new ();
self->pipe = zthread_fork (self->ctx, flcliapi_agent, NULL);
return self;
}
// Destructor
void
flcliapi_destroy (flcliapi_t **self_p)
{
assert (self_p);
if (*self_p) {
flcliapi_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self);
*self_p = NULL;
}
}
// .split connect method
// To implement the connect method, the frontend object sends a multipart
// message to the backend agent. The first part is a string "CONNECT", and
// the second part is the endpoint. It waits 100msec for the connection to
// come up, which isn't pretty, but saves us from sending all requests to a
// single server, at startup time:
void
flcliapi_connect (flcliapi_t *self, char *endpoint)
{
assert (self);
assert (endpoint);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "CONNECT");
zmsg_addstr (msg, endpoint);
zmsg_send (&msg, self->pipe);
zclock_sleep (100); // Allow connection to come up
}
// .split request method
// To implement the request method, the frontend object sends a message
// to the backend, specifying a command "REQUEST" and the request message:
zmsg_t *
flcliapi_request (flcliapi_t *self, zmsg_t **request_p)
{
assert (self);
assert (*request_p);
zmsg_pushstr (*request_p, "REQUEST");
zmsg_send (request_p, self->pipe);
zmsg_t *reply = zmsg_recv (self->pipe);
if (reply) {
char *status = zmsg_popstr (reply);
if (streq (status, "FAILED"))
zmsg_destroy (&reply);
free (status);
}
return reply;
}
// .split backend agent
// Here we see the backend agent. It runs as an attached thread, talking
// to its parent over a pipe socket. It is a fairly complex piece of work
// so we'll break it down into pieces. First, the agent manages a set of
// servers, using our familiar class approach:
// Simple class for one server we talk to
typedef struct {
char *endpoint; // Server identity/endpoint
uint alive; // 1 if known to be alive
int64_t ping_at; // Next ping at this time
int64_t expires; // Expires at this time
} server_t;
server_t *
server_new (char *endpoint)
{
server_t *self = (server_t *) zmalloc (sizeof (server_t));
self->endpoint = strdup (endpoint);
self->alive = 0;
self->ping_at = zclock_time () + PING_INTERVAL;
self->expires = zclock_time () + SERVER_TTL;
return self;
}
void
server_destroy (server_t **self_p)
{
assert (self_p);
if (*self_p) {
server_t *self = *self_p;
free (self->endpoint);
free (self);
*self_p = NULL;
}
}
int
server_ping (const char *key, void *server, void *socket)
{
server_t *self = (server_t *) server;
if (zclock_time () >= self->ping_at) {
zmsg_t *ping = zmsg_new ();
zmsg_addstr (ping, self->endpoint);
zmsg_addstr (ping, "PING");
zmsg_send (&ping, socket);
self->ping_at = zclock_time () + PING_INTERVAL;
}
return 0;
}
int
server_tickless (const char *key, void *server, void *arg)
{
server_t *self = (server_t *) server;
uint64_t *tickless = (uint64_t *) arg;
if (*tickless > self->ping_at)
*tickless = self->ping_at;
return 0;
}
// .split backend agent class
// We build the agent as a class that's capable of processing messages
// coming in from its various sockets:
// Simple class for one background agent
typedef struct {
zctx_t *ctx; // Own context
void *pipe; // Socket to talk back to application
void *router; // Socket to talk to servers
zhash_t *servers; // Servers we've connected to
zlist_t *actives; // Servers we know are alive
uint sequence; // Number of requests ever sent
zmsg_t *request; // Current request if any
zmsg_t *reply; // Current reply if any
int64_t expires; // Timeout for request/reply
} agent_t;
agent_t *
agent_new (zctx_t *ctx, void *pipe)
{
agent_t *self = (agent_t *) zmalloc (sizeof (agent_t));
self->ctx = ctx;
self->pipe = pipe;
self->router = zsocket_new (self->ctx, ZMQ_ROUTER);
self->servers = zhash_new ();
self->actives = zlist_new ();
return self;
}
void
agent_destroy (agent_t **self_p)
{
assert (self_p);
if (*self_p) {
agent_t *self = *self_p;
zhash_destroy (&self->servers);
zlist_destroy (&self->actives);
zmsg_destroy (&self->request);
zmsg_destroy (&self->reply);
free (self);
*self_p = NULL;
}
}
// .split control messages
// This method processes one message from our frontend class
// (it's going to be CONNECT or REQUEST):
// Callback when we remove server from agent 'servers' hash table
static void
s_server_free (void *argument)
{
server_t *server = (server_t *) argument;
server_destroy (&server);
}
void
agent_control_message (agent_t *self)
{
zmsg_t *msg = zmsg_recv (self->pipe);
char *command = zmsg_popstr (msg);
if (streq (command, "CONNECT")) {
char *endpoint = zmsg_popstr (msg);
printf ("I: connecting to %s...\n", endpoint);
int rc = zmq_connect (self->router, endpoint);
assert (rc == 0);
server_t *server = server_new (endpoint);
zhash_insert (self->servers, endpoint, server);
zhash_freefn (self->servers, endpoint, s_server_free);
zlist_append (self->actives, server);
server->ping_at = zclock_time () + PING_INTERVAL;
server->expires = zclock_time () + SERVER_TTL;
free (endpoint);
}
else
if (streq (command, "REQUEST")) {
assert (!self->request); // Strict request-reply cycle
// Prefix request with sequence number and empty envelope
char sequence_text [10];
sprintf (sequence_text, "%u", ++self->sequence);
zmsg_pushstr (msg, sequence_text);
// Take ownership of request message
self->request = msg;
msg = NULL;
// Request expires after global timeout
self->expires = zclock_time () + GLOBAL_TIMEOUT;
}
free (command);
zmsg_destroy (&msg);
}
// .split router messages
// This method processes one message from a connected
// server:
void
agent_router_message (agent_t *self)
{
zmsg_t *reply = zmsg_recv (self->router);
// Frame 0 is server that replied
char *endpoint = zmsg_popstr (reply);
server_t *server =
(server_t *) zhash_lookup (self->servers, endpoint);
assert (server);
free (endpoint);
if (!server->alive) {
zlist_append (self->actives, server);
server->alive = 1;
}
server->ping_at = zclock_time () + PING_INTERVAL;
server->expires = zclock_time () + SERVER_TTL;
// Frame 1 may be sequence number for reply
char *sequence = zmsg_popstr (reply);
if (atoi (sequence) == self->sequence) {
zmsg_pushstr (reply, "OK");
zmsg_send (&reply, self->pipe);
zmsg_destroy (&self->request);
}
else
zmsg_destroy (&reply);
}
// .split backend agent implementation
// Finally, here's the agent task itself, which polls its two sockets
// and processes incoming messages:
static void
flcliapi_agent (void *args, zctx_t *ctx, void *pipe)
{
agent_t *self = agent_new (ctx, pipe);
zmq_pollitem_t items [] = {
{ self->pipe, 0, ZMQ_POLLIN, 0 },
{ self->router, 0, ZMQ_POLLIN, 0 }
};
while (!zctx_interrupted) {
// Calculate tickless timer, up to 1 hour
uint64_t tickless = zclock_time () + 1000 * 3600;
if (self->request
&& tickless > self->expires)
tickless = self->expires;
zhash_foreach (self->servers, server_tickless, &tickless);
int rc = zmq_poll (items, 2,
(tickless - zclock_time ()) * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Context has been shut down
if (items [0].revents & ZMQ_POLLIN)
agent_control_message (self);
if (items [1].revents & ZMQ_POLLIN)
agent_router_message (self);
// If we're processing a request, dispatch to next server
if (self->request) {
if (zclock_time () >= self->expires) {
// Request expired, kill it
zstr_send (self->pipe, "FAILED");
zmsg_destroy (&self->request);
}
else {
// Find server to talk to, remove any expired ones
while (zlist_size (self->actives)) {
server_t *server =
(server_t *) zlist_first (self->actives);
if (zclock_time () >= server->expires) {
zlist_pop (self->actives);
server->alive = 0;
}
else {
zmsg_t *request = zmsg_dup (self->request);
zmsg_pushstr (request, server->endpoint);
zmsg_send (&request, self->router);
break;
}
}
}
}
// Disconnect and delete any expired servers
// Send heartbeats to idle servers if needed
zhash_foreach (self->servers, server_ping, self->router);
}
agent_destroy (&self);
}
flcliapi: Freelance client API in C++
// flcliapi class - Freelance Pattern agent class
// Implements the Freelance Protocol at http://rfc.zeromq.org/spec:10
#include "flcliapi.hpp"
// If no server replies within this time, abandon request
const int GLOBAL_TIMEOUT = 3000; // msecs
// PING interval for servers we think are alive
const int PING_INTERVAL = 500; // msecs
// Server considered dead if silent for this long
const int SERVER_TTL = 1000; // msecs
// This API works in two halves, a common pattern for APIs that need to
// run in the background. One half is an frontend object our application
// creates and works with; the other half is a backend "agent" that runs
// in a background thread. The frontend talks to the backend over an
// inproc pipe socket created by actor object:
// Constructor
Flcliapi::Flcliapi()
: actor_(std::bind(&Flcliapi::agent, this, std::placeholders::_1, std::ref(context_))) {}
Flcliapi::~Flcliapi() {}
// connect interface
// To implement the connect method, the frontend object sends a multipart
// message to the backend agent. The first part is a string "CONNECT", and
// the second part is the endpoint. It waits 100msec for the connection to
// come up, which isn't pretty, but saves us from sending all requests to a
// single server, at startup time:
void Flcliapi::connect(const std::string& endpoint) {
zmqpp::message msg;
msg.push_back("CONNECT");
msg.push_back(endpoint);
actor_.pipe()->send(msg);
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // Allow connection to come up
}
// request interface
// To implement the request method, the frontend object sends a message
// to the backend, specifying a command "REQUEST" and the request message:
std::unique_ptr<zmqpp::message> Flcliapi::request(zmqpp::message& request) {
assert(request.parts() > 0);
request.push_front("REQUEST");
actor_.pipe()->send(request);
std::unique_ptr<zmqpp::message> reply = std::make_unique<zmqpp::message>();
actor_.pipe()->receive(*reply);
if (0 != reply->parts()) {
if (reply->get(0) == "FAILED") reply.release();
} else {
reply.release();
}
return reply;
}
Server::Server(const std::string& endpoint) {
endpoint_ = endpoint;
alive_ = false;
ping_at_ = std::chrono::steady_clock::now() + std::chrono::milliseconds(PING_INTERVAL);
expires_ = std::chrono::steady_clock::now() + std::chrono::milliseconds(SERVER_TTL);
}
Server::~Server() {}
int Server::ping(zmqpp::socket& socket) {
if (std::chrono::steady_clock::now() >= ping_at_) {
zmqpp::message ping;
ping.push_back(endpoint_);
ping.push_back("PING");
socket.send(ping);
ping_at_ = std::chrono::steady_clock::now() + std::chrono::milliseconds(PING_INTERVAL);
}
return 0;
}
int Server::tickless(std::chrono::time_point<std::chrono::steady_clock>& tickless_at) {
if (tickless_at > ping_at_) tickless_at = ping_at_;
return 0;
}
Agent::Agent(zmqpp::context& context, zmqpp::socket* pipe)
: context_(context), pipe_(pipe), router_(context, zmqpp::socket_type::router) {
router_.set(zmqpp::socket_option::linger, GLOBAL_TIMEOUT);
sequence_ = 0;
}
Agent::~Agent() {}
// control messages
// This method processes one message from our frontend class
// (it's going to be CONNECT or REQUEST):
void Agent::control_message(std::unique_ptr<zmqpp::message> msg) {
std::string command = msg->get(0);
msg->pop_front();
if (command == "CONNECT") {
std::string endpoint = msg->get(0);
msg->pop_front();
std::cout << "I: connecting to " << endpoint << "..." << std::endl;
try {
router_.connect(endpoint);
} catch (zmqpp::zmq_internal_exception& e) {
std::cerr << "failed to bind to endpoint " << endpoint << ": " << e.what() << std::endl;
return;
}
std::shared_ptr<Server> server = std::make_shared<Server>(endpoint);
servers_.insert(std::pair<std::string, std::shared_ptr<Server>>(endpoint, server));
// actives_.push_back(server);
server->setPingAt(std::chrono::steady_clock::now() +
std::chrono::milliseconds(PING_INTERVAL));
server->setExpires(std::chrono::steady_clock::now() +
std::chrono::milliseconds(SERVER_TTL));
} else if (command == "REQUEST") {
assert(!request_); // Strict request-reply cycle
// Prefix request with sequence number and empty envelope
msg->push_front(++sequence_);
// Take ownership of request message
request_ = std::move(msg);
// Request expires after global timeout
expires_ = std::chrono::steady_clock::now() + std::chrono::milliseconds(GLOBAL_TIMEOUT);
}
}
// .split router messages
// This method processes one message from a connected
// server:
void Agent::router_message() {
zmqpp::message reply;
router_.receive(reply);
// Frame 0 is server that replied
std::string endpoint = reply.get(0);
reply.pop_front();
assert(servers_.count(endpoint));
std::shared_ptr<Server> server = servers_.at(endpoint);
if (!server->isAlive()) {
actives_.push_back(server);
server->setAlive(true);
}
server->setPingAt(std::chrono::steady_clock::now() + std::chrono::milliseconds(PING_INTERVAL));
server->setExpires(std::chrono::steady_clock::now() + std::chrono::milliseconds(SERVER_TTL));
// Frame 1 may be sequence number for reply
uint sequence;
reply.get(sequence, 0);
reply.pop_front();
if (request_) {
if (sequence == sequence_) {
request_.release();
reply.push_front("OK");
pipe_->send(reply);
}
}
}
// .split backend agent implementation
// Finally, here's the agent task itself, which polls its two sockets
// and processes incoming messages:
bool Flcliapi::agent(zmqpp::socket* pipe, zmqpp::context& context) {
Agent self(context, pipe);
zmqpp::poller poller;
poller.add(*self.getPipe());
poller.add(self.getRouter());
pipe->send(zmqpp::signal::ok); // signal we successfully started
while (true) {
// Calculate tickless timer, up to 1 hour
std::chrono::time_point<std::chrono::steady_clock> tickless =
std::chrono::steady_clock::now() + std::chrono::hours(1);
if (self.request_ && tickless > self.expires_) tickless = self.expires_;
for (auto& kv : self.servers_) {
kv.second->tickless(tickless);
}
if (poller.poll(std::chrono::duration_cast<std::chrono::milliseconds>(
tickless - std::chrono::steady_clock::now())
.count())) {
if (poller.has_input(*self.getPipe())) {
std::unique_ptr<zmqpp::message> msg = std::make_unique<zmqpp::message>();
pipe->receive(*msg);
if (msg->is_signal()) {
zmqpp::signal sig;
msg->get(sig, 0);
if (sig == zmqpp::signal::stop) break; // actor receive stop signal, exit
} else
self.control_message(std::move(msg));
}
if (poller.has_input(self.getRouter())) self.router_message();
}
// If we're processing a request, dispatch to next server
if (self.request_) {
if (std::chrono::steady_clock::now() >= self.expires_) {
// Request expired, kill it
self.request_.release();
self.getPipe()->send("FAILED");
} else {
// Find server to talk to, remove any expired ones
while (self.actives_.size() > 0) {
auto& server = self.actives_.front();
if (std::chrono::steady_clock::now() >= server->getExpires()) {
server->setAlive(false);
self.actives_.pop_front();
} else {
zmqpp::message request;
request.copy(*self.request_);
request.push_front(server->getEndpoint());
self.getRouter().send(request);
break;
}
}
}
}
for (auto& kv : self.servers_) {
kv.second->ping(self.getRouter());
}
}
return true; // will send signal::ok to signal successful shutdown
}
flcliapi: Freelance client API in C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using ZeroMQ;
namespace Examples
{
namespace FLCliApi
{
//
// flcliapi class - Freelance Pattern agent class
// Implements the Freelance Protocol at http://rfc.zeromq.org/spec:10
//
// Author: metadings
//
// This API works in two halves, a common pattern for APIs that need to
// run in the background. One half is an frontend object our application
// creates and works with; the other half is a backend "agent" that runs
// in a background thread. The frontend talks to the backend over an
// inproc pipe socket:
public class FreelanceClient : IDisposable
{
// Here we see the backend agent. It runs as an attached thread, talking
// to its parent over a pipe socket. It is a fairly complex piece of work
// so we'll break it down into pieces.
// Our context
ZContext context;
// Pipe through to flcliapi agent
public ZActor Actor { get; protected set; }
public FreelanceClient()
{
// Constructor
this.context = new ZContext();
this.Actor = new ZActor(this.context, FreelanceClient.Agent);
this.Actor.Start();
}
~FreelanceClient()
{
this.Dispose(false);
}
public void Dispose()
{
GC.SuppressFinalize(this);
this.Dispose(true);
}
protected void Dispose(bool disposing)
{
if (disposing)
{
// Destructor
if (this.Actor != null)
{
this.Actor.Dispose();
this.Actor = null;
}
if (this.context != null)
{
// Do context.Dispose()
this.context.Dispose();
this.context = null;
}
}
}
public void Connect(string endpoint)
{
// To implement the connect method, the frontend object sends a multipart
// message to the backend agent. The first part is a string "CONNECT", and
// the second part is the endpoint. It waits 100msec for the connection to
// come up, which isn't pretty, but saves us from sending all requests to a
// single server, at startup time:
using (var message = new ZMessage())
{
message.Add(new ZFrame("CONNECT"));
message.Add(new ZFrame(endpoint));
this.Actor.Frontend.Send(message);
}
Thread.Sleep(64); // Allow connection to come up
}
public ZMessage Request(ZMessage request)
{
// To implement the request method, the frontend object sends a message
// to the backend, specifying a command "REQUEST" and the request message:
request.Prepend(new ZFrame("REQUEST"));
this.Actor.Frontend.Send(request);
ZMessage reply;
ZError error;
if (null != (reply = this.Actor.Frontend.ReceiveMessage(out error)))
{
string status = reply.PopString();
if (status == "FAILED")
{
reply.Dispose();
reply = null;
}
}
return reply;
}
public static void Agent(ZContext context, ZSocket backend, CancellationTokenSource cancellor, object[] args)
{
// Finally, here's the agent task itself, which polls its two sockets
// and processes incoming messages:
using (var agent = new Agent(context, backend))
{
var p = ZPollItem.CreateReceiver();
while (!cancellor.IsCancellationRequested)
{
ZMessage msg;
ZError error;
// Poll the control message
if (agent.Pipe.PollIn(p, out msg, out error, TimeSpan.FromMilliseconds(64)))
{
using (msg)
{
agent.ControlMessage(msg);
}
}
else
{
if (error == ZError.ETERM)
break; // Interrupted
if (error != ZError.EAGAIN)
throw new ZException(error);
}
// Poll the router message
if (agent.Router.PollIn(p, out msg, out error, TimeSpan.FromMilliseconds(64)))
{
using (msg)
{
agent.RouterMessage(msg);
}
}
else
{
if (error == ZError.ETERM)
break; // Interrupted
if (error != ZError.EAGAIN)
throw new ZException(error);
}
if (agent.Request != null)
{
// If we're processing a request, dispatch to next server
if (DateTime.UtcNow >= agent.Expires)
{
// Request expired, kill it
using (var outgoing = new ZFrame("FAILED"))
{
agent.Pipe.Send(outgoing);
}
agent.Request.Dispose();
agent.Request = null;
}
else
{
// Find server to talk to, remove any expired ones
foreach (Server server in agent.Actives.ToList())
{
if (DateTime.UtcNow >= server.Expires)
{
agent.Actives.Remove(server);
server.Alive = false;
}
else
{
// Copy the Request, Push the Endpoint and send on Router
using (var request = agent.Request.Duplicate())
{
request.Prepend(new ZFrame(server.Endpoint));
agent.Router.Send(request);
break;
}
}
}
}
}
// Disconnect and delete any expired servers
// Send heartbeats to idle servers if needed
foreach (Server server in agent.Servers)
{
server.Ping(agent.Router);
}
}
}
}
}
public class Agent : IDisposable
{
static readonly TimeSpan GLOBAL_TIMEOUT = TimeSpan.FromMilliseconds(3000);
// We build the agent as a class that's capable of processing messages
// coming in from its various sockets:
// Simple class for one background agent
// Socket to talk back to application
public ZSocket Pipe;
// Socket to talk to servers
public ZSocket Router;
// Servers we've connected to
public HashSet<Server> Servers;
// Servers we know are alive
public List<Server> Actives;
// Number of requests ever sent
int sequence;
// Current request if any
public ZMessage Request;
// Current reply if any
// ZMessage reply;
// Timeout for request/reply
public DateTime Expires;
public Agent(ZContext context, ZSocket pipe)
: this (context, default(string), pipe)
{
var rnd = new Random();
this.Router.IdentityString = "CLIENT" + rnd.Next();
}
public Agent(ZContext context, string name, ZSocket pipe)
{
// Constructor
this.Pipe = pipe;
this.Router = new ZSocket(context, ZSocketType.ROUTER);
if (name != null)
{
this.Router.IdentityString = name;
}
this.Servers = new HashSet<Server>();
this.Actives = new List<Server>();
}
~Agent()
{
this.Dispose(false);
}
public void Dispose()
{
GC.SuppressFinalize(this);
this.Dispose(true);
}
protected void Dispose(bool disposing)
{
if (disposing)
{
// Destructor
this.Servers = null;
this.Actives = null;
if (this.Request != null)
{
this.Request.Dispose();
this.Request = null;
}
/* if (this.reply != null)
{
this.reply.Dispose();
this.reply = null;
} */
if (this.Router != null)
{
this.Router.Dispose();
this.Router = null;
}
}
}
public void ControlMessage(ZMessage msg)
{
// This method processes one message from our frontend class
// (it's going to be CONNECT or REQUEST):
string command = msg.PopString();
if (command == "CONNECT")
{
string endpoint = msg.PopString();
Console.WriteLine("I: connecting to {0}...", endpoint);
this.Router.Connect(endpoint);
var server = new Server(endpoint);
this.Servers.Add(server);
this.Actives.Add(server);
}
else if (command == "REQUEST")
{
if (this.Request != null)
{
// Strict request-reply cycle
throw new InvalidOperationException();
}
// Prefix request with sequence number and empty envelope
msg.Prepend(new ZFrame(++sequence));
// Take ownership of request message
this.Request = msg.Duplicate();
// Request expires after global timeout
this.Expires = DateTime.UtcNow + GLOBAL_TIMEOUT;
}
}
public void RouterMessage(ZMessage reply)
{
// This method processes one message from a connected
// server:
// Frame 0 is server that replied
string endpoint = reply.PopString();
Server server = this.Servers.Single(s => s.Endpoint == endpoint);
if (!server.Alive)
{
this.Actives.Add(server);
server.Refresh(true);
}
// Frame 1 may be sequence number for reply
int sequence = reply.PopInt32();
if (sequence == this.sequence)
{
reply.Prepend(new ZFrame("OK"));
this.Pipe.Send(reply);
this.Request.Dispose();
this.Request = null;
}
}
}
public class Server
{
public static readonly TimeSpan PING_INTERVAL = TimeSpan.FromMilliseconds(2000);
public static readonly TimeSpan SERVER_TTL = TimeSpan.FromMilliseconds(6000);
// Simple class for one server we talk to
// Server identity/endpoint
public string Endpoint { get; protected set; }
// true if known to be alive
public bool Alive { get; set; }
// Next ping at this time
public DateTime PingAt { get; protected set; }
// Expires at this time
public DateTime Expires { get; protected set; }
public Server(string endpoint)
{
this.Endpoint = endpoint;
this.Refresh(true);
}
public void Refresh(bool alive)
{
this.Alive = alive;
if (alive)
{
this.PingAt = DateTime.UtcNow + PING_INTERVAL;
this.Expires = DateTime.UtcNow + SERVER_TTL;
}
}
public void Ping(ZSocket socket)
{
if (DateTime.UtcNow >= PingAt)
{
using (var outgoing = new ZMessage())
{
outgoing.Add(new ZFrame(Endpoint));
outgoing.Add(new ZFrame("PING"));
socket.Send(outgoing);
}
this.PingAt = DateTime.UtcNow + PING_INTERVAL;
}
}
public override int GetHashCode()
{
return Endpoint.GetHashCode();
}
}
}
}
flcliapi: Freelance client API in CL
flcliapi: Freelance client API in Delphi
flcliapi: Freelance client API in Erlang
flcliapi: Freelance client API in Elixir
flcliapi: Freelance client API in F#
flcliapi: Freelance client API in Felix
flcliapi: Freelance client API in Go
flcliapi: Freelance client API in Haskell
flcliapi: Freelance client API in Haxe
flcliapi: Freelance client API in Java
package guide;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZThread.IAttachedRunnable;
// flcliapi class - Freelance Pattern agent class
// Implements the Freelance Protocol at http://rfc.zeromq.org/spec:10
public class flcliapi
{
// If not a single service replies within this time, give up
private static final int GLOBAL_TIMEOUT = 2500;
// PING interval for servers we think are alive
private static final int PING_INTERVAL = 2000; // msecs
// Server considered dead if silent for this long
private static final int SERVER_TTL = 6000; // msecs
// .split API structure
// This API works in two halves, a common pattern for APIs that need to
// run in the background. One half is an frontend object our application
// creates and works with; the other half is a backend "agent" that runs
// in a background thread. The frontend talks to the backend over an
// inproc pipe socket:
// Structure of our frontend class
private ZContext ctx; // Our context wrapper
private Socket pipe; // Pipe through to flcliapi agent
public flcliapi()
{
ctx = new ZContext();
FreelanceAgent agent = new FreelanceAgent();
pipe = ZThread.fork(ctx, agent);
}
public void destroy()
{
ctx.destroy();
}
// .split connect method
// To implement the connect method, the frontend object sends a multipart
// message to the backend agent. The first part is a string "CONNECT", and
// the second part is the endpoint. It waits 100msec for the connection to
// come up, which isn't pretty, but saves us from sending all requests to a
// single server, at startup time:
public void connect(String endpoint)
{
ZMsg msg = new ZMsg();
msg.add("CONNECT");
msg.add(endpoint);
msg.send(pipe);
try {
Thread.sleep(100); // Allow connection to come up
}
catch (InterruptedException e) {
}
}
// .split request method
// To implement the request method, the frontend object sends a message
// to the backend, specifying a command "REQUEST" and the request message:
public ZMsg request(ZMsg request)
{
request.push("REQUEST");
request.send(pipe);
ZMsg reply = ZMsg.recvMsg(pipe);
if (reply != null) {
String status = reply.popString();
if (status.equals("FAILED"))
reply.destroy();
}
return reply;
}
// .split backend agent
// Here we see the backend agent. It runs as an attached thread, talking
// to its parent over a pipe socket. It is a fairly complex piece of work
// so we'll break it down into pieces. First, the agent manages a set of
// servers, using our familiar class approach:
// Simple class for one server we talk to
private static class Server
{
private String endpoint; // Server identity/endpoint
private boolean alive; // 1 if known to be alive
private long pingAt; // Next ping at this time
private long expires; // Expires at this time
protected Server(String endpoint)
{
this.endpoint = endpoint;
alive = false;
pingAt = System.currentTimeMillis() + PING_INTERVAL;
expires = System.currentTimeMillis() + SERVER_TTL;
}
protected void destroy()
{
}
private void ping(Socket socket)
{
if (System.currentTimeMillis() >= pingAt) {
ZMsg ping = new ZMsg();
ping.add(endpoint);
ping.add("PING");
ping.send(socket);
pingAt = System.currentTimeMillis() + PING_INTERVAL;
}
}
private long tickless(long tickless)
{
if (tickless > pingAt)
return pingAt;
return -1;
}
}
// .split backend agent class
// We build the agent as a class that's capable of processing messages
// coming in from its various sockets:
// Simple class for one background agent
private static class Agent
{
private ZContext ctx; // Own context
private Socket pipe; // Socket to talk back to application
private Socket router; // Socket to talk to servers
private Map<String, Server> servers; // Servers we've connected to
private List<Server> actives; // Servers we know are alive
private int sequence; // Number of requests ever sent
private ZMsg request; // Current request if any
private ZMsg reply; // Current reply if any
private long expires; // Timeout for request/reply
protected Agent(ZContext ctx, Socket pipe)
{
this.ctx = ctx;
this.pipe = pipe;
router = ctx.createSocket(SocketType.ROUTER);
servers = new HashMap<String, Server>();
actives = new ArrayList<Server>();
}
protected void destroy()
{
for (Server server : servers.values())
server.destroy();
}
// .split control messages
// This method processes one message from our frontend class
// (it's going to be CONNECT or REQUEST):
// Callback when we remove server from agent 'servers' hash table
private void controlMessage()
{
ZMsg msg = ZMsg.recvMsg(pipe);
String command = msg.popString();
if (command.equals("CONNECT")) {
String endpoint = msg.popString();
System.out.printf("I: connecting to %s...\n", endpoint);
router.connect(endpoint);
Server server = new Server(endpoint);
servers.put(endpoint, server);
actives.add(server);
server.pingAt = System.currentTimeMillis() + PING_INTERVAL;
server.expires = System.currentTimeMillis() + SERVER_TTL;
}
else if (command.equals("REQUEST")) {
assert (request == null); // Strict request-reply cycle
// Prefix request with getSequence number and empty envelope
String sequenceText = String.format("%d", ++sequence);
msg.push(sequenceText);
// Take ownership of request message
request = msg;
msg = null;
// Request expires after global timeout
expires = System.currentTimeMillis() + GLOBAL_TIMEOUT;
}
if (msg != null)
msg.destroy();
}
// .split router messages
// This method processes one message from a connected
// server:
private void routerMessage()
{
ZMsg reply = ZMsg.recvMsg(router);
// Frame 0 is server that replied
String endpoint = reply.popString();
Server server = servers.get(endpoint);
assert (server != null);
if (!server.alive) {
actives.add(server);
server.alive = true;
}
server.pingAt = System.currentTimeMillis() + PING_INTERVAL;
server.expires = System.currentTimeMillis() + SERVER_TTL;
// Frame 1 may be getSequence number for reply
String sequenceStr = reply.popString();
if (Integer.parseInt(sequenceStr) == sequence) {
reply.push("OK");
reply.send(pipe);
request.destroy();
request = null;
}
else reply.destroy();
}
}
// .split backend agent implementation
// Finally, here's the agent task itself, which polls its two sockets
// and processes incoming messages:
static private class FreelanceAgent implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
Agent agent = new Agent(ctx, pipe);
Poller poller = ctx.createPoller(2);
poller.register(agent.pipe, Poller.POLLIN);
poller.register(agent.router, Poller.POLLIN);
while (!Thread.currentThread().isInterrupted()) {
// Calculate tickless timer, up to 1 hour
long tickless = System.currentTimeMillis() + 1000 * 3600;
if (agent.request != null && tickless > agent.expires)
tickless = agent.expires;
for (Server server : agent.servers.values()) {
long newTickless = server.tickless(tickless);
if (newTickless > 0)
tickless = newTickless;
}
int rc = poller.poll(tickless - System.currentTimeMillis());
if (rc == -1)
break; // Context has been shut down
if (poller.pollin(0))
agent.controlMessage();
if (poller.pollin(1))
agent.routerMessage();
// If we're processing a request, dispatch to next server
if (agent.request != null) {
if (System.currentTimeMillis() >= agent.expires) {
// Request expired, kill it
agent.pipe.send("FAILED");
agent.request.destroy();
agent.request = null;
}
else {
// Find server to talk to, remove any expired ones
while (!agent.actives.isEmpty()) {
Server server = agent.actives.get(0);
if (System.currentTimeMillis() >= server.expires) {
agent.actives.remove(0);
server.alive = false;
}
else {
ZMsg request = agent.request.duplicate();
request.push(server.endpoint);
request.send(agent.router);
break;
}
}
}
}
// Disconnect and delete any expired servers
// Send heartbeats to idle servers if needed
for (Server server : agent.servers.values())
server.ping(agent.router);
}
agent.destroy();
}
}
}
flcliapi: Freelance client API in Julia
flcliapi: Freelance client API in Lua
flcliapi: Freelance client API in Node.js
flcliapi: Freelance client API in Objective-C
flcliapi: Freelance client API in ooc
flcliapi: Freelance client API in Perl
flcliapi: Freelance client API in PHP
flcliapi: Freelance client API in Python
"""
flcliapi - Freelance Pattern agent class
Model 3: uses ROUTER socket to address specific services
Author: Min RK <benjaminrk@gmail.com>
"""
import threading
import time
import zmq
from zhelpers import zpipe
# If no server replies within this time, abandon request
GLOBAL_TIMEOUT = 3000 # msecs
# PING interval for servers we think are alivecp
PING_INTERVAL = 2000 # msecs
# Server considered dead if silent for this long
SERVER_TTL = 6000 # msecs
def flciapi_agent(peer):
"""This is the thread that handles our real flcliapi class
"""
pass
# =====================================================================
# Synchronous part, works in our application thread
class FreelanceClient(object):
ctx = None # Our Context
pipe = None # Pipe through to flciapi agent
agent = None # agent in a thread
def __init__(self):
self.ctx = zmq.Context()
self.pipe, peer = zpipe(self.ctx)
self.agent = threading.Thread(target=agent_task, args=(self.ctx,peer))
self.agent.daemon = True
self.agent.start()
def connect(self, endpoint):
"""Connect to new server endpoint
Sends [CONNECT][endpoint] to the agent
"""
self.pipe.send_multipart(["CONNECT", endpoint])
time.sleep(0.1) # Allow connection to come up
def request(self, msg):
"Send request, get reply"
request = ["REQUEST"] + msg
self.pipe.send_multipart(request)
reply = self.pipe.recv_multipart()
status = reply.pop(0)
if status != "FAILED":
return reply
# =====================================================================
# Asynchronous part, works in the background
# ---------------------------------------------------------------------
# Simple class for one server we talk to
class FreelanceServer(object):
endpoint = None # Server identity/endpoint
alive = True # 1 if known to be alive
ping_at = 0 # Next ping at this time
expires = 0 # Expires at this time
def __init__(self, endpoint):
self.endpoint = endpoint
self.alive = True
self.ping_at = time.time() + 1e-3*PING_INTERVAL
self.expires = time.time() + 1e-3*SERVER_TTL
def ping(self, socket):
if time.time() > self.ping_at:
socket.send_multipart([self.endpoint, 'PING'])
self.ping_at = time.time() + 1e-3*PING_INTERVAL
def tickless(self, tickless):
if tickless > self.ping_at:
tickless = self.ping_at
return tickless
# ---------------------------------------------------------------------
# Simple class for one background agent
class FreelanceAgent(object):
ctx = None # Own context
pipe = None # Socket to talk back to application
router = None # Socket to talk to servers
servers = None # Servers we've connected to
actives = None # Servers we know are alive
sequence = 0 # Number of requests ever sent
request = None # Current request if any
reply = None # Current reply if any
expires = 0 # Timeout for request/reply
def __init__(self, ctx, pipe):
self.ctx = ctx
self.pipe = pipe
self.router = ctx.socket(zmq.ROUTER)
self.servers = {}
self.actives = []
def control_message (self):
msg = self.pipe.recv_multipart()
command = msg.pop(0)
if command == "CONNECT":
endpoint = msg.pop(0)
print "I: connecting to %s...\n" % endpoint,
self.router.connect(endpoint)
server = FreelanceServer(endpoint)
self.servers[endpoint] = server
self.actives.append(server)
# these are in the C case, but seem redundant:
server.ping_at = time.time() + 1e-3*PING_INTERVAL
server.expires = time.time() + 1e-3*SERVER_TTL
elif command == "REQUEST":
assert not self.request # Strict request-reply cycle
# Prefix request with sequence number and empty envelope
self.request = [str(self.sequence), ''] + msg
# Request expires after global timeout
self.expires = time.time() + 1e-3*GLOBAL_TIMEOUT
def router_message (self):
reply = self.router.recv_multipart()
# Frame 0 is server that replied
endpoint = reply.pop(0)
server = self.servers[endpoint]
if not server.alive:
self.actives.append(server)
server.alive = 1
server.ping_at = time.time() + 1e-3*PING_INTERVAL
server.expires = time.time() + 1e-3*SERVER_TTL;
# Frame 1 may be sequence number for reply
sequence = reply.pop(0)
if int(sequence) == self.sequence:
self.sequence += 1
reply = ["OK"] + reply
self.pipe.send_multipart(reply)
self.request = None
# ---------------------------------------------------------------------
# Asynchronous agent manages server pool and handles request/reply
# dialog when the application asks for it.
def agent_task(ctx, pipe):
agent = FreelanceAgent(ctx, pipe)
poller = zmq.Poller()
poller.register(agent.pipe, zmq.POLLIN)
poller.register(agent.router, zmq.POLLIN)
while True:
# Calculate tickless timer, up to 1 hour
tickless = time.time() + 3600
if (agent.request and tickless > agent.expires):
tickless = agent.expires
for server in agent.servers.values():
tickless = server.tickless(tickless)
try:
items = dict(poller.poll(1000 * (tickless - time.time())))
except:
break # Context has been shut down
if agent.pipe in items:
agent.control_message()
if agent.router in items:
agent.router_message()
# If we're processing a request, dispatch to next server
if (agent.request):
if (time.time() >= agent.expires):
# Request expired, kill it
agent.pipe.send("FAILED")
agent.request = None
else:
# Find server to talk to, remove any expired ones
while agent.actives:
server = agent.actives[0]
if time.time() >= server.expires:
server.alive = 0
agent.actives.pop(0)
else:
request = [server.endpoint] + agent.request
agent.router.send_multipart(request)
break
# Disconnect and delete any expired servers
# Send heartbeats to idle servers if needed
for server in agent.servers.values():
server.ping(agent.router)
flcliapi: Freelance client API in Q
flcliapi: Freelance client API in Racket
flcliapi: Freelance client API in Ruby
flcliapi: Freelance client API in Rust
flcliapi: Freelance client API in Scala
flcliapi: Freelance client API in Tcl
flcliapi: Freelance client API in OCaml
This API implementation is fairly sophisticated and uses a couple of techniques that we’ve not seen before.
-
Multithreaded API: the client API consists of two parts, a synchronous flcliapi class that runs in the application thread, and an asynchronous agent class that runs as a background thread. Remember how ZeroMQ makes it easy to create multithreaded apps. The flcliapi and agent classes talk to each other with messages over an inproc socket. All ZeroMQ aspects (such as creating and destroying a context) are hidden in the API. The agent in effect acts like a mini-broker, talking to servers in the background, so that when we make a request, it can make a best effort to reach a server it believes is available.
-
Tickless poll timer: in previous poll loops we always used a fixed tick interval, e.g., 1 second, which is simple enough but not excellent on power-sensitive clients (such as notebooks or mobile phones), where waking the CPU costs power. For fun, and to help save the planet, the agent uses a tickless timer, which calculates the poll delay based on the next timeout we’re expecting. A proper implementation would keep an ordered list of timeouts. We just check all timeouts and calculate the poll delay until the next one.
Conclusion #
In this chapter, we’ve seen a variety of reliable request-reply mechanisms, each with certain costs and benefits. The example code is largely ready for real use, though it is not optimized. Of all the different patterns, the two that stand out for production use are the Majordomo pattern, for broker-based reliability, and the Freelance pattern, for brokerless reliability.