Chapter 8 - A Framework for Distributed Computing #
We’ve gone though a journey of understanding ZeroMQ in its many aspects. By now you may have started to build your own products using the techniques I explained, as well as others you’ve figured out yourself. You will start to face questions about how to make these products work in the real world.
But what is that “real world”? I’ll argue that it is becoming a world of ever increasing numbers of moving pieces. Some people use the phrase the “Internet of Things”, suggesting that we’ll see a new category of devices that are more numerous but also more stupid than our current smart phones, tablets, laptops, and servers. However, I don’t think the data points this way at all. Yes, there are more and more devices, but they’re not stupid at all. They’re smart and powerful and getting more so all the time.
The mechanism at work is something I call “Cost Gravity” and it has the effect of reducing the cost of technology by half every 18-24 months. Put another way, our global computing capacity doubles every two years, over and over and over. The future is filled with trillions of devices that are fully powerful multi-core computers: they don’t run a cut-down “operating system for things” but full operating systems and full applications.
And this is the world we’re targeting with ZeroMQ. When we talk of “scale”, we don’t mean hundreds of computers, or even thousands. Think of clouds of tiny smart and perhaps self-replicating machines surrounding every person, filling every space, covering every wall, filling the cracks and eventually, becoming so much a part of us that we get them before birth and they follow us to death.
These clouds of tiny machines talk to each other, all the time, over short-range wireless links using the Internet Protocol. They create mesh networks, pass information and tasks around like nervous signals. They augment our memory, vision, every aspect of our communications, and physical functions. And it’s ZeroMQ that powers their conversations and events and exchanges of work and information.
Now, to make even a thin imitation of this come true today, we need to solve a set of technical problems. These include: How do peers discover each other? How do they talk to existing networks like the Web? How do they protect the information they carry? How do we track and monitor them, to get some idea of what they’re doing? Then we need to do what most engineers forget about: package this solution into a framework that is dead easy for ordinary developers to use.
This is what we’ll attempt in this chapter: to build a framework for distributed applications as an API, protocols, and implementations. It’s not a small challenge but I’ve claimed often that ZeroMQ makes such problems simple, so let’s see if that’s still true.
We’ll cover:
- Requirements for distributed computing
- The pros and cons of WiFi for proximity networking
- Discovery using UDP and TCP
- A message-based API
- Creating a new open source project
- Peer-to-peer connectivity (the Harmony pattern)
- Tracking peer presence and disappearance
- Group messaging without central coordination
- Large-scale testing and simulation
- Dealing with high-water marks and blocked peers
- Distributed logging and monitoring
Design for The Real World #
Whether we’re connecting a roomful of mobile devices over WiFi or a cluster of virtual boxes over simulated Ethernet, we will hit the same kinds of problems. These are:
-
Discovery: how do we learn about other nodes on the network? Do we use a discovery service, centralized mediation, or some kind of broadcast beacon?
-
Presence: how do we track when other nodes come and go? Do we use some kind of central registration service, or heartbeating or beacons?
-
Connectivity: how do we actually connect one node to another? Do we use local networking, wide-area networking, or do we use a central message broker to do the forwarding?
-
Point-to-point messaging: how do we send a message from one node to another? Do we send this to the node’s network address, or do we use some indirect addressing via a centralized message broker?
-
Group messaging: how do we send a message from one node to a group of others? Do we work via a centralized message broker, or do we use a pub-sub model like ZeroMQ?
-
Testing and simulation: how do we simulate large numbers of nodes so we can test performance properly? Do we have to buy two dozen Android tablets, or can we use pure software simulation?
-
Distributed Logging: how do we track what this cloud of nodes is doing so we can detect performance problems and failures? Do we create a main logging service, or do we allow every device to log the world around it?
-
Content distribution: how do we send content from one node to another? Do we use server-centric protocols like FTP or HTTP, or do we use decentralized protocols like FileMQ?
If we can solve these problems reasonably well, and the further problems that will emerge (like security and wide-area bridging), we get something like a framework for what I might call “Really Cool Distributed Applications”, or as my grandkids call it, “the software our world runs on”.
You should have guessed from my rhetorical questions that there are two broad directions in which we can go. One is to centralize everything. The other is to distribute everything. I’m going to bet on decentralization. If you want centralization, you don’t really need ZeroMQ; there are other options you can use.
So very roughly, here’s the story. One, the number of moving pieces increases exponentially over time (doubles every 24 months). Two, these pieces stop using wires because dragging cables everywhere gets really boring. Three, future applications run across clusters of these pieces using the Benevolent Tyrant pattern from Chapter 6 - The ZeroMQ Community. Four, today it’s really difficult, nay still rather impossible, to build such applications. Five, let’s make it cheap and easy using all the techniques and tools we’ve built up. Six, partay!
The Secret Life of WiFi #
The future is clearly wireless, and while many big businesses live by concentrating data in their clouds, the future doesn’t look quite so centralized. The devices at the edges of our networks get smarter every year, not dumber. They’re hungry for work and information to digest and from which to profit. And they don’t drag cables around, except once a night for power. It’s all wireless and more and more, it’s 802.11-branded WiFi of different alphabetical flavors.
Why Mesh Isn’t Here Yet #
As such a vital part of our future, WiFi has a big problem that’s not often discussed, but that anyone betting on it needs to be aware of. The phone companies of the world have built themselves nice profitable mobile phone cartels in nearly every country with a functioning government, based on convincing governments that without monopoly rights to airwaves and ideas, the world would fall apart. Technically, we call this “regulatory capture” and “patents”, but in fact it’s just a form of blackmail and corruption. If you, the state, give me, a business, the right to overcharge, tax the market, and ban all real competitors, I’ll give you 5%. Not enough? How about 10%? OK, 15% plus snacks. If you refuse, we pull service.
But WiFi snuck past this, borrowing unlicensed airspace and riding on the back of the open and unpatented and remarkably innovative Internet Protocol stack. So today, we have the curious situation where it costs me several Euro a minute to call from Seoul to Brussels if I use the state-backed infrastructure that we’ve subsidized over decades, but nothing at all if I can find an unregulated WiFi access point. Oh, and I can do video, send files and photos, and download entire home movies all for the same amazing price point of precisely zero point zero zero (in any currency you like). God help me if I try to send just one photo home using the service for which I actually pay. That would cost me more than the camera I took it on.
It is the price we pay for having tolerated the “trust us, we’re the experts” patent system for so long. But more than that, it’s a massive economic incentive to chunks of the technology sector–and especially chipset makers who own patents on the anti-Internet GSM, GPRS, 3G, and LTE stacks, and who treat the telcos as prime clients–to actively throttle WiFi development. And of course it’s these firms that bulk out the IEEE committees that define WiFi.
The reason for this rant against lawyer-driven “innovation” is to steer your thinking towards “what if WiFi were really free?” This will happen one day, not too far off, and it’s worth betting on. We’ll see several things happen. First, much more aggressive use of airspace especially for near-distance communications where there is no risk of interference. Second, big capacity improvements as we learn to use more airspace in parallel. Third, acceleration of the standardization process. Last, broader support in devices for really interesting connectivity.
Right now, streaming a movie from your phone to your TV is considered “leading edge”. This is ridiculous. Let’s get truly ambitious. How about a stadium of people watching a game, sharing photos and HD video with each other in real time, creating an ad-hoc event that literally saturates the airspace with a digital frenzy. I should be able to collect terabytes of imagery from those around me, in an hour. Why does this have to go through Twitter or Facebook and that tiny expensive mobile data connection? How about a home with hundreds of devices all talking to each other over mesh, so when someone rings the doorbell, the porch lights stream video through to your phone or TV? How about a car that can talk to your phone and play your dubstep playlist without you plugging in wires.
To get more serious, why is our digital society in the hands of central points that are monitored, censored, logged, used to track who we talk to, collect evidence against us, and then shut down when the authorities decide we have too much free speech? The loss of privacy we’re living through is only a problem when it’s one-sided, but then the problem is calamitous. A truly wireless world would bypass all central censorship. It’s how the Internet was designed, and it’s quite feasible, technically (which is the best kind of feasible).
Some Physics #
Naive developers of distributed software treat the network as infinitely fast and perfectly reliable. While this is approximately true for simple applications over Ethernet, WiFi rapidly proves the difference between magical thinking and science. That is, WiFi breaks so easily and dramatically under stress that I sometimes wonder how anyone would dare use it for real work. The ceiling moves up as WiFi gets better, but never fast enough to stop us hitting it.
To understand how WiFi performs technically, you need to understand a basic law of physics: the power required to connect two points increases according to the square of the distance. People who grow up in larger houses have exponentially louder voices, as I learned in Dallas. For a WiFi network, this means that as two radios get further apart, they have to either use more power or lower their signal rate.
There’s only so much power you can pull out of a battery before users treat the device as hopelessly broken. Thus even though a WiFi network may be rated at a certain speed, the real bit rate between the access point (AP) and a client depends on how far apart the two are. As you move your WiFi-enabled phone away from the AP, the two radios trying to talk to each other will first increase their power and then reduce their bit rate.
This effect has some consequences of which we should be aware if we want to build robust distributed applications that don’t dangle wires behind them like puppets:
-
If you have a group of devices talking to an AP, when the AP is talking to the slowest device, the whole network has to wait. It’s like having to repeat a joke at a party to the designated driver who has no sense of humor, is still fully and tragically sober, and has a poor grasp of the language.
-
If you use unicast TCP and send a message to multiple devices, the AP must send the packets to each device separately, Yes, and you knew this, it’s also how Ethernet works. But now understand that one distant (or low-powered) device means everything waits for that slowest device to catch up.
-
If you use multicast or broadcast (which work the same, in most cases), the AP will send single packets to the whole network at once, which is awesome, but it will do it at the slowest possible bit rate (usually 1Mbps). You can adjust this rate manually in some APs. That just reduces the reach of your AP. You can also buy more expensive APs that have a little more intelligence and will figure out the highest bit rate they can safely use. You can also use enterprise APs with IGMP (Internet Group Management Protocol) support and ZeroMQ’s PGM transport to send only to subscribed clients. I’d not, however, bet on such APs being widely available, ever.
As you try to put more devices onto an AP, performance rapidly gets worse to the point where adding one more device can break the whole network for everyone. Many APs solve this by randomly disconnecting clients when they reach some limit, such as four to eight devices for a mobile hotspot, 30-50 devices for a consumer AP, perhaps 100 devices for an enterprise AP.
What’s the Current Status? #
Despite its uncomfortable role as enterprise technology that somehow escaped into the wild, WiFi is already useful for more than getting a free Skype call. It’s not ideal, but it works well enough to let us solve some interesting problems. Let me give you a rapid status report.
First, point-to-point versus access point-to-client. Traditional WiFi is all AP-client. Every packet has to go from client A to AP, then to client B. You cut your bandwidth by 50%, but that’s only half the problem. I explained about the inverse power law. If A and B are very close together, but both are far from the AP, they’ll both be using a low bit rate. Imagine your AP is in the garage, and you’re in the living room trying to stream video from your phone to your TV. Good luck!
There is an old “ad-hoc” mode that lets A and B talk to each other, but it’s way too slow for anything fun, and of course, it’s disabled on all mobile chipsets. Actually, it’s disabled in the top secret drivers that the chipset makers kindly provide to hardware makers. There is a new Tunneled Direct Link Setup (TDLS) protocol that lets two devices create a direct link, using an AP for discovery but not for traffic. And there’s a “5G” WiFi standard (it’s a marketing term, so it goes in quotes) that boosts link speeds to a gigabit. TDLS and 5G together make HD movie streaming from your phone to your TV a plausible reality. I assume TDLS will be restricted in various ways so as to placate the telcos.
Lastly, we saw standardization of the 802.11s mesh protocol in 2012, after a remarkably speedy ten years or so of work. Mesh removes the access point completely, at least in the imaginary future where it exists and is widely used. Devices talk to each other directly, and maintain little routing tables of neighbors that let them forward packets. Imagine the AP software embedded into every device, but smart enough (it’s not as impressive as it sounds) to do multiple hops.
No one who is making money from the mobile data extortion racket wants to see 802.11s available because city-wide mesh is such a nightmare for the bottom line, so it’s happening as slowly as possible. The only large organization with the power (and, I assume the surface-to-surface missiles) to get mesh technology into wide use is the US Army. But mesh will emerge and I’d bet on 802.11s being widely available in consumer electronics by 2020 or so.
Second, if we don’t have point-to-point, how far can we trust APs today? Well, if you go to a Starbucks in the US and try the ZeroMQ “Hello World” example using two laptops connected via the free WiFi, you’ll find they cannot connect. Why? Well, the answer is in the name: “attwifi”. AT&T is a good old incumbent telco that hates WiFi and presumably provides the service cheaply to Starbucks and others so that independents can’t get into the market. But any access point you buy will support client-to-AP-to-client access, and outside the US I’ve never found a public AP locked-down the AT&T way.
Third, performance. The AP is clearly a bottleneck; you cannot get better than half of its advertised speed even if you put A and B literally beside the AP. Worse, if there are other APs in the same airspace, they’ll shout each other out. In my home, WiFi barely works at all because the neighbors two houses down have an AP which they’ve amplified. Even on a different channel, it interferes with our home WiFi. In the cafe where I’m sitting now there are over a dozen networks. Realistically, as long as we’re dependent on AP-based WiFi, we’re subject to random interference and unpredictable performance.
Fourth, battery life. There’s no inherent reason that WiFi, when idle, is hungrier than Bluetooth, for example. They use the same radios and low-level framing. The main difference is tuning and in the protocols. For wireless power-saving to work well, devices have to mostly sleep and beacon out to other devices only once every so often. For this to work, they need to synchronize their clocks. This happens properly for the mobile phone part, which is why my old flip phone can run five days on a charge. When WiFi is working, it will use more power. Current power amplifier technology is also inefficient, meaning you draw a lot more energy from your battery than you pump into the air (the waste turns into a hot phone). Power amplifiers are improving as people focus more on mobile WiFi.
Lastly, mobile access points. If we can’t trust centralized APs, and if our devices are smart enough to run full operating systems, can’t we make them work as APs? I’m so glad you asked that question. Yes, we can, and it works quite nicely. Especially because you can switch this on and off in software, on a modern OS like Android. Again, the villains of the peace are the US telcos, who mostly detest this feature and kill it or cripple it on the phones they control. Smarter telcos realize that it’s a way to amplify their “last mile” and bring higher-value products to more users, but crooks don’t compete on smarts.
Conclusions #
WiFi is not Ethernet and although I believe future ZeroMQ applications will have a very important decentralized wireless presence, it’s not going to be an easy road. Much of the basic reliability and capacity that you expect from Ethernet is missing. When you run a distributed application over WiFi, you must allow for frequent timeouts, random latencies, arbitrary disconnections, whole interfaces going down and coming up, and so on.
The technological evolution of wireless networking is best described as “slow and joyless”. Applications and frameworks that try to exploit decentralized wireless are mostly absent or poor. The only existing open source framework for proximity networking is AllJoyn from Qualcomm. But with ZeroMQ, we proved that the inertia and decrepit incompetence of existing players was no reason for us to sit still. When we accurately understand problems, we can solve them. What we imagine, we can make real.
Discovery #
Discovery is an essential part of network programming and a first-class problem for ZeroMQ developers. Every zmq_connect () call provides an endpoint string, and that has to come from somewhere. The examples we’ve seen so far don’t do discovery: the endpoints they connect to are hard-coded as strings in the code. While this is fine for example code, it’s not ideal for real applications. Networks don’t behave that nicely. Things change, and it’s how well we handle change that defines our long-term success.
Service Discovery #
Let’s start with definitions. Network discovery is finding out what other peers are on the network. Service discovery is learning what those peers can do for us. Wikipedia defines a “network service” as “a service that is hosted on a computer network”, and “service” as “a set of related software functionalities that can be reused for different purposes, together with the policies that should control its usage”. It’s not very helpful. Is Facebook a network service?
In fact the concept of “network service” has changed over time. The number of moving pieces keeps doubling every 18-24 months, breaking old conceptual models and pushing for ever simpler, more scalable ones. A service is, for me, a system-level application that other programs can talk to. A network service is one accessible remotely (as compared to, e.g., the “grep” command, which is a command-line service).
In the classic BSD socket model, a service maps 1-to-1 to a network port. A computer system offers a number of services like “FTP”, and “HTTP”, each with assigned ports. The BSD API has functions like getservbyname to map a service name to a port number. So a classic service maps to a network endpoint: if you know a server’s IP address and then you can find its FTP service, if that is running.
In modern messaging, however, services don’t map 1-to-1 to endpoints. One endpoint can lead to many services, and services can move around over time, between ports, or even between systems. Where is my cloud storage today? In a realistic large distributed application, therefore, we need some kind of service discovery mechanism.
There are many ways to do this and I won’t try to provide an exhaustive list. However there are a few classic patterns:
-
We can force the old 1-to-1 mapping from endpoint to service, and simply state up-front that a certain TCP port number represents a certain service. Our protocol then should let us check this (“Are the first 4 bytes of the request ‘HTTP’?").
-
We can bootstrap one service off another; connecting to a well-known endpoint and service, asking for the “real” service, and getting an endpoint back in return. This gives us a service lookup service. If the lookup service allows it, services can then move around as long as they update their location.
-
We can proxy one service through another, so that a well-known endpoint and service will provide other services indirectly (i.e. by forwarding messages to them). This is for instance how our Majordomo service-oriented broker works.
-
We can exchange lists of known services and endpoints, that change over time, using a gossip approach or a centralized approach (like the Clone pattern), so that each node in a distributed network can build-up an eventually consistent map of the whole network.
-
We can create further abstract layers in between network endpoints and services, e.g. assigning each node a unique identifier, so we get a “network of nodes” where each node may offer some services, and may appear on random network endpoints.
-
We can discover services opportunistically, e.g. by connecting to endpoints and then asking them what services they offer. “Hi, do you offer a shared printer? If so, what’s the maker and model?”
There’s no “right answer”. The range of options is huge, and changes over time as the scale of our networks grows. In some networks the knowledge of what services run where can literally become political power. ZeroMQ imposes no specific model but makes it easy to design and build the ones that suit us best. However, to build service discovery, we must start by solving network discovery.
Network Discovery #
Here is a list of the solutions I know for network discovery:
-
Use hard-coded endpoint strings, i.e., fixed IP addresses and agreed ports. This worked in internal networks a decade ago when there were a few “big servers” and they were so important they got static IP addresses. These days however it’s no use except in examples or for in-process work (threads are the new Big Iron). You can make it hurt a little less by using DNS but this is still painful for anyone who’s not also doing system administration as a side-job.
-
Get endpoint strings from configuration files. This shoves name resolution into user space, which hurts less than DNS but that’s like saying a punch in the face hurts less than a kick in the groin. You now get a non-trivial management problem. Who updates the configuration files, and when? Where do they live? Do we install a distributed management tool like Salt Stack?
-
Use a message broker. You still need a hard-coded or configured endpoint string to connect to the broker, but this approach reduces the number of different endpoints in the network to one. That makes a real impact, and broker-based networks do scale nicely. However, brokers are single points of failure, and they bring their own set of worries about management and performance.
-
Use an addressing broker. In other words use a central service to mediate address information (like a dynamic DNS setup) but allow nodes to send each other messages directly. It’s a good model but still creates a point of failure and management costs.
-
Use helper libraries, like ZeroConf, that provide DNS services without any centralized infrastructure. It’s a good answer for certain applications but your mileage will vary. Helper libraries aren’t zero cost: they make it more complex to build the software, they have their own restrictions, and they aren’t necessarily portable.
-
Build system-level discovery by sending out ARP or ICMP ECHO packets and then querying every node that responds. You can query through a TCP connection, for example, or by sending UDP messages. Some products do this, like the Eye-Fi wireless card.
-
Do user-level brute-force discovery by trying to connect to every single address in the network segment. You can do this trivially in ZeroMQ since it handles connections in the background. You don’t even need multiple threads. It’s brutal but fun, and works very well in demos and workshops. However it doesn’t scale, and annoys decent-thinking engineers.
-
Roll your own UDP-based discovery protocol. Lots of people do this (I counted about 80 questions on this topic on StackOverflow). UDP works well for this and it’s technically clear. But it’s technically tricky to get right, to the point where any developer doing this the first few times will get it dramatically wrong.
-
Gossip discovery protocols. A fully-interconnected network is quite effective for smaller numbers of nodes (say, up to 100 or 200). For large numbers of nodes, we need some kind of gossip protocol. That is, where the nodes we can reasonable discover (say, on the same segment as us), tell us about nodes that are further away. Gossip protocols go beyond what we need these days with ZeroMQ, but will likely be more common in the future. One example of a wide-area gossip model is mesh networking.
The Use Case #
Let’s define our use case more explicitly. After all, all these different approaches have worked and still work to some extent. What interests me as architect is the future, and finding designs that can continue to work for more than a few years. This means identifying long term trends. Our use case isn’t here and now, it’s ten or twenty years from today.
Here are the long term trends I see in distributed applications:
-
The overall number of moving pieces keeps increasing. My estimate is that it doubles every 24 months, but how fast it increases matters less than the fact that we keep adding more and more nodes to our networks. They’re not just boxes but also processes and threads. The driver here is cost, which keeps falling. In a decade, the average teenager will carry 30-50 devices, all the time.
-
Control shifts away from the center. Possibly data too, though we’re still far from understanding how to build simple decentralized information stores. In any case, the star topology is slowly dying and being replaced by clouds of clouds. In the future there’s going to be much more traffic within a local environment (home, office, school, bar) than between remote nodes and the center. The maths here are simple: remote communications cost more, run more slowly and are less natural than close-range communications. It’s more accurate both technically and socially to share a holiday video with your friend over local WiFi than via Facebook.
-
Networks are increasingly collaborative, less controlled. This means people bringing their own devices and expecting them to work seamlessly. The Web showed one way to make this work but we’re reaching the limits of what the Web can do, as we start to exceed the average of one device per person.
-
The cost of connecting a new node to a network must fall proportionally, if the network is to scale. This means reducing the amount of configuration a node needs: less pre-shared state, less context. Again, the Web solved this problem but at the cost of centralization. We want the same plug and play experience but without a central agency.
In a world of trillions of nodes, the ones you talk to most are the ones closest to you. This is how it works in the real world and it’s the sanest way of scaling large-scale architectures. Groups of nodes, logically or physically close, connected by bridges to other groups of nodes. A local group will be anything from half-a-dozen nodes to a few thousand nodes.
So we have two basic use cases:
-
Discovery for proximity networks, that is, a set of nodes that find themselves close to each other. We can define “close to each other” as being “on the same network segment”. It’s not going to be true in all cases but it’s true enough to be a useful place to start.
-
Discovery across wide area networks, that is, bridging of proximity networks together. We sometimes call this “federation”. There are many ways to do federation but it’s complex and something to cover elsewhere. For now, let’s assume we do federation using a centralized broker or service.
So we are left with the problem of proximity networking. I want to just plug things into the network and have them talking to each other. Whether they’re tablets in a school or a bunch of servers in a cloud, the less upfront agreement and coordination, the cheaper it is to scale. So configuration files and brokers and any kind of centralized service are all out.
I also want to allow any number of applications on a box, both because that’s how the real world works (people download apps), and so that I can simulate large networks on my laptop. Upfront simulation is the only way I know to be sure a system will work when it’s loaded in real-life. You’d be surprised how engineers just hope things will work. “Oh, I’m sure that bridge will stay up when we open it to traffic”. If you haven’t simulated and fixed the three most likely failures, they’ll still be there on opening day.
Running multiple instances of a service on the same machine - without upfront coordination - means we have to use ephemeral ports, i.e., ports assigned randomly for services. Ephemeral ports rule out brute-force TCP discovery and any DNS solution including ZeroConf.
Finally, discovery has to happen in user space because the apps we’re building will be running on random boxes that we do not necessarily own and control. For example, other people’s mobile devices. So any discovery that needs root permissions is excluded. This rules out ARP and ICMP and once again ZeroConf since that also needs root permissions for the service parts.
Technical Requirements #
Let’s recap the requirements:
-
The simplest possible solution that works. There are so many edge cases in ad-hoc networks that every extra feature or functionality becomes a risk.
-
Supports ephemeral ports, so that we can run realistic simulations. If the only way to test is to use real devices, it becomes impossibly expensive and slow to run tests.
-
No root access needed, it must run 100% in user space. We want to ship fully-packaged applications onto devices like mobile phones that we don’t own and where root access isn’t available.
-
Invisible to system administrators, so we do not need their help to run our applications. Whatever technique we use should be friendly to the network and available by default.
-
Zero configuration apart from installing the applications themselves. Asking the users to do any configuration is giving them an excuse to not use the applications.
-
Fully portable to all modern operating systems. We can’t assume we’ll be running on any specific OS. We can’t assume any support from the operating system except standard user-space networking. We can assume ZeroMQ and CZMQ are available.
-
Friendly to WiFi networks with up to 100-150 participants. This means keeping messages small and being aware of how WiFi networks scale and how they break under pressure.
-
Protocol-neutral, i.e., our beaconing should not impose any specific discovery protocol. I’ll explain what this means a little later.
-
Easy to re-implement in any given language. Sure, we have a nice C implementation, but if it takes too long to re-implement in another language, that excludes large chunks of the ZeroMQ community. So, again, simple.
-
Fast response time. By this, I mean a new node should be visible to its peers in a very short time, a second or two at most. Networks change shape rapidly. It’s OK to take longer, even 30 seconds, to realize a peer has disappeared.
From the list of possible solutions I collected, the only option that isn’t disqualified for one or more reasons is to build our own UDP-based discovery stack. It’s a little disappointing that after so many decades of research into network discovery, this is where we end up. But the history of computing does seem to go from complex to simple, so maybe it’s normal.
A Self-Healing P2P Network in 30 Seconds #
I mentioned brute-force discovery. Let’s see how that works. One nice thing about software is to brute-force your way through the learning experience. As long as we’re happy to throw away work, we can learn rapidly simply by trying things that may seem insane from the safety of the armchair.
I’ll explain a brute-force discovery approach for ZeroMQ that emerged from a workshop in 2012. It is remarkably simple and stupid: connect to every IP address in the room. If your network segment is 192.168.55.x, for instance, you do this:
connect to tcp://192.168.55.1:9000
connect to tcp://192.168.55.2:9000
connect to tcp://192.168.55.3:9000
...
connect to tcp://192.168.55.254:9000
Which in ZeroMQ-speak looks like this:
int address;
for (address = 1; address < 255; address++)
zsocket_connect (listener, "tcp://192.168.55.%d:9000", address);
The stupid part is where we assume that connecting to ourselves is fine, where we assume that all peers are on the same network segment, where we waste file handles as if they were free. Luckily these assumptions are often totally accurate. At least, often enough to let us do fun things.
The loop works because ZeroMQ connect calls are asynchronous and opportunistic. They lie in the shadows like hungry cats, waiting patiently to pounce on any innocent mouse that dared start up a service on port 9000. It’s simple, effective, and worked first time.
It gets better: as peers leave and join the network, they’ll automatically reconnect. We’ve designed a self-healing peer to peer network, in 30 seconds and three lines of code.
It won’t work for real cases though. Poorer operating systems tend to run out of file handles, and networks tend to be more complex than one segment. And if one node squats a couple of hundred file handles, large-scale simulations (with many nodes on one box or in one process) are out of the question.
Still, let’s see how far we can go with this approach before we throw it out. Here’s a tiny decentralized chat program that lets you talk to anyone else on the same network segment. The code has two threads: a listener and a broadcaster. The listener creates a SUB socket and does the brute-force connection to all peers in the network. The broadcaster accepts input from the console and sends it on a PUB socket:
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml
The dechat program needs to know the current IP address, the interface, and an alias. We could get these in code from the operating system, but that’s grunky non-portable code. So we provide this information on the command line:
dechat 192.168.55.122 eth0 Joe
Preemptive Discovery over Raw Sockets #
One of the great things about short-range wireless is the proximity. WiFi maps closely to the physical space, which maps closely to how we naturally organize. In fact, the Internet is quite abstract and this confuses a lot of people who kind of “get it” but in fact don’t really. With WiFi, we have technical connectivity that is potentially super-tangible. You see what you get and you get what you see. Tangible means easy to understand and that should mean love from users instead of the typical frustration and seething hatred.
Proximity is the key. We have a bunch of WiFi radios in a room, happily beaconing to each other. For lots of applications, it makes sense that they can find each other and start chatting without any user input. After all, most real world data isn’t private, it’s just highly localized.
I’m in a hotel room in Gangnam, Seoul, with a 4G wireless hotspot, a Linux laptop, and an couple of Android phones. The phones and laptop are talking to the hotspot. The ifconfig command says my IP address is 192.168.1.2. Let me try some ping commands. DHCP servers tend to dish out addresses in sequence, so my phones are probably close by, numerically speaking:
$ ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_req=1 ttl=64 time=376 ms
64 bytes from 192.168.1.1: icmp_req=2 ttl=64 time=358 ms
64 bytes from 192.168.1.1: icmp_req=4 ttl=64 time=167 ms
^C
--- 192.168.1.1 ping statistics ---
3 packets transmitted, 2 received, 33% packet loss, time 2001ms
rtt min/avg/max/mdev = 358.077/367.522/376.967/9.445 ms
Found one! 150-300 msec round-trip latency… that’s a surprisingly high figure, something to keep in mind for later. Now I ping myself, just to try to double-check things:
$ ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_req=1 ttl=64 time=0.054 ms
64 bytes from 192.168.1.2: icmp_req=2 ttl=64 time=0.055 ms
64 bytes from 192.168.1.2: icmp_req=3 ttl=64 time=0.061 ms
^C
--- 192.168.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1998ms
rtt min/avg/max/mdev = 0.054/0.056/0.061/0.009 ms
The response time is a bit faster now, which is what we’d expect. Let’s try the next couple of addresses:
$ ping 192.168.1.3
PING 192.168.1.3 (192.168.1.3) 56(84) bytes of data.
64 bytes from 192.168.1.3: icmp_req=1 ttl=64 time=291 ms
64 bytes from 192.168.1.3: icmp_req=2 ttl=64 time=271 ms
64 bytes from 192.168.1.3: icmp_req=3 ttl=64 time=132 ms
^C
--- 192.168.1.3 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 132.781/231.914/291.851/70.609 ms
That’s the second phone, with the same kind of latency as the first one. Let’s continue and see if there are any other devices connected to the hotspot:
$ ping 192.168.1.4
PING 192.168.1.4 (192.168.1.4) 56(84) bytes of data.
^C
--- 192.168.1.4 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2016ms
And that is it. Now, ping uses raw IP sockets to send ICMP_ECHO messages. The useful thing about ICMP_ECHO is that it gets a response from any IP stack that has not deliberately had echo switched off. That’s still a common practice on corporate websites who fear the old “ping of death” exploit where malformed messages could crash the machine.
I call this preemptive discovery because it doesn’t take any cooperation from the device. We don’t rely on any cooperation from the phones to see them sitting there; as long as they’re not actively ignoring us, we can see them.
You might ask why this is useful. We don’t know that the peers responding to ICMP_ECHO run ZeroMQ, that they are interested in talking to us, that they have any services we can use, or even what kind of device they are. However, knowing that there’s something on address 192.168.1.3 is already useful. We also know how far away the device is, relatively, we know how many devices are on the network, and we know the rough state of the network (as in, good, poor, or terrible).
It isn’t even hard to create ICMP_ECHO messages and send them. A few dozen lines of code, and we could use ZeroMQ multithreading to do this in parallel for addresses stretching out above and below our own IP address. Could be kind of fun.
However, sadly, there’s a fatal flaw in my idea of using ICMP_ECHO to discover devices. To open a raw IP socket requires root privileges on a POSIX box. It stops rogue programs getting data meant for others. We can get the power to open raw sockets on Linux by giving sudo privileges to our command (ping has the so-called sticky bit set). On a mobile OS like Android, it requires root access, i.e., rooting the phone or tablet. That’s out of the question for most people and so ICMP_ECHO is out of reach for most devices.
Expletive deleted! Let’s try something in user space. The next step most people take is UDP multicast or broadcast. Let’s follow that trail.
Cooperative Discovery Using UDP Broadcasts #
Multicast tends to be seen as more modern and “better” than broadcast. In IPv6, broadcast doesn’t work at all: you must always use multicast. Nonetheless, all IPv4 local network discovery protocols end up using UDP broadcast anyhow. The reasons: broadcast and multicast end up working much the same, except broadcast is simpler and less risky. Multicast is seen by network admins as kind of dangerous, as it can leak over network segments.
If you’ve never used UDP, you’ll discover it’s quite a nice protocol. In some ways, it reminds us of ZeroMQ, sending whole messages to peers using a two different patterns: one-to-one, and one-to-many. The main problems with UDP are that (a) the POSIX socket API was designed for universal flexibility, not simplicity, (b) UDP messages are limited for practical purposes to about 1,500 bytes on LANs and 512 bytes on the Internet, and (c) when you start to use UDP for real data, you find that messages get dropped, especially as infrastructure tends to favor TCP over UDP.
Here is a minimal ping program that uses UDP instead of ICMP_ECHO:
C | C++ | Java | Python | Ada | Basic | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCamlThis code uses a single socket to broadcast 1-byte messages and receive anything that other nodes are broadcasting. When I run it, it shows just one node, which is itself:
Pinging peers...
Found peer 192.168.1.2:9999
Pinging peers...
Found peer 192.168.1.2:9999
If I switch off all networking and try again, sending a message fails, as I’d expect:
Pinging peers...
sendto: Network is unreachable
Working on the basis of solve the problems currently aiming at your throat, let’s fix the most urgent issues in this first model. These issues are:
-
Using the 255.255.255.255 broadcast address is a bit dubious. On the one hand, this broadcast address means precisely “send to all nodes on the local network, and don’t forward”. However, if you have several interfaces (wired Ethernet, WiFi) then broadcasts will go out on your default route only, and via just one interface. What we want to do is either send our broadcast on each interface’s broadcast address, or find the WiFi interface and its broadcast address.
-
Like many aspects of socket programming, getting information on network interfaces is not portable. Do we want to write nonportable code in our applications? No, this is better hidden in a library.
-
There’s no handling for errors except “abort”, which is too brutal for transient problems like “your WiFi is switched off”. The code should distinguish between soft errors (ignore and retry) and hard errors (assert).
-
The code needs to know its own IP address and ignore beacons that it sent out. Like finding the broadcast address, this requires inspecting the available interfaces.
The simplest answer to these issues is to push the UDP code into a separate library that provides a clean API, like this:
// Constructor
static udp_t *
udp_new (int port_nbr);
// Destructor
static void
udp_destroy (udp_t **self_p);
// Returns UDP socket handle
static int
udp_handle (udp_t *self);
// Send message using UDP broadcast
static void
udp_send (udp_t *self, byte *buffer, size_t length);
// Receive message from UDP broadcast
static ssize_t
udp_recv (udp_t *self, byte *buffer, size_t length);
Here is the refactored UDP ping program that calls this library, which is much cleaner and nicer:
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCamlThe library, udplib, hides a lot of the unpleasant code (which will become uglier as we make this work on more systems). I’m not going to print that code here. You can read it in the repository.
Now, there are more problems sizing us up and wondering if they can make lunch out of us. First, IPv4 versus IPv6 and multicast versus broadcast. In IPv6, broadcast doesn’t exist at all; one uses multicast. From my experience with WiFi, IPv4 multicast and broadcast work identically except that multicast breaks in some situations where broadcast works fine. Some access points do not forward multicast packets. When you have a device (e.g., a tablet) that acts as a mobile AP, then it’s possible it won’t get multicast packets. Meaning, it won’t see other peers on the network.
The simplest plausible solution is simply to ignore IPv6 for now, and use broadcast. A perhaps smarter solution would be to use multicast and deal with asymmetric beacons if they happen.
We’ll stick with stupid and simple for now. There’s always time to make it more complex.
Multiple Nodes on One Device #
So we can discover nodes on the WiFi network, as long as they’re sending out beacons as we expect. So I try to test with two processes. But when I run udpping2 twice, the second instance complains “‘Address already in use’ on bind” and exits. Oh, right. UDP and TCP both return an error if you try to bind two different sockets to the same port. This is right. The semantics of two readers on one socket would be weird to say the least. Odd/even bytes? You get all the 1s, I get all the 0’s?
However, a quick check of stackoverflow.com and some memory of a socket option called SO_REUSEADDR turns up gold. If I use that, I can bind several processes to the same UDP port, and they will all receive any message arriving on that port. It’s almost as if the guys who designed this were reading my mind! (That’s way more plausible than the chance that I may be reinventing the wheel.)
A quick test shows that SO_REUSEADDR works as promised. This is great because the next thing I want to do is design an API and then start dozens of nodes to see them discovering each other. It would be really cumbersome to have to test each node on a separate device. And when we get to testing how real traffic behaves on a large, flaky network, the two alternatives are simulation or temporary insanity.
And I speak from experience: we were, this summer, testing on dozens of devices at once. It takes about an hour to set up a full test run, and you need a space shielded from WiFi interference if you want any kind of reproducibility (unless your test case is “prove that interference kills WiFi networks faster than Orval can kill a thirst”.
If I were a whiz Android developer with a free weekend, I’d immediately (as in, it would take me two days) port this code to my phone and get it sending beacons to my PC. But sometimes lazy is more profitable. I like my Linux laptop. I like being able to start a dozen threads from one process, and have each thread acting like an independent node. I like not having to work in a real Faraday cage when I can simulate one on my laptop.
Designing the API #
I’m going to run N nodes on a device, and they are going to have to discover each other, as well as a bunch of other nodes out there on the local network. I can use UDP for local discovery as well as remote discovery. It’s arguably not as efficient as using, e.g., the ZeroMQ inproc:// transport, but it has the great advantage that the exact same code will work in simulation and in real deployment.
If I have multiple nodes on one device, we clearly can’t use the IP address and port number as node address. I need some logical node identifier. Arguably, the node identifier only has to be unique within the context of the device. My mind fills with complex stuff I could make, like supernodes that sit on real UDP ports and forward messages to internal nodes. I hit my head on the table until the idea of inventing new concepts leaves it.
Experience tells us that WiFi does things like disappear and reappear while applications are running. Users click on things, which does interesting things like change the IP address halfway through a session. We cannot depend on IP addresses, nor on established connections (in the TCP fashion). We need some long-lasting addressing mechanism that survives interfaces and connections being torn down and then recreated.
Here’s the simplest solution I can see: we give every node a UUID, and specify that nodes, represented by their UUIDs, can appear or reappear at certain IP address:port endpoints, and then disappear again. We’ll deal with recovery from lost messages later. A UUID is 16 bytes. So if I have 100 nodes on a WiFi network, that’s (double it for other random stuff) 3,200 bytes a second of beacon data that the air has to carry just for discovery and presence. Seems acceptable.
Back to concepts. We do need some names for our API. At the least we need a way to distinguish between the node object that is “us”, and node objects that are our peers. We’ll be doing things like creating an “us” and then asking it how many peers it knows about and who they are. The term “peer” is clear enough.
From the developer point of view, a node (the application) needs a way to talk to the outside world. Let’s borrow a term from networking and call this an “interface”. The interface represents us to the rest of the world and presents the rest of the world to us, as a set of other peers. It automatically does whatever discovery it must. When we want to talk to a peer, we get the interface to do that for us. And when a peer talks to us, it’s the interface that delivers us the message.
This seems like a clean API design. How about the internals?
-
The interface must be multithreaded so that one thread can do I/O in the background, while the foreground API talks to the application. We used this design in the Clone and Freelance client APIs.
-
The interface background thread does the discovery business; bind to the UDP port, send out UDP beacons, and receive beacons.
-
We need to at least send UUIDs in the beacon message so that we can distinguish our own beacons from those of our peers.
-
We need to track peers that appear, and that disappear. For this, I’ll use a hash table that stores all known peers and expire peers after some timeout.
-
We need a way to report peers and events to the caller. Here we get into a juicy question. How does a background I/O thread tell a foreground API thread that stuff is happening? Callbacks maybe? Heck no. We’ll use ZeroMQ messages, of course.
The third iteration of the UDP ping program is even simpler and more beautiful than the second. The main body, in C, is just ten lines of code.
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCamlThe interface code should be familiar if you’ve studied how we make multithreaded API classes:
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCamlWhen I run this in two windows, it reports one peer joining the network. I kill that peer and a few seconds later, it tells me the peer left:
--------------------------------------
[006] JOINED
[032] 418E98D4B7184844B7D5E0EE5691084C
--------------------------------------
[004] LEFT
[032] 418E98D4B7184844B7D5E0EE5691084C
What’s nice about a ZeroMQ-message based API is that I can wrap this any way I like. For instance, I can turn it into callbacks if I really want those. I can also trace all activity on the API very easily.
Some notes about tuning. On Ethernet, five seconds (the expiry time I used in this code) seems like a lot. On a badly stressed WiFi network, you can get ping latencies of 30 seconds or more. If you use a too-aggressive value for the expiry, you’ll disconnect nodes that are still there. On the other side, end user applications expect a certain liveliness. If it takes 30 seconds to report that a node has gone, users will get annoyed.
A decent strategy is to detect and report disappeared nodes rapidly, but only delete them after a longer interval. Visually, a node would be green when it’s alive, then gray for a while as it went out of reach, then finally disappear. We’re not doing this now, but will do it in the real implementation of the as-yet-unnamed framework we’re making.
As we will also see later, we have to treat any input from a node, not just UDP beacons, as a sign of life. UDP may get squashed when there’s a lot of TCP traffic. This is perhaps the main reason we’re not using an existing UDP discovery library: it’s necessary to integrate this tightly with our ZeroMQ messaging for it to work.
More About UDP #
So we have discovery and presence working over UDP IPv4 broadcasts. It’s not ideal, but it works for the local networks we have today. However we can’t use UDP for real work, not without additional work to make it reliable. There’s a joke about UDP but sometimes you’ll get it, and sometimes you won’t.
We’ll stick to TCP for all one-to-one messaging. There is one more use case for UDP after discovery, which is multicast file distribution. I’ll explain why and how, then shelve that for another day. The why is simple: what we call “social networks” is just augmented culture. We create culture by sharing, and this means more and more sharing works that we make or remix. Photos, documents, contracts, tweets. The clouds of devices we’re aiming towards do more of this, not less.
Now, there are two principal patterns for sharing content. One is the pub-sub pattern where one node sends out content to a set of other nodes simultaneously. Second is the “late joiner” pattern, where a node arrives somewhat later and wants to catch up to the conversation. We can deal with the late joiner using TCP unicast. But doing TCP unicast to a group of clients at the same time has some disadvantages. First, it can be slower than multicast. Second, it’s unfair because some will get the content before others.
Before you jump off to design a UDP multicast protocol, realize that it’s not a simple calculation. When you send a multicast packet, the WiFi access point uses a low bit rate to ensure that even the furthest devices will get it safely. Most normal APs don’t do the obvious optimization, which is to measure the distance of the furthest device and use that bit rate. Instead, they just use a fixed value. So if you have a few devices close to the AP, multicast will be insanely slow. But if you have a roomful of devices which all want to get the next chapter of the textbook, multicast can be insanely effective.
The curves cross at about 6-12 devices depending on the network. In theory, you could measure the curves in real time and create an adaptive protocol. That would be cool but probably too hard for even the smartest of us.
If you do sit down and sketch out a UDP multicast protocol, realize that you need a channel for recovery, to get lost packets. You’d probably want to do this over TCP, using ZeroMQ. For now, however, we’ll forget about multicast UDP and assume all traffic goes over TCP.
Spinning Off a Library Project #
At this stage, however, the code is growing larger than an example should be, so it’s time to create a proper GitHub project. It’s a rule: build your projects in public view, and tell people about them as you go so your marketing and community building starts on Day 1. I’ll walk through what this involves. I explained in Chapter 6 - The ZeroMQ Community about growing communities around projects. We need a few things:
- A name
- A slogan
- A public github repository
- A README that links to the C4 process
- License files
- An issue tracker
- Two maintainers
- A first bootstrap version
The name and slogan first. The trademarks of the 21st century are domain names. So the first thing I do when spinning off a project is to look for a domain name that might work. Quite randomly, one of our old messaging projects was called “Zyre” and I have the domain name for it. The full name is a backronym: the ZeroMQ Realtime Exchange framework.
I’m somewhat shy about pushing new projects into the ZeroMQ community too aggressively, and normally would start a project in either my personal account or the iMatix organization. But we’ve learned that moving projects after they become popular is counterproductive. My predictions of a future filled with moving pieces are either valid or wrong. If this chapter is valid, we might as well launch this as a ZeroMQ project from the start. If it’s wrong, we can delete the repository later or let it sink to the bottom of a long list of forgotten starts.
Start with the basics. The protocol (UDP and ZeroMQ/TCP) will be ZRE (ZeroMQ Realtime Exchange protocol) and the project will be Zyre. I need a second maintainer, so I invite my friend Dong Min (the Korean hacker behind JeroMQ, a pure-Java ZeroMQ stack) to join. He’s been working on very similar ideas so is enthusiastic. We discuss this and we get the idea of building Zyre on top of JeroMQ, as well as on top of CZMQ and libzmq. This would make it a lot easier to run Zyre on Android. It would also give us two fully separate implementations from the start, which is always a good thing for a protocol.
So we take the FileMQ project I built in Chapter 7 - Advanced Architecture using ZeroMQ as a template for a new GitHub project. The GNU autoconf tools are quite decent, but have a painful syntax. It’s easiest to copy existing project files and modify them. The FileMQ project builds a library, has test tools, license files, man pages, and so on. It’s not too large so it’s a good starting point.
I put together a README to summarize the goals of the project and point to C4. The issue tracker is enabled by default on new GitHub projects, so once we’ve pushed the UDP ping code as a first version, we’re ready to go. However, it’s always good to recruit more maintainers, so I create an issue “Call for maintainers” that says:
If you’d like to help click that lovely green “Merge Pull Request” button and get eternal good karma, add a comment confirming that you’ve read and understand the C4 process at http://rfc.zeromq.org/spec:22.
Finally, I change the issue tracker labels. By default, GitHub offers the usual variety of issue types, but with C4 we don’t use them. Instead, we need just two labels (“Urgent”, in red, and “Ready”, in black).
Point-to-Point Messaging #
I’m going to take the last UDP ping program and build a point-to-point messaging layer on top of that. Our goal is that we can detect peers as they join and leave the network, that we can send messages to them, and that we can get replies. It is a nontrivial problem to solve and takes Min and me two days to get a “Hello World” version working.
We had to solve a number of issues:
- What information to send in the UDP beacon, and how to format it.
- What ZeroMQ socket types to use to interconnect nodes.
- What ZeroMQ messages to send, and how to format them.
- How to send a message to a specific node.
- How to know the sender of any message so we could send a reply.
- How to recover from lost UDP beacons.
- How to avoid overloading the network with beacons.
I’ll explain these in enough detail so that you understand why we made each choice we did, with some code fragments to illustrate. We tagged this code as version 0.1.0 so you can look at the code: most of the hard work is done in zre_interface.c.
UDP Beacon Framing #
Sending UUIDs across the network is the bare minimum for a logical addressing scheme. However, we have a few more aspects to get working before this will work in real use:
- We need some protocol identification so that we can check for and reject invalid packets.
- We need some version information so that we can change this protocol over time.
- We need to tell other nodes how to reach us via TCP, i.e., a ZeroMQ port they can talk to us on.
Let’s start with the beacon message format. We probably want a fixed protocol header that will never change in future versions and a body that depends on the version.
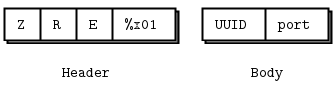
The version can be a 1-byte counter starting at 1. The UUID is 16 bytes and the port is a 2-byte port number because UDP nicely tells us the sender’s IP address for every message we receive. This gives us a 22-byte frame.
The C language (and a few others like Erlang) make it simple to read and write binary structures. We define the beacon frame structure:
#define BEACON_PROTOCOL "ZRE"
#define BEACON_VERSION 0x01
typedef struct {
byte protocol [3];
byte version;
uuid_t uuid;
uint16_t port;
} beacon_t;
This makes sending and receiving beacons quite simple. Here is how we send a beacon, using the zre_udp class to do the nonportable network calls:
// Beacon object
beacon_t beacon;
// Format beacon fields
beacon.protocol [0] = 'Z';
beacon.protocol [1] = 'R';
beacon.protocol [2] = 'E';
beacon.version = BEACON_VERSION;
memcpy (beacon.uuid, self->uuid, sizeof (uuid_t));
beacon.port = htons (self->port);
// Broadcast the beacon to anyone who is listening
zre_udp_send (self->udp, (byte *) &beacon, sizeof (beacon_t));
When we receive a beacon, we need to guard against bogus data. We’re not going to be paranoid against, for example, denial-of-service attacks. We just want to make sure that we’re not going to crash when a bad ZRE implementation sends us erroneous frames.
To validate a frame, we check its size and header. If those are OK, we assume the body is usable. When we get a UUID that isn’t ourselves (recall, we’ll get our own UDP broadcasts back), we can treat this as a peer:
// Get beacon frame from network
beacon_t beacon;
ssize_t size = zre_udp_recv (self->udp,
(byte *) &beacon, sizeof (beacon_t));
// Basic validation on the frame
if (size != sizeof (beacon_t)
|| beacon.protocol [0] != 'Z'
|| beacon.protocol [1] != 'R'
|| beacon.protocol [2] != 'E'
|| beacon.version != BEACON_VERSION)
return 0; // Ignore invalid beacons
// If we got a UUID and it's not our own beacon, we have a peer
if (memcmp (beacon.uuid, self->uuid, sizeof (uuid_t))) {
char *identity = s_uuid_str (beacon.uuid);
s_require_peer (self, identity,
zre_udp_from (self->udp), ntohs (beacon.port));
free (identity);
}
True Peer Connectivity (Harmony Pattern) #
Because ZeroMQ is designed to make distributed messaging easy, people often ask how to interconnect a set of true peers (as compared to obvious clients and servers). It is a thorny question and ZeroMQ doesn’t really provide a single clear answer.
TCP, which is the most commonly-used transport in ZeroMQ, is not symmetric; one side must bind and one must connect and though ZeroMQ tries to be neutral about this, it’s not. When you connect, you create an outgoing message pipe. When you bind, you do not. When there is no pipe, you cannot write messages (ZeroMQ will return EAGAIN).
Developers who study ZeroMQ and then try to create N-to-N connections between sets of equal peers often try a ROUTER-to-ROUTER flow. It’s obvious why: each peer needs to address a set of peers, which requires ROUTER. It usually ends with a plaintive email to the list.
Experience teaches us that ROUTER-to-ROUTER is particularly difficult to use successfully. At a minimum, one peer must bind and one must connect, meaning the architecture is not symmetrical. But also because you simply can’t tell when you are allowed to safely send a message to a peer. It’s a Catch-22: you can talk to a peer after it’s talked to you, but the peer can’t talk to you until you’ve talked to it. One side or the other will be losing messages and thus has to retry, which means the peers cannot be equal.
I’m going to explain the Harmony pattern, which solves this problem, and which we use in Zyre.
We want a guarantee that when a peer “appears” on our network, we can talk to it safely without ZeroMQ dropping messages. For this, we have to use a DEALER or PUSH socket that connects out to the peer so that even if that connection takes some non-zero time, there is immediately a pipe and ZeroMQ will accept outgoing messages.
A DEALER socket cannot address multiple peers individually. But if we have one DEALER per peer, and we connect that DEALER to the peer, we can safely send messages to a peer as soon as we’ve connected to it.
Now, the next problem is to know who sent us a particular message. We need a reply address that is the UUID of the node who sent any given message. DEALER can’t do this unless we prefix every single message with that 16-byte UUID, which would be wasteful. ROUTER does do it if we set the identity properly before connecting to the router.
And so the Harmony pattern comes down to these components:
- One ROUTER socket that we bind to a ephemeral port, which we broadcast in our beacons.
- One DEALER socket per peer that we connect to the peer’s ROUTER socket.
- Reading from our ROUTER socket.
- Writing to the peer’s DEALER socket.
The next problem is that discovery isn’t neatly synchronized. We can get the first beacon from a peer after we start to receive messages from it. A message comes in on the ROUTER socket and has a nice UUID attached to it, but no physical IP address and port. We have to force discovery over TCP. To do this, our first command to any new peer to which we connect is an OHAI command with our IP address and port. This ensure that the receiver connects back to us before trying to send us any command.
Here it is, broken down into steps:
- If we receive a UDP beacon from a new peer, we connect to the peer through a DEALER socket.
- We read messages from our ROUTER socket, and each message comes with the UUID of the sender.
- If it’s an OHAI message, we connect back to that peer if not already connected to it.
- If it’s any other message, we must already be connected to the peer (a good place for an assertion).
- We send messages to each peer using the per-peer DEALER socket, which must be connected.
- When we connect to a peer, we also tell our application that the peer exists.
- Every time we get a message from a peer, we treat that as a heartbeat (it’s alive).
If we were not using UDP but some other discovery mechanism, I’d still use the Harmony pattern for a true peer network: one ROUTER for input from all peers, and one DEALER per peer for output. Bind the ROUTER, connect the DEALER, and start each conversation with an OHAI equivalent that provides the return IP address and port. You would need some external mechanism to bootstrap each connection.
Detecting Disappearances #
Heartbeating sounds simple but it’s not. UDP packets get dropped when there’s a lot of TCP traffic, so if we depend on UDP beacons, we’ll get false disconnections. TCP traffic can be delayed for 5, 10, even 30 seconds if the network is really busy. So if we kill peers when they go quiet, we’ll have false disconnections.
Because UDP beacons aren’t reliable, it’s tempting to add in TCP beacons. After all, TCP will deliver them reliably. However, there’s one little problem. Imagine that you have 100 nodes on a network, and each node sends a TCP beacon once a second. Each beacon is 22 bytes, not counting TCP’s framing overhead. That is 100 * 99 * 22 bytes per second, or 217,000 bytes/second just for heartbeating. That’s about 1-2% of a typical WiFi network’s ideal capacity, which sounds OK. But when a network is stressed or fighting other networks for airspace, that extra 200K a second will break what’s left. UDP broadcasts are at least low cost.
So what we do is switch to TCP heartbeats only when a specific peer hasn’t sent us any UDP beacons in a while. And then we send TCP heartbeats only to that one peer. If the peer continues to be silent, we conclude it’s gone away. If the peer comes back with a different IP address and/or port, we have to disconnect our DEALER socket and reconnect to the new port.
This gives us a set of states for each peer, though at this stage the code doesn’t use a formal state machine:
- Peer visible thanks to UDP beacon (we connect using IP address and port from beacon)
- Peer visible thanks to OHAI command (we connect using IP address and port from command)
- Peer seems alive (we got a UDP beacon or command over TCP recently)
- Peer seems quiet (no activity in some time, so we send a HUGZ command)
- Peer has disappeared (no reply to our HUGZ commands, so we destroy peer)
There’s one remaining scenario we didn’t address in the code at this stage. It’s possible for a peer to change IP addresses and ports without actually triggering a disappearance event. For example, if the user switches off WiFi and then switches it back on, the access point can assign the peer a new IP address. We’ll need to handle a disappeared WiFi interface on our node by unbinding the ROUTER socket and rebinding it when we can. Because this is not central to the design now, I decide to log an issue on the GitHub tracker and leave it for a rainy day.
Group Messaging #
Group messaging is a common and very useful pattern. The concept is simple: instead of talking to a single node, you talk to a “group” of nodes. The group is just a name, a string that you agree on in the application. It’s precisely like using the pub-sub prefixes in PUB and SUB sockets. In fact, the only reason I say “group messaging” and not “pub-sub” is to prevent confusion, because we’re not going to use PUB-SUB sockets for this.
PUB-SUB sockets would almost work. But we’ve just done such a lot of work to solve the late joiner problem. Applications are inevitably going to wait for peers to arrive before sending messages to groups, so we have to build on the Harmony pattern rather than start again beside it.
Let’s look at the operations we want to do on groups:
- We want to join and leave groups.
- We want to know what other nodes are in any given group.
- We want to send a message to (all nodes in) a group.
These look familiar to anyone who’s used Internet Relay Chat, except that we have no server. Every node will need to keep track of what each group represents. This information will not always be fully consistent across the network, but it will be close enough.
Our interface will track a set of groups (each an object). These are all the known groups with one or more member node, excluding ourselves. We’ll track nodes as they leave and join groups. Because nodes can join the network at any time, we have to tell new peers what groups we’re in. When a peer disappears, we’ll remove it from all groups we know about.
This gives us some new protocol commands:
- JOIN - we send this to all peers when we join a group.
- LEAVE - we send this to all peers when we leave a group.
Plus, we add a groups field to the first command we send (renamed from OHAI to HELLO at this point because I need a larger lexicon of command verbs).
Lastly, let’s add a way for peers to double-check the accuracy of their group data. The risk is that we miss one of the above messages. Though we are using Harmony to avoid the typical message loss at startup, it’s worth being paranoid. For now, all we need is a way to detect such a failure. We’ll deal with recovery later, if the problem actually happens.
I’ll use the UDP beacon for this. What we want is a rolling counter that simply tells how many join and leave operations (“transitions”) there have been for a node. It starts at 0 and increments for each group we join or leave. We can use a minimal 1-byte value because that will catch all failures except the astronomically rare “we lost precisely 256 messages in a row” failure (this is the one that hits during the first demo). We will also put the transitions counter into the JOIN, LEAVE, and HELLO commands. And to try to provoke the problem, we’ll test by joining/leaving several hundred groups with a high-water mark set to 10 or so.
It’s time to choose verbs for the group messaging. We need a command that means “talk to one peer” and one that means “talk to many peers”. After some attempts, my best choices are WHISPER and SHOUT, and this is what the code uses. The SHOUT command needs to tell the user the group name, as well as the sender peer.
Because groups are like pub-sub, you might be tempted to use this to broadcast the JOIN and LEAVE commands as well, perhaps by creating a “global” group that all nodes join. My advice is to keep groups purely as user-space concepts for two reasons. First, how do you join the global group if you need the global group to send out a JOIN command? Second, it creates special cases (reserved names) which are messy.
It’s simpler just to send JOINs and LEAVEs explicitly to all connected peers, period.
I’m not going to work through the implementation of group messaging in detail because it’s fairly pedantic and not too exciting. The data structures for group and peer management aren’t optimal, but they’re workable. We use the following:
- A list of groups for our interface, which we can send to new peers in a HELLO command;
- A hash of groups for other peers, which we update with information from HELLO, JOIN, and LEAVE commands;
- A hash of peers for each group, which we update with the same three commands.
At this stage, I’m starting to get pretty happy with the binary serialization (our codec generator from Chapter 7 - Advanced Architecture using ZeroMQ), which handles lists and dictionaries as well as strings and integers.
This version is tagged in the repository as v0.2.0 and you can download the tarball if you want to check what the code looked like at this stage.
Testing and Simulation #
When you build a product out of pieces, and this includes a distributed framework like Zyre, the only way to know that it will work properly in real life is to simulate real activity on each piece.
On Assertions #
The proper use of assertions is one of the hallmarks of a professional programmer.
Our confirmation bias as creators makes it hard to test our work properly. We tend to write tests to prove the code works, rather than trying to prove it doesn’t. There are many reasons for this. We pretend to ourselves and others that we can be (could be) perfect, when in fact we consistently make mistakes. Bugs in code are seen as “bad”, rather than “inevitable”, so psychologically we want to see fewer of them, not uncover more of them. “He writes perfect code” is a compliment rather than a euphemism for “he never takes risks so his code is as boring and heavily used as cold spaghetti”.
Some cultures teach us to aspire to perfection and punish mistakes in education and work, which makes this attitude worse. To accept that we’re fallible, and then to learn how to turn that into profit rather than shame is one of the hardest intellectual exercises in any profession. We leverage our fallibilities by working with others and by challenging our own work sooner, not later.
One trick that makes it easier is to use assertions. Assertions are not a form of error handling. They are executable theories of fact. The code asserts, “At this point, such and such must be true” and if the assertion fails, the code kills itself.
The faster you can prove code incorrect, the faster and more accurately you can fix it. Believing that code works and proving that it behaves as expected is less science, more magical thinking. It’s far better to be able to say, “libzmq has five hundred assertions and despite all my efforts, not one of them fails”.
So the Zyre code base is scattered with assertions, and particularly a couple on the code that deals with the state of peers. This is the hardest aspect to get right: peers need to track each other and exchange state accurately or things stop working. The algorithms depend on asynchronous messages flying around and I’m pretty sure the initial design has flaws. It always does.
And as I test the original Zyre code by starting and stopping instances of zre_ping by hand, every so often I get an assertion failure. Running by hand doesn’t reproduce these often enough, so let’s make a proper tester tool.
On Up-Front Testing #
Being able to fully test the real behavior of individual components in the laboratory can make a 10x or 100x difference to the cost of your project. That confirmation bias engineers have to their own work makes up-front testing incredibly profitable, and late-stage testing incredibly expensive.
I’ll tell you a short story about a project we worked on in the late 1990’s. We provided the software and other teams provided the hardware for a factory automation project. Three or four teams brought their experts on-site, which was a remote factory (funny how the polluting factories are always in remote border country).
One of these teams, a firm specializing in industrial automation, built ticket machines: kiosks, and software to run on them. Nothing unusual: swipe a badge, choose an option, receive a ticket. They assembled two of these kiosks on-site, each week bringing some more bits and pieces. Ticket printers, monitor screens, special keypads from Israel. The stuff had to be resistant against dust because the kiosks sat outside. Nothing worked. The screens were unreadable in the sun. The ticket printers continually jammed and misprinted. The internals of the kiosk just sat on wooden shelving. The kiosk software crashed regularly. It was comedic except that the project really, really had to work and so we spent weeks and then months on-site helping the other teams debug their bits and pieces until it worked.
A year later, there was a second factory, and the same story. By this time the client, was getting impatient. So when they came to the third and largest factory, a year later, we jumped up and said, “please let us make the kiosks and the software and everything”.
We made a detailed design for the software and hardware and found suppliers for all the pieces. It took us three months to search the Internet for each component (in those days, the Internet was a lot slower), and another two months to get them assembled into stainless-steel bricks each weighing about twenty kilos. These bricks were two feet square and eight inches deep, with a large flat-screen panel behind unbreakable glass, and two connectors: one for power, one for Ethernet. You loaded up the paper bin with enough for six months, then screwed the brick into a housing, and it automatically booted, found its DNS server, loaded its Linux OS and then application software. It connected to the real server, and showed the main menu. You got access to the configuration screens by swiping a special badge and then entering a code.
The software was portable so we could test that as we wrote it, and as we collected the pieces from our suppliers we kept one of each so we had a disassembled kiosk to play with. When we got our finished kiosks, they all worked immediately. We shipped them to the client, who plugged them into their housing, switched them on, and went to business. We spent a week or so on-site, and in ten years, one kiosk broke (the screen died, and was replaced).
Lesson is, test upfront so that when you plug the thing in, you know precisely how it’s going to behave. If you haven’t tested it upfront, you’re going to be spending weeks and months in the field ironing out problems that should never have been there.
The Zyre Tester #
During manual testing, I did hit an assertion rarely. It then disappeared. Because I don’t believe in magic, I know that meant the code was still wrong somewhere. So, the next step was heavy-duty testing of the Zyre v0.2.0 code to try to break its assertions, and get a good idea of how it will behave in the field.
We packaged the discovery and messaging functionality as an interface object that the main program creates, works with, and then destroys. We don’t use any global variables. This makes it easy to start large numbers of interfaces and simulate real activity, all within one process. And if there’s one thing we’ve learned from writing lots of examples, it’s that ZeroMQ’s ability to orchestrate multiple threads in a single process is much easier to work with than multiple processes.
The first version of the tester consists of a main thread that starts and stops a set of child threads, each running one interface, each with a ROUTER, DEALER, and UDP socket (R, D, and U in the diagram).
The nice thing is that when I am connected to a WiFi access point, all Zyre traffic (even between two interfaces in the same process) goes across the AP. This means I can fully stress test any WiFi infrastructure with just a couple of PCs running in a room. It’s hard to emphasize how valuable this is: if we had built Zyre as, say, a dedicated service for Android, we’d literally need dozens of Android tablets or phones to do any large-scale testing. Kiosks, and all that.
The focus is now on breaking the current code, trying to prove it wrong. There’s no point at this stage in testing how well it runs, how fast it is, how much memory it uses, or anything else. We’ll work up to trying (and failing) to break each individual functionality, but first, we try to break some of the core assertions I’ve put into the code.
These are:
-
The first command that any node receives from a peer MUST be HELLO. In other words, messages cannot be lost during the peer-to-peer connection process.
-
The state each node calculates for its peers matches the state each peer calculates for itself. In other words, again, no messages are lost in the network.
-
When my application sends a message to a peer, we have a connection to that peer. In other words, the application only “sees” a peer after we have established a ZeroMQ connection to it.
With ZeroMQ, there are several cases where we may lose messages. One is the “late joiner” syndrome. Two is when we close sockets without sending everything. Three is when we overflow the high-water mark on a ROUTER or PUB socket. Four is when we use an unknown address with a ROUTER socket.
Now, I think Harmony gets around all these potential cases. But we’re also adding UDP to the mix. So the first version of the tester simulates an unstable and dynamic network, where nodes come and go randomly. It’s here that things will break.
Here is the main thread of the tester, which manages a pool of 100 threads, starting and stopping each one randomly. Every ~750 msecs it either starts or stops one random thread. We randomize the timing so that threads aren’t all synchronized. After a few minutes, we have an average of 50 threads happily chatting to each other like Korean teenagers in the Gangnam subway station:
int main (int argc, char *argv [])
{
// Initialize context for talking to tasks
zctx_t *ctx = zctx_new ();
zctx_set_linger (ctx, 100);
// Get number of interfaces to simulate, default 100
int max_interface = 100;
int nbr_interfaces = 0;
if (argc > 1)
max_interface = atoi (argv [1]);
// We address interfaces as an array of pipes
void **pipes = zmalloc (sizeof (void *) * max_interface);
// We will randomly start and stop interface threads
while (!zctx_interrupted) {
uint index = randof (max_interface);
// Toggle interface thread
if (pipes [index]) {
zstr_send (pipes [index], "STOP");
zsocket_destroy (ctx, pipes [index]);
pipes [index] = NULL;
zclock_log ("I: Stopped interface (%d running)",
--nbr_interfaces);
}
else {
pipes [index] = zthread_fork (ctx, interface_task, NULL);
zclock_log ("I: Started interface (%d running)",
++nbr_interfaces);
}
// Sleep ~750 msecs randomly so we smooth out activity
zclock_sleep (randof (500) + 500);
}
zctx_destroy (&ctx);
return 0;
}
Note that we maintain a pipe to each child thread (CZMQ creates the pipe automatically when we use the zthread_fork method). It’s via this pipe that we tell child threads to stop when it’s time for them to leave. The child threads do the following (I’m switching to pseudo-code for clarity):
create an interface
while true:
poll on pipe to parent, and on interface
if parent sent us a message:
break
if interface sent us a message:
if message is ENTER:
send a WHISPER to the new peer
if message is EXIT:
send a WHISPER to the departed peer
if message is WHISPER:
send back a WHISPER 1/2 of the time
if message is SHOUT:
send back a WHISPER 1/3 of the time
send back a SHOUT 1/3 of the time
once per second:
join or leave one of 10 random groups
destroy interface
Test Results #
Yes, we broke the code. Several times, in fact. This was satisfying. I’ll work through the different things we found.
Getting nodes to agree on consistent group status was the most difficult. Every node needs to track the group membership of the whole network, as I already explained in the section “Group Messaging”. Group messaging is a pub-sub pattern. JOINs and LEAVEs are analogous to subscribe and unsubscribe messages. It’s essential that none of these ever get lost, or we’ll find nodes dropping randomly off groups.
So each node counts the total number of JOINs and LEAVEs it’s ever done, and broadcasts this status (as 1-byte rolling counter) in its UDP beacon. Other nodes pick up the status, compare it to their own calculations, and if there’s a difference, the code asserts.
The first problem was that UDP beacons get delayed randomly, so they’re useless for carrying the status. When a beacons arrives late, the status is inaccurate and we get a false negative. To fix this, we moved the status information into the JOIN and LEAVE commands. We also added it to the HELLO command. The logic then becomes:
- Get initial status for a peer from its HELLO command.
- When getting a JOIN or LEAVE from a peer, increment the status counter.
- Check that the new status counter matches the value in the JOIN or LEAVE command
- If it doesn’t, assert.
Next problem we got was that messages were arriving unexpectedly on new connections. The Harmony pattern connects, then sends HELLO as the first command. This means the receiving peer should always get HELLO as the first command from a new peer. We were seeing PING, JOIN, and other commands arriving.
This turned out to be due to CZMQ’s ephemeral port logic. An ephemeral port is just a dynamically assigned port that a service can get rather than asking for a fixed port number. A POSIX system usually assigns ephemeral ports in the range 0xC000 to 0xFFFF. CZMQ’s logic is to look for a free port in this range, bind to that, and return the port number to the caller.
This sounds fine, until you get one node stopping and another node starting close together, and the new node getting the port number of the old node. Remember that ZeroMQ tries to re-establish a broken connection. So when the first node stopped, its peers would retry to connect. When the new node appears on that same port, suddenly all the peers connect to it and start chatting like they’re old buddies.
It’s a general problem that affects any larger-scale dynamic ZeroMQ application. There are a number of plausible answers. One is to not reuse ephemeral ports, which is easier said than done when you have multiple processes on one system. Another solution would be to select a random port each time, which at least reduces the risk of hitting a just-freed port. This brings the risk of a garbage connection down to perhaps 1/1000 but it’s still there. Perhaps the best solution is to accept that this can happen, understand the causes, and deal with it on the application level.
We have a stateful protocol that always starts with a HELLO command. We know that it’s possible for peers to connect to us, thinking we’re an existing node that went away and came back, and send us other commands. Step one is when we discover a new peer, to destroy any existing peer connected to the same endpoint. It’s not a full answer but at least it’s polite. Step two is to ignore anything coming in from a new peer until that peer says HELLO.
This doesn’t require any change to the protocol, but it must be specified in the protocol when we come to it: due to the way ZeroMQ connections work, it’s possible to receive unexpected commands from a well-behaving peer and there is no way to return an error code or otherwise tell that peer to reset its connection. Thus, a peer must discard any command from a peer until it receives HELLO.
In fact, if you draw this on a piece of paper and think it through, you’ll see that you never get a HELLO from such a connection. The peer will send PINGs and JOINs and LEAVEs and then eventually time out and close, as it fails to get any heartbeats back from us.
You’ll also see that there’s no risk of confusion, no way for commands from two peers to get mixed into a single stream on our DEALER socket.
When you are satisfied that this works, we’re ready to move on. This version is tagged in the repository as v0.3.0 and you can download the tarball if you want to check what the code looked like at this stage.
Note that doing heavy simulation of lots of nodes will probably cause your process to run out of file handles, giving an assertion failure in libzmq. I raised the per-process limit to 30,000 by running (on my Linux box):
ulimit -n 30000
Tracing Activity #
To debug the kinds of problems we saw here, we need extensive logging. There’s a lot happening in parallel, but every problem can be traced down to a specific exchange between two nodes, consisting of a set of events that happen in strict sequence. We know how to make very sophisticated logging, but as usual it’s wiser to make just what we need and no more. We have to capture:
- Time and date for each event.
- In which node the event occurred.
- The peer node, if any.
- What the event was (e.g., which command arrived).
- Event data, if any.
The very simplest technique is to print the necessary information to the console, with a timestamp. That’s the approach I used. Then it’s simple to find the nodes affected by a failure, filter the log file for only messages referring to them, and see exactly what happened.
Dealing with Blocked Peers #
In any performance-sensitive ZeroMQ architecture, you need to solve the problem of flow control. You cannot simply send unlimited messages to a socket and hope for the best. At the one extreme, you can exhaust memory. This is a classic failure pattern for a message broker: one slow client stops receiving messages; the broker starts to queue them, and eventually exhausts memory and the whole process dies. At the other extreme, the socket drops messages, or blocks, as you hit the high-water mark.
With Zyre we want to distribute messages to a set of peers, and we want to do this fairly. Using a single ROUTER socket for output would be problematic because any one blocked peer would block outgoing traffic to all peers. TCP does have good algorithms for spreading the network capacity across a set of connections. And we’re using a separate DEALER socket to talk to each peer, so in theory each DEALER socket will send its queued messages in the background reasonably fairly.
The normal behavior of a DEALER socket that hits its high-water mark is to block. This is usually ideal, but it’s a problem for us here. Our current interface design uses one thread that distributes messages to all peers. If one of those send calls were to block, all output would block.
There are a few options to avoid blocking. One is to use zmq_poll() on the whole set of DEALER sockets, and only write to sockets that are ready. I don’t like this for a couple of reasons. First, the DEALER socket is hidden inside the peer class, and it is cleaner to allow each class to handle this opaquely. Second, what do we do with messages we can’t yet deliver to a DEALER socket? Where do we queue them? Third, it seems to be side-stepping the issue. If a peer is really so busy it can’t read its messages, something is wrong. Most likely, it’s dead.
So no polling for output. The second option is to use one thread per peer. I quite like the idea of this because it fits into the ZeroMQ design pattern of “do one thing in one thread”. But this is going to create a lot of threads (square of the number of nodes we start) in the simulation, and we’re already running out of file handles.
A third option is to use a nonblocking send. This is nicer and it’s the solution I choose. We can then provide each peer with a reasonable outgoing queue (the HWM) and if that gets full, treat it as a fatal error on that peer. This will work for smaller messages. If we’re sending large chunks–e.g., for content distribution–we’ll need a credit-based flow control on top.
Therefore the first step is to prove to ourselves that we can turn the normal blocking DEALER socket into a nonblocking socket. This example creates a normal DEALER socket, connects it to some endpoint (so that there’s an outgoing pipe and the socket will accept messages), sets the high-water mark to four, and then sets the send timeout to zero:
C | C# | Java | Python | Ada | Basic | C++ | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCamlWhen we run this, we send four messages successfully (they go nowhere, the socket just queues them), and then we get a nice EAGAIN error:
Sending message 0
Sending message 1
Sending message 2
Sending message 3
Sending message 4
Resource temporarily unavailable
The next step is to decide what a reasonable high-water mark would be for a peer. Zyre is meant for human interactions; that is, applications that chat at a low frequency, such as two games or a shared drawing program. I’d expect a hundred messages per second to be quite a lot. Our “peer is really dead” timeout is 10 seconds. So a high-water mark of 1,000 seems fair.
Rather than set a fixed HWM or use the default (which randomly also happens to be 1,000), we calculate it as 100 * the timeout. Here’s how we configure a new DEALER socket for a peer:
// Create new outgoing socket (drop any messages in transit)
self->mailbox = zsocket_new (self->ctx, ZMQ_DEALER);
// Set our caller "From" identity so that receiving node knows
// who each message came from.
zsocket_set_identity (self->mailbox, reply_to);
// Set a high-water mark that allows for reasonable activity
zsocket_set_sndhwm (self->mailbox, PEER_EXPIRED * 100);
// Send messages immediately or return EAGAIN
zsocket_set_sndtimeo (self->mailbox, 0);
// Connect through to peer node
zsocket_connect (self->mailbox, "tcp://%s", endpoint);
And finally, what do we do when we get an EAGAIN on a peer? We don’t need to go through all the work of destroying the peer because the interface will do this automatically if it doesn’t get any message from the peer within the expiration timeout. Just dropping the last message seems very weak; it will give the receiving peer gaps.
I’d prefer a more brutal response. Brutal is good because it forces the design to a “good” or “bad” decision rather than a fuzzy “should work but to be honest there are a lot of edge cases so let’s worry about it later”. Destroy the socket, disconnect the peer, and stop sending anything to it. The peer will eventually have to reconnect and re-initialize any state. It’s kind of an assertion that 100 messages a second is enough for anyone. So, in the zre_peer_send method:
int
zre_peer_send (zre_peer_t *self, zre_msg_t **msg_p)
{
assert (self);
if (self->connected) {
if (zre_msg_send (msg_p, self->mailbox) && errno == EAGAIN) {
zre_peer_disconnect (self);
return -1;
}
}
return 0;
}
Where the disconnect method looks like this:
void
zre_peer_disconnect (zre_peer_t *self)
{
// If connected, destroy socket and drop all pending messages
assert (self);
if (self->connected) {
zsocket_destroy (self->ctx, self->mailbox);
free (self->endpoint);
self->endpoint = NULL;
self->connected = false;
}
}
Distributed Logging and Monitoring #
Let’s look at logging and monitoring. If you’ve ever managed a real server (like a web server), you know how vital it is to have a capture of what is going on. There are a long list of reasons, not least:
- To measure the performance of the system over time.
- To see what kinds of work are done the most, to optimize performance.
- To track errors and how often they occur.
- To do postmortems of failures.
- To provide an audit trail in case of dispute.
Let’s scope this in terms of the problems we think we’ll have to solve:
- We want to track key events (such as nodes leaving and rejoining the network).
- For each event, we want to track a consistent set of data: the date/time, node that observed the event, peer that created the event, type of event itself, and other event data.
- We want to be able to switch logging on and off at any time.
- We want to be able to process log data mechanically because it will be sizable.
- We want to be able to monitor a running system; that is, collect logs and analyze in real time.
- We want log traffic to have minimal effect on the network.
- We want to be able to collect log data at a single point on the network.
As in any design, some of these requirements are hostile to each other. For example, collecting log data in real time means sending it over the network, which will affect network traffic to some extent. However, as in any design, these requirements are also hypothetical until we have running code so we can’t take them too seriously. We’ll aim for plausibly good enough and improve over time.
A Plausible Minimal Implementation #
Arguably, just dumping log data to disk is one solution, and it’s what most mobile applications do (using “debug logs”). But most failures require correlation of events from two nodes. This means searching lots of debug logs by hand to find the ones that matter. It’s not a very clever approach.
We want to send log data somewhere central, either immediately, or opportunistically (i.e., store and forward). For now, let’s focus on immediate logging. My first idea when it comes to sending data is to use Zyre for this. Just send log data to a group called “LOG”, and hope someone collects it.
But using Zyre to log Zyre itself is a Catch-22. Who logs the logger? What if we want a verbose log of every message sent? Do we include logging messages in that or not? It quickly gets messy. We want a logging protocol that’s independent of Zyre’s main ZRE protocol. The simplest approach is a pub-sub protocol, where all nodes publish log data on a PUB socket and a collector picks that up via a SUB socket.
The collector can, of course, run on any node. This gives us a nice range of use cases:
-
A passive log collector that stores log data on disk for eventual statistical analysis; this would be a PC with sufficient hard disk space for weeks or months of log data.
-
A collector that stores log data into a database where it can be used in real time by other applications. This might be overkill for a small workgroup, but would be snazzy for tracking the performance of larger groups. The collector could collect log data over WiFi and then forward it over Ethernet to a database somewhere.
-
A live meter application that joined the Zyre network and then collected log data from nodes, showing events and statistics in real time.
The next question is how to interconnect the nodes and collector. Which side binds, and which connects? Both ways will work here, but it’s marginally better if the PUB sockets connect to the SUB socket. If you recall, ZeroMQ’s internal buffers only pop into existence when there are connections. It means as soon as a node connects to the collector, it can start sending log data without loss.
How do we tell nodes what endpoint to connect to? We may have any number of collectors on the network, and they’ll be using arbitrary network addresses and ports. We need some kind of service announcement mechanism, and here we can use Zyre to do the work for us. We could use group messaging, but it seems neater to build service discovery into the ZRE protocol itself. It’s nothing complex: if a node provides a service X, it can tell other nodes about that when it sends them a HELLO command.
We’ll extend the HELLO command with a headers field that holds a set of name=value pairs. Let’s define that the header X-ZRELOG specifies the collector endpoint (the SUB socket). A node that acts as a collector can add a header like this (for example):
X-ZRELOG=tcp://192.168.1.122:9992
When another node sees this header, it simply connects its PUB socket to that endpoint. Log data now gets distributed to all collectors (zero or more) on the network.
Making this first version was fairly simple and took half a day. Here are the pieces we had to make or change:
- We made a new class zre_log that accepts log data and manages the connection to the collector, if any.
- We added some basic management for peer headers, taken from the HELLO command.
- When a peer has the X-ZRELOG header, we connect to the endpoint it specifies.
- Where we were logging to stdout, we switched to logging via the zre_log class.
- We extended the interface API with a method that lets the application set headers.
- We wrote a simple logger application that manages the SUB socket and sets the X-ZRELOG header.
- We send our own headers when we send a HELLO command.
This version is tagged in the Zyre repository as v0.4.0 and you can download the tarball if you want to see what the code looked like at this stage.
At this stage, the log message is just a string. We’ll make more professionally structured log data in a little while.
First, a note on dynamic ports. In the zre_tester app that we use for testing, we create and destroy interfaces aggressively. One consequence is that a new interface can easily reuse a port that was just freed by another application. If there’s a ZeroMQ socket somewhere trying to connect this port, the results can be hilarious.
Here’s the scenario I had, which caused a few minutes’ confusion. The logger was running on a dynamic port:
- Start logger application
- Start tester application
- Stop logger
- Tester receives invalid message (and asserts as designed)
As the tester created a new interface, that reused the dynamic port freed by the (just stopped) logger, and suddenly the interface began to receive log data from nodes on its mailbox. We saw a similar situation before, where a new interface could reuse the port freed by an old interface and start getting old data.
The lesson is, if you use dynamic ports, be prepared to receive random data from ill-informed applications that are reconnecting to you. Switching to a static port stopped the misbehaving connection. That’s not a full solution though. There are two more weaknesses:
-
As I write this, libzmq doesn’t check socket types when connecting. The ZMTP/2.0 protocol does announce each peer’s socket type, so this check is doable.
-
The ZRE protocol has no fail-fast (assertion) mechanism; we need to read and parse a whole message before realizing that it’s invalid.
Let’s address the second one. Socket pair validation wouldn’t solve this fully anyway.
Protocol Assertions #
As Wikipedia puts it, “Fail-fast systems are usually designed to stop normal operation rather than attempt to continue a possibly flawed process.” A protocol like HTTP has a fail-fast mechanism in that the first four bytes that a client sends to an HTTP server must be “HTTP”. If they’re not, the server can close the connection without reading anything more.
Our ROUTER socket is not connection-oriented so there’s no way to “close the connection” when we get bad incoming messages. However, we can throw out the entire message if it’s not valid. The problem is going to be worse when we use ephemeral ports, but it applies broadly to all protocols.
So let’s define a protocol assertion as being a unique signature that we place at the start of each message and which identities the intended protocol. When we read a message, we check the signature and if it’s not what we expect, we discard the message silently. A good signature should be hard to confuse with regular data and give us enough space for a number of protocols.
I’m going to use a 16-bit signature consisting of a 12-bit pattern and a 4-bit protocol ID. The pattern %xAAA is meant to stay away from values we might otherwise expect to see at the start of a message: %x00, %xFF, and printable characters.

As our protocol codec is generated, it’s relatively easy to add this assertion. The logic is:
- Get first frame of message.
- Check if first two bytes are %xAAA with expected 4-bit signature.
- If so, continue to parse rest of message.
- If not, skip all “more” frames, get first frame, and repeat.
To test this, I switched the logger back to using an ephemeral port. The interface now properly detects and discards any messages that don’t have a valid signature. If the message has a valid signature and is still wrong, that’s a proper bug.
Binary Logging Protocol #
Now that we have the logging framework working properly, let’s look at the protocol itself. Sending strings around the network is simple, but when it comes to WiFi we really cannot afford to waste bandwidth. We have the tools to work with efficient binary protocols, so let’s design one for logging.
This is going to be a pub-sub protocol and in ZeroMQ v3.x we do publisher-side filtering. This means we can do multi-level logging (errors, warnings, information) if we put the logging level at the start of the message. So our message starts with a protocol signature (two bytes), a logging level (one byte), and an event type (one byte).
In the first version, we send UUID strings to identify each node. As text, these are 32 characters each. We can send binary UUIDs, but it’s still verbose and wasteful. We don’t care about the node identifiers in the log files. All we need is some way to correlate events. So what’s the shortest identifier we can use that’s going to be unique enough for logging? I say “unique enough” because while we really want zero chance of duplicate UUIDs in the live code, log files are not so critical.
The simplest plausible answer is to hash the IP address and port into a 2-byte value. We’ll get some collisions, but they’ll be rare. How rare? As a quick sanity check, I write a small program that generates a bunch of addresses and hashes them into 16-bit values, looking for collisions. To be sure, I generate 10,000 addresses across a small number of IP addresses (matching a simulation setup), and then across a large number of addresses (matching a real-life setup). The hashing algorithm is a modified Bernstein:
uint16_t hash = 0;
while (*endpoint)
hash = 33 * hash ^ *endpoint++;
I don’t get any collisions over several runs, so this will work as identifier for the log data. This adds four bytes (two for the node recording the event, and two for its peer in events that come from a peer).
Next, we want to store the date and time of the event. The POSIX time_t type was previously 32 bits, but because this overflows in 2038, it’s a 64-bit value. We’ll use this; there’s no need for millisecond resolution in a log file: events are sequential, clocks are unlikely to be that tightly synchronized, and network latencies mean that precise times aren’t that meaningful.
We’re up to 16 bytes, which is decent. Finally, we want to allow some additional data, formatted as text and depending on the type of event. Putting this all together gives the following message specification:
<class
name = "zre_log_msg"
script = "codec_c.gsl"
signature = "2"
>
This is the ZRE logging protocol - raw version.
<include filename = "license.xml" />
<!-- Protocol constants -->
<define name = "VERSION" value = "1" />
<define name = "LEVEL_ERROR" value = "1" />
<define name = "LEVEL_WARNING" value = "2" />
<define name = "LEVEL_INFO" value = "3" />
<define name = "EVENT_JOIN" value = "1" />
<define name = "EVENT_LEAVE" value = "2" />
<define name = "EVENT_ENTER" value = "3" />
<define name = "EVENT_EXIT" value = "4" />
<message name = "LOG" id = "1">
<field name = "level" type = "number" size = "1" />
<field name = "event" type = "number" size = "1" />
<field name = "node" type = "number" size = "2" />
<field name = "peer" type = "number" size = "2" />
<field name = "time" type = "number" size = "8" />
<field name = "data" type = "string" />
Log an event
</message>
</class>
This generates 800 lines of perfect binary codec (the zre_log_msg class). The codec does protocol assertions just like the main ZRE protocol does. Code generation has a fairly steep starting curve, but it makes it so much easier to push your designs past “amateur” into “professional”.
Content Distribution #
We now have a robust framework for creating groups of nodes, letting them chat to each other, and monitoring the resulting network. Next step is to allow them to distribute content as files.
As usual, we’ll aim for the very simplest plausible solution and then improve that step-by-step. At the very least we want the following:
- An application can tell the Zyre API, “Publish this file”, and provide the path to a file that exists somewhere in the file system.
- Zyre will distribute that file to all peers, both those that are on the network at that time, and those that arrive later.
- Each time an interface receives a file it tells its application, “Here is this file”.
We might eventually want more discrimination, e.g., publishing to specific groups. We can add that later if it’s needed. In Chapter 7 - Advanced Architecture using ZeroMQ we developed a file distribution system (FileMQ) designed to be plugged into ZeroMQ applications. So let’s use that.
Each node is going to be a file publisher and a file subscriber. We bind the publisher to an ephemeral port (if we use the standard FileMQ port 5670, we can’t run multiple interfaces on one box), and we broadcast the publisher’s endpoint in the HELLO message, as we did for the log collector. This lets us interconnect all nodes so that all subscribers talk to all publishers.
We need to ensure that each node has its own directory for sending and receiving files (the outbox and the inbox). Again, it’s so we can run multiple nodes on one box. Because we already have a unique ID per node, we just use that in the directory name.
Here’s how we set up the FileMQ API when we create a new interface:
sprintf (self->fmq_outbox, ".outbox/%s", self->identity);
mkdir (self->fmq_outbox, 0775);
sprintf (self->fmq_inbox, ".inbox/%s", self->identity);
mkdir (self->fmq_inbox, 0775);
self->fmq_server = fmq_server_new ();
self->fmq_service = fmq_server_bind (self->fmq_server, "tcp://*:*");
fmq_server_publish (self->fmq_server, self->fmq_outbox, "/");
fmq_server_set_anonymous (self->fmq_server, true);
char publisher [32];
sprintf (publisher, "tcp://%s:%d", self->host, self->fmq_service);
zhash_update (self->headers, "X-FILEMQ", strdup (publisher));
// Client will connect as it discovers new nodes
self->fmq_client = fmq_client_new ();
fmq_client_set_inbox (self->fmq_client, self->fmq_inbox);
fmq_client_set_resync (self->fmq_client, true);
fmq_client_subscribe (self->fmq_client, "/");
And when we process a HELLO command, we check for the X-FILEMQ header field:
// If peer is a FileMQ publisher, connect to it
char *publisher = zre_msg_headers_string (msg, "X-FILEMQ", NULL);
if (publisher)
fmq_client_connect (self->fmq_client, publisher);
The last thing is to expose content distribution in the Zyre API. We need two things:
- A way for the application to say, “Publish this file”
- A way for the interface to tell the application, “We received this file”.
In theory, the application can publish a file just by creating a symbolic link in the outbox directory, but as we’re using a hidden outbox, this is a little difficult. So we add an API method publish:
// Publish file into virtual space
void
zre_interface_publish (zre_interface_t *self,
char *filename, char *external)
{
zstr_sendm (self->pipe, "PUBLISH");
zstr_sendm (self->pipe, filename); // Real file name
zstr_send (self->pipe, external); // Location in virtual space
}
The API passes this to the interface thread, which creates the file in the outbox directory so that the FileMQ server will pick it up and broadcast it. We could literally copy file data into this directory, but because FileMQ supports symbolic links, we use that instead. The file has a “.ln” extension and contains one line, which contains the actual pathname.
Finally, how do we notify the recipient that a file has arrived? The FileMQ fmq_client API has a message, “DELIVER”, for this, so all we have to do in zre_interface is grab this message from the fmq_client API and pass it on to our own API:
zmsg_t *msg = fmq_client_recv (fmq_client_handle (self->fmq_client));
zmsg_send (&msg, self->pipe);
This is complex code that does a lot at once. But we’re only at around 10K lines of code for FileMQ and Zyre together. The most complex Zyre class, zre_interface, is 800 lines of code. This is compact. Message-based applications do keep their shape if you’re careful to organize them properly.
Writing the Unprotocol #
We have all the pieces for a formal protocol specification and it’s time to put the protocol on paper. There are two reasons for this. First, to make sure that any other implementations talk to each other properly. Second, because I want to get an official port for the UDP discovery protocol and that means doing the paperwork.
Like all the other unprotocols we developed in this book, the protocol lives on the ZeroMQ RFC site. The core of the protocol specification is the ABNF grammar for the commands and fields:
zre-protocol = greeting *traffic
greeting = S:HELLO
traffic = S:WHISPER
/ S:SHOUT
/ S:JOIN
/ S:LEAVE
/ S:PING R:PING-OK
; Greet a peer so it can connect back to us
S:HELLO = header %x01 ipaddress mailbox groups status headers
header = signature sequence
signature = %xAA %xA1
sequence = 2OCTET ; Incremental sequence number
ipaddress = string ; Sender IP address
string = size *VCHAR
size = OCTET
mailbox = 2OCTET ; Sender mailbox port number
groups = strings ; List of groups sender is in
strings = size *string
status = OCTET ; Sender group status sequence
headers = dictionary ; Sender header properties
dictionary = size *key-value
key-value = string ; Formatted as name=value
; Send a message to a peer
S:WHISPER = header %x02 content
content = FRAME ; Message content as ZeroMQ frame
; Send a message to a group
S:SHOUT = header %x03 group content
group = string ; Name of group
content = FRAME ; Message content as ZeroMQ frame
; Join a group
S:JOIN = header %x04 group status
status = OCTET ; Sender group status sequence
; Leave a group
S:LEAVE = header %x05 group status
; Ping a peer that has gone silent
S:PING = header %06
; Reply to a peer's ping
R:PING-OK = header %07
Example Zyre Application #
Let’s now make a minimal example that uses Zyre to broadcast files around a distributed network. This example consists of two programs:
- A listener that joins the Zyre network and reports whenever it receives a file.
- A sender that joins a Zyre network and broadcasts exactly one file.
The listener is quite short:
#include <zre.h>
int main (int argc, char *argv [])
{
zre_interface_t *interface = zre_interface_new ();
while (true) {
zmsg_t *incoming = zre_interface_recv (interface);
if (!incoming)
break;
zmsg_dump (incoming);
zmsg_destroy (&incoming);
}
zre_interface_destroy (&interface);
return 0;
}
And the sender isn’t much longer:
#include <zre.h>
int main (int argc, char *argv [])
{
if (argc < 2) {
puts ("Syntax: sender filename virtualname");
return 0;
}
printf ("Publishing %s as %s\n", argv [argv [2](1],));
zre_interface_t *interface = zre_interface_new ();
zre_interface_publish (interface, argv [argv [2](1],));
while (true) {
zmsg_t *incoming = zre_interface_recv (interface);
if (!incoming)
break;
zmsg_dump (incoming);
zmsg_destroy (&incoming);
}
zre_interface_destroy (&interface);
return 0;
}
Conclusions #
Building applications for unstable decentralized networks is one of the end games for ZeroMQ. As the cost of computing falls every year, such networks become more and more common, be it consumer electronics or virtual boxes in the cloud. In this chapter, we’ve pulled together many of the techniques from the book to build Zyre, a framework for proximity computing over a local network. Zyre isn’t unique; there are and have been many attempts to open this area for applications: ZeroConf, SLP, SSDP, UPnP, DDS. But these all seem to end up too complex or otherwise too difficult for application developers to build on.
Zyre isn’t finished. Like many of the projects in this book, it’s an ice breaker for others. There are some major unfinished areas, which we may address in later editions of this book or versions of the software.
-
High-level APIs: the message-based API that Zyre offers now is usable but still rather more complex than I’d like for average developers. If there’s one target we absolutely cannot miss, it’s raw simplicity. This means we should build high-level APIs, in lots of languages, which hide all the messaging, and which come down to simple methods like start, join/leave group, get message, publish file, stop.
-
Security: how do we build a fully decentralized security system? We might be able to leverage public key infrastructure for some work, but that requires that nodes have their own Internet access, which isn’t guaranteed. The answer is, as far as we can tell, to use any existing secure peer-to-peer link (TLS, BlueTooth, perhaps NFC) to exchange a session key and use a symmetric cipher. Symmetric ciphers have their advantages and disadvantages.
-
Nomadic content: how do I, as a user, manage my content across multiple devices? The Zyre + FileMQ combination might help, for local network use, but I’d like to be able to do this across the Internet as well. Are there cloud services I could use? Is there something I could make using ZeroMQ?
-
Federation: how do we scale a local-area distributed application across the globe? One plausible answer is federation, which means creating clusters of clusters. If 100 nodes can join together to create a local cluster, then perhaps 100 clusters can join together to create a wide-area cluster. The challenges are then quite similar: discovery, presence, and group messaging.